
Abstract
In existing sequential recommendation systems, user behavior data are directly used as training data for the model to complete the training process and address recommendation tasks. However, user-generated behavioral data inevitably contains noise, and the use of the Transformer’s recommendation model may lead to overfitting on such noisy data. To address this issue, we introduce a sequence recommendation algorithm model named FAT-Rec, which incorporates fusion filters and converters through joint training. By employing joint training methods, we establish both a transformer prediction layer and a CTR prediction layer. Toward the end of the model, we assign weights and sum up the losses from the Transformer and CTR prediction layers to derive the final loss function. Experimental results on two widely used datasets, MovieLens and Goodbooks, demonstrate a significant enhancement in the performance of the proposed FAT-Rec recommendation algorithm compared with seven comparative models. This validates the efficacy of the fusion filter and transformer within the context of sequence recommendation tasks under the joint training mechanism.
Introduction
With the rapid development of the Internet, the abundance of information resources has grown exponentially. To enable users to access the information they need quickly and accurately, recommendation algorithms have emerged and become widely applied on online platforms [1]. These algorithms aim to predict user interests and provide corresponding product or information recommendations. In practical applications, user interests often evolve over time, making it essential to accurately capture the sequential characteristics of user behavior sequences and provide suitable recommendations. These objectives are at the core of sequence recommendation [2].
Since the introduction of the Transformer sequence model by the Google team in 2017 [3], it has demonstrated significant advantages in the field of sequence recommendation, garnering attention from scholars recently. Subsequently, in 2019, the Google team proposed BERT [4], which leverages the Transformer’s Encoder with 12 layers of stacking. BERT places a strong emphasis on pre-trained models, as well as modifications and transfer learning techniques based on pre-trained models.
Existing Transformer-based sequence recommendation algorithms primarily focus on using only the encoder component. For example, NR-TrHGN [5] utilizes the encoder in the Transformer to extract users’ short-term interests from recently browsed news and model them, whereas BST [6] captures the sequential information of user behavior sequences by employing the Encoder in the Transformer. ASReP [7] employs the Transformer’s Encoder structure to pretrain a transformer with reverse sequences to predict previous items. At the outset of short sequences, the transformer generates historical items and fine-tunes itself using these enhanced sequences to predict the next item based on temporal order. However, it lacks effective utilization of the Decoder and thus fails to fully explore the feature information in user behavior sequences. DecT [8] achieved good results by using self attention mechanism to match convolution to obtain independent properties of HED channel information.
Existing Transformer-based methods [9, 10] have demonstrated significant performance in recommendation tasks by stacking multiple self-attention layers. Nevertheless, self-attention layers come with many parameters, potentially leading to the over-parameterization of Transformer-based models [11]. This concern is exacerbated by the fact that these models are trained on user behavior data, which inherently contains noise [12] and may even include false or maliciously manipulated data [13]. In the Sequential Recommendation task, noise can come from multiple sources, which may affect the performance and prediction accuracy of the model. The following are some common sources of noise in serialization recommendations: The randomness of user behavior: Users may exhibit different behaviors at different time points, including purchase decisions, click and browse behaviors. Users may be influenced by emotions, needs, or other unpredictable factors at the time, leading to randomness in their behavior, which can introduce noise. Long-term and short-term behavioral changes: User interests and preferences may change over time, with some projects being temporary interests and others being long-term interests. The model should identify this change and adjust the recommendation strategy; otherwise, it may introduce noise due to overfitting long-term or short-term behavior. False behavior and fraud: Some users may intentionally provide false behavior data or attempt to deceive the system to affect recommendation results, which can introduce noise.
Deep neural networks, including self-attention-based recommendation models, tend to overfit when trained on noisy data [14]. This issue becomes even more critical for self-attention-based recommendation models because they incorporate all the items used for sequence modeling. The Transformer model has many parameters and a multi-layer self-attention mechanism. When the model is too complex, it has the ability to capture noise in the training data, and even treat noise as a signal. This can lead to overfitting of the training data by the model, which cannot be well generalized to new, less noisy data.
To address the aforementioned issues, a combination of filters and Transformer for recommendation prediction can effectively mitigate the influence of noise on the model. Moreover, by harnessing both the Encoder and Decoder components of the Transformer, it becomes feasible to extract feature information from the sequence and predict users’ historical behavior sequences to obtain auxiliary feature data. Incorporating this auxiliary feature information into subsequent recommendation predictions can substantially enhance the performance of recommendations. Therefore, the primary contributions of this study are as follows: Leveraging filter components to effectively attenuate noise information in the data and extract meaningful features across all frequencies, thereby confirming the efficacy of filters in sequence recommendation within the context of joint training mechanisms. Demonstrate the effectiveness of the Decoder in sequence recommendation tasks by utilizing both the Encoder and Decoder components of the Transformer within the joint training framework. Implement a joint training mechanism and construct a loss function tailored to this model architecture to enhance the performance of the recommendation results.
Related work
Sequence-based recommendation
Sequential recommendation algorithms have become a prominent research topic in the current field of recommendation systems. Existing sequential recommendation primarily models the interactions between users and items in user behavior sequences to suggest items that users may find appealing [15]. In this recommendation system, users and items are considered to be two distinct entities, each with multiple interaction events occurring over time. Sequential recommendation organizes these interaction events in chronological order, employs various modeling techniques to extract sequence information features, and uses them to support the recommendation of one or more items in subsequent moments.
Existing sequential recommendation algorithms can be broadly categorized into three categories: Sequential recommendation based on user’s short-term preferences: This approach captures users’ short-term preferences by using their recent behavior sequences to model local information. For example, GRU4REC [16] employs recurrent neural networks with stacked GRU layers to extract sequence information. Similarly, STAMP [17] combines a sequence model with an attention mechanism to capture temporal dependencies within a session. FPMC [18] models a Markov transition matrix for each user based on Markov chains to integrate sequence and personalization information. Sequential recommendation based on user’s long-term preferences: This approach entails modeling global information using user-item interaction sequences to capture users’ long-term preferences. For instance, SASRec [19] and DREAM [20] rely on recurrent neural networks and self-attention mechanisms to process sequence data. Sequential recommendation based on user’s long-term and short-term preferences: This category emphasizes the importance of considering both global sequences and recent interactions for item prediction. For instance, LISC [21] uses matrix factorization and recurrent neural networks to model users’ long-term and short-term interests, combining them through generative adversarial networks. Similarly, AttRec [22] employs collaborative metric learning and an attention mechanism to model users’ short-term and long-term interests, subsequently combining them using linear weighting.
