
Abstract
Privacy policies are intended to inform users about the collection and use of their data by websites, mobile apps and other services or appliances they interact with. This also includes informing users about any choices they might have regarding such data practices. However, few users read these often long privacy policies; and those who do have difficulty understanding them, because they are written in convoluted and ambiguous language. A promising approach to help overcome this situation revolves around semi-automatically annotating policies, using combinations of crowdsourcing, machine learning and natural language processing. In this article, we introduce PrivOnto, a semantic framework to represent annotated privacy policies. PrivOnto relies on an ontology developed to represent issues identified as critical to users and/or legal experts. PrivOnto has been used to analyze a corpus of over 23,000 annotated data practices, extracted from 115 privacy policies of US-based companies. We introduce a collection of 57 SPARQL queries to extract information from the PrivOnto knowledge base, with the dual objective of (1) answering privacy questions of interest to users and (2) supporting researchers and regulators in the analysis of privacy policies at scale. We present an interactive online tool using PrivOnto to help users explore our corpus of 23,000 annotated data practices. Finally, we outline future research and open challenges in using semantic technologies for privacy policy analysis.
Introduction
As people interact with an increasing number of technologies during the course of their daily lives it has become impossible for them to keep up with the many different ways in which these technologies collect and use their data. Privacy policies are too long and difficult to read to be useful and few, if any, ever bother to read them [30,33]. Yet studies continue to show that people care about their privacy. This results in a general sense of frustration with many people feeling that they have no or little control over what happens to their data. There is a disconnect between service providers and their consumers: privacy policies are legally binding documents, and their stipulations apply regardless of whether users read them. This disconnect between Internet users and the practices that apply to their data has led to the assessment that the “notice and choice” legal regime of online privacy is ineffective in the status quo [36]. Additionally, policy regulators – who are tasked with assessing privacy practices and enforcing standards – are unable to assess privacy policies at scale.
These shortcomings have prompted our team to develop technology to semi-automatically retrieve salient statements made in privacy policies, model their contents using ontology-based representations, and use semantic web technologies to explore the obtained knowledge structures [38]. The research described in this paper focuses in particular on the knowledge modeling and elicitation part. This includes reasoning about statements that are explicitly made in policies as well as statements that may be missing, ambiguous or possibly inconsistent. End users can benefit from such reasoning functionality, as it can be used to help them better appreciate the ramifications of a given policy (e.g., a statement indicating that a site can share personally identifiable information can be used to infer that the site’s policy provides no guarantee that it will not share the user’s email address with third parties). Reasoning functionality can also be used to raise user awareness about issues that a policy does not explicitly address or glosses over (e.g. a site that does not mention whether it collects the user’s location or shares it with third parties is a site that does not make any guarantee about such practices and therefore one that could engage in such practices). Reasoning can help operators identify potential compliance violations or inconsistencies in their policies, and help them address these issues. Similar functionality can also help regulators check for compliance at scale (e.g. compliance with regulations such as the Children Online Privacy Protection Act, the California Online Privacy Protection Act, or the EU General Data Protection Directive). It can also be used to compare policies within and across different sectors, look for trends over time and more. One can also envision interfaces that could enable end-users to identify alternative websites or mobile apps (e.g., “I don’t like that this site provides no guarantee about the sharing of my location: are there other sites offering the same service that will not be sharing my location with third parties?”).
We introduce PrivOnto, a semantic technology (ST) framework to model and reason about privacy practice statements at scale. PrivOnto has been validated on a corpus of over 23,000 privacy policy annotations made publicly available by the Usable Privacy Policy (UPP) project, the project that is also the umbrella under which we developed PrivOnto.1
Usable Privacy Policy Project:
The Usable Privacy Policy Project builds on recent advances in natural language processing (NLP), privacy preference modeling, crowdsourcing, and privacy interface design to develop a practical framework that uses websites’ existing natural language privacy policies to empower users to more meaningfully control their privacy. Figure 1 provides an overview of the approach. We discuss our main research areas below:2
See [38] for a more complete overview of the project.
