
Abstract
The task of conversational machine reading comprehension (CMRC) is an extension of single-turn machine reading comprehension to multi-turn settings, to relflect the conversational way in which people seek information. The correlations between multiple rounds of questions mean that the conversation history is critical to solving the CMRC task. However, existing CMRC models ignore the interference that arises from using excessive historical information to answer the current question when incorporating the dialogue history into the current question. In this paper, an effective Question Selection Module (QSM) is designed to select most relevant historical dialogues when answering the current question through question coupling and coarse-to-fine matching. In addition, most existing approaches perform memory inference by stacked RNNs at context word level, without considering semantic information flowing in the direction of conversation flow. In view of this problem, we implement sequential recurrent reasoning at the turn level of the dialogue, where the turn information contains all the filtered historical semantics for the current step. We conduct experiments on two benchmark datasets, QuAC and CoQA, released by Stanford University. The results confirm that our model satisfactorily captures the valid history and performs recurrent reasoning, and our model achieves an F1-score of 83.0% on CoQA dataset and 67.8% on QuAC dataset, outperforming the best alternative model by 4.6% on CoQA and 2.7% on QuAC.
Keywords
Introduction
Machine reading comprehension (MRC) is a natural language processing (NLP) task that has the potential to revolutionize the mode of interaction between humans and machines, and has attracted increasing attention in recent years. Traditional MRC methods involve training a machine to answer numerous isolated questions based on pieces of text, which is a suitable way to evaluate how well a computer system can understand human language. However, since many people seek information in a conversational way by asking follow-up questions via technologies such as open-domain question-answering systems and chatbots, researchers have extended the problem of single-turn questions to a sequence of dependent multi-turn questions, giving rise to another challenging NLP task called conversational machine reading comprehension (CMRC). This offers a simplified but concrete setting for building conversational AI systems. Meanwhile, several public large-scale CMRC datasets such as CoQA [1], QuAC [2] and FriendsQA [3] have been developed to evaluate the efficacy of MRC models in terms of conversational reading comprehension settings. Experiments on these datasets have demonstrated that traditional MRC models without specifically dealing with session streams show much lower performance than humans. In other words, understanding and memorizing the conversation flow is an essential part of addressing the task of CMRC.
Previous approaches have attempted to handle conversational history from two perspectives. In the first, researchers predicted correct answers using advanced single-turn MRC models with historical questions and answers appended to the current question or passage context [1,2, 4–7]. Experiments by Reddy et al. [1] suggest that most questions in a conversation have a limited dependency within the scope of two turns. In the second approach, several well-designed multi-turn CMRC models have been proposed for reasoning through conversational flow based on all historical information [8–13]. For example, Huang et al. [8] proposed a flow mechanism to integrate the intermediate layer context representation into the reasoning process as sequential historical information, while Qu et al. [11] introduced an HAE structure to incorporate all historical information in a disordered manner by identifying the position of all historical answers in context encoding process. However, these existing models neglect the adverse impact of redundant information that arises due to the sensitivity of the matching process, especially when successive questions have significant word overlap with historical ones.
In general, a question in a CMRC setting falls into one of three categories: Topic Continue, where the current question is related to the last one; Topic Change, where the current question starts a new topic unrelated to any previous questions; and Topic Recall, where the current question is related to discontinuous previous questions. Figure 1 shows an instance from the CoQA dataset. It can be seen that Q2 continues the previous topic by omitting the clause What day did May head with Nicole to Children’s Memorial Hospital. Q3 is an independent question that can be inferred only from the given context. Q4 is not related to Q2 and Q3, and leads the conversation back to Q1. Obviously, not all historical information is required to answer some questions. Moreover, adding all historical information to the current question may cause misunderstanding in some models.

A fragment of an instance from CoQA dataset.
To tackle this problem, we introduce an effective Question Selection Module (QSM) that selects the most relevant historical information for answering the current question through the use of question coupling and coarse-to-fine matching. It can be observed that many instances of the current question consist of only one or two words (such as who?, what day?), meaning that they are entirely dependent on the last utterance. We therefore generate two different question targets, and conduct multi-granularity matching with historical questions to each of the targets.
Some existing methods [6, 13] use stacked RNNs for reasoning after historical information is added. Although multi-level contextual features can be captured and more complex contextual representations can be generated in this way, these methods ignore the flow of semantic information as the conversation proceeds. FlowQA [8] and FlowDelta [9] model the reasoning processes by incorporating intermediate representations or intermediate information gained through dialogue, but approaches such as these cannot apply selective memory in historical semantics. We therefore adopt extra context-level recurrent reasoning in which the whole attended context is regarded as a unit, and apply reasoning in a step-by-step manner in the direction of dialogue flow to predict possible answers. The contributions of this work can be summarized as follows:
We design a QSM to select the most relevant questions for subsequent context comprehension using question coupling and multi-granularity matching to avoid the negative effects of redundant information. We conduct question-attended context-level recurrent reasoning in the direction of conversation flow to model the dialogue stream and deduce the correct answers. We perform extensive experiments to explore the validity and interpretability of our method on two benchmark datasets, CoQA and QuAC. The results demonstrate that our method outperforms the alternative methods by a noticeable margin.
