
Abstract
In this paper we present Spatial-KWD, a free open-source tool for efficient computation of the Kantorovich-Wasserstein Distance (KWD), also known as Earth Mover Distance, between pairs of binned spatial distributions (histograms) of a non-negative variable. KWD can be used in spatial statistics as a measure of (dis)similarity between spatial distributions of physical or social quantities. KWD represents the minimum total cost of moving the “mass” from one distribution to the other when the “cost” of moving a unit of mass is proportional to the euclidean distance between the source and destination bins. As such, KWD captures the degree of “horizontal displacement” between the two input distributions. Despite its mathematical properties and intuitive physical interpretation, KWD has found little application in spatial statistics until now, mainly due to the high computational complexity of previous implementations that did not allow its application to large problem instances of practical interest. Building upon recent advances in Optimal Transport theory, the Spatial-KWD library allows to compute KWD values for very large instances with hundreds of thousands or even millions of bins. Furthermore, the tool offers a rich set of options and features to enable the flexible use of KWD in diverse practical applications.
Introduction
In several statistical domains that involve a spatial component it is often required to deal with measurements or estimates of physical or social quantities defined over a finite geographic region. In particular, we address in this contribution the case where (i) the target variable of interest to be measured or estimated is non-negative and (ii) the spatial domain is represented by a regular square grid. In such applications, the spatial distribution of the non-negative variable of interest is represented by a bi-dimensional histogram. A prominent example are census population grids.1
Population and housing census 2021 available from
In this paper we address the issue of comparing quantitatively pairs of bi-dimensional histograms, i.e., quantifying their degree of (dis)similarity. The necessity to quantify (dis)similarity between spatial histograms is encountered in different application domains and may serve different purposes. For instance, when the same target quantity (physical or social) may be measured/estimated in multiple alternative ways – that may either represent completely different approaches, or methodological variants of a single approach – the ability to judge the performance of one method against the others relies on the possibility to assess quantitatively the relative goodness of their respective estimates/measurements. This is critical not only for selecting the best measurement/estimation method within a given set of candidate options, but also to guide their refinement and the development of future, improved methods. This was specifically the case that motivated the present work, which was triggered in the context of investigating methods to estimate the spatial density of present population based on Mobile Network Operator [19, 18]. More in general, the problem of comparing spatial distributions of physical quantities is encountered in several Earth Sciences, from Meteorology [9] and Geology [14] to Hydrology [15] and Oceanography [12], and may emerge also in other domains targeting physical quantities (e.g., pollutants in Environmental Statistics).
The main goal of this paper is to present an additional tool to researchers and practitioners addressing the problem of quantifying dissimilarity between spatial distributions given in the form of bi-dimensional histograms. We make here three contributions. First, we briefly review the mathematical concept of Kantorovich-Wasserstein Distance (KWD) and discuss the potential benefits of KWD over other dissimilarity measures that are often encountered in the literature. Second, on a more pragmatic level, we present Spatial-KWD, an open-source ready-to-use tool that enables the application of the KWD concept to large real-world maps, up to several hundreds of thousands bins, and with a rich set of features and options intended to facilitate practical application. Third, we make an entirely novel conceptual contribution by introducing a “localised” version of KWD designed to quantify the dissimilarity between sub-maps defined over a smaller portion (“Focus Area”) of a larger region of interest.
The rest of the paper is organised as follows. Section 2 introduces the notation and terminology used throughout the paper. In Section 3 we elaborate the interpretation of dissimilarity metric as a total spatial error when comparing estimates/measurements to “ground truth” data. In Section 4 we explain the difference between bin-by-bin metrics and cross-bin measures and highlight the limitations of the former. Section 5 defines formally KWD as the solution of an optimal transport problem over a lattice graph, showing how a family of tight approximations to the exact value can be obtained, at considerably lower computational cost, by solving the optimisation problem on a reduced lattice graph. This approach lies at the core of the open-source Spatial-KWD tool. Section 6 presents a number of options and features implemented in Spatial-KWD to facilitate its use in practical real-world applications. In Section 7 we introduce a novel approach to compute local dissimilarity metrics in a pre-defined sub-region, called “Focus Area” (FA), embedded in a larger region of interest. This feature provides a measure of local dissimilarity and is meant to provide more detailed insight in scenarios where the degree of dissimilarity yields large spatial variations (e.g., urban vs. rural areas). Finally, in Section 8 we conclude and identify possible directions for future work.
In this section we present the formal notation and terminology that will be used throughout the paper. We assume the spatial domain is represented by a regular square grid and use interchangeably the terms “bin” and “tile” to refer to the generic grid unit.2
With this choice we aim at preserving continuity with previous literature from different research communities that had adopted one or the other term.
We use the term “map” to refer to the collection of variable values over all the bins (equivalently: tiles) covering the given region of interest.3
We prefer the term “map” instead of “distribution” or “histogram”, as the latter terms tend to be associated to a probabilistic interpretation that is not necessarily applicable to, or relevant for, the applications of interest here. In fact, in the general case considered here the non-negative variable of interest does not represent a probability measure.
For the generic bin
Furthermore, we stress that in the general case the variable of interest (i.e., the map co-domain) does not represent a probability measure: it may have a physical or social dimension and the total mass is not constrained to sum to unity.4
The case of the variable of interest representing a probability measure, hence the map constituting a bi-dimensional probability distribution, should be regarded as a special case.
Consider the case where one needs to compare different measurement/estimation approaches (or different prediction models) delivering different maps for the same target quantity of interest. Let the map
It is customary in several scientific fields to rely on synthetic scenarios and simulations based on more or less sophisticated generative models, for which parameters can be explicitly controlled, giving the possibility to explore the parameter space and understand the relative advantages and limitations of different approaches.
In the scenario described above, choosing a “distance metric” is tantamount to assuming (or defining) a particular error model.
The selection of a suitable dissimilarity measure is a critical design choice in the process of methodological development, instrumental to, and not less important than, the development of the core measurement/estimation method itself. An incorrect or anyway sub-optimal choice of goodness measure will drive towards preferring or developing a sub-optimal measurement/estimation method method.
Examples of dissimilarity measures for discrete distributions. The last columns indicate whether the measure is symmetric (sym.) and whether it is a full distance metric (dist.)
