
Abstract
With the development of artificial intelligence technology, the assessment method based on machine learning, especially the ensemble learning method, has attracted more and more attention in the field of credit assessment. However, most of the ensemble assessment models are complex in structure and costly in time for parameter tuning, few of them break through the limitations of lightweight, universal and efficient. This paper present a new ensemble model for personal credit assessment. First, considering the conflicts and differences among multiple sources of information, a new method is proposed to correct the category prior information by using the difference measure. Then, the revised prior information is fused with the current sample information with the help of Bayesian data fusion theory. The model can integrate the advantages of multiple benchmark classifiers to reduce the interference of uncertain information. To verify the effectiveness of the proposed model, several typical ensemble classification models are selected and empirically studied using real customer credit data from a commercial bank in China, and the results show that among various assessment criteria: the proposed model not only effectively improves the multi-class classification performance, but also outperforms other advanced multi-class classification credit assessment models in terms of parameter tuning and generalizability. This paper supports commercial banks and other financial institutions examination and approval work.
Introduction
With the continuous development of commercial bank credit business, credit risk assessment has become the focus of attention. It is an effective way for banks and other financial institutions to identify defaulting customers and potential value customers by a scientific and effective credit assessment model. And it is also important for banks and other financial institutions to avoid risks by assessing the credit risk level of customers timely and accurately [1].
There are many studies on credit risk assessment, mainly based on the customer’s historical credit record, with the help of classification method to build a credit rating assessment model, so as to obtain the probability of default risk of the customer [2]. Fernandes et al. [3] judged whether a customer is in default or not by logical regression (LR) [3]. Although the LR model is simple and easy to understand, the assessment accuracy is not high, and the statistical assessment model usually had strong assumptions [4, 5].
With the growing demand for credit, artificial intelligence machine learning algorithm breaks the limitations of traditional statistical methods on data distribution assumptions [6, 7]. Akkoc proposed a fuzzy neural network classification model, which is superior to traditional assessment models such as linear discriminative analysis (LDA) and LR in terms of estimating classification error cost and correct classification rate [8]. Harris et al. [9] constructed an enhanced binary classification model of support vector machine, which can effectively handle high-dimensional data, with better classification accuracy than statistical assessment and also reduces the computational cost. However, the data structure of credit risk in different environments is complex in real life. A single classifier is only applicable to a certain type of data, and cannot solve all data situations well. Most of the models can only meet the current credit assessment situation and can hardly be universally applicable to other different credit datasets [10, 11].
And the ensemble classification algorithm greatly improves this defect [12, 13]. Zhu et al. [14] compared and analyzed six methods of credit risk assessment with the help of financial data of enterprises, and concluded that ensemble learning method has higher classification performance. Chen et al. [15] integrated multiple classification models based on support vector machines by adjusting kernel function and penalty factor parameters to improve the classification accuracy. Xia et al. [16] proposed a tree based heterogeneous ensemble credit binary classification assessment model with the main advantage of dynamically assigning weights to benchmark classifiers based on over fitting measures.
In the classification assessment of bank credit rating, more and more scholars pay attention to the method of ensemble classification, and has made some progress [17]. Since the credit rating of bank customers is affected by many factors, the shortcomings of the existing ensemble assessment models are also obvious: First, in order to improve classification accuracy, complex assessment frameworks are often built or a lot of parameter tuning is performed, which is time-consuming and less interpretable. Second, most of the existing ensemble classification assessment methods are based on the same type or different types of benchmark classifiers, and rarely consider the differences between classifiers and the unique performance of a single classifier [18, 19].
To improve this shortcoming, an ensemble model of multi-class classification credit assessment based on Bayesian fusion theory is proposed, which takes into account the conflicts and differences of multi-source information, and integrates the advantages of several different benchmark classifiers, including LR,DT, SVM, KNN, RF and XGboost. With the help of Bayesian fusion theory, to achieve an optimal combination of the differences between various benchmark classifiers and the individual performance of a single classifier. The model makes full use of the difference and complementarity between multiple sources of information to reduce the interference of uncertainty information of a single classifier, thus improving the classification accuracy. The model classification after Bayesian fusion has higher accuracy and stronger stability, and also has high generalizability.
The main contributions of this study are as follows: (1) A new multi-class classification credit assessment ensemble model is constructed with a view to providing a more refined five-level classification assessment compared to most binary studies; (2) An innovative fusion of five different single classifiers with the help of Bayesian theory, which makes full use of a priori information, which takes into account the conflicts and differences of multi-source information, integrates the advantages of each classifier and reduces the uncertainty of a single classifier, thus improving the overall assessment performance of the model; (3) The multi-class classification assessment model constructed in this paper is more lightweight, and the benchmark classifiers adopt basically conventional default parameters, which reduces the time cost of parameter tuning and greatly improves the operability and efficiency of the model. To further verify the effectiveness of the proposed model, three different representative ensemble models are selected for comparison, and the comparison results show that the superior classification performance competence of the proposed model.
