Preference representation and reasoning play a central role in supporting users with complex and multi-factorial decision processes. In fact, user tastes can be used to filter information and data in a personalized way, thus maximizing their expected utility. Over the years, many frameworks and languages have been proposed to deal with user preferences. Among them, one of the most prominent formalism to represent and reason with (qualitative) conditional preferences (CPs) are conditional preference theories (CP-theories). In this paper, we show how to combine them with Semantic Web technologies in order to encode in a standard SPARQL 1.1 query the semantics of a set of CP statements representing user preferences by means of RDF triples that refer to a “preference” OWL ontology. In particular, here we focus on context-uniform conditional (cuc) acyclic CP-theories [Artif. Intell. 1752011, 1053–1091]. The framework that we propose allows a standard SPARQL client to query Linked Data datasets, and to order the results of such queries relative to a set of user preferences.
Dealing with user preferences is an important aspect of every application designed to provide personalized information to the end-user. The original interest in preferences can be found in decision theory, as a way to support complex, multifactorial decision processes [20], and nowadays every personalized system needs a preference model to capture what the user likes or dislikes. Once the user model has been represented, it is then exploited to filter information coming from a data source, e.g., a database, in order to provide a ranked list of results matching the order encoded in the preferences of the user.
Query languages usually let us specify the information that we want to be returned (hard constraints), where the result set contains elements with no specific order with reference to user preferences. It contains all those resources that exactly match the constraints represented by the query. As a matter of fact, if just one of the requirements representing the query is not fulfilled, the result set can be empty. At the same time, returning huge and unordered sets of answers could be useless and even counter-productive. A possible way to bypass these issues is to allow the language to represent both hard constraints—used to return only relevant results—and soft ones, i.e., preferences—to rank the results by fulfilling a user’s tastes. Approaches to preference representation can be either quantitative or qualitative [11]. The former are based on a total ordering of the outcomes, given by a scoring function, while the latter enable the representation of partial orders, since preferences are treated as independent dimensions. From a user perspective, a qualitative approach is more natural than the quantitative one [37]. Indeed, in the first case, the user has just to provide pairwise qualitative comparisons, while in the second case, she has to assign a value to many alternatives, which very often are represented in a multi-attribute setting. Regarding the Linked (Open) Data world, the notion of qualitative preferences in SPARQL queries was introduced in [40] by Siberski et al., whose preference-based querying language extends SPARQL through the introduction of solution modifiers (the PREFERRING clause). Their query formulation retrieves only items that are the most preferred ones, or equivalently undominated. The work [26] builds on the earlier approach of [40], but adds preferences at the level of filters, rather than as a solution modifier. The PrefSPARQL syntax of [26] needs no additional solution modifier to express qualitative preferences, as it leverages the expressive power of SPARQL 1.1. However, the approaches proposed in [40] and [26] both have an important limitation: they are not able to provide an order of all the available outcomes that reflects user preferences. That is, they return only the undominated (a.k.a. Pareto-optimal) results, i.e., those outcomes best satisfying user preferences. Unfortunately, the size of the resulting answer set could be too small to be of practical use. This fosters moving beyond the Pareto-optimal set identification to a top-k scenario [37], where firstly available outcomes are ordered, even if with the ties implied by a qualitative approach, from best (most preferred) to worst (less preferred) according to a given user’s preferences, and then the first k results are returned.
In this paper, the focus is on model-based preference reasoning, which relies on specific assumptions about the structure of the preference relation [22]. The simplest assumption that can be made is that the target ranking of a set of resources, described in terms of multiple attributes, can be represented as a lexicographical order [12]. Lexicographical preference models define orders of importance on the attributes that describe the objects of a domain. As an example, consider the choice of a movie. Typically, the most important attribute that one considers is the genre of the movie (e.g., drama, superhero, etc.). Then, among the movies of the preferred genre, the choice can rely on the movie’s actor (e.g., Tom Hanks, Christian Bale, etc.). The assumption of a lexicographical order restricts significantly the hypothesis space, but induces a bias rarely justified in practical applications. In fact, preferences on individual attributes are generally not independent of each other. With reference to the movie domain, Tom Hanks may be preferred to Christian Bale, if the movie genre is drama, while Christian Bale may be preferred in case of a superhero film. CP-nets [3] offer a language to express preferences on the values of single attributes, and, at the same time, allow one to model dependencies of this type. A CP-net is a qualitative graphical representation that reflects conditional dependence and independence of preferences under a ceteris paribus (all else being equal) interpretation. It is a compact representation of a complex preference relation (partial order), where each node refers to a single attribute and is associated with a function that assigns a preference relation on the values of that attribute to each combination of the values of the parent attributes. More precisely, CP-nets require that the user specifies (i) for any attribute A of interest, which other attributes can impact her preferences for values of A (the parents of A), and (ii) for each instantiation of the parent attributes, the preference ordering over values of A. Points (i) and (ii) could make CP-nets a rather rigid formalism, compared to the expressive needs of a user. Furthermore, some statements that are very natural for the user to assess cannot be represented within a CP-net. Conditional preference theories (or CP-theories) [44] are a more general and flexible formalism for qualitative preferences that allows one to go beyond the expressiveness limitations of CP-nets.
In our previous work [39], we focused on the well-known CP-net graphical language and have addressed the problem of preference representation and reasoning with Linked Data from different perspectives. We have proposed a vocabulary to represent statements formulated according to the ceteris paribus semantics and have shown how to encode a CP-net by means of this vocabulary. Inspired by [26], we have also explained how to embed such a compact preference model into a SPARQL 1.1 query in order to access semantic data in a personalized way. The present work extends the leading motivation and the approach of our previous paper [39], but embraces the more general and flexible formalism of CP-theories. We point out that the approach proposed here only deals with context-uniform conditional (cuc) acyclic CP-theories [44], which are a special type of CP-theories exposing nice polynomial computational properties while comparing outcomes.
This paper heavily extends the approach presented in [39] in many points. First of all, here we deal with the much more expressive CP-theories instead of CP-nets. A new extended vocabulary as well as a completely new algorithm to encode CP-theories in SPARQL is also proposed. Moreover, an implementation of the overall framework is presented together with experimental evaluations targeted at assessing the users’ experience in representing their preferences as CP-theories and the performance of the tool. The main contributions of this work can be summarized as follows:
presentation of RDF vocabularies to represent qualitative preference statements over Linked Data, built on top of the vocabulary proposed in [39], but adjusted for more general preference statements;
an encoding into RDF triples of the qualitative preferential information represented by a CP-theory and the exploitation of theoretical results of [43] to compute a partial order over items for cuc-acyclic cases;
a procedure to translate conditional preference statements into a SPARQL 1.1 query able to retrieve a ranked list of resources whose order reflects the user preferences;
an application framework that meets a user’s needs while representing her preferences as a CP-theory encoded in RDF and that eventually allows a SPARQL-enabled software agent to retrieve a ranked list of resources according to the users’s tastes;
An experimental evaluation to verify the effectiveness of the proposed approach.
The rest of this paper is structured as follows. Section 2 presents the motivating scenario that fostered the overall approach. The semantics of CP-theories and a recap on some relevant results and theorems is provided in Section 3. In Section 4, we propose an RDF vocabulary to represent a CP-theory with the preferential statements of a user, and then we show how to embed the RDF version of the CP-theory into a SPARQL query able to retrieve a ranked list of results ordered according to user’s preferences. Section 5 describes the tool that supports the user both in the formulation of her preferences under the CP-theories semantics and in retrieving the resources of interest ordered according to her preferences. The results on a user study are reported in Section 6, where we also measure the performance of the implemented system on a synthetic dataset. Section 7 provides an overview of related work about preference reasoning and enabling query languages with preferences. Conclusions close the paper.
Motivating scenario
The leading scenario behind the framework that we propose here is that of a distributed system where a user may pose a query to a SPARQL endpoint and have the returned results ordered with respect to a set of personal preferences on a specific knowledge domain. For instance, a user might be willing to get a list of books to read by querying DBpedia and then have it ranked according to a set of preferences hosted on their own Web page. A possible implementation of the approach that we propose is depicted in Fig. 1,1
For ease of presentation, in this paper, we use DBpedia as the main dataset to query. The approach can be adapted to any Linked Data dataset.
where the main building blocks required to implement the whole framework are shown:
A graphical representation of the proposed approach. The Deploy and Interact steps only rely on the adoption of standard technologies and languages.
a reference model to encode and reason with preferences (CP-theory in our case);
an ontological vocabulary to represent preferences by adopting Web languages;
a tool able to handle and manage preferences as well as to encode them in a set of SPARQL queries.
In order to implement the whole framework, we propose the following deployment and interaction steps.
Deploy.
Model user preferences. We adopt CP-theories [43] as reference model to represent user preferences. As we will see in Section 3, they are a formalism to represent and reason with sets of qualitative preferences.2
The interest here is not whether such preferences are automatically learned from data or manually modeled and set by a human agent.
Encode preferences in RDF by means of a preference ontology. We developed an OWL ontology to represent CP-theory statements encoding user preferences (see Section 4).
Publish user preferences publicly on the Web. The aim is to foster a principled adoption of user preferences by systems interested in providing a personalized access to data available in the Linked Data cloud. User preferences can be encoded and published in an RDF file.
Interact.
Use SPARQL to get user preferences. A preference handler loads3
the preference model of the user encoded in RDF by means of a general purpose SPARQL query engine.
The preference handler formulates SPARQL 1.1 queries able to retrieve and order resources by taking into account user preferences. Standard SPARQL queries are formulated in order to rank the result set with reference to the preferences expressed by the user.
A strong requirement that we had in mind while developing our solution was to use only standard Web technologies and languages to implement the overall framework. Indeed, we selected RDF to model user preferences and the power of SPARQL 1.1 to perform preference-based reasoning in order to rank the results of a query. In fact, as we will see in Section 4.2, advanced features of the last version of the SPARQL query language can be employed to perform preference reasoning over a model based on CP-theories. In Section 2, all the details needed to implement the Deploy and Interact steps in a pure Linked Data setting will be provided.
