
Abstract
CrunchBase is a database about startups and technology companies. The database can be searched, browsed, and edited via a website, but is also accessible via an entity-centric HTTP API in JSON format. We present a wrapper around the API that provides the data as Linked Data. The wrapper provides schema-level links to schema.org, Friend-of-a-Friend and Vocabulary-of-a-Friend, and entity-level links to DBpedia for organization entities. We describe how to harvest the RDF data to obtain a local copy of the data for further processing and querying that goes beyond the access facilities of the CrunchBase API. Further, we describe the cases in which the Linked Data API for CrunchBase and the crawled CrunchBase RDF data have been used in other works.
Introduction
CrunchBase1
See http://crunchbase.com/, requested on Feb 4, 2016.
See https://about.crunchbase.com/partners/advertising-partners/, requested on Oct 19, 2016.
Initially founded in 2007, CrunchBase is nowadays used “by millions of users”3
See https://about.crunchbase.com/, requested on Oct 16, 2016.
The CrunchBase schema predefines entity types, attributes and relations. Since the CrunchBase data is internally stored as a graph, the database is also called Business Graph.4
See https://info.crunchbase.com/the-business-graph/, requested on Feb 4, 2016.
The data stored in the CrunchBase database is usually accessed via a web browser. However, CrunchBase also provides its data in other ways. The following options for data access are provided:
Open Data Map (ODM) is a package of JSON or CSV files which provides daily updated information about people and organizations. The ODM only provides a restricted set of entity attributes.
The Excel Data Export provides a monthly updated spreadsheet, containing a partial view (companies, rounds, investments, and acquisitions) on the overall data.
The REST API allows for accessing the entire contents of the CrunchBase database.
Noteworthy is the unusual licensing model of CrunchBase. On the one hand, all CrunchBase data is licensed partly under Creative Commons Attribution-NonCommercial License 4.0 (CC-BY-NC) and partly under Creative Commons Attribution License 4.0 (CC-BY), independent how it is provided (e.g., via browser or API).5
See https://about.crunchbase.com/docs/terms-of-service/, requested Oct 19, 2016.
Using Semantic Web technologies such as RDF on the CrunchBase API leads to the following benefits:
More complex queries: Although the CrunchBase data is internally stored as a graph, CrunchBase does not provide an interface for querying with a graph query language such as SPARQL. Instead, the CrunchBase API only allows entity-centric requests, revealing information in JSON format about specific entities with their attributes and relations. A typical API request can be formulated in natural language as: “Show me all stored acquisitions of Facebook Inc.”6
The corresponding HTTP GET request looks like:
In contrast, many professional CrunchBase users may want to formulate more elaborate queries.7
The CrunchBase API mailing list provides examples for such requested queries, see, for instance, https://groups.google.com/d/msg/crunchbase-api/xiAQdg5CAo4/GN51XIlptWMJ, https://groups.google.com/d/msg/crunchbase-api/k24Sy0tHOTo/7OrRJ3d6NXcJ, and https://groups.google.com/d/msg/crunchbase-api/g99E-Ft2aCk/cF89E44Z1egJ; requested on Oct 17, 2016.
This question is based on the CrunchBase mailing list post available at https://groups.google.com/d/msg/crunchbase-api/xiAQdg5CAo4/GN51XIlptWMJ, accessed on Oct 17, 2016.
Using CrunchBase data with existing Semantic Web data: Semantic Web technologies are often used to integrate data from separate data sources. The integration becomes possible once data has been transformed into RDF. With the CrunchBase data available in RDF, one can combine the data with other RDF data. For instance, the information about the location and the technology sector of companies in CrunchBase can be combined with information about job offers from an online job seeker platform. By integrating data from both platforms, one can pose queries such as: “Find all companies within the area of city X which offer jobs in the field of Y.” Mochol et al. [8] give an example of how to use Semantic Web data to achieve the answering of such questions.
