
Abstract
Many museums are currently providing online access to their collections. The state of the art research in the last decade shows that it is beneficial for institutions to provide their datasets as Linked Data in order to achieve easy cross-referencing, interlinking and integration. In this paper, we present the Rijksmuseum linked dataset (accessible at
Introduction
Publishing cultural heritage collections as Linked Data improves reusability of the data and allows for easier integration with other data sources [1,13]. Concepts providing context for collection items are often shared among multiple cultural heritage organisations, which is an ideal basis for creating connections between collections and allowing reuse of information [6,9]. The availability of data models tailored towards publishing cultural heritage data helps to make the data available in an interoperable way [3,4]. These benefits have become apparent to the sector, resulting in an increase of attention and the development of methodologies to help institutions overcome the hurdles involved in publishing data according to the Linked Data principles [1,13,16].
The Linked Data version of the Rijksmuseum collection has some unique features. The data is a result of a joint effort between the museum, CWI and VU University Amsterdam and has evolved with input from many research projects [12,15,17]. Nowadays, employees of the museum are in control of the publishing process, creating and maintaining a conversion layer from collection management system to Linked Data. The museum’s digitisation process includes the use of external datasets for adding contextual concepts (e.g. creator or technique), creating manually curated links towards external datasets [8]. The data is continuously extended: every day new objects and descriptions are added and both metadata and images are released under open licenses when possible.
This paper describes the current state of the Rijksmuseum Linked Data and provides insights into the lessons learned during its creation. In the next section, we describe the characteristics of the Rijksmuseum collection and its digitisation process. The historical development of the dataset is given in Section 3 and the conversion approach in Section 4. Sections 5 and 6 provide details on the data model and the number of digital objects currently available. In Section 7 we give an overview of the links from collection objects to external data sources. In Section 8 we illustrate uses of the data, before we conclude in Section 9 with a discussion.
The Rijksmuseum in a digital age
The Rijksmuseum Amsterdam is one of the most visited museums in the Netherlands, with a mission to provide a representational overview of Dutch art from the Middle Ages onwards. It is well known for its Golden Age paintings, including artworks by Rembrandt and Vermeer. The collection comprises over a million objects, of which only a fraction can be on display at a given time. To open up the remaining collection the museum started digitising objects and publishing them online.
Digitising large collections is a time consuming and costly endeavour. To address the backlog of items to be digitised, the Rijksmuseum started a dedicated digitisation project, employing cataloguers and a professional photographer. The cataloguers register objects in the collection management system and describe the objects, using structured vocabularies if available [8]. The photographer takes high-quality images which are released under a public domain license when possible, waiving the rights of the museum.
The digitised collection items are accessible through the website of the museum. Online visitors can explore the collection using categories or they can search for specific keywords. The presentation of the website focusses on high-quality images of collection objects, encouraging users to save, manipulate, and share them [7]. Developers can use an Application Programming Interface (API) to get access to information about the collection objects, sub-collections created by users, and event information.1
The Linked Data version of the Rijksmuseum dataset has a long history, influenced by a number of research projects. A first Resource Description Framework (RDF) version comprising 750 top pieces was created by converting a datadump from an educational database [5]. As a next step, in an effort to integrate Dutch cultural heritage collections, the datamodel was changed to follow the VRA Core specification,2
In a next version, contextual concepts from in-house thesauri of the Rijksmuseum were aligned with the Getty thesauri and WordNet, resulting in a dataset of 27,993 triples [12]. At the time, the Getty vocabularies were only available under license and in XML format, which resulted in the need for an internally maintained conversion to RDF. In a similar effort, the vocabulary Iconclass was converted and aligned using the Simple Knowledge Organization System (SKOS) to formalise its structure [6]. The experiences gained served as input for the SKOS specification.
The Rijksmuseum dataset was one of the first entries in the Europeana Thought Lab,4
The Europeana Data Model today has a set of core and contextual classes that can capture collection information. The data model is designed with reuse of existing classes and properties in mind. It includes elements from the Dublin Core metadata initiative and the Object Reuse and Exchange definition of the Open Archives Initiative.5
To create Linked Data, a conversion needs to take place from the data contained in the collection management system into RDF. As of March 2016, the collection management system includes 597,193 registered objects which can be described using 597 available fields. Multiple steps are taken to select and convert a subset of fields and objects, which we will describe in the remainder of this section.
