
Abstract
Simple ontology alignments, largely studied in the literature, link a single entity of a source ontology to a single entity of a target ontology. A limitation of these alignments is their lack of expressiveness which can be overcome by complex alignments. While diverse state-of-the-art surveys mainly review the matching approaches in general, to the best of our knowledge, there is no study of the specificities of the complex matching problem. In this paper, a review of the different complex matching approaches is provided. It proposes a classification of the complex matching approaches based on their specificities (i.e., type of correspondences, guiding structure). The evaluation aspects and the limitations of these approaches are also discussed. Insights for future work in the field are provided.
Introduction
Ontology matching is an essential task for the management of semantic heterogeneity in open environments. This task is often associated with the schema matching problem [100] as they share the same goal: interoperability. Broadly speaking, the matching process aims at generating a set of correspondences (i.e., an alignment) between the entities of different knowledge representation models (e.g., ontologies, schemata). Two types of correspondences can be distinguished. While approaches generating simple correspondences are limited to matching single entities (i.e., linking a single entity from a source ontology to a single entity of a target ontology), complex matching approaches are able to generate correspondences which express more complex relationships between entities from different ontologies. With the increasing number of knowledge sources made available on the Linked Open Data (LOD) cloud and their variety of modelling choices, the relationships between entities of these sources are required to be more expressive. Simple correspondences are not expressive enough to fully overcome conceptual heterogeneity. However, currently, few complex alignments are available and published on the LOD cloud even if the need for these alignments has become more and more present in various application fields. For example, in the cultural heritage domain, the need for complex correspondences has been identified for data integration or data translation applications [16,60,80,111]. To tackle the issue, complex matching systems are used [111], or complex correspondences are manually created [60,80]. In the agronomic domain, complex alignments help cross-query linked open data repositories [112]. In the biomedical domain, complex alignments have also been used to build a consensual model from heterogeneous terminologies [56]. Complex alignments between medical ontologies have also been published [38,40].
Different complex matching approacheswhich adopt a diversity of strategies and deal with different knowledge representation models, have emerged in the literature. Nevertheless, complex matching remains a challenge. In [83], ontology matching researchers were surveyed about future challenges in the field and they agree that “automatically discovering complex relations, instead of 1:1” is one of them.
Diverse surveys in the literature have focused on the different aspects of schema and ontology matching [17,24,35,61,76,83,91,100] without paying attention to the specificities of complex matching (underlying strategy, structure of complex correspondences, etc.). The aim of this survey is to provide a review of the complex matching approaches dealing with different kinds of knowledge representation models such as taxonomies, XML schemata, database schemata, formal ontologies, etc. A classification of the approaches based on the specificities of complex alignments is proposed and the evaluation aspects of these approaches reviewed. The limitations of both the approaches and evaluations are discussed and insights for future work in the field are provided, in particular to foster the generation of complex alignments on the LOD cloud.
The rest of this paper is organised as follows. After background definitions (Section 2), complex alignment languages, visualisation and edition tools are presented (Section 3). A classification of complex matching approaches is proposed (Section 4), followed by a description of state-of-the-art approaches (Section 5). The works on complex alignment evaluation are examined (Section 6) and finally, perspectives for the field are discussed (Section 7).
Background
This section defines the scope of this study and provides the definitions related to alignments. The different knowledge representation models considered are presented and the notions of alignment and correspondence introduced. The ontology fragments used for the examples in the paper are presented in Fig. 1.
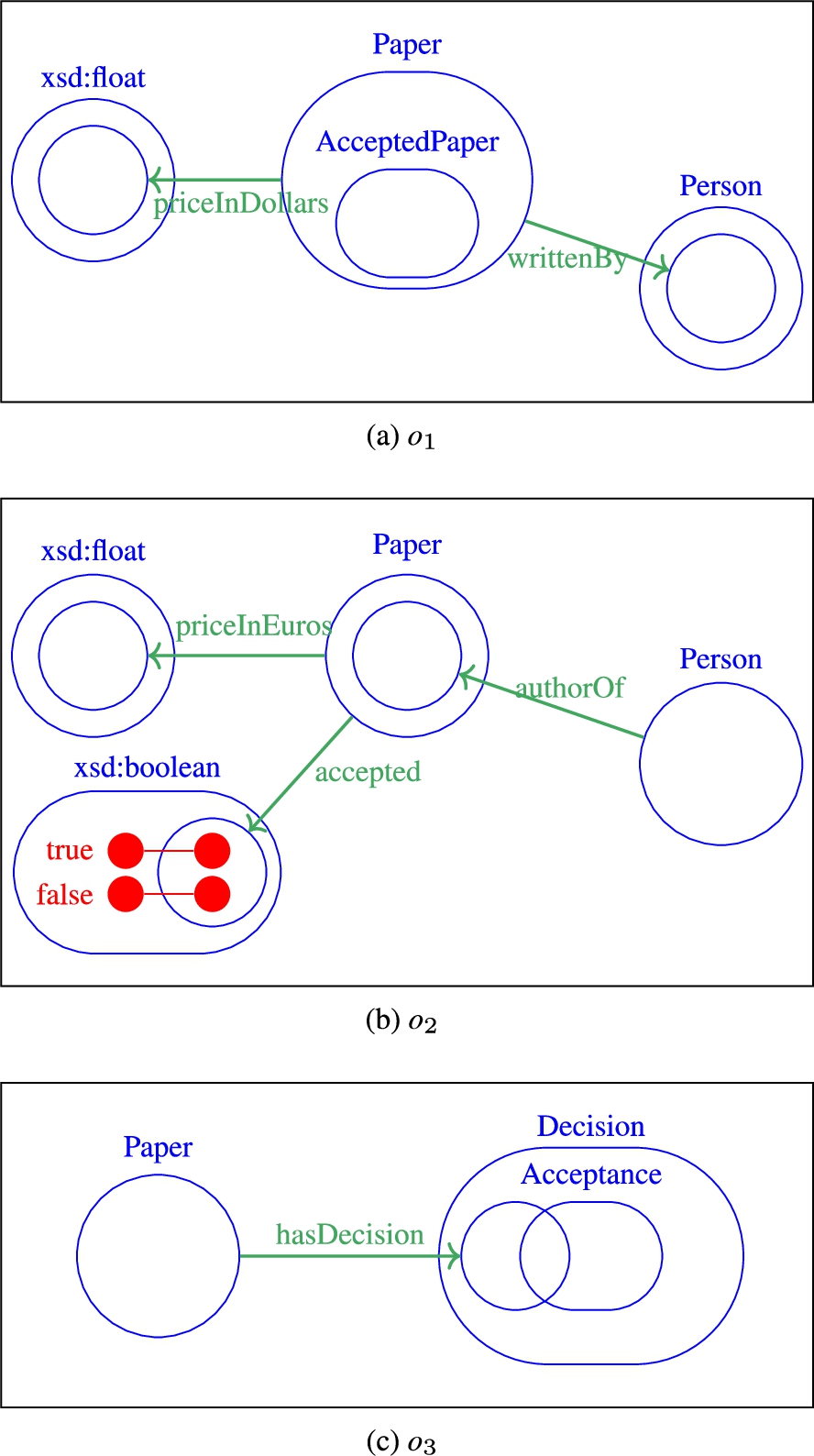
Example ontologies. The format used to represent the ontologies is described in [104].
In the literature, different knowledge representation models have been so far referred to as “ontologies”. As stated in [35], “an ontology can be viewed as a set of assertions that are meant to model some particular domain. Usually, they define a vocabulary used by a particular application. In various areas of computer science, there are different data and conceptual models that can be thought of as ontologies.” In this survey, the term “ontology” is used in a broad sense for the definitions, and a more specific qualification of the knowledge representation models is given in the description of the approaches when possible.
In this survey, we consider the knowledge representation models defined as follows.
Table schemata A table schema is a flat schema instantiated as tabular data. The table schema refers to the name of the table columns (also called attributes).
Relational database schemata (RDB) Relational database schemata require the data to be organised as relations implemented by tables. The name of each relation is given, as well as the names and types of the relations’ attributes. This model includes the notions of primary key and foreign key providing the links between the relations.
Document-oriented schemata (DOS) DTDs, XML schemata and JSON schemata define the structure of documents (XML or JSON documents). These document-oriented schemata include elements, attributes and types. Elements can be either complex when specifying nested sub-elements, or simple when specifying built-in data types, such as string, for an element or attribute.
Conceptual models (CM) Conceptual models include entity-relationship models, used to abstract a relational database schema, and UML models, used to abstract object-oriented programs and databases. The entities of these models describe the internal structure of domain objects. The entities can be organised as a hierarchy. Moreover, these models can also express relations (associations) with a multiplicity of constraints between the entities.
Formal ontologies Formal ontologies are axiomatised theories. Their entities are most often classes, object properties, data properties, instances and values. The expressiveness of the ontology’s axioms is limited to the fragment of logic they implement (e.g.,
Expressions
The correspondences and alignments rely on the definition of expressions.
