
Abstract
Though the existing load balancing designs successfully make full use of available parallel paths and attain high bisection network bandwidth, they reroute flows regardless of their dissimilar performance requirements. But traffic in modern data center networks exhibits short bursts characteristic, which can easily lead to network congestion. The short flows suffer from the problems of large queuing delay and packet reordering, while the long flows fail to obtain high throughput due to low link utilization and packet reordering. In order to solve these inefficiency, we designed a fine-grained load balancing method (FLB), which uses an active monitoring mechanism to split traffic, and flexibly transfers flowlet to non-congested path, effectively reducing the negative impact of burst flow on network performance. Besides, to avoid packet reordering, FLB leverages the probe packets to estimate the end-to-end delay, thus excluding paths that potentially cause packet reordering. The test results of NS2 simulation show that FLB significantly reduces the average and tail flow completion time of flows by up to 59% and 56% compared to the state-of-the-art multi-path transmission scheme with less computational overhead, as well as increases the throughput of long flow.
Introduction
Burst traffic in data center networks refers to a type of intense burst traffic with a short duration. Micro burst traffic can reduce the performance of data center services. On the one hand, micro burst traffic can cause network packet loss, and then increase the flow completion time (FCT: As the flow completes transmission, the current time at the receiving end minus the start time at the sending end); On the other hand, micro burst traffic can lead to congestion misjudgment, resulting in the bandwidth not being fully utilized and reducing network throughput [2,17,27].
Through simulation experiments, the characteristics of data center network traffic were measured in detail, and the measurement results found that the duration of these bursts of traffic in data center network(DCN) is extremely short, and more than 70% of them are less than 100 μs, and even if the average utilization of the link is very high, the switch will still have a high buffer occupancy rate, and even buffer occupancy rate reaches 100%. Therefore, load balancing research on micro-burst traffic has become the focus of data center network load balancing research.
Equal Cost MultiPath (ECMP) [16] is the most typical flow-level load balancing scheme in production datacenter, but is far from efficient because of hash collision and the inability to reroute paths. Random Packet Spraying (RPS) [9] and DRB [4] adopts fine-grained rerouting, hence are more flexible and efficient than ECMP. However, they are oblivious to path condition thus suffering from serious packet reordering. DRILL [10] is a distributed load balancing mechanism designed for micro-burst traffic. It compares two random output ports and the least-loaded port in the last round, and chooses the one with least queueing length to forward a packet. LetFlow [25] and Presto [12] make a good balance between packet reordering and link utilization by adopting per-flowlet and per-flowcell switching granularity to reroute flows. Nonetheless, both of them are inherently passive and fail to timely react to the change of path condition. What’s more, none of the above schemes is aware of the burst traffic and proactive prediction path diversity, thereby leading to the unsatisfied transmission performance.
In this paper, in order to make the load balancing scheme resilient to micro-bursts, we propose a cross-layer load balancing mechanism called FLB, which actively monitoring and processing burst traffic. Before the burst traffic is sent, flowlet splitting will be performed first, so that the data-intensive burst traffic transmitted on a single path in the network becomes more finely divided traffic segments. It reduces the load pressure of a single link and reduces the probability of congestion. At the same time, in order to reduce the occurrence of disorder, at the receiver, the delay of all transmission paths is estimated by reverse detection, and then the burst traffic is flexibly transferred to all non-congested paths. Moreover, FLB is deployed on sender and switch with negligible overhead, while making no modifications on the existing TCP/IP protocols.
In summary, our major contributions are:
We conduct an extensive simulation-based study to analyze the impact of micro-burst on the load balancing performance. We demonstrate experimentally and theoretically why proactive prediction is effective in avoiding large tailed flow completion time (FCT) and packet reordering under large path asymmetry.
We propose a flowlet-level load balancing scheme FLB to spread flowlet across the multiple paths, which are adaptively rerouting according to path diversity. FLB rationally adjusts the number of paths to improve link utilization and reduce tailed latency.
By using large-scale NS2 simulations, we demonstrate that FLB performs remarkably better than the state-of-the-art load balancing designs under different realistic traffic workloads. Especially, FLB greatly reduces the mean FCT up to ∼15–59% over ECMP, DRILL, LetFlow and Presto.
The remainder of this paper is structured as follows. In Section 2, we demonstrate existing approaches. we describe our design motivation in Section 3. Then we present the design overview and details of FLB in Section 4–5. In Section 6, we evaluate the performance of FLB using NS2 simulation. Finally, we conclude the paper in Section 7.
Related works
In recent years, researchers have proposed various load balancing mechanisms to facilitate parallel data transmission across multiple paths, thereby further gaining performance enhancements. The state-of-the-art schemes mainly include Hermes, Fastpass, CoFUSO, AG, TR, JCDME and TEL. The pros and cons comparisons is shown in Table 1.
