
Abstract
Aiming at the problems of poor accuracy of insulator defects, bird’s nests and foreign objects detection in transmission lines, and the difficulty of algorithm hardware deployment, this paper proposes an improved YOLOv5s multi-hidden target detection algorithm for transmission lines, firstly, in backbone, the CA attention(Coordinate attention) mechanism is integrated into the C3 module to form the C3CA module, which replaces the C3 module of the sixth and the eighth layers, and enhances the feature fusion capability; secondly, in the neck, the GSConv convolution and VoVGSCSP modules are used to replace the standard convolution and C3 modules to form a BiFPN network, which reduces the floating-point operations of the network; finally, the improved algorithm is deployed into Raspberry Pi and accelerated by OpenVINO to realize the hardware deployment of the algorithm, which is demonstrated by experiments that: the mAP value of the algorithm is comparable to that of YOLOv3, YOLOv5 and YOLOv7 by 4.7%, 1.1%, and 1.2%, respectively. The model size is 14.2MB, and the average time to detect an image in Raspberry Pi is 78.2 milliseconds, which meets the real-time detection requirements.
Introduction
As an important part of the power system, the safe and stable operation of transmission lines is very important for the power system [1–3]. According to incomplete statistics, China’s 110 (66) kV and above voltage level transmission line length of more than 1.4 million kilometers, any point in the transmission line failure may lead to power system failure [4], and transmission line bird nests, foreign objects and insulator defects lead to transmission line faults accounted for about half of the total failure.And insulators as the main component of transmission lines, its use is to support the conductor to prevent the current back to the ground and increase the creepage distance, for the stable operation of the power grid has an important role.Transmission line inspection has become the most important daily work of the power sector, and there are problems such as long working lines, heavy tasks, less specialized equipment and low detection accuracy. Therefore, it is of great significance to carry out the research on transmission line multi-hidden target detection and hardware realization.
With the development of artificial intelligence and machine learning, it is applied in many aspects. Literature [5, 6] applies AI-related algorithms to marine ship classification and biomedicine, respectively. Literature [7] proposes A Hybrid Lion-based Butterfly Optimization Algorithm (L-BOA) combined with YOLOv4 algorithm to achieve prediction of heart disease from echocardiographic images. Literature [8] proposes an improved YOLOv4 algorithm to solve complex problems in human detection tasks. And this paper focuses on a category of artificial intelligence - recognition on transmission lines.It can be mainly divided into two main categories: one is the two-stage deep learning target detection algorithm based on candidate frames, which is an algorithmic model that directly completes the algorithm from features to classification and regression prediction, such as RCNN [9], Fast RCNN [10] and Faster RCNN [11]. The second category is target detection algorithms based on one-stage deep learning, such as YOLO (You Only Look Once) [12], SSD (Single Shot Multibox Detector) [13], YOLOv2 [14], YOLOv3 [15] and YOLOv4 [16]. Although the two-stage target recognition algorithm has good accuracy, the method is relatively time-consuming. In contrast, the single-stage target recognition algorithm can satisfy the fast recognition detection, and due to the limitation of hardware storage space and power consumption, a lightweight model is needed to make it more convenient to be deployed on hardware devices in order to complete the deployment in hardware. Literature [17] proposed a model based on Faster RCNN and morphological detection for localization and feature extraction of insulators. The algorithm has high accuracy, but its model parameters are large. Literature [18] proposed an insulator detection method using improved ResNeSt and RPN networks, constructing a new network based on ResNeSt and RPN to realize the detection of insulators. Literature [19] proposed a lightweight YOLOv4 model, using MobileNet network to replace the backbone, combined with GraphCut image enhancement method, the recognition accuracy and speed to achieve a good detection effect. Literature [20] proposed a local feature detection method to localize insulators by training local features. Literature [21] proposed an improved insulator detection method with Regional Convolutional Neural Network (R-CNN), which can effectively improve the detection speed, but its accuracy is slightly lower. Literature [22] proposed an improved YOLOv3 network to detect insulators, which adopted a multiscale feature fusion structure and subsequently used a multilevel feature mapping module in the network to enrich the semantic information, which realized the improvement of the accuracy, but its detection speed was still low. Literature [23] proposed a two-way fusion YOLOv3 target detection algorithm, and used the EIOU loss function to accelerate the convergence speed of the network, the average accuracy of insulator defects reaches 89%, and the detection speed reaches 93 ms/image. The balance of speed and accuracy is basically realized. Literature [24] proposed an improved YOLOv4-Tiny lightweight target detection algorithm that uses the self-attention mechanism and ECA-Net and keeps the model size at 24.9 MB. however, this algorithm loses in accuracy. Literature [25, 26] has improved the accuracy of insulator defect recognition by modifying the backbone network of YOLOv4, but its model weights are still not favorable for deployment in embedded platforms. Literature [27] proposed a transmission line foreign object detection method based on improved YOLOX, using Atrous space pyramid pooling (ASPP) and CBAM attention mechanism, and finally using the GIOU loss function to improve the convergence speed, with a large improvement in accuracy and a slight reduction in speed compared to the original algorithm. Literature [28] proposed a multi-scale residual neural network based insulator surface breakage recognition, which has good detection effect on insulators with single background. Literature [29] proposed a deep learning-based bird nest detection for transmission lines, deploying the YOLOv5 algorithm on a UAV, whose operational robustness and detection accuracy need to be tested and optimized by a large number of field flights. Literature [30] proposed an insulator detection model based on YOLOv5, which can effectively identify insulator defects by using K-means clustering method, but the highest accuracy rate is only 86.8%.
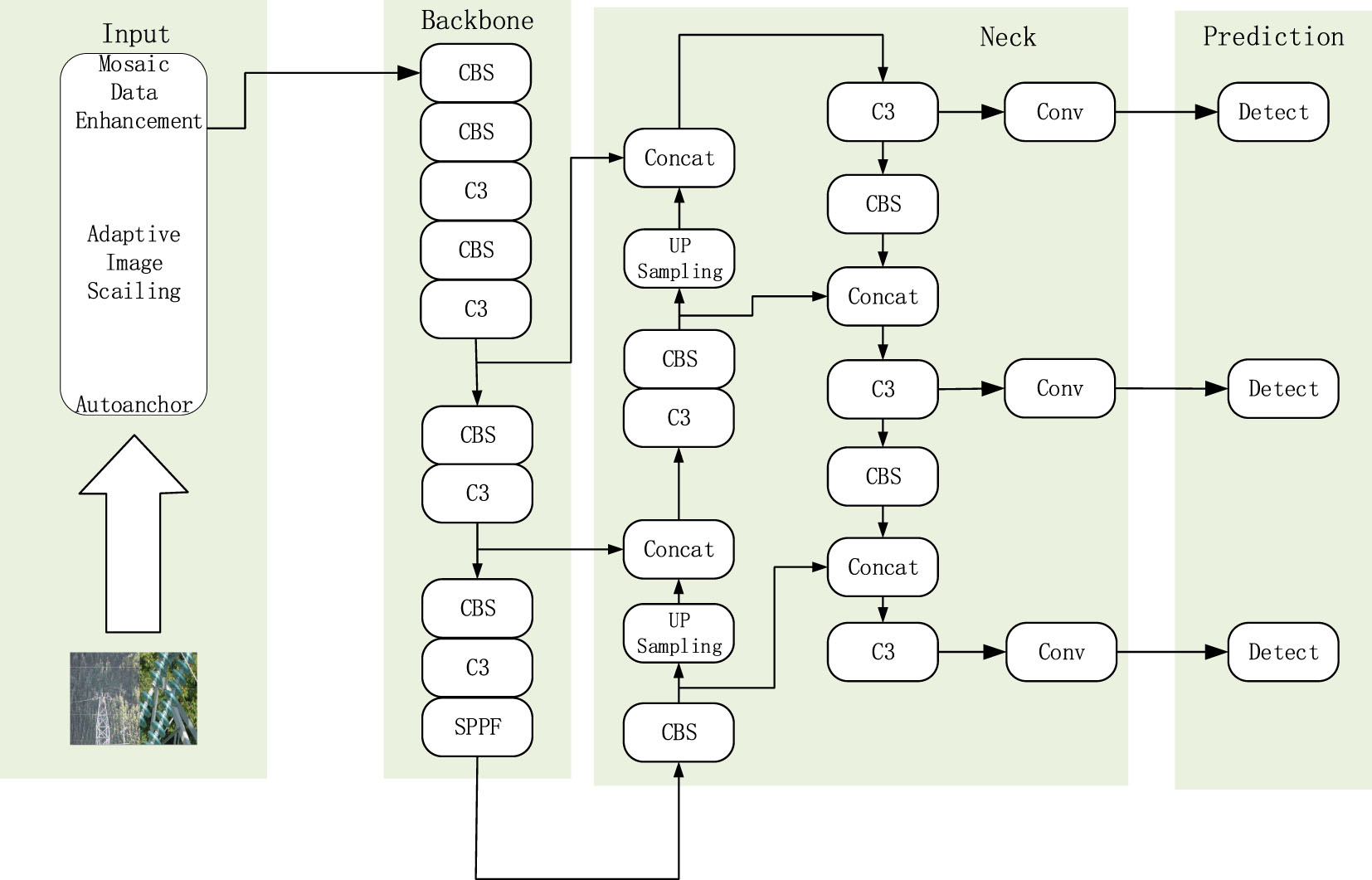
YOLOv5 network architecture.
