
Abstract
An efficient model to detect and track the objects in adverse weather is proposed using Tanh Softmax (TSM) EfficientDet and Jaccard Similarity based Kuhn-Munkres (JS-KM) with Pearson-Retinex in this paper. The noises were initially removed using Differential Log Energy Entropy adapted Wiener Filter (DLE-WF). The Log Energy Entropy value was calculated between the pixels instead of calculating the local mean of a pixel in the normal Wiener filter. Also, the segmentation technique was carried out using Fringe Binarization adapted K-Means Algorithm (FBKMA). The movement of segmented objects was detected using the optical flow technique, in which the optical flow was computed using the Horn-Schunck algorithm. After motion estimation, the final step in the proposed system is object tracking. The motion-estimated objects were treated as the target that is initially in the first frame. The target was tracked by JS-KM algorithm in the subsequent frame. At last, the experiential evaluation is conducted to confirm the proposed model’s efficacy. The outcomes of Detection in Adverse Weather Nature (DAWN) dataset proved that in comparison to the prevailing models, a better performance was achieved by the proposed methodology.
Introduction
An explosion of studies in automated video analysis for object detection and tracking has been brought about by the exponential growth in hardware facilities like processing machines, cameras, mobile phones, et cetera. Thus, in the field of computer vision as well as image processing, it is regarded as the predominant topic of research [1]. In an extensive range of applications like home automation, retail, traffic monitoring, security, safety, and control applications, these systems are utilized [2]. The process of detecting moving objects ahead of time in video sequences with the aid of a camera is termed object tracking. Relating the target objects along with the shape or features, and objects’ location in successive video sequences is the major intention behind this process [3]. In object tracking, (a) moving object detection, (b) object classification, and (c) frame-to-frame object tracking is subsumed in video analysis. Object detection includes the process of identifying the objects as of video frames together with clustering these objects’ pixels [4]. In the tracking process, the first step is object detection. An object detection mechanism is required by the tracking methodologies either in the frames’ sequence or when the object becomes visible first in the video frame [5]. Over the decades, a wide study has been conducted on object detection. At the same time, various optimistic detectors are capable of detecting objects of interest in clear images like images that are generally captured as of ground-centric cameras [6]. In the real environment, often weather conditions change unpredictably, which makes the detection process highly challenging [7]. The images’ visual quality could be degraded by certain common weather conditions like mist, fog, along with haze [8]. Likewise, the images’ contrast might be degraded by poor atmospheric conditions; thus, affecting the visibility. The contrast degradation relies on the coefficient of the light scattering via aerosols that are dispersed in the atmosphere [9]. Owing to the scattering by medium aerosols, the prime characteristics of the sources of the light like color, polarization, intensity, together with coherence are altered [10]. In addition, the ambient brightness might get changed by most of the above-mentioned interferences; thus, resulting in performance degradation of the moving object detection system [11]. Moreover, the process of detecting objects as well as following their route in the scene is made complicated by these factors [12].
Until now, for Object Detection and Tracking, various successful machine learning algorithms have been developed [13]. In general, for detecting objects in a video, various conventional methodologies like background subtraction or Haar Cascade classifiers [14], the Scale-Invariant Feature Transform (SIFT), the Histogram Of Oriented Gradients (HOG), the optical flow model and the Frame Difference (FD) methodology have been utilized [15]. The conventional object detection methodologies were almost substituted by the Convolutional Neural Networks (CNNs)-centric models with the advance of CNN on object detection [16]. Greater progress has been achieved by CNN-based object detection; consequently, commenced to be successfully applied to real-life [17]. Conversely, on certain weather factors like on wet nights, unclear vision conditions like mist or raindrops might interfere with the camera imaging; thus, making object detection highly complicated owing to the visual contamination of tracked targets by scattered bright regions in the image [18]. In object tracking, accurate localization of specified objects in complicated scenes and differentiating varied objects are highly significant [19]. In various applications where image quality must be enhanced owing to degradations like lower contrast, resolution, blurring, or noise, the image enhancement is utilized to resolve the issues that have been eventuated [20]. Therefore, by utilizing TSM-EfficientDet and JS-KM with Pearson-Retinex, a novel technique has been proposed here for ODT under AWC.
The organization of the present paper is as follows. Section 1 introduces object detection and tracking, and its various aspects and Section 2 elucidates the related works of the existing methods regarding object detection and tracking. Then, the proposed object detection and the tracking technique using TSM-EfficientDet and Jaccard Similarity based Kuhn-Munkres (JS-KM) with Pearson-Retinex are illustrated in Section 3.
And, in Section 4, the proposed method’s performance is discussed and compared with the existing methods. Finally, in Section 5, the conclusions drawn from the results of the present study is given with the suggestions for further enhancements that can be made in the future.
Related works
Rajib Ghosh [21] presented a model for on-road vehicle detection along with tracking in changing weather conditions utilizing various Region Proposal Networks (RPNs) of Faster R-CNN. Here, initially, the image frames enclosing vehicles were inputted to the CNN’s input layer. After that, in the CNN architecture, various RPNs had been generated; subsequently, the setting of various anchors with different scales together with aspect rations was performed in every single RPN. Then, all the RPNs and ROIs were merged as well as pooled. Next, during the training of every single RPN, the vehicles were recognized regarding the trained system. The outcomes displayed that the presented methodology has better efficacy than the traditional Faster R-CNN along with other similar conventional methodologies. Nevertheless, under AWC, the vehicle detection system’s processing speed was established to be considerably lower and inaccurate owing to the utilization of various RPNs.
Elhoseny [22] presented a Multi-ODT (MODT) model utilizing an optimal Kalman filtering methodology for tracking the moving objects in video frames. Regarding the number of frames, the video clips were transmuted into morphological operations by utilizing the region growing model. After differentiating the objects, for parameter optimization, the Kalman filtering was applied by utilizing the probability-centric grasshopper algorithm. The selected objects were tracked by utilizing the optimal parameters in every single frame by a similarity measure. The outcomes demonstrated that higher detection along with tracking accuracy was achieved by the MODT model than that of the prevailing methodologies. However, the detection rate was extremely low. Moreover, to obtain a better detection rate, the motion estimation methodologies were not espoused for MODT.
Matteo Dunnhofer et al. [23] proposes a comprehensive analysis of state-of-the-art tracking algorithms for First Person Vision (FPV), which is the task of tracking objects from a first-person perspective using wearable cameras. The study evaluates the performance of various tracking algorithms on a new dataset of FPV videos, introduces new performance measures for tracking evaluation, and provides insights into the strengths and weaknesses of different tracking methods. The authors also suggest that there is potential for improving FPV pipelines by integrating visual trackers and that there is room for improving the performance of visual object trackers in this new domain. Nevertheless, the computational time was high.
