
Abstract
With the development of the Semantic Web, a lot of new structured data has become available on the Web in the form of knowledge bases (KBs). Making this valuable data accessible and usable for end-users is one of the main goals of question answering (QA) over KBs. Most current QA systems query one KB, in one language (namely English). The existing approaches are not designed to be easily adaptable to new KBs and languages.
We first introduce a new approach for translating natural language questions to SPARQL queries. It is able to query several KBs simultaneously, in different languages, and can easily be ported to other KBs and languages. In our evaluation, the impact of our approach is proven using 5 different well-known and large KBs: Wikidata, DBpedia, MusicBrainz, DBLP and Freebase as well as 5 different languages namely English, German, French, Italian and Spanish. Second, we show how we integrated our approach, to make it easily accessible by the research community and by end-users.
To summarize, we provide a conceptional solution for multilingual, KB-agnostic question answering over the Semantic Web. The provided first approximation validates this concept.
Introduction
Question answering (QA) is a research field in computer science that started in the sixties [38]. In the Semantic Web, a lot of new structured data has become available in the form of knowledge bases (KBs). Nowadays, there are KBs about media, publications, geography, life sciences and more.1
Selection of QA systems evaluated over the most popular benchmarks. We indicated their capabilities with respect to multilingual questions, different KBs and different typologies of questions (full = “well-formulated natural language questions”, key = “keyword questions”)
There are multiple reasons for that. Many QA approaches rely on language-specific tools (NLP tools), e.g., SemGraphQA [3], gAnswer [66] and Xser [60]. Therefore, it is difficult or impossible to port them to a language-agnostic system. Additionally, many approaches make particular assumptions on how the knowledge is modelled in a given KB (generally referred to as “structural gap” [12]). This is the case of AskNow [19] and DEANNA [61].
There are also approaches which are difficult to port to new languages or KBs because they need a lot of training data which is difficult and expensive to create. This is for example the case of Bordes et al. [5]. Finally there are approaches where it was not proven that they scale well. This is for example the case of SINA [48].
In this paper, we present an algorithm that addresses all of the above drawbacks and that can compete, in terms of F-measure, with many existing approaches.
This publication is organized as follows. In Section 2, we present related works. In Section 3 and 4, we describe the algorithm providing the foundations of our approach. In Section 5, we provide the results of our evaluation over different benchmarks. In Section 6, we show how we implemented our algorithm as a service so that it is easily accessible to the research community, and how we extended a series of existing services so that our approach can be directly used by end-users. We conclude with Section 7.
In the context of QA, a large number of systems have been developed in the last years. For a complete overview, we refer to [12]. Most of them were evaluated on one of the following three popular benchmarks: WebQuestions [4], SimpleQuestions [5] and QALD.2
WebQuestions contains 5,810 questions that can be answered by one reified statement. SimpleQuestions contains 108,442 questions that can be answered using a single, binary-relation. The QALD challenge versions include more complex questions than the previous ones, and contain between 100 and 450 questions, and are therefore, compared to the other, small datasets.
The high number of questions of WebQuestions and SimpleQuestions led to many supervised-learning approaches for QA. Especially deep learning approaches became very popular in the recent years like Bordes et al. [5] and Zhang et al. [62]. The main drawback of these approaches is the training data itself. Creating a new training dataset for a new language or a new KB might be very expensive. For example, Berant et al. [4], report that they spent several thousands of dollars for the creation of WebQuestions using Amazon Mechanical Turk. The problem of adapting these approaches to new dataset and languages can also be seen by the fact that all these systems work only for English questions over Freebase.
A list of the QA systems that were evaluated with QALD-3, QALD-4, QALD-5, QALD-6, QALD-7, QALD-8 can be found in Table 3. According to [12] less than 10% of the approaches were applied to more than one language and 5% to more than one KB. The reason is the heavy use of NLP tools or NL features like in Xser [60], gAnswer [66] or QuerioDali [37].
The problem of QA in English over MusicBrainz3
In summary, most QA systems work only in English and over one KB. Multilinguality is poorly addressed while portability is not addressed at all. The few systems that address multilinguality rely on syntactic parsing techniques [31,51,59].
