English is a common global communication medium for exchanging diverse cultural elements between countries/people. The role of language is significant in developing political and economic aspects between nations. Such developments rely on voluptuous data from the past to the present happenings, reasoning, and conversations. Considering the significance of the English language in international cultural exchange and developments, this article introduces a Harmonious Data Analytical Scheme (DAS)-processed by Deep Learning (DL) paradigm. This scheme analyzes the available and accumulated data for cultural improvements and exchanges between diverse countries. The DL process identifies the matching aspects between the country’s culture and the accumulated data. Identifying such a point is repeatedly verified for the developments from the beginning to the current level of cultural improvements. The process discards the obsolete cultural data that are less considerable for exchanges and developments in the past. This process refines precise data to be utilized in further cultural exchanges reducing the data handling time and complexity. Finally, the proposed scheme is reliable in identifying the cultural development-based data through the common English language aspects. The DAS-DL method attains Identification rate by 0.98s, refining rate by 0.79% and data accumulation rate by 95.2% compared to existing methods.
English is widely used in many countries to communicate without any barriers. The English language plays a vital role in sharing cultures and ideas [1]. The English language is mostly used as a communicative language that develops a bond among people. English is also used in the cultural exchange process [2]. Language is a must in every cultural exchange process, which helps people to communicate with each other. The English language also creates an effective environment for people by eliminating wanted issues in the communication process [3, 4]. Communication builds a sense of community among the people who exchange cultural details. The English language is a unique way which shares cultural information among people [5]. The language and culture exchange (LCE) approach is commonly used in educational systems. LCE approach provides foreign cultural meaning to the students that exchange the cultural aspects among the students. The LCE approach also provides beneficial services in the cultural exchange process.
Big data analysis is widely used in various fields to analyze information from a huge amount of data. Big data is used in cultural development processes. Big data first diverse the data presented in the database, then produces optimal data for further processes [6]. Big data technology is commonly used for English language-based cultural development systems. English language-based cultural techniques are used for the development process, which minimizes the complexity of the exchange process [7, 8]. Big data increases the volume and velocity of data available in the cultural development process. The big data technique uses blockchain technology to detect values [9]. The blockchain technique identifies the necessary cultural aspects shared via the English language. The big data technique reduces cultural development systems’ time and energy consumption ratio [10]. Big data-based technique understands the exact meaning and content of data used to perform tasks in development processes [11]. A big data-based strategy is also used for cultural development systems. The designed strategy explains the characteristics and activities of culture via the English language. The big data technique minimizes the error range in understanding the cultural features among people.
Data analysis methods are used for the international cultural exchange process. An evaluation and meta-analysis method is mostly used to evaluate intercultural communication services [12]. The meta-analysis method examines the important characteristics that are presented in communication. The examined value produces relevant cultural exchange evaluation and analysis data [13]. The meta-analysis method measures the exact communication competence relevant to cultures and predicts the quantitative data shared among the users [16]. The meta-analysis method increases the effectiveness and performance range of cultural exchange systems. The refinement measures are also used to analyze the quality of international cultural exchange [14]. Various refinement approaches are used to improve the cultural exchange range. Developing independent ideas and teaching methods are provided to encourage cultural exchange capabilities among people. Teaching methods provide the users with the exact meaning and values of cultures, which minimizes the misunderstanding ratio of the people [10, 15, 16]. However, the existing process requires the frequent learning process and templates to improve the data analysis efficiency. In addition, the inputs are depending on the present, past happenings and conversations which consumes high computation difficulties. The DL approach can process the large volume of the data which helps to train the information according to different cultural backgrounds, cultural expression related languages, images, visual bias and cultural norms. The DL techniques explores the diverse data collections that minimize the bias and maximizes the generalization. In addition, the training models uses the learning algorithms that used to detect the bias mitigations which helps to manage the cultural sensitivity. The contributions of this article are listed below:
Designing a novel harmonized big data analytical scheme for identifying the cultural developments between nations/people.
Employing the DL paradigm for identifying and classifying obsolete and development-based data for any accumulation period.
Performing a data-induced validation with an appropriate discussion that correlates the proposed mathematical expressions and conceptual analysis.
Performing a comparative analysis discussion using different methods and metrics to verify the proposed scheme’s consistency.
Then the rest of the paper is organized as follows: Section 2 discusses the various research opinions on cultural language analysis. Section 3 elaborates the dataset description and Section 4 describes the working process of Data Analytical Scheme (DAS)-processed by Deep Learning (DL) Paradigm. The data accumulation process is described in Section 5 and conclusion is defined in Section 6.
Related works
Zang et al. [17] designed a field programmable gate array (FPGA) based on Cross-Cultural Communication For Travelling Learning (CCC-TL). The main aim of the technique is to create a traveling cultural awareness among the users. The designed technique helps the user to recognize the cultural aspects based on preferences. The actual meaning of cultural details is identified from the conversation shared among the users. The designed technique provides the exact behaviors of culture to the users. However, the system requires the large dimensionality of user travelling data to maximizes the CCC-TL performance.
Mizell [18] introduced a culturally sustaining systemic functional linguistics (CS-SFL) for culturally sustaining pedagogies (CSP). The introduced CS-SFL architecture creates a figure that brings the users a proper cultural view. CSP requires proper cultural functions to perform tasks in an application. SFL is used here that produce optimal services to the users to learn cultural aspects that minimize the complexity of language learning systems. Although, the linguistic functionalities are difficult to understand during the diversity cultural functions.
Bennett et al. [19] proposed a bilingual cross-cultural language for human-robot interaction (HRI) in-game environments. The proposed method is commonly used among different language speakers to understand the actual meaning of the content. The proposed bilingual method identifies the negative speech content shared among the individuals. The proposed method improves the performance range of interaction between humans and robots. The system difficult to maintain the reliability and flexibility.
Nielsen et al. [20] developed a Cross-Cultural Analysis (CCA) using evidence-based persuasion. The linguistic characteristics and functionalities are analyzed based on preference and priorities. The developed technique is commonly used among English and Spanish language speakers. The actual goal is to analyze the actual lingual pitch of the speakers. The developed analysis technique enhances the feasibility and efficiency level of the systems but requires the learning process to improve the system efficiency.
Valledor et al. [21] proposed a new investigation method for global textbooks. The proposed method evaluates the exact language accents presented in the textbooks. The main aim is to provide optimal English language services to learners. The proposed method calculates the students’ cultural aspects, pronunciation, vocabulary, and cultural exchange. The proposed method minimizes the latency in the analysis and recognition processes; even though it requires the training patterns to maximize the learning efficiency.
Canals et al. [22] introduced task-based language learning (TBLL) for oral interaction exchange. The online interaction services provide episodes and sessions for the learner to understand the meaning of the content. TBLL examines the learner’s interaction skills based on vocabulary and fluency. TBLL reduces the latency in understanding new topics for the learners. Experimental results show that the introduced model improves the efficiency range of online oral interaction services when it uses the diversity of tasks.
Lu et al. [23] designed a phenomenology approach for language socialization in internship trips. The designed approach is widely used to provide good commands to travelers and workers. It is commonly used as a second language acquisition that provides relevant services to the users. The proposed approach maximizes the English proficiency range during traveling. The designed approach increases the experience of travelers.
Koyama et al. [24] introduced a new Cross-National Analysis Cultural Representation (CAN-CR) method that examines the cultural representation in textbook. The introduced analysis method classifies the cultural details and elements based on representations. Features such as communication skills, intercultural skills, and multicultural aspects are analyzed from the textbooks. Compared with other methods, the introduced method balances the cultural representation and provides optimal cultural knowledge to the learners.
