
Abstract
A Monte Carlo simulation study was conducted to investigate the performance of full information maximum-likelihood (FIML) estimator in multilevel structural equation modeling (SEM) with missing data and different intra-class correlations (ICCs) coefficients. The study simulated the influence of two independent variables (missing data patterns, and ICC coefficients) in multilevel SEM on five outcome measures (model rejection rates, parameter estimate bias, standard error bias, coverage, and power). Results indicated that FIML parameter estimates were generally robust for data missing on outcomes and/or higher-level predictor variables under the data completely at random (MCAR) and for data missing at random (MAR). However, FIML estimation yielded substantially lower parameter and standard error bias when data was not missing on higher-level variables, and in high rather than in low ICC conditions (0.50 vs 0.20). Future research should extend to further examination of the impacts of data distribution, complexity of the between-level model, and missingness on the between-level variables on FIML estimation performance.
Keywords
Introduction
Missing data is one of the most frequently encountered issues for applied researchers. Missing data tends to confound/weaken designed data structure and make complex data analyses difficult/impossible to proceed technically (Orchard & Woodbury, 1972; Peugh & Enders, 2004). Traditionally in practice, the “standard” approach to missing data is the application of various ad hoc methods to avoid directly addressing the problem (Van Buuren, 2018). In other words, missing data are simply deleted often using either listwise deletion (LD) or pairwise deletion (PD) (Enders, 2001; Roth, 1994). However, despite their convenience and ready availability as default options of handling incomplete data in many statistical software packages (e.g., SPSS, SAS, Stata), these ad hoc solutions have been found severely biasing parameter estimates of means, regression coefficients and correlations when data are NOT normally distributed and/or missing completely at random (MCAR), in addition to the obvious consequence of associated information loss (Enders, 2010; Little & Rubin, 1989, 2019; Schafer & Graham, 2002).
Fortunately, in the past three decades, considerable developments have been made in the theory, methodology and software packages for handling missing data problems. As a result, maximum-likelihood (ML) estimators for missing data, or full information maximum-likelihood estimation (FIML), have been researched as generally appropriate analyses under most missing data situations (i.e., MCAR, MAR, and MNAR), superior to LD and PD in substantially reducing the bias in parameter estimation (Arbuckle, 1996; Enders & Bandalos, 2001; Muthén et al., 1987) and improving estimation efficiency and model fit accuracy (Brown, 1994; Grund et al., 2018; Kaplan, 1995; Wothke, 2000).
However, more complex issues emerge when similar methodological discussion on handling missing data extends to multilevel modeling. One of the most prominent challenges specific to multilevel missing data handling relates to the estimation and/or imputation of incomplete data in the predictors, especially in the higher-level predictors. Because unlike missingness in single-level modeling, multilevel models are relatively well equipped to handle missing values in the outcomes, such as using FIML estimation for unbalanced cluster sizes or various attrition patterns across time waves in longitudinal studies (Hox & Roberts, 2011; Van Buuren, 2018). However, the known capacities of the FIML estimator in handling missing data at the higher levels in multilevel models are controversially limited (Enders, 2010; Van Buuren, 2011); while other missing data handling techniques in multilevel models (e.g., multilevel multiple imputation by joint modeling or fully conditional specification) are still being developed and/or refined (Van Buuren, 2011 2018).
Literature review
Three conceptual frameworks and related research literature are discussed in the following literature review, including (a) Muthén’s (1994) approach to multilevel SEM and FIML estimation in Mplus, (b) other factors influencing FIML estimation in multilevel SEM, and (c) missing data handling in SEM.
Multilevel SEM and FIML estimation in Mplus
Multilevel SEM assumes random sampling at both individual and group levels. The total population of
Muthén’s (1994) developed an ML-based procedure to estimate the between- and within-group covariance matrix (Cheung & Au, 2005; Hox, 1993). This procedure starts with the orthogonal decomposition of the observed score vectors into an individual and a group component.