Hermes [26] senses the path congestion state based on RTT and ECN, adopts a prudent and timely rerouting strategy, comprehensively considers the number of sent bytes of the flow and the path congestion state, and switches the forwarding path only when the rerouting is profitable. However, there is a certain delay in the perception of congestion on the host side, so it cannot deal with the inrush situation in time, and there are many parameters in the path perception and rerouting algorithms. How to choose the appropriate parameters needs to be selected according to the network conditions.
Fastpass [23] is a centralized hybrid mechanism. It combines transmission control and traffic scheduling to achieve zero queuing delay and high throughput in data center networks. Fastpass utilizes a central controller to assign transmission time slots and transmission paths to each packet. The path selection mechanism uses the graph coloring algorithm to distribute the data packets with allocated time slots to the path with zero queuing delay. The link utilization of Fastpass is affected by the transmission slot utilization.
CoFUSO [20] adopts the same multi-path loss recovery manner and bears the same philosophy of being both fast and cautious as FUSO [5]. But instead of retransmitting from the oldest unACKed packet, CoFUSO generates proactive recovery packets using an erasure code. Specifically, when there is a chance to conduct proactive retransmission, CoFUSO will send a coding packet which codes all the potentially lost packets together. As such, the sender can always “retransmit” the right packet without accurately predicting which one is lost, since the receiver can decode the actually lost packet once it has received other packets.
AG [19] is a packet-granularity load balancing mechanism against asymmetric scenarios. The AG adaptively adjusts the path switching granularity by sensing the multi-path delay difference. The AG uses probe packets to periodically measure the one-way delay between switches to obtain path congestion information. When the path delay difference is large, the path switching granularity is increased to reduce disorder, and when the path delay difference is small, the path switching granularity is reduced to improve link utilization. AG randomly assigns paths to each flowcell and link delay measurement overhead is higher.
TR [28] identifies flow types and executes flexible and traffic-aware rerouting to balance the performances of both short and long flows. Besides, to avoid packet reordering, TR leverages the reverse ACKs to estimate the switch-to-switch delay, thus excluding paths that potentially cause packet reordering.
JCDME [3] model the energy consumption by considering the computing costs of the Virtual Elements on the physical servers, the costs for migrating Virtual Elements across the servers, and the costs for transferring data between Virtual Elements. In addition, JCDME introduces a weight parameter to avoid an excessive number of Virtual Element migrations.
TEL [22] contains two Fast Re-Route (FRR) mechanisms, namely, TEL-C and TEL-D. The first one computes backup forwarding rules in the control plane, satisfying max-min fair allocation. The second mechanism provides FRR in the data plane. Both algorithms require minimal memory on programmable data planes and well-suited with modern line rate match-action forwarding architectures (e.g., PISA).
The pros and cons comparisons of related work
The pros and cons comparisons of related work
In this section, we provide empirical research to show the micro-burst traffic is very common in the modern data center. Then, we use experiments to analyze the distribution of micro-burst traffic in the data center network, and illustrates the impact of burst traffic on the existing load balancing scheme.
The distribution of burst traffic in the production network
In order to further understand the burst traffic in the data center network, we built a small data center network through the simulation platform, and conducted a more detailed measurement and analysis of the traffic in the network.
We taking 25 μs as the measurement interval, the traffic whose buffer occupancy rate exceeds 50% in the continuous measurement interval is called a burst. Figure 1 shows the statistical distribution of the duration of the three business traffic: Web, Cache, and Hadoop. It can be found from the graph that, with the exception of the Hadoop business, more than 80% of the burst durations do not exceed 50 μs, 80% of the three types of services do not exceed 100 μs, and almost all the burst durations measured do not exceed 500 μs. It can be seen that the duration of burst traffic is always on the order of tens or hundreds of microseconds. It is precisely because of the duration of microseconds that this type of burst traffic is widely known as Micro-burst.
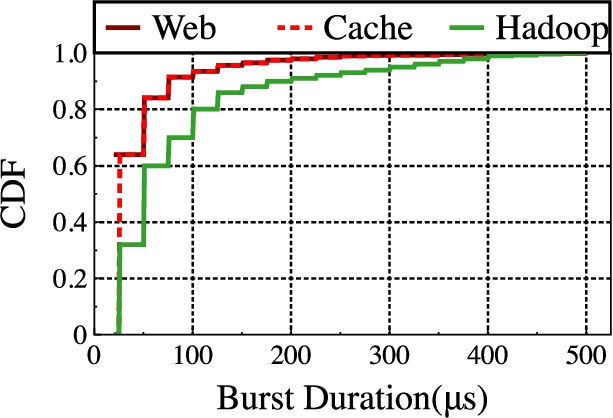
Burst duration distribution.
