
Abstract
The article introduces JudO, an OWL2 ontology library of legal knowledge that relies on the metadata contained in judicial documents. JudO represents the interpretations performed by a judge while conducting legal reasoning towards the adjudication of a case. To the aim of this application, judicial interpretation is intended in the restricted sense of the acts of judicial subsumption performed by the judge when he considers a material instance (token in Searle’s terminology), and assigns it to an abstract category (type). The ontology library is based on a theoretical model and on some specific patterns that exploit some new features introduced by OWL2. JudO provides meaningful legal semantics, while retaining a strong connection to source documents (fragments of legal texts). The application task is to enable detection and modeling of jurisprudence-related information directly from the text, and to perform shallow reasoning on the resulting knowledge base. The ontology library is also supposed to support a defeasible rule set for legal argumentation on the groundings of judicial decisions.
Keywords
« I see, these books are probably law books, and it is an essential part of the justice dispensed here that you should be condemned not only in innocence but also in ignorance ».
Franz Kafka, The Trial
Representing the judicial framework
Precedents (or case law) are core elements of legal knowledge worldwide: by settling conflicts and sanctioning illegal behaviors, judicial activity enforces law provisions within national borders, supporting the validity of laws as well as the sovereignty of the government that issued them. Moreover, precedents are a fundamental source for legal interpretation, to the point that the exercise of jurisdiction can influence the scope of the same norms it has to apply, both in common law and civil law systems – although to different extents.
Capturing the semantics of human-created texts to be processed by machines is not a linear process. In order to provide a comprehensive representation of the contents of a document it is necessary to adopt multiple perspectives, and to account for different aspects and granularity of representation. Legal documents require special attention when representing their semantics, as they do not typically express factual knowledge, rather codifying an order of an authority that can be translated by means of logical operators, but whose syntax is not fixed. Unlike a generic text, where the intended meaning of the combination of signs is either common knowledge or is explained by the author, interpretation of legal documents is a different matter. The language used is important by itself, its conventional meaning being codified by the legal system. However, it is also commonly accepted that assigning a meaning to legal dispositions is not straightforward: there are gray areas in the interpretation of legal, open-textured concepts, and the effects of legal acts are susceptible to change in time, either depending on a change of the legal text itself, or on external influences (i.e. other norms or judgments). The AI & Law research community has gathered significant results on this topic since the 1980s, with different approaches: legal case-based reasoning [2,11], ontology-based systems [34], and formal argumentation [24,26,44].
This papers covers part of a research (see [13]) whose aim is to define a Semantic Web framework for precedent modeling, by using knowledge extracted from text, metadata, and rules [5], while maintaining a strong text-to-knowledge morphism, in order to fill the gap between legal document and its semantics [38]. The input to the framework includes metadata associated with judicial concepts and an ontology library representing the structure of case law.
The research relies on previous efforts of the community in the field of legal knowledge representation [35] and rule interchange for applications in the legal domain [27]. The issue of implementing logics to represent judicial interpretation has already been faced e.g. in [9,22], albeit only in sample cases. The aim of the research is to apply legal theories to a set of real legal documents, defining OWL axioms in a Judicial Ontology Library (JudO) that provides a semantically expressive representation and a solid ground for a (future) legal argumentation system based on a defeasible subset of predicate logics. The JudO ontology library thus constitutes the cornerstone for semantic tools to enrich and reason on the XML mark-up of precedents (i.e. the metadata of case-law), supporting legal reasoning in the large.
Some new features in the recent version of OWL (OWL2, see [53]) unlock useful reasoning features for legal knowledge, especially if combined with defeasible rules. The main task is thus to formalize legal concepts and argumentation patterns contained in a judgement, with the following requirement: to check, validate and reuse the discourse of a judge – and the argumentation he produces – as expressed by judicial text. In order to achieve this, four different models that make use of standard languages from the Semantic Web layer cake (Fig. 1) have been used:
A
A
A
An
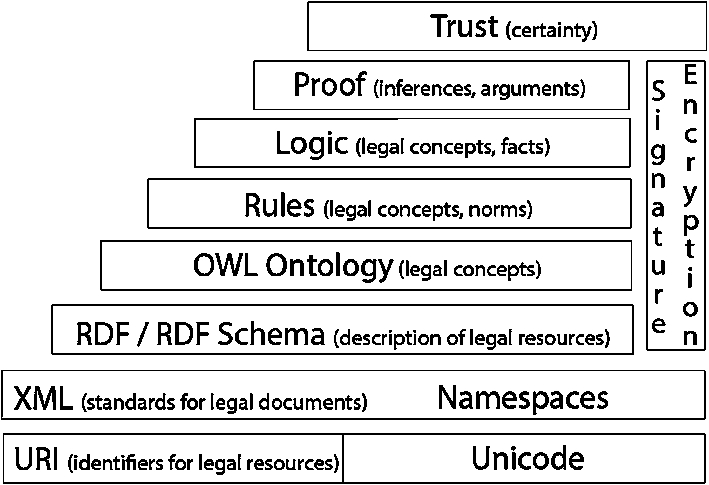
Tim Berners Lee’s Semantic Web layer cake, adapted to the legal domain in [47].
This work deals with issues related to the core and domain ontologies – (b) and (c) – which organize the metadata annotating the text of judicial decisions and infer relevant knowledge about precedents. The metadata structure is obtained from the Akoma Ntoso standard (see Section 3.1), while multiple solutions are being tested for building argumentation out of the ontology library: an application of the ontology library to the Carneades Argumentation System is described in [15], while future research will focus on applications on Drools (see [42]) and SPINdle (see [43]).
The paper is structured as follows: Section 2 presents the requirements and the design methods for the ontology library; Section 3 describes the ontology library design, and how it is used to represent knowledge related to judicial interpretation. The method is exemplified in Section 4 with reference to a sample of Italian case law. Section 5 presents an evaluation of the ontology, discussing related work in both legal ontology and legal reasoning fields, and some remaining issues with the proposed solution.