Yu et al. [25] proposed a new evaluation method for the English language system. The main aim of the method is to evaluate the communication value of the students. The communication values are evaluated based on the student’s academics, skills, and knowledge. The proposed uses an independent indicator to identify the key communication values of the students. The proposed method maximizes the accuracy in evaluation which improves the communication level of the systems.
Tseng et al. [26] discussed Online English learning resources in terms of hedonic and utilitarian perspectives. The intention of this study is to analyze the impact of the online learning using the Structural Equation Modelling (SEM). During the analysis 157 users information is examined with the help of the hypothesis testing in which system identifies the many several benefits while learning English in online.
Based on the survey, there are several issues with existing methods in attaining high identification rate, refining rate and data accumulation rate. Selecting precise data for distributed cultural exchange relies on nature, country, and people for validating multiple aspects. The considerations from distinguishable features are required for improving the analytical accuracy with controlled complexity. The methods above rely on single-feature methods for improving the validations across multiple accumulated data instances. Therefore, the classification, detection, and validation rely on augmented data preventing multiple flaws across sufficient time intervals. Considering these constructive and differential features, this article introduces an analytical scheme for obsolete data detection and sequence variation.
Dataset description
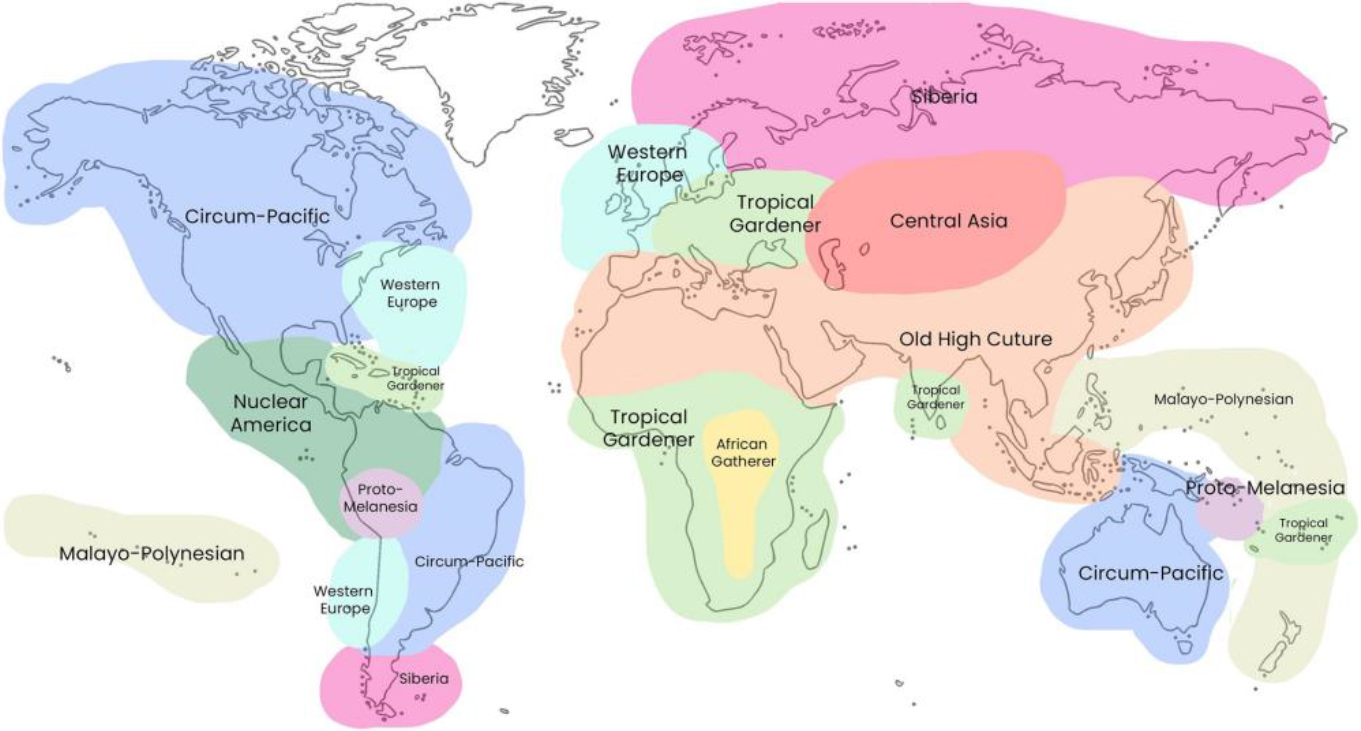
The reference data (https://zenodo.org/record/4898385) is utilized in this article for English-based cultural exchange validation. The source concerns the parametric conversation among different societies with 224 cultures. The information considers different speakers’ opinions and the development between two (communicating) societies from a cultural perspective. In the process, 1400 inputs from the “Data” record are utilized for validation. From the given reference, the societal considerations from different countries are highlighted. The same colored countries represent the recent cultural exchange features [27].
Consideration of countries.
The above combination is presented based on Global Jubebox, interest, and people’s opinions, from 2008 to 2020. The raw data is utilized for validating 47 societies and 51 parametric conversations. This reference is used throughout the article, and the correlation using appropriate equations is presented (Fig. 1).
Data analytical scheme (das)-processed by deep learning (DL) paradigm
This harmonious data analytical scheme aims to maximize data accumulation to exchange diverse cultural elements between countries/people. The voluptuous data observed from the past to the present results in obsolete cultural data of reducing data accumulation and time of cultural exchange is given in Eq. (1). In a cultural exchange, one person from one culture shares their knowledge, customs, and experiences with another person from a different culture.
Contrarily,
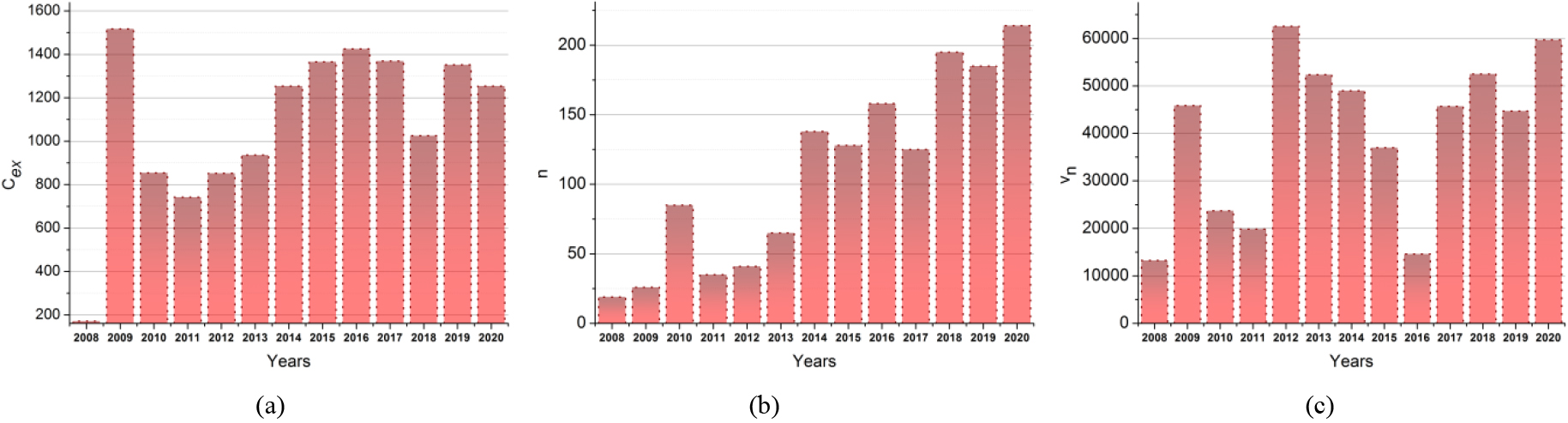
As per the Eqs (1) and (2), the variable means the probability of data accumulation and cultural exchange based on different peoples/nations connecting through the common English language EL and the cultural language CL. If the variable used to represent the number of peoples (or) countries for time and represent the number of cultural data exchanges between the country’s culture and the accumulated data. The maximum probability of cultural exchange satisfies high data accumulation for the English language-based cultural exchange and developments analyzed by DAS and processed by DL. Contrarily, and is not idle due to EL as is the balancing condition. Therefore is not assured at different time interval solution in cultural exchange drops, development drops, data handling time, and complexity. These problems are referred to as obsolete cultural data that are less considerable for exchanges and developments in the past. The assisting big data and DL are jointly used in the proposed data analytical scheme to maximize development occurrence. Where the variable and denotes the data accumulation of cultural exchange from the beginning to the present. In big data-assisted cultural language analysis, the different peoples/nations are satisfied by culture exchange from the beginning to the present. The in the (2008 to 2020) from the data source is illustrated in Fig. 2.
