
Abstract
Human motion prediction is a classic problem in computer vision and graphics, and the prediction of human motion diversity has a wide range of practical applications. To tackle this problem, this study proposes predicting the future motion diversity of the human body based on conditional denoising diffusion probabilistic models combined with the kinematics of human joints. First, the observed and predicted sequences were integrated into the same sample space using the mask mechanism, and Gaussian noise was gradually injected into the predicted sequence leveraging the cosine noise scheduler to destroy the sequence structure. Subsequently, the spatial-temporal feature extractor and channel enhancement module were used to form a denoiser to learn the temporal dynamic evolution of the sample and the potential correlation between the nodes in the diffusion process to complete the noise prediction and restore the sample information. The proposed method was verified on the Human3.6M and HumanEva-I datasets, and the experimental results show that the proposed method is competitive with previous methods in diversity prediction.
Introduction
Human motion sequence prediction has gained significant attention due to its wide-ranging applications in human–robot interactions (Bütepage et al., 2018), autonomous driving (Mangalam et al., 2020; Paden et al., 2016), and assistive robotics (Cui et al., 2020; Kundu et al., 2019). The core challenge lies in predicting future sequences from observed data, a task complicated by the intrinsic uncertainty and randomness of human behavior (Dang et al., 2022). While prior studies (Ma et al., 2022; Mao et al., 2019) achieved promising accuracy in deterministic predictions, they overlooked the critical need for modeling diverse future motions—an essential requirement for safe decision-making in scenarios where robots must adapt to unpredictable human actions. For example, a home robot caring for an elderly person relies on diverse motion predictions to prepare multiple response strategies for situations like sudden stumbles or changes in posture (Dang et al., 2022).
Early approaches to motion prediction, such as recurrent neural networks (RNNs) and graph convolutional networks (GCNs) (Butepage et al., 2017; Chiu et al., 2019; Xu et al., 2022), focused on capturing spatio-temporal features to predict the most likely future motion. These methods evaluated performance by measuring the distance between predicted skeletons and ground truth, achieving moderate success in short-term prediction (Butepage et al., 2017). However, they inherently lacked the ability to model the stochasticity of human movement, limiting their utility in applications where uncertainty must be explicitly addressed (Dang et al., 2022).
With the development of deep generative modeling, methods like generative adversarial networks (GANs) and variational autoencoders (VAEs) (Hernandez et al., 2019; Kundu et al., 2019; Lin & Amer, 2018; Yan et al., 2018; Yuan & Kitani, 2020) emerged to generate diverse motion sequences. These models assessed performance using probability metrics (e.g., minimum distance to ground truth) and diversity metrics (e.g., average distance between prediction samples) (Lin & Amer, 2018). While they introduced stochasticity, challenges such as mode collapse and unstable training limited their effectiveness in producing realistic and varied motions (Hernandez et al., 2019).
Denoising diffusion probabilistic models (DDPMs) (Ho et al., 2020) have since emerged as a promising framework for motion prediction, leveraging their capacity to transform noise into plausible sequences through iterative denoising. The DDPM has not only become a new state-of-the-art image generation model (Dhariwal & Nichol, 2021; Lugmayr et al., 2022; Saharia et al., 2022), but has also been successfully applied to speech generation (Kim et al., 2022). Lugmayr et al. (2022) applied it to image painting and verified that the model could generate high-quality and diverse images for any form of lacquer painting. Dhariwal et al (Dhariwal & Nichol, 2021) also demonstrated the superiority of the DDPM over generative adversarial networks in terms of images, DDPMs have been adapted to human motion prediction with notable advancements (Ahn et al., 2023; Chen et al., 2023; Tashiro et al., 2021; Wei et al., 2023; Wen et al., 2023).
