
Abstract
Background:
The NeuroNEXT SMA Infant Biomarker Study, a two year, longitudinal, multi-center study of infants with SMA type 1 and healthy infants, presented a unique opportunity to assess multi-site rater reliability on three infant motor function tests (MFTs) commonly used to assess infants with SMA type 1.
Objective:
To determine the effect of prospective MFT rater training and the effect of rater experience on inter-rater and intra-rater reliability for the Test of Infant Motor Performance Screening Items (TIMPSI), the Children’s Hospital of Philadelphia Infant Test of Neuromuscular Disorders (CHOP-INTEND) and the Alberta Infant Motor Scale (AIMS).
Methods:
Training was conducted utilizing a novel set of motor function test (MFT) videos to optimize accurate MFT administration and reliability for the study duration. Inter- and intra-rater reliability of scoring for the TIMPSI and inter-rater reliability of scoring for the CHOP INTEND and the AIMS was assessed using intraclass correlation coefficients (ICC). Effect of rater experience on reliability was examined using ICC. Agreement with ‘expert’ consensus scores was examined using Pearson’s correlation coefficients.
Results:
Inter-rater reliability on all MFTs was good to excellent. Intra-rater reliability for the primary MFT, the TIMPSI, was excellent for the study duration. Agreement with ‘expert’ consensus was within predetermined limits (≥85%) after training. Evaluator experience with SMA and MFTs did not affect reliability.
Conclusions:
Reliability of scores across evaluators was demonstrated for all three study MFTs and scores were reproducible on repeated administration. Evaluator experience had no effect on reliability.
Keywords
INTRODUCTION
Spinal muscular atrophy (SMA) is the leading genetic cause of infant death [1]. SMA is a motor neuron disease characterized by progressive muscular weakness and in the most common and severe form (type 1), infants do not achieve sitting or higher level motor skills. Respiratory insufficiency and death often occur within the first two years of life [2, 3]. Clinical trials for infants with SMA type 1 are moving forward rapidly due to recent advances in therapeutics, and have benefitted from multi-center study designs to effectively recruit adequate patient numbers due to the rare nature of the disorder [4–6]. For medically fragile infants with type 1 SMA, travel to specialized clinic sites for research or clinical management and follow-up is difficult, making multi-center trials essential for adequate study recruitment and participation.
Motor function tests (MFTs) have demonstrated applicability [7–10], reliability [9, 11–14] and validity [11, 15–18] for those with SMA when carried out by experienced raters and are commonly used as indicators of disease severity. Within the context of the changing landscape for SMA [19] and recent drug development acceleration, MFTs have been used to support drug approval [20, 21] and will continue to be central to determining clinically meaningful change in clinical trials and response to therapy [22]. While MFTs used to assess those with SMA require focused training, minimal equipment is required, and their use in natural history studies, clinical trials and within the non-research based clinic setting are recommended as standard of care [3, 24].
Researchers and clinicians specializing in the care of patients with SMA have expended considerable effort to guarantee the reliability of clinical evaluators (CEs) administering MFTs to those with SMA. The efficacy of these methods has been demonstrated for clinical evaluators within a variety of clinical settings. Methods used have included education of underlying conceptual theories, the use of standardized instruction, test item review, and live and video-recorded examinations of infants with SMA [7, 25–27]. It is notable that previous studies examining reliability and validity for MFTs have primarily focused on reliability of outcomes for those with SMA type 2 and 3 [7, 25], and there is relatively less information for multi-center trials for infants with SMA type 1. Another challenge when interpreting CE reliability outcomes in prior studies is that they have: 1) been carried out at ‘expert’ centers, 2) utilized a tight core of experienced, well trained CEs familiar with the MFTs being utilized, and 3) have not focused upon reliability longitudinally [9, 16].