(a) in . (b) in and (c) in .
The above representation for , and from 2008 to 2020 from the considered data source is given. Based on the the between (different countries/societies) is computed. In particular, the countability acquires distinguishable EL and parlametrics (Fig. 2). The available and accumulated data processing is performed for cultural improvements and exchanges between diverse countries by the DL paradigm. The DL detects the matching aspects between the country’s culture and accumulated data to monitor the contrary occurrence of obsolete cultural data, as in Eqs (1) and (2). The probability of cultural exchange is based on a large volume of data successfully without obsolete cultural data. The probability of data accumulations from the beginning to the present period is given as
In Eq. (3), the variables and used to illustrate the developing political and economic aspects based on modifications in cultural language development at different periods , and the actual voluptuous data relies on cultural exchange and developments. For simplicity, the obsolete cultural data identifying the condition of is represented as ObD. The first condition for maximizing the probability of data accumulation is based on the contrary part in this proposed scheme; this accumulated data is the varying factor for cultural developments and periods. Hence, the proposed DAS-DL scheme analyzes the cultural improvements and exchanges between diverse countries relying on the available and accumulated data is processed using the condition . The data utilization of Ce in different is identified through the DL, and big data helps to perform a decision for both cultural improvements and exchange with the . Identifying the matching aspects is repeatedly verified for the developments from the beginning to the current level of cultural improvements is computed using Eq. (4)
In the above Eq. (4), the cultural exchange of the available and accumulated data based on the peoples/nation is identified in different . If the above condition exceeds, then an obsolete cultural data occurrence is identified, for instance. A failure in cultural development maximizes ObD and defaces the analysis of cultural exchange. The big data holds the available and accumulated data of CL as post the cultural exchange or is processed in different for precise cultural improvements to be achieved. The output for the cultural exchange of the present-day is analyzed using current data accumulation and is made by big data and DL. Hence, the available cultural data is updated with the DL paradigm. The cultural changes are accounted for in the recommendation for identifying and classifying the occurrence of development and obsolete cultural data through DL. In this scheme, the further cultural exchange process is predictive using accumulated data classification by Recurrent Deep Learning (RcDL), and it depends on cultural improvements and exchanges for and Ce for the contrary occurrence identifying the condition as per Eq. (1). The DL classifies and for the cultural improvements and exchange time interval as in Eq. (1). This sequential cultural data analysis refers to the normalized and overloaded data accumulations for the cultural development analysis. Therefore, the normalized data accumulation and overloaded data accumulation is identified as
And,
Where,
Based on the above Eqs (5)–(8), and is computed for identifying the current cultural improvement and exchange based on the availability and accumulated data with ObD to identify the precise cultural development. Therefore, the beginning cultural data relies on and CL whereas the present cultural data relies on Ce and . In this case, and Ce satisfies either 1 or 0 for achieving cultural development successfully. Table 1 presents the and probabilities across EL and CL for two years span.
and Probabilities
Years
EL
CL
2008
0.325
0.85
0.097
0.966
2010
0.244
0.89
0.112
0.951
2012
0.425
0.71
0.210
0.789
2014
0.369
0.82
0.189
0.856
2016
0.514
0.69
0.321
0.698
2018
0.632
0.67
0.411
0.590
2020
0.751
0.61
0.390
0.645
In Table 1, the and and CL are presented from the raw data in the data source. The data accumulation varies for EL and CL based on ; the native English speakers and other language origin people decide the accumulation rate. This includes data availability and missing instances in terms of using green and red color mark; the cases of CL and EL are different. Some cultural exchanges rely on acts, expressions, and stage performances, due to which EL is less available. On the contrary condition, , then unnecessary data does not occur. This normalized data accumulation relies on and in which the data allocation for all languages independently in . The obsolete cultural data of is appropriate for the linear output of is computed for the data handling time-based function of and . The cultural development and exchange prediction-based decision-making process classifies the accumulated data from the past to the present for identifying and thwarting obsolete cultural data in as this is the role of languages in given , where . In this first analysis, and is used to compute the precise data utilization through RcDL based on Ce. This cultural improvement and exchange are modeled using the factor that is computed as
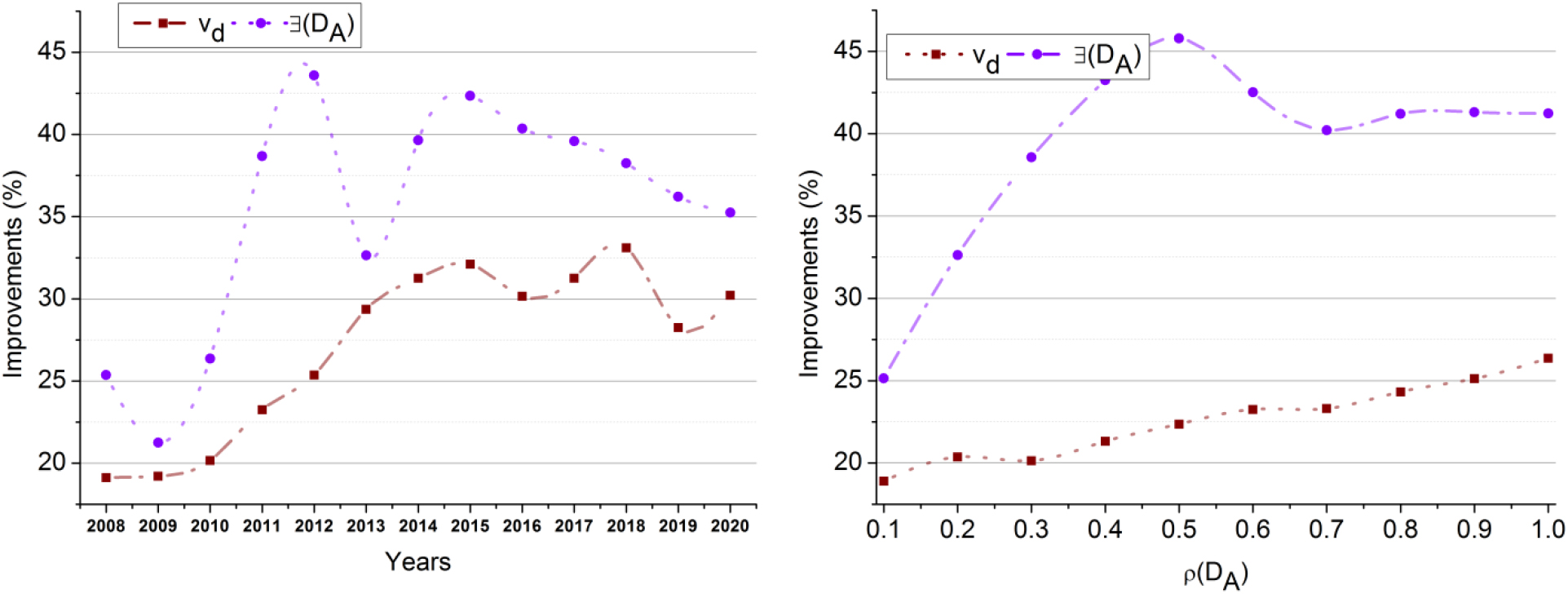
From Eqs (10) and (10), the first combination of cultural exchange provides a solution of 1 as the process refines precise data for further cultural exchanges. Therefore, the necessary development data is used as a reference for future cultural exchange with (or) is processed until is addressed for achieving cultural improvement. Instead, the sequential data allocation is performed for storing the observed voluptuous data between nations, where the probabilistic accumulated data classification and appropriate matching aspects between the country’s cultures are explained in detail. The improvement-focused data identification is analyzed in Fig. 3.