Dimitrios Meimetis et al. [24] acknowledge that the framework still faces challenges in detecting objects that are far away and in scenes with high population density and video noise. Additionally, the framework’s performance may be affected by changes in object appearance and occlusion. While the authors suggest that future work could focus on improving the framework’s performance in these challenging scenarios, they do not provide specific recommendations for how to address these limitations. Therefore, further research is needed to develop more robust and accurate multiple-object tracking frameworks that can handle a wider range of scenarios and challenges.
Hyochang Ahn and Han-Jin Cho [25] provided a model for assessing images with a knowledge-centric deep learning technology aimed at MODT enhancement. In this, an algorithm was developed; this algorithm amalgamated optical flow whilst retaining the detection performance via a knowledge-centric CNN. Regarding the objects’ position in the current frame, the position of objects in the subsequent frame was forecasted by the optical flow-centric tracker. By means of the knowledge-centric mining methodology betwixt the 2 images, a CNN-guided detector could identify the objects’ positions. The experiential outcomes demonstrated that the algorithm amalgamated detecting together with tracking multiple objects in a video stream. This model performed ODT even in a complicated environment. Conversely, the model’s accurateness was influenced by certain factors like alterations in the objects or scenes, sudden movements of objects, the shape modifications in the objects, changes in illumination, along with occlusion owing to the surrounding background.
Hassaballah et.al [26] presented vehicle detection along with tracking methodology under AWC by utilizing a deep learning framework. Initially, a visibility enhancement model was developed in which (i) illumination enhancement, (ii) reflection component enhancement and (iii) linear weighted fusion were the ‘3’ stages included. After that, by utilizing a multi-scale deep CNN, robust vehicle detection along with tracking methodology was developed. The traditional Gaussian mixture probability hypothesis density filter-centric tracker was utilized in cooperation with Hierarchical Data Associations (HDA). The Hungarian algorithm was utilized to solve the cost matrix of every single phase. The experiential outcomes displayed that when analogized with the prevailing models, the presented system showed better efficacy in tracking objects under AWC. Nevertheless, every single grid in the YOLO detection system could utilize merely ‘2’ bounding boxes; thus, detecting closer objects was a complex task.
System framework
The process of identifying along with tracking objects precisely and effectively in a video sequence is termed as Object Detection and Tracking. Object detection is the base of tracking by removing the irrelevant environmental effects like noise, light, along with occlusion, interesting objects in a video sequence are determined. In the past, numerous effectual algorithms, as well as benchmark evaluations, have been developed even then owing to weather conditions like mist, fog, along with haze, detection and tracking are still remaining a complicated process since the aforementioned conditions might affect the image quality and degrade the image contrast. Thus, by utilizing TSM-EfficientDet and JS-KM with Pearson-Retinex, a novel technique was proposed to address the above-mentioned issues and to enhance the object detection and tracking accuracies under Adverse Weather Condition (AWC).
The following are the steps were carried out in the proposed model. Primarily, for obtaining a clear image of the distorted image, pre-processing is performed. (a) denoising, (b) visibility enhancement, (c) contrast enhancement, and (d) YCbCr conversions are executed in pre-processing. Then, object detection, classification, segmentation, and motion estimation are performed. Lastly, object tracking is carried out. Figure 1 exhibits the block diagram of the object detection and tracking system.
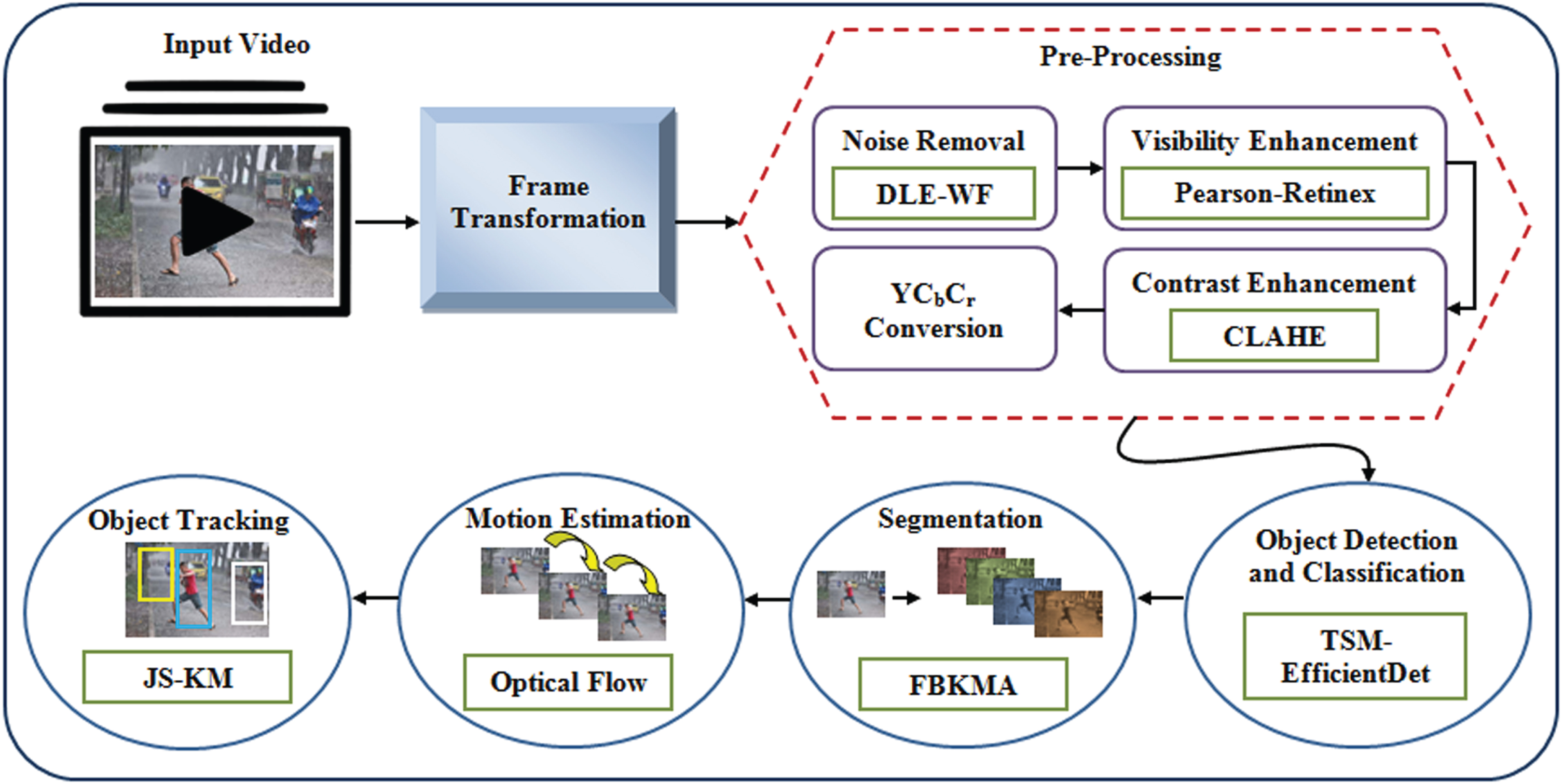
Block diagram of the proposed system framework.