To address the above problems related to low accuracy, high model weights, and difficult hardware deployment. In this paper, an improved YOLOv5s algorithm is proposed for multi-hidden target detection of bird nests, insulator defects and foreign objects, and hardware deployment is realized on Raspberry Pi. Through YOLOv5s deployed on a Raspberry Pi and applying the YOLOv5s technology to the monitoring and maintenance of transmission lines to improve the reliability and security of the power system, reduce the risk of potential outages, and reduce operation and maintenance costs. This research can have a positive impact on the modernization and automation of the power industry. The main contributions of this paper are as follows: improvement of the YOLOv5s network by using the C3CA module instead of the C3 module, the GSConv convolution and VoVGSCSP modules, which reduce the amount of floating-point operations of the network, the use of the EIOU loss function to accelerate the convergence of the network, and finally, the success of the improved YOLOv5s algorithm deployed on hardware (Raspberry Pi) to complete the algorithm hardware. The main structure of this thesis is as follows: firstly, the overall framework of the algorithm of YOLOv5s, followed by the structure and role of the improved module, followed by the production of the data set, model training, result analysis, and the deployment of the algorithm on hardware. Finally, it summarizes the research of the changed thesis and the outlook for the future.
The YOLOv5 algorithm is a one-stage target de-tection algorithm that is now available in five types: x, l, m, n, and s. In this paper, YOLOv5s algorithm is chosen as the basis, which has a small model. Its model structure is shown in Fig. 1, which is mainly composed of four parts: image input module (Input), preliminary feature extraction module (Backbone), enhanced feature extraction module (Neck) and prediction module (Prediction). Before the images are trained, the images are processed using Mosaic data enhancement, an automatic image stitching operation. The preliminary feature extraction network mainly consists of standard convolution and C3 module, after preliminary feature extraction, three effective features can be obtained, which are 80×80×256, 40×40×512 and 20×20×1024 feature maps. The enhanced feature extraction network reextracts the features obtained from the preliminary feature extraction network, completes the splicing and downsampling of the image for feature fusion and reextraction. The extracted abstract semantic in-formation and shallow feature information are fused for better feature extraction, and finally input into the prediction module for classification and prediction. Complete the detection and recog-nition of the target.
Improved YOLOv5s algorithm
YOLOv5s is a small model that is easy to deploy into hardware. Meanwhile, in order to improve the accuracy of YOLOv5s, the CA (Coordinate attention) attention mechanism is firstly fused in the C3 module of the sixth and eighth layers in the preliminary feature extraction network, and the GSConv convolution and VoVGSCSP module are used instead of the stand-ard convolution and the C3 module in the en-hancement of the feature network. The EIOU loss function is used to accelerate the network conver-gence. After improvement, the accuracy is realized. Its improved YOLOv5s network structure is shown in Fig. 2.
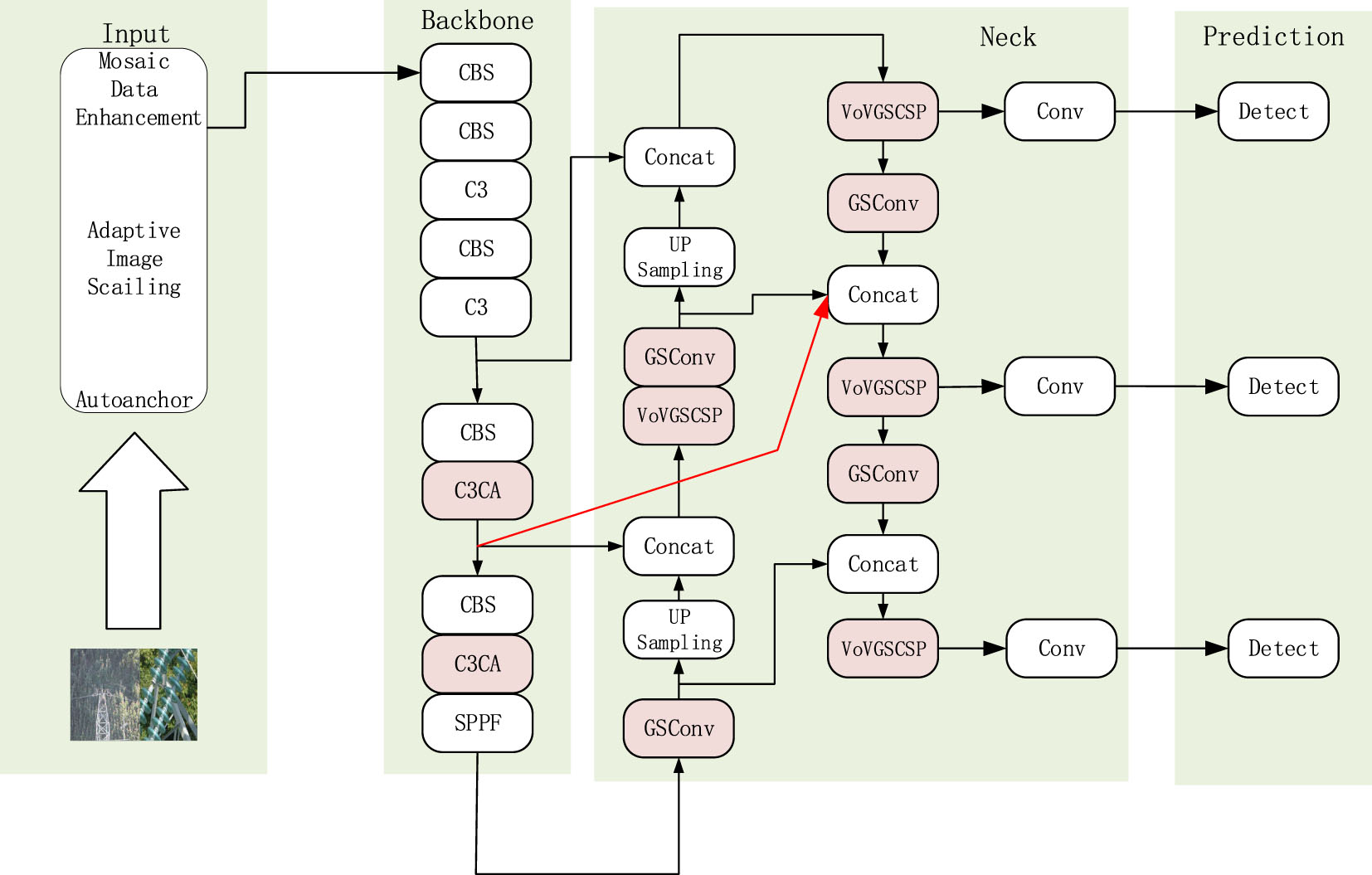
Improved YOLOv5s network structure.
