
Abstract
Web APIs enjoy a significant increase in popularity and usage in the last decade. They have become the core technology for exposing functionalities and data. Nevertheless, due to the lack of semantic Web API descriptions their discovery, sharing, integration, and assessment of their quality and consumption is limited. In this paper, we present the Linked Web APIs dataset, an RDF dataset with semantic descriptions about Web APIs. It provides semantic descriptions for 11,339 Web APIs, 7,415 mashups and 7,717 developer profiles, which make it the largest available dataset from the Web APIs domain. The dataset captures the provenance, temporal, technical, functional, and non-functional aspects. In addition, we describe the Linked Web APIs Ontology, a minimal model which builds on top of several well-known ontologies. The dataset has been interlinked and published according to the Linked Data principles. Finally, we describe several possible usage scenarios for the dataset and show its potential.
Introduction
Web APIs have become the first-class citizens on the Web and the core functionality of any Web application. Targeting the developer audience, they lower the entry barriers for accessing valuable enterprise data and functionalities. Back in late 2008, ProgrammableWeb.com,1
In order to achieve these goals, we have developed the Linked Web APIs dataset. It provides information about Web APIs, mashups which utilize Web APIs in compositions, and mashup developers. The primary source for the dataset is the ProgrammableWeb.com directory, which acts as central repository for Web APIs descriptions. The dataset re-uses several well-known ontologies developed by the Semantic Web community. In order to conform to the Linked Data principles,2
The remainder of this paper is structured as follows. Section 2 describes the source of information and how the data was collected. Section 3 describes the developed ontology for modelling relevant Web APIs information. The creation of the Linked Web APIs dataset and its technical details are described in Section 4. The approach for interlinking the dataset with other LOD datasets is described in Section 5. Section 6 discusses the quality of the ontology and the dataset. Section 7 presents selected use cases and the results from a survey on the potential and the usefulness of the dataset. Section 8 discusses related vocabularies and potential data sources. Finally, Section 9 concludes the paper.
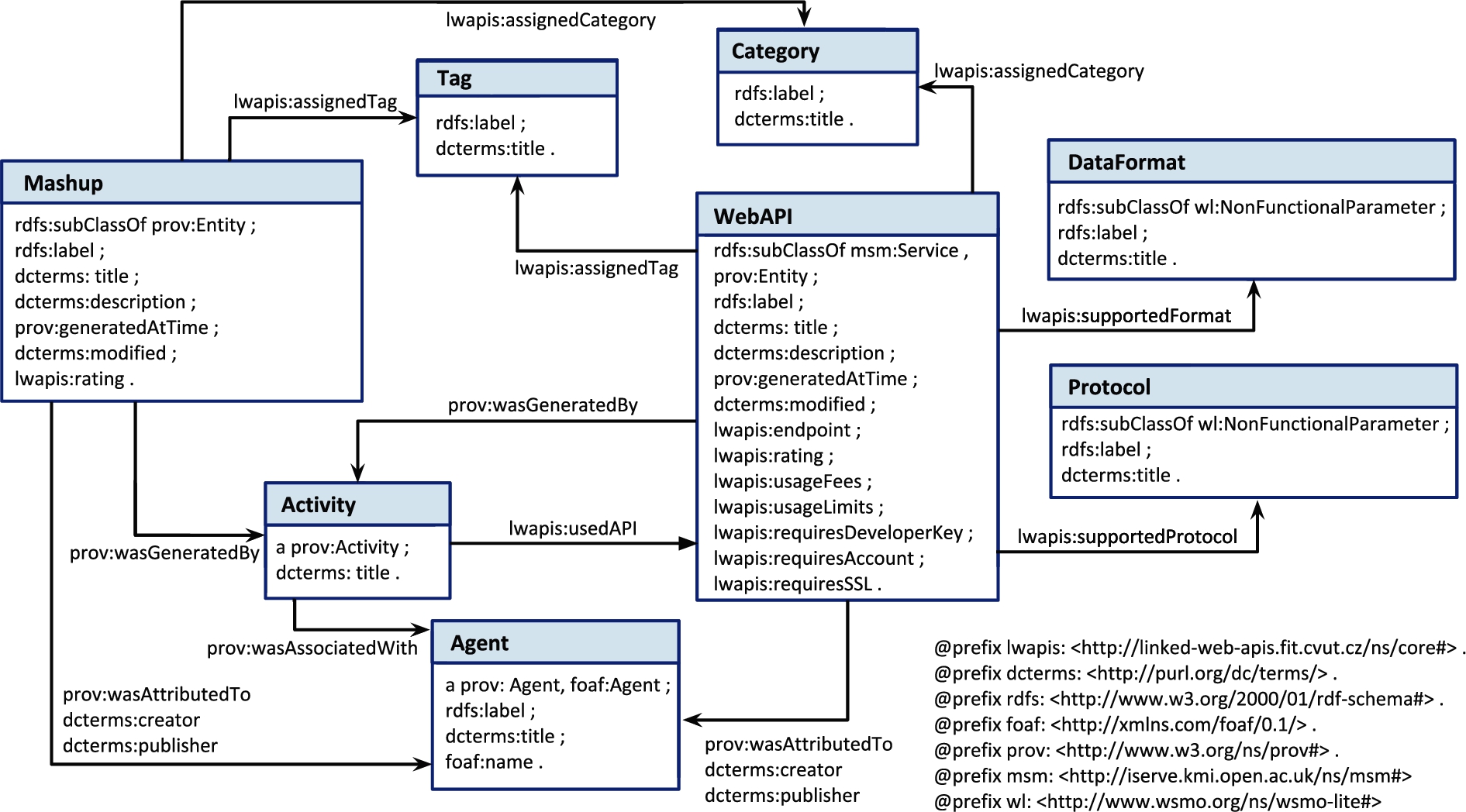
The Linked Web APIs ontology.