A
A
A
Alignment and correspondence
An
A if the correspondence is if the correspondence is r is a relation, e.g., equivalence (≡), more general (⊒), more specific (⊑), disjointedness (⊥) holding between alignment systems usually assign a confidence value to each correspondence, such that correspondences are sometimes defined as quadruples (
The members of the correspondences can be a simple expression, noted s, or a complex expression, noted c. A simple correspondence is always (s:s) whereas a complex correspondence can be (s:c), (c:s) or (c:c). The (1:1), (1:n), (m:1), (m:n) notations have been used for the same purpose in the literature [91,129] (1 for s and m or n for c). However, they can be misinterpreted as the alignment arity or multiplicity [32].
We provide below some examples of complex correspondences, based on the definitions above and the fragment of the ontologies in Fig. 1.
= (
= (
= (∃
= (
= (∃
As opposed to a
The pairwise definition of a matching process (between a source and a target ontology) can be extended to cover multiple ontologies. A
This section presents reflections on the scope of the survey.
Type of matched objects
Complex alignments can also occur between other objects such as business process models [39], strings [75], etc. However, these objects are different from the knowledge representation models studied in this survey. The nature of their elements is not the same as those of the representation model elements (concepts, relations, attributes). For example, business processes are graph-like models of a process, they have a begin and an end node, the nodes of their graph are either connectors or activities which take input and output elements. The strings have no explicit structure. For these reasons, these types of matching are out of the scope of this survey.
Ontology matching and ontology evolution
Some connections can be made between ontology matching and ontology evolution. As defined in the survey presented in [127], ontology evolution is the process which consists in maintaining a resource up to date according to changes occurring in the represented knowledge domain or to new requirements of the application(s) relying on the ontology. Ontology evolution is divided into different tasks: detecting the need for evolution, suggesting changes, validating changes, assessing the impact of the changes and managing changes. The latter includes the activities of change recording and ontology versioning. These activities are defined as “the ability to handle changes in ontologies by creating and managing different variants of it” [64]. Most approaches dealing with such activities rely on relations considering both the variants, also called versions, of an ontology and the entities within the two representations. Finding these relations can be in some ways similar to ontology matching. When taking a deeper look at what “version relations” express, not only must conceptual or logical relations between entities be considered but also (and mainly) change relations, which represent what has actually been transformed between the two versions of the ontology [65]. The first kind of relations (conceptual or logical relations) specifies correspondences between the entities of the source and the target ontologies (as defined previously). On the other hand, the second type of relations (change relations) specifies transformations, via a set of change operations, to apply on the source ontology in order to obtain the target ontology (for example adding a new domain to a property, merging two classes, etc.). Such relations are either captured at design time through the tool used to make the ontology evolve (such as Protégé or KAON [105]) or identified a posteriori through ontology “diff tools” [77,84,116,128]. Most works in the field have focused on proposing approaches in order to identify the second type of relations, i.e., “change relations”. Existing ontology matching approaches are generally reused in this task for finding the initial overlap between the two ontology versions.
As pointed out in [77] the aim of managing changes in ontology evolution is to highlight differences, whereas the ontology matching task concentrates on similarities.
An analogous classification is made between simple and complex changes according to the entities involved in the changes: “simple changes refer to the addition, modification or deletion of individual schema constructs, while complex changes refer to multiple such constructs and may be equivalent to multiple simple changes” [43]. The two types of changes are also called low level/high level operations [84], elementary/composite changes [105] or atomic/complex changes [106]. According to [84], high level operations are “intuitive, concise, closer to the intentions of the ontology editors and capture more accurately the semantics of a change” even if the authors point out that it is impossible to define an exhaustive list of such operations. Most languages proposed to represent changes make this distinction [77,105].
The work in [26] gives another point of view on the link between the two tasks, and studies the impacts of evolution changes on existing correspondences between ontologies. Even if the task of change management is complementary to the task of ontology matching, it can benefit from advances in the field of complex matching.
Complex alignment representation and visualisation
This section presents the languages and vocabularies used for complex alignment representation as well as works on graphical interfaces for complex alignment visualisation and edition.
Complex alignment representation
In the following, we present first the languages originally designed to describe axioms or rules outside the specific scope of alignment representation. Then, we introduce the dedicated languages. Examples of complex correspondences expressed in some languages are provided.
Generic representations
OWL OWL [70] can represent complex alignments as axioms involving logic constructors and entities from the source and target ontologies. These axioms form a merging ontology. The expressiveness of the correspondences in OWL (taking into account the expressiveness of the aligned ontologies) is restricted to the
Web-PDDL The Web-PDDL [27] is a strongly typed FOL (first-order logic) language. It allows the use of variables, constants, conditions, logical constructors and quantifiers. The predicates and constants take the form of URIs. An example of Web-PDDL for representing the correspondence
SWRL The Semantic Web Rule Language (SWRL) [49] helps to define rules, in the form of FOL Horn-rules, between OWL ontologies. These rules have no expressiveness restriction and provide flexibility thanks to the use of variables in the definition of the rules. This language comes with an XML Concrete Syntax to express the rules as XML documents. SWRL can be extended by built-ins based on the XQuery and XPath built-ins. These built-ins express transformation functions. An example of SWRL representing the correspondence
Other logic syntaxes such as DataLog, RIF, etc. using URIs as predicates can be used to express logic formulae. Even if they were originally meant to express these formulae inside one ontology, they can be used to express correspondences when involving IRIs from more than one ontology.
Alignments can be directly represented through semantically equivalent queries (or views) of their data. SQL is the language for querying relational databases, XQuery for XML documents and SPARQL for knowledge bases (ontologies). These query languages can use filters (or equivalent) to express transformation functions inside a query. The following queries represent
XSLT, XPath XML to XML, Logic, Transformation XSLT (eXtensible Stylesheet Language Tansformations) [63] is a language with an XML concrete syntax. This language describes rules to transform a source tree (XML document) into a target tree (XML document). This language is based on transformation patterns and reuses XPath expressions. XPath (XML Path Language) defines expressions with logical operators and transformation functions over XML nodes. The XPath functions are often reused in other alignment languages.
Dedicated alignment representations
Various formats have been proposed to represent alignments between two different knowledge representation models. A survey on ontology alignment formats is presented in [98].
EDOAL EDOAL [34] is an extension of the Alignment format to represent the complex correspondences between OWL ontologies. This language is based on correspondence patterns [98] and can be processed by the Alignment API [15]. The Alignment format can be extended by other languages to express complex correspondences.
XeOML XeOML [87] is a language which represents alignments for ontologies and can be extended to other kinds of knowledge representation models. It is based on an XML schema (Abstract Mapping schema) to describe the structure of an alignment and is completed by two other schemata (Ontology Element Definition and Mapping Definition).
SBO MAFRA [68,102] is a framework for constructing and editing DAML+OIL ontology alignments. The alignment representation part of the framework is based on the Semantic Bridge Ontology (SBO). This (not maintained) ontology provides a vocabulary to express complex correspondences with logical constructors and some transformation functions such as string concatenation.
Complex alignment formats, “Logic” shows whether the format can represent logic constructors, “Transformations” shows whether the format can represent value transformation functions
Complex alignment formats, “Logic” shows whether the format can represent logic constructors, “Transformations” shows whether the format can represent value transformation functions
SPIMBench The SPIMBench vocabulary was defined in an instance matching benchmark [97]. It allows for the description of data transformation between ontologies. These transformations include logic rules (based on OWL axioms) and value transformation functions.
In the area of OBDA (Ontology-Based Data Access) [123], different formats to express correspondences between relational databases and RDF datasets have been proposed in the literature. A comprehensive review of different formats can be found in [46]. Here, the W3C R2RML format and some of its extensions are briefly introduced.
R2RML The R2RML is a W3C format [14] used to represent correspondences between relational databases and RDF datasets. R2RML correspondences are expressed as RDF datasets. A few string operations can be expressed in the correspondences. The R2RML correspondences show how the data from the source schema should be transformed into the target ontology.
RML The RML language [22] extends the R2RML format by allowing other kinds of data sources such as XML schema, JSON, or tabular data (CSV). The FnO ontology [20] can be used in RML to describe transformation functions in the correspondences.
xR2RML The xR2RML language [72] extends the R2RML format by allowing the description of correspondences of mixed formats in the source schema. For example, if a JSON object is the value of a cell in a relational database.
D2RML The D2RML language [13] is based on R2RML and RML, allowing conditional case statements and programming inside the correspondences.
Table 1 gives a summary of the complex alignment formats presented in this section with their context of application. For instance, alignments represented in OWL are usually used for the task of ontology merging. The distinction between data integration and data transformation is that, in a data integration process, there is no transformation of the data. A data integration application can be data querying without loading the data in a central repository [35].
Complex alignment visualisation and edition tools
Complex alignment visualisation and edition tools
As discussed below (Section 5.6), despite the work on the different representation languages, complex matchers still fail on using those proposals. Many of them output FOL or DL correspondences in a simple text format, use their own specific syntax, or are not strict to EDOAL syntax.
Few tools allow for complex correspondence visualisation and edition. Some solutions are provided as part of specific standalone matching systems, while others are rather generic solutions, as we describe below. Table 2 presents a comparison of the tools.