A recent focus in delivering SMA therapeutics immediately after birth led to the initiation of the SMA Biomarkers Study in the Immediate Postnatal Period of Development (ClinicalTrials.gov ID: NCT01736553). This study was the premier clinical study of the NINDS NeuroNEXT clinical trial network, with the goal to define well-characterized, longitudinal measures of motor function and putative SMA molecular and physiological biomarkers in infants with type 1 and healthy controls during the first two years of life that could be useful in the design of future interventional trials [28, 29]. The SMA Infant Biomarker Study had fifteen enrolling study sites, of which fourteen enrolled patients with study visits occurring at 3 or 6-month intervals [28, 30]. A primary endpoint was to examine the relationship between the three study MFTs [Test of Infant Motor Performance Screening Items (TIMPSI) [11, 31], the Children’s Hospital of Philadelphia Infant Test of Neuromuscular Development (CHOP-INTEND) [32] and the Alberta Infant Motor Scales (AIMS) [33, 34] and the physiologic and molecular biomarkers for both infants with SMA and control infants across the two years of the study [28]. Therefore, the integrity of the data set was dependent upon continuous MFT clinical evaluations. Success of the study relied on careful administration and reliable scoring of MFTs across all sites, which required ensuring the scoring reliability of the evaluators.
The primary aim of this study was to examine scorer reliability for all MFTs which comprised the three motor function outcomes (TIMPSI, CHOP-INTEND and AIMS) used during the NN101 study. A secondary objective was to compare reliability between CEs with less experience with SMA and the specific MFTs used versus CEs with more experience.
MATERIALS AND METHODS
This study was approved by The Ohio State University Wexner Medical Center, the NeuroNEXT Central Institutional Review Board [35], and Northwestern University Institutional Review Boards and informed consent was received for all participants involved in training sessions.
Tools
Motor function tests selected for the SMA Infant Biomarker study included the TIMPSI [11, 31], CHOP-INTEND [32], and the AIMS [33, 34]. All three MFTs assess spontaneous movement, postural control, and gravity eliminated and antigravity strength in a variety of postures and positions. The TIMPSI and the CHOP-INTEND also assess reflexive movements [9, 36]. Both the TIMPSI and the CHOP-INTEND have previously demonstrated concurrent and discriminant validity and good to excellent scorer reliability in smaller studies when used with infants with SMA [11, 32]. The AIMS has demonstrated reliability and validity in large populations of typically developing and at risk infants [37, 38] and has recently been used in a clinical case study of a child with SMA type 1 [39]. Instructional manuals, adapted from the original test manuals, with detailed operational definitions, administration directions, illustrations and scoring criteria were provided for each MFT at the start of the study [31, 41]. A standardized SMA MFT video library (available via nuptpalslab@northwestern.edu) was developed which included 8–16 professionally recorded videos of each study MFT. The videos included infants with and without SMA, between two weeks and 12 months of age that were the expected ages of study subjects that would be enrolled. Each video was reviewed and edited by two different expert evaluators to assure administration fidelity and that all items were captured at angles to allow for scoring by those viewing the videos. Each video was then scored by the same two expert evaluators and scores were compared for agreement. If item scores were not in agreement, items were discussed to come to agreement. If agreement consensus was not achieved (n = 2) the item was dropped from the video. Once consensus was achieved, expert clinician (consensus) scores were recorded and saved for each video for later use in reliability and agreement with expert rater assessments. Videos from the training library were utilized for training and for sessions assessing reliability of scores and agreement with expert rater. MFT library videos utilized in both training and reliability were rotated from session to session to reduce impact of bias by having raters score different videos after each training session.
Clinical evaluators
Twenty-three total clinical evaluators from the fifteen participating centers participated in reliability training across the duration of the study. Participation in any one training/reliability session varied based on availability/attendance at the time of training sessions and when they entered the study as a CE. All CEs had varying years of clinical experience [0–37 years, median 10.5 (interquartile range or IQR = 22.2) years], as well as varying degrees of experience with SMA [0–36 years, median 4.5 (IQR = 8) years]. Twenty-two were physical therapists and one was a research kinesiologist. Eighteen CEs (77%), including the kinesiologist, had experience in pediatrics and with children with SMA. Five CEs had adult clinical experience only; two of those had previous experience with SMA. Raters were grouped for later analyses of experienced vs novice CEs. Groups were determined by years of experience with the MFT being assessed prior to the start of the study. Group 1 (experienced evaluators) included those with any previous experience with the MFT being assessed and Group 2 (novice evaluators) included those with no prior experience with the MFT.
