
Abstract
The objective of this paper is to investigate the scope of OWL-DL ontologies in generating multiple choice questions (MCQs) that can be employed for conducting large scale assessments, and to conduct a detailed study on the effectiveness of the generated assessment items, using principles in the Item Response Theory (IRT).
The details of a prototype system called Automatic Test Generation (ATG) system and its extended version called Extended-ATG system are elaborated. The ATG system (the initial system) was useful in generating multiple choice question-sets of required sizes from a given formal ontology. It works by employing a set of heuristics for selecting only those questions which are required for conducting a domain related assessment. We enhance this system with new features such as finding the difficulty values of generated MCQs and controlling the overall difficulty-level of question-sets, to form Extended-ATG system (the new system). This paper discusses the novel methods adopted to address these new features. That is, a method to determine the difficulty-level of a question-stem and an algorithm to control the difficulty of a question-set. While the ATG system uses at most two predicates for generating the stems of MCQs, the E-ATG system has no such limitations and employs several interesting predicate based patterns for stem generation. These predicate patterns are obtained from a detailed empirical study of large real-world question-sets. In addition, the new system also incorporates a specific non-pattern based approach which makes use of aggregation-like operations, to generate questions that involve superlatives (e.g., highest mountain, largest river etc.).
We studied the feasibility and usefulness of the proposed methods by generating MCQs from several ontologies available online. The effectiveness of the suggested question selection heuristics is studied by comparing the resulting questions with those questions which were prepared by domain experts. It is found that the difficulty-scores of questions computed by the proposed system are highly correlated with their actual difficulty-scores determined with the help of IRT applied to data from classroom experiments.
Our results show that the E-ATG system can generate domain specific question-sets which are close to the human generated ones (in terms of their semantic similarity). Also, the system can be potentially used for controlling the overall difficulty-level of the automatically generated question-sets for achieving specific pedagogical goals. However, our next challenge is to conduct a large-scale experiment under real-world conditions to study the psychometric characteristics (such as reliability and validity) of the automatically generated question items.
Keywords
Introduction
Web Ontology Language (OWL) ontologies are knowledge representation structures that are designed to represent rich and complex knowledge about things, groups of things, and relations between things [25,26]. These ontologies have widely flourished in recent years due to the advancement of Semantic Web technologies and due to the ease of publishing knowledge in online repositories. The use of knowledge captured in these ontologies, by e-learning systems, to improve learning and teaching process in a particular domain, is an advancing area of research.
Assessment test (or question-set) authoring modules are the first to be implemented and currently the most accepted component in e-learning systems [10,11]. Majority of the existing e-learning systems (such as Moodle1
The problem of automated generation of assessment tests has recently attracted notable attention among computer science researchers as well as among educational communities [17]. This is particularly due to its importance in the emerging education styles; for instance, the MOOCs (Massive Open Online Courses) administrators need to conduct multiple choice quizzes at regular intervals, to evaluate the mastery of their students [8,34].
One possible solution for this problem is to incorporate an intelligent module in the e-learning system which can generate possible domain related question items from a given knowledge source. Knowledge sources like ontologies are of great use here, since they can represent the knowledge of a domain in the form of logical axioms. But, having a question generation module does not fully resolve the underlying problem. There should be effective mechanisms for selecting those questions which are apt for conducting an assessment test. In a pedagogical environment, an e-learning system should be intelligent enough to serve various assessment goals. For example, the system should be able to handle the scenarios like selecting the top ten students who are having high domain knowledge proficiency, using a question-set with limited number of questions, say 20 or 25. To tackle such common scenarios, an e-learning system should be able to predetermine the difficulty-levels of the question items which they generate. Also, there should be provisions for controlling both count of questions in the final question-set and its overall difficulty-level. Therefore, the objectives of this work are:
to describe a question-set generation system which can address the aforementioned scenario, based on our prior work;
to develop this new system, by extending the existing system with several new functionalities such as finding the difficulty-level of the generated question items;
to evaluate the implemented system, by testing it against several ontologies and by making use of various principles in the Item Response Theory (IRT).
The specific motive driving our research was to study the effectiveness of Web Ontology Language (OWL) ontologies in generating question-sets which can be employed for conducting large-scale multiple choice questions (MCQs) based assessments. The initial study was done by implementing a prototype system called Automatic Test Generation (ATG) system. The details of the study are given in [39].
There are several works in the literature, which describe the usefulness of OWL ontologies in generating MCQs [2,5,15,36,45]. Studies in [3] have shown that ontologies are good for generating factual (or knowledge-level) MCQs. These knowledge-level questions help in testing the first level of Bloom’s taxonomy [18], a taxonomy of educational objectives for a cognitive domain. Throughout this paper, we use the term “MCQ” for “factual-MCQ”.
Recently, publications such as [1,3,39], show that MCQs can be generated from assertional facts (ABox axioms) that are associated with an ontology. We can categorize the approaches that use ABox axioms to generate MCQs into two types: 1) Pattern-based factual question generation and 2) Non-Pattern-based factual question generation. (We termed the second approach as “Ontology-specific question generation approach” in our earlier work, but later determined that “Non-Pattern-based approach” would be the appropriate term for it.) In our earlier work [39], we focused mainly on the first approach and did not explore the second approach fully. That is, we introduced a systematic method for generating Pattern-based MCQs, where we considered predicate (or property) patterns associated with individuals in an ontology, for generating MCQ stems. We have also incorporated a heuristics based question (or tuple) selection module (Module-2) in the ATG system, for selecting only those questions which are ideal for conducting a domain-specific assessment; a detailed summary of this module in given in Section 6.
In this work, we will first do a detailed study of the Pattern-based question generation approach and then explore a sub-category of Non-Pattern-based questions called Aggregation-based questions, and its generation technique.

The figure shows the workflow of the ATG system. The two inputs to the system are: a domain ontology and the question-set size.

