
Abstract
The publication and interchange of RDF datasets online has experienced significant growth in recent years, promoted by different but complementary efforts, such as Linked Open Data, the Web of Things and RDF stream processing systems. However, the current Linked Data infrastructure does not cater for the storage and exchange of sensitive or private data. On the one hand, data publishers need means to limit access to confidential data (e.g. health, financial, personal, or other sensitive data). On the other hand, the infrastructure needs to compress RDF graphs in a manner that minimises the amount of data that is both stored and transferred over the wire. In this paper, we demonstrate how HDT – a compressed serialization format for RDF – can be extended to cater for supporting encryption. We propose a number of different graph partitioning strategies and discuss the benefits and tradeoffs of each approach.
Introduction
In recent years, we have seen an increase in the amount of structured data published online using the Resource Description Framework (RDF), in a manner that not only lends itself to data integration but also supports data exchange. Although Linked Data publishers focus on exposing and linking open data, there are scenarios where individuals and organisations need to store and share sensitive or private data. Additionally, there are number of regulations concerning the financial, medical, personal, or otherwise sensitive data that require companies to employ strong data protection mechanisms, such as encryption and anonymisation. In order to ensure confidentially it is necessary to encrypt the data not only when it is in transit but also when it is at rest. In such scenarios, where multiple users have different access rights to different parts of the data, users should only be able to access the data they are allowed to access.
When it comes to Linked Data protection, to date research has focused on the encryption of partial RDF graphs using eXtensible Markup Language (XML) encryption techniques [12–14] or proposing strategies for querying encrypted RDF data [21]. One of the primary challenges of existing encryption strategies is that they result in a verbose serialization that prevents their use at scale. RDF compression is an emerging research area that focuses on reducing the space requirements of traditional RDF serializations. One approach to efficient data exchange is a (binary) RDF serialization format known as HDT (Header Dictionary Triples) [10] that can be used to compress large datasets in a manner than can be queried without prior decompression [25]. Together encryption and compression mechanisms could be used to cater for the compact storage and efficient exchange of confidential data.
In this paper, we combine “compression+encryption” functionality for RDF datasets, thus allowing service providers to store and share confidential data while reducing storage and bandwidth usage. In particular, we propose
The contributions of our paper can be summarised as follows, we: (i) demonstrate how HDT compression can be extended to cater for encrypted RDF data; (ii) examine a number of alternative partitioning strategies that can be used to reduce the number of duplicates in encrypted HDT (referred to as
The rest of the paper is structured as follows: In Section 2 we discuss related work on RDF encryption and compression. Section 3 provides the necessary background information on HDT and Section 4 describes how compression can be combined with encryption. Section 5 details the different partitioning strategies that can be used in conjunction with graph based encryption. In Section 6 we evaluate using both real-world and synthetic RDF datasets and discusses the trade-off between space and performance. Finally, we conclude and highlight future work in Section 7.
Related work
When it comes to encryption and RDF, the focus to date has been on proposing strategies for the partial encryption of RDF graphs [12–14] or the querying of encrypted data [21]. Giereth [13,14] demonstrate how XML based encryption techniques can be used to encrypt confidential data in an RDF-graph, while all non-confidential data is left as plaintext. Gerbracht [12] built on this work by examining how encryption techniques can be used to encrypt RDF elements and RDF subgraphs, in a manner that reduces the storage overhead. Kasten et al. [21] in turn discuss how data can be encrypted and queried according to SPARQL triple patterns. However this proposal suffers from scalability problems given that each triple is encrypted multiple times depending on whether or not access to the subject, predicate and/or object is restricted. A recent work by Fernández et al. [8] uses Predicate-based Encryption [22] to enable controlled access to encrypted RDF data, i.e., data providers can generate query keys based on (triple-)patterns, whereby one decryption key can decrypt all triples that match its associated triple pattern. In the database and cloud community, Searchable Symmetric Encryption (SSE) [6] has been extensively applied to store and search data in a secure manner. SSE techniques focus on the encryption of outsourced data such that an external user can encrypt their query and subsequently evaluate it against the encrypted data. The more recent Fully Homomorphic Encryption (FHE) [11] technique allows any general circuit/computation over encrypted data, however it is prohibitively slow for most operations [4,29]. None of these works examine the interplay between encryption and compression, which is the focus of our present paper. In particular, we investigate different HDT compression strategies for RDF datasets, which are organised into different RDF graphs that need to be encrypted with different keys. However, our approach could be adapted to work with partially encrypted graphs.