MFT training and reliability assessments for CEs
Initial investigator meeting: training and reliability assessment
Clinical evaluators (n = 15) from each study site attended the initial investigator meeting (IM) in September 2012 for a five-hour training on the three MFTs that would be utilized throughout the study. Formal instruction on each of the measures included the conceptual theory of the outcome, standardized administration methods, and details of all items and scoring rules. Videos were utilized to demonstrate scoring and emphasize key points of test administration. After receiving formal instruction on the three MFTs at the study investigator meeting, all CEs in attendance, as well as CEs who were unable to attend the IM that were trained later via live webinar (n = 5), were asked to independently rate a series of four videotaped patients with SMA type 1 for the primary MFT, the TIMPSI. The CEs were required to view the four standardized TIMPSI videos via self-paced review at two separate time points with a minimum of a two-week interval between ratings. Initial ratings were compared to the expert clinician consensus score to determine ability to agree with the expert for each of the four assessments. A passing score was defined as a score that was within at least 85% of the expert-rater score. Once all raters completed this phase, the raters’ scores for each of the four assessments were utilized to determine inter-rater reliability for the group. After a period of at least two weeks, the evaluators were then asked to re-rate the same four TIMPSI videos a second time without reference to their prior responses. These scores were then compared to the initial set of scores and utilized to provide a measure of intra-rater reliability (Fig. 1).
Rater training process for TIMPSI. Legend: MFT- motor function test; TIMPSI- Test of Infant Motor Performance Screening Items.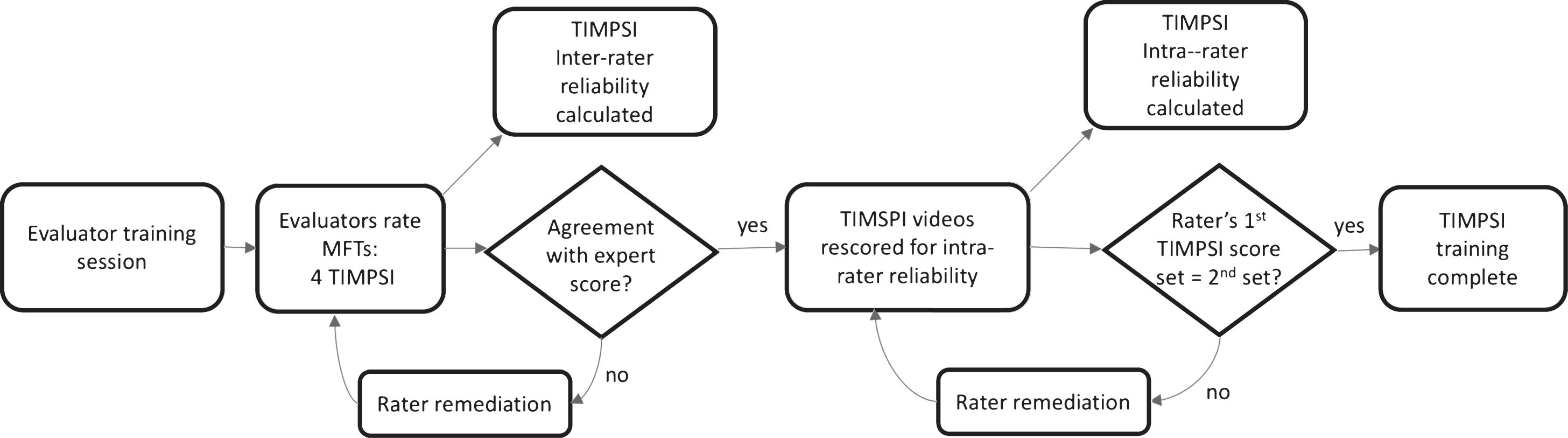
Raters who did not pass the initial agreement with the expert rater (<85%) underwent follow-up remediation sessions conducted by the study’s MFT expert trainer. The remediation focused on individualized retraining by videoconference and a discussion period during which any uncertainties in the use of the MFTs were addressed. The evaluator was then required to re-rate the videos. Once they met the≥85% agreement criterion the remediation process was complete. They could then move on to scoring the videos again two weeks later for intra-rater reliability. Raters who were not successful after an initial remediation session, repeated remediation training and follow up video scoring until they were successful (Fig. 1).