Data from the collection management is harvested daily and loaded into a database which serves the website. Not all of the 597 available metadata fields are included in the output of the collection management system, a subset of 245 fields is specified in a dedicated file.6
On top of the database runs an API, which is used for outputting RDF. Not all of the 597,193 registered collection objects are included in the output, a subset is selected based on copyright statements and the ownership of the object. This results in a set of 351,814 objects which are under management of the museum and are free of rights. Whether a collection object is under management of the museum is loosely defined, it includes objects owned by the museum, the state and the city of Amsterdam, but also objects which are on permanent loan. Objects which are on loan for a period shorter than six months are not considered.
Selected collection objects are converted into RDF with a second XSLT file.8
For some fields only textual values are available, others are described using contextual concepts. These concepts are manually added in the collection management system by employees documenting the collection objects. Employees can select concepts from a combination of Rijksmuseum thesauri and external datasets and all concepts have a unique identifier. If for selected fields such an identifier is encountered during the conversion, a reference to the resource is added as well as text in the form of the label of the resource.
The output of the API is used to obtain a complete harvest of the data, which is in turn loaded into a graph database, also known as a triple store. These harvests are run on a monthly basis by an employee of the museum, who updates the triple store by loading the latest version and who provides links to downloads of older datadumps, which are versioned according to the year and month they were obtained. The file
The Linked Data version of the Rijksmuseum collection is modelled according to the Europeana Data Model (EDM). EDM reuses elements from existing models such as Dublin Core. The structure of the model is expressed with RDF Schema, using constructs like subclass and subproperty relations. The Web Ontology Language is used to relate EDM elements to other data models.
The data model makes a distinction between a collection item and its digital representation(s). This is achieved with three core classes: edm:ProvidedCHO for cultural heritage objects, edm:WebResource for web resources and ore:Aggregation for aggregations of resources. Figure 1 shows the metadata of a Rembrandt painting and its core and contextual classes.

Example of the painting “Jeremiah Lamenting the Destruction of Jerusalem” modelled according to the EDM data model.
An ore:Aggregation is used to connect the metadata of a cultural heritage object to web resources. Every collection item in the collection management system gets an aggregation object with its persistent identifier as URI. Information can be added to the ore:Aggregation, Fig. 1 for example shows that the Rijksmuseum served as data provider.
Every ore:Aggregation is connected to a resource with class edm:ProvidedCHO, representing a description of the physical cultural heritage object. Figure 1 shows four of the properties used to describe objects in the Rijksmuseum dataset: dc:creator, dc:title, dc:format and dc:subject. When possible, concepts are used to describe aspects of the artwork, such as the thesaurus term purl:PEOPLE.5706 for Rembrandt and the concept aat:300015050 for oil paint. Section 6 lists the occurrences of predicates used to describe objects in the Rijksmuseum dataset.
When a digital representation is available, the aggregation points to the URL were the image can be obtained. This URL is of type edm:WebResource and can in turn be described with metadata, adding for example information about its creator. Note that the creator of the image most often differs from the creator of the artwork. The Rijksmuseum dataset currently includes information about the date of creation and the file format of the image.
Not all subtleties of the collection data can be captured by using constructs included in the Europeana Data Model description. While the original data includes detailed information about creator roles and fields like ‘rejected creator’, no such properties exist in Dublin Core. EDM allows for refining and extending the data model, so in the future the museum can choose to introduce its own more specific constructs or find others to reuse. This could increase the coverage of data in the collection management system included in the Linked Data version.
Overview of the predicates that describe collection items
Persistent identifiers in the form of handles9
As of March 2016 the Linked Data version of the Rijksmuseum collection11
Table 1 lists the predicates used to describe collection items. A title is provided for almost all artworks, of which the majority is unique. Although most of the titles are in Dutch, some of them are also available in English. Over half of the objects have the predicate dc:description, which includes textual information about the subject matter and art-historical background of the object. For example, the description of Fig. 1 includes the following text: “Downcast, the biblical prophet Jeremiah leans his tired head on his hand” and “Rembrandt used powerful contrasts of light and shadow to heighten the drama of the scene”.
There are over thirty thousand unique creators, which are mostly described using resources from the person database of the museum. Half of the dc:creator literals are based on labels from resources in the person database, while the other half is used for adding nuances to the creator field which are difficult to capture in an resource of type edm:Agent. This includes textual descriptions such as “Anonymous”, “possibly Rembrandt” and “follower of Rembrandt”. The predicate dc:contributor refers to names of additional persons involved in the creation process.