Axiom and rule editors which allow the import of different ontologies can be used for complex alignment edition, as Protégé [74]. It can be used to edit OWL axioms involving entities from different ontologies. The complex correspondences (as axioms) can be visualised using the Manchester syntax. Another solution is the Axiomé [44] SWRL rule editor. The rules are represented as tree structures and can be paraphrased in English.
Tools as part of existing matchers such as Clio [126] or KARMA [66], Ontologies Alignment Tool (OAT) [12] provide a user-interface for complex alignment edition and correction.
Dedicated complex alignment editors use different strategies for the visualisation of the correspondences. MAFRA [68] is an edition and visualisation framework which allows for complex alignment representation as an instantiation of their Semantic Bridge Ontology (SBO). Klint [95] provides a graph-based visual interface for integration rule (correspondence) validation and edition. The correspondences are represented as labelled graphs involving variables. OntoStudio [119] is a suite of software for ontology engineering. Its OntoMap plugin [120] allows for manual edition of complex correspondences (logic and value transformations). OntoMap uses its own internal alignment language which is not public. Many R2RML correspondence editors have emerged in the past years using different strategies to represent the correspondences: block metaphor [57,58], graph-like [6,47,67,101] or tree-like [66]. Wrangler [62] proposes a graphical interface for the edition of value transformation functions such as scripts between tables.
Classification of complex matchers
Ontology matching approaches have been classified in various surveys [17,24,35,61,76,83,91,100]. These classifications however do not address the specificities of the complex approaches. After presenting the main existing classifications of ontology matching approaches (Section 4.1), we introduce axes for the classification of complex matching approaches (Section 4.2).
Classifications of ontology matching approaches
Euzenat and Shvaiko [35,100] define three matching dimensions: input, process and output which will be the guiding thread to present the classifications below. Most classifications so far focused on input and process dimensions [24,35,76,91,100].
Regarding the input dimension, the instance vs ontology classification (called instance vs schema in [91]) divides the matchers into those which deal with information from the
For the process dimension, Rahm et al. [91] propose classification axes such as element vs structure, linguistic vs constraint-based. All of these classification axes are put together into a taxonomy.
This classification [91] has been developed and extended by Euzenat and Shvaiko in [35,100]. For instance, they distinguish whether an input is considered syntactically or semantically by the approach. The two-way taxonomy ends in basic approach strategies (e.g., string-based, model-based, formal resource-based).
The classification of schema matching techniques of Doan et al. [24] separates rule-based techniques from learning-based techniques. Considering both input and process dimensions, rule-based techniques only exploit schema-level information in specific rules while learning-based techniques may exploit data instance information with machine-learning or statistical analysis.
Noy [76] proposes two main categories of ontology matching approaches: in the first, the matching process is guided by a top-level ontology from which the source and target ontologies derive; in the second, the matching process uses heuristics or machine-learning techniques.
Regarding the output dimension of the matching approaches, Rahm et al. [91] consider the output alignment arity as a characteristic of the approaches which could be integrated into its taxonomy.
In sum, among the ontology matching classifications so far, that of Euzenat and Shvaiko [35] is the most extensive (all the others can be represented in this classification). However, even if considered, the output dimension of the matching approaches is rarely a basis for classification, whereas it becomes of interest when considering complex correspondences.
More generally, the classifications of ontology matching cited above do not address the specificities of the complex matching problem. The characteristics of the processes leading to the generation of complex correspondences need to be studied, in particular the kind of structure guiding the discovery of correspondences. The next section presents classification axes for complex ontology matching approaches.
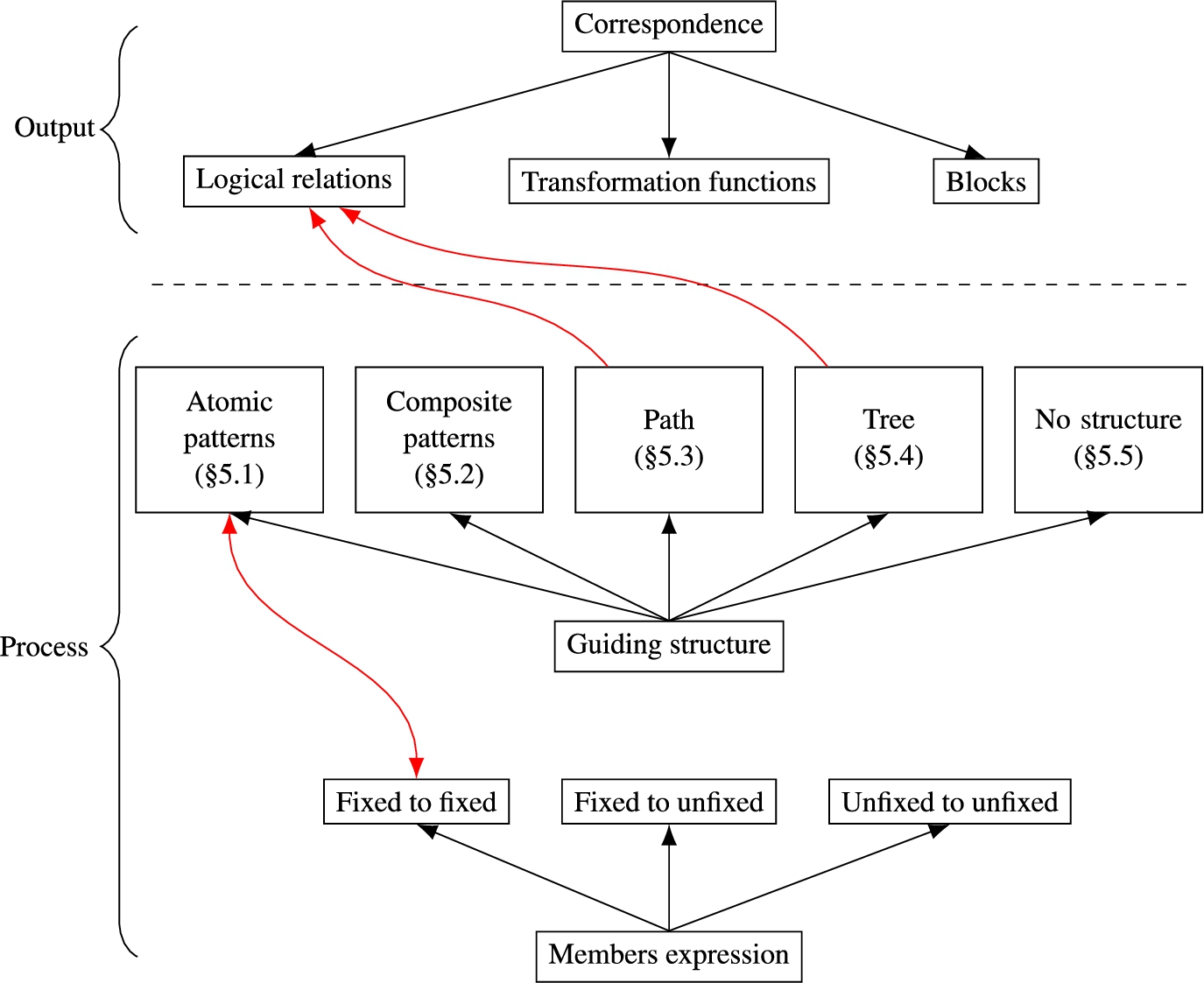
Two axes to characterise the complex matching approaches: output and process. The correlation between the categories are represented with red arrows.
The specificities of the complex matching approaches rely on their output and their process. These are the two axes of the proposed classification. In this section, the different types of output (types of correspondences) and the structures used in the process to guide the correspondence detection are presented (guiding structures).
Type of correspondence The correspondences (output of the matching approaches) are divided into three main categories according to their type: logical relations, transformation functions and blocks. The ( ( ({
Correspondence 1 is a logical relation correspondence, correspondence 2 is a transformation function correspondence and correspondence 3 is a block correspondence. No precise relation is specified between the entities involved in the third correspondence. It cannot therefore be classified as logical relation or transformation function correspondence. Note that in theory, a correspondence could have members expressed with transformation functions combined with logical constructors but no approach able to generate such a kind of correspondence was found. However, some approaches are able to generate both types independent of each other. An example of this correspondence expressed would be: (
Guiding structures These categories aim at classifying the (complex) matching approaches based on their process dimension. It focuses on the structure on which the process generating the correspondences relies:
The structures are used to guide the matching process, and therefore impact the structure of the output correspondences. However, a given correspondence, for example (
The member expression pre-definition specifies whether one of the members of the correspondence is assigned a fixed structure or not before the process. Three types of pre-definition are possible: fixed to fixed, fixed to unfixed and unfixed to unfixed.
The
The
The
A matching approach can exploit many different matching strategies to find complex correspondences. In the following, the matching strategies are classified on their guiding structure. Therefore, the same approach can appear in multiple sections.
Some correlations can be noted as depicted in Fig. 2: a path or tree-based approach will only output logical correspondences. There is also an equivalence between the fixed to fixed category and the atomic pattern category.
