
Abstract
The ability to compare systems from the same domain is of central importance for their introduction into complex applications. In the domains of named entity recognition and entity linking, the large number of systems and their orthogonal evaluation w.r.t. measures and datasets has led to an unclear landscape regarding the abilities and weaknesses of the different approaches. We present
Keywords
Introduction
Named Entity Recognition (NER) and Named Entity Linking/Disambiguation (NEL/D) as well as other natural language processing (NLP) tasks play a key role in annotating RDF knowledge from unstructured data. While manifold annotation tools have been developed over recent years to address (some of) the subtasks related to the extraction of structured data from unstructured data [20,28,38,40,42,48,52,59,62], the provision of comparable results for these tools remains a tedious problem. The issue of comparability of results is not to be regarded as being intrinsic to the annotation task. Indeed, it is now well established that scientists spend between 60 and 80% of their time preparing data for experiments [23,30,47]. Data preparation being such a tedious problem in the annotation domain is mostly due to the different formats of gold standards as well as the different data representations across reference datasets. These restrictions have led to authors evaluating their approaches on datasets (1) that are available to them and (2) for which writing a parser and an evaluation tool can be carried out with reasonable effort. In addition, many different quality measures have been developed and used actively across the annotation research community to evaluate the same task, creating difficulties when comparing results across publications on the same topics. For example, while some authors publish macro-F-measures and simply call them F-measures, others publish micro-F-measures for the same purpose, leading to significant discrepancies across the scores. The same holds for the evaluation of how well entities match. Indeed, partial matches and complete matches have been used in previous evaluations of annotation tools [11,57]. This heterogeneous landscape of tools, datasets and measures leads to a poor repeatability of experiments, which makes the evaluation of the real performance of novel approaches against the state-of-the-art rather difficult.
Thus, we present
This paper is a significant extension of [64] including the progress of the
In the rest of this paper, we explain the core principles which we followed to create GERBIL and detail our new contributions. Thereafter, we present the state-of-the-art in benchmarking Named Entity Recognition, Typing and Linking. In Section 4, we present the
Insights into the difficulties of current evaluation setups have led to a movement towards the creation of frameworks to ease the evaluation of solutions that address the same annotation problem, see Section 3.
Repeatable settings:
Archivable experiments: Through experiment URLs,
Open software and service:
Leveraging RDF for storage: The results of
Fast configuration: Through the provision of results on different datasets of different types and the provision of results on a simple user interface,
Any knowledge base: With
FAIR principles and how Gerbil addresses each of them
FAIR principles and how
To ensure that the Easy integration of annotators: We provide a wrapping interface that allows annotators to be evaluated via their HTTP interface. In particular, we integrated 15 additional annotators not evaluated against each other in previous works (e.g., [11]). Easy integration of datasets: We also provide means to gather datasets for evaluation directly from data services such as DataHub.2
Easy addition of new measures: The evaluation measures used by
Extensibility:
Available at
Diagnostics: The interface of the tool was designed to provide developers with means to easily detect aspects in which their tool(s) need(s) to be improved.
Portability of results: We generate human- and machine-readable results to ensure maximum usefulness and portability of the results generated by our framework.
Entity Matching. The comparison of two strings representing entity URIs is not sufficient to determine whether an annotator has linked an entity correctly. For example, the two URIs
Deprecated entities in datasets. Most of the gold standards in the NER and NED research area have not been updated after their first creation. Thus, the URIs they rely on have remained static over the years while the underlying KBs may have been refined or changed. This leads to some URIs in a gold standard being deprecated. As in the first requirement, there is hence a need to provide means to assess a result as true positive when the URI generated by a framework is a novel URI which corresponds to the deprecated URI.
New tasks and Adapters.
Finally,
Named Entity Recognition and Entity Linking have gained significant momentum with the growth of Linked Data and structured knowledge bases. Over the past few years, the problem of result comparability has thus led to the development of a handful of frameworks.