Following the categorization in [27], an RDF compressor can be classified as either syntactic or semantic. Syntactic compressors try to detect redundancy at the serialisation level, whereas semantic compressors try to eliminate logical redundancies. HDT was designed as a binary serialisation format for RDF graphs, but its optimised encodings means that HDT also excels as a syntactic RDF compressor [10,25]. In HDT RDF data is encoded into two main data-driven components: a Dictionary that maps all distinct terms in the dataset to unique identifiers (IDs) (reducing symbolic redundancy), and a triple component that encodes the inner RDF structure as a compact graph of IDs (reducing structural redundancy). This kind of redundancy is also addressed in
Likewise, Joshi et al. [20] use rules to discard triples that can be inferred from others, and they only encode these “primitive triples”. In doing so they reduce the number of triples and consequently save space. The authors also propose a combination of semantic and syntactic compression, by integrating their approach with syntactic HDT compression techniques. Interestingly the results were similar to those obtained by simply using HDT. Recently, Wu et al. [27] have proposed SSP, a hybrid syntactic and semantic compressor. Their evaluation demonstrates that SSP+bzip2 is slightly better than HDT+bzip2. Other approaches, like HDT-FoQ [25] or WaterFowl [5] also enable compressed data to be retrieved without the need for decompression. Both techniques, based on HDT serialization, report competitive performance at the price of using more space than other compressors such as
Preliminaries
Before we present our approach, we need to introduce some concepts and terminology from RDF and HDT. Thereafter, in Section 4, we propose a general mechanism to extend HDT with encryption, termed
As usual, an RDF Graph G is a finite set of triples from
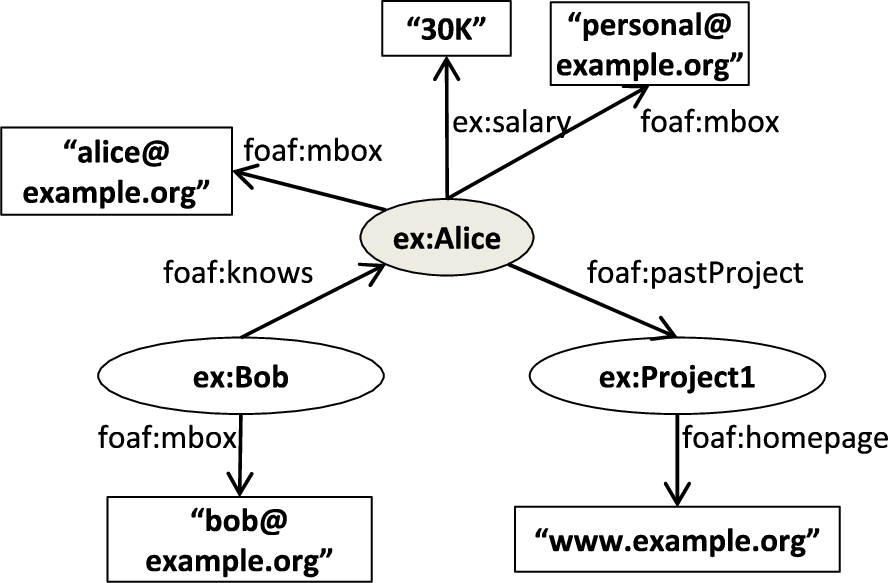
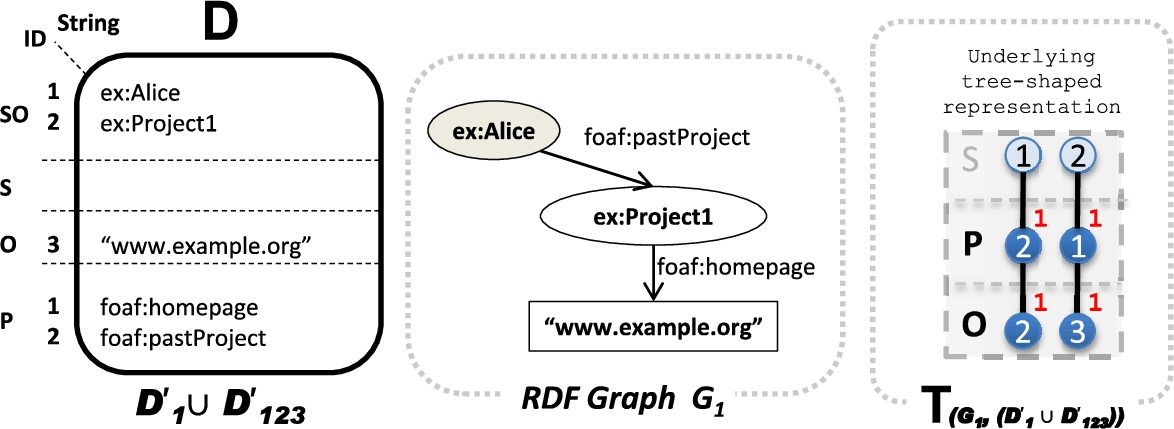
Example of an RDF graph G.

HDT Dictionary and Triples for our full graph G.
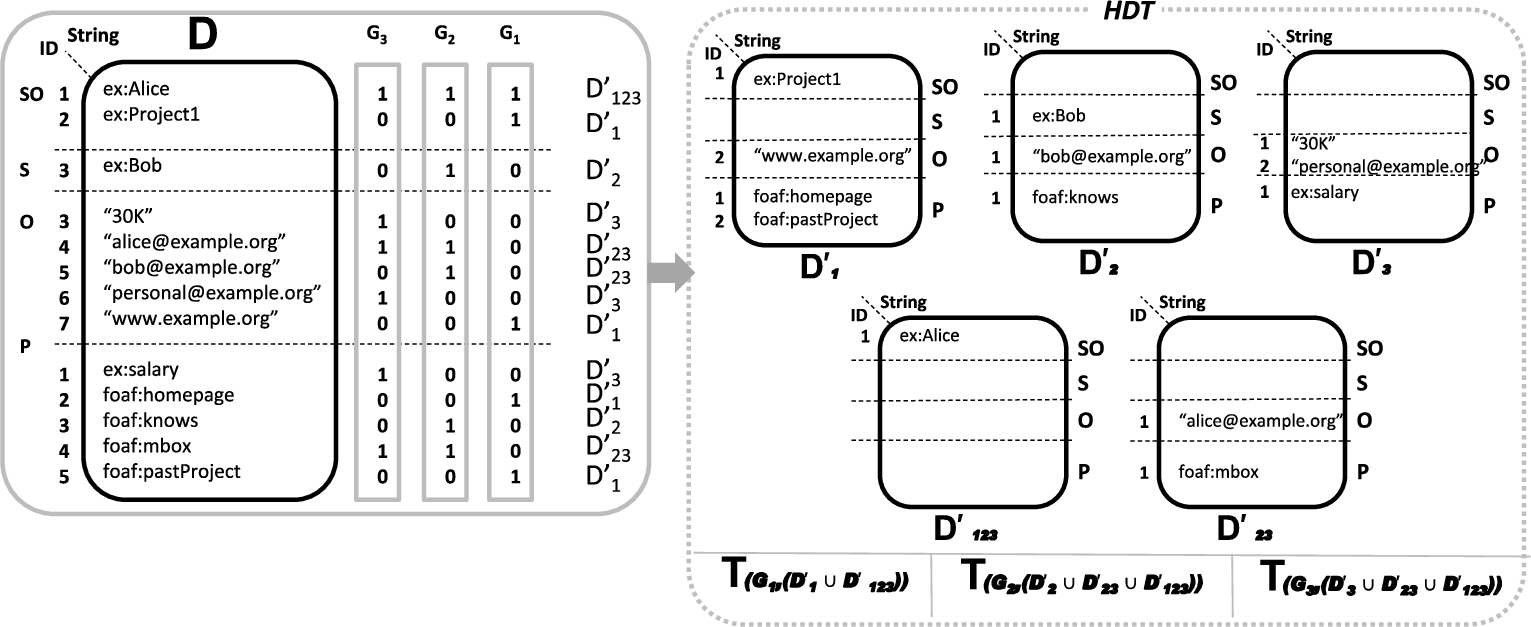
HDT [10] is a binary, compressed serialization format for optimized RDF storage and transmission, which also allows certain lookups and queries over compressed data. It is therefore very suitable for the efficient exchange and querying of large datasets. HDT encodes an RDF graph G into three components: the Header component H holds metadata, including relevant information necessary for discovery and parsing; the Dictionary component D is a catalogue that encodes all RDF terms in G and maps each of them to a unique identifier; the Triple component T compactly encodes G’s graph structure as tuples of three IDs that are used to represent the directed labelled edges in an RDF graph.