Using existing analytics methods in conjunction with CrunchBase data: For market insight purposes (e.g., detecting acquisitions in news texts), already some well-performing Semantic Web methods such as text annotation – i.e., linking mentions in a text to their corresponding Knowledge Base entries – and relation extraction – extracting triples from text – are available. However, these methods often only work well for specific underlying data sets such as Wikipedia or DBpedia. The data which is useful for market monitoring tasks (e.g., acquisitions of companies) such as CrunchBase data, in contrast, is often not supported by these tools. However, if entities in CrunchBase are linked via
Links to resources

Schematic view of the steps taken to create a Linked Data version of the CrunchBase API.
In this paper, we make the following contributions:
We provide a process-oriented description of creating a Linked Data wrapper, which transforms JSON provided by an API into RDF (in both JSON-LD and N-Triples serializations). We implement our workflow on the CrunchBase REST API, but the method can serve as template for wrapping any access-restricted REST API with JSON output. Both an implementation of the Linked Data wrapper and a deployed version of it are available online (see Table 1). The CrunchBase Linked Data API has been applied in two use cases so far (see Section 4).
We show how an up-to-date RDF data set of CrunchBase can be obtained at any time with the help of the Linked Data wrapper. The data set can subsequently be used for a variety of use cases such as market monitoring and is freely available for further usage. So far, besides internal usage for information extraction on text, the crawled CrunchBase RDF data set has been used by others for data integration. Similar CrunchBase data sets have been used for exploratory data analysis.
Regarding the linked data set description papers published by the Semantic Web Journal so far [4], five out of all 38 papers mention JSON as input data format, but only the description of the Facebook RDF Wrapper [10] and of LinkedSpending [3] describes a conversion of JSON to RDF. For the Facebook RDF Wrapper, JSON-LD was considered, but disregarded, “since its conventions varied too widely from the existing JSON format.” [10]
Since the publication of [10], things have changed: JSON-LD became a W3C recommendation9
See https://www.w3.org/TR/json-ld/, requested on Feb 5, 2016.
See https://trends.builtwith.com/docinfo/JSON-LD, requested on Feb 5, 2016.
Other approaches often convert entire data sets to RDF. In contrast, we first provide a Linked Data interface to the API to access live data as RDF, and then create a data set via crawling. Such an approach allows for the collection of parts or all of the data, and provides up-to-date access to data about entities.
In the following, we give a short overview of the Linked Data API and of the RDF data set, before describing them in more detail in the following sections.
Our workflow to create the Linked Data API is shown in Figure 1. We first set up a simple RDF API to harvest an initial RDF data set via crawling. We use the initial RDF data set to enrich our Linked Data API with

UML sequence diagram illustrating the use of the wrapper. The wrapper supports different representations via content negotiation. The API key is passed to the wrapper via an
We have implemented the Linked Data API for CrunchBase. The code of the wrapper is available on GitHub11
See https://github.com/aifb/linked-crunchbase, requested on Feb 5, 2016.
See http://km.aifb.kit.edu/services/crunchbase/, requested on June 28, 2016.
For setting up a local CrunchBase RDF Knowledge Base for research on news monitoring [1], we built a CrunchBase RDF data set with the help of the implemented CrunchBase Linked Data API. We thereby restricted ourselves to facts of organizations, people, products, and acquisitions, since entities of those types contain the facts which are – in our minds – the most important for our news monitoring task. We crawled in October 2015 and retrieved 7,373,480 unique entities. The crawled CrunchBase RDF data set can be reused by all researchers who want to extend existing Knowledge Bases with CrunchBase data or who want to analyze the RDF data set for their own purposes.
The rest of the paper is organized as follows: In Section 2, we present our Linked Data API for CrunchBase, which is designed as a wrapper around the official CrunchBase REST API. In Section 3, we give insights into our CrunchBase RDF Knowledge Graph whose data was crawled with the help of the CrunchBase Linked Data API. After describing the usage of the Linked Data API and the crawled RDF data in Section 4, we conclude in Section 5.
We now give an overview of our implemented CrunchBase Linked Data API. Figure 2 shows the basic workflow when accessing data via our Linked Data API. We can distinguish between the following steps:
A user application, such as the data integration system Linked Data-Fu [9], calls the CrunchBase Linked Data API via a HTTP GET request. The request contains the URI, the requested content type, and the CrunchBase API user key.13
An example API call with cURL is
The Linked Data API servlet takes the HTTP request and calls the official CrunchBase REST API using the specified information.
