
Abstract
Fulfilling occupants’ comfort whilst reducing energy consumption is still an unsolved problem in most of tertiary buildings. However, the expansion of the Internet of Things (IoT) and Knowledge Discovery in Databases (KDD) techniques lead to research this matter. In this paper the EEPSA (Energy Efficiency Prediction Semantic Assistant) process is presented, which leverages the Semantic Web Technologies (SWT) to enhance the KDD process for achieving energy efficiency in tertiary buildings while maintaining comfort levels. This process guides the data analyst through the different KDD phases in a semi-automatic manner and supports prescriptive HVAC control strategies. That is, temperature of a space is predicted simulating the activation of HVAC systems at different times and intensities, so that the facility manager can choose the strategy that best fits both the user’s comfort needs and energy efficiency. Furthermore, results show that the proposed solution improves the accuracy of predictions.
Introduction
Concerns over changing climatic conditions (i.e. global warming, depletion of ozone layer, etc.), energy security, and adverse environmental effects are growing among governments, researchers, policy makers, and scientists in developed as well as developing countries [75]. In order to meet the energy sustainability and minimize the climate change, the European Commission agreed a set of binding legislations inside the EU 2020 package. One of the spotlighted sectors regarding this package is the building sector which, according to the UNEP (United Nations Environment Programme), consumes about 40% of global energy and is responsible for 36% of CO2 emissions in the EU. Therefore, efficient management of building energy plays a vital role and is becoming the trend for a future generation of buildings.
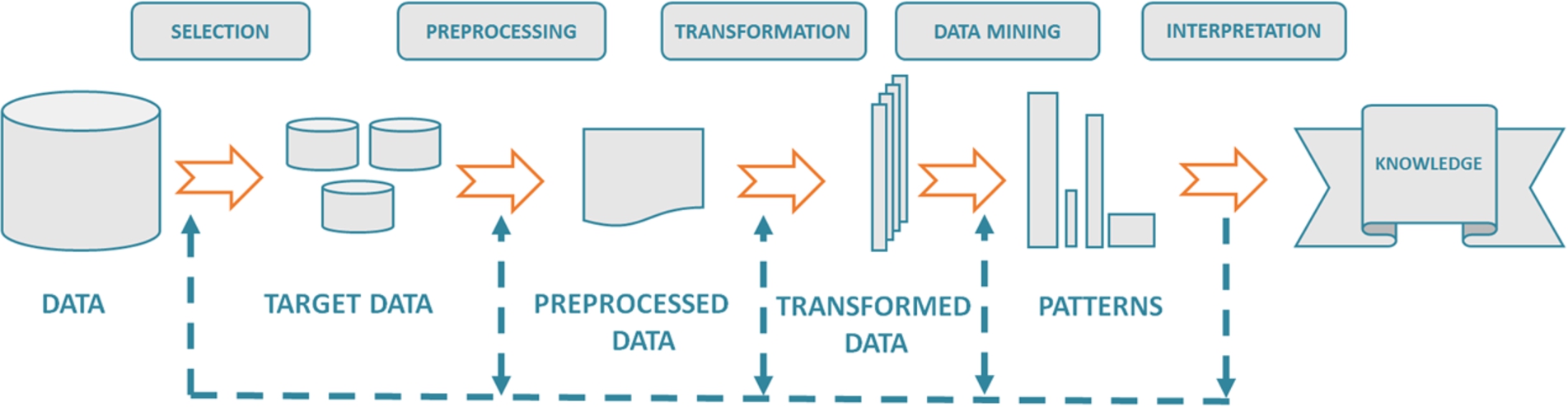
An overview of the steps that compose the KDD Process proposed in [27].
However, energy efficiency is not the only concern related with buildings. Since approximately 90% of people spend most of their time in buildings, feeling comfortable indoors is a must and poses a huge impact to preserve inhabitant’s health, morale, working efficiency, productivity and satisfaction. As a consequence, a system is needed which fulfills the occupants’ expected comfort index whilst reducing energy consumption during the operation of a building. In this context, the expansion of the Internet of Things (IoT) and Knowledge Discovery in Databases (KDD) techniques will lead to both researching the reduction of such prominent impact and the improvement of comfort levels.
The achievement of energy efficiency while maintaining users’ comfort in tertiary buildings is not a trivial question. There are many complementary ways to save and optimize energy use in buildings, but since temperature is the most important ambient parameter affecting electric load, forecasted indoor temperatures constitute a basic ingredient in energy efficiency plans [1].
Let us consider the following scenario. The facility manager of a given building seeks to establish an activation strategy for the HVAC (Heating, Ventilation and Air Conditioning) system, so that energy is used in the most efficient way while maintaining the optimal comfort1
Optimal comfort can be understood in many ways: a temperature that ranges between some given values, a temperature that varies less during a period of time, etc.
The KDD can be understood as a five steps process leading to the extraction of useful knowledge from raw data [27], applicable for instance in decision support systems. The five steps can be summarized as follows:
Selection of datasets and subset of variables or data samples on which discovery will be performed.
Preprocessing tasks to ensure data quality and preparation for a subsequent analysis.
Transformation or production of a projection of the data to a form which data mining algorithms can work with and improve their performance.
Data mining by selecting the algorithm that best matches the user’s goals and their application to search for hidden patterns.
Interpretation and evaluation of the results, patterns and models derived, in support of decision making processes.
This process can involve significant iteration and can contain loops between any two of the mentioned steps as can be seen in Fig. 1.
Data analysts in charge of the KDD process are confronted with large, diverse and heterogeneous data. First of all, data related to the given space and its structural element properties including materials, heat transfer coefficients, and orientation of their boundaries. They also need to take into account information about sensors and actuators deployed in the building, their location, features and certainly their measurements. Likewise, data about weather conditions and weather forecasts for the building location are relevant. Furthermore, there is other information to consider such as the space occupancy, work schedule or human related organization. Under such circumstances where a deep energy efficiency and building domain knowledge is required, having insufficient domain expertise could make data analysts feel overwhelmed. Consequently, they typically resort to a trial and error approach searching for variables and tasks that could be confidently used to make accurate predictions. This is definitely an undesirable approach and it would be much more profitable to count with an assisted KDD process supported by technologies that enable the management of data semantics, data interrelationships, and knowledge representation.
Semantic Web Technologies (SWT) enable the explicit representation of knowledge both in human and machine understandable form. Moreover, SWT have been successfully used in the data integration as well as system interoperability tasks, and they enable the representation of expert knowledge obtained via knowledge elicitation processes. Once represented in semantic resources, SWT open a range of possibilities to exploit knowledge, such as full fledged data querying or further processing to infer new knowledge from implicitly hidden knowledge. Furthermore, if domain expert knowledge is adequately complemented with tools that support the assistance throughout the KDD process, its usability and exploitation capabilities will be at hand.
This paper presents the EEPSA (Energy Efficiency Prediction Semantic Assistant) process to address the aforementioned problematic scenario in the energy efficiency in tertiary buildings domain, leveraging Semantic Web Technologies such as ontologies, ontology-driven rules and ontology-driven data access.
The EEPSA process targets different KDD phases and each one poses its requirements. First of all, data needs to be semantically annotated with appropriate ontological terms. This semantic annotation is fundamental for enriching data, integrating heterogeneous data and representing it in a more domain-oriented way, as well as for enabling the improvement of the upcoming KDD phases. In the data selection phase the data analyst is assisted to decide which might be the most relevant variables for the matter at hand. Ontology-driven queries and inferencing capabilities support this task. The preprocessing phase intends to clean data from noise, missing values or inconsistencies to name a few. Ontology-driven rules help detecting such problematic data and classifying them according to their potential cause, as well as in proposing possible methods to fix them according to the established goal. The transformation phase generates additional knowledge in form of new attributes. Knowledge-driven rules, inferencing capabilities and external data sources are critical in this phase. All the enhancements in these phases could contribute to improve the robustness and performance of machine learning algorithms applied in the data mining phase and would ease the interpretation of the obtained results. Moreover, the proposed process is expected to be reusable in similar use cases of the same domain due to its high abstraction level.
