
Abstract
This entry presents a research study on semantic interoperability that could be achieved in PHAIDRA International persistent ecosystem with support of aligned metadata and Knowledge Organization Systems. Several approaches from LODE-BD Recommendations and from some modeling and alignment techniques for controlled vocabularies are presented. The implementation of a state-of-the-art open source tool, VocBench, is proposed, to support collaborative development and multi-language concept alignment of controlled vocabularies (COAR and other) using SKOS. To aggregate, centrally manage, monitor and share all necessary information on metadata, vocabularies and mappings implemented in PHAIDRA Ecosystem, the development of PHAIDRA Knowledge Base underpinned by a terminology server is suggested.
Keywords
Metadata and controlled vocabularies implemented in PHAIDRA. Problem statement
PHAIDRA (Permanent Hosting, Archiving and Indexing of Digital Resources and Assets) International1 consists of fourteen Open Archives Initiative (OAI) persistent digital repositories (digital asset management systems) in use internationally at universities in Austria, Serbia, Montenegro and Italy. PHAIDRA is involved in content aggregation, reliable storing/archiving, linking for creation and archiving of multi-resource content types with a view to long-term data preservation [7].
Documentation of digital contents uploaded and aggregated in PHAIDRA repositories is accomplished by means of metadata assignment [4,13] on several levels: single file (individual item), collection, container (multiple content datastreams) and paper (single file with relations to other objects).
Metadata adopted in PHAIDRA allow clear assignments of data covering contextual and provenance information. Besides automatically assigned structural and technical metadata, PHAIDRA has a number of widely-endorsed descriptive metadata standard schemas (element sets, vocabularies), such as Metadata Object Description Schema (MODS) crosswalked to Dublin Core (DC), and Learning Object Metadata (LOM). Moreover, PHAIDRA metadata comprises also locally developed administrative metadata (e.g., UWmetadata crosswalked to DC and a short list of other metadata solutions) implemented as minimum representation information needed to satisfy requirements of different designated communities, including re-using projects, services, applications and partners/stakeholders (e.g., Digital Humanities Centers, OAPEN Foundation, OpenAIRE, e-Infrastructures Austria, EUROPEANA Libraries, local CRIS and Institutional Repositories).
The overall interoperability between PHAIDRA and designated communities is in accordance with policies (based on technical, content, organization agreements) about the perpetual use of data, Open Access (OA), Open Science and specific community recommendations, such as, for example, COAR Roadmap: Future Directions for Repository Interoperability [2] providing common meaning to the requested and exchanged services and data in order to lower possible (technical, syntactic, functional, semantic) conflicts.
PHAIDRA allows to perform advanced search and browsing through querying full-text, metadata, organizational units, object types, languages, and subject classifications presented in PHAIDRA with fourteen Knowledge Organization Systems (KOSs). These latter are implemented in PHAIDRA as static files, i.e. in fixed-schema depending databases, and are trapped within stand alone formats. This scenario hampers interoperability between content objects hosted by PHAIDRA repositories.
PHAIDRA repositories could overcome existing limitations obstructing powerful semantic interoperability [14] through application of Linked Data (LD) principles [10].
This article proposes to publish, integrate, manage and update Linked Open Data (LOD)-enabled ‘metadata and KOS values’ pairs in PHAIDRA in a common (to all PHAIDRA repositories) PHAIDRA Knowledge Base (KB) underpinned by a terminology server. Playing the role of a flexible and sustainable Semantic Hub, the PHAIDRA KB should address the challenge of ensuring that digital content remains accessible in an environment that is subject to continual change. Moreover, this KB should warrant that metadata and KOSs are properly harmonized to support aligned indexing, cross-semantic search, browsing and semantic interoperability of PHAIDRA content objects.
PHAIDRA towards linked open data environment
The twofold interrelated question, focused on decisions on how to organize data elements into more efficient and semantically richer structures starting from “most interoperability efforts” ([14], p. 9) – focused on metadata and KOSs − is the following:
How to align the encoding of subject-matter metadata terms (‘properties’ in LOD terminology) so that they become LOD-ready in all PHAIDRA repositories?
