
Abstract
Contributive resources, such as Wikipedia, have proved to be valuable to Natural Language Processing or multilingual Information Retrieval applications. This work focusses on Wiktionary, the dictionary part of the resources sponsored by the Wikimedia foundation. In this article, we present our extraction of multilingual lexical data from Wiktionary data and to provide it to the community as a Multilingual Lexical Linked Open Data (MLLOD). This lexical resource is structured using the LEMON Model.
This data, called DBnary, is registered at
Introduction
The GETALP (study group for speech and language translation/processing) team of the LIG (Laboratoire d’Informatique de Grenoble) is in need of multilingual lexical resources that should include language correspondences (translations) and word sense definitions. In this regard, the data included in the different Wiktionary1
Alas, many inconsistencies, errors and differences in usage do exist in the different Wiktionary language editions. Hence, we decided to make an effort to extract precious data from this source and provide it to the community as Linked Data. After a first version that used an RDF version of the LMF model [3,4] and was described in [10], we decided to adapt our extractors to the LEMON model [8]. This linked dataset won the “Monnet-Challenge” in 2012.
Motivation
Errors and inconsistencies are inherent to a contributive resource like Wiktionary. Some language editions (like French and English) have many moderators who limit the number of inconsistencies among entries of the same language. These languages, which contain the most data, use many templates that simplify the extraction process. For instance, the translation section of the French Wiktionary always uses a template to identify each individual translation (e.g.
This is not true anymore with less developed Wiktionary language editions. For instance, in the Finnish edition, some translations into French are introduced by the appropriate template (i.e.
Such inconsistencies and some errors in the data make the development of an extractor quite tedious. As many people in NLP are trying to use these data for different applications, we decided to extract lexical data from as many Wiktionary language editions as we could and provide it to the community while ensuring interoperability with other lexical data.
The DBnary extractor is written in java and is open-source (LGPL licensed, available at http://dbnary.forge.imag.fr). Anyone may contribute to this extraction effort by taking contact with the author.
Scope of the extracted data
The main goal of our efforts is not to extensively reflect the content of Wiktionary, but to create a lexical resource that is structured as a set of monolingual dictionaries complemented by bilingual translation information. This way, the structure of extracted data follows the usual structure of Machine Readable Dictionaries (MRD). We originally extracted those data as we needed translations in many languages along with textual definitions of senses that we used to compute semantic similarity between senses (using an adapted Lesk measure) for the Blexisma multilingual lexical disambiguation system [9].2
We also used this dataset to build an UIMA component for word sense disambiguation, more details are available at http://getalp.imag.fr/WSD.
The monolingual data are always extracted from their own Wiktionary language edition. For instance, the French lexical data are extracted from the French language edition.3
We use the term “French language edition” to refer to the data available on
We also filtered out some parts of speech in order to produce a result which is closer to existing monolingual dictionaries. For instance, in French, we disregard abstract entries that are prefixes, suffixes or flexions (e.g.: we do not extract data concerning in- or -al that are prefixes or suffixes and have a dedicated page in the French language edition).
DBnary data are made available using a Creative Commons Attribution-ShareAlike 3.0 license ( ). It may be downloaded from the DBnary website4
). It may be downloaded from the DBnary website4
As the Wiktionary language editions constantly evolve with entry modifications and additions, the DBnary dataset also evolves. Each time the Wikimedia foundation provides a new dump5
Dumps are available at
DBnary data are also available as Linguistic Linked Open Data (LLOD). All DBnary IRIs are dereferencable and a SPARQL endpoint is available at http://kaiko.getalp.org/sparql. However, as the DBnary data change almost everyday, the data that is available this way is not necessarily up to date.
Our work focuses only on the lexical data. Hence, we do not provide any reference to any ontology. Moreover, in this dataset, we only try to extract lexical data from Wiktionary, but we do not try (yet) to enrich it. Hence, this dataset is not (at the time of printing) linked to other lexical linked data.
Also, any interlinking with DBnary data will require that we take into account the constantly evolving nature of the dataset that changes every two days on average (as Wikimedia dumps are made available). Indeed, there is a chance that URIs of lexical senses may change between two versions as word senses may be reordered in the original Wiktionary data.6
Strictly speaking, even URIs of lexical entries may change, but this is even more unfrequent.
As the DBnary data have been extracted regularly since almost one year, with about 25 different versions per language, diachronic studies may now be performed to evaluate the frequency of such changes. However, such studies are not trivial to implement as a change in a definition does not necessarily imply that the lexical sense has changed.
Using LEMON for legacy lexical data
The LEMON model itself is not sufficient to represent lexical data that are currently available in classical monolingual and bilingual dictionaries. For instance, LEMON does not contain anything to represent translations between languages as it assumes that such a translation will be handled by the ontology description. Moreover, LEMON assumes that all data is well-formed and fully specified. As an example, the synonymy relation is a property linking a
As an example, in the English language edition, one may find a synonymy relation between cat_n and bitch. This relation links a Lexical Entry with a Vocable. Creating a corresponding lexico-semantic relation from Lexical Sense to Lexical Sense would imply: (1) detecting the correct sense of cat_n (here sense #4/15); (2) deciding which is the target lexical entry (here, bitch has 2 lexical entries, but only one is nominal); (3) deciding which lexical sense it is (#2/9). As such a process is error prone, we decided to provide the data as they appear in Wiktionary and to leave these decisions to further processing.