In the object detection and tracking system, initially, from the image DAWN datasets [26], the input images are gathered. Furthermore, for removing the image’s noises along with deformation that occurred owing to bad weather, the frame conversion pre-processing of input frames or images was performed. Altering the actual input image before inputting it to the classification system for enhancing the image quality is mentioned as pre-processing. Here, denoising, visibility enhancement, contrast enhancement, and YCbCr color conversion are the steps included in pre-processing.
Noise removal by DLE-WF
During the acquisition process, noises might occur in the image affecting the pixels’ values along with intensities. A digital image can be contaminated by noises, which are of various types. In the proposed model, DLE-WF is utilized to remove noises. In general, the noisy image is filtered by the Wiener Filter (WF) by utilizing the desired input image’s spectral properties. A lot of information will be enclosed in the distorted input image; thus, during noise removal, information preservation is highly needed. Consequently, in the normal WF, rather than computing the pixel’s local mean, the Log Energy Entropy (LEE) value was gauged amongst the pixels. For denoising the images effectively, the difference betwixt the minimum and the maximum entropy values are estimated. Thus, object detection is performed effectively by preserving the information present in the image. This alteration of differential entropy computation in the traditional WF is termed DLE-WF. The DLE-WF’s image denoising process is explicated below.
Let the input image with pixel co-ordinates (a, b) be x
i
(a, b), then, the WF transfer function (Γ) is formulated as,
Where, the input image’s variance and LEE are specified as σ2 (●) and E, respectively, the noise component present in the input image is signified as n i (a, b), the image pixels’ intensity is notated as I (a, b) and the differential entropy measure is symbolized as D E .
The image pixels’ LEE (E) is computed as,
Here, the probability of image pixels is defined as p(●), and the number of image pixel that coordinates accordingly are proffered as N, M.
Next, the differential entropy measure (D E ) is measured as,
Where, the maximum and minimum entropy of image pixels (a, b) are illustrated as Emax (a, b) and E min (a, b).
After that, the image’s variance is modelled as,
Likewise, regarding the wiener transfer function, the noisy image pixels were substituted with the entropy values by computing the LEE along with the variance of image pixels. Lastly, the noise-removed image pixels were attained; consequently, they were specified as
The visibility enhancement is performed following the completion of the denoising process. The visibility of the images along with frames that are affected by bad weather conditions like haze, fog, mist, rain, and snow is enhanced by utilizing this methodology. For image enhancement and for the restoration of degraded foggy images, the Retinex algorithm is espoused successfully. Retinex, which is grounded on the color constancy theory, is a biologically inspired model.
Color constancy is applied automatically in human vision to enable humans to observe the world in various illumination conditions. The Retinex theory decomposes the image into illumination and reflectance. The sharp details in the image, that is to say, the edges, are comprised in the reflectance image; conversely, the illumination image is designed to be spatially smooth. To prevent halo artifacts on the image edges, the Gaussian kernel coefficient is extensively utilized in the conventional Retinex model. Nevertheless, while removing artifacts, the crucial information available in the image edges is also reduced by the Gaussian kernel coefficient. Therefore, instead of utilizing the Gaussian kernel coefficient, the Pearson correlation methodology is employed for preserving the details in image edges along with enhancing the image accuracy. Thus, the enhanced form of Retinex is renowned as Pearson-Retinex. The following steps elucidate the visibility enhancement of images utilizing Pearson-Retinex.
Step 1: Initially, the noise-removed image
Where, the luminance component is specified as l (a, b) and the reflectance component of the pixels in the image
Step 2: Obtaining the r (a, b) component as of the input
Here, the weight factor is specified as ω j , the number of scales of R, G, B color components is signified as j = 1, 2, …, n, and the Pearson correlation coefficient is notated as C (a, b).
Step 3: The Pearson correlation C (a, b) is evaluated as,
Step 4: After that, for making the color tone closer to the actual one, a color correction step was executed, which is specified as,
Where, the color corrected image is specified as r
cr
(a, b), every single channel coefficient is signified as К
j
, which is adjusted to make the image’s color tone approximate to the original one, the merge function is distinguished by
Step 5: By amalgamating the gain
Where, the final image that obtained after visibility enhancement is symbolized as rfinal (a, b). Thus, it was established that the resultant image
The process of enhancing the perceptibility of objects in the scene by advancing the brightness difference betwixt an object and its background is mentioned as contrast enhancement. By eliminating the noisy features like edges along with contrast boundaries, the image features are sharpened by the proposed methodology. To enhance the image contrasts, the CLAHE model is utilized here. The CLAHE is the modification of adaptive histogram equalization; in this, the over-amplification of contrast is abated in the homogenous regions of an image. Instead of working on the entire image, it operates only on the smaller portion of an image termed tiles. To eliminate the artificial boundaries, the nearest portions are amalgamated utilizing the bilinear interpolation. The following steps are included in the CLAHE procedure for contrast enhancement. along with occlusion owing to the surrounding background.
Step 1: Firstly, the input image (П) was partitioned into equally-sized rectangular blocks; then, in every single block, the histogram adjustment is performed for contrast enhancement. (i) Histogram creation, (ii) clipping, and (iii) redistribution are subsumed in the histogram adjustment.
Step 2: Following the completion of histogram calculation, the clip limit (γ) is estimated as,
Step 3: After that, the clipped pixels were redistributed to every single grey level; subsequently, the maximum contrast was enhanced. Then, the local histogram was executed on all regions. Next, a mapping function was computed regarding the cumulative distribution function (χ) to redistribute grey levels of image blocks. It is specified as,
Step 4: Finally, to obtain the enhanced image, every single pixel value is interpolated as of the mapping functions in the surrounding blocks; thus, preventing blocking artifacts. A lower computational complexity was achieved by CLAHE for contrast enhancement owing to the independent processing of blocks. Consequently, the contrast-enhanced image was symbolized as Ĩ.
Here, to enhance the performance of the object detection as well as classification model, the RGB image was transmuted into an YCbCr color model. In general, real images are represented in RGB color space. Nevertheless, for efficient processing, the image in RGB color space has to be transmuted into other color spaces in the digital image processing. Thus, to obtain effectual outcomes, the YCbCr color conversion was applied. The RGB image’s intensity model was partitioned into luminance (Y) and chrominance components (Cb and Cr) by the YCbCr color model. The intensity information is enclosed in the luminance component; similarly, the image’s color information is comprised in the chrominance component. In addition, the difference betwixt the blue component and reference is proffered as Cb, and the color difference betwixt the red component and the reference value is specified as Cr. The color conversion of RGB to YCbCr color space is formulated as,
EfficientDet is a state-of-the-art object detection algorithm; it generally follows a single-stage detector pattern. It includes ‘3’ parts in it; they are: (1) pre-trained EfficientNet, (2) BiFPN, and (3) classification as well as detection box prediction network. The pre-trained EfficientNet is regarded as the backbone network. The BiFPN operates as the feature network; subsequently, it obtains approximately 3 to 7 features as of the backbone network; also, it continually conducts a top-down as well as a bottom-up bi-directional fusion of features. To achieve object class and bounding box predictions, the features being synthesized are transferred to a classification and detection box prediction network respectively. For feature fusion, the softmax fusion was utilized in the classification together with the detection network.