Semi-Automated Data Practice Extraction: We aim to extract relevant data practices from privacy policy text in a hybrid approach that combines crowdsourcing and NLP. We leverage crowdsourcing to obtain annotations of privacy policies in terms of topics such as the information collected by a website, whether that information is shared with third parties with or without the user’s consent, and whether the collected data can be deleted by users [48]. In parallel, we have developed a corpus of privacy policies annotated by skilled workers with fine-grained detail about the data practices they contain [47]. We plan to use the data from this fine-grained corpus to decompose the annotation task into those subtasks that can be fully automated, such as identification of paragraph topics [27] and user options [40], and those which remain most suitable for crowdworkers.
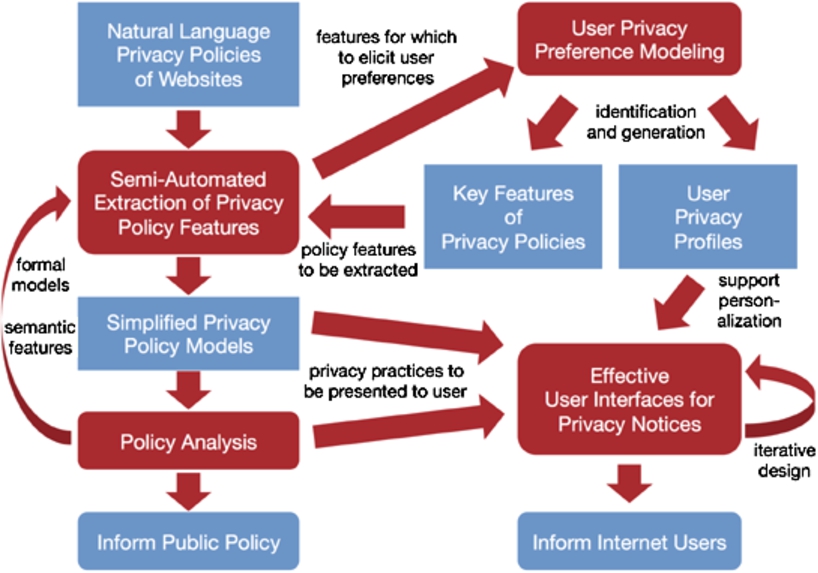
Overview of the Usable Privacy Policy Project.
Privacy Policy Analysis: We use salient information extracted from privacy policies to reason about a website’s data practices and conduct extensive privacy policy analysis for multiple purposes. Translating policy features into descriptive logic statements facilitates detection of inconsistencies and contradictions in privacy policies [5] and annotation disagreement among crowdworkers further helps identifying potential ambiguities in the policy. Comparing a website’s privacy policy with those from similar websites holds the potential to detect likely omissions in the privacy policy. Temporal monitoring of changes in privacy policies facilitates content-based trend analysis. Automated analysis of privacy policies and application code can further help identify potential privacy compliance violations, for instance in the context of mobile apps [49]. We use policy analysis results to provide more effective and accurate privacy notices to users. In addition, we plan to make analysis results available to website operators in order to help them improve their privacy policies.
Privacy Preference Modeling: The major goal of our approach is to make privacy policies more usable and accessible for website users. Thus, an important aspect of our work is the identification of those key features in privacy policies that are relevant to users. For this purpose, we have been conducting numerous user studies on privacy concerns, perceptions, and preferences. Furthermore, we strive to gain a deeper understanding of cognitive biases that may negatively affect individuals’ privacy decisions, in order to learn how users can be made aware of privacy risks in an effective manner [1].
Effective Privacy User Interfaces: Features extracted from privacy policies as well as results from privacy policy analysis and privacy preference modeling inform our design of user interfaces for privacy notices. The goal is to make those policy features that users care about more accessible, for instance, with nutrition label-inspired privacy notices [16] or privacy icons symbolizing data practices. We are also investigating the potential of just-in-time notices that highlight data practices when they become relevant for the individual user. For instance, data practices concerning the collection and sharing of contact or financial information may only be relevant when the user creates an account or makes a purchase. We are in the process of designing browser extensions that leverage policy extraction results and offer notices to users independently of website operators. We follow a user-centric iterative design process to enhance and evaluate the effectiveness of developed privacy interfaces in user studies.
