
Abstract
We introduce new OWL ontologies for observations and sampling features, based on the O&M conceptual model from OGC and ISO 19156. Previous efforts, (a) through the W3C SSN project, and (b) following ISO rules for conversion from UML, had dependencies on elaborate pre-existing ontologies and frameworks. The new ontologies, known as om-lite and sam-lite, remove such dependencies, and can therefore be used with minimal ontological commitment beyond the O&M conceptual model. Time and space concepts, for which there are multiple existing solutions, are implemented as stub-classes, and patterns for linking to the existing ontologies are described. PROV is used to support certain requirements for the description of specimens. A more general alignment of both observation and sampling feature ontologies with PROV is described, as well as mappings to some other observation models and ontologies.
Introduction
Observations and measurements are used to determine values of properties, through application of some procedure at a particular time and place. The result of an observation is strictly an estimate of the true value, conditioned by procedure and circumstances, so description of the latter are important in the assessment of the reliability of the estimate.
A conceptual model for observations and measurements (O&M) is described in ISO 19156:2011 [9,29]. This builds on a pattern, developed originally by Fowler and O’Dea [15], which uses the term ‘observation’ to refer to the observation act or event. The O&M model establishes a domain-neutral vocabulary for an observation and its associated properties. The key design goal was to provide a common terminology for both in-situ observations and remote-sensed observations, around which some confusion existed. This is accomplished by separating concerns, with classes for the feature of interest, the procedure, the observed property, the result, and the act of observation itself. This allows places and times associated with each to be distinct if necessary. O&M also included an important module for sampling features, covering things like stations, transects, cross-sections, images and specimens. The role of a sampling feature is to assist the characterization of the ultimate feature of interest. Sampling is almost ubiquitous in scientific and environmental observations.
A number of other projects have developed ontologies for observations. A review of the state of the art in 2011 was included in a report from the W3C Semantic Sensor Network incubator group [37], mostly using O&M as a framework for comparing existing observation models and ontologies. The incubator group then developed the Semantic Sensor Network ontology (“SSNO”) [5], particularly leveraging the Stimulus-Sensor-Observation pattern (SSO) [34,44], which adds the notion of ‘stimulus’ to the core model based on O&M. Meanwhile, Cox [11] described an ontology for O&M (“OMU”) based on automatic conversion of the original UML model, using rules developed in ISO 19150-2 [31].
However, these implementations present some barriers to adoption for new applications. In particular
SSNO includes elements for sensors and observations, but omits sampling features, which are a key element required for many practical applications;
SSNO is linked to the Dolce-ultra-lite (DUL) implementation of the DOLCE foundational ontology [16], with SSNO concepts directly inheriting from a number of DUL classes and properties. This introduces ontological commitments which conflict with earlier assumptions;
The UML-OWL conversion rule used for OMU triggers a web of dependencies on additional, sometimes highly detailed, ontologies derived from other ISO 19100-series UML models. This introduces a large amount of baggage, of uneven quality.
In this paper, we introduce a new OWL implementation of O&M which aims to overcome these limitations with two new ontologies. The new ontologies include both the observation and sampling feature models from O&M, and have fewer dependencies on existing ontologies than either OMU or SSNO. We expect that these ontologies can either serve as foundations for more domain-specific treatments, or as bridging ontologies for alignment of existing ontologies developed around specific applications or domains.
The paper is structured as follows: in Section 2 we review the O&M UML model from ISO 19156; in Section 3 we present the om-lite and sam-lite ontologies and some examples to illustrate their use; in Section 4 we explore mappings with existing ontologies for observations, and integration of existing models for space, time and measure; in Section 5 we discuss some issues arising from the approach to dependencies, the use of the new ontologies in alignment exercises, the use of PROV for real world entities, and the importance of sampling features. Section 6 provides a summary of the main points.
O&M conceptual model
Background
Observations and Measurements (O&M) [7–9,29] is one of a group of standards developed through the Sensor Web Enablement initiative (SWE) from Open Geospatial Consortium (OGC). O&M provides a user-centric viewpoint (i.e. user of observation data) that complements the provider-centric viewpoint given in SensorML [2]. The main elements of O&M were established in version 1, published in two parts by OGC in 2007 [7,8], and then refined and aligned with the Geographic Information standards from ISO Technical Committee 211, and published as version 2 in 2011 [9,10,29]. For consistency with the ISO 19100 series, the O&M model was specified using the Unified Modeling Language (UML) [32] and re-uses classes from a number of other standards in the series. An XML implementation [10] is used primarily in the context of OGC Sensor Observation Service and Web Feature Service [4,28,45].
O&M has been widely used in environmental monitoring, climate and weather, ocean observations, soils, geology, and some defense and intelligence applications [12], and was adopted as part of the INSPIRE conceptual model [22].