CP-theories
Utility functions can be considered as the ideal tool for representing and reasoning with preferences, but the total order that they allow to represent does not always reflect the actual user model. Partial orders among preferences are a more natural way to represent a user’s tastes. Qualitative statements, e.g., “given u, I preferover”, permit a system to encode partial orders among user preferences, thus granting the representation of a more realistic user model. Let us consider the following example. The previous example is a typical conditional statement where the core notion of a CP-statement is explicitly represented. We have that when a particular condition u is true, a user prefers to enjoy items where also is true, rather than items where is true, given that and cannot be true at the same time.
(Books).
“Giorgio has just finished his exams and wants to relax with a book. Giorgio can read both English and French, but he would like to improve his French to enrich his curriculum and so he prefers to read French books. Giorgio prefers reading crime books over autobiographical ones for French books, since he believes that crime plots are more captivating and therefore more useful while learning a foreign language. The reverse order holds for English books. Giorgio is a good reader and, therefore, given an English book, he prefers those being part of a saga. The literary genre and the presence of a subsequent work have not the same importance to Giorgio: in case of English books, he considers the choice on the genre more important than the one dependant on sequels, while the opposite happens for French books. Finally, for books characterized by a sequel, Giorgio regards positively the presence of a cinematographic version”.
By looking at Example 1, we find it quite hard (even impossible) to directly represent Giorgio’s preferences by means of a score assigned to his preferential statements. In fact, Giorgio’s preferences can be better expressed as qualitative (pairwise) comparisons.
Relevant frameworks to represent and reason with qualitative preferences are built according to the ceteris paribus semantics [27] and specifically consist of conditional preference networks (or CP-nets) [3] and a formalism along similar lines to CP-nets, but with a richer language of preference statements, namely, conditional preference theories (or CP-theories) [44].
Syntax. Formally, given a set of variables V, a CP-theory Γ is a set of preference statements φ of the general form:
where is an assignment to a set of variables , and are different assignments to some variable , and is some subset of .
Semantics. The interpretation of φ is that, given , is strictly preferred to , all else being equal, but irrespective of the values of variables in .
That is, φ compactly states that for all assignments w, to and assignments t to , is preferred to .
In what follows, we will use the word outcome to indicate a complete assignment to all the variables in V and denote the set of all outcomes as . For the statement φ, we denote by the set of pairs of outcomes , where t is an assignment to , and w, are assignments to . Further defining , it is then natural to define for the CP-theory Γ a strict partial order , induced by Γ on the set of outcomes , as the transitive closure of . The CP-theory formalism allows one to express the usual CP-net ceteris paribus statements by simply considering and identifying with , the parents of a variable X, that is, variables which the preferences on X depend on. However, as anticipated in Section 1, under the stricter CP-net formalism, for each variable X, a parent set must be defined and instantiated when the preference order over values of X is established. This is not required in CP-theories, where you can find more statements related to the same variable X, but with different sets U. In addition, CP-theories allow stronger conditional preference statements than CP-nets, which are natural for users to express. For example, they represent a formalism even more general than TCP-nets [4], an enhancement of CP-nets where (conditional) relative importance between variables can be expressed. TCP-nets can be represented through statements with W containing at most one variable. Moreover, there are statements, such as I preferoverirrespective of the values of all other variables, that cannot be expressed in CP-nets or TCP-nets, but correspond in the new formalism of CP-theories to , where ⊤ is the assignment to an empty set of variables.
(Books cont’d).
The CP-theory
=
=
=
=
=
=
=
The overall profile of Giorgio may be modelled by means of the CP-theory , that is, the set of statements given in Table 1. There, a set of binary variables (abbreviated as C, , , and F, respectively) is considered. Their domains are given by:
(for France and United Kingdom),
(for and ),
(indicating if a book has a sequel or not),
(indicating whether there is a cinematographic version of the book or not).
For a CP-theory Γ, the preference ranking over outcomes introduced above, can be equivalently induced under the worsening swap semantics. Hereafter, we use the notation to indicate that the variable is assigned the value in o, and analogously to state that in o.
Given two outcomes o and of , there is a worsening swap from o to , if there exist a variable and an assignment to the variables set such that:
= and ,
,
, and
.
The preference relation over is therefore the transitive closure of worsening swaps.
A CP-theory Γ is consistent, if it has a model, i.e., if there exists a strict total order > that satisfies Γ, which is equivalent to , that is, > extends . In [43], it is proved that the irreflexivity of (or equivalently the acyclicity of ) is a necessary and sufficient condition for consistency.
The consistency of a CP-theory implies that there are no cycles generated by . Avoiding cycles is of paramount importance, as they introduce conflicting information while ordering the outcomes in . Let us consider the ordering represented in Fig. 2, where an edge from to represents . As we cannot establish what is the correct ordering of the outcomes due to the cycle created by and , we could even have situations where we cannot compute the most preferred (undominated) outcome. For example, suppose in Fig. 2, we do not have . What would then be the best solution for the user in this case?
An example of cycle among outcomes.
A necessary condition for consistency is local consistency. Consider a CP-theory Γ, a variable , and an assignment a to a set of variables . An ordered pair () of X values is validated by a, if there exists a statement φ of the form in Γ, such that a extends u, that is, a projected to gives u.
The local ordering (abbreviated as ) on X values is defined as the transitive closure of the set of pairs () validated by a. Γ is locally consistent, if is irreflexive for all variables X and outcomes α. Local consistency is a necessary condition for consistency, since if Γ is not locally consistent, then there exist an outcome α, a variable X, and a sequence , …, of values of X with associated statements such that α extends and .
This gives a worsening swapping sequence from α to α (only involving changing variable X), thus implying that is not irreflexive, or equivalently that Γ is not consistent. In general, deciding whether a CP-theory is locally consistent is coNP-complete, but it can be shown that if the size of the parent sets and the size of the domain sets are bounded by a constant, then deciding local consistency is polynomial [44]. Moreover, for CP-nets and TCP-nets, local consistency is always guaranteed [44].
Given a CP-theory Γ, there are several kinds of directed graphs that can be defined on the set of variables V. For , we indicate with the set of edges , omitting the set brackets, if S or T is a singleton set, e.g., abbreviating with .
The dependency graph consists of edges for all φ in Γ, that is, all the pairs of the form (), with and . That is, the edge () belongs to iff there is some conditional preference statement that makes the preferences for X conditional on Y. Relative importance is not encoded in .
On the other side, we define to contain and for all φ in Γ, i.e., . contains both dependency and relative importance information: it is with the addition of edges (), if there is any statements φ representing a preference on values of X irrespective of the value of Z (then, X is more important than Z, with importance meant as in the TCP-net formalism [4]).
A CP-theory Γ is fully acyclic, if is acyclic. For fully acyclic CP-theories, consistency and local consistency are equivalent [44].
For a CP-theory Γ and assignment a to a set of variables , we can define another directed graph on V made of the set of edges for all and also the set for all such that and a extends .
A CP-theory Γ is context-uniformly conditionally acyclic (or cuc-acyclic), if it is locally consistent, and for each outcome , is acyclic. It can be proved that a cuc-acyclic CP-theory is always consistent [43]. The condition of cuc-acyclicity is weaker than the full acyclic one, and it requires only to be acyclic [44] instead of .
Cuc-acyclicity implies a less expressive power in terms of preferences that the user may express, but, as we will see in the following, it grants a nicer computational complexity when ranking a set of outcomes (along with guaranteeing always consistency, while deciding the consistency of general CP-nets and CP-theories is PSPACE-complete [23]).
To better clarify the expressive limits of cuc-acyclic CP-theories, we consider the following CP-theory whose is shown in Fig. 3.
Crime Fiction : Agatha Christie > Andrea Camilleri [∅]
Isaac Asimov : Science Fiction > Crime Fiction [∅]
Due to the interrelation between the two preferences, is cyclic, and so cannot be cuc-acyclic.
Although there might be cases where cuc-acyclicity is a strong limitation in the representation of user preferences, it represents a limited subset of all possible CP-theories that can be used to model a user profile.
In what follows, we show two results, both proved in [44], which determine a strict partial order extending . The approaches proposed to compare outcomes are strongly related to the ordering queries defined in [3] and already discussed in [39] for CP-nets, and can be seen as a generalization of Corollary 4 and Theorem 5 of [3]. The first result is applicable for a fully acyclic CP-theory Γ. It proposes to compare two outcomes by looking (using the appropriate local ordering) at their value on each of the most important variables on which they differ, where importance is defined according to the graph .
In Theorem 1, we denote with the set of variables of V on which outcomes α and β differ, i.e., . If , we build as the set of -maximal elements of , being the transitive closure of . is therefore the set of variables such that there exists no with () .
Let Γ be a locally consistent and fully acyclic CP-theory, and let the binary relationonbe defined as follows, for any pair of outcomes α and β:iffandfor all. Then,is a strict partial order extending, and the comparison between any pair of outcomes requires polynomial time.
The second result deals with cuc-acyclic CP-theories [44]. In Theorem 2, is still used to denote the set of different variables in outcomes α and β. If , is defined as the set of -undominated elements of , being the transitive closure of : iff there exists no Z in with () .
Let Γ be a cuc-acyclic CP-theory, and let the binary relationonbe defined as follows, for any pair of outcomes α and β:iffandfor all. Then,is a strict partial order extending, and the comparison between any pair of outcomes requires polynomial time.
Theorem 2 proposes a more general approach to generate a strict partial order on , which although requiring a pretty strong condition on the CP-theory, i.e., cuc-acyclicity, does not need full acyclicity. In particular, if Γ is fully acyclic, and α and β are two outcomes to compare, then and so . Therefore, . This implies that if then , so that is a closer approximation of than .
Section 4.2 will ground on this more general Theorem 2 to formulate a SPARQL query able to rank outcomes according to user preferences encoded in a CP-theory model.
(Books cont’d).
Relative to the CP-theory with Giorgio’s preferences (see Table 1), the use of Theorem 2 produces the following sound ranking solution:
where outcomes within round parentheses are not comparable.