The remainder of this paper is organized as follows. Section 2 presents related work. Subsequently, Section 3 describes the details of the proposed model. Section 4 presents the experimental design, which mainly includes dataset description, data preprocessing, performance metrics, and the implementation and assessment details. Section 5 presents an analysis of the experimental results. The conclusion is provided in Section 6.
Related work
Classification model
In this section, we mainly describe the advantages and disadvantages of the chosen basic models and present the underlying principles of these models. Our goal is to construct an efficient, general and lightweight multi-class credit assessment model. The model needs to realize the integration optimization of the differences between various benchmark classifiers and the individual performance of a single classifier, which has better classification accuracy and stronger generalization ability compared with the single classifier that is more sensitive to data. In order to meet the research requirements, we select six different benchmark classification models, namely logistic regression(LR) [8], decision tree (DT) [20], support vector machine (SVM) [21], K-nearest neighbor (KNN) [22], random forest (RF) [23] and XGboost [24]. Because the logistic regression model is a widely used statistical modeling technique, and the most important feature of this model is that it is highly interpretable relative to other multi-classification algorithms (e.g., SVMs, neural networks, RF,etc.), DT is a classical and commonly method, SVM has good robustness and generalization ability, KNN is simple and effective [25], RF algorithm has good processing capabilities for unbalanced datasets, XGboost is more flexible and efficient, with good computing performance [26].
Information fusion theory
Information fusion, also known as data fusion, first originated from military applications in the 1970 s. It is the combination or integration of information or data from multiple sources at different levels of abstraction to eventually obtain more complete, reliable and accurate information or inference [27]. Data fusion in the research field of credit rating classification is mainly a classification method that considers the combination or integration of complex and diverse information from different sources [28]. On the premise of ensuring sufficient and effective information, the redundancy of information should be reduced as far as possible to improve the classification accuracy. Among the information fusion technology, Bayesian fusion theory is widely used in information synthesis for its superiority in providing reliable prior information [29, 30].
Bayesian theory is a statistical theorem about probability theory proposed by Thomas Bayes, an English mathematician in the 18th century. With the development of computers, Bayes’ theorem has been widely used in many fields. Since Bayes’ theorem requires large scale data computational reasoning to highlight the effect, it is favored by more researchers in the context of big data era [31, 32], and its basic idea is all about finding the result that maximizes the posterior probability [33].
P (AB) denotes the probability of simultaneous occurrence of events A, B. If event A and event B are two events that are independent of each other, then:
The derivation process above proves that if A and B are mutually independent events, then the probability of event A occurring is independent of event B. The formula can be transformed into:
Bayesian data fusion theory
Bayesian data fusion theory is a common reasoning method based on probability statistics. It is mainly based on Bayesian theorem to determine the prior distribution according to the existing category prior information. After obtaining the sample information, the prior information is fused with the current sample information, so as to obtain the posterior distribution of the category population and realize the inference of the sample category population. In this process, the uncertainty is described by probability, and the sample to be classified is assigned to the category to which it is most likely to belong or to the category with the least expected risk. Compared with other estimation methods, the greatest advantage of Bayesian theory is that it makes full use of prior information [34].
In this study, the classification accuracy of each classifier output is taken as one information source, and according to Bayesian fusion theorem, when only two information sources S1 and S2 are considered, the fusion rule of the two information sources can be expressed in the following form:
Where C
i
is the ith category, P (C
i
) is also the prior probability distribution of the ith category, and P (S
k
|C
i
) , (i = 1, 2, …, 5 ; k = 1, 2, …, m .) represents the conditional probability obtained by the kth information source in the ith category. Consider that the probability distribution of each information source is independent of each other. Therefore, Equation (6) can be expressed as:
By the same inference, when M information sources are considered, the fusion rule of M information sources can be expressed as:
Compared with other fusion methods, Bayesian fusion can make full use of prior information. In view of the conflicts and differences existing in multi-source information, the distribution of category prior information is modified according to the difference measure, and the prior information is fused with the current sample information by means of Bayesian data fusion theory, so as to obtain the posterior distribution of category population, enrich the completeness of information and reduce the overall uncertainty.