Incorporating the CA attention mechanism into the C3 module in Backbone, the C3CA module was constructed to replace the C3 module in Layers six and eight. The attention mechanism is able to focus on important information with high weight and ignore irrelevant information with low weight, which makes it possible to select important information even in different situations, and enhances the effect of the network to extract features, thus improving the accuracy of the algo-rithm.
CA attention mechanism
CA attention mechanism was proposed by Qibin Hou [31], this attention mechanism not only con-siders the channel information, but also the direc-tion-related position information, which can realize plug-and-play, and has been widely used in algorithms for image recognition.The structure of CA attention mechanism is shown in Fig. 3.
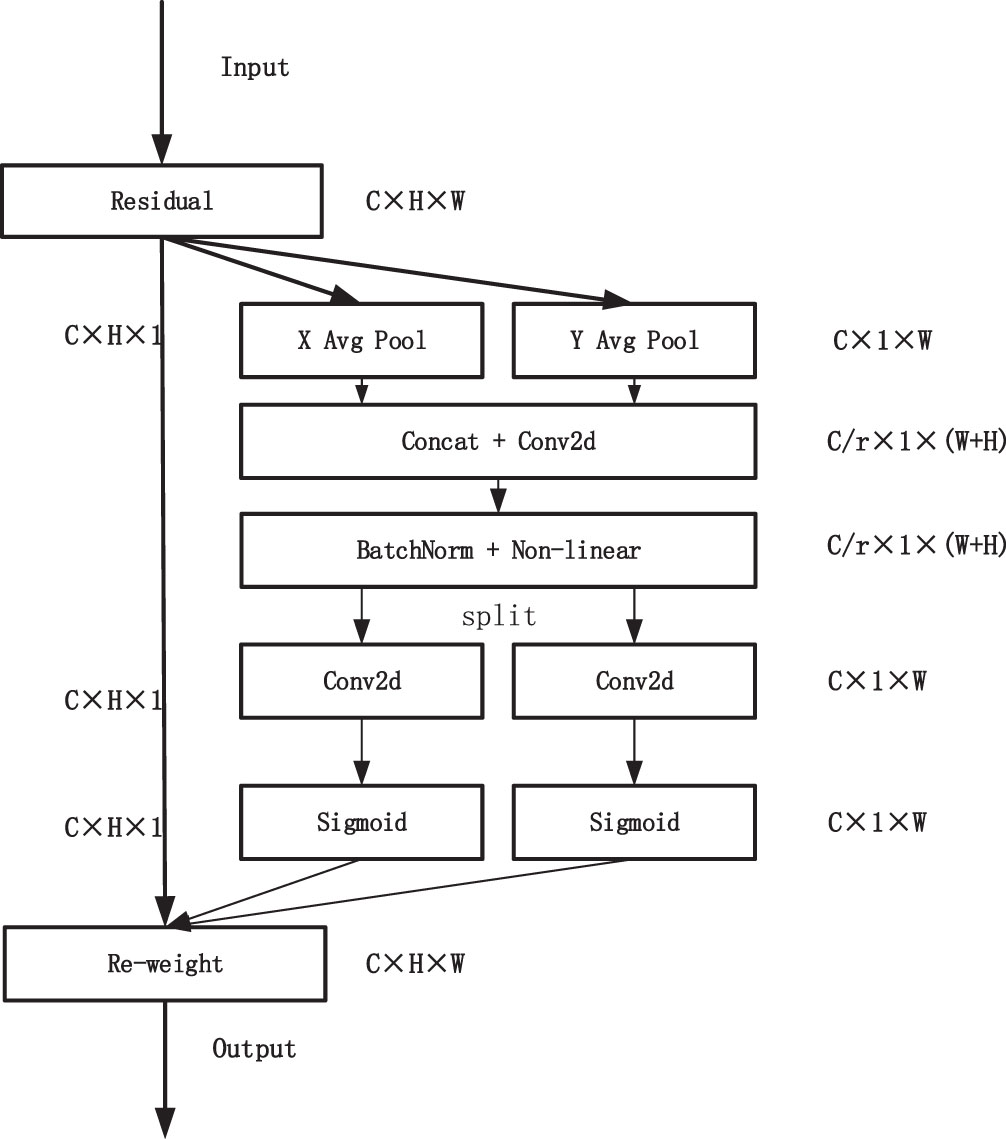
Structure of CA attention mechanism.
In order to obtain the attention on the width and height of the image and encode the exact location information, the input feature map is first globally average pooled for each of the two directions, width and height, and the channels in the horizontal and vertical directions are encoded using pooling kernels with dimensions (H, 1) and (1, W). At the c-th channel, the features at the height and width of H and W, respectively, are used as outputs, and the operation process is expressed in formulas (1), (2):
In the above equation h and w are the height and width of the current input image feature, respectively, and H and W are the dimensions of the pooling kernel,
Through a one-dimensional average pooling operation, we aggregate features along two directions to produce a pair of direction-aware feature maps, and these two operations allow our model to better understand the relationship between different spatial locations and retain precise positional information in the spatial direction, which helps the network to locate objects of interest more accurately. Secondly spatial dimensional convolution and compression is performed to stitch them together, using the 1×1 convolutional transform, the operation of which can be expressed by Formula (3) as.
where [zh, zw] denotes the cascade operation along the spatial dimension, δ is a nonlinear activation function, f ∈ RC/r×(H+W) is an intermediate feature map that encodes spatial information in the horizontal and vertical directions. r denotes is the reduction ratio of the module control size. Then we decompose the spatial dimension f into two independent tensors along the spatial dimension f, and transform the two dimensions using two 1×1 convolutions respectively to obtain the tensor with the same channel as the initial input, and after the activation function, we obtain the attention weights of the feature map in height and width. Finally, the two obtained attention images are multiplied with the feature image to complete the operation of CA attention mechanism on the feature map.