This research applies state-of-the-art techniques in ontology design and DL reasoning for the representation of knowledge extracted from legal documents, stressing OWL2 axiomatization capabilities in order to provide an expressive representation of judicial documents, and a solid ground for an argumentation system that uses a defeasible subset of predicate logics.
Modeling judicial knowledge involves the representation of situations where strict deductive logic is not sufficient to reproduce the legal reasoning as performed by a judge. In particular, defeasible logics [28] seem necessary to represent the legal rules underlying judicial reasoning. For example, many norms concerning contracts are not mandatory: they could be overruled by a different legal discipline through specific agreements between the parties. The problem of representing defeasible rules is a core problem in legal knowledge representation.
Moreover, argumentation theories (including the dialogue model of adjudication by [44], and argumentation schemes by [26]) introduce tools that are fundamental to perform effective reasoning on legal issues. This perspective adopts a procedural view on argumentation, which is necessary in order to properly represent those processes in an argument graph.
However, not all reasoning on judicial knowledge needs defeasible rules and argumentation, therefore we can safely apply classical deductive reasoning to a substantial subset. For example, the fact that most legal concepts do not admit both necessary and sufficient conditions is sometimes regarded as a limitation for a classical representation of legal concepts. However, it is common practice in domain ontologies to introduce mostly necessary conditions, which have a major role in reasoning, although enabling a smaller amount of inferences. In addition, some relevant domain concepts in law can be represented through class axioms instead of rules, so providing an explicit account of domain-level classical reasoning. The JudO class
The ontologies introduced in this paper address the classical subset of legal knowledge, in order to enrich the metadata annotating a legal document by performing deductive reasoning, and thus preparing a knowledge base for additional reasoning performed by tools based on deontic defeasible logics and argumentation schemes.
Following the requirement schema for legal ontologies that has been proposed in [19], the JudO ontology library is supposed to satisfy the following functional, domain, and application requirements. Functional requirements include:
Social frames, concerning the effects of the legal text in the social world (extra-legal perspective);
Procedural frames, concerning the effects of the legal text in the identification of different steps in a legal proceeding;
Substantial frames, concerning the effects of the legal text in the application of the norms it expresses.
Identify the acts which have legal force, distinguishing them on the basis of their strength (this has been achieved, for example, by distinguishing between “weak links” created by contracts and “strong links” created by judicial interpretation, which can overrule previous ones);
Create a conceptual frame bound together by the acts with legal force. JudO is based on the notion of qualifying legal expression (see Section 3.2.1), whose function is to create links between legal concepts under a same hat. The framing works by modeling those links as a relation between the qualification (the legal act) and the qualified elements.1
In practice, these links do not contribute to uniquely characterizing a legal object (because several – and possibly inconsistent – qualifications may involve the same object), but rather constitute a net of relations that provide the bread and butter of judicial interpretation. In the legal domain, relations seem to be more important than categories.2For example, signing a contract clause at the end of the page it is contained in could be considered as a specific signing of the clause in a judgement A, while not so in a judgement B. With JudO, we do not intend to determine which interpretation is more accurate, but rather to annotate both of them, together with the contextual information about the different judgements.
Judicial ontologies are intended to create an environment where knowledge extracted from the decision text can be processed and managed, and reasoning on the judicial interpretation that grounds the decision is enabled. Reasoning intends to satisfy the following domain requirements3
See [13] for an implementation of the ontology library into the Carneades Argumentation System.
laws cited;
legal figures evoked;
factors present in the material circumstances;
reproduce the semantics of legal consequences brought forward by legal rules; be able to automatically infer its application.
Such inference can then be compared to the outcome of the real legal case (classified in the ontology as an instance of the
the legal concepts
the galaxy of connections between the pieces of knowledge in the ontology can be based on either crisp or fuzzy categories, since a main requirement is to emphasize indirect connections between concepts. Certainly, in order to take the most advantages from this assumption, we may need to add fuzzy reasoning to JudO OWL axioms (cf. [7,8]).
The structure of the ontology library also aims at integrating the representation of legal concepts at different layers of legal interpretation, as when considering concepts in laws together with concepts in legal principles.
Practical applications of the ontology library include:
The intended application of JudO is based on a multi-layer paradigm, where a legal resource is managed in separate, mutually connected levels, which are organized in order to allow multiple annotation, interpretation, and classification, with representation redundancy. The annotation layer consists of the following elements:
The JudO ontology is designed into two main modules (see also [16]):
a
LKIF Core base URI is http://www.estrellaproject.org/lkif-core/lkif-core.owl, but it is not resolvable at the moment of finalizing this paper. You might use instead: https://github.com/RinkeHoekstra/lkif-core as a page for its source code.
a
Our design method is based on a middle-out methodology that incrementally integrates a bottom-up approach for capturing and modeling legal domain ontologies, and a top-down one for modeling core ontology classes and argumentation theory components. The middle-out methodology is implemented here by using pattern-based design [6,19], where ontology design patterns are extracted from judicial text, and, whenever possible, they are defined complying with the core ontology according to requirements.
The notion of judicial interpretation is the central one. It involves:
The Description and Situations (D&S) ontology design pattern [22]6
See also [23] for a previous version tailored to norm dynamics.
The qualification pattern (see Section 3.2.1) is aimed at capturing some aspects of legal interpretation, while keeping an open approach in order to maximize the results of the reasoning, since in the legal field even remote, apparently counterintuitive inferences may be important.
Evaluation has been performed on a sample set of Italian case law including 27 decisions of different grades (Tribunal, Court of Appeal, Cassation Court) concerning the legal field of oppressive clauses in Consumer Contracts. The matter is specifically disciplined in the Italian “Codice del Consumo” (Consumer Code), as well as in many non-Italian legal systems, so that an extension of this research to foreign decisions (and laws) can be envisaged.