Figure 2 shows the Dictionary component (a), the underlying graph structure (b) and the final Triple component (c) for the previous RDF graph G (Fig. 1).
This component organises the terms in a graph G according to their positions in RDF triples, thus we also write
HDT triple component T
This component encodes the structure of the RDF graph after ID substitution, taking into consideration a particular dictionary D, thus, we write
HDT header component H
The HDT Header includes (i) the machine-readable metadata that is necessary to process an HDT file (format metadata); and (ii) additional human-readable information to describe the dataset (usually in the form of VoID1
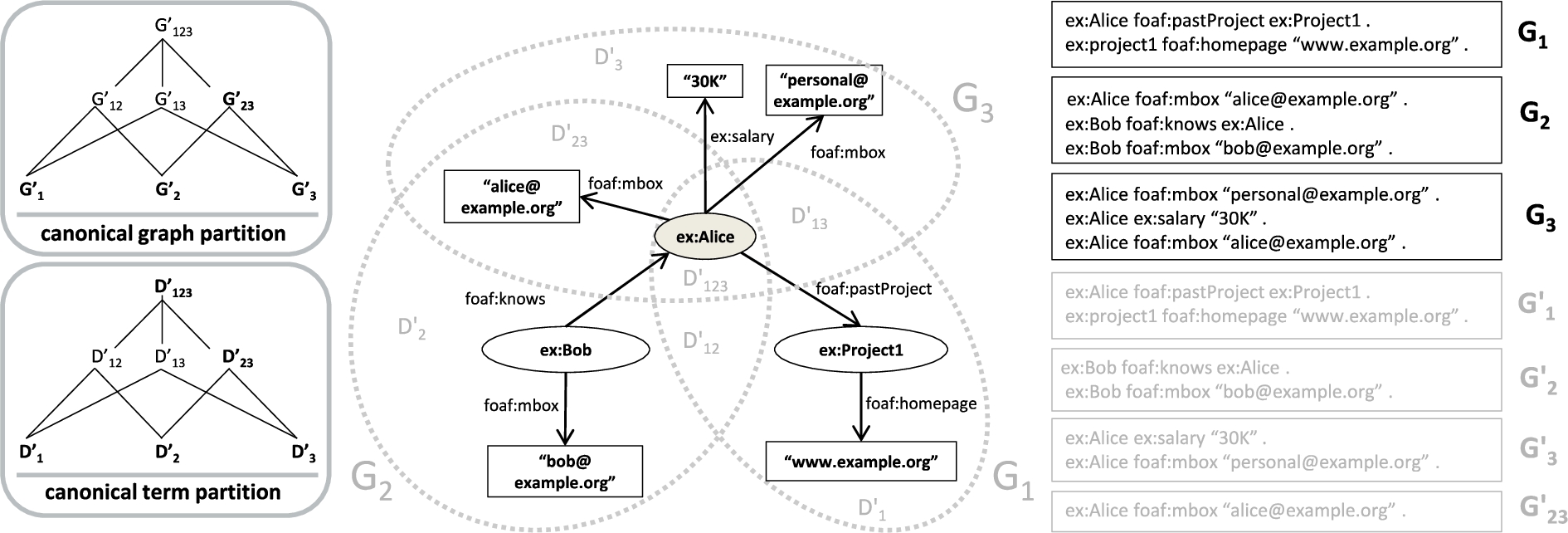
An access-restricted RDF dataset such that G comprises three separate access-restricted subgraphs
We introduce
Representing access-restricted RDF datasets
We consider hereinafter that users wishing to publish access-restricted RDF datasets divide their complete graph of RDF triples G into (named) graphs, that are accessible to other users, i.e. we assume that access rights are already materialised per user group in the form of a set (cover) of separate, possibly overlapping, RDF graphs, each of which are accessible to different sets of users.
Borrowing terminology from [17], an access restricted RDF dataset (or just “dataset” in the following) is a set
In the set-theoretic sense.