The structure of the C3CA module is shown in Fig. 4, which embeds the CA attention mechanism into the C3 module with enhanced model channel importance, and the key role of the CA attention mechanism is to dynamically adjust the weights of the feature map according to the importance of each channel. In the C3 module, this means that the model can automatically learn which channels are more important for the current task. In this way, the model can focus more on the information that is useful for a specific task, thus improving the discriminative nature of the features. In summary, incorporating the CA attention mechanism into the C3 module, by dynamically adjusting the channel weights, allows the model to better capture and represent useful information in the input data, thus improving the discriminative, generalization, and adaptive nature of the features. The C3 module is a combination of many residual structures, the main part continues to carry out the stacking of the original residual blocks, and the other part is connected to the main part after convolutional processing, and then the CA attention mechanism is processed to obtain the result, and the structure of its diagram is shown in Fig. 4:
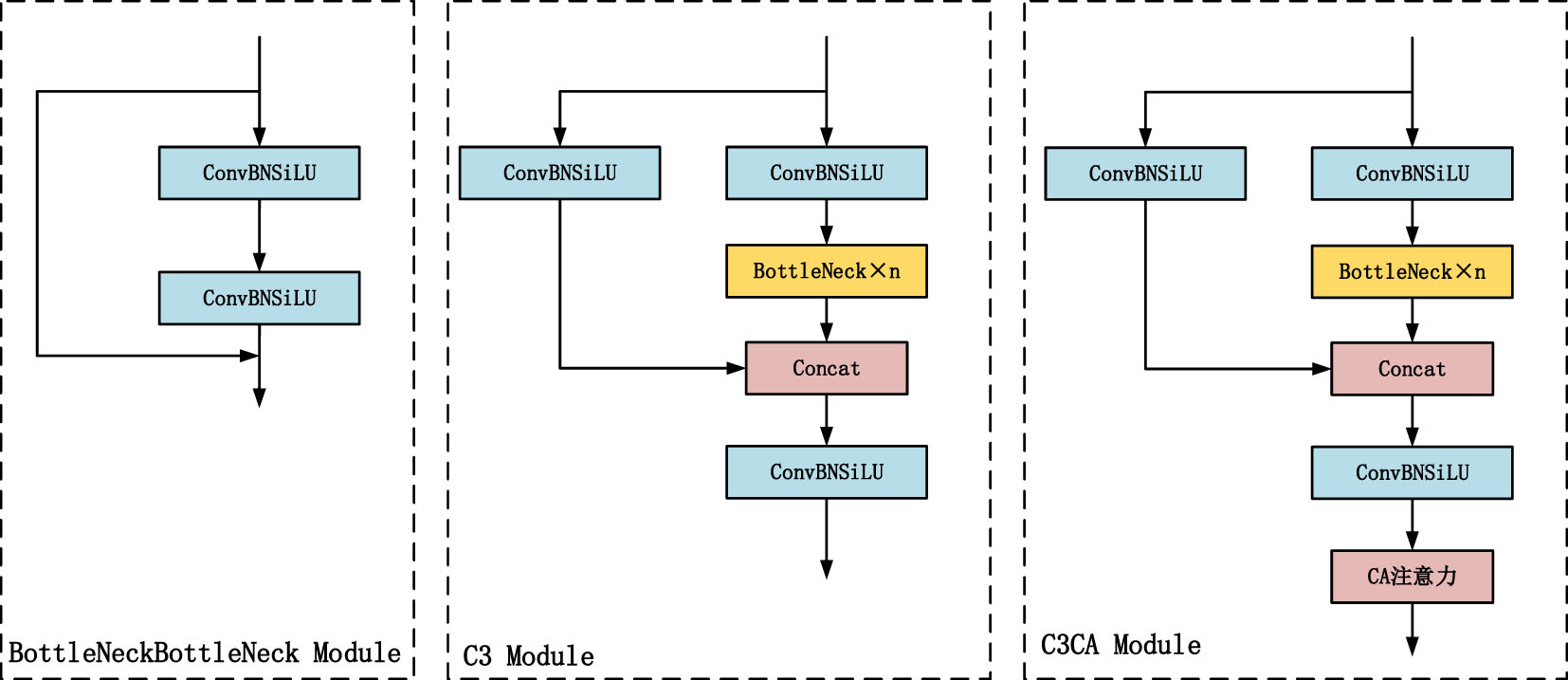
C3CA module structure.
In Fig. 1, we are able to see that Neck basically consists of ordinary convolution, C3 module, upsampling and downsampling. Since ordinary convolution and C3 module in the network leads to an increase in the floating point operations of the network, we use GSConv convolution and VoVGSCSP module [32] instead of ordinary convolution and C3 module.
GSConv convolution
GSConv convolution to replace the standard convolution, its computational cost is about 60% to 70% of the standard convolution, but its ability to learn the model is comparable to the standard convolution. In preliminary feature extraction networks, images are subject to a transformation: the features of the image are gradually transferred from the spatial information to the channel, and each time the spatial (width and height) compression of the feature map and the channel expansion result in the loss of some of the semantic information. Dense convolutional computation maximizes the retention of hidden connections between each channel, while sparse convolution cuts off these connections completely. The GSConv convolution preserves these connections as much as possible, but if this convolution is used in the initial extraction of the network, the model will have deeper layers of the network, and the deeper layers will exacerbate the resistance to the data flow, significantly increasing inference time. Therefore a better choice is to use GSConv convolution in the enhanced feature network, at this stage, the use of Gsconv to process the spliced feature maps is just right: there is less redundant repetitive information and no compression is needed.The core idea of GSConv convolution is to obtain information about neighboring nodes by graph sampling. It is different from the traditional (Graph Convolutional Network) GCN, which propagates information through a fixed neighbor matrix A. Instead, GSConv introduces a sampling process that randomly selects a subset of nodes from the neighboring nodes to propagate the information, which reduces the computational complexity and allows for the selection of a different subset of nodes in each convolutional layer to increase the diversity of the model. It is this principle that allows the model to capture features with increased capability.The structure of its convolution is shown in Fig. (5).
VoVGSCSP module
The VoVGSCSP module is derived from the GSConv convolution, a new residual structure composed using the GCSonv convolution on the basis of the standard residual block, which is used in the enhanced feature extraction network to make the extraction of features more effective. Its structure is shown in Fig. 5:
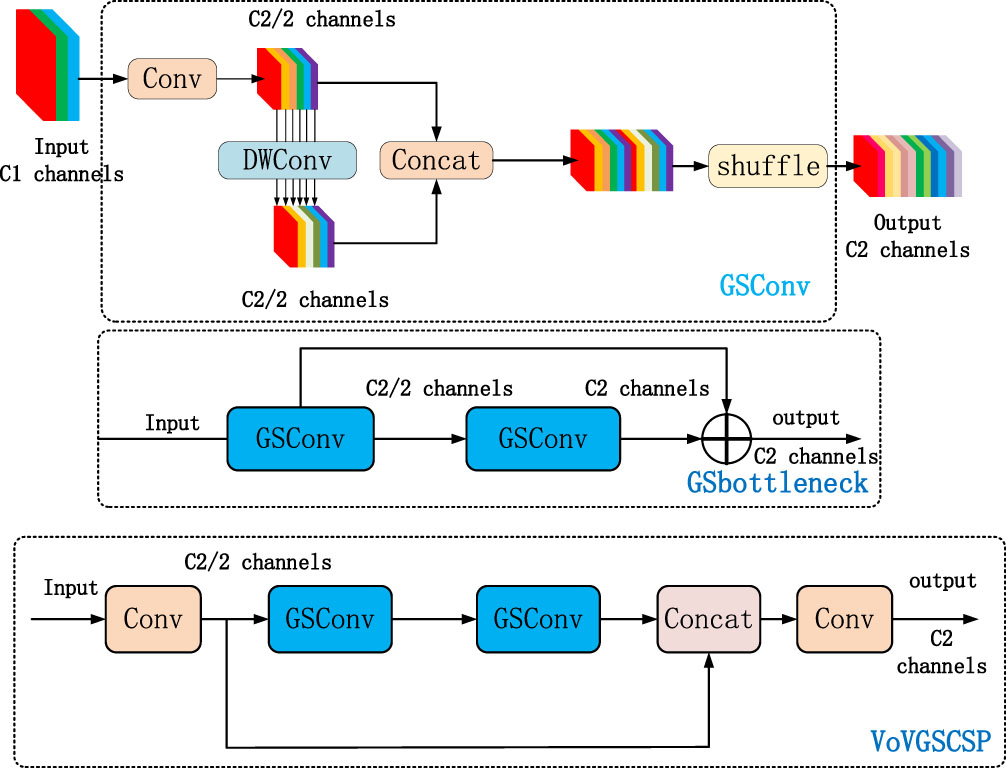
GSConv convolution and VoVGSCSP module.
