
Abstract
Concept prerequisite relation refers to the learning order of concepts, which is useful in education. Concept prerequisite learning refers to using machine learning methods to infer prerequisite relation of a concept pair. The process of concept prerequisite learning requires large amounts of labeled data to train classifier. Usually, the labels of prerequisite relation are assigned by specialists. The specialist labelling method is costly. Thus, it is necessary to reduce labeling expense. An effective strategy is using active learning methods. In this paper, we propose a pool-based active learning framework for concept prerequisite learning named PACOL. It is a fact that concept u and concept v cannot be prerequisite of each other simultaneously. The idea of PACOL is to select the concept pair with the greatest deviation between the classifier’s prediction and the fact. Besides, PACOL can be used in two situations: when specialists assign three kinds of labels or two kinds of labels. In experiments, we constructed data sets for three subjects. Experimental results on both our constructed data sets and public data sets demonstrate that PACOL outperforms than existing active learning methods in all situations.
Introduction
The teaching theory of “mastering learning” is put forth by the esteemed educationalist, Benjamin Bloom [1]. The theory of mastering learning posits that when students learn two ordered concepts, they must have mastered the first concept before learning the second concept. For example, as depicted in Fig. 1, there are five concepts. Students need to master concept “Differentiation” and concept “Integration” before they learn concept “Differential equation”. In the theory of mastering learning, concept prerequisite relation refers to the learning order of concepts. Concept prerequisite relation plays a significant role in designing the course sequencing [2], constructing educational knowledge maps [3], and modeling student behavior [4], which is useful in the education domain.
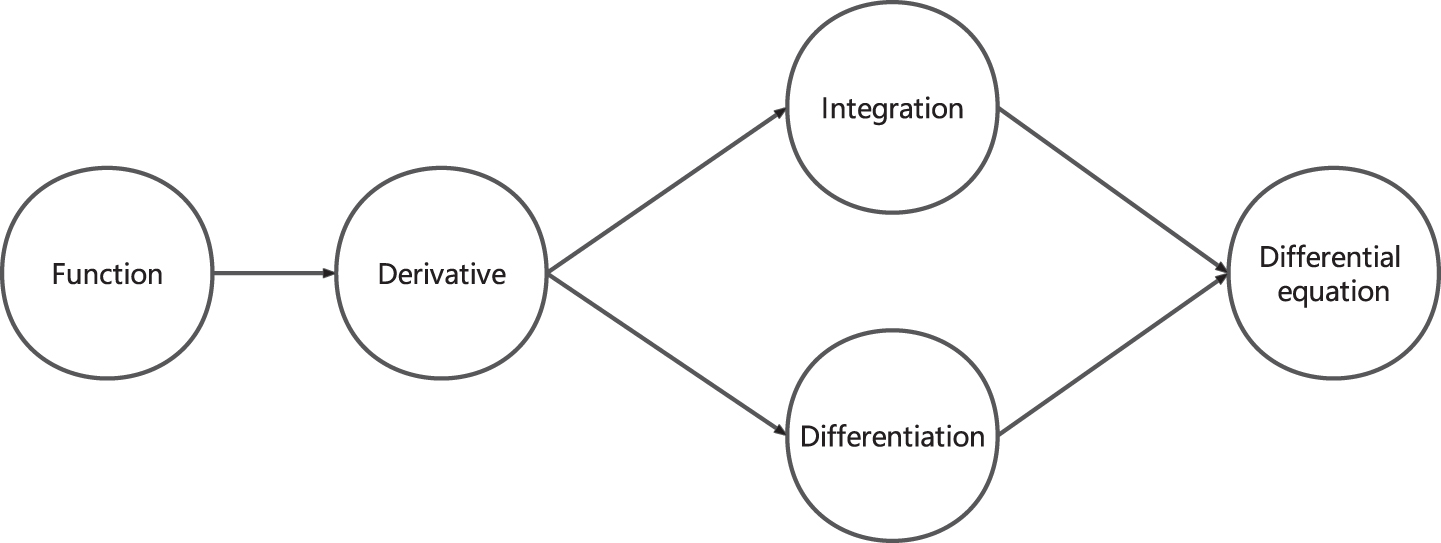
An example of concept prerequisite relation. The directed edge from vertex u to v indicates that students need to be proficient in concept u before they can begin to learn v.
A concept pair is an ordered pair that is made up of two distinct concepts. Concept pair <u, v> consists of concept u and concept v. We call concept pair <v, u> is reciprocal concept pair of concept pair <u, v>. There are twenty concept pairs between five concepts in Fig. 1, such as “<Function, Derivative> ”, “<Derivative, Function> ”, “<Function, Integration> ”, and other similar ordered pairs. For example, “<Function, Derivative> ” and “<Derivative, Function> ” are reciprocal concept pairs of each other.
Concept prerequisite learning focuses on predicting prerequisite relation between two concepts in one concept pair by using machine learning models. Previous works infer prerequisite relation from Wikipedia [5–7], text [8], MOOC [9–11], and scientific corpus [12].
The process of concept prerequisite learning requires large amounts of labeled data to train the classifier. Usually, the labels of prerequisite relation are assigned by specialists [5]. In some situations, specialists assign concept pair <u, v> with three kinds of labels: (1) u is prerequisite to v; (2) v is prerequisite to u; (3) there is no prerequisite relation between u and v. In the other situations, specialists label concept pair <u, v> with two kinds of labels: (1) u is prerequisite to v; (2) u is not prerequisite to v. Some examples of concept pairs and assigned labels are shown in Table 1.
Some examples of concept pairs and assigned labels
The specialist labeling method is inefficient and expensive in the context of the vast amount of educational resources available, whether specialists assign three or two kinds of labels. Thus, it is important to reduce the expense of labeling. An effective way to reduce the labeling expense is to use active learning methods. Several previous works focus on introducing active learning methods into concept prerequisite learning. In these works, the instance in active learning refers to the concept pair. Liang compared the performance of several classical active learning methods in concept prerequisite learning when specialists assign two kinds of labels [13]. Hu proposed an active learning method used in the situation where specialists assign three kinds of labels named CPAL [14]. The idea of CPAL is selecting two concept pairs where the classifier disagrees with their labels. But for the concept pair where the label indicates no prerequisite relation, CPAL is unable to select it, which is because of the limitation of CPAL’s evaluation function.
