
Abstract
Text classification is an important tasks in natural language processing. Multilayer attention networks have achieved excellent performance in text classification tasks, but they also face challenges such as high temporal and spatial complexity levels and low-rank bottleneck problems. This paper incorporates spatial attention into a neural network architecture that utilizes fewer encoder layers. The proposed model aims to enhance the spatial information of semantic features while addressing the high temporal and spatial demands of traditional multilayer attention networks. This approach utilizes spatial attention to selectively weigh the relevance of the spatial locations in the input feature maps, thereby enabling the model to focus on the most informative regions while ignoring the less important regions. By incorporating spatial attention into a shallower encoder network, the proposed model achieves improved performance on spatially oriented tasks while reducing the computational overhead associated with deeper attention-based models. To alleviate the low-rank bottleneck problem of multihead attention, this paper proposes a variable multihead attention mechanism, which changes the number of attention heads in a layer-by-layer manner with the encoder, achieving a balance between expression power and computational efficiency. We use two Chinese text classification datasets and an English sentiment classification dataset to verify the effectiveness of the proposed model.
Introduction
Text classification is a crucial task in natural language processing, as it seeks to convert textual information into a machine-readable form to achieve human-like performance. However, the large scale, complexity, and imbalance of textual data make it challenging to perform large-scale pretraining and fine-tuning, which in turn poses obstacles to obtaining precise feature representations and constructing effective classification models [1, 2]. Traditional machine learning algorithms, such as naive Bayes classifiers [3], KNN classifiers [4], and SVMs [5], have been effectively established for text classification tasks. Although these methods have achieved good performance, some issues remain, such as their inability to correctly express word orders and semantics and their text recognition limitations caused by the high dimensionality and sparsity of the given data. In recent years, with the rapid development of data mining techniques, neural networks based on CNN [6], LSTM [7, 8], and RNN [9] have gradually been used for text classification, and attention-based network models have been able to effectively solve the text classification problem. An attention mechanism focuses on extracting key semantic information by assigning different weights to words in a sentence to construct attention information and achieve improved model performance. However, multilayer attention networks also have many problems.
Multilayer attention networks can enhance performance by adding more attention layers. However, this also leads to significant time and space overheads. Increasing the number of parameters results in higher memory usage, while deepening a multilayer attention network increases the required training time and causes more gradient-related issues.
[10, 11] discussed the low-rank bottleneck problem that exists in multihead attention. While some heads in multihead attention mechanisms are redundant, simply reducing their frequency makes it difficult for the constructed model to fully learn the semantic information of the context. Moreover, increasing the vector dimensionality significantly increases the computational overhead of the model.
Self-attention mechanisms mainly focus on word-level cloze learning and do not fully utilize the semantic and spatial information contained in the given data. The extracted semantic feature space is limited, which poses a challenge for complex semantic text classification tasks.
The main contributions of this article are as follows. In this article, we propose a text classification model called variable multihead hybrid attention based on BERT (BVMHA). The model proposed in this paper achieves excellent results on several datasets without introducing external knowledge while requiring a small number of parameters and minimal hardware computations. We incorporate spatial attention into a self-attention module to improve the performance of the self-attention model in terms of extracting semantic information properties. We present a variable multihead attention-based self-attention mechanism that alleviates the low-rank bottleneck of multihead attention, enabling the model to balance its computational speed and expression power.
The paper is structured as follows. Chapter 2 reviews the related work, Chapter 3 describes the structure and details of the proposed model, Chapter 4 presents the experimental results and analysis, Chapter 5 provides a visual analysis to demonstrate the effectiveness of the proposed model, and Chapter 6 concludes the article and discusses future improvements.
Related works
As deep learning continues to be widely applied in natural language processing, related technologies and research algorithms are now being utilized in text classification tasks as well. The TEXTCNN [12] model uses a convolutional neural network for text classification by making some changes to the input layer of the CNN. The model primarily focuses on the local text information, thereby failing to obtain contextual information. Consequently, this limitation has an adverse impact on the model’s ability to understand the semantic meaning of the given text.
Traditional word vector models are built upon statistical approaches such as naive Bayes classifiers [3], SVMs [5], KNN classifiers [4], and other similar techniques. On the other hand, Word2Vec [13], a deep learning-based word vector model, and ELMo [14], proposed by M.E. Peters et al., utilize a bidirectional LSTM network to acquire the contextual representations of words. These models dynamically adjust their vector representations based on word-specific contextual information obtained from pretrained word vectors. However, ELMo handles the model loss issue by simply stacking the losses of the two models together.
In 2017, VASWANI [15] proposed the transformer model to parallelize the computation process by introducing a self-attention mechanism, which enables larger models to be trained on larger datasets. Starting in 2018, a series of transformer-based pretraining models emerged, and BERT [16] is one of the widely used pretraining models; it obtains pretraining models by performing two pretraining tasks, masked language modeling and next sentence prediction, and fine-tunes them on the text classification task to obtain models that are applicable to text classification with optimal results at that time. Since 2018, we have seen the rise of a set of large-scale transformer-based pretrained language models (PLMs). Transformer-based PLMs use deeper network architectures and are pretrained on larger text corpora to learn contextual textual representations by predicting context-based words. In a transformer-based model, the “pretraining + fine-tuning” training mode [17-20] occupies a dominant position in the NLP field. Multidimensional feature extraction in the semantic space was achieved in the literature [21] by adding a multidimensional convolution module after the BERT pretraining model. Reference [22] achieved better results using spatial attention-assisted semantic matching tasks. BERT models, convolutional neural networks, and recurrent neural networks have made some progress in text classification. However, BERT models mainly focus on word granularity for completion learning and do not fully utilize the lexical and semantic information contained in the input data. Recurrent neural networks can obtain the temporal information of text, but recurrent neural networks are not sensitive to local information. In the face of the above problems, we propose a variable multihead hybrid attention approach based on BERT (BVMHA) that achieves improved text classification performance with a small number of computations.
Model introduction
BVMHA structure
Google proposed the BERT pretrained model in 2018, and BERT excelled in 11 NLP task tests. BERT is based on the transformer implementation, and a key factor in the success of BERT is the powerful role of its transformer. The structure of the encoder network model contained in BERT is shown in Fig. 1.