Figure 3 shows an example of such a dataset composed of three access-restricted subgraphs (or just “subgraphs” in the following)
Thus, we consider hereinafter an HDT collection corresponding to a dataset
Thus, we define the following admissibility condition for R. An HDT collection is called admissible if:
For any admissible HDT collection
We now introduce the final encoding of the
Thus,
The operations to
For the decryption, it is assumed that an authorized user u has partial knowledge about these keys, i.e. they have access to a partial function
Integration operations
Finally, we define two different ways of integrating dictionaries
D-Union
The D-union is only defined for replace
replace all
D-Merge
In the more general case where the condition for D-unions does not hold on replace We use the directed operator ⊳ instead of ∪ here, since this operation is not commutative.
replace all
replace all
For convenience, we extend the notation of
After having introduced the general idea of
HDT
crypt-A
: A dictionary and triples per named graph in
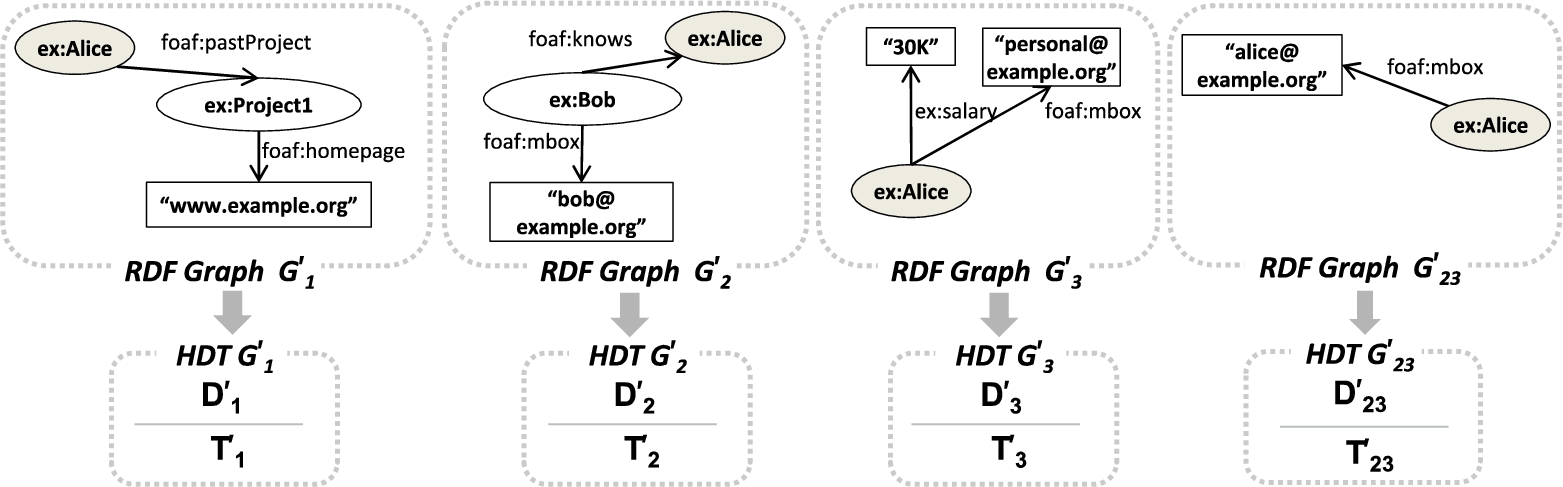
The baseline approach is straightforward, we construct separate HDT components

HDT crypt-A , create and encrypt one HDT per partition.
HDT crypt-B , extracting non-overlapping triples.
In order to avoid the overlaps in the triple components, a more efficient approach could be to split the graphs in the dataset
First, the user will decrypt all the components for which they have keys, i.e. obtaining a non-encrypted collection
HDT crypt-C , extracting non-overlapping dictionaries.
Union of dictionaries (in HDT crypt-C ) to codify the non-overlapping dictionaries of a partition.
Note that in the previous approach, we have duplicates in the dictionary components. An alternative strategy would be to create a canonical partition of terms instead of triples, and create separate dictionaries
Again, here
All
This auxiliary structure is maintained just at compression time and it is not shipped with the encrypted information.
The number of triple components in this approach are as in HDT
crypt-A
, one per graph
Given the partition definition, it is nonetheless true that a term appears in one and only one term-subset.

HDT crypt-D , extracting non-overlapping dictionaries and triples.
Figure 7 illustrates this merge of dictionaries for the graph
In HDT
crypt-D
, we combine the methods of both HDT
crypt-B
and HDT
crypt-C
. That is, we first create a canonical partition of terms as in HDT
crypt-C
, and a canonical partition of triples
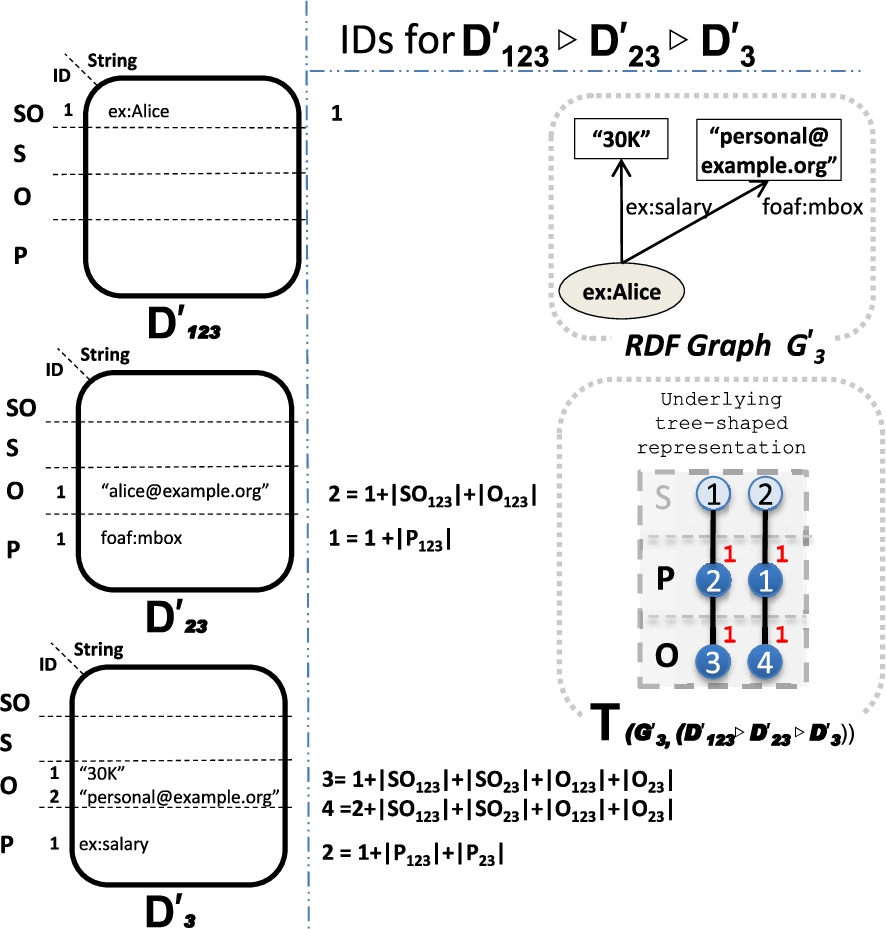
Merge of dictionaries (in HDT crypt-D ) to codify the non-overlapping dictionaries and triples of a partition.