The Linked Data API servlet receives the data from the CrunchBase REST API and transforms it into one of the provided content types. As far as mappings to DBpedia are available, links to DBpedia entities are included.
The user application receives the data from the Linked Data API and further processes the data.
Our CrunchBase Linked Data API provides three different content types:
Because we provide the CrunchBase Linked Data API as a third-party tool on top of the CrunchBase REST API (currently in version 3), the RDF wrapper needs to be modified as soon as the CrunchBase API changes. This is ensured by a process of monitoring the CrunchBase mailing list.
URI design for the CrunchBase Linked Data API using organizations as example entity type
URI design for the CrunchBase Linked Data API using organizations as example entity type
Since the official CrunchBase API is only accessible with an API key, users of the CrunchBase Linked Data API also need to provide a valid API key for requesting data. When using the CrunchBase JSON API, the key is passed via a parameter in the URI. However, applying this method to the CrunchBase Linked Data API, the API key would be part of the identifier and public for everyone. To resolve this issue, user agents can pass the API key through the
We use the
As the CrunchBase data is licensed under CreativeCommons licenses and can thus be reused,15
This is indicated in each returned RDF document by additional triples dedicated to the license.
Table 2 shows the URI design for accessing the Linked Data API. Since the URIs for the official CrunchBase API16
See https://data.crunchbase.com/docs/using-the-api/, requested on Aug 2, 2016.
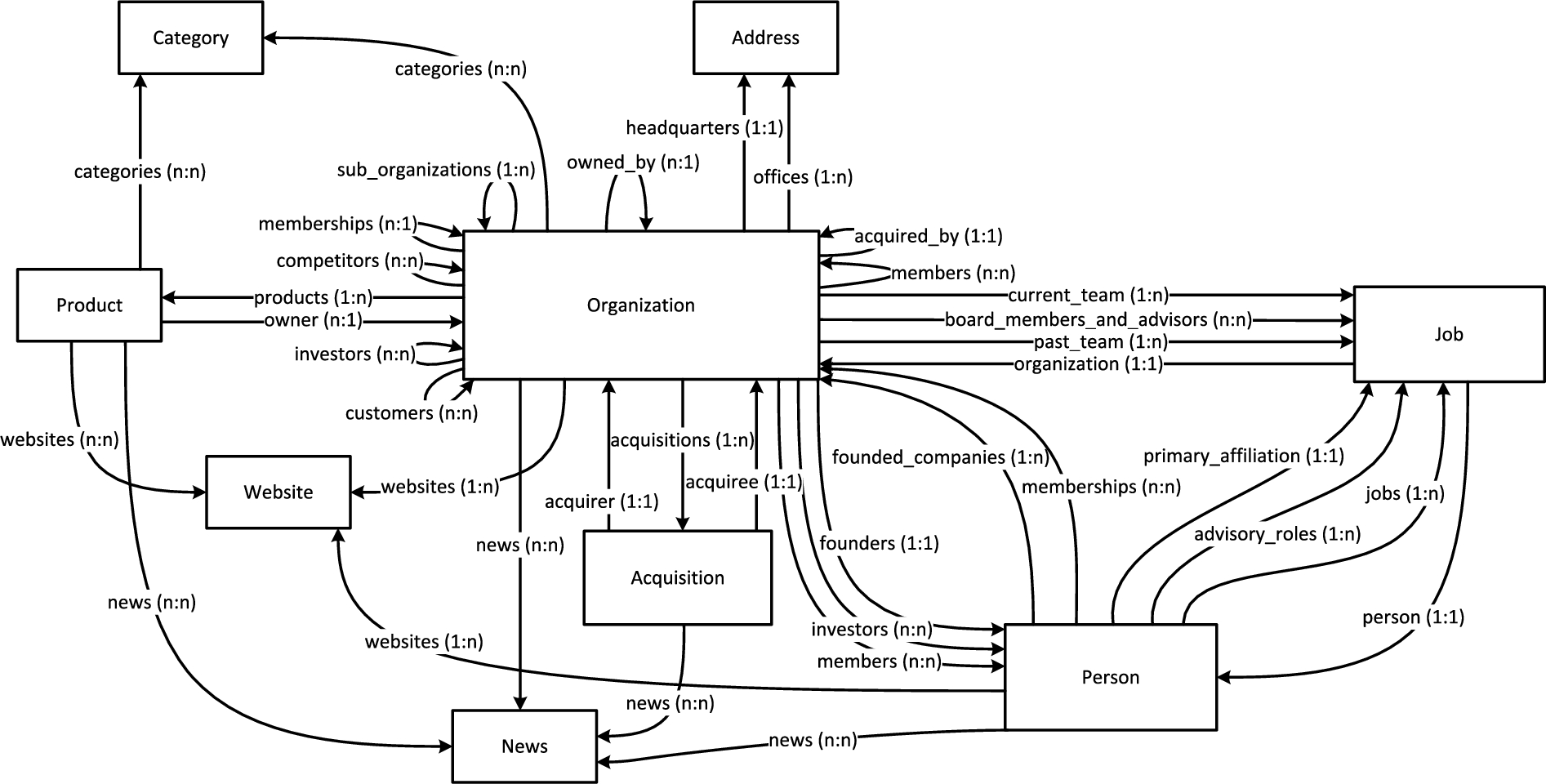
Diagram showing a subset of the classes and relations supported by the CrunchBase Linked Data API. We use a (source, target) notation to indicate the cardinality of relations.
For the CrunchBase Linked Data API, the data model of the official CrunchBase REST API is reused and only slightly modified. All entity types and the set of possible attributes and relations between entities remain. Figure 3 illustrates the classes and relations used in the data returned from the wrapper. The schema of the Linked Data API is dereferencable and described in an OWL file, which is provided on our Linked Data API entry page. Furthermore, we enriched our ontology with VOAF (Vocabulary-of-a-Friend)17