Transformer-based recommendation
Originally developed for machine translation, the Transformer network model, based on the self-attention mechanism, has found widespread application in recommendation algorithms because of its effectiveness. The Transformer comprises essential components, including the multi-head attention mechanism, encoder, and decoder structures, with the multi-head attention mechanism being particularly significant.
Existing Transformer-based recommendation algorithms, such as TKGN [23], use the self-attention mechanism to establish connections between news words and news entities. They also employ an additive attention mechanism to capture the impact of words and entities on news representation. For instance, TCL [24] integrates multiple levels of information, including local contextual information of items, global semantic information within a session, and associated semantics across different sessions. This integration leads to more accurate item predictions based on users’ interests.
Filter-based recommendation
Existing filter-based recommendation algorithms, such as FMLP-Rec [25], employ a stacked blocks structure based on Multi-Layer Perceptron (MLP) and integrate a filter component within each block. These algorithms use Fast Fourier Transform (FFT) [26] to convert the input representation into the frequency domain and then use an inverse FFT procedure to recover the denoised representation. CSFTRec [27] achieved good results by introducing comparative learning and Fourier transform into sequence recommendation.
Structure of the paper
The FAT-Rec model consists of six components:(1) Input Layer: This layer takes input feature data required for model training, such as user behavior sequences, target items, and more. (2) Embedding Layer: This layer converts the input features into fixed-size, low-dimensional vectors. (3) Filter Layer: The vectors from the embedding layer are passed to the filter layer, where filtering algorithms are applied. (4) Transformer Prediction Layer: This layer predicts user behavior sequences by using the Transformer’s Encoder and Decoder, which serve as auxiliary features. The auxiliary loss function is computed by comparing the predictions with the actual user behavior sequences. (5) CTR Prediction Layer: The target items processed by the embedding layer and filter layer are concatenated with the output of the Transformer’s Encoder layer. The resulting concatenation is then fed into the MLP layer for CTR prediction. (6) Output Layer: The final loss function is obtained by combining the weighted sum of the loss functions from the CTR prediction layer and the auxiliary loss function. The proposed FAT-Rec model is illustrated in Fig. 1.
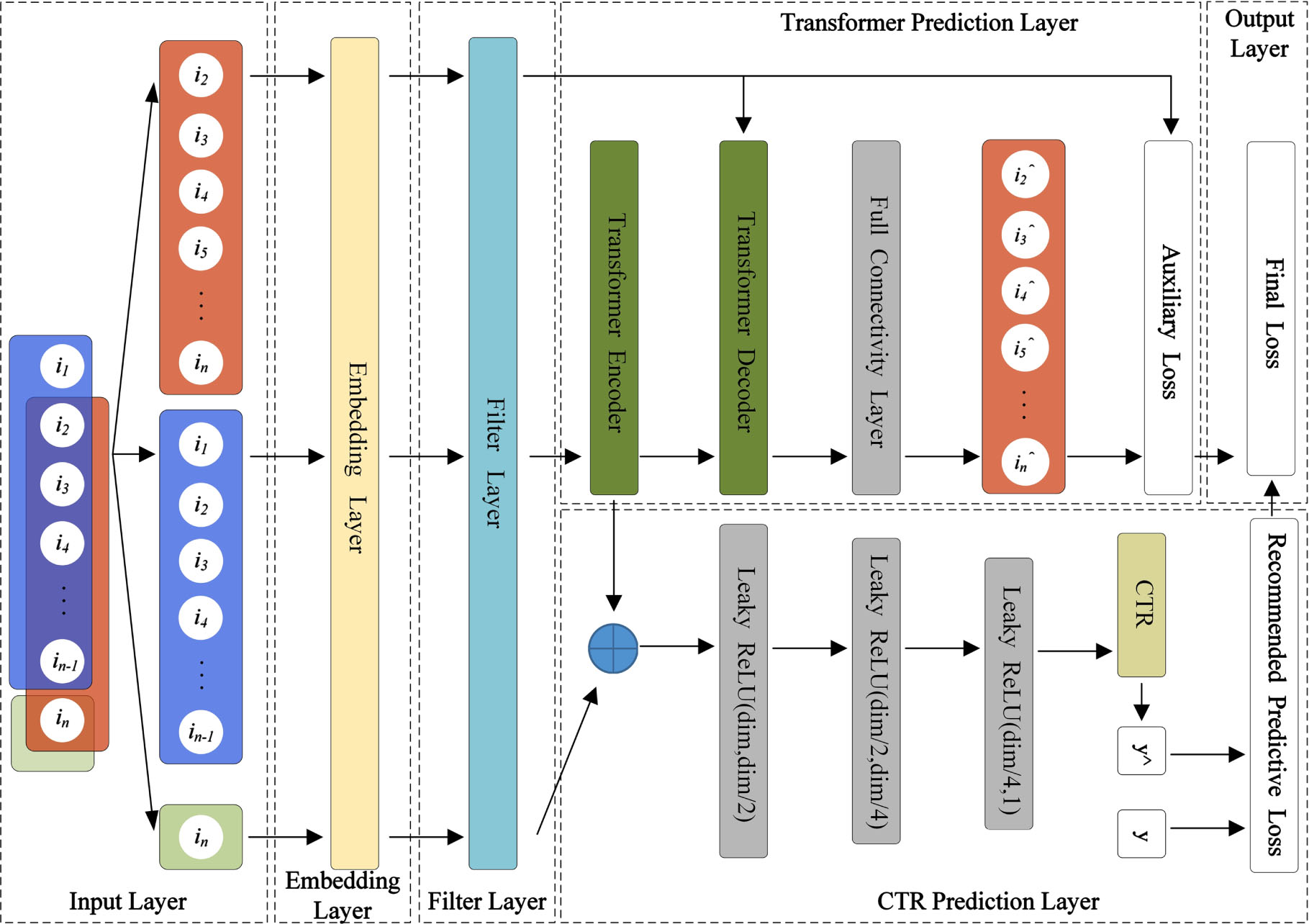
FAT-Rec model structure diagram.