Ongoing training and reliability after the IM
Reliability training session modules
Online live webinar training was utilized in January 2014 for the full CE group and was also utilized when any new CE entered the study across the time period of the study (September 2012- August 2015) or needed to make-up a missed on-site training. To lessen scheduling issues and minimize time online, each MFT had an individual webinar session that was 2–2.5 hrs in length. Total training time for all three MFTs via online sessions was seven hours. Periodically, new evaluators were added at sites to cover temporary leaves of absence and departure of previously trained evaluators. Individualized training sessions were carried out for three new raters in-person or via videoconference to ensure that they met reliability standards prior to their initial evaluation of a study participant.
Annual on-site training was comprised of multiple components. Both MFT practice with infants and expert facilitators and use of a professionally produced library of MFT videos were utilized for instruction and training. Evaluators received a detailed review of the three MFTs used in the study at each training. In addition, a live demonstration of all tests was performed using healthy infant volunteers. Evaluators were then separated into small groups, and performance on each MFT was assessed during practice evaluations of the healthy infants. Evaluator trainers (n = 4) were present to provide feedback on standardized performance, handling skills for successful test administration and scoring clarity. This allowed for practice of standardized MFT administration and scoring with immediate feedback and modeling.
Reliability assessment for trainings post IM
At each follow up training (webinar and in-person), reliability was assessed as previously described using four video-recordings of TIMPSI assessments (two infants with SMA and two without SMA) to determine agreement with expert (each time they submitted a set of scores), inter-rater agreement (using each rater’s first set of submitted scores to avoid bias) and intra-rater agreement (using a rater’s first set of submitted scores and their first set of repeat scores).
While all training sessions included instruction on all three MFTs, reliability was initially assessed for the TIMPSI as the primary MFT after the 2012 IM and the 2014 mid-year web-based training session. Starting in 2014, we added post-training assessment of inter-rater scorer reliability for the CHOP-INTEND (2 review videos) and the AIMS (2 review videos). Agreement with expert and inter-rater reliability for CHOP-INTEND and AIMS videos were established with the same parameters used for the TIMPSI. Intra-rater reliability was not examined for the CHOP-INTEND or the AIMS in an effort to decrease the time burden on raters attending trainings and completing post training reliability (Figs. 1 and 2). The MFT video library had an assortment of videos allowing use of different videos for training and for each annual reliability session (to minimize any inflation of reliability secondary to repeated use of the same videos). Training methods and time to complete reliability assessments are summarized in Table 1.