As an example, we may consider the outcome which is favoured in the comparisons made according to the order over every other outcome. In fact, the set
coincides with the set of distinct variables in the compared outcomes, namely,
being both equal to , and the preference can be used to locally order the first outcome over the second one. Analogously,
is equal to
and the preference can be exploited. The set
coincides with
and the preferences and can be exploited for the variables and F, respectively. While
it holds that
is composed of the only variable , and the preference can be used for this comparison. The preference can also be used when dealing with
which coincides with the set
As for Giorgio, SubsequentWork takes priority over LiteraryGenre for French books, according to , and takes priority over FilmVersion, because of the preference (or ), it follows that the set of distinct variables
has three elements , while
and the preference can be used in this case. For the last comparison involving France, the preference is still determinant, as
but . When comparing the outcome with any outcome in which appears, contains only the undominated variable , and the preference can be used to advantage over .
CP-theories and Linked Open Data
As we stated in Section 1, the target of this work is twofold. On the one hand, we want to supply the user with a vocabulary to represent qualitative statements formulated in terms of ceteris paribus semantics. On the other hand, we aim to provide an encoding of user preferences that can be used in a top-k query answering scenario. In this section, we start by proposing a first ontology that allows a system to represent preferential statements according to CP-theories in a very straightforward way and an extended version to manage the directed graph on V introduced in Section 3 and exploited in Theorem 2. Note that RDF triples encoding the directed graph can be automatically derived from the original preferential statements. In Section 5, we provide a description of an implemented tool to infer the RDF version of the directed graph, starting from a set of conditional preferences. We deal with the complementary target in Section 4.2, where we show how to employ a user profile represented as an instantiation of the extended ontology to encode the corresponding preferences in a standard SPARQL query able to retrieve and rank resources in a personalized way.
Figure 4 shows the ontology that we modeled to express user profiles in terms of CP-theory statements.4
The main idea behind the modeling of the ontology is that we may express preferences on properties of items that the user is looking for, e.g., dbo:literaryGenre, dbo:country, dbo:subsequentWork, or potentially dbo:filmVer-sion. Hereafter, the ontology in Fig. 4 will be referred to as the lite ontology. The aim of the lite ontology is that of creating an ontological vocabulary providing all the elements to syntactically represent conditional preference statements in a theory Γ. By means of this ontology, it is possible to encode whatever preference φ in its general form .
A graphical representation of the lite version of the ontology proposed to represent conditional statements.
The ontology is composed by four main classes and nine properties. The class Value represents possible values of a variable. If we look at the book GoodKnyght! in Example 5, we see that the “actual values” for which the user expresses a preference are composed by both a property (e.g., dbo:country) and its related object (e.g., db:United_Kingdom). This is the reason why the class Value is the domain of the two properties attribute and value. The former mapping the property, the latter mapping the object. Condition is used to express the conditional part of a preference statement , which is also the condition for the relative importance [4] of the variable over variables in in case . It is the domain of the property contains, whose range is Value. The class Preference represents the whole conditional statement φ. The properties having Preference as domain reflect the structure of the preferential statement “given a Condition, I prefer a Value over another Value, optionally irrespectiveOf some other variables”. The class Variable is used to model the variables of a CP-theory, and it is domain of variableDomain, whose range is Value. Finally, we have the bound property needed to explicitly state if the value associated to an attribute is an actual value (as for dbo:country and dbo:literaryGenre) or if it represents the situation that we (do not) have a triple involving the attribute, as for dbo:subsequent-Work or dbo:filmVersion. Here, we adopted the modeling choice of representing directly the conditions generated by the combination for the values of variables in instead of relating the variables themselves. As an example, in case we have “Given an English book that is part of a saga, I prefer…”, with reference to the previous example, the corresponding encoding will be5
Here, we use the prefix cpl to denote <http://sisinflab.poliba.it/semanticweb/lod/ontologies/cpt_light.owl#>.
cpl:combined-cond a cpl:Condition ; cpl:contains cpl:c1 ; cpl:contains cpl:s1 .
Here, cpl:combined-cond represents as a whole, while cpl:c1 and cpl:s1 represent the values and composing .
We will see how this modeling choice will be useful when embedding the CP-theory into a SPARQL query.
Notice that such classes and predicates are sufficient for the user to express the CP-theory with her preferential statements, and to facilitate the user experience even further, we built a user-friendly tool, where preferences related to a specific domain (e.g., books or movies) can be added. The aforementioned tool will be extensively described in Section 5.
(Books cont’d).
With respect to Giorgio’s preference “given an English book, he prefers those being part of a saga”, if we look in DBpedia, we may find, for instance, the book GoodKnyght!. Indeed, we have:
From the previous RDF statements, we see that Giorgio’s preference refers to values of objects in a triple with reference to a specific predicate. Indeed, given a set of resources of type dbo:Book such that the value for dbo:country is db:United_Kingdom, he prefers those with an associated triple whose predicate is dbo:subsequentWork. In order to be fully compliant with the Linked Data technological stack, we need a vocabulary/ontology that allows users to represent their preferences on different attributes of resources that they might be interested in. Hence, with reference to the ontology in Fig. 4, we have the following RDF triples modeling the preference introduced at the beginning of this example.
@prefix cpl: <http://sisinflab.poliba.it/ semanticweb/lod/ontologies/cpt_light.owl#>@prefix db: <http://dbpedia.org/resource/>@prefix dbo: <http://dbpedia.org/ontology/>### Variables ###cpl:country a cpl:Variable;cpl:bound true;cpl:variableDomain cpl:c1,cpl:c2.cpl:subsequentWork a cpl:Variable;cpl:bound false;cpl:variableDomain cpl:s1, cpl:s2.### Values allowed for each variable ###cpl:c1 a cpl:Value;cpl:attribute dbo:country;cpl:value db:United_Kingdom.cpl:c2 a cpl:Value;cpl:attribute dbo:country;cpl:value db:France.cpl:s1 a cpl:Value;cpl:attribute dbo:subsequentWork;cpl:value cpl:subsequentWorkYes.cpl:s2 a cpl:Value;cpl:attribute dbo:subsequentWork;cpl:value cpl:subsequentWorkNo.### Condition ###cpl:cond a cpl:Condition;cpl:contains cpl:c1.### Preference ###cpl:pref a cpl:Preference;cpl:given cpl:cond;cpl:prefer cpl:s1;cpl:over cpl:s2.
Once we have defined and modeled Γ in RDF, in order to compare two outcomes α and β as in Theorem 2, we may build the RDF version of the directed graph on V (see Section 3).
To this aim, the lite ontology is extended as shown in Fig. 56
The corresponding OWL file is available at http://sisinflab.poliba.it/semanticweb/lod/ontologies/cpt_full.owl.
to what we call the full ontology. Hence, starting from a set of preferences represented via the lite ontology, we derive its full version such that, once instantiated with an outcome α, it represents . The derivation step is performed by adding new statements via the following relations:
moreImportantThan
has Variable both as domain and as range, and it is used to model the transitive closure of dependency and (unconditional) relative importance information, i.e., for the transitive closure of edges , and, if , for , for any φ.
conditionallyMoreImportantThan
takes into account conditional relative importance information. Its range is an instance of the new class InstanceOfRelativeImportance, which is used to represent a pair (, Z), , for a statement φ with . In fact, the class InstanceOfRelativeImportance is the domain of the property hasCondition, whose range is the Condition instance representing , and of the hasLessImportantVariable property, whose range is the Variable instance for Z. In the following, we say “X is conditionallyMoreImportantThanY under the ConditionC” when X is linked via conditionallyMoreImportantThan to an instance of the class InstanceOfRelative-Importance, which, in turn, is linked by has-Condition to a ConditionC and by has-LessImportantVariable to a VariableY.
A graphical representation of the full ontology proposed to represent conditional statements.
Both properties must act as transitive relations. Therefore, we add more statements to the original preferences by means of the following rules involving the transitive closure of property moreImportantThan and then, for pairs of variables not linked by it, the transitive closure of property conditionally-MoreImportantThan.
if variable Y is moreImportantThan a variable X and at the same time variable X is conditionallyMoreImportantThan a variable Z, under a condition C not involving values of Y, then we add the RDF statements representing that “Y is conditionallyMoreImpor-tantThanZ under the condition C”;
if Y is conditionallyMoreImportantThan a variable X under a condition C, X is at the same time moreImportantThan a variable Z, and the condition C does not involve any value of Z, then the additional fact we add is “Y is conditionallyMoreImportantThanZ under the condition C”;
if Y is conditionallyMoreImportantThan a variable X under a condition C, and X is conditionallyMoreImportantThan a variable Z under a condition , then the additional fact added to the knowledge base is “Y is conditionallyMoreImportantThanZ under the condition ”, where is the condition joining C and , but only if does not contains values of Y, Z or two different values of any other variable.
According to the properties just introduced, given a pair of outcomes (α, β), if there exist no variable that is moreImportantThanX and no variable that is conditionallyMore-ImportantThan (u, X), with α extending u, then a variable X is in .
(Books cont’d).
The full encoding corresponding to for Giorgio’s preferences in Table 1, is represented in Listing 1.7
The RDF, version of the CP-theory in Table 1, according to the full ontology.
In Section 4.2, we will see how to pose a SPARQL query against the full version of Γ in order to compute , thus retrieving a ranked list of semantic resources ordered according to a user’s preferences.
The special case of CP-nets
Before moving to the description of how to encode a CP-theory in a SPARQL query for personalized results ranking, we point out that the ontological model just described subsumes the vocabulary introduced in [39] to represent CP-nets models. There, we proposed how to model the information encoded in a CP-net through an ontology and how to formulate the query able to order outcomes accordingly in a consistent way. On the other hand, we know that CP-nets are a special and simple case of CP-theories and, therefore, we want to show how the new ontology in Fig. 5 can deal with a CP-net.