Based on these components, a between-group sample covariance matrix and a pooled within-group covariance matrix can be calculated from the group mean and individual deviation from the group mean (Meuleman & Billiet, 2009).
The software package Mplus 8.2 (Muthén & Muthén, 2012) allow estimation of multilevel SEM using the above-specified ML-based procedure automatically, and the Mplus default option for handling multilevel missing data is full information maximum likelihood estimation (FIML) under MCAR (missing completely at random), MAR (missing at random), and NMAR (not missing at random) for continuous, censored, binary, ordered categorical (ordinal), unordered categorical (nominal), counts, or combinations of these variable types (Little & Rubin, 2002). However, in all models, missingness is not allowed for the observed covariates because they are not part of the model. The model is estimated conditional on the covariates and no distributional assumptions are made about the covariates. Covariate missingness can be modeled if the covariates are brought into the model and distributional assumptions such as normality are made about them (Muthén & Muthén, 2012).
FIML allows cases with missing values on some variables. In other words, it utilizes all observed variables for each case, and thus the name “full information.” FIML assumes that all variables are linearly related with each other and are multivariate normally distributed. When certain predictors/covariates are incompletely observed, FIML assumes that their conditional distribution on completely observed outcomes and other predictors is multivariate normal. The sample log-likelihood function can be written as below:
where
Previous research reveals that estimation problems within the multilevel SEM framework may be resulted from a variety of sources: the strength of relations between variables, the complexity of models, the ICCs, the size of the model, sample size, distribution of the variables, and amount and/or patterns of missing data, etc. (Enders, 2014; Meuleman & Billiet, 2009; Muthén & Muthén, 2002).
First, regarding group sample sizes (or other higher-level sample sizes), simulation studies by Hox and Maas (2001) indicated 100 groups were generally considered sufficient for unbiased parameter estimation in medium-level complex multilevel models; at least 40 groups were required if the research interests primarily focused on between-level factor structure; and a minimum size of 60 groups were needed to detect a large (
Second, the impact of the ICC on the estimation accuracy in multilevel SEM is indecisive, since the simulation study findings seemed conflicting: Hox and Maas (2001) suggested that percentage of inadmissible estimates, relative parameter and standard error bias were much smaller in higher than low ICC conditions; however, Hox and his colleagues (2007) were unable to replicate such an ICC effect in later simulation studies.
Third, related simulation studies (Meuleman & Billiet, 2009) led to the findings that reducing the between-level modal complexity (e.g., reducing the number of the between-level parameters to be estimated freely) could be an effective way to attenuate the estimation bias caused by small sample sizes. In addition, stronger factor loadings were also found positively related to improved estimation accuracy and efficiency and decreased estimation bias (Enders & Bandalos, 2001).
Finally, in terms of the impact of data distribution, a well-founded simulation research literature body (Browne, 1984; Chou & Bentler, 1995; Finch et al., 1997) suggested that non-normal data negatively affect the FIML estimator for missing data in a similar way they affect the complete data ML estimator (i.e., attenuated standard errors and inflated model rejection rates) (Enders, 2001, p. 369). However, the majority of these simulation conditions were set within the single-level SEM framework.
Missing data handling in SEM
Results from Monte Carlo simulation studies on handling missing data in SEM have been consistent in finding ML methods superior to ad hoc solutions (i.e., list-wise, and pair-wise deletion) and certain imputation methods (e.g., similar response pattern imputation) across all conditions of missing data mechanism. Specifically, FIML estimates were less biased and more efficient, and yielded lowest model rejection rate and near-optimal Type 1 error rates than other methods (Arbuckle, 1996; Enders, 2001; Enders & Bandalos, 2001; Marsh, 1998; Muthén et al., 1987; Wothke, 2000). However, the majority of these simulation studies were limited to single-level SEM.
