
Abstract
The DM2E dataset is a five-star dataset providing metadata and links for direct access to digitized content from various cultural heritage institutions across Europe. The data model is a true specialization of the Europeana Data Model and reflects specific requirements from the domain of manuscripts and old prints, as well as from developers who want to create applications on top of the data. One such application is a scholarly research platform for the Digital Humanities that was created as part of the DM2E project and can be seen as a reference implementation. The Linked Data API was developed with versioning and provenance from the beginning, leading to new theoretical and practical insights.
Introduction
The project “Digitised Manuscripts to Europeana” (DM2E)1
The transformation of various metadata and content formats describing and representing digital cultural heritage objects (CHOs) in the realm of digitized manuscripts from as many providers (cf. Section 2) as possible into the Europeana Data Model (EDM) to get it into Europeana, the European digital library.2
The stable provision of the data as Linked Data and the creation of tools and services to reuse the data in the Digital Humanities. The basis is the possibility to annotate the data, to link the data, and to share the results as new data.
The Linked Data representation of the metadata as described in this paper can be accessed online3
The rights statements for the described digitized objects are individually assigned by the content providers who have to choose an appropriate statement from the options6
DM2E data sources
ML: Metadata Language
CL: Content Language
M: Manuscripts / L: Letters / B: Books / I: Images / J: Journal Articles / A: Archival Items / F: Archival File
1: GND / 2: DBpedia / 3: DDC / 4: LCSH / 5: ZDB / 6: Geonames / 7: VIAF / 8: Freebase
European Association for Jewish Culture
One major aspect of the DM2E project was publishing metadata about a number of international high profile collections both as Linked Data and through Europeana. Despite its name, DM2E is not restricted to manuscripts but contains also other historical resources like letters, books, images, journal articles, or archival items. Table 1 shows an overview on the content available as Linked Data, broken down by provider and collection name, metadata and content language, type of content, instance count, used reference authorities and metadata source format. The stated counts represent the respective number of instances for which the property
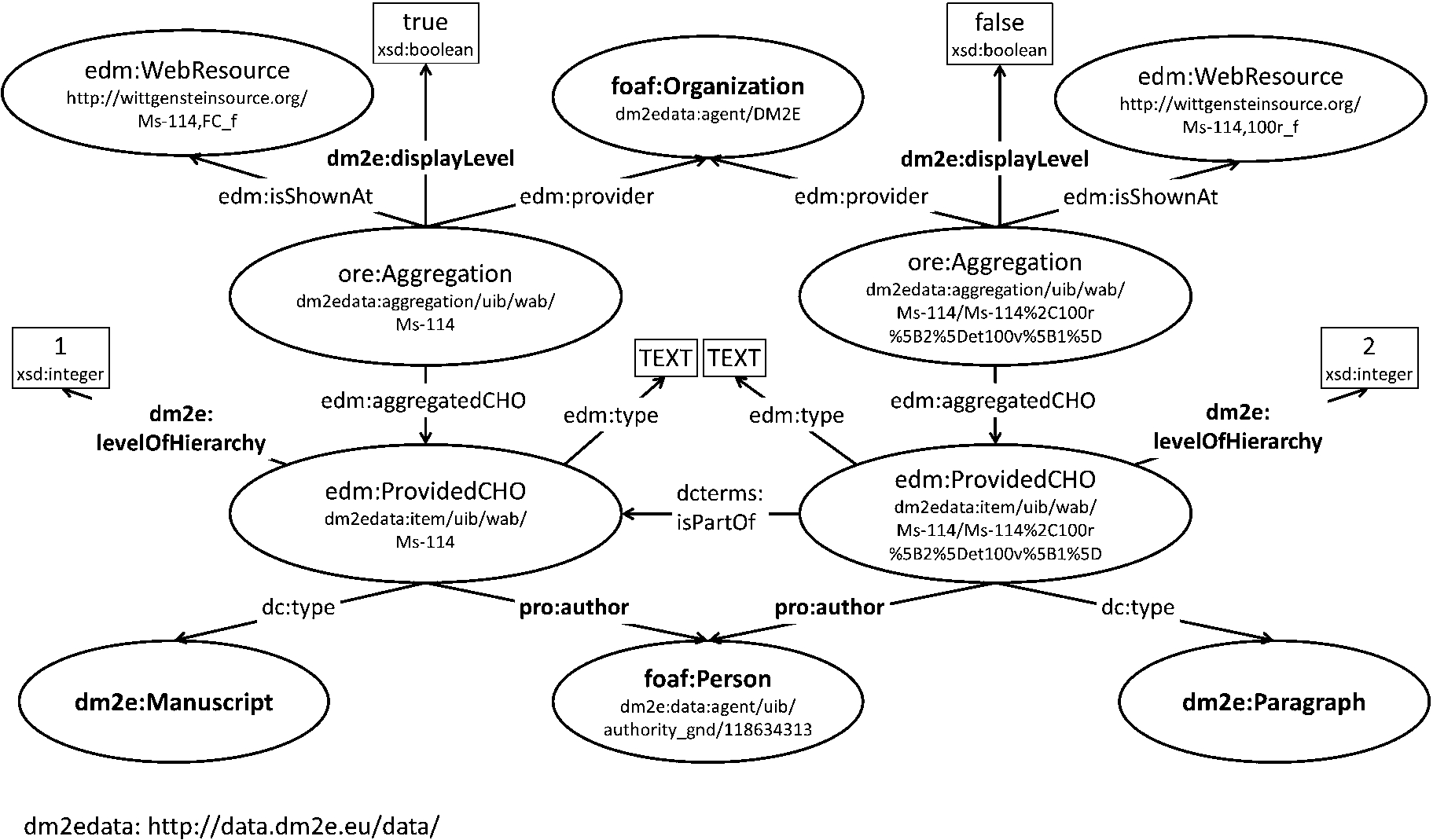
Example of the DM2E model in use: representation snippet of a Wittgenstein manuscript.