In our work, we have considered ProgrammableWeb as a primary source of information for creating the dataset. It adopts characteristics of a social Web platform where Web API providers can publish and share information about offered Web APIs and consequently increase their visibility. The API directory also allows developers to find appropriate APIs for their projects, or they can learn from showcases of existing mashup applications.
The implemented knowledge extraction process consists of four steps: (1) parsing and extraction of valuable information from pages describing Web APIs, mashups and developers, (2) pre-processing, cleanup and consolidation of information, (3) linking with LOD resources, and (4) lifting in RDF and publishing the data as Linked Data.
An example of a Web page which describes a Web API is the one which describes the Twitter API.7
We also captured the relationships between the Web APIs, mashups and developers. In other words, for each mashup we extracted the list of Web APIs which were used by the mashup and also the list of mashups created by each developer. The dataset also captures the temporal aspects – the creation time of the Web APIs, mashups and the time a user registered his profile.
In order to collect the data, we have implemented a script which systematically browses and parses relevant pages. The parsing mechanism has been implemented using the jsoup Java HTML parser.8
The Linked Web APIs ontology9
Provenance: It is important to keep information about Who (developers) created What (mashups) and How (using which APIs). In addition, information about APIs a provider provides need to be captured as well.
Functional and Non-functional Properties: What functionalities a Web API or mashup offers is more than important, as well as their usage limits and fees, supported security and authentication mechanisms.
Technical Properties: Information about the supported protocols, formats and the Web API endpoint location is as important, as it allows a Web API consumer to search only for APIs with preferred technical capabilities.
Temporal Information: When a mashup or Web API was created is a valuable information as well. For example, to analyze the recent trends in the API ecosystem or to discover the most recent Web APIs or mashups.
Figure 1 shows the overall Linked Web APIs ontology. The ontology contains three central classes: lso:WebAPI – describe Web APIs, lso:Mashup – describe mashup compositions, which utilize one or more Web API, and lso:Agent – represent all kinds of entities involved in the creation and/or consumption of Web APIs and mashups.