Rater training process for CHOP INTEND and AIMS. Legend: MFT- motor function test; CHOP- Children’s Hospital of Philadelphia Infant Test of Neuromuscular Dysfunction; AIMS- Alberta Infant Motor Scales.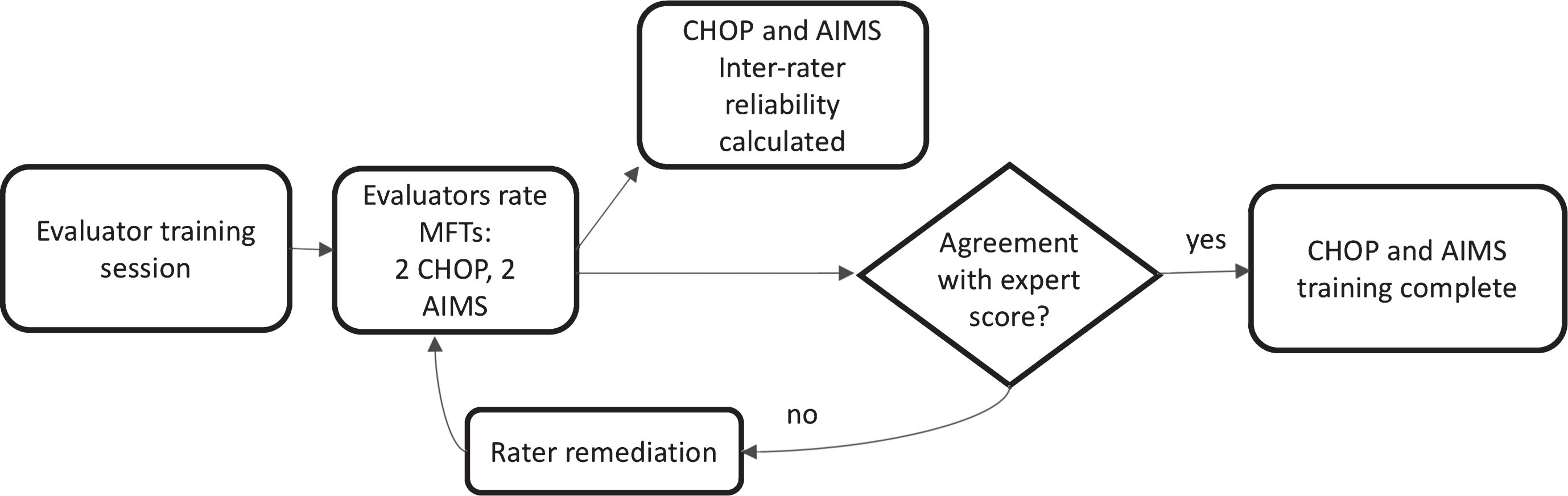
Remediation sessions post reliability assessment
Remediation sessions were conducted for CEs that did not meet initial agreement with expert pass rate for each MFT after each additional training session. Once the threshold of≥85% was met, CEs were instructed to re-rate the TIMPSI videos (n = 4) two weeks after passing remediation to assess their intra-rater reliability (Fig. 1).
Comparison of training groups
To assess if CEs with no experience with the study MFTs demonstrated similar reliability after training to those with previous experience with the study MFTs, we compared reliability assessments from the annual trainings for each of the three study MFTs for the two groups of raters: novice and experienced.
Statistical analysis
Clinical evaluator demographics were examined using descriptive statistics. Percent agreement and Pearson’s correlations were used to determine ability of raters to agree with the expert consensus score for the primary MFT video set (TIMPSI) after the IM and all additional reliability training sessions. Starting with the second annual training (Summer 2014), agreement with the expert for the CHOP-INTEND and AIMS was similarly assessed using percent agreement and Pearson’s correlations. Ability to agree with the expert was defined as a score that was≥85% of the expert-rater score for each individual video. Intra-rater reliability was calculated for each rater for the primary MFT (TIMPSI) after the IM and after each annual training session using intraclass correlation coefficients with a two-way random effects model and absolute agreement (ICC 2,1) and 95% confidence intervals (CI). Group inter-rater reliability on the TIMPSI was examined after the IM and after each subsequent annual training. Group inter-rater reliability was assessed for the secondary MFTs (CHOP-INTEND, AIMS) starting at the second annual training using a two way random effects model and consistency ICC(2,1) and 95% CI. General guidelines for reliability coefficients were used for the interpretation of reliability: values <0.40 indicated poor agreement, values 0.40–0.75 indicated good agreement, and values >0.75 indicated excellent agreement [42, 43]. Group reliability comparisons to determine if novice raters were any less reliable than experienced raters were conducted by examination of overlapping ICC confidence intervals between rater groups. If the point estimate of the ICC from one group was contained within the 95% CI of the ICC from the other group, the reliability of the groups was considered similar [44, 45]. Chi square test was used to examine experienced vs novice raters’ ability to agree with expert on first scoring attempt. All statistical analyses were completed using IBM SPSS 23 (IBM Corp, Armonk, New York).