The BAT-framework [11] is designed to facilitate the benchmarking of NER, NEL/D and concept tagging approaches. BAT compares seven existing entity annotation approaches using Wikipedia as reference. Moreover, it defines six different task types, five different matchings and six evaluation measures providing five datasets. Rizzo et al. [52] present a state-of-the-art study of NER and NEL systems for annotating newswire and micropost documents using well-known benchmark datasets, namely CoNLL2003 and Microposts 2013 for NER as well as AIDA/CoNLL and Microposts2014 [4] for NED. The authors propose a common schema, named the NERD ontology,6
Over the course of the last 25 years several challenges, workshops and conferences dedicated themselves to the comparable evaluation of information extraction (IE) systems. Starting in 1993, the Message Understanding Conference (MUC) introduced a first systematic comparison of information extraction approaches [60]. Ten years later, the Conference on Computational Natural Language Learning (CoNLL) offered the beginnings of a shared task on named entity recognition and published the CoNLL corpus [61]. In addition, the Automatic Content Extraction (ACE) challenge [17], organized by NIST, evaluated several approaches but was discontinued in 2008. Since 2009, the text analytics conference has hosted the workshop on knowledge base population (TAC-KBP) [37] where mainly linguistic-based approaches are published. The Senseval challenge, originally concerned with classical NLP disciplines, widened its focus in 2007 and changed its name to SemEval to account for the recently recognized impact of semantic technologies [31]. The Making Sense of Microposts workshop series (#Microposts) established in 2013 an entity recognition and in 2014 an entity linking challenge focusing on tweets and microposts [55]. In 2014, Carmel et al. [6] introduced one of the first Web-based evaluation systems for NER and NED and the centerpiece of the entity recognition and disambiguation (ERD) challenge. Here, all frameworks are evaluated against the same unseen dataset and provided with corresponding results.
Architecture overview

Overview of
Experiments run in our framework can be configured in several manners. In the following, we present some of the most important parameters of experiments available in
Experiment types
An experiment type defines the problem that has to be solved by the benchmarked system. Cornolti et al.’s [11] BAT-framework offers six different experiment types, namely (scored) annotation (S/A2KB), disambiguation (D2KB) – also known as linking – and (scored respectively ranked) concept annotation (S/R/C2KB) of texts. In [52], the authors propose two types of experiments, highlighting the strengths and weaknesses of the analyzed systems. Thereby, performing (i) entity recognition, i.e., the detection of the exact match of the pair entity mention and type (e.g., detecting the mention Barack Obama and typing it as a Person), and (ii) entity linking, where an exact match of the mention is given and the associated DBpedia URI has to be linked (e.g., locating a resource in DBpedia which describes the mention Barack Obama). This work differs from the previous one in its entity recognition experimentation, and annotation of entities to a RDF knowledge base.
We implement 8 types of experiments:
Entity Recognition: In this task the entity mentions need to be extracted from a document set D. To this end, an extraction function
D2KB: The goal of this experiment type is to map a set of given entities mentions (i.e., a subset
Entity Typing: The typing task is similar to the D2KB task. Its goal is to map a set of given entities mentions μ to the type hierarchy of K. This task uses the hierarchical F-measure to evaluate the types returned by the annotation system using the expected types of the gold standard and the type hierarchy of K.
C2KB: The concept tagging task C2KB aims to detect entities when given a document. Formally, the tagging function
A2KB: This task is the classical NER/D task, that is, a combination of the Entity Recognition and D2KB tasks. Thus, an A2KB annotation system receives the document set D, has to identify entities mentions μ and link them to K.
RT2KB: This task is the combination of the Entity Recognition and Typing tasks, i.e., the goal is to identify entities in a given document set D and map them to the types of K.
OKE 2015 Task1: The first task of the OKE Challenge 2015 [46] comprises Entity Recognition, Entity Typing and D2KB.