Through the measurement results in Fig. 1, combined with the characteristics of fine-grained time burst traffic in the data center network, it can be known that the equalization effect observed at a larger time granularity is the equalization effect in the long-term average sense, but the actual The network traffic presents the characteristics of burstiness at the microsecond level. When observing from the microsecond granularity, it can be found that the actual balance effect is poor. The flow-based coarse-grained balance method cannot be very good for the burst flow in the balance decision. The splitting and forwarding makes it easy for burst traffic in a very short time to converge on a single path, which reduces the actual balance effect, and easily leads to excessive load on a single link, resulting in congestion and packet loss.
In order to explore the impact of burst traffic on existing load balancing methods, we use the 8 × 8 leaf-spine topology shown in Fig. 2 to do test experiments. Firstly, we simulated Web, Cache, and Hadoop three kinds of real business traffic at the sending end to measure and compare the balancing effect of the ECMP method at two time granularity of 40μs and 1 s, and found the results shown in Fig. 3. The result shows the measurement data of the three types of service flows. The test index is the MAD value of the average utilization of each available link connected to the upper-layer network of the switch [27].
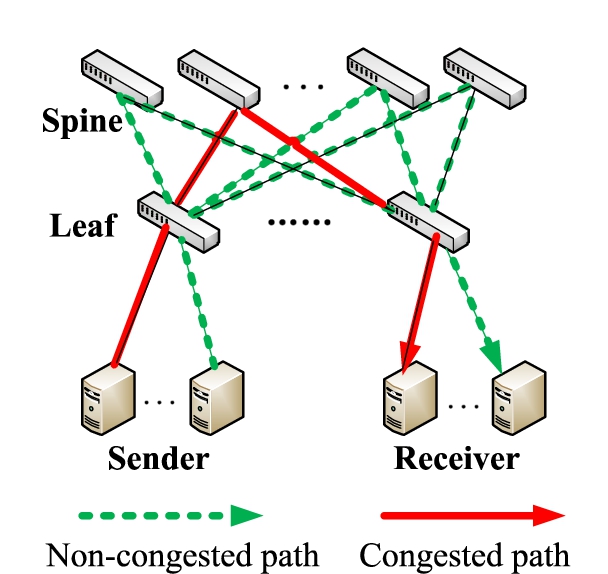
Leaf-spine topology.
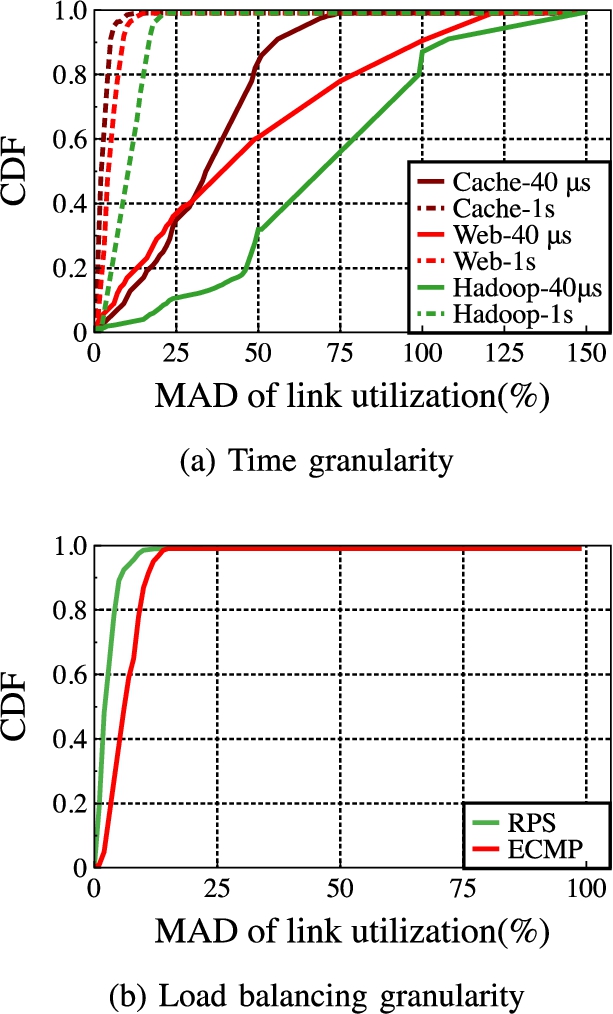
Performance comparison under different granularities.
From the measurement results in Fig. 3(a), it can be seen that the load balancing effect observed at a larger time granularity is better than the balancing effect in a short time, while the actual network traffic presents a burst characteristic of microsecond level, which is based on flow. The coarse-grained balancing method cannot achieve good distribution and forwarding of the burst traffic during the balancing decision, so that the burst traffic in a very short time is easy to converge on a single path, thereby reducing the actual load balancing effect, and it easily lead to excessive load on a single link, resulting in congestion and packet loss.
Secondly, we compare the average utilization of links between ECMP and RPS. Simulate Web search workload and send 100 flows at the sending end to calculate the average utilization of links per unit time. It can be seen from Fig. 3(b) that RPS of packet-based load balancing method is better than ECMP of flow-based.