Finally, in contrast to related work described in the next section, our outlined approach does not require any effort or cooperation by website operators. By making the content of privacy policies more salient and accessible, we hope to also nudge companies towards improving how they present their privacy practices.
Privacy-enhancing technologies (PETs) can be defined as the ensemble of technical solutions that preserve the privacy of individuals in their interactions with technological systems. In a recent overview, Heurix et al. [20] categorize PETs along relevant dimensions of privacy, such as the types of data being processed or communicated, application scenarios, grounding in security models, presence of a trusted third party, etc. What their classification fails to account for, however, is the knowledge dimension in PETs: without empowering users with the adequate resources to better understand data collection, use and sharing practices, their privacy awareness – the first barrier against any kind of violation – is hindered. In this regard, STs can be considered as knowledge-enabling solutions for PETs, and as support tools for developing context-aware applications [17,23,43,44].
According to Cuenca Grau [11], to be used as effective privacy-preserving systems STs need to embody the following functionalities: (F1) policy representation, namely a declarative representation of policies in a system; (F2) models of interaction, i.e., a set of queries that can extract relevant information from the system; and (F3) policy violation, which formalizes the cases when user preferences and data practices collide, leading to consequences that put users’ data at risk. These interconnected functionalities can emerge only when system development follows certain design stages, characterized by Cuenca Grau as: identification of clear privacy requirements and translation into a suitable formal language; realization of the formalized requirements in a computational system; and analysis and verification of the instantiated requirements [26].
Policy languages, meta-models and domain ontologies are necessary to implement (F1) and (F3), but are not sufficient to realize (F2). Enabling (F2), namely identifying suitable queries to extract privacy information, is a data-intensive task. In the UPP project we address this issue with an extensive data annotation effort conducted by domain experts. The centrality of (F2) is recognized by Kagal et al. [24] when outlining Rein. Rein is a semantic web framework for representing and reasoning over policies in domains that use different policy languages and knowledge expressed in OWL and RDF-S. Rein realizes a basic version of (F2): a rule-based inference engine checks for relations between a requester, a resource and some access properties. If a relation holds, the output will state whether the request is either valid or invalid. Kagal et al. note that to enhance the privacy and security of web applications more complex, yet user-friendly, query mechanisms need to be implemented. In the next sections, we articulate how this objective is being accomplished in our work by outlining
PrivOnto
: Knowledge base of privacy policies
The
Domain expert frame analysis of privacy policies
In order to study which data practices are expressed in privacy policies, and how data practices are described in privacy policy text, some of the authors and other members of the Usable Privacy Policy Project conducted an iterative multi-disciplinary analysis of privacy policies. The researchers involved in this activity were domain experts with backgrounds in privacy, public policy and law.
Analysis approach
The researchers studied multiple privacy policies of websites from US-based companies drawn from different categories (e.g., news, entertainment, government, shopping) in a iterative qualitative content analysis process. The analysis focused on US websites exclusively. This ensured that the same legal baseline applied to the privacy policy texts and that variations in language would not be attributable to different national legal rules. For example, European law has specific obligations for data practices and notice disclosures that are not found in US law. This means that EU corporate policies would not be accurately compared to US policies based solely on the text’s language.
The domain experts would initially read privacy policies individually and mark the types of data practices described in each paragraph of the policy document. Identified types of data practices were then discussed among the researchers and consolidated into consistent codes corresponding to data practice categories. Additional privacy policies were analyzed until no further data practice categories could be identified. This consolidation process was informed by the existing privacy and data protection framework in the United States, including the Federal Trade Commission’s Fair Information Practices [13]; the Platform for Privacy Preferences (P3P) [8]; specific privacy notice requirements prescribed by legislation, such as notice requirements in CalOPPA [7], COPPA [14], and the HIPAA Privacy Rule [45]; as well as prior research on privacy policy analysis [4,9,10,22,35]. The combination of content analysis grounded in privacy policy text with the consideration of US privacy legislation and literature ensured that resulting data practice categories are consistent with both (1) how data practices are expressed in privacy policies and (2) the terminology and notice requirements stipulated in US law and literature.