OKE 2015 Task2: The goal of the second task of the OKE Challenge 2015 [46] is to extract the part of the text that contains the type of a given entity mention and link it to the type hierarchy of K.
With this extension, our framework can now deal with gold standard datasets and annotators that link to any knowledge base, e.g., DBpedia, BabelNet [45] etc., as long as the necessary identifiers are URIs. We were thus able to implement 37 new gold standard datasets, cf. Section 4.4, and 15 new annotators linking entities to any knowledge base instead of solely to Wikipedia, as in previous works, cf. Section 4.3.1. With this extensible interface,
Matching
A matching defines which conditions the result of an annotator has to fulfill to be a correct result, i.e., to match an annotation of the gold standard. An annotation has either a position, a meaning (i.e., a linked entity or a type) or both. Therefore, we can define an annotation
The first matching type
For the D2KB experiments, matching is expanded to strong annotation matching
The strong annotation matching can also be used for A2KB and Sa2KB experiments. However, in practice this exact matching can be misleading. A document can contain a gold standard named entity, such as, “President Barack Obama” while the result of an annotator only marks “Barack Obama” as named entity. Using an exact matching leads to weighting this result as wrong while a human might rate it as correct. Therefore, the weak annotation matching
However, the evaluation of whether two given meanings are matching each other is more challenging than the expression
The key insight behind the solution to this problem in

Schema of the four components of the entity matching process.
URI set retrieval Since an entity can be described in several KBs using different URIs and IRIs,
URI checking While the development of annotators moves on, many datasets were created years ago using versions of KBs that are redundant. This is an important issue that cannot be solved automatically unless the datasets refer to their old versions, which is in practice rarely the case. We try to minimize the influence of outdated URIs by checking every URI for its existence. If a URI cannot be dereferenced, it is marked as outdated. However, this is only possible for URIs of KBs that abide by the Linked Data principles and provide de-referencable URIs, e.g., DBpedia.
URI set classification All entities can be separated into two classes [26]. The class
URI set matching The final step of checking whether two entities are matching each other is to check whether their two URI sets are matching. There are two cases in which two URI sets
Limitations This entity matching has two known drawbacks. First, wrong links between KBs can lead to a wrong URI set. The following example shows that because of a wrong linkage between DBpedia and data.nytimes.com, Japan and Armenia are the same:7
Second, the URI set retrieval as well as the URI checking cause a huge communication effort. Since our implementation of this communication is considerate of the KB endpoints by inserting delays between the single requests, these steps slow down the evaluation. However, our future developments will attempt to reduce this drawback.
While all cases are taken into account for the normal measures, the InKB measures focus on those cases in which either the URI set of the dataset or the URI set of the annotator are classified as
The different classification cases that can occur during the evaluation. A dash means that there is no URI set that could be used for the matching. A tick shows that this case is taken into account while calculating the measure
The different classification cases that can occur during the evaluation. A dash means that there is no URI set that could be used for the matching. A tick shows that this case is taken into account while calculating the measure
To support the development of new approaches, we implemented additional diagnostic capabilities such as the calculation of correlations of dataset features and annotator performance [63]. In particular, we calculate the Spearman correlation between document attributes (e.g., number of persons) and performance (i.e., F-measure) to quantify how the first variable affects the second. Figure 3 shows the correlation between the performance of systems and selected features of the datasets. This can help determine strengths and weaknesses of the different approaches.

Absolute correlation values of the annotators’ Micro F1-scores and the dataset features for the A2KB experiment and weak annotation match (
BAT-framework Adapter: In BAT, annotators can be implemented by wrapping using a Java-based interface.
NIF-based Services:
We describe the exact requirements for the structure of the NIF document on our project website’s wiki, as NIF offers several ways to build a NIF-based document or corpus.