The figure shows the workflow of the Extended-ATG system. The inputs to the system are: (1) a domain ontology (an OWL ontology), (2) size of the question-set to be generated and, (3) its difficulty-level.
Figure 1 shows the overview of the workflow of the ATG system, where the system takes two inputs: a domain ontology (an OWL ontology) and the size of the question-set to be generated, and it produces a question-set of size approximately equal to the required size. In this system, the count of the questions to be generated is controlled by varying the parameters associated with the heuristics in Module-2.
This paper mainly features the new modules that are introduced in the extended version of the ATG system (called Extended-ATG or simply E-ATG system), and their significance in generating question-sets which are useful for educational purposes. The E-ATG system is an augmented version of the ATG system, with added features such as determining and controlling the difficulty values (or difficulty-scores) of MCQs and controlling the overall difficulty-level of question-sets. An overview of the workflow of E-ATG is given in Fig. 2. In addition to the three modules of the ATG system, the E-ATG system has three additional modules.
Considering the approaches which we followed for building these three modules, the main contributions of this paper can be listed as follows:
A detailed study of Pattern-based MCQs, using patterns that involve more than two predicates, leading to an extended submodule for Pattern-based stem generation.
A generic (ontology independent) technique to generate Aggregation-based MCQs, resulting in a submodule for Aggregation-based stem generation.
A novel method to determine the difficulty of a generated MCQ stem, which give rise to a module for difficulty estimation of stem. An evaluation based on a psychometric model (from the IRT) is done to find the efficacy of the proposed difficulty value calculation method.
An algorithmic way to control the overall difficulty-level of a question-set, leading to a module for question-set generation and controlling its difficulty-level.
Considering the large scope of the work, to set the context for explaining the various aspects of the work, an overview of the aforementioned contributions are given in Section 3.
In this paper, we use examples from two well-known domains – Movies and U.S geography – for illustrating our approaches. In addition to the Geography ontology (U.S geography domain), we use Data Structures & Algorithms (DSA) ontology and Mahabharata ontology for the evaluation of the approaches. Three appendices are provided at the end of the paper. Appendix A gives an explanation about the psychometric model which we have adopted in our empirical study. A sample set of system-generated MCQ stems (from DSA ontology) that are used in the empirical study is listed in Appendix B. Appendix C shows the notations and abbreviations that are used in this paper.
Multiple Choice Questions (MCQs)
An MCQ is a tool that can be used to evaluate whether (or not) a student has attained a certain learning objective. It consists of the following parts:
Note: In this paper, we assume K as a singleton set, and we fix the value of m, the number of options, in our experiments as 4.
Pattern-based MCQs
Pattern-based MCQs are those MCQs whose stems can be generated using simple SPARQL templates. These stems can be considered as a set of conditions which ask for an answer which is explicitly present in the ontology. Questions like Choose a C? or Which of the following is an example of C? (where C is a concept symbol), are some of the examples of such stems. Example 1 is a Pattern-based MCQ, which is framed from the following assertions that are associated with the (key) individual
Choose a Movie , which isDirectedBy alejandro and hasReleaseDate “Aug 27, 2014” .
The possible predicate3
Includes both unary predicates (concept names) and binary predicates (role names).
Signifies the number of predicates in a combination.
Table 1 shows the formation of possible predicate combinations of size two and three by adding predicates to the four combinations of size one. The repetitions in the combinations are marked with the symbol “*”. Note that, in those predicate patterns, we consider only the directionality and type of the predicates, but not their order. Therefore the combinations like
The predicate combinations of sizes 1, 2 and 3, that are useful in generation Pattern-based MCQ stems are given below, where x denotes the reference-individual, i is a related individual,
The distractors for these MCQs are selected from the set of individuals (or in some cases datatype values) of the ontology which satisfies the intersection classes of the domain or range of the predicates in the stem. This set is known as the Potential-set of the stem. Detailed explanation of distractor generation is given in Section 9.
Aggregation-based questions are those questions which cannot be directly obtained from a domain ontology using patterns alone. These questions are again knowledge-level questions (or simply questions which check the students’ factual knowledge proficiency) of Blooms taxonomy [9]. But they require more reasoning skills to answer than Pattern-based MCQs. For example, “Choose the state which is having the longest river.”, is an Aggregation-based question. (We assume that the there are no predicates in the ontology that explicitly contain the answer, that is
A detailed study of Pattern-based MCQs
An initial study on the approach for generating Pattern-based MCQs is given in [39], where questions are limited to predicate combinations of at most two predicates. As we have seen in Section 2.2, we generalized the approach to generate questions that involve more than two predicates as well. Later in Section 4, we describe a study that we have done on a large set of real-world factual-questions, obtained from different domains, to explore the pragmatic usefulness and the scope of our approach.
A technique to generate Aggregation-based MCQs
A generic technique to generate Aggregation-based MCQs (or a subset of possible Aggregation-based MCQs) is proposed in Section 5. This technique incorporates a specific non-pattern based approach which make use of operations similar to aggregation, to generate questions that involve superlatives (e.g., highest mountain, largest river etc.).
A method to determine the difficulty of MCQ stems
Similarity-based theory [7] was the only effort in the literature [8,40], which helped in determining or controlling the difficulty-score of an ontology generated MCQ. The difficulty-score calculated by similarity-based theory considers only the similarity of the distracting answers with the correct answer – high similarity implies high difficulty-score and vice versa. In many a case, the stem of an MCQ is also a deciding factor for its difficulty. For instance, the predicate combination which is used to generate a stem can be chosen such that it makes the MCQ harder or easy to answer. Also, the use of indirect addressing of instances6
Instead of using the instance “Barack_Obama”, one can use “44th president of the U.S.”