The theoretical result exploited in [39] (namely Corollary 4 of [3]) orders an outcome o over another one , consistently with a CP-net , if there exists a variable X such that o and assign the same values to all ancestors of X in and given the assignment provided by o (and ) to the parents of X, i.e., , o assigns a more preferred value to X than that assigned by (according to the conditional preference table of X). The sufficient condition of Corollary 4 of [3] may be reformulated asking for a variable X such that there does not exist any variable moreImportantThanX different in o and , and, given the assignment provided by o (and ) to , o assigns a more preferred value to X than that assigned by . The predicate moreImportantThan, in fact, covers dependency information and, when applied to a CP-net, allows to define a set of variables coincident with the ancestor set. Moreover, for a CP-net, the predicate given for any instance of Preference ordering the values of a variable may be used to define the parent set of that variable. The ontological model proposed in [39] for CP-nets is hence subsumed by the full ontology of Fig. 5. On the other hand, if one wants to represent a CP-net according to the full ontology, one has to consider that the dependency information is the only kind of information required for CP-nets, because there is no relative importance encoded. This implies that the RDF version of the CP-net, in terms of the full ontology, would not contain any predicate conditionallyMoreImportantThan and irrespectiveOf or any instance of the class InstanceOfRelativeImportance.
Ordering SPARQL results via CP-theories
In the following, we assume that users are looking for the best k items satisfying some requirements and that the choice for the best ones is led by their preferences, formulated according to a CP-theory Γ, on a set of variables . Hence, we aim at solving a top-k query answering problem, where the ordering criterion is encoded in Γ. In the presented approach, we concentrate on cuc-acyclic CP-theories, to preserve the nice computational properties introduced in Section 3 and exploit the algorithmic approach suggested by Theorem 2.
The ultimate goal of our proposal can be summarized by the following query formulated in a meta-language on top of SPARQL:
SELECT ?item
WHERE {
?itemsatisfiesuser requirements
}
ORDER BY Γ
LIMITk
Here, user requirements are represented by a SPARQL graph pattern where at least one triple has ?item as subject. In the following, we use the notation to denote the user requirements associated with the variable ?item.
(Books cont’d).
“Giorgio really wants to relax, and so he is looking only for books with more than 300 pages”. In this case, Giorgio’s requirements are represented by:
?item a dbo:Book.
?item dbo:numberOfPages ?page.
FILTER(?page>300).
The computation of an answer to the previous query, goes through the exploitation of the full version of Γ. The overall approach is composed of two main steps.
Step 1.
Here, we compute a representation of α and β, starting from each and, by exploiting Theorem 2, an ordering based on for all possible outcomes is eventually returned. The representation of α and β as URIs goes through a string concatenation (we use the GROUP_CONCAT aggregate function of SPARQL).
Step 2.
This step deals with ranking the items matching according to as computed in the previous step.
Both steps are detailed in the following.
Ordering the outcomes (Step 1). From Theorem 2 in Section 3, we know how to build a strict partial order on a set of outcomes extending by comparing outcomes via . By means of the same meta-language that we used before, the ordering of outcomes can be done via the following query. There, we see the outcomes are ordered according to a counter representing the number of outcomes that they are able to -dominate.
SELECT ?outcome-Dominating
(COUNT(?outcome-dominated)
AS ?counter)
WHERE {
FILTER {?outcome-Dominating ≫Γ
?outcome-dominated }
}
GROUP BY ?outcome-Dominating
ORDER BY DESC(?counter)
In order to compute values for the two variables ?outcome-Dominating and ?counter, the previous query should act on one pair (α, β) per time by checking if .
The preference-based reasoning is performed exclusively by means of the SPARQL 1.1 query OrderingQuery whose generation is detailed in Algorithm 1 of Appendix A. The algorithm takes as input the full version of Γ and computes a query able to return a list of outcomes ordered according to ?counter. In particular, the query returns for each outcome, a numerical score representing its position in the ranking imposed by .
For a better clarification, the reasoning procedure under the comparison between the pair is summarized in the following:
The query computes the set by considering the variables X in the set for which there do not exist: (i) a variable linked to X by property cpt:moreImportantThan and (ii) a variable which is cpt:conditionallyMoreImportantThan than X under a condition extended by α.
It then counts the number of variables X from the set that let to state and compares it to the cardinality of .
If the numerical values coincide, which means that for each variable X in , holds, then the query concludes that .
In order to get all the information needed to check from the full version of Γ, OrderingQuery embeds Query 1 and Query 2 reported in the following. They return a set of quadruples ⟨?V, ?ConcatenatedParent, ?Prefer, ?Over⟩, with ?ConcatenatedParent optionally not instantiated, able to locally order α over β with respect to variable ?V.
Given a variable with , we use the following notation relative to the corresponding instances , of the class :
is the of the triple ;
denotes the of the triple ;
we call representative string of the concatenation of the two strings represented by and respectively. The combination of and is used to represent , as they uniquely identify a value in the domain of a variable. Indeed, in case we used only , ambiguous situations could arise when it is used in combination with different attributes.
Finally, for an instance of the class cp: Condition, we call conditional values of all the objects of the triples .
Query 1 processes elements φ of Γ with . Within the query, they are represented by the variable ?preference. The selection is made possible by the FILTER NOT EXISTS on the pattern {?preference cpt:given ?condition.} (line 8). Considering that the objects of properties cpt:prefer and cpt:over must be distinct values of the same variable, the query firstly extracts the variable that the preference acts on, i.e., ?V (line 1 and line 9). Then, it computes the representative strings, ?Prefer and ?Over (lines 2–3) for the objects ?p and ?o of the two triples involving cpt:prefer and cpt:over (lines 10–12).
Differently from the previous query, Query 2 is used to process statements φ belonging to Γ with . The selection is made via the pattern {?preference cpt:given ?condition.} (line 9). Let us consider first the nested subquery in lines 2–20. For each instance of class Preference, such query extracts the variable ?V that the preference is about (lines 2 and 12) and considers the cpt:given condition ?condition (line 9), extracting its corresponding conditional values (line 16). The representative strings of such conditional values are then computed (lines 17–18) and concatenated at lines 3–4 in ?ConcatenatedParent, grouping by condition. The variables ?Prefer and ?Over are defined similarly to Query 1. The external query is just used to restrict the result set to variables ?V, ?ConcatenatedParent, ?Prefer, ?Over.
Ordering the items (Step 2). Given the information on outcomes returned by the OrderingQuery at the previous step, on both values of variables and position in the ranking, an external RDF dataset, e.g., DBpedia, may be queried, asking for items satisfying the hard constraints () imposed by the user and such that, when limiting the attention on variables in V, they match the description of an outcome. Items are then ordered according to the ranking over corresponding outcomes.
We are well aware that the one we propose is just a possible rewriting of a CP-theory in a SPARQL query and other encodings are possible, ever more efficient from a computational perspective. Moreover, we may see that the performance of the overall approach decreases when the size of variable domains grows and, in its current version, the approach is not able to handle continuous domains as for distance and time. Nevertheless, we believe that the proposed approach is a good starting point to reason with preferences in a pure Linked Data environment, as it is a straight implementation of theoretical results coming form previous works [44].
Instantiation of the framework
The procedure to retrieve items ordered according to user’s preferences is made up of four phases:
the loading of user’s preferences;
an insert to add information about outcomes;
the execution of a federated query;
the (optional) dropping of user’s preferences.
First of all, the user’s preferences file representing the full version of Γ is loaded in the SPARQL server through a LOAD operation and becomes the user’s graph of preferences .
(Book cont’d).
If the path to the RDF file encoding Giorgio’s preferences (see Listing 1) is generally denoted as path_to_ttl_file, the load operation is executed as follows:
The OrderingQuery able to order the outcomes according to is then executed. The information returned by the OrderingQuery is used to integrate the graph of user preferences with additional triples on outcomes. Specifically, we add information about the score of an outcome and its description. Hence, the following triples are defined for each outcome:
a triple satisfying the pattern
?URIOutcome cpt:hasScore ?score
a set of triples instantiating the pattern
?URIOutcome cpt:hasValueForX ?ValueForX
for every variable X of Γ.
Such information are added to through an INSERT query.
(Book cont’d).
For the CP-theory with Giorgio’s preferences, the INSERT operation would behave as follows:
Here, OrderingQuery denotes the ordering query over outcomes returned by Algorithm 1 in Appendix A. The output of Algorithm 1 applied to Listing 1 is available in Appendix B.
The next step is the execution of a federated query, composed by two subqueries. The first subquery retrieves the items satisfying the requirements imposed by the user, i.e., , and for each item it looks for the values of variables in Γ. The retrieval of values grounds on the VALUES construct for variables that are cpt:bound true and on the combination of BIND, IF and EXISTS otherwise. The second subquery on the user’s preferences graph , retrieving for each outcome its score and the variables values. A matching between items and outcomes is hence performed through such values and the items are finally ordered according to the position in the ranking of the relative outcome.
The main reason behind the federation of two (or more) endpoints is that: while the graph containing the RDF version of the user’s preferences is encoded in the corresponding document (available at Preference URI in Fig. 1), all the information about the items that we want to retrieve and rank is encoded in a separate dataset, e.g., DBpedia. The main assumption here is that the user’s preferences are expressed with respect to a reference dataset/vocabulary, which can queried via a SPARQL endpoint.
(Book cont’d).
Suppose that Giorgio is interested in the top-5 list of books matching his hard constraints (see Example 7), ordered according to his preferences encoded in the CP-theory of Table 1. The federated query to carry out the searching task would be as follows:
Finally, the graph with the user’s preferences can be optionally eliminated with a DROP operation.
Please note that all SPARQL queries are executed in a simple entailment between RDF graphs on the full version of Γ as well as on the external dataset for the federated query. Hence, all the queries are executed under the RDF Entailment Regime of SPARQL.
(Book cont’d).