Contract law is an interesting field because the (either automatic or manual) markup of contract parts allows highlighting single clauses and their comparison to general rules, as well as the case law concerning the matter. Contract markup can be used to perform semi-automatic compliance checking of a contract draft. The domain considered is also interesting for knowledge representation, because it involves situations where strictly deductive logic is not sufficient to represent the legal reasoning as performed by a judge. In particular, defeasible logics [28] seems needed to represent the legal rules underlying judicial reasoning. For example, many norms concerning contracts are not mandatory: they could be overruled by a different legal discipline through specific agreements between the parties. The problem of representing defeasible rules, in fact, is a core problem in legal knowledge representation. Exploring how OWL2 could set the background for the application of defeasible logic is therefore one of the goals of the present research. See Sections 4 and 5 for a presentation of the results achieved by the judicial framework.
Judgement in Akoma Ntoso [4] is a type of XML document modeled to detect the relevant parts of a text describing a precedent (Fig. 2): a header for capturing the main information such as parties, court, neutral citation, document identification number; a body for representing the main part of the judgement, including the decision; a conclusion for including the signatures.
Judgement structure in Akoma Ntoso.
The body part is divided into four main blocks: introduction, where usually (especially in common law decisions) the story of a trial is introduced; background, dedicated to the description of the facts; motivation, where the judge introduces the arguments supporting his decision; decision, where the final outcome is given by the judge.
This partitioning allows the highlighting of facts and factors pertaining to the judgement: in the motivation part, arguments and counterarguments are detectable, while in the decision part lies the conclusion of the legal argumentation process. Those “qualified” fragments of text are annotated by legal experts with the help of a special editor (e.g. Norma-Editor, presented in [37]) that is handy to create links between text, metadata and ontology classes.
The judicial core ontology7
(Fig. 3), or JudO, implements the qualification ontology design pattern. JudO defines OWL entities for the main concepts and relations in the judicial legal domain, dealing with judicial decisions. Core ontologies are typically domain-generic; however, being the legal domain too large and heterogeneous, several core ontologies can be designed. The ontology presented here is conceived to represent interactions in Civil Law, especially where contracts, laws and judicial decisions are concerned. For other domains, e.g. public contracts, administrative law, tort law, etc. adaptations are needed.
JudO Core Ontology (right) alignment to LKIF-Core (left).
The backbone of the JudO Core Ontology is constituted by three classes:
In order to understand those classes and their main relations (Fig. 4), we need to get an intuition (here described in non-strictly legal terms) of a “judicial decision” as the result of actions aiming at using a certain subset of legal language (“expressions” resulting from linguistic constructions realized by syntactic, lexical, and textual forms) in order to assign (“considering”, “qualifying”) legally-relevant entities (“qualified” entities or tokens), with appropriate types (“judged as” such).
Qualifications produce expressions about how some legal entity (token qualified entity) is qualified by a type. A type can also be qualified on its turn, as conceptualized in the qualification pattern. For each class, some subclasses are provided as examples. The judged_as property is defined through a property chain of the main properties considered_by and applies.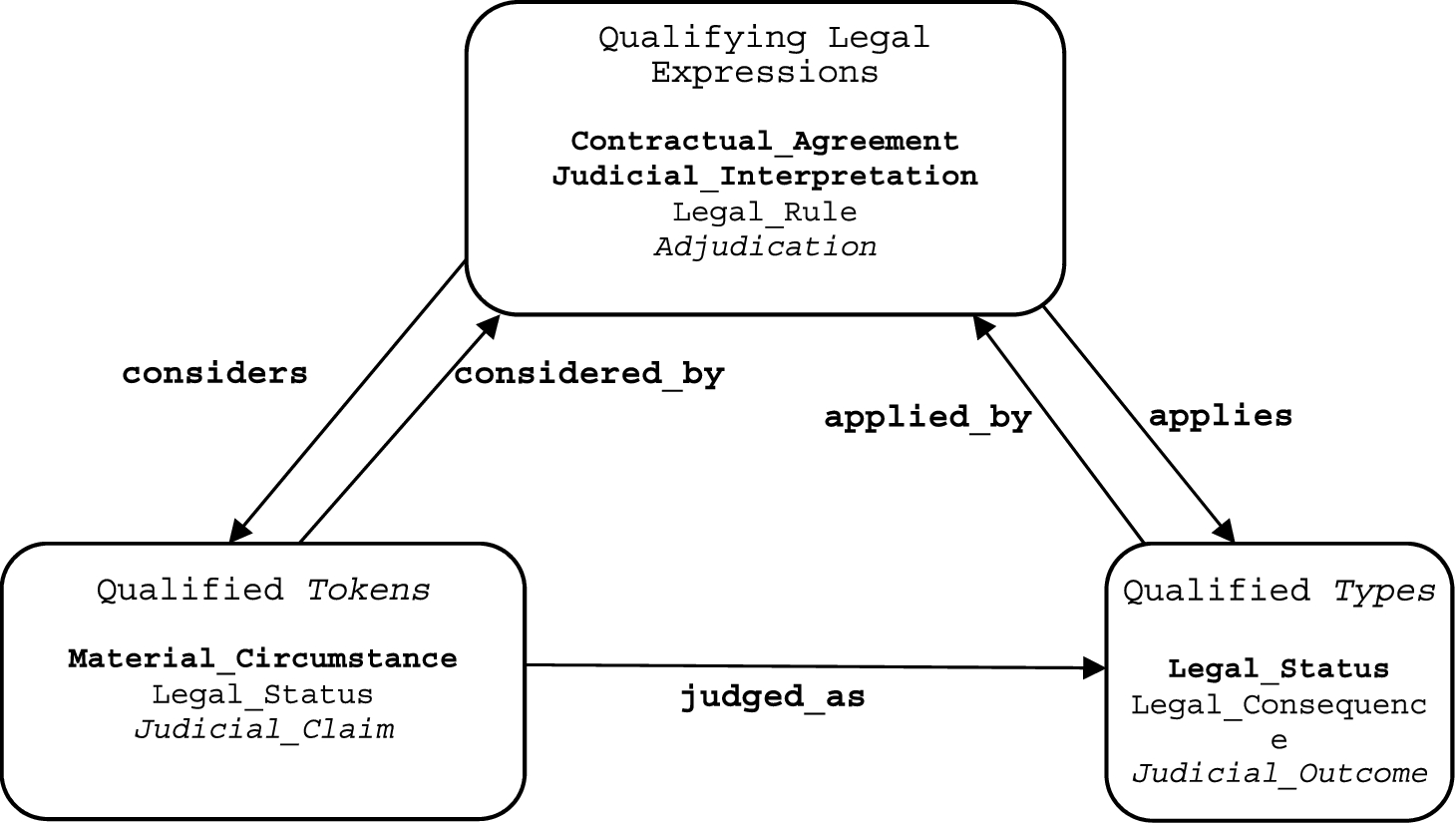
For example, a legal rule may express the situation, by which a legal consequence is “applied” for “judging” a certain legal status “considered” by that legal rule.