In this section, we provide a detailed discussion of related research on CMRC. In order to tackle the task of CMRC, researchers need to solve two main problems: integrating relevant historical information, and reasoning within the given context.
Handling with conversation history
Previous researches have adopted a variety of methods to effectively utilize conversation history. Beginning with those of Choi et al. [2] and Reddy et al. [1], several models append conversation history to the current question as Fig. 2. (a) shows. Enter the history as a whole, <q > Qt-n < a > At-n . . . < q > Qt-1 < a > At-1 < q > Q t , to classical sequence-to-sequence single-turn reading comprehension models, where <q> and <a> are symbols marking questions and answers, Q t is the current question, and n is the size of the history to be appended. For example, BiDAF++ [14] is based on a SQuAD [15] model that applies bidirectional attention (from context to questions and from questions to context). It augments context encoding by explicitly identifying the previous answers within the passage and simply encodes the turn number within the question embedding. SDNet [7] leverages the locking parameters of BERT (bidirectional encoder representations from transformers) [16] to apply a multi-attention mechanism to the passage and questions, in order to obtain an effective understanding of the context and history.
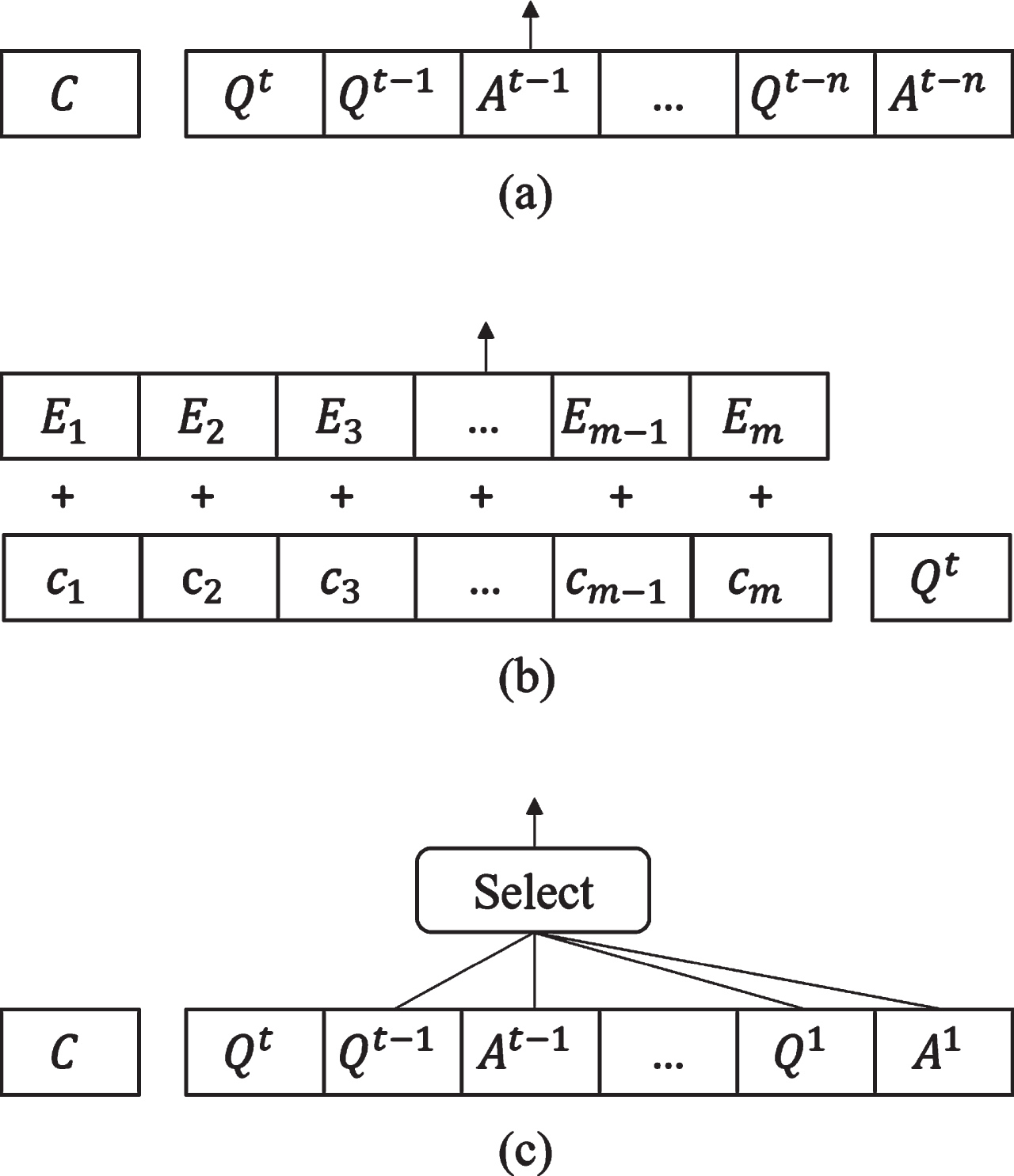
Three ways for encoding historical conversations.
