
Abstract
Gestures have long been recognized as an interaction technique that can provide a more natural, creative, and intuitive way to communicate with computers. However, some existing difficulties include the high probability that the same type of movement done at different speeds will be recognized as a different category of movement; cluttered, occluded, and low-resolution backgrounds; and the near-impossibility of fusing different types of features. To this end, we propose a novel framework for integrating different scales of RGB and motion skeletons to obtain higher recognition accuracy using multiple features. Specifically, we provide a network architecture that combines a three-dimensional convolutional neural network (3DCNN) and post-fusion to better embed different features. Also, we combine RGB and motion skeleton information at different scales to mitigate speed and background issues. Experiments on several gesture recognition public datasets show desirable results, validating the superiority of the proposed gesture recognition method. Finally, we do a human-computer interaction experiment to prove its practicality.
Introduction
In natural scenes, gesture acquisition faces background interference from occlusion, lighting variations, and low resolution. To cope with the challenges of the environment, most of the existing methods use human skeleton based action recognition instead of rgb based action recognition [1-3]. However, skeleton-based gesture recognition loses the information about the interaction between the background and the human body, leading to misjudgment of some similar actions. As shown in Fig. 1, the skeleton sequences of stair climbing and running are very similar, and stairs can clearly distinguish these two actions. Therefore, we solve the above problem by fusing the RGB features with the skeleton sequences while taking both into account. In order to satisfy the universality of the model, the dataset must contain videos of different people’s movements, but there is individual variability in each person, and the speeds of different people when they make the same movement are very different, and a large part of the error rate comes from this. To address this problem, we collect fast and slow biscale global motion features using one sample frame every other frame and one sample frame every two frames to overcome individual variability [4]. Most of the time the features to be fused are of the same class and the resulting data format is the same. It is conceivable that features whose data formats are too different from each other can hardly be fused with each other, but it is precisely this kind of fusion between features that is more valuable, because the information overlap between them is very low, and fusion can achieve a greater win-win situation and obtain a higher accuracy rate. Skeletal sequences, RGB and graph structures [2] are such features. In this paper, we select the bone sequence and RGB for fusion, and we reduce the bone sequence into the form of pseudo heatmap to facilitate its fusion with RGB, which not only speeds up the computation, but also enables the bone sequence to be perfectly fused with RGB. The innovations and contributions of this paper are summarized below.
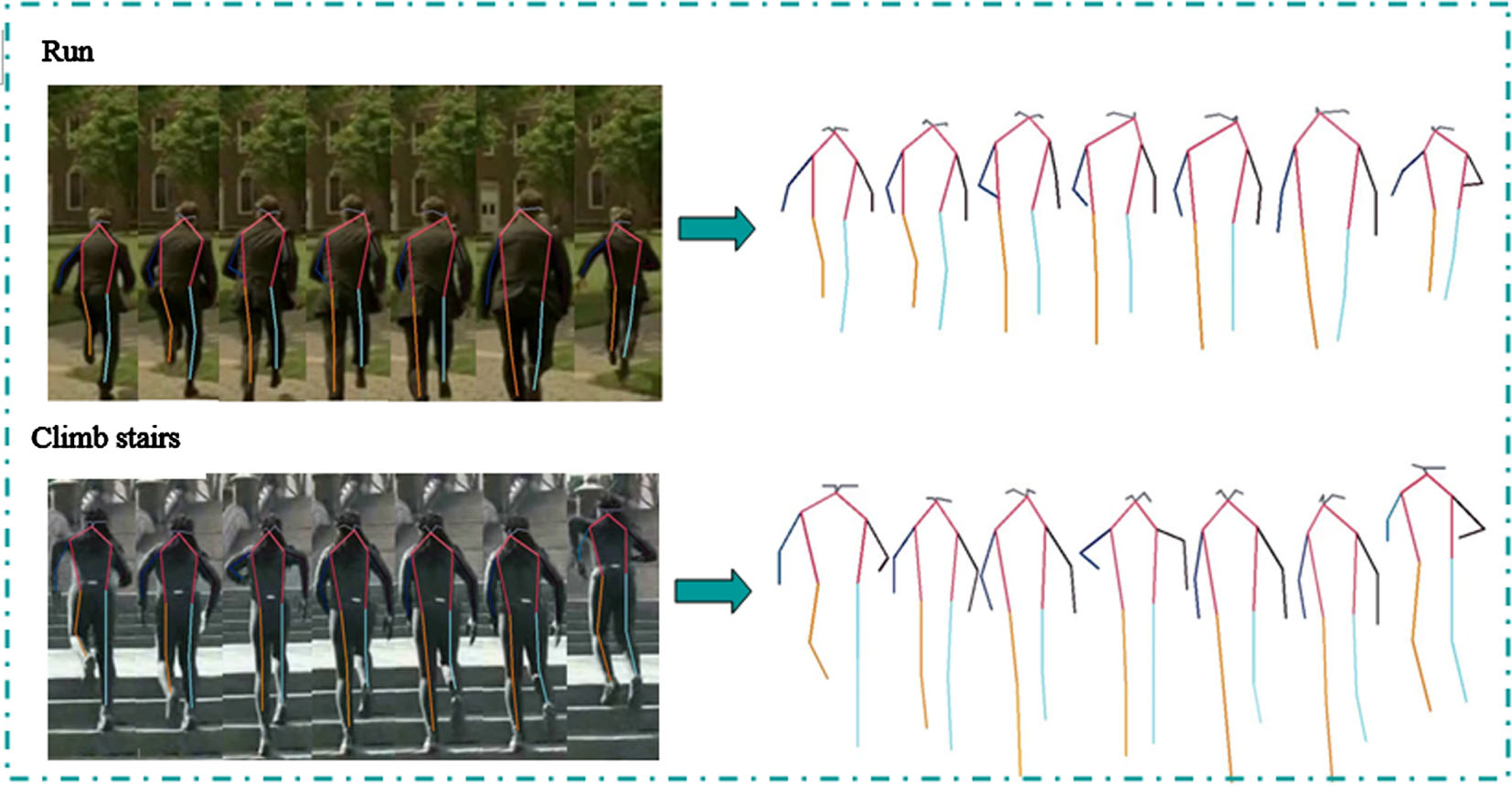
Skeleton sequences of stair climbing and running.
(1) A multimodal recognition method is proposed to fuse skeleton sequences of different scales of motion with RGB images, which not only solves the influence of environmental background but also preserves RGB features and takes into account the problem of temporal differences. In addition, we reformulate 2D poses into a 3D heatmap volume, which not only accelerates the calculation speed but also solves the problem that different features are difficult to fuse.
(2) A network structure for post-fusion is designed, and the superiority of the designed network structure is verified by using the method of mid-term fusion. The problem of complex fusion of different modal data is avoided.
