
Abstract
Remanufacturing, with its environmental and economic implications, is gaining significant traction in the contemporary industry. Owing to the complementarity between remanufacturing process planning and scheduling in actual remanufacturing systems, the integrated remanufacturing process planning and scheduling (IRPPS) model provides researchers and practitioners with a favorable direction to improve the performance of remanufacturing systems. However, a comprehensive exploration of the IRPPS model under uncertainties has remained scant, largely attributable to the high complexity stemming from the intrinsic uncertainties of the remanufacturing environment. To address the above challenge, this study proposes a new IRPPS model that operates under such uncertainties. Specifically, the proposed model utilizes interval numbers to represent the uncertainty of processing time and develops a process planning approach that integrates various failure modes to effectively address the uncertain quality of defective parts during the remanufacturing process. To facilitate the resolution of the proposed model, this study proposes an extended non-dominated sorting genetic algorithm-II with a new multi-dimensional representation scheme, in which, a new self-adaptive strategy, multiple genetic operators, and a new local search strategy are integrated to improve the algorithmic performance. The simulation experiments results demonstrate the superiority of the proposed algorithm over three other baseline multi-objective evolutionary algorithms.
Keywords
Introduction
The contradiction between the rapid development of society and environmental pollution has become increasingly prominent. As an important part of sustainable development, remanufacturing of end-of-life (EOL) products has attracted increasing attention in recent years [1, 2]. In remanufacturing systems, EOL products are restored to like-new condition by means of complete disassembly, reprocessing of defective parts, and reassembling [3]. Because traditional decision-making approaches are not effective in dealing with the complexity of EOL products in uncertain remanufacturing systems, different levels of remanufacturing decision-making approaches have been proposed at the strategic level [4], tactical level [5], and operational level [6].
Remanufacturing process planning and scheduling are two critical issues at the operational level in actual remanufacturing systems [1, 7]. Remanufacturing process planning provides guidance for the global scheduling of workshops according to resource constraints. Shop scheduling obtains the operation sequence of the machines within a specified time according to the process plan constraints. These two critical issues are dealt with separately and sequentially in traditional remanufacturing systems [8, 9]. However, this hinders the improvement of remanufacturing productivity and performance, and may lead to conflicts between the objectives of remanufacturing process planning and scheduling [10], e.g., the pre-defined process plans may be infeasible during the scheduling phase.
To overcome this problem, the current study focuses on the integration of remanufacturing process planning and scheduling. Compared with the traditional manufacturing environment, remanufacturing systems have more intrinsic uncertainties, such as highly variable processing times, uncertain quality of defective parts, and stochastic routings for reprocessing operations [3]. A few studies have investigated the integrated remanufacturing process planning and scheduling (IRPPS) models in remanufacturing system, however, they ignored either the uncertain quality of defective parts or the uncertainty of processing time. In practice, the processing time of an EOL product in a remanufacturing system is not always fixed and may fluctuate within an interval because of its intrinsic uncertainty. In addition, the selection of a process plan based on the quality differences of defective parts is more conducive to the improvement of remanufacturing scheduling efficiency and the reduction of energy consumption. Therefore, establishing a mathematical model under uncertainties is more suitable for an actual remanufacturing environment.
To fill the above gaps, a new IRPPS model is proposed to coordinate the process planning and scheduling under uncertainties in remanufacturing systems with the objective of minimizing energy consumption, makespan, and maximum machine load, which considers not only the uncertainty of processing time, but also the uncertainties related to the quality of defective parts. The proposed model utilizes interval numbers to represent the uncertainty of processing time and develops a process planning approach that integrates various failure modes to effectively address the uncertainties during the remanufacturing process.
The IRPPS problem is a typical multi-objective NP-hard problem. Up to now, researchers have investigated Pareto-based multi-objective evolutionary algorithms to tackle a variety of NP-hard problems. In recent years, the non-dominated sorting genetic algorithm-II (NSGA-II) [11] has been extensively implemented and has achieved good performance [12–14] to tackle various multi-objective optimization problems. However, the basic NSGA-II cannot be directly applied to address the IRPPS model because its standard one-dimensional representation scheme does not model the multiple dimensions of the IRPPS model comprehensively. In addition, the basic NSGA-II has several weaknesses, including weak exploitation and exploration abilities. Therefore, an extended NSGA-II (ENSGA-II) is proposed in this study for solving the IRPPS model. The proposed ENSGA-II has extended the basic NSGA-II by incorporating a new multi-dimensional representation scheme, a new self-adaptive strategy, and a new local search strategy. Simulation experiments are performed through different instances, demonstrating that the ENSGA-II is superior to the three other baseline multi-objective algorithms.
The contributions of this paper are the following: A new IRPPS model with the objective of minimizing energy consumption, makespan, and maximum machine load is proposed for the first time and a mathematical model is established. The proposed model comprehensively considers the uncertainties of the remanufacturing environment. It utilizes interval numbers to represent the uncertainty of processing time and develops a process planning approach that integrates various failure modes. In order to solve the proposed model, an ENSGA-II with a new multi-dimensional scheme is proposed, integrating a new self-adaptive strategy and multiple genetic operators to enhance population diversity, and designing a new local search strategy to improve the algorithmic efficiency. Experiments are conducted on 24 sets of instances, which shows that the proposed algorithm outperforms the three other baseline multi-objective algorithms in solving the proposed model, and highlights its efficacy and potential for broader applications in the realm of remanufacturing systems.
This paper is organized as follows. Section 2 outlines the cutting-edge technologies. Section 3 presents a new IRPPS model under uncertainties. Section 4 provides the introduction of the basic NSGA-II and proposes the ENSGA-II for solving the IRPPS model. Section 5 provides the experiments conducted to evaluate and compare the performance of the ENSGA-II. Section 6 concludes this study and presents future work.
Related work
Remanufacturing process planning and scheduling have received much attention as two critical issues in actual remanufacturing systems. This section demonstrates the cutting-edge technologies from three aspects and summarizes the gaps to be filled.
Remanufacturing process planning and scheduling
Most of the existing studies on remanufacturing systems focus on remanufacturing process planning or scheduling of remanufacturing shops. For example, Wang et al. [8] proposed a fault feature characterization-based optimization method to solve the remanufacturing process planning problem. Shi et al. [6] presented an environmentally friendly remanufacturing scheduling system that involves parallel flow-shop-type non-dedicated reprocessing lines. Zhang et al. [9] constructed a multi-objective scheduling model that integrated parallel disassembly/reassembly shops and a flexible job-shop-type reprocessing shop with the aim of reducing makespan and energy consumption. Zhang et al. [15] developed an uncertain remanufacturing scheduling model that takes into account the risk of rework during the remanufacturing process. Wang et al. [16] studied the energy-aware remanufacturing system scheduling model by integrating three core production stages, i.e., disassembly, reprocessing, and reassembly. Guo et al. [17] proposed an integrated scheduling method for a disassembly-reprocessing-reassembly remanufacturing system that considers the commonality of components, aiming to minimize both makespan and energy consumption.
However, the above studies only addressed remanufacturing process planning and scheduling separately, and research on IRPPS modeling is still in its infancy. Owing to the high complexity of remanufacturing systems, the scheduling factors should be considered during remanufacturing process planning to address the conflicts between the objectives of remanufacturing process planning and scheduling. Hence, Zhang et al. [18] studied the IRPPS model with two probably conflicting objective functions, considered both remanufacturing process planning and scheduling, and addressed this model using simulation-based optimization. Gong et al. [1] presented an evolutionary IRPPS model with five optimization objectives and tackled it using a hybrid multi-objective evolutionary algorithm. Zhang et al. [19] proposed an IRPPS model that incorporates parallel disassembly workstations, a flexible job-shop-type reprocessing shop, and parallel reassembly workstations. Zhang et al. [20] proposed an energy-efficient multi-objective IRPPS model that focuses on the energy efficiency in the IRPPS model.
However, the existing IRPPS models have not comprehensively addressed the intrinsic uncertainties of remanufacturing systems. They ignored either the uncertainty of the processing time of defective parts, or the uncertainties related to the quality of defective parts and their production. In addition, these studies did not properly consider the integration of resource constraints to realize energy-efficient remanufacturing. Thus, this study proposes a new IRPPS model to fill these gaps. A feasible modeling scheme is given to coordinate the process planning and scheduling more comprehensively under remanufacturing uncertainties.
Interval number theory
In many previous studies, uncertainty-based mathematical analysis theories (e.g., rough set theory, fuzzy theory, grey system theory, etc.) have been used to describe the uncertainties of the remanufacturing environment [21]. However, these methods have disadvantages in that they rely on known membership and probability distribution functions before formalizing an uncertainty model. The integration of interval number theory with uncertainty modeling can overcome these difficulties.
In recent years, the interval number theory has been widely applied to optimization areas [22]. In particular, shop scheduling problems constructed with interval numbers have received extensive attention from researchers. For instance, Jamrus et al. [23] constructed the flexible job-shop scheduling problem (FJSSP) for semiconductor fabrication, in which the processing times are represented as intervals. Fang et al. [24] defined the processing time as the interval numbers in a disassembly shop to construct an appropriate uncertainty model.
The above studies have mainly elaborated on shop scheduling problems using interval number theory. However, few studies have focused on the IRPPS model combined with the interval number theory. Hence, the current study attempts to solve the IRPPS model using the interval number theory under the uncertainties of remanufacturing systems.
The basic interval arithmetic of the interval numbers is shown in Equations (1)–(3) [22]. For example, let A = [A
L
, A
R
] (or A = {A
C
, A
W
}) and B = [B
L
, B
R
] (or B = {B
C
, B
W
}) be two interval numbers.
The interval order relations between two intervals A and B for the minimization problems are shown in Equation (4) [25].