There are also several prominent models that integrate historical information skillfully. Huang et al. [8] introduced a FLOW mechanism that can fuse intermediate representations generated by context representations of answering previous questions, and proposed the FlowQA model. FlowDelta [9] is an improvement on FlowQA that explicitly models the information gains, replacing implicitly modeled context representations in the process of reasoning. Chen et al. [10] proposed the innovative GraphFlow model, which dynamically constructs context graphs at each turn and conducts sequential inference by applying a recurrent graph neural network (RGNN) to context graphs. However, those Flow-based models use all previous questions step by step without a selection for historical information. Qu et al. [11] seamlessly integrated the conversation history into an MRC model by adding an extra token embedding, which demotes whether a token is a part of history answer or not. As shown in Fig. 2. (b), E m indicates whether this context word is a previous answer word. HAM [12] conducted a soft selection of conversation history by calculating attention scores for all historical questions. Ohsugi [6] used BERT to encode a context that was independently conditioned on each question and answer in the dialogue. Zhang et al. [17] proposed a multi-perspective convolution cube (MC2) that represented each conversation as a cube and extracted three-dimensional information using a convolutional neural network (CNN). TT-Net [18] employed a temporal convolutional network (TCN [19]) to capture topic transfer features using different sizes of history window. Zaib et al. [5] also noted that noise in a conversation could reduce the model performance, and introduced a method BERT-CoQAC to select history questions as Fig. 2. (c) shows. However, BERT-CoQAC oversimplified the similarity between question sentences, and an artificial threshold of 0.5 was applied to filter the relevant history.
An alternative approach is to rewrite the current question. To enable the rewriting of confusing questions caused by coreferences (e.g., via pronoun use) or ellipses in the dialogue into an out-of-context form question, Brabant et al. [20] released the CoQAR dataset, which was rewritten by two specialist native speakers.
Common Trends across CMRC models
Most existing models use all of the historical information at the reasoning stage. Even those that consider the redundancy of information rely on the long short-term memory of an RNN or an artificial threshold for selection. What makes our work different from its predecessors is the use of multi-granularity matching and question coupling matching to filter more relevant histories.
For semantic reasoning with a given context and questions, existing methods typically rely on large-scale pre-trained language models, which have been demonstrated to be particularly effective on a variety of NLP tasks. These pre-trained language models based on a transformer have the ability to learn common language representations from a large-scale unannotated corpus and to transfer this knowledge to downstream tasks. Language models of this type include GPT [21–23], BERT [16], XLNet [24], RoBERTa [25], spanBERT [26], and T5 [27]. When used for CMRC, context and question representations encoded by pre-trained language models inherently contain semantic information for reasoning about appropriate answers. Following in the footsteps of our predecessors, we used BERT for context and question encoding.
Table1 provides a comprehensive comparison of CMRC models in terms of the way they use conversation history.It can be seen that only three methods (including ours) are capable of addressing all three types of topics. It should also be noted that the manual setting of thresholds is not a highly dependable approach. Question rewriting is a pipelined process that can lead to the accumulation of errors, depending on the quality of the rewritten questions. In contrast, our model is an end-to-end multi-level and multi-granularity question selection model, which shows competitive performance in terms of both reliability and accuracy.
Method
Task formulation
The CMRC task can be formally expressed as a sequence labeling problem (answer span prediction) over a sequential context and an additional classification task (dialogue action prediction).
Model overview
As illustrated in Fig. 3, our proposed model consists of four modules. First, the pre-trained language model encodes the input words semantically. The QSM then explicitly selects the most relevant historical information to the current question by two types of key, and carries out attention mechanism between each round of filtered historical information and context representation. Recurrent reasoning is then applied to locate key clues in a step-by-step manner. Finally, a history-aware context representation is used to predict pinpoint answers. We explain each component in more detail in the following sections.