(3) The state-of-the-art performance of the proposed recognition method is verified on a public action recognition dataset. The simulation platform also realizes the simulation of gesture control of the robot.
The remainder of this document is organized as follows: Chapter 2 presents the related work, including the 3D convolutional neural network, the three features of different motion scale skeletons, RGB, and the feature fusion method used in this paper. Chapter 3 presents the design of the main network structure, the primary data processing methods, and the methods used for the post-feature fusion. Chapter 4 presents various experiments to validate the proposed recognition method, including comparison, ablation, and simulated experiments in a robot. Chapter 6 presents the conclusion and further work.
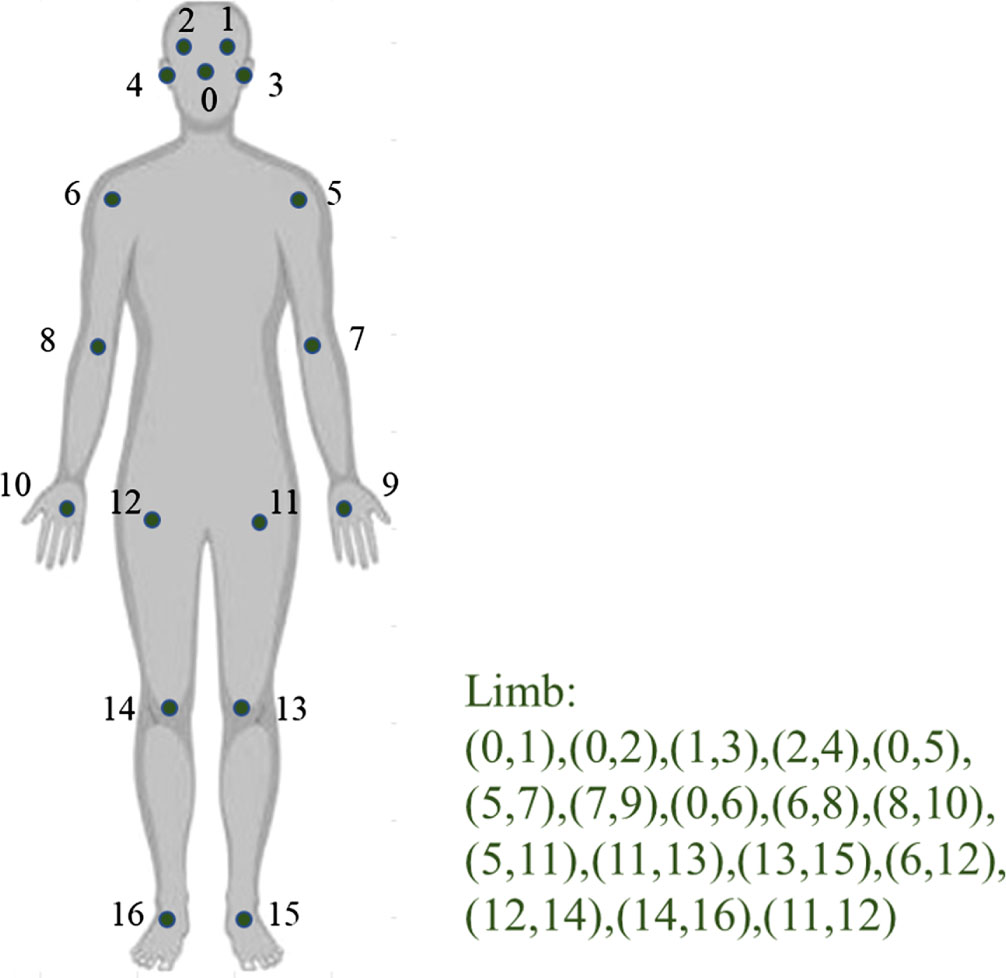
key points and limbs annotation example.
In the following, we discuss the neural networks closely related to our work and the features involved.
3D CNNs
A simple way to apply deep convolutional neural networks(CNNs) to video is to apply CNNs to each frame for recognition, which can be done by networks such as image classification [5-11]. Nevertheless, this approach needs to take into account the motion information between consecutive frames. 3D CNNs [12] synthesize this motion information well. 3D convolution is performed by stacking several consecutive frames to form a cube and then applying 3D convolution kernels in the cube. In this structure, each feature map in the convolution layer is connected to multiple neighboring contiguous frames in the previous layer, thus capturing motion information. Therefore, 3D CNNs [13] is widely used in motion recognition, and many advanced model architectures have been proposed one after another. In this paper, we construct a 3D CNNs-based multimodal gesture recognition network that combines and assembles RGB and 3D skeletal pseudo-heatmaps of two motion modes into a framework that provides complementary RGB features to skeletal-based methods to improve recognition accuracy.
Skeleton-based methods and RGB-based gesture recognition
Skeleton-based gesture recognition is a popular research topic in the field of computer vision and has been widely used in video understanding [14], human-computer interaction [15], robot vision, autonomous driving, aerospace, medical [16] and other fields. Skeletal data consists of 3D coordinates of multiple spatiotemporal skeletal joints, effectively representing motion dynamics. With the emergence of more superior pose estimation algorithms, it can be easily acquired not only by low-cost depth sensors [17-19], but also directly from 2D images by video-based bit-pose estimation algorithms [1, 20-22]. Unlike RGB and optical flow, the skeleton data is small in data size, computationally efficient, and the skeleton data is highly robust to illumination changes and background disturbances. However, despite this, when it is faced with similar actions, it also leads to unsatisfactory recognition because of the lack of information about objects interacting with the human body. So even though skeletal data carries rich and vital information, he still complements RGB. With the rapid development of 3D skeletal data acquisition, the field of skeleton-based gesture recognition research [23-26] can be described as blossoming, with various advanced and effective recognition methods [27-30] coming out one after another. For methods based on Recurrent Neural Network(RNN) [31], the skeleton sequence is a natural time series of joint coordinate positions, which can be regarded as a sequence vector, while RNN itself is suitable for processing time series data due to its unique structure. Long short-term memory(LSTM) is also suitable for processing time series data. Despite the good results of RNN-based methods, this approach cannot effectively learn spatial relationships between skeletal joints. To explore spatial information explicitly, many researchers reformulate 2D poses into a 3D heatmap volume. The representations that provide CNN-based methods have the advantage of a natural ability to learn spatial information from skeletal joints. The GCN-based approach [32], which has been very successful, constitutes the skeleton as a graph in space, the joints as vertices, and the natural connections in the human body such as arms, legs, and temporal connections of the same joint points as edges. The method combines spatial map convolution and interleaved temporal convolution for spatiotemporal modeling, which can mine as much discriminative information as possible in both the spatial and temporal domains. However, this skeleton map also dramatically restricts the fusion with other modal features and has limited scalability. Based on this, we choose a CNN-based approach to fuse RGB and 3D heatmap volume from 2D skeleton data, which more smoothly fuses multiple complementary modal features to improve the final accuracy.