Summarizing, the main contributions of this paper are the following:
Description of a domain ontology that provides enough concepts and relations to express all the relevant information for the identified tasks and enables the representation of actionable expert knowledge.
Outline of a process for assisting data analysts throughout a KDD process by leveraging SWT, with focus on some phases to show the mechanics of this proposal.
A real-world evaluation of the proposed approach for illustrating the process.
The rest of this paper is structured as follows. Section 2 introduces the related work and analyses existing ontologies in the field. Section 3 presents the EEPSA ontology and the EEPSA process through the different KDD phases. Section 4 shows the application of this process on a real-world use case and evaluates and discusses obtained results. Finally the conclusions of this work are shown in Section 5.
KDD for energy efficiency in buildings
KDD have traditionally been used to achieve energy efficiency in buildings such as in [33], where Artificial Neural Networks (ANN) and historic values have been used for short-time load forecasting in buildings. However, existing BMS (Building Management Systems) generally fail to fully optimize energy consumption in buildings. [35] states that current and forecasted information about events and weather (e.g. rain or snow) would help increasing the stability of the control systems minimizing energy consumption and increasing the occupants comfort. External meteorological conditions are used to improve the energy usage predictions in [4]. But not all external weather factors have the same impact in the energy consumption forecasting in buildings. In the use case presented in [51] for instance, effects of humidity and sun radiation had a less significant impact in energy consumption, compared with the external temperature.
Related work in [50,67] and [79] shows that not only external climatologic factors affect the energy use in buildings. Most modern buildings still condition rooms assuming maximum occupancy rather than actual usage. As a result, rooms are often over conditioned. [24] proposes different HVAC control strategies based on occupancy prediction of rooms. In a similar way [66] focuses on a better heating scheduling by predicting future occupancy. Wireless motion sensors and door sensors are used in [48] to infer occupants presence and activate or deactivate HVAC systems accordingly. [55] aims at developing predictive control strategies that use both weather and occupancy forecasts to limit peak electricity demand while maintaining high user comfort.
According to the related work shown in previous paragraphs, it has been proved that meteorological factors as well as occupancy of buildings have a significant impact both on the building energy consumption and comfort. The HVAC control strategies have also been deeply studied as a measure to achieve these two goals. However, the process of combining all these data sources into the KDD for exploiting them poses a big challenge. The research presented in this paper proposes the use of SWT towards a holistic approach to the improvement of the whole KDD process and obtained results.
Semantic Web Technologies for KDD
In the last years, advantages of semantic technologies for data understanding as well as for the data mining process itself have been highlighted in [42] and [60]. Furthermore, many approaches have proposed the use of Semantic Web data to enhance different KDD phases. Semantic Web Technologies address how one would discover the required data in today’s chaotic information universe, how one would understand which datasets can be meaningfully integrated, and how to communicate the results to humans and machines alike.
According to [20], the Internet of Things (IoT) and Open Data are particularly promising in real time predictive data analytics for effective decision support, and the dynamic selection of Open Data and IoT sources for that purpose is the main challenge. Data quality is tackled in [28,29] and [30], where data quality problems in Semantic Web data are identified by means of data validation rules. A review of the existing data quality work based on ontologies for the health domain is shown in [47]. In [62] desiderata and challenges for developing a framework for unsupervised generation of data mining features from Linked Data are identified. [43,56] and [64] are examples of systems for enriching data with features that are derived from LOD (Linked Open Data). In [76] a feature-selection method based on ontology is proposed. The data mining environment RapidMiner [40] includes a LOD extension which provides a set of operators for augmenting existing datasets with additional attributes from open data sources [63]. In [53] semantic technologies are used to assist data scientists in selecting appropriate modelling techniques in the field of statistics or machine learning and building specific models as well as the rationale for the techniques and models selected. [38] presents an ontology to support the meta-learning for algorithm selection in the data mining, while in [6] one of the first intelligent discovery assistants is proposed. An overview of existing intelligent assistants for data analysis is provided in [68]. In [7] it has been noted that SWT can also have a potential impact in the Decision Support.
A detailed and extended survey on SWT within the KDD process can be found in [65]. The survey shows that, while many impressive results can be achieved already today, the full potential of Semantic Web Technologies for KDD is still to be unlocked.
Aforementioned work show that even though some initiatives apply SWT to improve a specific KDD phase, at the moment of writing this article no solution tackling the KDD process as a whole has been recognized. The research presented in this paper intends to be a preliminary effort towards that goal within the energy efficiency in tertiary buildings domain.
Existing ontologies in the field
BIM (Building Information Modelling) deals with the representation of functional and physical characteristics of a building [22]. That is, static information of a building element may be available and queryable in a BIM model; for example a door, its location, the material it is made of, and occasionally, even when it was installed. But for instance, it is not possible to know whether the door is opened or closed in a given moment. This is why, in order to transform the building static data into live data, it is necessary to integrate information coming from IoT and sensing device network nodes. This data integration across several data sources can be obtained by adopting SWT. Further applications of SWT in this field are surveyed in [59]. All of them need conceptual foundation provided by ontologies.
Keeping this in mind, a brief summary of relevant ontologies of the current research domain is presented below. They cope with the building domain (ifcOWL, DogOnt, BOT), sensors and actuators domain (SSN, SAREF, FIESTA-IoT, IoT-O), and the weather domain (SmartHomeWeather). Other ontologies such as Semanco [49] or the Aemet Network of Ontologies [5] have also been analysed, but are not reflected in this paper. Some of the consulted surveys to identify these ontologies have been [23] and [44]. An interesting comparison between different IoT ontologies is also covered in [69]. The catalogues Linked Open Vocabularies [74] and LOV4IoT [34] have been used to search vocabularies covering desired concepts.
ifcOWL ontology
IfcOWL ontology2
The ifcOWL ontology aims at supporting the conversion of IFC instance files into equivalent RDF files. It defines a faithful mapping of the IFC EXPRESS schema, which is the master schema for IFC models, and therefore replicates its object-oriented conceptualization, which has been found inconvenient for some practical engineering use cases (see [57]). Moreover, the ifcOWL conceptualization of some relationships and properties as instances of classes (i.e. ifc:IfcRelationship, ifc:IfcProperty) is counterintuitive to semantic web principles, that would expect OWL properties to represent them. A systematic transformation of this modelling issue has been presented in [19], producing the IfcWoD (IFC Web of Data) ontology, and some advantages of this semantic adaptation are claimed such as simplification of query writing, optimization of query execution and maximizing of inference capabilities. However, to the best of our knowledge, the IfcWoD ontology announced in that paper is not publicly available at the time of writing this article. In summary, the ifcOWL ontology is a necessary tool to incorporate IFC models to the semantic web infrastructure but is too complex for some use cases. IFC is used in construction industry and it rather focuses on building elements such as walls or doors, and their relations and geometries, with a granularity that is inconvenient for some scenarios. Furthermore, it is of secondary importance that an instance RDF file can be modelled from scratch using the ifcOWL ontology and an ontology editor.
The DogOnt ontology3
However, building elements information such as measurements or insulation is not described in DogOnt. Observations made by sensing devices which are essential for a KDD process in the energy efficiency context, are not covered either.
Building Ontology Topology (BOT)4
The Semantic Sensor Network (SSN) ontology6
The initial SSN ontology was aligned with DOLCE ultra-lite (DUL) ontology7
The new SSN ontology follows a horizontal and vertical modularization architecture by including a lightweight but self-contained core ontology called SOSA8
The SSN ontology does not contain properties which can be measured by sensors. Neither is covered related material such as units of measurements of these properties, locations or hierarchies of sensor types, or time-related concepts. All this knowledge has to be modelled or imported from other existing vocabularies.
The Smart Appliances REFerence (SAREF) ontology9
SAREF enables modelling devices and sensors in terms of functions, states and services they provide. Nevertheless, the ontology does not address the description of the observation in an interoperable manner to ease further tasks such as reasoning. It provides the link to the FIEMSER10
SAREF4BLDG ontology11
FIESTA-IoT Ontology12
Despite sensing devices are deeply described and covered, tagging and actuating devices are not at the same level. Furthermore, even though the smart building domain is described, building elements and its features are not.