Due to the differences among different benchmark classifiers, the resulting information sources also have differences and conflicts. In order to effectively realize the integration optimization of the differences between various benchmark classifiers and the individual excellent performance of a single classifier. This study constructs a multi-class classification credit assessment ensemble model based on Bayesian information fusion (BIF-MCCA), considering the differences among multiple information sources. The model uses the difference measure to modify the category prior information, and then fuses the revised prior information with the current sample information with the help of Bayesian data fusion theory, thus integrating the advantages of multiple benchmark classifiers and reducing the interference of uncertain information. The benchmark classifiers selected in this study are all based on default parameters, which reduces the time cost of parameter tuning compared with other ensemble models. The BIF-MCCA model is concise and lightweight in structure, with higher time efficiency and lower spatial complexity. The flow chart of the BIF-MCCA model in this paper is shown in Fig. 1. The calculation process is as follows:
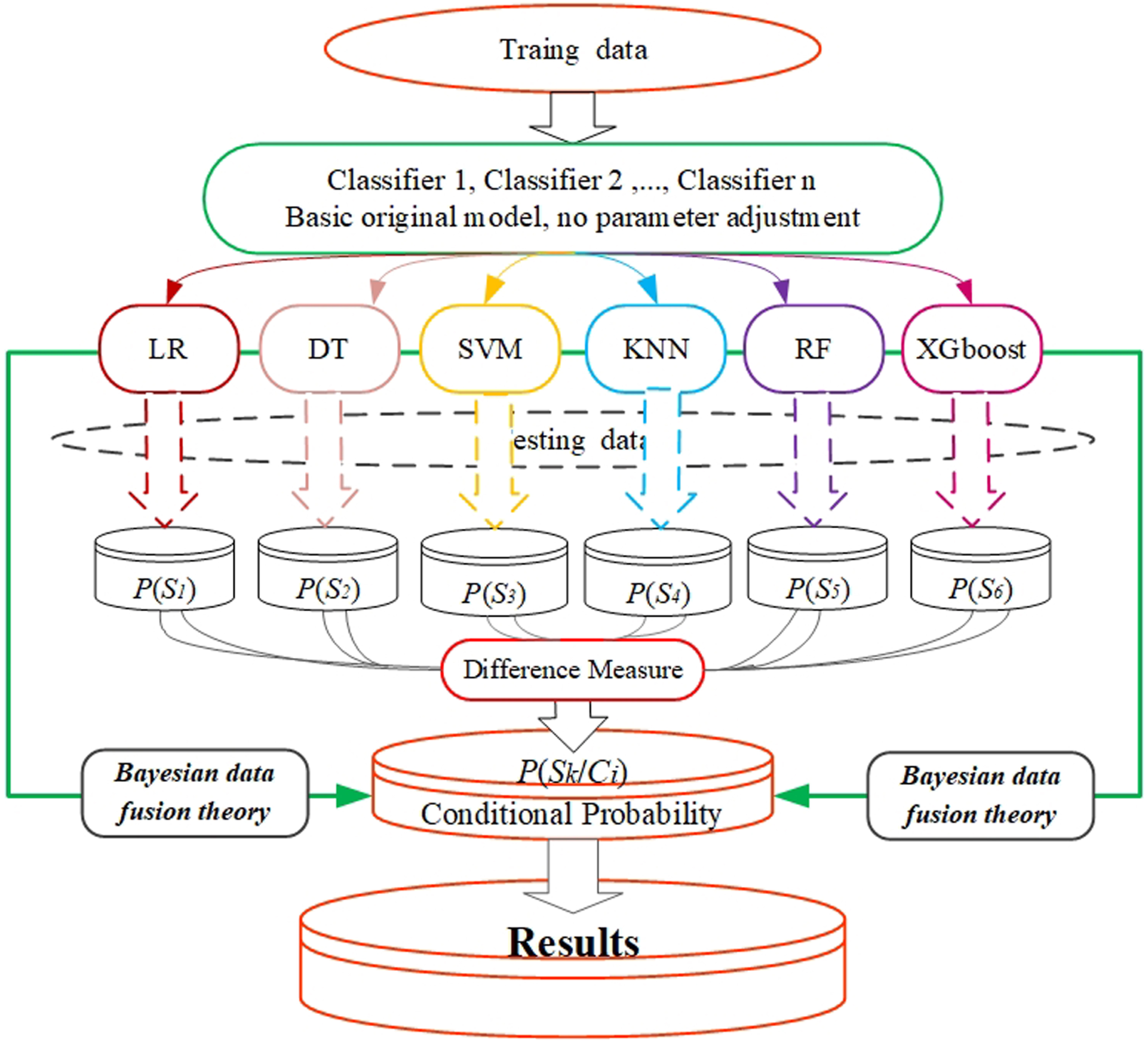
Flow chart of BIF-MCCA algorithm.