Different scale motion
Due to the variability of the human body, different people do the same action, or even the same person in different situations does the same action in time; the postural form is different [33]. It is easy to understand that the frequency and span of the legs of the fast and slow runners in a running race are different, and the frequency of the palms of the same person is also different when he is happy and upset. For either fast or slow motion scales, we consider different motions simultaneously and apply the method of fusing different motion features to form multi-scale motion features to improve the robustness of the model and the final accuracy.
Methodology
In the following, we present the overall approach, including the preliminary data processing method steps, the network framework for feature input, and the post-feature fusion method.
Global network framework
Take the experiment with the dataset JHMDB as an example. As shown in Fig. 3, the network framework consists of three parts, which are divided into RGB, slow motion, and fast motion according to the input features. The second layer also contains a 3D convolutional layer and a downsampling layer, similar to the first layer, which also doubles the size of the output and increases the number of channels to twice the base channels; the third and fourth layers are of the same size, containing two 3D convolutional layers and a downsampling layer, but the second convolutional layer does not increase the number of channels. Finally, the pooling layer and the fully connected layer are used to obtain a 1×21 array indicating the confidence level of each gesture category, and the recognition result is the one with the highest confidence level. We put the multimodal fusion at the end, that is, the prediction layer, and use the weighted summation method to multiply the prediction results obtained from each of the three features by their corresponding weights and then add them together to obtain the final fusion result, which is also a 1×21 array. The weights are set according to the accuracy of each feature trained separately in the ablation experiment.
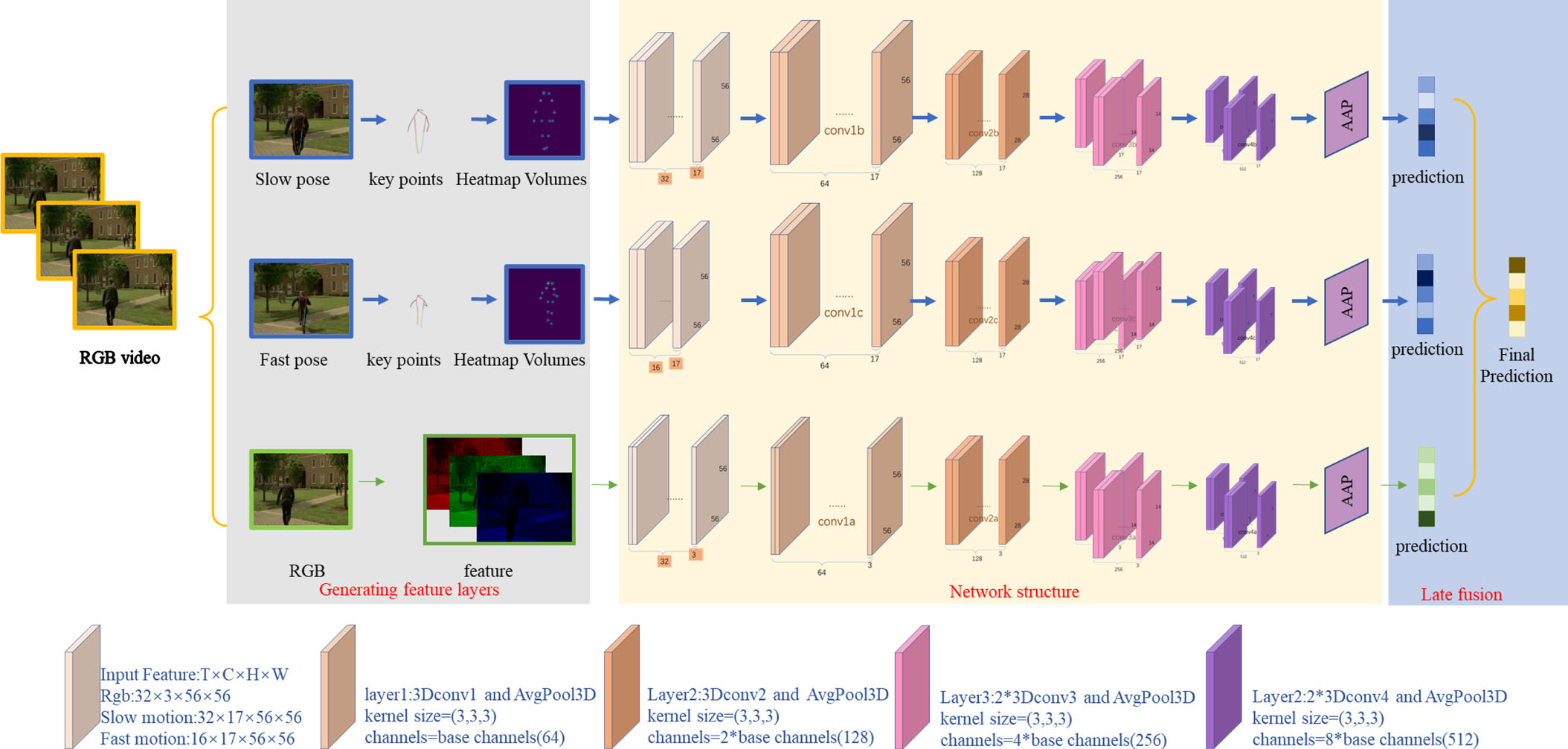
The concept of gesture recognition framework based on 3D CNN multimodal fusion extracts the feature information of all modalities and fuses them for prediction in the prediction layer. labyer3:2*3Dconv3 and AvgPool3D indicate that the third layer of the network consists of two 3D convolutions and an average pooling down sampling. The other layers are defined in the same format. Where base channels=64 and AAP denotes Adaptive averaging pooling.
We use the pose estimation algorithm for extraction instead of direct acquisition from a public dataset. This approach facilitates the training of our dataset, eliminates the tedious labeling work, and enables the inclusion of the skeletal information of non-key characters appearing in the video, making the dataset more realistic and natural and improving the results’ robustness. Using Faster R-CNN [34] to frame the tasks that appear in the video for subsequent key point detection, the Faster R-CNN detection system achieves a frame rate of 5 frames/second on the GPU for the intense deep VGG-16 model (including the desired step). Compared to most high-resolution to low-resolution networks, HR-net [35] maintains a high-resolution representation throughout, so the predicted key point heat map is more accurate and spatially precise.
For the dataset annotation problem, we choose coco [36] dataset keypoint annotation format. As shown in Fig. 2, this symmetrical labeling format facilitates later testing of the set of folded flip feature maps.