In general, although burst traffic has caused transmission problems such as increased switch buffer occupancy rate and packet loss rate, the existing load balancing methods cannot effectively solve the problems caused by such burst traffic. Therefore, it is necessary to improve the existing equalization method to improve the method’s ability to forward burst traffic.
In this section, we plot the architecture of FLB. The two key points of FLB are using fine-grained splitting flowcell and rerouting to solve the head-of-line blocking and out-of-order problem, respectively. Specifically, on the one hand, it is necessary to actively monitor or predict the transmitted traffic at the sender, so as to realize timely processing before the burst traffic causes link congestion. On the other hand, the link delay is estimated by sending probe packets in the reverse direction, and then the link information is transmitted to the sender. The sender select non-congested path to reduce the impact of out-of-order packets. FLB consists of three modules, as shown in Fig. 4.
(1)
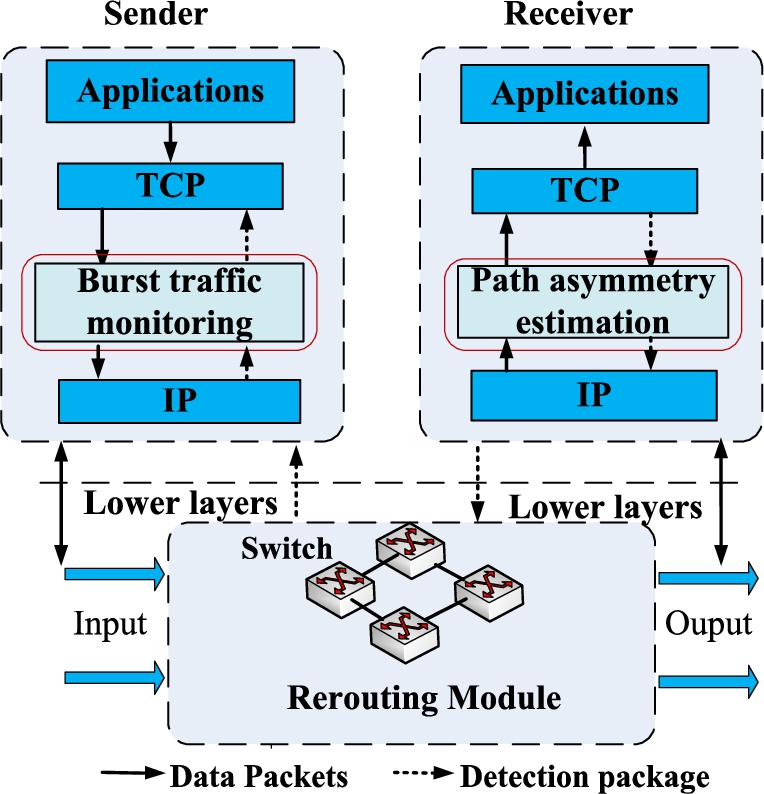
The architecture of FLB.
(2)
(3)
In this section, we needs to solve several key challenges. Firstly, FLB needs to periodically collect path delays with limited overhead to distinguish congested and non-congested paths. Secondly, We need to modify the flow table of the switch port so that it can perform path selection for the split flowlet. Finally, a flexible rerouting strategy is designed to reduce out-of-order.
End-to-end latency measurement
As congestion control in datacenters needs to react within RTTs orders of magnitude smaller than in WAN, most proposals for datacenter congestion control leverage ECN or explicit in-network feedback. We describe and compare them with latency-based feedback [18]. The comparison of End-to-End measurement algorithm is shown in Table 2.
The comparison of end-to-end measurement algorithm
The comparison of end-to-end measurement algorithm
To make correct forwarding decisions, the load balancing schemes should gather the congestion states from multiple paths. In our design, FLB mainly uses detection packets to measures the latency from the source host to the destination one. According to the detection result, the data packet transmission path is selected. The detection packet is initialized by the six-tuple method to realize the measurement of all paths. The arrival sequence of the detection packet reflects the congestion of the link. When the detection packet is received, the transmission of the data packet is triggered, and follow the reverse path transmission of this probe packet.
As shown in Algorithm 1, end-to-end latency measurement consists of three steps. Firstly, the source host requests the destination host to transmit data. The source host actively initiates a connection request, establishes a connection with the destination host through a three-way handshake, and carries a probe packet in the SYN packet to send a request signal. After the destination host receives the SYN packet and obtains the request detection packet identifier, it calls the relevant module to generate the detection packet. The source IP, destination IP, source port number, and destination port number of these detection packets are encapsulated with the information of the corresponding data flow to ensure that the detection is the reachable path of this data flow. At the same time, set the TTL value of the probe packet, and assign different values to the TTL field of different probe packets. The destination host completes the encapsulation of the detection packet and sends it to the source host at a fixed rate.
