
Abstract
The increasing publication of linked data makes the vision of the semantic web a probable reality. Although it may seem that the web of data is inherently multilingual, data usually contain labels, comments, descriptions, etc. that depend on the natural language used. When linked data appears in a multilingual setting, it is a challenge to publish and consume it. This paper presents a survey of patterns to publish Multilingual Linked Data and identifies some issues that should be taken into account. As a use case, the paper describes the patterns employed in the DBpedia Internationalization project.
Introduction
The linked data paradigm is based on a small set of best practices which were outlined in [7]:
Use URIs [5] as names for things;
Use HTTP1
Return useful information when upon lookup of those URIs (esp. RDF);2
include links by using URIs, that dereference to other documents.
Since the publication of those guidelines, an increasing number of projects have been devoted to the publication of linked data, making the vision of a semantic data web more plausible [11].
The principles of linked data have been described in several publications and books [10,28]. There is even a book devoted to linked data patterns [16].
Nevertheless, most of the projects that publish linked data employ English as the primary language. In fact, most popular vocabularies contain descriptions and labels only in English.
A study by Ell et al. [22] has shown that language tags are a rarely used feature in popular datasets: the web resources directly available that employed one language tag were only 4.7% and only 0.7% employed more than one language tag.
It was discovered that the most popular language tag was English (44.72%), while the rest of the languages had a very low appearance: German (5.22%), French (5.11%), Italian (3.96%), etc. As can be seen, this distribution does not reflect the number of people that speak those languages, or even the number of web pages written in them.
The lack of multilingualism in linked data can be attributed to its recent birth. However, another reason may be that there is a lack of design patterns and guidelines to help the community that wants to publish multilingual linked data.
In this paper, we collect, justify and explain a comprehensive set of those patterns. It must be noted, that we do not propose the patterns as best practices. In most of the cases, the proposed patterns offer a possible design decision with pros and cons that must be taken into account. The aim of this paper is to clarify the benefits of those decisions.
In this way, the main contribution of this paper is to collect a catalog of design patterns related to multilingual linked data. For each pattern we provide a short description, the context where it can be applied, a motivating example, a discussion of the pros/cons, and we also relate that pattern to other patterns.
We assume that the reader is familiar with basic RDF and SPARQL concepts.3
We use popular aliases which can be expanded using the
The paper is structured as follows. Section 2 contains a short overview of the main concepts related to internationalization of semantic web technologies. In Section 3 we define the concept of multilingual linked data and give a running example that we will employ along the rest of the paper. Section 4 contains the proposed catalog of multilingual linked data patterns. Section 5 describes DBpedia International as a use case of a multilingual linked data solution and we describe and justify the solutions taken. Finally, we describe related work in Section 6 and outline conclusions and further work in Section 7.
One of the goals of the World Wide Web is the development of a global information system which can be used by any person independently of its language. This principle has been described by the World Wide Web Consortium (W3C)5
In fact, the first WWW Conference in 1994,7
It is convenient to distinguish between internationalization, localization and translation.9
One of the basic aspects of internationalization is character representation. Initial standards such as ASCII10
Unicode started in 1987 as a project of the Unicode Consortium to develop a universal character set. The International Standards Organization (ISO) also chartered a working group with the same goal called ISO/IEC 10646. In 1991 both institutions worked together to synchronize both specifications.
The goal of the Unicode project is to cover all characters from all writing systems of the world, modern and ancient. It also includes technical symbols, punctuations, and many other characters used in written text.
In Unicode, each character is assigned a code point. It is convenient to distinguish between the code point and the glyph of a character.11
Some code points may have the same glyph. For example, the character o in the Latin alphabet corresponds to the code point
In other cases, the same glyph can be obtained by combining several characters. For example, the letter ñ can be directly represented as
Unicode proposed several solutions called normalization forms to avoid these ambiguities and to check whether two sequence of Unicode characters are equivalent.12
In the case of the Web architecture, the solution adopted was Normalization Form Canonical Composition (NFC) and is described in [49]. The use of normalization is important for linked data as it is necessary to have a non-ambiguous way to check if two identifiers are the same.
One of the cornerstones of Web architecture is the use of Uniform Resource Identifiers (URIs) [5] to identify any kind of resource. URIs were formally described by the IETF RFC 3986 [8] and their design offered a trade-off solution between readability and usability.
The readability goal can be achieved when URIs are easily remembered and interpreted by people, employing meaningful or familiar components. To that end, people from non-Latin alphabets should be allowed to use their own alphabets (i.e. Unicode characters) in their URIs. However, due to the usability design trade-off, the URI specification restricted the character repertoire to US-ASCII characters for easier transmission and storage in legacy systems
The use of non-ASCII characters in URIs can be achieved by percent encoding the octets of the character, decreasing the ability to read and remember those URIs.