The input layer takes the user behavior sequence as its input data. The input user behavior data is divided into three parts: (1) The user behavior sequence to be predicted is denoted as [i2,i3,i4,...,in]. This sequence excludes the first interaction item of the input user behavior sequence. It represents the sequence that includes the target item and corresponds to the red rectangular box in Fig. 1 in the input layer. (2) The user behavior sequence [i1,i2,i3,...,in - 1], which is the sequence of items with which the user has interacted, is arranged chronologically according to the user interaction items. This corresponds to the blue rectangular box in Fig. 1 in the input layer. (3) The target item in, which refers to the item that will be recommended to the user, corresponds to the green rectangular box in Fig. 1 in the input layer. The target item rating, denoted as y, represents the actual rating the user gives to the target item. The target item rating y is used after calculating CTR by computing the cross-entropy loss between the CTR output result y∧ and y, in order to obtain the recommendation prediction loss. During the training of the FAT-Rec model, the last item in the user’s interaction sequence is treated as the target item for model training.
Embedding layer
The embedding layer converts all input features into fixed-size, low-dimensional vectors. It forwards the user behavior sequence and target items, as proposed in the input layer, to the filter layer. In the Transformer prediction layer, the user behavior sequence output by the filter layer is passed to the Transformer’s encoder layer. In the CTR prediction layer, the target item, which has passed through the embedding and filter layers, is concatenated with the output from the encoder in the Transformer prediction layer. This concatenated result is then used as the input data for the MLP.
Filter layer
In the filter layer, the user interaction sequence matrix
Among them,
Where ⊙ is element-wise multiplication. The term learnable filter indicates that it can be optimized by SGD to adaptively represent arbitrary filters in the frequency domain. Finally, use the inverse FFT to transform the modulated spectrum
Among them,
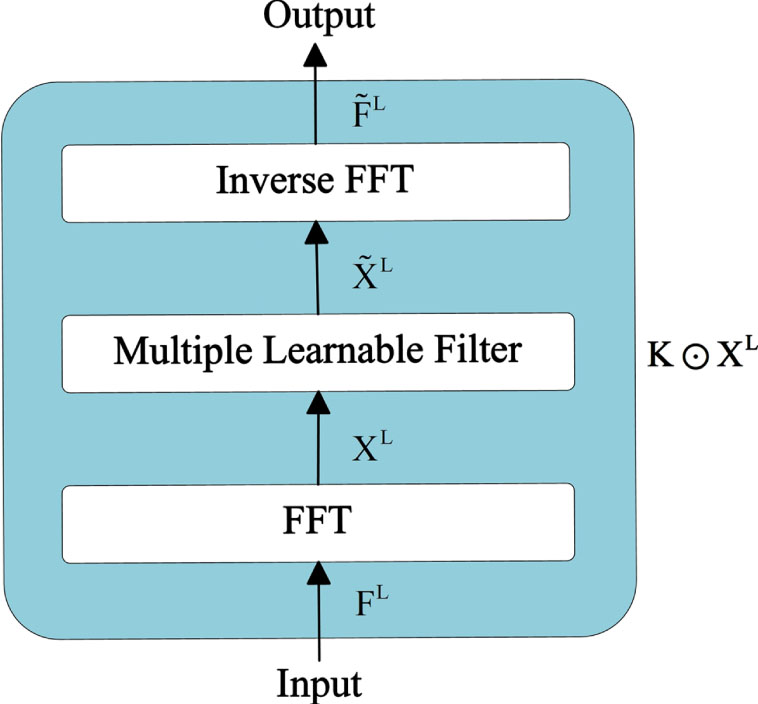
Filter layer structure diagram.
As depicted in Fig. 3, the Transformer consists of two main components: the Encoder and Decoder layers. The input to the Transformer prediction layer includes the user behavior sequences [i1,i2,i3,...,in - 1] and the target user behavior sequence [i2,i3,i4,...,in]. Both sequences undergo preprocessing through the embedding and filtering layers. The output of the Transformer prediction layer is referred to as TransformerLoss serving as the auxiliary loss function. The operational procedure of the Transformer prediction layer is as follows: (1) The user behavior sequences [i1,i2,i3,...,in - 1], after being processed through the embedding and filtering layers, are fed as input to the Encoder. Subsequently, the Encoder’s output is then used as input to the Decoder and simultaneously passed to the CTR prediction layer. (2) The Decoder’s primary function is to perform sequence prediction. The output sequence of the Decoder is further passed through a fully connected layer to facilitate learning the interplay among different features. (3) This output sequence is compared with the target user behavior sequence [i2,i3,i4,...,in] using cross-entropy loss to calculate the auxiliary loss function, TransformerLoss.
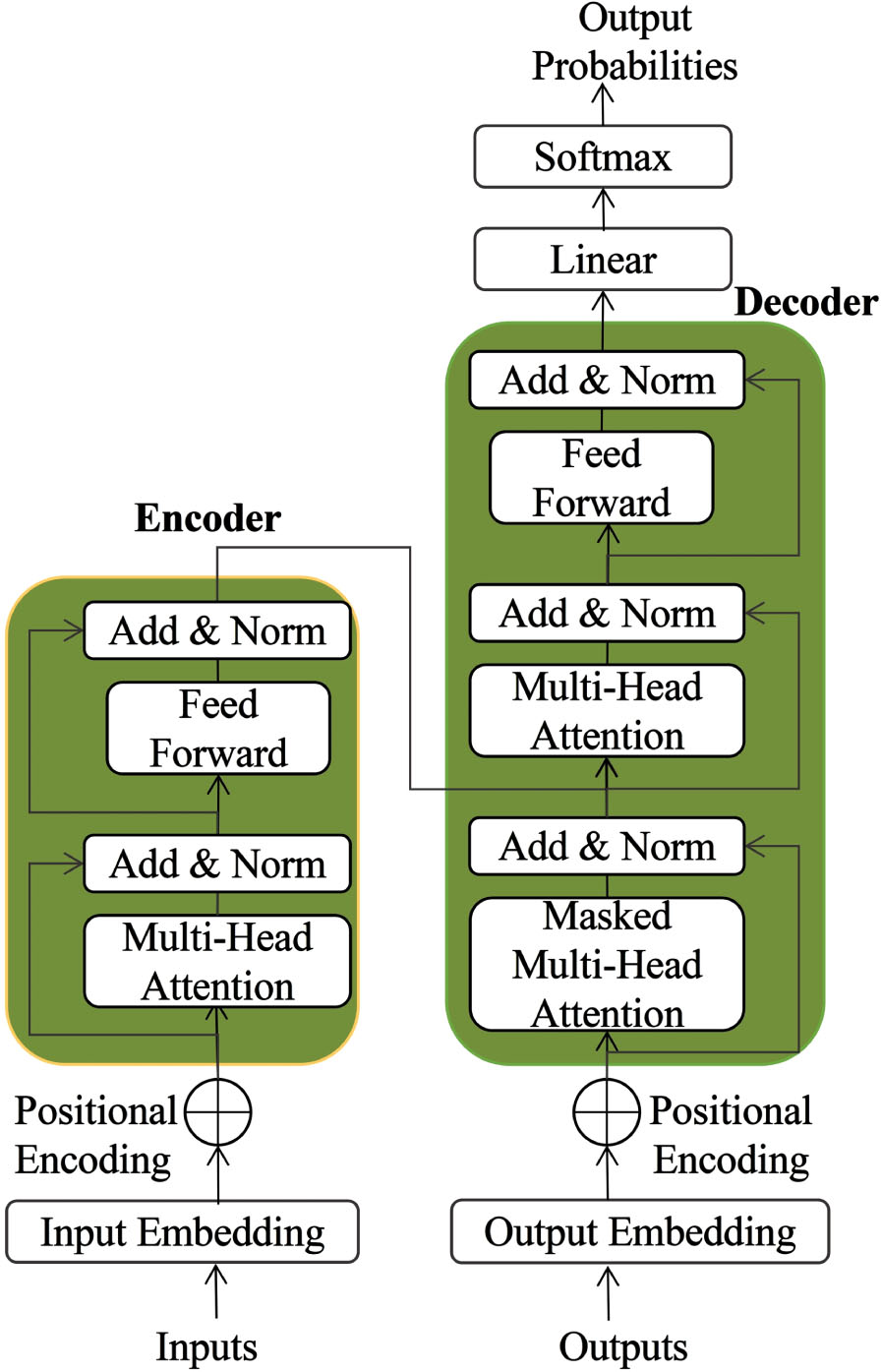
Transformer structure diagram.