Bin-by-bin (“vertical”) vs. cross-bin (“horizontal”) measures (credit: picture inspired by J. Kun’s blog).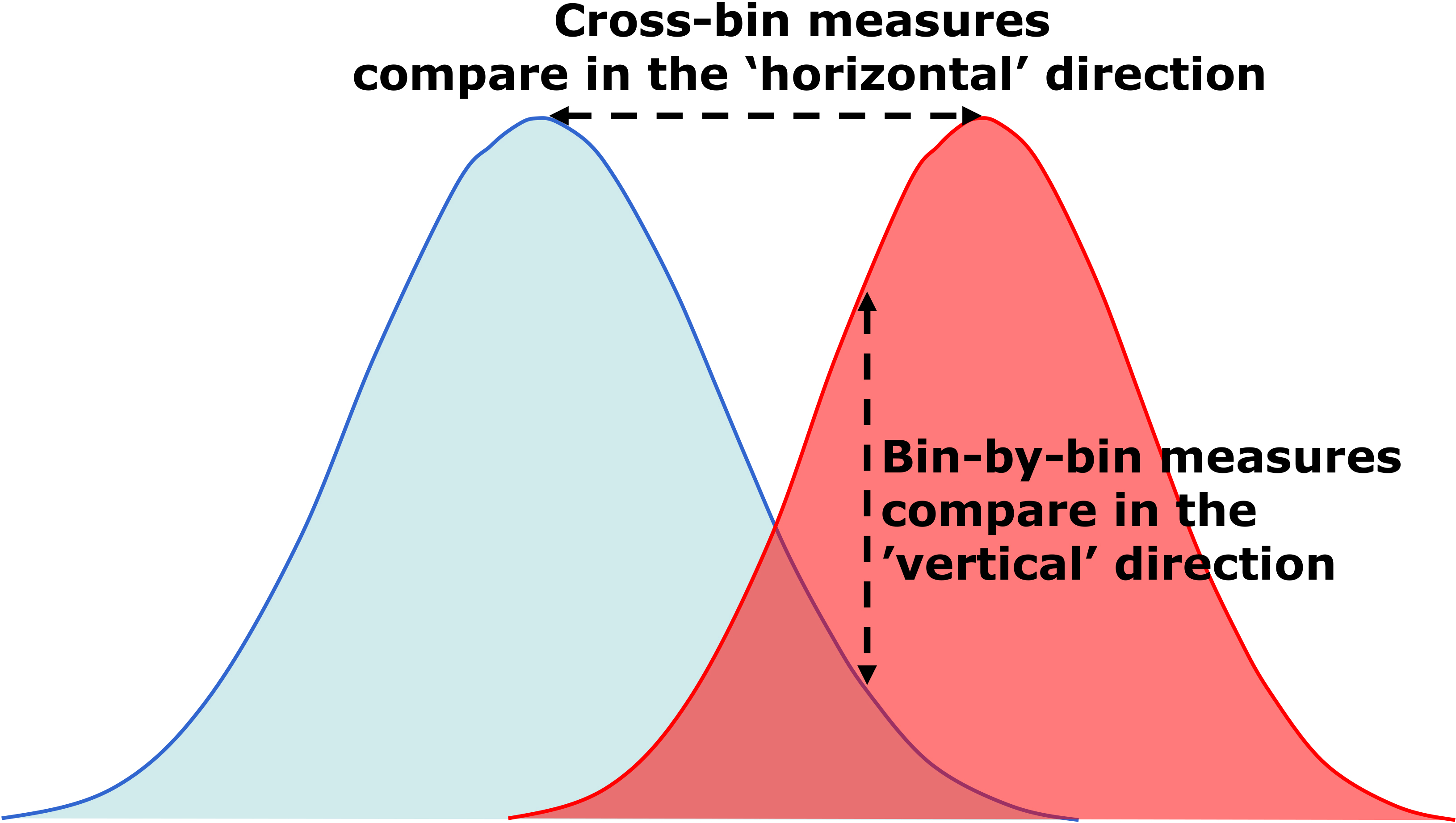
Borrowing the terminology introduced by [21] we divide all dissimilarity measures into two large groups: bin-by-bin measures and cross-bin measures. The fundamental difference between the two groups of measures can be intuitively grasped by the graphical representation in Fig. 4.6
Credit: Figure was inspired by the original image appearing in J. Kun’s blog available at:
In Table 1 we report a partial list of different measures found in the literature. All such measures are based on the same common structure:
wherein some outer transformation function
Recall that a measure
The distance from any point to itself is zero: Positivity: Symmetry: Triangular inequality:
Notably, not all the measures given in Table 1 are distance metrics. Note also that some of the measures are defined only for bins with non-zero mass (typically due to the function
As noted above, bin-by-bin measures fail to capture the geographical nature of the distribution domain, and therefore the spatial displacement error that may be at play in spatial applications. Recalling Section 3, let us consider the case where one argument, say
Toy Example # 1. All bin-by-bin measures would yield 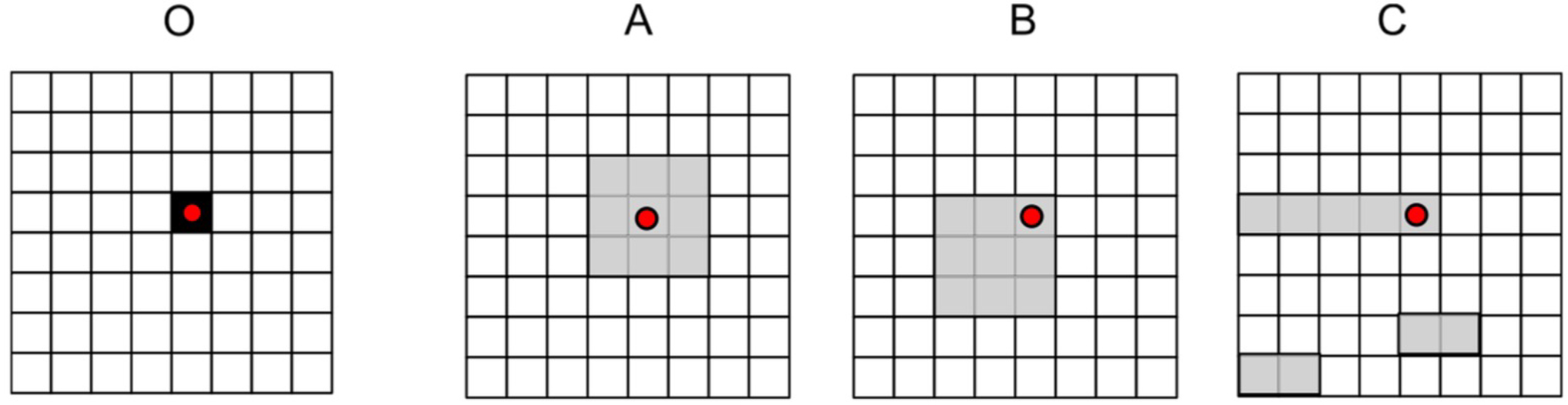
In this small simple example the goodness ordering is rather obvious: map
Having established the main imitation of bin-by-bin measures, we are interested to explore alternative measures that are able to capture the magnitude of the displacement error in addition to the amount of displaced mass. To do so, we must consider measures that are able to take into account the structural properties of the underlying geographical domain. Such class of measures was called “cross-bin measures” in [21]. Again inspired by Fig. 4 we shall refer to this group as “horizontal” measures to distinguish them from the “vertical” bin-by-bin measures introduced earlier.