How to turn KOS subject-matter data values from static (literal values, hosted in fixed databases) to dynamic (non literal, LOD-enabled values) representation in all PHAIDRA repositories?
LODE-BD Recommendations [12] were born to provide clear practical solutions for these cutting edge issues. LODE-BD is a reference tool providing practical support on significant metadata modeling decisions (in both depth and detail), metadata encoding (enabling data re-use) and implementation (satisfying local and/or specific needs), while insuring sharing of meaningful (with clear purport) and comprehensive (both to humans and web engines) bibliographic data. LODE-BD also clarifies what kind of KOS values should be used to produce high-quality LOD-enabled bibliographic data, easily exchangeable through open repositories and sharable on the SW.
The present use-case proposes to align the encoding of metadata properties in all PHAIDRA RDF-aware repositories according to LOD-BD strategies encouraging the reuse of different LD-enabled KOS data values in property–value statement pairs.
As stated by Zeng & Chan ([14], p. 5), “within the spectrum of different perspectives on interoperability, semantic interoperability lies at the heart of all matters”, and goes “beyond those implementing the canonical search paradigm for seeking relevant information”.2
Different KOSs published by a number of communities worldwide have been already: shared through different registries (e.g., VEST, BARTOC.org, CKAN DataHub, European Union Open Data Portal, CIARD RING; COAR controlled vocabularies); aligned with each other (e.g., according to ISO 25964); published as LOD and linked on the frontline of the Semantic Web (SW, Web of Data; RDF/SKOS), with the help of web-based tools (VocBench, SILK, PoolParty, Amalgame, Protégé) and other concept and (meta)data harmonizing approaches.
The COAR Roadmap [2] stresses that LOD and their provision have the most important interoperability function in the SW environment and, consequently, to be considered the best candidates for interoperable web services for repositories. By engaging both LOD-enabled metadata and KOS data values published as LOD trustworthy (i.e. maintained in long term by authoritative organizations) sources, repositories can augment access to the best (i.e. most relevant, reliable and sharable) sources of the required information.
The supporting LOD aspect in the COAR Roadmap is cross-linked with other (cross-independent) aspects, such as: improving metadata quality; extending/replacing metadata exposition protocols; supporting long-term preservation and archiving; extending usage of visualization tools (along with implementing best practices for search engine optimization); handling of complex/compound/nested repository objects (e.g., enhanced publications); monitoring OA mandate compliance; exposing versioning information; extending the bi-directional connectivity of repositories and their services (technical issues and strategic benefits).
Information, data and knowledge modeled and processed according to LD techniques “surpass the current syntax-based possibilities in a qualitative fashion and thus can be processed, exchanged, referred and linked to different statement levels” ([5], p. 35).
To experience how LOD-ready data (metadata properties and controlled vocabulary value-data pairs) represent and support navigation of (external) related contents, one can access International Information System for the Agricultural Sciences and Technology (AGRIS)3 platform and search for some contents. AGRIS leverages the power of descriptive LOD-enabled metadata (encoded according to LODE-BD Recommendations [11]) as well as AGROVOC LOD Thesaurus mapped (through skos:closeMatch, skos:exactMatch RDF/SKOS syntaxes) to other sixteen LOD-ready controlled vocabularies on its backbone [11], and openly shared via CKAN Data Hub.4
KOSs implemented in PHAIDRA could be processed and aligned with trustworthy (based on persistent URIs) controlled vocabularies such as EUROVOC Thesaurus, Dewey classification, Association for Computing Machinery (ACM) classification, Art & Architecture Thesaurus, and COAR controlled vocabularies – encoded in RDF/SKOS – with help of a web-based, multilingual, editing and workflow tool VocBench2.5 In order to be properly reused, all concepts should be rendered/identified with persistent URIs and stored in a triplestore PHAIDRA KB.