It is worth mentioning that no ambiguity is present in the order of the D-merge as it is implicitly given by the partition
We abuse notation to denote the cardinality of a set, e.g.
This section evaluates the performance of
Matching RDF triples in which each component may be a variable.
Finally, we provide a summary and discussion of the results in Section 6.5. Additional experiments can be found in the Appendix.
Statistical dataset description
% Duplicates and size of subgraphs
The proof-of-concept
Source code and all experiment data are available at the
The evaluation is performed on three different datasets, described in Table 1.
First, we selected DBpedia, the well-known RDF knowledge base extracted from Wikipedia, which was chosen due to the volume and variety of the data and large number of dictionary terms therein. We used two different versions, DBpedia 3.813
Additionally, in order to test the scalability of the various partitioning strategies we use the Lehigh University Benchmark (LUBM) [15] data generator to obtain synthetic datasets of incremental sizes from 1,000 universities (LUBM1K, including 0.13 billion triples) to 4,000 universities (LUBM4K, 0.53 billion triples). Table 1 shows the original dataset sizes in plain N-Triples (NT). In addition, we provide details of the size of the datasets compressed with gzip,
For the LUBM dataset we group data based on the
12 subgraphs, composed of UnderGraduateStudent (
9 subgraphs, composed of the union of UnderGraduateStudent and GraduateStudent (
6 subgraphs, composed of UnderGraduateStudent and GraduateStudent (
When triples represent relations between resources of different types all incoming/outgoing relations are replicated in both subgraphs.
For DBpedia (in the case of both versions), we generate 6, 9 and 12 subgraphs, each containing randomly selected triples amounting to 10% of the entire corpus (thus ensuring overlaps among subgraphs). Triples that do not appear in any subgraph are subsequently distributed evenly among the subgraphs.
In the case of SAFE, the dataset is already organised in 8 subgraphs, composed of 5 external graphs, including statistical data from well-known organisation such as Eurostat and FAO, and 3 internal graphs including aggregated clinical data represented as RDF data cubes [23].
Given that the complexity of the partitioning is directly related to the number of duplicates across subgraphs, the size of each of the subgraphs and the overall duplicate ratio, as
In the following we show the performance results of each of the algorithms (compression and encryption, decryption and decompression, integration and querying). Experiments were performed in a –commodity server – (Intel Xeon E5-2650v2 @ 2.6 GHz, 16 cores, RAM 180 GB, Debian 7.9.). All of the reported (elapsed) times are the average of three independent executions in a cold cache scenario (caches are empty at the start of each process).
Performance of compression and encryption algorithms
Number of dictionaries/triples in each approach
Table 3 shows the compression and encryption times as well as corresponding resulting file sizes15
Note that encryption produces negligible size overheads on the compressed files.
The results show that HDT crypt-C is both the fastest and also produces the most compact representation (only marginally outperformed in space by HDT crypt-D in particular LUBM cases). HDT crypt-C is 37% faster than the baseline approach HDT crypt-A in DBpedia (we refer to the average in both DBpedia versions hereafter), and 40% faster in LUBM. In SAFE, with few duplicates, HDT crypt-C is still 18% faster.
In contrast, HDT crypt-B is the slowest approach with a mean of 68% over the baseline, because it needs to create many dictionaries (e.g. 3904 in DBpedia 2016-10 as shown in Table 4) with overlapping terms. In turn, HDT crypt-D is highly influenced by the number of dictionary components, due to the additional complexity of creating the resp. triple components from the D-merge. Thus, HDT crypt-D is faster than the baseline in LUBM with 6 or 9 subgraphs, with few components as shown in Table 4, but it shows a worse performance in LUBM 12 subgraphs, as well as in all DBpedia and SAFE datasets.