For each of the identified data practice categories, the experts further identified descriptive attributes that collectively represent and define a data practice. For example, a practice describing data collection by the first party (i.e., the website) is defined by how and where information is collected, the type of information being collected and whether it is personally-identifiable information, for what purpose the information is collected, from what user groups information is collected, whether the information is provided explicitly by a user or collected implicitly, and whether users have any choice regarding the practice (e.g., whether they can opt-out). The attributes used to represent data practices, as well as common attribute values were identified in a similar iterative process as the categories, combing the qualitative analysis of attribute and attribute value representations in privacy policy documents with legal requirements in the United States.
This analysis process resulted in a collection of frames that codify the different data practice categories, their descriptive attributes, and typical attribute values as they are expressed in privacy policies. Each frame has its own respective structure of frame-roles and values [15]. These frames were refined over multiple iterations involving their application to additional privacy policies and extensive discussions among the domain experts.

Protégé visualization of
The resulting collection of frames represents ten categories of data practices, which are defined as follows:
Privacy practice describing data collection or data use by the service provider operating the service, website or mobile app a privacy policy applies to.
Privacy practice describing data sharing with third parties or data collection by third parties. A third party is a company or organization other than the first party service provider operating the service, website or mobile app.
A practice describing general choices and control options available to users.
A practice describing if and how users may access, edit or delete the data that the service provider has about them.
A practice specifying the period and purposes for which collected user information is retained.
A practice describing how user data is secured and protected, e.g., from confidentiality, integrity, or availability breaches.
A practice on whether and how the service provider informs users about changes to the privacy policy, including any choices offered to users.
A practice specifying if and how Do Not Track signals (DNT)3
A Practice that pertains only to a specific group of users, e.g., children, California residents, or Europeans.
Additional sub-labels for introductory or general text in the privacy policy, contact information, and practices not covered by other categories.
A data practice statement belongs to one of these categories, and is characterized by a category-specific set of attributes. The frames define a set of potential values for each attribute. Each attribute is supported by a text fragment in the privacy policy, which serves as the natural language evidence for the annotated attribute value.

LEFT: an example that shows how
For example, a First Party Collection/Use practice is represented by four mandatory and five optional attributes. The mandatory attributes are whether the practice is a positive or negated statement (Does or DoesNot), how the first party obtained information (action-first-party), what kind of information is collected (personal-information-type), and for what purpose (purpose). In addition, a first party practice statement may indicate whether information is collected implicitly or if the user explicitly provides information (collection-mode), whether collected information is linkable to a user’s identity (identifiability), whether the practice applies to registered users only (user-type), and if a user choice is offered explicitly for this practice (choice-type and choice-scope). Data practices in other categories are represented with similar sets of attributes.
Mandatory and optional attributes reflect the level of specificity with which a specific data practice is typically described in privacy policies. Optional attributes are less common, while mandatory attributes are essential to a data practice. However, the experts’ analysis of privacy policies found that descriptions of data practices in privacy policies are often ambiguous on many of these attributes [34]. Therefore, a valid value for each attribute is Unspecified in order to express and capture the absence of information. For instance, the fragment “we disclose information to third parties only in aggregate or de-identified form” exemplifies vagueness in data practices as it remains unspecified what information might be disclosed or for what purposes.
This collection of data practice frames constitutes the semantic foundation for the
The
The Object property
Fragments are labeled with a unique identifier (UID), consisting of the policy number, the segment number, and the start and end indexes of the selected text. In the same way, we assigned UIDs to instances of practice categories. Thanks to this modeling strategy, we can refer to different annotations of the same fragment, so that the “raw” policy content is kept distinct from all the annotations that refer to it. For example, a fragment stating that “by use of our websites and games that have advertising, you signify your assent to SCEA’s privacy policy” is annotated as an instance of
The ontology also includes ANNOTATOR, a class whose instances denote the individuals involved in the annotation task: the relation
PrivOnto was instantiated based on the OPP-115 corpus [47], a corpus of 115 privacy policies of US-based companies, each independently annotated by three legal experts according to the developed collection of data practice frames. In this section, we characterize the OPP-115 corpus and the annotation process.