Secondly, the probe packet is sent from the destination host and sent to the source host through different switches. When the detection packet arrives at the switch, the routing information is obtained according to the destination IP address, and the corresponding program is called to obtain the six-tuple data, which is calculated by the packet forwarding module, and the corresponding forwarding port is found from the routing information table. Because the six-tuple information of the detection packet is different, the calculated result is different, and the detection packet is sent out along different ports to realize the detection of multiple paths [8,15,24].
Thirdly, after the detection packet arrives at the source host, the sender completes the sending of the data packet according to the arrived detection packet. After the end node receives the data packet from the network, the receiving module will first determine the type of the packet. If it is a probe packet, obtain the flow information corresponding to the packet header, trigger the sending of the data packet in this data flow, and set the TTL of the probe packet. The field is assigned to the data packet, and after the processing is completed, the data packet is pressed into the output queue, waiting to be sent. If it is a data packet, the data information is passed to the upper application to confirm the data packet.

Pseudo code of end-to-end measurement
In addition, in order to reduce the load of the link and alleviate congestion. When a probe packet is discarded during the forwarding process due to congestion, it does not reach the source host, and the data packet will not be transmitted along this path.
The modified flow table structure is shown in Fig. 5. The original port number field in table entry 1 is replaced by the offset field (offset value range: 0–63). When a packet needs to be sent, firstly perform a hash operation on its quintuple, find the corresponding entry in the modified flow table according to the operation result, and then perform corresponding processing according to the value of the valid bit field in the entry:

Modified flowlet table.
(1) When the valid bit value is 1, set the age bit to 0. At the same time, read the offset field, add the value of the offset field to the value of the source port field of the packet TCP header, and then reassign it to the TCP source port field. Then record the offset value in front six bits of the TOS field of on IP header, and finally send the packet.
(2) When the valid bit value is 0, set the valid bit to 1 and the age bit to 0, at the same time, hash the offset value to 64 and update it, and then compare the updated offset value with the source port field of the packet TCP header. The values are added and reassigned to the TCP source port field of the packet, and the new offset value is recorded in front six bits of the TOS field on IP header, and finally send the packet.
Of course, in addition to the processing when sending packet, the modified flowlet table will periodically check and update the value of each table entry field based on the time size of the flowlet split interval.
The load balancing algorithm at switch is shown in Algorithm 2–3. In order to deal with the forwarding of burst traffic and prevent congestion caused by the transmission of excessive load on a single link, we adopt a mechanism to periodically monitor the sent traffic. Given a flow monitoring period △t and a threshold

Flexible rerouting algorithm

Path_selecting procedure
The rerouting logic of FLB is illustrated in Algorithm 3, which is triggered for the cases of burst traffic greater than the threshold, the current path is congested or kicked out. FLB tries to select an available non-congested path to transmission. In this way, traffic monitoring and active cutover make up for the lack of flowlet splitting mechanism to monitor and process burst traffic. Before burst traffic is sent, flowlet splitting will be performed first, so that the data-intensive burst traffic that should be transmitted on a single path in the network becomes more fragmented traffic segments. This reduces the load pressure on a single link and reduces the probability of congestion.
As a typical flow-based multi-path algorithm, ECMP randomly hashes the flow to one of the equivalent paths [16]. LetFlow uses fllowlet as the switching granularity to randomly send flowlets to available paths. Thus, the time complexity of ECMP and Letflow is O(1). Since FLB needs to probe all n paths to adjust the flowlet split, its time complexity is O(n). Fortunately, in the typical leaf-spine topology, the number of leaf-to-leaf paths n is the number of leaf switches, which is not very large.
In this section, we conduct numerous NS2 simulation tests to evaluate the performance of FLB. Firstly, we redo the microbenchmark in Section 3.2 to observe whether FLB performs as expected. Then, we evaluate the performance of FLB in the asymmetric scenario. After that, we construct a large-scale simulated scenario and install several typical and realistic datacenter workloads to make a comprehensive evaluation. We conduct NS2 simulations to evaluate the performance of FLB in the large-scale scenarios.
We compare FLB with the state-of-the-art load balancing schemes, such as ECMP [16], DRILL [10], LetFlow [25] and Presto [12]. The primary goal of load balancing is to evenly distribute traffic to various parallel paths, improve network link utilization, and avoid network congestion caused by high load traffic. Therefore, we mainly compare and discuss the average flow completion time and tailed flow completion time as performance metric for each scheme.
Basic performance
The leaf-spine topology shown in Fig. 2 is used in the basic performance experiment. The topology in the experiment consists of 8 leaf switches and 4 spine switches. The link bandwidth is set to 10 Gbps, each leaf switch is connected to 2 hosts. The delay of the good path is set to 100μs, and the delay of the bad path is set to 300 μs. We generate 2 TCP flows with size of 50 MB. Within 50 ms, at sender generates 4 flows and sends them to receiver at line rate, and the size of each flow is 1 MB. These bursts last about 8 ms. Figure 6 shows the comparison of the performance metrics of buffer occupancy, packet loss rate, and flow completion time between LetFlow and FLB.