Credit dataset description
The dataset used in this study is obtained from real information from an anonymous commercial bank in China, and all data are ensemble on customer personal loan application records, as shown in Table 1, where the commercial bank provides 27,522 credit data of bank customers’ personal loans for a total of 24 months from July 2018 to July 2020, with 23 features including target classification features and attribute descriptive features in each credit data. Among them, there are five levels of credit classification features, which are Normal Category (C1), Secondary Category (C2), Concern category (C3), Suspicious category (C4) and Loss category (C5). The attribute features mainly include 22 features of loan customers in four dimensions: personal information, credit information, loan information and guarantee information.
Details of the credit dataset
Details of the credit dataset
Among the four dimensions, personal information includes five features:x1:Customer ID, x2:Industry Sector Engaged, x3:Number of Houses, x4:Month Property Costs, x5:Family Monthly Income. Credit information includes three features:x6: Whether Interest is Owed, x7:Whether Devalue Account, x8:Safety Coefficient. The loan information includes nine features:x9: Type of Loan Business, x10:Whether Self-service Loan, x11:Date Code, x12:Approval Deadline, x13:Down Payment Amount, x14:Whether Personal Business Loan, x15:Installment Repayment Method (numerical type), x16:Repayment Type, x17:Installment Repayment Cycle (numerical type). Guarantee information includes:x18:Guarantee the Balance, x19:Account Connection Amount, x20:Security Guarantee Amount, x21:Type of Guarantee, x22:Collateral Value (CNY), x23: Guarantee Method.
The credit data information in the original data set provided by commercial banks is mostly incomplete, noisy and low-quality data, which is not conducive to direct data analysis. Therefore, after acquiring the data source, the data structure is first analyzed to screen out useless and duplicate redundant information. Next, data cleaning is performed, which mainly includes removing or filling missing values and outliers, and coding discrete variables with one hot, and due to the imbalance between the five categories of the original data [35], this paper uses the SMOTE algorithm, which is simple to implement, easy to understand and widely used, to deal with the imbalance of data [36, 37]. At the same time, the correlation analysis is also performed for credit attribute characteristics to test the rationality of indicator selection [38]. The final credit features after cleaning and normalization are shown in Table 2.
Description of credit attribute characteristics of commercial bank customers
Description of credit attribute characteristics of commercial bank customers
Confusion matrix can comprehensively reflect the performance of the model, and many metrics can be derived from it. In order to verify the classification performance of the model, we choose four common classification assessment metrics: Accuracy, Precision, Recall, and F1-score. For common binary confusion matrix, personal credit of customers is divided into two categories: “good” and “bad". There are four types of personal credit of each customer during the binary classification, which are True Positive (TP), True Negative (TN), False Negative (FN), False Positive (FP), as shown in Table 3. For the multi-category credit assessment problem, each category should be regarded as “positive” separately, and the other categories as “negative"[39]. The metrics derived from the confusion matrix are defined as follows [40]:
Confusion matrix
Confusion matrix
Accuracy represents the overall performance of a classifier; Precision mainly reflects the reliability of the output of the classifier results; Recall reflects the coverage degree of classification effect; F1-score is a reliable comprehensive index for evaluating unbalanced data, and is the harmonic mean of recall and accuracy, assuming that both are equally important. Precision and recall are contradictory measures; in general, recall tends to be low when precision is high, and precision tends to be low when recall is high.
To enhance the robustness of the experiments, a hold-out validation strategy is used where the dataset is randomly divided into a testing set with the 20% of the total data and the remaining 80% is used as training data, which is further randomly separated into two parts: 90% is used as the training set and 10% is used as the validation set to perform 10-fold cross-validation [41, 42]. Finally, the final assessment is performed in a test set, which remains unused during the calibration process. All the experiments were conducted on a PC running Python Version 3.7 with 3.0 GHz Intel CORE i7 processor, 32 GB of RAM, and Microsoft Windows 10 operating system.
Empirical analysis and results
Our experiments have two objectives: First, to verify that compared with a single classifier, BIF-MCCA ensemble assessment model can effectively assess the credit risk level of commercial banks’ customers; Second, compared with other multi-class classification ensemble models, BIF-MCCA improves the accuracy, efficiency and generalization versatility of multi-class classification of commercial banks’ customer credit rating. Section 5.1 shows the assessment performance of basic classifiers, and Section 5.2 shows the assessment performance of BIF-MCCA and other multi-class classification ensemble models.
Baseline classifier results
This section aims to assessment the performance of five basic classifiers. In Section 5.1.1, we compared the model’s assessment performance results at five classification levels using precision, recall, and F1-score. In Section 5.1.2, the overall classification accuracy performance of the model is measured.