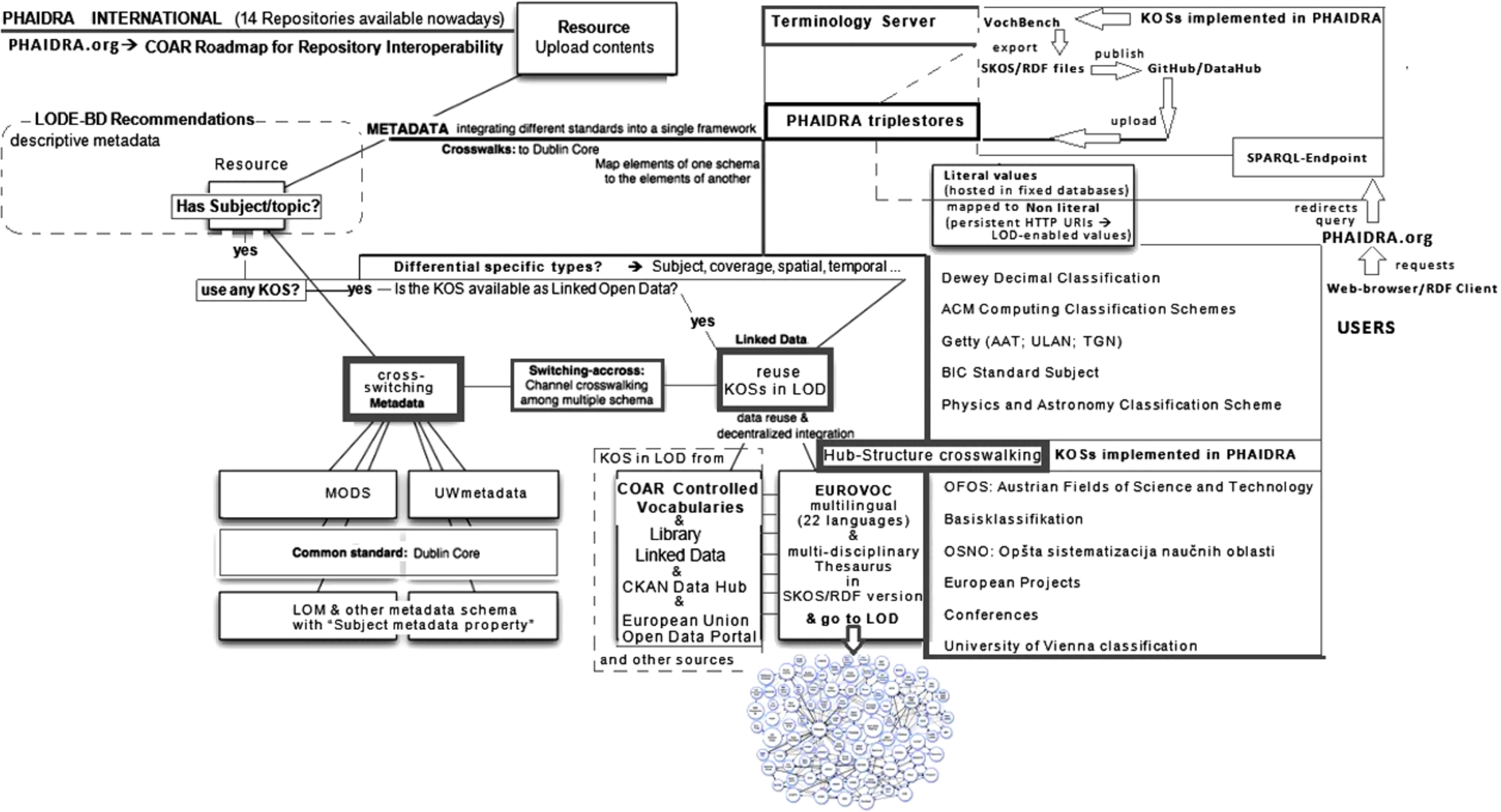
Alignment of metadata and controlled vocabularies in PHAIDRA International.