Privacy policies vary along many dimensions of analysis, including length, legal sophistication, readability, coverage of services, and update frequency. Large companies’ policies may cover multiple apps, services, websites, and retail outlets, while privacy policies of smaller companies may have narrower scope. Accordingly, privacy policies were chosen for inclusion in the UPP corpus using a procedure that encouraged diversity.
Websites were selected using a two-stage process: (1) relevance-based website pre-selection and (2) sector-based subsampling. This first stage consisted of monitoring Google Trends [19] for one month (May 2015) to collect the top five search queries for each trend; then, for each query, the first five websites were retrieved on each of the first ten pages of search results. This produced a selection of 1799 unique websites. For the second stage, websites were chosen from each of DMOZ.org’s top-level website sectors (e.g., News, Shopping, Arts).6
Note that the DMOZ.org’s “World” sector was excluded and that the “Regional” sector was limited to the “U.S.” subsector in order to exclude non-US privacy policies and to insure that all policies were subject to the same legal baseline.For each sector, eight websites were selected based on occurrence frequency in Google search results. More specifically, the eight websites were randomly selected two-apiece from each rank quartile. Each selected website was manually verified to have an English-language privacy policy and to belong to a US company (according to contact information and the website’s WHOIS entry). Websites that did not meet these requirements were replaced with random redraws from the same sector and rank quartile. Notably, some privacy policies covered more than one selected website (e.g., the Disney privacy policy covered disney.go.com and espn.go.com). The consolidation of the corpus resulted in a final dataset of 115 privacy policies of US-based companies across 15 sectors.
We developed a web-based annotation tool, shown in Fig. 4, to facilitate annotation of the UPP corpus’ privacy policies by expert annotators according to our frame-based annotation scheme. Privacy policies were divided into segments and shown to annotators sequentially in the tool. Each segment may be annotated with zero or more data practices from each category. To annotate a segment with a data practice, an annotator assigns a practice category and specifies values and respective text spans (fragments) as appropriate for each of its attributes.
Each privacy policy was independently annotated by three expert annotators. In total, we hired 10 law students as experts on an hourly basis to annotate the complete set of 115 privacy policies. Note that the average annotation time per policy was 72 minutes. The annotation of the corpus resulted in about 23,000 annotations of data practices, which were used to populate the

Web-based tool for expert privacy policy annotation.
Version 1.1: https://www.w3.org/TR/2013/REC-sparql11-query-20130321/.
Despite being extensive and detailed, this library is not meant to be exhaustive, and can be further expanded.
Our architecture for mapping the structured annotation corpus to the

Semantic server architecture for querying

Screenshot of the Apache Jena Fuseki server used for querying
Targeted information and related query types
Queries are sent to the Apache Jena Fuseki server that runs the
We created 57 SPARQL queries to analyze different aspects of the 115 privacy policies represented in the
It is important to point out that all 57 queries return the annotated text associated with a policy fragment: this feature realizes a crucial aspect of model of interaction (see functionality F2 in Section 3), i.e., the possibility for legal experts and users to understand and evaluate the machine-readable semantic models and queries in relation to a privacy policy’s original text.
Table 1 shows the different kinds of information that can be extracted from the knowledge base, along with sample queries. Percentage and count type questions help gain an overall understanding of the privacy policy data.
For example the query below, which calculates the ‘number of policies that allow users to export their data,’ returns 1 as the answer. Thus, only one out of 115 policies in our data set provides for the export of collected data, which shows the exceptionality of this data practice in the considered dataset.
In order to verify facts in the ontology, we can use ASK queries. For instance, the query below, which matches the question ‘Does any policy state that personal information is shared or collected as part of a merger?,’ returns
Our SPARQL queries also help gain specific information about different practice categories. For instance, the query exemplified by the question ‘How many websites mention each audience type?’ lead us to discover that clauses are generally added for children (86 out of 115 privacy policies), which suggests that a large number of privacy policies aim to be compliant with the Children Online Privacy Protection Act (COPPA) [14], but also shows that 25% of the privacy polices in our corpus have no provisions specific to children.