Recently, multi-objective optimization algorithms have been widely used in process planning and scheduling fields. For example, Huang et al. [26] proposed and demonstrated that an improved multi-objective particle swarm optimization (MOPSO) algorithm could efficiently address the FJSSP. Fang et al. [24] presented a disassembly scheduling problem with different capability constraints imposed on the robots and solved it using a multi-objective simulated annealing algorithm. Abed-Alguni and Alawad [27] proposed a discrete variation of the Distributed Grey Wolf Optimizer to handle dependency task problems on virtual machines with the objective of minimizing computation and data transmission costs. Wang et al. [28] presented a multi-objective optimization algorithm, which incorporates a multi-region division sampling strategy, a genetic algorithm and a differential evolutionary algorithm for solving the flexible job shop scheduling problem. Alawad and Abed-alguni [29] proposed a discrete island-based cuckoo search algorithm with a highly disruptive polynomial mutation and an opposition-based learning strategy for scheduling workflow applications in cloud computing environments. Bezdan et al. [30] applied the Pareto-based hybrid bat algorithm to deal with the cloud computing task scheduling problem. Lu et al. [31] utilized a Pareto-based collaborative multi-objective optimization algorithm to tackle an energy-efficient flow shop scheduling problem. Liu et al. [32] applied a hybrid meta-heuristic algorithm to solve the problem of appliance scheduling, with the goal of minimizing electricity costs and user dissatisfaction.
In particular, the NSGA-II has been widely adopted to solve multi-objective scheduling problems owing to its good performance in engineering optimization. For example, Wu and Sun [33] employed NSGA-II to address the FJSSP, which involves the energy-saving factors. Zhang et al. [34] presented a game-theoretic-based NSGA-II to schedule business services provided by different manufacturers. Yuan et al. [35] improved the NSGA-II by incorporating several enhancements including a modified evaluation function, a competition mechanism, a cross-variance strategy, and an elite retention strategy to solve the workshop resource scheduling problem. Afsar et al. [36] proposed a multi-objective enhanced memetic algorithm that combines NSGA-II with three intensification strategies to solve the green job shop scheduling problem. It is worth noting that, according to the design principles of memetic algorithms [37], the ENSGA-II proposed in this study can also be considered as a memetic algorithm. Wang et al. [38] implemented an extended NSGA-II specifically tailored for the hybrid flow shop scheduling problem with variable machine speeds. Deng et al. [14] integrated the NSGA-II, fuzzy rough set, and sliding window to forecast and simulate the high-frequency price directions of crude oil futures in the market.
In this study, the NSGA-II is employed to address the proposed IRPPS model. However, the basic NSGA-II only uses a one-dimensional representation scheme, which cannot be directly used to solve the proposed IRPPS model with multiple dimensions. In addition, the exploitation and exploration abilities of the basic NSGA-II still have room for improvement. Therefore, a new ENSGA-II is proposed in this study to solve the IRPPS model.
An illustration of the flexible process plans
An illustration of the flexible process plans
This section presents a new IRPPS model, and a mathematical model constructed under uncertainties of both processing time and the quality of defective parts is described.
Problem description
The IRPPS model can be described through the following example. For a set of the same parts (e.g., crankshafts) of a batch of EOL products, each part has one or more features that need to be reprocessed. Each feature has one or more failure modes with different degrees or types. For example, the failure modes of the “surface” feature include “slight abrasion,” “severe abrasion,” “slight crack” and “severe crack,” which need to be reprocessed through different operations. Thus, various features with different failure modes will influence the selection of the process plan for a defective part.
Table 1 shows an illustrative example: the IRPPS model is described through some sets, including machine set M = {M1, M2, …, M4}, operation set O = {O1, O2, …, O10}, part set P = {P1, P2, P3}, and feature set F = {F1, F2, …, F5}. For example, three features (i.e., F1, F3, and F4) in P1, two features (i.e., F1 and F2) in P2, and one feature (i.e., F5) in P3, need to be reprocessed. F1 has four possible failure modes: FM1 = {FM11, FM12, FM13, FM14}. If the feature F1 fails owing to failure mode FM12, it can be restored through operations O2 or O4. The operation O2 can be executed on machines M1 or M4 with interval processing times [5, 9] or [8, 13], respectively. Operation O4 can be executed on machines M2 or M3 with interval processing times [4, 9] or [9, 12], respectively. Feature F1 needs to be reprocessed prior to all other features according to the corresponding feature constraint. So do the explanations to other features F2, F3, F4, and F5.
Suppose the features F1, F3, and F4 of part P1 fail owing to failure modes FM11, FM32, and FM41, respectively; the features F1 and F2 of part P2 fail owing to failure modes FM12 and FM21, respectively; and the feature F5 of part P3 fails owing to failure mode FM51. Then, the candidate process plan sets of parts P1, P2, and P3 are {O1 - O7 - O8, O1 - O8 - O7, O1 - O7 - O9, O1 - O9 - O7}, {O2–O10, O4–O10}, and {O4, O6}, respectively.
After the process plan of each part is selected with appropriate machine allocation, the nearly optimal scheduling scheme for each part is obtained accordingly. For example, one feasible process plan with appropriate machine allocation of parts P1, P2, and P3 is O1 (M1)–O7 (M3)–O8 (M2), O2 (M4)–O10 (M1), and O4 (M2), respectively, following which, a nearly optimal scheduling scheme is obtained, as shown in the Gantt chart in Fig. 1. The interval start time is marked under the timeline, and the interval completion time is marked above. The scheduling schemes of different parts are represented by different solid lines with different thicknesses and distances to the timeline. For part P1, operation O1 is executed on machine M1 at the interval start time [0, 0] and interval completion time [1, 4]; operation O7 is executed on machine M3 at the interval start time [1, 4] and interval completion time [5, 17]; and operation O8 is executed on machine M2 at the interval start time [5, 17] and interval completion time [13, 29]; respectively. So do the explanations for other parts P2 and P3.
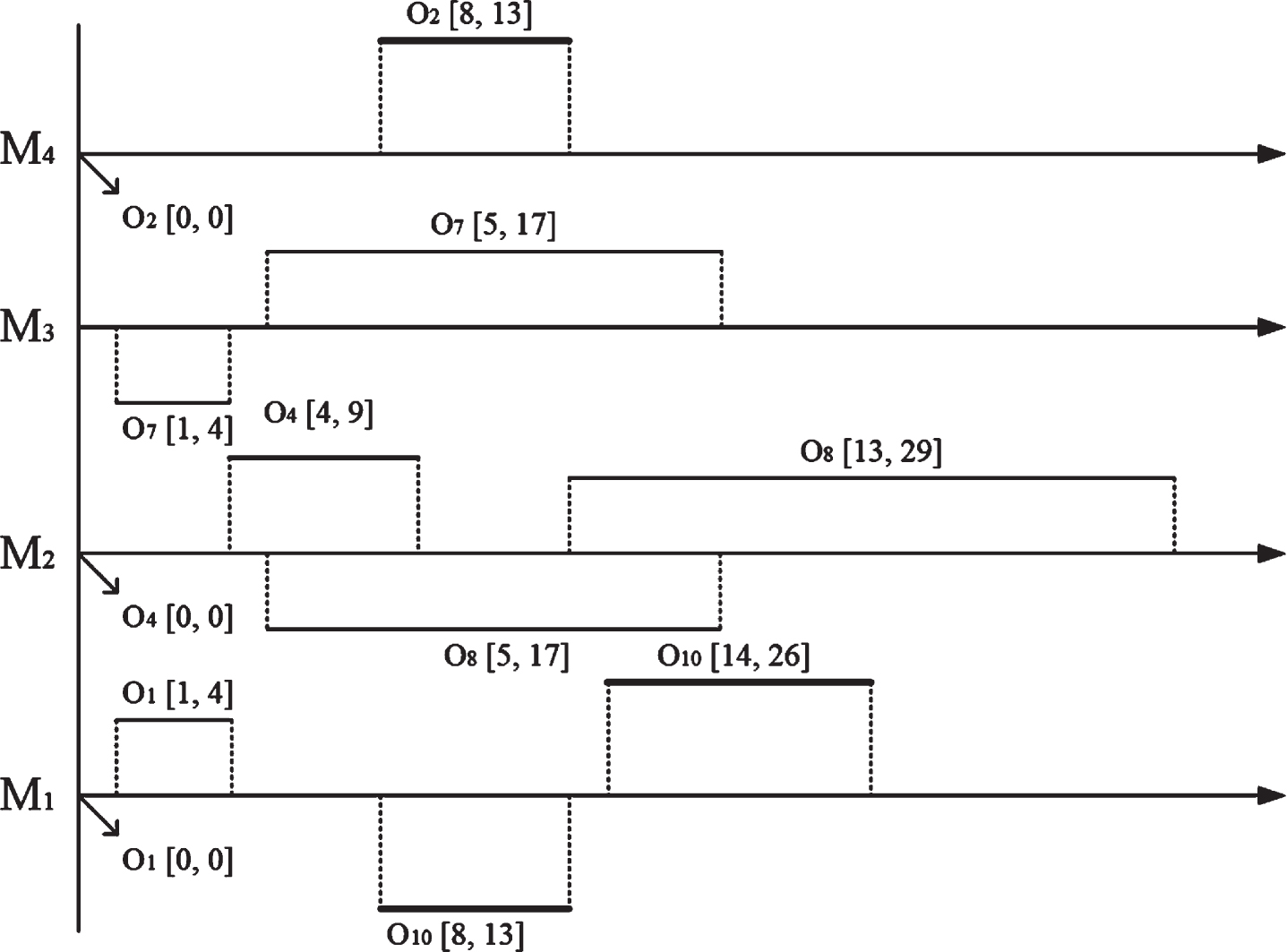
Gantt chart of the scheduling example with interval processing time.
The IRPPS model presented in this study focuses on three conflicting objectives, that is, minimizing energy consumption, makespan, and maximum machine load, and deals with the trade-offs among them.