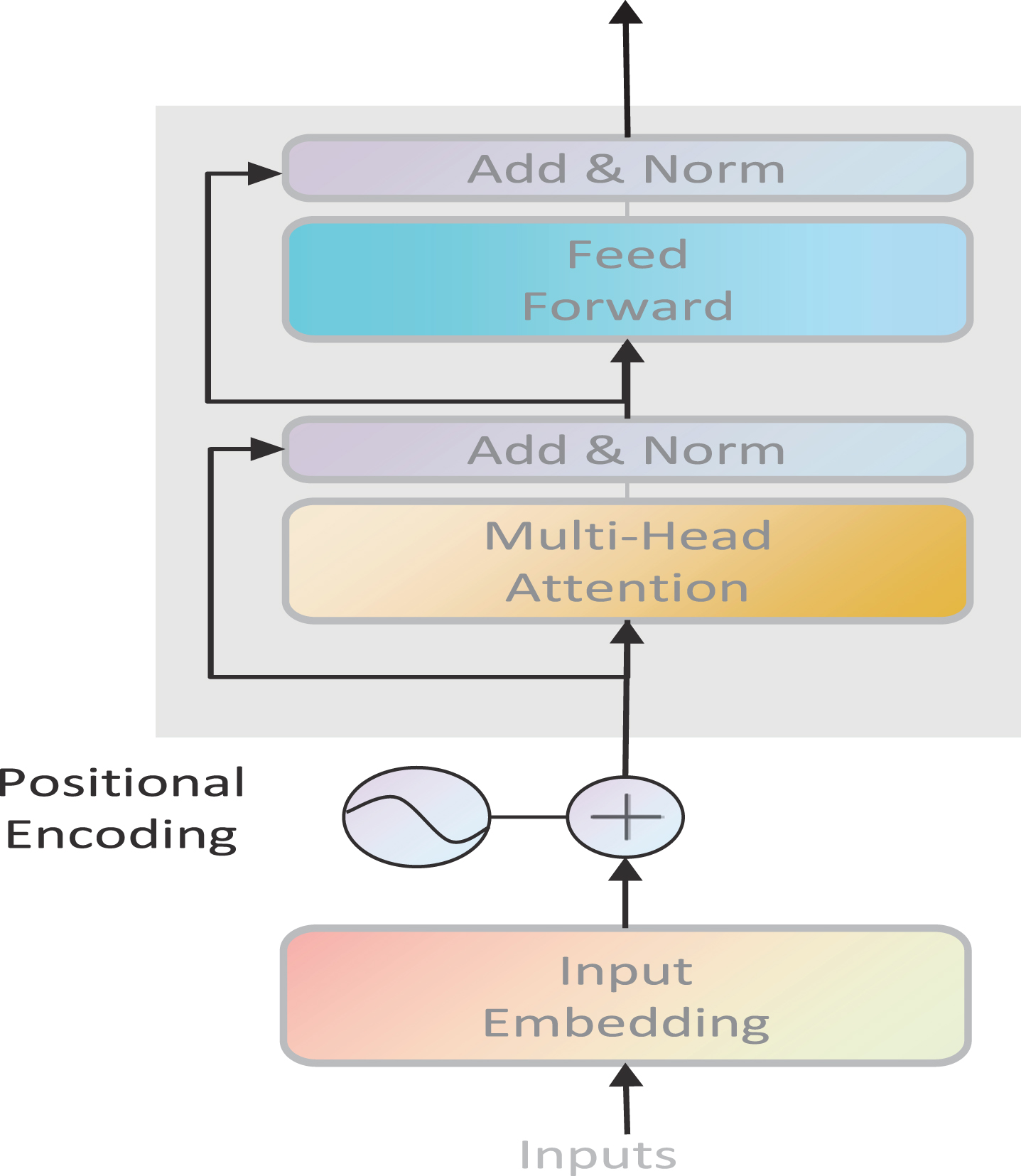
The structure of BERT.
This article proposes a text classification model called BVMHA based on the BERT pretraining model. The improvements of BVMHA over BERT include prompt templates and a multifeature semantic extraction module. The BVMHA text classification model proposed in this paper takes a text utterance as input and constructs a complete label-sentence utterance by integrating it into a prompt. The utterance is then mapped to a word embedding matrix with a positional encoding added as the input layer. The pretrained word vector is then fed through a variable multihead hybrid attention layer to extract semantic features from the text. The output of this layer is passed through a residual normalization layer and then through a feedforward network-based residual normalization layer, where the obtained output is used as the next input layer. After n layers, the semantic spatial information is extracted after a linear layer, the dimensionality is reduced to the number of classification steps, and softmax is performed to output the maximum probability classification. The complete structure of BVMHA is shown in Fig. 2.
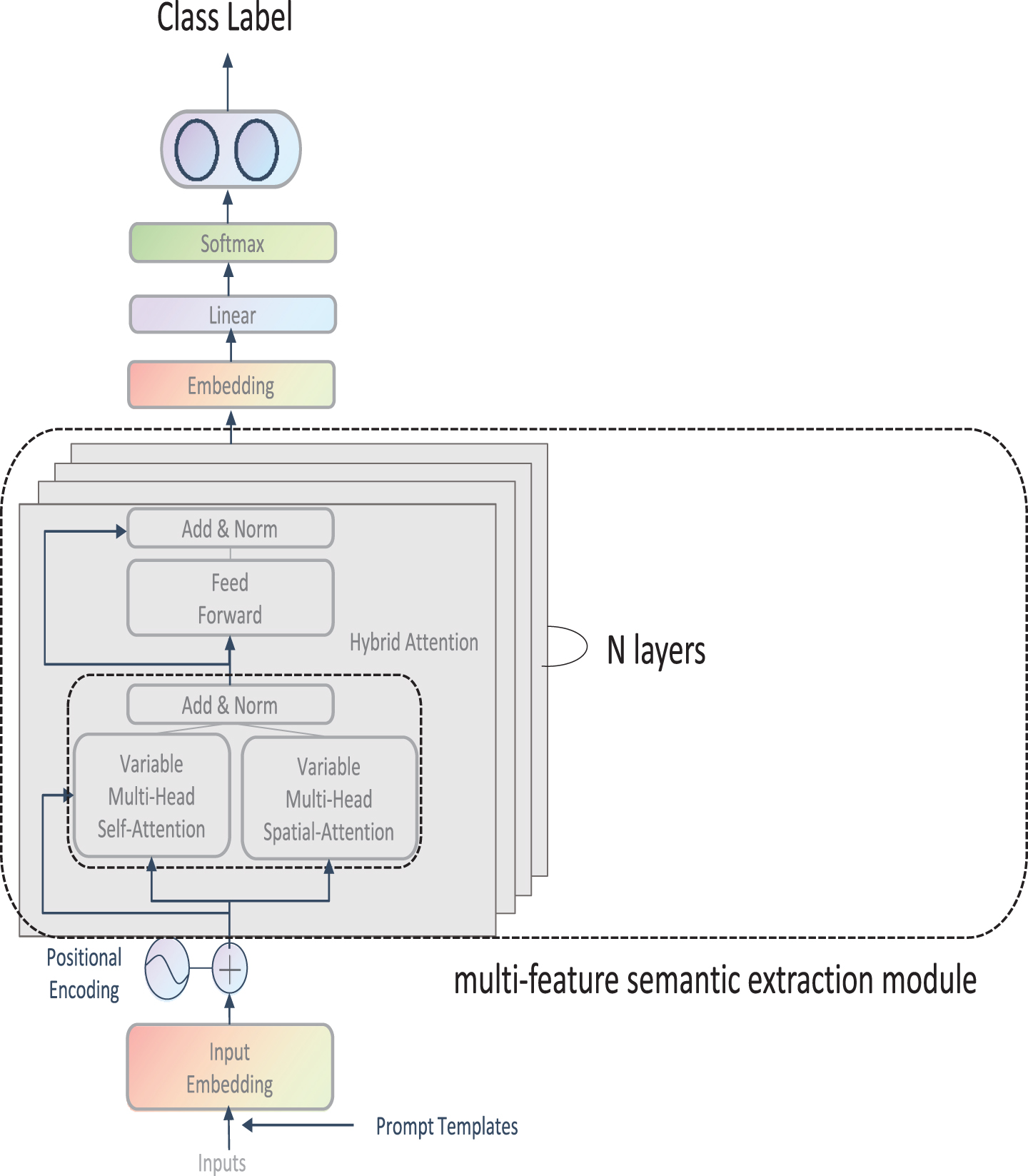
The structure of BVMHA.
Before the given word sequences are fed into BERT, 15% of the words in each sequence are replaced with a [MASK] token. The model then tries to predict the masked words based on the context provided by the other unmasked words in the sequence. From a technical point of view, the output word prediction process must do the following. 1. The layer is used for classification after the encoder output of the model is obtained. 2. The output vector is multiplied by the embedding matrix of the word list to convert the dimensionality of the output to the word list dimensionality. 3. Softmax is used to calculate the probability of each word in the word list being the [MASK]. Prompt-based learning [23] has been widely explored in classification-based tasks where prompt templates can be constructed relatively easily, such as text classification [24] and natural language inference [25]. This paper presents an approach that achieves enhanced text classification performance by incorporating a prompt during the fine-tuning stage of the BERT model. Specifically, this approach involves constructing a sentence that includes both the text label and the prompt, which are subsequently utilized during the fine-tuning process. The BERT model is then able to insert a ([CLS]) token at the beginning of the text and compute an output vector that represents the semantic representation of the entire text, which is subsequently used for classification purposes.