Despite considerable similarity with single-level SEM in terms of handling missing data, incomplete data issues in multilevel structure may become more complex and difficult to address since they can occur in the outcome variables, lower-level predictors, higher-level predictors, and the class variables (Goldstein, 2011; Hill & Goldstein, 1998; Hox, 2010; Van Buuren, 2011 2018). Missingness in high-level variables are especially challenging to handle due to the difficulties in estimating between-level variance of the random effects in the presence of between-level heteroscedasticity, non-normal distribution of residual errors, cross-level interactions, and/or other nonlinear terms (Mistler & Enders, 2017; Van Buuren, 2018).
To tackle these problems, maximum-likelihood estimation (FIML) and multilevel multiple imputation techniques (i.e., joint modeling imputation and imputation by fully conditional specification, JM and FCS) have been found the two most viable options rather than ad hoc solutions or simply adding derived variables as part of the analysis (Audigier et al., 2018; Enders et al., 2016; Kunkel & Kaizar, 2017; Mistler & Enders, 2017). Simulation studies comparing these two superior approaches suggested that for random intercept models, JM and FCS imputation methods were equally effective, and both were better than FIML; for models with random slopes and cross-level interactions, FCS was found almost unbiased for the main effects; for categorical data, both JM and FCS were suitable for creating multiple imputations; and finally, missing data on higher-level variables were handled equally well by JM, FCS, and FIML (Enders et al., 2016; Grund et al., 2018; Van Buuren, 2018).
Purpose of the study
Given the paucity of current research, the purpose of this Monte Carlo simulation study was to examine the different impacts on the performance of FIML estimator in multilevel SEM with missing data on the outcome variables and higher-level predictor variables, particularly in terms of estimation accuracy (i.e., model convergence rates, relative parameter bias, relative standard error bias, coverage, and the empirical power) and structural parameter (i.e., level-1 and level-2 regression coefficients) recovery.
Thus, two specific research questions were addressed as follows:
Are there any differences in the FIML estimator performance (attenuated by ICC conditions) in terms of estimation accuracy for missing data on outcome variables or on level-2 predictor variables in multilevel SEM? Are there any differences in the FIML estimator performance (attenuated by ICC conditions) in terms of structural parameter recovery for missing data on outcome variables or on level-2 predictor variables in multilevel SEM?
