
Abstract
The model of a probabilistic neural network (PNN) is commonly utilized for classification and pattern recognition issues in data mining. An approach frequently used to enhance its effectiveness is the adjustment of PNN classifier parameters through the outcomes of metaheuristic optimization strategies. Since PNN employs a limited set of instructions, metaheuristic algorithms provide an efficient way to modify its parameters. In this study, we have employed the Aquila optimizer algorithm (AO), a contemporary algorithm, to modify PNN parameters. We have proposed two methods: Aquila optimizer based probabilistic neural network (AO-PNN), which uses both local and global search capabilities of AO, and hybrid Aquila optimizer and simulated annealing based probabilistic neural network (AOS-PNN), which integrates the global search abilities of AO with the local search mechanism of simulated annealing (SA). Our experimental results indicate that both AO-PNN and AOS-PNN perform better than the PNN model in terms of accuracy across all datasets. This suggests that they have the potential to generate more precise results when utilized to improve PNN parameters. Moreover, our hybridization technique, AOS-PNN, is more effective than AO-PNN, as evidenced by classification experiments accuracy, data distribution, convergence speed, and significance. We have also compared our suggested approaches with three different methodologies, namely Coronavirus herd immunity optimizer based probabilistic neural network (CHIO-PNN), African buffalo algorithm based probabilistic neural network (ABO-PNN), and
Introduction
The process of classification plays a crucial role in our daily lives and is considered the most commonly used decision-making function performed by humans. By assigning an object to a particular category or class, we categorize it based on several distinct predetermined qualities, which may or may not be related to the object being classified [1, 2, 3].
Various classification algorithms use different strategies to identify patterns in instances, including naïve Bayes, stochastic gradient descent, and k-nearest neighbors. Choosing an effective classification strategy is crucial, and neural networks are one such strategy that can extract meaning from complex or inaccurate data to identify patterns and predict trends that may be too complex for humans or other computational techniques [4, 5]. Neural networks perform tasks in numerous permutations and combinations, making them well-suited for modern big data applications. They can also handle ambiguous, conflicting, or incomplete data by using controlled processes when accurate models are unavailable [6, 7].
In 1990 Specht [8] introduced probabilistic neural networks (PNNs), which are based on Bayes theory. PNN is a classifier that maps input patterns across multiple class levels and can approximate a more general function. It implements the kernel discriminant analysis statistical algorithm and is organized as a multilayer feed-forward network with input, pattern, summation, and output layers. The PNN derives most of its parameters from the training data, with the only item that requires tuning being the smoothing factor that limits the deviations of Gaussian functions [9, 10].
The benefits of PNNs over other types of neural networks can be summarized as having a faster training process and avoiding local minima issues. Additionally, as the size of the training set increases, it ensures better coverage for an optimal classifier. However, PNNs also have some drawbacks, such as delayed network execution due to multiple layers and high memory requirements, among others [11, 12].
Training neural networks is a challenging task that requires experimentation, including error analysis and learning, due to the constantly changing properties of the search space from one scenario to the next. To fit a neural network, a training dataset is utilized to update the model weights and establish a reliable mapping of inputs to outputs [13, 14]. This approach involves exploring a range of potential values for the neural network model weights to identify a set of weights that perform well on the training dataset [15, 16]. Recently, one of the widely used techniques is employing a fast and accurate random search mechanism for metaheuristic algorithms to modify the weights generated by neural networks [17, 18, 19].
A metaheuristic is a computational method or heuristic in computer science and mathematical optimization that aims to discover, generate, or select a heuristic that can provide a satisfactory solution to an optimization problem, particularly when information is incomplete or imprecise, or when computing resources are limited [20, 21, 22]. Metaheuristics identify a subset of solutions that would otherwise be too large to examine fully. As they make minimal assumptions about the problem, they are useful in a wide range of applications [23, 24]. Modern metaheuristic algorithms were developed to address three primary objectives: faster problem-solving, handling large-scale problems, and producing robust algorithms [25, 26].
In combinatorial optimization, metaheuristics can often identify satisfactory solutions with less computational effort than optimization algorithms, iterative methods, or simple heuristics by exploring a vast array of possible solutions [21, 27] While much of the literature on metaheuristics is empirical and based on computer experiments, some formal theoretical findings have been made, including convergence and the possibility of achieving global optimality [28, 29].
Population-based metaheuristic algorithms use local and global search mechanisms. The exploitation of individuals in the algorithm population to search locally for better solutions near the identified solutions is referred to as exploitation [30, 31]. In modeling a metaheuristic algorithm, striking a balance between local and global search is a significant implementation challenge [32, 33]. To address this issue, a hybrid approach that combines the global search capabilities of a population-based metaheuristic algorithm with the exploitation capabilities of a local-based algorithm is being explored as a means of maintaining the balance between the two search phases [34].
There exist various metaheuristic algorithms utilized in solving classification problems, such as particle swarm optimization (PSO) [35], genetic algorithm (GA) [36], ant colony algorithm (ACO) [37], mine blast algorithm (MBA) [38], harmony search (HS) [39], artificial bee colony (ABC) [40, 28], Salp Swarm Algorithm (SSA) [41], and others, which will be discussed in the next chapter. Despite the application of numerous algorithms in solving classification problems, continued research is necessary to discover novel algorithms capable of addressing this challenge. The reason behind this is that no single approach can effectively tackle every type of problem, and no method is universally optimal because each methodology has advantages in specific areas of interest, and the results depend on the nature and intricacy of the problem [10].
In this paper, a cutting-edge algorithm, known as the Aquila optimizer algorithm, was selected to modify the weights of the PNN. When compared to previous metaheuristic optimization methods, the algorithm developed by Abualigah et al. [42] has produced excellent results. It is currently commonly utilized in complicated optimization situations after successful testing. As a result, the Aquila optimizer method is used in this study to improve the classification process’s performance by modifying the weights of the PNN. The Aquila optimizer algorithm is applied in two different ways in this paper. The first approach, Aquila optimizer based probabilistic neural network (AO-PNN), utilizes only the local and global search capabilities of the Aquila optimizer algorithm. The second approach, hybrid Aquila optimizer and simulated annealing based probabilistic neural network (AOS-PNN), hybridizes the global search capability of the Aquila optimizer algorithm with the local search mechanism of simulated annealing in a hybrid method. The main contributions of this study are as follows:
Present the PNN network as a solution to the general classification problems. Use the Aquila Optimizer (AO) algorithm as a learning strategy for PNN to determine the weights of the optimal values. Addresses the weakness in the local search mechanism by hybridizing the simulated annealing algorithm with the Aquila optimizer algorithm. Constructing three different classification models (e.g., PNN, AO-PNN, and AOS-PNN) and contrasting them statistically to find the best one. Compare the original AO as well as three state-of-the-art algorithms with the hybrid approach (AOS-PNN).
The remainder of this paper is structured as follows: Section 2 presents the most relevant works to this research. Following this, Section 3 discusses the proposed approach, specifically AO-PNN, while Section 4 delves into AOS-PNN. Section 5 presents the experiments and their corresponding results. Lastly, Section 6 outlines the conclusion and highlights potential directions for future work.
The effectiveness of metaheuristic algorithms can be attributed to their ability to explore and apply the hybridization approach to addressing classification problems. This approach successfully identifies and utilizes the search space during the search process through adjusting the weights and biases till they are very close to the ideal values. In several interesting publications listed here, the neural network has been employed as a classifier. Additionally, the methods for metaheuristic optimization were emphasized to achieve a better result that is closer to the optimal outcome.
To solve categorization issues, several different local search approaches have been employed. The review’s first significant publication is that by Onyezewe et al. [43] used simulated annealing to find optimum k in the k-Nearest Neighbor classifier, removing the need for an exhaustive search. The results of four distinct classification tasks demonstrate a noteworthy enhancement in computational efficiency in comparison to k-Nearest Neighbor methods, which employ an exhaustive search for k. k-Nearest Neighbor classification, produces precise nearest neighbors more quickly, resulting in a reduction in computation time. In another study, Gupta and Raza [44] developed a novel way for optimizing the number of hidden layers and their associated neurons for a deep feedforward neural network. The strengths of tabu search and Gradient descent are combined in this study with a momentum backpropagation training technique. The suggested technique was evaluated on four distinct classification benchmark datasets, and the optimized networks demonstrated improved generalization ability.