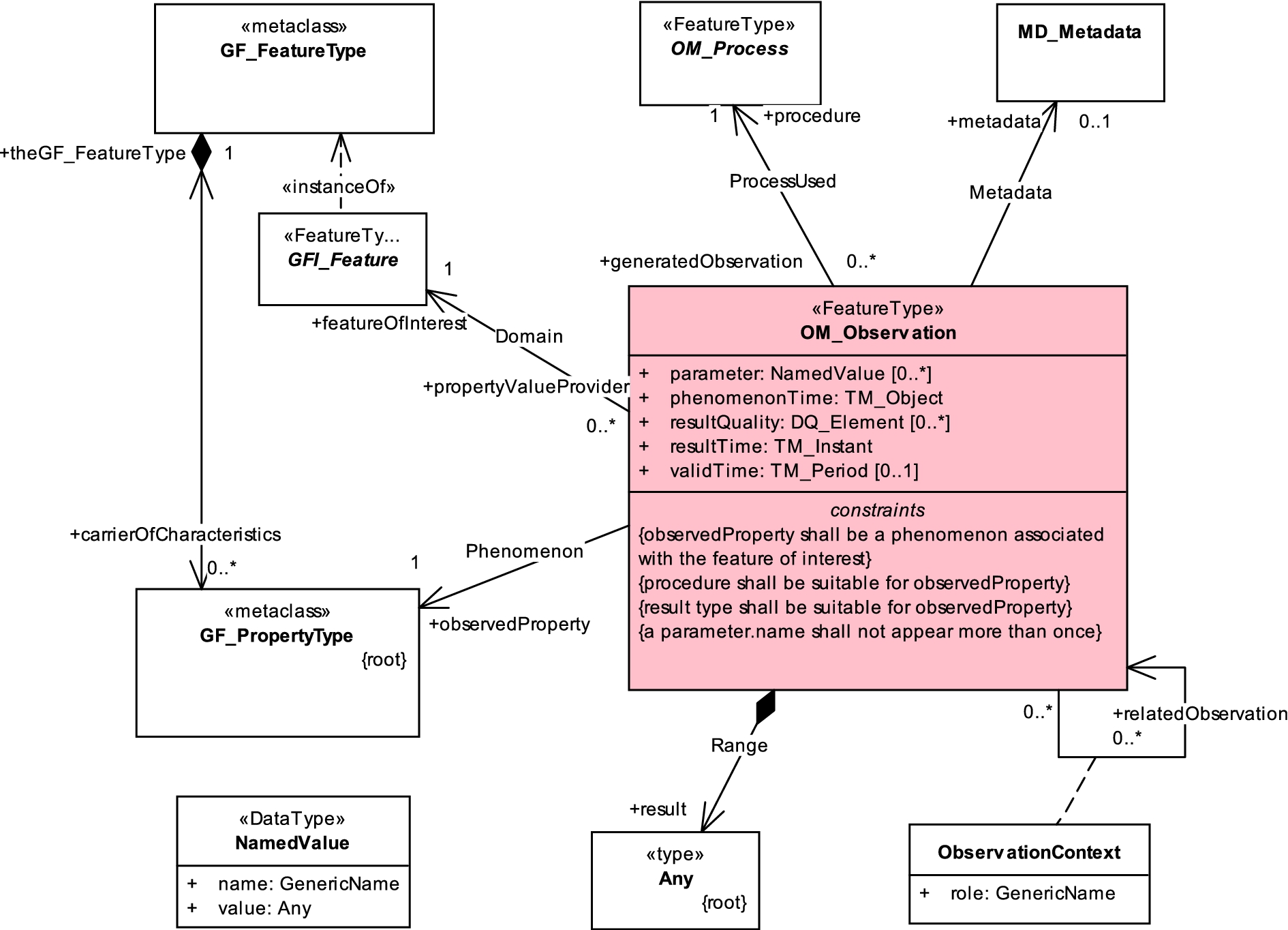
UML classes and properties in core observation model from O&M in ISO 19156:2011 [29]. This UML is integrated with other models from the ISO 19100 series: classes with the prefix TM_ are from the Temporal Schema in ISO 19108 [23], with the prefix GF_ from the General Feature Model in ISO 19109 [27], MD_Metadata is from the Metadata Schema in ISO 19115 [24], and DQ_Element is from the model for Data Quality in ISO 19157 [30].
The core of the Observation model from O&M v2 [9,29] is shown in Fig. 1 and summarized here. An observation is conceived as an event or activity, the result of which is an estimate of the value of a property of the feature of interest, obtained using a specified procedure. The term ‘feature’ is used here in the sense defined in the ‘Reference Model’ used by OGC [42] and by ISO Technical Committee 211 – Geographic Information [26], referring to a conceptualization of an entity in the real world.
Standard observation properties support a variety of applications. The ‘observed property’ supports important discovery scenarios. Description of the ‘procedure’ supports discovery and the assessment of the quality of the result. Multiple locations may be associated with an observation, with a location tied to the ‘feature of interest’ most commonly used in spatial analysis and cartographic representation. However, separating the feature of interest from the observation and procedure classes, and decoupling ‘location’ from observation, was a key choice made to support descriptions of remote-sensing (where the location of the feature of interest and instrument are different), in-situ observation and monitoring (where the procedure is located in the feature of interest), and ex-situ observations (involving specimens taken from a location in the feature of interest for observation in a remote laboratory) using a common terminology. If the location of the feature-of-interest is itself time dependent, then this must be reflected in its description, or else the location may itself the result of observation in parallel with the estimation of other properties. However, it is important that the detailed modeling of specific types of potential features-of-interest is beyond the scope of the general observation model, and is delegated to applications. In fact, values of the key properties are all specified as abstract or generic classes, and must be specialized for specific domains and applications. For example, the procedure is often an instrument or sensor, but may be an observer, or an algorithm or processing chain in the case of simulations or forecasts.

The event-based nature of observations gives the temporal properties particular significance. Multiple temporal properties are provided, to support the separate description of (i) the time the result was obtained, (ii) the time the result applies to the feature of interest, called ‘phenomenon time’ (which is sometimes contemporary, but may be in the past or future), and (iii) the time when the result is recommended for use, called ‘valid time’ (which is optional, but very useful in forecasting applications). The resultTime property reflects directly the event-ness of observations in this model. The phenomenonTime is also tied to the observation because, in most of the applications that drove the development of the model, feature-identity was more persistent than the values of its properties, whose time variation is often the motivation for observations. Other temporal properties are used in some applications, particularly simulations and numerical models, but the three defined in O&M were judged to be of sufficiently general interest to merit inclusion in the model.