IoT-O ontology17
A sensing module, based on SSN ontology.
An acting module, based on SAN (Semantic Actuator Network) ontology.18
A service module, based on MSM (Minimal Service Model).19
A lifecycle module, based on a lifecycle vocabulary and an IoT-specific extension.
An energy module, based on PowerOnt [9].
Smart Home Weather20
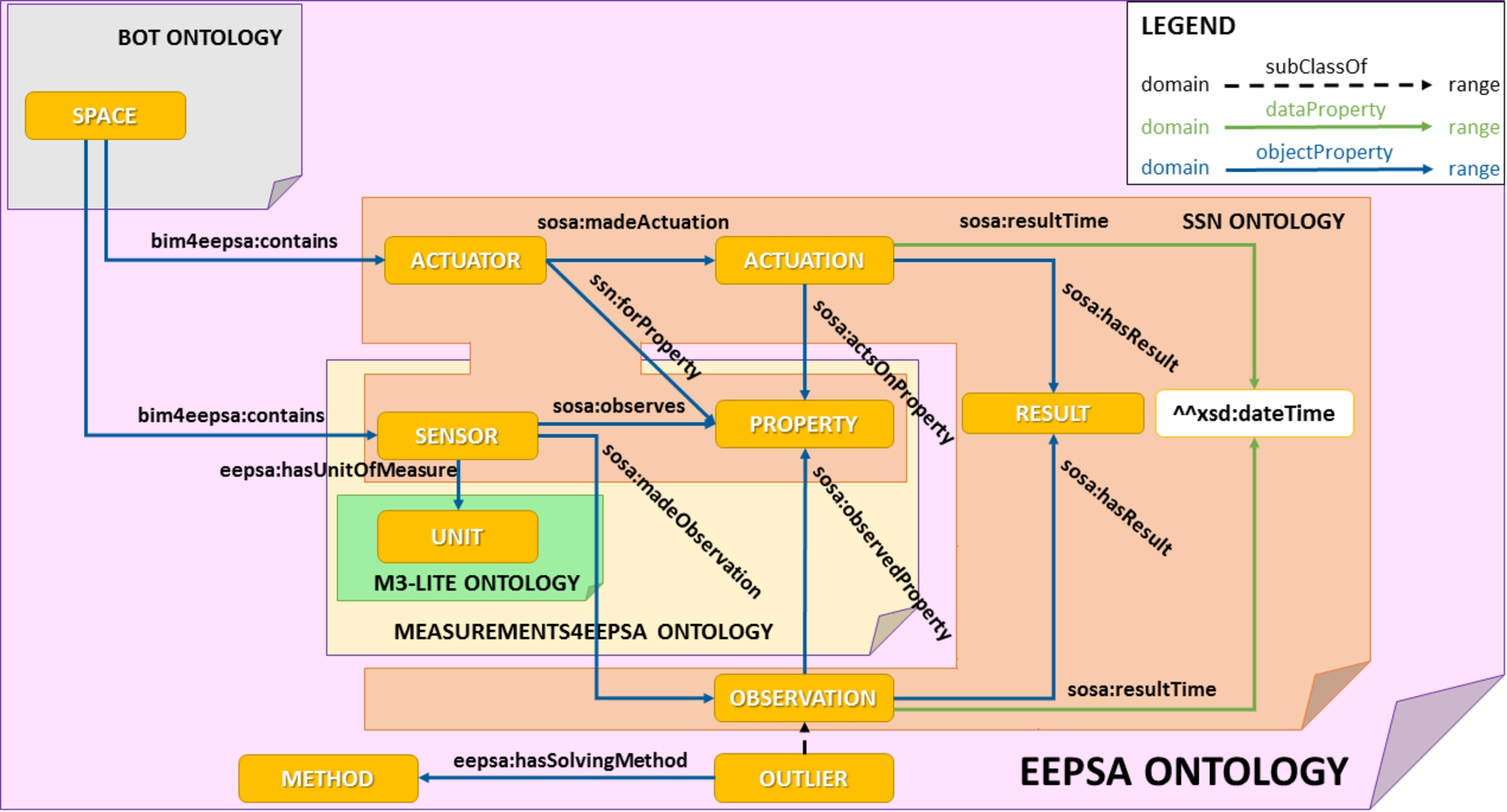
An overview of relevant classes and properties in EEPSA ontology.
The ontologies presented in this section cover different topics considered by our domain of discourse. Moreover, they overlap to a greater or lesser extent in some of their parts. However, none of them meet all the EEPSA process requirements by themselves. Therefore, we propose to fill the gap between the state of the art ontology offer and the identified requirements of the EEPSA process with the production of a proper ontology that covers the needed terminology, following the good practices of modularity and reuse. The decision for reusing all or parts of any of them in the ontology supporting the EEPSA process, was taken on the basis of a conceptual agreement with the requirements, axiomatic richness relating their terms, simplicity of the structure to facilitate querying, popularity of the ontology to improve interoperability, and documentation accessibility to facilitate new users. Reusing parts from one ontology prevents the reuse of parts of others to avoid redundancy issues. For instance, reusing bot:Building and bot:Element from BOT, prevents from using their equivalents ifc:Building and ifc:BuildingElement from ifcOWL. However, it is essential to explicitly express and maintain those equivalence mappings with related ontologies, as well as some other ontological relationships. For example, bot:Element rdfs:subClassOf saref4bldg:PhysicalObject and bot:hasSpace rdfs:subPropertyOf saref4bldg:haSpace from SAREF4BLDG. Only parts of some of them will be reused, and therefore a preliminary mapping process will be necessary to interoperate with datasets using the other vocabularies.
The suite of imported modules by the EEPSA ontology21
When following the EEPSA process the data analyst utilizes some off-the-shelf tools and others which are specifically designed. For the semantic annotation phase the data analyst counts on an ontology-driven editing framework to manually edit models and also semi-automatic tools to provide annotated data from data repositories, such as platforms to map relational databases to RDF data, or data wrangling tools for more unstructured data. The EEPSA framework will provide domain experts with facilities to design and upload parameterized queries and rules that will be properly stored and later offered to data analysts as pre-defined solutions to different tasks in the aforementioned phases. The analyst interacts freely with the EEPSA framework by accessing and managing data through the incorporated facilities.
Next, the EEPSA ontology is presented. Afterwards, the EEPSA ontology’s support in the EEPSA process through the different KDD phases is explained.
The EEPSA ontology
Following best practices for ontology design, a set of competency questions were identified in order to establish the ontology requirements. A glossary of terms extracted from those competency questions and their answers were used to look for ontological and non-ontological resources to be considered in the ontology design. In the energy efficiency in buildings domain, there are three main areas of discourse: (i) the space in which the energy efficiency is going to be performed, (ii) the devices deployed in it, and (iii) the data gathered and actuations made by those devices.
Regarding the buildings and spaces area, it must be kept in mind that tertiary buildings have spaces with specific features that may be different from the typically rather small rooms in residential buildings. Therefore, characteristics that are specific for the tertiary buildings have to be covered. Environmental context of the space has to be described, such as the location and orientation. The physical structure and building element properties such as surface area or thermal mass are relevant and need to be described. Tertiary buildings may house many different activities, which need to be described as well as other related concepts like capacity and occupancy rate. Furthermore, the building and spaces area needs to add expert knowledge related with the energy efficiency; for instance, the causality relationships between different environmental conditions. Concerning the sensing and actuating devices deployed within a space, the EEPSA process needs to describe its specifications and functionalities. It needs to describe the type of device too (e.g. motion sensor or window blind actuator), as well as the properties they observe or act on, and contextual information like their location and orientation. Last but not least, the area concerning the data gathered by these devices needs to represent their measurements. Alongside with them, instant of time when these are completed and their values need to be described. Furthermore, a whole coverage of outliers, their potential causes and possible solutions are also required.