Accordingly, there is no common workflow for providers to map their data to the DM2E model. Starting with the tools and the documentation provided by DM2E, providers therefore developed their own metadata transformations mainly based on XSLT, although some chose to directly implement export routines into their collection management systems. Initial consistency checks for mapped data revealed that despite the very detailed specification of the DM2E model some providers showed great creativity in individual interpretations of specific model features, most notably regarding the representation of hierarchies. In order to maintain a homogeneous data representation, specific mapping rules have been established for such cases and distributed amongst the providers in form of a recommendation document. In some cases, transformations created by one provider could be reused or adapted for other providers. This especially proved to be effective for the highly standardized library metadata formats such as MARC, METS/MODS and MAB2. The mapping recommendations and the resulting metadata crosswalks are documented on the DM2E wiki,7
The DM2E model is an application profile of EDM, i.e., an application-specific specialization for the representation of manuscripts and similar historical content like old prints, posters, books and old journals [6]. EDM itself is very generic to represent resources provided by museums, libraries, archives and galleries all over Europe. It is based on top-level ontologies like OAI-ORE, Dublin Core and SKOS. Core classes are
The example of a manuscript by the philosopher Ludwig Wittgenstein shown in Fig. 1 illustrates how DM2E data is built-up. Bold resources have been added in the DM2E model, others are part of the underlying EDM.
The DM2E model adds mostly subclasses and – properties for the domain of manuscripts to existing elements of the EDM. Main additions have been made for person roles, e.g.
Whenever possible, established vocabularies have been reused, precisely: BIBFRAME, BIBO, CIDOC-CRM, FABIO, PRO, rdaGr2, VIVO and VoID. DM2E-specific usage guidelines for each reused element are provided via
Application
Two applications consuming the DM2E Linked Data have been implemented in the DM2E project to provide the scholarly research platform. The first one is a faceted browser that allows scholars to make sense of the DM2E collections and navigate them along several dimensions, iteratively restricting the search results by language, author, publishing institutions, and other metadata fields. Facets are derived from a SOLR8
The API response in a JSON array, from which the dereferenciable URL of Linked Data resources are easily retrievable by looking at the “id” slot. SOLR does not provide a direct way to get all the facets used in the index, which would facilitate the developer in writing queries. However such a list can be retrieved with a work-around with the following query:
Based on the SOLR API, a end-user faceted browser was developed by customising Ajax-SOLR. Each resource shown in the faceted browser can be opened in its provider’s own digital library (following the EDM property
Furthermore, for datasets containing links to annotatable digital objects, users are provided with “Annotate with Pundit” links that direct them to the DM2E semantic annotation environment. The latter constitutes the second Web application built on top of the data and is based on Pundit and Feed, two software components developed as part of the DM2E project.
