
Abstract
Quantitative analysis of professional basketball become an attractive field for experienced data analysts, and the recent availability of high-resolution datasets pushes data-driven basketball analytics to a higher degree. We present a qualitative discussion on quantitative professional basketball. We propose and discuss the dimensions, the levels of granularity, and the types of tasks in quantitative basketball. We review key literature in the past two decades and map them into the proposed qualitative framework, with an evolutionary perspective and an emphasis on recent advances. A list of questions around professional basketball that could be approached with quantitative tools is displayed, pointing to directions for future research. We touch on the new landscapes of virtual basketball at enriching the space for quantitative analysis. This report serves as a qualitative primer for quantitative analysis of professional basketball, exhibiting the growing prospect of the promising research area.
Introduction
Basketball is among the most popular sports in the world with fans of all ages (Hulteen et al., 2017). The International Basketball Federation (FIBA) estimates that around 450 million people participate in this dynamic and fluid team sport 1 , which attracts 125 million fans in China (according to the Chinese Basketball Association (CBA)), and ranks the second most popular sport in the United States 2 . Professional basketball has flourished rapidly in various countries, especially during the past two decades. The National Basketball Association (NBA) in the United States, so far the most successful professional basketball league (according to Forbes Magazine, the top five NBA teams are worth 16.8 billion USD in total), has witnessed steady revenue increase in recent years 3 ; hit hard by the COVID-19 pandemic during 2019 to 2021, NBA revenue soon recovers in 2022 (Figure 1c). This increase in popularity is supported by Google Trends (Da et al., 2011): the search strength of the keyword “basketball” has seen a steady growth (noting the seasonal pattern), despite that the search strength of “sports” is experiencing a decline from around a decade ago.
This upward trend of basketball’s popularity is currently not accompanied by a sufficient trending of its analytics. As the search strength of “sports analytics” is gaining clear momentum, the focus on “basketball analytics” sees a large potential (Figure 1a); after COVID-19, the new fervor on “quantitative sports” is soon to be diffused to “quantitative basketball” (Figure 1b). The field of quantitative basketball is in great demand and in good progress, which can benefit from recent years’ fast development of data sciences (software) and game-tracking devices (hardware) as well as other technologies.

Trends in popularity during 2008 to 2022 around basketball/basketball analytics and sports/sports analytics, and trend of NBA revenue (data source: Google Trends, statista.com).
In this essay, we review key scientific literature on quantitative professional basketball published in the past two decades. We summarize popular topics in existing studies, focusing on game-play-related topics rather than topics in psychological, physiological, or social domains. Inspired by existing works, we propose the multiple dimensions (time, space, static and dynamic strategy at in-game analysis, season and league at cross-game analysis) and multiple levels of granularity (second-level, possession-level, game-level, season-level) in quantitative basketball; reviewed literature are mapped into the proposed qualitative framework. Based on this framework, we present 32 research questions around professional basketball, and summarize four types of analytical tasks that could help answer these questions: metric design, inference, evaluation system engineering, and game decision-making. During the literature review, we note the application of the newly available optical player-tracking data that provide hide-resolution materials for quantitative analysis; comparison between this novel dataset and traditional game statistics underlines their suitability for different analytical subjects.
We provide suggestions on future research directions of quantitative basketball. It is foreseeable that quantitative tools from various engineering fields will be further adopted in future analysis. Some emerging technologies, including e-game and augmented/virtual reality, have started to empower basketball analytics with novel elements and broader potential. Nonetheless, although the reviewed publications are well-cited, the majority of which are published in top sports journals and conferences, we are by no means presenting an exhaustive literature summary in this qualitative discussion. We try to balance the ideas and convey useful information on a limited scale. Besides, as basketball teams and organizations may possess massive internal data, methodologies, and strategies that are not openly shared, and team operations and analytics often rely much on information, tactics, and technologies that remain private, there is a large portion of literature missing from the current discussion. That said, we believe that the proposed qualitative framework for quantitative basketball well applies to those contents.
Quantitative analysis of professional basketball maintains a short research history yet has been drawing increasing attention in the past two decades (e.g., Huyghe et al., 2022). In the vast research space, several key topics emerge from existing literature, including outcome prediction, behaviors in games, game statistics, and team interaction. Studies forge close ties with industry groups and have witnessed successful applications, on par with other fields of data analytics. The recent availability of high-resolution optical data makes quantitative professional basketball more attractive to experienced data analysts than ever. Below we introduce important research topics in the field, which is by no means close to a comprehensive review of the literature. In particular, we focus on game-play-related analytics and leave out the majority of studies related to sports medicine/physiology/psychology.