The graph related to Giorgio’s preferences may be dropped as follows:
The tool is available at http://cptheorysparql.cloudapp.net:10002/.
implementing the framework described in previous sections and aimed at supporting the end-user in retrieving a list of semantic resources ordered according to her preferences formulated under the CP-theory formalism. The tool just asks for preferential statements formulated under the CP-theory formalism, i.e., “given, is strictly preferred to, all else being equal, but irrespective of the values of variables in”. With reference to the ontologies introduced in Section 4, this means that for this preliminary step of preference definition, the interested user only has to deal with classes and properties of the lite ontology of Fig. 4. In particular, after the selection of the domain of interest, the user inserts her preferences as depicted in Fig. 6. The interface manages both instances of variables cpt:bound true and cpt:bound false, as introduced in Section 4. In the former case, the variable which the preference is “about” and the couple of values separated by the word “over” must be introduced; in the latter case, the user has to specify whether the presence or the absence of a variable is preferred. Optionally, she can insert a “Condition” under which the above order holds and make explicit, in the “Irrespective” section, the set of variables for the (conditional) relative importance. She can insert as much preferences as she wants with the “add Another Preference” button or complete the insertion procedure with the “Insert Preferences” button.
Preferences insertion.
When this second button is pressed, the tool takes care that the user has defined the transitive closure of those preferential statements related to multiple values of a variable. More specifically, if and have been inserted, with x, , , and and do not contain two different values of the same variable, then the rule is added, if missing (where is the condition joining and , and is the intersection of sets and ). As an example in the movie domain, one may state that () the actor Hugh Grant is preferred over Colin Firth for comedy films irrespective of the country of production and that () Colin Firth is preferred over Joaquin Phoenix for movies directed by Woody Allen. In this case, the additional fact to add would be that () Hugh Grant is preferred over Joaquin Phoenix for comedy movies directed by Woody Allen ceteris paribus and with no relative importance specification, since the intersection of sets and is empty. The tool then exploits the lite version of Γ to generate its full version by managing the transitive closure of moreImportantThan and conditionallyMoreImportantThan, as described in Section 4 .9
The rules that allow the system to manage the definition and the transitive closure of both properties moreImportantThan and conditionallyMoreImportantThan have been implemented in Prolog and are available at http://sisinflab.poliba.it/semanticweb/lod/ontologies/rules.pl.
The tool also helps the user to understand if her CP-theory is cuc-acyclic or not. It returns an error message to the user if the CP-theory is not locally consistent or the directed graph on V, for any introduced by the user in her preferential statements, is cyclic. Otherwise, it returns the encoding that can be used to query the DBpedia dataset.
As an alternative to the manual insertion of preferences, the user can decide to upload a file of preferences written according to the lite ontology, using the specific top right button. The transitivity and cuc-acyclicity checking and the introduction of the additional class and properties of the full ontology is performed in this case as well.
At this point, a file with the full version of Γ is available and can be visualized by pushing the button in Fig. 7(a) or exploited directly to formulate a query against DBpedia through the button in Fig. 7(b).
The buttons to display the Full RDF File (a) or to formulate a preference-based query (b).
More specifically, when the button of Fig. 7(b) is pressed, an interface as the one depicted in Fig. 8 appears. The interface mimics the query presented at the beginning of Section 4.2. There, the users may insert their own requirements and specify the number k of results to use in the LIMIT modifier, which by default is set to 10. The URL displayed after the ORDER BY clause represents the location of the RDF file containing the full version of Γ.
The query returns the top-k list of items belonging to the domain of interest (e.g., books as in Fig. 8), satisfying and ordered according to user’s preferences.
The interface to build the query.
(Book cont’d).
Introducing Giorgio’s preferences, contained in the CP-theory of Table 1, in the proposed tool would produce the top-5 list of results shown in Table 2. The results refer to the release of DBpedia 2015-0410
http://wiki.dbpedia.org/dbpedia-data-set-2015-04
(also known as: 2015 A).
By looking in DBpedia, one can observe an exact matching with the expected order shown in Example 4, according to the following triples:
The top-5 list of items retrieved for preferences in the CP-theory of Table 1
?item_D
?score
db:An_Uncertain_Place
15
db:Requiem_for_a_Fish
15
db:Blood_Red_Rivers
15
db:Tropic_of_Capricorn_(novel)
13
db:Have_Mercy_on_Us_All
9
Experiments
In order to asses the effectiveness of the presented approach and the implemented tool, we set up two different experiments.
The first experiment consisted of 20 real users using the tool to express their preferences. After the test, users were asked to fill up a questionnaire (reported in Table 5). The dataset adopted consisted of a subset of DBpedia 2015-04 related to the four popular domains of: Movies, Food, Music and Books. The statistics of the dataset used for experiments are detailed in Table 3.
Dataset statistics
Classes
Instances
Properties
1 hop resources
dbo:Book
31172
36
12964
dbo:Film
90063
31
82922
dbo:Food
6003
21
2367
dbo:Song
7195
27
2220
Total
134433
115
100473
It is worth noticing that CP-statements can also be automatically extracted from users data [30,33–35]. Nevertheless, we set up the previous experiment to have a hint on the average number of CP-statements φ needed to model a user profile as well as on what is, from a user perspective, the most tricky version of φ to represent among:
,
,
.
The second experiment consisted of simulating 168 users using the platform and expressing an overall number of 6720 preferences and 6720 queries to retrieve the resources ranked by taking into their preferences. The aim of this experiment was that of evaluating the response time of the overall system in retrieving a list of resources based on a set of user preferences.
Test on real users
In order to test the capability of a user to exploit the platform and even to test if human users unaware of CP-theories were able to express their preferences, we selected 20 users that did not know anything about CP-theories and, after a 5 minutes tutorial, we asked them to express their preferences by using our tool. We asked them to insert as many preferences as they wanted for each domain on the platform, and we then asked them to fill up a post-experience questionnaire in order to acquire some feedback about the experience. The motivation of this experiment is twofold: the first information that we wanted to collect was the number of preferences that a user is prone to explicitely express. The result for this evaluation is shown in Table 4. The users provided an overall number of 322 preferences. The average numbers per user are quite similar among the different domains (between 4 and 6) with a little higher propensity to express preferences over books w.r.t. songs. The similar average values, and the similar standard deviations, suggest that there exists a commonality in the number of expressed preferences over a specific domain.
The second relevant information that we wanted to collect is how much the CP-theories expressiveness may fit a “natural” way of expressing preferences by a human being. To this aim, we submitted a small questionnaire with 10 questions whose relative answers in aggregate form are shown in Table 5 and Fig. 9. All the questions but Q.2 needed to express a value in a 5-star rating scale, with 1 being the worst answer and 5 the best one.
How easy is to represent a preference like “About a property I prefer a Value over another Value”?
1
5
4.1667
1.3048
Q.4
How easy is to represent a preference like “I prefer a resource that has a certain property”?
2
5
3.5556
1.0966
Q.5
How easy is to represent a preference like “Given a condition I prefer a Value over another Value”?
2
5
3.8889
0.9852
Q.6
How easy is to represent a preference like “About a property I prefer a Value over another Value irrespectively to a property”?
2
5
3.6111
1.2005
Q.7
How easy was to represent the first preference?
1
5
3.2222
1.3492
Q.8
After the first preference how easy was to represent the next two ones?
2
5
3.9444
0.9852
Q.9
After the first three preferences how easy was to represent the next ones?
1
5
4.1111
1.2783
Q.10
How much this way of expressing preferences is similar to your own?
1
5
3.7778
1.1448
Users felt that representing preferences was not a trivial operation (3.2 corresponds to the lowest value of the overall questionnaire), but this perceived difficulty is clearly dependent on the type of preference (it is worth to notice that for every specific kind of preference, the score is higher than the overall score).
Thanks to the survey, we can list in an increasing order of difficulty the different kinds of preferences:
“About a property, I prefer a Value over another Value” corresponding to .
“Given a condition, I prefer a Value over another Value” corresponding to .
“About a property, I prefer a Value over another Value irrespectively to a property” corresponding to .
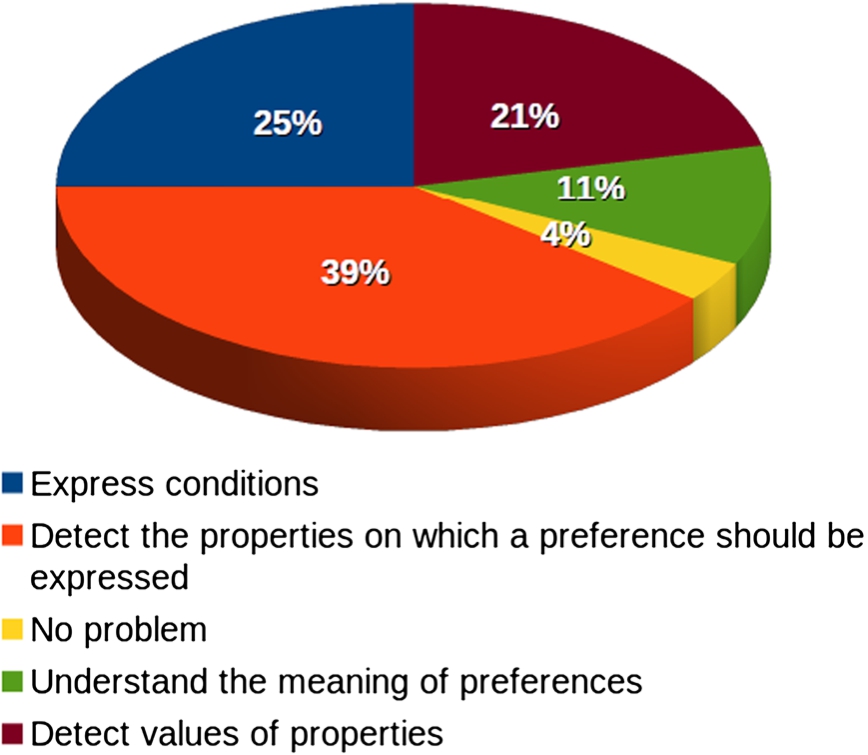
Moreover, if we look at the pie chart in Fig. 9, it emerges that the most difficult part of the process was to detect the properties (variables V) on which the preferences should be expressed. Another information that we wanted to collect was if the possible difficulty in expressing preferences is stable or it progressively vanishes as the number of expressed preferences increases. Questions 7, 8 and 9 show that the first preference was quite hard to express, but, as the experience goes on, it becomes much easier reaching an average value of 4.1.
The last relevant information that we wanted to collect is how much the expressiveness of CP-theories can correspond to a perceived “natural” way to express preferences. Also in this case, the result is interesting, because CP-theories are perceived as a quite good way of expressing preferences with a high value of 3.8.