Currently,
Cucerzan: As early as in 2007, Cucerzan presented a NED approach based on Wikipedia [13]. The approach tries to maximize the agreement between contextual information of input text and a Wikipedia page as well as category tags on the Wikipedia pages. The test data is still available10
Wikipedia Miner: This approach was introduced in [40] in 2008 and is based on different facts like prior probabilities, context relatedness and quality, which are then combined and tuned using a classifier. The authors evaluated their approach based on a subset of the AQUAINT dataset.11
Illinois Wikifier: In 2011, [9,50] presented an NED approach for entities from Wikipedia. In this article, the authors compare local approaches, e.g., using string similarity, with global approaches, which use context information and lead finally to better results. The authors provide their datasets13
DBpedia Spotlight: One of the first semantic approaches [15] was published in 2011, combining NER and NED approaches based on DBpedia.15
AIDA: The AIDA approach [28] relies on coherence graph building and dense subgraph algorithms and is based on the YAGO218
TagMe 2: TagMe 2 [20] was published in 2012 and is based on a directory of links, pages and an inlink graph from Wikipedia. The approach recognizes named entities by matching terms with Wikipedia link texts and disambiguates the match using the in-link graph and page dataset. Afterwards, TagMe 2 prunes the identified named entities considered non-coherent to the rest of the named entities in the input text. The authors publish a key-protected webservice20
NERD-ML: In 2013, [65] proposed an approach for entity recognition tailored for extracting entities from tweets. The approach relies on a machine learning classification of the entity type which uses (a) a given feature vector composed of a set of linguistic features, (b) the output of a properly trained Conditional Random Fields classifier and (c) the output of a set of off-the-shelf NER extractors supported by the NERD Framework. The follow-up, NERD-ML [52], improved the classification task by re-designing the selection of features. The authors assessed the NERD-ML’s performance on both microposts and newswire domains. NERD-ML has a public webservice which is part of
KEA NER/NED: This approach is the successor of the approach introduced in [59], which is based on a fine-granular context model taking into account heterogeneous text sources as well as text created by automated multimedia analysis. The source texts can have different levels of accuracy, completeness, granularity and reliability, all of which influence the determination of the current context. Ambiguity is solved by selecting entity candidates with the highest level of probability according to the predetermined context. The new implementation begins with the detection of groups of consecutive words (n-gram analysis) and a lookup of all potential DBpedia candidate entities for each n-gram. The disambiguation of candidate entities is based on a scoring cascade. KEA is available as a NIF-based webservice.23
WAT: WAT is the successor of TagME [20].24
Dexter: This approach [7] is an open-source implementation of an entity disambiguation framework. The system was adopted to simplify the implementation of an entity linking approach and allows the replacement of single parts of the process. The authors used several state-of-the-art disambiguation methods. Results in this paper are obtained using an implementation of the original TagMe disambiguation function. Moreover, Ceccarelli et al. provide the source code25
AGDISTIS: This approach [62] is a pure entity disambiguation approach (D2KB) based on string similarity measures, an expansion heuristic for labels to cope with co-referencing and the graph-based HITS algorithm. The authors published datasets26
Babelfy: The core of this approach draws on the use of random walks and a densest subgraph algorithm to tackle the word sense disambiguation and entity linking tasks jointly in a multilingual setting [42] thanks to the BabelNet28
FOX: FOX [57] is an ensemble-learning based framework for RDF extraction from text. It makes use of the diversity of NLP algorithms to extract entities with a high precision and a high recall. Moreover, it provides functionality for keyword and relation extraction.
FRED: In 2015, Gangemi et al. [10] present FRED(*), a novel machine reader based on TagMe. FRED extends TagMe with entity typing capabilities.
FREME: Also in 2015, the EU project FREME publish their e-entity service which is based on Conditional Random Fields for NER while NED relies on a most-frequent-sense method. That is, candidate entities are chosen based on a sense of commonness within a KB.30
entityclassifier.eu: Dojchinovski and Kliegr [18] present their approach based on hypernyms and a Wikipedia-based entity classification system which identifies salient words. The input is transformed to a lower dimensional representation keeping the same quality of output for all sizes of input text.