Wei et al. (2023) modeled joint diffusion as thermally agitated particles to derive a parameter-free ‘‘whitened” latent space, reducing posterior collapse and improving diversity by addressing latent variable neglect in strong decoders. This approach addresses the limited diversity that latent variables learned after the joint training of sampling and decoding tend to be ignored by strong decoders. Score-based diffusion models have recently outperformed extant diffusion models in many tasks, such as image generation and audio synthesis; therefore, Tashiro et al. (2021) advanced score-based diffusion with conditional models, leveraging observed data to enhance deterministic accuracy and reduce calculation errors. Wen et al. (2023) integrated diffusion uncertainty with spatio-temporal graph networks to better model inherent variability in skeletal data, validated via experiments. Ahn et al. (2023) proposed a method of combining spatial and temporal transformers in series or parallel to fully learn the spatio-temporal structural information of noisy samples, which solves the problem that diffusion models cannot fully capture the spatio-temporal structural information of noisy samples during the training process. By evaluating the ability of the DDPM to model the diversity and determinism of human motion in the future, it was demonstrated that the denoiser trained by this method can accurately sample the original samples from the noisy space. Previous predictions of human motion have been made by encoding historical motion into latent representations, and then the latent representations are used to obtain the future motion of the human body by some decoding means. However, in practice, this approach remains inadequate owing to issues such as complex constraints and the diversity of predicted future movements. To address these weaknesses, Chen et al. (2023) discarded the encoding-decoding approach and proposed a masking mechanism combined with data-centered techniques to deal with human behavior prediction from a perspective. Specifically, historical and predicted motions were first merged, then a motion diffusion model was learned, and motions were generated from random noise.
Despite these innovations, DDPM-based motion modeling remains hindered by two key limitations. First, existing methods often treat each joint’s time series in isolation, neglecting the spatial correlations between body parts that are essential for biomechanically plausible predictions (Chen et al., 2023; Wei et al., 2023). Second, the sequential nature of motion data leads to inefficient training and inference, particularly for long-term prediction, as models struggle to encode global cross-frame dependencies without excessive computational cost (Ahn et al., 2023; Tashiro et al., 2021).
In this study, inspired by the three-dimensional (3D) skeleton diffusion model (Ahn et al., 2023), we propose a denoising diffusion network consisting of a spatio-temporal feature extractor (ST-FE) and a channel enhanced module (CEM). Specifically, ST-FE captures potential connections between joint points via a GCN and utilizes a transformer to model cross-frame global correlations. In addition, CEM estimates the useful information in the channel using a similarity function, which can reduce information aggregation between neighboring frames owing to local differences.
Figure 1 illustrates the network structure. The observed and predicted sequences after adding masks were input into the network, and plausible 3D human motion sequence were generated by diffusion modeling. Specifically, the DDPM forward process combines the observed sequences We provide a powerful denoiser that fully utilizes transformer and adaptive GCN to exploit spatio-temporal information of noisy samples. We present a new, practical, conditional diffusion-based model for 3D human motion prediction. Compared to previous work, this article achieves high accuracy on the Human 3.6M and HumanEva-I datasets. We demonstrate the excellent performance of the proposed method through comprehensive experiments and affinity matrices.
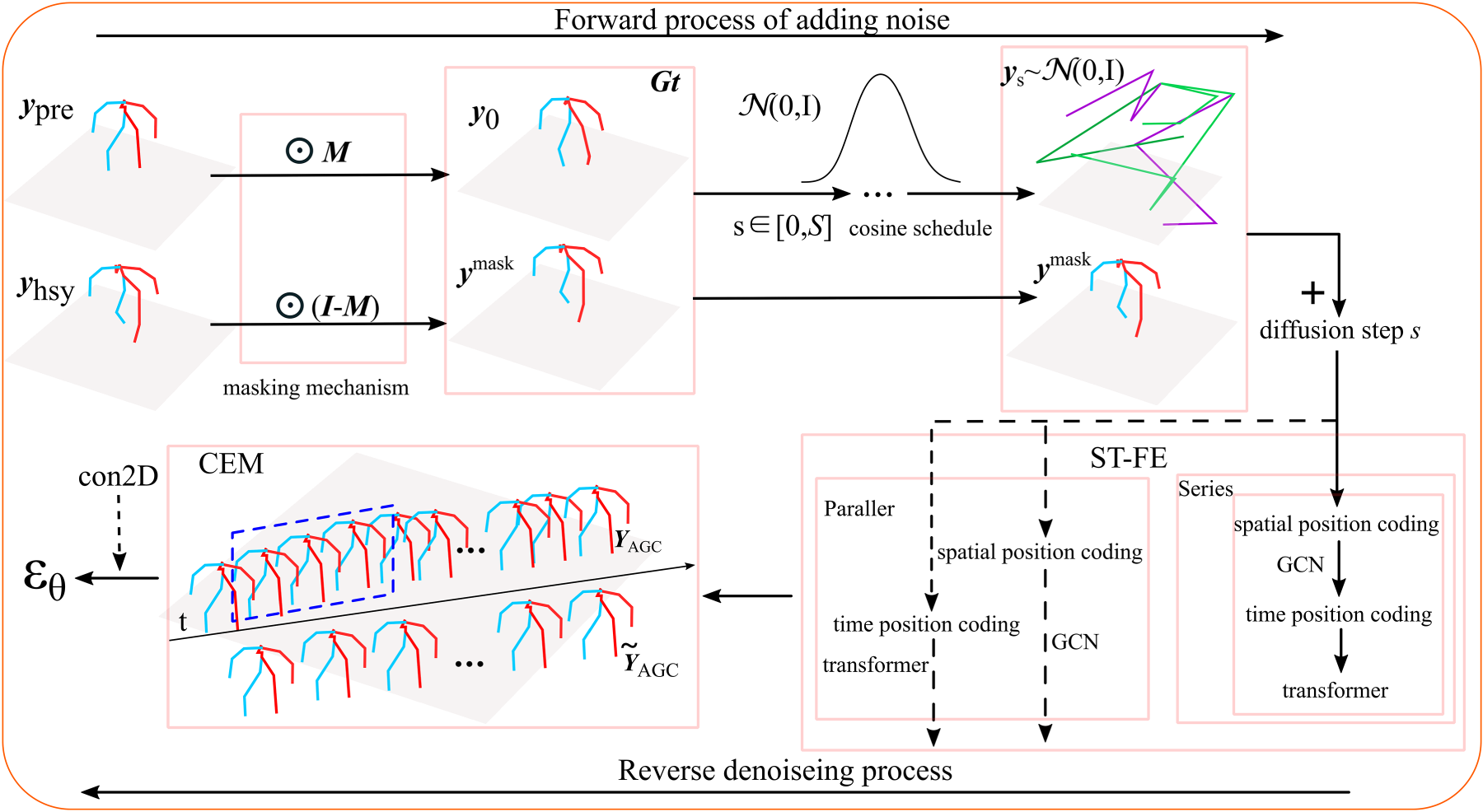
Network Structure.
The rest of the article is organized as follows. Section 2 introduces related works. Section 3 briefly introduces some related concepts of DDPM, masking mechanism, and position encoding. Section 4 models our motion prediction model. Section 5 details the process of constructing our human motion prediction model and how to train our denoiser. Section 6 shows the experimental study of the proposed method. Finally, Section 7 summarizes this work.
Deterministic Prediction
Deterministic prediction can be viewed as a regression task. Given past motion, predictions of future human motion produce the most likely single outcome. Most previous methods relied on RNNs for temporal modeling (Liu et al., 2022b), but their error accumulation and first-frame discontinuities limit long-term prediction. To address this, Bouazizi et al. (2022) proposed a multi-layer perceptron (MLP)-based architecture, employing spatial MLPs to capture joint dependencies and temporal MLPs to model temporal interactions, thereby avoiding RNN-induced error propagation. Building on transformer advancements in natural language processing (Vaswani et al., 2017), Aksan et al. (2021) developed a spatio-temporal transformer using self-attention mechanisms to model both spatial and temporal dimensions simultaneously, improving long-term modeling efficiency. GCNs further enhanced spatial reasoning by learning dynamic joint relationships (Dang et al., 2021; Mao et al., 2019; Zhong et al., 2022), with Zhong et al. (2022) integrating gated-neighborhood GCNs for adaptive spatio-temporal dependency modeling. Additionally, Cui et al. (2020) introduced dynamic graph learning to capture both physical and non-physical joint interactions, complementing traditional GCN approaches.