Among others, the ontologies presented in the Related work section were assessed and, finally, parts of some of them were reused or re-engineered. The EEPSA ontology has been designed by dividing it in loosely coupled, self-contained components [17], which facilitates its development and maintenance as well as reuse by imports and controlled extension of parts of the ontology. Fig. 2 shows an excerpt of relevant classes and properties.
Since the EEPSA process may be used by non-experts in the building domain, there is a need to describe buildings and spaces in which energy efficiency is aimed in a rather simple way. Looking at the AEC (Architecture, Engineering and Construction) domain ontologies, overlapping concepts can be easily discovered and a neglected integration of them would produce redundancy problems as discussed in Section 2. Therefore, a single vocabulary covering basic building concepts and physical structures in a fairly simple manner was devised. Towards that purpose, top level concepts of the SAREF4BLDG ontology were taken into account, but finally the BOT ontology was preferred. That decision was based on the clean and simple conceptualization of the BOT basic concepts bot:Building, bot:Space, and bot:Element, in addition to a proper alignment with the SAREF4BLDG ontology, explicit links to ifcOWL ontology terms, and a well explained documentation. However, specialized subclassing structure below the bot:Space or bot:Element classes is not developed and therefore, it was needed to be extended to meet the EEPSA process requirements.
Several ontologies were assessed for the description of spaces. DogOnt ontology targets residential buildings but, although they could resemble tertiary buildings, service, heating and energy demands are different [73]. Furthermore, tertiary buildings are considerably more heterogeneous, encompassing hospitals, schools, restaurants and lodgings [72]. Therefore the EEPSA ontology needs to offer more generic spaces than dogont:Bedroom or dogont:LivingRoom. Moreover, coverage of building elements in the DogOnt ontology is not as broad as needed for the EEPSA process, even though entire buildings can be represented by extending it through subclassing of dogont:BuildingEnvironment and through the definition of proper relationships [8].
IfcOWL represents the IFC open standard for building and construction data. It is mainly designed for the construction industry and, as a result, it is not well suited to space modelling as needed by the EEPSA process. However, ifcOWL presents a comprehensive collection of property sets (known as PSETs) for describing building, spaces and building elements features. Following the semantic transformations proposed in [19], some of those properties (for instance, PSET Building Common) were re-engineered and used by the EEPSA ontology to describe specific spaces such as those located at an underground storey (eepsa:BelowGroundLevelSpace). This re-engineering method provides domain experts a flexible procedure for extending the EEPSA ontology. Moreover, this method improves interoperability since parts of ifcOWL models could be automatically translated to EEPSA models applying the simplification processes explained in [57].
It was already noted in Section 2 that the W3C LBD community group is aiming to produce PRODUCT ontologies that extend from bot:Element class towards more specific element classes, but those ontologies are not available at the time of writing this article. Therefore, in order to cover building structures, BOT classes were extended with some other generic classes. For instance, bim4eepsa:Door, bim4eepsa:Wall, and bim4eepsa:Window were defined as subclasses of bot:Element. Furthermore, bim4eepsa:WeatherStation was defined as subclass of bot:Building. All those axioms were gathered in a module named bim4EEPSA shown in Fig. 3, which is imported into the EEPSA ontology. Notice that this modular design allows to easily change this building-related hierarchy replacing the imported module.
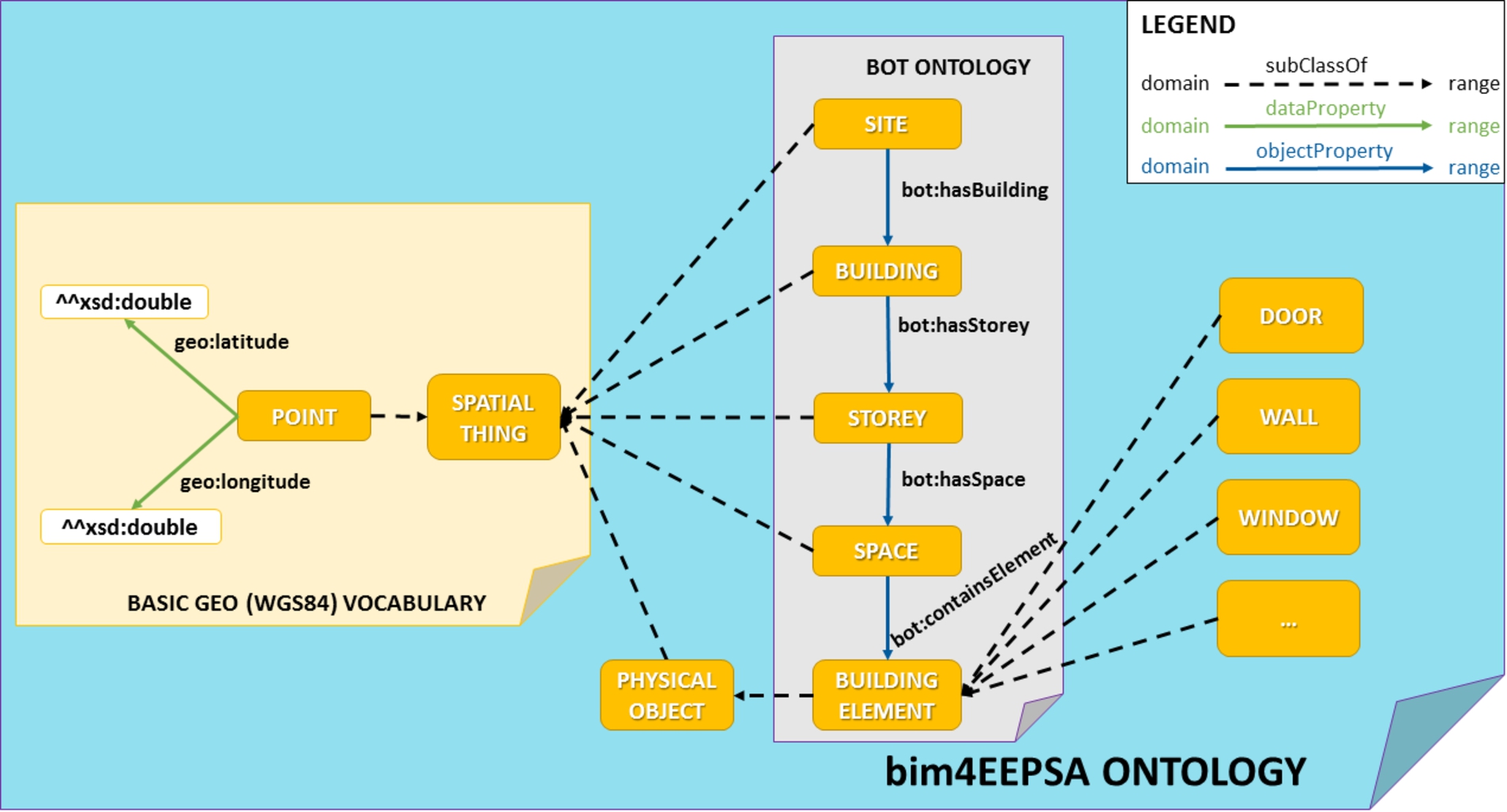
An overview of the bim4EEPSA ontology’s main classes and properties.
Furthermore, the EEPSA ontology encodes expert knowledge that represents causality relationships among different variables, and also includes the definition of queries and rules for the EEPSA process. For instance, the object property eepsa:isAffectedBy relates spaces to climatic variables that affect their environmental conditions. An individual of class eepsa:NaturallyEnlightenedSpace (a space containing a skylight or an external window, defined in Listing 1) will have its indoor temperature affected by the variable m3-lite:SolarRadiation, while this same variable will have nearly no effect in an individual of class eepsa:BelowGroundLevelSpace.