For instance, the Spanish letter “ó” is percent encoded to “%F3”. In this way, the name of a city like
IRIs [20] were designed to identify resources using Unicode characters. An example of an IRI is:
Throughout this article, we refer to last part of a IRI which usually succeeds the last slash or # symbol as the local name of the IRI. For example, the local name of
The conversion from IRIs with Unicode characters to ASCII-only URIs is performed in two parts: the path and the domain name. The path is percent encoded using UTF-8 characters as we have shown in the previous example. In the case of domain names, the conversion employs an algorithm called punycode, which efficiently converts characters between Unicode and ASCII. As an example, the domain name
In Unicode there are a large number of characters, whose glyphs look actually the same. An example is the glyph ‘a’, which looks identically in Latin, Greek and Cyrillic alphabets, but has different Unicode character codes depending on the alphabet. Homograph attacks now use identically looking glyphs for faking URLs. In order to prevent homograph attacks browsers can display the original IRI or the punycode representation depending on the user language preferences.
Languages and the Web
From the beginning, the architecture of the Web has taken the existence of different languages and the need for language-aware protocols and specifications into account. As an example, HTML13
At the protocol level, HTTP provides the
In the case of linked data, it is a well-known practice to dereference a URI and return different representation formats (HTML, RDF/XML,15
Language declarations must employ IETF language tags defined in BCP47 [41], like
A rationale of the Web of Data is to develop technologies that enable machines to consume data. Although one may consider that data is intrinsically multilingual, we can see that data usually contain references to textual information in some natural language.
As a running example, imagine that we want to declare the following information:
“Juan is a professor at the University of León. He was born in Armenia and is 50 years old”
In that paragraph, there is data that does not depend on multilingualism, like the age, so it could be considered language neutral, and be represented as: 
However, even the numbers could be culturally dependant: 50 is represented as  in ancient Armenian. Most of the data contains references to human-readable textual and culturally dependant information that is multilingual.
in ancient Armenian. Most of the data contains references to human-readable textual and culturally dependant information that is multilingual.
In the same example, if we want to declare that the position of 
That data is language dependent and if our application is meant to work with other languages we may want to attach localized literals.
For example, if we are planning to translate the linked data application to Spanish we may not be interested in declaring that Juan is Professor (in English) but Catedrático (in Spanish).
This simple example can be solved by employinglanguage-tagged literals that correspond to the multilingual labels pattern (cf. Section 4.3.2) that we will present later. 
Multilingual data is defined as data that appears in a multilingual setting and contains references to human readable textual information in several languages.
In the context of this paper, we are interested in multilingual linked data, which is multilingual data thatfollows the linked data principles. Some examples of multilingual linked data are international vocabularies like Agrovoc or multilingual datasets like DBpedia (cf. Section 5). When publishing multilingual linked data it is necessary to take into account that future applications of that data may need to be localized to different environments.
Multilingual linked data should be published in a way that enables that process. In the following section we will review the main patterns related to multilingualism and linked data. Our proposed list of patterns tackles mainly multilingual textual information leaving other localization and cultural issues out of the scope of the current set of patterns.
In this section, we present a catalog of patterns for implementing multilingual linked data solutions. The patterns are classified according to the common tasks that have to be performed to publish linked data:
Naming. This task refers to the process of URI design and dataset description from a multilingual point of view.
Dereferencing. This task describes patterns to handle dereferencing in a multilingual environment. For example, should we return the same or different representation depending on the language?
Labeling. When publishing linked data, there are a number of reasons to label different resources. In a multilingual setting, how can we provide labels for different languages?
Longer descriptions. Not all textual information attached to resources are labels. In fact, longer descriptions like comments or even book chapters, can be encoded in literals and contain textual information in different languages.
Linking. In a multilingual setting, it is possible to have different resources representing the same thing in different languages. How can we link those resources?
Reuse. Linked data is all about reuse of data. When multilingual data is linked to vocabularies, is it better to have multilingual vocabularies or to localize existing ones?
Table 1 gives an overview of the proposed catalog of patterns which are described in the following sections.
Overview of Multilingual LOD patterns
Overview of Multilingual LOD patterns
It is a well known best practice that URIs should not change [6] and should not depend on implementation techniques, file name extensions, etc. In order to obtain stable URIs, the first step in a linked data development lifecycle is to design good URIs [13].
Descriptive URIs
Descriptive URIs use ASCII characters that are combined to represent terms or abbreviations of terms in some natural language. It is usually done with terms in English or in other Latin-based languages, like French, Spanish, etc. where only a small fraction of their alphabets is outside ASCII characters.