The fact that QA systems often reuse existing techniques and need several services to be exposed to the end-user, leads to the idea of developing QA systems in a modular way. At least four frameworks tried to achieve this goal: QALL-ME [21], openQA [40], the Open Knowledge Base and Question-Answering (OKBQA) challenge6
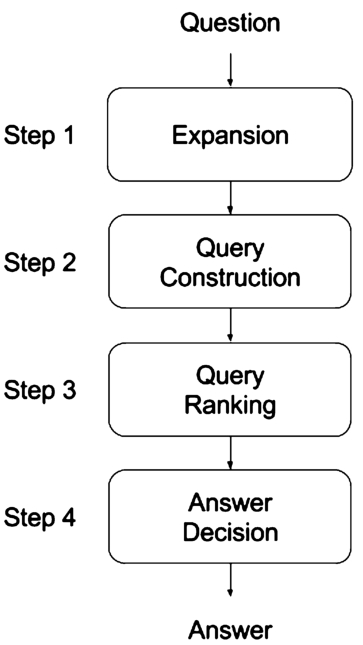
Conceptual overview of the approach.
In this section, we present our multilingual, KB-agnostic approach for QA. It is based on the observation that many questions can be understood from the semantics of the words in the question while the syntax of the question has less importance. For example, consider the question “Give me actors born in Berlin”. This question can be reformulated in many ways like “In Berlin were born which actors?” or as a keyword question “Berlin, actors, born in”. In this case by knowing the semantics of the words “Berlin”, “actors”, “born”, we are able to deduce the intention of the user. This holds for many questions, i.e. they can be correctly interpreted without considering the syntax as the semantics of the words is sufficient for them. Taking advantage of this observation is the main idea of our approach. The KB encodes the semantics of the words and it can tell what is the most probable interpretation of the question (w.r.t. the knowledge model described by the KB).
Our approach is decomposed in 4 steps: question expansion, query construction, query ranking and response decision. A conceptual overview is given in Fig. 1. In the following, the processing steps are described. As a running example, we consider the question “Give me philosophers born in Saint-Etienne”. For the sake of simplicity, we use DBpedia as KB to answer the question. However, it is important to recognize that no assumptions either about the language or the KB are made. Hence, even the processing of the running example is language- and KB-agnostic.
Expansion step for the question “Give me philosophers born in Saint Étienne”. The first column enumerates the candidates that were found. Here, 117 possible entities, properties and classes were found from the question. The second, third and fourth columns indicate the position of the n-gram in the question and the n-gram itself. The last column is for the associated IRI. Note that many possible meanings are considered: line 9 says that “born” may refer to a crater, line 52 that “saint” may refer to a software and line 114 that the string “Saint Étienne” may refer to a band
Expansion step for the question “Give me philosophers born in Saint Étienne”. The first column enumerates the candidates that were found. Here, 117 possible entities, properties and classes were found from the question. The second, third and fourth columns indicate the position of the n-gram in the question and the n-gram itself. The last column is for the associated IRI. Note that many possible meanings are considered: line 9 says that “born” may refer to a crater, line 52 that “saint” may refer to a software and line 114 that the string “Saint Étienne” may refer to a band
Following a recent survey [12], we call a lexicalization, a name of an entity, a property or a class. For example, “first man on the moon” and “Neil Armstrong” are both lexicalizations of All IRIs are searched whose lexicalization (up to stemming) is a word n-gram (up to stemming) in the question. If an n-gram is a stop word (like “is”, “are”, “of”, “give”, …), then we exclude the IRIs associated to it. This is due to the observation that the semantics are important to understand a question and the fact that stop words do not carry a lot of semantics. Moreover, by removing the stop words the time needed in the next step is decreased.
An example is given in Table 2. The stop words and the lexicalizations used for the different languages and KBs are described in Section 5.1. In this part, we used the well-known Apache Lucene7
In this step, we construct a set of queries that represent possible interpretations of the given question within the given KB. Therefore, we heavily utilize the semantics encoded into the particular KB. We start with a set R of IRIs from the previous step. The goal is to construct all possible queries containing the IRIs in R which give a non-empty result-set. Let V be the set of variables. Based on the complexity of the questions in current benchmarks, we restrict our approach to queries satisfying 4 patterns:

and

These correspond to all queries containing one or two triple patterns that can be created starting from the IRIs in R. Moreover, for entity linking, we add the following two patterns:
Note that these last queries just give back directly an entity and should be generated for a question like: “What is Apple Company?” or “Who is Marie Curie?”. An example of generated queries is given in Fig. 2.