Overview of implemented annotator systems. Brackets indicate the existence of the implementation of the adapter but also the inability to use it in the live system
xLisa: Zhang and Rettinger present the x-Lisa annotator [68] which is a three-step pipeline based on cross-lingual Linked Data lexica to harness the multilingual Wikipedia. Based on these lexica, they calculate the mention-candidate-similarity using n-grams. In the third step, x-Lisa constructs an entity-mention graph using the Normalized Google Distance as weights for page rank.
DoSer: In 2016, Zwickelbauer et al. present DoSer [69], a pure named entity linking approach which is – similiar to AGDISTIS – knowledge-base-agnostic. First, DoSer computes semantic embeddings of entities over one or multiple knowledge bases. Second, given a set of mentions, DoSer calculates possible candidate URIs using existing knowledge base surface forms or additional indexes. Finally, DoSer calculates a personalized page rank using the semantic embeddings of a disambiguation graph constructed from links between possible candidates.
PBOH: This approach [22] is a pure entity disambiguation approach based on light statistics from the English Wikipedia corpus. The authors developed a probabilistic graphical model using pairwise Markov Random Fields to address the entity linking problem. They show that pairwise co-occurrence statistics of words and entities are enough to obtain a comparable or better performance than heavy feature engineered systems. They employ loopy belief propagation to perform inference at test time.
NERFGUN: The most recent NED system is NERFGUN [24]. This approach reuses ideas from many existing systems for collective named entity linking. First, it uses several indexes based on DBpedia to retrieve a set of candidate entities, such as anchor link texts
Table 3 compares the implemented annotation systems of
Datasets, their formats and features. Groups of datasets, e.g., for a single challenge, have been grouped together. A ⋆ indicates various inline or keyfile annotation formats. The experiments follow their definition in Section 4.2
Datasets, their formats and features. Groups of datasets, e.g., for a single challenge, have been grouped together. A ⋆ indicates various inline or keyfile annotation formats. The experiments follow their definition in Section 4.2