Generate skeletal feature maps
The popular features in the field of motion recognition are RGB images and skeletal images. Although RGB images are becoming less and less popular with the emergence of skeletal image features, there is no denying that they still have irreplaceable feature information. In a sense, RGB and skeletal images complement each other. The skeleton image is composed of key points predicted from RGB images by some pose estimation algorithms, and the skeleton information composed of key points is left alone by removing the background to solve the influence of RGB images caused by background lighting and other factors. However, when the background is removed, the information associated with the background and the subject acting is also removed. In order to retain this information to improve the recognition accuracy, we choose to retain both kinds of features and fuse them to achieve higher accuracy.
The previous approach only divided RGB images and skeletal images into two feature inputs to form a two-branch network structure, which did not consider the robustness of the motion features, as different people move at different rhythms, and both fast and slow rhythms should be considered.
The RGB image data consists of R, G, and B values of one pixel by one. The data format of a video is T×C×H×W, which refers to the number of frames, the three RGB channels, and the length and width of the image, respectively. The skeleton information comprises 2D or 3D coordinates of one key point. The data format is T×N×D, which refers to the number of frames, key points, and coordinate dimensions. The data formats of the two features are completely different, and for better integration, we reduce the extracted 2D pose to the form of an image [37, 38] The obtained N key points are reduced to N images matrix of length and width H, W. Each image is reduced to the image matrix form by using the Gaussian mapping method with the key point as the center so that the data of N×H×W can be obtained, and finally, the data format of T×N×H×W similar to RGB image is obtained by stacking in the time dimension. The specific method flow is shown in Fig. 4.
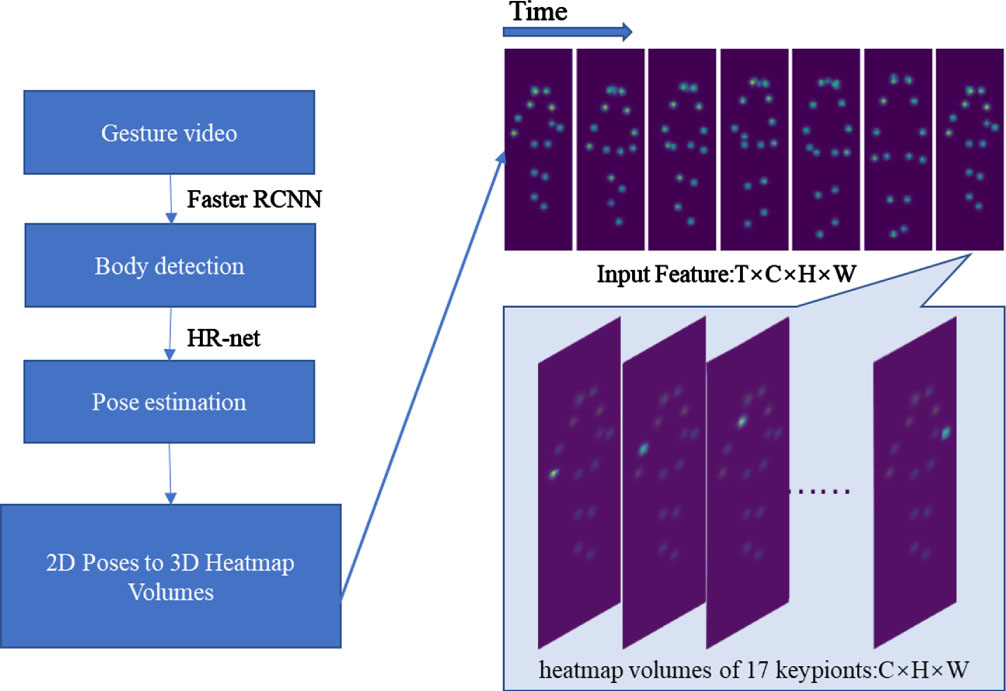
Skeletal feature generation framework. Extraction is performed for the input action video stream using the faster RCNN(body detection) + HR-net(pose estimation) to extract the two-dimensional human pose. The key point coordinates are saved and reduced to a pseudo heat map using Gaussian mapping. Finally, the input data is stacked in spatial and temporal dimensions to obtain the four-dimensional input data.
There may be more than one person in the same image, which means there is more than one key point of the same kind. In this case, to ensure the uniform data format, the key points of the same kind are mapped to the same image, ensuring the uniform data format and recognizing the motion of multiple people.
In order to obtain the motion rhythm of the two skeleton images, frame-skipping sampling was used in the past, which means sampling a frame in a video interval. This approach is too simple and brutal, and we adopt a random frame sampling approach for better results. The video is divided into T segments according to the selected number of frames T (e.g., 32 frames for this experiment). One frame is selected in each segment by random sampling and finally reorganized into T frames. The fast-paced sampling method is similar, except that a factor of K reduces the selected number of frames. The video is divided into T/K segments, so the final number of frames obtained is also T/K.
The three input features fall into two categories, RGB and skeleton, which are so different that they are suitable for fusion processing as complementary features to improve recognition accuracy. Previous fusions have used pre-fusion or mid-fusion to stack multiple tensors into one tensor by dimensionality, which will cause some feature information to be lost due to the corruption of features with low similarity and non-uniform data format by forcibly stacking them together, which is not as effective as post-fusion.
We design four network layers and finally do post-fusion in the prediction layer [39]. The first layer: Stem layer (conv3D (3×3×3), base channels), the second layer: max pool (1×2×2) → stage1 (conv3D (3×3×3), 2*base channels), the third layer: max pool (1×2×2) → stage2 (conv3D (3×3×3), 4*base channels)*2, and the fourth layer: max pool (1×2×2) → stage3 (conv3D (3×3×3), 8*base channels)*2. The first layer is the only difference between the three branching networks because the second dimension of the three input feature data is different. Finally, three one-dimensional tensor q
rgb
, q
fast
, q
slow
of length n
c
are obtained after the fully connected layer. where n
c
is the total number of action categories to be recognized.
The post-fusion part uses a custom weighted fusion method. In Equation (2), the weights α rgb , α fast , and α slow are defined by the accuracy obtained from the validation set of each corresponding feature trained separately. The final result is the maximum confidence of the fused.
Finally, we choose the cross-entropy loss function [40] for the loss function segment. The more similarity between the q(predicted data distribution) and p(real data distribution) learned by the model in the training data, the better the cross-entropy function can measure the similarity between p and q. And in using the sigmoid function in gradient descent, the cross-entropy loss function can also avoid the problem of decreasing the learning rate like the mean square error loss function. Therefore, many neural network models dealing with classification problems use cross-entropy as the loss function.
This section contains experimental validation results. Firstly, we present the experimental results and validation images of a 3D CNN-based multimodal fusion gesture recognition network. Secondly, we show the experimental results and details of the simulation of gesture transmission of the robot model in the Unity platform.