The table shows the essential question-templates for real-world FQ generation, where the circled variables in the patterns denote the key-variables. The corresponding stem-templates and potential-set formulas are also listed

In this paper, by difficulty value or difficulty-score we mean a numeric value which signifies the hardness of an MCQ and by difficulty-levels we mean the predetermined ranges of difficulty-scores, corresponding to the standard scales: high, medium and low.
In Section 8, we propose a practically adaptable algorithmic method to control the difficulty-level of a question-set. This method controls the overall difficulty-level of a question-set by varying the count of the questions which are having (relatively) high difficulty-scores in the question-set.
Other contributions
In addition to the above mentioned contributions, in Section 6, we discuss the existing heuristics for question-set generation (which we used in the ATG system), and possible modifications in these heuristics to generate question-sets which are more closer to human generated ones. We used the modified heuristics in the E-ATG system. For the completeness of the work, a section on distractor generation (Section 9) is also given, which illustrates the approach which we followed in the distraction generation module of the ATG system as well as in its extended version.
A detailed study of Pattern-based MCQs
The stem of a Pattern-based MCQ can be framed from the tuples that are generated using the basic set of 40 predicate combinations, as mentioned in Section 2.2. In the next subsection, we describe an empirical study which we have done on a large set of real-world FQs (factual-questions), to identify common FQs and their features. Based on that study, we will show how to select a subset from the basic set of 40 predicate combinations (along with the possible position of their keys) as the essential question-templates for real-world FQ generation. In the Pattern-based stem generation submodule of the E-ATG system, we make use of these essential question-templates for stem generation.
An empirical study of real-world FQs
In order to show that our approach could generate FQs which are useful in conducting any domain specific test and are similar to those questions which are contributed by human authors who are having different levels of domain proficiencies, we first analyzed 1748 FQs gathered from three different domains: the United States geography domain,7
From these question-sets, we removed invalid questions and (manually) classified the rest into Pattern-based and Non-Pattern-based questions. We manually identified 570 Pattern-based questions and 729 Non-Pattern-based questions from the question-sets. We then tried to map each of these Pattern-based questions to any of the 40 predicate combinations (given in Table 1). Interestingly, we could map each of the 570 Pattern-based questions to at least one of the predicate combinations. This demonstrates the fact that our patterns are effective in extracting almost all kinds of real-world (pattern-based) questions that could be generated from a given domain ontology.
We have observed that most of the predicate combinations are not being mapped to by any real-world Pattern-based questions. Out of 40 combinations only 13 are found to be necessary to generate such real-world questions. We call those predicate combinations as the essential predicate combinations, for real-word FQ generation.
From the 13 essential predicate combinations, we have framed 19 question patterns based on our study on the features of real-world FQs. We call these question patterns as the essential question-templates. These question-templates are obtained by identifying the variables in the essential predicate combinations whose values can be considered as keys – we call such variables as the key-variables of the patterns. We list the identified essential question-templates in Column-2 of Table 2. The circled variables in the patterns denote the positions of their key (i.e., the key-variables). The square boxes represent the variables whose values can be removed while framing the stem. For example, the question: What is the population of the state with capital Austin? can be generated from the pattern: 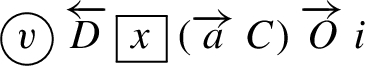 , with v as the key-variable, D as the property
, with v as the key-variable, D as the property
Suitable stem-templates11
These are sample-templates for the readers reference. Minor variation on these templates were introduced at a later stage, to improve the question quality.
Word-segmentation is done by using Python WordSegment (
We discuss the details of the Potential-sets (given in Column-4 of Table 2) corresponding to each of the question patterns in the forthcoming sections.
For the efficient retrieval of data from the knowledge base, we transform each of the essential question-templates into SPARQL queries. For example, the stem-template and query corresponding to the question pattern  are:
are:
Choose a
These queries, when used to retrieve tuples from ontologies, may generate a large result set. Last column of Table 3 lists the total count of tuples that are generated using the 19 question-templates from a selected set of domain ontologies. These tuple counts represent the possible Pattern-based questions that can be generated from the respective ontologies. From the Restaurant ontology, using the query corresponding to the question pattern number 6 alone, we could generate 288594 tuples.
An MCQ based exam is mainly meant to test the wider domain knowledge with a fewer number of questions. Therefore, it is required to select a small set of significant tuples from the large result set, to create a good MCQ question-set. But, the widely adopted method of random sampling can result in poor question-sets (we have verified this in our experiment section). In Section 6, we propose three heuristic based techniques to choose the most appropriate set of tuples (questions) from the large result set.
The specifications of the test ontologies and the count of the tuples that were generated using the 19 question-templates are given below
The specifications of the test ontologies and the count of the tuples that were generated using the 19 question-templates are given below
The MCQ question stems like:
Choose the Movie with the highest number of academy awards Choose the Movie with the lowest number of academy awards
which cannot be explicitly generated from the tuples that are generated using the predicate combinations, can be framed by performing operations similar to aggregation.
To generate such MCQ stems, the method which we have adopted involves three steps: grouping of the generated tuples w.r.t the properties they contain, sorting and selecting border values of the datatype properties, and including suitable adjectives (like highest or lowest) for stem enhancement. In the example MCQ stems (from the Movie ontology),
Since we are making use of datatype property values for generating Aggregation-based MCQ stems from OWL ontologies, it should be noted that, many of the XML Schema datatypes are supported by OWL-2 DL [24]. OWL-2 DL has datatypes defined for Real Numbers, Decimal Numbers, Integers, Floating-Point Numbers, Strings, Boolean Values, Binary Data, IRIs, Time Instants and XML Literals.
Question generation in detail
This section details the operations that are carried out in the Aggregation-based stem generation submodule of the E-ATG system.