Descriptive URIs are appropriate when most of the terms are in English or in Latin-based languages. It can be also applied when interoperability with existing systems is vital.
An example of a URI that represents Armenia could be: 
The characters that appear in a URI usually represent natural language terms to improve human-readability. Using simple URIs in ASCII has the advantage that ASCII characters are very well supported by almost any computer system. This pattern offers a good balance between readability and usability of resource identifiers. However, for most languages other than English, the natural script usually contains characters outside of ASCII. In the case of languages with completely non-Latin scripts (Armenian, Arabic, Greek, etc.) ASCII only URIs are very restrictive and percent-encoding local names renders them unreadable.
The Descriptive URIs pattern is similar to the meaningful URI local names recommendation in [40], although they refer only to the local name part of the URI.
This pattern is opposed to the opaque URIs pattern (4.1.2). When the restriction of only ASCII characters is removed, this pattern becomes the same as Full IRIs (4.1.3) or Internationalized paths only (4.1.4).
It is related to the URL slug pattern in [16] where URIs are generated from text of keywords.
Opaque URIs are resource identifiers which are not intended to represent terms in a natural language.
Opaque URIs are a good solution when most of the resources are obtained automatically from other systems like relational databases, tables, etc. This pattern can also be applied when there is a need to have multilingual concepts and it is preferred not to have any language bias. Considering that URIs are not intended to appear in end-users’ interfaces, using opaque URIs can help to separate the concept from its different textual representations.
An opaque URI can be: 
Opaque URIs can help to emphasize the independence of a resource from its natural language representation. This pattern emphasizes that URIs are not meant for end users but for internal applications.
Resources with opaque URIs usually depend on labels, so an application can hide the URI from the end user and show the corresponding label.
Depending on the context, URIs without human-readable local names make it more difficult for some users and application developers to manage and debug linked data applications.
Opaque URIs are described in [40]. There are some well-known vocabularies that employ opaque URIs, like EuroWordnet [47] or Agrovoc [12]. This pattern is associated to the Label everything (4.3.1) pattern so that the application can show some information to the end user. This pattern is also related to the Natural Keys pattern in [16], in the sense that Opaque URIs are often the result of a mapping process between some external identifiers which are algorithmically converted to linked data URIs.
This patterns consists of using unrestricted IRIs which can contain Unicode characters outside the ASCII repertoire.
In a multilingual setting, it is necessary to take into account that human-readability is not a generic aspect, but depends heavily on people’s culture and background. URIs employing only ASCII characters are difficult to handle by people used to non-Latin alphabets. This pattern can solve that situation by allowing the application to use Unicode characters in resource identifiers.
A full IRI using the Armenian language can be: 
IRIs with Unicode characters are more natural for people whose primary language is not Latin based. Since machines should be able to identify resources in either encoding and the technologies have already been developed, a further step is to make resource identifiers human friendly. Although it is said that the end user should not be exposed to URIs and that they should act as internal identifiers, in practice, they are handled by application developers and sometimes even by end users.
Human friendly IRIs can facilitate the adoption of linked data technologies by more people in the long term. However, as explained in Section 2.2, the use of IRIs may be exposed to visual spoofing attacks given that glyphs with the same appearance may refer to different characters.
Another important issue is the lack of support of IRIs by current software libraries. Although the support is improving, nowadays it is still a challenge [4] and most of the tools only offer partial support.
Unicode has published some security considerations for IRIs which should be taken into account [17]. A soft version of this pattern is Internationalized paths only (4.1.4). According to [32, Section 6.1], IRI dereferencing should be handled carefully as the HTTP Protocol (RFC 2616) [24] can transfer only URIs.
Internationalized paths only are IRIs where the domain part is restricted to ASCII characters while the path can contain Unicode characters.
This pattern can offer a trade-off between security and readability. On one hand, it limits ASCII characters for the domain part, which may be subject to homograph attacks. On the other hand, the use of local names with Unicode characters improves readability.
Armenia can be identified with this hybrid approach by: 
This pattern avoids the problems associated with domain name spoofing while it offers more human-friendly resource identifiers. While this partially solves the problem, the possibility of spoofing using visual equivalent IRIs for different purposes remains. However, as the domain name is preserved as the authoritative source, it is much more difficult to accomplish such attacks.
This pattern is opposed to the Opaque URIs pattern (4.1.2). It extends the Descriptive URIs pattern (4.1.1) but is more restrictive than the Full IRIs pattern (4.1.3). It is employed in DBpedia International (cf. Section 5).
This pattern proposes to insert a language identifier in the URI. Thus, datasets of different languages can be easily recognized by the URI.