In order to capture the provenance information, the Linked Web APIs ontology integrates the PROV-O ontology10
For the functional (tags and categories) and non-functional (formats and protocols) properties of the Web APIs and mashups we introduce new classes in our namespace. The ontology also integrates the wl:NonFunctionalParameter class from the WSMO-lite ontology12
Coverage and availability
The Linked Web APIs dataset is the first of its kind with descriptions for more than 11,339 Web APIs, 7,415 mashups and 7,717 mashup creators. Overall, the dataset contains over 550K RDF triples. For all the resources we mint URIs in our own namespace (http://linked-web-apis.fit.cvut.cz/resource/{name}). The
All the URIs are dereferenceable and served according to the Linked Data principles in RDF/XML and Turtle format. The dataset is available via a Virtuoso SPARQL endpoint and as an RDF dump. The landing page for the dataset is
Details of the Linked Web APIs dataset
Currently, we employ the same versioning approach as the one used by DBpedia – versioning at the dataset level. Nevertheless, versioning at the resource level will be considered in the near future. Versioning at the resource level would be appropriate when integrating the APIs.io16
The computer center of the Czech Technical University in Prague kindly provided us with persistent web space for the publication of the dataset and the ontology. This will guarantee persistent URI identifiers for the dataset resources.
The ongoing maintenance of the dataset is carried out at the data level, as well as at the ontology level and its alignment with relevant existing and emerging vocabularies.
Our long-term goal is to establish the Linked Web APIs as a central Linked Data hub for Web API descriptions. To this end, we aim at providing support for various Web API description models (cf. Section 8.1) and data sources with relevant Web API information (cf. Section 8.2).
It takes over 29 hours (with four seconds crawl delay) to complete the crawling, information extraction and RDF generation process. The process is fully automated and currently it has to be manually triggered. The dataset has been already integrated with DBpedia (via owl:sameAs links; see Section 5) and we plan to synchronize the Linked Web APIs dataset generation with the DBpedia releases and generate the dumps on bi-annual basis. Since new APIs are published every day, we also plan to provide a live extraction service which pulls updates in real-time and updates the triple store.
Dataset linking
In order to assure maximal reusability and integrability, we linked the dataset with four central LOD datasets. Two multi-domain datasets, DBpedia and Freebase, and two geographical datases, GeoNames and LinkedGeoData. From the information we linked the Web APIs supported data formats, supported protocols, developers’ city and country of residence. Since GeoNames and LinkedGeoData are geographical datasets, only users’ city and country of residence were linked to those datasets. DBpedia and Freebase are multi-domain datasets and therefore we linked all information to these datasets. The links to DBpedia, and respectively to Freebase, were generated following the most-frequent-sense based approach which is used as entity linking method in the Entityclassifier.eu NER system [3]. The linking to LinkedGeoData was governed by the intuition that the names of the cities and countries in our dataset have same names in the LinkedGeoData dataset. The approach was supported by SPARQL queries which retrieve resources with a given label. Following this linking methodology we generated 1,440 links out of which 722 are DBpedia links, 299 Freebase links, 326 GeoNames links and 93 LinkedGeoData links. Table 2 provides more information about the linking.
Number of linked resources per type and dataset
Number of linked resources per type and dataset
We opted for these linking approaches, since we have the tooling in place and they served their purpose.
It is important to note that our dataset has also received in-links17
According to the 5-star classification system [1], defined by Tim Berners-Lee, the Linked Web APIs classifies as a five-star dataset. The five stars are credited for the open license, availability in a machine-readable format, use of open standards, use of URIs for identification, and the links to the other LOD datasets.
Dataset quality
Zaveri et al. [11] provide a list of indicators for evaluation of the intrinsic quality of Linked Data datasets. We have checked the data for each of the metrics (where applicable) described for syntactic validity and semantic accuracy.
Syntactic validity: no errors were found when checked for syntax errors, syntactically accurate values and malformed literals. Raptor18
Semantic accuracy: checked whether the data values correctly represent the real world facts. To this end, we have randomly created a set of 100 triples and manually checked their validity. Only two triples representing tags have been spotted as invalid. Note that no invalid triples were spotted for the provenance, technical and non-functional information.