RESULTS
Agreement with expert rater
Agreement with expert rater for the TIMPSI
≥85% agreement with expert for individual and full set of videos;
≥85% agreement of 1st attempt with 2nd (intra-rater agreement); TIMPSI = Test of Infant Motor Performance Screening Items; exp = experienced; Under CEs passed row raters passed per attempt is noted by number of raters and % of raters that passed at each attempt to agree with expert rater.
Twenty CEs were retrained via three refresher webinars, one for each MFT, over a one-month period extending from February to March, 2014. Upon completing the evaluators scored four TIMPSI videos to assess agreement with expert consensus. Seventy percent of CEs (14/20) passed agreement with expert consensus on the TIMPSI videos at the first post meeting assessment, and six evaluators required one remediation session each to achieve agreement. One rater left the study prior to their intra-rater assessment, and all remaining evaluators (n = 19) achieved agreement on their first intra-rater assessment attempt (Table 2).
Agreement with expert rater for the CHOP INTEND
≥85% agreement with expert for individual and full set of videos; exp = experienced; CHOP = Children’s Hospital of Philadelphia Infant Test of Neurologic Dysfunction; Under CEs passed row raters passed per attempt is noted by number of raters and % of raters that passed at each attempt to agree with expert rater.
Agreement with expert rater for the AIMS
≥85% agreement with expert for individual and full set of videos; exp = experienced; AIMS = Alberta Infant Motor Scales Under CEs passed row raters passed per attempt is noted by number of raters and % of raters that passed at each attempt to agree with expert rater.
Fourteen raters attended the final in-person training in July 2015. Four TIMPSI, two CHOP-INTEND and two AIMS videos were rated once. TIMPSI: All fourteen (100%) CEs passed agreement with the expert for the set of four videos on their first attempt. CHOP-INTEND: Fourteen CEs scored both CHOP-INTEND videos, while one rater only scored one video. Of the thirteen raters that scored both videos all met the≥85% pass threshold successfully on their first attempt. AIMS: All evaluators (n = 14) scored both AIMS videos and passed agreement with the expert on their first attempt (Tables 2, 3 and 4).
Intra-rater scorer reliability
Intra-rater reliability for TIMPSI*
All reliability significant at p < 0.001; ICC = intraclass correlation coefficient; CI = confidence interval;
CHOP INTEND and AIMS intra-rater reliability was not examined in this study.
Inter-rater agreement
Inter-rater reliability across all groups on 1st assessment attempt after each reliability session
All reliability significant at p < 0.001; ICC = intraclass correlation coefficient; CI = confidence interval; TIMPSI = Test of Infant Motor Performance Screening Items; CHOP-INTEND = Children’s Hospital of Philadelphia Test of Infant Motor Performance; AIMS = Alberta Infant Motor Scales.
Comparison of training groups
The 95% CI values overlapped for raters in both the experienced and novice groups, indicating no significant differences in reliability amongst novice and experienced raters on any of the MFTs across the course of the study (Table 6). Additionally, inability to agree with expert rater on 1st attempt was random and was not selectively specific to novice or experienced raters (p < 0.01). Different raters disagreed at each session, and for each test and no correlations between experience were observed.
Time to complete reliability assessments
After the first two training sessions time to complete assessments ranged from one week to three months after post-training assessments were assigned. For the last two sessions, assessments were completed on-site immediately after the training sessions (Table 1).
DISCUSSION
This study reports the scoring reliability of CEs conducting MFTs on infants with type 1 SMA and healthy infants across the three-year duration of a multi-site clinical study. Overall scoring reliability was good to excellent suggesting that the judgment process used in scoring was stable and the resulting scores were consistent and reproducible across raters and sites for each MFT. The high degree of reproducibility previously reported in single centers and trial groups with experienced raters for MFTs commonly used in type 1 SMA [9, 11] was demonstrated across fifteen clinical sites with varying levels of rater experience. These results suggest that training that includes ongoing and consistent education with reliability assessment can assure reliability of MFT scores within large multi-center trials.