Assessment performance of the model at each classification level
The pre-processed data are substituted into each benchmark classification model and the BIF-MCCA model constructed in this paper to obtain the assessment standard results of precision, recall and F1-score values of each model in the five credit levels, as can be seen in Table 4 and Fig. 2.
Precision, recall and F1-score of baseline classifiers and MIF-MCCA model under the five credit categories
Precision, recall and F1-score of baseline classifiers and MIF-MCCA model under the five credit categories
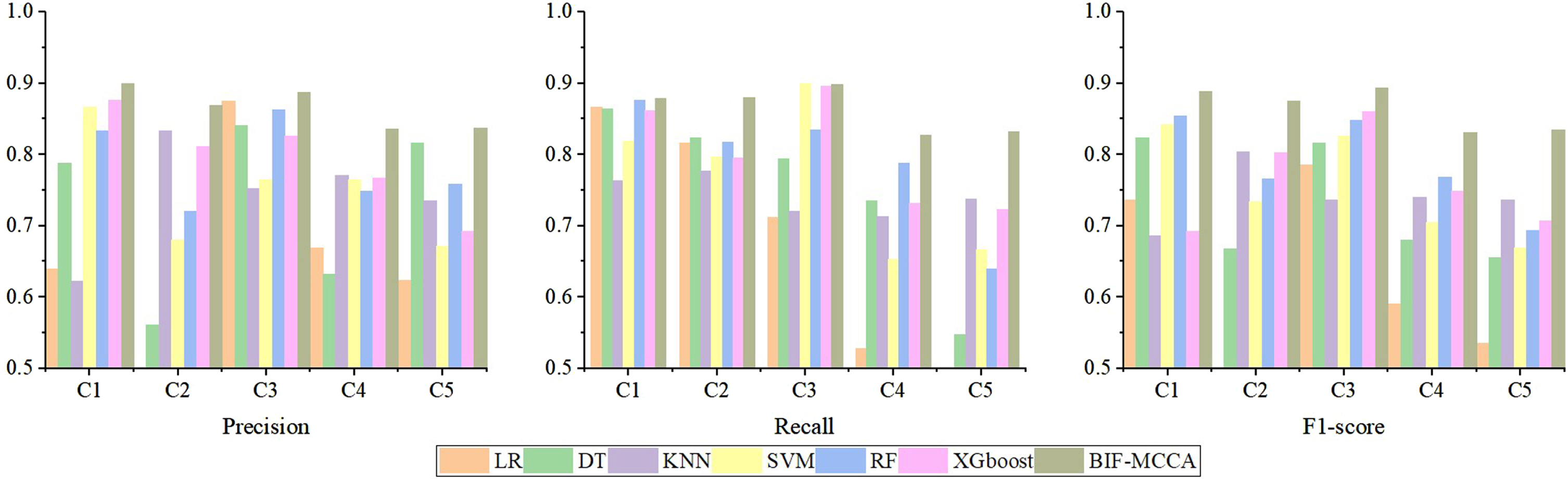
Precision, Recall and F1-score of baseline classifiers and MIF-MCCA model under the five credit categories.
In terms of precision, assessment criteria. In the C1 credit category, XGboost has the highest precision, followed by SVM and RF, then BIF-MCCA model, and KNN model has the lowest precision; In the C2 credit category, BIF-MCCA model has the highest precision, followed by KNN model and XGboost model, and the worst is SVM and DT, with only 0.6801 and 0.5617 precision respectively; In the C3 credit category, the BIF-MCCA model has the highest precision, followed by RF and DT, the lowest is KNN; In the C4 credit category, the precision of BIF-MCCA model is also the highest, followed by KNN and XGboost, and DT is the lowest. In the C5 credit category, the BIF-MCCA model still has the highest precision, followed by DT and RF, and the lowest is SVM. To sum up, the precision of the BIF-MCCA model is the highest in all four categories except for the C1 category, while the lowest precision of DT and KNN occurs most frequently, which shows that the precision of DT and KNN performs poorly in the five categories compared to other models.
In terms of recall assessment criteria, in the C1 credit category, the BIF-MCCA model has the highest recall, followed by RF and DT, and the lowest is KNN; In the C2 credit category, the BIF-MCCA model has the highest recall, the DT model ranks second, followed by RF, and the lowest is KNN; In the C3 credit category, BIF-MCCA model ranks fourth, SVM model has the highest recall, followed by XGboost and RF, and KNN has the lowest recall. In the C4 credit category, BIF-MCCA model has the highest recall, followed by RF and DT, and SVM has the lowest recall. In the C5 credit category, the recall of BIF-MCCA model is also the highest, KNN ranks the second, and DT is the lowest. To sum up, the recall of the BIF-MCCA model is the highest in all four categories except for the C3 credit category.