Pundit14
Pundit server API documentation:
On the other hand, the Feed REST API provides access to Pundit “as a service” by using the URL of a Web page to be annotated as a call parameter. An extension to the Feed API has been developed in DM2E, allowing this call parameter to also be a dereferenceable URL of an RDF description of a digitized object. Feed parses this RDF description to create a customized annotation environment. While the faceted search application only works on resources at display level (e.g. entire books), the annotation environment allows users to go deeper into the hierarchy. The
Annotatable page example:
By annotating digital objects with Pundit, users in fact create additional RDF knowledge. This could be, for example, links connecting a geographical map of Metz, depicted in a manuscript page, to the city of Metz in DBpedia, or links from a sentence of a manuscript transcription to a DBpedia entity that is mentioned in such a sentence. Such RDF data, in turn, can be indexed to enrich the faceted search interface, thus improving search and discovery. Demonstrative examples of such end-user information enrichments can be seen in an online screencast.19
As of September 30, 2014, about 6,600 annotations for about 900 digital objects from the DM2E dataset have been created by scholars using our research platform.
Linking our datasets to external sources like GND,20
Number of links per external source
Altogether, about 24,000 links have been automatically generated. With a manual analysis of 150 random links from agents to DBpedia and 150 random links from places to Linked Geodata, we evaluated the quality. For agents, 125 correct links have been detected which results in a precision of 0.83. Since DBpedia covers several labels, we can for example correctly link “Jakobä” to the DBpedia agent “Jacqueline Countess of Hainaut.” The incorrect links result either from ambiguous names, e.g. “Heinrich Fischer” who refers to a Swiss rower in DBpedia and not to an author, or from incomplete information, e.g. if only the first name or surname is given.
For places, 128 correct links can be detected, resulting in a precision of 0.85 which is similar to the precision for agents. Since Linked Geodata includes labels in various languages, even places with a German label such as “München” can be linked to “Munich”. The reasons for incorrect links, however, are the same to the ones for agents, e.g. the German city “Heidelberg” is mapped to the city “Heidelberg” located in South Africa due to identical labels.
Across all datasets, about 18% of all agents and 60% of all places are linked on average. With a different linkage rule it is possible to detect more links but with the risk to reduce the precision. Further, the amount of detected links as well as their quality highly depend on the popularity and currency of the resources. Since more than one linkset can be available in our system and the user can track their provenance, more liberal linkage rules can also be applied and the user can be informed about its quality.
At the core of DM2E’s infrastructure is a Jena TDB24
DM2E collection metadata dump: http://data.dm2e.eu/dm2e-fuseki-direct.2016-01-07.final.nquads.gz (13.01.2016).
DM2E contextualized links dump: http://data.dm2e.eu/dm2e-fuseki-direct.2016-01-07.linksets.nquads.gz (13.01.2016).
There are two user interfaces that allow data providers or mapping institutions to deliver data to DM2E: A Linked Data-based workflow engine with an HTML5 Web interface allows casual users to test their transformations and the ingestion process (Omnom)27
Omnom is centered on the idea that RDF’s flexible graph-based structure combined with the semantic expressivity of ontologies29
The command line suite of tools is developed with a server environment in mind and consists of a set of Java tools for DM2E validation, provenance-tracking data ingestion, DM2E-EDM-conversion and EDM validation, as well as shell scripts encapsulating XSLT transformers and RDF serializers and for orchestrating the various operations.