Furthermore, Alweshah et al. [45] developed a method by integrating African buffalo optimization (ABO) with PNN to configure a hybrid method in order to address classification issues. ABO method has been employed to carry out the improvement, which aims to optimize the weights of the PNN in order to enhance classification accuracy. According to results from 11 benchmark datasets, the new ABO algorithm beats the old PNN on all datasets. Also, Alweshah [32] enhanced the effectiveness of the PNN classification model using the Coronavirus herd immunity optimizer (CHIO) method. The PNN initiates the process by randomly generating a preliminary solution for the CHIO in order to modify the weight parameters of the PNN. All of this is done by employing beneficial random phase control, resulting in the successful discovery of a search process capable of identifying the optimal value. Eleven benchmark datasets were utilized to assess the developed CHIO-PNN approach for classification accuracy, and outcomes are compared to the PNN and three additional algorithms: firefly algorithm (FFA), African buffalo (ABO), and
Bai and Bain [46] conducted another study wherein they introduced weighted lazy naive Bayes (WLNB) to mitigate the issue of variance by increasing the nearest neighbors of a test instance. A self-adaptive evolutionary technique is used in WLNB to instantly acquire two crucial parameters. The technique proves to be highly effective, as Evolutionary Weighted Lazy Naive Bayes (EWLNB) leverages Differential Evolution to identify the optimal parameter values. EWLNB surpasses naive Bayes and many other improved naive Bayes techniques in experiments carried out on 56 datasets extracted from University of California at Irvine (UCI) dataset based classification performance as well as class probability forecasting. To further improve the accuracy of clothing image recognition, Zhou et al. [47] introduced a classification approach for clothing, which was based on a parallel convolutional neural network (PCNN) and coupled with an optimized random vector functional link (RVFL). To extract characteristics from garment photos, the approach use the PCNN model. Then, to tackle the difficulties of typical CNNs, the structure-intensive with dual convolutional neural network is adopted. The experimental findings demonstrate that the algorithm in this work achieves 92.93 percent accuracy on the fashion-Mnist dataset.
In a separate study, Alweshah et al. [48] improved the performance of PNN by utilizing the
On the other hand, Bangyal et al. [50] presented an improved bat algorithm based neural network for classification problems through enhanced the traditional bat algorithm’s exploitation capabilities while avoiding fleeing from local minima. Aziz et al. [51] proposed a hybrid technique for tackling optimization challenges of independent component analysis (ICA) extracted genes based on cuckoo search (CS) method and ABC to find the best selection of features to improve ICA for the naive Bayes classifier performance. Sheik Abdullah [52] proposed a method-based binary fish swarm optimization for the purpose of feature selection and decision trees and the Gaussian nave Bayes algorithm for classification approaches. Zhou et al. [47] proposed a clothing classification approach which is based on a parallel convolutional neural network (PCNN) paired with an optimized random vector functional link based on grasshopper optimization algorithm (GOA) to increase accuracy in clothing picture identification (RVFL).
Abd Elaziz et al. [53] combined swarm-based approaches and deep learning to create an approach for COVID-19 image classification using the AO Algorithm. MobileNetV3 is used as a deep learning model to extract key visual features and the AO is utilized as a feature selection to decrease the dimensionality of image representations and improve classification performance. The proposed system is validated using two datasets, including X-ray and CT COVID-19 images. The experimental results demonstrate that the proposed method performs well in terms of classification accuracy and feature extraction and selection phases. In a separate study, Fatani et al. [54] investigated various feature extraction and selection techniques for the Intrusion Detection System (IDS) based on the AO algorithm. They developed a feature extraction method based on conventional neural networks (CNN) and used the AO for feature selection. The developed IDS approach is evaluated on four well-known datasets, including CIC2017, NSL-KDD, BoT-IoT, and KDD99, to demonstrate its competitive performance against different optimization techniques. Various evaluation metrics were utilized to demonstrate the developed approach’s excellent performance.
Furthermore, Vashishtha and Kumar [55] proposed a method for detecting bearing defects in a Francis turbine using a sound signal, a minimal entropy deconvolution (MED) filter, and an AO algorithm. The MED filter length was adjusted based on the autocorrelation energy to recover a single random pulse from a weak defective signal, and the AO adaptively selected the best filter length using the autocorrelation energy as the fitness function. Meanwhile, Aribowo et al. [56] used the AO algorithm to estimate the parameters of a proportional-integral-derivative (PID) controller for a DC motor speed control system, which was first tested on benchmark optimization tasks. The AO was compared with several other optimization techniques, and the results showed that the AO approach was effective and outperformed the others in determining PID parameters. Mehmood et al. [57] utilized the AO for control autoregressive system parameter estimation and statistically evaluated the AO’s reliability and robustness at different noise levels. The experimental findings demonstrated that the AO was accurate, convergent, and resilient, and the proposed method was effective in comparison to other state-of-the-art methods using nonparametric statistical tests.
It is clear that there is no single classification model that can be universally applied to all types of problems, and there is no classification strategy that can be considered the best for all scenarios as each strategy offers benefits for particular fields of concern. Regarding the PNN, it has been shown to outperform many other techniques and can be utilized to solve various types of problems. PNN is less sensitive to outliers and closer to Bayes optimum categorization. As the size of the representative training set grows, PNN is certain to reach an ideal classifier; therefore variant metaheuristics proposed in the literature to solve classification problems through adjust the PNN’s weights.
In summary, the existing methods in this section address various issues related to metaheuristic algorithms and classification problems. Some of the main problems and limitations identified in these methods include: exploration and hybridization in metaheuristic algorithms, local search approaches for classification, optimization of neural network parameters, integration of metaheuristic algorithms with neural networks, comparative evaluations and benchmarking, evaluation metrics and validation, and limited discussion on negative results.
As for AO algorithm, after reviewing the most important studies demonstrating the use of AO, it has been noted that the AO produced outcomes that were either superior to or nearly equal to other well-known approaches. Furthermore, by conducting empirical investigations of engineering challenges, it is possible to assess the generated AO’s suitability for dealing with real-world applications. AO gained remarkable accuracy results in previous work. It is capable of dealing with the challenge of restricted engineering optimization as well as providing a quick convergence rate. It can also be used with other optimization techniques. Furthermore, the computational cost is very low; therefore the time complexity is decreased. According to the previous discussion, which demonstrated the superiority of the produced AO, it can open up a broad range of future works.
As there is no one-size-fits-all solution for every problem, and each method has its own strengths depending on the area of application, it is important to explore various techniques to find the most appropriate approach for each specific problem. In this regard, the AO algorithm can be studied further to enhance the accuracy of classification tasks and compared with other established metaheuristic techniques.
Aquila optimizer based probabilistic neural network (PNN)
A common data mining approach called the PNN model has been applied to solve a variety of classification and pattern recognition problems. PNN is an efficient strategy to cope with classification challenges. The PNN has a faster training process compared to a backpropagation neural network because it maximizes the size of the representative training set and allows for the addition or removal of training samples without requiring extensive retraining. Additionally, an equivalent structure in the PNN provides convergence with the best classifier [58].
For tasks involving pattern recognition and classification, feedforward neural networks of the type PNN are used. It comprises three levels of nodes, and its algorithm approximates the performance of each category’s parent likelihood distribution using a non-parametric approach and a Parzen window [59].
There are several steps, which called layers, that the PNN classifier takes to complete the classification process, but in general, all of these steps (layers) are included under two main processes, namely training and evaluation [60]. The construction of a PNN Classifier is seen in Fig. 2.
According to Fig. 2, the training part of the dataset was used to train the PNN, and the unclassified occurrences were then categorized using the testing part of the datasets. Finally, the classification accuracy was calculated using Eq. (1) [61].