According to the 5-star vocabulary classification [6], the Linked Web APIs ontology credits four out of five stars: for the machine and human-readable information about the vocabulary (2 stars), it is linked to other vocabularies such as WSMO-lite and PROV-O (3 stars) and for the provided metadata information for the vocabulary (4 stars). The fifth star is credited for vocabularies which have been referenced by other vocabularies. However, the Linked Web APIs vocabulary has not been yet used and referenced by other vocabularies.
Known shortcomings
The information extraction process is not entirely flawless due to its dependency on the HTML structure. From early 2012, when we created the initial snapshot of the dataset, until early 2016, the HTML has changed only two times, which is approximately every two years. Nevertheless, we are also considering other potential data sources, which will soon be integrated as part of the Linked Web APIs dataset. APIs.io and mashape marketplace19
As for the ontology, some properties, such as “usageFees” and “usageLimits”, are currently modeled as plain literals. The main reason for such a decision was the diversity of the possible values of these properties in the data. Very often these properties are expressed in a natural language, thus its modeling is a challenging task. In the future, if a data source provides data of a greater quality for these properties, we will appropriately extend the ontology.
Use cases
The availability of a dataset with Web APIs descriptions in RDF can support various use cases, including, but not limited to personalised Web API provisioning, API ecosystem analysis and automated processing of Web API descriptions. In this section, we describe selected use cases and existing applications of the Linked Web APIs dataset.
Use case 1: Personalised Recommendations. The Linked Web APIs dataset contains links between the mashup and the developer resources, which can be used as a pertinent source of information for developing Web API recommendation methods. As an example, a user, who has already picked a Web API for his/her mashup, could search for other compatible Web APIs. Such a scenario can be supported with the SPARQL query from Listing 1 which returns the top 5 most used Web APIs.

Top 5 most used Web APIs with Google Maps API.
In a different scenario, a developer could customize the search query to narrow down the results to Web APIs which support a particular data format (e.g., JSON) or APIs from a specific category (e.g., social, government, etc.).
In the context of personalised recommendations, the dataset has been recently employed in several works around personalised recommendation of Web APIs [4] and Linked Data resources [5]. The papers describe methods which accommodate the user preferences by analyzing their history. The method proposed in [5] recommends resources of interest for users with similar tastes. Both works focus on developing graph based algorithms on top of the Linked Web APIs dataset which utilize the provisioning information (who developed what), functional properties (tags and categories) and temporal information (when a mashup or an API was developed). The target audience in both methods are ultimately API consumers.
Use case 2: Support for Automated API Discovery, Composition and Orchestration. There are semantic models which provide mechanisms for automated Web service discovery, composition and orchestration. SADI [10] defines a mechanism for fully automated processing and integration of Web services. In such scenarios, the Linked Web APIs dataset can be used as a relevant source of discovery for Web APIs for a composition workflows. Assuming a user composer already picked her/his favorite API(s), with a query which is similar to the one in Listing 1, then he can retrieve a list of candidate APIs. These candidate APIs can be further validated and added to the composition workflows.

Number of mashups utilizing the Google Maps API in 2013.

Web API utilization over time.
Use case 3: Temporal Analysis. The dataset also captures the temporal aspect, i.e., the time when a mashup or a Web API was developed. These kind of information can help Web APIs providers to get better insights about the recent developments and study the consumption of a Web API, or the whole Web API ecosystem over a period of time. The benefits from having temporal information can be illustrated with the SPARQL query from Listing 2.
The SPARQL query in the listing gives information about the total number of mashups which utilized the Google Maps API in 2013. Figure 2 visualizes the results of the analysis for three popular APIs and their utilization over a period of time.
The Web API provider might be also interested to find out in what kind of mashups their API was used. An answer to such a question can be answered with the SPARQL query in Listing 3.