This study also revealed important information about novice and experienced raters. While study CEs had variable levels of experience with SMA, novice raters’ reliability was consistent with experienced raters after training. While the majority of CEs were physical therapists and had pediatric, infant handling, and observation of movement and muscle activation experience, five CEs had only adult clinical experience and many in the total group of raters had minimal to no previous exposure to SMA and/or the MFTs used in SMA research prior to study participation. With the exception of one rater, those that struggled with agreement with expert on first pass differed for the various assessments across the study. While inter-rater reliability was good to excellent for all three outcomes, there were differences between each MFT that may have been due to a broader range of score variability in the TIMPSI and AIMS video sets as compared to the CHOP-INTEND video set, the inherent nature of test item differences and the number of videos rated for each test. Moving forward in training it will be important to assure that an adequate number of videos with a broad range of score variability are utilized for each test assessed.
Overall benefits to the standardized training and reliability process included the ability to: 1) train evaluators in use of the MFTs in a standardized manner fostering a consistent approach to administration and scoring, 2) focus on scoring discrepancies between raters across items at annual and midterm training sessions which allowed for targeted training of problematic items, and 3) identify examiners early on who did not meet reliability standards, using standardized video assessment, who could then receive remediation training to assure that they met and maintained reliability standards. Scoring comparisons with expert raters allows one to readily observe tendencies for a rater to over or underscore [46]. Utilizing agreement with expert comparisons allowed us to efficaciously remediate individual evaluators who performed outside predetermined agreement thresholds and fostered improved understanding of MFT scoring which likely improved agreement with expert rater pass rates across the study’s duration. When considering study design the component of agreement with expert rater allowed for identification of raters that needed additional training. Quarterly or bi-annual vs annual training may more readily identify raters who need additional training and should be considered in future study development.
A limitation to our study is that we did not assess rater reliability prior to training, and therefore are unable to define pre-training reliability. Moreover, we assessed raters using two different scenarios (on-site and webinar) that may have played a role in differences seen from session to session. Changes in training methods after the IM, including SMA-MFT video library use, increased time allotted for subsequent training sessions, evaluators’ practice using MFTs at the trainings and in clinical practice within their home clinics once subjects were enrolled at their site, likely improved the ability for raters to meet expert agreement pass rates in the visits after the IM. Setting specific time frames (two to four weeks) to complete reliability assessments after hands-on training is recommended to minimize session to session drift. Trainee adherence to protocol was also not assessed in our study and could have varied by trainer and/or setting. Site visits and ongoing monitoring, as would occur in a therapeutic trial, would ensure protocol adherence.
Longitudinal, clinical MFT assessments may be required to maintain insurance coverage for some therapies [47–49]. Our method to train and assess reliability may be applied to local clinical management and our experience provides evidence that CE experience does not affect reliability. Thus, travel burden to expert centers for evaluation and follow up care at sites closer to home for these vulnerable, medically fragile infants with limited tolerance for travel could be reduced.
In summary, efforts expended in the SMA Infant Biomarker Study to train evaluators for observational MFT assessments were effective. Frequent, proactively planned and consistent in-person and online evaluator training and remediation meetings are recommended to sharpen rater skills, foster scoring consistency and maintain these skills over the entire study period. The quality of CE ratings is an important methodological variable worthy of continued attention and study.
CONFLICT OF INTEREST
The authors have no conflicts of interest to report.
Footnotes
ACKNOWLEDGMENTS INCLUDING SOURCES OF SUPPORT
This is a secondary study funded by the Muscular Dystrophy Association (MDA287450) from data collected during the NeuroNEXT SMA Infant Biomarker Study that was funded by grant NIH/NINDS U01NS079163 and received support from CureSMA, MDA and SMA Foundation. The sponsors had no role in the conduct of this study. We acknowledge the NeuroNEXT Clinical Trial Network and the NN101 SMA Biomarker Investigators and Evaluators. We gratefully acknowledge all of the study subjects (the ‘Super Babies’) and their families.