To generate Aggregation-based question stems, the tuples generated using the 19 patterns (in Table 2), are grouped based on the properties they contain. We call the ordered list of properties which are useful in grouping as the property sequence (represented as
In Table 4, the highlighted rows (or tuples), which bore the border values of the datatype property, can be used for framing the Aggregation-based question stems; we call these rows as the base-tuples of the corresponding Aggregation-based questions. The datatype property names in the 1st and 3rd highlighted rows are paired with the predefined-adjectives (like maximum, highest, oldest, longest, etc.) and the pair with the highest ESA relatedness score is determined (see details in the next subsection). Then the stemmed predicate (i.e., for example, “hasPopulation” is stemmed to “Population”), the adjective and the template associated with the question pattern are used to generate stems of the following form (where the underlined words correspond to the predicates used):
Choose the
Choose the
Similarly, the predicates in the 2nd and 4th highlighted rows are paired with the adjectives like minimum, shortest, smallest, minimum, etc., to generate stems of the form:
Choose the
Choose the
The table shows the list of tuples from the Geography ontology that are grouped and are sorted based on their property sequences and datatype property values respectively. The highlighted rows denote the tuples that are chosen for generating Aggregation-based questions

The table shows the list of tuples from the Geography ontology that are grouped and are sorted based on their property sequences and datatype property values respectively. The highlighted rows denote the tuples that are chosen for generating Aggregation-based questions
Out of the large set of datatypes offered by OWL-2 DL, datatypes of Binary Data, IRIs and XML Literals are avoided for stem formation, as they are not useful in generating human-understandable stems.
Having a property in hand, to fix which quantifying adjective – highest and lowest or longest and shortest – to use, is determined by calculating pairwise relatedness score and, then, choosing the one with highest score using Explicit Semantic Analysis (ESA) [20] method. ESA method computes semantic relatedness of natural language texts with the aid of very large scale knowledge repositories (like Wikipedia). EasyESA13
The pair – (predicate, predefined-adjective) – with highest ESA relatedness score are used for framing the question. For example, as shown in Table 5, the datatype property
The ESA scores of some sample predicate–adjective pairs
The heuristics-based tuple selection module of the ATG system uses three screening heuristics which mimic the selection heuristics followed by human experts. These heuristics help in generating question-sets that are unbiased and cover the required knowledge boundaries of a domain knowledge. A summary of the three screening methods is given in the next subsection. In the E-ATG system, instead of the third heuristic, we adopted a new heuristic to achieve better results. The drawback of the third heuristic and the details of the new heuristic are explained in Sections 6.1.3 and 6.2 respectively.
Even though these heuristics were meant for Pattern-based questions, we apply the same heuristics, except the third heuristic, to Aggregation-based questions as well. This is achieved by considering the base-tuples of Aggregation-based questions.
Summary of the existing heuristics
The three heuristics introduced in [39] were:
Property based screening
Concept based screening
Similarity based screening
Interested readers can refer [39], for a detailed explanation of the rationales for using these heuristics.
Property based screening
The property based screening was mainly meant to avoid those questions which are less likely to be chosen by a domain expert for conducting a good MCQ test. This is achieved by looking at the triviality score (called Property Sequence Triviality Score, abbreviated as PSTS) of the property sequence of the tuples.
PSTS of a property sequence
Potential-set of
In the property based screening, the position of the reference-individuals (introduced in Section 2.2) is taken as r for finding the potential-set. The third column of Table 2 lists the generic formula to calculate the potential-sets for the 19 patterns. But, it should be noted that, the calculation is w.r.t. the key-variables – we later use this in Section 9.
A suitable threshold for PSTS is fixed based on the number of tuples to be filtered at this level of screening.
Concept based screening
This level of screening was mainly meant to select only those tuples which are relevant to a given domain, for MCQ generation.
The table shows the list of tuples in two locally-similar groups (Group-1 and Group-2), generated from the Movie ontology. The highlighted rows denote the representative tuples – selected based on their popularities

The table shows the list of tuples in two locally-similar groups (Group-1 and Group-2), generated from the Movie ontology. The highlighted rows denote the representative tuples – selected based on their popularities
We achieve this by looking at the reference-individual in a given tuple. If the individual satisfies any of the key-concept14
In the implementation, we used KCE API [31] to extract a required number of potentially relevant concepts (or simple key-concepts) from a given ontology.
The number of tuples to be screened in this level, is controlled by varying the count of the key concepts.
The tuple-set S, selected using the first two levels of screening, may contain (semantically) similar tuples; they will make the final question-set biased. To avoid this biasing, selecting only a representative set of tuples from among these similar set of tuples is necessary. In [39], this issue was addressed by considering an undirected graph
A dominating set for a graph
Drawback of this heuristic In our observation, selecting representative tuples based on minimum dominating set (MDS) – using an approximation algorithm16
JGraph MDS.
The tuples that are screened after two levels of filtration are grouped based on their similarity. The similarity measure from the previous subsection is reused for this grouping. In case if a tuple shows similarity to multiple groups, we place the tuple in the group to which it shows maximum similarity. Each of these groups are addressed as locally-similar groups; appropriate minimum similarity score (called minimum local-similarity threshold (denoted as
Within a locally-similar group, a popularity based score is assigned to each of the tuples. The most-popular tuple from each group is taken as the representative tuple. An illustration of the selection of representative tuples is shown in Table 6, where the highlighted tuples denote the selected ones. In the table, the third tuple and the first tuple in Group-1 and Group-2 respectively have higher popularity score than the rest of the tuples in the respective groups, making them the suitable candidates for the question-set.