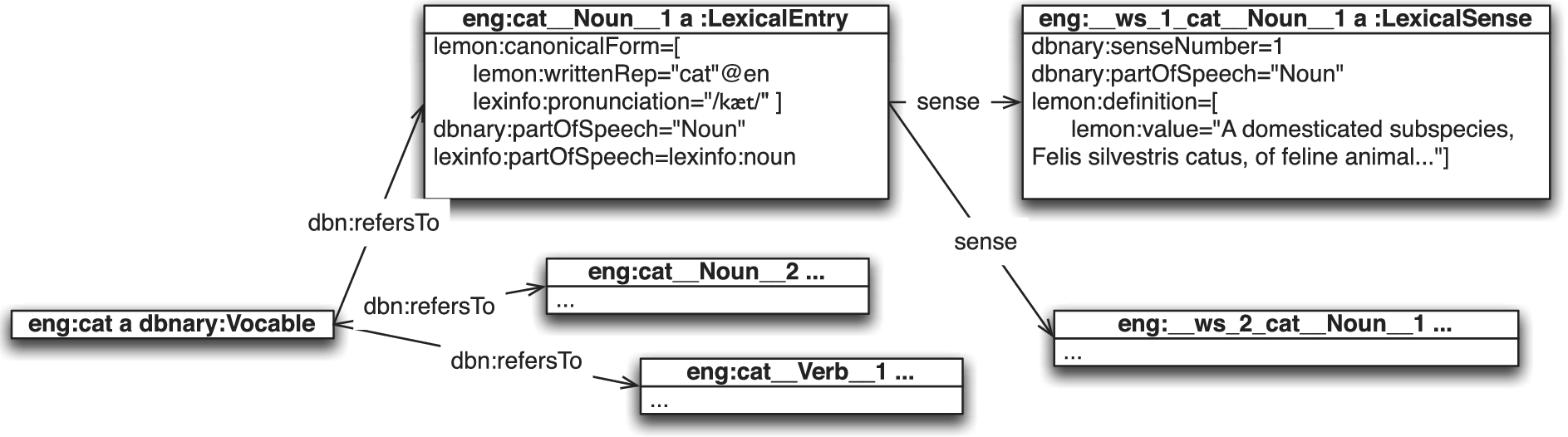
An extract of the DBnary entry “cat” in English, showing the respective roles of

A subset of the translations related to the lexical entry
In order to cope with these legacy data, we extended the LEMON model by adding new classes and properties. However, when a piece of data is representable as a LEMON entity, then we do it. Moreover, when possible, we use the ISOcat registry [11] to identify standard elements in the lexical data.
The LEMON model has been extended to cope with legacy lexical data. Added classes and properties are:
Several lexical entries may be contained in a single Wiktionary page, and most lexical relations are simply targeted to Wiktionary pages. Hence, we introduced the The
Lexical relations should usually link two Lexical Senses. However, most relations found in legacy lexical data are underspecified. Some relations link a Lexical Sense to a Vocable or to a Lexical Entry. Others even link two Lexical Entries. In order to cope with such underspecified relations, we introduced the
Indeed, we could have simply defined the domain/range of lexical relations and translations as a
Most Wiktionary language editions provide “nymy” relations (mainly synonymy, antonymy, hypernymy, hyponymy, meronymy and holonymy), that are almost always underspecified. Hence, DBnary introduces 6 new “nymy” properties (in
As there is no way to represent bilingual translation relations in LEMON, we introduced the
E.g.
This means that, in an ideal situation, the translation should be linked to this Lexical Sense, instead of the Lexical Entry, however, such a linking may be error prone, hence, we decided to make such refinements afterwards.