Proportion between number of matches and processing times for a subset of 20 queries. The labels in the x-axis represent types of information collected, shared, or mentioned in a policy and returned by suitable SPARQL queries. The y-axis represents the corresponding number of matches (blue histograms) and the retrieval time in milliseconds (red histograms).
The second dimension through which our SPARQL queries can be classified is based on different practice categories. Each practice category provides very specific information about privacy policies. By organizing the queries in this way, we can concentrate on specific characteristics of a policy, and draw parallel conclusions from different categories. Table 2 shows example queries from each category.
While running experiments in the Jena Fuseki environment, we observed that the queries’ processing time depends on the complexity of the SPARQL expression, while being only partially correlated with the number of matches. In particular, Fig. 7 represents the proportion between number of matches and retrieval times for a subset of 20 SPARQL queries chosen across all data practice categories to highlight relevant types of information in a policy. For instance, the figure shows that only four queries had processing time higher than 1500 ms: these queries included SPARQL constraints like OPTIONAL and MINUS. The queries labeled as ‘Financial Information and Purpose’, ‘General Information and Purpose’, ‘Unspecified Information and Purpose’ refer to user’s collected information at different levels of granularity, and specify the purpose of collection only when found in a policy: this condition was expressed in the SPARQL request by an OPTIONAL clause on the ‘Purpose’ attribute of the ‘First Party Collection/Use’ category. In the case of the query labeled as ‘Policies with User Choice,’ the high processing time was brought about by the MINUS clause, introduced to discard from the results all the policies with no real user choice, but only with take-it-or-leave-it option (this aspect is further analyzed in Section 5.3.3).
Queries on information collected from users or shared about users. Number of fragments are visualized, as well as coverage across policies
In this section we provide an overview of the quantitative and qualitative results of our query-based semantic analysis of about 23,000 data practices instantiated in the
Personal information collection/sharing
For the practice categories User Choice, First Party Collection/Use, and Third Party Sharing/Collection, we observed that privacy policies specify the information collected or shared, though the purpose of data collection is rarely mentioned in the same fragment. Therefore, we collected the purpose information from the other fragments present in the parent segment. We observed that, apart from ‘unspecified,’ ‘basic service’ and ‘additional service’ were the most mentioned purposes. ‘Device information’ and user’s ‘online activity’ are collected from users’ for ‘analytics/research’ purposes, whereas ‘finance’ and ‘contact information’ were collected for ‘marketing’ and ‘advertising purposes.’ Purpose for which information is highly shared is ‘Advertising’ (14.6%), and the purpose for which information is highly collected is for ‘basic service/feature’ (16%).
Table 3 presents the comparison of different personal data types which are collected and shared. We observed that most of the data types collected and shared are unspecified (last row). This result can be explained by the fact that the word “information” is often used with no further description or specification in the policies. As a result, the privacy policies make it difficult for consumers and regulators to determine which information is actually collected or shared by a company. The following text fragments exemplify this vagueness: “the information we learn from customers helps us personalize and continually improve your Amazon experience” and “any information that we collect from or about you.”
Table 3 also shows that ‘device,’ ‘location identifiers,’ and ‘contact information’ are often collected by the websites, but are not explicitly mentioned in statements with respect to third party sharing. Because of the extensive use of generic descriptions for information types, the privacy policies do not indicate whether these data items are actually shared with third parties.
‘Contact information,’ ‘user online activities,’ and ‘general personal information’ are the top referenced types of information. ‘Contact information’ appears frequently as collected information, while ‘general personal information’ is highly shared. ‘General personal information’ is also often ambiguous. The corresponding policy fragments describe this information as “personally identifiable information” or “personal information.” For example, one policy in the corpus shares “any and all personal identifiable information collected from our customers” with third parties.
Out of 115 policies, 90 privacy policies state that the service providers do not share some information with third parties, and 78 policies explicitly state what information they do not collect from users. The top categories of information type reportedly not collected or not shared are ‘generic personal information,’ ‘cookies and tracking elements,’ and ‘contact’ information. While this appears to contradict the previous finding that contact information is frequently collected and general personal information is widely shared, the contradiction reflects that privacy policies are explicit when they do not share data.