In the improved YOLOv5s network, the PANet network is improved to BIFPN network. BIFPN (Bidirectional Feature Pyramid Network) network is a weighted bidirectional feature pyramid network, which was proposed by Mingxing Tan [33] et al. in 2020. This network is able to realize multiple feature fusion and avoids information loss.
The traditional network fusion features only perform unidirectional feature fusion. In order to solve this problem, a bottom-up path aggregation network is added on the basis of PANet network to better accomplish the fusion of features, and the BIFPN network realizes the splicing of three kinds of feature maps on the basis of PANet network. After the operation of the initial feature extraction network C3CA, a feature is obtained, and this feature is spliced with the features obtained from the enhanced feature network to achieve cross scale feature fusion, which makes the network to fuse the features with increased capability and remove the nodes that do not contribute much to the feature capability. Making the network more focused on the important levels. The structure of the network is shown in Fig. 6:
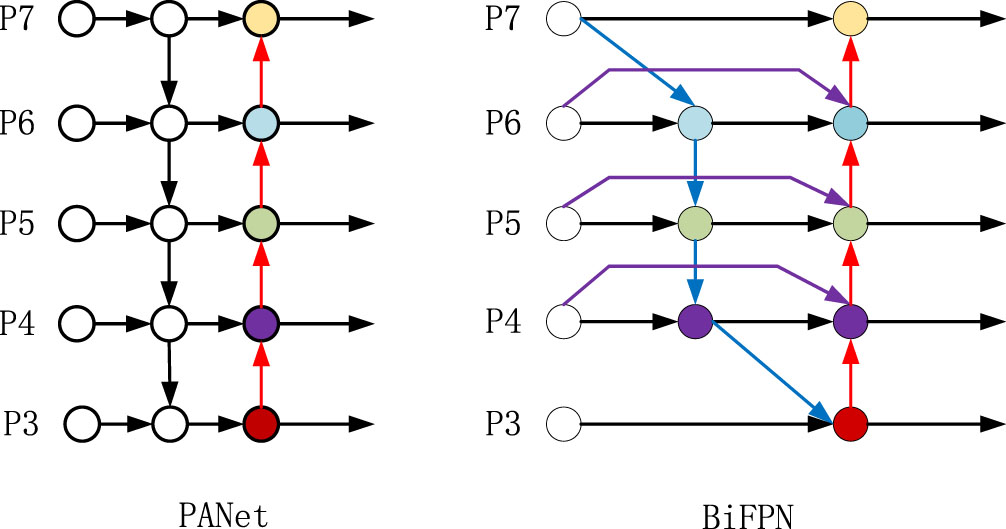
BIFPN network structure diagram.
Experimental platform
This experiment is completed under Windows11 system with a computer config-uration as follows: the 12th Gen Intel(R) Core(TM) i7-12700KF@3.61 GHz CPU, 32GB memory, NVDIA GeForce RTX 3080 Ti GPU, 12GB video memory, software Anacon-da3, version 3.8 Python, and Pytorch1.12.1 deep learning framework.
Data collection and processing
The dataset of this paper is from Baidu open source dataset, and its images are mostly from high-definition images taken by drones in the inspection process, which have high resolution. Among them, there are 3460 images of insulators, bird nests, insulator defects and foreign objects. The label files in xml are formed by labeling the desired targets using labelimg software. The images are in jpg format and the dataset is formatted using the VOC dataset format, the Anotations directory is used to store the label files in xml format and the JPEGImages folder contains images corresponding to each of the xml files containing the name of the image, the category of the target in the image, and the bounding box coordinates. The JPEGImages directory is used to store the original images of the dataset.The ImageSets directory is used to store the files corresponding to the data processing.All the file types are in txt format. During the YOLOv5s training process, the labeled xml files need to be converted into txt files to finalize the data processing. The ratio of training set + validation set to test set is 9:1 and the ratio of training set to validation set is 9:1. some of the dataset images are shown in Fig. 7.

Pictures of selected datasets.
Deep learning models are complex models consisting of multiple neural network layers, and the training process of the model is to pass the input data to the model, and through training, the model output is close to the real label. The idea of transfer learning was utilized in improving the YOLOv5s model training with pretraining weights. In the training process, stochastic gradient descent (SGD) optimizer is used with learning rate momentum and weight decay coefficient of 0.937 and 0.0005, respectively. the initial learning rate is 0.01 and the batch size is set to 32. The mosaic data enhancement method is used in the training process, where four images are randomly read from the dataset at one time for scaling or cropping, and are combined to get a new image. The combined images have different backgrounds, which makes the spatial semantic information richer and enhances the generalization ability of the model. Label smoothing training method is used to better calibrate the data, which leads to better generalization and produces more accurate predictions of the data. The training process of the model is optimized and accelerated by setting the training parameters well. Finally, the cosine annealing algorithm is used to avoid the network from falling into a local optimum solution, the principle is shown in Formula (4):
Where i represents the first index value,
The loss function measures the difference between the model’s predictions and the true labels, and the parameters of the model are optimized by minimizing the loss function so that the model can accurately predict the location, category, and other attributes of the target. The loss function for its YOLOv5s is the CIOU loss function as shown in formula (5):
Among them:
In formulas (5), (6) and (7), w, h, w
gt
and h
gt
represent the width and height of the prediction frame and the true frame, respectively, and ρ2 (b, b
gt
) represent the Euclidean distance between the centroid of the prediction frame and the true value, w
c
, h
c
denote the width and height of the minimum outer rectangle of the prediction frame and the real frame, and IOU denotes the intersection and merger ratio. In this paper, the EIOU loss function is used as shown in formula (8):
L IOU , L dis , L asp and denote the IOU Loss, Distance Loss, and Width-to-Height Loss, respectively. CIOU Loss, although it takes into account the overlap area, centroid distance, and aspect ratio of the bounding box regression, sometimes prevents the model from effectively optimizing the similarity because of the difference in aspect ratio reflected through its formula rather than the true difference between the width and height respectively and its confidence level. To address this problem, Zhang Yi-Fand et al. [34] proposed EIOU Loss by splitting the aspect ratio on the basis of CIOU, and added Focal focusing on high quality anchor box, the penalty term of EIOU is based on the penalty term of CIOU by splitting the influence factor of the aspect ratio to compute the length and width of the target box and the anchor box, respectively, and the loss function contains three parts: the overlap loss, the center distance loss, and the width-height loss, the first two parts continue the method in CIOU, but the width-height loss directly minimizes the difference in the width and height of the target box and the anchor box, which makes the convergence speed faster.
In this paper, a total of three sets of comparative experiments are done, the first set of experiments are YOLOv3, YOLOv5s, YOLOv7, and Improved YOLOv5s, the second set of experiments are comparative ablation experiments with YOLOv3-Tiny, Improved YOLOv5s, and YOLOv7-Tiny, and the third set of experiments are comparative ablation experiments with Improved YOLOv5s. Precision P, Recall R, Mean Accuracy (mAP) and Time to Detect Picture (T) are used as the main evaluation metrics for the evaluation of the algorithm in the experiments.The P-R curve helps us in the performance of the algorithm at different confidence levels. mAP values are used to measure the detection performance of the model on different categories. The formulas are shown in (9) to (12).