The main challenge is the efficient construction of these SPARQL queries. The main idea is to perform in the KB graph a breadth-first search of depth 2 starting from every IRI in R. While exploring the KB for all IRIs

Some of the 395 queries constructed for the question “Give me philosophers born in Saint Etienne”. Note that all queries could be semantically related to the question. The second one is returning “Saint-Etienne” as a band, the third one the birth date of people born in the city of “Saint-Etienne” and the forth one the birth date of persons related to philosophy.
Now the computed candidates need to be ordered by their probability of answering the question correctly. Hence, we rank them based on the following features:
Number of the words in the question which are covered by the query. For example, the first query in Fig. 2 is covering two words (“Saint” and “born”, where “born” is covered by the property The edit distance of the label of the resource and the word it is associated to. For example, the edit distance between the label of The sum of the relevance of the resources, (e.g. the number of inlinks and the number of outlinks of a resource). This is a knowledge base independent choice, but it is also possible to use a specific score for a KB (like page-rank [16]). The number of variables in the query. The number of triples in the query.
If no training data is available, then we rank the queries using a linear combination of the above 5 features, where the weights are determined manually. Otherwise we assume a training dataset of questions together with the corresponding answers set, which can be used to calculate the F-measure for each of the SPARQL query candidates. As a ranking objective, we want to order the SPARQL query candidates in descending order with respect to the F-measure. In our implementation we rank the queries using RankLib8

The top 4 generated queries for the question “Give me philosophers born in Saint Étienne”. (1) is the query that best matches the question; (2) gives philosophical schools of people born in Saint-Étienne; (3), (4) give people born in Saint-Étienne or that live in Saint-Étienne. The order can be seen as a decreasing approximation to what was asked.
The computations in the previous section lead to a list of ranked SPARQL queries candidates representing our possible interpretations of the user’s intentions. We could directly give back the result of first ranked query from the previous step. This will (nearly) always generate an answer. However, there are situations where no suitable interpretation is generated for the question, or where the question is not answerable over the given KB. To determine if such a situation occurred, we add an additional step in which we decide if the result-set of the first query should be returned or if the system should not give back any result. This corresponds to a binary classification problem. We train a model based on logistic regression. We use a training set consisting of SPARQL queries and two labels equal to True or False. True indicates if the F-score of the SPARQL query is greater than a threshold
Multiple KBs
Note that the approach can also be extended, as it is, to multiple KBs. In the query expansion step, one has just to take in consideration the labels of all KBs. In the query construction step, one can consider multiple KBs as one graph having multiple unconnected components. The query ranking and answer decision step are literally the same.
Discussion
Overall, we follow a combinatorial approach with efficient pruning, that relies on the semantics encoded in the underlying KB.
In the following, we want to emphasize the advantages of this approach using some examples.
which probably most users would have expected, but also the query
which refers to an overview article in Wikipedia about the capitals of France and that most of the users would probably not expect. This important feature allows to port the approach to different KBs while it is independent of how the knowledge is encoded.
Here
A disadvantage of our exemplary implementation is that the identification of relations relies on a dictionary. Note that, methods not based on dictionaries follow one of the following strategies. Either they try to learn ways to express the relation from big training corpora (like in [5]), s.t. the problem is shifted to create suitable training sets. Alternatively, text corpora are used to either extract lexicalizations for properties (like in [4]) or learn word embeddings (like in [31]). Hence, possible improvements might be applied to this task in the future.


and
Note that all these properties could be intended for the given question, even if
To conclude, the proposed approach uses the knowledge encoded in the KB to construct candidate queries. This is novel and responsible for the main distinctive features of the approach: easy portability to new languages, easy portability to new KBs and robustness to different types of questions.
Fast candidate generation
In this section, we explain how the SPARQL queries described in Section 3.2 can be constructed efficiently.
Let R be a set of resources. We consider the KB as a directed labeled graph G:
(Graph).
A directed labeled graph is an ordered pair V is a non-empty set, called the vertex set; E is a set, called edge set, such that For a set L called labeled set, f is a function
To compute the pairwise distance in G between every resource in R, we do a breadth-first search from every resource in R in an undirected way (i.e. we traverse the graph in both directions).