To illustrate, for a sentence such as “This item is of poor quality” with a prompt, the model transforms the sentence into “Negative is the classification of ‘This item is of poor quality”’. To improve upon this, we propose a new sentence construction; namely, “[CLS][MASK] is the classification of ’this product is of poor quality”’, where ([MASK]) serves as a placeholder for the word “negative”. The classification and labeling output of the model are computed via the cross-entropy loss.
Our experimental results demonstrate that incorporating the prompt into the training process can effectively improve the model’s ability to learn relational features between text and labels without the need for changes to the model architecture or an increase in its computational burden. Figure 3 depicts the process of constructing a prompt.
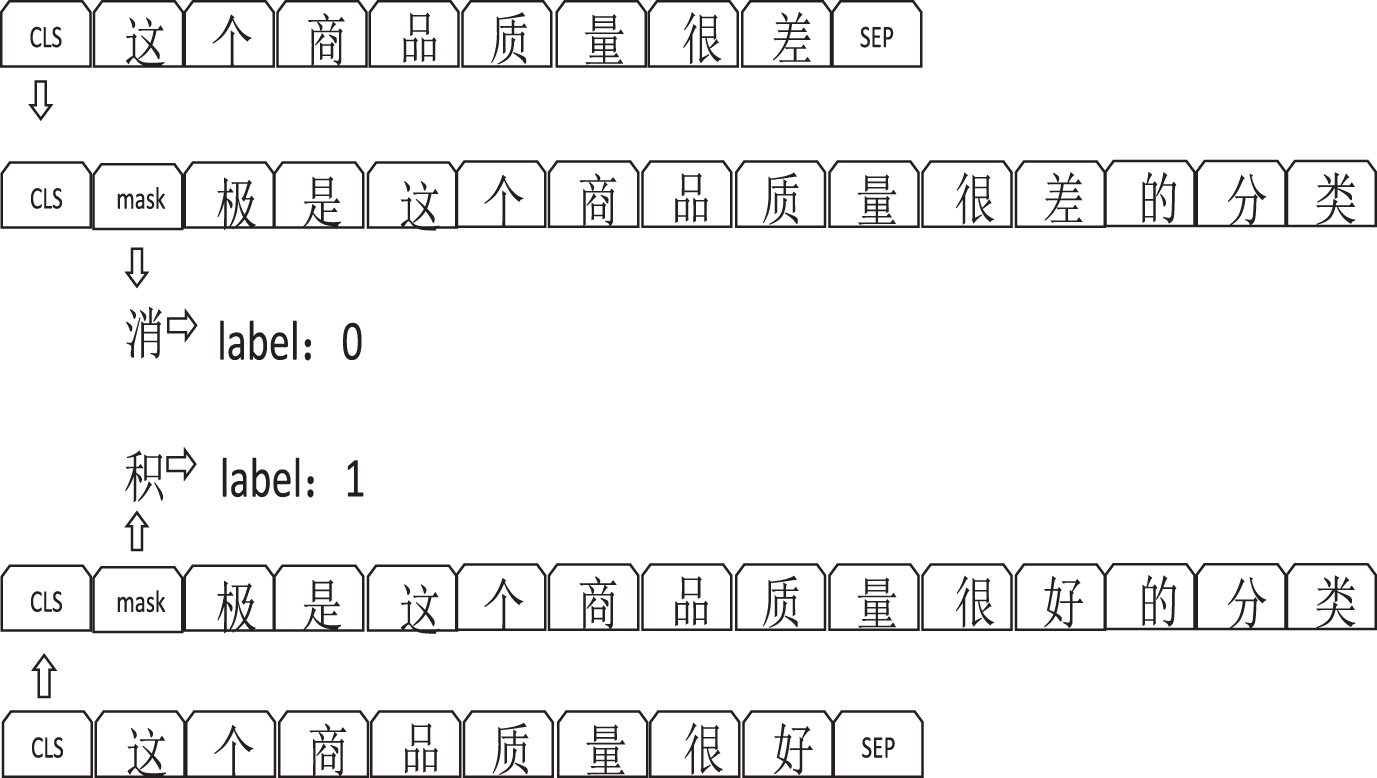
Process of constructing a prompt.
The proposed multifeature semantic extraction module in this paper consists of two parts: a variable multihead attention layer and a spatial attention layer, and the module extracts different semantic spatial information features for fusion and finally outputs a classification. The complete structure of the multifeature semantic extraction module is shown in Fig. 4.
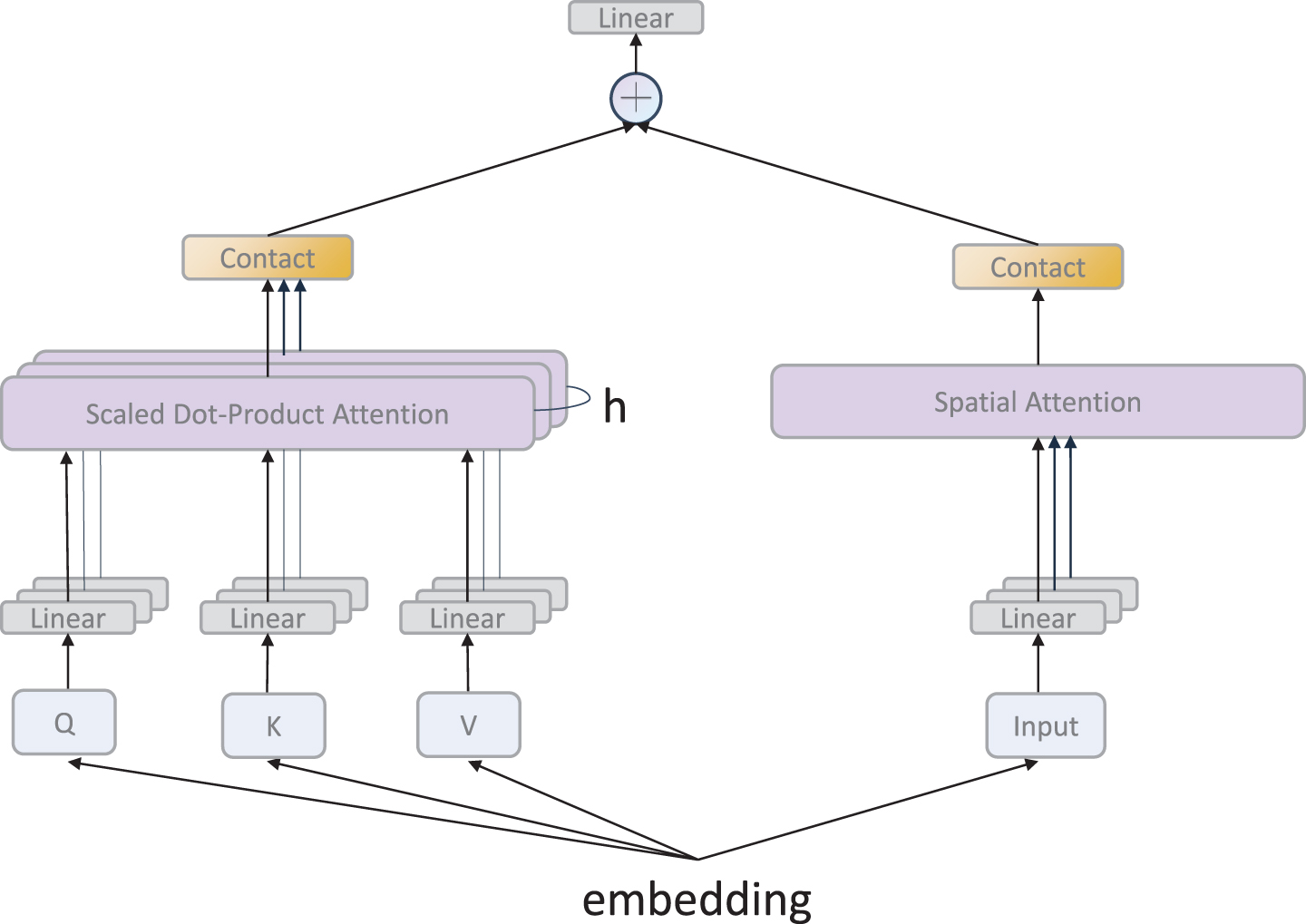
The multifeature semantic extraction module.