Now, using the D&S framework [20], we can conceptualize judicial decisions in the given example as follows: a legal consequence is a description of a situation involving a legal status, whereas the legal rule is a description of the reasons (another situation) why the “typing” is applied in order to judge the considered fact.
This layering of descriptions and situations is a typical feature of D&S that allows to overcome the ambiguity of extensional “typing”, as in the case of a class “Person” used to type a person, versus intensional “typing” as in the case when we want to take a different perspective on a fact or entity, i.e. what the legal consequence case is about.
From the logical viewpoint, this is non-trivial because we need at the same time to refer to a class, as well as to talk about that class [21].
Remarkably, the classes we (re)define here are actually reused from the LKIF-Core ontology, in order to align our pattern to it. In fact, LKIF-Core does not attempt to axiomatize the intuition we have just described, and limits itself to distinguishing two “mental objects”:
x is a citizen
x is an intellectual work
x is a technical invention
The
Legal acts are typically speech acts (cf. [3]) influencing the behavior of people and institutions by means of the performative or normative value of the meaning they express (semiotics.owl8
is an ontology design pattern formalizing speech acts in OWL, see also [19] for an application to legal ontologies).The modeling of qualifying legal expressions also takes into account Searle’s theory of constitutive acts, and the distinction between fact-tokens and fact-types (see [49]), which is modeled following D&S as situations vs. descriptions. The generalization over the entities that can be qualified is provided by
In the examples, both “x” (e.g. a material circumstance or legal fact), and its types (e.g. citizen, intellectual work, technical invention) are qualified elements, because a qualification tells us something about x, but at the same time it provides an example of citizen, intellectual work, or technical invention. In formal ontology, this means that qualifications provide both instantiation and exemplification [32]. In cognitive science, this means that qualifications introduce both a categorization, and a prototype [46].
Since the main object to be represented in JudO is the normative/judicial qualification brought forward by performative utterances (contractual agreements, legal rules and – most important – judicial interpretations), the classes presented above constitute the nucleus of the judicial core ontology. As we anticipated, the three classes constitute an ontology design pattern [19] specializing a part of the D&S framework [18,20]: qualifications are speech acts that produce descriptions (expressed by qualified legal expressions) that characterize qualified elements (either at the instance or type level), and can describe relevant legal situations when legal performatives and norms are applied to the social world.
From the design viewpoint, the qualification design pattern (Fig. 4) defines two further object properties:
Considering that qualifications are also expressed by qualifying legal expressions, they are designed as a reification of a ternary relation that in first-order logic would be represented e.g. as
The Descriptions and Situations framework provides a vocabulary to the well-known n-ary reification pattern, enabling to model both entities and concepts in the same first-order model. The availability of “punning” in OWL2 helps managing this meta-level flavor (see [21] for a detailed analysis of design alternatives with n-ary relation reification and the Descriptions and Situations patterns).
The qualification pattern can be used for different scenarios:
A
A
A
An
LKIF-Core [30] is an established generic legal ontology, and as we have mentioned, JudO is compatible to it. In this section we explain some of the measures taken to obtain this compatibility.
The Taxonomical relations for the Legal_Expression class. Taxonomical relations for the Qualifying Legal Expression class. Taxonomical relations for the Qualification class.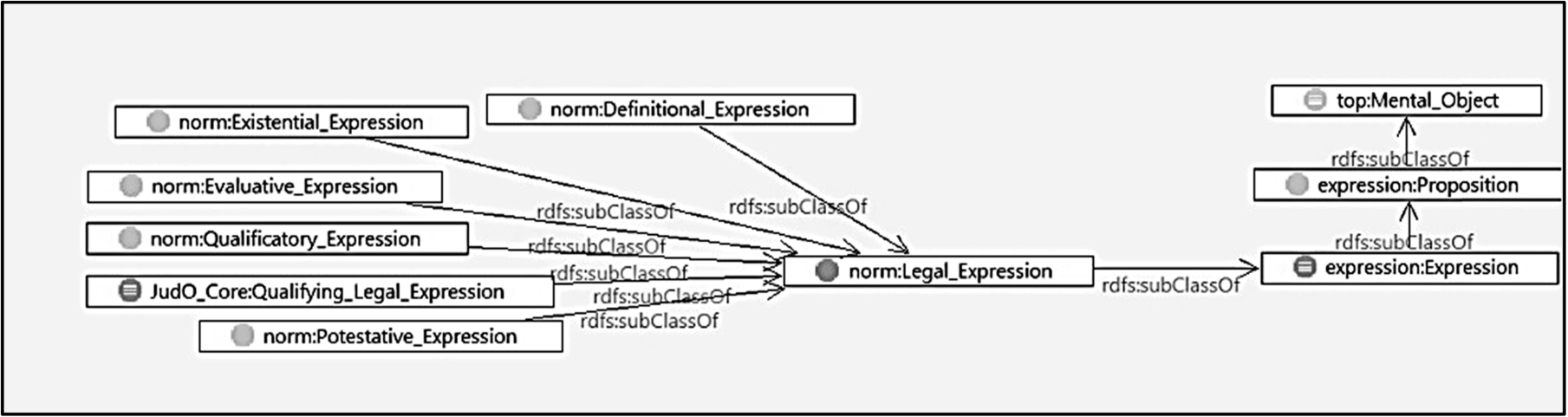


JudO also specializes the
The
Since
As
The
The
The
The content of the answer (rebuttal/acceptation of the claim or any other possible outcome foreseen by the law) is represented by the Taxonomical relations for the Qualified class. Visualization of the Adjudication class and of its semantic connections.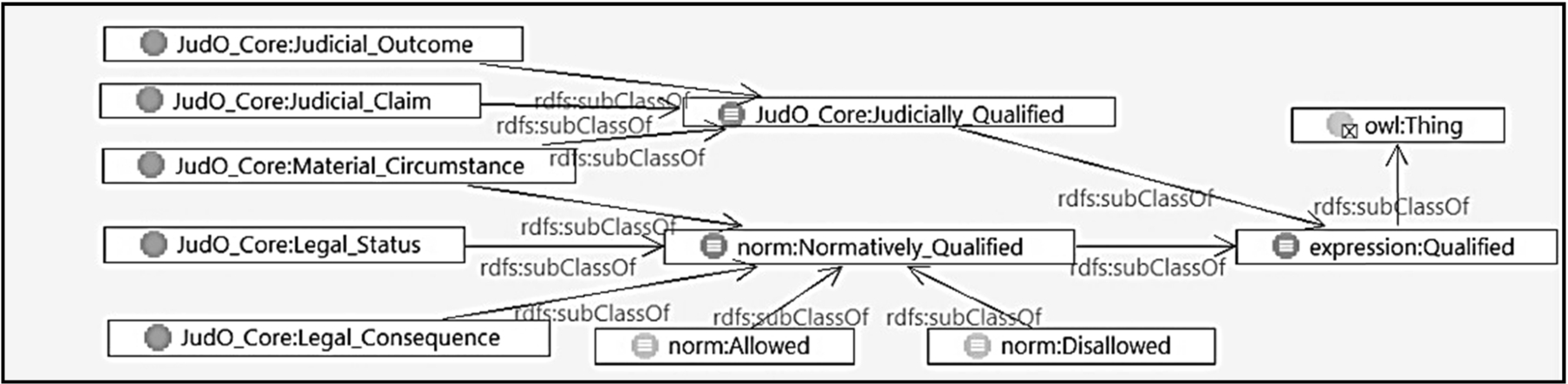