Improvement-focused data identification analyses.
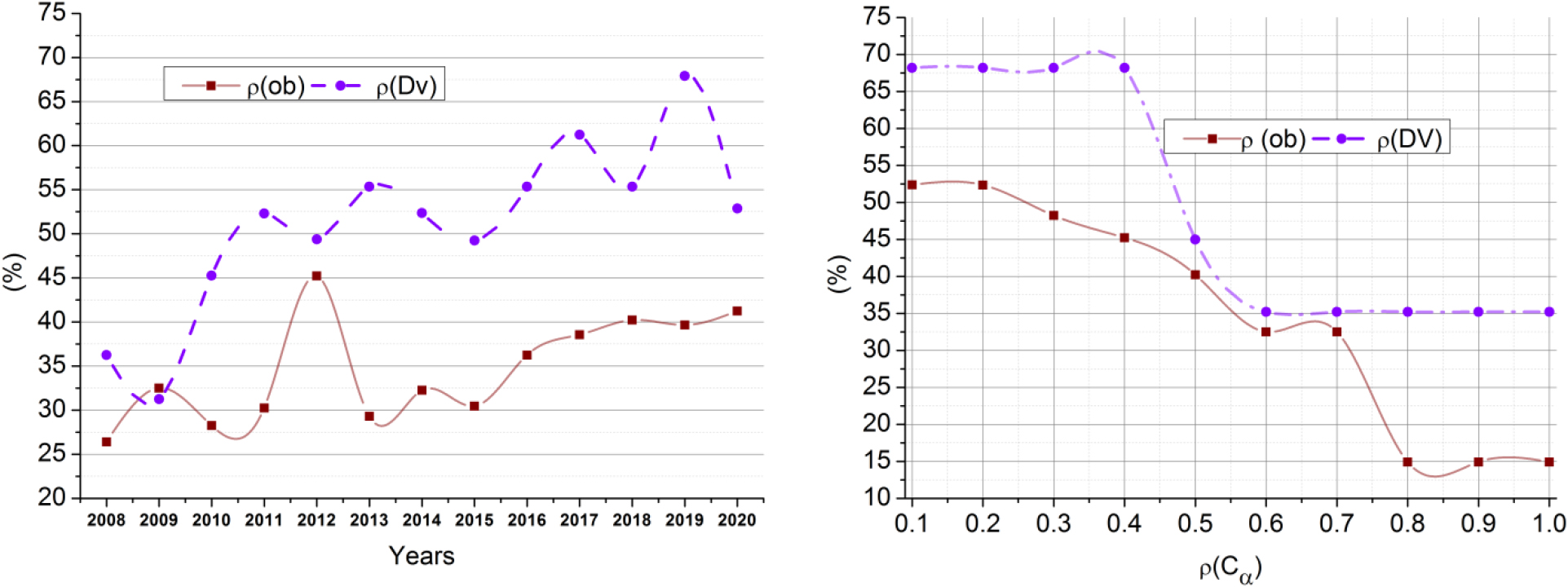
The improvement ratio for the varying years and is analyzed in Fig. 3. The improvements rely on the maximum for individual . In particular, the is leveraged using normalization to supporting . The normalization for minimization is performed such that and developments are also considered. Considering the validity of the the next data induction and accumulation are performed (Fig. 3).
Accumulated data classification
The previous probability of data accumulation and Ce influences the development and data availability in promoting international cultural exchange. In particular, the contrary part of the above Eq. (1) is observed in the data accumulation process to maximize cultural development. The probability of cultural development relies on the people/nation’s requirements is expressed
In Eq. (11), the computation of is processed for identifying obsolete cultural data from the beginning to the current level of cultural improvements. In any instance, if then cultural development drops and obsolete cultural data occurs, resulting in computation complexity. The likelihood LKH for both development and obsolete of cultures between people/countries is computed in the consecutive occurrence of cultural improvements to ensure as in Eq. (12)
From this consideration of cultural improvement and exchange in different and for the current level, the probability of likelihood is evaluated for periods. Therefore, the occurrence of either developed or obsolete cultural data identified through English-speaking people/nations in any is considerable for maximizing cultural improvements and exchange. Figure 4 presents the learning process for data classification.
Data classification process.
The proposed scheme identifies a prime condition as such that and is included. Using the the classification of the and increases for the next . If increases, then LKH between successive is from 0 to for Dv improvement. Contrarily if is pursued then is segregated; the is pursued for preventing complexity (Fig. 4). From the The linear output is achieved based on the probability of development or obsolete at any time. In the occurrence of is identified from the current level, the objective is to reduce the data handling time and complexity to stabilize the precise data utilization for further cultural exchange. As the final relies on both development and obsolete cultural data, the maximization of cultural exchange is the achievable output as obtained with the conditional satisfaction of is achieving the maximum cultural development and . The likelihood that cultural data is stored in big data by the DL process for discarding obsolete cultural data, thereby reducing past exchanges and development. The large volume of data handling processes from the to the is analyzed using the condition , the data classifications are decided by RcDL that is given as follows. For the different time intervals , the different cultural languages, and the English language that is shared between peoples/nations, is estimated to identify obsolete cultural data based on where . Therefore, let , then
In Eq. (13), the data availability and accumulated data are segregated based on development and obsolete. This means if , then the data accumulation of cultural language is improved in increasing order. The data accumulation relies on both beginning and present cultural data is analyzed as a linear function at different time intervals. The occurrence of cultural development and obsolete is grouped for identifying accurate data availability through big data and DL. On the other hand, if obsolete cultural data is identified in any instance, the process is discarded, data availability is maximized, and cultural improvement is achieved by RcDL along with periods. In Table 2, the LKH based on and varying years are tabulated.
