
Abstract
In order to promote the construction of enterprise informatization, the author studied the adaptive optimization method of Efficient Management Information System (EMIS). The author proposes to combine the fuzzy C-means algorithm to form a server clustering algorithm, and adds an improved Drosophila optimization algorithm to overcome the problems of slow Rate of convergence of GRNN and easy to fall into the minimum, and the cloud platform collects 23 performance indicators, the output results of the coordinated evolutionary algorithm are analyzed by the neighborhood rough set analysis of algorithms to select features to avoid the curse of dimensionality problem. The experimental results indicate that, compared with existing research results, the algorithm proposed by the author has increased its speed by 1.43, 3.22, and 3.72 times, respectively; In terms of convergence steps, they have also been reduced by 1.61, 5, and 6 times respectively, and when running the algorithm, the computer’s memory and CPU usage are controlled at around 50%, without affecting normal functionality. This proves that the task scheduling of the cloud platform is more balanced, and indirectly proves the accuracy of the algorithm’s clustering effect.
Keywords
Introduction
Nowadays, the world is developing rapidly, with new things emerging one after another, a lot of information and a large amount of data, belonging to a generation of information explosion. With the popularization of various intelligent devices, we are facing an era of intelligence, with the widespread application of Internet of Things technology [1]. The management of enterprises is an eternal theme. In today’s enterprise management, the decision-making method based on information management has become an inevitable choice for management [2]. Let data speak, everything should be based on data, and making business and management decisions is becoming a trend. In the current era of intelligence, the competition in the entire market is exceptionally fierce, and the management of enterprises is facing more and more problems. The customer base of enterprises is constantly increasing, and the demand is becoming increasingly complex. The delivery time requirements for enterprises are constantly shortening, which tests their operational and management capabilities. In the intelligent era, many small and medium-sized enterprises are facing the market environment with intensified competition [3]. In order to adapt to the market changes in the intelligent era, the management of enterprises must be innovative, and the management mode should be optimized, therefore, the management of enterprises should strengthen the optimization of information management to find a suitable path for their own development, improve the efficiency of the overall operation of the enterprise, improve the core competitiveness of the entire enterprise through information management, actively and quickly respond to customer needs, and enable advanced information management concepts to provide help for enterprises to take the lead in various increasingly complex market competition environments.
Cloud computing technology is based on the Internet and virtual resources to provide users with relevant services. Cloud computing has extremely strong computing power, which can calculate one billion times per second. It can predict weather, simulate nuclear explosions, and predict the development trend of the Prediction market [4]. People only need to use computers and other electronic devices to access the data center, and calculate according to demand, therefore, the development and application of cloud computing technology have received widespread attention from all sectors of society.
With the rapid development of information technology in China, the informationization construction of vocational colleges has made great progress. The vast majority of vocational colleges have invested and purchased a large amount of infrastructure to build campus networks, set up network centers and computing centers, and built campus networks and application systems to promote the informationization management of schools. However, in the process of information technology construction in vocational colleges, from the actual effect, the return rate of these huge investments is relatively low, and there are problems such as unscientific planning, incomplete personnel, unreasonable institutions, unsmooth implementation, and inaccurate positioning. It is difficult to keep up with the development of information technology, resulting in many vocational colleges’ low level of information management, poor connectivity, and poor application effects, It has affected the education and teaching of vocational colleges and hindered their innovative development. The emergence and widespread application of cloud computing technology in military, commercial and other fields have brought new opportunities for the innovative development of information management in vocational colleges. The use of cloud computing technology in vocational colleges can effectively complete the storage and management of teaching resources, server allocation and management, and network information platform management in vocational colleges. Cloud computing technology is high-quality, efficient, and low-cost, which can ensure the efficient operation of information management in vocational colleges. The emergence of cloud computing technology has had a profound impact on the innovation of information management in vocational colleges, and has determined a new development direction for information management in vocational colleges.
The adaptability of EMIS refers to the ability of Efficient Management Information Systems to adapt to internal and external environments (such as increasing information volume, markets, laws, government regulations, etc.) and various needs in order to improve management efficiency and enhance management functions. In the study of EMIS adaptability, although there is a large amount of research on Efficient Management Information Systems, there is not much research on their adaptability, mainly including the following aspects: (1) Analysis of the influencing factors of EMIS adaptability. (2) Research on the evaluation of EMIS adaptability. (3) Empirical research on the adaptability of EMIS. (4) The research on strategies for improving the adaptability of EMIS, that is, how to improve the adaptability of information systems, mainly aims to improve the adaptability of software systems that implement EMIS. These studies have deepened the understanding of the adaptability of EMIS, but research on the adaptability performance of EMIS is mostly qualitative and empirical, failing to elucidate the internal mechanisms that produce various external manifestations. Therefore, it is not yet sufficient to guide how to improve the adaptability of EMIS. Therefore, studying the optimization of EMIS adaptability has important theoretical significance [5].
References
Due to the close relationship between the adaptability of EMIS, which is usually achieved through software systems, the study of software system adaptability can provide reference for the study of EMIS adaptability. Although there are many studies on software system adaptability, there is a fundamental difference between EMIS and software system adaptability. Adaptability refers to the system’s ability to adapt to the environment, while the environment of a software system refers to the software’s operating carrier, development platform, etc, the environment of EMIS refers to the external markets, policies, and internal operational processes of an enterprise [6]. The quantification of adaptability requires the help of the Formal methods of EMIS - object knowledge network, so as to realize the quantitative evaluation of EMIS adaptability. By adopting formal methods for research, not only can the adaptability of EMIS be discussed in detail with the support of mathematical theory, but also for understanding the structure of information systems, the in-depth study of its operating mechanism is of great significance, and it is a necessary path for the research of information systems to shift from qualitative to quantitative and continuously deepen.