We define a distance function d as follows. Assume we start from a vertex r and find the following two edges

Algorithm to compute the pairwise distance between every resource in a set R appearing in a KB
The algorithm of our exemplary implementation simply traverses the graph starting from the nodes in R in a breadth-first search manner and keeps track of the distances as defined above. The breadth-first search is done by using HDT [20] as an indexing structure.9
Based on the numbers above, we now want to construct all triple patterns with K triples and one projection variable recursively. Given a triple pattern T, we only want to build connected triple-pattern while adding triples to T. This can be done recursively using the algorithm described in Algorithm 2. Note that thanks to the numbers collected during the breadth-first search operations, this can be performed very fast. Once the triple patterns are constructed, one can choose any of the variables, which are in subject or object position, as a projection variable.
The decision to generate a
To validate the approach w.r.t. multilinguality, portability and robustness, we evaluated our approach using multiple benchmarks for QA that appeared in the last years. The different benchmarks are not comparable and they focus on different aspects of QA. For example SimpleQuestions focuses on questions that can be solved by one simple triple-pattern, while LC-QuAD focuses on more complex questions. Moreover, the QALD questions address different challenges including multilinguality and the use of keyword questions. Unlike previous works, we do not focus on one benchmark, but we analyze the behaviour of our approach under different scenarios. This is important, because it shows that our approach is not adapted to one particular benchmark, as it is often done by existing QA systems, and proves its portability.
We tested our approach on 5 different datasets namely Wikidata,10
As stop words, we use the lists, for the different languages, provided by Lucene, together with some words which are very frequent in questions like “what”, “which”, “give”.

Recursive algorithm to create all connected triple patterns from a set R of resources with maximal K triple patterns. L contains the triple patterns created recursively and
Depending on the KB, we followed different strategies to collect lexicalizations. Since Wikidata has a rich number of lexicalizations, we simply took all lexicalizations associated to a resource through
For MusicBrainz we used the lexicalizations attached to
purl:
foaf:
For Freebase, we considered the lexicalizations attached to
We want to briefly discuss the strategies we used here. We do not see any option other than manually indicating the lexicalizations for instances. For example, in MusicBrainz the property
This table summarizes the results obtained by the QA systems evaluated with QALD-3 (over DBpedia 3.8), QALD-4 (over DBpedia 3.9), QALD-5 (over DBpedia 2014), QALD-6 (over DBpedia 2015-10), QALD-7 (2016-04), QALD-8 (2016-10). We indicated with “∗” the systems that did not participate directly in the challenges, but were evaluated on the same benchmark afterwards. We indicate the average running times of a query for the systems where we found them. Even if the runtime evaluations were executed on different hardware, it still helps to give an idea about the scalability
(Continued)
To show the performance of the approach on different scenarios, we benchmarked it using the following benchmarks.
The table shows the results of WDAqua-core1 over the QALD-7 task 4 training dataset. We used Wikidata (dated 2016-11-28)
The table shows the results of WDAqua-core1 over the QALD-7 task 4 training dataset. We used Wikidata (dated 2016-11-28)
The results are given in Table 3 together with state-of-the-art systems. To find these, we used Google Scholar to select all publications about QA systems that cited one of the QALD challenge publications. Note that, in the past, QA systems were evaluated only on one or two of the QALD benchmarks. We provide, for the first time, an estimation of the differences between the benchmark series. Over English, we outperformed 90% of the proposed approaches. We achieve similar results as gAnswer2 [34], while we do not beat Xser [60], UTQA [59] and AMAL [46]. Note that Xser and UTQA required additional training data than the one provided in the benchmark, which required a significant cost in terms of manual effort. AMAL uses manual translations of the labels to address the lexical gap and can answer only questions with one triple pattern. Moreover, the robustness of these systems over keyword questions is probably not guaranteed. We cannot prove this claim because for these systems neither the source code nor a web-service is available.
Due to the manual effort required to do an error analysis for all benchmarks and the limited space, we restricted to the QALD-6 benchmark. The error sources over the 100 questions are the following:
40% (26 errors) are due to lexical gap (e.g. for “Who played Gus Fring in Breaking Bad?” the property 28% (18 errors) come from wrong ranking 12% (8 errors) are due to the missing support of superlatives and comparatives in our implementation (e.g. “Which Indian company has the most employees?”) 9% (4 errors) from the need of complex queries with unions or filters (e.g. the question “Give me a list of all critically endangered birds.” requires a filter on 6% (4 errors) come from out of scope questions (i.e. question that should not be answered) 2% (1 error) from too ambiguous questions (e.g. “Who developed Slack?” is expected to refer to a “cloud-based team collaboration tool” while we interpret it as “linux distribution”).