It can be applied when datasets are clearly separated by language. In this way, the different datasets may be generated, and even maintained by different servers which publish their corresponding language dependent datasets separately.
The Armenian version of the country Armenia could be:  where
where
In a multilingual setting, being able to easily recognize the language of a resource may facilitate the development. A more practical benefit is to separate different datasets, which can be obtained from different sources, by language.
However, notice that the employment of a language tag in the URI may contradict the Cool URIs philosophy in the sense that we are encoding extra information in the URI that may be subject to changes in the future.
Adding languages to the URI can become unwieldy if we consider sub-languages, dialects and regions. There are more than 7000 languages already registered17
which can be very specialized. For example,Another design decision is where to put the language tag.
It is possible to have alternative URI patterns depending on where we include the language tag in the URI. 
The last pattern is less convenient as it mixes the Unicode characters of the local name with the ASCII characters of the language tag.
This pattern can be combined with the language content negotiation pattern (4.2.1). It is possible to have a language agnostic URI for a concept without language tag and to use HTTP language content negotiation to redirect to the preferred dataset. This pattern is also related to the Patterned URIs pattern in [16] in the sense that URIs are defined to follow a naming pattern (including the language). It is also related to Hierarchical URIs of the same book.
The dereference of a URI is the retrieval of the representation of the resource identified by that URI. Although this process seems orthogonal to multilingualism, the HTTP protocol includes the possibility of content negotiation in which the server can return different representation depending on the preferences of the user agent. This process can also involve language preferences. In general, there are two possibilities which are identified in two opposite patterns: return different representations depending on language preferences, or return always the same representations.
Language-based content negotiation
In this pattern, the server attends the language preferences of the user agent, presented in the
This pattern can be used to reduce network bandwidth and client processing. Notice that a user agent retrieves a subset of all the triples in languages that he has included in the header.
Imagine that the server contains the following triples  If we try to obtain those triples from a server, which does language-content negotiation, and the header contains
If we try to obtain those triples from a server, which does language-content negotiation, and the header contains  while if the header is
while if the header is  Notice that the semantics of the HTTP content negotiation mechanism should return the whole dataset, if there is no language preference.
Notice that the semantics of the HTTP content negotiation mechanism should return the whole dataset, if there is no language preference.
This feature reduces network traffic and the load of client applications as the server would only send triples of a given language.
Content negotiation is part of the Web architecture. This solution can improve the performance of clients limiting the number of triples in languages that they are not interested.
Implementing language content negotiation complicates the development. Another problem is that if we return different representations in different languages, we should ensure that the content represented in one language is equivalent to the content represented in other language. This can raise problems on semantic equivalence between natural language text.
This pattern is related to the content negotiation exposed as a best practice recipe for publishing RDF vocabularies in [9] where language content negotiation is applied to offer different representations for HTML or RDF content. Although that pattern was meant for human oriented representations, like HTML, for RDF there was no such recommendation.
In contrast to the Language-based content negotiation pattern (4.2.1), this pattern returns always the same triples without taking into account the
RDF is meant for machines which are natural language agnostic, so ignoring the language preferences seems a reasonable option. This pattern can be employed when the amount of multilingual data is manageable and there are no big constraints on datasets consumers.
Implementations that always return the same data could be considered more consistent. Ignoring the
With this pattern the data representation of a resource offered is independent of the language preferences, so there is no need to care about semantic equivalence of textual information.
However, localized client applications may receive unnecessary triples that could create computation and network overhead. This overhead can have an impact in low computation and bandwidth devices such as smart-phones and sensors.
This is the opposite pattern to 4.2.1.
Applications based on linked data will need to expose data to the end user. It is a common practice to associate labels to resources so the application can show those labels to the end user.
The most accepted property for displaying labels is
In this section we discuss the different patterns related to labeling and multilingualism. We separate labeling from longer descriptions in the sense that labels are short textual information attached to a resource.
Label everything
Linked data datasets should provide labels for all resources: individuals, concepts and properties, not just the main entities.
Linked data applications that contain data which is supposed to be exposed to an end-user in some natural language.
Although URIs may be human-readable, they are not expected to be seen by the end user. In order to improve user experience it is necessary to expose data and entities in human-readable ways. Labels facilitate:
displaying data to end-users, instead of URIs searching over the Web of Data indexing purposes, training, use of annotation tools, etc.
In general, associating labels is a good idea. It is always better to offer a textual information to the end user than a URI. However, in some applications it can be difficult to find the right label for a resource, specially when resources are automatically generated.
When labeling resources, one must take into account that the purpose of those labels is mainly for humans. Using camel-case or similar notations should be avoided and the use of uppercase, space delimiters etc. should be consistent [40].