In the context of this study, the Encoder layers are designed to capture intricate relationships between the user behavior sequence and other items, allowing for the acquisition of more in-depth representations for each item.
Regarding the Decoder layers, they consist of two multi-head attention mechanisms, each serving a distinct purpose. The first mechanism incorporates a masking mechanism, that effectively prevents the Decoder from accessing future information during the decoding process. The second mechanism computes attention over the outputs of the Encoder using query vectors Q and key-value pairs (K, V) obtained from the Encoder, with the corresponding formula as follows:
In this context, Q represents the Query vector, K stands for the Key vector, and V denotes the Value vector. All of these vectors, Q, K, and V, are derived from the input user behavior sequence vectors.
The sequence processing within the Decoder layer is similar to that of the Encoder layer. After performing multi-head attention and residual connections, the processed sequence is used as the Value vector (V) and combined with the output from the Encoder to enter a new multi-head attention layer.
Subsequently, the Decoder layer in the Transformer generates an output that passes through a fully connected layer to produce the predicted user behavior sequence. To calculate the auxiliary loss function, TransformerLoss (T
L
), the predicted user behavior sequence is compared with the target user behavior sequence. The formula for TransformerLoss is as follows:
In this context, D represents the set of all samples, where y∈ { 0, 1 } indicates whether a user clicks on a particular item, serving as the label. p(x) represents the network output after applying the Sigmoid function, indicating the predicted probability of the target item x being clicked.
CTR is the abbreviation for Click-through rate. In the field of recommendation, CTR usually refers to the ratio of the number of times a user clicks on an item to the number of times the item is displayed. Usually presented as a percentage and used to measure the performance of recommendations.
The CTR Prediction Layer takes the input from the Encoder layers of the Transformer Prediction Layer, the target item in after undergoing preprocessing via the embedding layer and the filtering layer, and the corresponding target item score, denoted as y. The output of the CTR Prediction Layer is represented by the Recommended Prediction Loss function, CTRLoss.
In this research, the target item in is concatenated with the output of the Encoder in the Transformer Prediction Layer. Subsequently, this concatenated input is passed through a three-layer fully connected neural network to facilitate learning the interactions between features. The model is devised as a binary classification model, aiming to predict whether a user will click on the target item. To calculate the loss, the model’s output is compared with the actual score assigned by the user to the item. The Recommended Prediction Loss function, CTRLoss (C
L
), is expressed as follows:
In this study,
The final output of the model, termed as the Final loss, is computed by taking a weighted sum of the CTRLoss obtained from the CTR Prediction Layer and the TransformerLoss obtained from the Transformer Prediction Layer. To account for the varying impact of the Transformer Prediction Layer and the CTR Prediction Layer in the joint training mechanism, a trainable weight parameter, denoted as α, is introduced. The formula for the final loss (F
L
) is as follows:
To strike a balance in model performance, based on the experimental results shown in Fig. 7, the value of α is set to 0.5.
The use of joint training can improve the generalization ability of the model, making it more accurate when processing new data. We extracted advantages from different existing methods and combined them, to demonstrate better performance in experiments than existing methods.
Algorithm: Sequence Recommendation Algorithm Fusing Filter and Transformer under Joint Training
Input: The sequence of items with which the user has interacted with [i1,i2,i3,...,in], and the user’s rating data for the item in.
Output: The algorithm predicts the user’s rating of the project in, resulting in a loss.
Step 1: Divide the input dataset by dividing the input user interaction item sequence [i1,i2,i3,...,in] into the predicted user behavior sequence [i2,i3,i4,...,in], user behavior sequence [i1,i2,i3,...,in - 1], and target item in.
Step 2: Embed the three partitioned data in a fixed size dimension.
Step 3: Filter the embedded data using Equation (1), Equation (2), and (3) to filter the noisy data in order to reduce the impact of noise on the model.
Step 4: Use Equation (4) to encode and decode the user behavior sequence [i1,i2,i3,...,in - 1], and predict the user’s next behavior sequence through a three-layer fully connected layer.
Step 5: Using Equation (5), calculate the cross entropy loss between the predicted user behavior sequence from the fully connected layer and the actual user behavior sequence, and obtain the auxiliary loss.
Step 6: Concatenate the output of the Encoder with the target item in, then transfer it to three layers of MLP to learn the relationship between features, and finally perform CTR prediction.
Step 7: Applies Equation (6) to the results of CTR prediction and the actual user’s rating of the project item in, and performs cross entropy loss to obtain the recommended prediction loss.
Step 8: Uses Equation (7) to weight and sum the auxiliary loss and recommended prediction loss to obtain the final loss of the model.
Filters are typically used for data pre-processing and post-processing. In recommendation systems, they can be used to filter out irrelevant or low-quality data to improve the quality of model training and recommendation results. Filters in user behavior logs can be used to remove noisy data or abnormal behavior, thereby improving the robustness and performance of the model.