KWD is a prominent example of cross-bin measure in the sense defined by [21]. Another example of cross-bin measure given in [21] is the quadratic form
Discussion
Having introduced the notions of “vertical” bin-by-bin and “horizontal” cross-bin measures, we now present some qualitative considerations concerning the relation between vertical measures and spatial displacement error.
We start from the consideration that any horizontal displacement (i.e., misplacing a unit of mass from tile
If the coupling is sufficiently strong, then for practical purposes it may suffice to use some bin-by-bin measure to capture (indirectly) the horizontal displacement, with no need to resort to computationally heavier cross-bin measures. In other words, we may consider some simpler bin-by-bin measure as a good proxy for the more complex cross-bin measure. However, this “proxy” approach is viable only when the analyst knows or may safely assume in advance that a strong coupling is in place between horizontal displacement and vertical deviation for the particular application at hand. This is not always the case, and for instance it was not the case with the examples depicted in Fig. 2.
At this point it is natural to raise the question: How well is a bin-by-bin measure able to capture (partially, indirectly) the displacement error? Or equivalently: How well may a bin-by-bin measure serve as proxy for a cross-bin measure?
Speaking qualitatively, the answer depends on the particular conditions of the problem instance at hand, and specifically on the interplay between (a) the displacement mechanism and (b) the spatial distribution patterns. At one extreme, in some special cases the horizontal error induces a particular pattern of vertical deviation that is well captured also by a bin-by-bin measure, and therefore the latter is an excellent proxy for cross-bin measure. At the other extreme, we may have situations conceptually similar to the simple example shown in Fig. 2, where the horizontal displacement pattern cannot be “decoded back” from the vertical deviation effect that it produces, and bin-by-bin measures would be completely inadequate.
Conducting an exhaustive assessment goes beyond the scope of the present contribution and is left for future investigation. Here it suffices to say that in certain applications, where the displacement mechanisms and their vertical deviation effects are well understood, it may be sufficient to adopt a bin-by-bin measure as a lighter proxy for the more computationally expensive cross-bin approaches. However, such situations should be considered as special cases, not representative of general situations. In exploratory research, and in general when the mechanisms at play are not (yet) well understood, resorting exclusively to bin-by-bin measures carries a high risk of incurring experimental fallacies. It would be better in such conditions to consider a set of multiple dissimilarity measures that include also some cross-bin measures, with KWD being a natural candidate to be considered for the latter group.
The Kantorovich-Wasserstein Distance
Overview
The Kantorovich-Wasserstein Distance (KWD) is known with several alternative names, see [5, 10] and references therein. It corresponds to the Wasserstein-1 distance, a special case of the Wasserstein-
KWD was originally introduced in the field of Optimal Transport [17, 22] and later adopted in the field of Image Processing [21], Machine Learning [1] and Statistical Inference [6], often with the name of “Wasserstein distance” or “Earth Mover Distance”.
The application of KWD as a tool for data analysis has recently started to spread across Earth sciences, from Meteorology [9] and Geology [14] to Hydrology [15] and Oceanography [12]. While obviously the physical quantity of interest varies across the different scientific domains (from chemical pollutants density to rainfall intensity, from grain size to chlorophyll concentration, to stay with the cited papers), we can identify a few prominent use-cases for KWD as a descriptive tool that are transversal to the different domains. First, KWD is used to perform model-to-data comparison, i.e. to quantify the (dis)agreement between spatial distributions obtained from model-based predictions or simulations and real-world data obtained from in situ measurements. Second, KWD is used to quantify temporal changes, i.e., to condense into a scalar value the variation across time of the spatial distribution of the quantity of interest. Third, KWD can be leveraged to summarise multiple distributions through the concept of “Wasserstein barycenter”: given a set of
On the practical side, one key issue to be considered when using KWD is the relatively high computational complexity that prevents the computation of the exact value for very large maps. However, the recent work by Bassetti, Gualandi and Veneroni [5] has shown that a close approximation, within a provable deterministic bound, can be computed in reasonable time on standard off-the-shelf machines, paving the way towards the application of KWD also to large maps of practical interest for spatial statistics. The approach proposed by Bassetti, Gualandi and Veneroni [5], hereafter referred as the “BGV method” for short, is the basis for the open-source tool Spatial-KWD . In the rest of this section we first introduce the exact KWD definition and then present the BGV method.
Exact definition
Let us start considering the basic case where the two maps have equal total mass, i.e.