[22] enumerates some uses for labels and contains a thorough study on the use of labels in popular datasets. This pattern also appears with the same name in [16] where dataset creators are urged to “Ensure that every resource in a dataset has an
In general, it is important to attach language tags to textual information, in order to help identify the appropriate label for applications.
This pattern can be applied when labels have information in some natural language. The pattern is not only intended for multilingual applications. It can also be employed for linked data solutions with only one natural language to declare the language of the labels. In this way, it makes easier to internationalize the application adding labels with other languages in the future.
We can declare that Juan’s position is Professor in English and Catedr’atico in Spanish. 
Multilingual labels are part of the RDF standard and well supported by semantic web tools. For example, the following SPARQL query asks for people whose position is Professor and would return  Dealing with big multilingual linked data repositories where all literals have a language tag makes SPARQL queries more verbose. The following SPARQL query for Example 8 would return no results.
Dealing with big multilingual linked data repositories where all literals have a language tag makes SPARQL queries more verbose. The following SPARQL query for Example 8 would return no results.  There are some patterns and built-in SPARQL functions that deal with language tagged literals like:
There are some patterns and built-in SPARQL functions that deal with language tagged literals like:
Using the 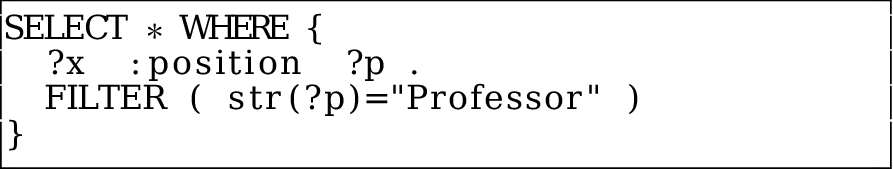
This pattern is the same as the Multi-lingual literal pattern in [16]. This pattern is also related to the Repeated property pattern where a resource can have several values for the same property. In this case, the values are literals in different languages.
Apart of language-tagged labels, one can also associate plain labels without a language tag.
This pattern emerges as a practical advice to facilitate SPARQL queries over multilingual linked data.
Using a language without language tag, Example 8 can be expressed as: 
Using this pattern SPARQL queries do not need to be aware of the multilingualism of the
Although this practice facilitates SPARQL queries, it is controversial and can be also considered to be an anti-pattern. For instance, in which language should the literal without language tag be written? That would depend on the language spoken by the majority of the linked data users. In most cases it could be English but in other contexts it could be quite a different language.
The use of labels without language tags has been proposed by Richard Cyganiak in [15]. This pattern can be associated with the language in URI pattern (4.1.5), so that there is a hint on what is the default language of a dataset. It is possible to make assertions about the language of a whole dataset using the
Although labels can be really helpful in the case of human-enabled applications, there are cases where they do not suffice. Labels are meant to be very short descriptions of a resource. Depending on the context, short descriptions may cause ambiguity and thus, a better description may be required.
There are ways to provide longer descriptions for a resource. For example, there are some common properties (like
Divide long descriptions
By decomposing long descriptions into new resources that can be represented with shorter labels or lexical entities, one can facilitate their future reuse and adaptation to other environments.
Resources with very long descriptions are usually a symptom that the knowledge base structure (i.e. vocabulary or ontology) is not sufficiently developed. In general, it is good to foresee to associate short labels with resources. This way, a model where resources have long descriptions can be further decomposed into small pieces with shorter descriptions or labels. Multilingual applications with more fine grained textual information can be better localized and adapted to other languages.
In order to declare that Juan is a professor from the University of León, one can assert: The following triple represents the job title of Juan:  The description can be decomposed in two components: the title (Professor) and the University (University of León).
The description can be decomposed in two components: the title (Professor) and the University (University of León).  A multilingual application can recognize the different components and create a better user experience.
A multilingual application can recognize the different components and create a better user experience.
Applications can generate more readable information to the end user, especially when they are localized. Decomposing the resources of a dataset to more fine grained atoms can make the dataset more user-friendly.
However, this pattern increases the complexity of the model. It is necessary to find a good balance between verbose models with fine-grained resources and lighter models with a fewer resources and longer descriptions.
This pattern is related to Link not label in [16] where the authors describe situations in which it is better to use resources instead of labels.
Using this pattern, we can describe the lexical content of longer descriptions.
Longer descriptions that can not be modified or that are preferred to be kept untouched, can be enriched with lexical information. This pattern can also be applied to short labels.
The following triples describe “University of León” using external descriptions 
Providing lexical metadata for a resource can help linked data applications to visualize and manage textual information. However, this can also add a complexity overhead to the dataset that may be undesired.