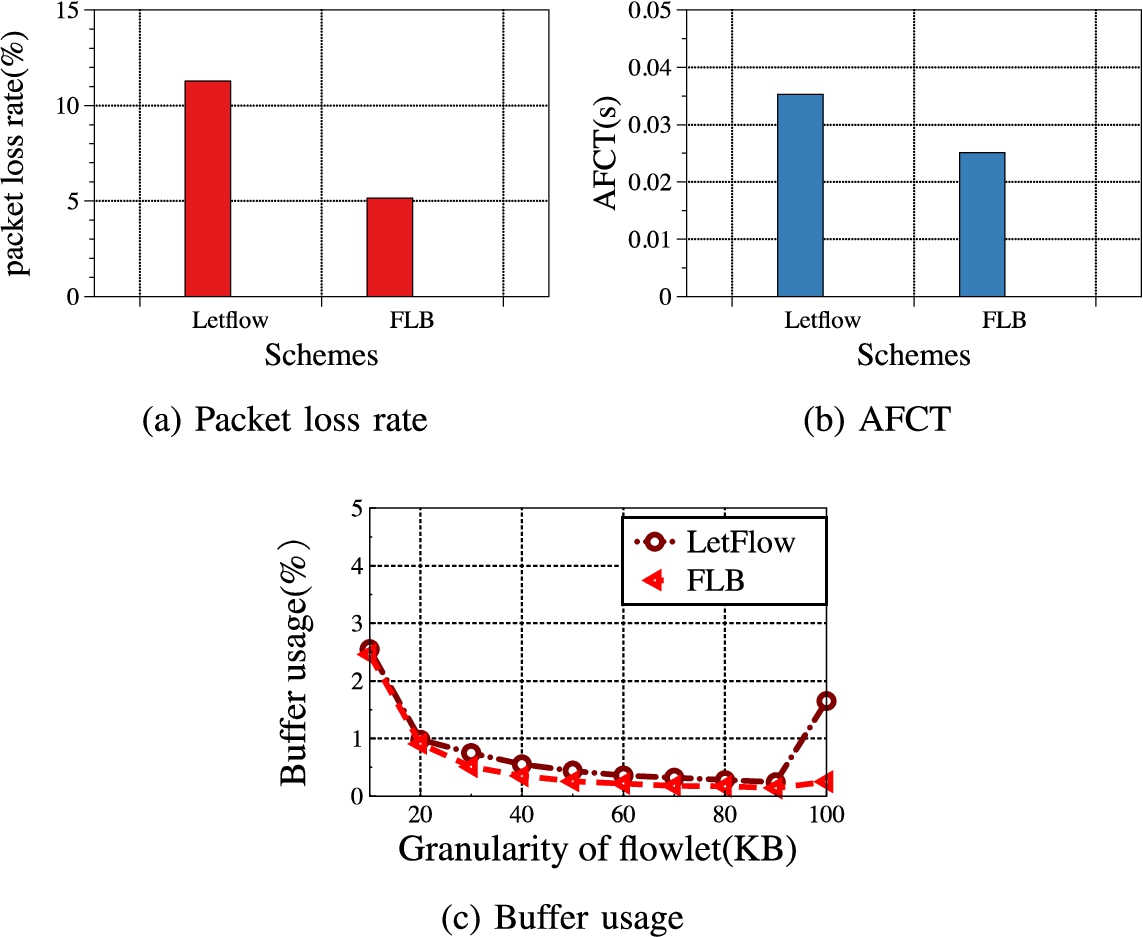
Basic performance.
Comparing the performance metrics, it can be found that due to the asymmetry of the network topology, more burst traffic is generated in the experiment, the link load is high, and the network transmission pressure is large, so the packet loss rate of the LetFlow method is high, resulting in many retransmissions of school packets. Average flow completion time is large. In FLB, due to the active cutting and timely load sharing mechanism, link resources can be more fully utilized, which greatly reduces the occurrence of link congestion and reduces packet loss caused by burst traffic.
In Fig. 6(c), compared with the LetFlow method, the FLB greatly reduces the buffer occupancy rate, and the ability of the FLB to equalize and divide the burst traffic is stronger than that of the LetFlow method. As the granularity of flowlet becomes finer and finer, the equalization effect of the LetFlow method is released, and the size of the buffer occupancy rate is also significantly reduced, but it is still significantly higher than that of the improved method.
We use the leaf-spine topology to test large scale experiment. The topology in the experiment consists of 128 hosts, 16 leaf switches and 8 spine switches. The leaf switches and spine switches pass through a link with a bandwidth of 10 Gbps connection, each leaf switch is connected to 8 hosts through a 10 Gbps link. The delay of the good path is set to 100 μs, and the delay of the bad path is set to 300 μs. We use two widely-used realistic workloads observed from deployed datacenters: web-search [4] and data-mining [11]. As shown in Fig. 7 and Fig. 8, both distributions are heavy-tailed. Particularly, the data-mining workload is more skewed with 95% of all data bytes belonging to about 3.6% of flows that are larger than 35 MB, which makes it more challenging for load balancing [9]. We adopt the flow generator in [25], which generates flows between random senders and receivers under different leaf switches according to Poisson processes with varying traffic loads. We use flow completion time (FCT) as the primary performance metric. Besides the overall average FCT, we also break down the FCT for small flows (<100 KB) and large flows (>10 MB) in some cases to better understand the results. The results are the average of 5 runs.