EfficientDet, a compound scaling model was utilized for attaining higher accuracy. The overall dimensions of depth, width, backbone resolution, BiFPN, and box along with class prediction networks are enhanced by this compound scaling methodology. Nevertheless, the drawback in the softmax function is that the gradients for negative input were zero. It specified that the weights were not updated during back propagation for activations in that region. The dead neurons, which never get activated, were generated by this. Object detection, as well as classification accuracy, was affected by this condition. Consequently, the Tanh Softmax function is utilized as a future fusion in the proposed model to abate the drawback that exists in the traditional EfficientDet object detection system. Furthermore, by utilizing the Min-Max normalization methodology, the weights are normalized.
By considering the alterations made in the conventional EfficientDet, the proposed methodology is named as TSM-EfficientDet. Figure 2 exhibits the general structure of EfficientDet.
EfficientNet: This is the backbone network of the TSM-EfficientDet architecture. It is a series of convolution blocks with activation at the end of every single block. To capture more information as of the image, the conventional EfficientNet architecture was scaled by utilizing the compound scaling methodology; thus, bringing about performance increment. Scaling factors like depth factor, width factor, and resolution factors were utilized for scaling the EfficientNet to capture more features.
BiFPN: The BiFPN is utilized to extract features of an input image as of the EfficientNet. The features extracted were fused repeatedly utilizing the Tanh Softmax function (ψ), which is expressed as,
Compound scaling: A family of models, which could gratify a wide spectrum of resource constraints, was developed for optimizing the accuracy along with the efficacy of object detection and classification. This is evaluated as,
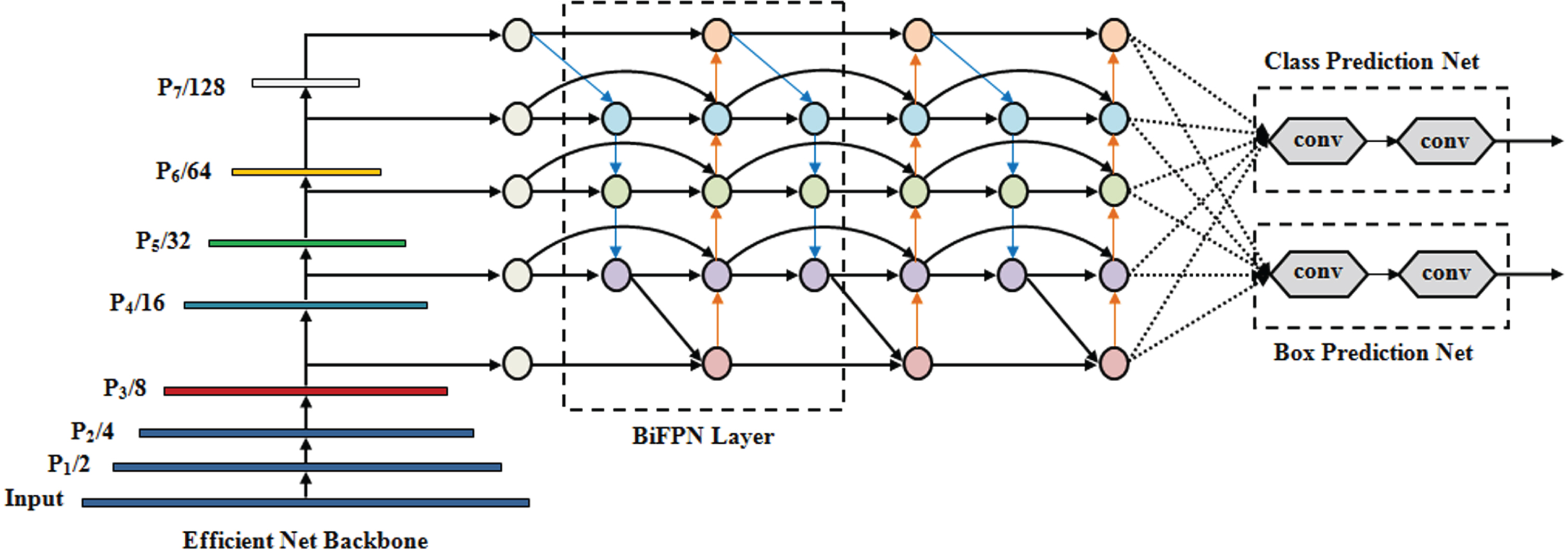
General structure of EfficientDet.
The BiFPN network’s width augments exponentially while the depth elevates linearly, which gratifies the following formula,
Following the completion of object detection along with classification in the images, for object tracking, the object’s motion was estimated by performing segmentation. The process of breaking the image into several subgroups termed image segments is proffered as segmentation; in this, the image’s complexity is abated to make the further processing or evaluation of the image simpler. A cluster-centric segmentation algorithm termed FBKMA is utilized in the presented study. To segment the detected objects as of the input images, KMA, a clustering algorithm, is extensively employed. The objects are separated into M different clusters (number of objects in the images) with the aid of this methodology; after that, to estimate the distance betwixt every single data object and the cluster centers, the Euclidean distance was gauged. Nevertheless, the misclassification amongst the cluster of white fringes and the cluster of black fringes was caused by the intensity of inhomogeneities in the images engendered by non-uniform illumination and noise. Thus, by introducing a term, the standard KMA algorithm was altered to permit the labelling of a pixel to be influenced by the labels in its immediate neighborhood. The alteration of FB in conventional KMA is termed FBKMA. The FBKMA includes the following steps.
Step 1: Primarily, the target object (detected object) is specified as α f , where, the number of target objects is signified as f = 1, 2, ⋯ , N; then, every single target object is segmented into M number of clusters (k i = k1, k2, ⋯ . k M ). The cluster center (C j ) is computed as,
Where, the number of cluster centers is notated as j=1,2,..., N.
Step 2: From the clustering center, the Euclidean distance D e for every target object is computed as,
The target objects were assigned to the nearest cluster regarding the Euclidean distance; subsequently, the criterion function is calculated.