Pie chart depicting the results of the second question of the survey.
Test on simulated users
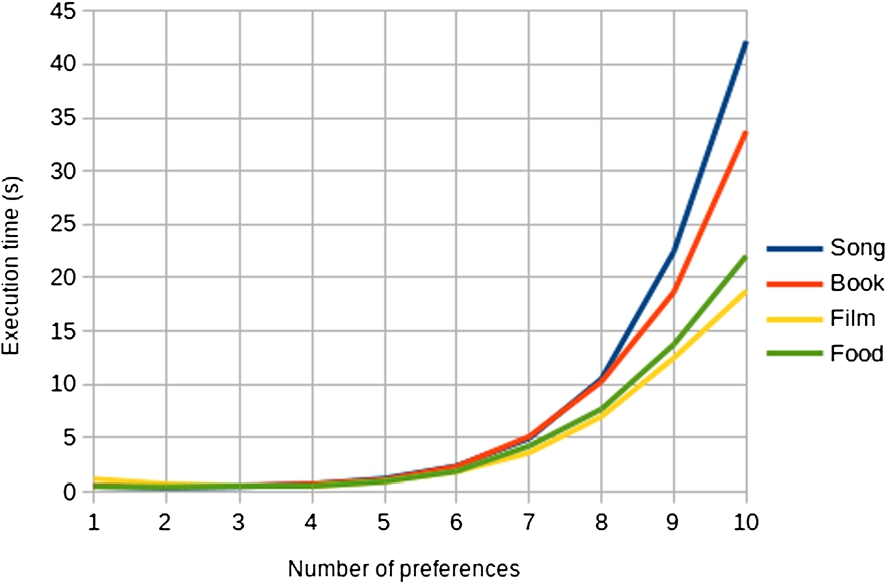
In order to closely simulate the behavior of a real user, we designed a tool able to perform the classical operations of expressing a preference and asking the system for an ordered list of relevant resources. For each domain of interest, the simulated users randomly extract (with a uniform distribution) a property that they might be interested in, and then randomly select the other components of the preference (e.g., in case of a simple preference, , they select either the more liked resource x and the less liked one ). The composed preference is then sent to the server to be processed and stored. The system checks if the preference produced a cycle, eventually warning the user (in case of a cycle, a new preference is produced). Once the preference is correctly inserted, the simulated user performs a query to the system to retrieve an ordered list of the 100 most relevant resources. The system continues, inserting a new preference for the same domain, and asking the system for a new list. The process ends when 10 preferences are inserted for each domain and the 10 related queries accomplished. Based on the previous experiment, we considered 10 as a representative number of preferences per user. Figure 10 shows the average execution time for an increasing number of preferences related to the simulated users.11
For those interested in a more fine-grained view of the data, a report of the execution times is publicly available at https://github.com/sisinflab/CP-theories-SPARQL/blob/master/evaluation/evaluationResults.tsv.
The SPARQL engine adopted for the experimental evaluation is Jena Fuseki v. 2.3.1 running on a Linux server (kernel v. 4.4.0-28-generic) with an Intel Xeon @ 2.30 GHz CPU and 8 GB RAM, while the local version of DBpedia had been loaded in a Virtuoso Server (v. 07.20.3212), running on a Linux server (kernel v. 4.2.0-23-generic) with an Intel Xeon @ 2.40 GHz CPU and 56 GB RAM.
Average execution time for increasing number of preferences (1 to 10) in the four domains of: Song, book, film and food.
The results show that queries based on a number of preferences lower than six take approximately less than one second to return results to the user. This is even more interesting if we consider results of the previous experiments, where we saw that users tend to express an average number of preferences between 4 and 6.
Related works
The ability to infer, model, and reason with user preferences has been recognized as a prominent research direction in many fields, especially artificial intelligence (AI) [17,38]. Preferences are generally classified as quantitative, if they make use of a scoring function to assess an order over the available resources, resulting in a total order, or qualitative, if they are treated independently, resulting in incomparable resources and a partial preference order. Much work has focused on qualitative approaches, since these are closer to how people express their preferences; among the earliest logic-based approaches is von Wright’s [42]. Following the overview over qualitative multi-attribute preference reasoning approaches provided by [37], in AI, there are, in particular, (i) methods adopting graphical structures to represent and reason about preferences, e.g., CP-nets [3] and TCP-nets [4]; (ii) methods that extend constraints satisfaction problems and incorporate soft constraints, as in the approximation of CP-nets with soft constraints described in [15,16]; and (iii) methods that use specific logic-based languages to represent qualitative preferences and derive utility functions, exploiting, e.g., machine learning techniques, such as support vector machines [13,14].
Conceptually close in spirit to the present paper is in particular [36], where ontological knowledge expressed via existential rules in is combined with CP-theories to represent qualitative conditional preferences along with domain knowledge, and to perform preference-based answering of conjunctive queries. Another related work [9] combines Datalog with CP-theories, but only considers atomic queries. The present paper, in contrast, focuses on SPARQL queries in a more restricted ontological context and conditional preferences specified via cuc-acyclic CP-theories. There is also a large body of work on handling preferences in logic programming, e.g., asprin [6], which is a framework for handling preferences among the stable models of a logic program. Similarly, the qualitative choice logic [5] is a propositional logic for representing a preference relation among models, which allows to specify alternative, ranked options for problem solutions. The above two and similar works on handling preferences in logic programming are fundamentally different from the present paper, as they are about preferences for ordering models of a logic program, rather than preferences for ordering the answers to a query subject to all models of a knowledge base.
Databases are another research area where preferences have been investigated. In a relational database management system, for example, the top-k (or ranking) queries represent a quantitative approach, since they return the k best matches according to a numerical score. In [32], a formalism supporting ranking queries for a relational database is presented. With reference to the qualitative approach instead, skyline queries [2] extend the notion of best matching to contexts, where multiple independent scores have to be taken into account. The result of a skyline query is a set of objects that are no worse than any other across all dimensions of a set of independent Boolean or numerical preferences [2]. Within the database community, both Chomicki [7,8] and independently Kießling and colleagues [28,29] formalized the first examples of preference-based querying languages, that is, extensions of SQL that support the specification of quantitative and qualitative queries.
The notion of preference is of primary importance also in the Linked Open Data context. The provision of means to enable users to look for data sources (e.g., SPARQL endpoints) and data content that is tailored to their individual preferences is one of the target of the original project by Tim Berners-Lee et al. Even the motivating example proposed in the introductory article about the Semantic Web [1] can be interpreted as a preference-based search, as extensively discussed in [40]. Based on this insight, in [40], the authors add preference-based querying capabilities to the most known Semantic Web query language, SPARQL. However, when the paper was published, it was not possible to specify multiple (independent) preference dimensions in SPARQL, and consequently the authors had to introduce the PREFERRING solution modifier. For example, the following query provides a preference-enabled SPARQL query for a user who is searching for an appointment, preferring excellent therapist, appointments out of the rush hour and later appointments over earlier ones, if both are equal with respect to the rush hour constraint.
At line 6, the PREFERRING clause behaves as a solution modifier, and the AND keyword separates independent preference dimensions. The CASCADE keyword at line 8 allows to give higher priority to the left-hand preference over the right-hand one. In their paper, the authors state that within the same SPARQL query, the use of a LIMIT k statement in combination with PREFERRING ones could inform the query evaluator to go deeper in the retrieval of skyline solutions, thus allowing the system to return a set of results ordered by user preferences.
A mapping operation between an OWL ontology, called OWLPref, and the SPARQL Preference syntax of [40] has been proposed by [31]. OWLPref allows for representing in a declarative, domain-independent and machine-interpretable way several kinds of preferences, namely, SimplePreference, CompositePreference (which makes compositions of the former), and ConditionalPreference (which models preferences that vary according to the context, thanks to a property OnCondition). However, considering the unavailability of conditional preferences in the SPARQL Preference syntax of [40], the use of ConditionalPreference in OWLPref seems of marginal utility.
The PrefSPARQL syntax of [26] keeps the goal of identifying the Pareto-optimal set, but introduces preferences at the level of filters. It still uses the AND to separate independent dimensions and to build what the authors call MultidimesionalPref. Each “dimension” is either a conditional preference (IF-THEN-ELSE) or an atomic preference, which in turn can be a simple expression or can involve more complex constructs [26]. Besides the support for conditional preferences and the substitution of CASCADE with PRIOR TO, the main innovative point of [26] with respect to [40] is perhaps that the proposed preference-enabled query can be completely rewritten using SPARQL 1.1 characteristics. In particular, [26] uses the FILTER NOT EXISTS. The translation of the previous query according to the PrefSPARQL query rewriting is given below.
The query looks for appointments ?appointmentA satisfying a certain pattern expressed in lines 2–5. The research is carried out checking that there is no ?appointmentB that verifies the same pattern (lines 10–13) and dominates ?appointmentA in any preference dimension. The example refers to only two independent preference dimensions and the situations when ?appointmentB dominates ?appointmentA are represented in the branches of symbol at line 21, that is, lines 18–20 and lines 22–24. For the sake of completeness, ?appointmentB would dominate ?appointmentA if it was better in one dimension (line 18 or line 23–24) and no worse in the other one (line 19–20 or line 22). The PRIOR TO preference relation is encoded in lines 19–20 and 23–24 through the operator.
Although PrefSPARQL allows the user to encode conditional preferences in a SPARQL 1.1 query, it differs from the approach that we presented here in at least three main aspects: (i) in PrefSPARQL, the focus is on computing the most preferred solution (undominated outcome), given a set of conditional preferences, while we provide a list of results ordered by user preferences; (ii) they deal with conditional preferences in the form , while our approach is able to manage CP-statements in the form , which result to be much more expressive for finite and discrete domains even in their cuc-acyclic version that we consider here; (iii) we provide an ontological vocabulary and a procedure to automatically encode preferences in a SPARQL query. However, thanks to its more agile structure, differently from our approach, PrefSPARQL allows the user to express preferences on variables with continuous domains as well as the usage of comparison operators.