The aspects taken into consideration during a legal proceeding are included in the
Media, propositional attitudes and agents
Some LKIF-Core properties and classes support the representation of the context of an
The
The
In order to represent the authors of a qualifying legal expression, a generic
The modeling of roles (already present in LKIF, DOLCE, and other ontologies) is needed to represent critical factors of particular precedents.
Modularity of the core ontology
JudO is currently oriented to the representation of elements involved in civil-law cases regarding contract law. Nevertheless, JudO provides general – and relatively open – categories for judicial activity in general, and can be considered as a core to be extended with categorization from other branches of law, since the basic concepts introduced here may come into play also in judgements concerning different subjects.
Figure 10 represents the classes and properties of the core ontology. Figure 11 shows the same information, but provides a simpler intuition of the links between the classes of the ontology.
The Core Ontology graph: boxes represent classes; continuous arrows represent either the bears, attitude or considers properties; dashed arrows represent the applies property. Semantic relations between represented knowledge. Grey arrows represent the bears property, continuous arrows represent the considers property, dashed arrows represent the applies property. The connection from legal statuses to legal rules is ensured through a qualified class (see Section 3.3.1).

Following JudO, the metadata taken from judicial documents are represented in the Domain Ontology.9
The modeling was carried out manually by a legal expert, which actually represents the only viable choice in the legal domain, albeit giving rise to bottleneck issues (see below Section 5.3.1). Also, building a legal domain ontology is similar to writing a piece of legal doctrine, thus it should be manually achieved in such a way as to maintain a reference to the author of the model, following an open approach (i.e. allowing different models of the same concept by different authors).The laws involved in the considered domain are represented into the ontology in a quite complex fashion, in order to allow full expressivity of their deontic powers. First of all, they are represented as instances of the Stated property assertion of a Legal Rule instance. Visualization of the Contractual_Agreement class, including the subclasses introduced by the legal rules. Axiom for the classification of Contractual Agreements under the legal rule Art. 1341 comma 2.


A contract is a composition of one or more Description and property assertions of the contract clause’s content.
In the actual model, the material circumstances considered by the contractual agreement were not included, because the legal effects of the clause have no relevance when capturing the sheer interpretation instances these agreement undergo: it would rather become useful when delving deeper into semantic representation of interpretations.
The instances of the Description and property assertions of the Judicial Interpretation.
The consistency of the Knowledge Base was checked with the Hermit 1.3.610
An immediate application of this semantically enriched knowledge base consists in performing advanced querying on precedents, but more can be achieved by combining different Inferred knowledge on the Contractual Agreement instance.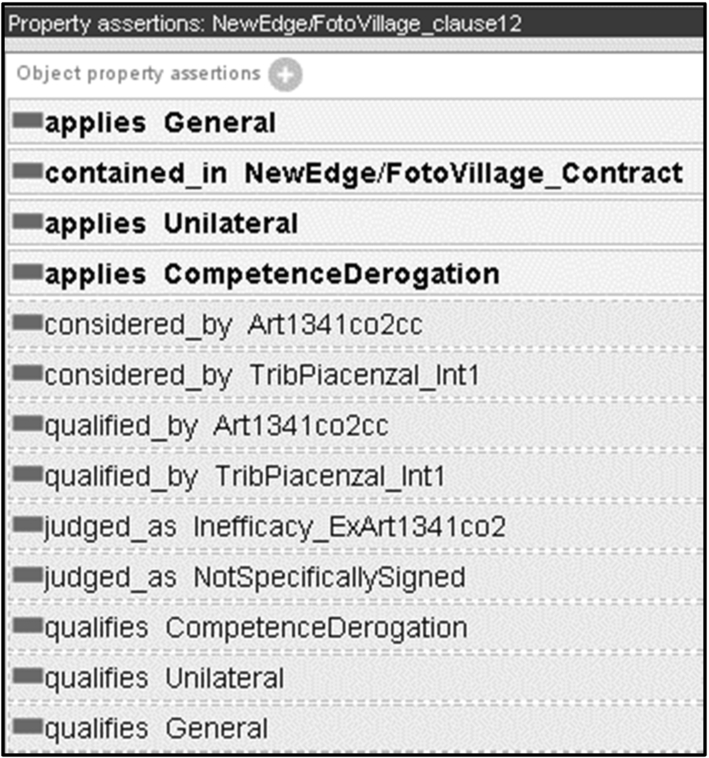
This inferred knowledge is important for two reasons:
by predicting the judge’s final statement on the clause (even if not the one on the claim), this knowledge represents a deontic check on the legal consequences the judge takes from its interpretation;
it gives a fundamental element for an argumentation system to support the explanation of the adjudication of the claim. The argumentation system, in fact, will be able to use the (stated and inferred) elements of the decision’s groundings to support and explain the
OWL2 [53] is a milestone standard for the Semantic Web, introducing new useful modeling patterns, and is relevant to any project willing to contribute to the “Web of Data”). In the case of legal reasoning, it is important to assess to what extent we can use those new patterns.