In terms of classification, the following terms are used: True Positives (TP), which occur when the predicted value matches the actual output value; True Negatives (TN), which occur when the predicted value is false and the actual value is also false; False Positives (FP), which occur when the predicted value is true but the actual value is false; and False Negatives (FN), which occur when the predicted value is false but the actual value is true.
The processes in this form of (NN) are divided into four layers: input, pattern, summation, and output. The initial layer (input) records the size of the input vector, while the following layer (pattern) keeps track of how many instances there are in the training set overall. The third layer (summation) records the amount of classes existing in the group. Finally, the fourth layer (output) records the number of classes in the group [62]. Figure 3 shows the structure of PNN classifier.
As seen in the PNN architecture figure above, the input layer contains N nodes. These N nodes are linked to the hidden layer by a branch, thus the hidden node receives the entire input feature. For each X class, the hidden nodes are organized into groups. Each hidden node in the class X group corresponds to a Gaussian function centered on the class’s associated feature. The X output nodes receive these Gaussian functional values and send them to the output layer [62]. The four essential operational levels of the PNN model are shown below:
Input layer: Each neuron in the input layer has a predictive parameter, with values provided by neurons. Pattern layer: For each training sample, a single layer outputs a product depending on the input vector
where
Output layer: evaluates the target category by analyzing the weighted votes for each target gathered by the pattern layer based on the most significant vote.
Construction of a PNN classifier.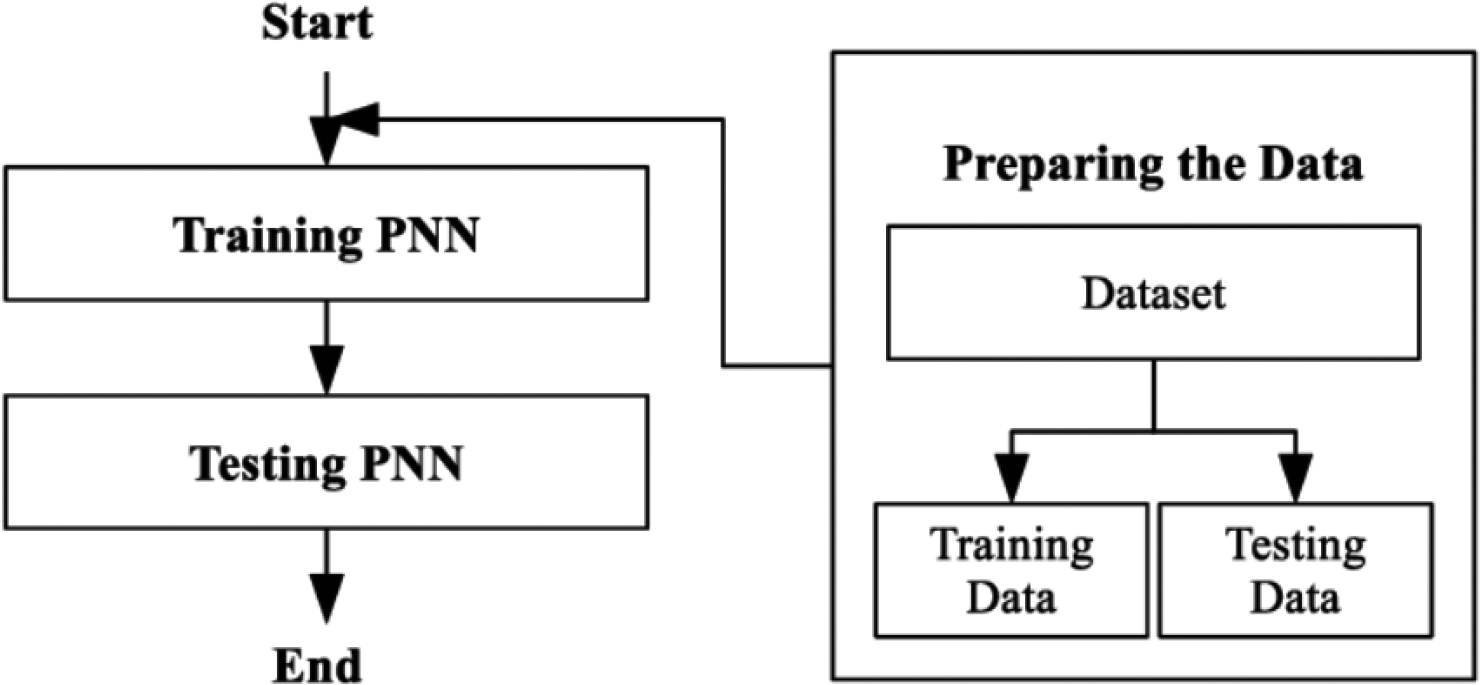
Probabilistic neural network (PNN) structure [1].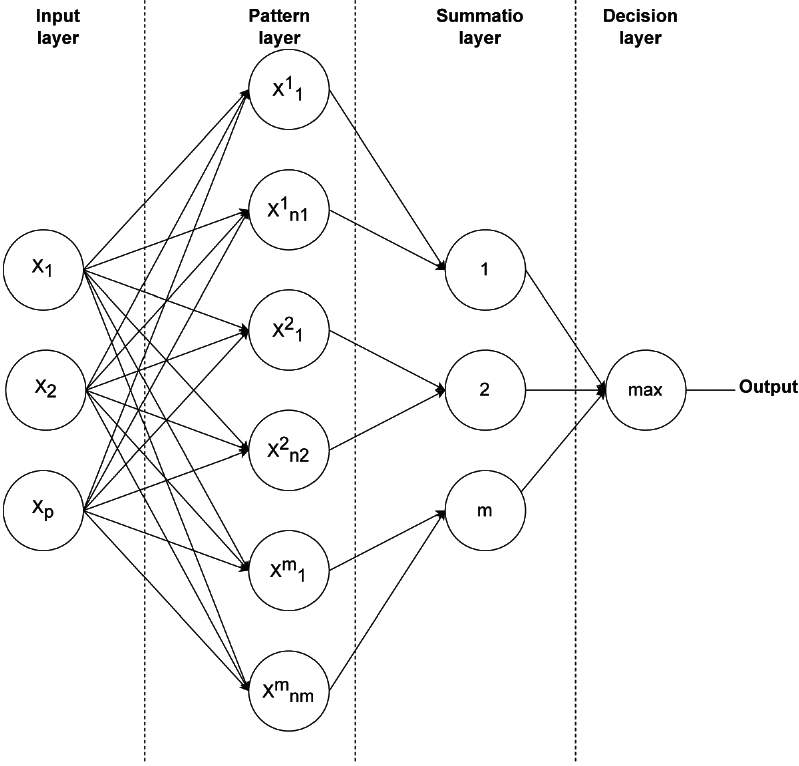
Proposed AO-PNN model.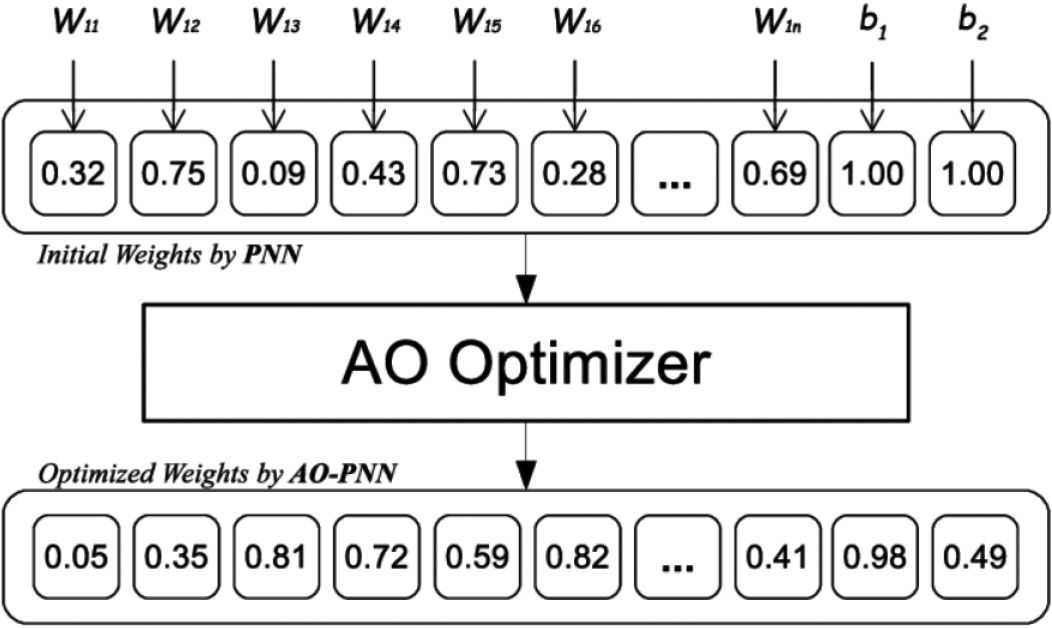
All nodes have a single weight
where
All these steps are described in the Algorithm-1 pseudocodes. Figure A.10 shows the AO algorithm flowchart.