Stochastic Prediction
Stochastic prediction produces multiple predictions of future human motion given past motion, and its predictions are usually generated by generative models that produce a number of columns of possible motions (Yan et al., 2018). Diversity is a key aspect in evaluating the quality of a campaign generation task. GANs have excelled in image synthesis (Creswell et al., 2018) and motion modeling, enabling diverse, realistic motion sampling while addressing short-term prediction limitations (Hernandez et al., 2019) and absolute positional inaccuracies through adversarial training (Sigal et al., 2010). VAEs complement this via representation learning for probabilistic motion forecasting (Hernandez et al., 2019; Yan et al., 2018), though multi-network architectures are often required to capture subtle motion patterns. Based on previous methodology, DLow (Yuan & Kitani, 2020) pioneered reparameterized latent flows and diversity optimization objectives to generate diverse motion predictions, decoupling stochastic sampling from pose quality constraints via a shared deterministic network. Mao et al. (2021) introduced kinematic constraint propagation with inverse kinematics layers and temporal smoothness losses, addressing the trade-off between diversity and physical plausibility in long-term predictions. Xu et al. (2022) proposed multi-level spatio-temporal anchors and multi-scale temporal modeling, enabling structured reasoning for complex human–object interactions.
Denoising Diffusion Probabilistic Model
The diffusion model has become the state-of-the-art deep learning generative model and has shown great potential in many fields, such as computer vision and time series modeling. In particular, its performance on text-conditional image synthesis has struck awe in researchers and the public (Saharia et al., 2022). Its forward process destroys the original data by gradually adding noise through a Markov chain, whereas reverse denoising gradually restores the original data. Recently, diffusion models—inspired by their image generation breakthroughs (Ho et al., 2020; Wei et al., 2023)—have gained traction for human motion prediction (Ahn et al., 2023; Tashiro et al., 2021), offering superior probabilistic modeling compared to traditional likelihood-based methods. This study explores DDPM-based diffusion models (Ho et al., 2020) for human behavior prediction, leveraging their hierarchical denoising process to balance diversity and temporal coherence in long-term motion synthesis.
Researchers have attempted to use the powerful synthetic features of diffusion models for behavioral prediction (Ahn et al., 2023; Wei et al., 2023). To take advantage of the correlations in temporal data, the conditional score-based interpolated diffusion model directly models the data distribution using observations as conditions (Tashiro et al., 2021). It uses self-supervised training to optimize the diffusion model and proposes a new time series interpolation method using score-based diffusion models. Ahn et al. (2023) explored the competitiveness of using diffusion probability models for 3D motion prediction tasks. The experimental results show that the diffusion model cannot completely replace existing techniques for both deterministic and stochastic motion prediction tasks. However, they found a glimmer of hope in the diffusion model, as it was valid for both types of predictions after a single training process and was able to appropriately tradeoff between context and the need for diverse motion sampling.
Subsequently, HumanMAC (Chen et al., 2023) masked motion completion with transformer architectures to mitigate error accumulation in long-term prediction, establishing a foundation for spatiotemporal consistency. Building on this, BeLFusion (Barquero et al., 2023) and MCLDN (Gao et al., 2024) expanded conditional generation by integrating behavioral semantics and scene-aware priors, respectively, enabling contextually grounded motion synthesis. Tian et al. (2024) further unified transformer-based temporal attention with diffusion steps, improving both fidelity and inference efficiency. To address the diversity-quality trade-off, Yu et al. (2024) introduced contrastive language-image pre-training-guided latent space regularization to avoid mode collapse, while CoMusion (Sun & Chowdhary, 2024) harmonized stochastic diversity with temporal smoothness through trajectory clustering and consistency constraints. Finally, Curreli et al. (2025) redefined the noise modeling paradigm by introducing direction-aware covariance matrices, resolving biomechanical implausibility in 3D joint rotations—a critical limitation in prior isotropic diffusion frameworks.
Background Knowledge
Denoising Diffusion Probabilistic Model
DDPM is an unconditional generative model, and the entire modeling process consists of a forward process and a reverse process based on Markov chains, learning a model distribution