Step 3: By considering the effect of intensity inhomogeneities and noise, the criterion function was computed as,
Step 4: Here, the fringe pattern’s intensity distribution [I (p, q)] is formulated as,
Step 5: The modified criterion function for uneven illumination fringe patterns binarization is modelled as,
Here, by utilizing the optical flow methodology, the segmented objects’ movement was identified. To obtain vectors that specify the estimated motion, the objects’ movement in an image sequence was verified by motion estimation. Owing to its ability to extract the motion pattern, the optical flow is regarded as a dominant model for video analysis. Estimating the direction along with the speed of moving objects as of one frame to another is the intention behind the optical flow model. The motion betwixt two image frames, which were taken during the times τ and τ + Δτ at every pixel position, is computed by this methodology. In this, by utilizing the Horn-Schunck algorithm, the optical flow was calculated. This algorithm has the capacity to calculate dense optical flow, globality, and the possibility to effectively parallelize its computations; thus, it is utilized. The following steps illustrate the motion estimation done by utilizing the Horn-Schunck Optical Flow algorithm.
Step 1: Let the two-dimensional image intensity of segmented objects be Y (r, s, τ); here, the location of a pixel in image coordinates at time τ is symbolized as r, s. The image pixel’s horizontal and vertical displacement is notated as h, v respectively. For every single pixel, the optical flow was obtained as an energy function (ℓ
m
), which is expressed as,
Step 2: To minimize the energy function, the multi-dimensional Euler-Lagrange equation is utilized. It is expressed as,
Step 3: The successive iterations of horizontal and vertical displacements h, v are formulated as,
In this proposed model, object tracking is the final step following the completion of the motion estimation process. In the first frame, initially, the motion-estimated objects were considered as the target. In the next frame, by utilizing the JS-KM algorithm, the target was tracked. For tracking, the motion-estimated objects in the successive frames were utilized; subsequently, the target along with its new position was indicated by the maximum correlation output value. The objects were tracked by the Kuhn-Munkres (KM) algorithm by extracting the appearance, shape, along with the motion of the detected objects, which are jointly optimized for tracking. Several similarity measures like scale, velocity, and appearance were subsumed in the construction of the similarity matrix betwixt trajectories and targets. The Jaccard Similarity (JS) metric was wielded as the similarity model. By utilizing the Horn-Schunck algorithm, the motion was estimated. In object detection, the appearance features and the shape features are extracted synchronously. This JS-centric KM algorithm for object tracking is mentioned as JS-KM. The JS-KM algorithm encompasses the following steps.
Step 1: Let, the detected classes of objects are F, the j
th
trajectory T (j), and the j
th
detection D (j). Regarding appearance, the Pearson Similarity metric (σ
sim
) is computed as,
Step 3: The shape similarity metric (σ
shape
) was measured as,
Step 4: The overall similarity metric (σ) amongst trajectories and targets was computed as,
In this section, the proposed framework’s final outcome is analyzed in detail. The performance, as well as comparative analysis, is performed to prove the proposed work’s efficacy. From the DAWN dataset [26] which are accessible on the internet, the data were gathered.
Performance analysis of proposed DLE-WF
Gaussian filtering, WF and Histogram are the prevailing methodologies with which the proposed model’s performance is analyzed regarding several performance metrics like Mean-Square Error (MSE), Peak Signal-to-Noise Ratio (PSNR), along with Structural Similarity Index (SSIM) to prove its efficacy. Regarding PSNR, MSE, and SSIM, the proposed model is comparatively analyzed with the prevailing WF, Gaussian filter, and Histogram methodologies in Fig. 3. From Fig. 3, it is established that the image with better quality can be obtained with a higher PSNR value. Here, the PSNR rate attained by the proposed DLE-WF is 21.38694 dB whereas the prevailing methodologies obtained an average of 13.121916 dB.
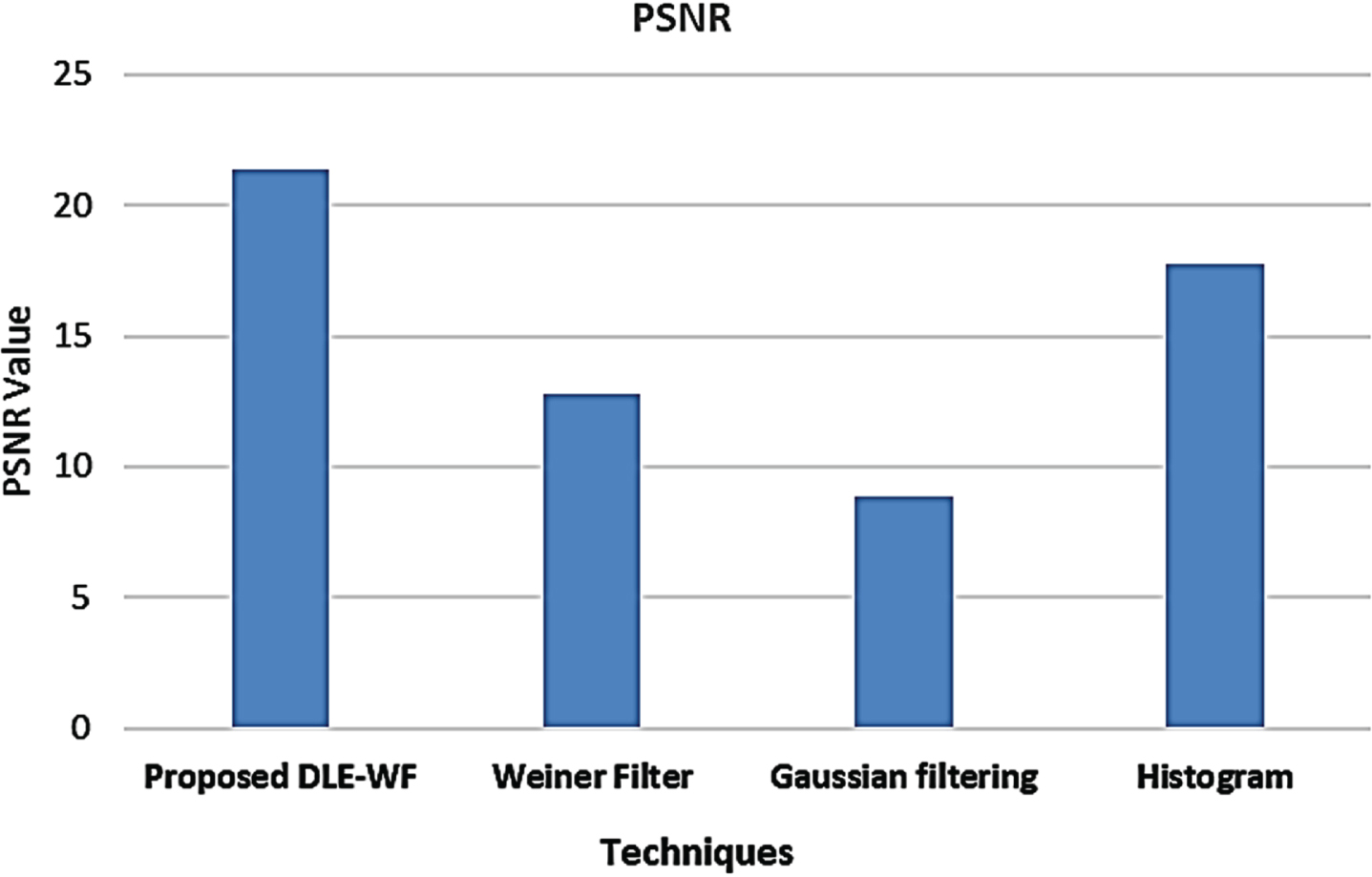
Comparative analysis of proposed DLE-WF based on PSNR.