Following the establishment of the PNN, a set of network weights is changed to roughly attain the desired outcomes. A training algorithm is used to carry out the process, which alters different weights until a set of error criteria is met [45].
The performance of a PNN is heavily dependent on the smoothing parameter that is chosen, especially whenever the training dataset is restricted, small results in a multimodal distribution, greater results in interpolation between points. Extremely huge approaches Gaussian Probability Density Function (PDF). In theory, should be determined by the frequency of the samples. The most straightforward approach for each dimension or characteristic is to make use of the standard deviation of the training samples. Cross-validation (using training and validation datasets) improves generalization. Another option is clustering, Zhong et al. [63] built on these strategies in gap-based estimation by modeling the distances between a training sample and its neighbors. They calculated per input feature, observing that estimating per class is less accurate.
Flowchart of AO-PNN model.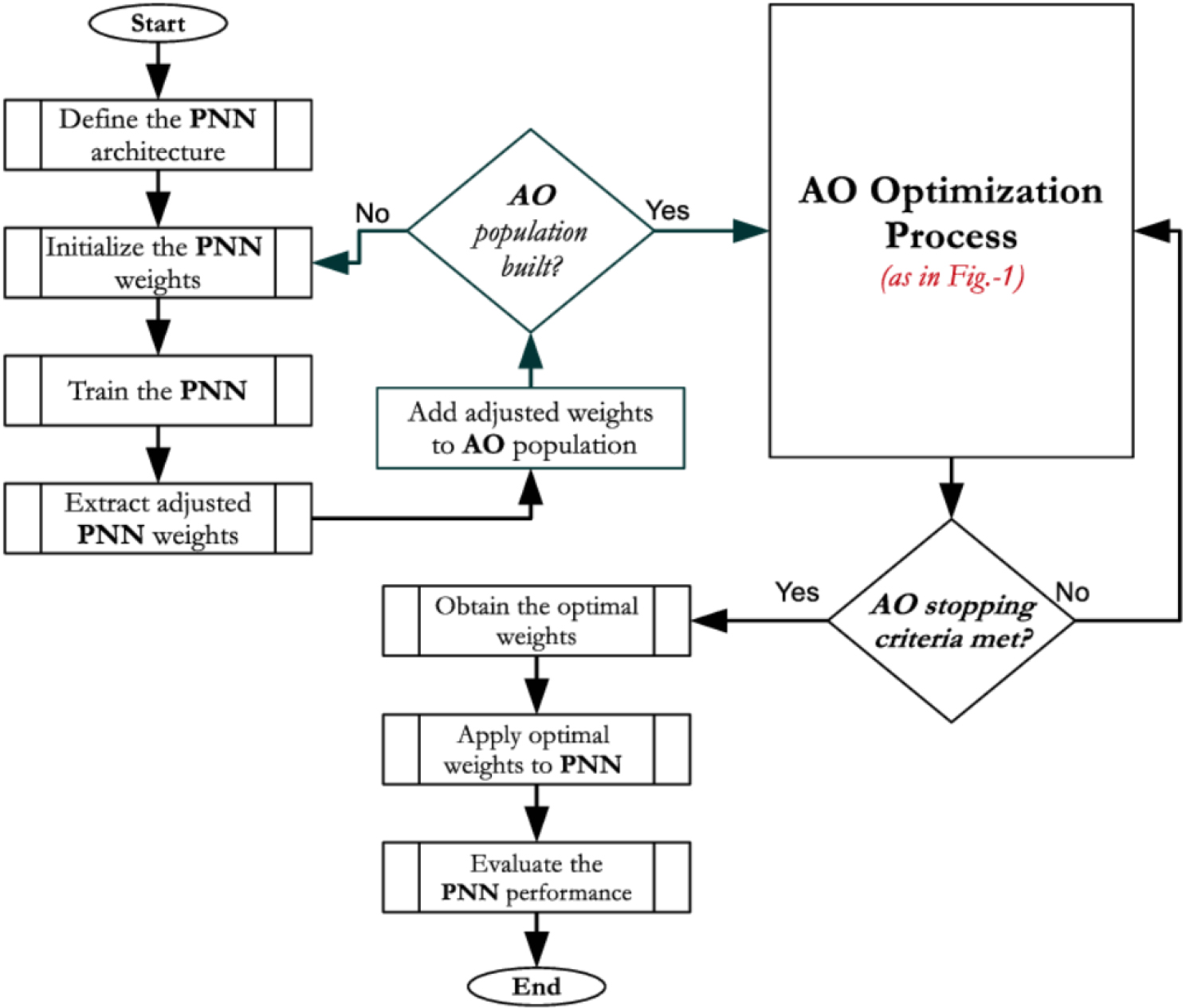
Optimizing neural network weights to improve classification accuracy and speed up convergence is one of the study’s goals. This study looks into using the Aquila AO method with the PNN network, where the AO is used to change the weights of the PNN. An integration strategy incorporating PNN and AO is given for classification issues in order to evaluate this approach.
Initially, the conventional PNN is used to assess the accuracy of classification issues. First, the AO is used to refine the initial solutions produced by the PNN, which is then used to further enhance the classification process.
The PNN is trained using the AO algorithm in this work, which modifies the weights and finds the ideal values. The main goal is to arrive at precise answers for classification issues. The PNN first calculates the outputs for the hidden and output layers and creates random weights. The difference between the expected and actual outputs is then computed using the error rate. The suggested AO-PNN model, which integrates the AO with the PNN, is shown in Fig. 4.