The dc:subject predicate provides information about the subject matter, where resources from both the Iconclass vocabulary as well as the Rijksmuseum thesaurus are used. Subjects are also described using Dutch literals, since not all subject matter falls within the scope of the available vocabularies. The predicate dcterms:spatial refers to places, for which both terms from the thesaurus as well as language agnostic literals are used.
The museum describes temporal aspects using the predicates dc:coverage for periods and dcterms:created for creation dates. Dutch as well as English literals are used for both predicates, where creation dates are expressed using a year or estimated years (e.g. “1630” or “c.1600–c.1625”) and periods are expressed using textual descriptions (e.g. “second quarter 17th century” or “18th century”).
The predicate dc:type uses a mixture of concepts from the Art & Architecture thesaurus, the museum’s thesaurus and literals to idenfity the type of artwork (e.g. print or painting). The same applies to dc:format, which is used to specify materials such as the resource aat:300015050, which stands for “oil paint”. In the next section we describe in more detail how many of such connections are made to external datasets. Physical dimensions of the work are recorded using dcterms:extent, specifying the height and width of objects in centimeters. The painting in Fig. 1 has for example “height 58 cm” and “width 46 cm”.
Objects can be connected to each other with the dcterms:hasPart and dcterms:isPartOf predicates. These relations are for example used to link photographs to their album. Related sources (often books) are linked to the object using dcterms:isReferencedBy. These three predicates currently refer to literals representing identifiers, which in a later stage can be converted to resources matching the objects indicated by the identifiers. Every object has two identifiers, one for internal use (e.g. “SK-A-3276”) and one persistent identifier in the form of a handle (e.g. “hndl:RM0001.COLLECT.5242”).
The predicate dc:provenance encodes the provenance in a literal enumerating the present and past owners of the artwork. Most of the intellectual property rights are part of the public domain, while sometimes specific persons are specified who own the copyrights. Europeana requires some values to be present and limited to a set range. The publisher is alway the “Rijksmuseum”, while dc:language is the language code of the country of the institution, in this case “nl”. The edm:type is “IMAGE”.
As outlined in Section 4, some of the literals are based on the labels of resources. Although adding both the literal and resource introduces redundant information, this can support applications that do not handle the added complexity of resources well. The literals from dc:type, dc:format and dcterms:spatial all directly originate from the museum’s thesaurus. 77 percent of the literals of the dc:subject field come from either resources contained in thesaurus or the person database. The remainder of the subject literal values mainly describe specific dates and periods such as “1701–1703”. We describe the resources contained in the thesauri and links to external datasets in the next section.
Institutions often maintain their own vocabularies containing their perspective on contextual concepts. When the contextual concepts of collection items are replaced with objects from standardised vocabularies such as the Getty vocabularies, these nuances in perspectives are in danger of disappearing. So while collection objects and contextual concepts in the thesauri of the Rijksmuseum are linked to an increasing number of available datasets maintained by other institutions, the Rijksmuseum chooses to also maintain and use its own. This allows the museum to preserve its own perspective and in a later stage vocabulary alignment tools can be used to match the concepts with similar concepts in external datasets [14].
Types in the Rijksmuseum thesaurus with more than 500 values
Types in the Rijksmuseum thesaurus with more than 500 values
Five contextual classes are defined in the Europeana Data Model for relating collection items to contextual information: edm:Agent, edm:Place, edm:TimeSpan, and skos:Concept. These classes correspond to the types of thesaurus records in the databases of the Rijksmuseum: the person database maps to the agent class and the general thesaurus database contains information about places, historical events, and other concepts. However, the type of concepts in the museum’s thesaurus are divided into finer grained types. An overview of the type of terms is presented in Table 2 along with the number of available resources and labels.