Method validation of 3D CNN-based multimodal fusion gesture recognition
Dataset description
Our models are trained and tested on the JHMDB [41], HMDB51 [42], and UCF101 [43] datasets. The experimental dataset was created as shown in Table 1. The JHMDB dataset contains 928 videos divided into 21 categories, of which 664 videos are used as the training set and 264 videos are used as the test set. The HMDB51 dataset contains 5100 videos divided into 51 categories, of which 3570 videos are used as the training set and 1530 videos are used as the test set. The UCF101 dataset contains 13320 videos divided into 101 categories, of which 9537 videos are used as the training set and 3783 videos are used as the test set.
Setup of the experimental datasets
Setup of the experimental datasets
The HMDB51 dataset is a extensive collection of real videos from different sources, including movies and web videos. The dataset contains 51 action categories with 6766 video clips. Each action category is divided into 70 clips for training and 30 for testing. The 51 classifications are divided into five major categories: general facial action smile, facial manipulation with object manipulation, general body action, interaction with object action, and human action.
JHMDB dataset is a secondary annotation of the HMDB dataset, i.e., joint-annotated HMDB. JHMDB is a frame-by-frame annotated data covering: sit, run, pull up, walk, shoot gun, brush hair, jump, pour, pick, kick ball, golf, shoot bow, catch, clap, swing baseball, climb stairs, throw, wave, shoot ball, push, stand 21 categories include the behavior of only one person. Each of these categories has 35-55 samples, each sample includes the start and end time of the behavior, and each sample includes 14-40 frames. There is a maximum of one target behavior per video, and the anchor box only marks the person doing the target behavior.
UCF101 is an action recognition dataset of realistic action videos collected from YouTube, providing 13320 videos from 101 action categories. Each short video varies in length (from zero to a dozen seconds), is 320*240 in size, has a variable frame rate, typically 25 or 29 fps, and contains only one category of human behavior in a video. Each category (folder) is divided into 25 groups of 4 to 7 short videos. Including boxing, boxing speed bag, head massage, playing guitar, lead balloon, etc.
The dataset contains RGB video, 2D key points (2D coordinates and confidence levels), and 3D key points (3D coordinates and confidence levels). The key points only contain information about the target actor, and others in the video are excluded. While this approach facilitates identification accuracy, it can also lead to results that do not reflect the state-of-the-art of the model well. Therefore, we only utilize the video files in the dataset. The input skeleton information in the model is calculated from the pose estimation algorithm. The calculation results contain the key point information of everyone in the video, which enhances the universality and resistance to interference and makes it possible to simulate natural scenarios better. Finally, the JHMDB dataset is divided into training/testing sets in the ratio of 2.5:1.
The experiments were conducted on an RTX A4000 graphics machine, and the models were trained and tested under the pytorch framework, and all environments were set up on the unbuntu system. The experimental training on the dataset JHMDB is set to epoch=24, batch size is set to 32, initial learning rate is set to 0.4, and the training process uses the learning rate adjustment method CosineAnnealingLR with a lower limit of 0. Due to the large size of the other two datasets, migration learning was used, and the model was trained using the kinetics-400 pre-training model. Equal interval adjustment of the learning rate StepLR was used, setting the learning rate to 0.01 0.001 after the 10th epoch and 0.0001 after the 11th epoch. The parameter k characterizing the different scales of motion is taken as 2. The number of frames in the input data is selected as 32 and 48, so the final input contains 32 or 48 frames for slow motion features, 8 frames for both RGB features, and 16 frames for fast motion. Scale the image to 56×56 size. The specific input size and network details are shown in Figure Table 2. The parameter σ = 0.6 for the Gaussian function is used to generate the pseudo-heat map. The weights of the subsequent weighted fusion are selected as the accuracy obtained by training the corresponding features individually, respectively. To demonstrate the superiority of the designed network model, we did not apply any integration strategy or pre-training weights on the smaller dataset JHMDB to improve the performance. However, the dataset UCF101 and the dataset HMDB51 are larger and therefore trained using the pre-trained model on the dataset Kinetics-400. Validation adds to the operation of flipping images. Three accuracy rates were calculated for the evaluation test, top 1 accuracy, top 5 accuracy, and mean class accuracy, respectively.
Network composition of the training experiment (T is the dimension of frame rate)
Network composition of the training experiment (T is the dimension of frame rate)
Results on JHMDB(Using 2D skeletons from HR-net)
Results on HMDB51(Using 2D skeletons from HR-net)
Results on UCF101(Using 2D skeletons from HR-net)
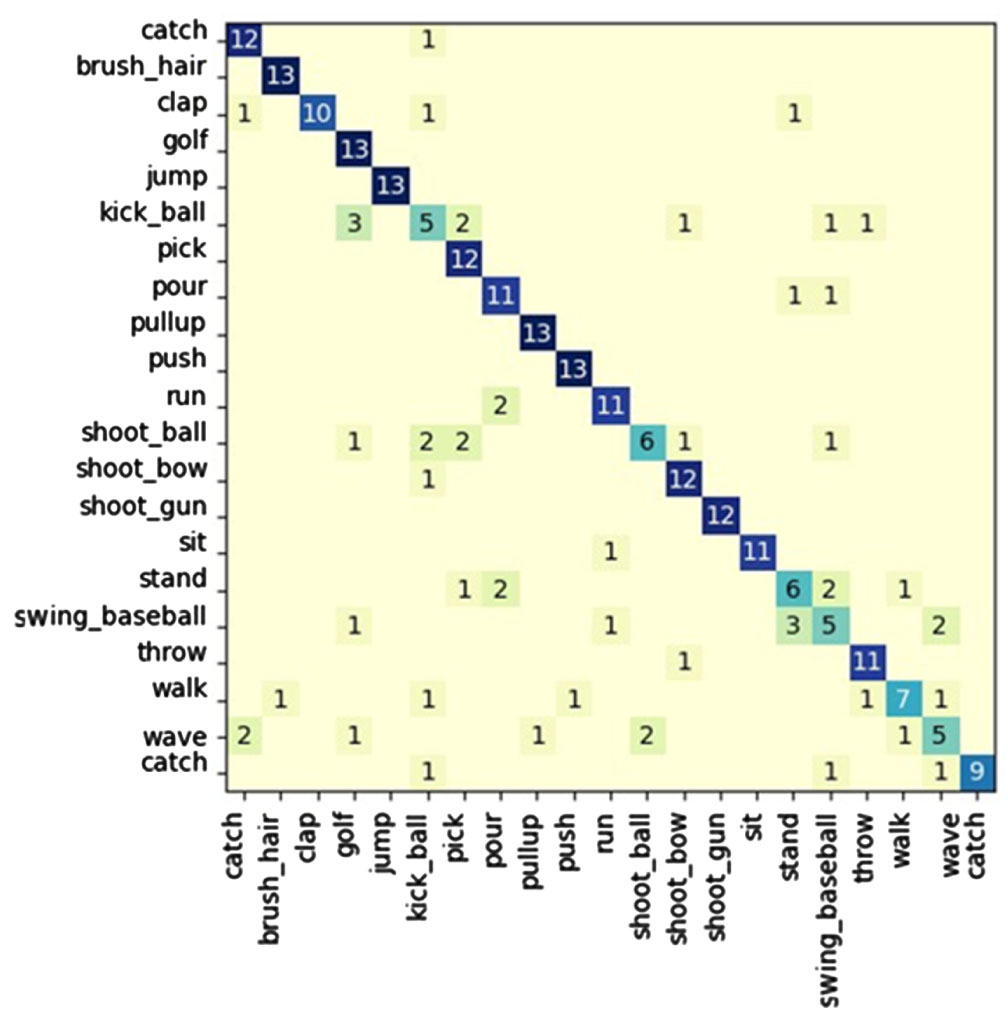
Confusion matrix of JHMDB dataset (21 hand actions)obtained.