The feature matrices extracted by the self-attention and spatial attention modules are added and fused, and the formulas for doing so are shown below.
The input embedding matrix M is linearly transformed three times using W q , W k and W v to obtain the Q, K, and V matrices, respectively; the Q matrix is recorded as the query matrix, the K matrix is recorded as the key matrix, and the V matrix is recorded as the value matrix. SelfAttention (·) is described in Equation (5). The main implementation steps of the self-attention mechanism are shown in Fig. 5.
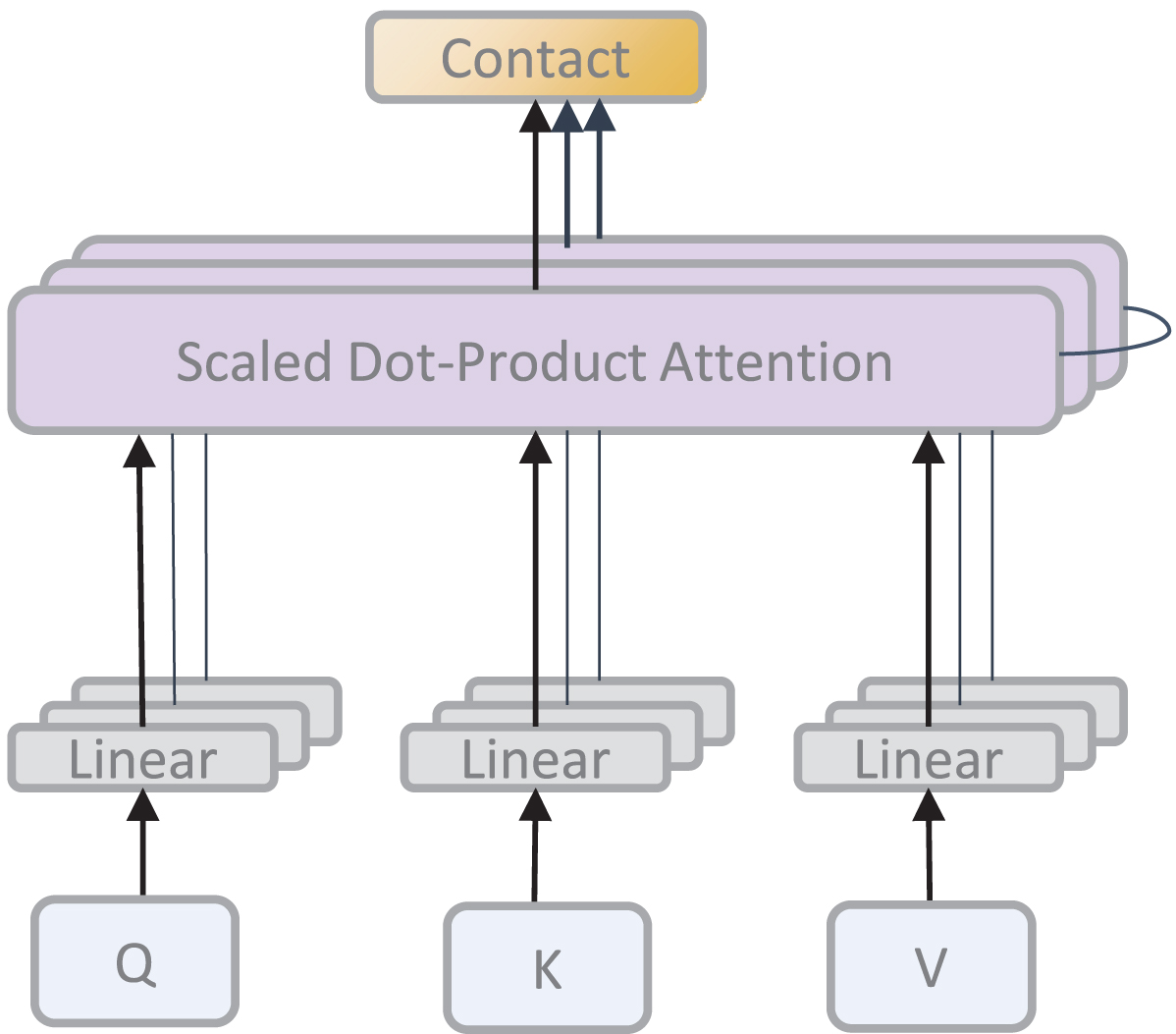
Self-attention.
We describe SpatialAttention (·) in detail in Section 3.3.2.
Due to the number of static attention heads set in BERT, this paper proposes a variable multihead attention mechanism, which enables the model to learn semantic features from different angles while reducing the number of redundant attention heads. The number of attention heads h decreases with the number of encoder layers. It should be noted that h needs to be divisible by the length of the word embedding dimensionality. When it is not divisible, h is still the value of the previous h. For example, suppose that h is 12, and the hidden embedding dimensionality is 768. When the model reaches the first encoder layer, h is 12. When the second layer is used, h should be 10, but this value is not divisible by the hidden embedding dimensionality, so the value of the previous h is still 12. In the third layer, h is 8, and this reduction process continues in a layer-by-layer manner; the specific mechanism is shown in Fig. 6.
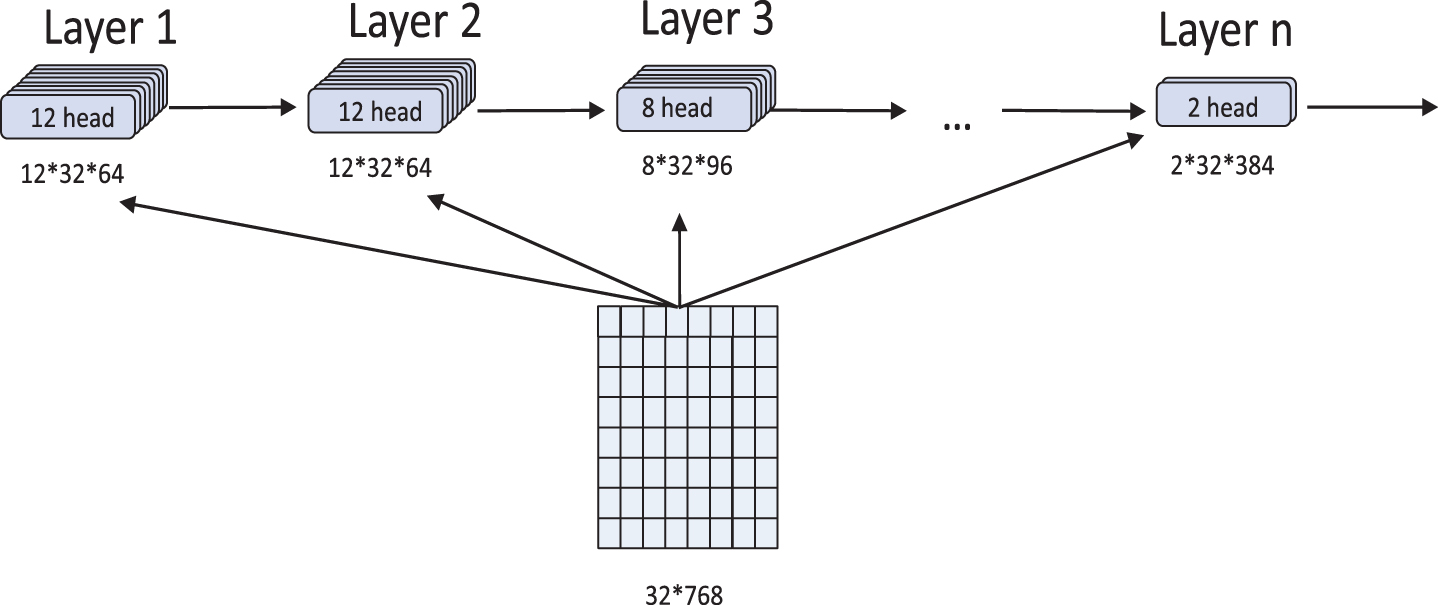
Variable multihead attention mechanism.