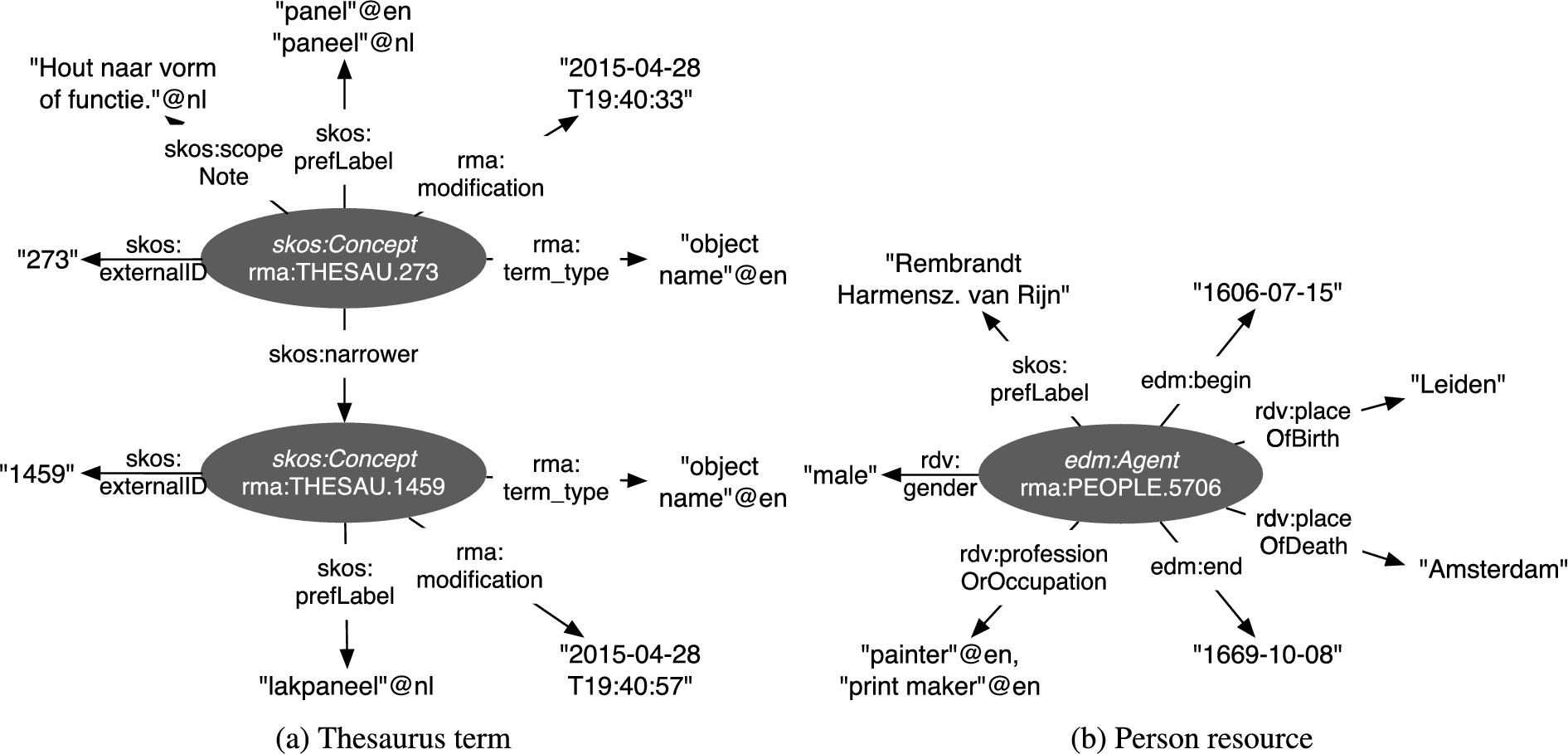
Diagrams of contextual concepts representing “panel” thesaurus terms and the person “Rembrandt”.
The thesaurus forms a hierarchy of terms using relations such as broader and narrower, which are represented using SKOS. Figure 2(a) shows two object terms, where the type of term is indicated using the rma:term_type predicate. All of the 33,800 concepts in the thesaurus have a Dutch label, only 1,539 have an English label. For 3,254 terms a skos:scopeNote is available, describing the appropriate use of the term. Every term has its own unique skos:externalID and the last modification date of the term is recorded using rma:modification.
The person database contains concepts of type edm:Agent, Fig. 2(b) shows “Rembrandt” as an example. The names of persons are indicated using skos:prefLabel and every person has a name, either represented as a Dutch, English, or language independent literal. Additional information about persons is added using the Resource Description and Access (RDA)13
The Art & Architecture Thesaurus14
The Rijksmuseum uses the Art & Architecture Thesaurus for the dc:type and dc:format metadata fields. A small subset of the available concepts is used: 305 distinct formats and 124 distinct types. As can be seen in the type frequency distribution in Fig. 3(a), a small number of concepts is often used. This is also the case for the format field. For example, the top three types are prints (183,916), stereoscopic photographs (3,480) and plates (1,617). The museum refrains from assigning art styles to objects, since it is often debatable to which art style an object belongs.