Calculation of the popularity of a tuple The widely used popularity measure for a concept is based on the count of the individuals of the other concepts that are connected to the individuals of that concept [35]; we follow a similar approach to find the popularity of an individual. That is, the popularity of an individual x in an ontology
On getting the popularities of the individuals in a tuple t, we calculate the popularity of t in
A method to determine the difficulty of MCQ stems
One possible way to decide the difficulty value (or difficulty-score) of a stem is by finding how its predicate combination is making it difficult to answer. Our study on FQs which have been generated from different domain ontologies shows that, increasing the answer-space of the predicates in a stem has an effect on its difficulty value. For example, the stem “Choose a
The predicate combinations of such type can be easily identified by finding those property sequences with less triviality score; this is because, all the predicate combinations with at least one specific predicate and at least one generic predicate, will have a less PSTS. But, having a less PSTS does not always guarantee that one predicate in it is generic when compared to the other roles in the property sequence; the following condition also needs to be satisfied.
The tuples that satisfy Condition-1, can be assigned a difficulty-score based on its triviality score as shown in Eq. (2), where
A difficulty-score of 0.3 is given, since the maximum value of PSTS is 1, and the minimum possible value from Eq. (2) is 0.368.
In addition to the above method to find tuples (or questions) which are difficult to answer, the difficulty-score of a question can be further increased (or tuned) by indirectly addressing the individuals present in it. We have already illustrated this in Section 4.1. Patterns 5 b, 6, 8 b, 9 a, 10 a, 10 b, 11 a, 11 c, 12 and 13 in Table 2, where indirect addressing of the reference-individuals can be done, can be used for generating questions (or tuples) which are comparatively difficult to answer than those generated using the rest of the patterns. For such tuples, we simply double their assigned difficulty-scores, to make their difficulty-scores relatively higher than the rest of the tuples.
As we pointed out in Section 2.2.1, the Aggregation-based questions are relatively difficult to answer than the rest of the questions. Therefore, we give them a difficulty-score of thrice the value obtained using Eq. (2), by giving their base-tuples as input.
Controlling the difficulty-level of a question-set helps in posing only those set of questions which are necessary to test a learner’s skill-set. In an e-learning system’s environment, for the tasks such as controlling the student-shortlisting criteria, selection of top k students etc., question-sets of varying difficulty-levels are of great use [28].
In the E-ATG system, we adopted a simple algorithm to generate question-sets of difficulty-levels: high, medium and low. This algorithm can be further extended to generate question-sets of required difficulty-levels.



Method
The set of heuristically selected tuples (denoted as
An edge in G can be thought of as the inter-similarity (or dependency) of tuples that are taken from two locally similar groups. Ideally, we only need to include one among those dependent vertices, for generating a question-set which is not biased to a portion of the domain-knowledge. To generate an unbiased question-set which covers the relevant knowledge boundaries, we need to include all isolated vertices (tuples) and one from each of the dependent vertices. Clearly, this vertex selection process is similar to, finding the maximal independent-set of vertices from G. To recall, a maximal independent-set of a graph
In our implementation, we use the procedure
Generation of distractors
Distractors (or distracting answers) form a main component which determines the quality and difficulty-level of an MCQ item [43]. Selection of distractors for a stem is a time consuming as well as a skillful task. In the ATG system, we utilized a simple automated method for distractor generation. We have adopted the same distractor generation module in the E-ATG system. In the E-ATG system, we considered the difficulty-score of an MCQ due to its stem features alone in generating a question-set of a required difficulty-level. We used the distractor generation only as the functionality of the last stage module in the E-ATG system, where the selection of distractors is done with an intention to further tune the difficulty-level calculated by the preceding stage.
Method
Distractors are generated by subtracting the actual answers from the possible answers of the question. By actual answers, we mean those instances in the ontology which satisfy the conditions (or restrictions) given in the stem. Consider A as the set of actual answers corresponding to the stem. And, the possible answers correspond to the potential-set (see Table 2 for details) of the tuple.
The set of distractors of a tuple t with k as the key and q as the corresponding question-template is defined as:
For the Aggregation-based questions, we find the distractors in the same manner.
Evaluation
The proposed E-ATG system produces a required number of MCQ items that can be edited and used for conducting an assessment. In this section, (in Experiment-1) we first evaluate how effectively our heuristics help in generating question-sets which are close to those prepared by domain experts; secondly (in Experiment-2), we correlate the predicted difficulty-levels of the stems (obtained by the method given in Section 7) with their (actual) difficulty-levels which are estimated using Item Response Theory in a classroom set-up.
Implementation The implemented prototype of the E-ATG system has the following modules:
Module18 Generates tuples (or base-tuples) for the stem generation of both Pattern-based and Aggregation-based MCQs.
Module for selecting tuples based on proposed heuristics.
Module for finding the difficulty-score of a stem.
Module for generating a question-set with a given difficulty-level.
Module for generating the distractors.
Equipment description The following machine was used for the experiments mentioned in this paper: Intel Quad-core i5 3.00 GHz processor, 10 GB 1333 MHz DDR3 RAM, running Ubuntu 13.04.
Our objective is to evaluate how close the question-sets generated by our approach (a.k.a. Automatically generated question-sets or AG-Sets) are to the benchmark question-sets.
Datasets We considered the following ontologies for generating question-sets.
Data Structures and Algorithms (DSA) ontology: models the aspects of Data Structures and Algorithms.
Mahabharata (MAHA) ontology: models the characters of the epic story of Mahabharata.
Geography (GEO) ontology:20
https://files.ifi.uzh.ch/ddis/oldweb/ddis/research/talking-to-the-semantic-web/owl-test-data/ (last accessed 26th Jan 2016).
The specifications of these test ontologies are given in Table 3. The DSA ontology and MAHA ontology were developed by our research group – Ontology-based Research Group21
Benchmark question-set preparation As a part of our experiment, experts of the domains of interest were asked to prepare question-sets from the knowledge formalized in the respective ontologies, expressed in the English language. The experts of the domains were selected such that they were either involved in the development of the respective ontologies (as domain experts) or have a detailed understanding of the knowledge formalized in the ontology. The question-sets prepared by the domain experts are referred from now on as the benchmark question-sets (abbreviated as BM-Sets). Two to three experts were involved in each of the BM-Sets’ preparation. The BM-sets contain only those questions which are mutually agreed upon by all the experts who are considered for the specific domain.