BAT enables the evaluation of different approaches using the AQUAINT, MSNBC, IITB and the four AIDA/CoNLL datasets (Train A, Train B, Test and Complete). With
We capitalize upon the uptake of publicly available, NIF based corpora from the recent years [53,58].31
The extensibility of datasets in
The licenses and instructions can be found at
RDF DataCube is a vocabulary standard and can be used to represent fine-grained multidimensional, statistical data which is compatible with the Linked SDMX [5] standard. Every
To describe annotators in a similar fashion, we extended DataID for services. The class
Offering such detailed and structured experimental results opens new research avenues in terms of tool and dataset diagnostics to increase decision makers’ ability to choose the right settings for the right use case. Next to individual configurable experiments,
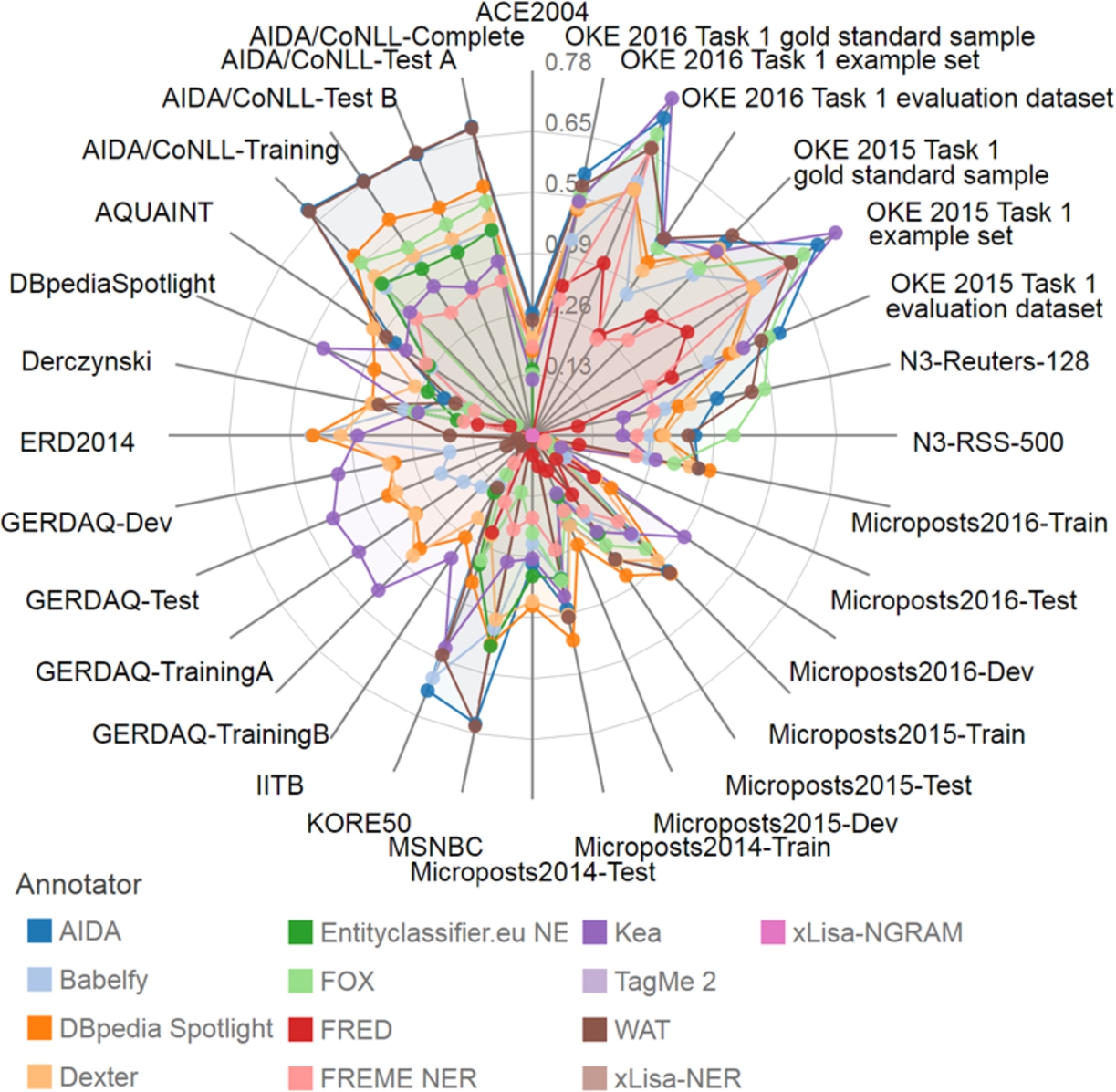
Example spider diagram of recent A2KB experiments with weak annotation matching derived from our online interface (
One of
Number of tasks executed per annotator. By caching results we did not need to execute 12,466 tasks but only 9906. Data taken from 15th February 2015
Number of tasks executed per annotator. By caching results we did not need to execute 12,466 tasks but only 9906. Data taken from 15th February 2015
Furthermore, we evaluated the amount of time that 5 experienced developers needed to write an evaluation script for their framework and how long they needed to evaluate their framework using GERBIL. The comparative times of writing an evaluation script for a system and a single dataset compared to the time needed to write an adapter for

Comparison of effort needed to implement an adapter for an annotation system with and without
In this paper, we presented and evaluated
In the future,
Another development is the further support of developers with direct feedback, i.e., showing the annotations that have been marked incorrect in the documents. This feature has not been implemented because of licensing issues. However, we think that it would be possible to implement it without license violations for datasets that are publicly available.
Footnotes
Acknowledgements
This work was supported by the Eurostars projects DIESEL (E!9367) and QAMEL (E!9725) as well as the European Union’s H2020 research and innovation action HOBBIT under the Grant Agreement number 688227.