The Iconclass vocabulary15
The museum uses the Iconclass vocabulary to describe subject matter. Iconclass codes are added by cataloguers during the registration process described in Section 2. Out of the 39,578 concepts in the vocabulary, 10,434 are used to add information to an object. Of the 351,814 collection objects, 172,059 have one or more Iconclass annotations. As Fig. 3(b) shows, many of the concepts are often used, while on average a code is used 27 times.
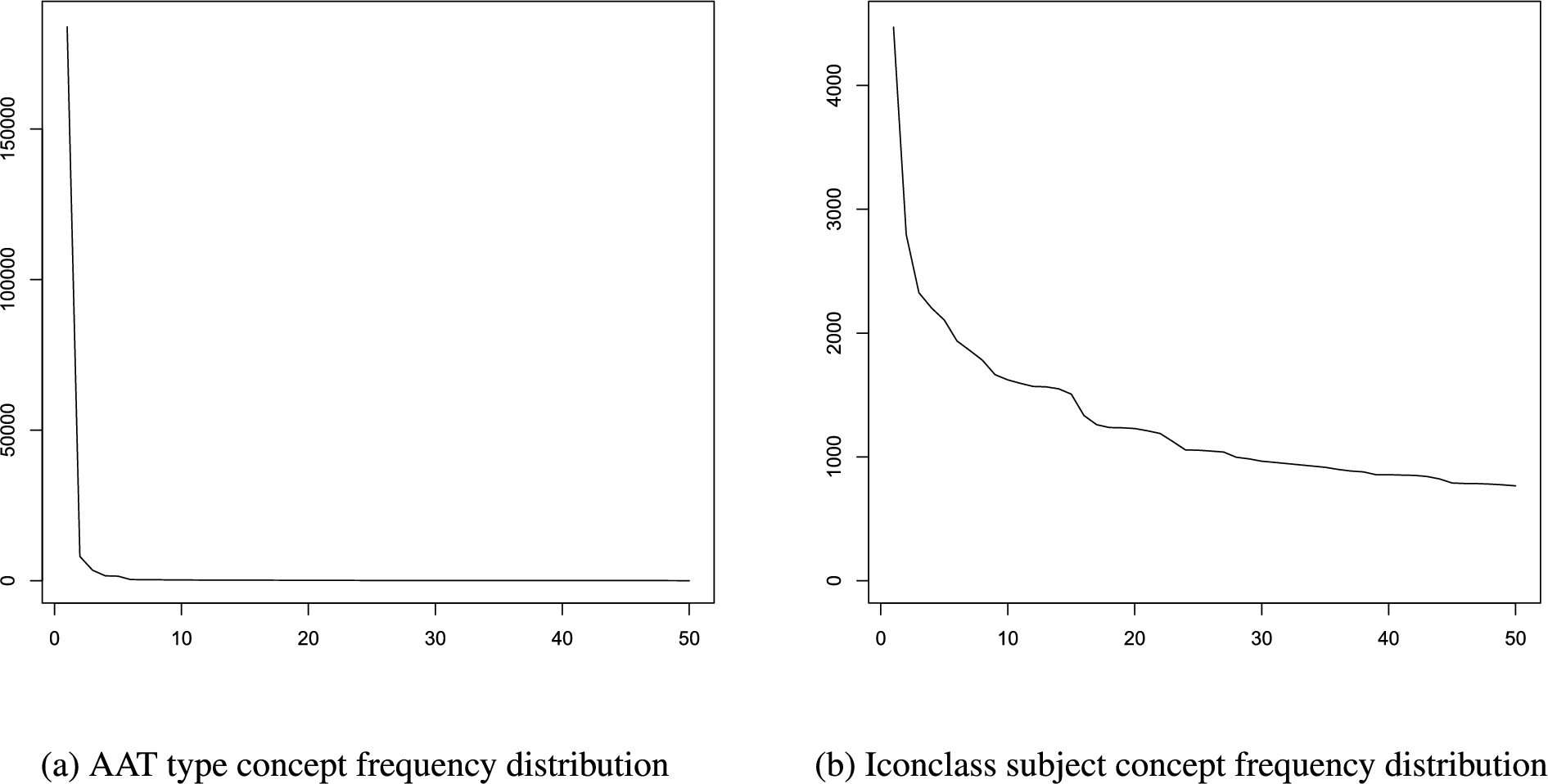
Frequency distributions of the top 50 concepts of AAT and Iconclass that the collection objects are linked to.