The domain experts prepared three BM-Sets23
In the benchmark question set files in our website, initial questions are (sometimes) same. This is because, the domain experts prepared the three benchmark questions in three iterations. In the first iteration, they prepared a question-set of the smallest cardinality (25), by picking the most relevant questions (which cover the entire domain knowledge) of a domain. Further, they (mainly) augmented the same question-set with new question – in some cases, they also removed a few questions – to generate question-sets of cardinalities 50 and 75.
For each domain, the AG-Sets corresponding to the prepared BM-Sets – Set-A, Set-B and Set-C – are generated by giving the question-set sizes 25, 50 and 75 respectively as input to the E-ATG system, along with the respective ontologies.
In the screening heuristics that we discussed in Section 6, there are three parameters which help in controlling the final question count:
Question-sets of required sizes (
The cardinalities of the AG-Sets and the computational time taken for generating the question-sets are given below
The cardinalities of the AG-Sets and the computational time taken for generating the question-sets are given below
The parameters
Overall cost To find the overall computation time, we have considered the time required for the tuple generation (using 19 patterns), the time required for heuristics based question selection process and time required for controlling the difficulty-level of the question-set. The time required for the distractor generations and further tuning of the difficulty were not considered, since, we focus only on the proper selection of MCQ stems. The overall computation time taken for generating the AG-sets from each of the three test ontologies is given in Table 7.
We have used the evaluation metrics: precision and recall (as used in [39]), for comparing two question-sets. This comparison involves finding the semantic similarity of questions in one set to their counterpart in the other.
To make the comparison precise, we have converted the questions in the BM-Sets into their corresponding tuple representation. Since, AG-Sets were already available in the form of tuple-sets, the similarity measure which we used in Section 6.1.3 is adopted to find the similar tuples across the two sets. For each of the tuples in the AG-Sets, we found the most matching tuple in the BM-Sets, thereby establishing a mapping between the sets. We have considered a minimum similarity score of 0.5 (ensuring partial similarity) to count the tuples as matching ones.
After the mapping process, we calculated the precision and recall of the AG-Sets, to measure the effectiveness of our approach. The precision and recall were calculated in our context as follows:
It should be noted that, according to the above equations, a high precision does not always ensure a good question-set. The case where more than one question in an AG-Set matching the same benchmark candidate is such an example. Therefore, the recall corresponding to the AG-Set (which gives the percentage of the number of benchmark questions that are covered by the AG-Set) should also be high enough for a good question-set.
The precision and recall of the question-sets generated by the proposed approach and the random-selection method, calculated against the corresponding benchmark question-sets
The precision and recall of the question-sets generated by the proposed approach and the random-selection method, calculated against the corresponding benchmark question-sets
Results Table 8 shows the precision and recall of the question-sets generated by the proposed approach as well as the random-selection method,25
Selecting required number of question-items randomly from a pool of questions.
The evaluation shows that, in terms of precision values, the AG-Sets generated using our approach are significantly better than those generated using random method. The recall values are in an acceptable range (≈ 50%). We avoid a comparison with those question-sets that were generated by the ATG system [39], since the system does not generate the Aggregation-based questions, and the Pattern-based questions involving more than two predicates.
Discussion Even though the feasibility and potential usefulness of using the E-ATG system in generating question-sets that are semantically similar to those prepared by experts are studied, the quality (reliability and validity) of these generated question items relative to that of items developed manually by domain experts has not been scrutinized. A detailed item analysis (to find statistical characteristics such as p-values and point-biserial correlations [38]) can only provide the psychometric characteristics of items (that can support their reliability and validity). Therefore, we cannot, at this point, conclude that, under real life conditions, the question items that are generated using our approach are an alternative for manually generated test items. A large-scale assessment to compare the automatically generated MCQs and manually prepared MCQs in terms of their psychometric characteristics has to be done in future. Also, there are several guidelines that have been established for authoring MCQ based tests and the machine-generated approach cannot at present guarantee that the generated questions follow these guidelines [14,22,29,41].
One of the core functionalities of the presented E-ATG system is its ability to determine the difficulty-scores of the stems it generates. To evaluate the efficacy of this functionality, we have generated test MCQs from a handcrafted ontology, and determined their difficulty-levels (a.k.a predicted difficulty-levels) (of the stems), using the method proposed in Section 7 and using statistical methods. Then, we compared these predicted difficulty-levels with their actual difficulty-levels that were estimated using principles in the Item Response Theory.
Estimation of actual difficulty-level
Item Response Theory is an item oriented theory which specifies the relationship between learners’ performance on test items and their ability which is measured by those items. In IRT, item analysis is a popular procedure which tells if an MCQ is too easy or too hard, and how well it discriminates students of different knowledge proficiency. Here, we have used item analysis to find the actual difficulty-levels of the MCQs.
Our experiment was based on the simplest IRT model (often called Rasch model or the one-parameter logistic model (1PL)). According to this model, we can predict the probability of answering a particular item correctly by a learner of certain knowledge proficiency level (a.k.a trait level), as specified in the following formula.
A detailed theoretic background of the 1PL model is provided in Appendix A. To find the (actual) difficulty value, we can rewrite the Eq. (7) as follows:
From now on, we use α and θ for (actual) difficulty and proficiency respectively. For experimental purpose, suitable θ values can be assigned for high, medium and low trait levels. Given the probability (of answering an MCQ correctly by learners) of a particular trait level, if the calculated α value is (approximately) equal or greater than the θ value, we can assign the trait level as its actual difficulty-level.
Experiment setup
A controlled set of question stems from the DSA ontology has been used to obtain evaluation data related to its quality. These stems were then associated with a set of distractors which is selected under the similarity based theory [7] such that all the test MCQs will have same difficulty-level w.r.t. their choice set. This is done to feature the significance of stem difficulty, rather than the overall MCQ difficulty involving the difficulty-level due to the choice set.