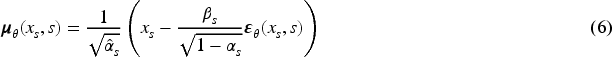

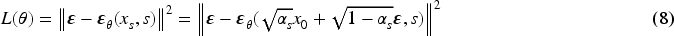
Conditional score-based computational diffusion modeling is devoted to the time series computation of diffusion models. Conditional diffusion models allow us to utilize useful information from the observed series to perform accurate calculations equations (4) and (5) is added to the observed sequence
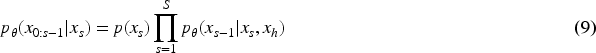
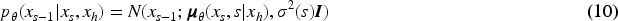
During the training process, to enhance the computational efficiency of the model, the observed sequence



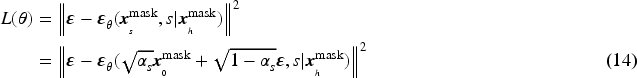
Compared to equation (8), this equation makes full use of the favorable information in the observed data to accurately calculate and reconstruct the predicted data.
Vaswani et al. (2017) proposed positional coding that applies to periodic data in a transformer model, where the key idea is to encode words as vector space representations based on their position and context in the text,

Given
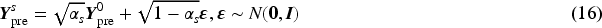
However, Nichol and Dhariwal (2021) found that the linear noise scheduler is not suitable for low resolution images. Therefore, we use the cosine noise scheduler, as in equation (17), which proves to be useful for low resolution data and is gentler than the linear noise scheduler when adding noise,
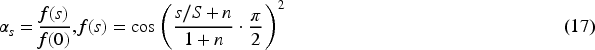
The denoising network consists of ST-FE and CEM as shown in Figures 2 and 3, which gradually learns the spatial structure and temporal information of the data from the corrupted samples and predicts the noise of the forward process

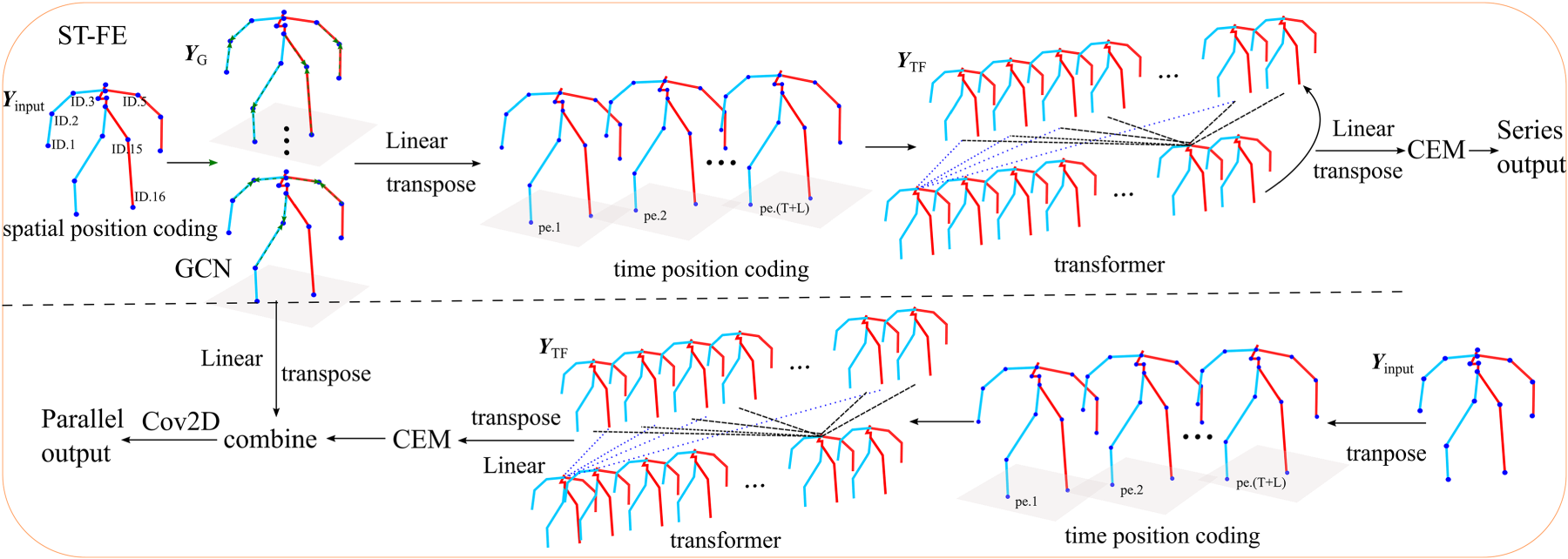
Spatio-Temporal Feature Extractor (ST-FE) Structure.
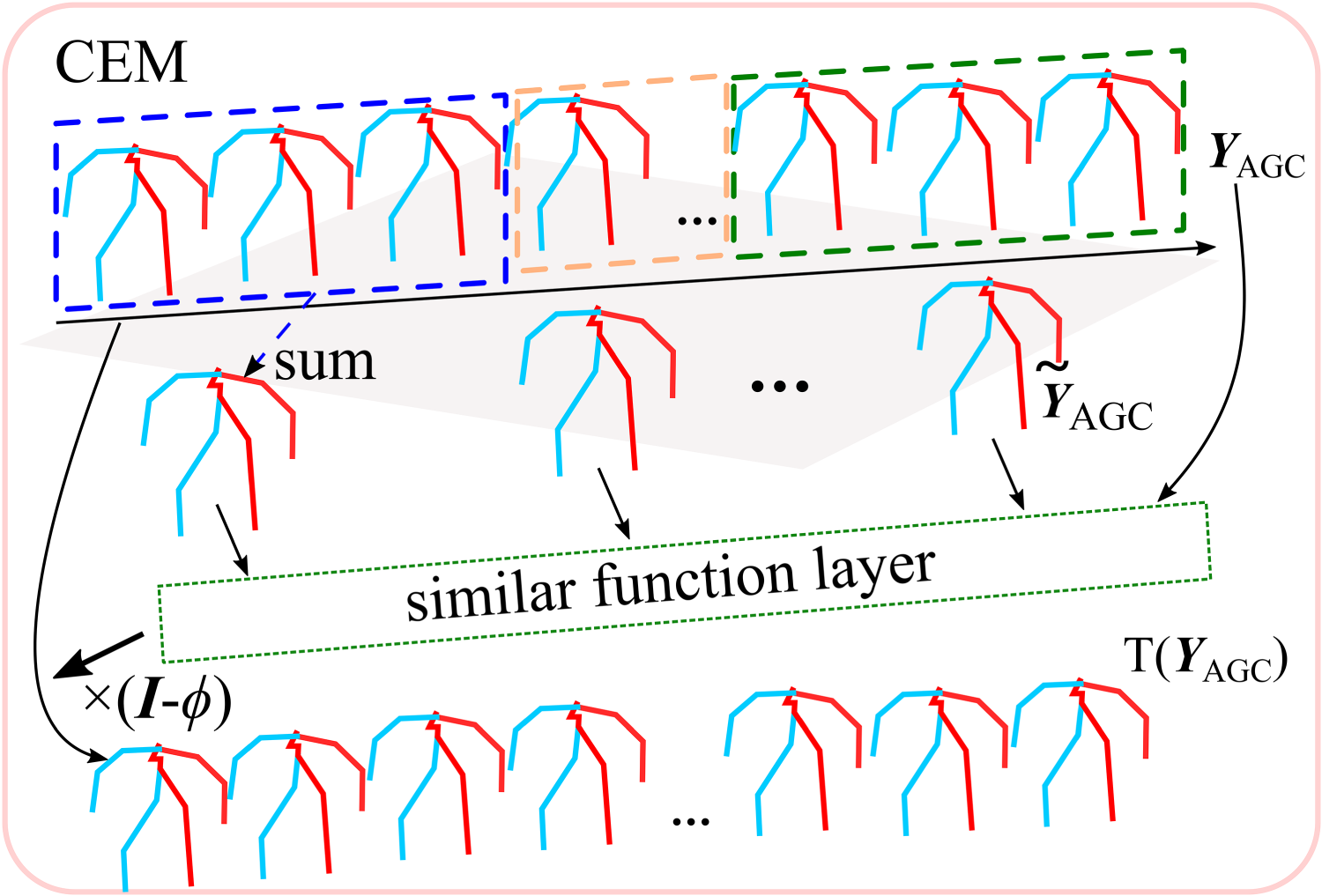
Channel Enhanced Module (CEM) Structure.
At the end of training, we sampled using equation (20) and gradually denoising from
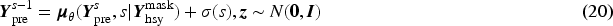
A sequence of human motion can be viewed as the movements of 3D joint points. The spatial characteristics of the motion were obtained by exploiting the correlation between the joint points, and we used a neural network with spatio-temporal information extraction capability to model
Denoising in series: Input sample sequence