Figure 1 illustrates the main elements characterizing a lexicon entry in the DBnary data. Each Wiktionary page is represented by a
Each lexical entry is related to its canonical form and possibly to alternate forms (that are represented using
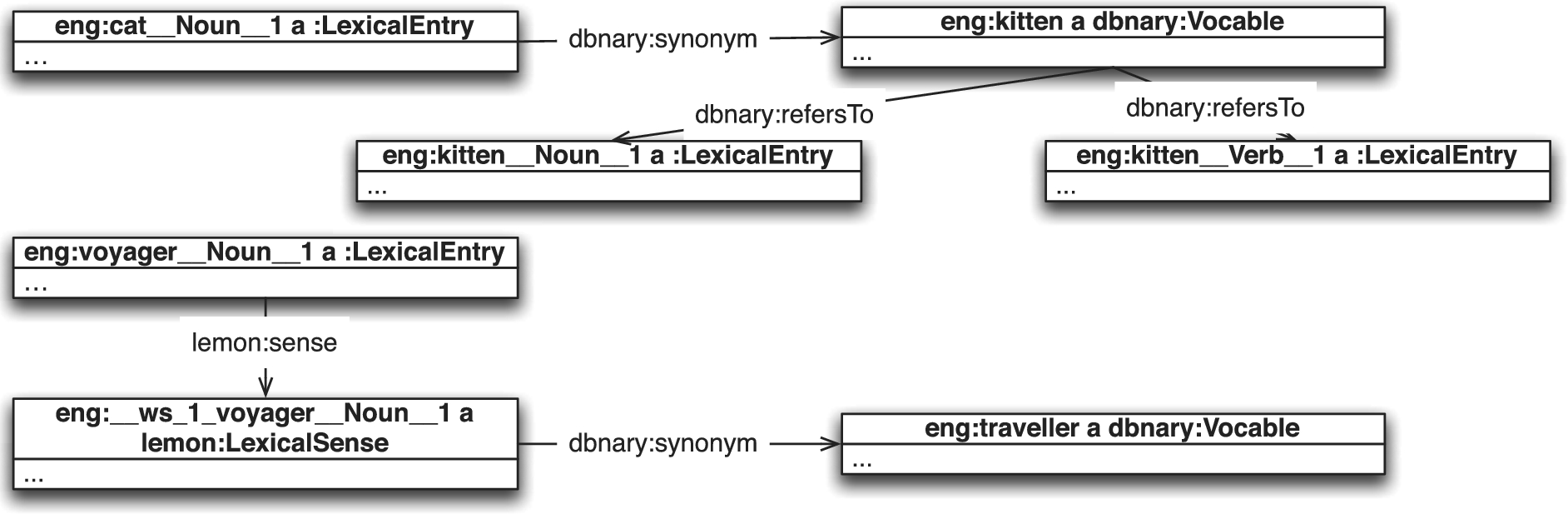
An example of a synonymy relation for the lexical entry
Figure 2 illustrates the DBnary extension to LEMON that is used to represent the numerous translations available in Wiktionary. Each translation is represented as a
Number of resources by type and language, sorted by number of lexical entries
Number of lexico-semantic relations. Languages are sorted according to their number of lexical entries
Number of lexico-semantic relations. Languages are sorted according to their number of lexical entries
Extracted translations vs interwiki links ratio, on a random sample of 1000 entries
All sizes indicated in this section reflect the state of the DBnary data at the time of writing (June 2013). These numbers are constantly evolving, as the original Wiktionary data is edited and as the extractor itself is improved.11
Statistics concerning the latest extracts will be made available on the DBnary website.
The currently extracted languages are (by increasing order of the ISO 639-3 language codes): German (deu), Greek (ell), English (eng), Finnish (fin), French (fra), Portuguese (por), Russian (rus).
Number of translations from/to the 8 currently extracted languages. Source languages are sorted according to their number of lexical entries. Target languages are sorted by their ISO 639-3 language code. The number of different target languages is also given
Table 2 gives an overview of the number of lexico-semantic relations available in each language edition.
Table 4 shows the number of translations available in each language edition, for the 8 currently extracted languages. It also gives the total number of translations and the number of the different target languages with translations. Not surprisingly, the English language edition shows the largest number of translations to more than 1000 different languages.
Asserting the quality of the extracts is difficult. We may compare the data with other Wiktionary extraction initiatives like [12] (contained in UBY [5]) or Wiktionary2RDF [6]. But this will only give informations regarding the common extracted languages.
In order to guide the extractors definition and maintenance, we compare the extracted data with the count of interwiki links13
Interwiki links are links going from one Wiktionary language edition to another. This count is a rough estimate of the translations available in an entry.
Finally, by comparing the evolution of extracted data over time, we are able to detect when an editorial decision is made in a language edition that leads to a loss of extracted data. That was the case when the French language editors decided to change the names of the macros used to represent a translation.
We have presented the DBnary dataset, a LEMON-based lexical network built from different Wiktionary language editions. That work is interesting for many users as it enables them to use the extracted data in their own NLP systems. Moreover, as the extracted resource uses the Resource Description Framework (RDF) standard and the LEMON model, the extracted data are also directly usable by researchers working on the Semantic Web, where it could be used to ease the ontology alignment systems when terms in different languages are used to describe ontologies of a domain.
DBnary contains a significant number of entries for at least English and French, which makes it comparable to Wordnet [2]. Moreover, it contains many translations with certain language pairs that makes it also comparable to the Open Multilingual Wordnet [1] (an aggregation of several existing multilingual Wordnets).
Our next objective is to better generalize the treatments of the current extractors, so that it will be easier to create and maintain extractors for other languages. We have recently introduced extractors for the Russian and Greek languages, and are working on others. We welcome all initiatives aiming at the addition of new languages to this open-source tool.
We will also enhance the DBnary data by providing more lexico-semantic relations and translations linked on the lexical sense level.
Acknowledgements
The work presented in this paper was conducted in the Videosense project, funded by the French National Research Agency (ANR) under its CONTINT 2009 programme (grant ANR-09-CORD-026).