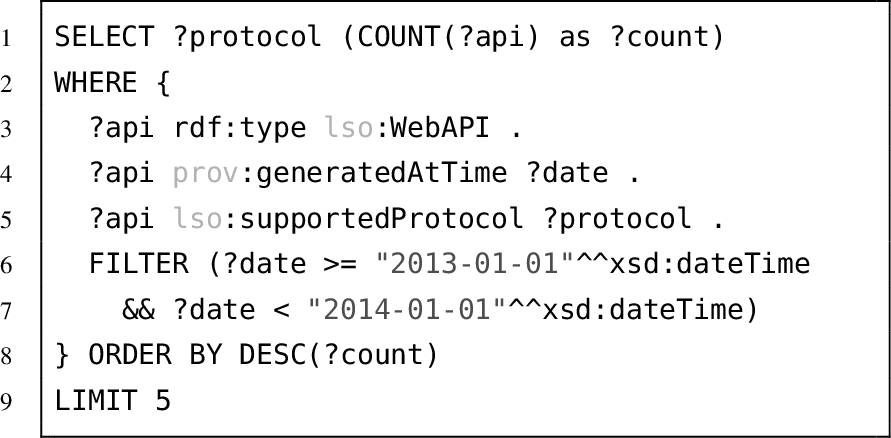
Further, a Web API analyst might be interested in the latest trends in the API ecosystem. Questions such as “What protocols and formats are supported the most by the APIs?” or “Which domains provided the most APIs in 2013?” are likely to occur. Using the SPARQL query in Listing 4 we can get the top 5 most popular protocols in 2013, which is also illustrated in Fig. 3 for the two most used protocols REST and SOAP, for a period of ten years.

The number of mashup categories the Google Maps API was used.
The most popular API protocols in 2013.
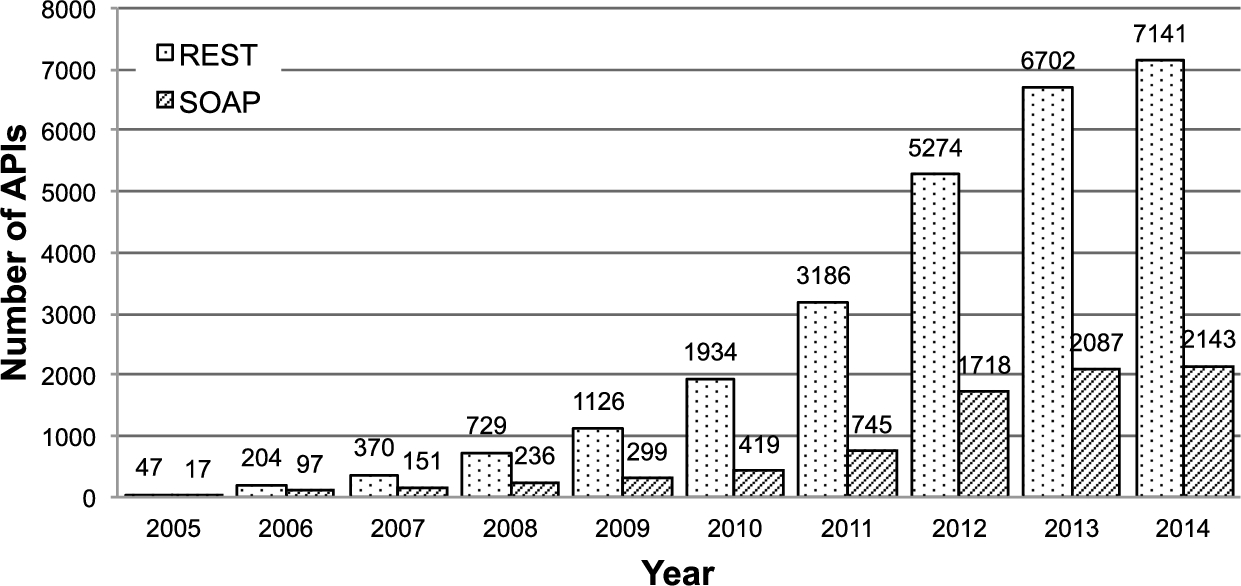
Popularity of REST and SOAP protocols over time.