Test MCQs and instructions We have employed a question-set of 24 test MCQs each to participants, with the help of a web interface. Appendix B lists the stems of the MCQs that are used in our study. These 24 stems were chosen such that, the test contains 8 MCQs each of high, medium and low (predicted) difficulty-levels. The difficulty-scores of these stems were pre-determined using the method detailed in Section 7. Difficulty-levels (predicted difficulty-levels) were then assigned by statistically finding three equal intervals (corresponding to low, medium and high) from the obtained difficulty-scores of all the stems. All the test MCQs were carefully vetted by human-editors to correct grammatical and punctuation errors, and to capitalize the proper nouns in the question stems. Each MCQ contains choice set of cardinality four (with exactly one key) and two additional options: SKIP and INVALID. A sample MCQ is shown in Example 2.
Choose an Internal Sorting Algorithm with worse case time complexity n exp 2.
The responses from (carefully chosen) 54 participants – 18 participants each with high, medium and low trait levels – were considered for generating the statistics about the item quality. The following instructions were given to the participants before starting the test.
The test should be finished in 40 minutes.
All questions are mandatory.
You may tick the option “SKIP” if you are not sure about the answer. Kindly avoid guess work.
If you find a question invalid, you may mark the option “INVALID”.
Avoid use of the web or other resources for finding the answers.
In the end of the test, you are requested to enter your expert level in the subject w.r.t this test questions, in a scale of high, medium or low. Also, kindly enter your grade which you received for the ADSA course offered by the Institute.
Participant selection Fifty four learners of the required knowledge proficiencies were selected from a large number of graduate level students (of IIT Madras), who have participated in the online MCQ test. To determine their trait levels, we have instructed them to self assess their knowledge-confidence level on a scale of high, medium or low, at the end of the test. To avoid the possible errors that may occur during the self assessment of trait levels, the participant with high and medium trait levels were selected from only those students who have successfully finished the course: CS5800: Advanced Data Structures and Algorithms, offered at the computer science department of IIT Madras. The participants with high trait level were selected from those students with either of the first two grade points26
The evaluation data collected for the item analysis is shown in Table 10 and Table 11.
The probabilities of correctly answering the test MCQs (represented as P) by the learners are listed in Table 10. In the table, the learner sets
Table 11 shows the
We are particularly interested in the highlighted rows in Table 11, where an MCQ can be assigned an actual difficulty-level as shown in Table 9. That is, for instance, if the trait level of a learner is high and
Thumb rules for assigning difficulty-level
Thumb rules for assigning difficulty-level
Figure 3 shows the statistics that can be concluded from our item analysis.

The figure shows the count of MCQs whose actual difficulty-levels are matching (and not matching) with the predicted difficulty-levels.
The probabilities of correctly answering the test MCQs (P values) are shown below. Learners in
The test MCQs
Even though the results of our difficulty-level predication method have shown a high correlation with the actual difficulty-levels, there are cases where the approach had failed to give a correct predication. In our observation, the repetition of similar words or part of a phrase in an MCQ’s stem and its key is one of the main reasons for this unexpected behavior. This word repetition can give a hint to the learner, enabling her to choose the correct answer. Example 3 shows the MCQ item
The

Grammatical inconsistencies and word repetitions between stem, key and distractors, are some issues that are not addressed in this work. For example, if the distractors of an MCQ are in singular number, and if the key and stem are in plural number; no matter what the difficulty-level of the MCQ, a learner can always give the correct answer. In an assessment test, if these grammatical issues are not addressed properly, the MCQs may deviate from their intended behavior and can even confuse the learners.
A validity check based on the quality assurance guidelines of an MCQ question (suggested by Haladyna et al. in [23]) has to be done prior to finding the difficulty-levels of the MCQs. This would prevent the MCQs that have the above mentioned flaws becoming part of the final question-set.
In the literature, there are several works such as [2,3,5,6,15,36,45] that are centering on the problem of question generation from ontologies. These works have addressed the problem w.r.t. specific applications. Some of these applications that were widely accepted by the research communities are question driven ontology authoring [32], question generation for educational purpose [4,39,40], and generation of questions for ontology validation [1]. For a detailed review of related literature, the interested readers are required to refer to [4,40].
Ontologies with potential educational values are available in different domains. However, it is still unclear how such ontologies can be fully exploited to generate useful assessment questions. Experiments in [3,39] show that question generation from assertional facts (ABox axioms) is useful in conducting factual-MCQ tests. These factual-MCQs, considered to be the first level of learning objectives in Bloom’s taxonomy [18], are well accepted in the educational community for preliminary and concluding assessments.
When it comes to generating questions from ABox axioms, pattern-based methods are of great use. But the pattern-based approaches such as [1,8,30,32,44] use only a selected number of patterns for generating questions. A detailed study of all the possible type of templates (or patterns) is not explored by any research group. Also, since the applicability of these pattern-based approaches is limited due to the enormous number of generated questions, there was also a need for suitable mechanisms to select relevant question items or to prevent the generation of useless questions. We have addressed this issue in this paper by proposing a set of heuristics that mimic the selection process by a domain expert. Existing approaches select relevant questions for assessments by using techniques similar to text summarization. For instance, in ASSESS [12] (Automatic Self-Assessment Using Linked Data), the authors find the properties that are most frequently used in combination with an instance as the relevant properties for question framing. Sherlock [27] is another semi-automatic quiz generation system which is empowered by semantic and machine learning technologies. Educationalists are of the opinion that the question-sets that are generated using the above mentioned existing approaches, are only good for conducting quiz-type games, since they do not satisfy any pedagogical goals. In the context of setting up assessments, a pedagogical goal is to prepare a test which can distinguish learners having a particular knowledge proficiency-level, by controlling the distribution of difficult questions in the test. Our focus on these educational aspects clearly distinguishes our work from the existing approaches. Furthermore, Williams [42] presented a prototype system for generating mathematical word problems from ontologies based on predefined logical patterns, which are very specific to the domain. Our research is focused on proposing generic (domain independent) solutions for assessment generation. Another feature which distinguishes our work from the rest of the literature is our novel method for determining the stem-difficulty.