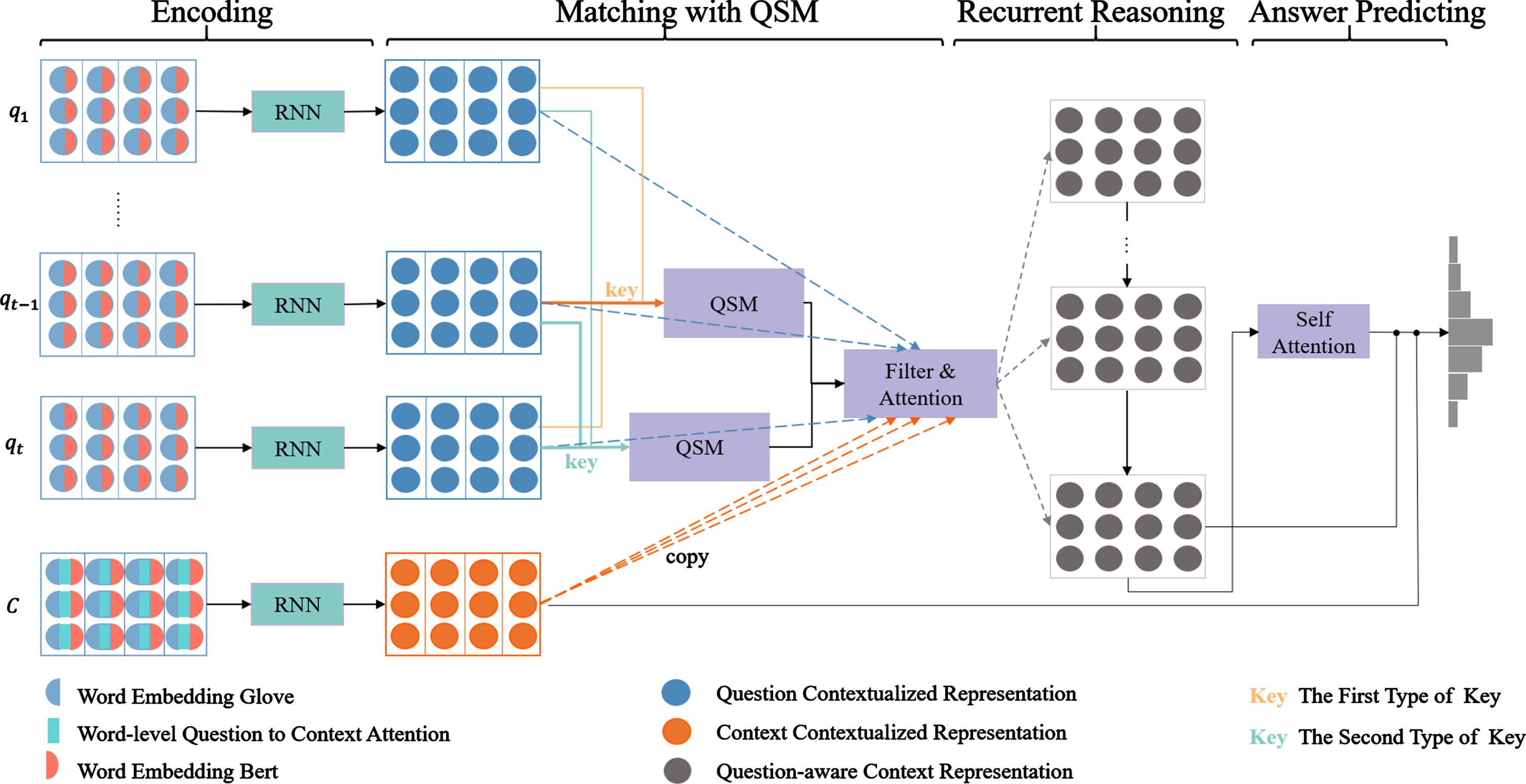
The overall architecture of proposed CMRC model with QSM.
Encoding layer aims to integrate contextual semantics into low-dimensional vectors, which lays the foundation for subsequent computational reasoning. Our encoding layer consists of the following parts.
Pre-trained word embedding. We encode each word of the input context and questions using 300-dimensional Glove [28] and 768-dimensional locked parameters of BERT [16] to obtain contextual information. The encoded context and question words are represented as Pre (c
i
) and
Word-level alignment. For each context word, we perform word-level attention from question to context based on Glove. Each attended context word vector is defined as Align (c
i
) and it is computed by Eqs. (1) and (2),
Feature embedding. We also encode a linguistic feature vector Lin (c i ) for each context word which is concatenated via 12-dim part of speech (POS) embedding, 8-dim named entity recognition (NER) embedding, and 3-dim exact matching (which indicates whether each context word appears in the question) embedding.
Thus, each embedded context word W
c
i
= [Pre (c
i
) ; Align (c
i
) ; Lin (c
i
)] and each embedded question word
Contextualized representation. A bi-directional RNNs (Bi-LSTM) layer is added to transform the different lengths of the context and questions embeddings into fixed dimensional vectors while forming a contextualized understanding of them. As shown in Eqs. (3) and (4), U
C
and U
Q
t
are the contextualized representations of the context and tth question, respectively.
As described above, not all of the historical questions and answers are necessary to answer the current question, and the QSM is therefore required to select comparatively relevant histories for the current question. To do this, we construct two types of key. For each, we calculate coarse-grained and fine-grained matching features between the key question and its historical information at the turn level and the word level, respectively. We obtain two relevance scores for the two types of key and finally fuse the two scores to generate a filter attention map of the historical information.
Word level selector. For the first type of key, Q
k
is defined as current question to be answered. We apply a cross-attention mechanism at word level to obtain a similarity matrix between the contextualized representations of the key question and each historical question. We apply Eq. (5) to the entire dialogue,
We then carry out average pooling of the word similarity matrix s
w
to find the matching score between two sentences as Eq. (6).
The word-level similarity can only match superficial correlations between the current question and its history, and cannot reflect whether this question and its history are compatible at a semantic level. We therefore also calculate the relevance at the turn level.
Turn level selector. At the turn level, we first feed word-level question representation into another BiLSTM layer as Eq. (7) and concatenate the two-way output of last state as semantic turn-level question representation.
The cosine similarity is then used to obtain the relevance score between the key question
When the similarity scores at the word-level and turn-level have been obtained, we multiply the two scores and filter out any irrelevant history using the sigmoid function as Eq. (9).
Question coupling selector. Although multi-grained selection can be applied to the current question to choose the relevant historical information, we found in the experiment that there were several short questions in the datasets. For example, in Figure 1, The question what day? contains very little information, and is clearly a continuation of the previous session, in the same way as the questions Who?, Where?, and so on. These questions may lead to a lack of focus on history when sifting through relevant questions. Therefore, We construct a second type of key by coupling the current question with the immediately preceding round of conversation, meaning that each question Q
t
is replaced by a splice of the question itself and its immediately preceding round of conversation, expressed by the formula Q
t
′ = [Q
t
; Qt-1 ; At-1]. We then implement same multi-granularity matching between the second type of key question and its historical information. We obtain a second similarity score s2 by Eq. (10),
Finally, we combine the similarity scores generated by the two types of key and apply the result to filter the historical information before applying reasoning. Note that in order to implement parallel computation, we simultaneously carry out multi-granularity interactions between each question and its history in one conversation. The final score needs to pass through an upper triangular matrix, as only previous questions can be seen when answering the current question and future conversations are not visible. The final score is expressed as Eq. (11).