•Given the obvious economic incentive, a large portion of research efforts in basketball analysis focus on the prediction of game outcomes. Models from multiple streams, including analytical models and expert models, have been proposed to conduct (normally probabilistic) sports forecasts, in particular on the win-lose result or the point spread (typical in basketball betting odds) of games (e.g., Strumbelj, 2014). One could see reviews on sports game prediction over the past two decades in Stekler et al. (2010) (2010s) and Horvat and Job (2020) (2020s). Regarding analytical approaches, machine learning techniques, statistical/econometric analysis, optimization methods, game theoretical attempts, and network science techniques are summoned to address the problem; a partial list of sports forecast models includes Markov models (e.g., on game outcome (Strumbelj and Vracar, 2012) or shoot strategy (Sandholtz and Bornn, 2020)), state-space models (e.g., on game outcome (Manner, 2016) or player’s hot hand (Mews and Otting, 2021)), synergy graph models (e.g., on game outcome (Liemhetcharat and Luo, 2015)), neural networks (e.g., on game outcome (Loeffelholz et al., 2009) or physical fitness evaluation (Yuan et al., 2021)), classification trees (e.g., on performance indicators (Zuccolotto et al., 2021, 2023)), and statistical regression models (e.g., on performance statistics (Song et al., 2018)) etc. Over the years, game prediction has become an active playground for data scientists from various expertise.
•Another popular line of research in quantitative basketball pays attention to behavioral phenomena in sports games, some of which are unique in basketball, including the home advantage (Ribeiro et al., 2016; Leota et al., 2021), the hot (and cold) hands in general (Yaari and Eisenmann, 2011; Stone and Arkes, 2018) or at free-throws (Arkes, 2010), effective strategies for underdogs (Skinner, 2011), the price of anarchy in basketball (Skinner, 2010), the comparison of starters and non-starters (Gonzalez et al., 2013), the comparison of all-stars and non-all-stars (Sampaio et al., 2015), the relationship between coach gender and team performance (Smittick et al., 2019), the link between fans’ age and team identity (Toder-Alon et al., 2019), the driving factor of coach dismissal (Wangrow et al., 2018), the attachment of fans upon team’s geographical proximity, local superstar recognition and team success (Grimshaw and Larson, 2021) etc. These research works investigate the existence of the target phenomena, attempt to model and explain them, and further try to extrapolate the phenomena to a broader context beyond basketball. Studies in this category have less predictive power and are not directly applicable to the industry, yet the identification and quantitative discussion of behavioral phenomena in basketball can be substantially useful for the team and the game-play.
•Both in academia and in industry, people spend efforts studying game statistics, a most straight-forward topic for the general sports audience. People discuss well-established metrics for basketball games (e.g., the four factors; see a classic summary in Kubatko et al. (2007)), study the effects that may influence existing metrics (Sampaio et al., 2010), explore ways to combine basic metrics (e.g., box scores) into advanced statistics, and try to devise new metrics of higher resolution, in most cases with abstract meanings (Franks et al., 2016). Recently, there has been an interest in metrics that characterize players’ defense skills (Franks et al., 2015a,b; Keshri et al., 2019), which so far have been underdeveloped compared to offense metrics. Studies dive deep into the strategy space and try to “quantify the unquantified elements” in sports games, such as shot selection (Skinner, 2012), shot quality (Chang et al., 2014) (in particular at free throws (Wolch et al., 2021)), team strategy (considering the decision network (Fewell et al., 2012) or game possession (Miller and Bornn, 2017)), repetitive patterns in play (Miller et al., 2014; Franks et al., 2015b), ball movements (D’Amour et al., 2015; Ma et al., 2018), as well as abstract elements such as team efficiency (in decision making (Goldman and Rao, 2011) or considering the overall game flow (Moreno and Lozano, 2014; Villa and Lozano, 2018)) and player’s performance (Neiman and Loewenstein, 2011; Sarlis and Tjortjis, 2020) in particular the shooting performance (Zuccolotto et al., 2018, 2021). With these quantitative progress, traditional box scores have advanced companions in the near future.