The proposed FLB has lower overall average FCT than others state-of-the-art multi-path transmission scheme, FLB greatly reduces the mean FCT up to ∼15–59%. This is achieved timely reaction to congestion avoiding its harmful spreading. For heavy congestion, the FLB further detour non-congestion flows to other available light-load paths, providing better load balance. As shown in Fig. 7, we find a degradation in FCT for mice flows, which confirms that the proposed FLB benefits for mice flows (<100 KB), while it has little impact on the elephant flow (>1 MB). Figure 8(a) shows poor performance promotion for data-mining workload than enterprise workload as shown in Fig. 7(a). This is because data-mining workload is more “heavily congested” than the enterprise workload. In addition, data-mining workload has more elephant flows than enterprise workload. So, there are more path collisions happen and the FLB scheme can achieve better performance promotion for data-mining workload from the load balancing perspective.
Figure 7(b) and Fig. 8(b) show the AFCT of short flows with varying workload. Under the web search workload, FLB reduces AFCT by 12–59%. Under the data mining workload, FLB reduces AFCT by 24–66%. We observe that, compared with the other load balancing schemes, ECMP performs poorly. The reason is that, when ECMP randomly selects paths, most flows are hashed onto congested paths, resulting in large AFCT for short flows.
Figure 7(c) and Fig. 8(c) show the 99th percentile FCT of short flows under different traffic loads. Compared with the other four scheme, FLB significantly reduces the tail FCT of around 8%-52% and 20%-56% under web search and data mining workload, respectively.
Figure 7(d) and Fig. 8(d) show the AFCT of long flows under different traffic loads. FLB reduces the FCT of long flows by mitigating the packet reordering and reducing queueing delay.
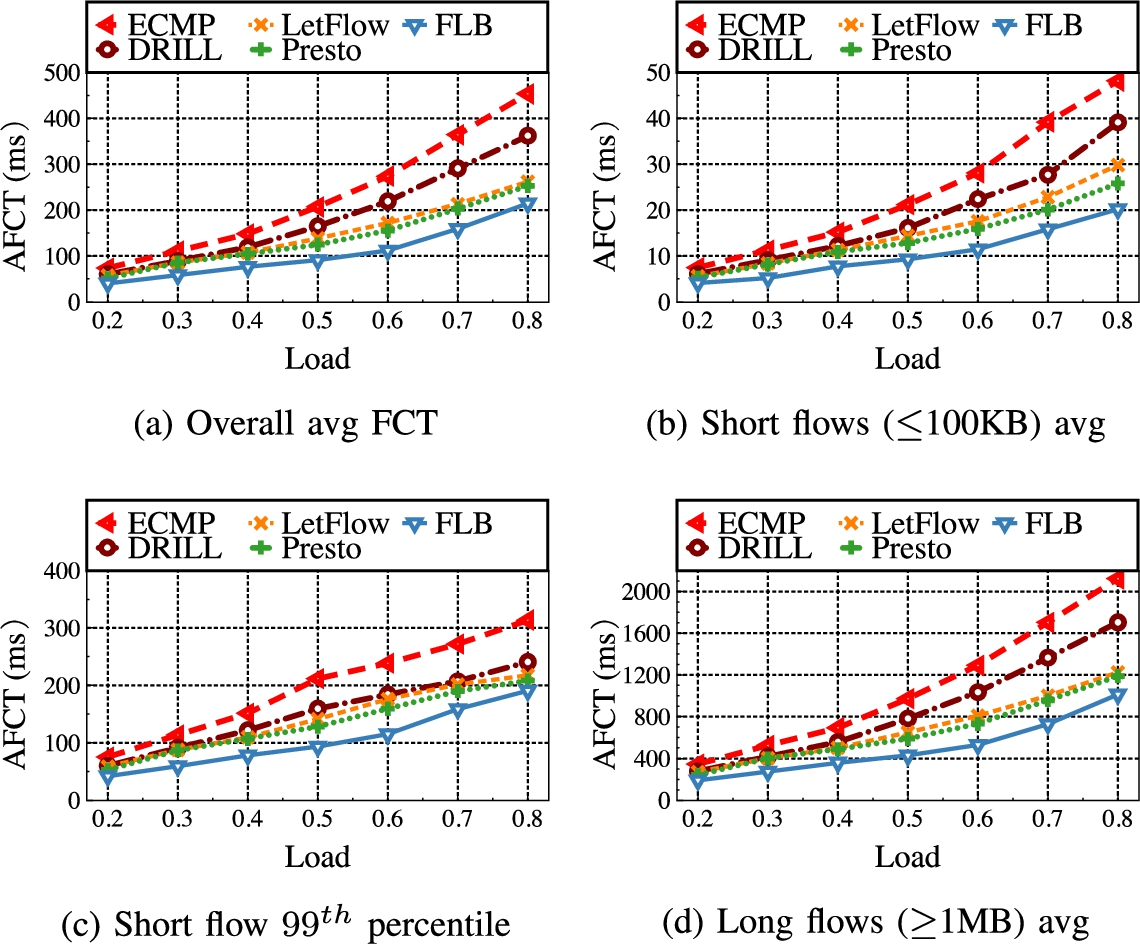
FCT statistics for web search workload.