Through this process, we can filter most relevant historical information based on the selector score S generated by our QSM to answer the current question.
After making relatively reliable choices about historical information, we leverage a series of time-dependent contexts and questions to deduce a possible answer. We essentially do two tasks in order: the first is to ensure that the context is aware of each turn of the question by calculating the attention between them as Eq. (14) show, and the second is to incorporate the previous reasoning process into the current reasoning process in a controlled manner. We adopt the concept of an RNN due to its advantages in terms of sequence learning. However, unlike when an RNN is used directly, each element in the sequence is no longer a word token in this case, but the whole context containing the historical reasoning process.
Finally, we concatenate the original context representations, reasoned context representations and redistributed attention context representations to predict two scores for each word in the given context, corresponding to the probability that the answer starts and ends at that word, respectively.
The input of this layer is
For the CoQA dataset, the answer types may be "can not answer", "yes" or "no". Referring to the method [12] to estimate answers’ type, a fully connected layer and the softmax function are used to map the context representation onto a space of size three to classify the answer. The formula is expressed as Eq. (19). W
a
is a parameterized matrix.
During the training process, we use the negative log-likelihood function to calculate the loss and minimize the likelihood probability. Eq. (20) describes the negative log likelihood probability of start position of predicted answer L
s
. The end position L
E
and the answer type prediction L
A
are calculated in the same way. i
s
is the golden truth start token position. L is the total loss need to be minimized and calculated by Eq. (21).
Dataset
We conducted experiments on two benchmarks QuAC [2] and CoQA [1], which are large-scale conversational question-answering datasets that were released in 2018 and 2019, respectively.
QuAC was collected from students and teachers having conversations based on a section. The students asked questions to learn as much as possible about the contents when the title and history of each section were visible, and the teachers answered these questions with spans based on the evidence context, resulting in a series of productive dialogues.
CoQA was generated by two annotators, a questioner and an answerer, who carried on an interactive conversation about a passage with discuss and monitor each other. These text passages covered seven diverse domains, two of which applied to an out-of-domain evaluation.
We present some statistics for these two datasets in Table 2. Both datasets have more than 15 question-answering turns per passage, meaning that many of these questions require a contextual understanding about the conversation history to obtain the correct answer.
Data Statistics of CoQA and QuAC Datasets
Data Statistics of CoQA and QuAC Datasets
Experimental results are compared with several periodic classic works in CoQA and QuAC Leaderboard
1
,
2
. One of the alternative models is SDNet [7], which we implemented based on its released public code
3
due to its separate encoding of context and questions. The scores for the other models were derived from results presented in published papers. We provide a concise description of these models below.
PGNet [29]. This model employs a copy mechanism to copy words from the source text in the decoder of an LSTM-based sequence-to-sequence model. It incorporates historical information by appending the conversation history directly to the current question. DrQA [30]. This extracts text spans as answers from multiple documents for open domain question retrieval. Past questions and answers are prepended to each question to take into account the history of the conversation. DrQA+PGNet [1]. This is a combined model in which DrQA first locates the answer evidence in the given text and PGNet is applied to the evidence to generate answers. BiDAF ++ [14]. This is a bidirectional attention mechanism BiDAF model augmented with self attention and ELMo [31] contextualized embeddings. FlowQA [8]. This model applies sequential reasoning to both context words and question turns, using all historical questions. FlowDelta [9]. This models the information gain between the current question and the last question on the basis of FlowQA, which implicitly considers the continuity of questions. SDNet [7]. This network employs BERT with locked parameters to encode the input context and questions, while reasoning through self-attention and inter-attention mechanisms. SDNet appends all historical information to the current question. Graphflow [10]. This constructs a question-aware context graph for each question turn and uses GRU to reason about these consecutive graphs. HCFTR [13]. This includes a multi-flow transition mechanism and a multi-level flow-context attention mechanism for comprehensive reasoning. All historical information is used. HAE [11]. This incorporates historical information by adding a layer of historical answer embedding to BERT to mark the locations of historical answers in the original context. HAM [12]. This model encodes the distance of the historical information based on HAE and performs a soft selection of historical information with an attention mechanism. BertCoQAC [5]. This network is based on BERT, and selects historical questions through manually set thresholds.
Evaluation metrics
Comparision of F1 Scores on CoQA dev set
Comparision of F1 Scores on CoQA dev set
The creators of QuAC provided two evaluation scores for this dataset: the macro-average F1 and the human equivalence score (HEQ). The F1 score is a function of precision and recall, calculated by taking into account the overlap of prediction words and references after removing stop words. HEQ was proposed to compensate for the shortcomings of the F1 score in terms of evaluating multiple valid answers, and is a performance measure for estimating whether the output of a system is as good as a human’s performance. HEQ-Q and HEQ-D are the percentages of instances in which the F1 score exceeds or matches that of a human for a given question or an entire dialog, respectively.