•Since sports game-play depends a lot on the interaction between players of the same team and of competing teams, among different lines of sports studies (including and beyond basketball) there is a particular and emerging focus on using graph theory/network science as a core element in analysis (e.g., Onody and de Castro, 2004; Yamamoto and Yokoyama, 2011; Pena and Touchette, 2012; Fewell et al., 2012; Brandt and Brefeld, 2015; Skinner and Guy, 2015; Oh et al., 2015; Ahmadalinezhad et al., 2019). Models based on the PageRank have been widely proposed (Mukherjee, 2012; Hu et al., 2015; Brown, 2017; Zhou et al., 2022), which are used to rank teams, captains (Mukherjee, 2012), or coaches (Hu et al., 2015). This is a sophisticated approach compared with traditional ranking methods based on game results (see a meta-study on comparing game ranking methods: the “ranking of ranking” (Barrow et al., 2013)). A network data envelopment analysis model for basketball games is proposed (Moreno and Lozano, 2014; Li et al., 2021); an adversarial synergy graph model is constructed for game outcome prediction (Liemhetcharat and Luo, 2015); centrality is frequently addressed in performance rankings (Piette et al., 2011; Reed et al., 2018); and finally, the link prediction problem finds interesting applications in sports games (Zhang et al., 2013). In general, network sciences are pinning down a broader context for sports analysis, especially in studying team/player interactions, and basketball emerges as one suitable field of application.
•Finally, with the availability of high-resolution optical player tracking data since around 2010s (Terner and Franks, 2021), a growing number of studies are considering using this new big data. Several studies published in engineering journals work on the visualization of sports games based on abundant datasets (Du and Yuan, 2021), trying to design new engineering techniques for tasks such as event detection (Xu et al., 2003; Lee et al., 2018), game narrative (Chen et al., 2016), and play retrieval (Sha et al., 2016). As for modeling and analysis, given the improved granularity of these new data, studies address the spatial dimension of the game and decompose the court into different regions (e.g., Miller et al., 2014; Franks et al., 2015b; Miller and Bornn, 2017; Cervone et al., 2014, 2016b,a; Sandholtz and Bornn, 2018). With the help of big data, more sophisticated models are developed, which try to quantify the latent states of the game, such that one could simulate the play in a finer view (Oh et al., 2015; Sandholtz and Bornn, 2018) and therefore study the performance of players/teams with a closer look (Skinner and Guy, 2015), for example, by partitioning the game court into different performance areas (Zuccolotto et al., 2021, 2023). It is evident that optical data of basketball games serve as a good companion to traditional game statistics, and embody great potential for future research.
Dimensions of quantitative professional basketball
The full solution to quantitative basketball is multi-dimensional. A comprehensive modeling of basketball games needs to consider the temporal dimension (the clock), the spatial dimension (the court), both static strategies (line-ups, substitutions, defense matchings) and dynamic strategies (shot choices, team tactics). Game events (shots, turnovers, fouls, substitutions, etc.) derive from outcomes of interactions between those dimensions. Besides these in-game dimensions, two cross-game dimensions, the season (e.g., 82 games plus pre-season and playoffs in NBA) and the league (e.g., 30 franchises from two conferences in NBA), are to be considered in a complete quantitative model space, where individual games are organized into sequences. Most studies focus on one or two of these six dimensions; it is demanding yet useful to consider multiple dimensions of professional basketball games in modeling and analysis.
Quantitative tools borrowed from various fields can help address different dimensions of the game. Time series analysis and spatial decompositions are necessary for untangling the temporal-spatial complexity; game strategies can be formulated as optimization problems, and dynamic strategies could rely on Markov state-space models; the strategy space is also a suitable playground for machine learning techniques, game theories, and network science applications. Further, the season and the league can be viewed as the temporal-spatial coupling on a larger scale, which interacts heavily with the strategy space and calls for aggregate quantitative tools. These six dimensions are explicit to the general audience through game broadcasting; training (Schelling and Torres-Ronda, 2013) and health (Dijkstra et al., 2014) are two off-game dimensions that have a fundamental impact on professional basketball (Figure 2). These two dimensions are intertwined as training and the recovery/maintenance of players’ health depend on each other (Cervone et al., 2016b; Calleja-González et al., 2018). The off-game factors determine that quantitative analysis along the six on-game dimensions embodies great variance. Yet this pity in quantitative analysis is necessary for sports games: games are not appealing to audiences if their outcomes are highly predictable or if game states can be sufficiently simulated, as we may sometimes find in e-sports (Cunningham et al., 2018; Funk et al., 2018).

Dimensions and granularity levels of quantitative professional basketball.