Additional associations could be identified and might have been included in the model. The ones included satisfied requirements of a large number of use-cases examined during its development, primarily from earth and environmental sciences and monitoring, together with some security and intelligence applications.
Specializations of the observation class have been classified by the result-type. For example a Measurement is an observation whose result is a scaled quantity (or ‘Measure’ [33]), and a TruthObservation is an observation whose result is a Boolean value.
Because it was designed to be compatible with the ISO 19100 series of standards issued through ISO/TC 211, the UML formalization of O&M makes extensive use of types and classes from models from these standards, as noted in the caption of Fig. 1.


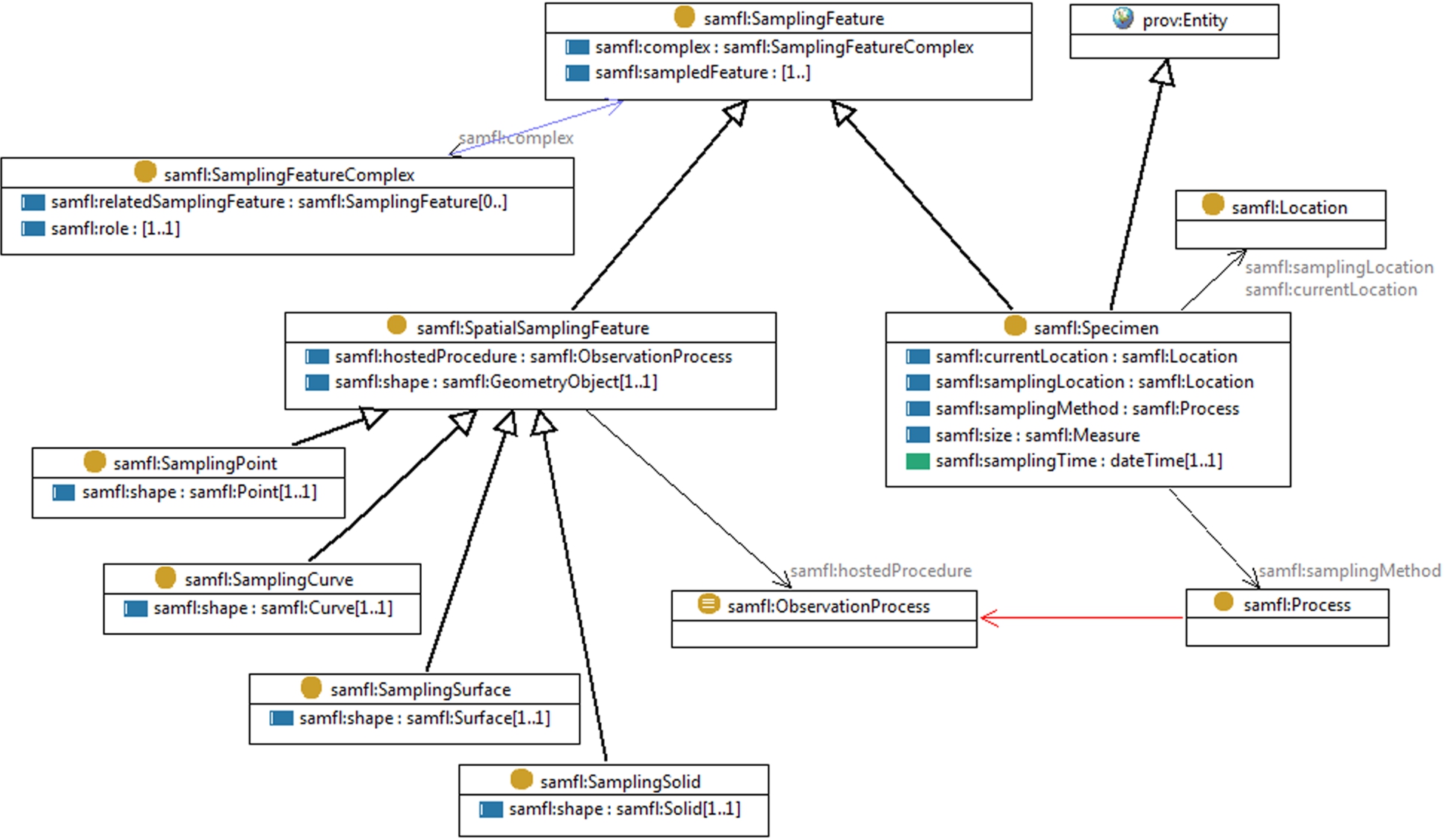
Most observations are actually made on representative samples of the feature of interest, so a model of features used for sampling was developed as separate part of O&M v1 [8] and further refined in O&M v2 [9,10]. A Sampling Feature is a feature constructed to support the observation process, which may or may not have a persistent physical expression but would either not exist or be of little interest in the absence of an intention to make observations. The core model is shown in Fig. 2. The only essential property of a generic Sampling Feature is the ‘sampled feature’ relationship with the feature that it samples.
Some common sampling strategies appear in a number of earth and environmental science disciplines, particularly related to spatial subsets of the feature of interest of an observation. A taxonomy of these was developed based on precedents in climate science [47] with specialized sampling feature types characterized by topological dimension – sampling at a point, sampling along a line or curve, sampling on a surface or section, and sampling in a volume (Fig. 3).
Retrieval of a specimen from the feature of interest for ex-situ observation, in a lab or using a procedure that cannot be introduced into the natural environment, is another very common sampling strategy. This is modeled as another specialization, shown in Fig. 4.