The CoQA dataset is evaluated by seven F1 scores, consisting of five in-domain and two out-of-domain F1 values.
For the encoding layer, we used a 300-dimensional pretrained Glove and 768-dimensional locked parameters bert based on our computing resources support. We set the embedding size of POS, NER, exact matching feature to 12, 8 and 3, respectively. The size of the hidden unit for all LSTM or GRU layers was 125, meaning that the bi-direction output had 300 dimensions. All the recurrent weight matrices were initialized with random orthogonal matrices, and the biases were initialized with zero vectors. The maximum lengths of questions and answers were set to 30 and 25. Sentences that exceeded this length were cut, and sentences that fell short were filled with zeros. To avoid overfitting, a dropout [32] rate of 0.4 is applied in embedding layer and a dropout rate of 0.3 is applied in interaction and reasoning layer. We utilize Adam [33] as the optimizer to train the model and the initial learning rate is set to 1e-2. For recurrent reasoning, the batch size was set to 1, meaning that a batch contains all the questions in one dialog. The training process requires at least 30 epochs. Our model is implemented on PyTorch.
Experimental results and analysis
CoQA and QuAC results
The results of our experiments on CoQA and QuAC are presented in Tables 3 and 4, respectively.
Since the test sets of both CoQA and QuAC have not been made public, we report the scores for the development set in the tables. The effectiveness of our model on the task of CMRC can be seen.
Comparision on QuAC dev set
Comparision on QuAC dev set
Ablation test of model structure on CoQA
Comparison of F1-scores of different pre-trained models
From Table 3, we can make three observations, as follows. The performance of methods based on pre-trained language models is significantly better, and the performance of our model is much higher than the first six alternative models in the table. In comparison to other models based on a pre-trained BERT, our model also shows superior performance. Compared with the cornerstone model SDNet, our QSM has improved its F1 score by 6.4%, thus demonstrating the importance of the way we treat the historical information and the reasoning processes. The improved performance of our model is seen across all areas of CoQA dataset, indicating that our approach is domain-independent.
Table 4 also shows that the performance of our model on QuAC dataset is significantly improved compared with other models based on pre-trained BERT. Although both are CMRC datasets, the performance of our model differed more from human beings on QuAC (5.8%) than on CoQA (13%). From a careful analysis, we found that unanswerable questions made up 20.2% of the QuAC dataset, which affected the performance of our model. Reasoning about unanswerable questions will therefore become the focus of our research in future.
In order to examine the impact of each component on the overall performance of the proposed QSM, we conducted an ablation study by removing each of the most important innovations in this module, including the first key for history selection, the second key for history selection, and the recurrent reasoning module. Table 5 shows the ablation results. “No_F1” represents the F1 score for questions with the answer “no”, whereas “Yes_F1” represents the F1 score for questions with the answer “yes”. “No_answer_F1” indicates F1 score for questions without an answer.
From the data presented in the table, it is apparent that each of the proposed modules are important in achieving good results. However, there are several interesting findings that are worthy of note. (i) The contribution from each component to the holistic architecture is different. It is obvious that the F1 score decreases most when the question coupling selection module is removed, thus proving that short sentences contain limited information we focus is essential. (ii) Although the overall performance of our method is better than the alternatives, it has great difficulty with unanswerable questions. This is an inherently difficult problem for black-box neural networks, but the marked decline in the performance of our network suggests that excessive reasoning operations will tend the model to output a result. We may focus on this problem in subsequent research work.
Implementation of alternative pre-trained models
Here, we compare the performance of BERT with an alternative pre-trained model RoBERTa [25]. The results are presented in Table 6. It can be seen that pre-trained language models are of great significance in the task of CMRC, and our proposed QSM module consistently enhance performance on the basis of these pre-trained models. In terms of pre-trained model scales, employing a larger model when sufficient resources are available can improve model performance significantly. When comparing BERT with RoBERTa, the latter outperforms BERT by a large margin, owing to its additional training dataset, extended training duration, and dynamic adjustment on MASK. Nevertheless, the QSM module exhibits less improvement when applied to RoBERTa. We believe that RoBERTa is better at capturing semantics in CMRC tasks, thereby handling a portion of the historical selection task.
Question length analysis
The original intention of history selection in this paper is to make better context understanding for short questions. We therefore studied F1-scores under different question lengths in CoQA dev set. According to Fig. 4, F1-scores are improved in question lengths ranging from 1 to 11, especially when the question length is one, which meets our expectations. We initially have concerns about whether question coupling would adversely affect longer questions. However, upon evaluating the results, we observed that the F1-score also exhibited improvement for questions exceeding 13 words in length. This improvement can be attributed to our multi-level, multi-granularity question selection module, which allows us to gain a deeper understanding of the question history. For question lengths greater than 16, The results of model show oscillates. It is primarily caused by the quantity distribution of questions in the CoQA verification set. Within this set, There are only two instances of each question length of 18, 19, and 20 words. When all answers are predicted correctly, the F1-score reaches 100%, while when all answers are predicted incorrectly, the F1-score drops to 0%, leading to fluctuations in the figure. We believe that the model’s performance will become more stable with sufficient and balanced available data.