Dimensions of analysis go with the granularity of analysis at quantitative basketball, which essentially depends on the type of data used in the analytics. In general, the granularity of quantitative basketball is cut into four levels (Figure 2). The most granular analysis could be carried out on each second (even millisecond) of the game, e.g., when utilizing the optical tracking data having a sampling rate as high as 25 per second. Studies on this time scale are difficult but can be extremely useful, e.g., for winning decisions in the last minutes, or for learning good real-time defensive strategies (Wang et al., 2018). The second level is ball possession, a natural and effective cut of the continuous game flow; people found it surprising that possession was not an officially tracked statistic in basketball (Kubatko et al., 2007). Analysis targeted at every possession of the ball (or on the same level, every touch of the ball/every game event) become popular in recent years with the availability of optical data. The next level is individual games, and a major body of sports studies rely on the statistical summary of games, e.g., box scores. Analysis on this level is the most straightforward to the industry and the general audience. Finally, we could conduct season-wise or across-season analysis at the highest research granularity. On this level, observers may identify patterns using data across games or seasons, and may study overarching phenomena intrinsic to basketball games (e.g., the hot hand).
64 well-cited studies from 2010 to 2022 (including 6 before 2010; the year of recent publications are subject to updates) on quantitative basketball (studies cited more than 2 (2023 - X) times on Google Scholar (as of Dec. 2022) with X being the year of publication) are mapped onto the dimensions and granularity levels of analysis (Figure 3). Consider three levels of granularity (possession, game, and season), and three aggregate dimensions (in-game strategy: static or dynamic, in-game non-strategy, and cross-game). Consistently, most studies focusing on in-game strategies conduct analysis at the ball possession level; game-level analysis are sufficient for discussions around individual games but not on game-play strategies; season-level or more general analysis are suitable for addressing cross-game phenomena.
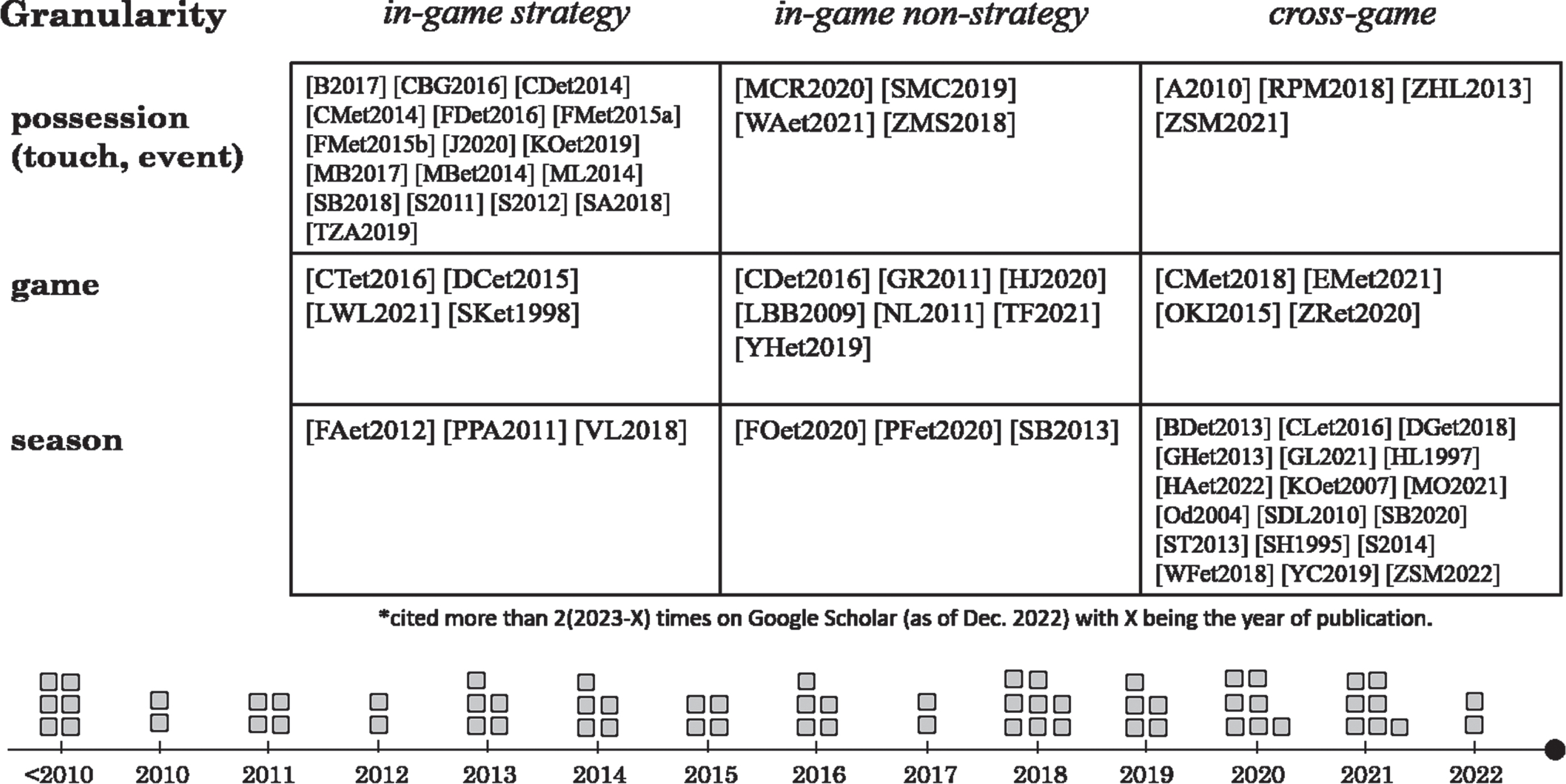
Mapping existing studies on quantitative professional basketball into dimensions and granularities of analysis. Consider studies cited more than 2 (2023 - X) times on Google Scholar (as of Dec. 2022) with X being the year of publication (updates may apply to recent publications). Indicate the publication with the capital letters of authors (for 1, 2, or 3 authors) or the first two authors and ‘et’ (for more than 3 authors) plus the publication year.