There are other ways to describe lexical information. Gananis et al. [25] propose NaturalOWL to linguistically annotate ontology concepts while Hellman et al. [29] propose a URI scheme to refer to fragments of a text. In this way, it is possible to annotate text fragment with assertions about their lexical structure.
Metadata attached to textual information can even be applied to support natural language user interfaces. Much research work is being done regarding the generation of natural language descriptions for RDF and for SPARQL querying [21,45] which can benefit from lexical metadata.
This pattern is related with the Add linguistic metadata pattern 4.5.3 through which it is possible to add linguistic metadata to the different resources. Both patterns are usually combined.
Literals in the RDF model may structured values in XML or HTML. Using structured literals, it is possible to offer longer descriptions leveraging the Internationalization practices that have already been proposed for those languages.
When longer descriptions are obtained from external sources it is better to keep them in their original form or to encode them using XML or HTML. Also, when there are long textual descriptions with lot of internationalization information (localization workflows, multilingualism, etc.) it may be better to employ structured literals following the proposed XML internationalization techniques.
A description of the University of León could be:  Notice that the example uses the
Notice that the example uses the
Using structured literals makes it possible to leverage existing Internationalization techniques like bi-directionality, ruby annotations, localization notes, etc.
One issue is the interaction between the two abstraction levels: RDF and XML/HTML. Including large portions of structured literals can hinder the linked data approach.
The W3C developed a document on Best Practices for XML internationalization [43] which are complemented by the Internationalization Tag Set (ITS) [33]. The new version ITS 2.0 [34] contains categories that are format neutral, supporting both XML, HTML and the RDF based NIF (NLP Interchange Format).18
Although the linking process is independent of any natural language, there are two points that must be taken into account when designing multilingual linked data. How to relate resources that refer to the same entity in different languages and how to describe linguistic aspects of a dataset.
Inter-language identity links
Add an
When dealing with resources in a multilingual linked data environment, it may be necessary to keep those resources separate and identifiable.
Suppose we have information about Armenia in English which is identified by  while the URI
while the URI  contains information about Armenia in Spanish. We can declare that both URIs refer to the same thing by asserting:
contains information about Armenia in Spanish. We can declare that both URIs refer to the same thing by asserting: 
This pattern is a special case of the Equivalence links in [16].
Use a soft property to state that two resources are inter-language linked.
Example 13 could be written as follows: 
Soft links are weaker regarding semantic implications than an
Halpin et al. [27] describe the uses and abuses of
Add linguistic metadata, like localization information or the default language of the dataset.
Some linked data applications, like thesaurus, controlled vocabularies, etc. need to have a finer control on the linguistic terms that they are handling. They may need, for example, to express the linguistic relationship between two concepts or the language in which they are expressed.
Given that it is not possible to have literals as subjects in the RDF model, it is necessary to employ resources as literal representatives and to assert declarations between those resources.
The following example shows how we can declare that Catedrático means Professor and that it is a Spanish term (represented by the code

SKOS-XL [37] offers a mechanism for treating labels as first class objects making it possible to declare properties for those labels.
In the following example we declare the concept This pattern exposes the semantic relationships between multilingual labels, so they can be connected with other resources. The properties Although it has been proposed to add a property to declare the default language of a named graph in RDF 1.1, it was not accepted. The new JSON-LD working draft allows to declare the default language of a given context. The Lexvo project [18,19] defines an ontology of linguistic terms. Lexvo proposes a general framework to publish multilingual knowledge bases. For example, it declares a property

SKOS-XL [37] defined an extension of SKOS [38] providing additional support for describing and linking lexical entities.
This pattern is related with the Provide lexical information pattern 4.4.2 in the sense that it is possible to add linguistic metadata to the lexical entities identified in that pattern. It this way, it is also possible to employ the Lemon-based metadata in this pattern.
Reuse is one of the main motivations for linked data. In fact, the best advice to develop linked data solutions is to provide links to existing vocabularies.
It is a good practice to link to popular vocabularies which are well known by the community and can help to integrate different sources of data. In general, the chosen vocabularies can improve the success of a linked data application.
Monolingual vocabularies
Most of the popular vocabularies, such as FOAF or Dublin Core, are not localized at all. The URIs that represent concepts contain English words in ASCII and labels are only provided in English.
Vocabularies with a global scope maintain their terms in a single language, usually English.
Most popular vocabularies and ontologies for the semantic web (FOAF, Dublin Core, OWL, RDF Schema, etc.) are monolingual and only employ one language, usually English, both for labels and comments.
In monolingual vocabularies, it is easy to control the vocabulary evolution and avoid the appearance of bad translations or ambiguities between language versions. When using monolingual vocabularies in a multilingual application, it is necessary to have a translation layer for those English terms.