Experiments show that variable multihead attention can enrich the angle of feature extraction and semantic feature space information, leading to better performance than that of static multihead attention. In this paper, the step size is set to 2, and the number of attention heads is in the [2, 12] range. The corresponding formula is shown in Equation (6).
In the formula, Hl+1 represents the current number of attention heads, H l represents the number of attention heads in the previous layer, l represents the current number of layers, Step represents the step size for reducing the number of attention heads and n represents the current number of layers.
This article combines spatial attention and self-attention to construct hybrid attention. Unlike the self-attention mechanism that focuses on global features, spatial attention can make the model focus on important task-related regions. For example, in classification tasks, spatial attention finds important parts for processing. First, maximum pooling and average pooling are applied in the channel dimension to obtain two representation matrices, and these two representation matrices are spliced together. Then, through the convolution layer with a sigmoid activation function, a weight coefficient M s is obtained. Finally, M s is multiplied by the semantic information to obtain the new scaled features. The spatial attention mechanism is shown in Fig. 7.
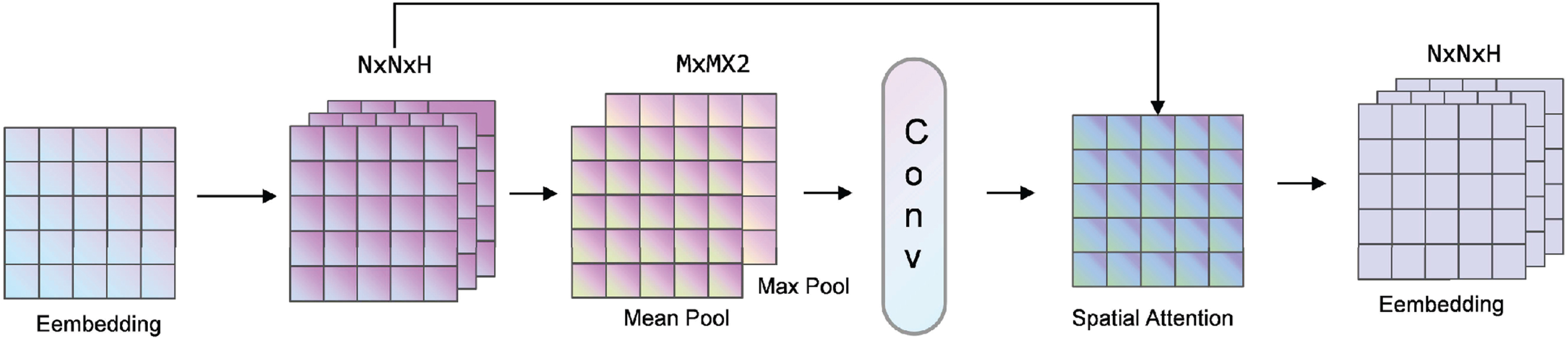
Spatial attention.
Because the word embedding matrix has only one channel, how to introduce spatial attention to adapt to the data characteristics of the given text is a key issue. Inspired by the multihead self-attention mechanism, this model uses multiple attention heads as channels to adapt spatial attention to the channel dimension. Here,
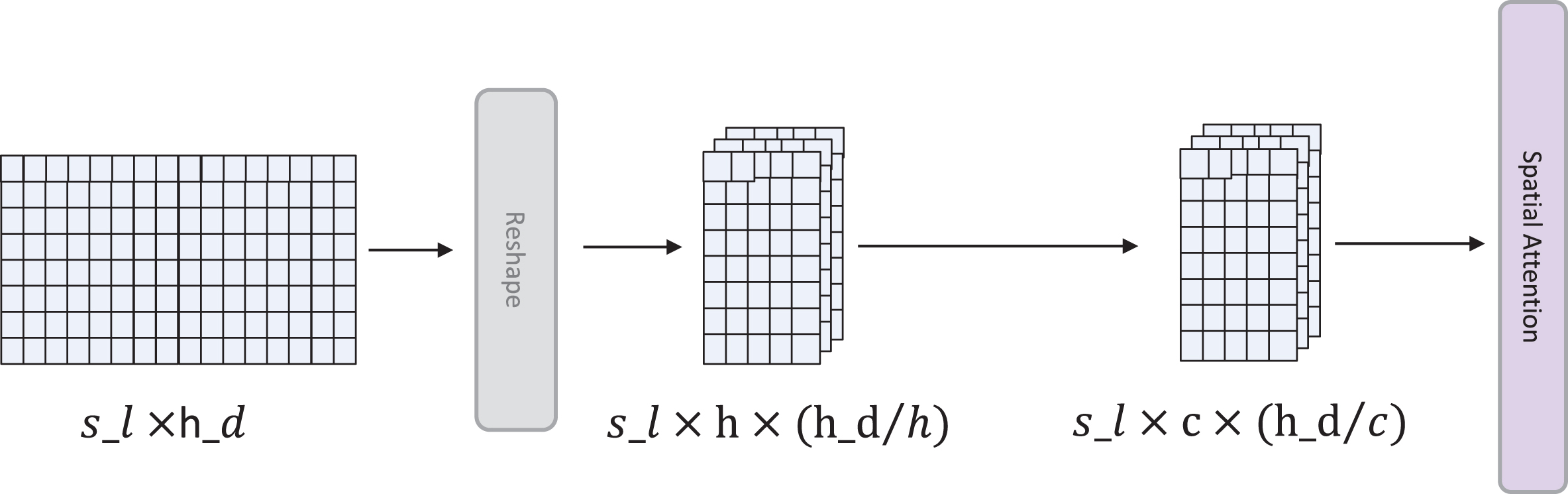
Spatial attention operations applied to a text embedding.
Experimental data sources and dataset construction
Three datasets are used in this experiment, and they are introduced as follows.
ChnSentiCorp is a Chinese sentiment analysis dataset containing online shopping reviews of hotels, laptops, and books.
SST-2 (The Stanford Sentiment Treebank, Stanford Sentiment Treebank), a single-sentence classification task, contains human annotations of sentences in movie reviews and their sentiments. This task is to determine the emotion of a sentence. The categories are divided into two types: positive emotions (positive, with a sample label corresponding to 1) and negative emotions (negative, with a sample label corresponding to 0), and only sentence-level labels are used. That is, this task is also a binary classification task, which is divided into positive and negative emotions at the sentence level. The dataset distribution is as follows.
COLDDateset [26 is a Chinese insulting language dataset. The dataset contains a total of 37 r516 sentences.
The results obtained on the dev dataset are used for model parameter tuning rfinding good hyperparameters rand simulating the test set to prevent the model from overfitting on the training set. The results obtained on the test dataset are used to evaluate the performance of the model.
We used 9600 sentences on ChnSentiCorp for training r1200 sentences for validation rand 1200 sentences for testing. We use 67350 sentences on SST-2 for training r873 sentences for validation rand 1821 sentences for testing. We use 25762 sentences for training on COLDateset ruse 6431 sentences for validation rand use 5323 sentences for testing.Details of all the datasets are shown in Table 1.
The statistics of the utilized datasets
The statistics of the utilized datasets
Experimental environment: A Ubuntu 16.4 system ran Nvidia Quadro P5000 GPU.
Experimental parameters: The experiments used the PyTorch deep learning framework(version 1.11.0) with an embedding dimension of 768 for each word ra total word list size of 21128 ra sentence length of 128 r6 Encoder layers r12 attention matrix heads rand matrix initialization range of 0.02. The model used the cross-entropy function as the loss function rand the AdamW optimizer was used to update the parameters with a pre. The Epoch of the fine-tuning is 20. The batch size is set to 64 rthe learning rate is set to 2e-5 rthe gradient clipping max grad norm is set to 10.Results are from the average of five randomized seed experiments.