Where the number of positive samples with correct prediction is represented by TP, the number of positive samples with incorrect prediction is denoted by FP, and the number of negative samples with incorrect prediction is denoted by FN. n denotes the number of categories targeted for detection, and N is the number of detected images. An intersection and concatenation ratio is set for this experiment as the ratio of intersection and concatenation of predicted and real frames, and its value is set to 0.5.Because in increasing the threshold can reduce false positives but may increase false negatives. Lowering the threshold can reduce false negatives but may increase false positives. Therefore, tradeoffs need to be made based on specific tasks and needs. Secondly in YOLOv5s source code non-maximum suppression (NMS) is used to remove overlapping bounding boxes. It helps to reduce false positives and increase the accuracy of the test.
Table 1 shows the experimental results for YOLOv3, YOLOv5s, YOLOv7, YOLOv4, SSD, and improved YOLOv5s, and Table 1 shows the first set of comparison experiments. The confidence interval for each of its algorithms is 0.5.
Comparative experiment I
Comparative experiment I
From Table 1, we can see that the improved algorithm has better accuracy and mAP values, with accuracy improvements of 11.7%, 5.1%, and 3.4% over YOLOv3, YOLOv5s, and YOLOv7, respectively, which proves the improvement of its detection accuracy. The mAP values are improved by 4.7%, 1.1%, 1.2%, 0.08%, and 1.38% with YOLOv3, YOLOv5s, YOLOv7, YOLOv4, and SSD, respectively. From the table we can also see that the SSD algorithm detects fast because SSD is proposed on the background of YOLOv1 to YOLOv4 to make an integration of accuracy and speed. Instead of an explicit candidate box generation step, it integrates target detection and classification directly in a convolutional neural network, which reduces computational and time overhead.First of all, the improvement of the algorithm accuracy is due to the fact that we have integrated the CA attention mechanism into the C3 module to form a new module for extracting features, the C3CA module, which is able to improve the ability of extracting features from images compared to the C3 module, and, the CA attention mechanism itself is able to embed the location information into the channel attention to avoid the loss of important location information. And in the enhancement of feature extraction network, the use of GSConv convolution, this convolution first ordinary convolution operation, the number of channels of the obtained features into the original half, and then use the depth of the separable convolution of the features again convolution, the characteristics of the obtained features for the splicing and conversion, has been completed on the fusion of the features, after the experiments proved that the convolution can reduce the amount of floating-point operations of the network. The VoVGSCSP module is a combination of this convolution, through which the improved network can be used without loss of accuracy and without too much reduction in speed.The original CIOU loss function is replaced by the EIOU loss function, which continues the overlap loss and center distance loss of CIOU, but EIOU adjusts the width and height loss to directly process the prediction results of and, which can better respond to the width and height differences between the prediction frame and the target frame, accelerating the convergence of the network, and helping to improve accuracy. From Table 1 we can see that the speed of detecting an image is 13 ms, compared with the original YOLOv5s network, the detection time is only improved by 0.7 ms.The smaller the value of the model’s weights during hardware deployment, the lower the hardware requirements and the more blocky its detection is compared to the detection with large model weights.
Table 2 shows the results of the comparison experiments of the improved YOLOv5s with the YOLOv3-tiny and YOLOv7-tiny lightweight networks.
Comparison experiment II
Comparison experiment II
Ablation experiments
From Table 2, we can see that compared with YOLOv3-tiny, YOLOv7-tiny, the improved YOLOv5s algorithm is higher in its precision, recall and mAP than these lightweight algorithms of YOLOv3-tiny, YOLOv7-tiny, although it is slightly lower than YOLOv3-tiny, YOLOv7-tiny in terms of its model weight and speed, the improved YOLOv5s algorithm has a higher precision, and it can achieve a balance between the detection precision and the speed, which is more suitable for deploying on top of Raspberry Pi hardware.
In the ablation experiments, we did four sets of comparison experiments, the first one is the experiment of YOLOv5s, and the improvement 1 is the improvement of Neck network and loss function on the basis of YOLOv5s by using GSConv convolution, VoVGSCSP module and BIFPN network. From Table 3 we are able to see an increase of 0.4% in its mAP value. Improvement 2 improves on Improvement 1 by using C3CA modules instead of C3 modules in the sixth and eighth layers in Backbone, which increases its mAP value by another 0.7% compared to Improvement 1 algorithm. Improvement 3 replaces the C3 module with C3CA module in the second and fourth layers in Backbone on the basis of Improvement 2, which is experimentally verified that the mAP value is not better than Improvement 2, although the mAP value is higher than that of the original YOLOv5s by 0.6%, so this paper improves the YOLOv5s algorithm as Improvement 2 algorithm. Overall, the C3CA module strengthens the extraction of features, the BIFPN network strengthens the feature fusion of the algorithm, the GSConv convolution and VoVGSCSP module reduces the floating-point operation of the network, and the EIOU accelerates the convergence speed of the network. The detection effect of its improvement 2 is shown in Fig. 8:

Diagram of detection results.
Raspberry Pi hardware diagram and VNC interface diagram.
In Fig. 8, we have done plots of the predic-tion results of the improved YOLOv5s algorithm, the YOLOv5s algorithm, and other algorithms to compare the experiments in terms of a single category, multiple categories, and different hues, respectively. In Fig. 8, from (a), it can be seen that the original YOLOv5s has misdetection in detecting the bird’s nest, while the improved YOLOv5s not only does not have misdetection, but its score is also higher than that of YOLOv5s, and still has the highest score compared with other algorithms. In Improved YOLOv5s (c) and (d), it can be found that the improved YOLOv5s still achieves the recognition of the target under different color tones and the bird’s nest is occluded. And the higher the hue, the better its score.