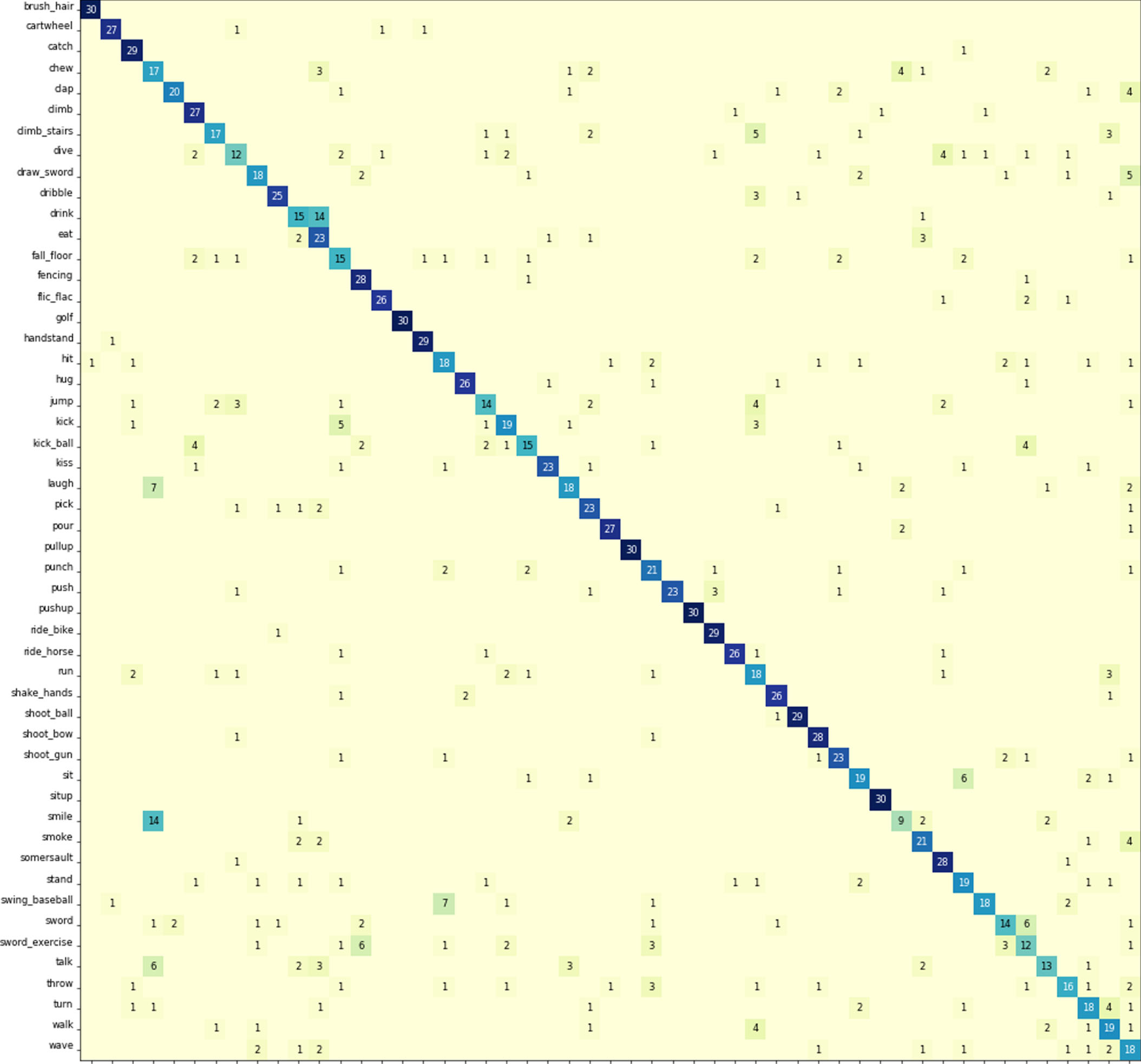
Confusion matrix of HMDB51 dataset (51 hand actions)obtained.