Regarding sensing and actuating devices deployed in buildings, the latest SSN ontology was selected due to its well founded design and careful documentation, in addition to its wide recognition. For instance, sensors are described with sosa:Sensor and actuators with sosa:Actuator. Since the SSN ontology does not cover types of sensors or actuators, observable or actuatable properties, units of measurements or orientation of devices, the EEPSA ontology imports the module measurements4EEPSA. This module is composed of a set of subclasses of sosa:Sensor, ssn:Property and qudt:Unit (and their corresponding properties among others) from the M3-Lite ontology. The Locality Module Extractor24
Concerning measurements and actuations made by devices, sensing device measurements are represented as individuals of sosa:Observation and actuations made by actuating devices as individuals of sosa:Actuation, and so reusing terms from the SSN ontology. Time instants when their actions are made are represented with data property sosa:resultTime, whereas their value is represented with the sosa:Result class. In the EEPSA ontology a class eepsa:Outlier is defined as subclass of sosa:Observation in order to represent observations that do not conform to the expected behaviour. A hierarchy of outlier types are defined as subclasses, classifying outliers according to their potential cause. These subclasses will be populated with outliers detected in the Preprocessing phase of the EEPSA process, such as those caused by the rain (eepsa:OutlierCausedByRain) or by a device malfunction (eepsa:OutlierCausedByDeviceError). Outliers can occur for various reasons and understanding them might help determining what action to perform. Factors that may affect sensors are represented with the property eepsa:susceptibleToOutliersCausedBy. Furthermore, each outlier type class is linked to a proposed method to offset the problem, by means of property eepsa:hasSolvingMethod. For example, a temperature outlier caused by a sensing device heated by direct sunlight (eepsa:OutlierCausedBySolarRadiation) is linked to two recommended solution methods: eepsa:DeviceRelocation, which recommends to relocate the device to an adequate place where it is not exposed to direct sun and eepsa:DeviceShelter, recommending to shield the device with a Stevenson Screen or a similar instrument to cover it from direct heat radiation. Following any of these advices should prevent the device from getting heated by direct sunlight and consequently, from measuring erroneous observations.

eepsa:NaturallyEnlightenedSpace class axiom
This EEPSA Ontology provides the necessary conceptual terminology and support for all the KDD steps as detailed in the next sections.
A preliminary phase to a KDD process assisted by SWTs consists in annotating data with terms selected from appropriate ontologies and thus providing them with semantics. In the EEPSA process context, semantic annotation of data means to construct an RDF model of the data, giving identifying URIs to resources and inter-relating them using ontology terms. When linking or mapping raw data to existing ontologies or vocabularies a better representation of data is achieved, structuring it and setting formal types and relations among them. Data integration is also achieved [52], and additional background knowledge can be added to the dataset. Furthermore, the resulting dataset improves semantic interoperability [54], providing both human and machines with a shared meaning of terms. This increases the dataset value and the potential to improve the upcoming KDD phases. In addition to the aforementioned integration and interoperability advantages, the resulting data is more domain-oriented than the original source, and makes the solution more application-independent. Consequently, after the Semantic Annotation phase, there is no need for the data analyst to be aware of the structure of the underlying raw data.
The semantic annotation task can be performed by manually editing an RDF model with the help of an adapted graphical user interface (GUI) or a data wrangling tool, or else with a properly programmed automatic middleware. In this phase, all data regarding the building, space and its features, sensing and actuating devices, and their corresponding measurements/actuations are semantically annotated with the selected terms from their corresponding domain ontologies gathered in the EEPSA ontology. Note that the EEPSA ontology, which is the main contribution of this paper to this phase, is designed to favour the reuse of well-known ontologies and therefore facilitates the eventual transformation of models annotated with terms of diverse ontologies to models annotated with the EEPSA ontology. Whether the annotated data is stored natively as RDF or viewed as RDF via middleware, SPARQL queries will be later used to access data across diverse data sources.
Summarizing, after semantically annotating data based on terms contained in the EEPSA ontology, data integration, interoperability and independence from original source are improved. Moreover, this semantic annotation enables the upcoming EEPSA process phases towards the goal of improving the energy efficiency.
Data selection
This is the first phase of a typical KDD process. Relevant datasets and subsets of variables that will form the data input for machine learning algorithms are selected. To that end, the data analyst has to understand the data itself: which is the knowledge captured in it, and which is the additional knowledge that can be extracted from it. However, this step is often not trivial and in most cases, domain-specific knowledge is needed to successfully complete it.
Existing work focuses on the use of tools and approaches to visualize and explore LOD to understand data [15]. However, no relevant work that supports the data analyst in the data selection phase has been spotted. In the EEPSA process, SWT are used to support the data analyst choosing the most relevant datasets and variables related with the energy efficiency problem at hand.
Once the target building space is semantically annotated (Semantic Annotation phase) and thanks to the knowledge captured in the form of OWL axioms in the EEPSA ontology, a reasoner classifies the space into one or several space types, and moreover infers that it might be affected by some specific variables (which in the EEPSA ontology are represented with subclasses of ssn:Property). For example, a space with windows towards the outside, is a naturally enlightened space (eepsa:NaturallyEnlightenedSpace) and due to the axioms:
the reasoner infers that the space’s indoor temperature may be affected by variables such as sun radiation and sun position elevation, among others. Consequently, in the EEPSA process’ Data Selection phase, the data analyst will get to know, in an automatic way, which variables might be relevant for the target space even though not being an expert in the domain.
After having suggested which variables are the most relevant ones for the task at hand, the data analyst needs to know which of them are being collected by the devices or other mechanisms deployed on the space and which are not. This can be obtained by instantiating and running a parameterized and pre-defined SPARQL query (see Listing 2) available in the EEPSA framework over the semantically annotated data.

SPARQL query for retrieving properties that affect but are not observed within a space “eepsa:mySpace”.
Summarizing, the EEPSA process uses OWL inferences to assist the data analyst in classifying the space at hand and suggesting variables affecting it. Furthermore, parameterized SPARQL queries are also provided in order to extract more relevant information (for instance, to know whether those variables are being collected by devices deployed in the space or not). This paper has presented some illustrating examples of reasoning tasks and semantic technology resources (SPARQL queries) to assist data analysts deciding which data may be relevant.
The next phase deals with preprocessing the collected data in order to ensure their quality.
Today’s real-world datasets are highly susceptible to noisy, missing, and inconsistent data due to their typically big size and their likely origin from multiple, heterogeneous sources [37]. These factors have a direct impact in the data quality and low quality data will lead to low quality mining results. This is why it is important to ensure data quality in KDD processes. There are several data preprocessing techniques to increase data quality (e.g. filtering, outlier detection and missing data treatments), which can consequently improve the accuracy and efficiency of data mining algorithms. Moreover, these techniques are not mutually exclusive and may be applied together.
Outlier detection
Outliers are data objects that stand out amongst other data objects and do not conform to the expected behaviour in a dataset [45]. In addition, outliers can worsen data quality, complicate the knowledge extraction process and lead to wrong conclusions. The process of finding those data objects in a dataset is known as Outlier Detection and it is an essential task in a wide range of domains including fault detection in safety critical systems, intrusion detection for cyber-security and data monitoring in WSNs (Wireless Sensor Networks). This process has been a widely researched topic for many years and there has been an abundance of work from statistics, geometry, machine learning, database, and data mining communities. There are many outlier detection methods divided into groups such as model-based, distance-based or density-based, according to their assumptions regarding normal data objects versus outliers. Further information regarding these and other outlier detection methods can be found in [11] and [39].

SemOD Method’s constraint pattern describing an object’s sun exposure times

SemOD Method’s constraint pattern describing $OBJECT’s sun exposure times
Outliers can occur for various reasons and understanding their provenance helps to determine what actions to take after detecting them. In some cases the aim might be to isolate the outlier and act on it (e.g. fraud detection in credit cards) while in others, outliers are filtered out to avoid inaccurate results (e.g. data analytics). However, identifying the potential cause of outliers still remains an unsolved challenge in most cases: it is not always straightforward and it may become an arduous task. There are also challenging scenarios where a data object may be considered an outlier in one context (e.g. 40°C measurement is an outlier for a winter day in the north of Spain), but not an outlier in a different context (e.g. 40°C measurement is not an outlier for a summer day in the south of Spain). With regards to WSNs, which are essential components to capture building conditions, several factors make them prone to outliers due to their particular requirements, dynamic nature and resource limitations [26]. Apart from these factors, WSNs are also context dependent, so that results obtained after applying conventional techniques might be skewed.