One can see that keyword queries always perform worse as compared to full natural language queries. The reason is that the formulation of the keyword queries does not allow us to decide if the query is an
To show the performance over Wikidata, we consider the QALD-7 task 4 training dataset. This originally provided only English questions. The QALD-7 task 4 training dataset reuses questions over DBpedia from previous challenges where translations in other languages were available. We moved these translations to the dataset. The results can be seen in Table 4. Except for English, keyword questions are easier than full natural language questions. The reason is the formulation of the questions. For keyword questions the lexical gap is smaller. For example, the keyword question corresponding to the question “Qui écrivit Harry Potter?” is “écrivain, Harry Potter”. Stemming does not suffice to map “écrivit” to “écrivain”, lemmatization would be needed. This problem is much smaller for English, where the effect described over DBpedia dominates. We can see that the best performing language is English, while the worst performing language is Italian. This is mostly related to the poorer number of lexicalizations for Italian. Note that the performance of the QA approach over Wikidata correlates with the number of lexicalizations for resources and properties for the different languages as described in [36]. This indicates that the quality of the data, in different languages, directly affects the performance of the QA system. Hence, we can derive that our results will probably improve while the data quality is increased. Finally we outperform the presented QA system over this benchmark.
This table summarizes the QA systems evaluated over SQA2018. This benchmark is designed to measure the scalability of the approach, i.e. how many questions can be answered on increasing load
This table summarizes the QA systems evaluated over SQA2018. This benchmark is designed to measure the scalability of the approach, i.e. how many questions can be answered on increasing load
This table summarizes the QA systems evaluated over SimpleQuestions. Every system was evaluated over FB2M except the ones marked with (∗) which were evaluated over FB5M
This table summarizes the results of WDAqua-core1 over some newly appeared benchmarks
Comparison on QALD-6 when querying only DBpedia and multiple KBs at the same time
Note that the SimpleQuestions dataset is highly skewed towards certain properties (it contains 1629 properties, the 20 most frequent properties cover nearly 50% of the questions). Therefore, it is not clear how the other QA systems behave with respect to properties not appearing in the training dataset and with respect to keyword questions. Moreover, it is not clear how to port the existing approaches to new languages and it is not possible to adapt them to more difficult questions. These points are solved using our approach. Hence, we provided here, for the first time, a quantitative analysis of the impact of big training data corpora on the quality of a QA system.
Note: We did not tackle the WebQuestions benchmark for the following reasons. While it has been shown that WebQuestions can be addressed using non-reified versions of Freebase, this was not the original goal of the benchmark. More then 60% of the QA systems benchmarked over WebQuestions are tailored towards its reification model. There are two important points here. First, most KBs in the Semantic Web use binary statements. Secondly, in the Semantic Web community, many different reification models have been developed as described in [29].
All experiments were performed on a virtual machine with 4 cores of Intel Xeon E5-2667 v3 3.2GH, 16 GB of RAM and 500 GB of SSD disk. Note that the whole infrastructure was running on this machine, i.e. all indexes and the triple-stores needed to compute the answers (no external service was used). The original data dumps sum up to 336 GB. Note that across all benchmarks we can answer a question in less then 2 seconds except when all KBs are queried at the same time which shows that the algorithm should be parallelized for further optimization.
Provided services for multilingual and multi-KB QA
We have presented an algorithm that can be easily ported to new KBs and that can query multiple KBs at the same time. In the evaluation section, we have shown that our approach is competitive while offering the advantage of being multilingual and robust to keyword questions. Moreover, we have shown that we can achieve acceptable run-times on a modern laptop. In this section, we describe how we integrated the approach to an actual service and how we combine it to existing services so that it can be directly used by end-users.
First, we integrated WDAqua-core1 into Qanary [6,13], a framework to integrate QA components. This way WDAqua-core1 can be accessed via RESTful interfaces for example to benchmark it via Gerbil for QA [58]. It also allows to combine it with services that are already integrated into Qanary like a speech recognition component based on Kaldi19
Secondly, we reused and extended Trill to make it easily portable to new KBs. While Trill originally supported only DBpedia and Wikidata, now it also supports also MusicBrainz, DBLP and Freebase. We designed the extension so that it can be easily ported to new KBs. Enabling the support for a new KB is mainly reduced to writing an adapted SPARQL query for the new KB. Additionally, the extension allows to select multiple KBs at the same time.