Notations and assumptions
To represent the IRPPS model, the following notations and assumptions are used:
Formula of the IRPPS model
(1) Objective function for the total energy consumption
In this IRPPS model, the total energy consumption consists of two parts: total interval processing energy consumption and total interval idle energy consumption. In addition, the turn-on/off mode is applied in this model to reduce energy consumption. Inspired by Wu and Sun [33] and Lei et al. [39], to reduce the complexity of the proposed model, the machine needs to be turned off if its idle time exceeds a given time threshold. For example, H s = 7 means that machine M s needs to be turned off if its idle time exceeds 7 h.
The total interval processing energy consumption
The variable used to determine the total interval idle energy consumption is calculated using Equation (6) and
The objective function of the total interval energy consumption is calculated using Equation (8):
(2) Objective function for the interval makespan
The variables used to determine the makespan are calculated using Equations (9) and (10), as follows:
The objective function of interval makespan is calculated by Equation (11):
(3) Objective function for the maximum machine load
In the IRPPS model, the maximum machine load is calculated using Equation (12):
(4) Objectives and constraints
The standard multiple optimization objectives of the IRPPS model are formalized as Equation (13):
The below constraints need be taken into consideration to achieve the aforementioned objectives:
(5) Equivalent transformation of objective function value
According to Li et al. [10], the mean and variance of the interval numbers can be calculated using Equations (18) and (19), respectively, which are then used to transform the interval objective value into the real value using Equation (20).
This section introduces the basic NSGA-II and explores the proposed ENSGA-II.
The basic NSGA-II
The NSGA-II proposed by Deb et al. [11] has become a widely recognized method for optimizing multi-objective problems in the last two decades. To provide better convergence capabilities and maintain population diversity, the NSGA-II integrates fast non-dominated sorting and crowding distance approaches, which are briefly introduced as follows.
Fast non-dominated sorting
Fast non-dominated sorting is an effective approach for achieving better convergence capabilities. In a multi-objective optimization problem, conflicts may be produced among different objectives. When one objective value improves, the others may worsen. Thus, the fast non-dominated sorting is employed to classify all solutions into different non-dominated ranks. Solutions with lower non-dominated ranks dominate those with higher non-dominated ranks, and the solutions with the same non-dominated rank are not dominated by each other.
Crowding distance (CD)
CD is a common method for keeping the diversity of solutions that equips NSGA-II with lower computational complexities and can be employed to obtain a uniformly spreading Pareto-optimal solution set. The crowded-comparison operator is employed to select the solutions. It is defined as follows: if the solutions are of the same non-domination rank, a higher CD value is preferable. The interval CD is calculated using Equation (21) [22].
The uncertain IRPPS problem can be considered a hybrid problem that is divided into the remanufacturing process plan selection sub-problem and scheduling sub-problem. On the basis of Section 4.1, the ENSGA-II is proposed to obtain optimal solutions in the uncertain IRPPS model. Three improvements are made to the basic NSGA-II framework in this study: (1) a new multi-dimensional representation scheme is designed to comprehensively characterize the solutions; (2) a new self-adaptive strategy and multiple genetic operators are integrated to increase the diversity of the population; and (3) a new local search strategy is employed to avoid premature convergence and enhance algorithmic exploration.
In Fig. 2, the framework of the ENSGA-II is presented, where N represents the initial population size. P G and O G represent the parent and offspring populations in the Gth generation, respectively.
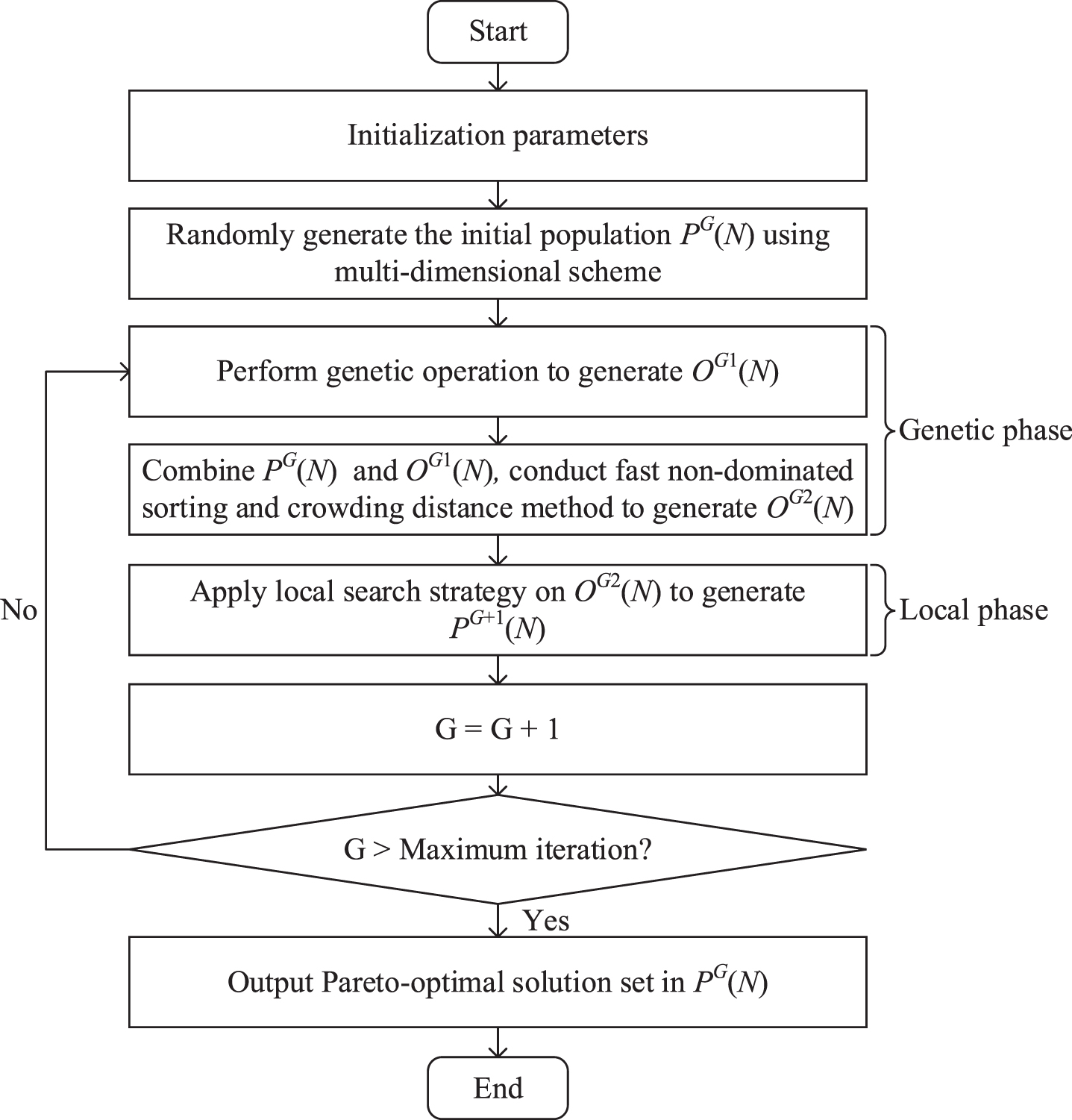
The framework of the ENSGA-II.
An efficient encoding scheme is an important part of connecting mathematical models and optimization algorithms. Considering the characteristics of the uncertain IRPPS model, a chromosome should reflect both the information and processing flexibility of the parts. To effectively characterize the IRPPS model, a multi-dimensional representation scheme is proposed.
The multi-dimensional representation scheme comprises two layers: a feature layer and a reprocessing layer. The former includes the part index, features, and failure mode information (i.e., the first dimension), while the latter includes a candidate operation string (i.e., the second dimension) and candidate machine string (i.e., the third dimension). Based on the illustrated flexible process plans shown in Table 1, an example is given to demonstrate the multi-dimensional representation scheme (Fig. 3). Each value in the first dimension represents a defective feature of one part that fails owing to a failure mode, and the length in this dimension indicates the cumulative number of all defective features of all parts that need to be reprocessed. For example, the last value [4, 1], indicates that defective feature 5 of part 4 fails owing to failure mode 1 (FM51). Each value in the second dimension represents the rth candidate operation that is selected to reprocess the corresponding defective feature. For example, the last value 2 indicates that the second candidate operation (i.e., O6) is selected to reprocess the above defective feature [4, 1]. Each value in the third dimension represents the qth candidate machine selected to execute the corresponding operation. For example, the last value 1 indicates that O6 is executed on the first candidate machine (i.e., M3).