Proposed AOS-PNN model.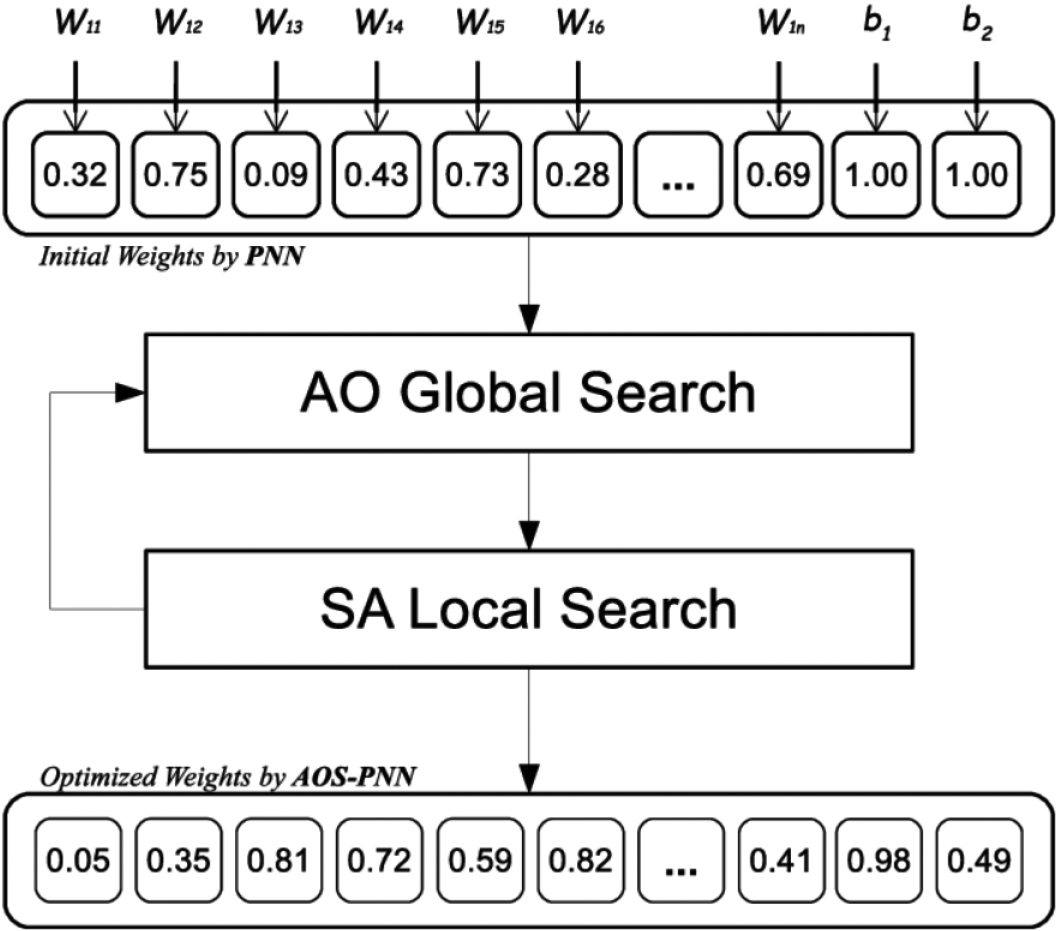
Comparison of classification accuracy of all methods.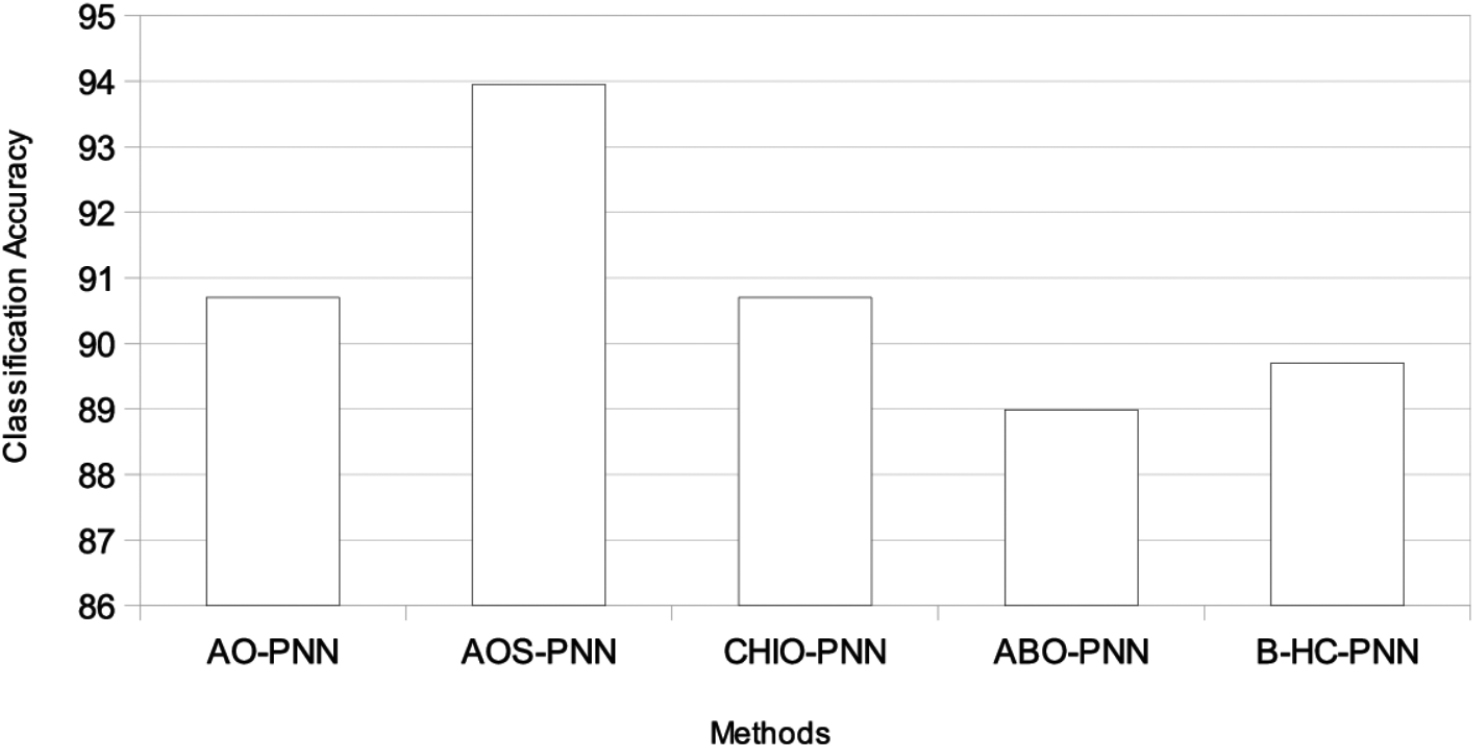
The AO iteratively computes and modifies weights to reduce error rates and improve rating accuracy for the datasets under classification, as shown in Fig. 4. This procedure is repeated until a predetermined number of iterations pass without additional weight modifications, signifying a decline in error rate. The AO refines the initial random solution used by the Probabilistic Neural Network (PNN) in order to maximize PNN weights. Therefore, one of the most important factors in enhancing PNN performance is the AO’s search capabilities.
Controlling random phases and selecting ideal parameters for PNN classification depend on how well the search region is determined. The flowchart that illustrates the AO-PNN model suggested in this work is shown in Fig. 5.
The AO method is a relatively new optimization technique that produces improved outcomes in a wide range of optimization challenges. The original AO method employed a blind operator to conduct exploitation independent of the fitness value of the current and operated solutions. In this paper, this blind operator is modified with a local search that begins with a solution, works on it, and then replaces the original solution with the improved one. This approach hybridizes local search algorithms – simulated annealing (SA) with global search algorithms – Aquila optimizer (AO). The AO algorithm makes use of the SA technique (shown in Fig. 6) to find a solution close to both the best-known solution and a randomly chosen one, and then replace an existing solution. Because the SA method operates as an operator within the AO algorithm in this way, the integration improves the exploitation capabilities of the AO algorithm.
The second goal of the study is to optimize the neural network weights for better classification accuracy and quick convergence by enhance the search capabilities of AO algorithm through hybridization process between global search of AO and the local search of SA. The use of the AO and SA based PNN – where the AO and SA was used to change the PNN’s weight – was investigated in this paper. As seen in Fig. 6, the PNN was used to generate the initial solutions at random, and the AO with SA was utilized to further enhance the PNN weights.
Experimental results
Following the formation of the solution models as outlined in the previous section, the proposed methods AO-PNN and AOS-PNN were tested using the 11 UCI datasets to assess how well they performed in optimizing the classification process by adjusting the PNN’s weights. The experiment was applied to each dataset individually, so in each PNN training run, there is a new model formulated specifically for that dataset. Therefore, we ensure that the optimized PNN- model is suitable for all health problems proposed for solution in this study. The accuracy rate, convergence speed, data distribution, and other measures of central tendency affect how much turbulence is produced. The results were compared to those of the other methods mentioned in the literature.
On a personal computer with an Intel(R) Core(TM) i7-6006U CPU @ 2.00GHz (4 CPUs), 2.0GHz, and 16 GB of RAM, the study validation for this paper is carried out. The suggested approaches were implemented in all experiments using Matlab R2018a and Python3, and the datasets were divided into 70% for data training and 30% for data testing.