Loss function and evaluation index
Loss function: We use the cross-entropy loss function to measure the deviation of the predicted value from the actual value. The cross-entropy loss function is shown in Equation (7).
Accuracy, Precision, Recall, and F1 are used as the evaluation indices of the model, and their calculation formulas are as follows. Accuracy is the number of correctly classified samples out of the total number of samples, and its calculation formula is shown in Equation (8).
Precision refers to the ratio of the number of actual positive samples among the positive samples predicted by the model to the number of predicted positive samples. Its calculation formula is shown in Equation (9).
The recall rate (Recall) refers to the proportion of actual positive samples among the predicted positive samples, and its calculation formula is shown in Equation (10).
The F1 value is the weighted average of the precision rate and the recall rate, and its calculation formula is shown in Equation (11).
The experimental results obtained on the dev set and test dev are included. The purpose of evaluating the dev set is to show the training effect of the model during the training process. The experimental data produced on the test set show the final performance of the optimal hyperparametric model.
To verify the effectiveness of the BVMHA model, this paper utilizes TEXTCNN, FastText [27], DPCNN- [28], BERT-CNN, BERT(bert-base-cased, bert-wwm-chinese), Albert-base [18] (Albert-base-v2, Albert-chi-nese-base), Albert-xlarge, RoBERTa [17], MacBERT- [29], ERNIE2.0 [30], and ERNIE3.0 [31] for comparative experiments. ERNIE2.0 introduced external knowledge for use in training, and ERNIE3.0 introduced large-scale knowledge graphs for the first time to tens of billions of pretrained models for pretraining large-scale knowledge-enhanced models. ERNIE3.0 is significantly different from ERNIE2.0 in terms of its training method and introduced knowledge. We add a comparison experiment involving ERNIE to verify our first contribution.
From Tables 2 to 5, it can be seen that the proposed model achieves excellent results in all comparative experiments. It outperforms RoBERTa, the best performer among the baseline models, on both the CHNSenticorp dev set and test set and outperforms RoBERTa and MacBERT on the COLD dev set. It also achieves excellent performance on SST-2. Compared with those of BERT, the F1 values achieved by the proposed model on the test set are increased by 0.88%, 1.55%, 0.25%.BVMHA is the best performer in terms of Iteration speed, mainly due to the significant reduction in the number of parameters in the model. The performance of the proposed model on the three datasets is significantly improved over that of Albert-base and Albert-xlarge. Compared to RoBERTa and MacBERT, which perform best among the comparison models, the proposed model achieves the same performance requires fewer parameters and calculations.
Experimental results obtained on the dev set
Experimental results obtained on the dev set
Experimental results obtained on the test set
Floating-point operations
Iteration speed of each model (iterations/s)
Although this model does not achieve the best performance on SST-2, its ACC and F1 values are 0.7% and 0.5%, respectively, which are lower than those of the best-performing RoBERTa method. After conducting a detailed experimental analysis of the text, it is found that this model does not surpass RoBERTa. The reason for this is that RoBERTa has a larger number of model parameters and more training data, and RoBERTa takes an order of magnitude more training time than BERT. However, the parameters of this model are only 50% of RoBERTa’s, and the number of calculations is only 49% of RoBERTa’s.
Compared with Alberta-base, which has a smaller number of parameters, the number of BVMHA hardware calculation is reduced by 50.1%.
Because the ERNIE series is a Chinese task model, there is no experimental result for the English dataset SST-2. We compare the experimental results of ERNIE (2.0 and 3.0).We can find that the performance of BVMH on CHNSenticorp, COLD is 1% lower than that of ERNIE series on average, which reflects the advantage of introducing knowledge. The pre-trained model can strongly improve the performance of the model in extracting semantic features and Chinese semantic understanding on the Chinese classification task by introducing Chinese knowledge.
However, the parameters of BVMHA are only 50.85% of ERNIE, and the number of calculations is only 36.55% of ERNIE. Substantial reductions in the number of parameters and the amount of computation are acceptable and are more competitive than an average 1% reduction in classification performance.
Through the experimental results, it can be found that the proposed model can achieve the same performance as the baseline models while achieving significant improvements in its number of parameters and calculations. The significant reduction in the number of parameters, iteration speed and computation is acceptable compared to the reduction in classification performance.
To discuss the impact of each module on the performance of the developed model, the three utilized strategies, removing the prompt, the spatial attention module, and the variable attention mechanism, are tested and compared. The experimental results are as follows.
It can be seen from Table 6 that after deleting the semantic prompt words on the basis of this model, the accuracy rate drops by 0.79%, and the F1 value drops by 0.81%. Deleting the spatial attention module on the basis of this model reduces the accuracy rate achieved on the test set by 0.7% and the F1 value by 0.8% compared to those of the full model. Deleting the variable multihead attention mechanism on the basis of this model reduces the accuracy rate achieved on the test set by 1.52%, and the F1 value also drops by 1.48%. These experiments prove the effectiveness of introducing each module.
Ablation experiment
Ablation experiment
To discuss the correlation between the variable multihead attention mechanism and the number of encoder layers, this paper proposes two strategies, which are increasing and decreasing the number of heads with the number of encoder layers. The increasing strategy involves an increase from 2 to 12, and the decreasing strategy entails a decrease from 12 to 2. The results of the two strategies are shown below. It can be seen in Table 7 that when the number of heads is in a decreasing state, the model performs better, with a 0.2% increase over the increasing strategy. When the initial number of heads is large, semantic features can be captured from more angles, and the model achieves better performance in terms of capturing low-level features. In the later stage, as the number of attention layers deepens, the model captures global sentence-level semantic information. Reducing the number of redundant heads increases the feature dimensionality of a single head and improves the expression ability of the model.
Experiment in which the number of attention heads is changed
We set different numbers of encoder layers to study the effect of the number of layers on the performance of the model. As shown in Fig. 9, the model with 6 layers has the best performance on the COLD test set. When the number of encoder layers is set to 6, the model maintains fewer parameters and achieves better performance.