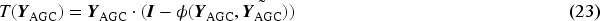
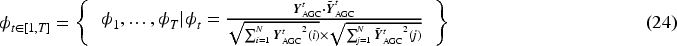
Subsequently, an adaptive graph convolution is performed for each frame as shown in the following equation:
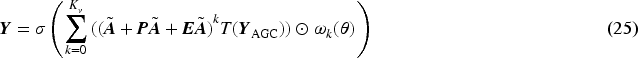
Denoising in parallel: The difference with series denoising is that the spatio-temporal features of the noise samples are processed in parallel, the noise sample

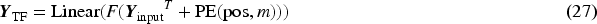
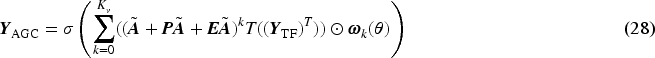
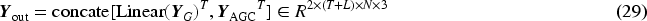

We performed better validation of the model for the prediction task. From the original samples for joining noise to the prediction of the joining noise, we provide specific details of the experiments and tests performed by the model in each dataset and the results of the model’s prediction of human behavioral diversity.
Dataset and Metrics
(1) Average pairwise distance (APD): Average
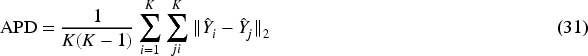
(2) Average displacement error (ADE) and final displacement error (FDE): ADE calculates the average