Finally, it is common for sampling features to occur as part of a complex, with specific relationships between them. For example, specimens retrieved along a borehole, stations along a traverse, or probe-spots on a polished mineral specimen. All of these are sampling features, existing only to support observations. The SamplingFeatureComplex association-class records the semantics of these relationships.
Observations
The new ontology for observations, known as “om-lite” (namespace prefix “oml:”), covers the key classes from O&M, i.e. OM_Observation and its subclasses, the supporting concept OM_Process, and the association class ObservationContext (Fig. 5).
TopBraid Composer http://www.topquadrant.com/tools/ide-topbraid-composer-maestro-edition/ was used to prepare the UML-style diagrams showing classes and relationships from om-lite and sam-lite.
Observation properties
Cardinality restrictions on oml:Observation shown in Fig. 5 reflect the expectation that six core properties characterize an observation: featureOfInterest, observedProperty, procedure, phenomenonTime, resultTime and result. (Note that these cardinality constraints strictly confine users to the OWL 2 DL language profile, as the less expressive profiles OWL 2 RL, QL and EL do not permit these restrictions [41].)
The key properties from om-lite are represented as shown in Table 1. The oml:resultTime property captures the time when the result became available. This is usually approximately contemporaneous, and usefully tied to the conventional clock and calendar, so the data-type used is xsd:dateTime. On the other hand, the oml:phenomenonTime property provides the time the result applies to the observed-property in the world. Its range is the more general oml:TemporalObject, since observations may estimate the value of a property at a wider range of times than is supported by the dateTime datatype. (Note that OWL-Time [17] is also not sufficient, for reasons explained in [13].) There is no global restriction on the range of oml:featureOfInterest or oml:observedProperty, since a generic model must accommodate observations of any property characterizing a feature or object from any application domain. Likewise, the range of oml:result is not specified for the generic observation class, since property values may have many types and may be characterized in many different ways. Nevertheless, a subset of the specialized O&M observation classes is implemented using local restrictions on the type of oml:result, including oml:Measurement, oml:TruthObservation, etc.
Sampling feature properties
Om-lite includes one significant change from the O&M conceptual model shown in Fig. 3. In the original model, a SamplingFeature could substitute for the feature-of-interest, with the ultimate feature-of-interest available via the sampledFeature property. An informal constraint that the observed-property was commensurate with the type of the feature-of-interest required some slippery logic to satisfy. In the OWL interpretation we clarify the semantics by separating the (optional) sampling-strategy from the (mandatory) feature-of-interest, and the latter is always the ‘ultimate’ feature-of-interest associated with the observed-property.
The ontology for sampling features, known as “sam-lite” (namespace prefix “samfl:”) includes all the classes from the O&M Sampling Features model (Fig. 6). Table 2 describes the representation in sam-lite of the key properties from O&M sampling features.
A cardinality restriction on samfl:SamplingFeature reflects the expectation that at least one samfl:sampledFeature property will be present, whose value indicates the intention of the sampling feature. No local or global restriction on the range of samfl:sampledFeature is provided, since a generic model must accommodate sampling any feature or object.
Sampling of a feature of interest is frequently achieved using a spatially-defined subset. This is represented by the subclass samfl:SpatialSamplingFeature, which has a functional property samfl:shape, whose range is samfl:GeometryObject. Specific subclasses restrict the type of samfl:shape, corresponding to common practice particularly in earth and environmental sciences, following the taxonomy described in O&M [9,29], which was influenced by Climate Science Modeling Language [47].
samfl:GeometryObject and its specializations are stub classes. A user can select any suitable vocabulary that implements these classes, such as GeoSPARQL [43] or W3C Basic Geo [3]. Furthermore, although samfl:GeometryObject is equivalent to oml:GeometryObject we did not introduce a direct dependency on om-lite in the core sam-lite vocabulary, as there will be applications that only use sampling features.
Specimens are physical samples retrieved from their natural environment and used (typically) in laboratory observations. This is represented by a subclass samfl:Specimen. Required properties are samfl:sampledFeature (from samfl:SamplingFeature) and samfl:samplingTime, whose value indicates when the specimen was retrieved from the sampled feature. Some additional convenience properties are provided (Table 2).
A critical aspect of specimen description is the record of their preparation and lineage. In the O&M model this was implemented using an association class “PreparationStep”. However, this approach was not fully satisfactory, particularly as the preparation step is not easily linked to an explicit predecessor specimen. In practice there is a very wide range of specimen preparation and provenance paths, so rather than trying to develop a new generic model we leverage PROV [36], which provides general patterns for description of relationships between activities, parties and related entities. We make samfl:Specimen a subclass of prov:Entity, thus accommodating the requirements of the O&M PreparationStep class as well as enabling relationships with predecessor specimens to be recorded.
Examples
We present a number of dataset examples serialized in Turtle [1]. For these examples the following additional axioms were introduced to allow concrete representations of time and space from existing W3C vocabularies [3,17] to be used as the value of properties whose range is one of the stub classes:
Observations
Listing 1 shows a measurement of the weight of a piece of fruit. This corresponds to the first example in Section 5.1 of OMU [11].2
URIs in the ‘example.org’ domain or subdomains are illustrative only, and are not dereferenceable. Abbreviated URIs with the ‘my:’ prefix are local examples only.

A simple measurement example.
Listing 2 shows a remote sensing observation, in which the result is provided as a link to an image dataset. This corresponds to C.2.3 from the XML (GML) implementation of O&M [10]. The OWL-Time vocabulary [17] is used for the value of oml:phenomenonTime (prefix=w3time:). The use of links to resources available elsewhere is available in GML through xlinks (to the result, in this case) but is a native capability supported by all RDF processors.
An observation whose result is provided out-of-band.