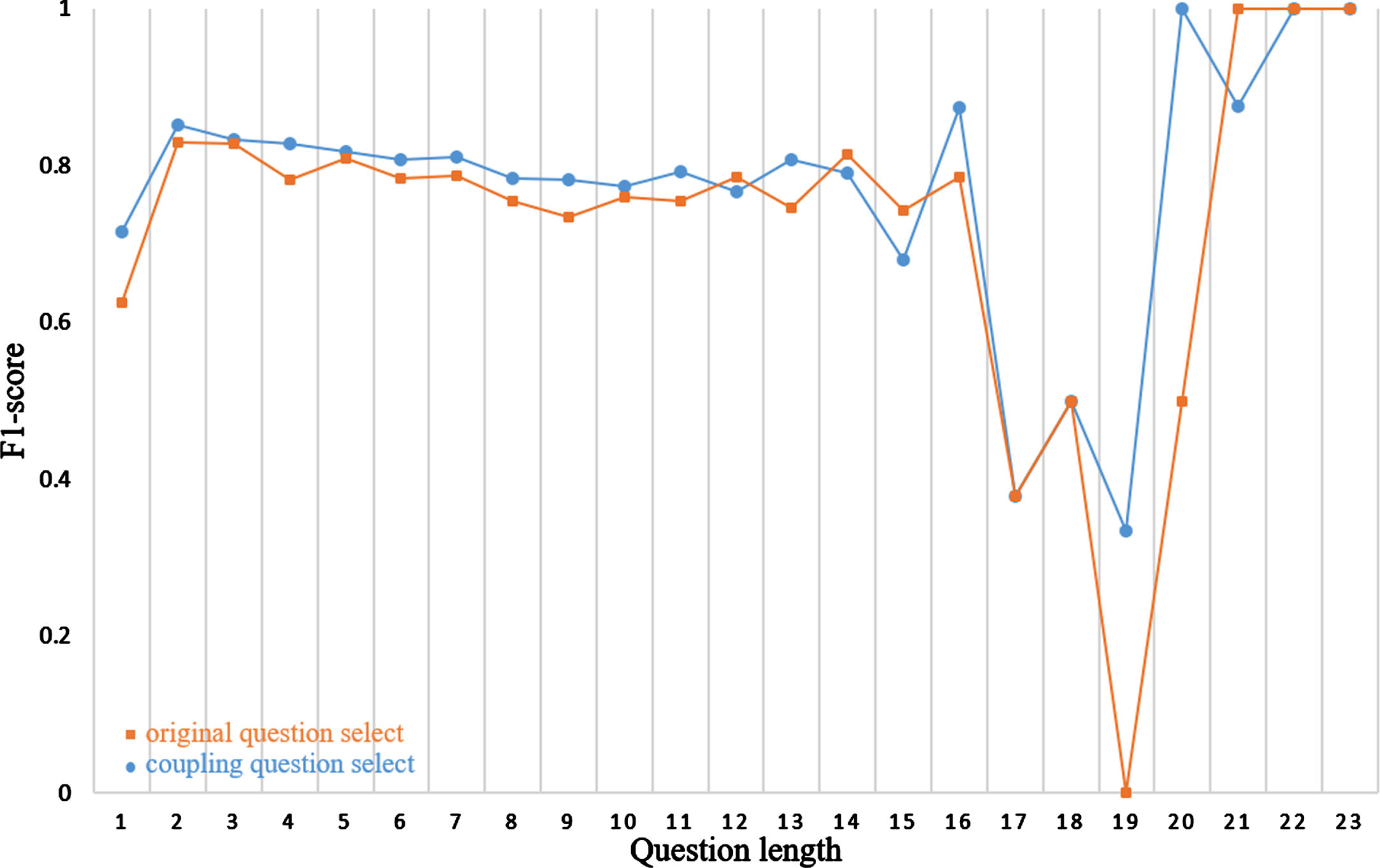
Relationship between F1-score and question length on CoQA.
In order to illustrate the functioning of our history selection module in an intuitive way, we extract a accurately predicted instance from the CoQA development set to visualize the distribution of attention between the current question and historical questions in the reasoning process, as represented by the similarity matrix S in Eq. (11) actually. The total predicted result is shown in Fig. 5 and the visualization of this example is shown in Fig. 6.

A complete example of CoQA dev dataset, including context, questions, golden answers, and predicted answers.
Each small square in the figure represents a similarity score between two corresponding questions on the horizontal and vertical axes. The darker the pink color, the stronger the correlation between two questions, whereas the darker the blue color, the less related the two questions are. Each square on the diagonal line represents the similarity of each question to itself, which has a value of one, meaning that the squares along the diagonal are brightest.
Inspection of the figure shows that entire conversation contains several separated topic flows, labeled with rectangular boxes R. For example, In rectangle R2, the conversation flow revolves around Kendra and the bus, while in rectangle R3, the conversation shifts to Kendra and the school teacher. Our similarity matrix largely captures this kind of continuous discussion on one topic, as most models do. It was more interesting to note that our model handled the change of topic well in round Q14, which was the main motivation for our study (that is, we do not use all of the historical information). When the topic changed, the similarities between the current question and previous rounds were very low, and the model needed to pay more attention to the original context information than the historical conversation, as this might cause a misunderstanding. We also found that the phenomenon of topic recall was captured in rectangle R1. When the conversation mentioned whether Kendra missed the bus, the model checked back for the bus stops mentioned in the second round. This control of the conversation history greatly improved the accuracy on the CMRC task in our study.