In sports analysis, questions are asked by multiple parties related to the game –leagues, teams, players, audiences, sponsors, etc.; they concern different aspects of the game and ask questions at various levels. From the perspectives of different parties, we recommend a list of questions on professional basketball, at the league, the team, and the player level, that quantitative analysis could help answer (Table 1). Questions in psychological, physiological (medical), and social domains (e.g., how to encourage players, how to release fatigue after a game, how to build up a good team atmosphere), are excluded from the list; generalizing questions are also excluded (e.g., what is a better way to predict game outcomes), as they concern with multiple levels of analysis and multiple categories of tasks in delivering answers to the complex problem. Some questions (or rather, their potential solutions) are specific to basketball (henceforth S.B. in Table 1); others may apply to other sports. Among the 32 questions, some have been extensively addressed by existing research (Y in Column E.A.; see discussion in Starting Points for Future Analysis), while a non-trivial fraction wait for considerable quantitative efforts. Consistent with the framework (Figure 2), questions in the list concern different granularities of basketball games, and address different dimensions of analysis in professional basketball.
List of questions on quantitative professional basketball. S.B.: specific to basketball. E.A.: extensively addressed. See text for the description of Task I to IV
List of questions on quantitative professional basketball. S.B.: specific to basketball. E.A.: extensively addressed. See text for the description of Task I to IV
The solution to each question derives from certain quantitative tasks, thus the question can be approached with corresponding analytical instruments. In general, tasks beneath these questions may fall into four categories: (I) metric design, dealing with visualization and quantification of game performance, (II) inference, including detection, classification, regression, and pattern recognition, (III) advisory system engineering, concerning evaluation system, recommendation system, alert system, etc., (IV) strategy design and decision-making, considering optimization problems. The desired properties of the solution differ at each task, depending on the type of quantitative analysis being carried out, the type of data utilized, and the application of analytic outputs.
(I) For metric design, the desired properties of game metrics include discriminativeness, independence, and stability (Franks et al., 2016).
(II) For quantitative inference, the desired properties of solutions include significance, robustness, and causality.
(III) For the engineering of advisory systems, both in-game (e.g., alert system, response system) and off-game (e.g., recommendation/evaluation system), the merited features include real-timedness, accuracy, and adaptiveness.
(IV) For strategy design and game decision-making, good solutions are expected to highlight novelty, effectiveness, and availability.
The four quantitative tasks are interdependent. The design of effective game metrics provides quantitative scales for advisory systems and game decision-making; the identification and classification of players, game patterns, and team tactics advance game strategy design. From task I to IV, arguably, the degree of quantitative sophistication increases; solutions of low-level tasks bring insights to the solution of high-level tasks. Due to the complexity of quantitative basketball analysis, several tasks on multiple dimensions of the game often need to be considered at the same time.