The following detailed description of the current Monte Carlo simulation study included (a) simulation design and data generation, and (b) data analysis plan.
Simulation Design and Data Generation
The simulation model is a two-level CFA model with continuous covariates, containing two within-level factors each measured by three indicators, and a between-level factor measured by the six indicators combined (see Fig. 1). At the within level, four structural paths were estimated from two level-1 predictors to the two within-level latent factors. Whereas at the between level, one structural path was estimated from a level-2 predictor to the between-level latent factor.
A two-level CFA with continuous covariates.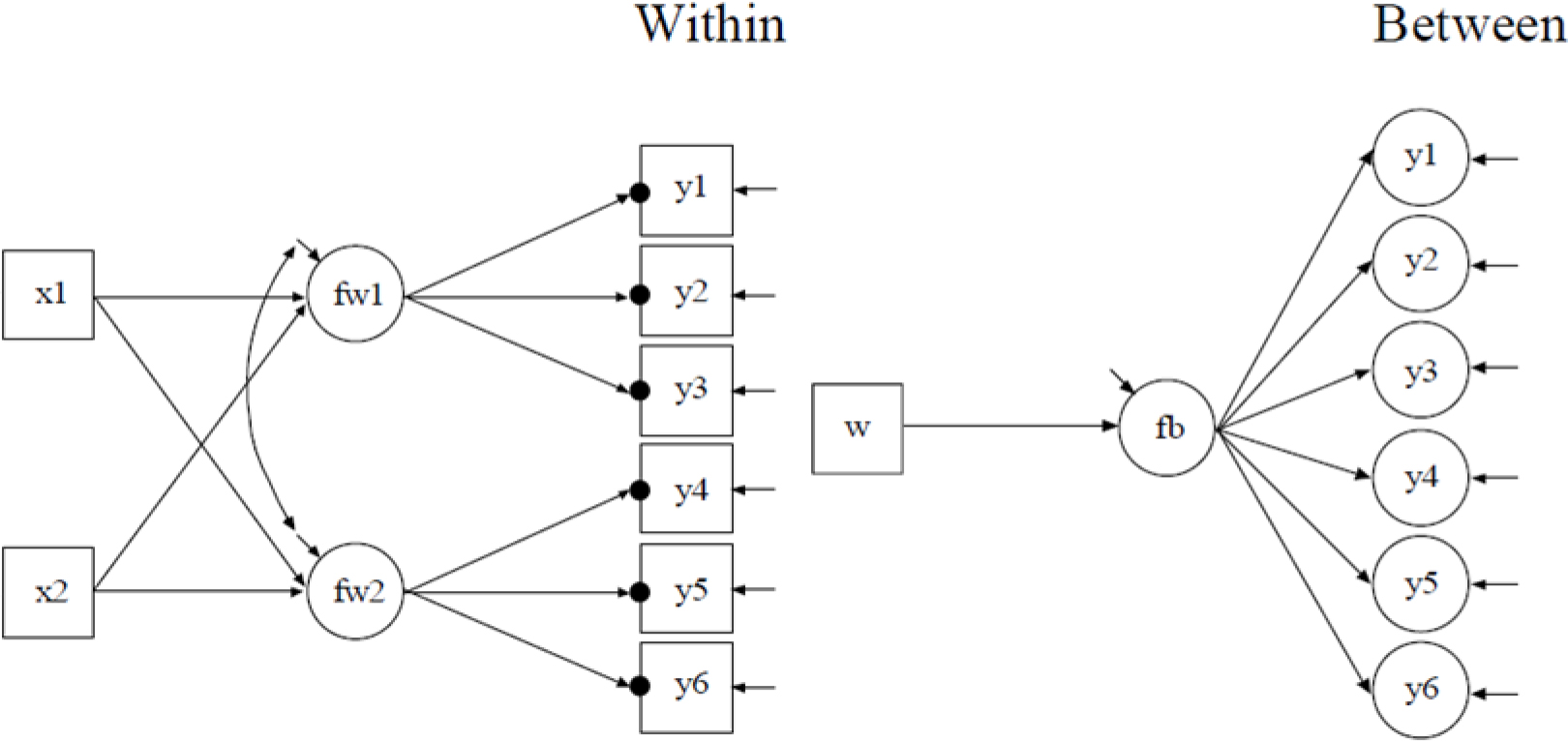
The simulated data sets were generated via Mplus 8.1 (Muthén & Muthén, 2018) as random samples from a hypothetical population with the following specifications (The details regarding the Mplus codes for the simulation can be supplied to a reader upon request):
The observed variables (indicators y1–y6, within-level predictors x1 and x2, as well as between-level predictor w) were drawn from a multivariate normal distribution. 110 groups of three different sizes (i.e., 40 groups of 5 individuals, 50 groups of 10 individuals, and 20 groups of 15 individuals) were specified to have 1,000 individual observations in total with an average group size of 9.09, which was based off previous research findings that generally 100 or more groups were sufficient for unbiased ML estimation and multilevel ML estimation was inherently robust against unbalanced group designs. The overall ICC of the six indicators y1–y6 was specified in a high condition (0.50) and low condition (0.20), since the previous relevant literature suggested possible impacts of ICCs on model estimation. Both of the within- and between-level standardized factor loadings were all specified to 1 for their respective latent factors, because the current study aimed to focus exclusively on the estimation issues resulting from missing data patterns. The within-level predictor, x1, was set to have a standardized effect of 0.05 and 0.07 on the within-level factors fw1 and fw2, respectively; while the other within-level predictor, x2, had a standardized effect of 0.07 and 0.05 on fw1 and fw2, respectively. The between-level predictor, w, was specified to have a stronger standardized effect of 1 on the between-level factor, fb. The complexity of the model was held consistent across all 8 simulated conditions (4 missing data patterns by 2 ICC conditions) with 33 free parameters. Missing data were generated under the combined MCAR and MAR mechanisms.