In order to formalise the concept of minimum cost, it is convenient to represent the grid as a directed graph
With these positions, and recalling that we have assumed equal total mass between the two arguments
wherein all sums run over the links included in
Replacing
In the LP problem (2) the
Example of transportation graph for a regular grid of 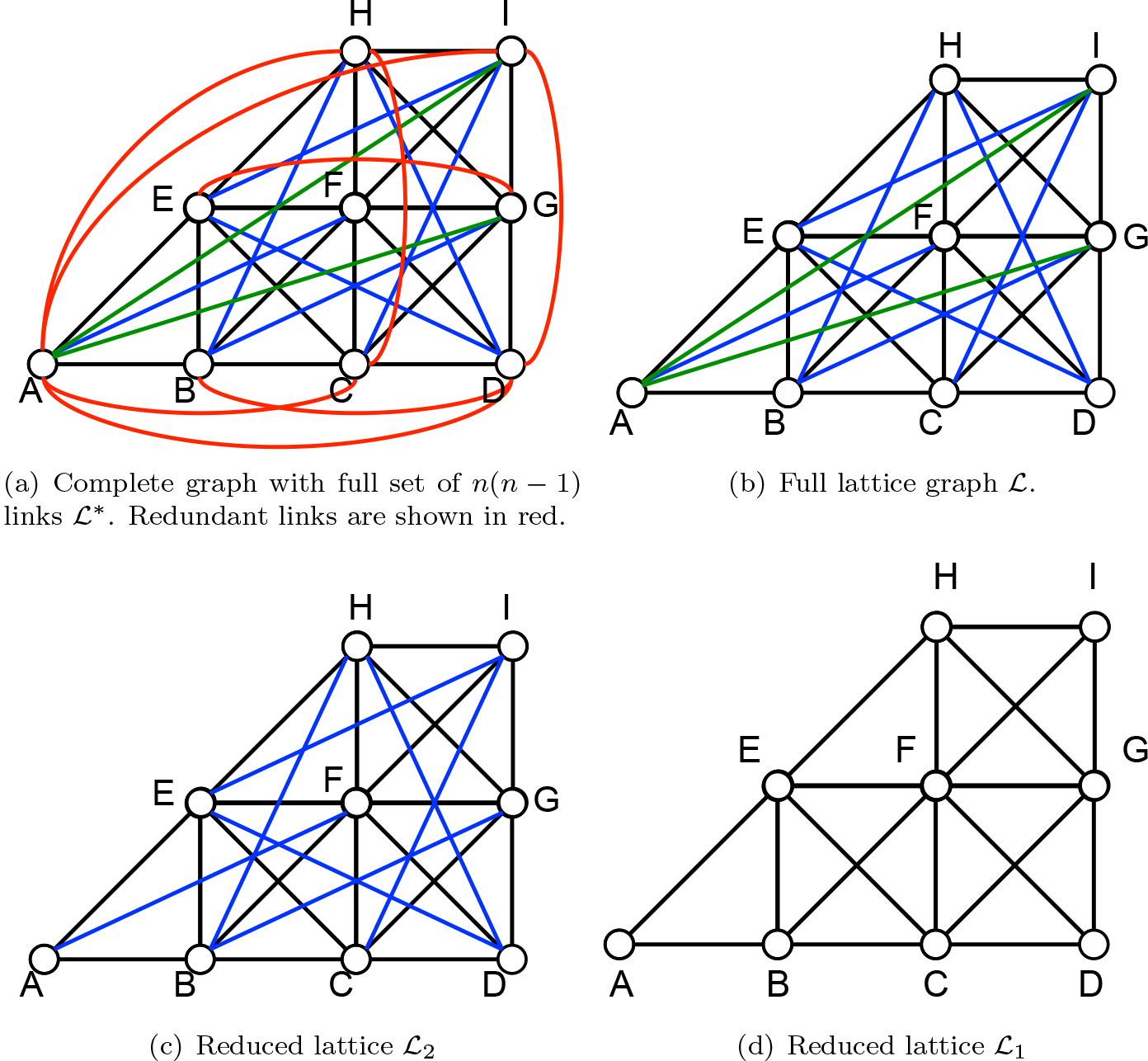
The very same solution to the LP problem (2) can be obtained by considering a reduced graph obtained from
wherein all sums run over the links included in
Note the different structure of the constraint in the two formulations (2) and (3). In the latter, a single balancing constraint is imposed on the generic node
The optimal solution
Bound (4) as a function of parameter 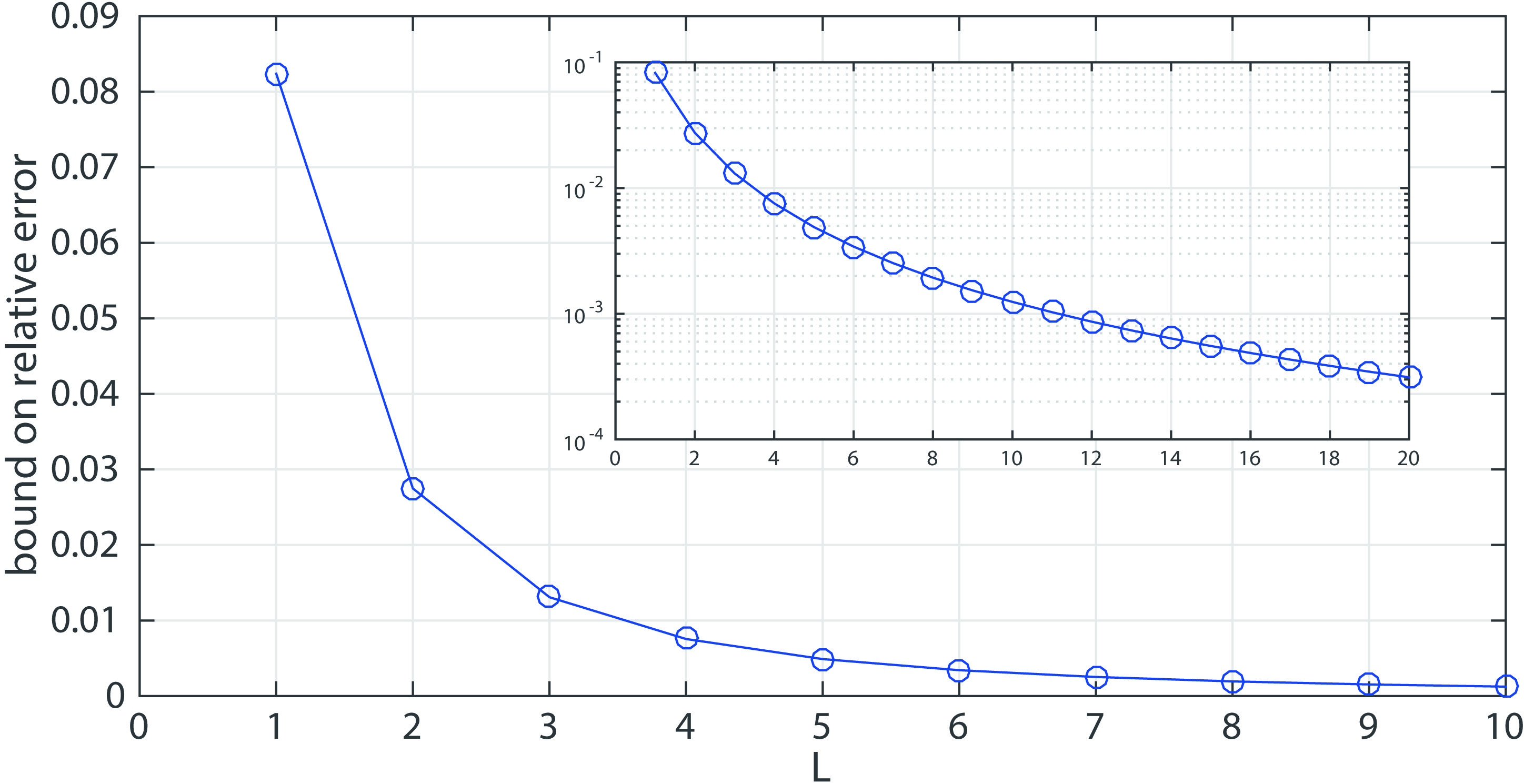
To further reduce the computational cost, we can run the LP problem (3) on a subset of the full lattice graph. However, the solution obtained in this way will be close, but not exactly equal to the KWD value computed on the full latice graph
Denote by
In other words, increasing
In their work Bassetti, Gualandi and Veneroni [5] make two key contributions. First, they show that, for a given value of
The value of the upper bound
The Spatial-KWD tool builds upon the BGV method from [5]. At its core, the tool builds the LP problem (3) and solves it through an advanced version of the simplex algorithm [7, 13]. The package is developed in standard C++11 and provides wrappers for R and Python. The R wrapper is based on RCPP [8]. The open-source code is publicly available under EUPL 1.2 license at the links that are given at the end of the paper.
To give an a idea of the run-time that may be expected by practitioners, we report in Table 2 the execution times obtained on a commercial workstation (DELL 7960, 56 cores, 4 GHz, 128 GB RAM, running Ubuntu Linux 22.04 LTS) for pairs of semi-synthetic benchmark maps covering the whole Belgium at different resolutions.8
The benchmark maps were derived from the real-world 2020 census grid at 1
Run-time of Spatial-KWD on a commercial desktop for benchmark maps covering the whole Belgium at different grid resolutions (