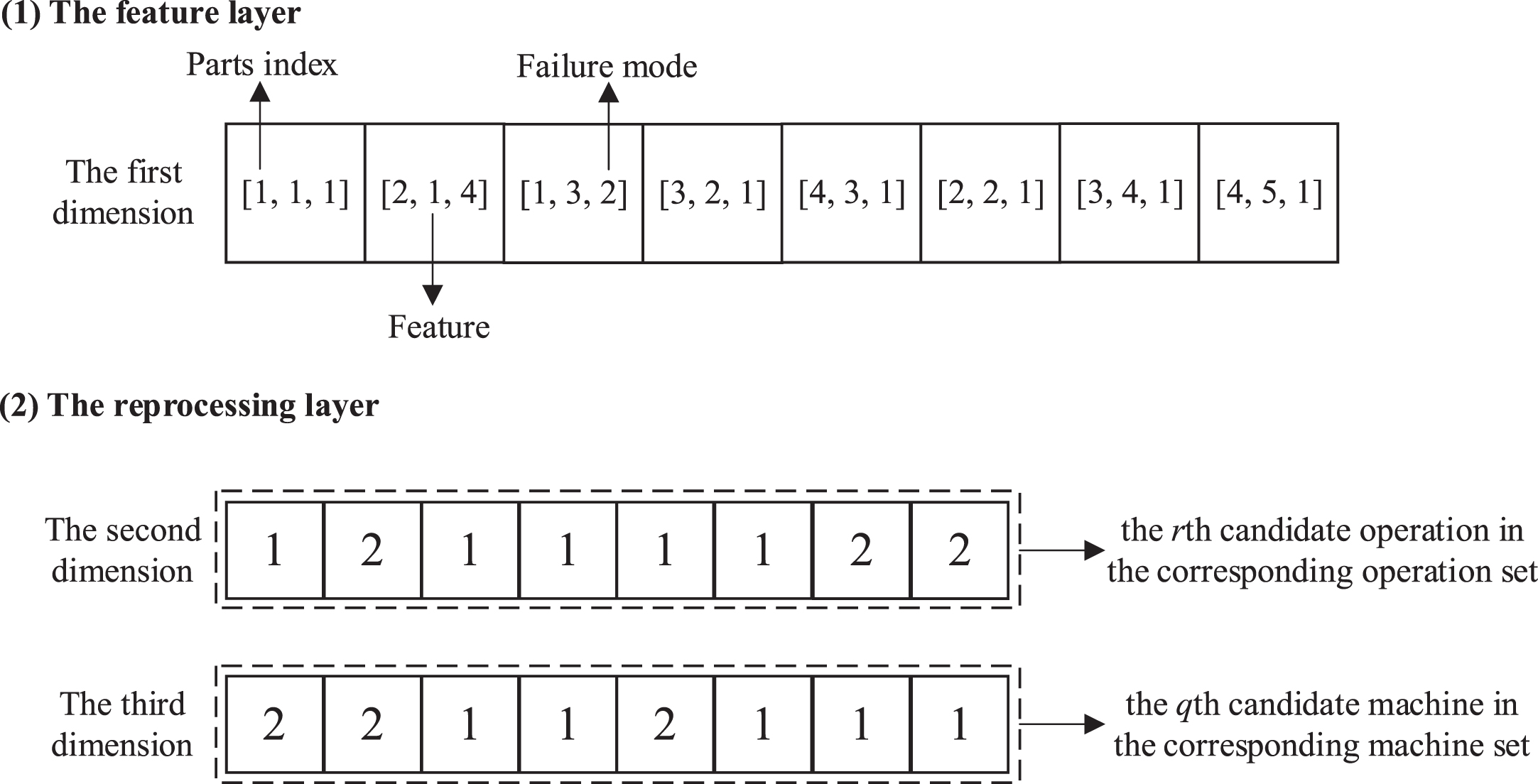
An example of the multi-dimensional representation scheme.
The precedence operation crossover (POX) and job-based order crossover (JOX) [40] are extended with the proposed multi-dimensional representation scheme, and then randomly selected as the crossover operator to generate the offspring.
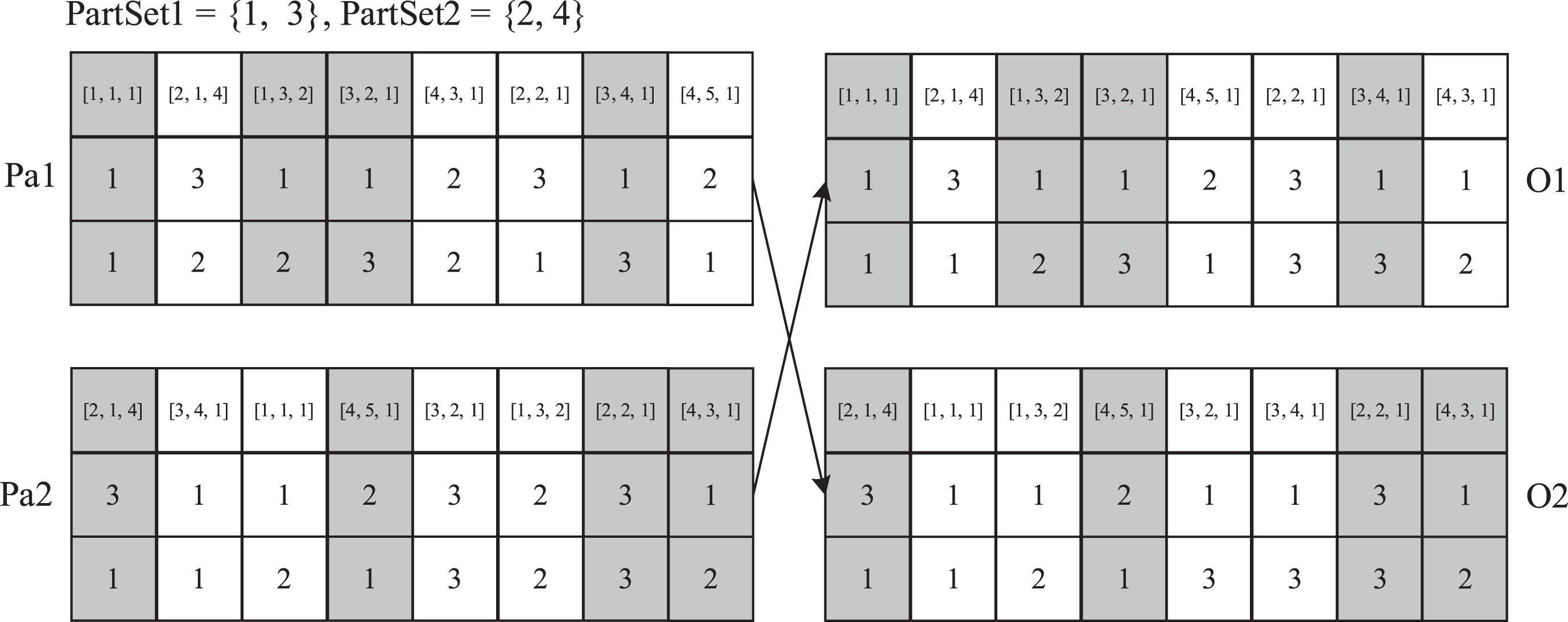
Figure 4 shows an example of the extended POX operator. Detailed steps are listed below: Randomly divide all the part numbers {1, . . . , n, . . . , N}, into two non-empty sets, PartSet1 and PartSet2. Duplicate the genes from parent1 (Pa1) and parent2 (Pa2) whose part numbers belong to PartSet1 into offspring1 (O1) and offspring2 (O2), respectively, at the same position. Duplicate the genes from Pa1 and Pa2 whose part numbers belong to PartSet2 into O2 and O1, respectively, and maintain their precedence order.
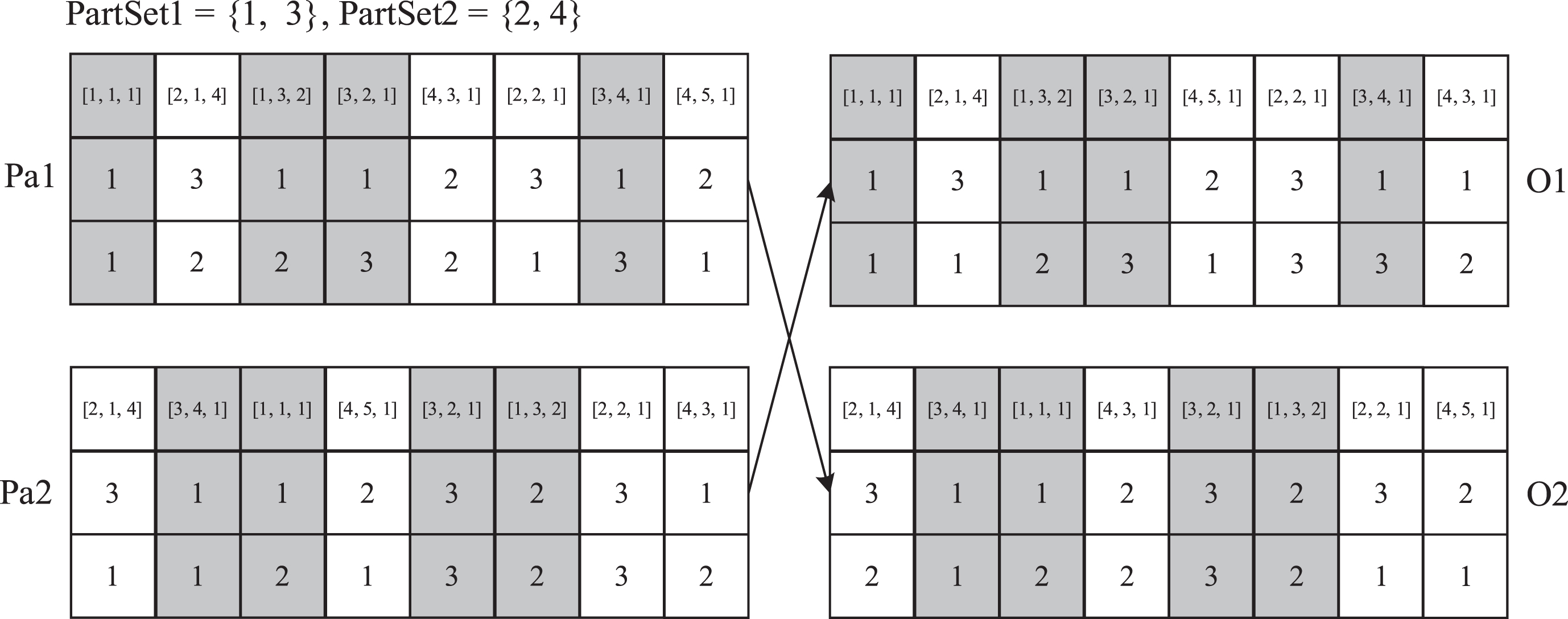
An example of the extended POX operator.