Also, we want to assess how OWL2 could help designing the background for the application of defeasible logic: OWL is not designed for managing defeasibility directly, being only able to capture the monotonic knowledge to be reused in the rule layer; nevertheless, the gap between ontology and rules is often underestimated, and the benefits coming from OWL2 have not yet been considered in detail. The assumption here is that the more we can use classical inferences, the better.
OWL2 introduces several features enriching the original Ontology Web Language, enabling a richer or simpler representation of knowledge, especially when dealing with meta-level assertions, properties and datatypes.
Some of the new features have been tested in JudO and the contract ontology, with varying results from the design perspective. For example, disjointness between properties can be used to reason about legal statuses, but it is necessary to create as many properties as possible statuses, which would negatively affect the readability of the ontology.
Other new constructs resulted to enhance expressivity without negatively affecting design and usability of the ontologies. We describe them by using OWL functional syntax.
Property chains
The OWL2 construct The property chain judged_as.
In the second case, a legal rule axiom works through an “anonymous qualified class” (see Section 3.3.1), which links all relevant expressions to the legal rule instance through the
A negative object property assertion such as:
Negative object property assertions are useful to avoid complicated workarounds for negating assertions. For example, the legal status
Keys
A
Annotation properties
Originally OWL allowed extra-logical annotations to be added to ontology entities, but did not allow annotation of axioms. OWL2 allows annotations on ontologies, entities, anonymous individuals, axioms, and annotations themselves.
This feature is used in the judicial ontology library to provide a full-fledged information structure about the author of each piece of the model (i.e., who modeled a certain axiom, which legal text it refers to, and who/when/how was the original legal text created). Moreover, it is possible to give domains (AnnotationPropertyDomain) and ranges (AnnotationPropertyRange) to annotation properties, as well as organize them in hierarchies (SubAnnotationPropertyOf). These special axioms have no formal meaning in OWL2 direct semantics, but carry the standard RDF semantics in RDF-based semantics, via the mapping to RDF vocabulary, therefore annotation axioms can still be used in queries and in shallow reasoning when needed.
N-ary datatypes
In OWL it was not possible to represent relationships between values for one object, e.g., to represent that a square is a rectangle whose length equals its width. N-ary datatype support was not added to OWL2 because it was “unclear” what support should be added. However, OWL2 includes all syntactic constructs needed for implementing n-ary datatypes. The Data Range Extension: Linear Equations W3C Note11
proposes an extension to OWL2 for defining data ranges in terms of linear (in)equations with rational coefficients. This kind of equations is important in the process of identifying individuals to classify under a legal ontology framework, based on the comparison between quantitative values corresponding to several factors for a same individual, even if the path-free limitation imposed by the W3C Note (i.e. we cannot compare the same kind of value for two different individuals) is actually a problem for some legal cases, as when comparing the age of a person, and the legal age limit stated by a norm.12This modeling issue can be solved by a SPARQL query on RDF data, which is a suboptimal solution with respect to complete reasoning.
While originally OWL allows for restrictions on the number of instances of a property (i.e. for defining the class of persons that have at least three children), it does not provide means to constrain object or data cardinality (qualified cardinality restrictions), i.e. for specifying the class of persons that have at least three children, who are girls). In OWL2 both qualified and unqualified cardinality restrictions are possible through the constructs:
An Example of judgement modeling
JudO domain application is explained here through a simple example of data insertion and knowledge management. The following is a description of the case to be modeled:
In the decision given by the 1st section of the Court of Piacenza on July 9th, 2009,13
Sent. N. 507 del 9 Luglio 2009, Tribunale di Piacenza, giudice dott. Morlini.
In order to represent the knowledge contained in the judgement text, three documents have to be modelled: Art. 1341 comma 2 of Italian Civil Code, the contract between the two enterprises α and β, and the decision by the Court of Piacenza.
The following is the law disposition involved in the judicial decision:
The disposition is represented as a
The list of legal statuses classified as oppressive.
The Stated property assertions for the sample agreement.
The Stated property assertions for the sample judicial interpretation. The graph showing the model of the sample case. The general classes of Fig. 10 have been substituted with the sample instances. The properties (arrows) connect the same classes of the core ontology.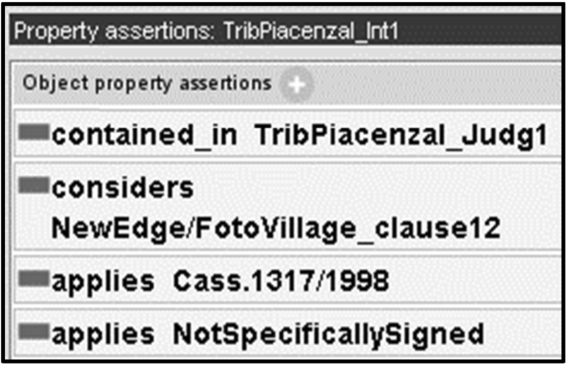

In the example, when all the relevant knowledge is represented into the ontology, an OWL2 reasoner is capable of inferring that “The agreement contained in clause 12 of the α/β contract is invalid ex article 1341 comma 2” (Fig. 23). As already explained, this result is reached through a subclass of the Inferred Description and property assertions for the contract clause content. Explanation for the sample agreement being inefficacious.