The image quality degradation caused by image compression along with other processing methodologies was enumerated by the MSE metric value in Fig. 4.
The model’s efficacy could be enhanced with a lower MSE value. While considering MSE, the proposed model attained 0.01785 whereas the prevailing models acquired an average of 0.12358. Further, the SSIM metric was evaluated to analyze the proposed work and shown in Fig. 5. The previous models attained an average of 0.37164 SSIM values, which is lower than that obtained by the proposed one 0.57846. From this evaluation, it is evident that the proposed system, which has the capacity to deliver a quality image devoid of any distortion, is claimed as an error-free model.
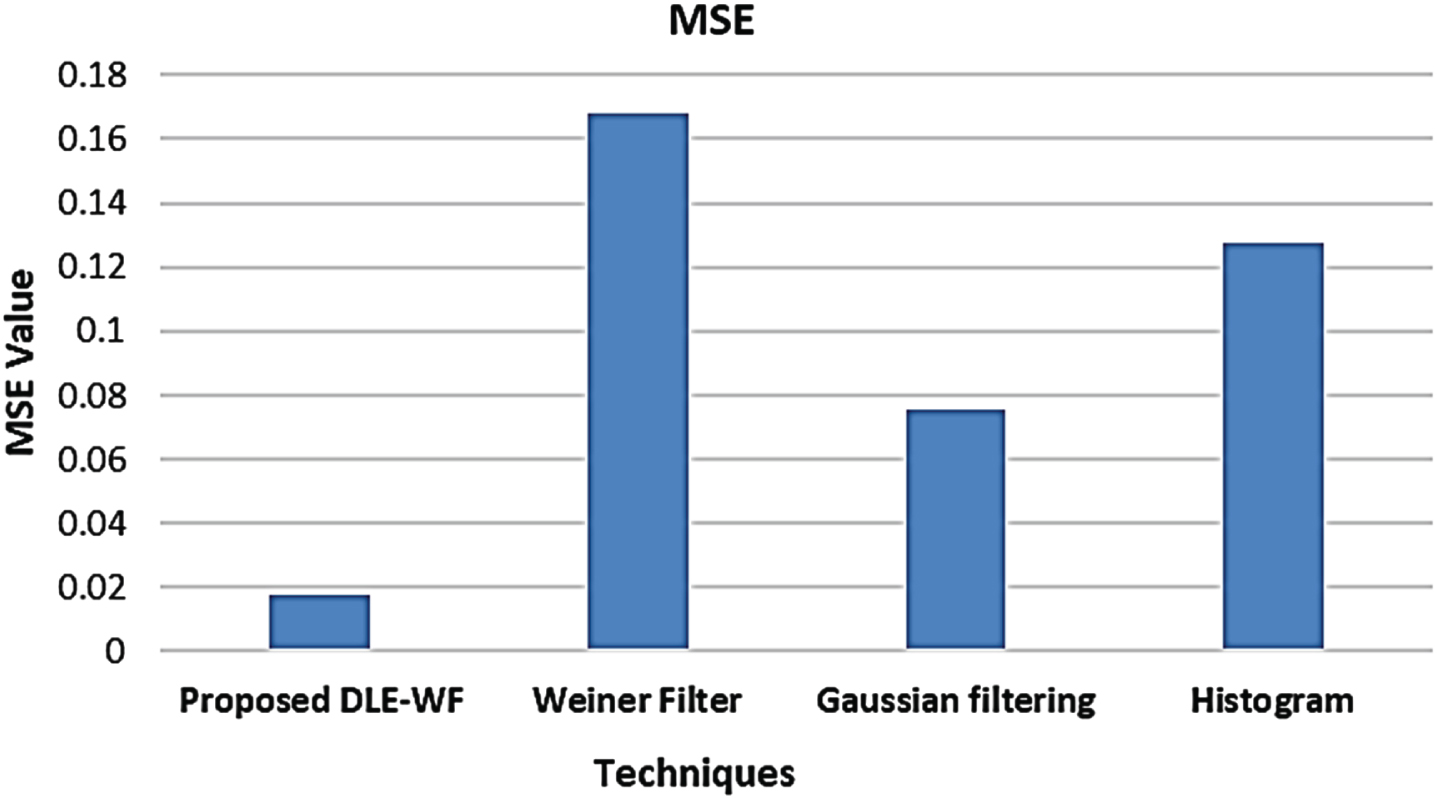
Comparative analysis of proposed DLE-WF based on MSE.
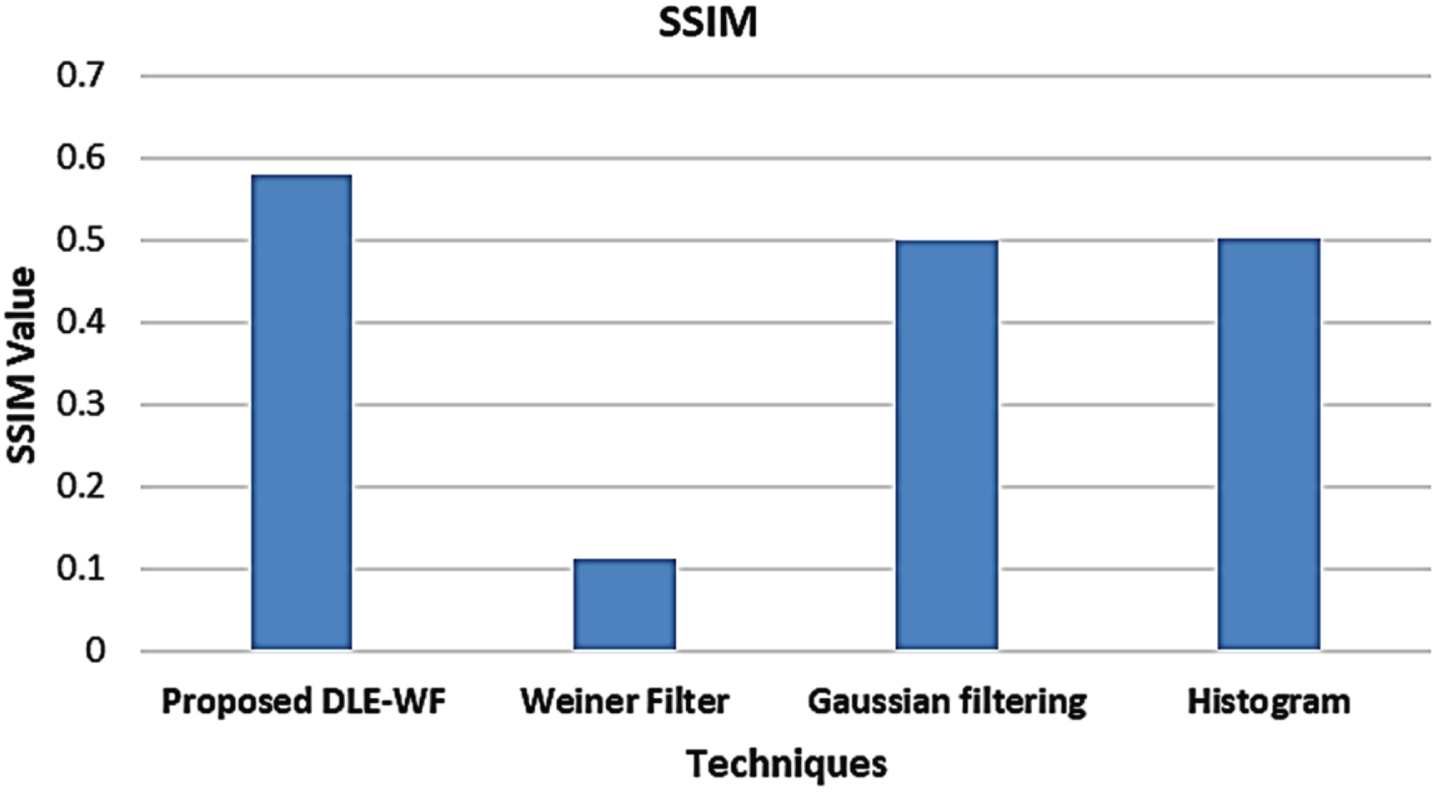
Comparative analysis of proposed DLE-WF based on SSIM.