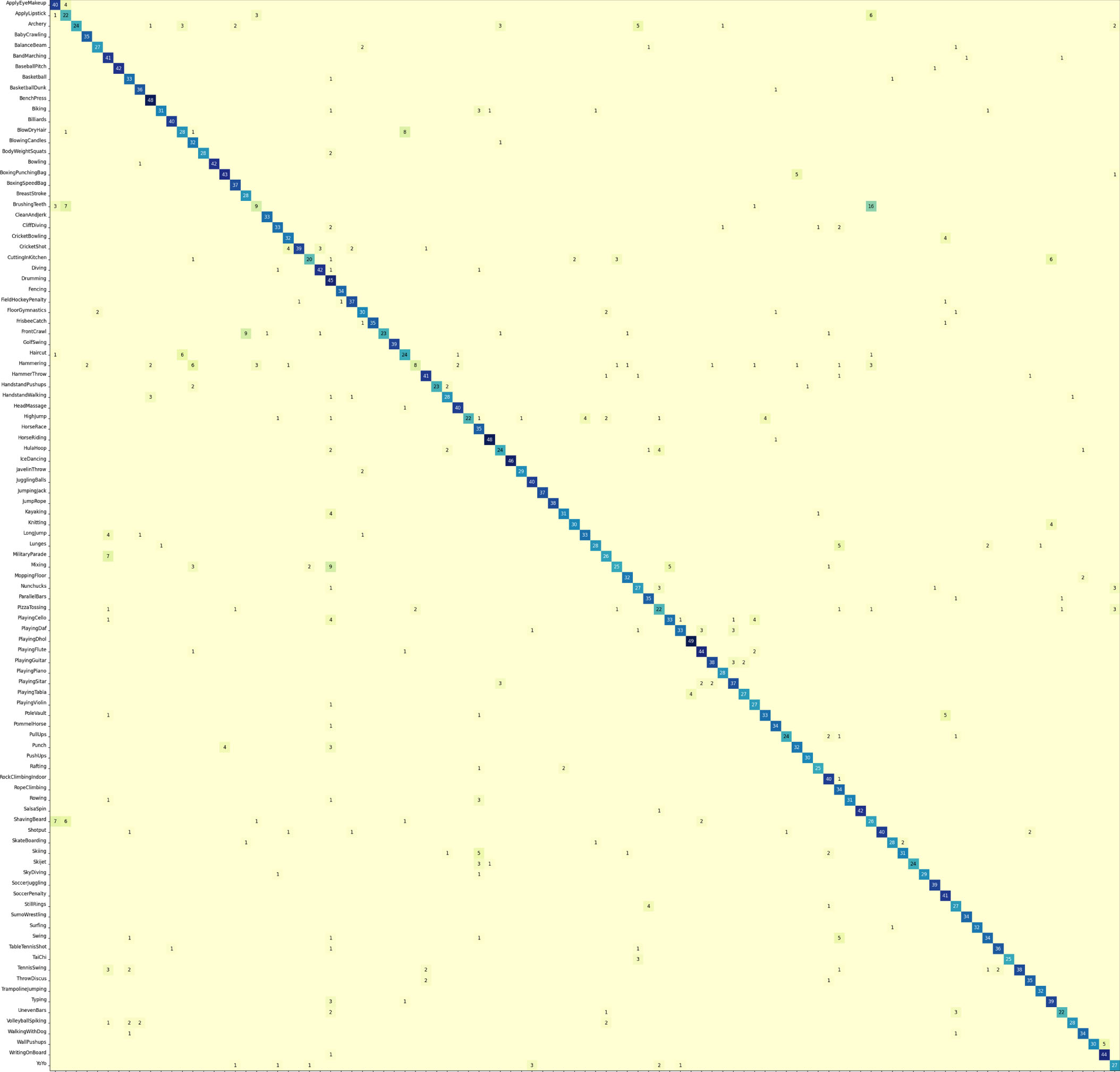
Confusion matrix of UCF101 dataset (101 hand actions)obtained.
Comparison experiments were conducted on the datasets JHMDB, HMDB51, and UCF101. The experimental results were compared with other advanced methods, and the comparison results are shown in 3 to 5. It is worth noting that not all the training on the dataset did not use the pre-trained model. Since the datasets of HMDB51 and UCF101 are relatively large, in order to shorten the training time and improve the training accuracy, We use a transfer learning approach, applying a pre-trained model on the kinetics dataset. In order to solve the problem of slow convergence, we use the resnet50 network to increase the number of layers and complexity of the network model. Finally, we achieved the accuracy of 0.812, 0.724, 0.887 on JHMDB, HMDB51, and UCF101 datasets. More details are listed in their confusion matrices. The confusion matrices for the three datasets are shown in 7. The robustness of the designed network structure is verified according to the matrix plot display. Overall, the 3D CNN-based multimodal fusion gesture recognition method can achieve good results on the JHMDB dataset, UCF101 dataset and HMDB51 dataset.
Ablation experiments
In ablation experiments, we explore the performance of action recognition by keeping other input features constant. In addition, we also look at the variation of performance with weights by adjusting the weights of post-fusion.
The results from the ablation experiments show that the RGB-based action recognition is the lowest for the same input conditions. Skeleton-based action recognition is much more accurate than RGB-based action recognition and solves some drawbacks of RGB features, such as background interference. Nevertheless, the recognition result of combining RGB and skeleton is again higher than that of the individual skeleton, thus indicating that the skeleton features lose some interactive information only available in RGB images. In addition, according to the table, the mid-term fusion method is slightly lower than the weighted post-fusion method we used, which confirms the drawback of losing information from the forced integration of data when the data formats are different. As described before, it shows the superiority of our designed network structure.
Robot simulation experiment
Implementation design
The simulation experiments are conducted using the Unity3D engine, which is commonly used for game development and is a perfect game engine with advanced rendering support for both 2D and 3D. The expected effect of the experiment is that the robot imported into Unity will do the corresponding actions according to the recognition results of the network model. As shown in Fig. 8. In order to make the robot’s movements more fluent, we abandoned the method of setting the corresponding movements and used the method of storing the movements in video and then imitating them, i.e., let the robot imitate the movements of the characters in the video, which makes the robot’s movements more natural and more fluent. For this purpose, four example action videos are given as a reference for the robot, which is instructed to perform the corresponding specified actions according to the recognition results.
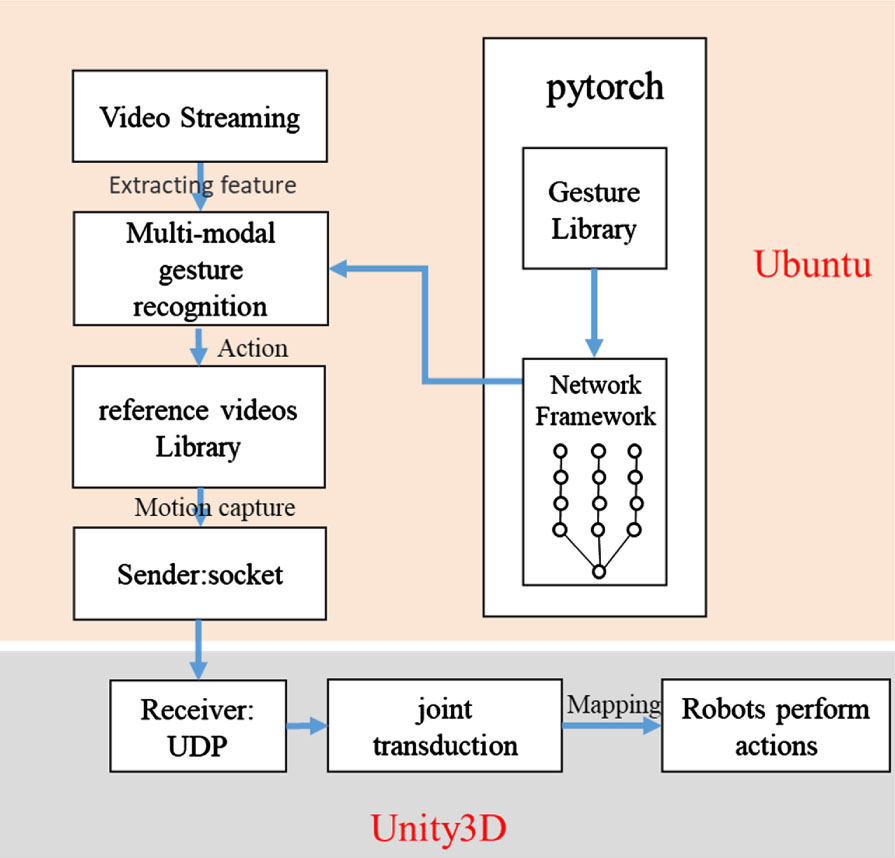
Robot simulation experiment framework.