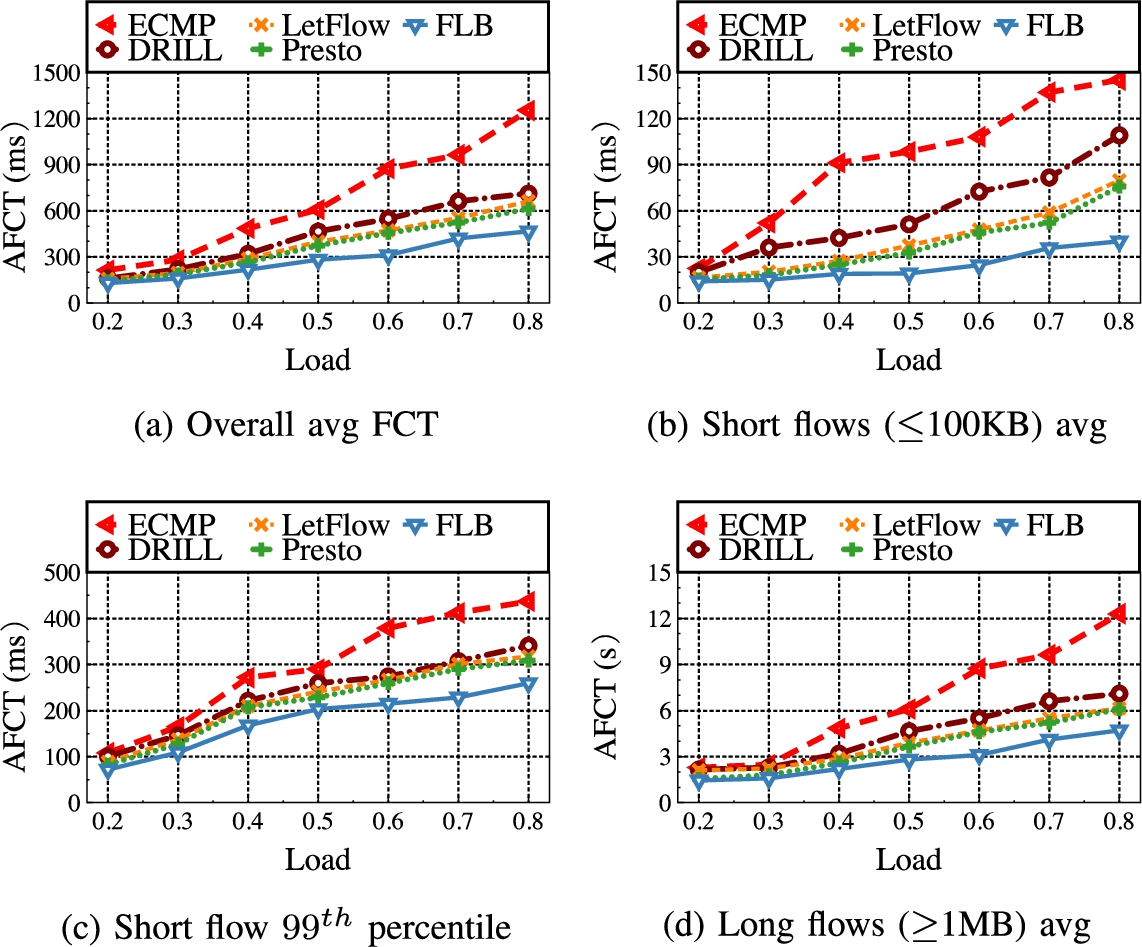
FCT statistics for data mining workload.
We proposed a fine-grained cross-layer load balancing scheme FLB, which uses an active monitoring mechanism to cutover traffic, and flexibly transfers the splitting traffic to non-congested path, effectively reducing the negative impact of burst flow on network performance. Moreover, FLB make full use of the powerful computing power and storage resources of the end host, while making no modifications on the existing TCP/IP protocols.
Footnotes
Acknowledgement
This work is supported by Hunan Provincial Social Science Fund (21YBA224), Hengyang Science and Technology Innovation Project, China (202250045133).
Conflict of interest
The authors have no conflict of interest to report.