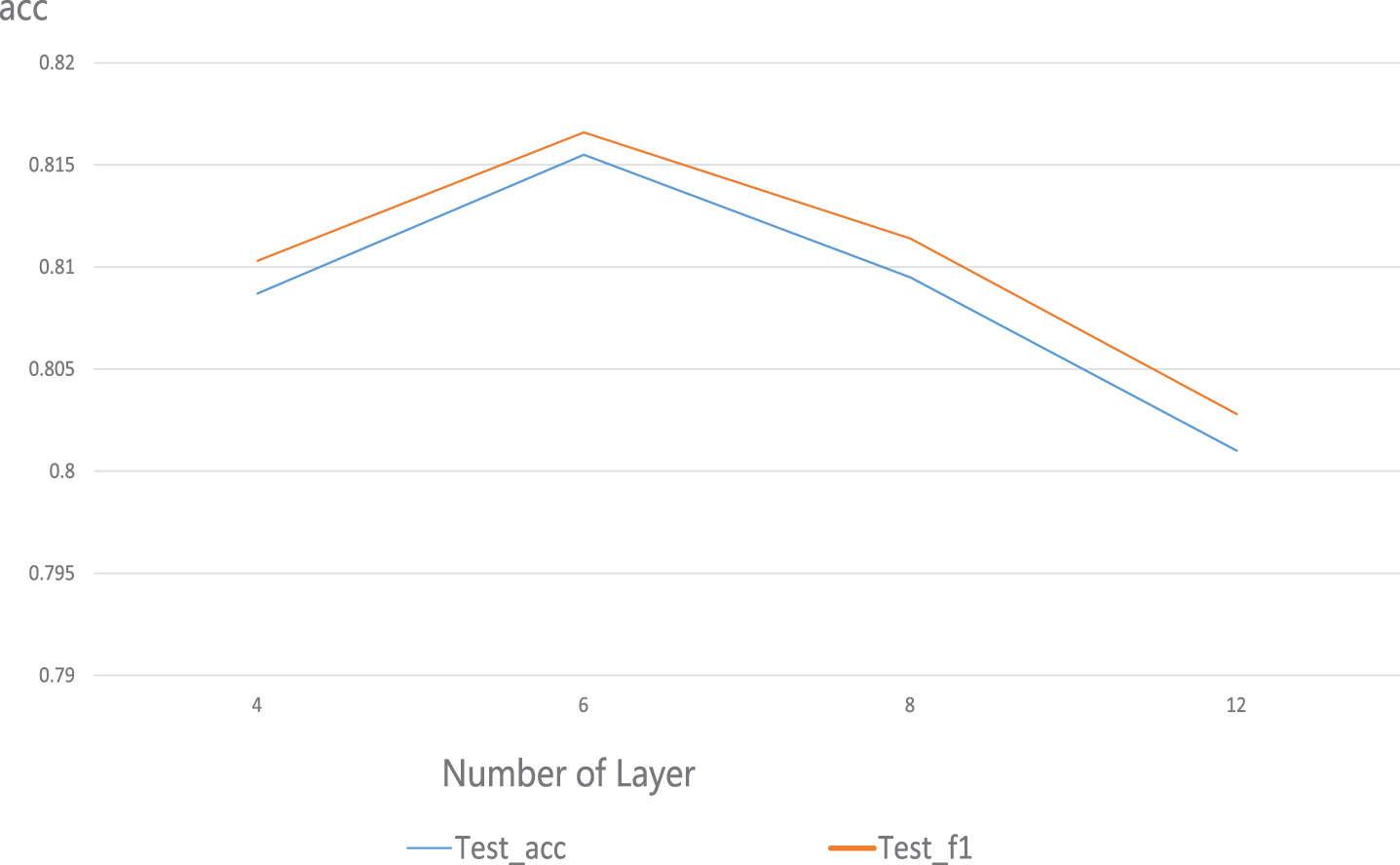
Effects of different numbers of layers on model performance.
This paper further discusses the impact of parameter sharing on the lightweight model. This experiment further reduces the number of parameters by adopting cross-layer parameter sharing, where length represents the length of the input sentence.
From Table 8, we can see that through cross-layer parameter sharing, the number of model parameters can be further reduced by 60%, and the performance exhibits a loss of 2% -3%. When the sentence length is set to 64, the training speed of the shared parameter model can be increased by 25.3%. Although parameter sharing can greatly reduce the number of parameters in the model, it weakens the expression ability of the model.
Parameter sharing ablation experiments
In this section, we provide a hybrid visual analysis of the attention module. The results of the visualization experiment are as follows. Figure 10 is a heatmap of BERT’s attention scores with seq_len equal to 128. Figure 11 is a heatmap of BVMHA’s attention scores with seq_len equal to 128. Figure 12 is the heatmap of the attention scores of BVMHA with seq_len equal to 64.
The input text is The input text is [CLS]. This book is really good [SEP]. terrible [SEP].
Because of the introduction of spatial attention, the attention weight obtained by mixed attention pay attention to contextual information from the visual level. Compared with BERT, this model more accurately captures the key areas and related information of the text. For example, in the example sentence, the negative emotional words related to the label are the focus of our attention, so from the perspective of visual perception, the degree adverbs related to “really terrible” are given higher attention weights. Despite the fact that seq_len is reduced by half, BVMHA is still able to focus on the words expressing emotions more effectively than BERT with seq_len equal to 128. The visualization results further prove that the introduction of spatial attention in this model improves the ability of the model to extract spatial information from semantic features.
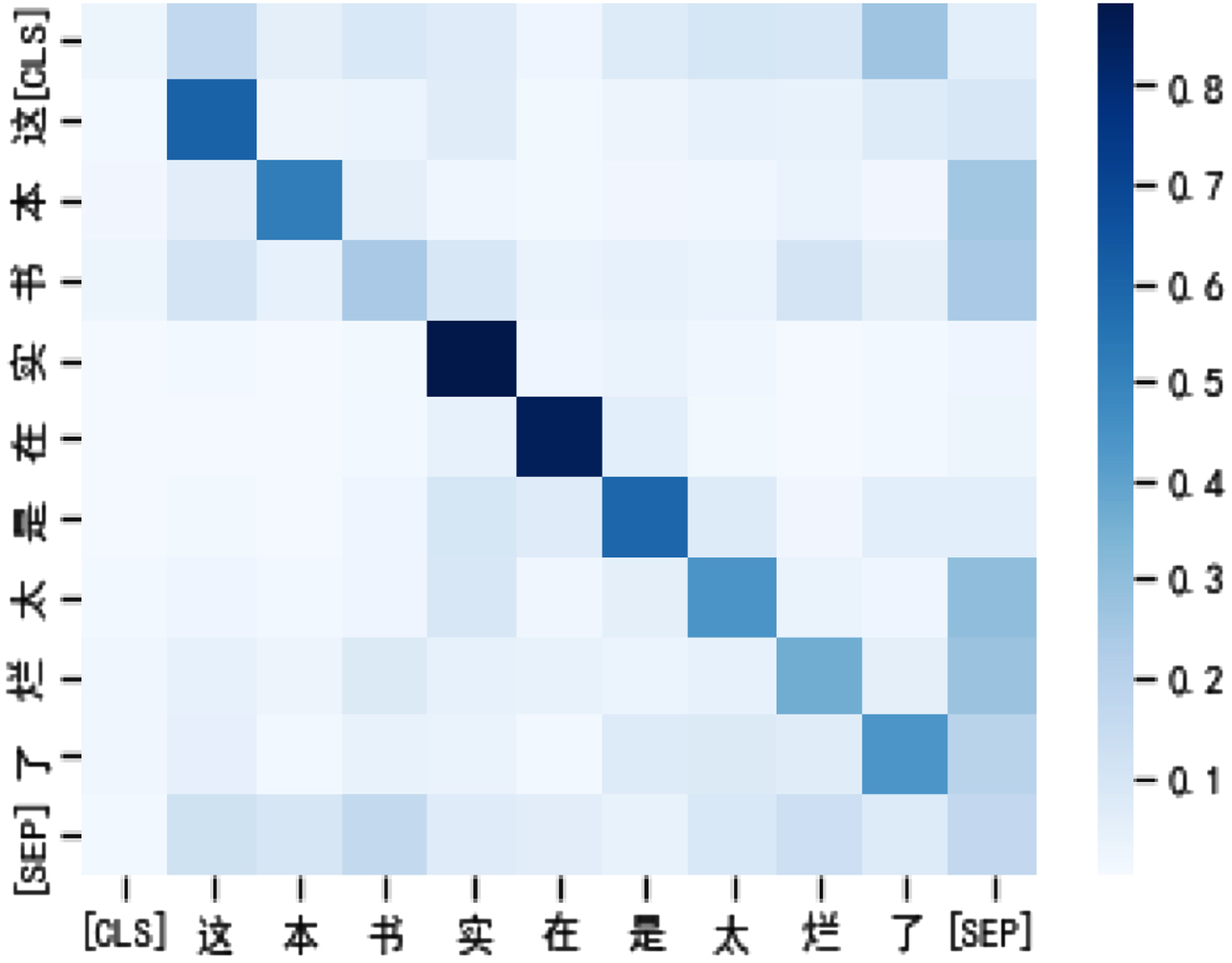
BERT self-attention score visualization.