Specifically, four patterns were simulated regarding missing data:
Complete data with no missingness. Missing data observed on the indicators (y4–y6) only, conditional on the predictors (x1, x2 and w). Missing data observed on the level-2 predictor (w) only, conditional on the level-1 predictors (x1 and x2) as well as on one indicator (y6). Missing data observed on both the indicators (y4–y6), conditional on the predictors (x1, x2, and w); and on the level-2 predictor (w), conditional on the level-1 predictors (x1 and x2) and on the indicator (y6). Missing data rates were specified as y4 (41%), y5 (57%), y6 (83%) and w (45%).
To address Research Question 1 (concerning the different impacts that the eight simulated missing data conditions have on FIML estimation accuracy), the overall model estimation accuracy (as demonstrated in within factor loadings, within error variances, within structural effects, between factor loadings, between error variances, and between structural effects) was assessed across the eight simulated conditions using the following five criteria. First, model convergence rates were compared and the presence of any inadmissible estimates (e.g., negative variance estimates) was checked.
Second, the relative parameter estimates bias was calculated and inspected as follows:
where
Third, relative standard error bias was calculated as:
where
Fourth, the coverage of a 95% confidence interval was calculated. This coverage referred to the proportion of replications for which a 95% confidence interval around the parameter estimate contains the population parameter. Muthén and Muthén (2002) proposed that coverage should range from 0.91 to 0.98, relatively close to 0.95.
Last, the empirical power of the statistical tests of factor loadings, error variances and structural parameters was examined. This power was calculated as the proportion of replications, for which the parameter was found to be statistically significant from zero (at alpha
To address Research Question 2 (regarding the different impacts that the eight simulated missing data conditions have on FIML parameter recovery), relative parameter and standard error bias, coverage, and empirical statistical power for the five structural parameters (i.e., the five path coefficients at both the within and between levels) of research interests were compared and evaluated following the same criteria as mentioned above.
The estimation algorithm converged for all 800 estimated models with a 0% model rejection rate. No inadmissible parameters, such as negative error variances, were observed across all replications. It was also noted that in all the 800 replications, the originally specified sample size (
The overall model estimation results of the simulation study with eight conditions (4 missing data conditions by 2 ICCs) were summarized in Table 1. It should be noted that in this table the results for factor loadings, error variances, and within-level structural effects did not refer to a single parameter, but instead were averages of all factor loadings, error variances, or structural effect at the within and/or between level in the same category. Table 2, on the other hand, contained the estimation accuracy measures for each of the five within- and between-level structural effects individually, for the purpose of investigating specific parameter recovery.
Model estimation accuracy for eight simulated missing data conditions
Model estimation accuracy for eight simulated missing data conditions
Parameter recovery for eight simulated missing data conditions
First, the overall model estimation accuracy of the within-model parameters was discussed as follows. In all the missing data conditions, parameter bias for the within-level parameters was practically ignorable, with the absolute values ranging from 0.0001 to 0.0102, well under or around 1%. The standard errors of the parameters, on the other hand, were found to be slightly biased, especially on the within-level error variances. The most severe standard error bias was found in the complete data condition and missing data on outcomes only condition. Relative standard error bias under these two conditions ranged between 0.0614 and 0.0819, indicating that the within-level standard errors for residual variances were overestimated by roughly around 7%. Given the 10% criterion mentioned earlier in the Method section, this amount of relative standard error bias was still acceptable. Standard error bias decreased slightly as the ICC coefficient decreased for these two missing data conditions. The overestimation of the variance of within-level model parameters also affected the coverage of the confidence intervals under these two conditions, since the empirical alpha-levels dangerously approaching 9%, which was notably higher than the nominal 5%. The coverage improved by degrees till it got close to 0.95 for the missing data on both outcome and level-2 predictor condition with ICC at 0.5. The power of the statistical tests for all within-model parameters was equal to 1, except for the within factor loadings with power
At the between level, on the other hand, more notable estimation problems were present for conditions with missing data on level-2 predictor, especially in terms of estimating between structural effect. First, factor loadings and error variances tended to be underestimated, while the structural effects were overestimated. In the case of data missing on both the outcomes and level-2 predictor, relative parameter bias for these parameters equaled 1.0, 2.1, and
Finally, parameter recovery for the five structural effects (four at the within level, and one at the between level) were compared across the eight simulated missing data conditions. For the estimates of the within-level structural effects, the largest relative parameter bias was found in the two conditions with data missing on the level-2 predictor by 0.8–1.4%, as compared to the complete data, or missing only on outcomes conditions. Similar patterns were also observed on standard error bias of these estimates: the largest relative SE bias was found in the two conditions that involved missing data on the level-2 predictor, especially when data were missing on both the outcomes and level-2 predictor, a SE bias as high as 9.55% were displayed for the model with ICC at 0.2. Coverage rates and statistical power for these within structural effects estimates, however, all fell within the acceptable ranges. Across all the missing data conditions at the within level, low ICCs also seemed to have intensified the already-existing estimation issues caused by missing data.