Listing 3 shows the description of a river sampling station including links to two observations made there. This corresponds to C.3.1 from the XML (GML) implementation of O&M [10]. The ‘Basic Geo’ vocabulary [3] is used for the value of samfl:shape (prefix=w3geo:). The station is a member of a collection of sampling features, captured using the samfl:complex property. We have also shown how this may be expressed using prov:wasMemberOf from the PROV ontology [36].
A sampling station with links to some related observations.
Listing 4 shows a description of a specimen of rock, corresponding to the example in Section 5.2 of [11]. The description includes links to the parent specimen from which it was generated. The property prov:wasGeneratedBy links to the activity that generated the current specimen, which in turn links to the previous specimen, to the process operator, and to the processing method. This example illustrates how the standard PROV ontology supports specimen preparation descriptions directly.
A specimen with provenance and preparation information.
An alternative formulation of the relationship to a parent specimen is shown in Listing 5. Here the my:split property is a sub-property of samfl:relatedSamplingFeature. Further specialization of the PROV properties could support many more elaborate scenarios.
Alternative formulation of sampling feature complex, based on property-derivation (compare with Listing 4).
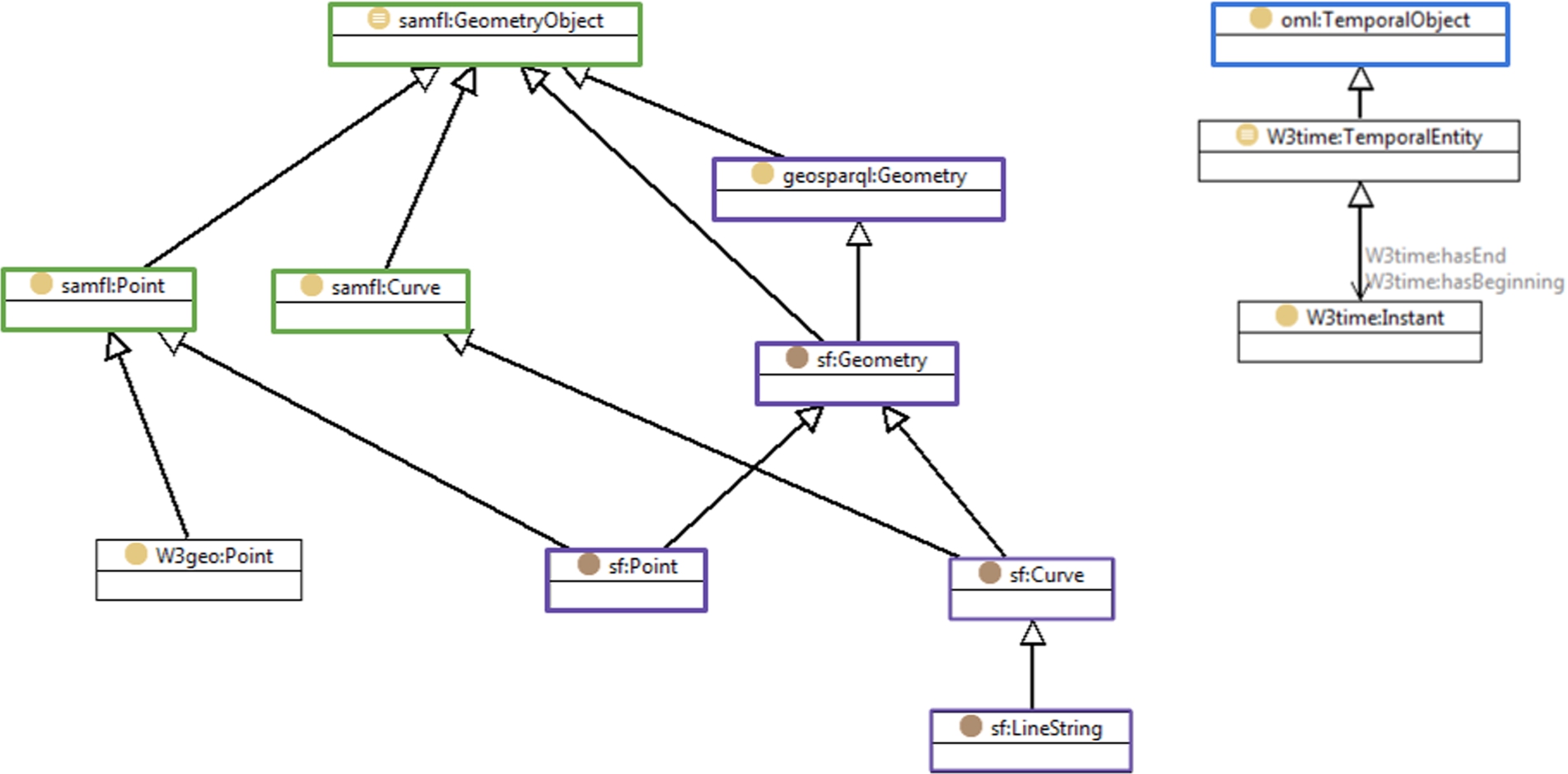
Alignment of existing ontologies with some of the stub classes for space and time from sam-lite and om-lite. The geosparql: and sf: classes from GeoSPARQL [43] are mapped to samfl: geometry objects through sub-classing. W3geo:Point from the Basic Geo Vocabulary developed by the W3C Semantic Web Interest group [3] is another sub-class of saml:Point. W3time: classes from OWL-Time [17] are mapped as sub-classes of oml:TemporalObject.