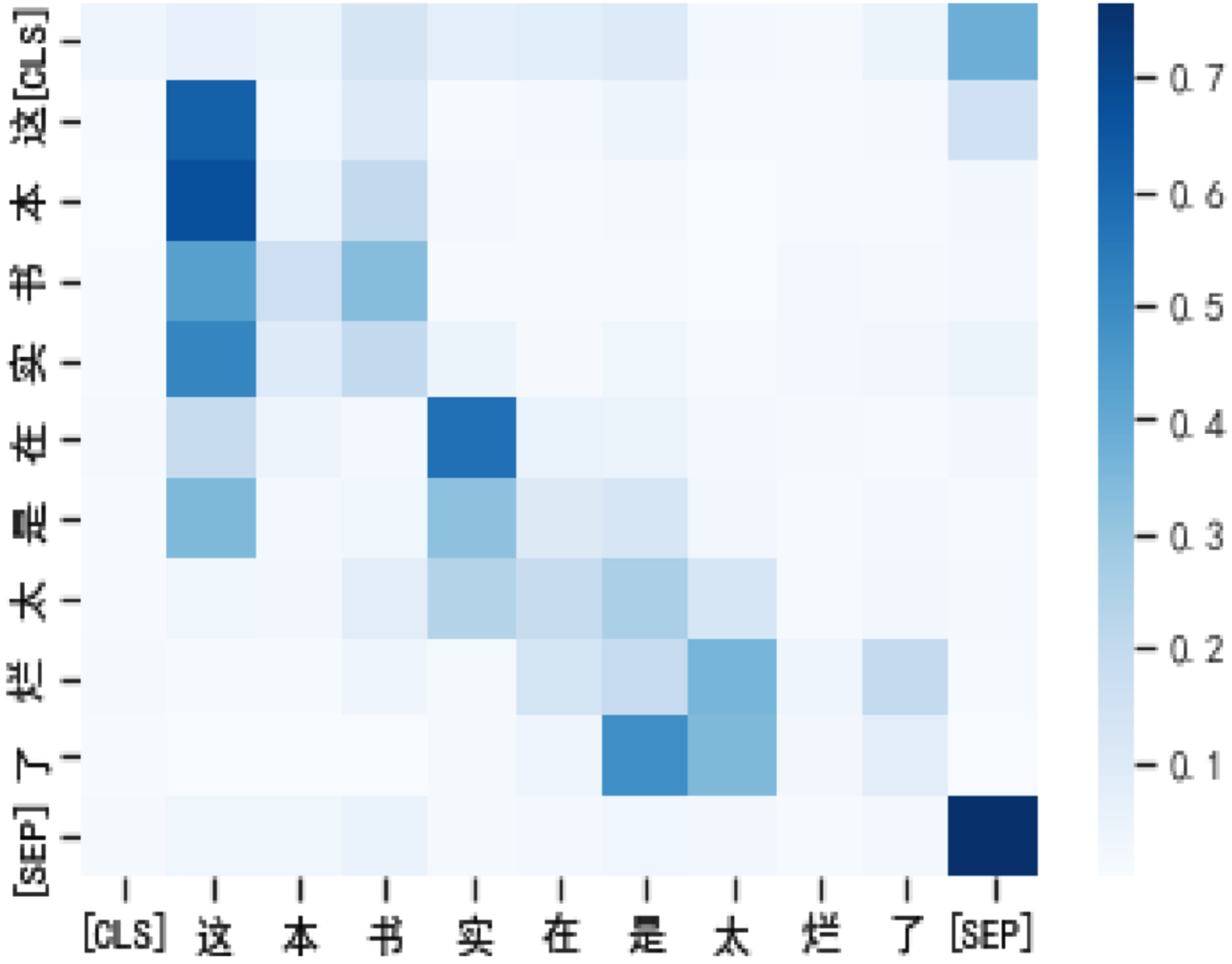
BVMHA attention score visualization with seq_len equal to 128.
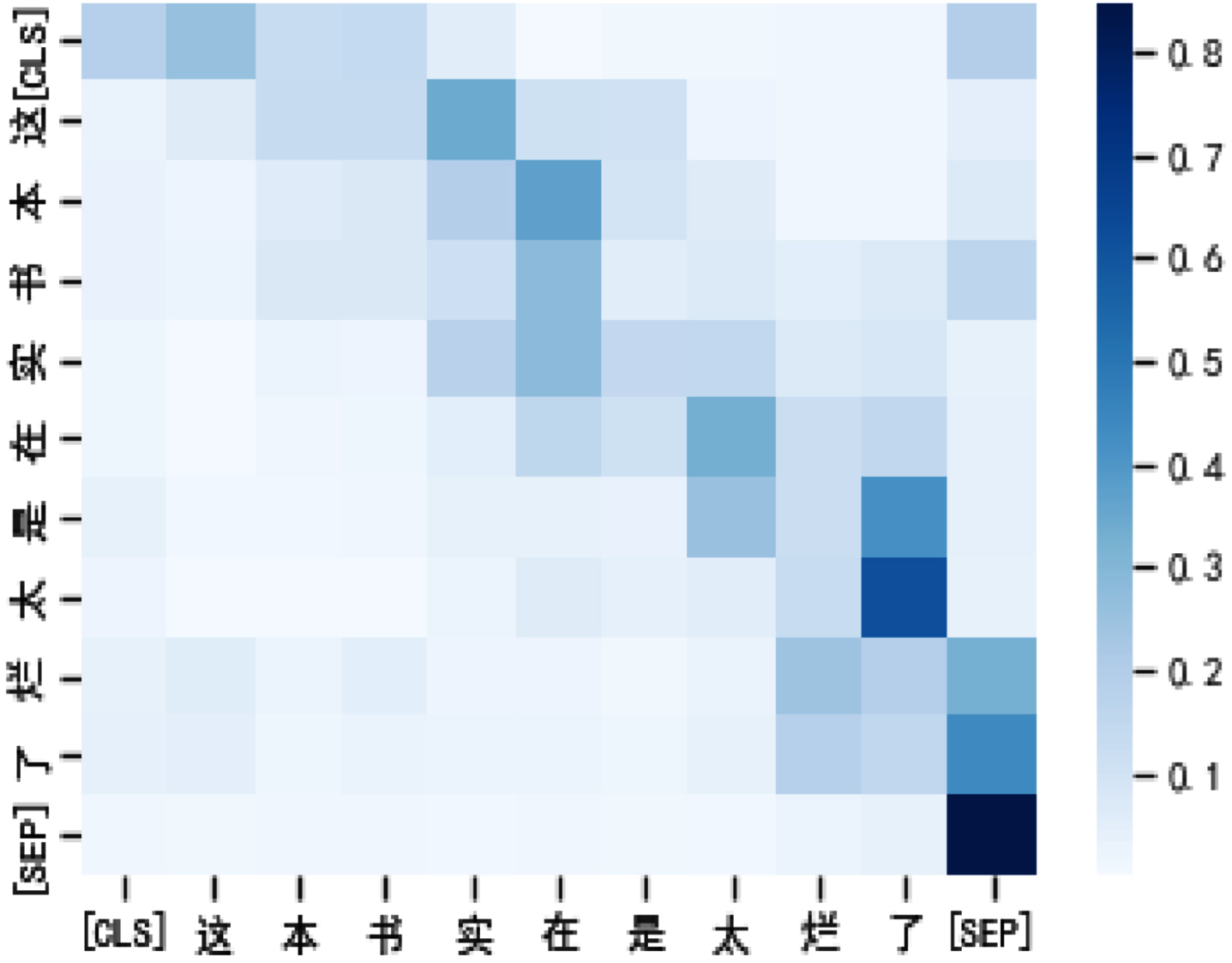
BVMHA attention score visualization with seq_len equal to 64.
In this paper, we combine spatial attention and variable multihead attention mechanisms to propose a BERT-based variable multihead hybrid attention-based text classification model (BVMHA). BVMHA can achieve the same text classification performance as that of the baseline model while significantly reducing the numbers of parameters and calculations. In our forthcoming research, we intend to delve deeper and seek more effective multifeature semantic extraction methods.
Footnotes
Acknowledgments
This work was supported by the Young Scientists Fund of the Autonomous Region Science and Technology Program (2022D01C83), Natural Science Foundation of Xinjiang Uygur Autonomous Region (2021D01C077), and Science and Technology Plan Project of the Xinjiang Uygur Autonomous Region (2022NC192, 2021B01002).