Surprisingly at the between level, various estimation accuracy measures tended to tell a mixed story: while the relative parameter bias were much lower in the two conditions without level-2 missing data (from
The zero convergence failures observed in this study was in accordance with previous research on SEM with missing data. Sample sizes of 100 or less have been shown to result in high rates of nonconvergence (Anderson & Gerbing, 1984; Enders, 2001; Boomsma, 1985; Sadikaj et al., 2021), even when there was no missing data. The overall sample size in the current study was 1,000. Also, according to Brown (1994), none-to-low convergence failures were also associated with strong factor loadings (all indicator loadings were specified to equal 1 in our simulation model) and low to medium missing data (around 10–16%). Despite the medium to high missing rates (41–80% on various variables) specified in the current study, the zero-convergence failure rate suggested that the high missing data rate could have been compensated by the overall large sample size, as well as using FIML estimator for MCAR and MAR mechanisms.
In the light of previous research (Hox, 2010), the results of the current study provided further support that under the combined MCAR and MAR mechanism, the FIML estimator was generally robust against the impacts of missing data on outcomes and/or level-2 predictor variables within the multilevel SEM framework. However, even though the majority of the estimation accuracy measures yield acceptable values (based on the given criteria) across the missing data conditions, it was clearly noted that the negative influence on the within-level estimation accuracy was more prominent and consistent for the conditions with missing data on level-2 predictor than those without.
Furthermore, consistent with Muthén et al. (1987), bias was generally confined to the structural parameters. Especially when the higher-level incomplete data interacted with the estimation of between-level structural parameters, the mixed results on the between-level structural estimates indicated handling missing data in multilevel SEM might still involve many more important influencers than the conditions included and simulated in the current study (Hox, 2017; Van Buuren, 2018; Rockwood, 2020; Wang, 2020).
Implications and future research
In practice, applied researchers may not have sufficient knowledge about the missing data mechanism. Thus, the results of the current study would suggest that applied researchers can confidently utilize FIML estimator as a generally preferable method for dealing with missing data under different conditions in multi-level structural equation models. More importantly, the current simulation study explored the impacts of missing data on higher-level predictors on FIML estimation accuracy and structural parameter recovery in multilevel SEM, which remained under-researched in the relevant literature. Thus, in this aspect, the results of this study could serve as initial findings that future studies along this line could be tested against.
Although a comprehensive set of factors was considered in the study (they were either examined directly as the focal interest of this study or were held consistent to highlight the impacts of other factors), further research might be needed to examine the additional effects of between-level model complexity on FIML estimation in multilevel SEM.
Moreover, future studies can explore the impacts of non-normality on FIML performance when missing data are observed on higher-level variables, especially class variables. Finally, further studies could also be conducted to compare the performances of FIML and various multilevel multiple imputation (MMI) methods in handling missing data in multilevel SEM.
Footnotes
Declarations of interest
None.