In this paper, we propose
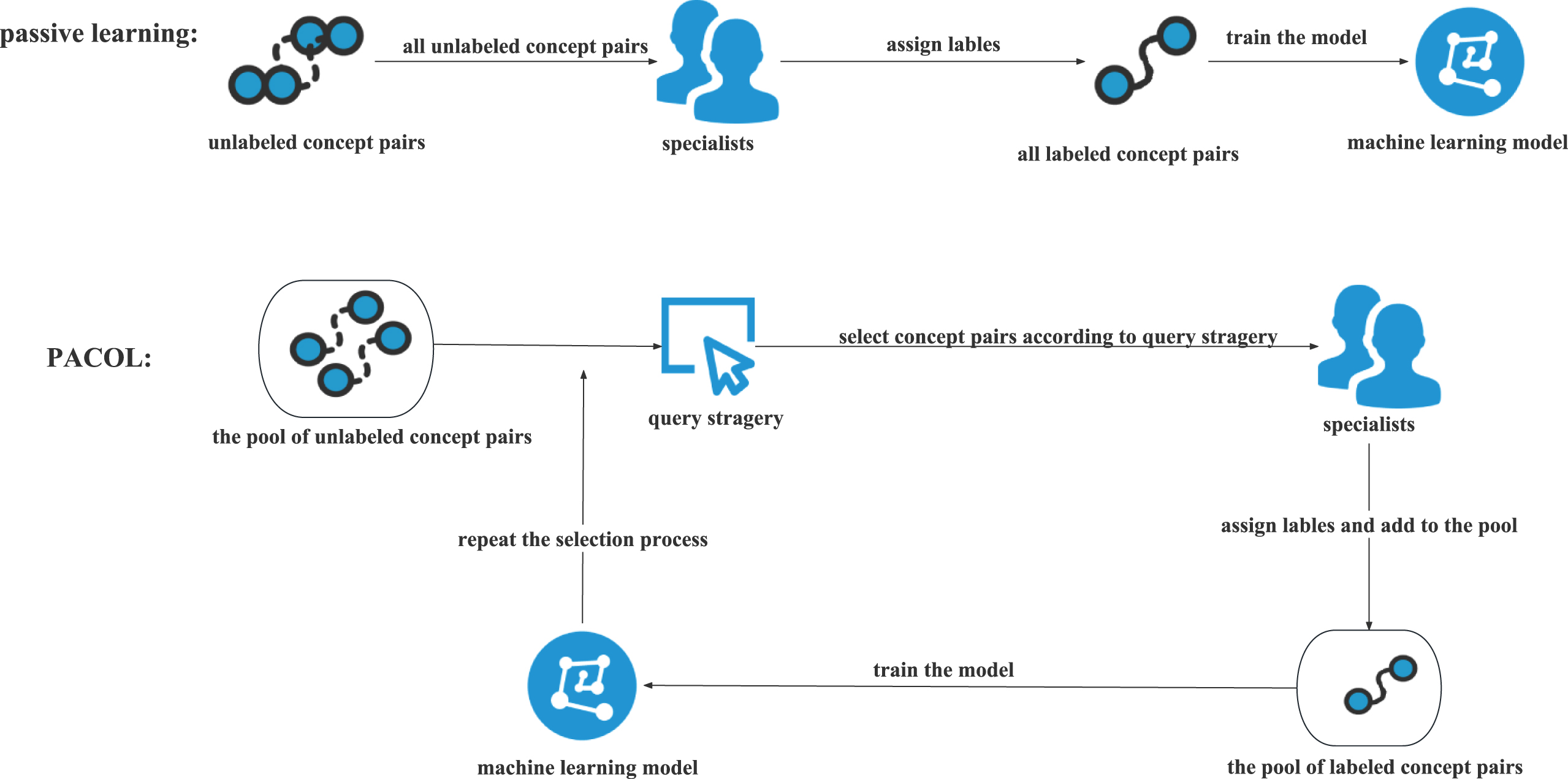
The processes of passive learning and PACOL.
•
•
•
Concept prerequisite learning
With the development of information technology, the explosive growth of educational data is a significant challenge to educational institutions [15]. Concept prerequisite relations have a wide range of applications in education. Concept prerequisite relation is significant in large-scale web-based learning, where learners are confronted with a multitude of instructional materials. In addition to designing courses [16] and constructing educational knowledge maps [3], some researchers have combined concept prerequisite relations with knowledge tracing models [4]. And the combined models perform well in predicting students’ abilities. Chen combined student modeling with course information to jointly infer prerequisite relations and student ability [17]. Similarly, Carmona added concept prerequisite relations to existing student models to enhance their efficiency and accuracy [18]. Passalacqua presented a set of visualization methods to assist researchers in better comprehending the problem of concept prerequisite relations, with the ultimate goal of making a meaningful contribution to designing intelligent textbooks [19].
Concept prerequisite learning refers to using machine learning models to infer concept prerequisite relation. Wikipedia is a reliable, consistent, and accurate online encyclopedia containing thousands of concepts [20]. Some researchers extracted prerequisite relation from Wikipedia. Talukdar predicted the order of reading material by extracting features of Wikipedia pages, the authors held that before reading a page, one must first understand the page of prerequisite concepts [5]. Liang held that a concept can be expressed through its associated concepts, and they calculated the reference distance for predicting relations [6]. Sayyadiharikandeh proposed that in the click stream of Wikipedia pages, most of the clicks are directed from the concept to its prerequisite concepts [7].
Some researchers extracted prerequisite relation from courses, including MOOC and traditional courses. Pan extracted features using various types of materials such as text and video of MOOC courses, and they proposed a method to infer the learning order of concepts based on representation learning [9]. A transformer-based model was proposed by Xiao in order to predict relation of concepts, which can then be used to judge whether there is a watching order between two teaching videos [11]. Alzetta proposed a model to extract prerequisite relations based on deep learning techniques in a real-world educational setting [21]. And they tested the effect of generating learning modules for concepts. Yang conducted an analysis of large-scale educational data to predict the dependencies among concepts, and then courses were designed according to the identified prerequisite relations [22]. And experiments were performed in randomly selected schools to demonstrate the method’s effectiveness. Sun proposed a contextual-knowledge-aware approach to discover concept prerequisite relations based on sparse and unstructured educational data [23]. By using resource concept graph, Zhang proposed a method based on graph network to identify concept prerequisite relation [24].
In addition to Wikipedia data and course data, text and scientific corpus can also be utilized to infer prerequisite relations. Liu mined concept prerequisite relations from the text based on two features: local properties of learning dependencies and distributional asymmetry of concepts [8]. Li used graph neural networks to infer concept prerequisite relations [10]. Gordon inferred prerequisite relations from scientific corpus to generate reading lists for students, which can help students optimally learn technical material [12]. Jia extracted concept prerequisite relation by combining both concept representation with features of concept pairs [25].
Active learning
Generally, domain specialists assign the labels of prerequisite relation, which is a costly process [26]. Thus, it is essential to reduce labeling expense. A suggested solution to solve the problem is active learning. Active learning is a kind of semi-supervised learning method that concentrates on selecting the most informative instances to query labels [27, 28]. Pool-based sampling is a well-established technique in the field of active learning [29]. Several well-known pool-based active learning methods can be applied in not only binary classification but also multi-classification problems, such as Query by Committee (QBC), Diversity Sampling (DS), Querying Informative and Representative Examples (QUIRE), and Learning Active Learning (LAL). There are also several pool-based active learning methods that are particularly designed for multi-classification problem, such as Margin Sampling (MS), Multiclass-Level Uncertainty (MCLU), and Kernel Machine Committee (KMC).
QBC strategy [30] maintains a committee containing multiple machine learning models, each of which has been trained on the currently labeled data set and assigns candidate labels for unlabeled instances. The framework then selects the instance with the greatest divergence. DS strategy [31] selects the instance whose features differ most from the labeled instances, thus increasing the diversity of labeled instances. QUIRE strategy [32] uses the interval between the instance and the current classification surface as a risk function. In other words, the smaller the interval with the classification surface, the higher the risk of the instance. Then the instances near the classification surface are selected. LAL strategy trains a regressor for predicting candidate instances’ predicted error reduction [33]. Expected Model Change Maximization (EMCM) strategy selects instances that result in the biggest change to the present model. The model change is assessed by the changes of model parameters [34]. ALLSH strategy selects instances with the greatest discrepancy between their predictive likelihoods and their perturbations [35]. And ALLSH performs well on several natural language processing tasks.
MS strategy selects instances that are closest to the classification interface [36]. MCLU strategy chooses two instances that are the furthest away from the classification interface and uses the difference of their distances as the criterion [37]. KMC strategy combines discriminative sparse kernel machines and Bayesian model to select instances [38]. In KMC strategy, sparse structure and convex duality are used to optimize joint evaluation function. Liu proposed an SVM-based active learning method to select instances by using uncertainty in multi-class classification [39].
Some researchers introduced active learning into the domain of concept prerequisite learning. In these works, the instance in active learning work refers to the concept pair. Liang compared several classical active learning models’ performances in concept prerequisite learning, and he concluded that QBC performs best among classical active learning models in the situation where specialists assign two kinds of labels [13]. Liang proposed relational reasoning that can be introduced to classical active learning methods to improve them [40]. Hu proposed an active learning model used in the situation where specialists assign three kinds of labels [14]. But this model cannot select the instances where the label indicates no prerequisite relation.
Preliminary
General pool-based active learning methods divide data set
Query strategies that are used in distinct pool-based active learning methods follow a greedy strategy:
Let Concepts = {1, 2, . . . , C} be C concepts in the course, <u, v> is a concept pair.
The kinds of concept prerequisite labels given by specialists can only be three or two. There are five concepts in Fig. 1, and there are twenty concept pairs between five concepts. Table 2 shows some examples of concept pairs.
Some examples of concept pairs
In some situations, specialists label concept pair <u, v> with three kinds of labels. Concept prerequisite learning can be considered as a triple classification problem in this situation, and ΔTri is a triple classifier. Let
In the other situations, specialists label concept pair <u, v> with two kinds of labels. In this situation, concept prerequisite learning can be considered as a binary classification problem, and ΔBin is a binary classifier. Let
Relational reasoning was proposed by Liang [40], which can be introduced into any standard active learning method to improve its performance. Concept prerequisite relation is seen as a strict partial order, and data sets are updated through closure operations. When updating
Overview of PACOL
In some situations, specialists assign three kinds of labels. In the other situations, specialists assign two kinds of labels. In both situations, it is a fact that concept u and concept v cannot be prerequisite of each other simultaneously. PACOL can be used in both situations. The following intuitive understanding serves as the foundation of PACOL. The greater the deviation between the classifier’s predictions and the fact, the higher the likelihood of selecting the concept pairs. PACOL concentrates on one concept pair and its reciprocal concept pair. The following is PACOL’s query strategy:
1:
2: Train classifier Δ using labeled data set
3: For each
4: Select <u*, v*> , < v*, u* > whose G (
5: Query the label y<u*,v*> of <u*, v*> and y<v*,u*> of <v*, u*>;
6:
7:
8:
We depict PACOL’s pseudo code in Algorithm 1. Figure 3 shows the flowchart of PACOL. The input of PACOL is the initial labeled data set
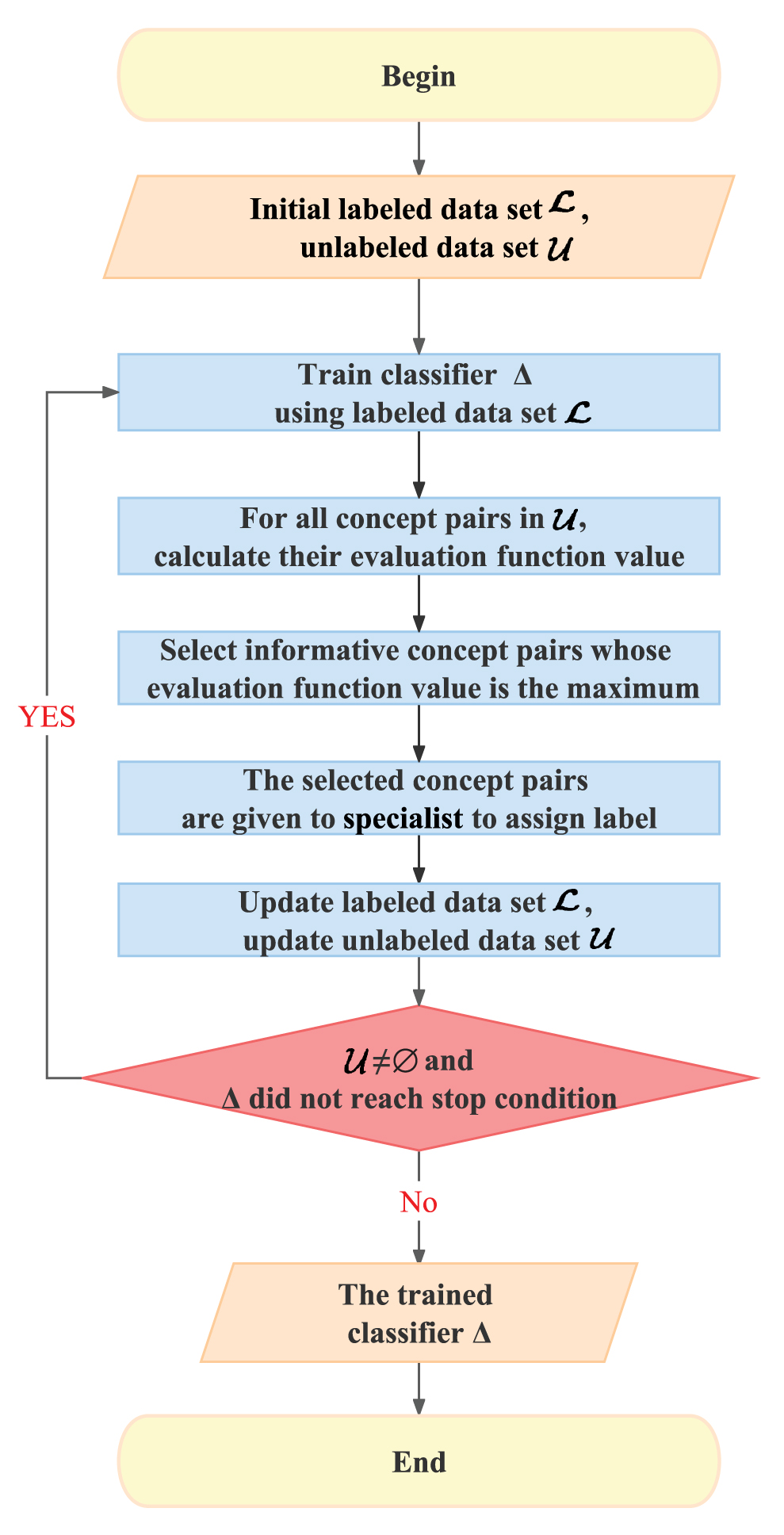
Flowchart of PACOL.
When specialists assign three kinds of labels, concept prerequisite learning can be seen as a triple classification problem. In this situation,
As shown in Table 3, when specialists assign three kinds of labels to concept pairs, it is a fact that concept u and concept v cannot be prerequisite of each other simultaneously:
Some examples of concept pair and its reciprocal concept pair when specialists assign three kinds of labels
Based on feature
Let
Let
Let
We derive the evaluation function GTri (
When specialists assign two kinds of labels, concept prerequisite learning can be viewed as a binary classification problem. In this situation,
As shown in Table 4, when specialists assign two kinds of labels to concept pairs, there is a fact:
Some examples of concept pair and reciprocal concept pairs when specialists assign two kinds of labels
Based on feature
Let
We derive the evaluation function GBin (
We conduct experiments to answer the following questions.
Data sets
There are two public data sets named MOOCCube [9] and LectureBank [10]. MOOCCube and LectureBank are widely used in concept prerequisite learning [11, 23–25], which involves utilizing machine learning methods to infer the prerequisite relation between concept pairs. MOOCCube contains concepts collected from computer science courses and math courses, respectively. For convenience, we call these two data sets MCS and MMT in this paper. There are 231 concepts collected from computer science courses in MCS. MCS contains various concepts such as “operating system”, “upload”, and “octal”. There are 221 mathematics concepts in MMT, such as “wiener process” and “chain rule”. LectureBank contains 208 concepts collected from network courses, such as “metropolitan area network”, and “hypertext transfer protocol server”. For convenience, we call this data set LNW in this paper.
We constructed data sets named EduRelation from three education subjects: primary math, secondary math, and data structure. For convenience, we abbreviate data sets as EPM, ESM, and EDS in this paper. The rationale behind constructing three new data sets is as follows. While MOOCCube contains 221 mathematics concepts, the majority of them, such as “wiener process” and “chain rule,” are excessively complex. Therefore, our endeavor is to construct data sets for primary and secondary math courses. Furthermore, data structure is a fundamental course in computer departments. The learning order of concepts in the data structure course is important. For instance, students need to master concept "subtree” before they learn concept “left subtree". Hence, we aim to construct a data set specifically for the data structure course.
Firstly, we obtained educational concepts from textbooks and generated concept pairs. Then we assigned concept pairs to domain specialists for annotating and we got the final labels by majority voting. Finally, in order to ensure the correctness of the labels, we solicited the assistance of other specialists and asked them to review the entire data set.
Table 5 presents a summary of the original data sets’ details. There are a large number of pages with defined formats that can give comprehensive explanations of concepts in Wikipedia. Following Liang, for each concept pair, we extracted 17 text-based features and 15 graph-based features from Wikipedia [13]. And these features were used to train the classifier.
Description of the original data sets
Description of the original data sets
As shown in Table 6, we generated data sets suitable for the binary classification problem from the original data sets, and we named them EPM-Tri, ESM-Tri, EDS-Tri, MCS-Tri, MMT-Tri, LNW-Tri. For example, EPM-Tri is constructed according to EPM, there are 18906 concept pairs <u, v> in EPM-Tri. Among these concept pairs, the number of concept pairs <u, v> that u is prerequisite to v equals 868, and the number of concept pairs <u, v> that v is prerequisite to u also equals 868, and there are 17170 concept pairs <u, v> that there is no prerequisite relation between u and v.
Description of constructed data sets for binary classification problem
Description of constructed data sets for binary classification problem
We chose common machine learning methods as the classifier, such as Support Vector Machine (SVM), Naive Bayes (NB), Logistic Regression (LR), Gradient Boosting Decision Tree (GBDT), and Random Forest (RF). In our experiments, we employed One-Versus-the-Rest(OVR) algorithm [41] for each classifier to solve triple classification problem. Synthetic minority over-sampling technique (SMOTE) [42] and random undersampling were used to solve the data imbalance problem.
5-fold cross validation was applied on all data sets. Micro precision, micro recall, micro F1-score, and micro AUC of ROC were reported as evaluation metrics. The results are shown in Table 7. Among all six data sets, all of the models perform well in ESM-Tri, which is probably because the proportion of prerequisite relations in ESM-Tri is higher than the other five data sets.
Comparison results of triple classifiers
As demonstrated in Table 7, NB has a poor performance in all evaluation metrics, because the features cannot meet the premise of strong independence. LR and SVM show similar performance, particularly in terms of micro F1-score. RF performs better than the other four methods. This might be because of that RF employs random feature selection, whereas some methods rely on linear combination of features. In the subsequent experiments, RF was chosen as the triple classifier, and micro AUC of ROC was used as the evaluation metric.
We conducted comparison experiments on all data sets. The data was divided into the training set
Our comparative strategies are as follows.
•Random: Random strategy selects instances from
•LAL: LAL strategy selects instances by using a trained regressor.
•QBC: QBC strategy selects instance that is more difficult to be distinguished by committees’ voting. We use query-by-bagging [43] to construct committees.
•ALLSH: ALLSH strategy selects the instances whose predictive likelihoods diverge the most from their perturbations.
•CPAL: CPAL strategy selects instances whose labels are not agreed by the classifier. But instances where the label indicates no prerequisite cannot be selected because of the limitation of the evaluation function.
•MCLU: MCLU strategy selects the two instances farthest from the classification interface.
•KMC: KMC strategy selects instances by using discriminative sparse kernel machines and Bayesian model.
LAL, QBC, and ALLSH can be utilized in both binary classification problems and multi-classification problems. And in this section, they are specifically applied to the triple classification problem. Figure 4 shows the experimental results.
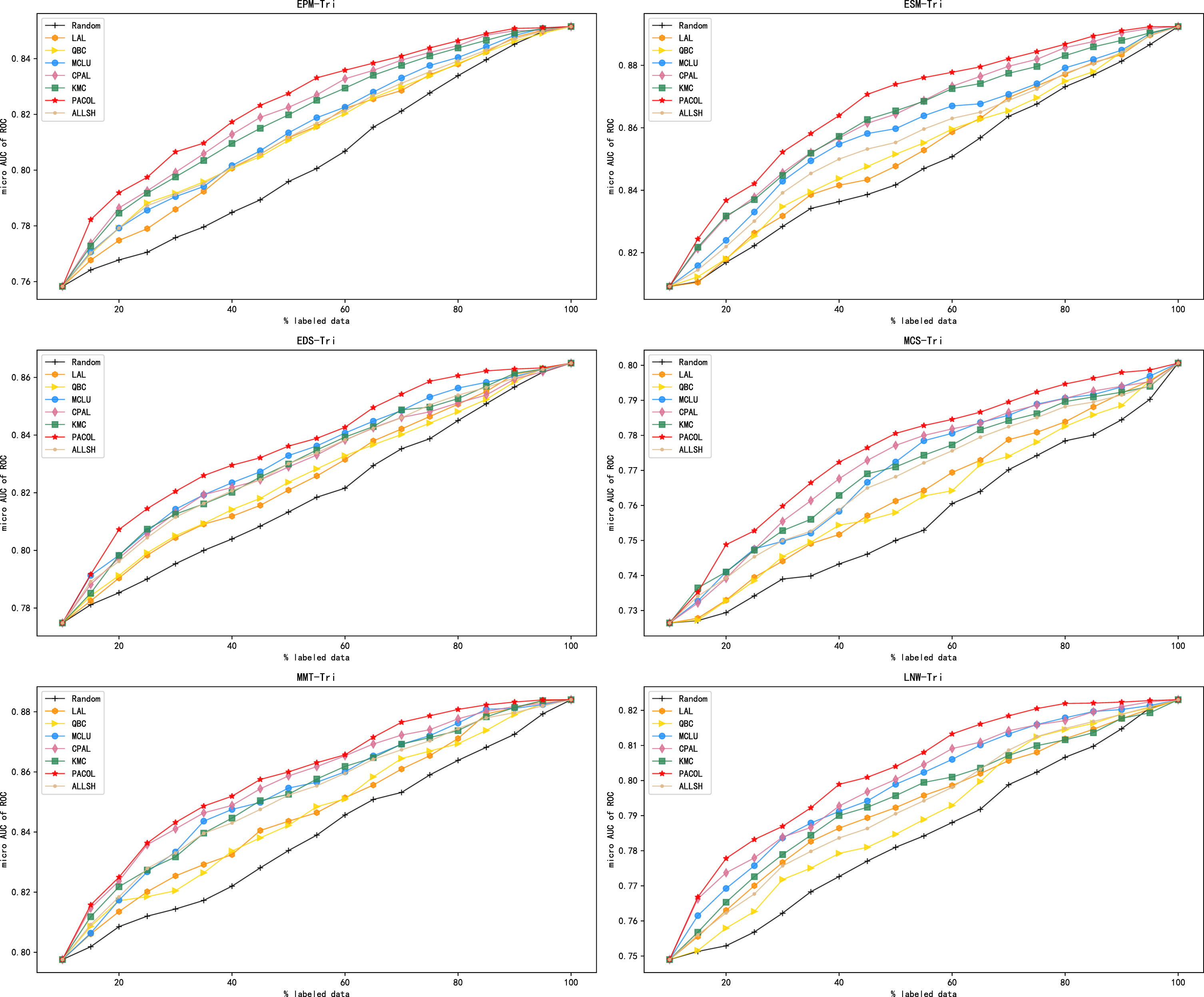
Comparison of standard active learning methods in the triple classification problem.
Liang introduced relational reasoning to enhance commonly used query strategies [40]. Liang improved standard active learning methods by incorporating relational reasoning in the process of selecting valuable instances and expanding the training set.
Following Liang, we introduced relational reasoning to PACOL and other comparative models. And we named them PACOL-R, Random-R, LAL-R, QBC-R, ALLSH-R, CPAL-R, MCLU-R, and KMC-R respectively. Then we conducted comparative experiments on all six data sets. Figure 5 shows the performance of active learning methods after introducing relational reasoning.
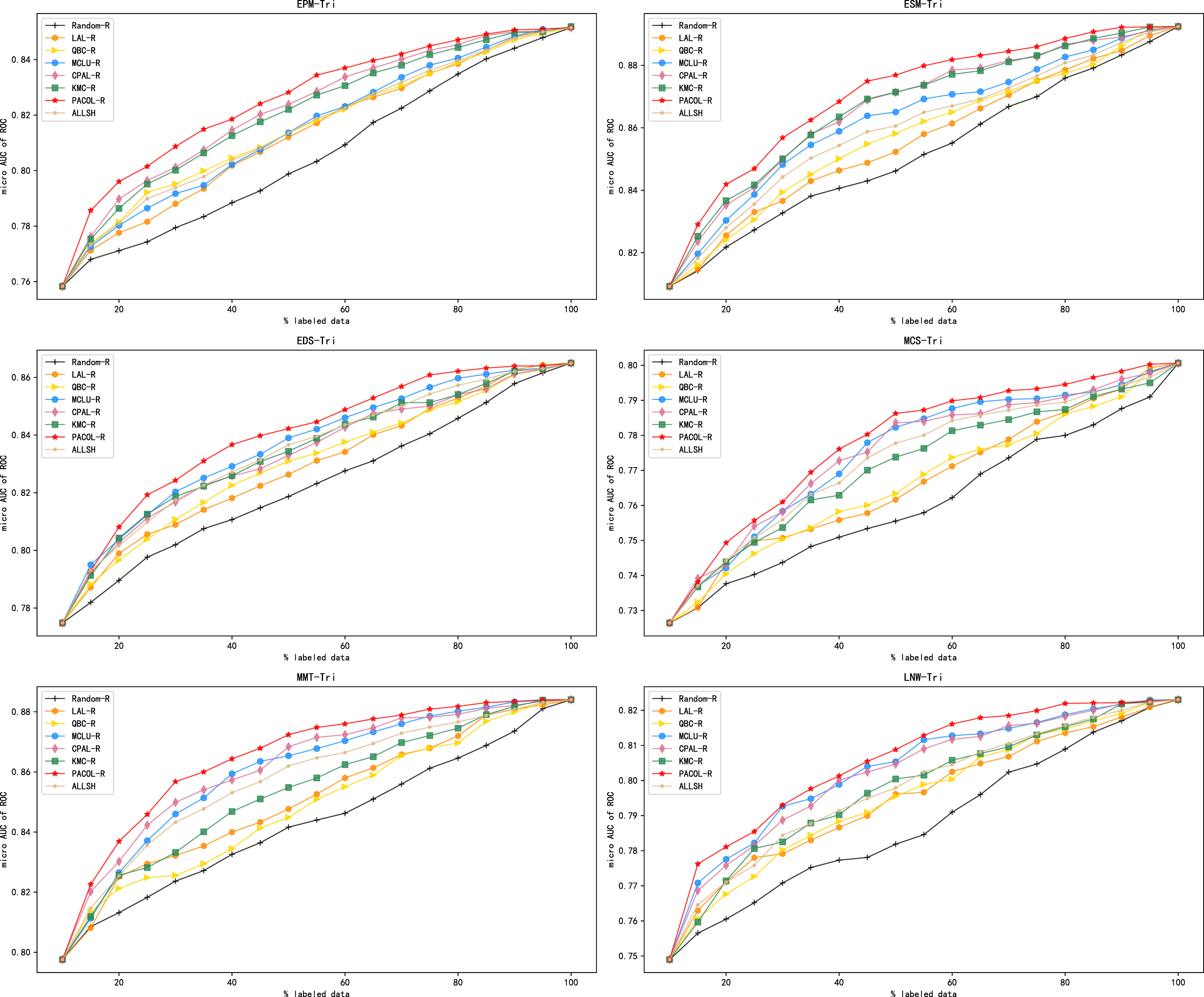
Comparison of methods after introducing relational reasoning in the triple classification problem.
As shown in Table 8, we generated data sets suitable for the binary classification problem from the original data sets, and we named them EPM-Bin, ESM-Bin, EDS-Bin, MCS-Bin, MMT-Bin, LNW-Bin.
Description of constructed data sets for binary classification problem
Description of constructed data sets for binary classification problem
For example, EPM-Bin is constructed according to EPM, there are 18906 concept pairs <u, v> in EPM-Bin. Among these concept pairs, the number of concept pairs <u, v> that u is prerequisite to v equals 868, and the number of concept pairs <u, v> that u is not prerequisite to v equals 18038.
Similar to the conduction in the triple classification problem, we chose SVM, NB, LR, GBDT, and RF as the classifier. SMOTE was used for data augmentation and random undersampling was used to solve the data imbalance problem. 5-fold cross validation was applied in all data sets. Then average precision, recall, F1-score, and AUC of ROC were reported.
Table 9 shows that the classification results vary depending on methods used. Similar to the performance of classifiers in the triple classification problem, RF and GBDT perform well on all evaluation metrics. In the following experiments, we chose GBDT as the binary classifier.
Comparison results of binary classifiers
Similar to the experiments in the triple classification problem, the data was divided into the training set
We use Random, LAL, QBC, ALLSH, DS, and QUIRE as comparative strategies. These methods can be used in both binary classification problems and multi-classification problems. And in this section, they are used for the binary classification problem. The descriptions of DS and QUIRE are as follows.
•DS: DS strategy selects unlabeled instances whose feature gap between the labeled instances is the largest, thus incorporating diversity of the labeled instances in active learning.
•QUIRE: QUIRE strategy selects the instance with the least distance from the classification surface formed by the labeled instances now.
Figure 6 shows the experimental results in the binary classification problem. The performance of various active learning methods on distinct data sets varies dramatically. However, PACOL generally outperforms the other methods.
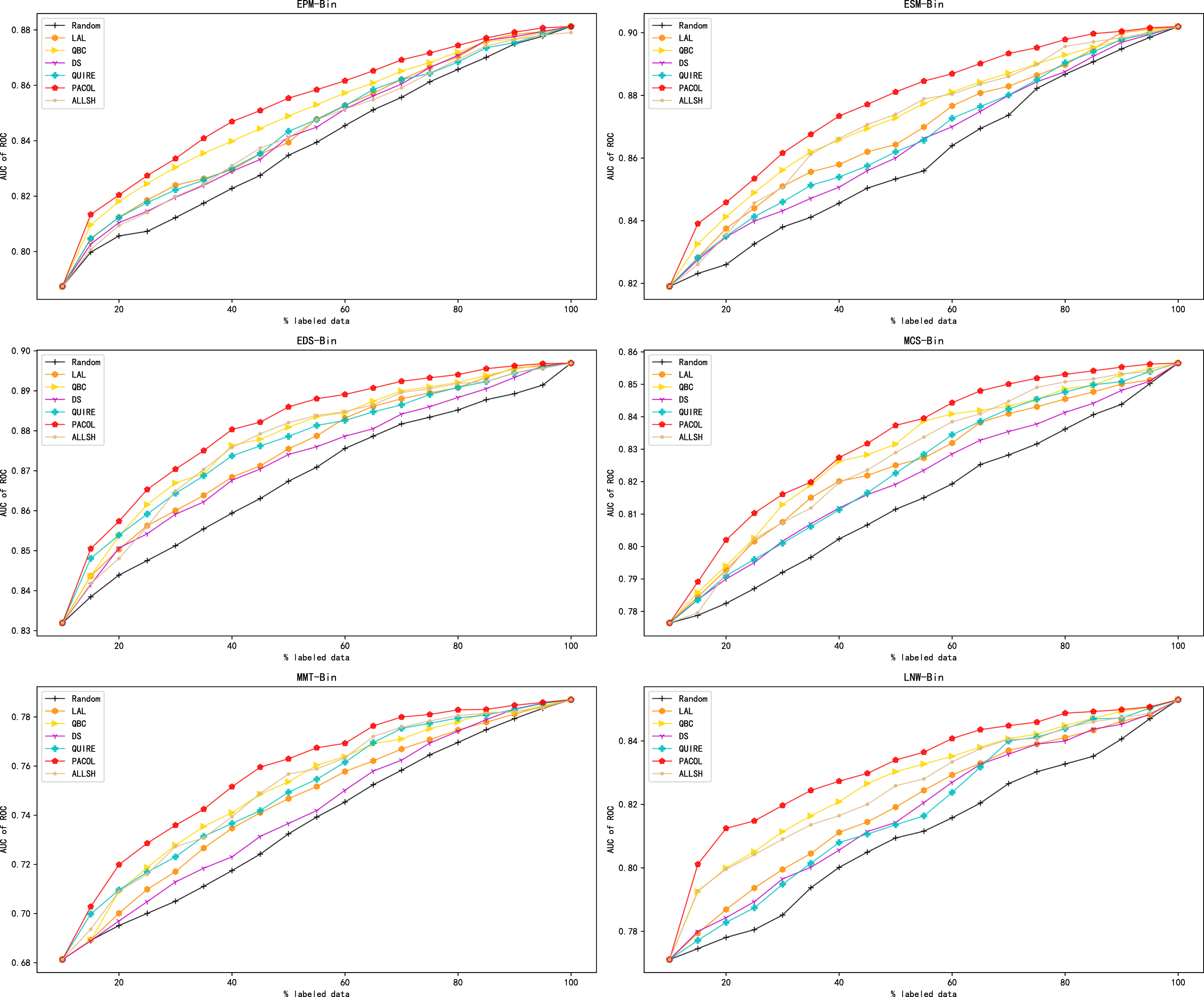
Comparison of standard active learning methods in the binary classification problem.
Similar to the conduction when specialists assign three kinds of labels, we added relational reasoning to PACOL and other comparative methods. We named them PACOL-R, Random-R, LAL-R, QBC-R, ALLSH-R, DS-R, and QUIRE-R, respectively. Figure 7 demonstrates the experimental results of active learning methods after introducing relational reasoning.
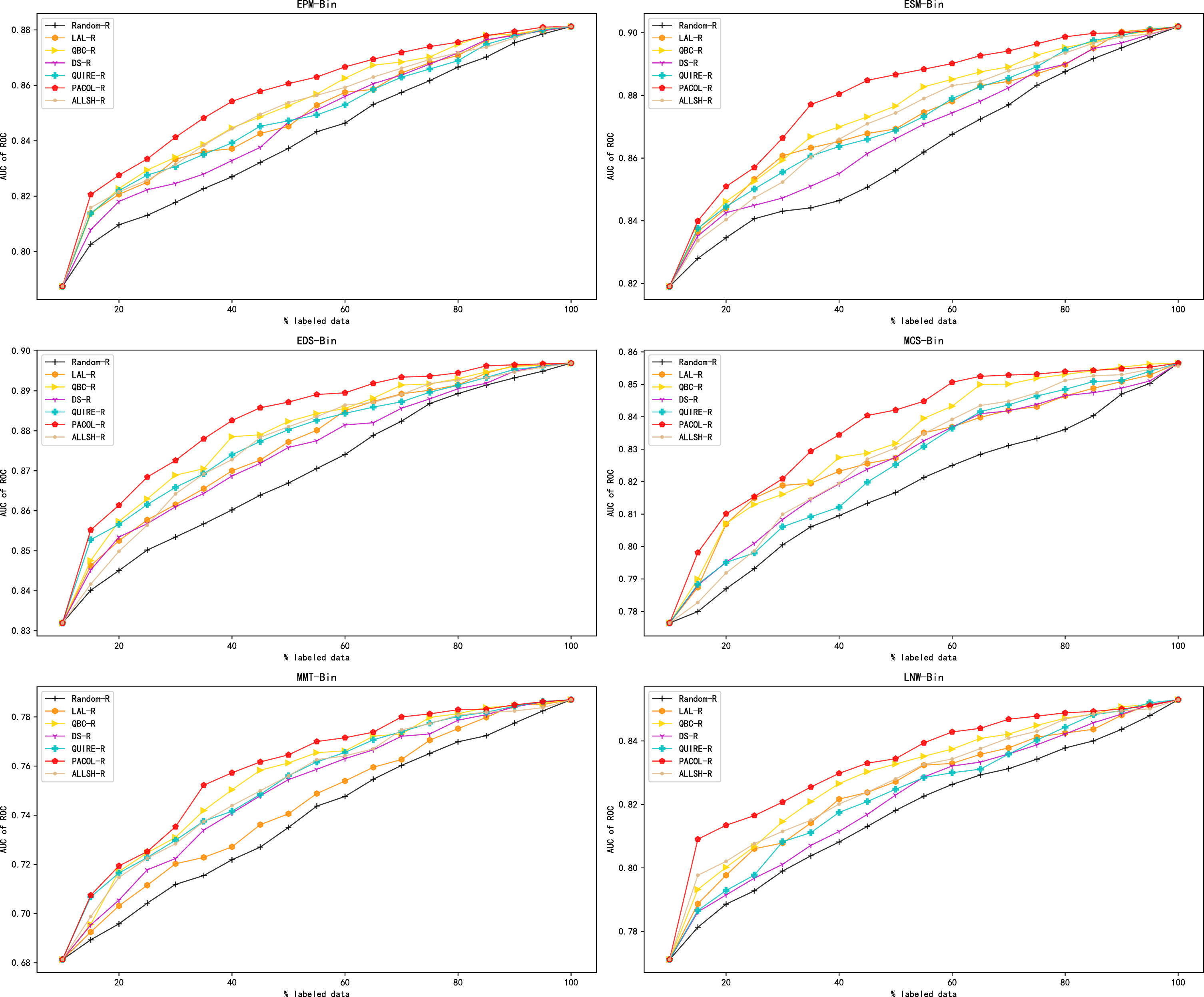
Comparison of methods after introducing relational reasoning in the binary classification problem.
We conduct experiments to answer questions mentioned at the beginning of this chapter.
Then we analyze every figure in this chapter. As shown in Fig. 4, when the classifier is trained on initial labeled data set, the performances of all active learning methods are same. PACOL performs better than other models virtually all of the time when the number of labeled instances is fixed. This is due to the fact that PACOL selects the concept pair with the greatest deviation between the classifier’s prediction and the fact. So the selected concept pair contains more information. Then the selected concept pairs are used to train a well-performed classifier. Unlike other active learning methods that treat all instances equally, PACOL can obtain a well-performed model at the early stage. The results of experiments demonstrate that PACOL excels at selecting the most informative instances for concept prerequisite learning.
In addition, for the other models besides PACOL, CPAL performs better in general. The idea of CPAL is selecting two concept pairs where the classifier disagrees on their labels. However, CPAL is unable to select instances with label 0, which is due to its limitation. CPAL performs better than other active learning methods. This is probably due to the fact that there are many instances with label 0 in the data sets, which are less important than other instances. LAL strategy, ALLSH strategy, and QBC strategy perform worse than MCLU strategy and KMC strategy. This is most likely due to the fact that the former two strategies are designed for both binary classification and multi-classification problems, while the latter two strategies are designed particularly for multi-classification problems. ALLSH strategy outperforms both the LAL and QBC strategies in the triple classification problem. This is likely attributed to the effectiveness of ALLSH in handling imbalanced data sets.
Figure 5 shows that PACOL-R still outperforms the other models after the introduction of relational reasoning. This proves that PACOL performs better than the other models in triple classification problem, regardless of whether relational reasoning is introduced or not.
As Fig. 6 shows, PACOL performs better than other models most of the time when the number of labeled instances is fixed. After a certain proportion of instances have been labeled, the performances of active learning models reach a stability stage. This might be due to the abundance of similar instances in the data sets, which offer limited information. Compared to other active learning methods, the performance of PACOL stabilizes significantly faster, which proves that PACOL can select useful instances more rapidly than other active learning methods. In general, QBC strategy and ALLSH strategy outperform the other models in the binary classification problem. QBC strategy demonstrates the advantages of using an ensemble method. Additionally, ALLSH strategy showcases the effectiveness of utilizing local sensitivity. Figures 4 and 6 demonstrate the effectiveness of PACOL in standard active learning.
As shown in Fig. 7, PACOL-R still outperforms the other methods after the introduction of relational reasoning. In other words, PACOL performs better than the other active learning methods in binary classification problem whether introducing relational reasoning or not. Figure 5 and 7 demonstrate the effectiveness of PACOL after introducing relational reasoning.
Conclusion
A novel pool-based active learning framework for concept prerequisite learning named PACOL is proposed in this paper. PACOL can be used in situations where the kinds of labels given by the specialists are three or two. In other words, PACOL is designed for using in both triple classification problem and binary classification problem in concept prerequisite learning. PACOL utilizes the fact of concept prerequisite relations to perform computational analysis on one concept pair and its reciprocal concept pair. Experimental results on our data sets and other public data sets reveal that PACOL outperforms several existing active learning methods in both problems, regardless of whether or not relational reasoning is introduced.
Future work can be explored in the following potential aspects. Firstly, we will try to extract prerequisite relations from courses by using natural language processing approaches. Secondly, we will try to construct the educational knowledge map based on concept relations. Thirdly, we will introduce the prerequisite relation into the process of exercise recommendation.