Box score –structured summaries of outcomes (of diverse types) from a sports competition, tabulating individual players’ or the entire team’s performance –is the most commonly used data in sports analyses. Statistics are often obtained after the game and are straightforward to the audience, rather than employing complex analytical properties. Analysis of box score statistics is thus the starting point in quantitative basketball. For example, using Pearson’s chi-square test and logistic regression, box score was analyzed and results showed that the probability of winning increases significantly from playing back-to-back games to having one day rest in between (Esteves et al., 2021). Conceptually, almost every statistic can be counted as a box score, and more and more such scores have been invented and utilized in analysis. This reflects the dynamic nature of quantitative basketball, where analytics are conducted with more data, and decision-making is performed at increasing granularities.
The availability of optical player tracking data from basketball games provides data scientists with new arsenals to address quantitative questions, some of which are not able to be approached with traditional game statistics. For example, the SportVU framework (Yu and Chung, 2019) provides additional features for data analytics, such as animated court visualization, and employs end-to-end functions to enable in-depth basketball analysis. Typically, the player tracking data records the (x, y) position of each player and the (x, y, z) position of the ball, from which the velocity and acceleration of objects (player or ball) can be calculated. These large continuous datasets are not directly interpretable to the general audience, yet such a granular representation of the basketball game undoubtedly embodies the great potential for professional analysis from experienced data analysts.
Box score statistics and optical tracking data have different pros and cons in usage. Optical data are very useful for in-game analysis, e.g., for the build-up of advisory systems (task III) and in-game strategic decision-making (task IV). Nevertheless, to provide real-time utilities, large datasets require substantial processing efforts which entail large computational costs, and the separation of signal from noise in massive data is a daunting task (Silver, 2012). On the contrary, game statistics are tighter and cleaner, effective for after-game or cross-game analysis, e.g., season- or league-wise analysis. For example, using traditional statistical methods to process season data, it is found that coaches must strictly manage training loads to improve team performance and reduce the risk of injury (Esteves et al., 2021). Game statistics nonetheless help less with in-game analysis and are futile when the question calls for a fast response or sophisticated tactics.
Among the 32 questions in the list, 7 are not in-game, where traditional game statistics can be sufficiently useful; the optical tracking data could be used in answering another 15, some of which are difficult to answer without such high-resolution data; 10 questions can be asked in two ways, both in-game and after/cross-game, whose answer may require two types of data (Table 2). Overall, the availability of optical data provides clear opportunities for the analysis of professional basketball; many questions that traditional game statistics have largely addressed are still under-resolved, and call for improved solutions with the new data. Indeed, the application of novel analytical methods such as machine learning on the new data category, can considerably advance the solutions to open problems such as game prediction (Thabtah et al., 2019).
Suitability of using box score statistics and/or optical tracking data in solving questions in Table 1
Suitability of using box score statistics and/or optical tracking data in solving questions in Table 1
Within a short research history, the four tasks in quantitative basketball (metric design, inference, evaluation system, game strategy) have been studied abundantly, through analysis at different levels of granularity, concerning different dimensions of the game.
From the reviewed literature, several questions in Table 1 are extensively addressed in particular: For question (5), graph tools (e.g., PageRank (Brown, 2017)), statistical network models (Piette et al., 2011), and player tracking data (Sampaio et al., 2015) are used to assess players’ performance; studies focus on players’ scoring abilities, which is highly valued in the public. For question (8), Ahmadalinezhad et al. (2019) used network analysis to evaluate team lineup, and Skinner (2011) provided a method for instant strategic planning on the court in a specific situation (underdog). For question (16), Cervone et al. (2014) and Yoon et al. (2019) discussed adopting real-time tracking data, possibly supplemented with deep learning, to conduct granular analysis on ball movements that consider the strategic use of the clock. For question (24), various approaches have been proposed to visualize players’ ball-shooting, including image feature extraction, machine learning (Ji, 2022), or utilizing the Markov process (Sandholtz and Bornn, 2020); on monitoring players’ shooting habits, efficient shooting and scoring strategies can be derived. Other questions are studied to a certain extent in the collected literature, leaving considerable space for quantitative efforts.
Referring to the many questions on quantitative basketball, several ideas emerge from the literature, implying the starting points for future analysis.