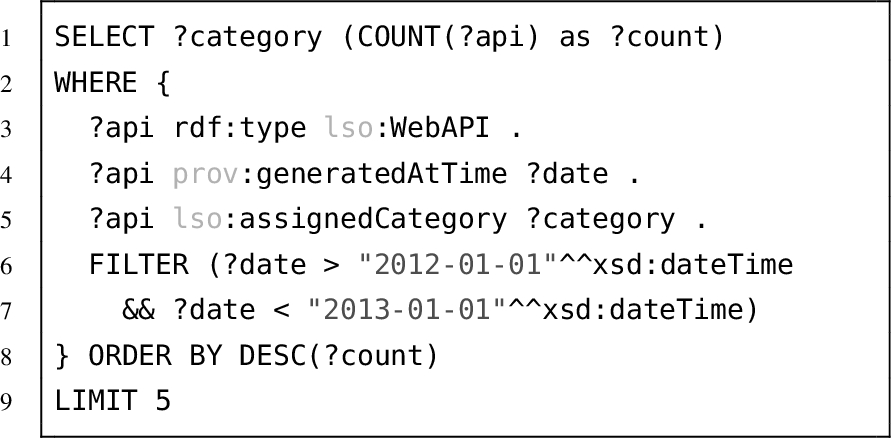
An answer to the question “Which domains provided most APIs in 2013?” can be answered with the SPARQL query in Listing 5.
The results show that the most popular API category is “tools”, followed by the “science”, “internet”, “enterprise” and “financial” categories. It is interesting that the “financial” and the “enterprise” categories are among the top five most popular API categories, which indicates that APIs are already understood as a relevant technology also by other domains than the internet and the social networks.
A more in-depth analysis using the Linked Web APIs dataset has been conducted in [8]. In particular, the dataset has been used as a reference dataset for link discovery in RDF graphs.
The most popular API categories in 2013.
In order to evaluate the potential and the usefulness of the dataset we have executed a survey. The survey targeted people who consume, develop and/or provide Web APIs. In the survey participated 29 people and all of the participants stated that they have searched or used an API, while 19 stated that they also provide an API. The results from the survey show that most of the developers have difficulties while searching an API – 3.4% find it very hard, 41.4% hard, and 27.6% somewhat hard. In addition, the majority of the participants welcome a central API repository – 34.5% find it very helpful, 37.9% helpful, 20.7% somewhat helpful, and 6.9% little helpful. In the survey, we have asked the participants to indicate the usefulness of the Linked Web APIs dataset from the perspective of a Web API consumer and provider. The results (cf. Fig. 4) show that both, the consumers and the providers find the dataset useful. The results also show that the dataset appears to be more useful for the API consumers than for the API providers.

Usefulness of the dataset as seen by the consumers (left) and providers (right).
From six participants who indicated that they have used ProgrammableWeb to search for an API, two indicated that they find the dataset very useful, two useful and two somewhat useful.
We further break down the results on the usefulness of the dataset from perspective of users that search for APIs (i) by using search engines such as Google, (ii) running keyword-based search in service directories such as ProgrammableWeb, or (iii) by asking other developers for an advice. The results are as follows:
Using search engines such as Google (27 users); 18% very useful, 54% useful and 28% somewhat useful.
Running keyword-based search in service directories such as ProgrammableWeb (6 users); 33% for very useful, useful and somewhat useful.
Asking other developers for an advice (21 users); 19% very useful, 48% useful and 33% somewhat useful.
Further, in order to evaluate new potential third-party uses of the dataset, we have also asked the participants if they will consider using the dataset in the near future (cf. Fig. 5). As shown in Fig. 5, consumers have shown more interest in using the dataset than the providers.