(3) Multi-modal average displacement error (MMADE) and multi-modal final displacement error (MMFDE) : The MMADE metric measures the average displacement error between the predictions and the multi-modal ground truth:
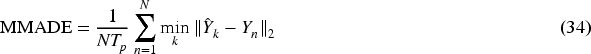
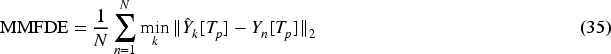
All the experiments were conducted based on the PyTorch deep learning framework implementation. The self-attention module of the transformer in our module ST-FE with eight multi-heads, each attention head has 64 dimensions, the GEM module considers three consecutive frames as a group, the value of
Qualitative Results
Experimental Results for the Dataset Human3.6M.
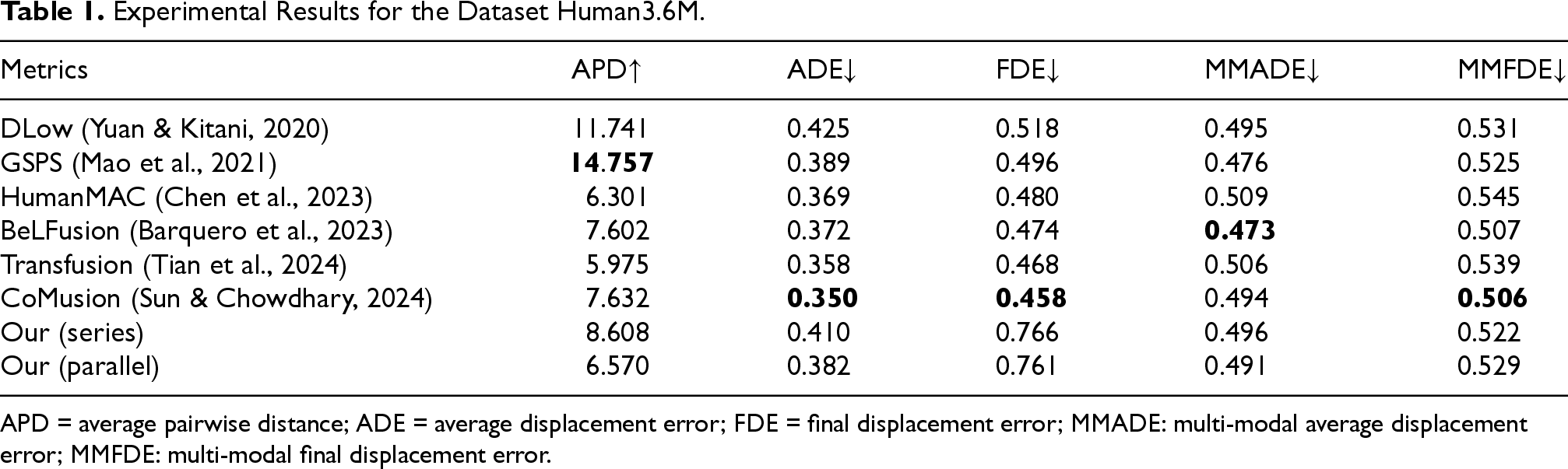
Experimental Results for the Dataset Human3.6M.
APD = average pairwise distance; ADE = average displacement error; FDE = final displacement error; MMADE: multi-modal average displacement error; MMFDE: multi-modal final displacement error.
To verify that the model also has a strong learning ability when the spatio-temporal feature extraction order is changed, in this study, we change the serial order of ST-FE, first learn the temporal features of the sequence using a transformer, and then use the GCN to aggregate the neighboring features of the joints; the final results of the experiments are shown in Table 2.
Experimental Results on Human3.6M After Changing the Spatio-Temporal Order.

APD = average pairwise distance; ADE = average displacement error; FDE = final displacement error; MMADE: multi-modal average displacement error; MMFDE: multi-modal final displacement error.
Furthermore, to verify the impact of spatio-temporal features on the diversity and accuracy of the model, we conducted further ablation experiments on the ST-FE. We used the transformer to learn the temporal features of the sequence and the GCN to aggregate the neighboring features of the joints, respectively. The final results of the experiment are shown in Table 3.
Experimental Results on Human3.6M After Selecting Different Features.

APD = average pairwise distance; ADE = average displacement error; FDE = final displacement error; MMADE: multi-modal average displacement error; MMFDE: multi-modal final displacement error.
The above experimental results show that, after changing the order of spatio-temporal feature extraction, the model’s experimental results on the Human3.6M dataset are relatively close to each other, and the model achieves a better prediction using the sequence features, whether it is learning the joint features or the correlation between the sequence at first. However, when using temporal or spatial features alone, the performance of the model is significantly affected: when using temporal features alone, the model shows a significant decline in diversity metrics (APD), and it is difficult to capture the rich changes in human behavior; while when using spatial features alone, the model significantly increases in accuracy metrics (ADE and FDE), resulting in a larger deviation between the predicted results and the true values. It can be seen that the synergistic effect of spatio-temporal features is crucial for the balance between the diversity and accuracy of the model, and neither of them can be dispensed with. Channel enhanced module is to improve the importance of key features in motion sequence, so it is necessary for learning sequence features, this paper proves that the CEM module is extremely important for human behavioral diversity prediction through ablation experiments and verifies whether adding the CEM module results is more competitive in Human3.6M dataset by connecting them in tandem, and the results of the experiments are as Table 4.
Ablation Experiments on the CEM on the Dataset Human3.6M.