The Spatial-KWD tool embeds additional features meant to facilitate its use across diverse application domains. In fact, KWD is an abstract mathematical concept and its adoption in practical analysis tasks involves a number of methodological design choices. Given a particular analysis task, the issue is not only whether KWD is a meaningful measure for the task at hand vis-à-vis other alternative measures, but rather how KWD can be applied meaningfully to the task. Practitioners should remain aware that even the “right” tool can be used in the “wrong” way. Furthermore, thw “right” way to apply KWD for one analysis task may be “wrong” for some other task.
In this section we describe some of the principal issues that practitioners will likely encounter when using KWD for practical tasks in spatial statistics. For each of them, we present the range of options that are currently supported by the Spatial-KWD tool. In fact, the tool was developed with a rich set of features and options in order to enable its use across a diverse range of application domains.
Non-convex regions
In practical applications, the region of interest may have an irregular shape, corresponding for instance to a whole country or to some administrative unit. If the region is convex, by definition all direct segments between any pair of bins (or more exactly, bin centers) lie entirely within the region. Instead, for a non-convex region this condition is not always satisfied. Figure 5 shows an example of non-convex region with two examples of bin pairs for which the direct path (red dashed line) crosses the region border. For such bin pairs, the question arises as to whether the link cost should be set equal to the unconstrained Euclidean distance (air distance, dashed red line) or, alternatively, to the shortest path constrained to lie entirely within the region of interest (geodetic distance, continuous green line). This is a design choice that depends on the application at hand, and specifically on the physical interpretation of the “displacement error” that we intend to capture by KWD. For example, if we are measuring the intensity of air pollutant that is not constrained to move within the region of interest, it is reasonable to consider the unconstrained distance. If instead we are considering density of people along a territory with a closed border that cannot be trespassed (e.g. a marine coast, or a barred border) we may opt for the constrained internal shortest path. This is a methodological design choice that depends on the application context, and the Spatial-KWD tool supports both options via a configurable parameter (refer to the documentation for details).