Atomic patterns used in the presented approaches. A, C are classes, a, b, c are properties, V is a value (instance or literal)
Atomic patterns used in the presented approaches. A, C are classes, a, b, c are properties, V is a value (instance or literal)
The choice of this guiding structure-based classification was made because guiding structures specific to complex matching. Not only do they guide the matching process, but the correspondence structure derives directly from them. Other classifications were considered before this choice:
A classification per type of knowledge representation model but it would not show the similarities between the matching systems even though they do not deal with the same type of knowledge representation model; A classification per type of correspondence output but this was not structuring enough; The classification from [35] but most complex matching approaches combine many of those basic matching techniques; A classification per type of entity (concepts, properties, etc.) dealt with by the matchers but this was not specific to complex alignment.
In some way, the structure-based classification can be considered as a specialisation of the graph-based techniques category in the classification of [35].
The following sections present the approaches according to our classification. Although these sections are organised according to the guiding structure (Fig. 2), a reference to the kind of output and member expression pre-definition is made in the text. The approaches are detailed in paragraphs with titles following a template: Name [ref] Type of knowledge representation models, [(s:c), (c:s), (c:c)].
Atomic patterns
Atomic patterns are used in approaches to detect logical relations as well as transformation functions. Table 3 presents several atomic correspondence patterns. Table 4 shows the atomic patterns of the correspondences which guide the state-of-the-art approaches of this category.
The atomic pattern-based approaches have different strategies for the definition of their patterns. For instance, some rely on the patterns defined by one of the ontologies to align [94], other approaches have their own pattern library [12,21,36,53,55,92,117]. Two main detection techniques appear: structuro-linguistic conditions (called matching patterns defined in [109]) [12,36,55,92–94], and statistical measures [21,53,117]. These approaches are detailed below.
Ritze et al. [ 92 , 93 ] OWL Ontology to OWL Ontologyy, (s:c) In [92,93], Ritze et al. propose a set of matching conditions to detect correspondence patterns: Class by Attribute Value, Class by Attribute Type, Class by Inverse Attribute Type, Inverse Properties and Property Chain defined by Scharffe [98] (cf. Table 3). The conditions are based on the labels of the ontology entities, the structures of these ontologies and the compatibility of the data-types of data-properties. The matching conditions to detect these patterns are an input to the matching algorithm. The user can add new matching conditions to detect other patterns.
The first approach1
Atomic patterns per approach
Conditions: (
Correspondence: (
The structural matching conditions are the same for both approaches. Example 1 is extended with structural constraints on the range and domain of
AMLC [ 36 ] OWL ontology to OWL ontology, (s:c) AMLC (Complex AgreementMakerLight) is the complex version of the AML (AgreementMakerLight) system. It relies on lexical similarity and structural conditions to detect correspondence patterns. This approach is very similar to that in [92]. Two types of patterns are sought: Class by Attribute Existence and Class by Attribute Type (cf. Table 3).
Oliveira and Pesquita [
82
] OWL ontology to OWL ontology, (s:c) The approach proposed in [82] looks for compound correspondences which in their target member involve entities from more than one ontology. The sought correspondences follow the pattern (
A source class
Rouces et al. [
94
] OWL ontology to the FrameBase ontology (OWL), (s:c) (c:s) Rouces et al. use FrameBase as a mediator ontology for complex alignment discovery. FrameBase is an ontology based on linguistic frames, seen as linguistic patterns in this approach. The approach identifies complex patterns in FrameBase from the linguistic patterns it describes. For each complex pattern identified, a corresponding candidate property is created (see Example 3). The names of the properties of the source ontology (the one to be aligned to FrameBase) are pre-processed, for example
Created property: frame:hasBirthDate(s, o) Pattern:frame:BirthEvent(e) ∧ frame:hasSubject(e,s) ∧ frame:hasDate(e,o) Source property preprocessing:
Simple correspondence: (
Bayes-ReCCE [
117
] OWL ontology to OWL ontology, (s:c) This approach detects Class Attribute Value Restrictions correspondences. Bayes-ReCCE uses the properties of matched instances of two classes
A reference alignment between
Ontologies Alignment Tool (OAT) [
12
], OWL Ontology to OWL Ontology, (s:c), (c:s), (c:c) The Ontologies Alignment Tool (OAT) presented in [12] presents a semi-automatic complex matcher. The user can input correspondences through a graphical interface by instantiating correspondence patterns. For each of the two ontologies, the automatic matcher creates a set of expressions following a list of patterns (object property range restriction, inverse property, etc.). These expressions from the two ontologies are then compared by their entities’ labels. If the similarity between two expressions is above a threshold, a correspondence putting these two expressions together is suggested to the user who can validate or invalidate it. The confidence of the correspondence is then set to respectively 1 or 0 and propagated to the other correspondences. For example, the system finds that the domain restriction dom(
iMAP, Dhamankar et al. [ 21 ] Relational database schema to relational database schema, (c:s) The iMAP system [21] uses a set of searchers to discover simple and complex correspondences between relational database schemata. The validity of each correspondence is then checked by a similarity estimator based on the columns’ name similarity and a Naive–Bayes classifier trained on the target data. The correspondences are finally presented to a user who validates or invalidates them. Each searcher implements a specific strategy. Some of the searchers use atomic patterns for correspondence detection. For instance, the numeric, category and schema mismatch searchers look for correspondences fitting given atomic patterns. The patterns of the numeric searcher are equation templates given by the user or from previous matches. The category correspondence looks for equivalent attribute-value pairs for attributes having a small set of possible values. The schema mismatch searcher looks for correspondences in which an attribute of the source schema has a true value if it appears in a list of attributes in the target schema. Examples of category and schema mismatch correspondences are presented in Example 5. These searchers base their confidence in a correspondence on the data value distribution using the Kullback–Leibler divergence measure. The unit conversion searcher is based on string recognition rules in the attributes’ names and data (such as “$”, “hour”, “kg”, etc.). The searcher finds the best match function from a predefined set of conversion functions.
Category searcher correspondence between schemata describing papers and their acceptance status: (∃
(
KAOM, Jiang et al. [
53
] OWL ontology to OWL ontology, (s:c) (c:s) (c:c) KAOM generates transformation function correspondences and logical relation correspondences. As the iMap’s system [21], KAOM implements different matching strategies: one for detecting transformation function correspondences, the other for logical relation correspondences. Here we present its transformation function correspondence detection approach, as it uses an atomic pattern. The logical relation correspondence approach is presented in Section 5.5. The atomic pattern used is a positive linear transformation function between numerical data properties
BootOX, Jimenez-Ruiz et al. [ 55 ] Relational database schema to OWL ontology, (c:s) The BootOX approach [55] produces correspondences between a relational database schema and a target ontology via the creation of a “bootstrapped” ontology. The approach proceeds in two phases. In the first phase, an ontology is bootstrapped (created/extracted) from a relational database schema based on a set of patterns. For example, a non-binary relation table in the source schema produces a class in the bootstrapped ontology. The patterns used in this approach lead to the creation of axioms involving class restrictions in the bootstrapped ontology. R2RML correspondences between the relational database and its bootstrapped ontology are the result of this phase. This bootstrapped ontology is then aligned with the LogMap [54] matcher to the target ontology. LogMap relies on linguistic and structural information to perform the matching. Put together, the transformation rules from RDB to ontology and the Logmap ontology alignment form a complex alignment between the RDB and the target ontology.
Other systems can bootstrap ontologies from relational database schemata [9,19] but their aim is not to align the schema to an existing ontology. They are therefore out of the scope of this study. In this survey, BootOX is considered with its LogMap extension.
Composite patterns per approach. A, B, C are classes, a, b, c, d are properties,
,
,
,
are values (instances or literals)
Composite patterns per approach. A, B, C are classes, a, b, c, d are properties,
Composite pattern-based approaches often focus on one or two patterns. Table 5 presents the different composite patterns detected by the approaches.
Some approaches iteratively construct the member(s) of the correspondence [21,25,59,86,118] (text searcher of iMap). Others first discover atomic pattern correspondences and merge them in a final (non-iterative) step [5,85]. Approaches use graph-pattern matching either as detection conditions [7,96,110,122] or over the properties of a mediating ontology [21,124,125] (iMap’s date searcher). Finally, [45,108] start by grouping schema attributes before matching the groups. Even though the holistic approaches [45,108] produce block correspondences (of properties only), it has been decided that these two approaches are composite pattern driven as the grouping phase follows a repetitive pattern. Some approaches search for composite patterns inside a tree structure [7,96,124,125]. These approaches could also be classified into the tree-based category. However, as their matching process relies on the identification of a composite pattern in those trees, they were classified in this category. In [110], the approach detects and matches N-ary relation reifications between ontologies. The N-ary relation contains a repetitive pattern, therefore [110] was classified in this category.
Parundekar et al. [ 86 ] OWL ontology to OWL ontology, (s:c) (c:s) In this approach proposed by Parundekar et al. [86], the type of correspondences sought is an attribute-value pair matched with an attribute and a union of its acceptable values. In the first step, the approach finds correspondences between attribute-value pairs from the linked instances of the two ontologies (instances linked with owl:sameAs predicate). The number of instances sharing both attribute-value pairs defines whether the correspondence has a subsumption or equivalence relation. The second step of is, for each subsumption correspondence of the previous step, to merge in a union all the attribute-pairs with a common attribute. The relation of the new correspondence is then re-evaluated according to the number of instances for each member. The following example shows the two-step approach.