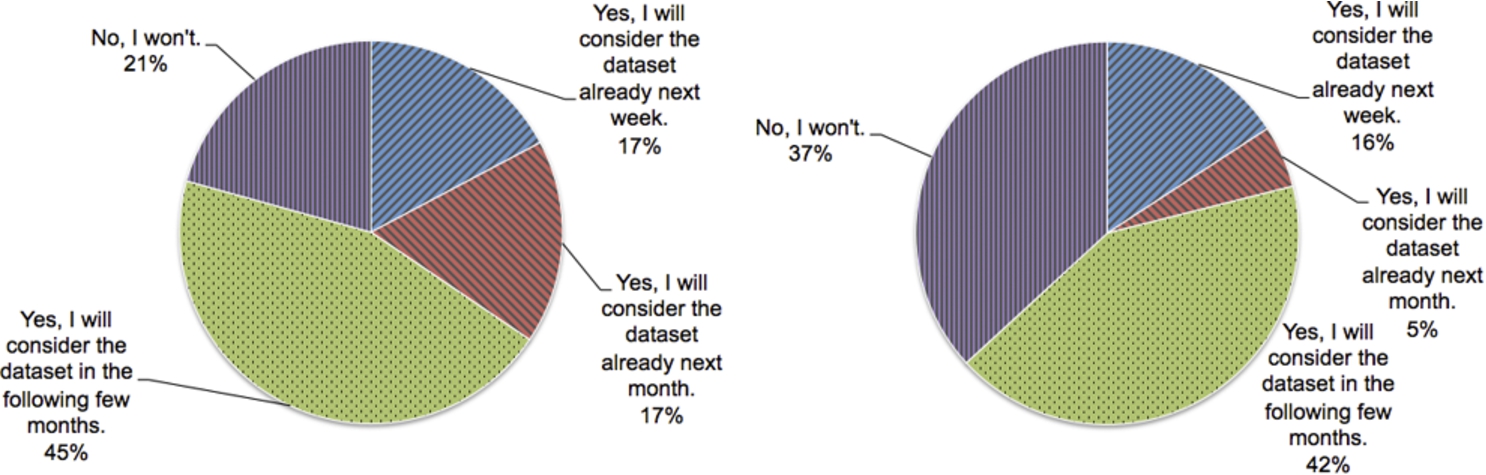
Will consumers (left) and providers (right) consider the dataset in the near future.
Finally, in the survey we have evaluated the usefulness of the dataset on several use cases. The results are as follows:
86% – Find and select relevant APIs.
86% – Increase the visibility of the APIs.
62% – Evaluate the recent trends in the API ecosystem.
59% – Compare APIs to others.
52% – Automated composition of Web APIs.
38% – Track the popularity of the Web APIs.
It can be observed that our goals for the dataset are well aligned with the possible use cases, as seen by the Web API consumers and providers. The results from the survey are also available online.20
Results from the survey:
In overall, the results from the survey confirm the usefulness and the potential of the Linked Web APIs dataset.
Relation to existing ontologies
There are several proposals on machine readable descriptions for Web services. hRESTS [7], SADI [10], WSMO-lite [9], Hydra21
Moreover, there are also non-Semantic Web standards such as WADL23
In our future work, we also plan to integrate ontologies such as the SPARQL Service Description26
Currently, the Linked Web APIs dataset is populated with data from the ProgrammableWeb.com repository. Nevertheless, our ultimate goal is to establish the Linked Web APIs as a central Linked Data hub for Web API descriptions. In order to achieve this goal, we are currently working on enriching the dataset with API descriptions from other data sources. Integration of the API repository APIs.io as part of the Linked Web APIs dataset is a currently ongoing effort. The repository provides over 1,000 API descriptions in the APIs.json30
We also plan to enrich the dataset with user profiles from traditional social networks. We want to interlink the tags and categories information with relevant datasets from the LOD cloud such as the Wikidata,32
The growing number of available Web APIs requires new mechanisms to support the process of sharing, discovery, integration and re-use of Web APIs at a large scale. In this paper, we have presented the Linked Web APIs dataset, the first Linked Data dataset which provides Web API descriptions. The dataset supports (i) API consumers – in the process of discovery, selection and use of Web APIs, (ii) API providers – in increasing the visibility and tracking the popularity of their Web APIs, and (iii) API analysts – in analyzing the API ecosystem. The dataset will also help to raise the awareness about the importance of providing semantic Web API descriptions and publishing them as Linked Data. The dataset has been validated in several recent works [4,5,8] in the context of personalized recommendations and link analysis. Also, on a set of usage scenarios we have shown the potential of the dataset.