Marketing and advertising
There were 886 fragments which described the collection of information for ‘Marketing’ and ‘Advertising’ purposes. Information collected for advertising purposes is typically identified as the user’s ‘online activities’ or ‘cookies and tracking elements’. Users’ ‘contact information’ is typically used for ‘marketing’ purposes.’ By contrast, ‘financial’ information is often identified for sharing with third parties when these are partners or affiliates.
User’s choice on enabling service
Almost all privacy policies (92%) have statements describing User Choices. But, of these privacy policies, 48% have statements that merely describe a take-it-or-leave-it choice. Instead of a real choice, users are told not to use the service or feature if they disagree with the privacy policy or with certain data practices. Examples are: “if you choose to decline cookies, you may not be able to fully experience the interactive features of this or other Web sites you visit” or “if you do not agree to this privacy policy, you should not use or access any of our sites.”
User data retention
About half of the privacy policies (56%) specify for how long they store user data. In 40% of these policies a retention period is explicitly ‘stated’ (e.g., 30 days) or the retention period is at least ‘limited’ (e.g., stored as long as needed to perform a requested service); while 7% express that the data will be stored indefinitely. The distinction between ‘Limited’ and ‘Stated’ retention periods is sometimes blurred due to drafting vagueness and annotator interpretation. For instance, the fragment “we will retain your data for as long as you use the online services and for a reasonable time thereafter” has been annotated both as “limited period” or as “stated period.” This creates ambiguity with respect to the duration that user data will remain in a service’s database.
Data export
As mentioned in the previous section, only one policy in our knowledge base describes how users can export data. The respective annotated fragment states: “California Civil Code Section 1798.83, also known as the Shine The Light law, permits our users who are California residents to request and obtain from us once a year, free of charge, information about the personal information (if any) we disclosed to third parties for direct marketing purposes in the preceding calendar year.”
Policy change
Privacy policies typically provide that users are notified about changes to the privacy policy through some form of general notice or through a website. Only 30% of the privacy policies containing descriptions of change in notification practices mention a notification of individual users (e.g., via email). The lack of personal notice for policy changes means that users are unlikely to be aware of changes to the privacy policy, although such changes may alter how information about them is collected, used, or shared by a service.
Data security