LKH based on and Years
Years
LKH
2008
0.242
0.42
0.26
0.37
0.062
2010
0.258
0.38
0.38
0.41
0.09
2012
0.369
0.258
0.49
0.32
0.12
2014
0.485
0.21
0.42
0.58
0.25
2016
0.528
0.14
0.58
0.65
0.28
2018
0.609
0.33
0.79
0.74
0.34
2020
0.598
0.28
0.65
0.71
0.30
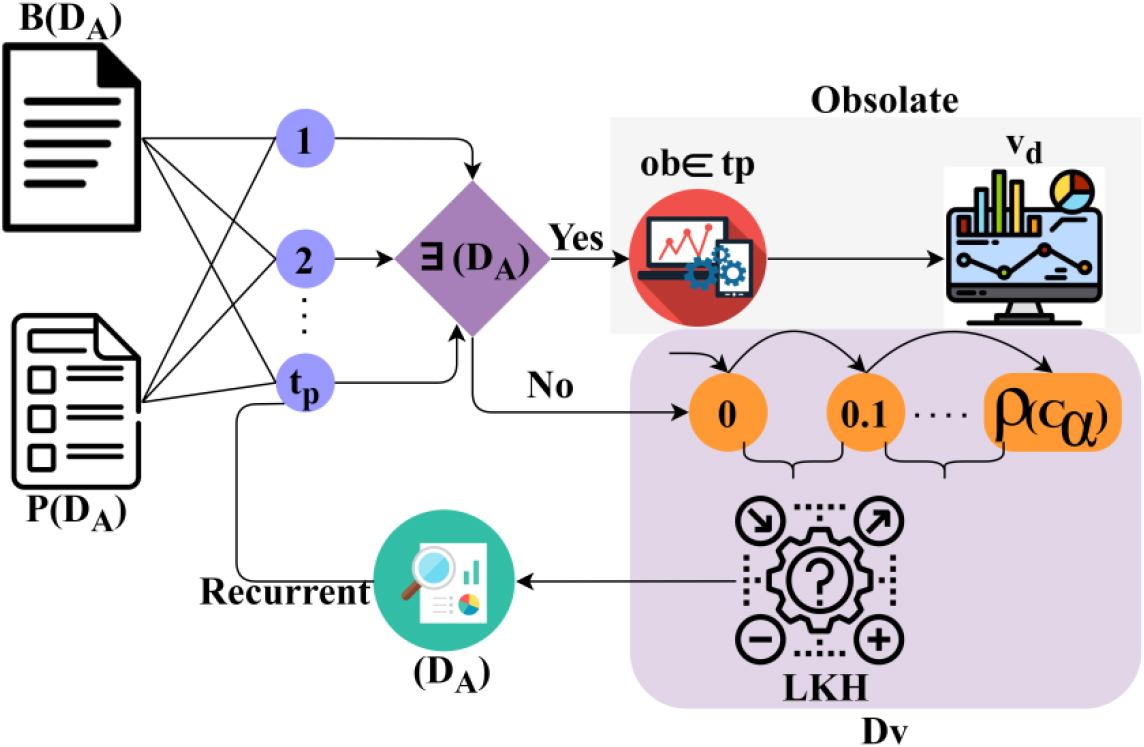
In Table 2, the and are analyzed using adjustments post the learning recurrences. Using multiple analysis of the invalid LKH and least possible are eradicated. Considering the available data and handling rate, the further complexities determine the invalid augmentation for precise increments. Such increments are pursued through classifications under conditional checks. Such classifications are void only if LKH is less than the previous probabilities. For this identified , the cultural development is achieved based on accumulated data classification for reliable identification of cultural development-based data through the common language aspects relies on the probability of and . If then the linear solution of analyzing the cultural improvements and exchanges between nations. The modified cultural exchange is ensured to be available and accumulated data through the DL paradigm in different time instances. This process helps to reduce the data handling time, and complexity is analyzed for cultural improvements and remaining. is to maximize cultural exchange. The assessment of the likelihood Relies on voluptuous data from the beginning to the present for achieving precise cultural development. The available data in all from the past to the present level is analyzed and processed for cultural improvements. Therefore, the pre-classification of accumulated data helps to identify obsolete cultural data to improve the cultural exchange of between different people/nations. The overall proposed scheme’s process is illustrated in Fig. 5.
Overall process of the proposed scheme.
The cultural language elements from the data source between and are used for classifications. In the classification process, development and obsolete data are recurrently validated. Through maximum recurrence and LKH, the classifications on and are validated. In particular, the operates on the voluptuous data accumulated between 2008 and 2020 for the varying . The optimal flexibility between the and are independently analyzed using the DL paradigm. This process is also handled using multiple condition for cumulative assessment, reducing complexity. The and classification from the beginning and present (2008 to 2020) and are analyzed in Fig. 6.
and analyses.
The ratio of and variations are independent for the years and . Considering the classifications to be viable, the is excluded if a high obsolete value is obtained. Based on the available , the LKH determines the for further exclusions. Therefore the learning between successive is scrutinized using and for which and is handled. This handling is validated using RcDL instances data (i.e.) is high (Fig. 6).
Results and discussions
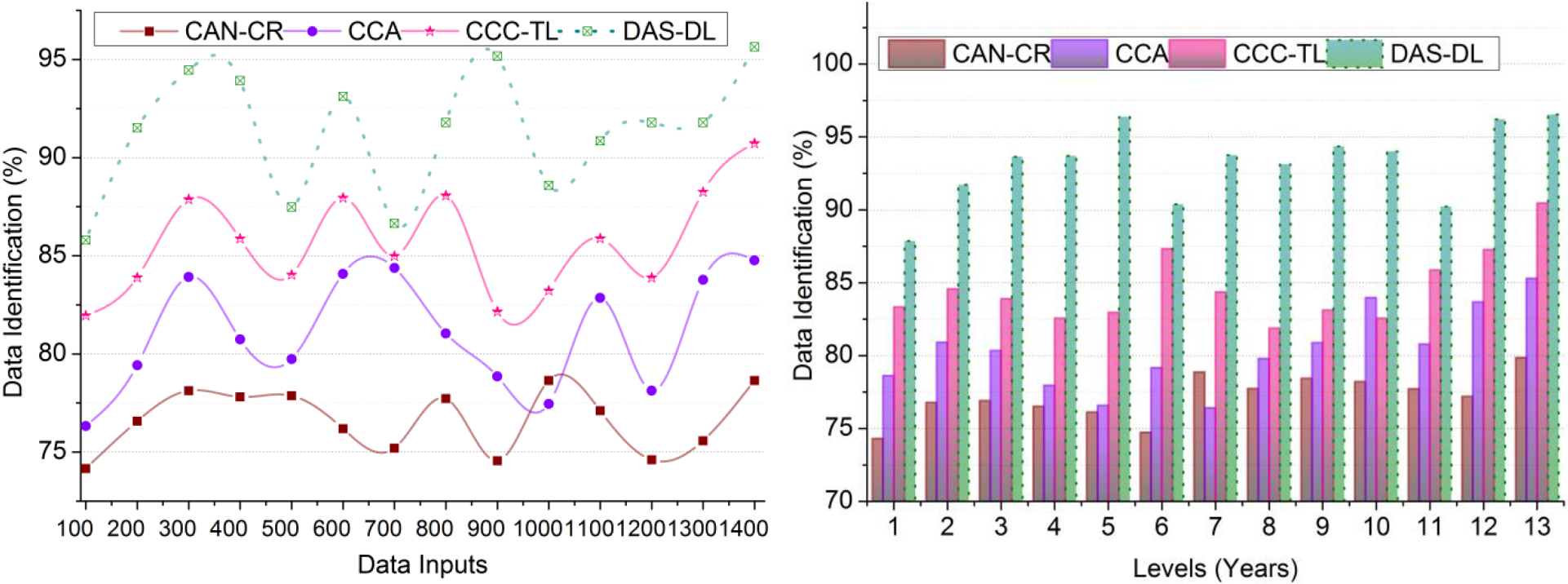
The metric-based analysis considers data identification, accumulation, obsolete data, identification time, and refining rate. The X-Axis is varied for data inputs and levels (years). The allied methods along the proposed scheme are Cross-Cultural Analysis (CCA) [20], Cross-Cultural Communication For Travelling Learning (CCC-TL) [17], Cross-National Analysis Cultural Representation (CAN-CR) [24] from the related works section.