Datasets description
Datasets description
The approaches, which are used to train the PNN classifier, are evaluated and benchmarked utilizing publicly recognized genuine datasets provided by the machine learning repository at the University of California at Irvine (UCI). These datasets are common used in classification problems [5]. The 11 benchmark datasets are available online and downloading from UCI website. Table 1 summarizes the properties associated with the datasets.
Parameters setting
The model parameters were generated by a number of thorough researches that required the suggested ways to deliver a greater level of performance. The outcomes of a few pilot trials were used to define the input settings. These variables made it possible for the suggested methods to deliver superior results. The execution of each model was equal in order to compare the outcomes generated by each one. The parameters values used in all of the trials are listed in Table 2.
Parameter settings
Parameter settings
When such number of FPs, FNs, TPs, and TNs were all equal to 0, the greatest classification accuracy was obtained in a binary classification with a single positive class as well as a single negative class. When the number of TPs, TNs, and FPs were all equal to 0, the best classification accuracy was discovered in a binary classification with a single positive class and a single negative class. The suggested approach successfully computes FP, FN, TP, and TN values. The categorization accuracy is then determined by measuring Eq. (1). The average accuracy rates for PNN, AO-PNN and AOS-PNN after 30 runs on each dataset are shown in Table 3.
Average of classification accuracy of PNN, AO-PNN and AOS-PNN
Average of classification accuracy of PNN, AO-PNN and AOS-PNN
Aquila optimizer algorithm (AO), Probabilistic neural network (PNN), best results in bold.
As seen in Table 3, the results clearly demonstrate the capacity of the AO Algorithm to provide more accurate results if it is employed as a search mechanism to alter the PNN’s weights since hybrid techniques, AO-PNN and AOS-PNN, outperform the PNN method in the accuracy field across all datasets.
Average of classification F1 score of PNN, AO-PNN and AOS-PNN
Aquila optimizer algorithm (AO), Probabilistic neural network (PNN), best results in bold.
In addition, the results in Table 4 also demonstrate the capacity of the AO Algorithm to provide more accurate results if it is employed enhance the PNN’s parameters since hybrid techniques, AO-PNN and AOS-PNN, outperform the PNN model in the accuracy field across most datasets.