In terms of F1-score assessment criteria. In the C1 credit category, the BIF-MCCA model has the highest F1-score value, the RF model is in second place, the DT is in third place, and the KNN is the lowest; in the C2 credit category, the BIF-MCCA model also has the highest F1-score value, followed by KNN and XGboost, and the lowest is DT; In the C3 credit category, the XGboost has the highest F1-score, the RF is the second, the BIF-MCCA is the third and the lowest is KNN. In both the C4 and C5 credit category, the BIF-MCCA model has the highest F1-score value. To sum up, the F1-score value of the BIF-MCCA is the highest in all four categories except for the C3 credit category.
In summary, comparing the results of the benchmark classification model and the BIF-MCCA model on the three assessment criteria of Precision, recall and F1-score value, it can be seen that the BIF-MCCA model has the highest accuracy in categories C2, C3, C4 and C5, the highest recall and F1-score value in all four categories except for the C3 category. It can be seen that the BIF-MCCA model constructed in this paper has higher classification performance compared with other benchmark models in the five credit ratings.
In this subsection, the accuracy is used to measure the overall assessment performance of the model, and the overall accuracy of each model is shown in Table 5 and Fig. 3. It can be seen that compared with the accuracy of the multi-class classification assessment model of commercial bank customer credit constructed by LR, DT, KNN, SVM, RF and XGboost, Obviously, the credit assessment results obtained by the ensemble method has better performance than the benchmark models. The overall assessment accuracy of the BIF-MCCA model constructed in this paper is as high as 85.05%, which has been significantly improved. Compared with the LR model, the accuracy of the model improved the most, up to 35.36%, and compared with the better performance of the XGboost model, the accuracy is also improved by 6.62%.
The overall accuracy of the personal credit assessment model
The overall accuracy of the personal credit assessment model
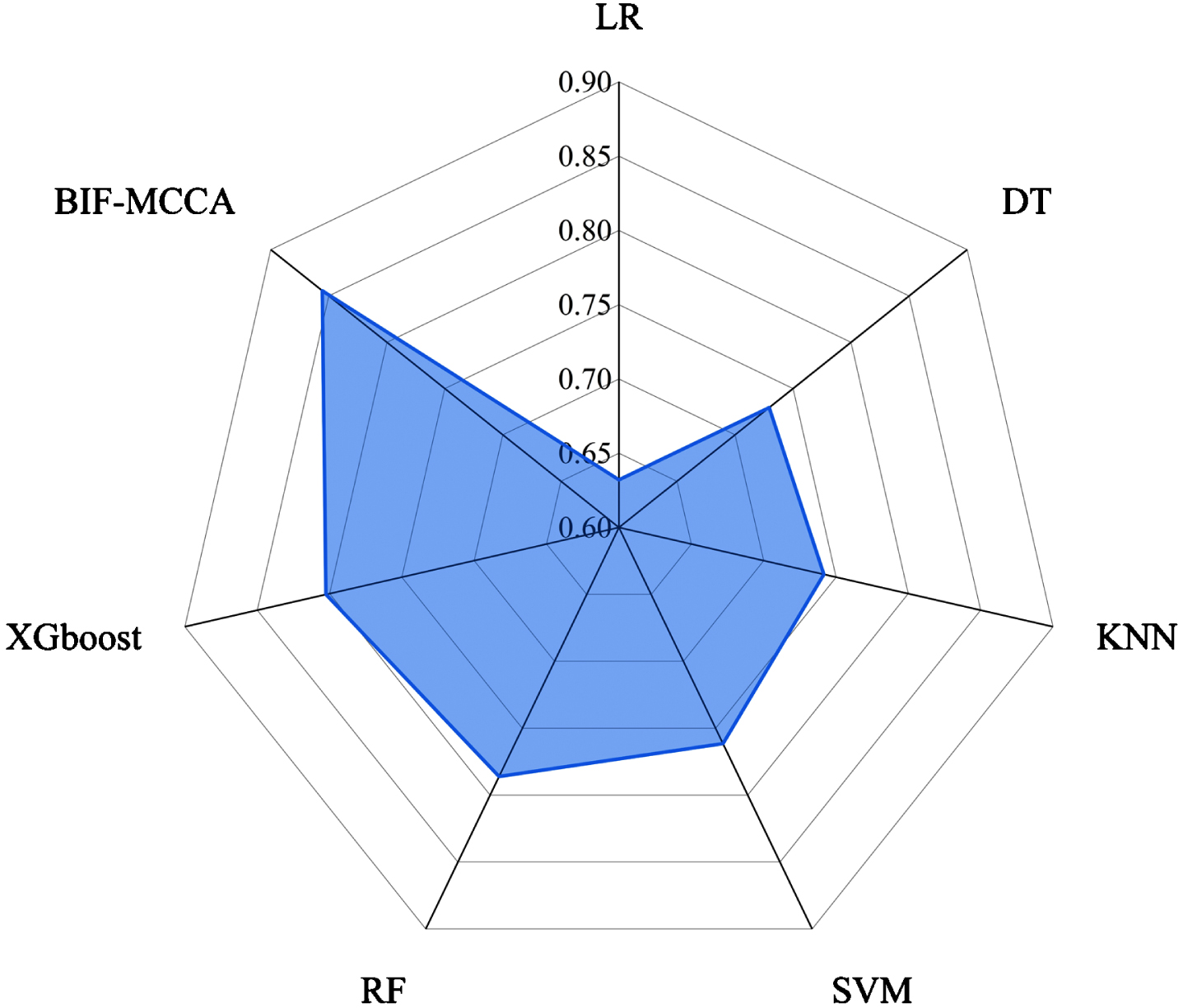
Overall accuracy of credit assessment models.