Transformers can learn about the complex relationships between users and items to better understand user interests. Capture contextual information to provide more targeted recommendations. The self-attention mechanism of the Transformer model helps to capture long-distance dependencies, thereby improving the accuracy and personalization of recommendations.
Overall, filters and Transformers can collaborate with each other to improve the performance of recommendation algorithms through data cleaning and modeling complex relationships. We extracted advantages from different existing methods and combined them to demonstrated better performance in experiments than existing methods. Filters help to purify data, whereas Transformer models help to better understand and utilize this data, providing more intelligent and personalized recommendations.
Experiments
Experimental setup
The experiments were conducted on a computer equipped with an Intel Core i5-7300HQ processor running at 2.6 GHz, an NVIDIA GTX 1050 GPU, and 16GB of RAM. Pytorch version 1.10.1 was used as the deep learning framework for the experiments.
The model data batch size was set to 128, and all models were trained for 200 epochs. For each baseline model, the remaining hyperparameters were set to the best-performing values as provided in the original papers. As for the FAT-Rec model, certain hyperparameters were experimentally set to achieve better performance: the learning rate was set to 0.001, the number of heads in the multi-head attention mechanism of the Transformer was set to 6, both the Encoder and Decoder were set to 5 layers, the data embedding dimension was set to 128, the weight α for the auxiliary loss function was set to 0.5, and the Adam optimizer was used to train the network model.
Two real-world public datasets were used in the experiments, namely the ML-latest-small dataset and the Goodbooks-10k dataset. The ML-latest-small dataset is used for movie recommendation and contains 100836 rating records from 610 users to 9742 movies. The dataset includes information such as user IDs, movie IDs, ratings, timestamps, and user details. This dataset is often used in research fields such as text classification, sentiment analysis, and recommendation systems. The Goodbooks-10k dataset is used for book recommendations and consists of approximately 6 million rating records from 53424 readers to 10000 books. The dataset includes information such as reader IDs, book IDs, and ratings. The problem domains of this dataset mainly include book recommendations and information retrieval.
The detailed information for the two experimental datasets is presented in Table 1:
Statistics of the experimental datasets
Statistics of the experimental datasets
The evaluation metrics used for the experiments were Precision, Recall, and Accuracy.
(1) Precision: Precision represents the percentage of correct predictions among all samples and is calculated using the following formula:
(2) Recall: Recall represents the probability of correctly detecting positive instances among all samples predicted as positive and is calculated using the following formula:
(3) Accuracy: Accuracy represents the percentage of correct predictions among the total samples and is calculated using the following formula:
Where True Positives (TP) means that the positive class is positive, meaning that an instance is positive and the result is positive. False Negatives (FN) indicate that the positive class is negative, i.e., an instance is positive but the result is negative. False Positives (FP) indicate that the negative class is positive, meaning that an instance is negative but the result is positive. True Negatives (TN) indicate that an instance is a negative class and the result is a negative class.
To demonstrate the effectiveness of our model, we compared it with seven other recommendation algorithm models on two datasets:
(1) BST [6]: This model uses an encoder structure to capture sequential information from the user’s historical behavior sequences and predicts the click-through rate (CTR).
(2) DIN [28]: It directly treats the user’s historical behavior data as the user’s interest features for recommendation.
(3) DIEN [29]: DIEN uncovers hidden user interest features from historical behavior data and captures the evolution process of user interests.
(4) GRU4Rec [16]: This model combines session information with GRU to perform recommendation, addressing long-term memory and gradient issues in backpropagation, resulting in improved recommendation performance compared with traditional KNN and matrix factorization methods.
(5) SASRec [19]: Uses self-attention mechanisms to model user interaction sequences and capture dynamic user interests.
(6) CL4Rec [30]: This model uses a contrastive learning framework to obtain self-supervised signals from raw user behavior sequences, extracting more meaningful user patterns and encoding user representations.
(7) DuoRec [31]: Contrastive learning is used to reconstruct sequence representations, incorporating a Dropout-based model-level enhancement for better semantic information retention.
The reason for choosing these comparative models is that they are currently one of the main models widely used in sequence recommendation tasks. These models are usually validated in different fields and tasks, so they can serve as benchmarks. These models perform well on some standard datasets or tasks, reflecting their competitiveness in the current field.
Comparison of experimental results between FAT-Rec model and comparison model on the ML-latest-small and Goodbooks-10k datasets, as shown in Table 2 and Table 3.
Performance on the ML-latest-small dataset
Performance on the ML-latest-small dataset
Performance on Goodbooks-10k dataset
Table 2 shows that on the ML-latest-small dataset, FAT-Rec improves the Precision index by 2.6% compared with the BST model, 1.1% compared with the DIN model, 13% compared with the DIEN model, 0.8% compared with the GRU4Rec model, and 0.9% compared with the SASRec model. It is 0.5% higher than the CL4Rec model and 0.2% higher than the DuoRec model. Under the Recall metric, the FAT-Rec model is 15.7% higher than the BST model, 5.3% higher than the DIN model, 42.3% higher than the DIEN model, 13.3% higher than the GRU4Rec model, 10% higher than the SASRec model, and 1.7% higher than the CL4Rec model. It is 0.4% higher than that of the DuoRec model. Under the Accuracy index, the FAT-Rec model is 8.1% higher than the BST model, 5% higher than the DIN model, 8.7% higher than the DIEN model, 3% higher than the GRU4Rec model, 4.6% higher than the SASRec model, 2.2% higher than the CL4Rec model, and 1% higher than the DuoRec model.
Table 3 shows that on the Goodbooks-10k dataset, FAT-Rec improves the Precision index by 4.8% compared with the BST model, 3.4% compared with the DIN model, 4.2% compared with the DIEN model, 3.1% compared with the GRU4Rec model, and 2.3% compared with the SASRec model. It is 0.9% higher than the CL4Rec model and 0.4% higher than the DuoRec model. Under the Recall metric, the FAT-Rec model is 5.2% higher than the BST model, 7.4% higher than the DIN model, 8.5% higher than the DIEN model, 3.6% higher than the GRU4Rec model, 3.4% higher than the SASRec model, and 2.8% higher than the CL4Rec model. It is 0.9% higher than that of the DuoRec model. In terms of Accuracy, the FAT-Rec model is 4.4% higher than BST model, 6% higher than DIN model, 6.1% higher than the DIEN model, 2.8% higher than the GRU4Rec model, 2.5% higher than the SASRec model, 2.1% higher than the CL4Rec model. It is 0.9% higher than that of the DuoRec model.