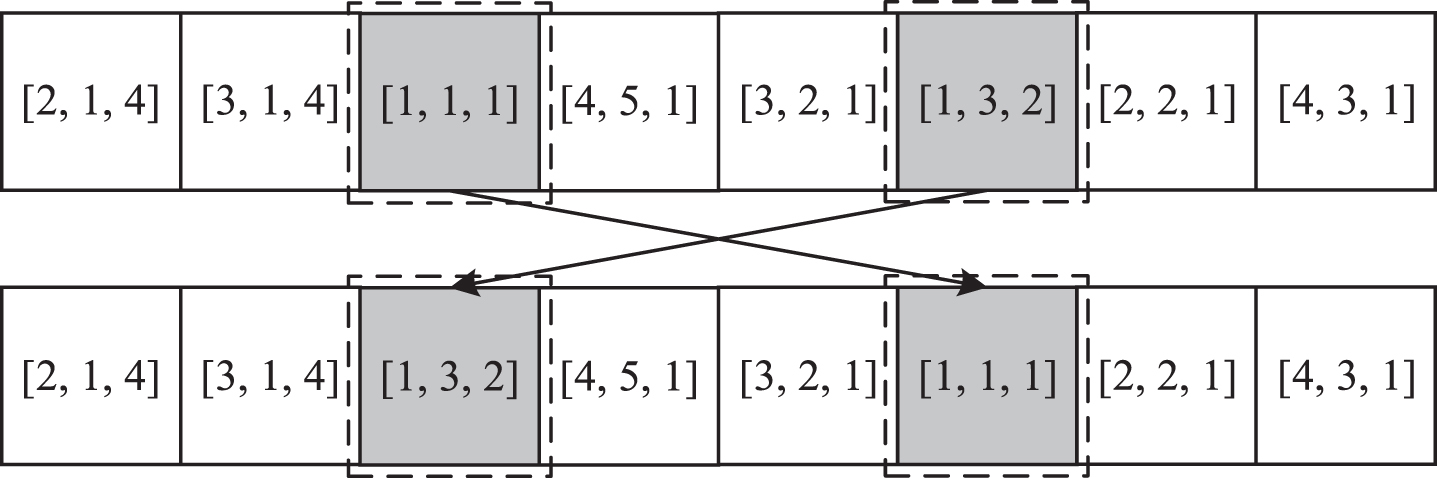
Figure 5 shows an example of the extended JOX operator. Detailed steps are listed below: Randomly divide all the part numbers {1, . . . , n, . . . , N} into two non-empty sets, PartSet1 and PartSet2. Duplicate the genes from parent1 (Pa1) whose part numbers belong to PartSet1 into offspring1 (O1), and duplicate the genes from parent2 (Pa2) whose part numbers belong to PartSet2 into O2 at the same position. Duplicate the genes from Pa1 whose part numbers belong to PartSet1 into O2, duplicate the genes from Pa2 whose part numbers belong to PartSet2 into O1, and maintain their precedence order.
An example of the extended JOX operator.
In this study, a self-adaptive strategy for crossover probability P
c
is proposed for the crossover operation, as shown in Equation (22), where Pc_initial is the initial crossover probability, iter_max and iter_current represent the maximum iteration and current iteration, respectively.
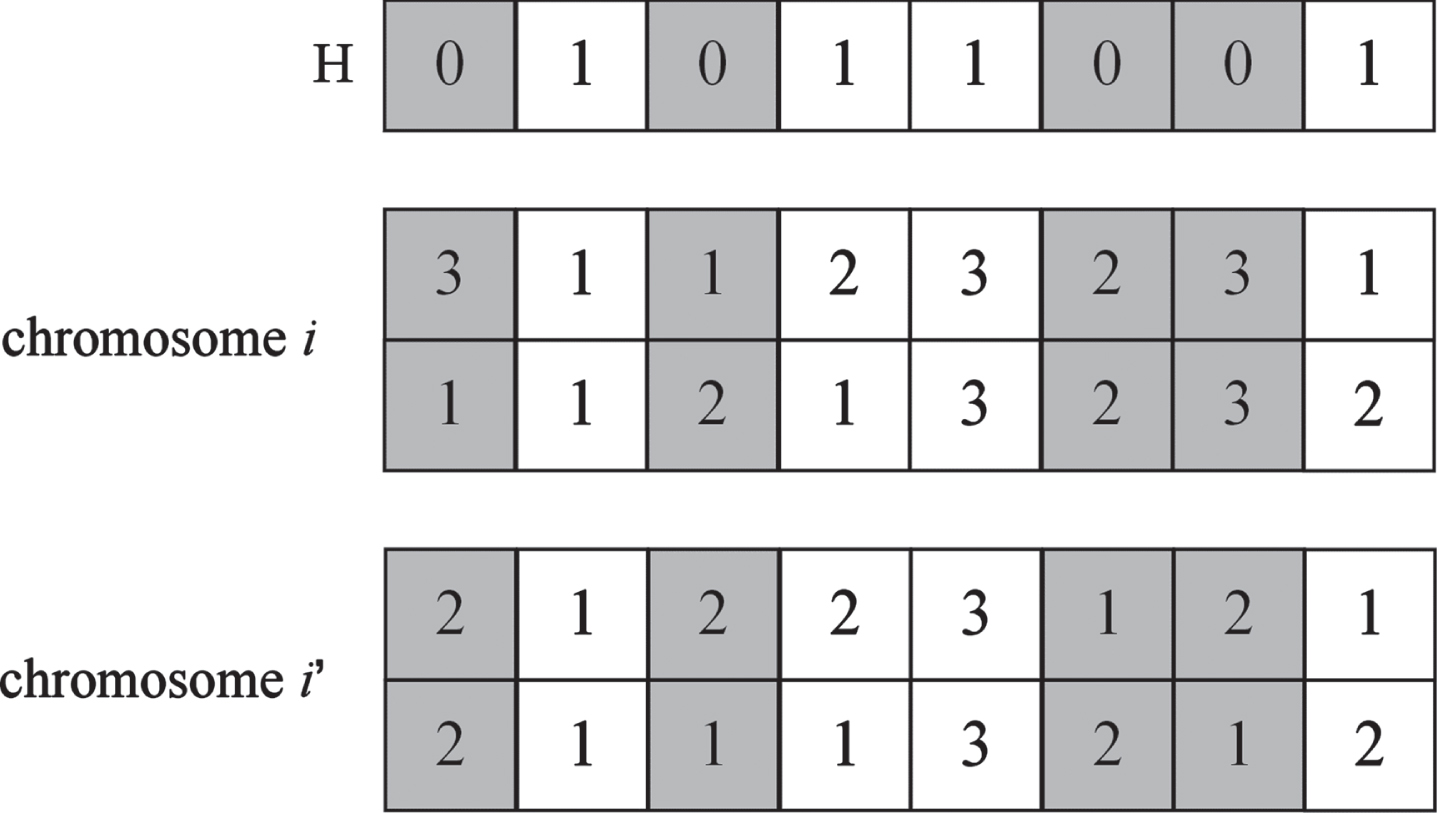
The two-point swapping operator is used to mutate the feature layer, and the single-point mutation operator is used to mutate the reprocessing layer.
For the two-point swapping operator, Fig. 6 shows an example of randomly selecting two points and swapping the corresponding genes.
For the single-point mutation operator, randomly select one point and replace the gene with a different gene in the candidate set, and do nothing if there is only one gene in the candidate set.
In this study, a self-adaptive strategy for mutation probability P
m
is proposed for mutation operation, as shown in Equation (23), where Pm_initial denotes the initial mutation probability.
An example of performing the two-point swapping operator.
To avoid premature convergence and improve algorithmic exploration, a local search strategy that includes four local search operators is employed to extend the basic NSGA-II algorithm. The first local search operator (LS1) is designed to find a better process plan for each part. The second local search operator (LS2) aims to find a new process plan and generate a scheduling scheme that is better than the current one. The third local search operator (LS3) aims to jump out of the local optimal solution to avoid premature convergence. The fourth local search operator (LS4) is designed to ameliorate the quality of solutions and repair the infeasible solutions obtained by LS3. The above four local search operators are described below.
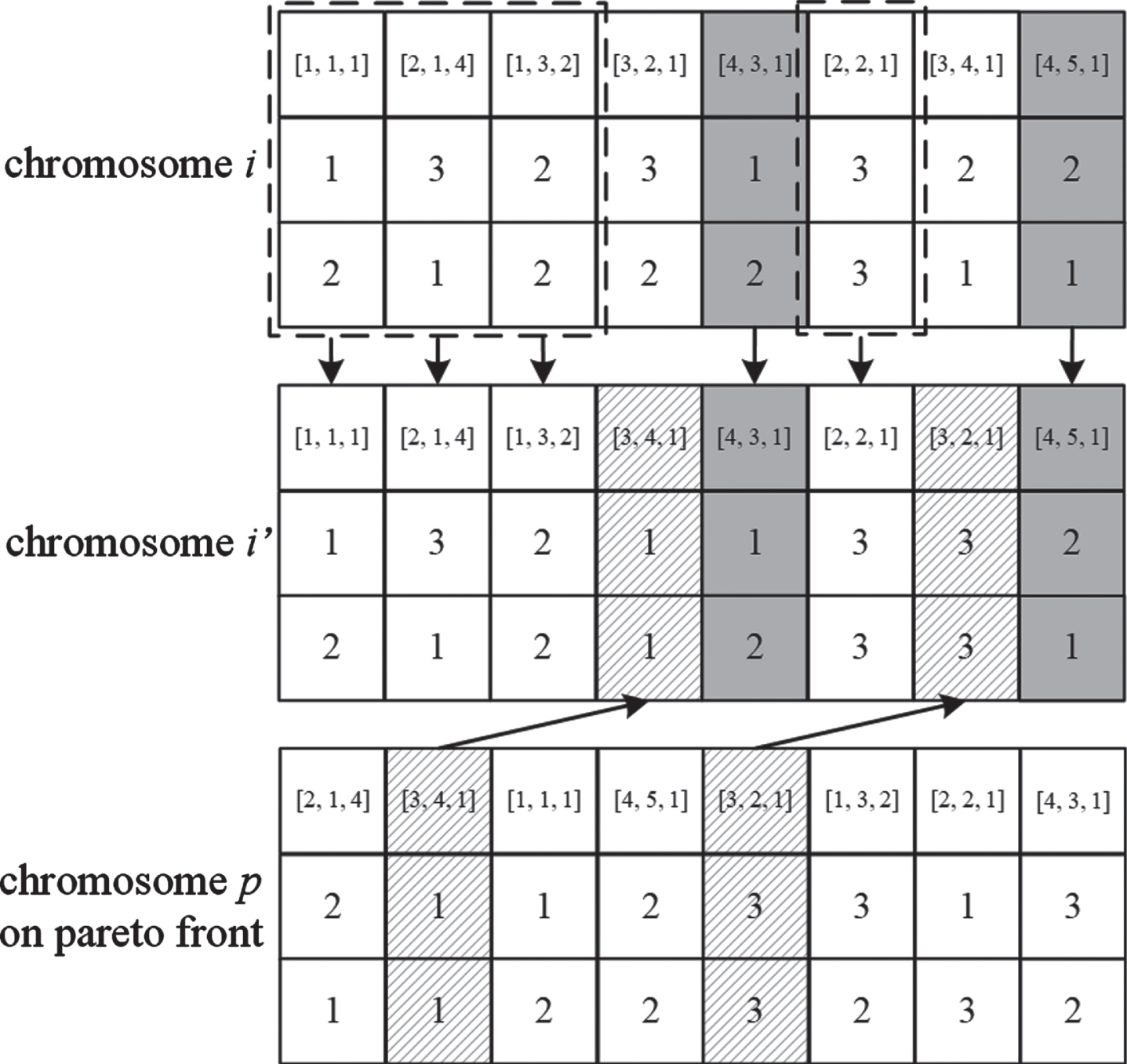
An example of performing LS1.