Using a monolingual vocabulary as the central knowledge representation system can be constrained by the language used. For example, some languages have different names for one concept that refer to only one name in another language. Also, some concepts in one language might not exactly match to a concept in another language. An example is the concept Professor, which in certain regions refers only to an academic holding a chair at a university (e.g. Germany), while it comprises in other regions also secondary or even primary school teachers (such as in Austria). This example illustrates, that such ambiguities can even occur in largely monolingual vocabularies, where the meaning of concepts differs in various regions.
This pattern is opposed to the Multilingual vocabularies pattern 4.6.2. Most of these vocabularies use descriptive URIs (4.1.1) with English terms.
Define vocabularies and ontologies where the concepts contain translations for several languages.
In a multilingual linked data application where we want to have more control about the translation process, it is better to provide our own translations defining multilingual versions of the ontologies.
In our running example, we can define a multilingual vocabulary for university positions with declarations like: 
Multilingual vocabularies offer an elegant solution for applications that need to express information in local languages. There is no need to translate labels and comments and the users of those languages can have access to more standard textual representations in their languages.
Some common vocabularies use only one language, usually English, as a canonical textual representation of the different concepts. Some concepts are difficult to translate and there may appear ambiguities in the translations. For example, the label Professor may be translated to Profesor in Spanish. However, the meaning of those concepts is different (in Spanish it is usually preferred as Catedrático).
There are a number of multilingual vocabularies, like Agrovoc21
Enrich existing vocabularies with local translations.
Localized applications that need to represent information in their local languages from external vocabularies that are not localized can define their own translations.
A linked data application in Spanish may use the Dublin Core vocabulary to indicate the contributors of a given work. The end-user should see the labels in his own language. To that end, one can add a localized label to 
A multilingual linked data application could transparently select the tagged literal corresponding to
This pattern follows the Anyone-can-say-Anything-about-Any-topic (AAA) paradigm [1]. This pattern can be considered a special case of the Annotation pattern from [16] which says that it is entirely consistent with the Linked Data principles to make statements about third-party resources.
This pattern advocates to create new localized properties and classes and relate them to existing ones using the
Linked data applications that need localized versions of existing vocabularies but prefer to keep the original vocabularies untouched.
One can create a custom 
This pattern gives freedom to vocabulary creators to tailor the vocabulary according to their exact needs. However, it can be more difficult for both humans and software agents to recognize and consume these new properties and classes.
This pattern is related to the Equivalence links pattern from [16] and to the Link base pattern which proposes to partition the core data from the links.
DBpedia is an effort to extract structured information from Wikipedia and publish this information as Linked Open Data [2]. Due to the interdisciplinary nature and broad term coverage of Wikipedia, DBpedia has managed to became one of the main hubs of LOD cloud.23
Linking Open Data cloud diagram, by Richard Cyganiak and Anja Jentzsch.
There have been three main attempts to also harvest this multilingual knowledge:
by DBpedia, extracting simple types of multilingual information,
by [4], extending the first approach with the use of IRIs and
by [32], extending the use of IRIs with a de-referencing solution and the addition of links between different DBpedia language editions.
The DBpedia project is an excellent case study for a multilingual dataset. In the following paragraphs we will show how the multilingual linked data patterns employed throughout the internationalization of the DBpedia project.
A common practice of the DBpedia project is the use of declarative URIs. For every page in Wikipedia, i.e.
Among other information, DBpedia added a label extracted from the page title using a language tag (cf. 4.3.2).
The triple representing the title of the resource about Armenia extracted from the English DBpedia is: 
To obtain information about the same topic in other Wikipedia language editions, DBpedia uses the Wikipedia Inter-Language Links (ILL).24
ILLs are special links in a Wikipedia page that link to the exact or meaningwise closest article in a different Wikipedia language edition.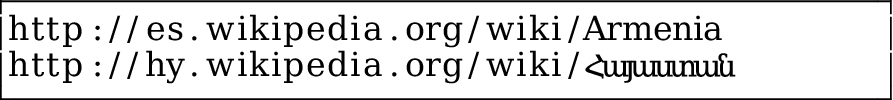
Early versions of DBpedia extracted only the English article and discarded this type of information. Later on, DBpedia extracted data from other Wikipedia language editions but, if and only if the non-English article had an ILL to an English article. If it did not, the article was discarded, otherwise it would use the English URI as an identifier.
All the aforementioned Wikipedia articles would have 
This approach helped the DBpedia project to enrich the existing data with multilingual information but had the following drawbacks:
ILLs are not always exact translations thus, a (small) part of this enrichment was inaccurate,
even exact translations may have conflicting information due to stalled content or different views on the subject (i.e. the population of a town) thus, collapsing everything to the same namespace (
local articles without an English translation were discarded.