The experimental results show that the FAT-Rec model performs superiorly to the seven comparison models, such as BST, DIN, and DIEN, on both the ML-latest-small and Goodbooks-10k datasets in terms of Precision, Recall and Accuracy evaluation indicators. Compared with the FAT-Rec model, the BST model typically requires a large amount of training data, and its performance may decrease in cases of data scarcity. In addition, BST may not perform well in handling long-distance dependencies in sequences. The DIN model mainly focuses on modeling user interests, but it may not fully consider the diversity and variability of users. It may also require more user behavior data for training. DIEN introduces the concept of interest evolution, but requires more complex models and more parameters. This may result in higher costs for training and deployment. GRU4Rec uses recursive neural networks, which may not be sufficiently parallelized, resulting in slower training and inference speeds. It may also be limited by the processing power of long sequences. The main drawback of the SASRec model is that it requires a larger model and more training data, which may not be practical for resource-constrained situations. The performance of the CL4Rec model may be highly dependent on the negative sample sampling strategy, and improper negative sample sampling may lead to a decrease in model performance. In addition, the training process is relatively complex. The DuoRec model should maintain two independent channels (explicit and implicit), which may increase the complexity of the model. Additionally, the efficiency of information transmission between channels may limit the performance of the proposed model.
According to the above results, in sequence recommendation, the use of filter components can effectively attenuate the noise information in the sequence data and extract meaningful features from all frequencies. Among them, the experimental results of the FAT-Rec model are better than BST model, which can prove the effectiveness of the Decoder in the sequence recommendation task. The joint training mechanism further enhances the accuracy of the model’s recommendation results.
As can be seen in Fig. 4, the loss curve of the FAT-Rec model gradually converges with increasing of epochs. The loss of the model will gradually decrease when the model starts training, and the loss value of the model will further decrease rapidly after the 31th epoch, until the model converges and the loss value becomes stable when the epoch is 200.
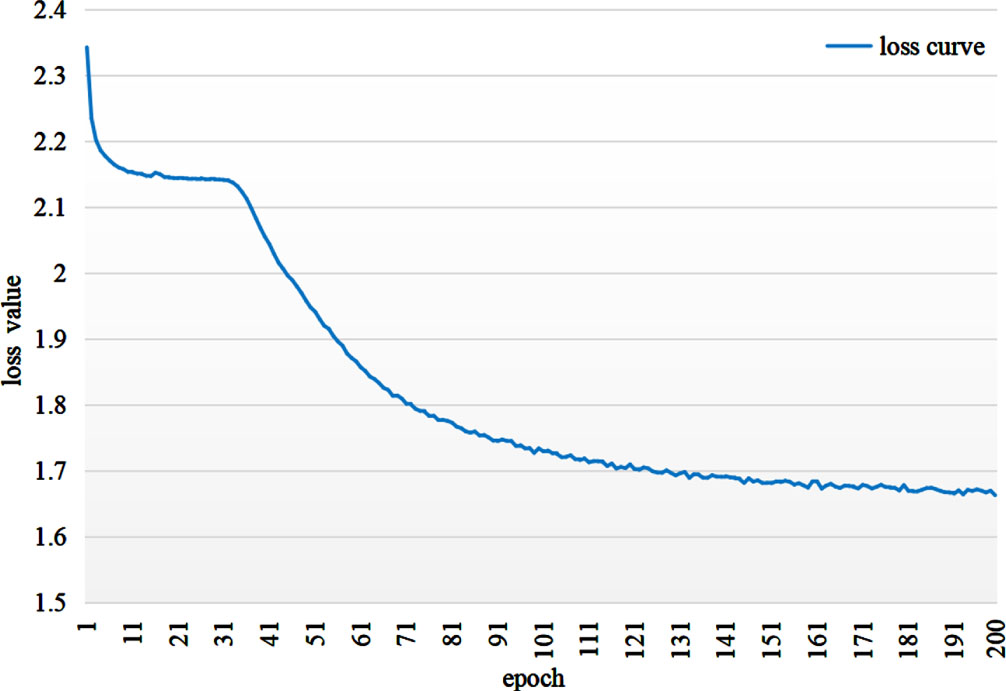
Loss convergence process.
In order to verify the influence of each variable on the experimental results, the influence of different parameters on the experimental results was analyzed on the ML-latest-small dataset.
The effect of different Batch-Sizes on the experimental results is illustrated in Fig. 5. We conducted a total of 5 experiments with different Batch-Size values, namely: 64, 128, 256, 512, and 1024. The model achieved the best performance with a Batch-Size of 128, and as the Batch-Size increased, the model’s performance showed a declining trend.
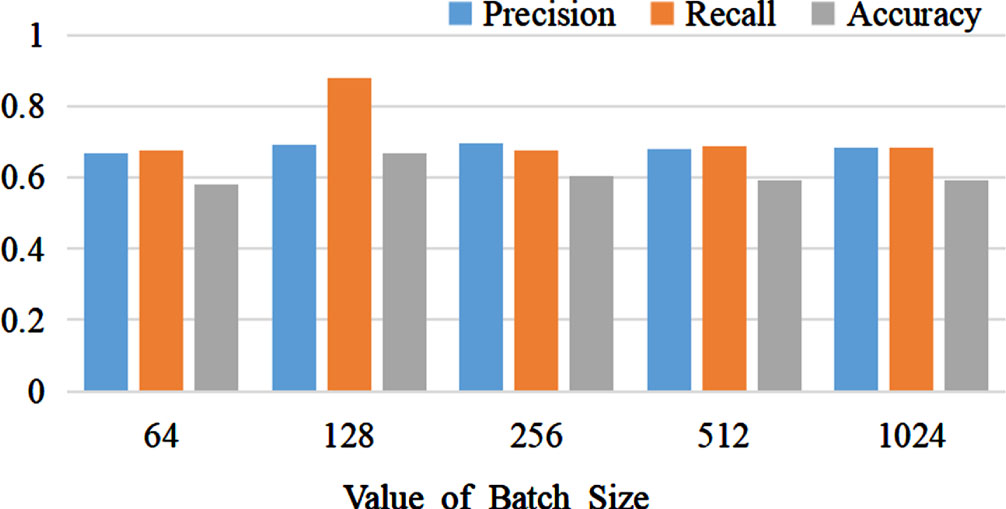
The Influence of Different Batch Sizes on Experimental Results.
The impact of different numbers of Transformer layers on the experimental results is illustrated in Fig. 6. We conducted a total of five experiments with varying values for the number of Transformer layers: 1, 2, 3, 4, and 5. The model achieved optimal performance when the number of Transformer layers was set to 5. Increasing the number of Transformer layers increases the model’s parameters. As the number of parameters increases, the model’s performance improves; however, this increase in parameters also raises the risk of model overfitting.