Figure 6 show the input image and the visibility-enhanced images, correspondingly. Therefore, it is confirmed that the images’ visibility is enhanced effectively by the proposed Pearson-Retinex; thus, detecting the object with higher accurateness. free model.

Image analysis of Pearson-Retinex.
The proposed TSM-EfficientDet was validated with several prevailing models like EfficientDet, ResNet, YOLO and Fast region-CNN with regards to numerous metrics like sensitivity, accuracy, precision, specificity, recall, along with F-measure. To prove the model’s efficacy, a comparative evaluation was performed with the conventional models. Figure 7 exhibits the resulted image of the proposed TSM-EfficientDet object detection system in the AWC environment.
The proposed model’s performance is assessed in Table 1 regarding the accuracy, sensitivity, and specificity with the prevailing EfficientDet, YOLO, ResNet, and Fast region-(CNN).

Image results for the proposed model.
Performance analysis of proposed TSM-EfficientDet
The evaluation outcomes displayed that the proposed model attained a higher accuracy, sensitivity and specificity of 98.34%, 97.57% and 98.36%, respectively. In the meantime, the overall accuracy, sensitivity, and specificity attained by prevailing methodologies are in the range of 85.93% –95.62%, 84.38% –93.18% and 84.72% –94.62%, in that order. Thus, it is evident that better performance was achieved by the proposed system. Regarding precision, recall, and F-measure, the proposed model is comparatively analyzed with the prevailing models in Fig. 8.
From the evaluation, it is established that a higher precision, recall, and F-Measure of 97.41%, 98.64%, and 97.73% respectively were attained by the proposed TSM-EfficientDet.
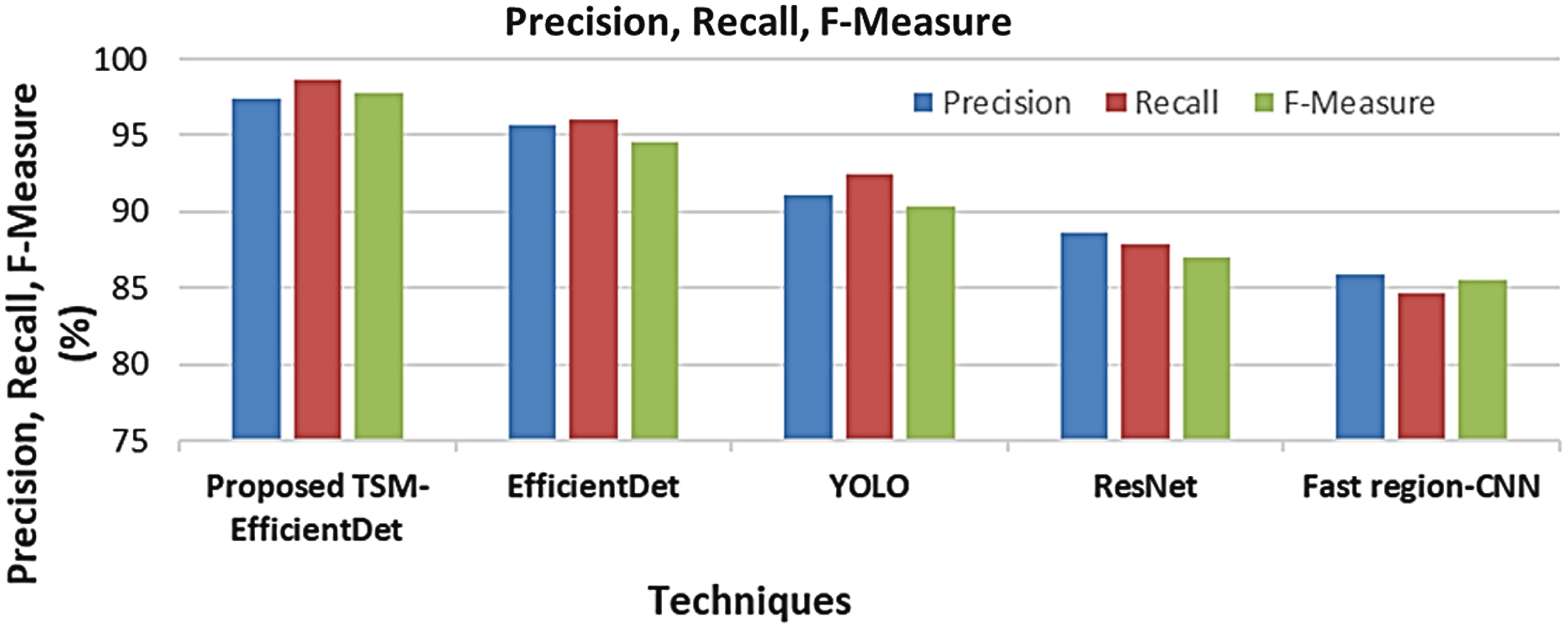
Graphical representation of the proposed TSM-EfficientDet based on precision, recall, and F-measure.