Raspberry Pi deep learning environment construction
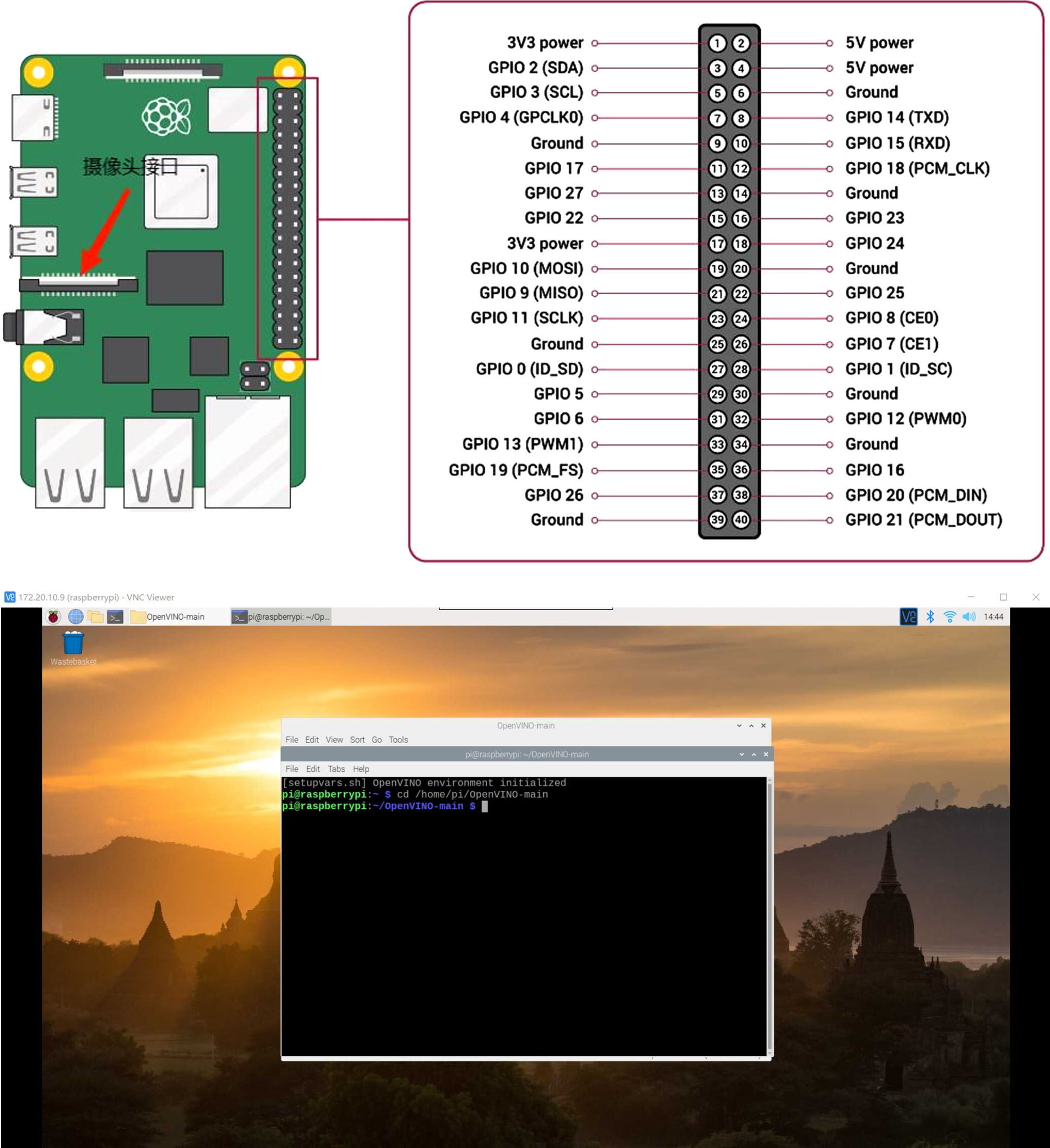
The hardware device used in this paper is the Raspberry Pi 4 generation development board, the system uses Linux system, provides CSI wiring and commonly used USB interfaces, which can realize the external connection of the camera, and also provides a variety of pins, the realization of the function is rich, the Raspberry Pi hardware is able to support the programming of the language Python, Java and C. The language used this time is Python. Raspberry Pi used by the image system for the 2021-05-07-raspios-buster-armhf.img, this time the language used is Python. in the Raspberry Pi to build a deep learning environment, the installation of opencv, used for image processing, and then continue to install the deep learning framework PyTorch, which needs to be compiled and installed through the source code, the first install the First, install the dependencies required by PyTorch before compiling and installing it. Then compile and install Torchvision, which is a library specialized for image processing in PyTorch.
The small size and low power consumption of Raspberry Pi makes it suitable as an embedded platform.The architecture of Raspberry Pi Model 4B is shown in Fig. 9.
The camera used in this experiment is Raspberry Pi Camera Module V2 camera with 5 megapixels with CSI wiring. VNC (virtual network computer) remote control is used, first turn on the VNC control of Raspberry Pi, then check the IP address of Raspberry Pi, and finally log in.The interface of VNC remote control of Raspberry Pi is shown in Fig. 9.
Model Acceleration with OpenVINO
OpenVINO is a set of deep learning tool libraries developed by Intel for hardware platforms, used for model acceleration and model optimization, in order to improve the inference speed of the model in the edge device.The deployment process of OpenVINO is as follows: download the OpenVINO toolkit, and then configure OpenVINO in the Raspberry Pi, set the environment variables, and use OpenVINO’s Model Optimizer tool to optimize the deep learning model. Use Model Optimizer to transform and optimize the model to generate IR (Intermediate Representation) files. Finally using the IR file you can perform inference on the Raspberry Pi. When converting IR files, especially during the inference process, the inference code may not recognize the IR file, so we need to install the corresponding OpenVINO version to avoid errors. After generating the IR file, it will not only be realized on the computer side, but also on other hardware to complete the recognition of the target.The connection between the Neural Compter Stick 2 and the Raspberry Pi is shown in Fig. 10.

Neural Compter Stick 2.
Since OpenVINO is not supported by the models trained on pytorch framework, it is necessary to convert the models trained on pytorch framework into ONNX format, and ONNX format into intermediate expression model IR files. The flowchart of model accelerated inference performed by OpenVINO is shown in Fig. 11.
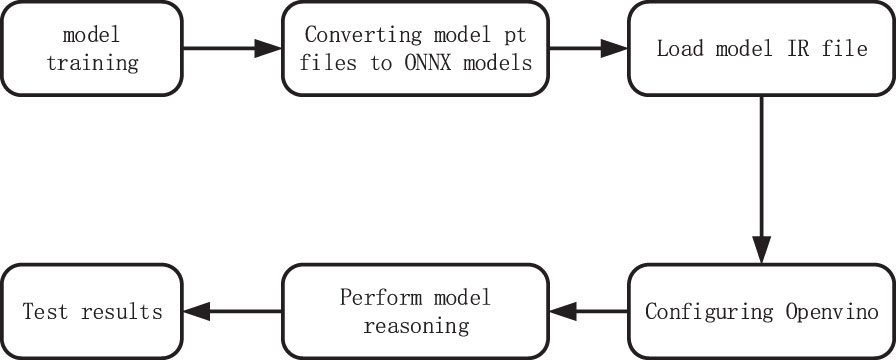
Model accelerated inference process.
Table 4 shows the speed detection experiments conducted at Raspberry Pi, a total of four sets of comparison experiments were conducted, which are the time taken by the improved YOLOv5s to detect pictures without OpenVINO acceleration. The time taken by the improved YOLOv5s, YOLOv3 and YOLOv7 to detect pictures with OpenVINO acceleration. Where the code test graph of inference time is shown in Fig. 12 and the real time detection result graph is shown in Fig. 13.
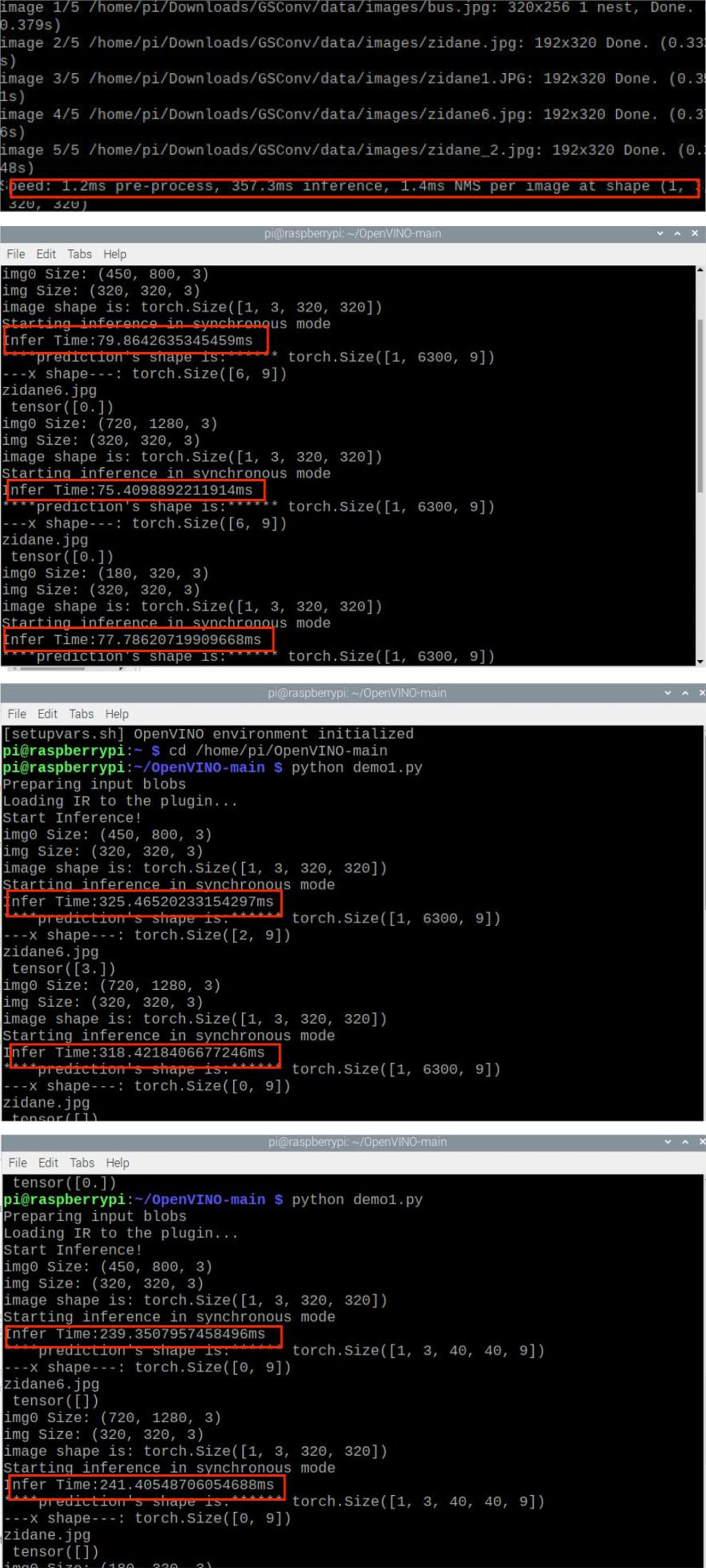
Code test plot for inference time.