The ontology library, tested on a sample taken from real judicial decisions, meets the following requirements:
Computability was not an issue in the last ontology library version (<5 seconds reasoning time on a Intel i5@3.30 Ghz), while the Carneades reasoner was moderately encumbered by the application of the rules to the ontology (8–15 seconds in the example described in [15]). This could be improved by optimizing the reasoner and/or with a further refinement of the ontology/rules structure.
Comparison to related work
The framework presented in this paper relies on previous efforts of the community in the field of legal knowledge representation [10] and rule interchange for applications in the legal domain [27]. The issue of implementing logics to represent judicial interpretation has already been faced in [9,22], albeit only for the purposes of a sample case, and in [54] on a realistic regulation knowledge base, but using a lighter description logic.
The methods applied for the construction of the core legal ontology are similar to those used for [12], an online repository of legal knowledge to provide answers to issues related to legal procedures. The main difference between the two approaches is that the latter relies on application of NLP techniques to user-generated questions in order to return the correct answer. The judicial ontology instead extracts information from official legal documents (laws, decisions, legal doctrine), whose content classification requires the intervention of a legal expert. Furthermore, the ontology in [12] focuses on legal procedure, while the present ontology concerns mainly judicial interpretations carried out by the judge in a decision, seen as subsumptions of material facts or circumstances under abstract legal categories.
The project presented in [48] focuses on a lower layer of the Semantic Web, concerning document structure and data interchange between different legal documents. For the same purposes, the present project relies on Akoma Ntoso (see Section 3.1). Besides its being foucused on administrative procedures, the project in [48] shows a rather interesting view on the procedural aspects of legal phenomena, which is something this ontology does not achieve, being this task demanded to an argumentation layer placed on top of the ontology layer.
[17] presents a semi-automatic construction of an ontology concerning the language of a legislative text. The project is focused on the linguistic aspects, in particular on the use of NLP techniques to normalize and formalize the text in a set of concepts previously modeled in an ontology. The ontology is built around DOLCE-based Core Legal Ontology [22] and LRI-Core, which makes it likely to be aligned with the ontology presented in this paper. The ontology in [17], in fact, ensures a close relation with the legal text, even though it does not includes axioms that enable shallow reasoning on specific legal phenomena.
The ontology in [50] is very interesting for the orientation towards NLP, the solid basis on metaphysics, and in that it allows shallow reasoning on a set of simple legal sentences. It is built around the NM ontology ([50] contains a comparison to LRI-Core), and relies on agents to bridge the legal text with the syntax. The approach is interesting, yet the focus on agents somehow overcomplicates the reasoning on complex legal concepts such as that of judicial interpretation. Detecting advanced concepts in legal documents requires in fact a highly complex semantic structure, which prevents reasoning on a large document corpus contents (for a general account on how to model complex legal concepts for automatic detection see [40]). Moreover, as already noted, modelling the dynamics of legal procedure requires a proper implementation of argumentation theory.
A bridge towards judicial argumentation
The argumentation system described in [14,15] combines the features of DL-based ontologies with non-monotonic logics such as Defeasible Logics. In particular, T.F. Gordon’s Carneades [25] is based on Walton’s theory [26], and takes into account most of Prakken’s considerations on the subject [44], including argumentation schemes and burden of proof. The Carneades application succeeded in performing the tasks of finding relevant precedents, validating the adjudications and suggesting legal rules, precedents, circumstances that could bring to a different adjudication of the claim.
Many projects tried to represent case-law during the nineties, most of which are related to the work of Kevin Ashley [2]. Their main focus is similar to that assumed in the present research: capturing the elements that contribute to the decision of a judge. They were meant to support legal argumentation teaching in law classes, and the approach was therefore based on concepts rather than on legal documents. No account for the metadata of the original text was given, and there is no ontology underlying the argumentation trees that reconstruct the judge’s reasoning.
Rather than representing a single judicial decision, the approach presented in this paper allows instead to connect knowledge coming from different decisions, and to highlight similarities and differences between them, not only on the basis of factors, dimensions or values, but also on the basis of the efficacy of the legal documents involved (e.g. under temporal and hierarchical criteria). Of course, templatizing legal documents is a very complex task, but the intention is not to provide a complete extraction tool, but to create an interface, through which a legal expert can easily identify the legal concepts evoked by the text, and combinations of them, in legal documents.
Deontic defeasible logic systems, such as those presented in [28,31,36], constitute indeed a powerful tool for reasoning on legal concepts. Most of them are explicitly built to import RDF triples, which means that they can perform reasoning on knowledge bases derived from ontologies such as the one presented in this paper. These projects can be placed at an upper layer than the one discussed here: an ontology, in the perspective of the research presented here, focuses on document semantics and basic relations, performing open world reasoning mostly oriented to data completion. Over such knowledge base, rule systems based on non.classical logic dialects can perform more reasoning (as e.g. supported by SPINdle [33]), by importing only the set of triples that best suits their needs. This may be preferable to approaches that try to extend DL to perform defeasible reasoning such as [1]: JudO shows that it is possible to perform classical reasoning while staying within OWL2, while deontic logic, defeasible reasoning and reasoning on argumentation schemes [54] come on top of it.
The same considerations come from the approach in [34], which provides a simple and intuitive way to encode default knowledge on top of terminological KBs.
From this perspective, the idea of deriving a closed-world subset of an OWL2 ontology as presented in [45] seems a good direction, and will in fact be explored, keeping in mind, though, that introducing negation-as-failure in OWL2 is not sufficient to grant the ontology layer the expressivity required for performing argumentation tasks.