As can be seen in Fig. 1, all contents uploaded in PHAIDRA go through the PHAIDRA metadata structure, thus enriching themselves with all necessary (for representation and preservation) metadata properties. At the point of Subject-matter metadata, every content object can assume different semantic profiles, according to its content type profile and user choose to describe information digital object with this or that KOS. All KOSs implemented in PHAIDRA and identified (at the backstage of PHAIDRA KB) with persistent non-literal URI values (mapped to literal ones), combining, in this way, “the data- and people-centric approaches and [working] toward a more integrative model of significant properties [
It is expected, that PHAIDRA metadata and KOSs, enabled as LOD data, will pursue three primary objectives:
bridge on the semantic level all formerly isolated (silos or data available as raw dumps sacrificing much of its structure and semantics) data hosted in PHAIDRA participating repositories;
connect PHAIDRA data with KOS datasets available in the LOD Cloud, thus empowering PHAIDRA indexing and enabling integrated inter-, multi-, trans- and pan- domain semantic search and browsing functionalities;
benefit from global distribution, connectivity and re-usability together with other datasets published (in exponential growth, Big Data6 ) and shared on the Web by libraries, archives, museums (LAM), research communities, government and private entities.
Simply expressing repository contents by means of semantic data values with static/fixed/traditional (flat files with literal values hosted in fixed databases) notation – while aspiring to achieve high levels of visibility and semantic interoperability of repository data on the Web – will be of very limited value, because literal data values are useless or misleading to executing SPARQL queries operating on the Web of Data. “Encoding the alignment degrees is an emerging process called upon by the Linked Data movement. The mashups, crosswalks, and interlinking all heavily rely on the alignment of the components in RDF triples (subject-predicate-object)” ([14], p. 20). Maximizing the amount of semantics that can be utilized in encoding metadata properties and making it increasingly explicit through non-literal (HTTP URI) data values would enable repository data to be easily integrated into and retrievable from the Web of Data.
In order to turn subject-matter KOS data values exploited in PHAIDRA from static to dynamic representation, literal values should be underpinned by non-literal Persistent HTTP URIs (PIDs). Besides, any KOS data value, already published in LD version, could be reused. Non-literal KOS data values can be efficiently structured in RDF triplestores and exchanged according to LOD sharing approach [10].
To investigate which KOS – conveying controlled subject headings and topic entries in PHAIDRA – are already published and maintained as LOD datasets, the official entry pages of KOSs, CKAN Data Hub7 and European Union Open Data Portal8 have been consulted. Consequently, the following LOD-ready KOSs have been detected: (1) EUROVOC LD version encoded in SKOS;9 (2) Dewey.info encoded in RDF using SKOS;10 (3) Association for Computing Machinery (ACM) Classification LOD version;11 (4) Art & Architecture Thesaurus LOD version.12 Concerning Physics and Astronomy Classification Scheme (PACS), the “RDF Encoding of Classification Schemes” document”13 states, that “no definitive URIs for PACS itself or any of the PACS values have been published by the American Institute of Physics”.
To those KOSs, that have not yet their corresponding LD versions and that are published as open data supporting user rights and roles in the publishing workflow, local PHAIDRA persistent URIs can be assigned enabling these KOSs to obtain LOD-readiness. PHAIDRA triplestore infrastructure projected as a system for long-term preservation governed by an authoritative body (University of Vienna) has all necessary requirements to provide administration and group management features permitting flexible roles for publishing, reorganizing, validation, quality assurance and maintenance of released trustworthy data, performing any updates needed.