Irregular non-convex region.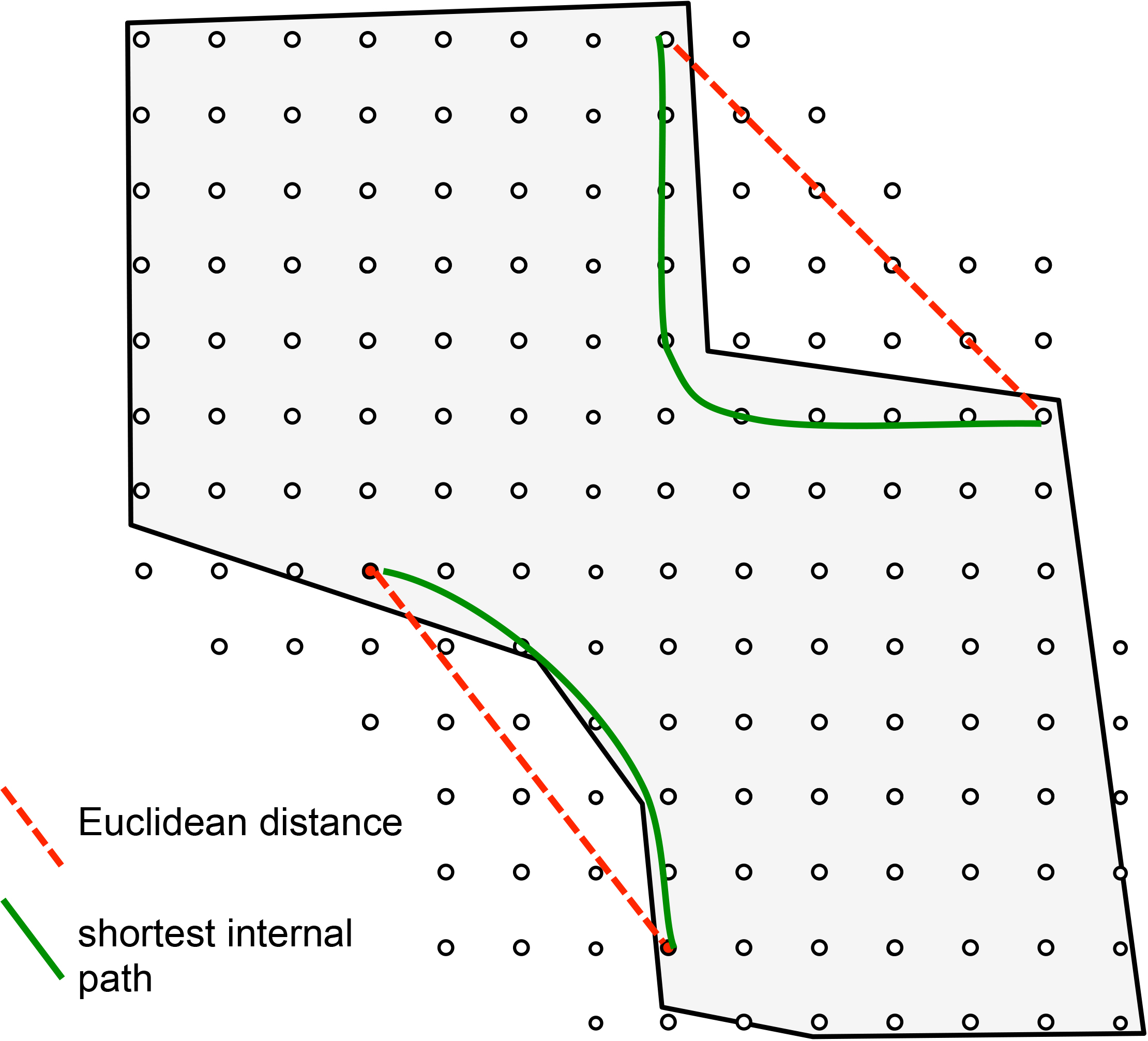
Recall that the LP formulations given above require input arguments with same total mass, i.e.,
Let
In the following we review some of the possible options to deal with input maps with unequal masses. We start by distinguishing two general types of approach:
[Type-I] Methods that modify the original maps with unequal masses into a new pair of maps with equal masses on the same set of bins and links. The transformation is achieved by redistributing the mass gap [Type-II] Methods that augment the graph underlying the LP problem with one auxiliary “virtual bin”, to which the mass gap
Rescaling
In this Type-I approach, the maps are simply re-scaled or re-normalised. In other words, one computes
Flooring
Instead of adding the mass proportionally to the value in each bin, in this alternative Type-I approach the gap mass is added uniformly over all bins as an additive constant value. In other words, assuming that
Virtual bin with fixed-cost virtual links
With the previous Type-I methods, the extra mass is positioned in the area of interest according to an explicitly criterion, i.e., proportionally to the bin value (rescaling) or as a constant term (flooring). In both cases, this approach requires making a “hard” design choice about the geographical distribution of the mass gap.
Type-II methods follow a completely different rationale: they assign the extra mass to an auxiliary “virtual bin”, connect the virtual bin with fixed-cost “virtual links” to a subset of the geographic bins (possibly all), and then let the optimisation process find the “best” way to reallocate the mass gap to the physical bins. This approach requires a slight modification of the LP problem, or more precisely of the support graph underlying the LP problem, to incorporate the auxiliary virtual bin and the corresponding virtual links. The links to and from the auxiliary bin are assigned a fixed cost
Examples of Type II approaches to handle unequal masses. The auxiliary “virtual bin” gets assigned the mass gap and, from there, it can flow to a subset of physical bins (i.e., insertion points) through auxiliary “virtual links” of fixed cost 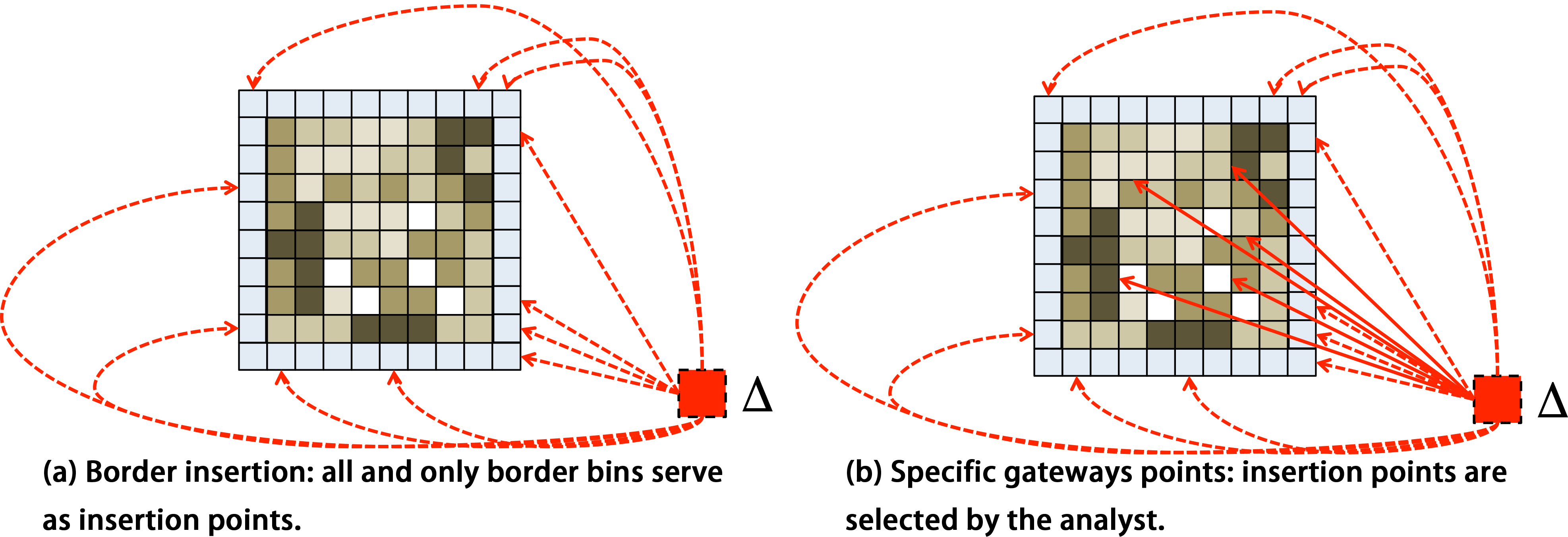
Two examples illustrating the FA concept. For each scenario (top and bottom row, respectively) the figure shows three distinct transport plans and corresponding KWD values: (a) globally optimised transport plan for the whole area of interest; (b) transport plan obtained with the naif approach of cropping the FA, ignoring all nodes and mass falling outside, and applying the standard optimisation to the cropped FA map; (c) local transport plan obtained with the FA formulation implemented in Spatial-KWD, taking into account external mass in the vicinity of (but not necessarily adjacent to) the FA.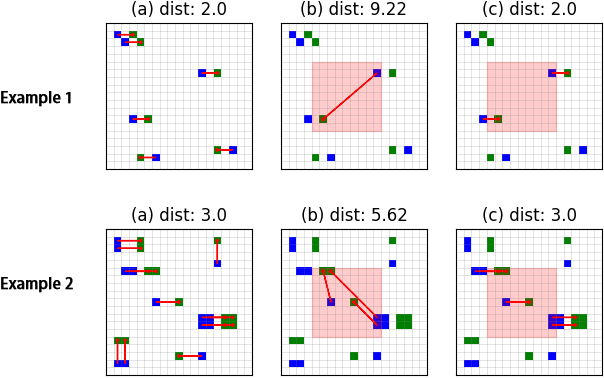
The physical bins connected to the auxiliary virtual bin represent the (physical) insertion points of extra mass. Configuring the set of insertion points represents a methodological design choice, but a softer one than the direct assignment of mass to bins as done in Type-I methods. The Spatial-KWD tool allows to configure freely which physical bins are connected to the virtual bin. Among the possible strategies for selecting the insertion points we highlight the following:
Ubiquitous insertion. All Border insertion. Insertion points are limited to the border bins at the perimeter of the region of interest, as exemplified in Fig. 6(a). Specific gateways. An arbitrary subset of bins are configured to serve as insertion points for the extra mass, as exemplified in Fig. 6(b). Such “getaway” bins may correspond to the location of qualified application-specific facilities (e.g., airports and train stations may serve as gateways for applications in the field of tourism and logistics, while factories may be relevant for applications in the field of environmental monitoring).