Compare the feature order of each part between chromosomes i and p. Because the feature orders of P1 (i.e., F1 are followed by F3) and P2 (i.e., F1 are followed by F2) are the same between chromosomes i and p, they are kept unchanged at the same position in the new chromosome i’.
Because the feature orders of P3 and P4 are different between chromosomes i and p, about half of the parts with the corresponding features (i.e., P4 with F3 followed by F5) are kept unchanged at the same position in the new chromosome i’.
Duplicate the remained parts with the corresponding features (i.e., P3 with F4 followed by F2) from chromosome p to the new chromosome i’, with their precedence order unchanged.
Randomly select chromosome i in the population and generate a string vector H with 0 and 1, with the same length as the chromosome i. The genes in the reprocessing layer corresponding to element 1 in the string vector H are kept unchanged at the same position in the new chromosome i’. The two dimensions in the reprocessing layer of chromosome i represent the selection of candidate operations and candidate machines, respectively. Replace the operation genes corresponding to element 0 in the string vector H with another candidate operation and replace the machine genes with another machine with the shortest processing time in the new chromosome i’.
An example of performing LS2 on reprocessing layer.
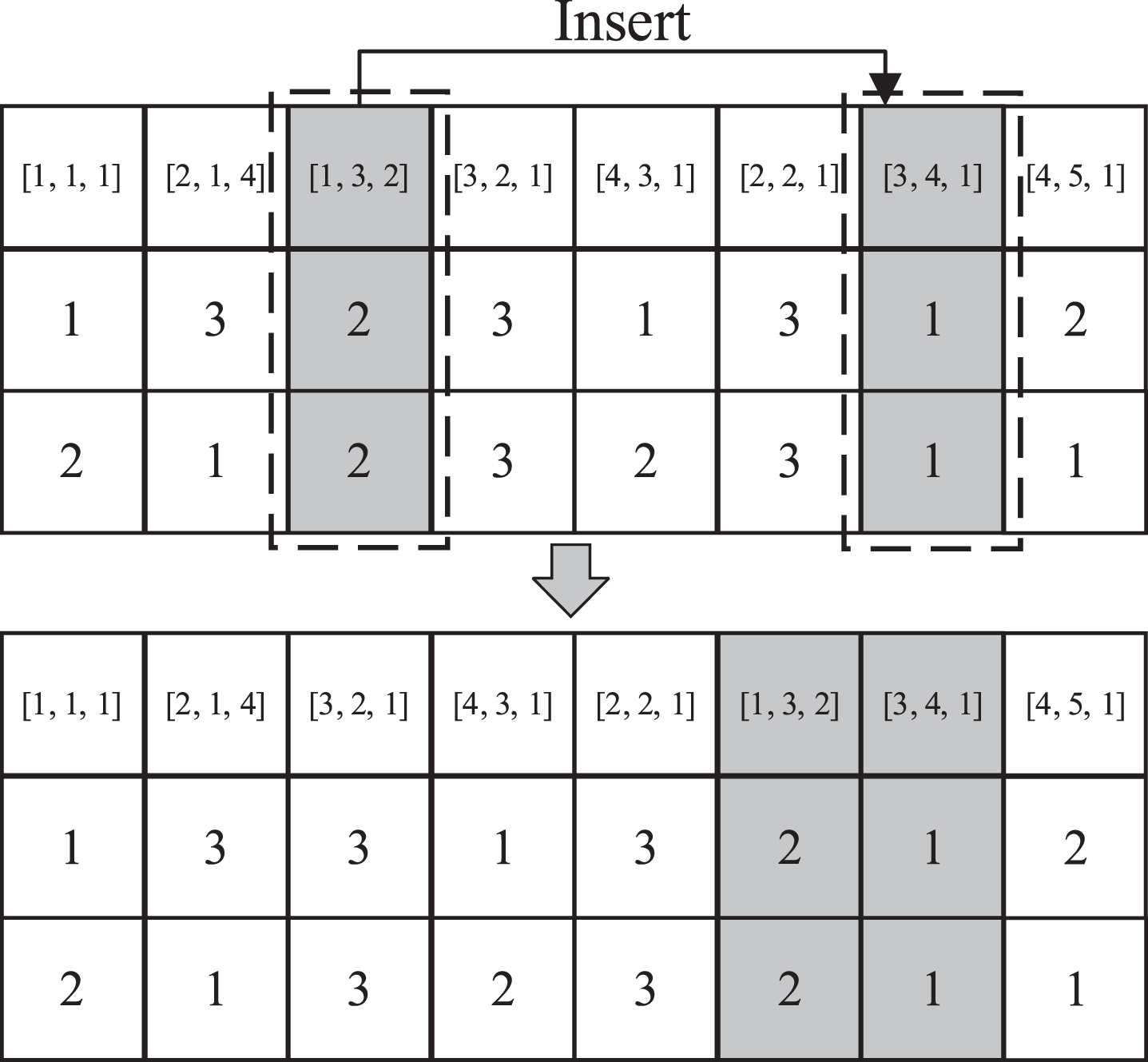
An example of performing LS3.
Repair of the feature layer. According to the feature constraints, check whether the feature order of each part meets the feature constraints. If one does not, randomly reorganize the feature genes belonging to the part to satisfy the feature constraints.
Repair of the reprocessing layer. According to the repaired feature layer, check whether the corresponding operations and machines can fulfill the required functions. If one does not, randomly select a feasible operation or machine gene in the corresponding candidate set to fulfill the required function.
The pseudocode of the local search strategy is shown in Algorithm 1, where R1, R2, and R3 represent the selection probabilities of LS1, LS2, and LS3, respectively.
The pseudocode of the ENSGA-II is shown in Algorithm 2.
Simulation experiments were conducted in this section to evaluate the performance of ENSGA-II. NSGA-II [34], strength Pareto evolutionary algorithm-2 (SPEA2) [41], and MOPSO [26] are Pareto-based multi-objective algorithms that have been widely used to solve multi-objective scheduling problems. Therefore, the proposed ENSGA-II was compared to the three other baseline multi-objective algorithms, i.e., the NSGA-II, SPEA2, and MOPSO, whose pseudocodes are shown in Algorithms 3–5, respectively. All the experimental simulations were performed in a Python environment on a personal computer with a 64-bit version of Windows 10, an Intel (R) Core with a CPU speed of 3.10 GHz, and 16 GB RAM.
Experimental design
To simulate the real remanufacturing environment, the experimental data and parameters were defined as follows. In each instance, the number of parts, which varied from 4 to 30, and the machine number, which ranged from 6 to 12, were randomly generated. The benchmark data of the parts are listed in Table 2, including the feature number range, the operation number, the number of feature constraints, and applicable parts. In addition, the specific feature constraints and other illustrative properties can be found in the literature given in the “Adopted from” column of Table 2. For each feature, the number of failure modes, which varied from 1 to 4, was randomly generated, as was the number of candidate operations for each failure mode and the number of candidate machines for each operation, which both ranged from 1 to 3. The parameters listed in Table 3 were also randomly generated within the corresponding ranges. All experimental data utilized in this study is publicly accessible through Figshare database (https://doi.org/10.6084/m9.figshare.16746637). For each instance in the database, the name includes the total number of parts, the benchmark dataset ID, and the total number of machines. For example, the “Exp (4/1/6)” indicates the total number of parts was 4, the benchmark dataset was #1, and the total number of machines was 6. To reduce accidental errors in experiments, each experiment was conducted 10 times independently and the results were averaged to obtain the final experimental results.
Benchmark datasets of parts
Benchmark datasets of parts
The parameters for experiments
To evaluate the proposed ENSGA-II comprehensively, three multi-objective algorithm evaluation indicators, namely, the set coverage [43], spacing [44], and hypervolume [43] indicators are adopted.
(1) Set coverage (SC)
The SC indicator was designed to evaluate the convergence of the Pareto-optimal solution set produced by the various multi-objective algorithms, as shown in Equation (24).
(2) Spacing indicator (SI)
The SI measures the distribution or spreading of solutions over the Pareto-optimal solution set, and are defined in Equations (25) and (26):
(3) Hypervolume (HV)
The HV indicator is utilized to comprehensively evaluate the convergence and distribution of the multi-objective algorithms, which is defined in Equation (27).
The maximum number of iterations was set to 300 for all algorithms. As the HV indicator comprehensively measures the performance of algorithms, it was used for sensitivity analysis of the parameters in the proposed ENSGA-II, including the selection probability of performing local search operators and population size.