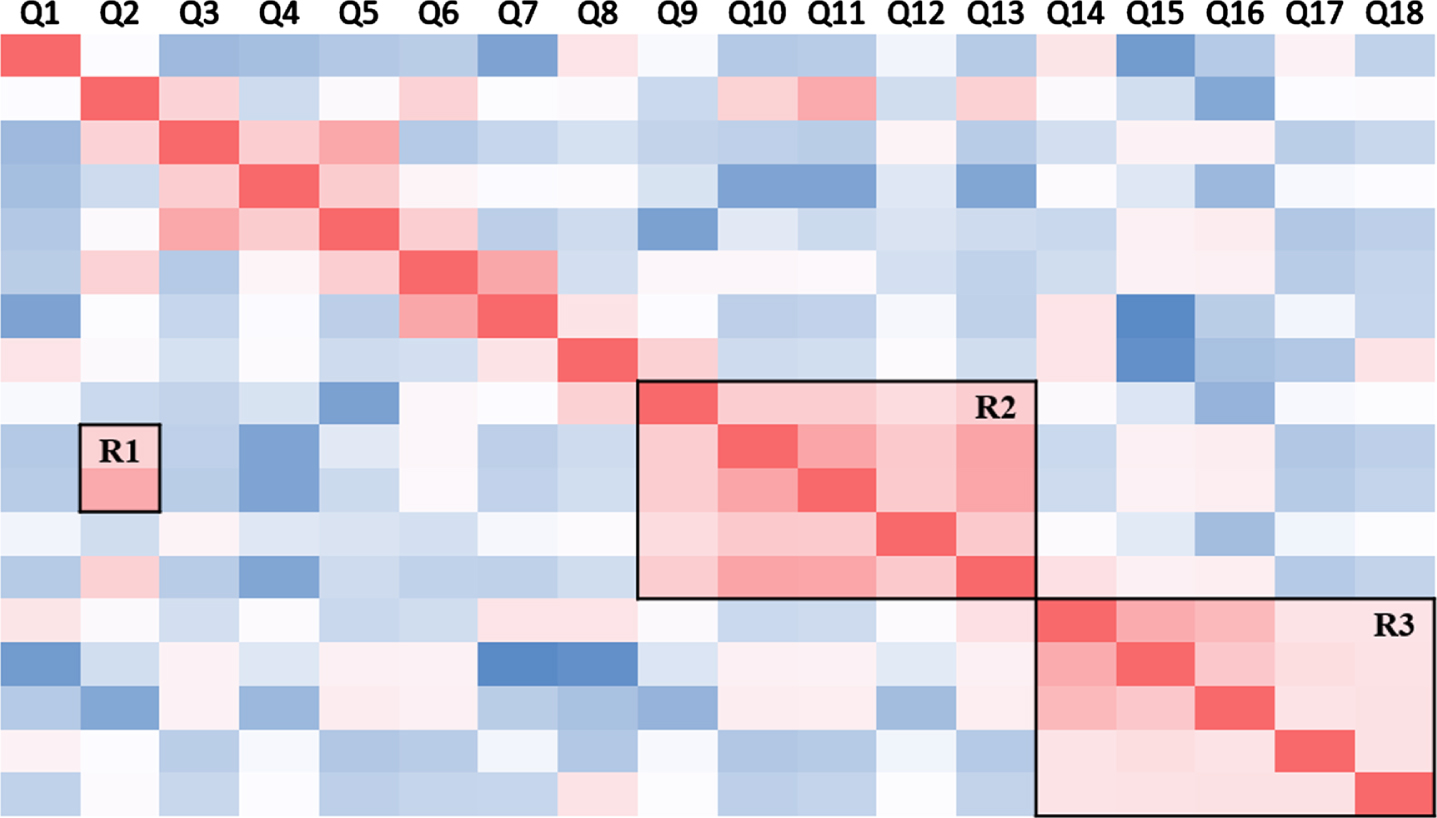
Visual analysis of the relevance of questions.
In this paper, we mainly consider the negative effects of using redundant historical information when answering the current question in the task of CMRC. Based on our observations of short questions with strong continuity, we perform coarse-to-fine historical matching for both the current question and the coupled question, respectively, to select the most effective historical information for subsequent reasoning. We then predict possible answers through recurrent reasoning at the level of the historical question-aware context. Recurrent reasoning takes into account the flow of semantic information in the direction of dialogue turns, thus making effective use of selected historical information. Finally, several experiments on two benchmark datasets CoQA and QuAC proved the effectiveness and superior performance of our proposed model. Although some progress has been made, historical modeling remains inefficient in terms of computational resources. Our model follows previous work in that we set the batch size to one. This is primarily due to the varying number of questions attached to each article and the need to calculate correlations among these questions. However, it means that the model cannot be trained in parallel, resulting in longer training times. In the future, we will investigate more efficient ways of handling conversational reading comprehension and will address the issue of unanswerable questions in our experiments.
Acknowledgments
This work was supported by Beijing Nova Program from Beijing Municipal Science & Technology Commission (grant number Z211100002121120).