Although being an often studied topic, outlier detection has not received sufficient attention from the Semantic Web Community. In [77] a domain ontology has been used to support the outlier detection based on a statistical method. In [31] segment outliers and unusual events are detected in WSNs combining statistical analysis and domain expert knowledge captured via ontology and semantic inference rules. That approach determines whether the sensor collects suspicious data or not by calculating its similarity with neighbours. To the extent of our knowledge, this proposal is one of the few works where Semantic Technologies have a direct role in outlier detection methods. However, it may not be applicable to isolated nodes where there are no nearby sensors to compare their similarity. Furthermore, the identification of the potential cause of outliers is not tackled in that approach.

SemOD Query pattern for detecting outliers caused by sun radiation
We believe that the role of SWT in Outlier Detection tasks could be more important and could have a prominent impact. Not only improving the outlier detection, but most importantly in the assistance of data analysts during this process and spotting the potential cause of outliers. This is why the EEPSA process proposes the SemOD (Semantic Outlier Detection) Framework [25], which focuses on contributing in these issues.

SemOD Query excerpt for detecting temperature outliers caused by sun radiation
The SemOD Framework is based on domain and expert knowledge expressed in the EEPSA ontology to identify circumstances that make sensors susceptible to errors. Each of these circumstances has been assigned a method (SemOD Method) in which constraints that describe outliers are generated. These constraints are generated in a (semi)automatic way following purposely defined steps and using a set of facilities, guided by the EEPSA ontology axioms. These resources have been designed by experts in a way that no previous knowledge regarding the domain or semantic technologies are required to take advantage of them. The data analyst is then assisted to make use of these methods to generate a SPARQL query (SemOD Query) which retrieves measurements made under a certain circumstance that makes them presumably outliers.
For example, when exposed to the sun, the glass of a temperature sensor can heat up and reach a much higher temperature than it really is, which is a circumstance for generating outliers. A SemOD Method for detecting outliers caused by this circumstance, firstly offers a constraint pattern describing a sensor’s sun exposure times as presented in Listing 3. Then, to fill this constraint pattern, the SemOD Method obtains values asserted in the ontology by means of the SPARQL query pattern shown in Listing 4. This query is parameterized by the wild card $OBJECT, which will be replaced with the corresponding sensor’s URI. Then, the instantiated constraints have to replace the wild card $PREVIOUSLY_GENERATED_CONSTRAINTS in the FILTER clause of the predefined SemOD Query pattern shown in Listing 5. These constraints also need to be casted into their corresponding data types. Moreover, the graph where the query is going to be performed needs to be specified in the FROM clause, replacing the $RDF_GRAPH wild card, and $PROPERTY wild card also needs to be specified with the corresponding variable’s URI. Finally, the SPARQL query is generated. When executed, it obtains the observations suspected to be outliers and they are asserted as individuals of class eepsa:OutlierCausedBySolarRadiation. Therefore, not only are outliers detected, but also they are classified according to their potential cause in their corresponding subclass of eepsa:Outlier. Listing 6 shows an excerpt of the SPARQL query (SemOD Query) generated to detect outliers caused by sun radiation. Further details of the SemOD Framework can be found in [25].
Missing Data or Missing Values are one of the most relevant problems in data quality nowadays. They are common in different domains ranging from medical research [21] to social sciences [2]. Sensors are no exception and usually suffer from missing values caused by several reasons like a communication malfunction [36]. Furthermore, many problems like the introduction of a substantial amount of bias and the complication of handling and analysis of data can arise due to the missing values. One of the most common solutions to handle missing values is the imputation, a process that replaces missing data with substituted values. There are multiple imputation methods and depending on the characteristics of the missing values (e.g. duration of missing values period) some of them may provide better outcomes than others.
We consider that SWT could play an important role in the imputation of missing values. Expert knowledge could be elicited, which would in turn allow the classification of missing values according to their characteristics and assist the data analyst suggesting the most suitable imputation methods [32]. This should be further studied in future work.
In summary, the Preprocessing phase in the EEPSA process provides the data analyst with a framework that facilitates the generation of SPARQL rules to detect outliers within the current dataset and classify them according to their potential cause. OWL inferences are also used to propose methods to solve outliers according to their cause and avoid them in the future. Those measures are expected to ensure data quality, which has an effect on data mining algorithms’ performance.
Once the current data is preprocessed and its quality is ensured, the next step in the KDD process is the Transformation phase.
Transformation
In this stage, a projection of the data is produced in a form that data mining algorithms can accept as input. Amongst all the possible tasks in the Transformation phase (e.g. feature extraction), the EEPSA process focuses on the feature generation task.
The vast majority of existing feature generation solutions such as [12,56] and [43] choose a general knowledge base like DBpedia or YAGO to obtain property values about the mapped entities and generate new attributes. This approach is considered to only partially exploit SWT capabilities, therefore other alternatives are proposed: the generation of new features from domain-specific knowledge bases and the inference of new features based on existing data.
For cases where a concrete variable is not being collected in the target space, captured knowledge in the EEPSA ontology lets the data analyst know which alternative data sources are available for that variable. For example, a space with bad insulation (eepsa:BadInsulatedSpace) might be affected by outdoor humidity among other variables. If there is no sensing device observing it (which can be determined with the SPARQL in Listing 2), a reasoner infers that relevant data values for that variable can be retrieved from a nearby weather station.
Nowadays, with the advent of (Linked) Open Data, there are many trustworthy third-party repositories containing valuable information. In the energy efficiency in buildings scenario, where it has been proved that external meteorology affects the energy consumption, weather services enable the possibility of increasing datasets value with specific knowledge. In most cases, weather services information may be accessible in Open Data repositories, but they are rarely offered in RDF Stores. Therefore, there is a need to develop a process to that end. Since weather stations’ data may have heterogeneous structures depending on the agency they are controlled by, it is infeasible to propose a generic process applicable to all of them. As a starting point, an ETL (Extract, Load, Transform) process has been defined for weather stations regulated by Euskalmet (Basque Meteorology Agency) and the observations they measure. This process extracts data from Open Data Euskadi (the Basque Open Data portal), annotates them semantically based on the EEPSA ontology using the JENA framework,25
All data has been provided by Open Data Euskadi and Euskalmet.
However, there are variables that cannot be obtained from third party data sources. For some of those cases, an alternative is expected to be offered as part of a future work. For example, indoor illuminance approximate values for sensing devices located in spaces with windows next to the outside (eepsa:NaturallyEnlightenedSpace) can be derived from the sky’s cloud cover, sun elevation and direction information. Expert knowledge is expected to be modelled in the form of rules so that, depending on the values of the cloud cover and sun position a reasoner can infer the approximate illuminance value for the sensing device. For example, when there were no clouds and the sun were in a particular point (i.e. a point where its light hit the sensing device through the window), the rule would determine a higher illuminance value than at night (when there were no sun).

IK4-TEKNIKER building’s Open Space.
The proposed feature generation task has to be performed as many times as demanded by the number of variables to generate. The goal is to get the variables previously suggested in the Data Selection phase towards the improvement of the upcoming Data Mining phase. Retrieved or inferred data is considered to have a minimum quality, so preprocessing tasks should not be necessary afterwards.
Summarizing, the current EEPSA process uses OWL inferences to identify sources of information where certain variables can be retrieved from.
This is the phase where intelligent methods such as machine learning algorithms are applied to extract knowledge. Data analysts will try to make the best predictions to achieve energy efficiency in the target space. For that purpose, data enhanced in previous phases has to be retrieved and integrated in the data analysis environment, mainly by means of SPARQL queries.
Interpretation
Interpreting results obtained from the data mining phase is not always a straightforward task. Many times, even being an expert in the domain is not enough to understand the results. If underlying semantics of data is not correctly interpreted, results may not be as precise and consistent as they can be [46].