We select several classical and commonly related assessment models for comparative analysis with the BIF-MCCA model. Among them, CatBoost is the classical ensemble credit assessment method. CFHM, OCHE and MIFCA are the latest ensemble credit assessment methods.
CatBoost is a powerful open-sourced GBDT-based technique that achieves promising results in a variety of machine learning [43]. CFHM is a fusion technique that considers intra-attribute and inter-attribute weight optimization and can be integrated using any of the benchmark classifiers [28], the effect of parameter tuning on the classification performance is investigated in the experiments, where the parameter γ ∈ [0,1], the accuracy varies with the step size of 0.1, and the parameter γ = 0.1 is finally taken as the default value. OCHE is a novel credit scoring models which considered selective heterogeneous ensemble developed by Xia et al., [16], which both the base models and the ensemble framework processed some hyper-parameters. In terms of the hyper-parameter in the ensemble framework, they set the penalized parameter d in Equation (4) as 3 and the bench marks and base models has many hyper-parameters, which can be seen in detail in Table 4 of Reference [16]. The MIFCA model does not consider the conflict difference between multiple sources of information, and integrates 6 different types of classifiers based on D-S evidence theory to reduce the uncertainty of the model. The base classifiers of the MIFCA model adopts default parameters [39]. The comparison results presented in Table 6 and Fig. 4.
As shown in Table 6 and Fig. 4, the results of the five classification algorithms on the real credit dataset for each classification performance assessment criterion show that the constructed BIF-MCCA has the highest classification performance. The performance of CFHM is similar to that of OCHE, but compared with the time cost of parameter tuning in CFHM and OCHE models, the BIF-MCCA models constructed in this paper are all under the default parameters, which reduces the time by not needing to perform parameter tuning, so the BIF-MCCA model is more concise and lightweight.
Comparison of the performance by other credit classification methods
Comparison of the performance by other credit classification methods
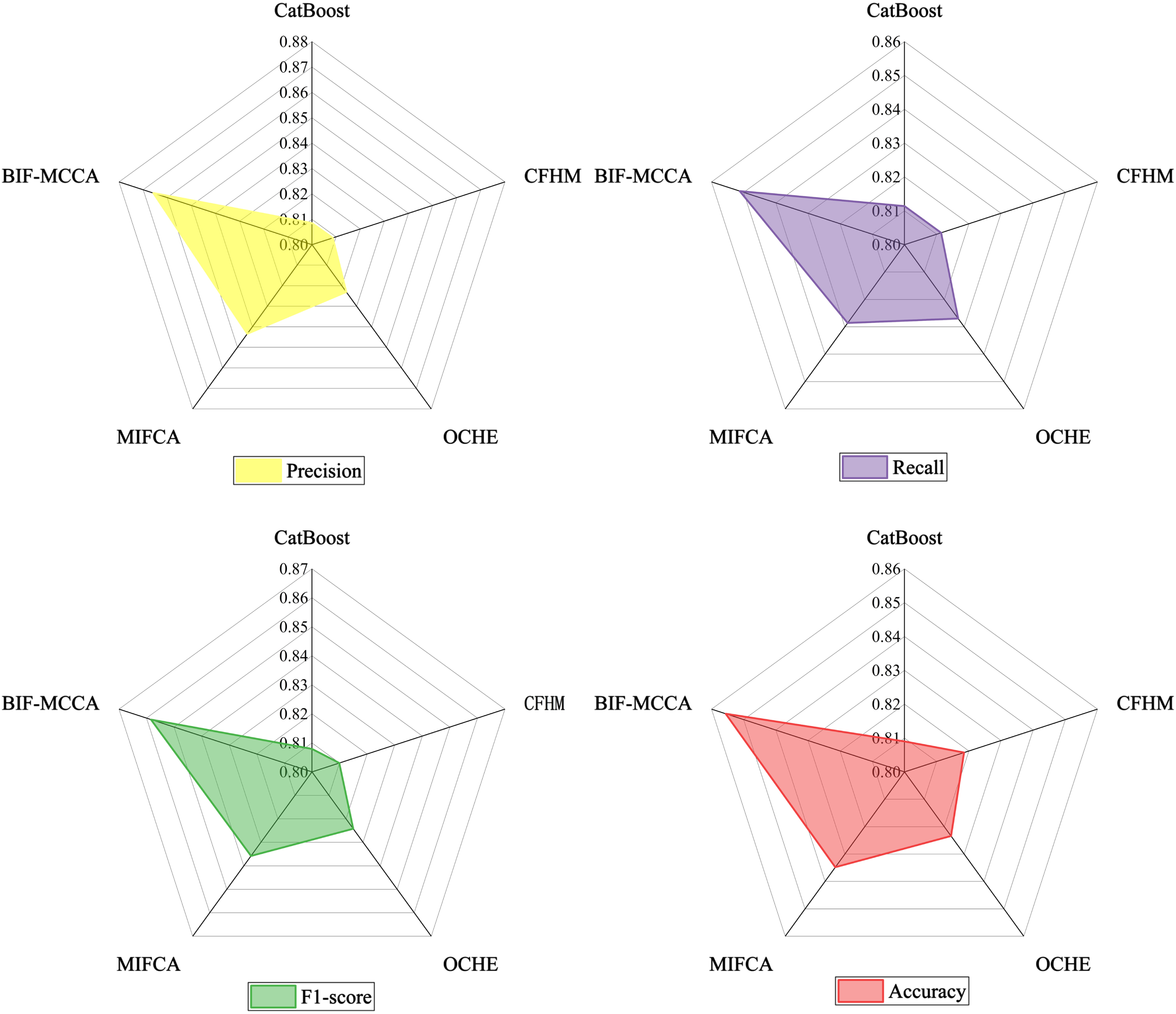
Classification performance results of LR, CatBoost, CFHM, OCHE and BIF-MCCA in four assessment criteria.
Meanwhile, BIF-MCCA considers the conflict differences between multi-source information, which further optimizes the limitation that MIFCA is only applicable to the situation where the differences between multi-source information are not obvious, and the generalization performance is stronger. Through the above experimental analysis, the excellent performance of the BIF-MCCA integrated assessment model constructed in this paper is verified.