The first experiment, Exp (15/1/8), tested the performance of ENSGA-II with different combinations of selection probabilities of local search operators (LS1, LS2, and LS3). In this experiment, the initial population size was fixed at 40. Table 4 shows 13 selection probability combinations of local search operators used for this experiment.
Selection probability combinations of local search operators
Selection probability combinations of local search operators
The HV values produced by ENSGA-II under various combinations of local search operator selection probabilities are shown in Fig. 10. It can be observed that the HV value of C06 is higher than that of the other combinations; therefore, the combinations of selection probabilities of local search operators are set as 0.1, 0.6, and 0.3, respectively, in the experiments that followed.
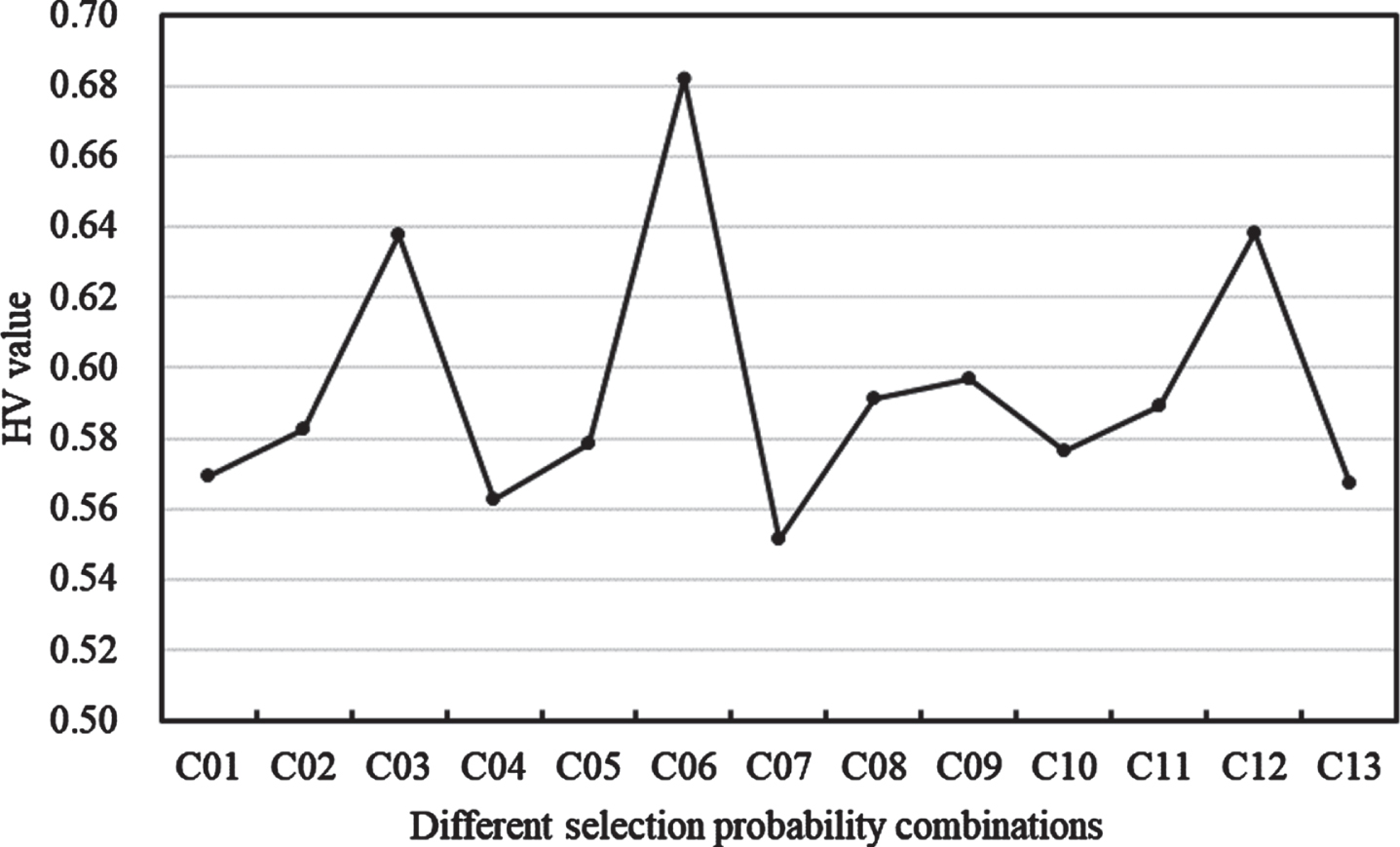
The HV values corresponding to various selection probability combinations.
The second experiment tested the HV values of ENSGA-II with different population sizes on differently scaled datasets. Figure 11 shows that the HV value changes slowly when the initial population size exceeds 40. As large population sizes increase the computational cost associated with the simulations, the initial population size is set to 40 in the experiments that follow. This population size also ensures that an efficient comparison could be made.
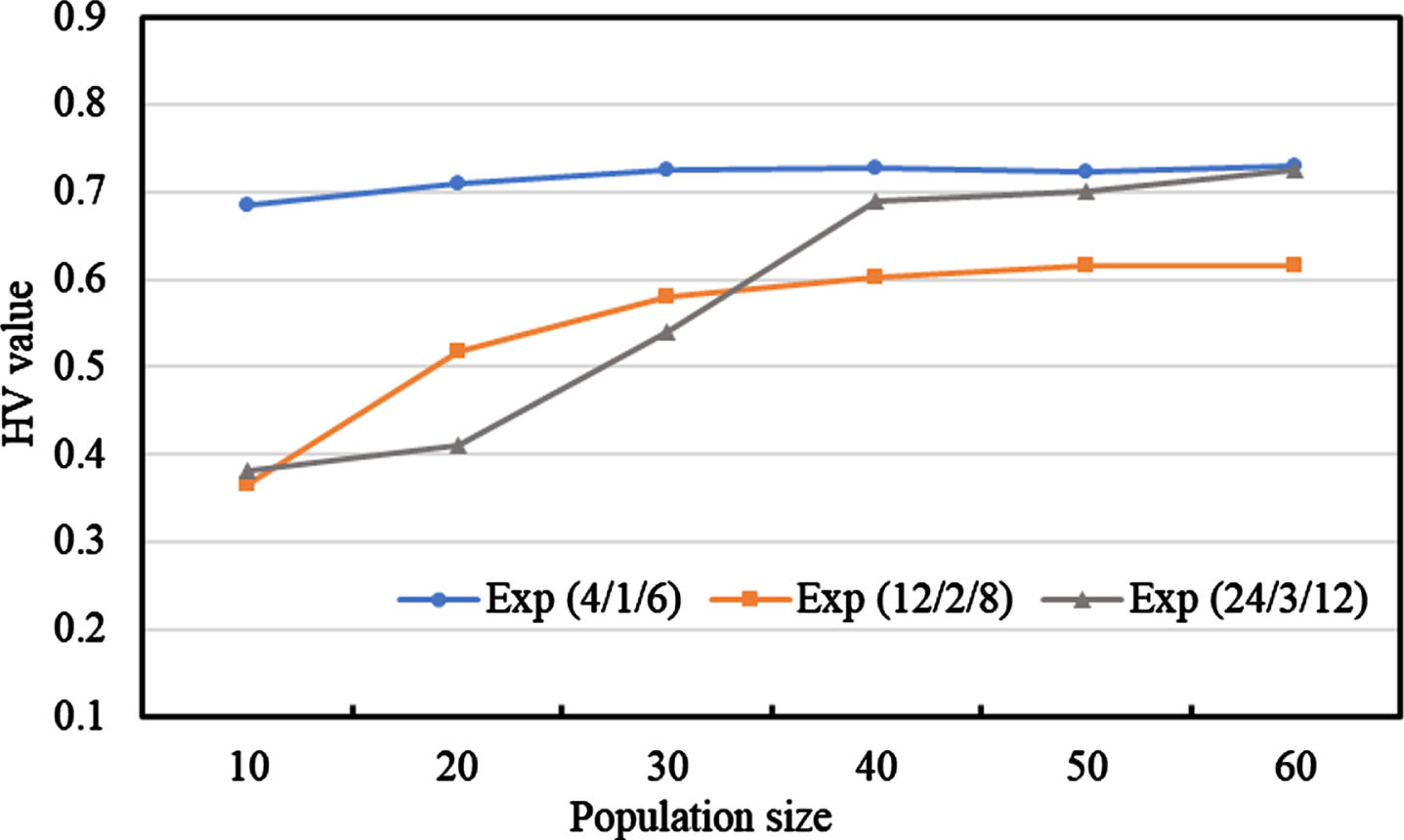
The HV values corresponding to different population sizes.
To make a fair comparison between ENSGA-II and three other baseline algorithms, the number of local search operators executed in the ENSGA-II and NSGA-II, as well as the number of neighborhoods in the MOPSO were all set to 10. Table 5 lists the other parameters of the multi-objective algorithms after the trial run.
The other parameters of multi-objective algorithms
In the following experiments, the performance comparison between the ENSGA-II and those of other baseline multi-objective algorithms, including the NSGA-II, SPEA2, and MOPSO, are evaluated comprehensively. Tables 6, 7, and 8 (better results are boldfaced) show the comparative results based on the SC, SI, and HV, respectively.
Table 6 compares the results of the SC indicator obtained by four algorithms. It is found that in all conducted experiments, the ENSGA-II demonstrates superior performance over other baseline algorithms significantly. The second and third columns reveal that at least one solution obtained by ENSGA-II dominates all the solutions obtained by NSGA-II in most of the experiments, while the solutions obtained by NSGA-II do not dominate any solution obtained by ENSGA-II. The fourth and fifth columns reveal that at least one solution obtained by ENSGA-II dominates all the solutions obtained by SPEA2, while the solutions obtained by SPEA2 do not dominate any solution obtained by ENSGA-II. The sixth and seventh columns reveal that at least one solution obtained by ENSGA-II dominates the partial solutions obtained by MOPSO, while the solutions obtained by MOPSO do not dominate any solution obtained by ENSGA-II in most of the experiments.