As the two proposed methods, AO-PNN and AOS-PNN, the AOS-PNN surpassed The AO-PNN in 10 datasets and has they have the same result in one dataset, namely Fourclass. The outcome shows that AO may be hybridized with the other algorithms to provide results that are more accurate. When SA is substituted for AO in the local search phase of a hybrid technique, it shows a limitation in the local search phase of AO. The algorithm’s inherent flaw is that local search is conducted at random rather than concentrating on the most effective solutions right now. The embedded method was used for this hybrid model to demonstrate AO’s potential to produce more accurate findings when hybridized, and that this is seen in the results. In all datasets used in the experiment, the AOS-PNN method is leading to higher efficiency and higher accuracy with smaller error sizes. The Finding is attainable by avoiding the local optima trapping during optimization. The AOS-PNN algorithm achieved this by balancing global and local searches.
As mentioned earlier in this chapter, the results obtained in Table 3 represent the average accuracy of 30 attempts per dataset. It is important that the results in all cases for each dataset are close to each other, which reflects the accuracy of the proposed approach in the convergence of the results and the non-randomness of the obtained values. An illustration of data that was gathered from a sample or population is called a data distribution. It is used to arrange and communicate voluminous volumes of information in a way that audiences can understand and retain.one of the important tools that can describe the data distribution of the values of 30 runs per each dataset is a boxplot which is a style of visual data display.
A box plot is a graph that shows data from a five-number summary that contains one of the central tendency metrics. It does not illustrate the distribution as clearly as a stem and leaf plot or histogram. However, it is usually used to determine whether a distribution is skewed and whether there are any possible outliers (abnormal observations) in the data collection. Boxplots are also useful when comparing or utilizing many data sets to understand how broadly the data values fluctuate or are spread out. The distributions may be easily compared using these boxplots since the center, spread, and overall range are all apparent.
Based on an overview of five statistics (the minimum, first quartile (Q1), median, third quartile (Q3), and “maximum”), the data distribution was displayed using a boxplot. It describes the traits of the exceptions and their perspectives. Additionally, it will demonstrate the degree of aggregation and regularity of the data. Figure 7 shows boxplots based on 30 runs for each datasets using PNN, AO-PNN and AOS-PNN methods.
Boxplots of PNN, AO-PNN and AOS-PNN for each dataset.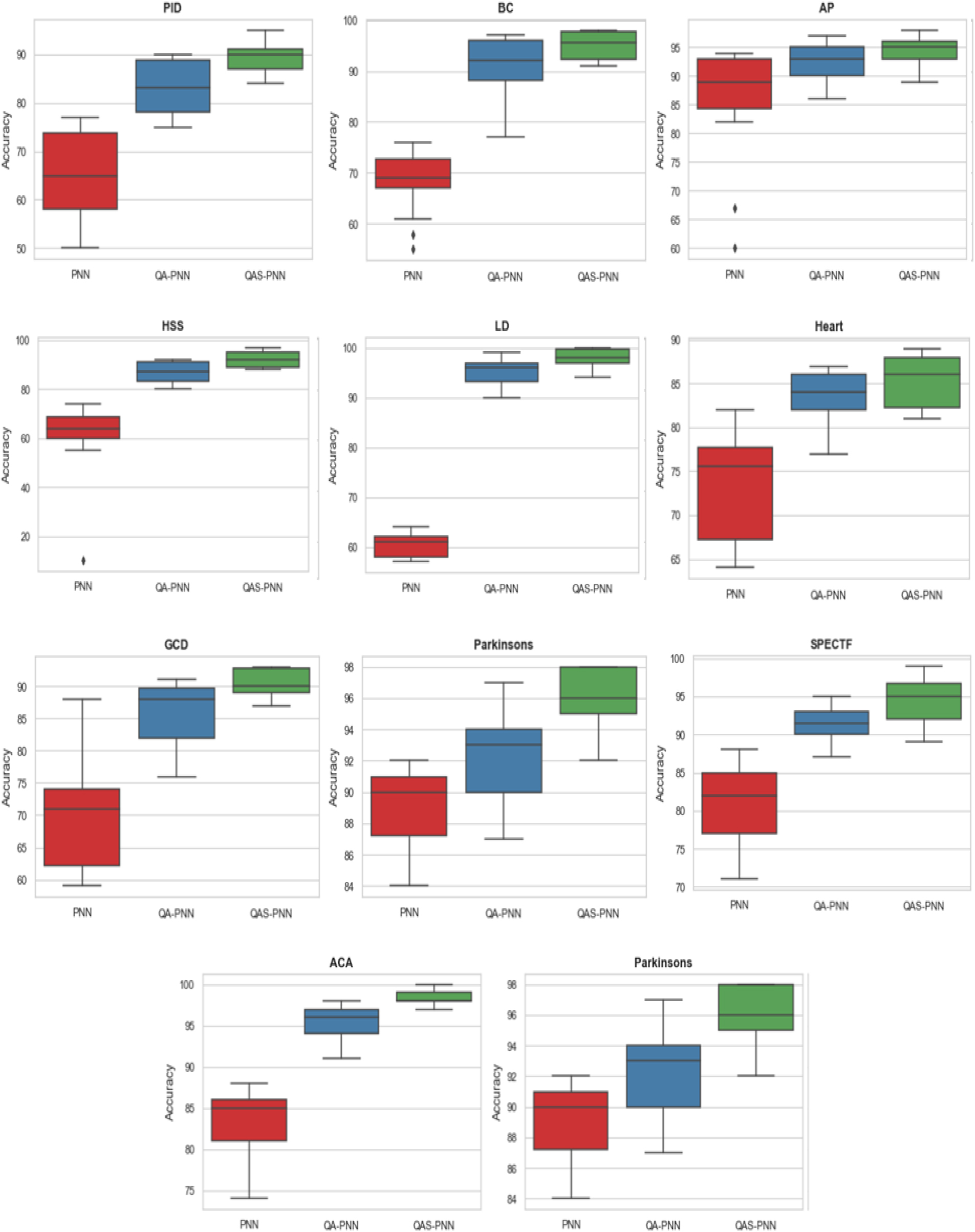
Swarmplots of PNN, AO-PNN and AOS-PNN for each dataset.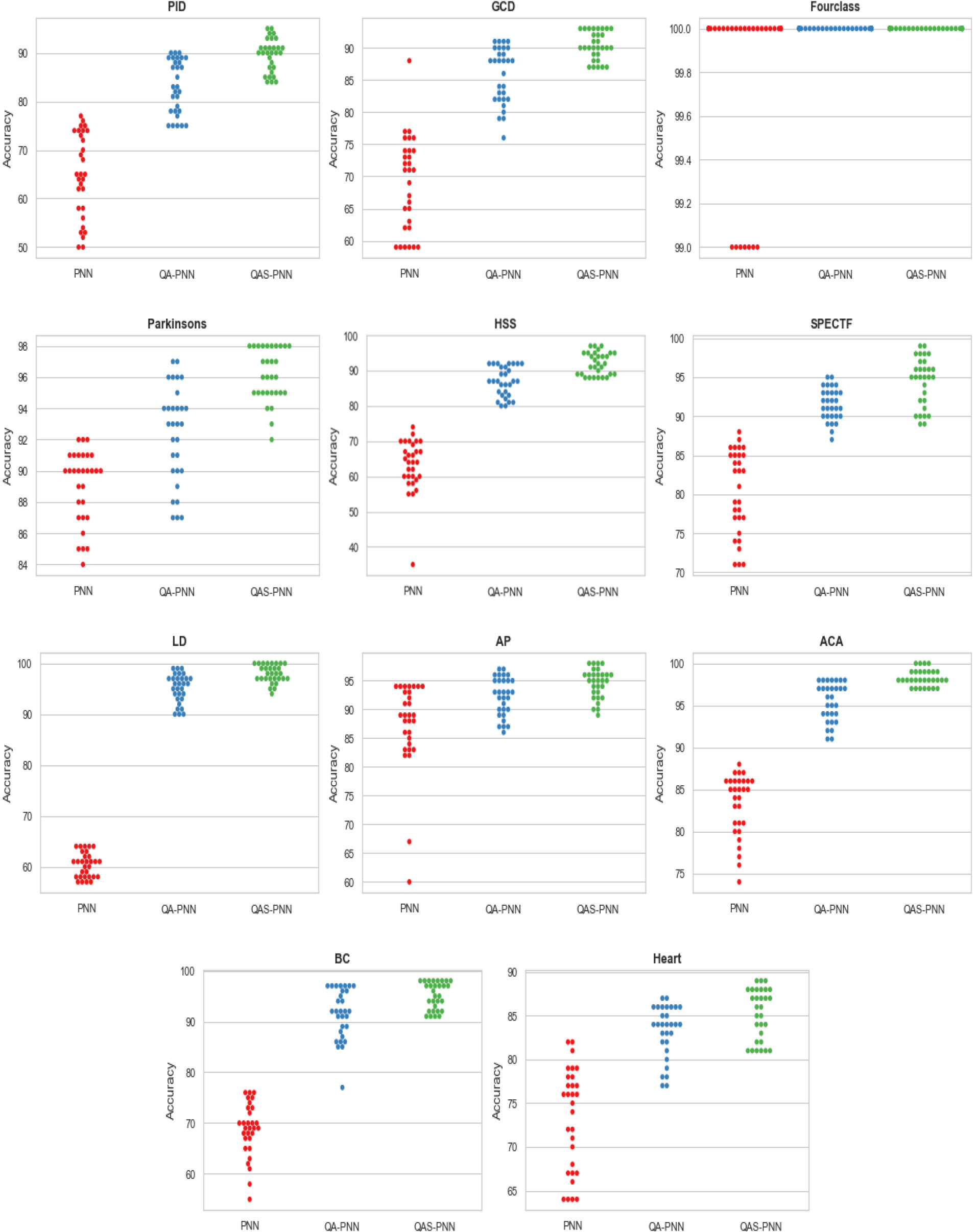
Convergence speed of PNN, AO-PNN and AOS-PNN methods.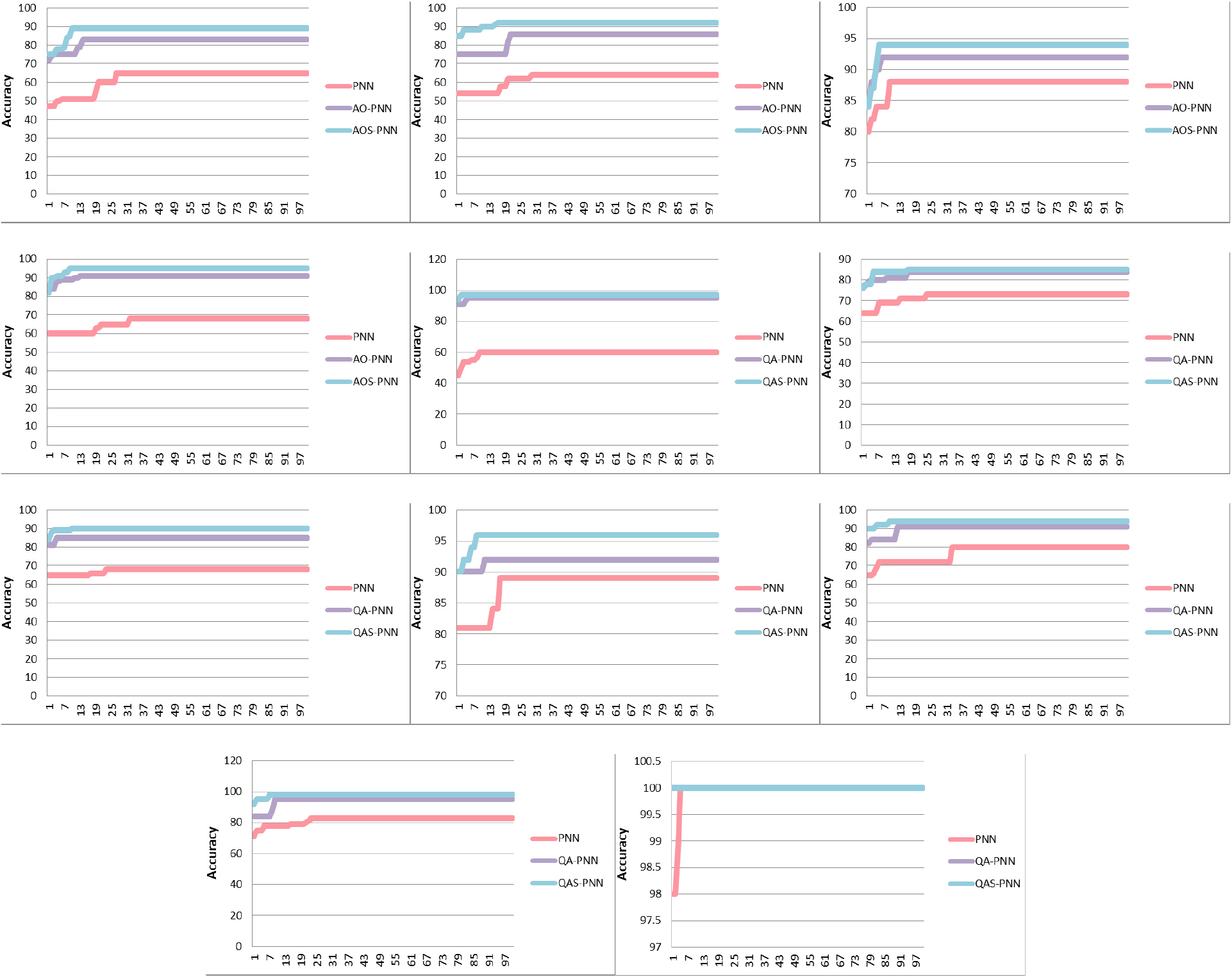
As seen in Fig. 7, the AOS-PNN technique yields improved effectiveness and higher accuracy with fewer error sizes across all datasets utilized in the experiment. By staying away from the local optima trapping during optimization, the Finding is possible. This was accomplished using the AOS-PNN algorithm by balancing global and local searches.