First step output: (∃
Parundekar et al. [
85
] OWL ontology to OWL ontology, (s:c) (c:s) (c:c) Parundekar et al. [85] look for conjunctions of attribute-value pairs, for instance correspondences of the form (∃
CGLUE, Doan et al. [
25
] DL ontology to DL ontology, (s:c) The GLUE system [25] is specialised in detecting (s:s) correspondences between ontologies’ classes using machine learning techniques such as joint probability distribution. CGLUE, also presented in [25], is an extension of the GLUE system. It can detect (s:c) class unions in class hierarchies such as (
ARCMA, Kaabi et Gargouri [
59
] OWL ontology to OWL ontology, (s:c) Kaabi et Gargouri [59] propose ARCMA (Association Rules Complex Matching Approach) to find correspondences of the form (
Let ( (
With the overlap of terms associated with
Boukottaya and Vanoirbeek [ 7 ] XML schema to XML schema, (s:c) (c:s) (c:c) Boukottaya et Vanoirbeek [7] propose an XML schema matching approach based on the schema tree and linguistic layer of the schema. This approach finds simple and complex correspondences. The complex correspondences follow a few patterns such as merge/split, union/selection and join. The first step calculates a similarity between nodes of the source and target schemata. A linguistic similarity is calculated. A datatype similarity is then computed for the linguistically similar nodes. The union/selection and merge/split correspondences are detected based on graph-mapping. Union/selection correspondences are detected when nodes have a common abstract type (based on their WordNet similarity) which matches a node from the other schema. Merge/split are computed when a leaf node matches a non-leaf node. The correspondences are filtered based on their structural context: ancestors and children nodes. The access path of each node is written in the final correspondences.
If a node
(concatenation(
If two nodes
(
COMA++, Arnold [ 5 ] Document-oriented schema to document-oriented schema, (s:c) As an improvement to the COMA system [69], Arnold [5] discusses a solution based on a lexical strategy on the schemata attribute names: several (s:s) attribute correspondences with the same attribute as target (or source), could be merged into a complex one. The initial approach generates simple correspondences with expressive relations such as meronymy part-of or holonymy has-a besides usual relations (⊒, ⊑, ≡). The extension for transforming the simple correspondences into a complex one can take into account the type of attribute (e.g., concatenation for a string attribute or sum for a numeric attribute). The following example shows a complex correspondence inferred from simple correspondences.
Part-of correspondences with same target member:
(
(
Aggregation in a new correspondence: (concatenation(
iMAP, Dhamankar et al. [ 21 ] Relational database schema to relational database schema, (c:s) As seen in the previous section, the iMAP system [21] uses a set of searchers to discover simple and complex correspondences between relational database schemata. Some of the searchers use composite patterns for correspondence detection. For instance, the text searcher looks for correspondences between an attribute from the target schema and concatenation of string attributes from the source schema. This searcher starts from ranking all possible simple correspondences between attributes. For this, a Naive–Bayes classifier is trained on the target data values to classify whether a given value can be from the target attribute. The average score given by this classifier to a correspondence is used for the ranking. Once the k best simple correspondences are selected, the process is reiterated but with combinations of concatenations of the selected source attribute and other source attributes as base correspondences. These new correspondences are scored, selected, and so on.
Another searcher implements a composite pattern search: the date searcher. It uses a date ontology as mediating schema containing date concepts (e.g., date, month, year) and the relations between them (e.g., concatenation, subset). The attributes of each schema are matched to the date ontology’s entities and the relations between them are reported as transformation functions in the resulting correspondence. The date ontology contains the composite patterns which are discovered by simple graph matching.
Xu and Embley [ 124 , 125 ] Conceptual model to conceptual model, (s:c) (c:s) Xu and Embley [124] propose a similar approach to iMap’s date matcher. It uses a user-specified domain ontology as mediator between the two conceptual models to be aligned. This ontology contains relations between concepts such as composition, subsumption, etc. It is populated thanks to regular expressions applied on source and target data. Simple correspondences (equivalence or subsumption) are first detected using recognition of expected value techniques between the source conceptual model (resp. target) entities and the ontology’s concepts. These simple correspondences are kept for the next phase if the number of common values between the conceptual model entity and the ontology concept are above a threshold.
The relation between the ontology concepts in simple correspondences will become the transformation functions between the attributes they are linked to. For example, s:street s:city are two entities from the source conceptual model and t:address is an entity from the target conceptual model. In the first matching phase, simple correspondences are drawn with concepts from the mediating ontology o:
(o:Address, t:address, ≡)
(o:Street, t:street, ≡)
(o:City, t:city, ≡)
In o, the concept o:Address has a composition relation with the concepts o:Street, o:City. Therefore, the output complex correspondence will state that t:address is a string concatenation of s:street and s:city.
The later version of Xu and Embley’s approach [125] completes this work with two new confidence calculations for simple attribute matching. The two new calculations do not consider a mediating ontology.
Warren and Tompa [ 118 ] Table schema to table schema, (c:s) Warren and Tompa [118] focus on finding correspondences between string columns of tabular data. They deal with correspondences that translate a concatenation of column sub-strings. The approach starts by ranking the source columns according to the q-grams (sequence of q characters) of its values found in the target column. Then it looks for matched instances (rows) according to a tf-idf formula on co-occurring q-grams. The source column that has the smallest editing distance from the target column is put in an initial translation rule. This translation rule is then iteratively refined with addition of sub-strings from other source columns.
A correspondence output by this approach could be: (concatenation(substr(
Šváb–Zamazal and Svátek [ 110 ] OWL ontology to OWL ontology, (s:c),(c:s),(c:c) This approach is based on structural and naming conditions to detect N-ary relation patterns as defined by the Semantic Web Best Practice (SWBP)3
in the aligned ontologies. First, reified N-ary relations are sought in the ontologies with the help of a lexico-structural pattern. The fragment of ontology represented in Fig. 3(a) shows an N-ary relation between a reviewer, a paper and its review appreciation. This pattern consists in an intermediate concept (here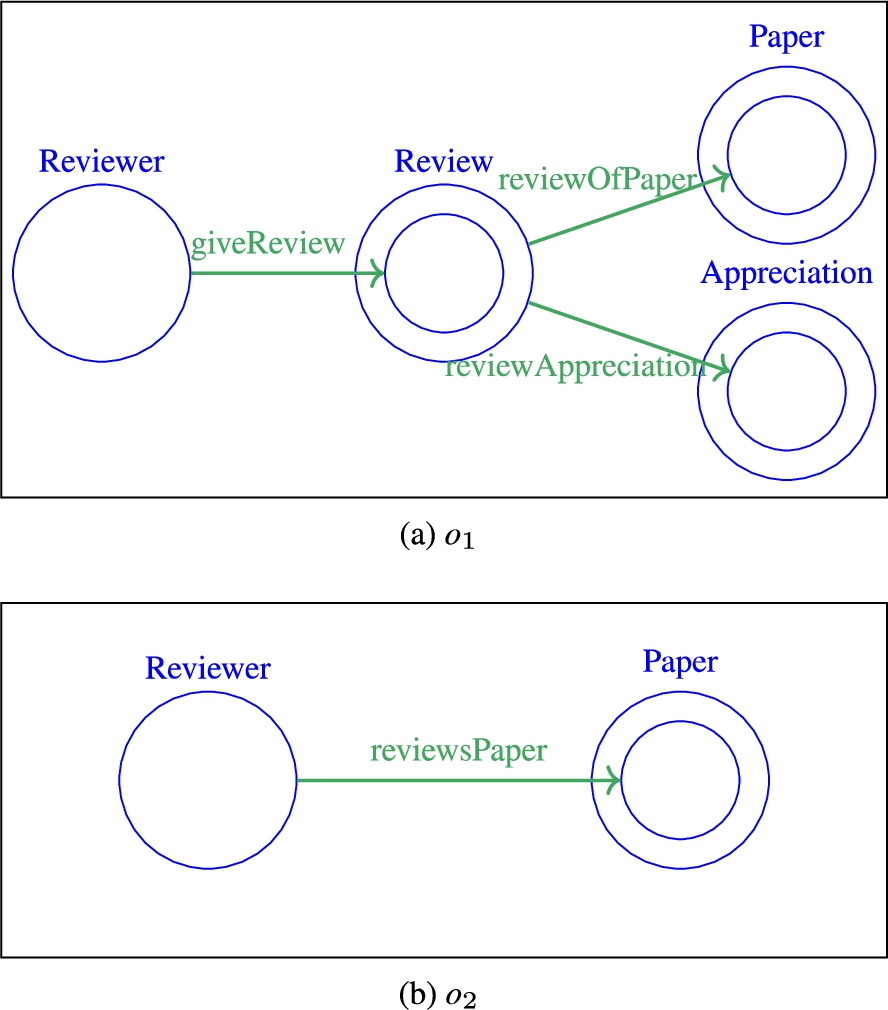
N-ary relation pattern.