In [18] and [71] Linked Open Data has been proposed as a source of additional information to support the interpretation of the data mining method results. However, an effective decision-making must result from reasoning and analysis of knowledge, and must also take into account the experience and expertise of decision-makers. The EEPSA ontology is intended to be extended with this knowledge in further stages of the research, in order to contribute in the Interpretation phase. In any case, thanks to the Semantic Annotation phase, data is enriched so that additional information about the domain can be brought, which contributes to an easier and more effective results interpretation.
Experiments and results
The feasibility of the EEPSA process is tested in the IK4-TEKNIKER building, a technological centre constituted as a not-for-profit foundation located in Eibar (Basque Country, Spain). The scenario on which the EEPSA process is applied to is the second floor of this building (from now on referred to as Open Space) shown in Fig. 4. It is a single large room without walls that acts as an office where over 200 people work on a daily basis. As regards the usual work schedule, Monday to Thursday is split-shift and Fridays have reduced working hours.
A service is needed for suggesting the facility manager when HVAC systems have to be activated in the Open Space in order to reach a minimum comfort temperature of 23°C at 08:00 a.m. (when the workday starts). The HVAC control strategy needs to be efficient from an energy expense point of view too. The EEPSA process is applied to meet the facility manager’s requirements.
The Open Space is equipped with sensing devices developed in the European FP-7 Tibucon project28
A sample of data gathered by Tibucon devices is available at
Air Handling Unit is an HVAC system component used to regulate and circulate air. There may be more than one AHUs associated to a single HVAC system, usually in charge of conditioning a specific space or zone.
A baseline model has been developed without the support of the EEPSA process. This baseline model’s results are compared with those obtained after applying the EEPSA process (see Section 4.3), to observe if they have improved and to what extent. Data spanning six months from 31st January 2016 to 1st August 2016 was sampled hourly. Around 20% of data in this period was not measured due to external problems and in many circumstances, temperature sensing devices measured unlikely high temperature values.
The following section details the application of the EEPSA process in the Open Space.
The first phase of the EEPSA process is the Semantic Annotation phase. As previously stated, in an energy efficiency in buildings problem, there are three main information sources to be annotated: (i) the space in which the energy efficiency is going to be performed, (ii) the devices deployed in it, and (iii) the information gathered by those devices.
In order to represent the Open Space, first of all an individual of class bot:Building was created to represent the IK4-TEKNIKER building (eepsa:ik4tekniker) in which it is contained. Then, the eepsa:floor2 was created as an individual of class bot:Storey, and related with the building by means of the property bot:hasStorey. The individual eepsa:openSpace belonging to class bot:Space is related with eepsa:floor2 by the property bot:hasSpace. Building elements of the Open Space are represented with individuals of classes such as bim4eepsa:Door or bim4eepsa:Window and are lined by the property bot:containsElement. Sensors and actuators within the Open Space (including the Tibucon sensing device located outdoors) are represented with sosa:Sensor and sosa:Actuator classes. A simplified RDF representation of the Open Space31
The representation of the Open Space is not contained in the EEPSA ontology, as it is an instance of a Building Space.

Excerpt of RDF representation of the Open Space

(Continued)
All data regarding deployed devices and their gathered observations are stored in a PostgreSQL Database. In order to semantically annotate this data with the EEPSA ontology, the Ontop tool32
Once the Open Space itself, the deployed devices and their observations are semantically annotated, the upcoming phase is the Data Selection phase. In order to make predictions as accurate as possible, variables affecting indoor conditions of the Open Space have to be identified. According to what is inferred33
All inferences are made using a HermiT 1.3.8.413 reasoner.
m4eepsa:IndoorRelativeHumidity
m4eepsa:IndoorTemperature
m4eepsa:OutdoorRelativeHumidity
m4eepsa:OutdoorTemperature
m4eepsa:SpaceOccupancy
m3-lite:CloudCover (*)
m3-lite:SolarRadiation (*)
m3-lite:SunPositionDirection (*)
m3-lite:SunPositionElevation (*)
m3-lite:WindSpeed (*)
However, after executing the SPARQL query defined in Listing 2, it is concluded that not all of these variables are being observed in the Open Space. Namely, the variables with an asterisk (*) are not being observed. Since not all variables affecting energy consumption in the Open Space are collected, predictions may not be as accurate as they could be. Therefore, upcoming phases of the EEPSA process prepare data towards the improvement of these predictions.
The Preprocessing phase deals with ensuring quality of available data, and the EEPSA process does so with the proposed SemOD Framework. The resulting SPARQL query generated after using the SemOD Framework (shown in Listing 6), was applied on the observations gathered in the Open Space. Results (which are further analysed in Section 4.3) showed that the outdoor device suffers from 1,253 outliers. This, together with the missing values the dataset had, was considered as a low quality dataset by the data analysts in charge of the problem. Since low quality data may lead to low quality results, it was decided that the information provided by this device (outdoor temperature of the Open Space) should be retrieved from a higher quality data source. This matter is tackled in the next step.
Within the Transformation phase, the EEPSA process focuses on the feature generation task in order to obtain variables affecting energy consumption of a space. Even though this task is intended for variables that are not currently being measured, it can also be used for variables that are being observed but for certain reason (e.g. inconsistent or noisy data) need to be generated. In the Open Space, as previously stated, the outdoor temperature was considered as a low quality dataset due to its outliers and missing values, so it was decided to generate its values in this phase. Owing to the EEPSA ontology’s OWL axioms, a reasoner inferred that the outdoor temperature could be obtained from a weather station.

GeoSPARQL query for retrieving IK4-TEKNIKER building nearby weather stations measuring temperature
The first step was to check if there were any weather stations measuring outdoor temperature nearby the Open Space. To do so, a data analyst executed the GeoSPARQL query shown in Listing 8 in the aforementioned Virtuoso SPARQL endpoint containing Euskalmet weather stations information.34
Once the data analyst decided which was the weather station chosen to retrieve the data, a parameterized SPARQL query was performed over the same endpoint. This time, the data analyst needed to determine the weather station, the variables and the time span to retrieve the needed information. For the Open Space use case, the SPARQL query was set with the variable outdoor temperature, the weather station Eitzaga and the time span between 31st January 2016 and 1st August 2016. The query returned the outdoor temperature values measured in the Eitzaga between the 31st January 2016 and 1st August 2016.
Looking at the results obtained after applying the SPARQL Query in Listing 2 (in the Appendix) during the Data Selection phase, it was observed that another variable that was not being collected but affected the Open Space was the Wind Speed. This variable can also be retrieved from a weather station, so the same process as for outdoor temperature was followed.
After repeating this feature generation task as many times as needed, all data was used in the following Data Mining phase. In this case, the RapidMiner Studio 7.1 version was used alongside with the Linked Open Data extension. Within this extension, the operator SPARQL Data Importer was used to query the RDF Store and retrieve the information. The Series extension was also used in order to work with time series.
A baseline model was developed without the support of the EEPSA process in the traditional KDD process. Different predictive models were built using different combinations of available variables and fine-tuning the parameters for their window sizes. Best results were obtained with a model built with RapidMiner’s Vector Linear Regression algorithm35
Closest Euskalmet weather stations to IK4-TEKNIKER building measuring outdoor temperature (results obtained after executing SPARQL query shown in Listing 8 the 20/07/2017)
Predictive models and the variables used to build them
MAE and RMSE obtained with different predictive models enabled by the EEPSA process (best results were obtained with EEPSA #4)
For the EEPSA-enabled model, first of all the Semantic Annotation phase was applied. Then, EEPSA data selection suggestions were taken into account and the outlier detection task was applied in observations gathered by devices. Thanks to the generation of new attributes, the available data pool became larger. Variable selection and their window sizes were fine tuned to create a model that accurately predicts Open Space’s upcoming 24 indoor temperatures. The most accurate model was built with RapidMiner’s Vector Linear Regression containing last 168 hours (7 days) indoor temperatures, last 24 hours observations for outdoor temperature, outdoor humidity, outdoor wind speed and HVAC status, 2 features to describe current space occupancy, and 4 features describing the date (month, hour, day of the week and date time). Table 2 shows the input data used by some of the models created with and without the support of the EEPSA process.36
Blank spaces mean that no variable has been used, and var(s) is a contraction for variable(s).