The superiority of the BIF-MCCA model constructed in this paper has been verified in 5.1 and 5.2, and to further illustrate the reliability of the experiments, we use the Friedman test advocated by Demsar to test the significance of the various methods [44]. The Friedman test is a typical non-parametric statistical test. In the Friedman test, 11 classification models were ranked, based on different evaluation indicators. These models included six base classifiers, four ensemble models, and the proposed model [45].
Table 7 summarizes the significance test results of the average method ranking using the Friedman test. The results show that the statistical values calculated using the Friedman test is higher than the Chi-square critical value, and the p-values is lower than the alpha value (0.05), the null hypothesis is rejected and the robustness of the model is verified.
Classifier ranking results of Friedman test
Classifier ranking results of Friedman test
Statistics of the Friedman test 39.639. p-value < 0.001. Note: the alpha value is 0.05; the Chi-square critical value is 7.81.
Improving the classification performance of customer credit assessment and accurately judging potentially valuable and defaulting customers are crucial for commercial banks and other financial institutions to avoid risks. A multi-class classification ensemble assessment model for personal credit rating of commercial banks based on multi-source information fusion was proposed, and the effectiveness of the proposed model is verified on a real dataset. The results show that BIF-MCCA has the following advantages: The proposed BIF-MCCA model integrates five different types of benchmark classifiers, which has better classification accuracy and stronger generalization ability compared with the single classifier that is more sensitive to data. Considering the conflicts and discrepancies between multiple sources of information, a new method for correcting the category prior information using difference measures is proposed, which makes full use of the prior information and thus improves the classification performance of the model. The benchmark classifiers adopted in this study use default parameters, which reduces the time-consuming cost of parameter tuning and thus makes the model operation more lightweight. And improving the accuracy, efficiency and generalization universality of the multi-class classification of commercial banks’ customer credit rating.
Footnotes
Acknowledgments
This work was partially supported by the Major Project of the National Social Science Fund of China (18ZDA104).