PORSCHE, Saleem et al. [
96
] XML schema to XML schema, (s:c) (c:s) PORSCHE (Performance ORiented SCHEma Matching) [96] matches a set of XML schema trees (schemata with a single root) simultaneously. It is a holistic approach. This approach outputs a mediating schema (all the schemata merged) as well as correspondences from each source schema to the mediating schema. An initial mediating schema is chosen among the source schema trees. It is then extended by the approach. For each node of each schema, the approach tries to find a corresponding node in the mediating schema. The tokenised labels of the nodes are compared with the help of an abbreviation table. The context of a node is also taken into account for the merging, where the ancestors of the nodes must match. The pattern used for the detection of the complex correspondences is: if a non-leaf node (e.g.,
The following two approaches are also holistic: they match many schemata simultaneously. They rely on web query interfaces.
DCM, He et al. [
45
] Table schema to Table schema, (s:c) (c:s) (c:c) DCM (Dual Correlation Mining) [45] is a holistic schema matching system. It aligns attribute names of Web Forms. It uses data-mining techniques (positive and negative correlation mining) on a corpus of web query interfaces to discover complex correspondences. The approach uses attribute co-occurrence frequency as a feature for the correlation algorithm. The first step of the algorithm is to mine frequently co-occurring attributes from the web query interfaces. These attributes are put together as groups (e.g., {
HSM, Su et al. [ 108 ] Table schema to Table schema, (s:c) (c:s) (c:c) HSM (Holistic Schema Matching) [108] is very similar to DCM [45] as it considers schema matching as a whole. It finds synonyms and grouping attributes based on their co-occurrence frequency and proximity in the web query interfaces. Two scores are computed between attributes: synonym scores (the confidence that two fields may refer to the same concept or thing) and grouping scores (confidence that two concepts are complementary to one-another). The algorithm then goes through the synonym scores in decreasing order and adds new correspondences to the alignment. If an attribute is a synonym of an attribute already involved in a correspondence, it may be added to an existing group of attributes according to its grouping score with them.
The approach explores the synonyms:
Wu et al. [ 122 ] Table schema to table schema, (s:c) (c:s) Wu et al. [122] propose a clustering approach to find attribute correspondences based on web query interfaces. It considers the hierarchical structure of an HTML form. It also considers the values taken in the table rows as the domain of an attribute.
The first step consists in finding complex correspondences of the form (s:c) or (c:s) in which the attribute in the simple member is called the singleton attribute and the attributes in the complex member, the grouped attributes. Two types of correspondences are sought: aggregate and is-a. An aggregate correspondence shows a value concatenation: ({date}, aggregate{day,month,year}, ≡). A is-a correspondence shows a union, sum, etc. of these values: ({passengers}, is-a{adults,children,seniors}, ≡). The detection conditions of these correspondences are based on the hierarchy of the web form attributes: the label of the parent node of the grouped attributes must be similar to that of the singleton attribute. For is-a, the grouped attributes’ domains must be similar to the singleton’s, whereas for aggregate, the domain of each grouped attribute must be similar to a subset of the singleton attribute’s domain.
A clustering technique then computes simple correspondences in a holistic manner between the interfaces. Simple correspondences and preliminary complex correspondences are merged. Other complex correspondences may be inferred from this merging phase. Even if the simple matching process is holistic, the detection of the complex correspondences is made interface to interface. Thus, the output correspondences are schema to schema.
The final step of the approach is user refinement. The system asks the user questions to refine the alignment and tune the parameters of the clustering algorithm and similarity calculation.
A specificity of the path-based approaches is that they all rely on simple correspondences (at instance or ontology level). Some of them discover these simple correspondences themselves as a preliminary step [28,90], others take them as input [3,4,73,126]. Most approaches perform the path search on the graph-like or tree-like structure of the schemata/ontologies directly whereas [4] creates a mapping graph on which the search will be performed.
An et al. [
3
] Document-oriented schema to CML ontology, (s:c) An et al. [3] map a web query form to a CML ontology. The attribute and fieldset names of the form are transformed into a form tree (derived from HTML), similar to an XML schema tree. The algorithm takes the form tree, the ontology and simple correspondences between the form tree and the ontology as input. The first step of the algorithm is to find for each edge of the form tree between two nodes, all sub-graphs
Clio, Miller et al. [ 73 ], Yan et al. [ 126 ] Relational database schema to relational database schema, (s:c) (c:s) (c:c) Based on structural information of relational database schemata, the Clio system4
Ontograte, Qin et al. [ 90 ], Dou et al. [ 28 ] OWL ontology to OWL ontology, (c:c) OntoGrate [90] is a framework that mines frequent queries and outputs them as conjunctive first-order logic formulae. The system can deal with ontology matching [90] and was adapted to relational database schema matching in [28] by transforming the relational database schema into a database ontology. In OntoGrate, the first step of the matching algorithm is to generate simple correspondences at ontology level. An object reconciliation phase then aligns instances from source and target knowledge bases. The instance correspondences from the object reconciliation fuel the simple correspondence generation. The algorithm iterates on both steps (simple correspondence generation and object reconciliation) until no new instance correspondence or simple correspondence is discovered. Once the simple correspondences are found, a group generator process generates groups of entities closely related to a source property. The group generation is done by exploring the ontology graph and finding a path between entities (e.g., classes) linked by a simple property/property correspondence (the property/property correspondence can be data-property/data-property or object-property/object-property). The path-finding algorithm is an exploration algorithm of the two ontology graphs where classes are the nodes and properties (object properties, data properties, subclass relations and super-class relations) are the edges. The ontology graphs are explored until two nodes, one in the source path and one in the target path, are found which were matched in the first steps of the matching process. The final steps of the matching process is Multi-Relational Data Mining (MRDM) to retrieve frequent queries among the matched instances for the given entity groups. If the support of a query is above a threshold, the query is considered frequent and kept. The frequent queries are then refined and formalised into first-order logic formulae.
The simple matching phase computed:
( (
However, the last correspondence is wrong as it is and considered incomplete because
The group entity algorithm starts with the following entity groups:
source: { target: {
The process searches both ontologies so that two equivalent classes can be found in the groups: the source: { target: {
If the matched instances give the entity groups enough support, the following correspondence is output:
(dom(
An and Song [
4
] CML ontology to CML ontology, (c:c) An and Song [4] introduce the concept of mapping graph between two ontologies in CML language. This process relies on a simple alignment between the concepts of the ontologies. The first step of the approach is to generate the mapping graph between the ontologies. The nodes of a mapping graph represent pairs of concepts from the two ontologies. For example ( If ( The correspondence translating this path is (dom(
While some approaches [1,2,66] rely on a semantic tree derived from the schema, the approaches focusing on structural transformations between two trees (addition of a node, deletion of an attribute, etc.) such as [37,42] often rely on tree-structure. However, they are out of the scope of this study as they are part of the ontology evolution field. Other approaches such as [18,79] use tree-based algorithms such as genetic programming. However they do not consider the schemata or ontologies as trees and therefore are not classified in this category.
MapOnto, An et al. [ 1 , 2 ] Relational database schema to CML ontology [ 1 ], XML schema to OWL ontology [ 2 ], (c:c) MapOnto5
Let PAPERS(id,title,accepted) be a table from a relational database schema. The following translation rule to map the PAPERS table to an ontology o can be output by this approach: PAPERS(id,title,author) ⇒ o:Paper(x) ∧ o:paperId(x, id) ∧ o:title(x,title) ∧ o:Author(y) ∧ o:authorOf(x,y) ∧ o:name(y,author)
KARMA, Knoblock et al. [ 66 , 121 ] Table schema, Relational database schema, XML schema, JSON schema to OWL ontology, (s:c),(c:s),(c:c) KARMA6
The approaches described in this section do not follow any of the above structures. While [50] is based on Inductive Logic Programming and builds its correspondences in an ad hoc manner, [114] relies on competency questions and common instance predicates, [53] uses Markov Logic Networks for combinatorial exploration, [51] uses classifying techniques to generate block correspondences, [21] uses a numeric searcher using context-free grammar for equation discovery, [121] applies a user-driven programming-by-example strategy and finally [18,79] use genetic programming to combine data value transformation functions.
Hu et al. [
50
] OWL ontology to OWL ontology, (s:c) The approach proposed by Hu et al. [50] uses Inductive Logic Programming (ILP) techniques to discover complex alignments. This technique is inspired by Stuckenschmidt et al. [107]. The approach is based on the common instances of a source and a target ontology. It outputs Horn-rules of the form
At the first iteration of the process, the head of the Horn-rule is set to a predicate (unary or binary) and the body of the Horn-rule is empty. Let us consider the case when the Horn-rule head is a binary predicate: ∀x,y, →
∀x,y, ∃z,
and in the next iteration: ∀x,y, ∃z,
Thiéblin et al. [ 115 ] OWL ontology to OWL ontology, (s:c) (c:s) (c:c) In [115], only class expression correspondences are sought. The approach takes as input a set of SPARQL queries over the source ontology defined as Competency Questions for Alignment (CQAs). These CQAs guide the matching process: the answers to each CQA are matched to instances of the target ontology. Then, the surroundings of these target instances are lexically compared to the CQA. The surroundings include the triples in which the target instance appears and the type of the objects or subjects of these triples which are not the target instance. The labels of the CQA used for comparison in the matching process are those of the entities which appear in the CQA. To find a correspondence, the two ontologies must have at least one common instance per CQA. The instance matching process uses existing links or the sharing of a label. The SPARQL query (CQA) is turned into a DL formula to become the source member of the correspondence. The most similar surroundings of the target instances (triple with or without object/subject type) are turned into DL formula to become the target member of the correspondence. The form of the correspondence depends on the structure of the CQA and the most similar surroundings of the target instances.