Keeping in mind that “KOS and metadata interoperability efforts have implemented similar methodologies” ([14], p. 12), LD versions underpinning fixed KOS notations used in PHAIDRA can be exploited through run-time/on-the-fly strategy described in LODE-BD (“This means to add a conversion service and leave the ad-hoc model unchanged”14 ). PHAIDRA metadata and KOS data values enabled as LOD should become primary building blocks to “get clean, enriched and linked”15 content indexing and expressivity easily respondent (exchangeable) to soundness of trustworthy LOD knowledge [1]. The run-time strategy in action can be viewed visiting AGRIS search infrastructure, that exploits AGROVOC multilingual (21 languages) LOD Thesaurus leveraging connections with other 16 multilingual LOD KOSs.16
To perform semantic agreements between all PHAIDRA KOS data at a higher level, it is important to address the next three issues:
overcome limits of the usability of some monolingual KOS;
mediate between diverse conceptual representations to determine semantic similarity in different KOS;
map/align/link semantically compatible KOS values following conventions of current standards for thesauri (ISO 25964:2013 – Thesauri and Interoperability with other Vocabularies).
“The process of mapping essentially consists of establishing equivalencies between concepts in different KOS vocabularies [“based on similarity of function or meaning of the elements”, which] may be presented with verbal terms, notation numbers, and/or Unique Permanent Identifiers” ([14], p. 18, 16).
To tackle theoretical and practical challenges entangled in issues just mentioned, this article proposes to consider three state-of-the-art methodological approaches reported in the “Open Metadata Handbook” [8], which are:
Value-based co-occurence mapping.
Switching-across or Hub-Structure crosswalking.
Robust and flexible data reuse and decentralized integration through LD.
Both replication and juxtaposing of these methods seems to be quiet feasible in PHAIDRA scenario in order to reach some semantic generalizations about significant subject properties and purposes for their mutual re-use in navigation.
Focusing on open repository interoperability issues, COAR vocabularies17 – published in traditional/fixed formats and anchored to URI-RDF/SKOS with the help of the VocBench – represent a high recommendable set of standardized multilingual controlled vocabularies. Concept labels of these latter can be easily used to encode metadata properties, thus providing the cornerstone of effective representation of bibliographical records for different communities of users.
COAR vocabularies formats are aligned with and replicating good practices of other open communities (e.g. CLARI18
) publishing controlled vocabularies. Moreover, COAR vocabularies adhere to the following principles: open vocabularies and open standards (under open licenses) are preferred over proprietary standards; formats and protocols are well-documented, verifiable, proven (being used in practice). COAR vocabularies can be implemented in repositories through plug in to import an RDF into the systems and integration through XML, with the name space for the vocabularies ⟨
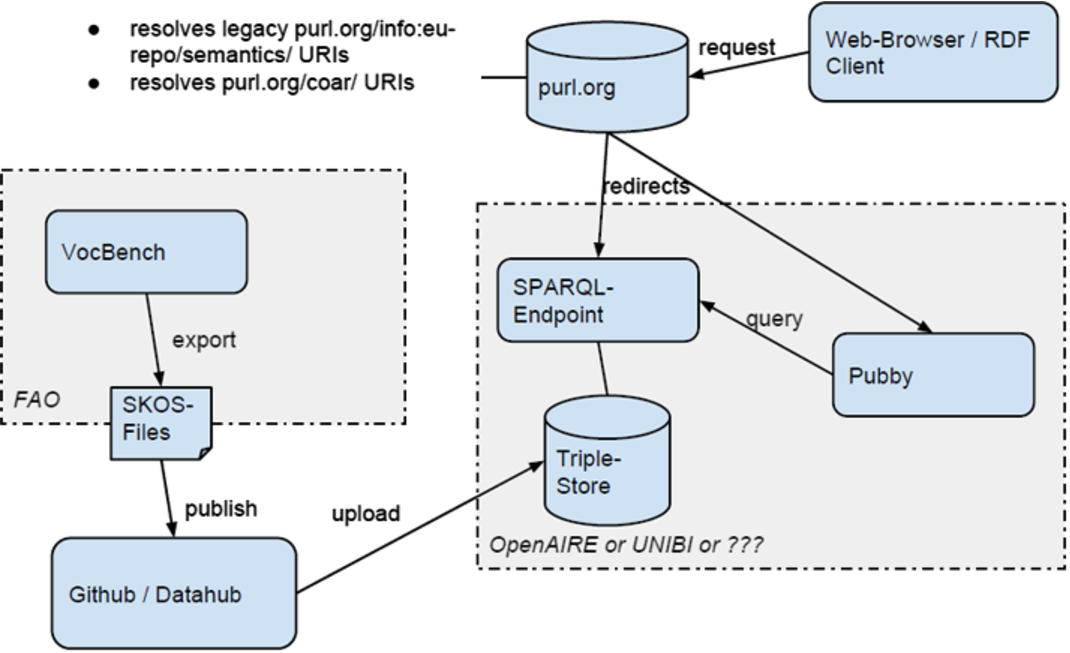
Data flow components for the COAR Controlled Vocabularies.