Simulation performance index
Using mediapipe’s human pose estimation method [50] to capture the movements of the person in the reference video (i.e., saving the coordinates of key points that change over time). By using socket and UPD communication and data transfer in localhost, the motion capture data is transferred in real-time to achieve the effect of imitating the motion in real-time. Connecting the armature in the robot model with the 33 key points obtained from the attitude estimation. The specific mapping is shown in Fig. 9.
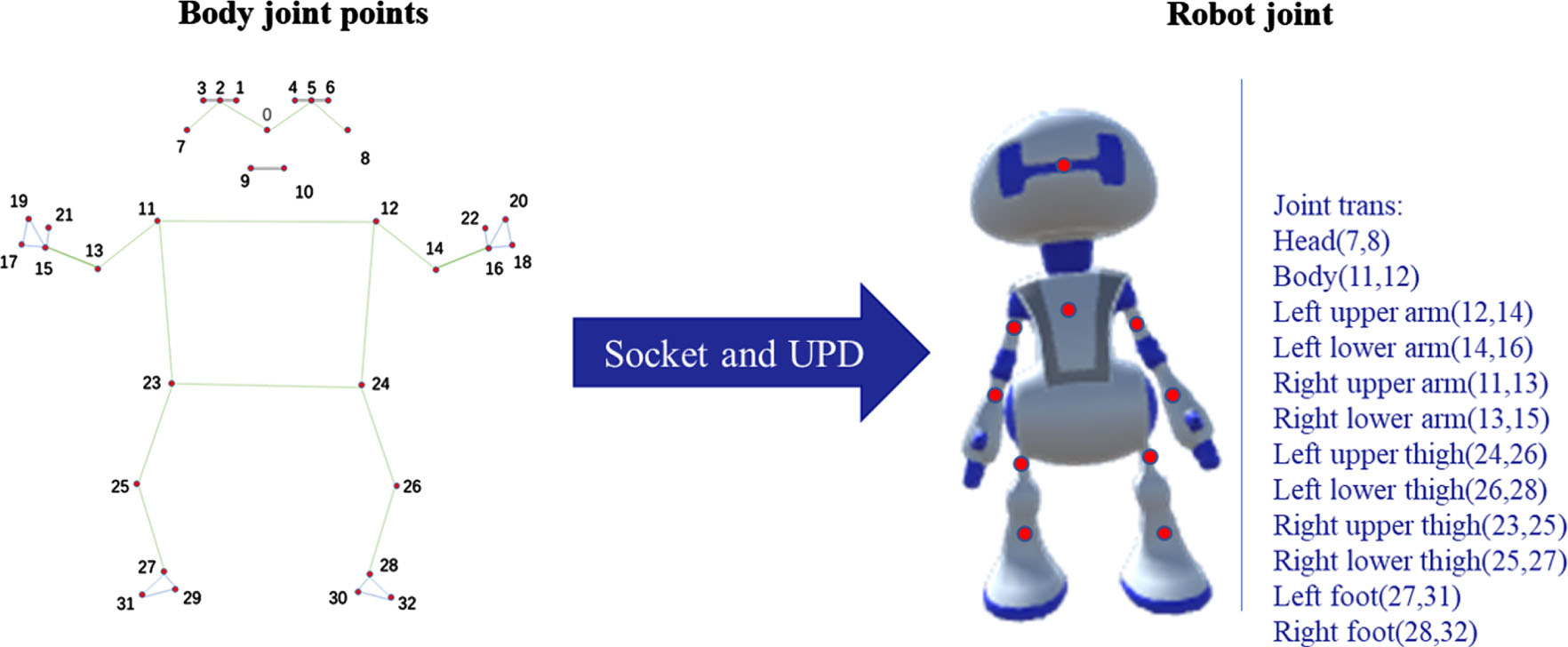
The mapping diagram of joint points of the human body and robot joints.
Take the midpoints of key points 7 and 8 and map them to the robot’s head, the midpoints of key points 11 and 12 and map them to the robot’s body, vector (12, 14) maps to the robot’s left upper arm, vector (14, 22) maps to the robot’s left lower arm, vector (11, 13) maps to the robot’s right upper arm, vector (13, 15) maps to the robot’s right lower arm, vector (24, 26) maps to the robot left thigh, vector (26, 28) maps to robot left lower leg, vector (23, 25) maps to robot right thigh, vector (25, 27) maps to robot right lower leg, vector (27, 31) maps to robot left foot, and vector (28, 32) maps to robot right foot.
Some experimental results are visualized to demonstrate further the robot simulation experiments, as shown in Fig. 10. As can be seen from the figure, according to the recognition results, the robot made four actions: beat, jump, walk, and wave.

Unity3D platform robot simulation simulation experiments, listed clap, jump, walk, wave four movements of the actual and simulation comparison video.
In order to better demonstrate the performance of the robot simulation, a table of experimental performance indicators was made and shown in Fig. 6.
We convert the two motion bone images into pseudo heatmaps before combining them with the RGB image. A three-channel post-fusion 3D CNNs network model was designed along with a three-channel mid-term fusion 3D CNNs network model for experimental comparison. The results demonstrated the improved accuracy of the experimental dataset, although only simple RGB videos were used. The superiority of the proposed method was glimpsed in the training results of the datasets JHMDB, HMDB51, and UCF101, and the application value was demonstrated by simulating the experiments on a robot model on the Unity3D platform.
This design contains only two types of features, RGB and bone. Other features, such as SIFT with a constant position viewpoint, can be added to improve accuracy. In addition, some advanced networks like I3D can be used to process the feature information. Of course, combining with target segmentation algorithms is also a good direction to achieve a complete recognition process for robots. During the experiment, we found a small detail: the difference in maximum execution time between action classes is vast. We often train with a uniform number of frames, which will inevitably cause information loss. Therefore, multiple execution times will be considered simultaneously in the subsequent research.
Footnotes
Acknowledgment
This paper is supported by National Key Research and Development Program of China under Grant Nos. 2018YFB1304600; National Natural Science Foundation of China under Grant 51775541, Grant 62006204; CAS Interdisciplinary Innovation Team under Grant Nos. JCTD-2018-11; in partly supported by the Shenzhen Science and Technology Program under Grant RCBS20210609104516043.