Note that, as stated in Section 5, the creation of HDT crypt-B , HDT crypt-C and HDT crypt-D assumes that the HDT representation of the full graph G is already computed.16
In fact, HDT is becoming popular to store and serve large datasets by publishers and third parties, and a large portion of datasets in the Linked Open Data cloud is already available in HDT thanks to the project LOD Laundromat [2], crawling and serving the HDT conversion of datasets (
Additionally, when compared with the baseline approach HDT crypt-A , HDT crypt-C achieves a mean of 33% space saving in DBpedia and 26% space saving in LUBM. In general, HDT crypt-B , HDT crypt-C and HDT crypt-D benefit from having an increasing number of overlapping dictionaries/triples, hence the DBpedia even distribution produces more space savings. For the same reason, an increasing number of subgraphs leads to more duplicates and space savings w.r.t the baseline, e.g. HDT crypt-C in LUBM achieves 24%, 26% and 27% savings with 6, 9 and 12 subgraphs respectively. It is worth mentioning that despite the fact that HDT crypt-D isolates the non-overlapping dictionaries and triples, there is an overhead in the representation as we do not use Bitmap Triples but Plain Triples (as stated in Section 5.4). This is more noticeable in DBpedia with long predicate and object lists. It is worth highlighting that, in SAFE, with almost no duplicates, only HDT crypt-C is competitive in space with the baseline, while HDT crypt-B and HDT crypt-D have to pay a slight overhead for keeping the different structures, which cannot leverage the minimal duplication across subgraphs.
Encryption times are only a small portion of the publication process, where HDT crypt-C is generally the fastest approach except for DBpedia 3.8 with 12 subgraphs and SAFE, for which HDT crypt-A is the fastest, and for LUBM3K/LUBM4K with 9 subgraphs as well as LUBM4K with 12 subgraphs where HDT crypt-D is marginally faster. Thus we can conclude that both the number of files that need to be encrypted as well as their respective file sizes influence the overall encryption time. Finally, it is worth noting that – as expected – the performance time of the compression and encryption, as well as the result file sizes show linear growth with increasing LUBM datasets.
Performance of decryption and decompression algorithms for
Performance of decryption and decompression algorithms for
According to our use case scenario we assume that a user has been granted access to more than one named graph, but not the whole dataset. For a fair comparison, given the skewed size distribution of subgraphs in LUBM (see Table 2), we set up a scenario where the user has been granted access to half of the total subgraphs, including the smallest, average and largest subgraphs. This configuration corresponds to decrypting and decompressing the subgraphs referred to as
Table 5 shows the time to decrypt and decompress each of the respective subgraphs in the case of DBpedia and LUBM, while Table 6 shows the results for SAFE.
Decryption times are almost negligible compared to the decompression time – similar to encryption vs. compression time. Again, the number of files is the dominating factor, hence HDT crypt-A is the fastest approach regarding decryption.
Regarding decompression, (as per compression) HDT
crypt-C
is the fastest approach, achieving a mean of 30% time savings in DBpedia and LUBM w.r.t the baseline HDT
crypt-A
. In DBpedia, given the even distribution, having 6 subgraphs is always slightly faster than 9 and 12 subgraphs as the latter generates more duplicates. Regarding the number of graphs in LUBM, 6 and 12 subgraphs behave similarly, while the decompression of 9 subgraphs is slightly slower. Nonetheless, we could verify that the difference between 9 and 12 subgraphs is due to the slightly bigger total file size produced by
Finally, although the results for the SAFE dataset (shown in Table 6) follow a similar behaviour, it is worth mentioning that HDT
crypt-B
and HDT
crypt-D
have to pay the price of loading additional structures (even in the presence of minimal duplication). Results show that, while this pays off in the case of the larger subset like
Querying compressed data
One of the main advantages of HDT compression is that it is possible to perform SPARQL triple pattern queries directly on the compressed data [25]. Whereas this also holds for approach HDT crypt-A , as it already consists of one file per subgraph, the other approaches presented, HDT crypt-B , HDT crypt-C and HDT crypt-D , split a subgraph in different dictionary (D) and triple (T) components. For these latter approaches, query resolution can be done by two strategies:
Querying an integrated HDT: This strategy integrates all the dictionary and triple components of a subgraph into a new HDT (i.e. converting to the baseline HDT crypt-A ) which can be then queried.
Local query on each dictionary and triple component: In this case, the query is performed locally in each dictionary and triple component and the results are then integrated. Note that HDT crypt-C is not viable for this strategy as it would require to perform the D-union of all the dictionaries in order to search the triples IDs, which is then equivalent to integrating HDT crypt-C into a new HDT to be queried.
The following evaluation first inspects the performance overhead of the integration required by the former strategy. Then, we evaluate the query performance of the latter. For exemplary purposes, we present the average results of the DBpedia datasets, while the performance for LUBM and SAFE can be found in the Appendix.
Note that, although there are a number of strategies for querying encrypted data directly (see e.g., [3]), we consider these orthogonal and leave combining them with our partitioning for future work.
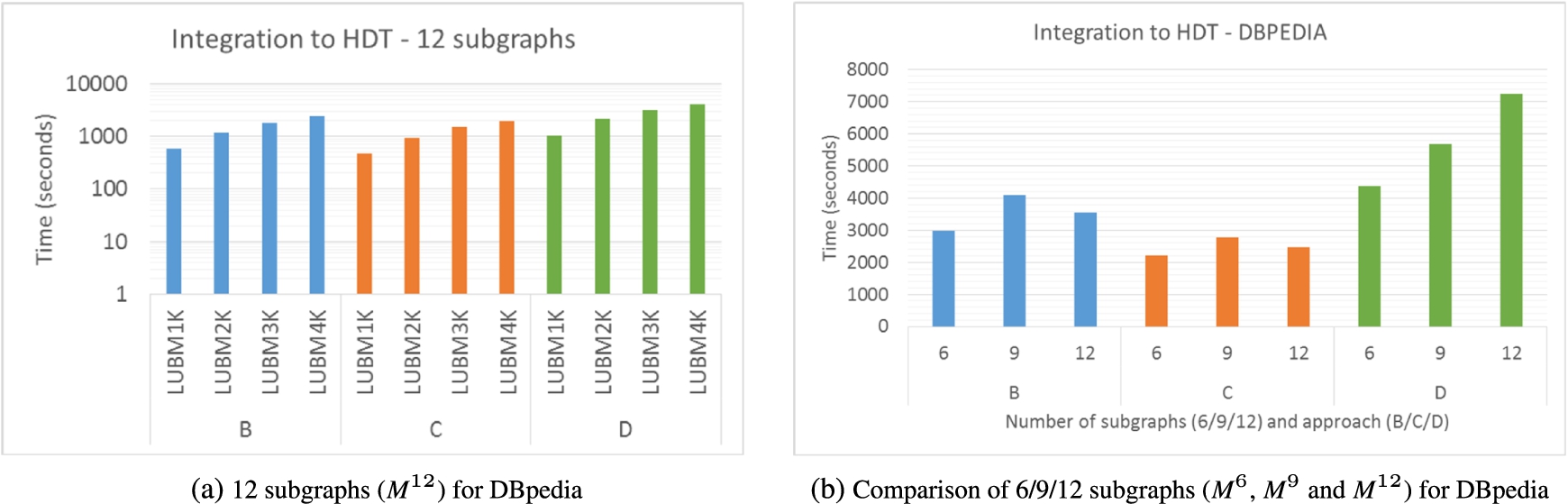
Integration of the dictionary and triple components of
Following our use case scenario, we assume that a user has decrypted half of the subgraphs, the i.e.