The solution that addressed these issues was the use of separate namespaces for every language (cf. 4.1.5), following the Wikipedia naming pattern.
The Armenian Wikipedia article,  would produce the following identifier:
would produce the following identifier: 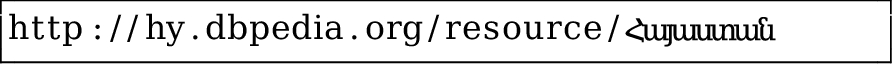
Since DBpedia was using descriptive identifiers, non-Latin languages used Internationalized local names (cf. 4.1.4) to ease the manual SPARQL querying and visual resource identification.
Different language versions of Armenia in DBpedia: 
In order to keep the ILLs, DBpedia introduced a new predicate in the DBpedia ontology,
By post-processing the ILLs it was proven that when two articles had both an ILL to each-other (two-way ILL) it was relatively safe to assume an exact translation. Thus, ILLs were transformed to owl:sameAs in the case of two-way links or rdfs:seeAlso in the case of one-way links (cf. 4.5.1 and 4.5.2).
ILLs between the different resources that represent Armenia in the different datasets: 
This paper can be seen as a continuation of the linked open data patterns book by Leigh Dodds and Ian Davis [16]. Although it contains some patterns related to multilingualism, the book is about linked data in general, while in this paper we concentrated on patterns that are crucial for multilingualism. Along the presentation of our catalog patterns, we aligned the our catalog patterns with the ones in that book.
There are also a good number of best practices and guidelines about publishing linked open data [9,10,31].
The linguistic community also considered challenges of a multilingual web of data [26]. The benefits of interlinked linguistic resources are presented in [3].
A lot of work has been done regarding multilingual ontologies. In particular, the Monnet25
[14] describes the limitations of the label systems in RDF, SKOS and OWL. The authors propose the LexInfo model which allows authors to associate linguistic information with the different elements of an ontology. McCrae et al. [35] propose the lemon model which consists of a lexicon object with a number of lexical entities. LexInfo was designed as a model for associating linguistic information with ontologies and provides special data categories for this mapping. LexInfo was originally based on LMF, however, this was found to be difficult to work with in a linked data setting, and the lemon model was created, as an adaptation of LMF to the challenges of linked data. Thus, LexInfo 2.0 acts as a data category repository and ontological model of lemon data.
DBpedia can be viewed as a comprehensive resource for linguistic research. Several authors have already used DBpedia to improve NLP tools [36].
Recently, the W3c has created a Best Practices on Multilingual Linked Open Data community group26
The web of data is not just for machines. At the end, applications based on the web of data will be used by humans and human beings speak many different languages.
We have proposed a set of guidelines or patterns to be taken into account when developing multilingual linked data applications. Some of those guidelines are frequently used while others, like language content negotiation, are rarely used. Future work should be done to really assess the benefits of the different approaches.
There are other issues like Unicode support by semantic web tools and standards, language declarations in Microdata, that are currently the subject of working groups. In fact, during the writing of this paper the RDF WG is working in RDF 1.1. Although we were following the discussions, in this paper we did not cover aspects that could change in future; so the patterns presented herein should not be affected by future changes.
Other internationalization topics like text direction, ruby annotations, notes for localizers, translation rules, etc. are handled by the W3C Internationalization group and the ITS 2 effort. It is expected that some alignment between that work and multilingual linked data will provide very fruitful results in the future which could result in the appearance of new patterns for the localization of linked data.
Recently there has also been some work on measuring the quality of linked open data. Hogan et al. [30] takes 14 principles for naming, linking, describing and referencing resources into account. Those principles are not focused on multilingual aspects, although a similar study can be carried out considering the patterns described in this paper. Increasing the quality of linked data is a very important goal, that must take into account the multilingual nature of people.
Acknowledgments
This work has been partially funded by Spanish project MICINN-12-TIN2011-27871 ROCAS (Reasoning on the Cloud by Applying Semantics). It was supported by grants from the EU’s 7th Framework Programme provided for the projects LOD2 (GA no. 257943) and DIACHRON (GA no. 601043). Some of these best practices were presented at the Multilingual Web Conference, Dublin 2012 and at the Multilingual Linked Open Data for Enterprises Workshop, Leipzig, 2012, we appreciate the comments and discussions of the participants of those events. We would also like to acknowledge the comments given by: Jose María Álvarez Rodríguez, Basil Ell, Manuel T. Carrasco, Aidan Hogan, Richard Cyganiak, Mohamed Morsey, John McCrae, Pablo Mendes, Elena Montiel and Jeni Tennison.