Let a CQA over the source ontology
An answer to the CQA is ( (
If the label of the object/subject is more similar to the CQA than its type, only its value is kept.
The triple (
KAOM, Jiang et al. [ 53 ] OWL ontology to OWL ontology, (s:c) (c:s) (c:c) KAOM (Knowledge Aware Ontology Matching) is a system proposed by Jiang et al. [53]. It uses Markov Logic Network as a probabilistic framework for ontology matching. The Markov Logic formulae presented in this approach use the entities of the two ontologies (source and target) as constants, the relations between entities and the input knowledge rules as evidence. The knowledge rules can be axioms of an ontology or they can be specified by the user. They do not have to be semantically exact. To handle numerical data-properties, KAOM proposes two methods to find positive linear transformations between rules. These methods are based on the values that the data-properties take in a given knowledge base (the distribution of the values or a way to discretise them). The correspondence patterns and conditions presented by Ritze et al. [92,93] can be translated into knowledge rules and therefore used into Markov Logic formulae. The knowledge rules can be obtained in various ways as was shown in the experiments where decision trees, association rules obtained from an a priori algorithm or manually written rules were translated as knowledge rules for three different test cases.
A knowledge rule could be“Many reviewers are also authors of paper”, which would be in
iMAP, Dhamankar et al. [ 21 ] Relational database schema to relational database schema, (c:s) As seen previously, the iMAP system [21] uses a set of searchers to discover simple and complex correspondences between database schemata. The overlap numeric searcher uses the LAGRAMGE algorithm for equation discovery based on overlapping data. This algorithm uses a contex-free grammar to define the search space of the arithmetic equations and executes a beam-search to find a suitable correspondence. The output of this search space is then stored as a pattern for the numeric searcher.
Nunes et al. [ 79 ] OWL ontology to OWL ontology, (c:s) Genetic programming can be used for finding complex correspondences between data-properties. It can combine and transform the data-properties of an ontology to match a property of another ontology. Nunes et al. [79] propose a genetic programming approach for numerical and literal data property matching. The correspondences generated are (c:s) as n data-properties from the source ontology are combined to match a target data-property. The source data-properties are chosen from a calculated estimated mutual information (EMI) matrix. Each individual of the genetic algorithm is a tree representing the combination operations over data properties. The elementary operations used for combination are concatenation or split for literal data-properties and basic arithmetic operations for numerical data-properties (sum, multiplication, etc.). The fitness of a solution is evaluated on the values given by this solution and the values expected (based on matched instances) using a Levenshtein distance.
de Carvalho et al. [ 18 ] Table schema to table schema, (s:c) (c:s) (c:c) De Carvalho et al. [18] apply a genetic algorithm to alignments as its “individuals”. Each “individual” is a set of correspondences. Each correspondence is a pair of tree functions made of elementary operations (as for Nunes et al. [79]) and having source (resp. target) attributes as leaves. Constraints over the correspondences have been defined: a schema attribute cannot appear more than once in a correspondence, crossover and mutation can only be applied to attributes of the same data type, the number of correspondences in an alignment is fixed a priori. Mutation and cross-over operations occur at the correspondence’s tree-level when parts of two tree functions are swapped, or changed. The fitness evaluation function of the schema alignments (individuals) is the sum of the fitness score of its correspondences. The fitness score of a correspondence can be calculated in two ways: entity-oriented with the similarity of matched instances (the data must be overlapping) or value-oriented with the similarity of all transformed source instances and target instances. The similarity metric for each correspondence is chosen by an expert. Compared to the approach of Nunes et al. [79] it can detect (c:c) correspondences thanks to its internal modelling. However the process may require more iterations than [79].
KARMA, Knoblock et al. [ 66 , 121 ] Table schema, Relational database schema, XML schema, JSON schema to OWL ontology, (s:c),(c:s),(c:c) The programming-by-example algorithm of KARMA (approach presented in the Tree category) creates data transformation functions. It considers the transformation functions as programs divided into subprograms to be applied to the data to transform it. At the beginning of the process, an example of source data (a table cell or row value) is given to the user and he or she gives what he or she expects as a result. This first pair of values constitutes an example and a program (transformation function) is then synthesised and applied to the other instances of the data. The user iteratively corrects the wrongly translated data, giving new examples from which the process refines its program by detecting and changing incorrect subprograms. The basic operations (or segments) of a program or subprogram are string operations (substring, concatenation, recognizing a number, etc.). As the input and the output of the process can cover one or many columns of the source and target tables, this part of KARMA can output (s:c), (c:s) or (c:c) correspondences.
A first example “PaperABC written by AuthorTT strong accept 2016” from the source database is given to the user. The user gives the expected value “PaperABC (2016)”. This first pair of values constitutes an example and a program (transformation function) is synthesised. For example, out of all the possible programs (called hypotheses) one could be:

where indexOf(LEFT, RIGHT, N) takes the left and right context of the occurrence and N denotes the n-th occurrence. START is the beginning of the value, END its end. WORD represents a ([A-Za-z]+) string, NUM a number, BNK a white-space. This program is then applied to the other instances of the data. The user iteratively corrects the wrongly translated data, giving new examples from which the process refines its program (the hypothesis space will be reduced).
BMO, Hu et al. [
51
] OWL ontology to OWL ontology, (s:c) (c:s) (c:c) BMO (Block Matching for Ontologies) focuses on matching sets of entities (classes, relations or instances) called blocks. This approach is articulated into four steps. The first step is the construction of virtual documents for each entity of both ontologies: the annotations and all triples in which an entity occurs are gathered into a document. The second one computes a relatedness matrix by calculating the similarity between each vectorised virtual document. In the third step, the relatedness matrix is used to apply a partitioning algorithm: this algorithm is recursively applied to the set of ontology entities. At the end of this algorithm, the similar entities are together in the same block while dissimilar entities are in distinct blocks. The final step consists in finding the optimal alignment given a number of blocks. Ontology entities which are in the same block can be separated into
Input of the approaches: type of aligned knowledge representation model and type of additional input information
Output of the approaches: correspondence members form, types of correspondences and correspondence format
Process characteristics of the approaches based on the proposed classification
Classification of the complex matchers on [35]’s basic techniques
The proposed classification is based on two main axes, the output (type of correspondence) and process (guiding structure) dimensions of the approaches. The following tables present the approaches in the order in which they first appear in the survey.
Table 6 summarises the type of knowledge representation models aligned by the approaches and the additional input. Most approaches require external output such as matched instances or a simple alignment. This table shows the variety of knowledge representation models for which complex matching approaches have been proposed. Table 7 presents the output by the approaches: the correspondence members form, the type of correspondence and the output format. Few approaches can generate both logic construction and transformation function correspondences. Most approaches output correspondences as FOL rules, without following a particular format. The latest approaches ([36,115] published in 2018) output correspondences in EDOAL, which coincides with their participation in the OAEI complex track (cf. Section 6).
Table 8 presents the process of the approaches according to our classification. Most approaches are pattern-based (atomic or composite). Only a few approaches have no guiding structure. There is no direct correlation between the member expression (fixed to fixed, unfixed to unfixed, etc.) and the (s:c), (c:s) kind of correspondence.
In the Ontology Matching book [35], the basic matching techniques are classified as follows:
Formal resource-based: rely on formal evidence: upper-level ontology, domain-specific ontology, linked data, linguistic frames, alignment Informal resource-based: rely on informal evidence: directory, annotated resources, web forms String-based: use string similarity: name similarity, description similarity, global namespace Language-based: use linguistic techniques: tokenisation, lemmatisation, thesauri, lexicon, morphology Constraint-based: use internal ontology constraints: types, key properties Taxonomy-based: consider the specialisation relation of the ontologies: taxonomy, structure Graph-based: consider the ontologies as graphs: graph homomorphism, path, children, leaves, correspondence patterns Instance-based: compare sets of individuals: data analysis, statistics Model-based: use the semantic interpretation: SAT solvers, DL reasoners
The complex matching approaches are described according to this classification in Table 9. The majority combine different matching techniques.
Few approaches are model-based (no semantic interpretation of the alignment). However, it is important to note that identifying the strategies based on Euzenat and Shvaiko’s classification was not always straightforward.
Another way of classifying the approaches is with respect to the kind of evidence they exploit (ontology-level or instance-level), as done in different surveys in the field. This classification was applied in the last 2 columns of Table 8. Most approaches use the ontology-level information as evidence. The approaches which output transformation functions mostly rely on instance-level information.
Evaluation of complex matchers
This section discusses the evaluation of complex alignments regarding the datasets and metrics. While most of the approaches have been manually evaluated, the few automatic evaluations are often done on approach-tailored datasets (e.g., correspondences following one pattern only). In this section, we do not analyse the evaluation section of each approach individually but we review the initiatives for complex alignment evaluation.