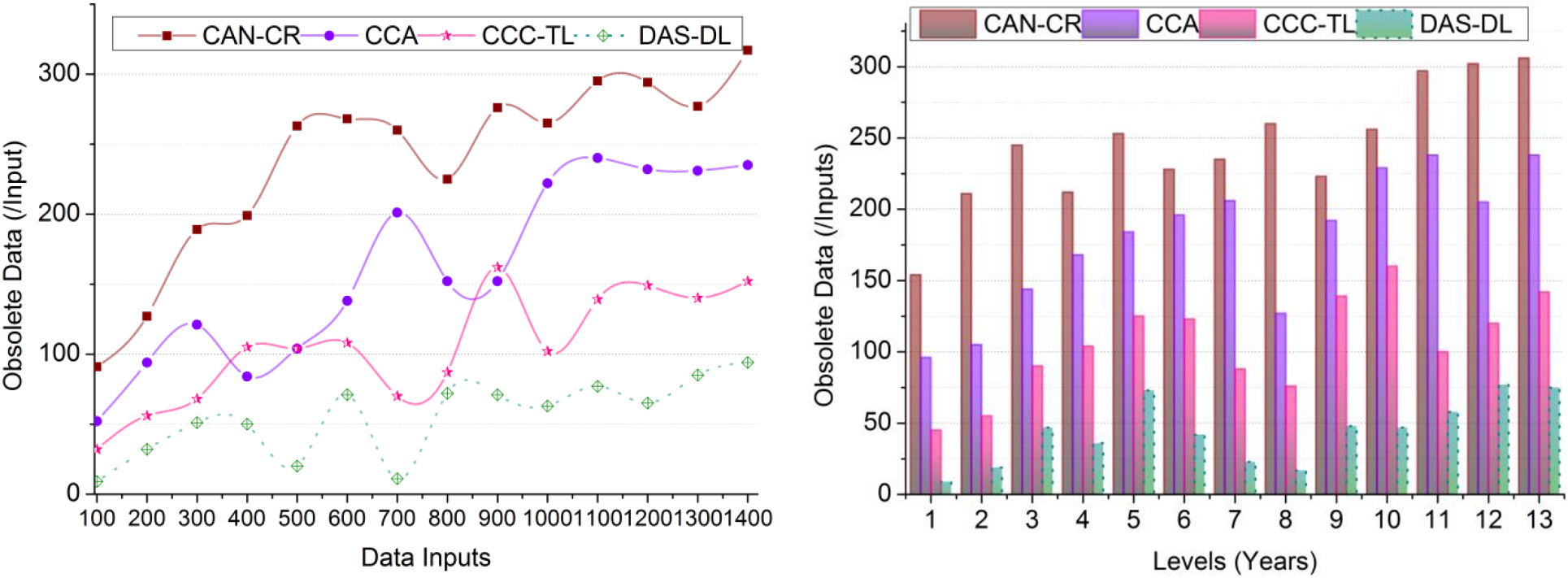
Graphical analysis of data identification.
This proposed scheme achieves high data identification based on different peoples/nations in any time intervals maximizing the data accumulation for reducing the data handling time (Refer to Fig. 7). The data handling time and complexity in a large volume of data analysis are mitigated through big data and DL for precise data utilization and identify the obsolete cultural data due to available unnecessary data for cultural improvements and exchanges between diverse countries. Using RcDL and accumulated data analysis is processed through the proposed scheme. The exchange of diverse cultural elements between countries/people is analyzed with DL to address obsolete data; this identification will increase cultural development for further cultural exchange. The voluptuous data observed from the past to the present are analyzed for identification time for improving cultural development to reduce the computational complexity in both instances. Similarly, the DL identified the matching aspects between the country’s culture and the accumulated data for increasing the cultural improvements and exchange relies on and and hence the obsolete data is reduced, and high data identification is achieved.
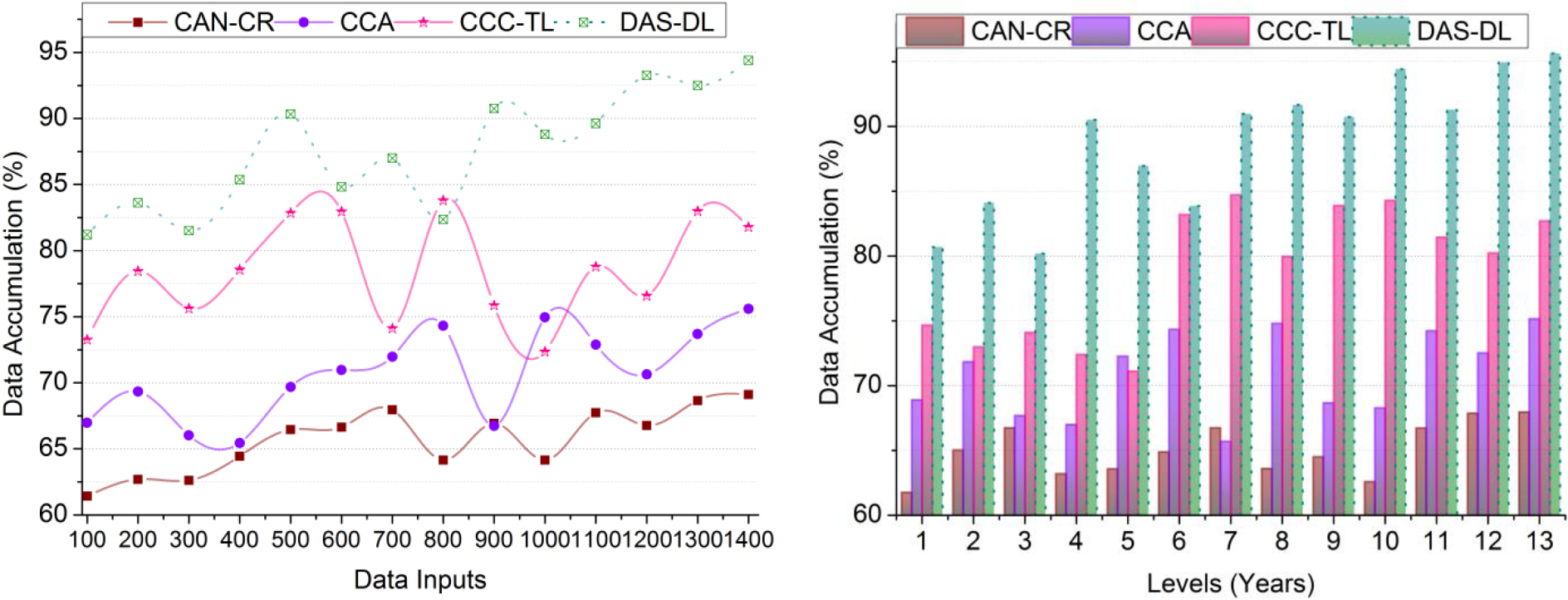
Graphical analysis of data accumulation.
The accumulated data is high in this proposed scheme, and the development from the beginning to the current level of cultural improvements is high compared to the other factors for precise cultural exchange (Refer to Fig. 8). In this process, the development occurrence is identified for improving cultural exchange at the time of present data analysis through data accumulations is to improve data refinement in further cultural exchanges. Based on the condition, cultural development is improved based on and [as in Eq. (3)], then the condition achieves obsolete-less cultural data. From the instance, is determined for successful cultural development and exchange. The obsolete data occurs due to maximum data refinement and computation complexity. This balancing of voluptuous data from the past to the present is maintained to improve cultural development and exchange and prevent computation complexity. Therefore, the different countries/people-based big data analysis is administered using a DL process. In this proposed scheme, the precise data will be used for development, so the data accumulation is high.