Table 7 compares the results of the SI obtained by four algorithms. It shows that the Pareto-optimal solution set obtained by ENSGA-II exhibits a more uniform distribution than those obtained with the baseline algorithms in most of the experiments.
Table 8 compares the results of the HV indicator obtained by four algorithms. The reference point R = (1, 1, 1) T . As shown in Table 8, the majority of experimental results indicate that the ENSGA-II generates the significantly higher HV values than the baseline algorithms. According to the results, the solutions obtained by the ENSGA-II exhibit better convergence and distribution compared to those obtained by the baseline algorithms.
The SC comparisons among four algorithms
The SC comparisons among four algorithms
The SI comparisons among four algorithms
The HV comparisons among four algorithms
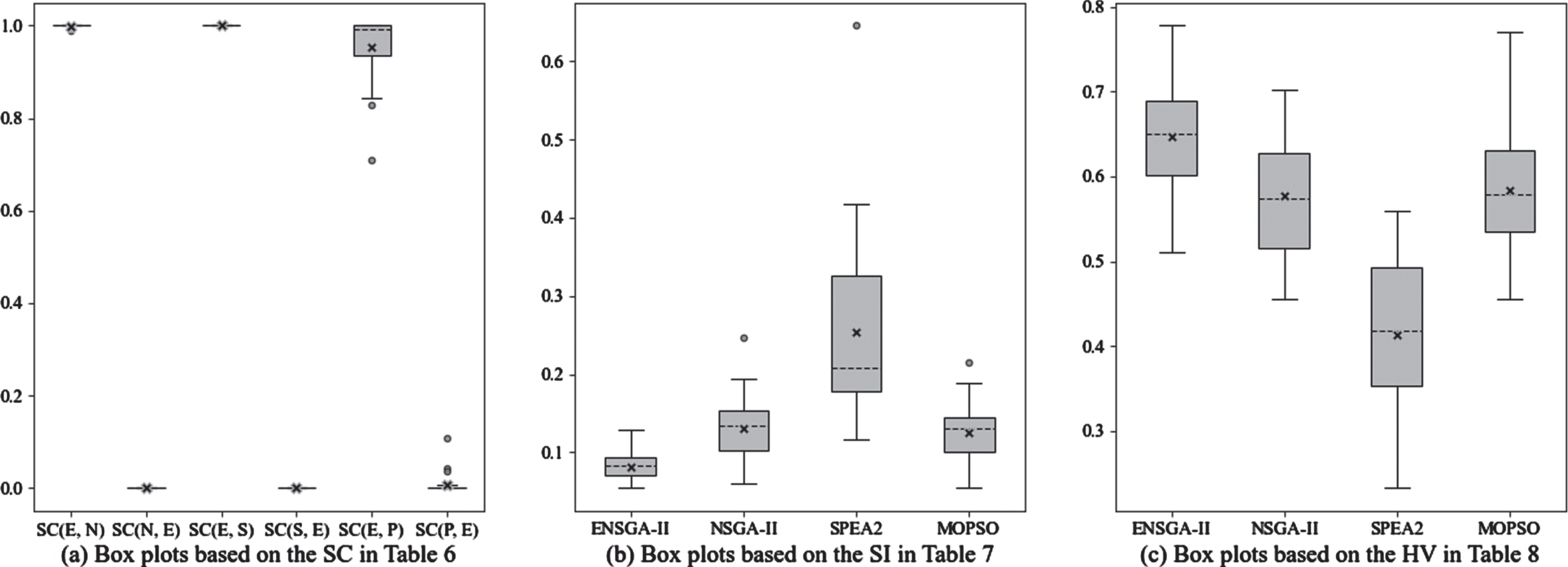
Box plots based on the experimental results.
To make the experimental results more intuitive, Fig. 13 reveals the Pareto-optimal solution sets produced by four algorithms. The majority of solutions produced by the baseline algorithms are dominated by the solutions produced by the ENSGA-II. Moreover, the solution set obtained by the ENSGA-II outperforms those of the baseline algorithms on the convergence and distribution in experiments with different scales. Besides, when the scale of the test instance increases, the ENSGA-II exhibits an excellent performance and reaches the Pareto-optimal solution set more easily than other baseline algorithms.
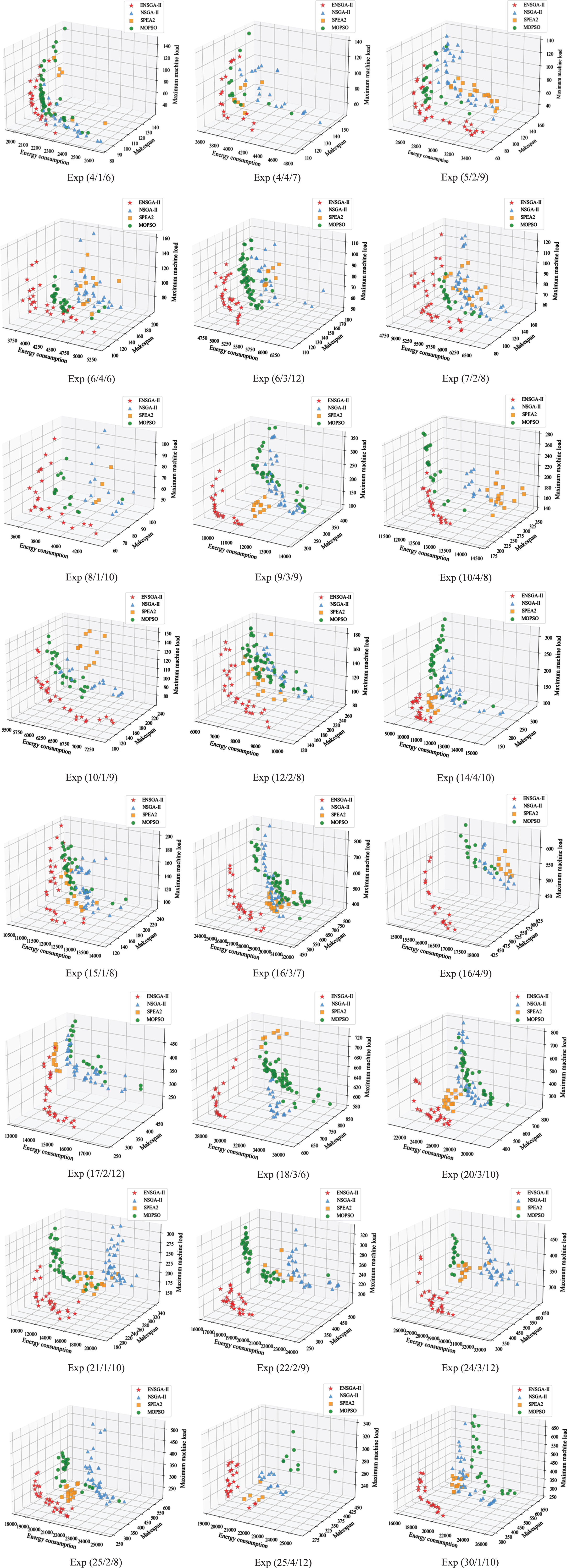
The Pareto-optimal solution sets produced by four algorithms.
In the case of instance Exp(4/4/7), Table 9 shows a set of Pareto solutions obtained by ENSGA-II and the three other baseline algorithms. The findings reveal that the solutions derived from ENSGA-II with three objectives consistently outperform those obtained by the three other baseline algorithms. Such superiority is attributed to the fact that every solution produced by each baseline algorithm is dominated by at least one solution generated by ENSGA-II.
The Pareto optimal solutions of four algorithms on the instance Exp(4/4/7)
With the depletion of resources and the worsening of environmental pollution, remanufacturing has gained significant attention from various sectors as an environmentally friendly approach to sustainable development. In the remanufacturing process, process planning and scheduling plays an important role in actual remanufacturing applications. To effectively cope with the intrinsic uncertainties of the remanufacturing environment, a new IRPPS model under uncertainties was proposed and solved using the ENSGA-II. This study contributes to existing remanufacturing research through the following three main aspects. A new IRPPS model with the objective of minimizing energy consumption, makespan, and maximum machine load is proposed. It applies interval numbers to represent the uncertainty of processing time and develops a process planning approach that integrates various failure modes to obtain a more practical and effective process plan and scheduling scheme. To effectively optimize the IRPPS model, the ENSGA-II was proposed by integrating a new multi-dimensional representation scheme, a new self-adaptive strategy, and a new local search strategy. Experiments were simulated to compare four algorithms in order to comprehensively evaluate the performance of the ENSGA-II in tackling the IRPPS model. The experiments were conducted on 24 sets of instances, showing that ENSGA-II outperforms three other baseline algorithms for all SC metrics, 83.3% for SI metrics, and 91.7% for HV metrics.
In addition, this study has the following deficiencies. In terms of modeling, there is a lack of application in actual remanufacturing cases and analysis of practical factors such as finite buffers and priority differences. In terms of algorithms, the applicability of the proposed algorithm to other scheduling models needs to be explored.
In the future, the following directions can be explored to further refine this study. First, the proposed model should be applied to an actual remanufacturing case and more larger-scale instances. Second, more practical factors should be considered in the proposed model. Furthermore, the issue of machine learning-based search strategies is intriguing and has the potential to enhance the applicability of ENSGA-II to other scheduling models.
Footnotes
Acknowledgments
This work has been supported by National Natural Science Foundation of China (No. 51975512), Philosophy and Social Science Program of Zhejiang Province (No. 21NDJC105YB), and Natural Science Foundation of Xinjiang Province (No. 2021D01A70).
Data availability statement
All experimental data for this research have been public in the Figshare database (https://doi.org/10.6084/m9.figshare.16746637).
Compliance with ethical standards
Conflicts of interest
The authors declare that there is no conflict of interests regarding the publication of this article.
Ethical standard
The authors state that this research complies with ethical standards. This research does not involve either human participants or animals.