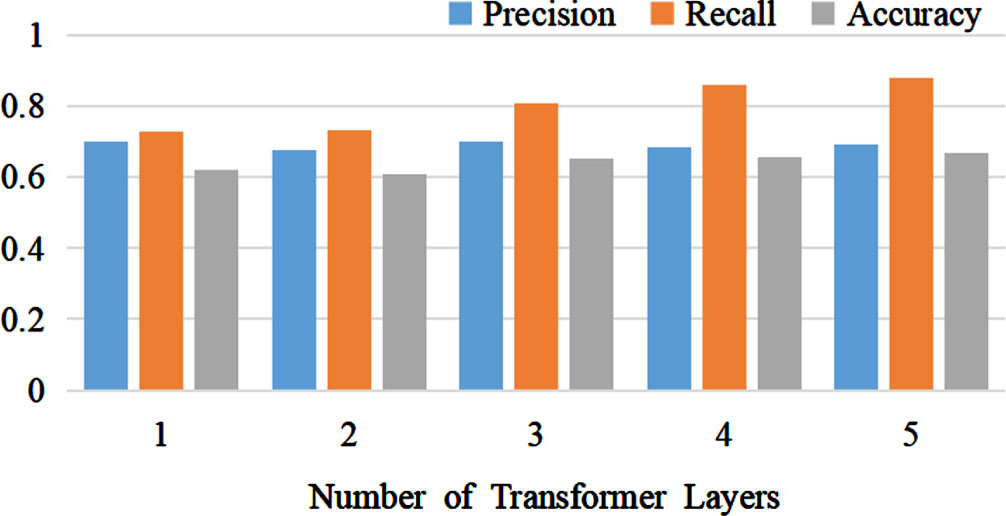
The Effect of Different Transformer Layers on Experimental Results.
The influence of different values of the auxiliary loss function weight α on the experimental results is depicted in Fig. 7. We conducted a total of five experiments using varying values for the auxiliary loss function weight α: 0.1, 0.2, 0.3, 0.4, and 0.5, respectively. The model achieved its optimal performance when the auxiliary loss function weight α was set to 0.5.
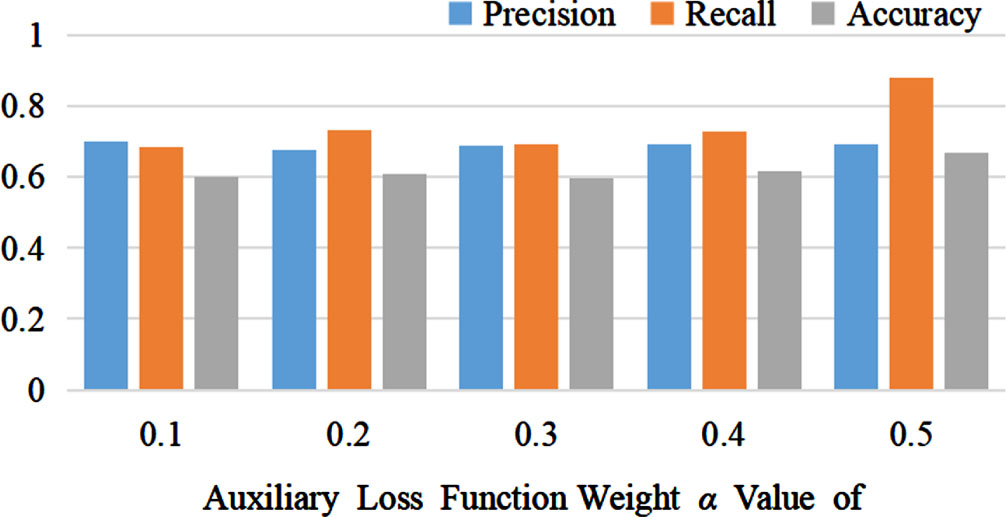
Weights of different auxiliary Loss function α Impact on experimental results.
The impact of different embedding layer dimensions on the experimental results is depicted in Fig. 8. We conducted a total of five experiments using various values for the embedding layer dimensions: 64, 128, 256, 512, and 1024, respectively. The model achieved its optimal performance when the dimension size of the embedding layer was set to 256. As the dimension of the embedding layer increased, the overall performance of the FAT-Rec model exhibited a declining trend.
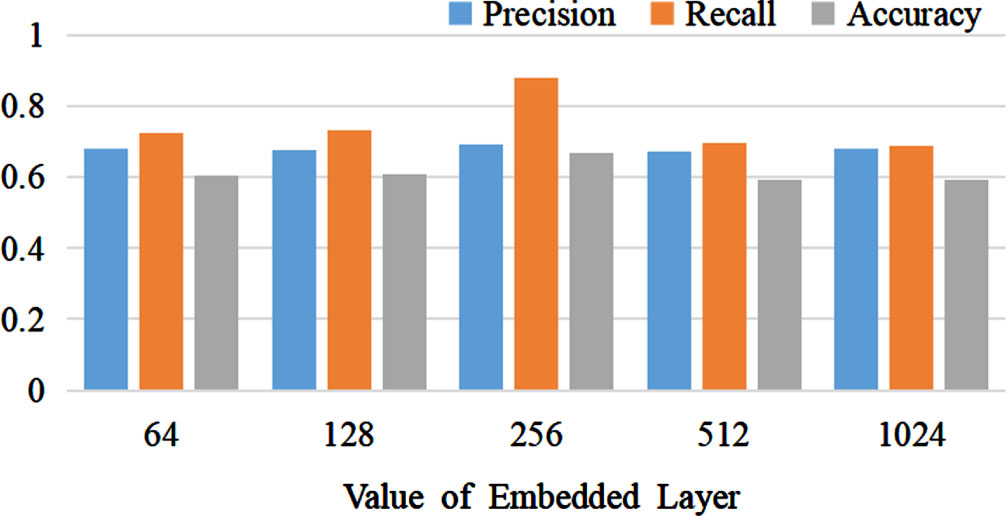
The influence of different embedding layer dimensions on experimental results.
The impact of different values for the number of attention heads in the multi-head attention mechanism on the experimental results is illustrated in Fig. 9. We conducted a total of 5 experiments with varying values for the number of attention heads: 2, 3, 4, 5, and 6. The model achieved its best performance when the number of attention heads was set to 6. As the number of attention heads increased, the overall performance of the FAT-Rec model exhibited an upward trend.