CEM = channel enhanced module; APD = average pairwise distance; ADE = average displacement error; FDE = final displacement error; MMADE: multi-modal average displacement error; MMFDE: multi-modal final displacement error.
For the experimental results on the Human3.6M dataset, the results of all metrics except the mFDE metric were better than those without CEM, again indicating that the CEM is helpful in predicting human behavioral diversity.
Figure 4 shows two comparative results of a transformer-based motion denoising device. For the motion observation labeled ‘‘walking,” the picture presents a visual comparison between our method and the baseline method in terms of the diversity of motion generation and the final posture.
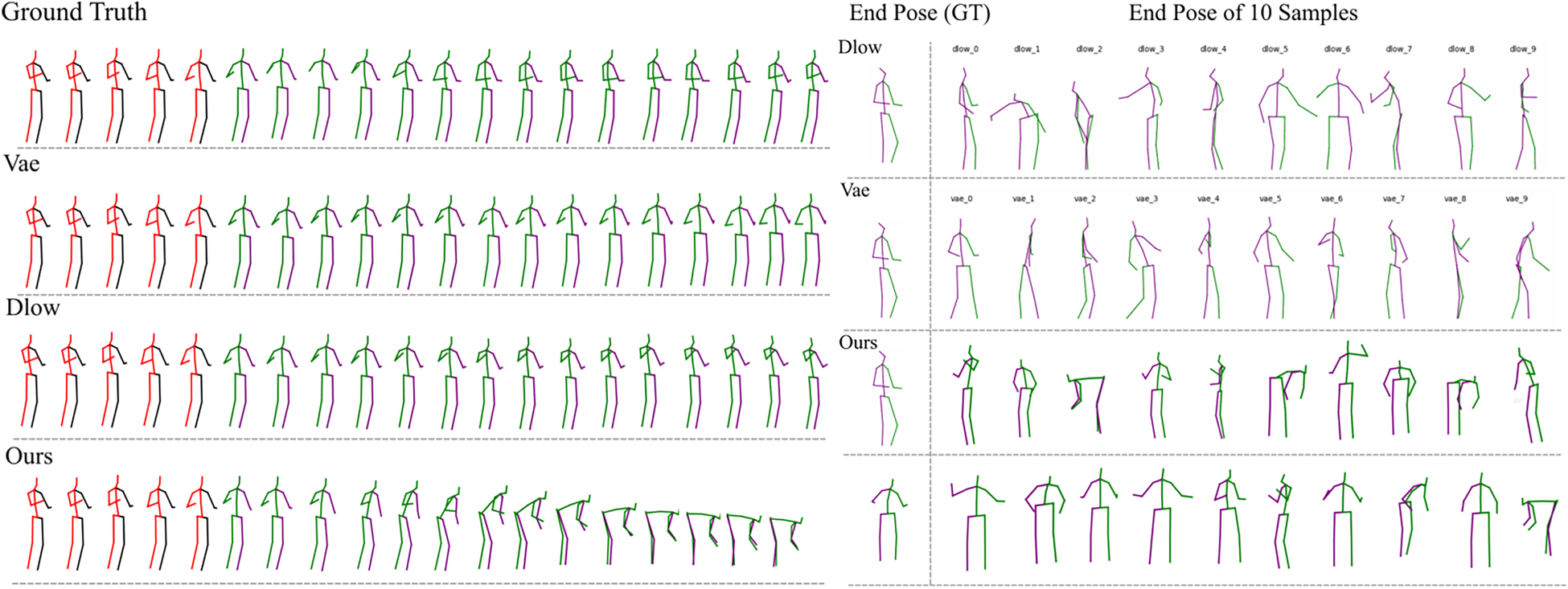
Visual Result. This is the Result From the Human3.6M Dataset. The Two Visualized Results, Respectively, Show the Visual Comparison Between Our Method and the Baseline Method in Terms of the Logicality and Diversity of the Generated Motions for the Action Category “walking.” The Observed Background is Represented by a Red and Black Skeleton, While the Future Motion is Represented by a Blue and Green Skeleton.
Experimental Results for the Dataset HumanEva-I.
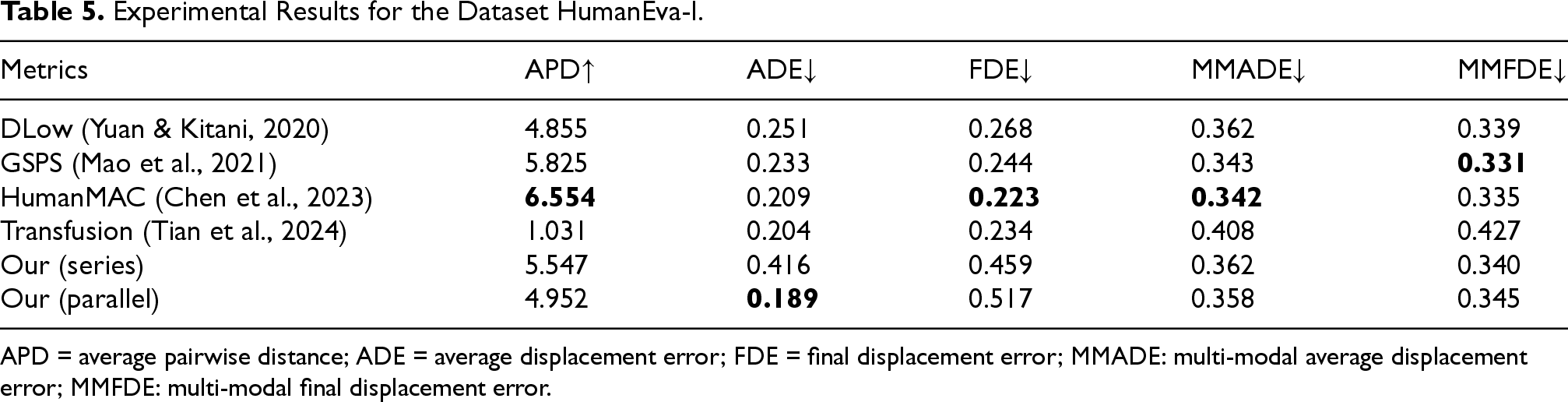
APD = average pairwise distance; ADE = average displacement error; FDE = final displacement error; MMADE: multi-modal average displacement error; MMFDE: multi-modal final displacement error.
We changed the serial order of ST-FE to verify that the model has a strong learning ability. We first learned the temporal features of the sequence using transformer and then used the GCN to aggregate the neighboring features of the joints. The final results of the experiments are shown in Table 6.
Experimental Results on HumanEva-I After Changing the Spatio-Temporal Order.

APD = average pairwise distance; ADE = average displacement error; FDE = final displacement error; MMADE: multi-modal average displacement error; MMFDE: multi-modal final displacement error.
The above experimental results show that after changing the order of spatio-temporal feature extraction, the model’s experimental results on the HumanEva-I dataset are relatively close to each other, and the model achieves a better prediction using the sequence features, whether it is learning the joint features or the correlation between the sequence at first. We again demonstrated the importance of the CEM in behavioral recognition using the HumanEva-I dataset, and the results of the experiments are shown in Table 7.
The experimental results on the HumanEva-I dataset were better with the addition of CEM to the model than without, except for the aDE and sFDE metrics.
To verify that the model coan better learn the correlation between two physically disconnected but semantically connected joints in space,on the dataset Human3.6M, the model-learned modulation affinity matrices exhibited a wider range of connections than the more spatially learned affinity matrices, as shown in Figure 5.
Ablation Experiments on the CEM on the Dataset HumanEva-I.