The authoritative source of the DM2E model is the textual/tabular DM2E Model Specification, which contains not only the definitions of all properties and classes to be used, but illustrates their usage with examples. The specs are synchronously formalized as an dereferenceable OWL ontology. However, the DM2E model puts restrictions on the usage of properties and classes that cannot be expressed under OWL’s Open World Assumption. These restrictions are targeted towards structural validation of subgraphs of DM2E data rather than inference of new facts. While DM2E is involved in the development of community standards for RDF validation [5], we implemented a custom solution using Java, available on GitHub.31
Being a domain aggregator for Europeana, DM2E has a strong focus on interoperability with the EDM, both on the model and data level. The DM2E model is a specialization of the EDM, i.e., after RDFS inference on the data and removing any statements with properties not contained in EDM, every DM2E-compliant subgraph is an EDM-compliant subgraph. DM2E uses this technique to convert the DM2E data into pure EDM to make the ingestion as easy as possible for the Europeana side, using a synthesis of the two models expressed in OWL.32
Due to its ubiquitious deployment in the GLAM sector and its proven track record for scalability, DM2E and Europeana agreed on OAI-PMH as the preferred mode of delivery of data for ingestion into Europeana. Using a multi-step process of extracting per-
The Linked Data API is implemented using a significantly advanced version of Pubby.35
Multiple resource handling DM2E implements the OAI-ORE resource map, i.e., whenever the URI of a resource or an aggregation is requested, the client gets redirected to the URI of a resource map. The resource map contains both information about a resource and information about the aggregation – which roughly represents a metadata record in EDM. This implementation also follows practical considerations from the point of view of application developers, as, more often than not, the data about a resource and the data about the aggregation are used together. So this leads to a substantial reduction of necessary requests to the API.
Versioning All DM2E data is versioned, i.e., the data provided under the URI of a resource map never changes. When updated data is ingested, the API redirects to the new resource map, but the new resource map gets a new URI and contains links to earlier versions of the data in the form of
Dataset provenance The full provenance of the DM2E data is provided by linking resource maps and other data pages to superordinate datasets using the VoID vocabulary [1]. The datasets are versioned and all data in a dataset shares the same provenance, following the idea of a common provenance context to support provenance-aware Linked Data applications [7]. The version of a resource map and the provided provenance information then simply corresponds to the version and provenance of the dataset. Versioned datasets are implemented as Named Graphs.
Statement-level provenance To support contextualized resources with statements from various enrichment processes, a special approach has been implemented using statement annotations [7]. Subject URIs are created for all statements and these URIs are linked to the datasets the statements originate from. The statement URIs are identified and described as statements using RDF reification. All reification triples are created on the fly, only where necessary, and can safely be ignored by applications not interested in the provenance of the statements. The HTML representation of the contextualized resources makes use of this information and provides an “Oh Yeah?” button for all – possibly wrong – links to external resources, leading to the provenance information of the statement.37
For example the city Nancy:
DM2E metadata term usage in
Several aspects make the DM2E dataset an interesting and unique source of information. First of all – following the goals of the DM2E project – it contains data from many, carefully selected collections of not only manuscripts, but also old prints, posters, books and old journals with historic value. The data model was developed specifically for this domain where no suitable comprehensive data models existed yet. The DM2E model is also an example of an application profile, an application-specific specialization of the EDM. As such, the data blends well with the huge amount of EDM data available through Europeana. In contrast to many other Linked Datasets, the model and the API have both been tailored to the original data as well as to consuming applications. From a technical point of view, the use of multiple resource representations, versioning and the provision of a full provenance chain have to be mentioned, particularly the proper separation of original, curated metadata from data enrichments generated by automated processes with varying quality. The main short-coming is arguably the lack of a publicly available SPARQL endpoint, mainly due to performance considerations. Fast response times for the scholarly research platform have higher priority. The SOLR-based search and browse interface, however, is provided as convenient entry point to the data and provides a RESTful search API sufficient for most use cases. The data itself also has some shortcomings due to the heterogeneity of the original data. The quality of the metadata ranges from rich descriptions with unambiguous identifiers from authority files for agents, places and subjects to sparse descriptions with few information hidden in free-text fields. It is insofar a dilemma that the contextualization works best for the better data and particularly the poor data is hard to improve. A remedy might be the feedback of data from the annotations provided by the scholars. We plan to investigate this as part of our future work, when more annotations will hopefully be available.