Issues
The knowledge acquisition bottleneck
Modelling the sample ontology library and extracting knowledge from the sample of case law was carried out manually by a graduated jurist. Similarly, qualified fragments of text under the Akoma Ntoso standard are supposed to be annotated by legal experts. Currently, manual data insertion seems the only viable choice in the legal domain, since automatic information retrieval and machine learning techniques do not yet ensure a sufficient level of accuracy, even if some progress in the field has been made (for example in applying NLP techniques to recognize law modifications, as in [38]).
Manual markup of judicial decisions, however, doesn’t seem to be sustainable in the long time. For an efficient management of the knowledge acquisition phase, a combination of tools supporting an authored translation of text into semantics should limit the effects of this still unavoidable bottleneck. Special editor tools (e.g. Norma-Editor) could enable an easy linking of text, metadata and ontology classes, while the more complex ontology constructs (e.g. the “considers/applies” chain) could be managed by an editor plug-in. Stronger constraints could be added to the legal core ontology in order to allow these plugins to automatically complete a part of the classification work, leaving to the user the duty of checking and completing the model drafted by the machine.
A possible new direction is to combine text fragment annotation à la Akoma Ntoso with semantic web machine reading as performed e.g. by FRED14
A critical issue in representing the decision’s content is represented by exceptions to legal rules. How to model a situation when a material circumstance applies all the legal statuses required by the legal rule, but nevertheless does not fall under that legal rule’s legal consequence because it follows some additional rule that defeats the first one? This issue has no straightforward solution inside the description logic fragment expressible in OWL2: once negative conditions are introduced for the rule to apply (in the form
However, a solution to this problem might rely on modeling the exceptional case as a subclass of the normal case, (see Fig. 25). In that way, only the instances that are relevant under the law are eligible to be an exception to the application of that law. This solution has the advantage of enabling reasoning on exceptions, without the need to apply defeasible rules. The backside is that the classification of the circumstance as exceptional is added to the classification of inefficacy, and not substituted to it (Figs 26 and 27).
Explanation of a sample contract clause being not inefficacious because of an exception. Explanation for Relevancy being inferred as a subclass of Inefficacious. Stated/inferred property assertions on the exceptional contractual agreement.
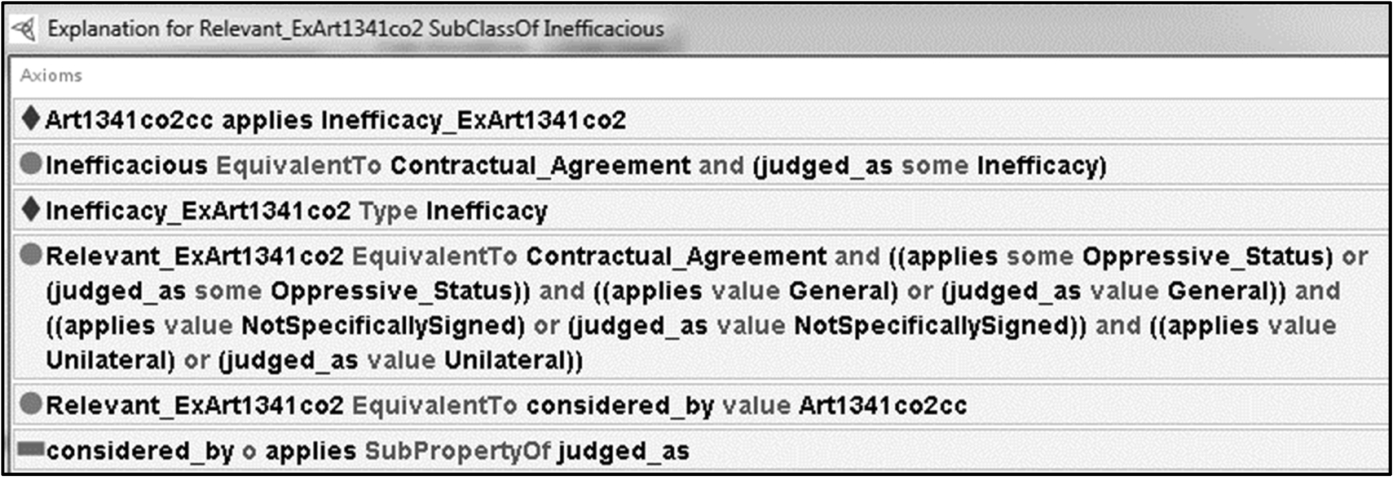

Again, this issue originates from the open world assumption, and cannot be easily avoided while remaining inside OWL-DL: whenever the reasoner is prevented to link a circumstance to a legal consequence, asking him to check that no exception exists, the reasoner will be incapable of inferring anything unless all information concerning the exceptions is explicitly provided in the ontology.
This issue represents the main reason why a complete modelling of legal rules is not feasible within JudO, requiring instead a rule system (such as LKIF-Rules [24], Clojure, or LegalRuleML [41]) to be fully implemented.
We have presented an ontology design pattern, JudO, which enables representation and reasoning over the content of judicial decisions. The pattern uses the conceptualization behind the Descriptions and Situation framework, and a semiotic ontology, but also reuses (and is aligned to) the LKIF-Core legal ontology. JudO is then specialized in a sample contract domain ontology, in order to show the capability of the pattern, and of some advanced features of OWL2 to express a larger part of legal knowledge in the OWL2 description logic fragment.
The ontology library presented in this article is the pivot of an innovative approach to case-law management, filling the gap between text, metadata, ontology representation and rules modeling, with the goal of detecting the information available in the text to be used to perform legal argumentation. This approach allows to directly annotate the text with peculiar metadata defined in core, domain and argument ontologies. OWL2 is used to get as close as possible to the rules, in order to exploit the computational advantages of description logics. This approach has a weakness in the management of exceptions: it is thus necessary to devolve this kind of reasoning features to different logics, e.g. defeasible logics, such as that presented in [28], with added support for argumentation schemes. Another limitation is that only text fragments get annotated, therefore deep semantic parsing is envisaged as a solution to this classical knowledge acquisition bottleneck.