Performance of the forecasters is characterized by two statistical estimates: the Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE). Measures based on percentage errors (e.g. Mean Absolute Percentage Error, MAPE) were dismissed because of their disadvantage of being infinite or undefined if data is zero, and having extreme values when close to zero. Therefore, a percentage error makes no sense when measuring the accuracy of temperature forecasts on the Fahrenheit or Celsius scales [41]. Predicted indoor temperatures for the future 24 hours in the Open Space have: a MAE of 0.80°C and a RMSE of 0.99°C for the baseline model, and a MAE of 0.57°C and a RMSE of 0.70°C for the EEPSA-enabled model.
Without a process recommending which variables to use, how to preprocess them or in which sources collect them, improving the baseline model would be an arduous task. Although being an expert in data analysis, being a non-expert in the energy efficiency in tertiary buildings domain would make it even more complicated, resorting to the trial and error approach. Following this trial and error approach, the whole KDD process and model generation would be a costly task in terms of time and effort. This cost is considerably reduced thanks to the assistance provided by the EEPSA process.
Moreover, results show that the model obtained after applying the EEPSA process, reduces the MAE and RMSE by over 28% (0.23°C in MAE and 0.29°C in RMSE), which could yield a more energy-efficient control [78]. However, as stated along the article, the true impact of the EEPSA process should not be solely based on predictions accuracy improvement. Table 3 shows the MAE and RMSE obtained after applying different models generated after applying the EEPSA process.
The Data Selection of the EEPSA process suggested the incorporation of some variables such as wind speed and outdoor humidity to build the predictive model. For example, incorporating the suggested wind speed variable in the predictive model (which may have been overlooked by a data analyst not expert in the domain), MAE was reduced by 5%. Therefore, thanks to the EEPSA process, the data analyst gets an assistant to define and create the predictive model. Anyway, it will be the decision of the data analyst whether to incorporate or not the suggested variables.
Thanks to the SemOD Framework applied in the data preprocessing phase, 1,253 anomalous temperature measurements were detected in the data registered by the Tibucon device located outdoors. Apart from labelling all these data objects as outliers, they have also been classified according to their potential provenance (eepsa:OutlierCausedBySunlight). This proves that the sensing device located outdoor gets hit by the sun in certain time spans, making its measurements unreliable. Thanks to the knowledge stored in the EEPSA ontology, the two possible solutions to this problem can be inferred: sheltering the device, or relocating it in a place with less direct sunlight exposure. Keeping this in mind, a new device was located in a more adequate place where it is protected from direct solar radiation. Furthermore, replacing the outdoor temperature data provided by the Tibucon sensor (considered to be low quality data) with a higher quality outdoor temperature source (a nearby weather station), MAE can be reduced by 6%, and even by nearly 13% in some specific days (namely in days with reduced working hours).
For the period of available data, a day not following expected work schedule was found. Specifically, the 23rd March 2016 (Wednesday) was a reduced hours workday, when typically it should have been a split shift schedule. This happened because in 2016, Easter started the 24th March. Comparing the predictions obtained with the baseline model, the EEPSA enabled model reduced MAE by 44% (0.28°C) and RMSE by 45% (0.38°C). As long as more data is available, it will be analysed to which extent the EEPSA enabled model reduces prediction errors in days with atypical work schedule.
Conclusions
Benefits of the EEPSA process
The EEPSA process leverages of SWT to enhance the KDD process towards the achievement of energy efficiency in tertiary buildings. The data analyst is guided through the different KDD phases in a semi-automatic manner. First of all, data is semantically annotated with terms contained in the EEPSA ontology, which aims to capture all the necessary expert knowledge for the EEPSA process mainly related to buildings, sensing and actuating devices, and their corresponding observations and actuations. This Semantic Annotation phase is fundamental for enriching data, integrating heterogeneous data and representing it in a more domain-oriented way, as well as for enabling the improvement of the upcoming KDD phases. In the data selection phase the data analyst is assisted by means of ontology-driven queries and inferences to decide which might be the most relevant variables for the matter at hand. The preprocessing phase leverages a framework to detect outliers and propose possible methods to solve them to ensure data quality. The transformation phase generates additional knowledge in the form of new attributes based on knowledge-driven rules and inferencing capabilities. All these tasks contribute to improve the robustness and performance of machine learning algorithms applied in the data mining phase and it eases the interpretation of the obtained results. Furthermore, the proposed process is expected to be reusable in similar use cases of the same domain due to its high abstraction level.
Future work
The EEPSA process proposed in this paper contributes to raise awareness of the possibilities of the SWT. However, SWT can be further exploited to improve the EEPSA process, implementing some of the tasks proposed in the article.
Data Selection phase: More expert knowledge elicitation should be performed, in order to define new space classes and variables affecting them, towards a more complete EEPSA process. Furthermore, more IFC PSETs should be re-engineered and captured in the EEPSA ontology.
Preprocessing phase: The EEPSA process mainly focuses on the outlier detection and classification by means of the SemOD Framework. However, current SemOD Framework only supports a SemOD Method, namely for the detection of outliers in temperature sensors caused by solar radiation. The SemOD Framework should be extended with further SemOD Methods (e.g. outliers caused by rain) for different sensor types (e.g. humidity or motion sensors), so that the data analyst could have a wide range of methods to detect and classify outliers generated in different sensor types and by different causes. Regarding the Missing Values treatment, as explained in Section 3.4.2, we believe that SWT could play a role assisting the data analyst by suggesting the most suitable imputation methods (depending on the missing values characteristics such as their length).
Transformation phase: The attribute generation task proposed by the EEPSA process takes leverage of meteorological measurements registered by Euskalmet weather stations. That is, the scope of the solution is limited to the Basque Country. Defining and implementing an ETL process for doing the same thing on AEMET weather stations would extend the applicability of this task to the whole Spanish territory. Furthermore, in Section 3.5, another attribute generation method has been proposed, which consists in offering approximate attribute values depending on the context. This proposal should be further studied and implemented in further stages of the research.
Interpretation phase: Although not covered currently by the EEPSA process, the interpretation phase has a big potential for exploiting semantics of data. This is why research on this topic should be conducted.
The EEPSA Ontology: IFC contains a lot of information, which would be interesting for the EEPSA process. For instance, information to reflect the effect of features like materials or building envelope sealing. This information should be captured in the bim4EEPSA module that is imported by the EEPSA ontology. This is thought to enable a greater assistance during the KDD process.
Although not directly related with the SWT but towards the facilitation of the EEPSA process application, interaction with the system could be improved. The EEPSA process is intended to be used by non-experts in the energy efficiency in buildings domain. If the semantic annotation of the target space has to be done manually, depending on the complexity of the space and the knowledge of the user, it can become a difficult and time-costing task. This task should be facilitated with a GUI where the user could add building elements and features to the space in an intuitive and easy manner.
Finally, in order to test the reusability of the EEPSA process, it is going to be applied in another tertiary building, namely in the Bilbao Exhibition Center (BEC). This building is located in Baracaldo (Basque Country, Spain) and covers an area of 251,055 square meters distributed in six pavilions intended for exhibitions.
Footnotes
Acknowledgements
Part of the presented work is based on research contacted within the project BID3ABI (Big Data para RIS3 2016), which has received funding from the Basque Government (ELKARTEK 2016) under grant agreed reference KK-2016/00096. This work is also supported by FEDER/TIN2013-46238-C4-1-R and FEDER/TIN2016-78011-C4-2-R.
We thank Euskalmet (Basque Meteorology Agency) for assistance with weather stations and observations, as well as Zuzenean (Basque Citizen’s Advice Service) for helping us with Open Data Euskadi (Basque Open Data portal).
This work was conducted using the Protégé resource, which is supported by grant GM10331601 from the National Institute of General Medical Sciences of the United States National Institutes of Health.