The major security measures which most websites describe are the use of ‘secure user authentication,’ the existence of a ‘privacy/security program,’ and the communication of data with ‘secure data transfer.’
The analysis above shows that query-based analysis of the
Semantic search
In the previous section, we analyzed the knowledge base created using

A screenshot of the UPP Explore website that visualizes the First Party collection data practice of the New York Times’ privacy policy.

Two screenshots of the qualitative and quantitative results visualized as a table in semantic search.
We have extended this functionality as a part of our UPP project’s data exploration portal.10

A screenshot of the search functionality in UPP website.
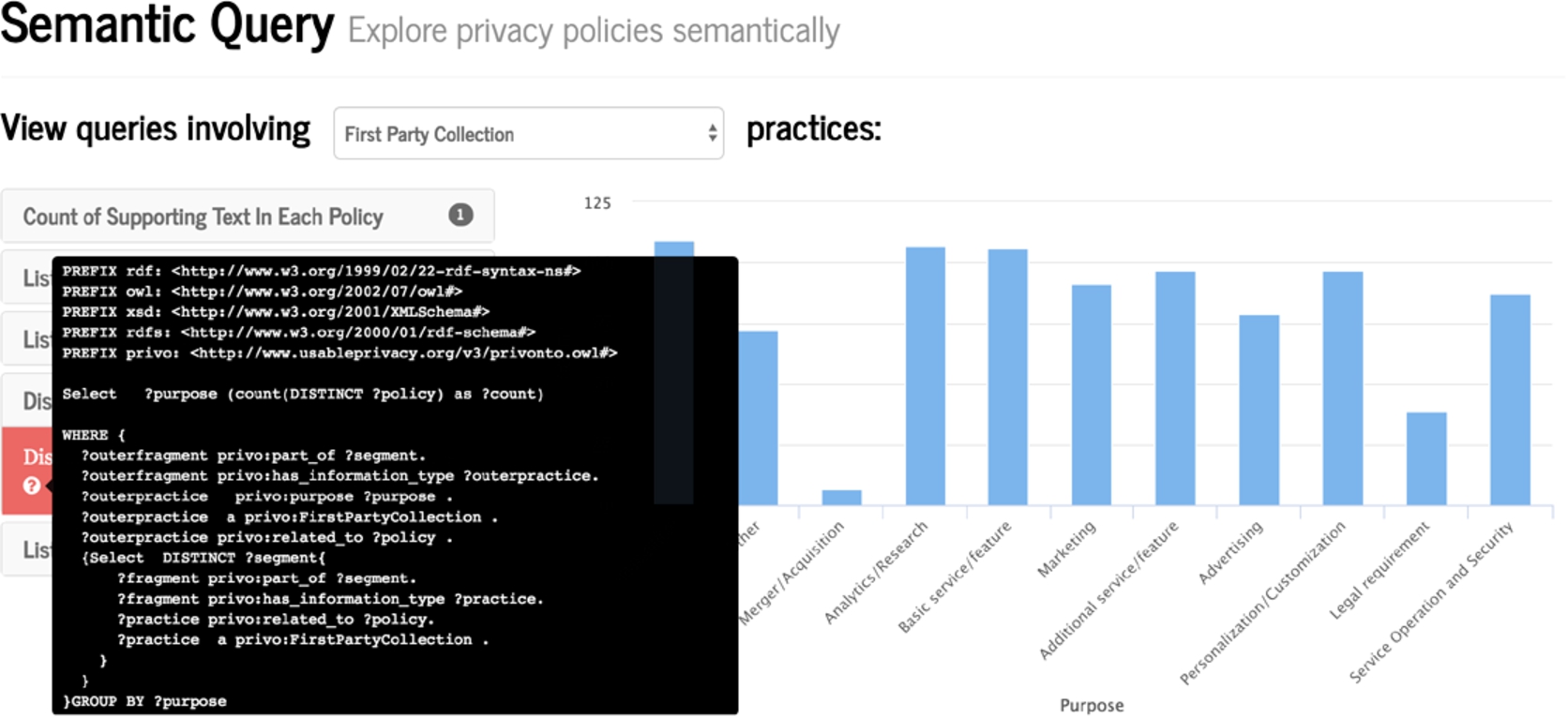
SPARQL version of a query in the search page.
In the initial version of the semantic search, we are presenting the users with the natural language queries. They can filter these queries based on the practice categories and question type as discussed in the previous section. For quantitative queries which extracts part of text from a website policies, we provide link to the paragraph of the policy the text comes using a link in website name column. Users can use this link to get more clarity on the results. Figure 10 shows an example of this functionality. For users who are interested in knowing the actual SPARQL query behind the results, a small button is added (see Fig. 11), to show the underlying SPARQL query.
In this paper we described
The
To the extent that contradictions have a logical nature, state-of-the-art inference engines like Pellet [42] would be sufficient to flag them. For instance, preliminary results show that there’s complete agreement when it comes to annotate if a Do Not Track data practice is ‘honored’ or ‘not honored’ by a given policy: but in cases when those two mutually exclusive values were to be selected for the same fragment, automatic reasoning with
Semantically-labeled privacy policies constitute an important resource for privacy analysts and regulators, but scaling the process of annotating natural language privacy policies accordingly can be challenging. As part of the efforts in the UPP project, we investigate the potential of crowdsourcing privacy policy analysis from non-experts, in combination with machine learning, in order to enable semi- or fully automated extraction of data practices and their attributes from privacy policy documents [3,6,48]. These efforts show promise for scaling up our analysis, which would enable further expansion of
Footnotes
Acknowledgements
This research has been partially funded by the National Science Foundation under grant agreements CNS-1330596 and CNS-1330214. The authors would like to acknowledge the entire Usable Privacy Policy Project team for its dedicated work; and especially thank Pedro Giovanni Leon, Mads Schaarup Andersen, and Aswarth Dara for their contributions to the design and validation of the annotation scheme, as well as the corpus creation.