Conversely, the prevailing EfficientDet, YOLO, ResNet, and Fast region-CNN methodologies attained lower values for all the metrics that overall range betwixt 84.62% –96.04%. Therefore, it is evident that when analogized with prevailing methodologies, the proposed one achieved better performance by delivering highly optimistic outcomes under varied complex circumstances.
Markov Decision Processes (MDP), RMN Multi-Object Tracking (RMOT), and Gaussian Mixture Probability Hypothesis Density GMPHD are the conventional techniques with which the proposed JS-KM is validated concerning several performance metrics like Mostly Tracked Object (MTO), Mostly Loss Targets (MLT), Number of track fragments (FRAG), and Identity Switch (IDS).
The object detected input image and tracked objects in rainy weather conditions is exhibited in Fig. 8. The process of tracking the movement of an object following detection is termed object tracking. Figure 9 demonstrated clearly that by employing the proposed JS-KM shows better tracking results for the detected objects in adverse weather conditions like rain.
The proposed JS-KM’s performance is analysed with the traditional MDP, RMOT, and GMPHD methodologies in Table 2. The number of fragments for the proposed methodology is 132 whereas the fragments obtained by the prevailing models are MDP (126), RMOT (112), and GMPHD (102), which are lower than that of the proposed work.

Object tracking.
Performance evaluation of JS-KM in terms of FRAG and IDS
Additionally, as mentioned in Table 2, the proposed methodology was assessed regarding IDS. The proposed JS-KM attained the IDS of 45. Nevertheless, the IDS attained by the MDP, RMOT, and GMPHD are 60, 71, and 82, respectively. Thus, it is confirmed that when analogized with the prevailing models, the proposed one tracks the objects with higher efficacy.
Figure 10 demonstrated that the proposed model attained a higher MTO and a lower MLT of 24% and 28.7%, respectively. Thus, it is evident that the proposed methodology was highly effective in tracking objects.
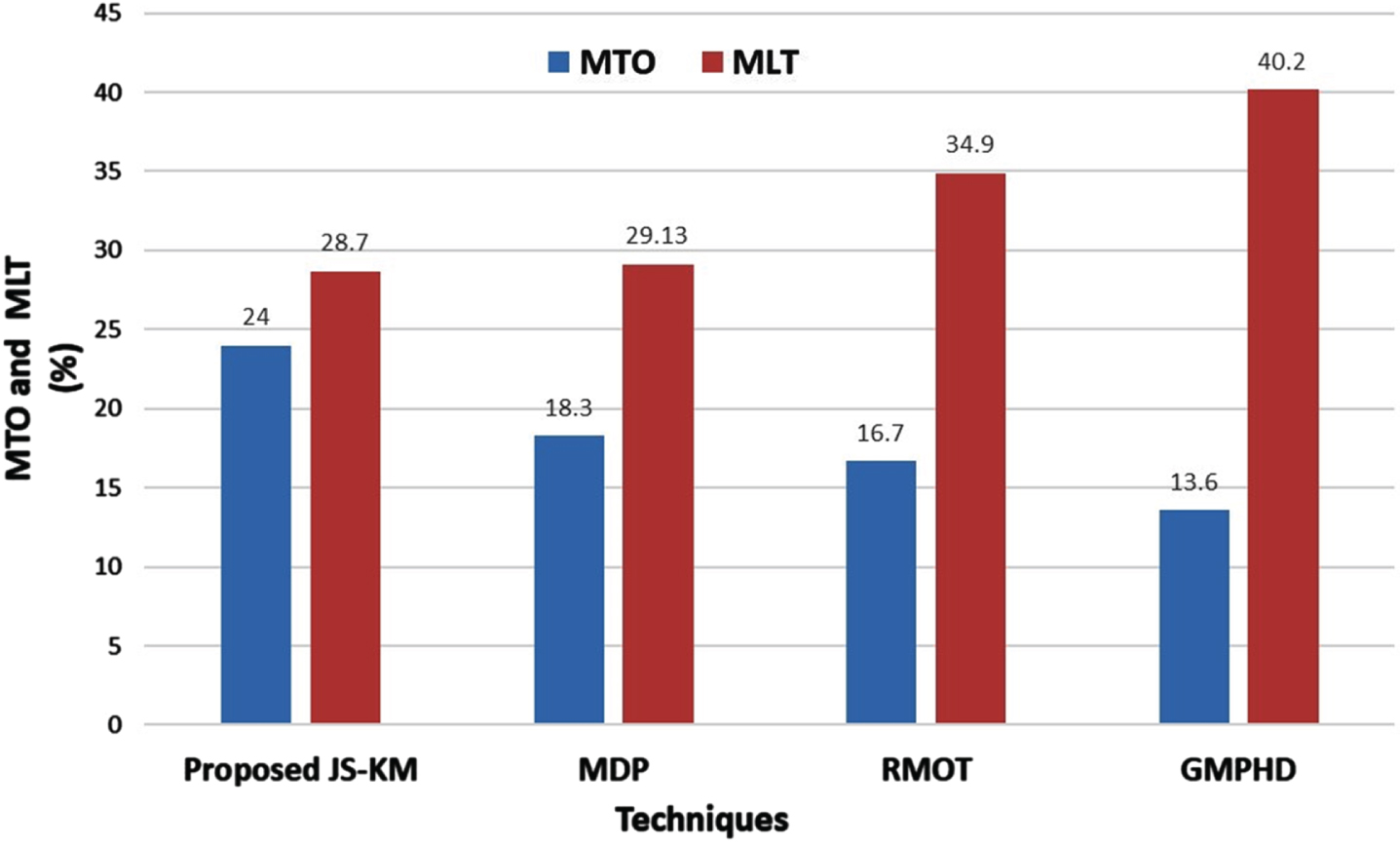
Performance assessment of proposed JS-KM based on MTO and MLT.
However, most of the traditional methodologies are ineffective in tracking objects for a complete sequence of frames with lower MTO and higher MLT. The previous MDP, RMOT, and GMPHD attained an MTO of 18.3%, 16.7%, and 13.6%, correspondingly. Likewise, the prevailing models attained an MLT of MDP (29.13%), RMOT (34.9%), and GMPHD (40.2%). Therefore, it is proved that the target was tracked more accurately by the proposed model with minimum loss than the other prevailing methodologies. environment.
In Employing TSM-EfficientDet and JS-KM with Pearson-Retinex, a model was proposed for object detection and tracking under adverse weather conditions. In this work, pre-processing, object detection, segmentation, motion estimation, and object tracking were the steps included in this model. The proposed model is proven to render more optimist outcomes by handling several uncertainties. The model was evaluated using DAWN dataset. In terms of accuracy, sensitivity, and specificity this model has achieved 98.34%, 97.57%, and 98.36%, in that order using DAWN dataset. Eventually, the proposed model is claimed to be highly reliable along with robust than the other prevailing methodologies. In the future, with some enhanced neural networks, the presented work can be extended to perform object detection and tracking on more complicated datasets.