Thirdly, we adapted some services that are used in Trill to be easily portable to new KBs. These include SPARQLToUser [11], a tool that generates a human readable version of a SPARQL query and SummaServer [16] a service for entity summarization. Finally we extended Trill to present aggregated information in from of collections of images and map aggregation depending on the available information [15]. All these tools now support the 5 mentioned KBs and the 5 mentioned languages.
A public online demo is available under: www.wdaqua.eu/qa
Moreover, there is an open API available that is described at
This is for example implemented by Gerbil for QA [58] and the DBpediaChat [1].20
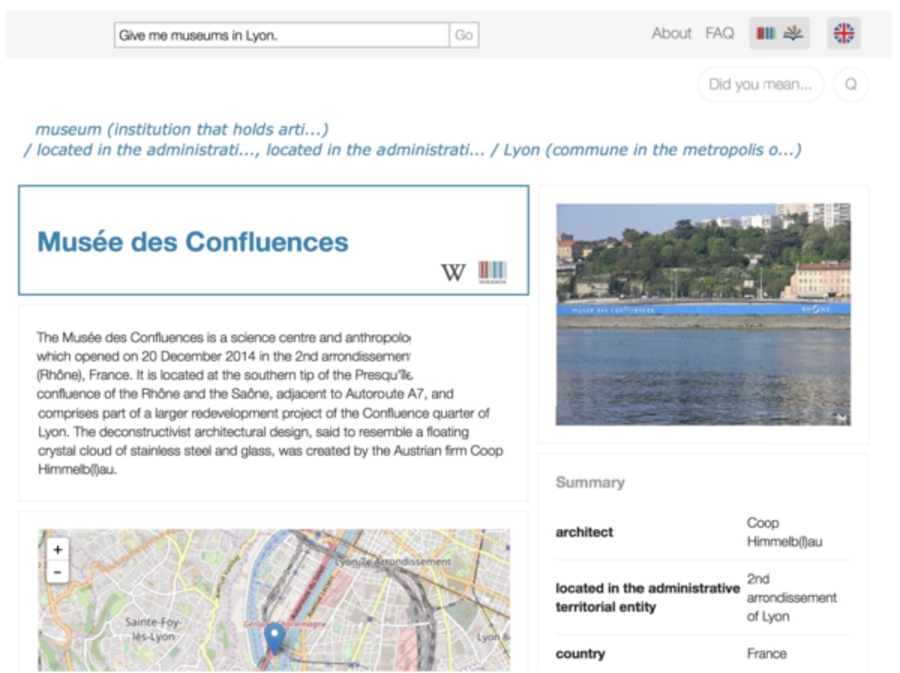
Screenshot of Trill, using in the back-end WDAqua-core1, for the question “Give me museums in Lyon”.
In this paper, we introduced a novel concept for QA aimed at multilingual and KB-agnostic QA. Due to the described characteristics of our approach portability is ensured which is a significant advantage in comparison to previous approaches. We have shown the power of our approach in an extensive evaluation over multiple benchmarks. Hence, we clearly have shown our contributions w.r.t. qualitative (language, KBs) and quantitative improvements (outperforming many existing systems and querying multiple KBs) as well as the capability of our approach to scale for very large KBs like DBpedia.
We have applied our algorithm and adapted a set of existing services so that end-users can query, using multiple languages, multiple KBs at the same time, using a unified interface. Hence, we provided here a major step towards QA over the Semantic Web following our larger research agenda of providing QA over the LOD cloud.
In the future, we want to tackle the following points. First, we want to parallelize our approach, s.t. when querying multiple KBs acceptable response times will be achieved. Secondly, we want to query more and more KBs (hints to interesting KBs are welcome). Thirdly, from different lessons learned from querying multiple KBs, we want to give a set of recommendations for RDF datasets, s.t. they are fit for QA. And fourth, we want to extend our approach to also query reified data. Fifth, we would like to extend the approach to be able to answer questions including complex operators like aggregations and functions. We believe that our work can further boost the expansion of the Semantic Web since we presented a solution that easily allows to consume RDF data directly by end-users requiring low hardware investments.
There is a Patent Pending for the presented approach. It was submitted the 18 January 2018 at the EPO and has the number EP18305035.0.
Footnotes
Acknowledgements
This project has received funding from the European Union’s Horizon 2020 research and innovation program under the Marie Sklodowska-Curie grant agreement No 642795.