The Short-Title catalogue Netherlands (STCN) is ‘the retrospective national bibliography of the Netherlands in the period 1540–1800’,16
http://www.kb.nl/expertise/voor-bibliotheken/short-title-catalogue-netherlands (accessed on 04-07-2014).
The cataloguers of the Rijksmuseum add references to the National Library by adding textual descriptions of the books in a notes field. To create links these descriptions are scanned for objects from the STCN that match the title, publication date and publisher. This automated matching process resulted in 3,598 links from the Rijksmuseum collection to 501 publications in the STCN catalogue. The links are encoded as dc:hasPart relations from the STCN vocabulary to the Rijksmuseum collection. Cataloguers estimate that roughly 14,000 works can potentially be linked to STCN. A more rigorous way of referring to STCN titles is in the making to support this.
Uses of the Linked Data of the Rijksmuseum include search, recommendation, collection integration and browsing. In this section we give an overview of how the museum data has been used in various research projects and provide statistics about the Rijksmuseum API. Most projects that contributed to the process of data development had demonstrators illustrating the power of Linked Data. The MultimediaN E-Culture project showcased a semantic search system, which won the 1st price in the 2006 International Semantic Web Conference Challenge [12]. It clustered search results based on the graph path leading from matching literal to artwork. The dataset was extended from 750 artworks to the entire Rijksmuseum collection in a search prototype of the Europeana Thought Lab (see footnote 4), showing advanced search functionality to be included in the portal at a later stage.
Other ways of accessing data were introduced in subsequent years. The CHIP demonstrator recommended artworks based on graph patterns [17]. The STITCH project took a different approach with facets based on Iconclass concepts, allowing the user to browse the collection based on different topics [6]. The Agora demo provided access to the collection with an emphasis on the events related to objects [15]. The Accurator crowdsourcing tool of the SEALINCMedia project uses graph patterns to recommend people artworks to which they can contribute information, gathering more accurate subject matter descriptions [2].
The Rijksmuseum maintains an API (see footnote 1) for application developers, optionally returning data formatted according to the Europeana Data Model. 587 people have registered for access to the API as of August 2015 and many different applications have been build on top of it.17
For decades, Linked Data has been a promise for data publication and integration in the cultural heritage sector. Despite widespread interest and apparent advantages, only a limited number of institutions have managed to make their collection available as Linked Data.18
As of March 2016
The majority of the Rijksmuseum collection items are part of the public domain since their intellectual property rights have expired. Although general understanding is that digitised representations of public domain works should again be released under the same license terms, many institutions are hesitant to do so, in fear of losing a possible revenue stream. The Rijksmuseum did release their high-quality images in the public domain in 2013, arguing that the increase in attention and exposure would result in a higher number of visitors [11]. In turn it allowed the museum to gain more control over the digital representations that had appeared online, replacing many inferior versions by its high-quality images.
The quality and correctness of metadata is of paramount importance to museums [13]. The Rijksmuseum has an extensive quality control process in place to ensure the correctness of metadata. By adding a direct conversion layer to the collection management system it ensures that the same level of quality is translated to the Linked Data version. All the criteria for five star Linked Data as defined in [10] are met. There is a description of the data online,19
Data aggregators such as Europeana enticed many institutions to provide digital versions of their collection, often relying on external expertise for the conversion process. This led to an increase of available collections, although providing access to data through aggregators has the major drawback that it creates a gap between the institution and its data [1]. We believe it is therefore still desirable that institutions publish their own data, if the required expertise is available. They thereby remain in control of choosing the most suitable data model, URI naming schemes, links to other datasets, and update processes.
The data of the Rijksmuseum is subject to constant change: newly digitised objects are added on a daily basis and employees extend and refine information regularly. The Linked Data version places the artworks in a broader context, allowing others to benefit from the progress made through easy reuse and the possibility to add new perspectives to the data.
Footnotes
Acknowledgement
This publication was supported by the Dutch national program COMMIT/.