(1) One should acknowledge the nature of basketball games. As an important source of entertainment, games, in general, maintain a rock-paper-scissor structure where for each strategy that one player/team could pursue, the other player/team can have a countermeasure that shuts it down (D’Amour et al., 2015). Game strategy is a rich playground for quantitative modelers, which by nature belongs to zero-sum repeated games (Sorin, 2002): the primary challenge for sports teams on offense is to maximize the value of each opportunity when they possess the ball, and equivalently, to minimize that value when their opponent possesses it (Cervone et al., 2014). The strategy space of team sports is larger than that of individual competitions such as chess or Go, where game theories and machine learning techniques directly apply, with results having been fruitful (e.g., Mnih et al., 2015; Ji, 2022). The complexity of team sports derives from player interactions: in basketball, such player interaction networks contribute to the evolutionary narrative of basketball games, where hubs on the network are dynamically changing in offense, as a result of avoiding certain targeted defense (Yamamoto and Yokoyama, 2011), and the game-play centers largely around the ball passing (Maimón et al., 2020). This network representation of basketball games not only preserves an excellent descriptive power but also largely prescribes the direction of game flow. For example, whether a player takes a shot or not depends not only on his propensity to shoot and his defender, but also on the propensity of his teammates (Oh et al., 2015).
(2) On the interaction network, if players are rational decision-makers, when player i passes to player j, it suggests that j is in a more valuable position than i (Cervone et al., 2016a); based on this basic assumption, pass relationships and ball movements can be analyzed in a dynamic setting with continuous data (Yoon et al., 2019). In real games, however, perfect rationality does not exist, and player interactions are more dynamic and unpredictable. This brings the second component of sports games’ entertainment: one should acknowledge that the flow of sports game-play, substantiated with both individual and team decision-making, is always sub-optimal. Many studies investigate the sub-optimality in sports games particularly in basketball. For example, Staw et al. (1995) showed that teams tend to give their best prospect players more playing time and keep them longer, even after accounting for performance, position, injuries, and trade status. Skinner (2010) suggested that it is possible that removing a key player from a team can result in the improvement of the team’s overall offensive efficiency. Neiman and Loewenstein (2011) investigated the outcome sequence of field goal attempts and found that it considerably influences the rate and success percentage of following shot attempts, an extended argument of the hot hand effect. Skinner (2012) showed that NBA teams may be over-reluctant to shoot the ball early in the shot clock. Strumbelj and Vracar (2012) found that teams often deliberately play below their actual strength, especially when the lead is large. Franks et al. (2015a) noted that the defender closest to the shot attempt is frequently not the most responsible defender. Petway et al. (2020) showed that elite athletes run shorter distances, have lower average speeds, and have lower maximum and average heart rates than youth athletes, while high-level players seem to be more efficient when moving around the field. The pervasive existence of sub-optimality in the game-play guarantees the entertainment of sports; this allows designing new tactics for sports to remain fruitful.
(3) The imperfectness of game metrics lies alongside the sub-optimality of games. Sports metrics suffer from multiple sources of variance: player’s intrinsic state, game context (e.g., influence from teammates), and pure chance (Franks et al., 2016). Many metrics currently in use are straightforward combinations of box scores and are not theoretically well-grounded, most of which focus on the offensive side of the game. Substantial quantitative efforts have thus been made in evaluating and designing effective metrics for basketball games (Shea and Baker, 2013). Kubatko et al. (2007) pointed out that the drawback of plus/minus statistics, which are among the most advanced basketball metrics, is that they confound a player’s performance with the performance of his teammates (as well as opponents) on the floor. Chang et al. (2014) noted that one should separate the quality of a shot from the ability to make that shot in effective field goal percentage (EFG); a variant of EFG –EFG+ –is designed accordingly. D’Amour et al. (2015) argued that offensive movements should be judged based on their ability to create open shots, whether or not these shots are taken. Franks et al. (2015b) suggested that an offensive player’s shooting habits should be decomposed into his shot frequency and shot efficiency, and correspondingly, a player’s defense ability could be measured by his ability to reduce the shot frequency and shot efficiency of the opponent. Cervone et al. (2016a) suggested that a player’s off-ball impact on offense could be measured by calculating the value of the space cleared up for his teammate. As one would expect, metric design for professional basketball will remain a hot topic; with the availability of high-resolution datasets, basketball game statistics may witness a great leap in progress.