Conclusion and future work
In this paper, we proposed an effective method to generate MCQs for educational assessment-tests from formal ontologies. We also give the details of a prototype system (E-ATG system) that we have implemented incorporating the proposed methods. In the system, a set of heuristics were employed to select only those questions which are most appropriate for conducting a domain related test. A method to determine the difficulty-level of a question-stem and an algorithm to control the difficulty of a question-set were also incorporated in the system. Effectiveness of the suggested question selection heuristics was studied by comparing the resulting questions with those questions which were prepared by domain experts. The correlation of the difficulty-levels of the questions which were assigned by the system to their actual difficulty-levels was empirically verified in a classroom-setup using the Item Response theory principles.
Currently, we described only a method to find the Aggregation-based questions (a sub-category of Non-Pattern-based questions) which can be generated from an ontology; it is an open question as to how to automatically extract other Non-Pattern-based questions.
The system generated MCQs have undergone an editing phase, before they were used in the empirical study. The editing works that have been taken care by human-editors include: correcting grammatical errors in the stem, removing those stems with words that are difficult to understand, correcting the punctuation in the stem and starting proper nouns with capital letters. As part of future work, it would be interesting to add a module to the E-ATG system that can carry out these editing tasks.
Despite of the fact that we have taken care various linguistic aspects of the MCQ components (either manually or programmatically), there are specific guidelines suggested by educationalists regarding the validity and quality of the MCQs that are to be employed in an assessment [14,22,29,41]. For example, the stem should be stated in positive form (avoid negatives such as NOT), is one of such guidelines suggested by Haladyna, Downing and Rodriguez [23]. A detailed study (item analysis) which is in line with the MCQ quality assurance guidelines (see the work by Gierl and Lai [21]) is necessary to conclusively state that E-ATG system is an alternative for manual generation of questions by human experts.
In this paper, we have focused only on generating question-sets that are ideal for pedagogical use, rather than the scalability and performance of the system. In future, we intend to enhance the implementation of the system, to include several caching solutions, so that the system can scale to large knowledge bases.
Footnotes
Acknowledgements
We express our gratitude to IIT Madras and the Ministry of Human Resource, Government of India, for the funding to support this research. A part of this work was published at the 28th International FLAIRS Conference (FLAIRS-28). We are very grateful for the comments given by the reviewers. We would like to thank the AIDB Lab (Computer Science department, IIT Madras) members and students of IIT Madras who have participated in the empirical evaluation. In particular, we would like to thank Kevin Alex Mathew, Rajeev Irny, Subhashree Balachandran and Athira S, for their constant help and involvement in various phases of the project.
IRT model and difficulty calculation
Item Response Theory (IRT) was first proposed in the field of psychometrics for the purpose of ability assessment. It is widely used in pedagogy to calibrate and evaluate questions items in tests, questionnaires, and other instruments, to score subjects based on the test takers abilities, attitudes, or other trait levels.
The experiment described in Section 10.2 is based on the simplest IRT model (often called Rasch model or the one-parameter logistic model (1PL)). According to this model, a learner’s response to a question item27
1PL considers binary item (i.e., true/false); since we are not evaluating the quality of distractors here, the MCQs can be considered as binary items which are either correctly answered or wrongly answered by a learner.
In the equation,
In our experiment, we intended to find the
In the equation,
Sample MCQ stems
Table 12 shows a list of sample MCQ stems that are generated from the DSA ontology. In the table, the stems 1 to 8, 9 to 16 and 17 to 24 correspond to high, medium and low (predicted) difficulty-levels respectively. These stems along with their choice sets (please refer to our project website) were employed in the experiment mentioned in Section 10.2.
Sample MCQ stems that are generated from the DSA ontology. Stems 1 to 8 have high predicted difficulty-levels, 9 to 16 have medium and 17 to 24 have low difficulty-levels
Item No.
Stems of MCQs
1.
Choose a polynomial time problem with application in computing canonical form of the difference between bound matrices.
2.
Choose an NP-complete problem with application in pattern matching and is related to frequent subtree mining problem.
3.
Choose a polynomial time problem which is also known as maximum capacity path problem.
4.
Choose an application of an NP-complete problem which is also known as Rucksack problem.
5.
Choose the one which operates on output restricted dequeue and operates on input restricted dequeue.
6.
Choose a queue operation which operates on double ended queue and operates on a circular queue.
7.
Choose a string matching algorithm which is faster than Robin-Karp algorithm.
8.
Choose the one whose worst time complexity is n exp 2 and with Avg time complexity n exp 2.
9.
Choose an NP-hard problem with application in logistics.
10.
Choose an all pair shortest path algorithm which is faster than Floyd-Warshall Algorithm.
11.
Choose the operation of a queue which operates on a priority queue.
12.
Choose the ADT which has handling process “LIFO”.
13.
Choose an internal sorting algorithm with worse time complexity m plus n.
14.
Choose a minimum spanning tree algorithm with design technique greedy method.
15.
Choose an internal sorting algorithm with time complexity n log n.
16.
Choose an Internal Sorting Algorithm with worse time complexity n exp 2.
17.
Choose the operation of a file.
18.
Choose a heap operation.
19.
Choose a tree search algorithm.
20.
Choose a queue with operation dequeue.
21.
Choose a stack operation.
22.
Choose a single shortest path algorithm.
23.
Choose a matrix multiplication algorithm.
24.
Choose an external sorting algorithm.