Time and space
Stub classes are used in om-lite and sam-lite to represent time and space concepts. When the ontology is used for data, additional axioms must be introduced or will be inferred, that link the stub classes to a concrete representation of time and space, as shown in 3.3. This is typically done by asserting that the type used is a sub-class of the stub class. The stub classes are therefore understood to be superclasses of all possible representations of these concepts.
Figure 7 shows possible sub-class relationships linking from W3C Basic Geo [3], GeoSPARQL [43] and the OWL-Time temporal ontology [17], to some of the stub classes from om-lite and sam-lite. Since the stub classes have no properties or constraints (or further superclasses) the subclassing axioms shown in Fig. 7 are “conservative”, and thus non-harmful in the sense described by Hogan et al. [19,20]. Nevertheless, such axioms should be introduced cautiously, usually only locally, in the context of data instances, as adding superclasses to legacy classes, also known as ‘ontology hijacking’, risks both performance and reasoning behaviour [19,20].
Quantity
The types oml:Measure and samfl:Measure that appear in Figs 5 and 6, Listing 1 and Table 2 are stubs for a generic scaled quantity. A simple representation is provided as oml:SimpleMeasure, having properties for the amount and unit-of-measure. Various other representations of this concept are available, such as qudt:QuantityValue [18], DUL:Region [16], which could be related to the stub classes by sub-class or equivalent-class relationships similar to those shown above for space and time.
Domain ontologies
Ontologies for observation applications may use one of two approaches to align with om-lite and sam-lite.
A new ontology may be explicitly based on om-lite and sam-lite. Classes and properties from om-lite and sam-lite can be used as-is, or else new classes may be specialized from classes in the om-lite and sam-lite ontologies, adopting the axioms and inheriting the existing constraints, and with new relationships and constraints.
An existing ontology can be mapped to om-lite and sam-lite by asserting class-class and property-property relationships.
Listing 6 shows relationships to align the OBOE ontology [39] with om-lite. In OBOE the term ‘Observation’ refers to a collection of individual ‘Measurements’ concerning different properties of the same feature of interest, so oboe:Measurement is the atomic concept corresponding with oml:Observation.
Alignment of classes and properties from OBOE [39] with om-lite.
Listing 7 shows relationships to align ODM2 [21] with om-lite and sam-lite (the ODM2 resource names are inferred from the ODM2 UML model).
Alignment of classes and properties from ODM2 [21] with om-lite and sam-lite.
PROV [36] is the only existing vocabulary used directly in the new ontologies, apart from the basic RDF, RDFS and OWL infrastructure.
The core O&M model concerns the production of data through observation events involving sensors, instruments and other observation processes. Samples are created and transformed by the application of other kinds of processes at specified times and places. Both of these appear to match well to the core PROV model, which is concerned with the production and transformation of Entities through time-bounded Activities, under the influence or control of Agents.
As described above, the motivation for the introduction of PROV in sam-lite was to support flexible description of specimen preparation chains, the details of which vary widely in different disciplines and communities. Hence, the primary axiom linking sam-lite to PROV is
As well as replacing the PreparationStep property in the context of specimens, PROV relationships could also be used in place of some applications of the samplingFeatureComplex property from the Sampling Features model (see Listings 3 and 4). The statement involving prov:wasMemberOf in Listing 3 entails that samfl:SamplingPoint is either equivalent to or subclassed from prov:Entity. So a more general subclassing axiom might be introduced:
The diversity of potential relationships between sampling features within a complex was managed in the original O&M model through a “role” property on the SamplingFeatureComplex class, which is implemented directly in sam-lite (Table 2). The same functionality can mostly be achieved by sub-properties of PROV properties whose domain and range allow for prov:Entity, in particular prov:wasInfluencedBy and prov:wasDerivedFrom. However, some common relationships between sampling features in a complex are not described using PROV semantics. The geometric relationships that connect stations to a transect, pixels to an image, or specimens to a borehole, etc., are “sibling” relationships, rather than the derivation relationships that are the focus of PROV traces. To retain the general functionality the properties samfl:complex and samfl:relatedSamplingFeature are included in sam-lite.
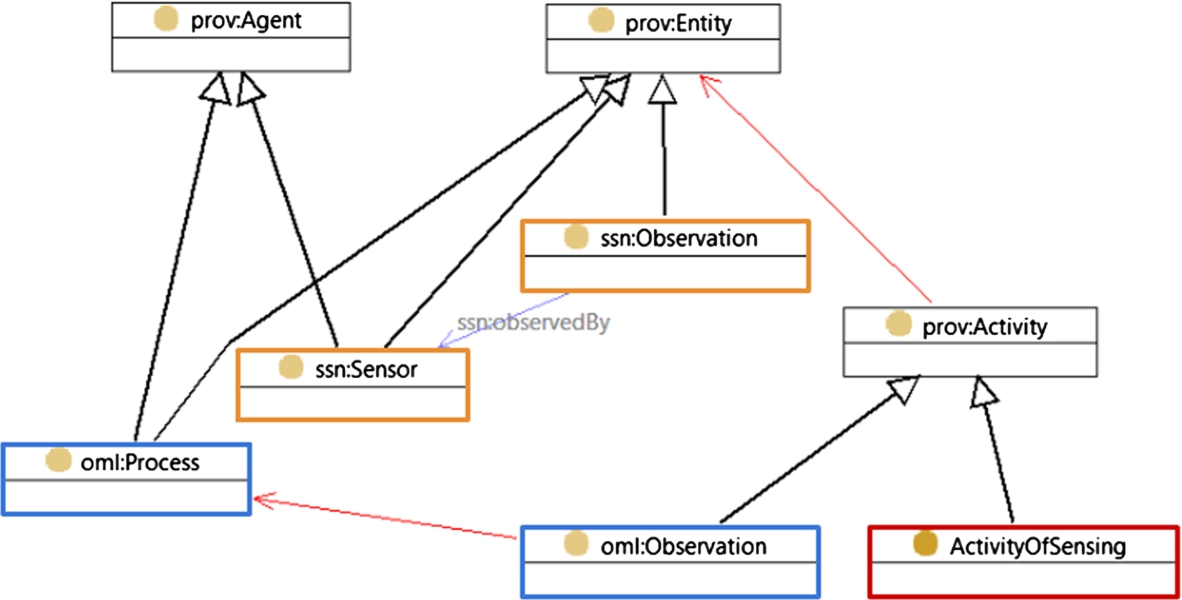
Alignment of SSNO and O&M with the core PROV classes. Note that ssn:Observation and oml:Observation are subclasses of two disjoint PROV classes (the disjoint relationship is indicated by a red arrow).