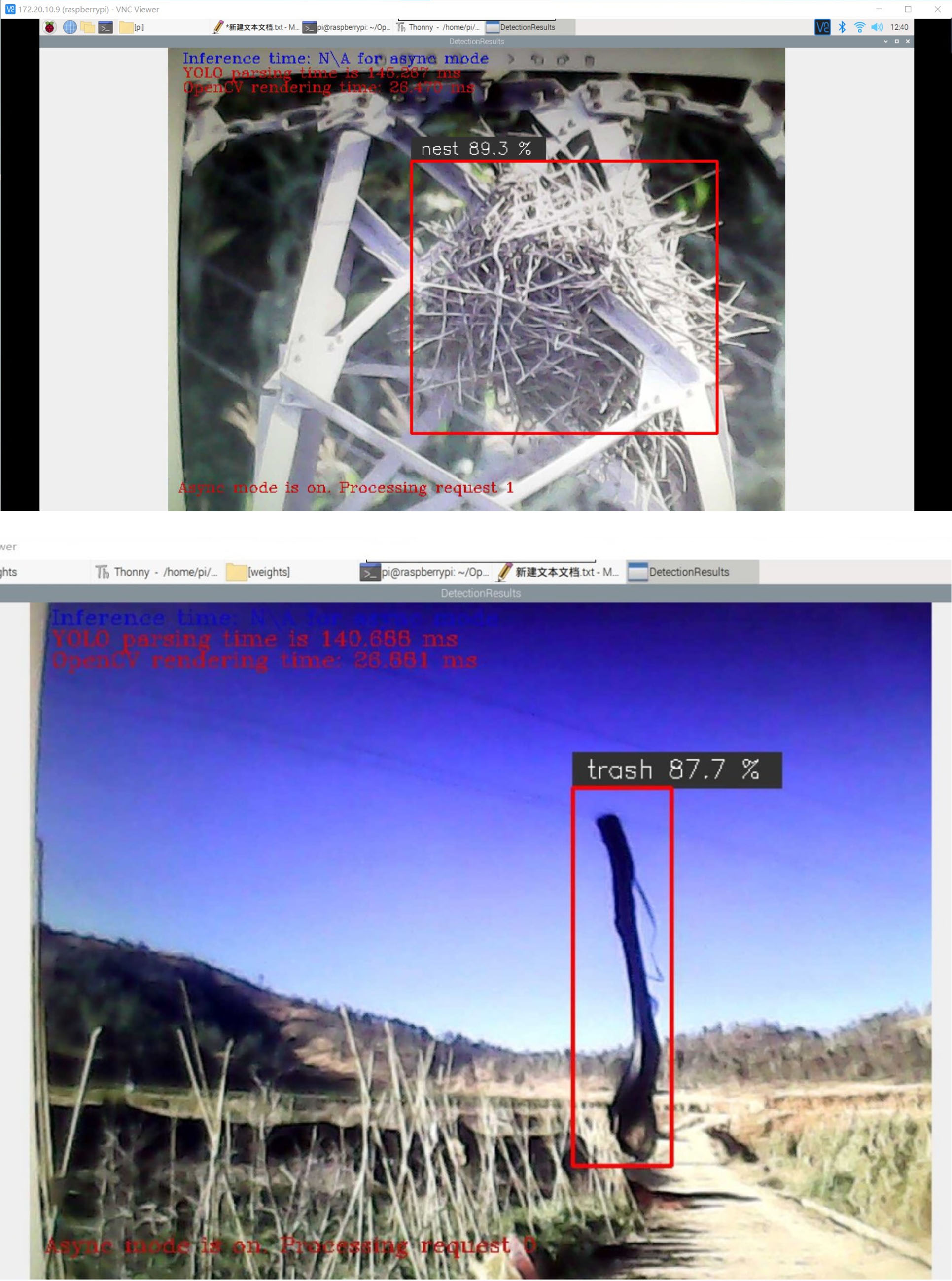
Real-time detection results graph.
Comparative Experiment I
From Table 4 and Fig. 12, we can see that the average time to detect an image in the Raspberry Pi hardware for the improved YOLOv5s is 375.3 milliseconds when there is no neural bar for acceleration, and by using neural bar for acceleration, the time to detect an image for its improved algorithm time is much shorter, and it can reach 78.2 milliseconds. Since the other algorithms are not as accurate as the improved YOLOv5s algorithm and may cause the risk of false detection. So the improved YOLOv5s algorithm is chosen for deployment. Deploying algorithms into hardware comes with the drawback that there is a slight reduction in accuracy when deployed into a Raspberry Pi.When not accelerated by OpenVINO, the algorithm could achieve detection but not real-time detection. When deploying the algorithm, instead of sacrificing accuracy for detection speed, the improved algorithm was accelerated using OpenVINO hardware. From Fig. 12 we can see that the detection time varies for different images in the same algorithm, so an average is taken. To obtain our average detection accuracy in Raspberry Pi. Figure 13 shows the real-time detection results, which are basically recognized.
In this paper, a transmission line inspection algorithm based on improved YOLOv5s is proposed to verify the superiority of the resultant algorithmic model by constructing its dataset and conducting comparative experiments with other algorithms, which guarantees the speed with good detection accuracy. The algorithm based on improved YOLOv5s reaches 96.1% in its accuracy and its mean average accuracy(mAP) reaches 89.2%, which are verified to be superior when compared with other algorithms and have a greater improvement in accuracy without loss of speed. Based on the improved YOLOv5s algorithm, it has been deployed on the Raspberry Pi hardware platform, and the neural rods are used to accelerate the algorithm, which is the basis for the subsequent re-mounting to UAVs, so as to complete the work of transmission line inspection. The algorithm still has some limitations for the detection of some small-sized targets, and its effectiveness still needs to be improved in some specific scenarios, and it usually requires a large amount of labeled data for the training of the current target detection model. One of the future research directions may be to improve the performance of target detection in small sample situations. Combining multiple sensors makes the target detection model more robust and robust and enables the algorithm to be utilized in different scenarios.