In summary, the Spatial-KWD tool provides great flexibility and customisation possibilities in handling the mass gap. For Type II methods, it supports the explicit configuration of the auxiliary link cost
Motivations: global vs. local accuracy
The KWD between two maps is a summary indicator quantifying the dissimilarity between two input maps over the whole region of interest. When one input map represents the “true” distribution and the other some measured/estimated version thereof, KWD represents a summary indicator of the global accuracy of the measurement/estimation method at hand throughout the entire region of interest.
In some practical applications, we may be interested to assess the local accuracy in a specific sub-region of the larger region of interest. This is relevant, for instance, when the measurement/estimation process under evaluation is subject to large variations in the spatial accuracy due to local conditions.9
For example, the context of estimating present population based on Mobile Network Operator data [20], the local accuracy depends on the size of the deployed radio cells, that in turn depends on the local intensity of mobile traffic, with large differences between urban, sub-urban and rural areas. This is just one concrete example motivating the development of “local” dissimilarity measures in specific area (or sub-region) within a larger map.
Focus area (FA) concept for localised metric. Continuous-line paths represent transportation flows entirely contained in FA. Dotted-line paths represent transportation flows between FA and the surrounding external bins.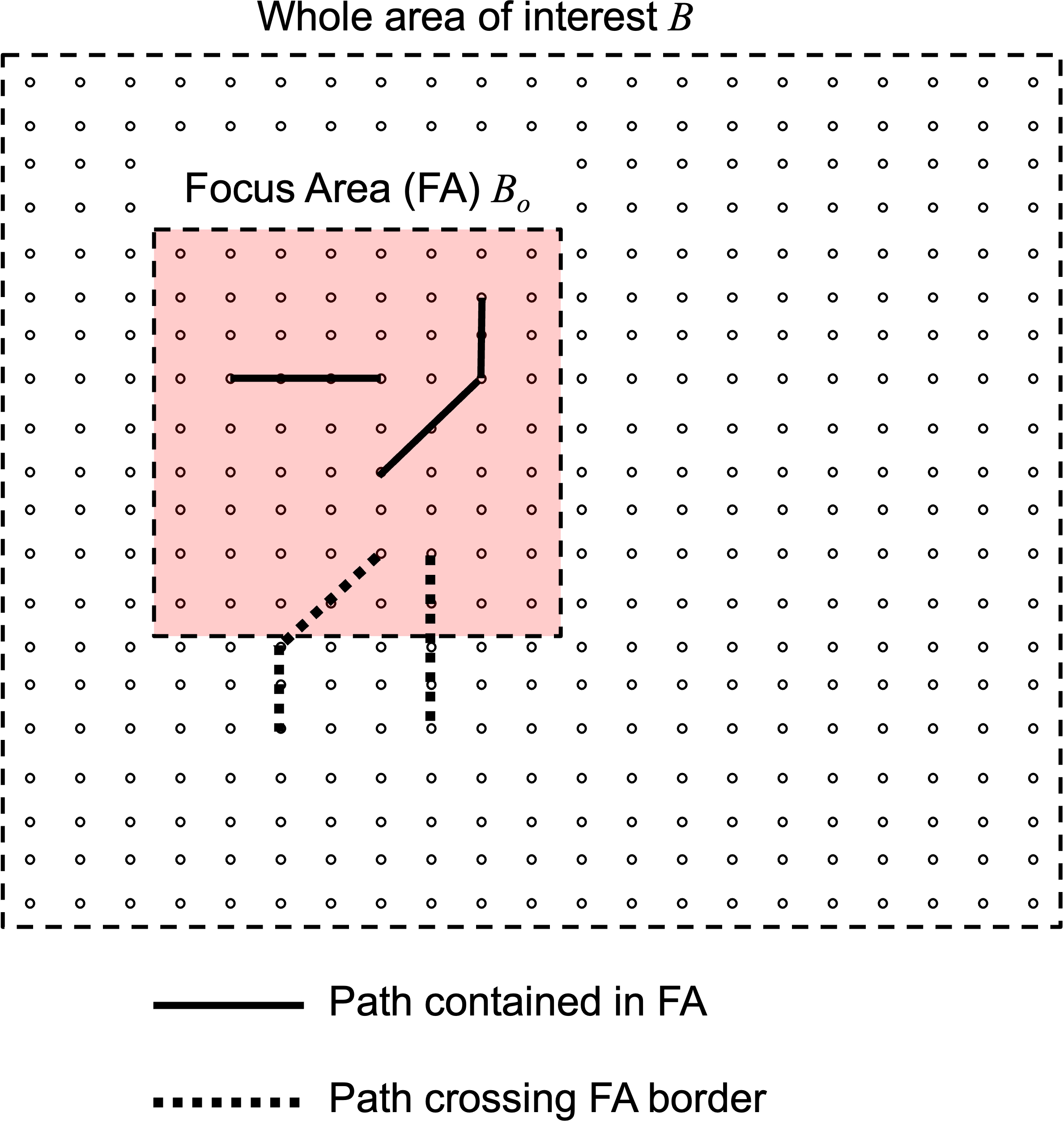
Before presenting our proposed approach, we explain the limitations of a naif approach. We do so by resorting to the two simple examples shown in Fig. 7. For each example, the figure reports three transport plans labelled (a), (b) and (c), with the corresponding minimum cost printed in each figure (labelled “dist.”). For each example the input maps, blue and green, are laid over the same
The problem with this approach is that all mass external to the FA, including the part thereof in the immediate vicinity of the FA, is completely ignored, thus forcing the transportation plan to rearrange exclusively the mass units internal to the FA. Furthermore, in practical applications it is likely that the cropping operation will return cropped maps with unequal masses, leaving to the analyst the decision to select one of the methods among those discussed in Section 6.2 to deal with unbalanced masses. Any choice would likely introduce additional distortion, since all the methods presented in Section 6.2 ignore the fact that the reduced map was sliced out of a larger map with a given mass distribution in the surroundings of the FA.
In order to mitigate such limitations, we propose hereafter a modified LP formulation that does not ignore the external mass outside the FA but treats it differently from the mass inside the FA. With the modified LP formulation given in Section 7.3, the transport plan computed for the FA would be the one shown in Fig. 7(c) for a minimum cost that is more in line with the global KWD value.