Swarm plot is another type of plot utilized for visual data distribution. By displaying individual points, it is intended to graphically depict how the values are distributed. It displays the lowest, maximum, and number of redundant values. It only makes sense if there are few data points. Figure 8 shows the swarm plots based on 30 runs for each datasets using PNN, AO-PNN and AOS-PNN methods.
As shown in Fig. 8, the AOS-PNN approach improves efficacy and accuracy while introducing fewer errors across all datasets used in the experiment. It can be seen from Fig. 8, the values of the 30 runs for each dataset, the min and the max, and how they are distributed. In most datasets, the values distribution of the proposed AO-PNN and AOS-PNN show a positively skewed, which means that most values are a higher than the median. From Figs 7 and 8, it can be shown that the two proposed methods, AO-PNN and AOS-PNN have more correlated accuracy results in each run more than the basic PNN classifier.
The rate of convergence in numerical analysis refers to the pace where a convergent sequence approaches its limit. Although a limit does not provide information about any finite first part of a sequence, this concept is useful when dealing with a sequence of successive approximations for an iterative algorithm, as less iteration are typically required to produce a useful approximation if the rate of convergence is higher.
The suggested method’s convergence speed performance curves were evaluated when they were applied to the 11 datasets for further evaluation. Figure 9 shows the averages of 30 different runs, assuming a total of 100 iterations for each dataset, and evaluates the convergence of PNN, AO-PNN and AOS-PNN to assess the effectiveness of the proposed approach. The figure depicts how a faster and more consistent convergence speed may result in better solutions.
As shown in Fig. 9, when compared to the PNN approach, the AO-PNN and AOS-PNN were able to improve the weight parameters of the PNN that were generated randomly, resulting in improved classification accuracy and convergence speed. As a consequence, the superiority of the proposed techniques is linked to the ideal balance of exploitation and exploration searches.
From Fig. 9, two criteria can be observed, which are the number of iterations needed to reach the highest classification accuracy as well as what the initial accuracy value in the first iteration was. Table 5 below summarized the information noticed in Fig. 9.
Information retrieved from the convergence curve
Information retrieved from the convergence curve
Aquila optimizer algorithm (AO), Probabilistic neural network (PNN), best results in bold.
As for number of iteration needed to reach the highest classification accuracy, the both proposed methods AO-PNN and AOS-PNN need less iteration than the original PNN. However, the hybrid AOS-PNN method surpassed the AO-PNN in term of iteration needed in 8 datasets, and has the same iteration in two datasets namely Heart and Fourclass. Only in one dataset the AO-PNN has less iteration, it needs 4 iterations in GCD, whereas the AOS-PNN needs 11 iterations in this dataset.
On the other hand, as for the initial accuracy in the first iteration the both proposed methods AO-PNN and AOS-PNN have better initial values than the original PNN in all datasets. However, the hybrid AOS-PNN method surpassed the AO-PNN in this criterion in 6 datasets out of 11. And the AO-PNN has the best initial accuracy in the first iteration in 2 datasets, namely BC and Heart. As for the 3 remind datasets, AP, Parkinson’s and Fourclass, the two AO-PNN and AOS-PNN have the same initial accuracy.
The proposed AOS-PNN model was compared to current approaches such as CHIO-PNN (Alweshah 2022), African buffalo algorithm (ABO) (Alweshah, Rababa et al. 2020), and
As seen in the table, the two proposed methods, AO-PNN and AOS-PNN, surpassed the other methods in the literature in most datasets with Average of accuracy 90.68 and 93.95, respectively. As for AOS-PNN, it exceeded CHIO-PNN in 9 out of 11 datasets. And it has the same result in Fourclass dataset, and only in one dataset namely AP the CHIO-PNN surpassed the AOS-PNN. In comparison with ABO-PNN, the AOS-PNN exceeded it in all datasets except the Fourclass dataset; the two methods have the same value. In addition, AOS-PNN exceeded B-HC-PNN in 9 out of 11 datasets. And it has the same result in Fourclass dataset, and only in one dataset namely Heart the B-HC-PNN surpassed the AOS-PNN.
Comparison of AO-PNN and AOS-PNN with the previous methods
Comparison of AO-PNN and AOS-PNN with the previous methods
Aquila optimizer algorithm (AO), Probabilistic neural network (PNN), best results in bold.
On the contrary, AO-PNN outperformed CHIO-PNN in 6 out of 11 datasets, which are HSS, BC, LD, Heart, GCD, and Parkinson’s. AO-PNN achieved the same result as CHIO-PNN in the Fourclass dataset, while CHIO-PNN surpassed AO-PNN in the remaining four datasets. In comparison to ABO-PNN, AO-PNN surpassed it in seven datasets: BC, HSS, LD, GCD, Heart, ACA, and SPECTF. AO-PNN obtained the same result as ABO-PNN in the Fourclass dataset, while ABO-PNN outperformed AO-PNN in the other two datasets. Additionally, AO-PNN performed better than B-HC-PNN in 7 out of 11 datasets, which are PID, LD, BC, HSS, GCD, ACA, and Parkinson’s. AO-PNN achieved the same result as B-HC-PNN in the Fourclass dataset, while B-HC-PNN surpassed AO-PNN in only 2 datasets. Figure A.10 depicts the classification accuracy of all approaches across all datasets.
The fact that metaheuristic algorithms assist in locating the optimal solution during the search process is one of their most noteworthy benefits. In terms of convergence rate, the AO was able to outperform the original PNN when searching for optimal solutions. The best weights were chosen to ensure that the identified solutions converged as soon as possible. As a result, randomization allowed AO to search the solution space from a local perspective while increasing the number of viable solutions. The AO-PNN approach would be shown to enhance accuracy and allow for quicker convergence. In comparison to several constructed algorithms discovered in previous relevant studies, the suggested AO-PNN provides more effective results. Furthermore, high-quality solutions for classification-related problems are addressed, resulting in more efficient accuracy and faster convergence.
The findings indicate that AO could be used with other algorithms to get more accurate results. When SA is used in place of AO in the local search phase of a hybrid approach, it reveals a restriction in AO’s local search phase. The algorithm’s inherent fault is that it conducts local search at random rather than focusing on the most effective solutions immediately. The embedded technique was utilized for this hybrid model to highlight AO’s ability to give more accurate results when hybridized, which is evident in the results. The AOS-PNN model leads to improved efficiency and accuracy with fewer error sizes in all datasets utilized in the experiment. The result is obtained by avoiding local optimization trapping during optimization. This was accomplished by balancing global and local searches in the AOS-PNN algorithm.
Conclusion
In this paper, the AO applied two different approaches. The two proposed approaches are employed to adjust the weights generated by PNN. The first approach, called AO-NN, just used the AO’s local and global search capabilities, while the second approach hybridized the AO’s global search with the local search mechanism of simulated annealing in a hybrid method called AOS-PNN. The results clearly demonstrate the capacity of the AO algorithm to provide more accurate results if it is employed as a search mechanism to alter the PNN’s weights since hybrid techniques, AO-PNN and AOS-PNN, outperform the PNN model in the accuracy field across all datasets. Based on the results of classification accuracy, data distribution, convergence speed, and the significant test, the hybrid approach AOS-PNN has the strength to enhance the weights of the PNN rather than the AO-PNN model. As well, the suggested methods’ performance efficiency has been assessed and compared to three recent approaches, including CHIO-PNN, ABO-PNN, and
As future work, the AOS-PNN could have been used and evaluated on massive data with over 100,000 instants and hundreds of features. It could also be used to solve real-world classification problems like medical diagnosis and intrusion detection.
Footnotes
Appendix
Author’s Bios