COAR vocabularies will be exported in PHAIDRA in RDF and HTML formats. Afterwards a list of all required (from COAR community) export functionalities will be investigated and a survey to identify the needs in terms of data (vocabulary) ingestion and data publication will be prepared.
Conclusions
In respect to the use-case PHAIDRA International there are some final considerations/proposals that can become actions/tasks to be undertaken: (1) all concepts of KOS implemented in PHAIDRA fixed formats could be turned to (persistent) URI-RDF/SKOS notations. Existing URI-RDF/SKOS versions of KOS could be re-used; (2) all concepts of KOS turned into URI-RDF/SKOS could be mapped/switched-off/crosswalked/cross-referenced on COAR vocabulary backbone based on LOD-ready concepts.
The implementation of COAR controlled vocabularies in PHAIDRA repositories will not only provide normalization and validation of metadata properties according to standard COAR community requirements (included as default for research contents, firstly at the European level), but also expand semantic expressivity of metadata in use.
Normalization and validation of PHAIDRA (meta)data properties through COAR vocabularies will certificate PHAIDRA as a trustworthy member [9] of European research community, highly and reciprocally tuned with OpenAIRE/Zenodo, DANS, Dataverse Network and other national and international research infrastructures.
COAR vocabularies in PHAIDRA International will serve as input for language tools to manipulate metadata records at international level, and to improve usability of PHAIDRA multilingual user interfaces according to hierarchical levels of the COAR vocabularies.
COAR controlled vocabulary interest group (in cooperation with other COAR groups) is planning to document serialization of specific formats, and fetching strategies to retrieve COAR vocabularies from web services and to import them into repository platforms.
Last but not least. All data, information and service provision should be of measurable quality and performed according to codified and interoperable policies. The detailed formalization of all aspects outlined in policies should be warranted by Data Management Plans (DMPs)19 expressing also all processes responsible for creation, analyzing, interoperability, presentation and preservation of data.
PHAIDRA managers have a strong interest in maintaining awareness and quality of metadata and KOS implemented in PHAIDRA, as well as in sustaining lifecycle management of this information while openly sharing it with other (potentially interested) repositories. The ideal scenario is a rich sustainable PHAIDRA International Open Persistent Ecosystem, on which dynamic collaborative data curation, authoring and reporting can be executed on a network scale. This ecosystem could receive a valid technical support by the implementation of robust services deriving from a PHAIDRA KB.
Footnotes
Available at:
2nd Linked Open Data-enabled Recommender Systems Challenge (2015). Available at:
Available at:
Available at:
Available at:
New H2020 Big Data Europe project. Available at:
Datahub, the free, powerful data management platform from the Open Knowledge Foundation, based on the CKAN data management system. Available at:
Available at:
Available at:
Available at:
Available at:
Available at:
Available at:
4.1. Implementation Options, LODE-BD. Available at:
Get clean, enriched and linked data from OpenAIRE. Available at:
Available at:
Available at:
Guidelines on Data Management in Horizon 2020 (2016). Available at: