
Abstract
The present work is an effort to support the typographical errors of keywords that are not supported by existing compilers and integrated development environment(IDE) in ’C’ language. The fuzzy automata modelling approximate string matching is proposed for error handling during lexical analysis. By introducing fuzziness to lexemes the typographical errors can be rectified at the time of compilation and flexibility of lexical analyser can be greatly improved. The recognition of fuzzy tokens during lexical analysis is described in order to correct errors caused by sticking key, deletion, typing and swapping key in keywords during C programming. Algorithms and pseudo code are being developed to measure the degree of membership of crisp and fuzzy lexemes. Accuracy is tested and examined once the fuzzy lexemes are trained using a neural network. The proposed method is an add on feature that can be incorporated in existing compilers and IDEs to increase their flexibility.
Introduction
Approximate string matching (ASM) is used in many applications such as information retrieval, text searching, text summarization, pattern recognition, spell checking, recognition of lexemes in lexical analyser etc. [7, 30]. ASM is a technique to compute similarity between a pair of strings. In literature ASM is broadly classified into string based similarity measures and term based similarity measures [11, 30]. There exists many approaches to compute similarity in ASM such as distance metrics [11, 22], n-gram methods [2], automata based methods [9, 23] and filtering algorithms [6]. The distance measure based on Damerau-Levenshtein edit distance [15, 22] counts minimum number of operations required to transform one string into another, including operations such as insertion, deletion, substitution, swapping of symbols having time complexity O (mn). Extensions of distance method proposed in [31] with k difference allowed has time complexity O (kn) and when alphabet size b is taken into consideration complexity is
Astrain et al. [14] proposed fuzzy automata with ϵ moves that allows fuzzy edit operations modelled by binary fuzzy relations. They suggested fuzzy measure to compute similarity using string alignment and edit operations to overcome limited number of errors. Authors [28] suggested a technique to search or match strings in special cases when some pairs of symbols are more similar to each other and discussed its applications in DNA computing and spellchecker.
Ravi et al. [21] introduced intuitionistic fuzzy automata for ASM to compute similarity as well as dissimilarity of all possible edit operations. Ko et al. [25] computed similarity using context free grammar and fuzzy automata considering linear, affin and concave gap costs using dynamic programming algorithms. Shaprio et al. [7] initiated deep learning model in combination with memoization for text classification to detect and correct spelling errors in OCR output. Boinski et al. [26] suggested n-grams methods for spelling errors and correction.
Essex [1] came up with secure approximate string matching for record linkage against errors using bigram decomposition and extended dice coefficient to threshold dice coefficient for string similarity. Recently, Faro et al. [24] introduced Range automaton by proposing Backward Range Automata Matcher algorithm and added features of swap matching and multiple string matching for text searching algorithms with quadratic run time complexity.
Research gap
In literature, there are edit distance, hamming distance, Levenshetein, Damerau-Levenshetein, n-grams, q-grams methods and algorithms developed so far for approximate string matching [11, 30]. The application of ASM in lexical analysis is not explored much. Crisp compilers use a bi-valued approach. In compilers, a string is either recognised or not recognised as a token. There is no technique for compilers in the ‘C’ language to accommodate typographical errors in existence. Mateescu et al. [3] discussed the applications of ASM and fuzzy automata in lexical analysis and proposed an extension of LEX compiler for UNIX with added features to deal with typographical errors. Bhosle et al. [27] has suggested a fuzzy lexical analyser for tiny language and proposed algorithm to consider typographical error during token recognition process. Their method is based on threshold value for acceptance of error keywords but it is limited to only eight keywords and ignores swapping key errors.
Basis of Study
The primary goal of our research is to use fuzzy automata in lexical analysis phase of compiler construction to allow lexical errors in keywords which may exist due to typographical errors taking edit operations of ASM into consideration. The typographical error or typo error refers to the unintentional typing error that occurs due to accidental hitting a wrong key. There are four kinds of typographical errors: deletion of key, swapping key, sticking key and typing key error. The motive of the research is to handle typographical errors in keywords by compiler itself instead of user intervention.
Existing IDEs deal with this issue in two ways: Case1: It recommends the feasible keywords while typing. Case 2: After compiling, they display a message i.e. not defined or implicit declaration of function. In the first case, programmer must opt correct suggestion and in case 2, one has to rectify these errors at the place manually. Whereas by proposed method, these errors can be handled at the time of compilation. Thus, it will save energy and time of the programmer. The proposed idea is an add on feature that can be incorporated in the existing compilers, where instead of showing errors it will accept keywords, on the basis of their membership values.
Contribution
String matching is used to implement lexical analyser which requires regular expressions and finite automata. Fuzziness in lexemes for token keyword is introduced to boost the flexibility of crisp compilers and to make them more user friendly. In proposed work, the keywords are categorised into crisp keywords and error keywords. Both are fuzzy in nature. Crisp keywords are correctly spelled keywords directly accepted by compilers and probable typing errors that result from sticking key (deletion), missing letter (insertion), sequencing (swapping), or mistyping of keys (substitution) are termed as error keywords or fuzzy keywords. Fuzzy regular expressions of keywords are generated in fuzzy lexical analysis. Fuzzy regular expressions are first converted into Non-deterministic Finite Automata with Fuzzy (final) States (FS-NFA) and then Deterministic Finite Automata with Fuzzy (final) States(FS-DFA) are constructed because FS-DFA are easy to simulate.
Algorithms along with pseudo code for calculating the membership value of crisp keywords and error keywords are proposed. At various levels of membership, the error keywords are accepted. These membership values are trained using a neural network, which enables lexical analyser to consider keywords with different membership value.
The present work is an effort to discuss ASM for handling typographical errors in tokens generated at the time of lexical analysis phase of C compiler. In the proposed approach, all the possible error keywords are generated corresponding to crisp keyword, along with edit operation we have added method to calculate the similarity between crisp and error keyword by considering membership value of generated error keywords.
The paper is laid out in following manner: The first section is an introduction. In section 2, some important concepts are recalled. Section 3, describes proposed method and procedure. The results are covered in Section 4, and the study concludes in Section 5.
Preliminaries
This section goes over some basic definitions of fuzzy languages and fuzzy automata. For more information, readers can refer [3, 8] and [29]. Throughout this paper Σ denotes any set of finite alphabets and Σ* be the set of finite strings constructed from elements of Σ.
the set for each
Regular expressions are used to represent strings in more declarative way in the form of algebraic expressions [4].
The union FRE is obtained by repeated applications of (i) and (ii) finite times.
S is a finite non-empty set of states. Σ is a finite non-empty set of input symbols. δ : S × Σ → S, is the transition function. s0 ∈ S is called initial state. F
M
: S → [0, 1] is the degree function for fuzzy final-state set.
For x ∈ Σ* and s1, s2 ∈ S, define δ* : S × Σ* × S → [0, 1]
A string x ∈ Σ* is accepted by FS-NFA with degree or membership value d M (x) , where d M (x) = max {F M (s) ∣ (s0, x, s) ∈ δ*} . The fuzzy language accepted by FS-NFA is denoted as L (M) = {(x, d M (x)) |x ∈ Σ*} .
A string x ∈ Σ* is accepted by FS-DFA with degree d M (x) , where d M (x) = F M (s) ∋ s = δ* (s0, x) and d M (x) =0 if δ* (s0, x) is not defined.
Methodology
Compilers convert a source language to a target language and report any errors back to the source language. Analysis and synthesis are the two phases of the compilation process. The first step in the analysis phase is lexical analysis, which involves breaking down the initial source language into parts and generating an intermediate representation. It is the interface between source language and compilers. During lexical analysis the source language is grouped into lexemes, which are meaningful sequence of words. For parsing, the lexemes are subsequently transformed to tokens. Tokens can be treated as identifiers, keywords, constants, operators and punctuation symbols. Every lexeme that is to be identified as a token follows a set of predefined grammar rules. Consider program code in C language:
Tokens and Lexemes
Tokens and Lexemes
Compilers in ‘C’ language do not support typographical errors in keywords, therefore Fuzzy Regular Expressions (FRE) for all 32 keywords [5] are generated, taking into account all conceivable errors. The algorithm 1 and algorithm 3 are suggested to calculate the membership values of crisp keywords and error keywords respectively. For all keywords, FS-NFA is constructed and for minimization FS-NFA is converted to FS-DFA.
Table 2 lists some possible typographical keyword errors.
Sticking key: particular character is typed twice or thrice Deletion key: particular character is not typed Swapping key: sequence of character is mistyped Typing key: typing of adjacent key in QWERTY keyboard
Possible typographical errors
The FRE for reserved word "float" is as follows: float/1 + (ff+ll*oo*aa*tt* + ff*ll+oo*aa*tt* + ff*ll*oo+aa*tt* + ff*ll*oo*aa+tt* + ff*ll*oo*aa*tt+)/m1 + (floa + flot + flat + loat + foat)/m2 + (fotla + flaot + lfoat + lfaot + oflat + olfta + afolt + aotfl + tfloa + tofla)/m3 + ((r + d + g + c) loat + f (o + k + p + i) oat + fl (i + l + p) at + flo (s + z + q) t + floa (r + y + g))/m4 Here, m1 denotes membership value due to sticking key error, m2 denotes membership value due to deletion key error, m3 denotes membership value due to swapping key error and m4 denotes membership value due to typing key error.
Algorithm 1 and its pseudo code are proposed to calculate the membership values of crisp keywords. The degree of letter specified in algorithm represents the membership value of letters placed at different position or index of crisp keyword contributing to calculate the membership value of crisp keyword. Each letter is contributing in formation of crisp keyword therefore the value of each letter is assumed to be same. Thus, the membership value of crisp keyword is calculated by determining the degree of each letter present in the keyword.
Initially the algorithm 1 has time complexity as O (m * n), where m is the length of keyword and n is the number of keywords i.e. 32. Since all keywords are of small length, m can be assumed to be constant. Hence, time complexity of algorithm 1is O (n).

Algorithm 1 is explained with the help of example 3.1.
crisp _ keyword = "struct"
length (crisp _ keyword) = length (struct) =6
Assume, membership _ value (struct) =0.0
Now calculate degree of each letter present in "struct" using, degree (letter) =1/length (crisp _ keyword)
All the possible errors have been considered, i.e. sticking key, deletion, swapping key and typing errors to find error keywords corresponding to each crisp keyword. Algorithm 3 is proposed for all these errors to calculate membership value of error keywords. The index of the letter plays an important role in proposed algorithm to calculate membership values of keywords. The membership value of error keywords is calculated by considering four different possible cases:
In deletion of key error the length of error keyword is less than crisp keyword, hence the degree (letter) =0 for missing letter, rest all degree (letter) will be same as in the crisp keyword. In QWERTY typing key error the degree of letter which is not matched at index will be considered as degree (letter) =0, rest all degree (letter) will be same as in the crisp keyword. In sticking key error the length of error keyword will be greater than the crisp keyword, hence for sticking letter occurrence of letter is taken into account. In swapping key error, the degree of letter in error keyword is depending on the degree (letter) of crisp keyword and count of interchanges, i.e. how many positions are required to shift the swapped letter.
If lengths of both keywords are equal then it will be considered as swapping key error or typographical error.
If length of error keyword is greater than length of crisp keyword it will be considered as sticking key error. Count the number of times each letter appears in error _ keyword . i,e. occ (letter) degree (error _ keyword [index]) =1/occ (letter) * length (crisp _ keyword) . membership _ value (error _ keyword) + = degree (letter)
If length of error keyword is less than length of crisp keyword it will be considered as deletion key error. membership _ value (error _ keyword) = length (error _ keyword)/length (crisp _ keyword) .
The time complexity of algorithm 3 is O (mlogm), where m is the length of error keyword.
Algorithm 3 is explained with the help of example 3.3. Python code is created to generate these error keywords and to compute membership value of error keywords. The greater the membership value of error keyword, the more it is considered similar to the crisp keyword.
crisp _ keyword ="float"
error _ keyword = "ffloaat"
membership _ value("ffloaat")= 0
length (error _ keyword) = length("ffloaat")= 7
length (crisp _ keyword) = length("float")= 5
length("ffloaat")>length("float"), therefore case II sticking key error of algorithm 3 arises.
Table 3 represents summary of some possible typographical error keywords corresponding to crisp keyword "float" and their membership values are computed using algorithm 3.
Membership Values of error keywords generated from crisp keyword "float"
Every language that can be accepted by FS-NFA can also be accepted by FS-DFA [16]. FS-NFA for keyword "float" is given in Fig. 1 containing 52 states. Corresponding to FS-NFA using subset construction, method FS-DFA is constructed. FS-DFA for keyword "float" is given in Fig. 2 which has less number of states as compared to FS-NFA.
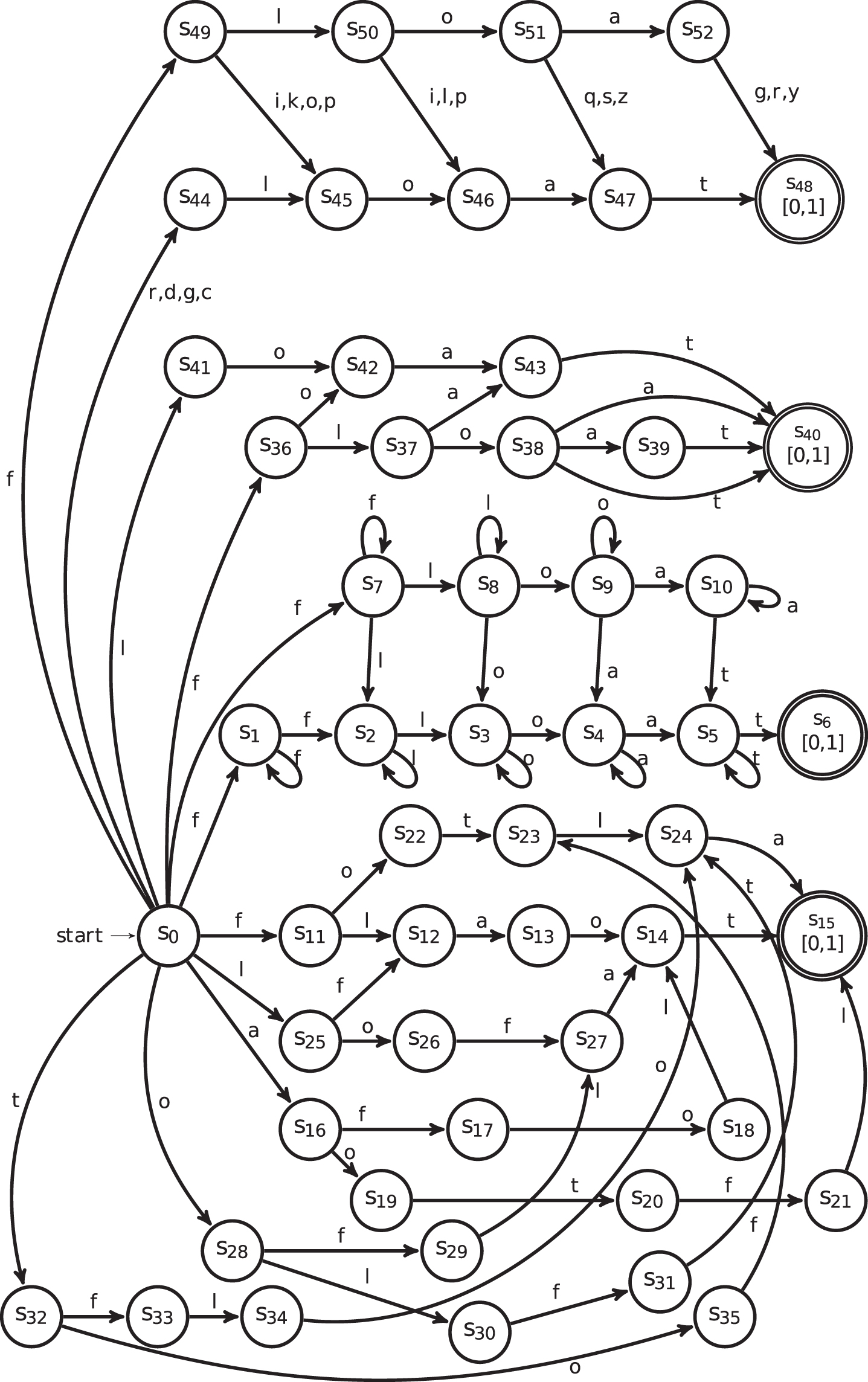
FS-NFA for keyword "float".
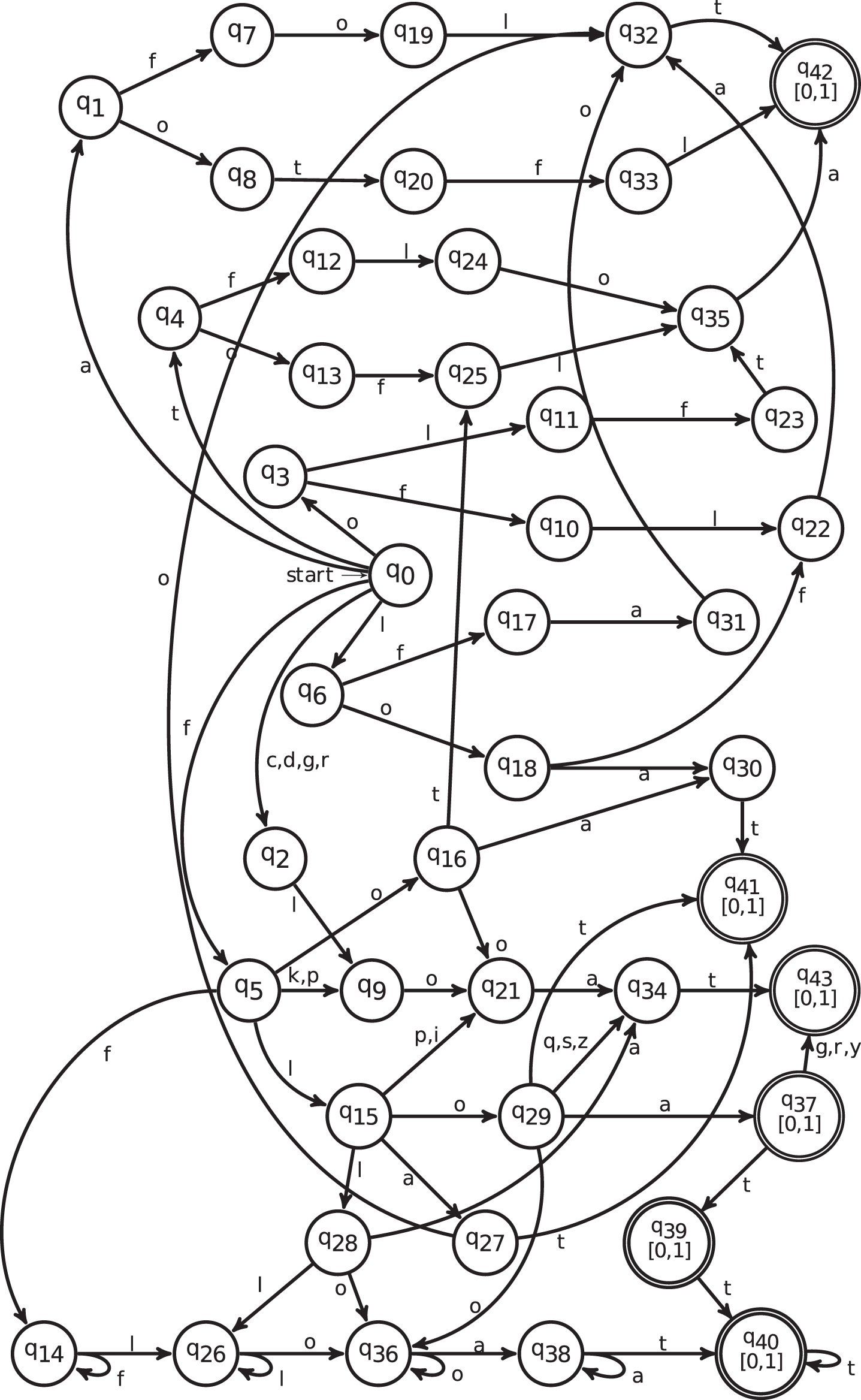
FS-DFA for keyword "float".
This section discusses the suggested method’s general implementation.
Results
For experimentation, a dictionary is created for all the 32 crisp keywords for ’C’ programming language using python. Corresponding to each crisp keyword, 40 keywords are generated by considering all the possible typographical errors. The dictionary contains 1280 keywords after appending all the errors considering deletion, sequencing, sticking key and typing errors. Each keyword is assigned a label and added with crisp keyword corresponding to that label. By reducing redundant comparison, accuracy is increased, and time complexity is decreased. The membership value of each keyword is calculated using the algorithm 1 and algorithm 3. The efficiency of method is further enhanced by using neural network to validate it for unseen data.
The data is split for training and testing using Keras framework. For training set 80 percent i.e. 1024 keywords are taken in to consideration. A neural network is trained for these membership values. The network is run with learning rate 0.7 and 90 epochs. The average accuracy measured is 82.81%. The loss graph in Fig. 3 depicts that, for the first 12 epochs, the loss in the training set falls off quickly. The loss for the test set does not decline as quickly as it does for the training set, but rather, after 40 epochs, it nearly remains constant. This shows that the model generalizes well to new data. Similarly, Figure 4 demonstrates how quickly accuracy rises in the first 10 epochs for both training and testing sets, hence the network is learning fast. Afterwards, the curve flattens indicating that the fewer training epochs are needed to train the model further.
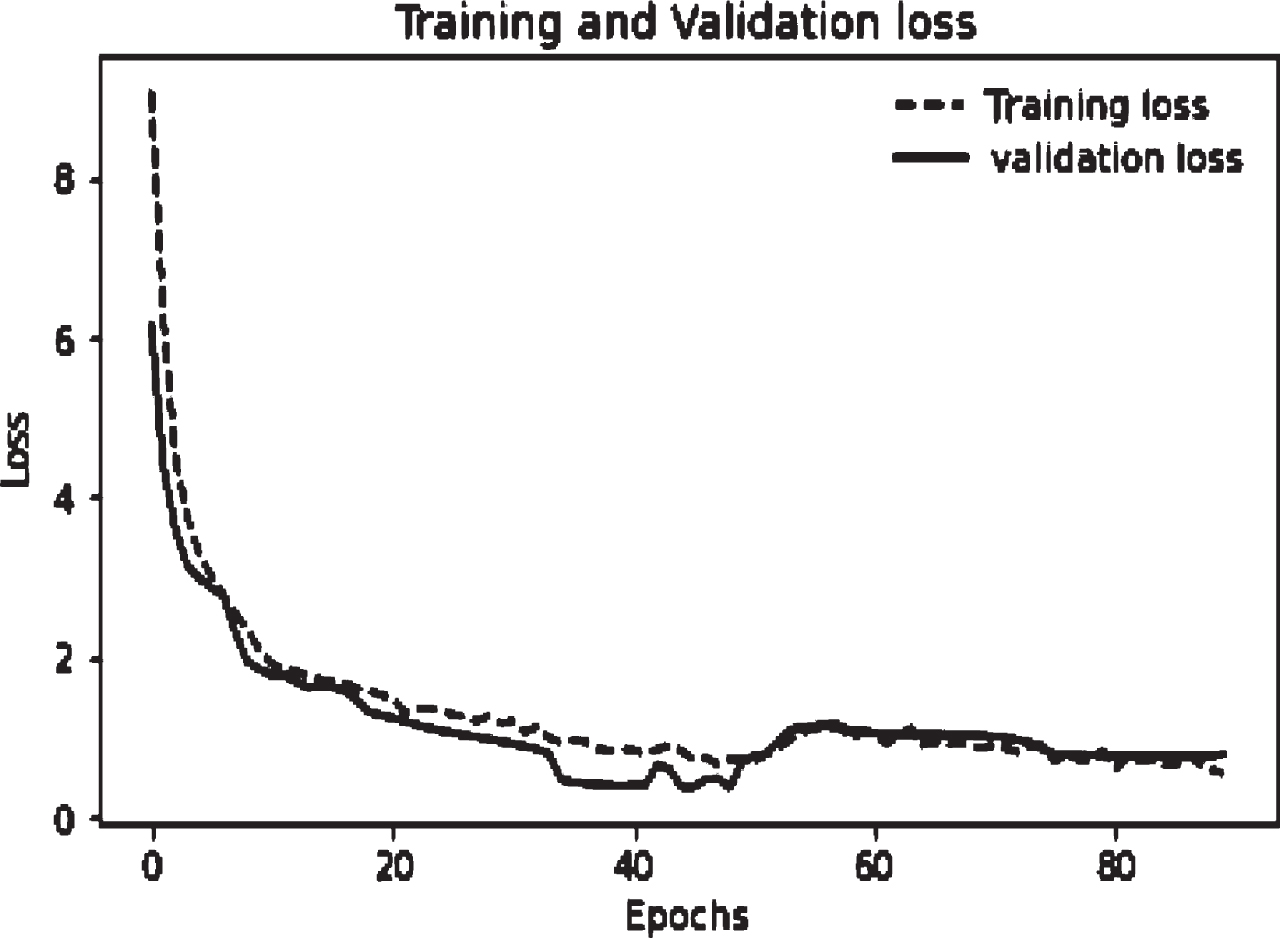
Training and Validation Loss.
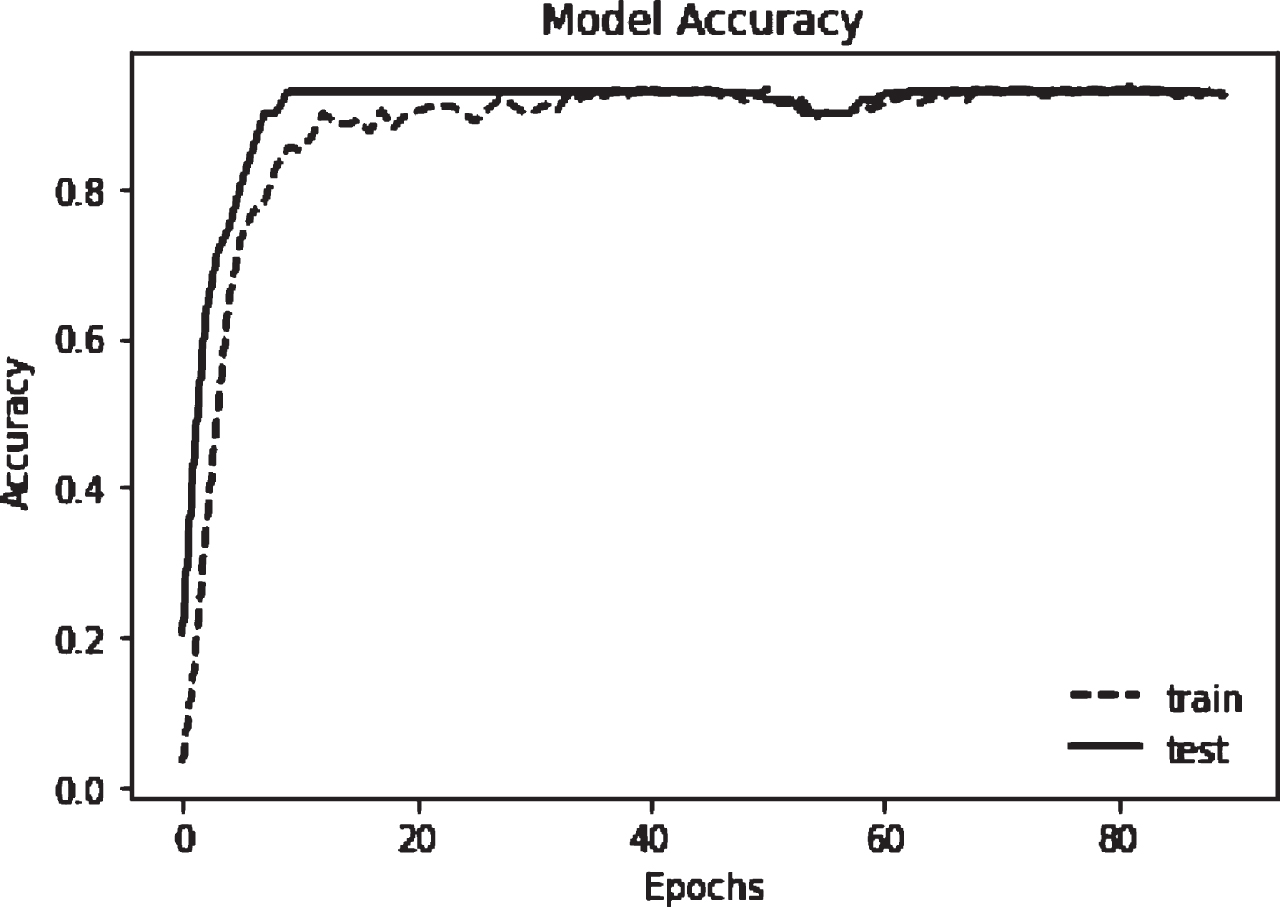
Model Accuracy.
The comparative analysis of calculating the membership values of keywords using suggested algorithms from the literature is presented in Table 4. In Ravi et al. [21], as the cost of all possible edit operations are predefined, therefore the membership values of error keywords are constant. In [27], the swapping of keys is not considered. In [10], while switching adjacent keys yields accurate results, switching all the letters in a word is not taken into consideration. The results demonstrate that the membership values obtained by our proposed algorithm are near to expected membership value as compared to other three methods in terms of recognition, encompassing all feasible scenarios.
Comparative Analysis of membership values of error keywords
Comparative Analysis of membership values of error keywords
In the proposed work, application of ASM using fuzzy automata is discussed in lexical analysis phase of C- compiler. The proposed idea is an add on feature which can be incorporated in existing compilers not only in ’C’ language but also in other compilers and IDEs. The authors team is not boasting to develop a new compiler, but different OS companies or programmers can take this approach as a new bench mark for future development of an efficient and flexible product.
Conclusion
The proposed method is a feature that can enhance the efficiency of existing compilers and make compilers more user friendly. The errors are rectified at the time of lexical analysis phase. This saves time for parsing and further analysis of source program. Traditional compiler of ‘C’ language does not support error handling in keywords, hence to improve the efficiency of existing compilers fuzziness in the token is introduced. Considering operations of ASM possible error keywords are compared with crisp keywords. Algorithms are proposed so that error keywords may be accepted at varying degrees of their membership values.
The keywords are further trained using neural network and an average classification accuracy of 83% is achieved.
In future, the method can be extended for operators and other tokens and full implementation of a fuzzy lexical analyser can be done. The proposed approach can be further tested and implemented in other compilers, IDEs to increase their flexibility and user friendliness.