Graphical analysis of obsolete data.
This harmonious data analytical scheme achieves less obsolete cultural data due to fewer cultural exchanges and developments in the past, as represented in Fig. 9. The past and present data accumulation based on cultural exchange is identified for augmenting development. If the condition exceeds, then obsolete cultural data occurrence is identified from the instance. A drop in cultural development maximizes ObD and again analyzes the data for high cultural exchange. This process is prominent in cultural language analysis for classifying the development of obsolete cultural data in different time intervals and reducing the data handling time and complexity. The big data holds the available and accumulated data of CL and post the cultural exchange or is analyzed in different for successfully achieving precise cultural improvements. The available cultural data is updated with the current level of cultural improvements for cultural exchange and is accounted for identifying and classifying the occurrence of development and obsolete cultural data through the DL. Hence, the past’s less considerable cultural exchanges and developments are analyzed to identify the refining rate through RcDL. Thus, the proposed scheme verifies which unnecessary data matches the current improvement and is analyzed, reducing the obsolete data.
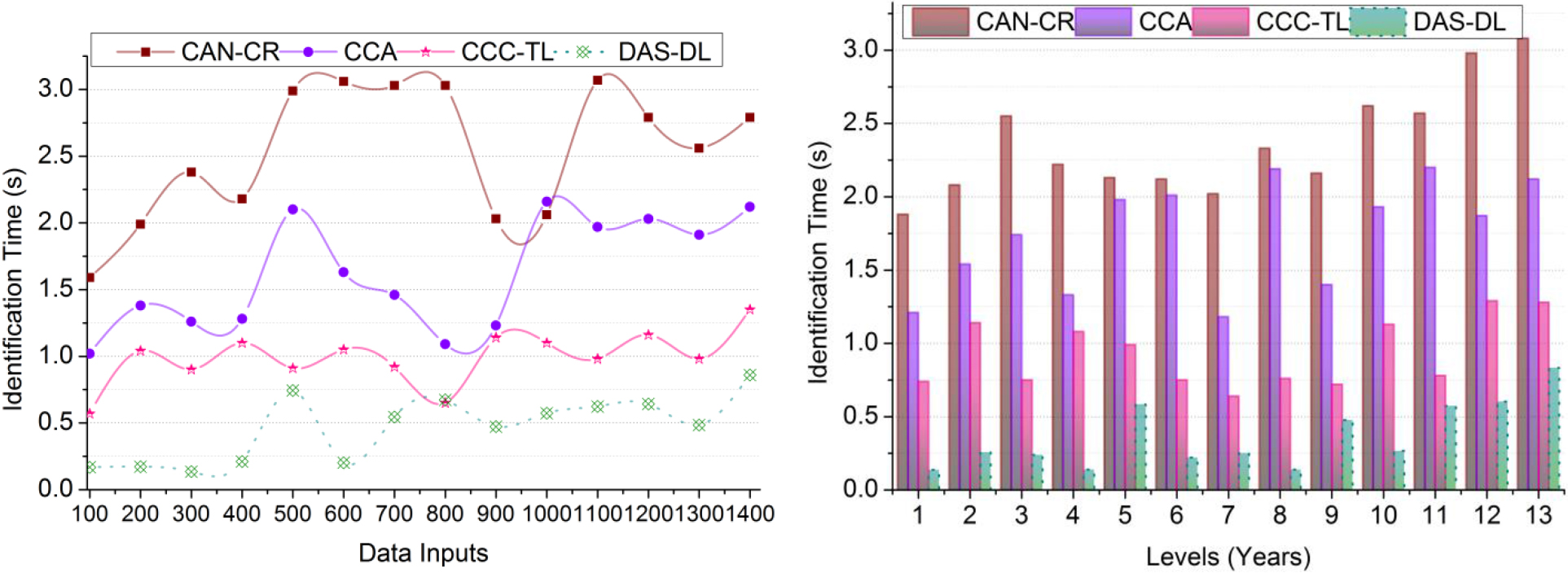
Graphical analysis of identification time.
This big data-assisted data analysis reduces identification time and obsolete cultural data occurrence in cultural development as it does not identify such a point between the country’s culture and the accumulated data. The cultural improvement is identified to overcome the data handling time and computation complexity by applying RcDL. The data refinement of is computed for both instances and is analyzed for . The DL classifies and for cultural improvement and exchange as in Eq. (2). This sequential cultural data analysis refers to the normalized and overloaded data accumulations for the cultural development analysis. Based on this output, the identification time is computed using the learning process and identifies the obsolete cultural data, preventing data handling time and complexity. Therefore, the beginning cultural data relies on and CL instead, the present cultural data relies on Ce and . In this condition, and Ce satisfies either 1 or 0 for achieving cultural development successfully. In this proposed scheme, such development is identified to achieve less identification time, as illustrated in Fig. 10.
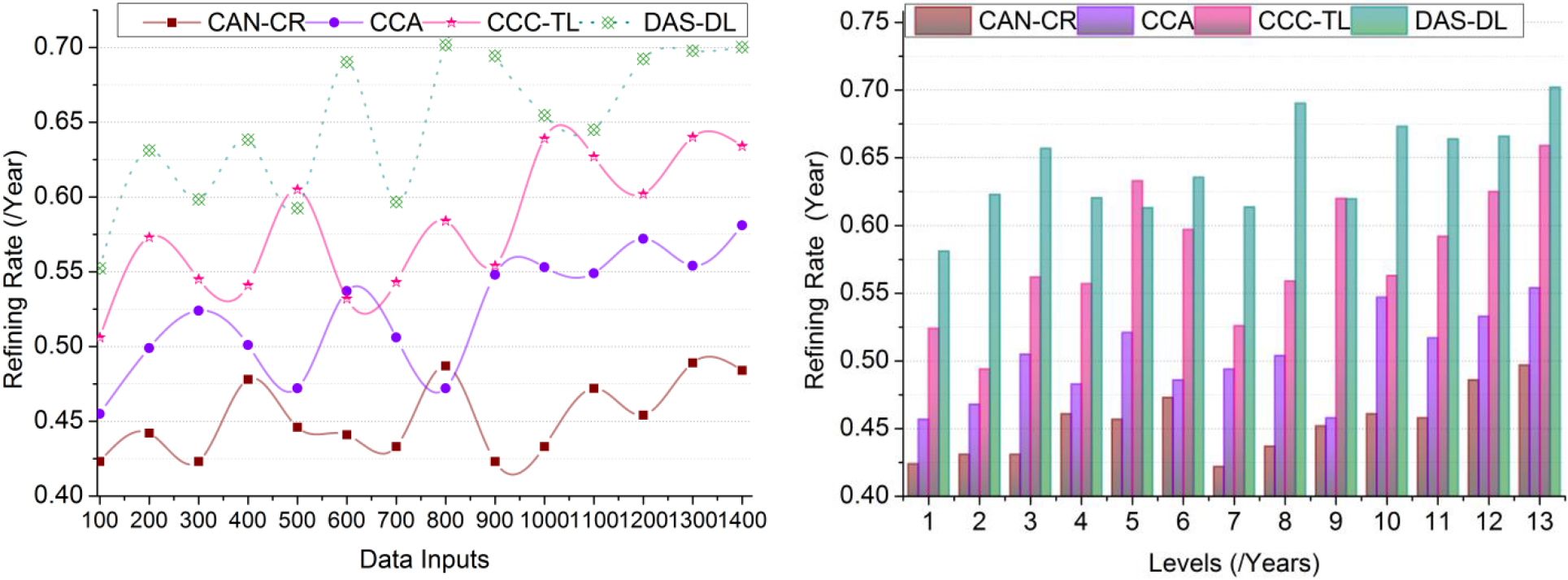
Graphical analysis of refining rate.