We remark that, in the general case, the local transport plan obtained in the FA with the proposed formulation is not guaranteed to correspond exactly to the globally optimised transport plan that would be obtained with a global minimisation across the whole area of interest without FA, and the local KWD value is not guaranteed to correspond exactly to the global KWD value. However, compared with the naif approach, the proposed formulation mitigates the kind of distortion illustrated above, leading to a transport cost value that is better representative of the local mass distribution.
Modified LP problem with FA
Let
For the generic node
The resulting LP formulation writes:
wherein
The Spatial-KWD tool implements a modified problem that is equivalent to the LP formulation (5) and allows for more efficient resolution. In order to take advantage of efficient solvers for transportation flow problems with equality constraints, the LP problem (5) is transformed into an equivalent instance defined on a modified grid, where auxiliary nodes are inserted and connected with capacitated zero-cost auxiliary links to the nodes outside the external areas. With this trick, the inequality constraints in (5) are replaced by equality constraints, allowing the application of efficient solvers.
In the current version of the tool, the FA location and size can be specified as input argument, either in the shape of a square or near-circular area, by providing the coordinates of the FA center and FA radius as parameters: all tiles that are at L1 norm (for square) or L2 norm (for near-circular) distance from the center are included in the FA.
In this paper we have presented the Spatial-KWD tool and illustrated its configuration features and options. We hope with this work to promote the consideration (and possibly the adoption) of the Kantorovich-Wasserstein Distance as a candidate dissimilarity metric in a wider range of spatial statistics applications. Spatial-KWD can be used to perform model-to-data comparison or to quantify the temporal changes in the spatial distribution of physical or social quantities, similarly to what is being pioneered in several Earth Science fields, from Meteorology [9] and Geology [14] to Hydrology [15] and Oceanography [12]. Our ready-to-use tool can support similar use-cases in other fields, from Environmental Statistics (distribution of pollutants) to Demography (distribution of present population).
At the time of writing, the tool has been used to support ongoing research on spatial density estimation of present population from Mobile Network Operator data [19, 18]. It was also considered for exploratory work in the field of Statistical Disclosure Control for spatial population grids [11]. We invite the statistical community to use the tool and share their experience with the authors, particularly for what concerns usability, new required features and indications for further development. The tools may be extended and enriched with additional features, and in this sense feedback from users and practitioners will help us to identify the most important direction for future development.
Among the possible venues for continuing this work, we would like to highlight the possible application of “Wasserstein barycenters” as a summarisation tool for (sets of) spatial distributions. As discussed earlier, when a set of
Disclaimer
The views expressed in this paper are those of the authors and do not necessarily represent the view of the European Commission.
Code
The open-source code of Spatial-KWD is publicly availabe under EUPL 1.2 license from
Footnotes
Acknowledgments
The implementation of Spatial-KWD was supported by Eurostat under Service Contract ESTAT.2020. 0257. The authors are grateful to Federico Bassetti from University of Milano for providing useful comments on an early draft of this work.