CEM = channel enhanced module; APD = average pairwise distance; ADE = average displacement error; FDE = final displacement error; MMADE: multi-modal average displacement error; MMFDE: multi-modal final displacement error.
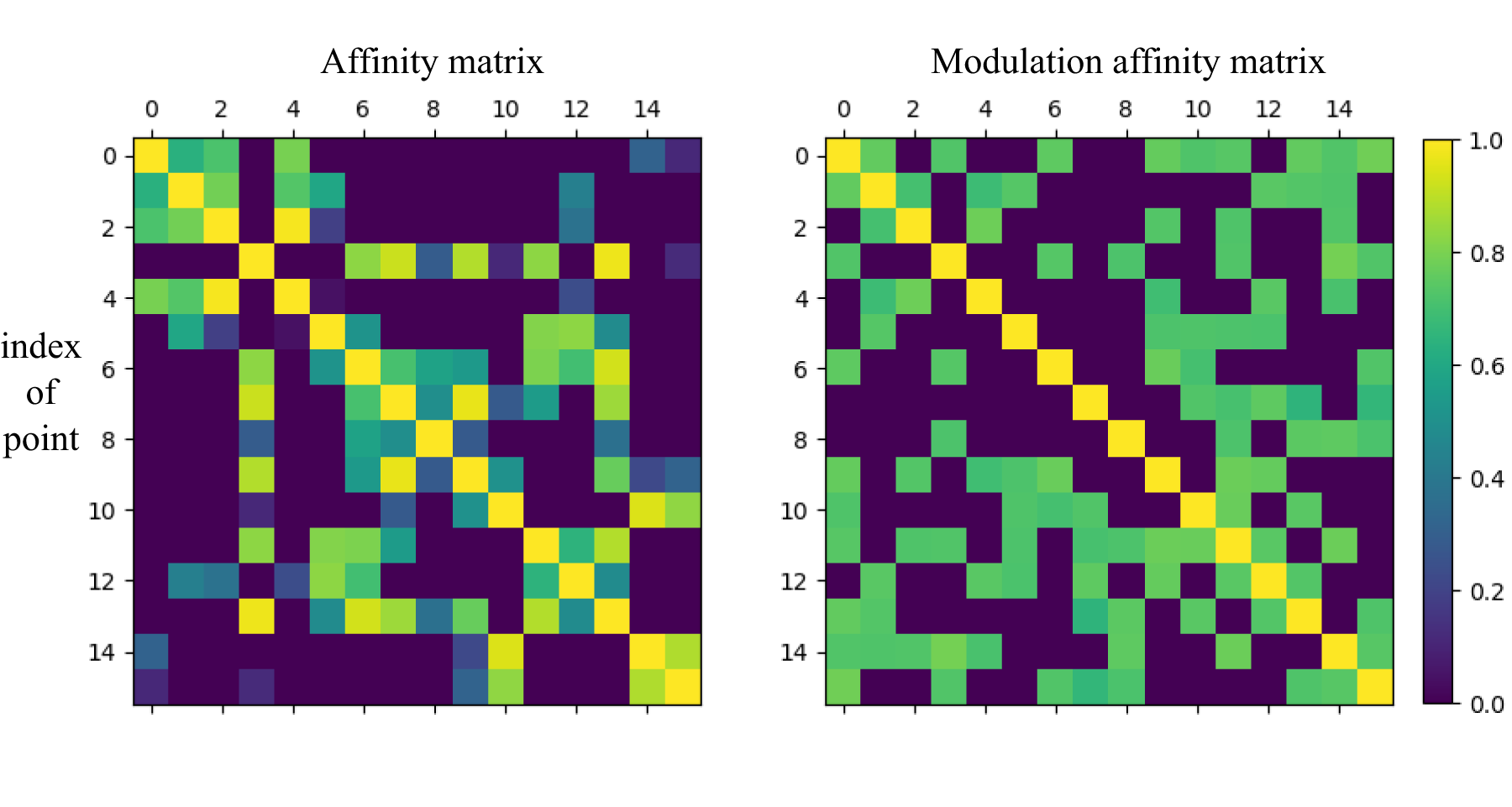
Affinity Matrices and Modulation Affinity Matrices.


In this study, we propose a novel human future motion prediction method that decombines conditional DDPM with human joint kinematics for human prediction. Firstly, the observed and predicted sequences were fused using masks. A cosine noise scheduler was used to slowly destroy the sequence structure. Then, sequence noise was removed step by step using the ST-FE module and CEM to learn the spatial features of the joint points and the temporal features of the motions. The denoiser is gradually trained to transform noise into reasonable predictions to generate different future motions. In addition, we combined the transformer and adaptive graph convolution in ST-FE in series and parallel to further improve the learning ability of the denoiser. The experimental results show that our method is competitive with existing methods.
Note that the algorithm in this study has the following shortcomings: the position encoding for the joint points still uses the encoding of the periodic sine-cosine function, which ignores the spatial structure information between the joint points. Secondly, when graph convolution is used to capture the spatial structure during the denoising process, the fixation of the adjacency matrix limits the extraction of the overall structural information, and the correlation between the non-physical connections of the joints cannot be captured.
In the future, we will further investigate the reasonable positional encoding of joint points and utilize the self-attention mechanism to enhance the learning ability of graph convolution. The CEM will be used with the transformer for the positional change to improve the useful information contained in each frame.
Footnotes
Acknowledgements
This publication was made by the National Natural Science Foundation of China No. 62171342, and the Natural Science Foundation of the Anhui Higher Education Institutions of China under Grant No.2024AH051682. The statements made herein are solely the responsibility of the authors.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.