(4) Along with the increasing adoption of optical datasets in sports analysis, a few methodological insights for the representation of basketball games emerge. Miller et al. (2014) proposed that a parsimonious, yet expressive representation of an NBA player’s shooting habits is desirable; that is, it is useful to design methods for quantitatively describing a basketball player’s shooting propensity succinctly. Cervone et al. (2016b) established that a state-space representation of basketball games should contain two scales: one continuous finer scale to describe ball and player movements, and another event-based coarser scale to effectively compress the game flow. For the task of game pattern recognition, Miller and Bornn (2017) suggests a two-step treatment: (1) the identification of action templates that different players share, and (2) the co-occurrence of actions under each possession of the team. Overall, the representation and visualization of basketball games require enormous collective efforts to reach the next level.
Virtual basketball: E-games and beyond
A new momentum is silently yet drastically changing the landscape of sports. Not only have we established the novel category of virtual sports adhering to video games, but that physical sports are entering the virtual world in an overwhelming manner (Consalvo et al., 2013). In basketball, the NBA (and NCAA) 2K league has become a celebrated e-sport series (Aldridge, 2018), attracting academic efforts from various research perspectives (e.g., matching problems (Schenk and Reed, 2020), gender stereotypes (Darvin et al., 2021), e-game sponsoring (Lopez et al., 2021), motivation differences for traditional vs. virtual game viewers (Rogers et al., 2022)). With the rapid growth of the video game industry (Shankar and Bayus, 2003; Zackariasson and Wilson, 2012; Marchand and Hennig-Thurau, 2013), e-sports has become an important research target.
This change fundamentally broadens the scope of quantitative analysis on (general, if not professional) basketball. Unlike offline games, online basketball games have perfect data availability that supports in-depth data analysis. For example, a novel system has been proposed to 3D-reconstruct a complete model of basketball players (Zhu et al., 2020) using pose estimation, jump estimation, an identity network that morphs the template mesh into the person, and a skin network that granularizes players’ detailed movements. New questions are to be asked, as the source of entertainment shifts from offline to online, combining the entertainment of basketball games and video games.
One important prospect of virtual reality (VR) (Halarnkar et al., 2012; Miles et al., 2012; Faure et al., 2020) application is at player training (Psotka, 1995). Training is an integral aspect of professional sports (Figure 2), which extends to the broader term of (non-professional) physical exercise (Weyerer and Kupfer, 1994; Scully et al., 1998): results suggest that participation in basketball offers both short-term and long-term physical and psychosocial benefits for children and adolescents (DiFiori et al., 2018); the relationships between external/internal workloads and variables in basketball training are important fields of research (Fox et al., 2020). In this background, VR can be used in virtual teaching or training systems, combined with kinematic modeling and multimedia signal processing (Huang et al., 2019). Similar to flight simulators, game simulators can be adopted in daily training for enhancing targeted skills (Santoso, 2018). Conceivably, as VR technologies get mature, virtual basketball training and teaching will substantially complement offline practice, notably in improving game tactics (Tsai et al., 2020) and decision-making (Pagé et al., 2019).
Concluding remarks
Quantitative analysis of professional basketball is a thriving field. While existing literature concentrates on a handful of directions that heavily rely on traditional game statistics in analysis, there is a vast research space to be opened with various questions to be answered from data-driven perspectives. The recent availability of high-resolution optical datasets considerably facilitates advanced modeling and analytics, fundamentally amplifying the overall research scope.
Quantitative basketball is nevertheless complex and demanding. Multiple dimensions (time, space, static strategy, dynamic strategy, season, league) need to be addressed during the modeling of basketball games, which attends to four categories of analytical tasks (metric design, inference, evaluation system, game strategy). Big data enables sophisticated modeling, and brings the analysis down to more granular levels, from considering seasons and individual games, to considering ball possessions in each game, and further to considering every second of the game. It is foreseeable that in future analyses, quantitative tools from various engineering fields will be adopted, and more experienced data analysts will join the field. Consequently, professional teams and players who equip themselves with advanced data-centered toolkits that help answer various quantitative questions around basketball games, can pin down an important strategic advantage.
Broadly, enhanced data availability and emerging technologies such as VR, open up venues for analysis on non-professional basketball (related to physical exercise), on virtual basketball (related to video games), and on derivative basketball (related to re-created games). These components augment quantitative basketball and bring enormous opportunities for analytics and research.
Footnotes
Acknowledgements
T.L. sincerely thanks Prof. Anette Hosoi and Prof. Munther Dahleh at the MIT Sports Lab for the guidance at the early stage of this essay and the many happy discussions in the good old days. Both authors thank Jianbo Xiao for the substantial help in data collection and analysis, and thank the two reviewers and the Associate Editor for the careful examination of the paper and the invaluable suggestions that substantially helped improve this work.