See http://lov.okfn.org/vocommons/voaf, requested on Feb 5, 2016.
See https://www.w3.org/wiki/SweoIG/TaskForces/CommunityProjects/LinkingOpenData, requested on Aug 1, 2016.
We can outline further characteristics of the data modeling used by the Linked Data API:
Not all relations between entities are modeled as single triples in the CrunchBase database. For instance, acquisitions do not only have an acquiree and an acquirer, but for instance also a date and a type of the acquisition. Events such as acquisitions are modeled as separate entities. In RDF, the concept of n-ary relations19
See https://www.w3.org/TR/swbp-n-aryRelations/, requested Aug 1, 2016.
These include the following entity types: Organizations, News, Images, Videos, Acquisitions, Categories, Addresses, Websites, Jobs, Investments, FundRaises, Products, Locations, Degrees, Markets, and WebPresence. The last two are not listed in the official CrunchBase API documentation.
Noteworthy is also the possibility to model uncertainty for date values. The uncertainty value is stored as decimal representation ranging from 0 (complete unknown/unsure) to 7 (very confident/knowing the exact date). Based on this encoding, property values stored as strings can be easily converted to the XML schema definition (XSD) format21
See https://www.w3.org/2001/XMLSchema, requested on Feb 5, 2016.
Linked Data is based on the best practice to use existing vocabularies and to link entities, classes, and properties between data sources in the Linking Open Data (LOD) cloud. As the topic of CrunchBase is to some degree domain-dependent, we did not find a proper vocabulary for CrunchBase. Therefore we decided to use our own vocabulary and link it to suitable entity types and properties from schema.org. We created 32
See http://km.aifb.kit.edu/services/crunchbase/ontology.owl, requested Feb 5, 2016.
Mappings (sample) between CrunchBase and schema.org entity types. We use
We created a list of
Organization mappings
The mapping between CrunchBase entities of type organization and DBpedia entities led to acceptable precision rates. For each CrunchBase organization, the mapping method checks whether it can find a DBpedia entity which possesses the same homepage domain as the CrunchBase entity; i.e., it compares the attribute value of
See Wikipedia’s notability guidelines at https://en.wikipedia.org/wiki/Wikipedia:Notability (requested Aug 2, 2016).