In O&M, an Observation is an event or activity, during which an observation process (sensor, instrument, algorithm) is responsible for generating a result. There is a straightforward alignment with PROV, as follows:
In the context of an Observation, an oml:Process (sensor, instrument, observer, algorithm) is classified as primarily an Agent, since it is an actor in the observation activity. An instrument or sensor might also be classified as an Entity for asset management purposes, and ‘Algorithm’ appears to also match prov:Plan which is a subclass of prov:Entity. Note that there is no inconsistency in this multiple sub-classification, since prov:Agent and prov:Entity are not disjoint classes.
Sampling processes are also agents, but the processes involved in observations and sampling are distinct, since they generate different outcomes (samples and observation-results, respectively), so:
A potential inconsistency between the Observation classes in the SSN ontology [5] and O&M was noted by Cox [11]. The concern is highlighted by the choice of alignment of SSNO with DOLCE: ssn:Observation is conceived as a sub-class of dul:SocialObject, which is disjoint with dul:Event, while in O&M Observations are intrinsically events, ending at the “result-time”.
A recent paper on SSNO-PROV alignment by Compton et al. [6] helps clarify this. The core of Compton et al.’s SSNO-PROV alignment is as follows:
In Fig. 8 we combine the om-lite-PROV alignment described above (Section 4.4) with the one from Compton et al. [6]. Notwithstanding the shared name, ssn:Observation and om:Observation do not play the same role. The new class ActivityOfSensing matches om:Observation, while ssn:Observation describes the output or record of an observation event. Listing 8 presents a SSNO-om-lite alignment derived from these considerations.

SSNO does not address sampling, so there is no overlap with sam-lite.
Dependencies
The primary motivation for this study was to develop an OWL ontology for O&M that does not introduce premature dependencies, either to a large infrastructure that was not strictly formalized as an ontology (the ISO model) or to a particular foundational ontology. Figure 9 shows the Observation class and its dependencies in the published versions of SSNO and OMU along with om-lite. The dependencies shown are those rendered by default by a popular IDE (TopBraid Composer3
TopBraid Composer http://www.topquadrant.com/tools/ide-topbraid-composer-maestro-edition/.
There are benefits in aligning a model with an upper- or foundational-ontology. It helps to ensure clarity in modeling, and to trap or avoid errors that have unintended reasoning implications. Nevertheless, the various candidate upper-ontologies, such as GFO, BFO, DOLCE (we may also consider the ISO 19100 series models, and PROV in this role) each have their particular biases [40]. These may lead to tension with the viewpoint of the application.

Comparison of the Observation class and its dependencies. In om-lite (top) the Observation class only links to other classes from om-lite, some of which are stubs, and none of which have super-classes. In SSNO (middle) there are immediate dependencies on super-classes from DOLCE Ultra-lite, each of which have further super-classes with properties that impose strict constraints on the interpretation of the Observation and Sensor classes. For example, ssn:Observation is disjoint with DUL:Event, and ssn:Sensor is always a Physical Object, which excludes algorithms, software agents, and possibly people. In OMU (bottom) the Observation classes requires use of classes from several other ISO 19100 standards, which are generally not well accepted outside the GIS community.
For example, through the alignment with DOLCE, ssn:Observation is disjoint from dul:Event (Fig. 9). This arises as a consequence of classifying observations as social objects (an understandable view), combined with DOLCE’s view that objects are disjoint from events. However, this is inconsistent with the conceptualization of observations in O&M, which are clearly event-like. Thus, the choice to align with specific classes from a foundational ontology can have side-effects. It is not clear if the side effects are harmful (Cox [11] found no information mismatch between SSNO and OMU, for example), but they can be disorienting. As noted above, Compton et al. [6] found it necessary to introduce additional classes to SSNO to complete the viewpoints.
The tensions might be avoided by omitting a priori dependencies on external ontologies, and instead capturing the alignments in separate graphs, which can then be used selectively for specific reasoning exercises.
The existing observation ontologies and models OBOE, ODM2 and SSNO are mapped to om-lite in Listings 6–8. Combining these also allows us to infer direct mappings. For example:
While these specific inferences could probably have been deduced directly, om-lite serves effectively as a bridging ontology when dealing with this network of applications using different local models or ontologies.
This is demonstrated by the counter-example already mentioned above. Even though O&M was used as the primary reference point in a review of prior work presented in the SSN project report [37], the SSNO still ended up using the term ‘Observation’ in a way that is inconsistent with how the term was defined in O&M (as described by Compton et al. [6] and shown above in Section 4.5). The narrative version of O&M adopted in that review was clearly not fully effective as a lingua franca, whereas a more precise view, such as provided by om-lite, particularly when augmented by the PROV alignment, might have mitigated the problem.
What’s in a name?