In this, cultural improvements and exchanges between different countries/people are repeatedly verified from the beginning to the current level achieving high data refining rate for identifying the data handling time and computational complexity by the learning process (Refer to Fig. 11). In any instance, if the condition then drops, and obsolete cultural data occurs in cultural development and is sequentially analyzed to reduce computation complexity. Big data and the DL help to identify the cultural development-based data for precise data identification for the current level of cultural improvement. The present cultural data relies on both development and obsolete cultural data, and maximizing the cultural exchange is the achievable output as required with the conditional satisfaction of . Therefore, the DL stores and processes the likelihood of discarding obsolete cultural data, reducing past exchanges and development. Hence, and is to be estimated for maximizing successful data refining rate; this reliable data identification has to satisfy two different conditions, preventing computational complexity. This article grouped cultural development and obsolete to identify accurate data availability through big data and DL to increase the refining rate.
Conclusion
This article introduced a big data analytical scheme for cultural exchange assessment between diverse peoples/countries. The assessment is performed to identify precise data that focuses on improvements other than stagnancy. This requires intense classification and detection that is performed recurrently using DL. First, the data accumulations are maximized to prevent losses in different cultural exchange sequences. This process allows development and obsolete data classifications to be validated through normalization for consenting complexity-less analytics. In this process, the data from the beginning to the present day with the maximum interaction and exchange based on the English language is exploited. This exploitation process categorizes the overloaded data and its adverse impact on cultural developments across various data inputs are analyzed. The inputs are validated using appropriate exchanges and harmonized time intervals for repeated verification. In verification stage, the development levels are observed in incrementing for examining data utilization and further accumulation. The DL process used to identify the cultural development data which helps to maximize the English learning process and cultural improvement. The complete process is validated using probabilities such as likelihood and individual improvements. Therefore, the proposed scheme optimizes the data handling rate under better identification from the voluptuous accumulations. The cultural exchanges between distinct nations/ people rely on other factors such as tourism, social infrastructure, arts, performance, etc. Thus, the proposed DAS-DL method attains Identification rate by 0.98s, refining rate by 0.79% and data accumulation rate by 95.2% compared to existing methods. Though the data source provides information on the same, the proposed scheme is less feasible for multi-level handling. Future proposals will rectify this drawback by augmenting heterogeneous classifications and featured data analysis.
References
1.
ŞahanÖSahanK. A narrative inquiry into the emotional effects of English medium instruction, language learning, and career opportunities. Linguist Educ.2023; 75: 101149.
2.
DerakhshanADewaeleJMNoughabiMA. Modeling the contribution of resilience, well-being, and L2 grit to foreign language teaching enjoyment among Iranian English language teachers. System.2022; 109: 102890.
3.
JeonM. Native-English speaking teachers’ experiences in East-Asian language programs. System.2020; 88: 102178.
4.
ParkWWuJYErduranS. The nature of STEM disciplines in the science education standards documents from the USA, Korea and Taiwan: Focusing on disciplinary aims, values and practices. Sci Educ, 2020; 29: 899-927.
5.
Mazlum,F. Is English the world’s lingua franca or the language of the enemy? Choice and age factors in foreign language policymaking in Iran. Lang Policy.2022; 21: 261-290.
6.
ReynoldsBLYuMH. Using English as an international language for fluency development in the internationalised Asian university context. Asia-Pac Educ Res.2022; 31(1): 11-21.
7.
AishFTomlinsonJ. Using the knowledge and expertise of English language specialists to enhance L1 English speaking lecturers’ lectures: A professional development project. J Engl Acad Purp.2022; 59: 101145.
8.
TauchidASalehMHartonoRMujiyantoJ. English as an international language (EIL) views in Indonesia and Japan: A survey research. Heliyon.2022; 8(10): e10785.
9.
ChamaniF. Alternative futures of English language education in Iran in the era of globalization. Linguist Educ.2023; 73: 101146.
10.
ErenÖ. Raising critical cultural awareness through telecollaboration: Insights for pre-service teacher education. Comput Assist Lang L.2023; 36(3): 288-311.
11.
LiuQGeertshuisSGraingerR. Understanding academics’ adoption of learning technologies: A systematic review. Comput Educ, 2020; 151: 103857.
12.
WaiteSEckerJRossLE. A systematic review and thematic synthesis of Canada’s LGBTQ2S+ employment, labour market and earnings literature. PloS One, 2019; 14(10): e0223372.
13.
RoslanRNishioYJawawiR. Analyzing English language teacher candidates’ assessment literacy: A case of Bruneian and Japanese universities. System.2022; 111: 102934.
14.
KobayashiY. Japanese university students’ longing for an idealized France and encounters with global English in Europe. High Educ.2022; 84(2): 451-463.
15.
TrangNHAnhKH. Culture expectations in foreign language classrooms – A case in Vietnam. Heliyon.2022; 8(8): e10033.
16.
PanQY. Traductology, linguistics, and culture: the contrastive function of omissions in English-Chinese translations of the intercultural collision in Little Red Riding Hood. Herit Sci.2021; 9(1): 159.
17.
ZangSN. Cross-cultural communication of language learning social software based on FPGA and transfer learning. Microprocessors Microsy.2021; 81: 103768.
18.
MizellJD. Culturally sustaining systemic functional linguistics: Towards an explicitly anti-racist and anti-colonial languaging and literacy pedagogy. Linguist Educ.2022; 72: 101108.
19.
BennettCCBaeYHYoonJHChaeYYoonELeeS, et al. Effects of cross-cultural language differences on social cognition during human-agent interaction in cooperative game environments. Comput Speech Lang.2023; 81: 101521.
20.
NielsenTRJorgensenK. Cross-cultural dementia screening using the Rowland Universal Dementia Assessment Scale: a systematic review and meta-analysis. Int Psychogeriatr, 2020; 32(9): 1031-1044.
21.
ValledorAOlmedoAHellínCJTayebiAOtón-TortosaSGómezJ. The eclectic approach in English language teaching applications: a qualitative synthesis of the literature. Sustainability, 2023; 15(15): 11978.
22.
CanalsL. The role of the language of interaction and translanguaging on attention to interactional feedback in virtual exchanges. System.2022; 105: 102721.
23.
LuLFWongIAZhangYA. Second language acquisition and socialization in international trips. J Hosp Tour Manag.2021; 47: 1-11.
24.
KoyamaSSaitoMCableNIkedaTTsujiTNoguchiT, et al. Examining the associations between oral health and social isolation: A cross-national comparative study between Japan and England. Soc Sci Med, 2021; 277: 113895.
25.
YuZLMaZWangHYJiaJWangL. Communication value of English-language S&T academic journals in non-native English language countries. Scientometrics, 2020; 125(2): 1389-1402.
26.
TsengFCLiuPHEChengTCETengCI. Using online English learning resources: utilitarian and hedonic perspectives. Online Inform Rev.2023; doi: 10.1108/OIR-03-2022-0157.
27.
WoodALKirbyKREmberCRSilbertSPassmoreSDaikokuH, et al. The Global Jukebox: A public database of performing arts and culture. Plos One.2022; 17(11): e0275469.