Note that this process slightly differs from the D-union as the latter only replaces the new IDs in each of the input triple component.
We present the time to integrate the dictionary and triple components of
A comparison in terms of number of subgraphs is shown in Fig. 10(b), reporting the times of merging
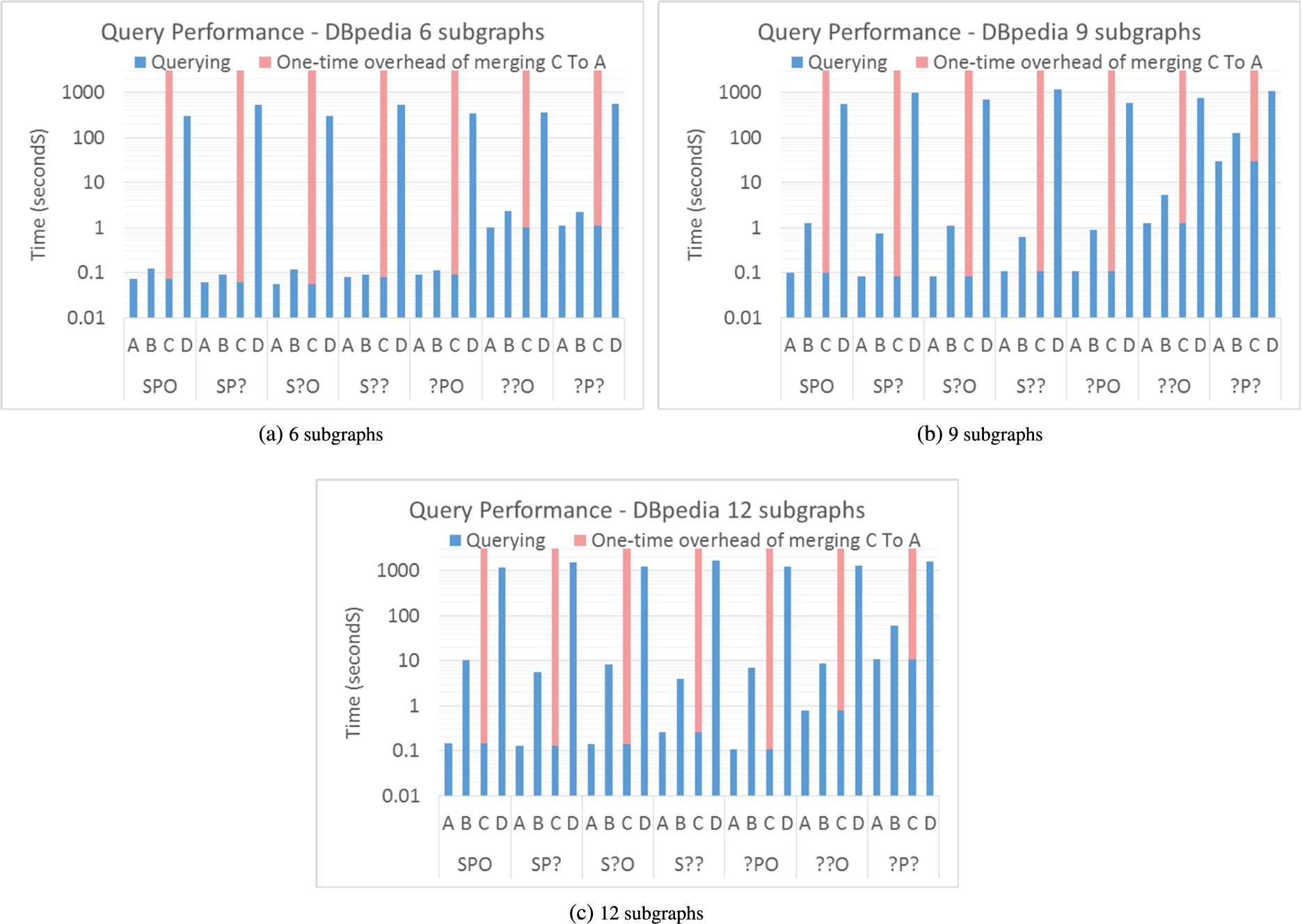
Performance of Triple Patterns over DBpedia (average of the performance in both DBpedia versions).
We evaluate the query performance of all partitioning strategies in our use case scenario. Thus, for each subgraph in
All queries are available at the HDTcrypt repository.