In [41], the authors present SPREFQL, an extension of the SPARQL language that allows for appending a “PREFER” clause, which expresses ‘soft’ preferences over the query results obtained by the main body of the query. The main ideas behind the approach are to associate relations of tuples with preference formulas, and to select the relations’ most preferred tuples via a so-called winnow operator. Consequently, the approach does not allow for expressing conditional ceteris paribus preferences as in CP-theories.
As a general remark, previous SPARQL-related works on preference reasoning have been mainly devoted to preference representation and the retrieval of undominated outcomes. In principle, one may encode each of them in a procedural approach able to compute the first level of undominated solutions, then the second one and so one. At each iteration step, the procedure should be able to filter out the results coming from the “higher levels” of results computed in the previous steps.
Less closely related are approaches to preference-based query answering over graph databases. In particular, [21] presents regular languages for graph queries, where answers are partially ordered via a partial order on the strings of the languages. In the same vein, [24] introduces preferential regular path queries for enhanced querying of semi-structured databases. Query symbols are annotated with preference weights for scaling up or down the importance of matching a symbol against a database edge label. The paper studies (progressive) query answering, (certain) query answering in LAV data-integration systems, and query containment and equivalence. A similar approach in [19] introduces a graph query language that enables to declaratively express preferences. None of the above approaches to preference-based query answering over graph databases (which are intuitively based on (potentially recursive) pattern-recognition-style regular expressions), however, allows for expressing conditional ceteris paribus preferences as in CP-theories. Less closely related are also information retrieval systems based on manipulating fuzzy truth values (which may also be interpreted as quantitative preferences), such as the fuzzy multimedia retrieval system in [18].
Conclusion and future work
In this paper, we have shown how user preferences can be taken into account while querying Linked Open Data datasets. Having realized that the Pareto-optimal set identification is not enough, we moved beyond it, proposing an approach to retrieve a ranked list of semantic resources, ordered according to a user’s soft constraints. We focused on qualitative preferences, which are closer to how a user makes decisions, especially in a multi-attribute context, and integrated the partial order implied by a qualitative approach into a top-k scenario, that is, returning to the user, who is formulating qualitative preferential statements, a ranked list of resources, optionally limited in its size, ordered according to her preferences. Among qualitative approaches to preference reasoning, we relied on CP-theories, a general and well-known formalism based on the ceteris paribus semantics. We proposed an ontological vocabulary to model CP-theories by means of RDF statements under the ceteris paribus semantics. Then, we presented an algorithm able to build a standard SPARQL 1.1 query encoding the CP-theory and able to retrieve a ranked set of resources satisfying the corresponding preferential constraints. To our knowledge, this is the first attempt to encode the semantics of a CP-theory into a SPARQL query and, along with [39], the first approach that lets SPARQL to retrieve a ranked list of resources ordered according to a user’s preferences.
We intend the proposed approach as a starting point for many future directions to reason with preferences in a pure Linked Data setting. More efficient encodings for the proposed queries could be investigated, able to mitigate some performance problems, related, for example, to the increase in the size of variables domains. Moreover, in its current version, the algorithm first computes the complete partial order of the outcomes, and then it matches them with items satisfying the users’ hard requirements. As the computation of the partial order is computationally expensive, an improvement could surely be to compute and order only those outcomes matching the users’ requirements, thus reducing the number of comparisons needed to return query results to the user. As a future direction of our research, we are also working on approaches proposed for automated CP-nets and CP-theories elicitation [10,25]. Another interesting topic for future research is to explore how our present work can be extended by integrating approaches to preference-based query answering over graph databases, such as the ones in [19,21,24], as well as how to deal with variables having continuous domains.
Footnotes
Query formulation algorithm for CP-theories
Algorithm 1 has the user’s preferences graph as input, that is, the RDF version of the user’s CP-theory Γ in terms of the full ontology and returns the SPARQL query able to order outcomes according to , a strict partial order extending (see Theorem 2). Line 5 computes, for each outcome o, the values (of variables in V) that it is composed of, through the string built with the for cycle of lines 2–4. The string contains just the names of variables in V with a suffix . Line 5 computes also the number of outcomes that o dominates according to , referred to as ?counter. The counting is made possible by the combination of the COUNT in line 5 and the GROUP BY in line 26. The ?counter variable is then used by the ORDER BY in line 27 to rank the result set. It is worth to notice that line 5 asks for URI(?outcome_D) and not just for ?outcome_D, since this entity will be employed as the subject of triples at the beginning of Step 2 described in Section 4.2. Given a pair of outcomes (o, ), lines 6 to 24 are used to identify the set of variables and among them the set of variables {: }. The first nested subquery (lines 7 to 21) considers one pair of outcomes at a time, ?outcome_D and ?outcome_d, where D and d stand respectively for Dominating and dominated. The for loop of lines 8–17 allows to consider first ?outcome_D and then ?outcome_d. For each of them, the nested loop of lines 9–11 introduces the values corresponding to the variables in V. For each variable , Algorithm 1 looks for values ?Xi_y filtering only elements of the set in the binary case, or elsewhere, through the VALUES assignment at line 10. The algorithm requires that a list W of variables is defined from the set of variables V of Γ: the variables that refer to each instance of Condition must appear in the same order in W, optionally allowing some recurrence. At lines 12–16, the outcome is explicitly built by concatenating, according to the order imposed by W, the values extracted for various ?Xi_y together with attribute(), for all members of W. Line 18 is added to verify that the pair of outcomes to compare is made of distinct elements.
At line 19, the patterns and the FILTER are used to identify the variables ?V with different values ?value1 and ?value2 in the outcomes ?out-come_D and ?outcome_d, namely the variables in the set . As imposed by the couple of FILTER NOT EXISTS of lines 20 and 21, these variables ?V are such that:
In particular, the nested subquery appearing within the FILTER NOT EXISTS of line 21 extracts only the instances of Condition extended by ?outcome_D, building the representative strings of the conditional values, concatenating them in ?Concatenated and checking the inclusion of the string ?Concatenated in ?outcome_D through FILTER and CONTAINS. The pair of FILTER NOT EXISTS of lines 20 and 21 allows therefore to identify the set of variables (?outcome_D, ?outcome_d).
The UNION of Query 1 and Query 2 is added at line 22. It returns a set of quadruples of the general form ⟨?V, ?ConcatenatedParent, ?Prefer, ?Over⟩, able to order an outcome over another one, locally with respect to ?V. For each variable ?V within the set (?outcome_D, ?outcome_d), the IF of line 23 verifies if one of the quadruples on variable ?V can be used to order ?outcome_D over ?outcome_d locally with respect to ?V. In particular, for quadruples with a missing value for ?ConcatenatedParent, it is sufficient to verify if ?outcome_D contains the better value of a preference, i.e., ?Prefer, and ?outcome_d contains the relative worse value ?Over. Instead, for quadruples with a bound value for ?ConcatenatedParent, it must happens that ?outcome_D contains the value of ?ConcatenatedParent, as well as ?Prefer and ?outcome_d contain the value of ?Over. If one of the (or) conditions happens, the BIND instantiate the value of ?counterBind to 1, otherwise to 0. The ?counterBind value is summed up across all instantiation of ?V in (?outcome_D, ?outcome_d), and it resolves into ?counterV at line 6. The same line computes also the cardinality of (?outcome_D, ?outcome_d), namely, the value ?counterVundominated. The FILTER at line 25 verifies if the pair of values ?counterVundomi-nated and ?counterV coincides, that is, if ?out-come_D?outcome_d for all variables X in (?outcome_D, ?outcome_d). In conclusion, if the FILTER of line 25 returns true then ?outcome_D dominates ?outcome_d with respect to , and its ?counter value is incremented of a unit. Only distinct dominated outcomes are counted, through the solution modifier DISTINCT at line 5.
If we consider the query in Appendix B resulting from the running example on Giorgio’s preferences, we see that the variables involved in CP-statements as well as the corresponding values are encoded in the initial part of the query (line 9–50) and in the GROUP BY statement (line 130). The remaining of the query is quite standard and does not depend on the underlying CP-theory Γ. As for the initial part of the query, it contains a number of VALUES statements, where we assign all the allowed values to variables in V and a BIND statement used to compose the strings representing all possible outcomes. We emphasize that the whole query is automatically generated by Algorithm 1, starting from the full version of Γ, and then the process is completely transparent to the user.
Ordering query for the book example
Thr ordering query generated for the book example is shown in the next pages.
Acknowledgements
The authors wish to thank Francesco Paolo Albano for his unvaluable help in the implementation of the full framework and for his continuous support in its maintenance and further development.
This work was supported by The Alan Turing Institute under the UK EPSRC grant EP/N510129/1, and by the EPSRC grants EP/R013667/1, EP/L012138/1, and EP/M025268/1.
References
1.
T.Berners-Lee, J.Hendler and O.Lassila, The semantic web, Sci. Am.284(5) (2001), 34–43. doi:10.1038/scientificamerican0501-34.
2.
S.Börzsönyi, D.Kossmann and K.Stocker, The skyline operator, in: Proceedings of the 17th International Conference on Data Engineering, April 2–6, 2001, D.Georgakopoulos and A.Buchmann, eds, IEEE Computer Society, Heidelberg, Germany, 2001, pp. 421–430. doi:10.1109/ICDE.2001.914855.
3.
C.Boutilier, R.I.Brafman, C.Domshlak, H.H.Hoos and D.Poole, Cp-nets: A tool for representing and reasoning with conditional ceteris paribus preference statements, J. Artif. Intell. Res.21 (2004), 135–191. doi:10.1613/jair.1234.
4.
R.I.Brafman and C.Domshlak, Introducing variable importance tradeoffs into cp-nets, in: UAI ’02, Proceedings of the 18th Conference in Uncertainty in Artificial Intelligence, University of Alberta, Edmonton, Alberta, Canada, August 1–4, 2002, A.Darwiche and N.Friedman, eds, Morgan Kaufmann, 2002, pp. 69–76.