To evaluate the precision of the gained
People constitute the second-largest group of entities after organizations. People entities, however, require higher effort for mapping. Using just the given name and surname leads to a very high rate (about 90%) of false positives, since a lot of people have the same names (e.g., Brian Ray, who is the CEO of Link Labs on CrunchBase, but a musician on DBpedia).24
See https://www.crunchbase.com/person/brian-ray#/entity and http://dbpedia.org/page/Brian_Ray, requested on Feb 2, 2016.
To evaluate the accuracy of this mapping strategy, we randomly picked 300 CrunchBase person entities and for each entity verified via manual investigation on Wikipedia whether there is a corresponding entity in DBpedia, whether there is no corresponding entity in DBpedia for sure, or whether no statement can be made, since, for instance, not enough information is available for disambiguation. We only considered people in Wikipedia with the same given name and family name as given in CrunchBase. We came to the following conclusions:
263 out of the 300 (87.7%) CrunchBase people entities do not exist in DBpedia. 5 out of the 300 have a counterpart in DBpedia. For 32 people, not enough information was available to determine with confidence whether the entity exists in DBpedia.
Based on these results, we decided not to create
Products exhibit similar difficulties w.r.t. mappings to DBpedia as people. There are almost no modeled relations or attributes for products which we could use, only the manufacturer/owner, the name, and the description. We leave product mappings therefore for future work.
The CrunchBase RDF data set
Besides creating a Linked Data API for CrunchBase, we also obtained an RDF data set containing information about CrunchBase organizations, people, acquisition, and products (including their attributes and relations).25
The RDF file is available at http://km.aifb.kit.edu/sites/crunchbase/crunchbase-dump-201510.nt.gz.
We built the CrunchBase RDF dump in conjunction with the information integration framework Linked Data-Fu [9] along the following steps:
We crawled all so-called summary data via the CrunchBase Linked Data API by using URIs for the summary lists of organizations, people, and products.26
I.e.,
We crawled all the information about people, products, and organizations by requesting the
As CrunchBase lists only eight entities per relation via those API requests, we have to crawl separately every relation of any entity in case the relation has more than eight different objects. Note that the API calls take time, as the Linked Data API is restricted to the same 1 second limit for requests that the official CrunchBase REST API has.
The original CrunchBase API uses some meta-data attributes such as
Since the crawled CrunchBase entities are highly linked to entities of further entity types, our final CrunchBase RDF data set included entities of 25 different entity types and 210 different relations (KB properties). We retrieved 83,737,509 unique triples in total. Table 4 shows the distribution of the entities among the different entity types. Not surprisingly, CrunchBase’ main focus is on organizations (including companies) and related entities such as people, products, acquisitions, and jobs. News and websites are also well covered due to the affiliation of CrunchBase to TechCrunch.
Distribution of entities among the different entity types in our crawled CrunchBase RDF data set (as of October 2015)
The VoID specification27
See http://www.w3.org/TR/void/, requested on Feb 3, 2016.
See http://km.aifb.kit.edu/services/crunchbase/void.ttl, requested on Feb 5, 2016.
There are two kinds of 5-star rating schemes in the Linked Data context:
The 5-star deployment scheme for Open Data developed by Tim Berners-Lee:29
See http://5stardata.info/, requested on Nov 3, 2016.
Linked Data vocabulary star rating [ 5 ]: This rating is intended to rate the use of vocabulary within Linked (Open) Data. By providing an OWL-file, linking our vocabulary to schema.org, and creating a Vocabulary-of-a-Friend (VOAF) file,30
See http://km.aifb.kit.edu/services/crunchbase/voaf.ttl, requested on Feb 5, 2016.
The presented CrunchBase Linked Data API and CrunchBase RDF data is useful in a variety of scenarios as CrunchBase provides data which is in most parts not covered by other Linked Open Data (LOD) data sets. We implemented the CrunchBase Linked Data API by means of the W3C Semantic Web standards RDF and JSON-LD; furthermore, we provide a schema description in OWL and a vocabulary description in VoID. All this allows the Linked Data API and the crawled data to be integrated in any Semantic Web application.