The tensions mentioned in the previous sections primarily relate to use of the term ‘observation’ to name a class in an ontology. While the class name is strictly a minor concern if its semantics match the way it is used in a particular dataset, the use of a common noun to denote a class inevitably conveys (informal) semantics to users. The term ‘observation’ is already used in different ways – sometimes subtly, sometimes starkly – in different communities, and this does lead to communications breakdown. The development of O&M [7,9] was originally a response to conversations involving people from different application areas, who were talking across each other while using the same words (this was in an OGC Testbed in 2002). For example, some said ‘observation’ where others said ‘value’ and still others ‘image’, and others ‘act of observation’. More recently it was discovered that the biodiversity community use ‘measurement’ for atomic observations, and ‘observation’ for what we might call an ‘observation collection’ (with particular homogeneity constraints). O&M, which matched a pattern previously described by Fowler in “Analysis Patterns” [15], resolved the misunderstandings. It was subsequently validated in a variety of other applications, mostly in earth and environmental sciences, including marine and climate [12].
The current work has uncovered that, even in the more rigorous setting of OWL, the name ‘observation’ is used in different ontologies for classes with significantly different commitments. Assessed using some frameworks they are disjoint. This is notable, and particularly so when the projects that developed the conceptualizations had some common lineage and participants (the SSN project made heavy use of O&M in the analysis phase, and the author of this paper is editor of the O&M standard [7–10] as well as a minor co-author on the SSN reports [5,37]). This paper draws attention to inconsistent use of the term ‘observation’ even within our community.
PROV – information resources, or real-world things?
The PROV specification [36] makes it clear that PROV is applicable to things in the real world, as well as to information resources. However, the examples in the W3C specification use prov:Entity almost exclusively for information resources (papers, reports, documents, datasets, graphs). A minor example of a biological specimen (drosophila-a) is mentioned in PROV-O, but has a very short provenance chain.
In the alignments proposed here, prov:Entity is the superclass in particular for samfl:Specimen and samfl:SamplingFeature, which are physical or notional objects in the world, not just documents or data. Adoption of PROV resolved a local problem in the sampling-features model, but also demonstrates the applicability of PROV to real-world things.
It is interesting to recall that the concept of ‘provenance’ originated in the art and museums world, where the focus is on ‘chain of custody’ of physical artefacts, in support of assessment of authenticity. PROV, on the other hand, focuses on the creation and transformation of entities, as the result of activities under the influence of agents. Custodianship in the conventional mode is less relevant to digital artefacts, which can be reproduced exactly at minimal cost. However, the two considerations come together particularly for specimens, where both transformation (sample preparation) and chain of custody are significant concerns. For example, specimens in forensic investigations, drug tests, or where there are financial market implications, such as assay values in mineral exploration, need careful provenance traces covering both transformation and custody considerations. The application and development of the PROV framework for physical and other real-world entities will be an interesting area of application.
Sampling features
Finally, it is notable that the other observation models and ontologies largely neglect the role of sampling features in the observation process, or subsume them as part of the description of the observation process or sensor model. This is a significant gap, as sampling is ubiquitous in practical observations scenarios, and some common patterns exist, separate from the description of observation processes. Sampling always involves subsetting the ultimate feature of interest in some way, and it is helpful to identify and describe both sampling features and the ultimate feature of interest separately and explicitly.
Spatially defined sampling is common in multiple domains in earth and environmental sciences (features with names like “station”, “transect”, “cross-section”, “swath” etc.), and multiple features are typically linked within a sampling strategy (specimens along a borehole; stations on a transect; flight-lines within an aerial survey; pixels within an image). The O&M spatial sampling features model was particularly influenced by Climate Science Modelling Language from the ‘fluid-earth’ community (oceans and atmospheres) [47], and the specimen model was influenced by a wider variety of use-cases, particularly geochemistry [14] and work in the biodiversity community that also led on to the development of the Biological Collections Ontology (BCO) [46].
The sampling features model in O&M provides a kernel for direct use, or for domain-based extension. Its implementation in sam-lite is thus a very important component of the observation ontologies.
Summary
We have described lightweight OWL ontologies for observations and measurements, and for sampling features, which implement the concepts from the ISO O&M model. In contrast to previous attempts, the new ontologies have no dependencies on either elaborate ontology networks or foundational ontologies, and thus do not require a user to commit to any existing framework. In particular, the classes defined in om-lite and sam-lite have no external super-classes. And types for geometry, time and measure (quantity value), which are required as the range of some key observation and sampling-feature properties, are implemented as ‘stubs’ with the expectation that they will be substituted at run time by types from an existing vocabulary. Each stub class is understood as the superclass of all concrete representations of geometry, time and measure. This is a potentially generally applicable pattern that maintains the requirement that suitable types be used, but without constraining the implementation in advance.
The single exception to the no-dependencies story is in the model for specimens, which re-uses elements from PROV. The motivation was to overcome some known limitations of the O&M model for specimens. However, we have also explored a more complete alignment with PROV. This is appropriate for the observation model – whose goal is to provide structured provenance information for estimates of property values. A side effect of the PROV alignment has been to clarify some tensions between the O&M model and the SSN Ontology. This also demonstrates that PROV may serve as a kind of upper ontology in alignment exercises.
The new ontologies may be used as-is,4
The om-lite ontology is published at
Footnotes
Acknowledgements
Thanks to David Ratcliffe for helpful pointers on OWL details, and Jonathan Yu for assistance in highlighting the key messages. The reviewers for Semantic Web Journal provided some excellent suggestions based on an impressively close reading of the text. This work is a contribution towards the harmonization of W3C and Open Geospatial Consortium standards for geospatial data, and was supported by the CSIRO Land and Water Flagship, the Water Information Research and Development Alliance, and the eReefs project.