G.Brewka, J.P.Delgrande, J.Romero and T.Schaub, asprin: Customizing answer set preferences without a headache, in: Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, Texas, USA, January 25–30, 2015, B.Bonet and S.Koenig, eds, AAAI Press, 2015, pp. 1467–1474.
J.Chomicki, Logical foundations of preference queries, IEEE Data Eng. Bull.34(2) (2011), 3–10.
9.
C.Cornelio, A.Loreggia and V.A.Saraswat, Logical conditional preference theories, abs/1504.06374, 2015.
10.
Y.Dimopoulos, L.Michael and F.Athienitou, Ceteris paribus preference elicitation with predictive guarantees, in: IJCAI 2009, Proceedings of the 21st International Joint Conference on Artificial Intelligence, Pasadena, California, USA, July 11–17, 2009, C.Boutilier, ed., 2009, pp. 1890–1895.
11.
C.Domshlak, E.Hüllermeier, S.Kaci and H.Prade, Preferences in AI: an overview, Artif. Intell.175(7–8) (2011), 1037–1052. doi:10.1016/j.artint.2011.03.004.
12.
C.Domshlak, E.Hüllermeier, S.Kaci, H.Prade, F.Yaman, T.J.Walsh, M.L.Littman and M.desJardins, Representing, processing, and learning preferences: Theoretical and practical challenges democratic approximation of lexicographic preference models, Artif. Intell.175(7) (2011), 1290–1307. doi:10.1016/j.artint.2010.11.012.
13.
C.Domshlak and T.Joachims, Efficient and non-parametric reasoning over user preferences, User Model. User-Adapt. Interact.17(1–2) (2007), 41–69. doi:10.1007/s11257-006-9022-5.
14.
C.Domshlak and T.Joachims, Unstructuring user preferences: Efficient non-parametric utility revelation, CoRR, abs/1207.1390, (2012).
15.
C.Domshlak, S.D.Prestwich, F.Rossi, K.B.Venable and T.Walsh, Hard and soft constraints for reasoning about qualitative conditional preferences, J. Heuristics12(4–5) (2006), 263–285. doi:10.1007/s10732-006-7071-x.
16.
C.Domshlak, F.Rossi, K.B.Venable and T.Walsh, Reasoning about soft constraints and conditional preferences: Complexity results and approximation techniques, in: IJCAI-03, Proceedings of the Eighteenth International Joint Conference on Artificial Intelligence, Acapulco, Mexico, August 9–15, 2003, G.Gottlob and T.Walsh, eds, Morgan Kaufmann, 2003, pp. 215–220.
17.
J.Doyle, Prospects for preferences, Computational Intelligence20(2) (2004), 111–136. doi:10.1111/j.0824-7935.2004.00233.x.
18.
R.Fagin, Combining fuzzy information from multiple systems, J. Comput. Syst. Sci.58(1) (1999), 83–99. doi:10.1006/jcss.1998.1600.
19.
V.Fionda and G.Pirrò, Querying graphs with preferences, in: 22nd ACM International Conference on Information and Knowledge Management, CIKM’13, San Francisco, CA, USA, October 27–November 1, 2013, Q.He, A.Iyengar, W.Nejdl, J.Pei and R.Rastogi, eds, ACM, 2013, pp. 929–938. doi:10.1145/2505515.2505758.
20.
P.C.Fishburn, Utility Theory for Decision Making. Publications in Operations Research, J. Wiley, 1970.
21.
S.Flesca and S.Greco, Partially ordered regular languages for graph queries, J. Comput. Syst. Sci.70(1) (2005), 1–25. doi:10.1016/j.jcss.2003.04.003.
22.
J.Fürnkranz and E.Hüllermeier (eds), Preference Learning, Springer, 2010. doi:10.1007/978-3-642-14125-6.
23.
J.Goldsmith, J.Lang, M.Truszczynski and N.Wilson, The computational complexity of dominance and consistency in cp-nets, J. Artif. Intell. Res.33 (2008), 403–432. doi:10.1613/jair.2627.
J.T.Guerin, T.E.Allen and J.Goldsmith, Learning cp-net preferences online from user queries, in: Algorithmic Decision Theory – Third International Conference, ADT 2013, Bruxelles, Belgium, November 12–14, 2013, P.Perny, M.Pirlot and A.Tsoukiàs, eds, Lecture Notes in Computer Science, Vol. 8176, Springer, 2013, pp. 208–220. doi:10.1007/978-3-642-41575-3_16.
26.
M.Gueroussova, A.Polleres and S.A.McIlraith, SPARQL with qualitative and quantitative preferences, in: Proceedings of the 2nd International Workshop on Ordering and Reasoning, OrdRing 2013, Co-Located with the 12th International Semantic Web Conference (ISWC 2013), Sydney, Australia, October 22nd, 2013, I.Celino, E.D.Valle, M.Krötzsch and S.Schlobach, eds, CEUR Workshop Proceedings, Vol. 1059, CEUR-WS.org, 2013, pp. 2–8.
27.
S.O.Hansson, What is ceteris paribus preference?, J. Philosophical Logic25(3) (1996), 307–332. doi:10.1007/BF00248152.
28.
W.Kießling, Foundations of preferences in database systems, in: VLDB 2002, Proceedings of 28th International Conference on Very Large Data Bases, Hong Kong, China, August 20–23, 2002, Morgan Kaufmann, 2002, pp. 311–322. doi:10.1016/B978-155860869-6/50035-4.
29.
W.Kießling, M.Endres and F.Wenzel, The preference SQL system – an overview, IEEE Data Eng. Bull.34(2) (2011), 11–18.
A.Leonardo and F.Vasco, OWLPref: Uma representação declarativa de preferências para web semântica, Anais do XXVII Congresso da SBC (2007), 1411–1420.
32.
C.Li, M.A.Soliman, K.C.Chang and I.F.Ilyas, Ranksql: Supporting ranking queries in relational database management systems, in: Proceedings of the 31st International Conference on Very Large Data Bases, Trondheim, Norway, August 30–September 2, 2005, K.Böhm, C.S.Jensen, L.M.Haas, M.L.Kersten, P.Larson and B.C.Ooi, eds, ACM, 2005, pp. 1342–1345.
33.
J.Liu, Y.Xiong, C.Wu, Z.Yao and W.Liu, Learning conditional preference networks from inconsistent examples, IEEE Trans. Knowl. Data Eng.26(2) (2014), 376–390. doi:10.1109/TKDE.2012.231.
34.
J.Liu, Z.Yao, Y.Xiong, W.Liu and C.Wu, Learning conditional preference network from noisy samples using hypothesis testing, Knowl.-Based Syst.40 (2013), 7–16. doi:10.1016/j.knosys.2012.11.006.
35.
W.Liu, C.Wu, B.Feng and J.Liu, Conditional preference in recommender systems, Expert Syst. Appl.42(2) (2015), 774–788. doi:10.1016/j.eswa.2014.08.044.
36.
T.D.Noia, T.Lukasiewicz, M.V.Martínez, G.I.Simari and O.Tifrea-Marciuska, Combining existential rules with the power of cp-theories, in: Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, IJCAI 2015, Buenos Aires, Argentina, July 25–31, 2015, Q.Yang and M.Wooldridge, eds, AAAI Press, 2015, pp. 2918–2925.
37.
I.Nunes, S.Miles, M.Luck and C.J.P.de Lucena, An introduction to reasoning over qualitative multi-attribute preferences, Knowledge Eng. Review30(3) (2015), 342–372. doi:10.1017/S0269888915000016.
38.
G.Pigozzi, A.Tsoukiàs and P.Viappiani, Preferences in artificial intelligence, Ann. Math. Artif. Intell.77(3/4) (2016), 361–401. doi:10.1007/s10472-015-9475-5.
39.
J.Rosati, T.D.Noia, T.Lukasiewicz, R.D.Leone and A.Maurino, Preference queries with ceteris paribus semantics for linked data, in: On the Move to Meaningful Internet Systems: OTM 2015 Conferences – Confederated International Conferences: CoopIS, ODBASE, and C&TC 2015, Proceedings, Rhodes, Greece, October 26–30, 2015, C.Debruyne, H.Panetto, R.Meersman, T.S.Dillon, G.Weichhart, Y.An and C.A.Ardagna, eds, Lecture Notes in Computer Science, Vol. 9415, Springer, 2015, pp. 423–442. doi:10.1007/978-3-319-26148-5_28.
40.
W.Siberski, J.Z.Pan and U.Thaden, Querying the semantic web with preferences, in: The Semantic Web – ISWC 2006, 5th International Semantic Web Conference, ISWC 2006, Proceedings, Athens, GA, USA, November 5–9, 2006, Proceedings, I.F.Cruz, S.Decker, D.Allemang, C.Preist, D.Schwabe, P.Mika, M.Uschold and L.Aroyo, eds, Lecture Notes in Computer Science, Vol. 4273, Springer, 2006, pp. 612–624. doi:10.1007/11926078_44.
41.
A.Troumpoukis, S.Konstantopoulos and A.Charalambidis, An extension of SPARQL for expressing qualitative preferences, in: The Semantic Web – ISWC 2017 – 16th International Semantic Web Conference, Proceedings, Part I, Vienna, Austria, October 21–25, 2017, C.d’Amato, M.Fernández, V.A.M.Tamma, F.Lécué, P.Cudré-Mauroux, J.F.Sequeda, C.Lange and J.Heflin, eds, Lecture Notes in Computer Science, Vol. 10587, Springer, 2017, pp. 711–727. doi:10.1007/978-3-319-68288-4_42.
42.
G.H.Von Wright, The Logic of Preference, Edinburgh University Press, 1963.
43.
N.Wilson, Extending cp-nets with stronger conditional preference statements, in: Proceedings of the Nineteenth National Conference on Artificial Intelligence, Sixteenth Conference on Innovative Applications of Artificial Intelligence, San Jose, California, USA, July 25–29, 2004, D.L.McGuinness and G.Ferguson, eds, AAAI Press/The MIT Press, 2004, pp. 735–741.
44.
N.Wilson, Computational techniques for a simple theory of conditional preferences, Artif. Intell.175(7–8) (2011), 1053–1091. doi:10.1016/j.artint.2010.11.018.