In the following, we elucidate concrete scenarios in which a CrunchBase Linked Data API or an RDF version of CrunchBase has been used.
Usage of the CrunchBase Linked Data API
The following RDF wrappers for CrunchBase have been developed and used so far:
Semantic CrunchBase31 See http://bnode.org/blog/2008/07/29/semantic-web-by-example-semantic-crunchbase and the dedicated host http://cb.semso.org/, which is not available any more; requested on Apr 6, 2016. See http://techcrunch.com/2008/07/15/crunchbase-now-has-an-api-so-grab-our-data/, requested on May 2, 2016.
Harth et al. [2] demonstrated in 2013 an on-the-fly integration of static and dynamic sources for applications that consume Linked Data. Among the data sources, an RDF version of CrunchBase was integrated to include office locations of technology companies in the overall system. Harth et al. used a first version of the CrunchBase Linked Data API as presented in this paper.
RDF data sets of CrunchBase have been used in the following ways so far:
Lee et al. [6] present an initiative of using Linked Data for financial data integration. The purpose of integrating CrunchBase and other financial data sources was to allow “both professional analysts and amateur individual investors to understand the performance of a particular company more efficiently.” This was achieved by linking heterogeneous financial data and by tracing their provenance. Lee et al. show that the integrated RDF data allows a better comparison of financial reports, that it supports new KPI definitions, and that it allows timely access to external data.
Regarding CrunchBase, RDF data about funding, competitors, company acquisitions, main people in charge, and products were integrated into the framework. The authors of [6] used a first version of our CrunchBase RDF data set. In the current article, we present an updated version of the CrunchBase RDF data set, which contains considerable more entities and more diverse entity types.
Result of a SPARQL query based on the search intent “Get all acquisitions of start-ups founded after 2010 with an price greater than 1 bn USD, sorted by price in descending order” depicted as diagram; see also http://km.aifb.kit.edu/sites/crunchbase/.
In [1] we showed the usage of the CrunchBase RDF dump as it is presented in this article for the purpose of monitoring news to find statements which are not in a Knowledge Base so far. We used the
The CrunchBase RDF data set can also be used for data visualization and exploratory data analysis. Figure 4 shows an example visualization, given the natural language query “Get all acquisitions of start-ups founded after 2010 with an price greater than 1 bn USD, sorted by price in descending order.” The CrunchBase RDF data set can be utilized not only by business people, but also by researchers such as of social studies. Xiang et al. [11] and Liang and Yuan [7] give an idea of that: They have made analyses on a CrunchBase data set which they created on their own. Liang and Yuan, for instance, used CrunchBase data to build a social network graph. Based on the graph, they applied various link prediction techniques to explore how similarity between investors and companies affects the investing behavior. One of their findings is that if investors and companies share too many common neighbors, investors are less likely to invest in such companies. For creating their CrunchBase data set, Liang and Yuan [7] used Facebook as seed entity and then crawled entities which are at most four hops away. This procedure resulted in about 12,000 companies and 12,000 people. The CrunchBase RDF data set proposed in this article, in contrast, contains about 568,000 organizations (including companies) and 430,000 people. Thus, more comprehensive and in-depth studies are possible based on our data set.
We have presented a method for bringing the CrunchBase API to the Semantic Web. To that end, (i) we have implemented a Linked Data API as wrapper around the publicly available CrunchBase REST API; (ii) we have crawled the data from the wrapper for building a local CrunchBase data set. Both the Linked Data API and the RDF data set are freely available. To ensure the best possible usage and impact of the Linked Data API and RDF data set, we proceeded along Linked Data best practices such as describing the API, the RDF dump, and the schema via published OWL and VoID files, mapping CrunchBase relations and classes to relations and classes from other vocabularies, and integrating
Footnotes
Acknowledgements
This work was carried out with the support of the German Federal Ministry of Education and Research (BMBF) within the Software Campus project SUITE (Grant 01IS12051).