Regarding the comparison between our strategies for partitioning, results show that HDT
crypt-A
and HDT
crypt-B
have the best performance for all patterns. This can be attributed to the fact that they benefit from efficient Bitmap Triples indexes, while HDT
crypt-D
must use Plain Triples (as stated in Section 5.4) that perform sequential scans to resolve queries. Note that HDT
crypt-D
is only competitive in the case of
In turn, it is also worth mentioning that HDT crypt-B query performance is closer to the baseline HDT crypt-A in the scenario with 6 subgraphs. This is mainly due to the larger number of dictionaries/triples to be queried in a scenario with a higher number of subgraphs (as shown in Table 4), which penalises the HDT crypt-B and HDT crypt-D methods. In this scenario, HDT crypt-A is the most efficient approach for query execution. The noticeable performance difference against the rest of the partitioning approaches suggests that the once-off merging that is required for HDT crypt-C can be amortised if the dataset is meant for intensive querying after decryption.
Summary of performance of different
Influence of the increasing number of subgraphs and duplicates in the performance of different
Overall, our empirical evaluation showed interesting results and allows us to draw conclusions on the applicability of each strategy. We summarize a ranking of results for each scenario in Table 7, and we outline the influence of the increasing number of subgraphs and duplicates in the data in Table 8, detailed as follows:
HDT crypt-C is the most effective technique in terms of compression and decompression times, as well as compression sizes. In particular, it achieves additional 26–33% space saving over the –already compressed – baseline (HDT crypt-A ), and it is 37–40% faster to compress, and 30% faster to decompress. Note that the impact of these space and time savings are even more noticeable when dealing with big data. As we noticed, if the original HDT of the full graph is not available beforehand, then the creation of HDT crypt-C can take more time than the baseline (it results in approx. the same time in LUBM and 35–50% slower in DBpedia, with a rich dictionary of terms), but it keeps the aforementioned noticeable space savings. In the extreme case of isolated subgraphs with few duplicates, as in SAFE, HDT crypt-C takes the same space as the baseline and is still 18% faster to encrypt.
In contrast, HDT crypt-C does not allow the user to directly query the exchanged information. If such a scenario is required, this can be solved with a once-off conversion from HDT crypt-C to HDT crypt-A . This conversion can be done for any strategy, but it is indeed faster for HDT crypt-C .
HDT crypt-B and HDT crypt-D also reduce the size of the baseline (HDT crypt-A ), and can be directly queried. Results show that HDT crypt-B and HDT crypt-D gain 6–24% and 24–26% space over the baseline respectively, at the cost of an extra 68% and 23% time for compression (performed only once by the data publisher). In turn, the decompression time outperforms the baseline by 7% and 9% for HDT crypt-B and HDT crypt-D respectively. In the extreme case of isolated subgraphs with few duplicates, as in SAFE, HDT crypt-B and HDT crypt-D suffer from a slight space overhead (15–23%) over the baseline, and non negligible additional decompressing times.
The performance of directly querying several subgraphs in HDT crypt-B is close to the baseline HDT crypt-A . Nonetheless, it is penalised at larger number of partitions (such as 12 in our experiments) and larger number of duplicates (such as our even distribution in DBpedia). HDT crypt-D suffers from the additional problem of performing sequential scans, and is not competitive but for queries that retrieve large number of results.
Encryption and decryption times are almost negligible compared to the compression/decompression counterparts.
Compression sizes, compression and decompression times show linear growth with increasing dataset size.
In general, an increasing number of subgraphs leads to more duplicates and more space savings of our novel HDT crypt-B , HDT crypt-C and HDT crypt-D partitioning approaches over the baseline HDT crypt-A . In turn, less data file sizes result in faster decompression of our novel approaches. In contrast, the compression time is penalised given that more components have to be generated. Our experiments also showed that the number of subgraphs does not have a strong influence on the query performance, but the skewed distribution of sizes and the large number of components (such as in DBpedia) can result in slight differences between scenarios.

Integration of the dictionary and triple components of
To date Linked Data publishers have focused on exposing and linking open data, however the Linked Data infrastructure could be extended to cater for the storage and exchange of confidential data. In this paper, we discussed how HDT compression can be extended to cater for RDF datasets which needs to be encrypted. Specifically, we proposed a number of different compression strategies that are compatible and demonstrated the need for careful integration when it comes to compressed encrypted RDF data. From our evaluation we can see that our proposal HDT crypt-C outperforms the other partitioning strategies both in terms of compression and decompression time, and it also produces the most compact representation, resulting in 26–31% space savings over the – already compressed – baseline. HDT crypt-B and HDT crypt-D also reduce the size of the baseline significantly. Whereas, when it comes to querying HDT crypt-A and HDT crypt-B outperform HDT crypt-C , which incurs additional overhead as the dictionaries and triples need to be integrated in order to support querying. Additionally, we note that compression, decompression and query performance is influenced both by the number of access restricted subgraphs and the distribution of triples across subgraphs, especially in HDT crypt-D . In future work, we plan to extend our existing work to cater for querying over encrypted compressed data without the need for decryption. Our current work considers basic triple pattern resolution, while the HDT approach can be used as the basic engine to resolve full SPARQL queries. Our plan is to support this possibility on the compressed and encrypted data in future work.
Footnotes
Acknowledgements
Supported by the European Union’s Horizon 2020 research and innovation programme under grant 731601, Austrian Science Fund (FWF): M1720-G11, the Austrian Research Promotion Agency (FFG) under grant 845638 (SHAPE) and grant 861213 (CitySpin), and MINECO-AEI/FEDER-UE ETOME-RDFD3:TIN2015-69951-R. Axel Polleres was supported by the “Distinguished Visiting Austrian Chair” program as a visiting professor hosted at The Europe Center and the Center for Biomedical Research (BMIR) at Stanford University. Special thanks to Ratnesh Sahay for providing the SAFE dataset.
Additional performance results
This appendix comprises the performance results for all datasets. See Section 6 for a description of the corpus and the complete discussion of results.