Complex alignment datasets
Datasets for complex alignment evaluation. KRM stands for knowledge representation model
Datasets for complex alignment evaluation. KRM stands for knowledge representation model
The diverse complex matching approaches exploit a variety of knowledge representation models (e.g., XML schemata, ontologies) and resources (e.g., linked instances, web forms). They also generate different types of correspondences. This makes their evaluation difficult and heterogeneous. The approaches were mostly evaluated on pairs of knowledge representation models over a wide range of domains (geography, biomedicine, conference organisation, sports, companies, libraries, etc.). Few systems were evaluated by comparison to a reference alignment, and even fewer of these reference alignments were made available online. In this section we present the datasets available online with reference to complex alignments and the benchmarks which deal with complex alignments. They are summarised in Table 10.
In the domain of schema matching (database or XML schema), dedicated complex alignment datasets have been constructed to evaluate the approaches dealing with these schemata. In general, these datasets contain mostly transformation functions. For instance, the Illinois semantic integration archive [23] is a dataset of complex correspondences on value transformations (e.g., string concatenation) in the inventory and real estate domain. This dataset only contains correspondences between schemata with transformation functions. The UIUC Web integration Repository [10] is a repository of schemata and query forms. XBenchMatch [30] is a benchmark for XML schema matching. The reference alignments of the person dataset contains correspondences with string concatenation.
For the purpose of evaluating matching hybrid structures, the RODI Benchmark [89] proposes an evaluation over given scenarii, R2RML correspondences between a database schema and an ontology. The benchmark relies on ontologies from the OAEI Conference dataset, Geodata ontology, Oil and gas ontology. The schemata are either derived from the ontologies themselves or curated on the Web. The RODI deals with R2RML alignment and uses reference SPARQL and SQL queries to assess the quality of the alignment.
SPIMBench [97] is a benchmark for instance matching but it could be used for complex ontology alignment evaluation. A set of transformations were applied to the BBC core and other domain ontologies in order to obtain derived ontologies with the same instances. The transformation rules can be considered as correspondences. Some transformation rules are even complex correspondences (either logic relations or value transformation functions). Each set of transformation rules between two ontologies was documented in the SPIMBench vocabulary and constitutes a reference complex alignment. However, the reference alignment is not considered in the evaluation process of the benchmark, which only focuses on instance matching.
This year, the first complex track of the Ontology Alignment Evaluation Initiative was conducted. It included four datasets [113] among which the GeoLink dataset [129] and a consensus version of [114].
Of all the datasets presented in Table 10, only SPIMBench contains common or matched instances. However, the derived datasets are synthetic. Because they needed common instances, some matchers have been evaluated on LOD repositories (DBpedia, Yago, Agrovoc, Geospecies, etc.) [50,85,86,115,117] or custom-made knowledge bases [18,21,53,79].
Complex matching evaluation can be performed under various dimensions such as time execution or the quality of the output alignment. In this section, the complex alignment quality metrics are presented. These metrics do not include approach-specific metrics as defined in [45,51,108] but those that can be generalised to all complex alignments.
The most usual metrics, adapted from information retrieval, used for evaluating the quality of alignments with respect to a reference one are precision and recall, combined into F-measure. The calculation of the recall and F-measure requires a reference alignment whereas the precision alone can be assessed by classifying correspondences as true positives or false positives. The usual precision and recall are the metrics which were the most used in the evaluation of the approaches. However, as reference alignments are not always available, the precision is often the only metric computed. The comparison of complex correspondences is a difficult task which is often performed manually. This makes the evaluation time-consuming and experts on the aligned ontologies are required during the evaluation process. The precision and recall metrics have been adapted into weighted precision and recall, relaxed precision and recall, and semantic precision and recall [15]. The weighted precision and recall take the confidence value of a correspondence into account. The relaxed precision and recall [31] take the subsumption relations into account: a correspondence is not discarded if it states an equivalence instead of a subsumption, its “score value” will be 0.5 instead of 1 for example. The semantic precision and recall [33] considers the alignments as sets of axioms and is measured by comparing their deductive closure, i.e., the set of axioms which can be derived from the alignment together with the ontologies.
The metrics of accuracy or top-x accuracy have been used in various evaluations [3,18,21,25,45,55,108,115] when the number of correspondences is predefined, e.g., one correspondence for each entity of the target schema/ontology. The accuracy is then the percentage of predefined questions having a correct answer. A “question” in this context could be a source entity to be matched and the “answers” the correspondences having this entity as source member. Some approaches output various answers for each question, e.g., a ranked list of correspondences for each source entity. In this case the top-x accuracy is the percentage of questions whose correct answer is in the top-x answers to the question. For example, top-3 accuracy is the fraction of source entities for which the correct correspondence is in the best three correspondences output by the system.
During this year’s OAEI complex track, the evaluation was mostly manual. The usual precision and recall metrics were reused for the Conference dataset. For the Hydrography and GeoLink dataset, three tasks were defined, but the matchers could be evaluated on the first one only using precision and recall:
Finding the entities which belong together in a correspondence, regardless to the correspondence structure; Finding the correct correspondence structure given the set of entities to match; Finding the correspondences from scratch.
Finally, the Taxon dataset was manually evaluated with a usual precision metric and within a query rewriting scenario. The accuracy, as the percentage of well rewritten queries, was also computed.
All the metrics presented above need either a reference alignment or a manual evaluation. Even with a reference alignment, the evaluation is not straightforward due to the difficulty of comparing two complex correspondences.
Summary
Until recently, there was little work on complex alignment evaluation. The latest works propose datasets. Only RODI [89] is an automated benchmark. Most of the OAEI complex track evaluation is still manually performed. This comes from the difficulty of comparing two complex correspondences. For example, (
The relation of the correspondences (
Finally, measuring the suitability of the output alignment for a given application, as done for the OA4QA track of the OAEI [103], for a library application [52] or the Taxon track of the complex OAEI track [113], could be considered.
Discussion
Interest in complex alignment has recently increased in the community. This probably comes from the fact that applications needing interoperability find simple alignment not sufficient.
Since the XML and database fields are older than ontology matching and ontology-based data access (OBDA), they have stable standards such as XSLT, XQuery and SQL. In the OBDA community, R2RML has become the norm, and many extensions to it proposed, there is a proliferation of edition and visualisation tools, as well as matching approaches. In the ontology matching community, this proliferation is not so marked. Event if various alignment formats have been proposed (cf. Section 3.1), the EDOAL vocabulary implemented in the Alignment API can be seen as an up-coming standard. It has indeed been used for the first OAEI track. However, EDOAL has limited expressiveness, as discussed in [129]. Moreover, there is only one edition or visualisation tool for this format (OAT [12]) but it is not available online. This makes EDOAL only usable or browse-able by experts. SPARQL could be an alternative to EDOAL as it does not suffer from such limitations and can be directly executed. The study of the approaches in this survey shows that, contrary to what intuition may suggest, matching more expressive knowledge representation models does not imply applying more sophisticated techniques. Most approaches consider knowledge representation models as graphs, trees or pools of annotated data regardless of their expressiveness. These common representations lead to similar techniques over diverse knowledge representation models. The proposed classification tried to capture some of the aspects described above, by focusing on the specificities of complex correspondences on two main axes. The first axis characterises the different types of output (type of correspondences) and the second the structures used in the process to guide the correspondence detection. With respect to this classification, some approaches adopt a mono-strategy (atomic patterns, for instance), while others can fall in diverse categories. Classifying some of the approaches into a specific category was not a simple task.
While some approaches rely on existing simple correspondences (at ontology or instance level), others are able to discover complex correspondences without this kind of input. Other resources are used as evidence such as web query interfaces, knowledge rules, competency questions for alignment or linguistic resources such as WordNet. Another aspect of the approach is related to the kind of correspondence relation they can output. As for simple alignments, most works are still limited to generating equivalences. The semantics of the confidence of a correspondence are rarely considered.
While the use of instance data evidence is valuable for the matching process, statistical approaches are directly impacted by the quality of this data. They can be faced with the problem of sparseness or with a specific corpus distribution that leads to incorrect correspondences. For example, if
Most approaches are limited to pair-wise matching. Holistic and compound complex matching approaches are scarce but may be needed in complex domains, such as bio-medicine, where several ontologies describing different but related phenomena have to be linked together [81]. As stated in [88], the increase in the matching space and the inherently higher difficulty to compute alignments pose interesting challenges to this task.
On a different matter, we observe that some correspondences are pragmatically coherent but not semantically equivalent. For example, (
Moreover, user involvement is under-exploited in complex matching. This aspect, related to the visualisation and edition of complex correspondences [29,78], is an important issue to be addressed in the future.
Regarding the evaluation of complex alignments, automatic correspondence comparison remains an open issue. The perspective of a benchmark with a reference alignment, real-life ontologies populated with controlled instances and metrics based on these instances, would be a useful resource in the field. As the interpretation of an ontology can vary from user to user, having a consensual benchmark with correspondence confidences reflecting the agreement between annotators, as in [11], could be also an interesting resource. Another direction would be to evaluate the complex alignments over a real-life application such as ontology merging, data translation or query rewriting. The suitability of the alignment for the given task could be automatically computed. The first OAEI complex track could –hopefully– stimulate new works on complex ontology matching, evaluation, visualisation, etc.