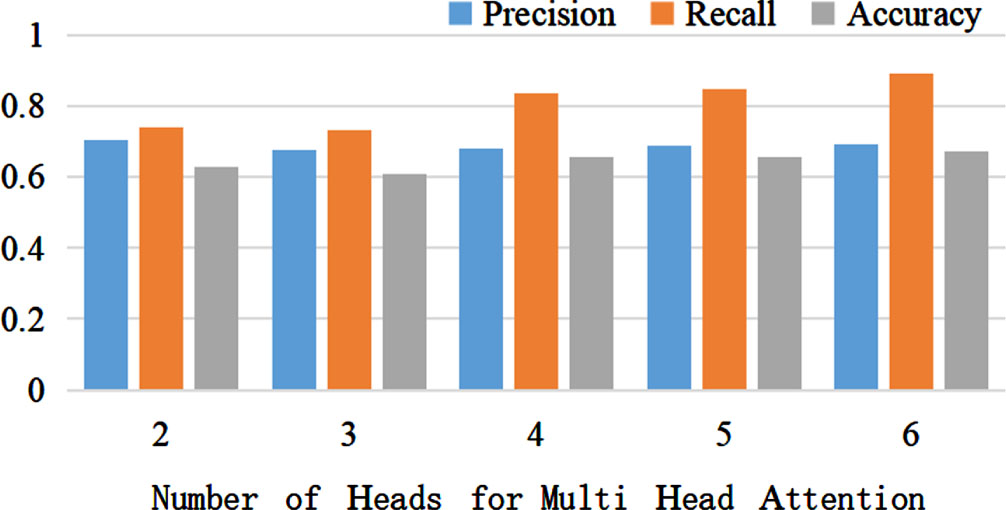
The Influence of Different Values of Attention Headers on Experimental Results.
To validate the effectiveness and necessity of each module in the FAT-Rec model, we designed and evaluated four variant models: FAT-Rec-C: Removal of the CTR prediction layer. This ablation model aims to verify the effectiveness and necessity of the CTR prediction layer. FAT-Rec-T: Removal of the Transformer prediction layer. This ablation model aims to verify the effectiveness and necessity of the Transformer prediction layer. FAT-Rec-D: Removal of the Decoder layer in the Transformer. This ablation model aims to verify the effectiveness and necessity of the Decoder layer for sequence prediction. FAT-Rec-F: Removal of the filter layer. This ablation model aims to verify the effectiveness and necessity of the filter layer.
The experimental results of FAT-Rec and its four variant models on the ML-latest-small dataset are presented in Table 4. Under the Precision metric, FAT-Rec exhibited improvements of 3.7% over FAT-Rec-C, 1% over FAT-Rec-T, 1.2% over FAT-Rec-D, and 1.4% over FAT-Rec-F. Regarding the Recall metric, FAT-Rec showed improvements of 7.2% over FAT-Rec-C, 23.6% over FAT-Rec-T, 24.8% over FAT-Rec-D, and 26.2% over FAT-Rec-F. In terms of the Accuracy metric, FAT-Rec exhibited improvements of 5.3% over FAT-Rec-C, 4.6% over FAT-Rec-T, 10.8% over FAT-Rec-D, and 12.5% over FAT-Rec-F.
Comparison of FAT-Rec models with different structures
Comparison of FAT-Rec models with different structures
Among them, the FAT-Rec-C model reduces the complexity and parameter count of the model by eliminating the CTR prediction layer, which helps alleviate the issue of model overfitting. However, removing the CTR prediction layer results in the model’s inability to determine whether users like the recommended items based on their ratings, leading to inaccurate recommendations. The FAT-Rec-T model, on the other hand, weakens the model’s ability for sequence prediction by removing the Transformer prediction layer. In addition, the model loses access to the auxiliary loss functions, which subsequently impacts the overall performance of the model. The experimental results underscore the significance of the Transformer prediction task and the auxiliary loss functions for the model’s effectiveness. The FAT-Rec-D model, by eliminating the Decoder layer in the Transformer prediction task, reduces the model’s parameter count but also loses the masking mechanism present in the Decoder layer. Consequently, the model encounters noise-related issues and cannot effectively predict user behavior information. The experimental results emphasize the importance of the Decoder layer in the Transformer prediction task for the model’s effectiveness. The overall performance of the FAT-Rec-F model was the weakest. This observation indicates that removing the filter layer from the model results in an excessively parameterized structure because of the stacking of self-attention layers and a large number of parameters in the Transformer [32]. Consequently, the model exhibits a tendency to overfit to noise in the data [9].
Possible application scenarios of the FAT-Rec model, such as news and article recommendations: Similar to movie or book recommendations, news and article recommendations can also generate personalized recommendation lists using user interest and behavior data. E-commerce recommendation: On e-commerce platforms, product recommendation is the key to improving user purchase rate and satisfaction. Music and video streaming services: Music and video streaming services can recommend new songs, albums, or movies to users based on their preferences and behaviors. In summary, it has potential scalability in many other recommendation tasks and fields. However, in order to ensure its effectiveness and accuracy in practical applications, it may be necessary to make certain adjustments and optimizations tailored to the data characteristics of specific fields.
Conclusion
We propose FAT-Rec, a sequence recommendation algorithm that integrates filter and Transformer models through joint training. Our approach uses a joint training mechanism, that incorporates both the Transformer prediction layer and the CTR prediction layer. In the Transformer prediction layer, we effectively combine the Encoder and Decoder to capture sequential features for recommendation prediction. We also construct corresponding loss functions to facilitate learning. Meanwhile, in the CTR prediction layer, we concatenate the output of the filter layer with that of the Transformer Encoder. We then pass this concatenated input through three fully connected layers to perform CTR prediction. The final loss function is derived by appropriately weighting the losses from the Transformer prediction layer and the CTR prediction layer. In the future, we plan to enhance our model training by integrating rich item attributes and contextual information, all while considering future information. Additionally, we will explore modifications to the Transformer architecture to reduce the model’s parameter count and improve training efficiency. These adaptations to the model architecture are expected to lead to further performance enhancements.
Footnotes
Acknowledgments
This study received support from the following funding projects: Natural Science Foundation of Xinjiang Uygur Autonomous Region of China (2023D01C17, 2022D01C692); National Natural Science Foundation of China (62262064, 61862060); Xinjiang Uygur Autonomous Region Natural Science Foundation Resource Sharing Platform Construction Project (PT2323); and Xinjiang Meteorological Bureau Guidance Project (YD202212).