Liu, T conducted a detailed analysis and optimization of modern artificial intelligence education information systems [7]. Orooje, M. S believes that in recent years, with the continuous development of IoT technology and the continuous improvement of artificial intelligence systems, new opportunities have been provided for building a health service system. However, the current Computerized maintenance management system of hospital buildings is characterized by slow process, redundancy and non integration, resulting in waste of funds, resources and time. Meanwhile, due to the lack of data and information in the digital model of project completion, the application of engineering informatization in equipment maintenance and management is greatly restricted. Therefore, it is necessary to optimize the collection and management of data [8]. Xia, Y believe that currently, the company’s compensation management methods, especially in the economic and management fields, have also attracted widespread attention. No matter in any enterprise, the salary system is very important. With the continuous development of China’s national economy, market competition has become more intense. For enterprises, in order to adapt to market competition, it is necessary to increase the requirements for salary systems and develop appropriate salary management systems according to market requirements, in order to improve efficiency and achieve a win-win situation between enterprises and employees [9].
Because the adaptive optimization of Efficient Management Information System is a nonlinear multi-objective optimization problem, it is difficult to solve it with conventional Linear programming methods or Nonlinear programming methods such as Gradient method. However, it can be realized with implicit enumeration algorithms such as genetic algorithm. In order to avoid premature convergence of the optimization algorithm, multi population is a good solution. At the same time, the idea of co evolution is introduced into the multi population Evolutionary algorithm to effectively improve the convergence and premature convergence of the optimization algorithm. Therefore, the server clustering algorithm based on Fuzzy clustering and GRNN proposed by the author, this not only overcomes the complex problem of manually selecting smoothing coefficients inherent in neural network algorithms, but also ensures relatively high accuracy in clustering algorithms even when there are few samples. Although this solution is designed for cloud platforms, it is also applicable to cloud platforms using the same scheduling algorithm.
Research on optimization of artificial intelligence cloud computing in information management design
Algorithm related technologies
Because the author needs to use the advantages of GRNN prediction algorithm, combined with the fuzzy C-means algorithm to transform it into a clustering algorithm, then, in view of the inherent problems of GRNN algorithm that is easy to fall into the minimum and slow Rate of convergence, the author adds an improved Drosophila optimization algorithm to improve it [10].
General regression neural network algorithm (GRNN)
Generalized regression neural network is one of RBF neural network algorithms, GRNN has higher teaching ability and learning speed of nonlinear network than RBF, it is definitely more powerful, finally the algorithm is changed to the best multidimensional regression, the sample data is large When it can guarantee good prediction results, for non-stationary data, the network still performs well, and the network model shown in Fig. 1.
Structure diagram of generalized regression neural network.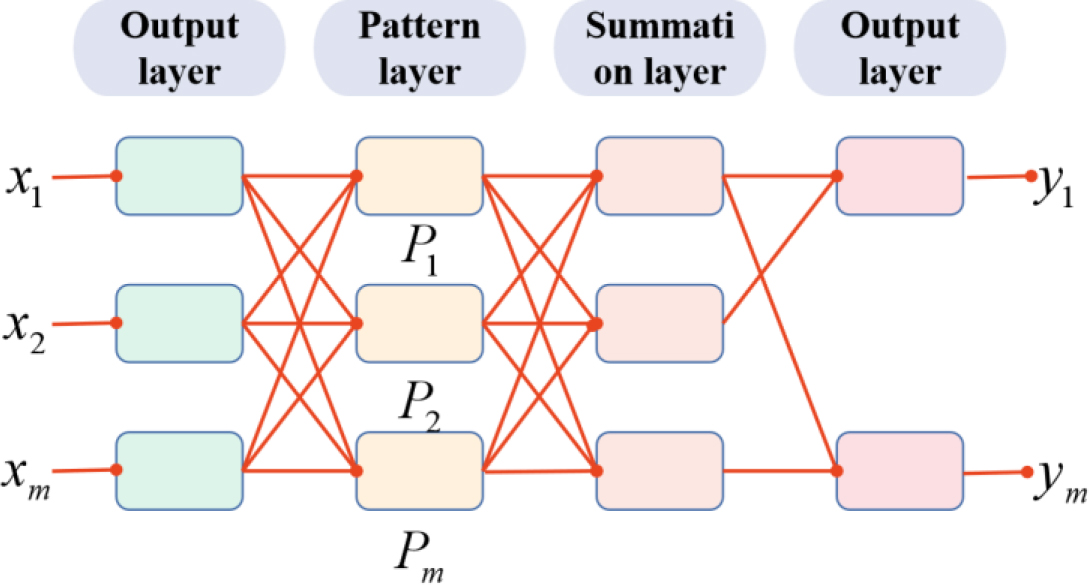
Input layer: There are several neurons in the input layer, and the total number of neurons is the number of bits learned by the training sample, the input data in the input layer is transmitted to the pattern layer through neurons; Pattern layer: The number of neurons in this layer is determined by the number of training samples
Sum layer: There are two main ways to sum, namely arithmetic sum and weighted sum. When performing arithmetic summation, the formula is:
At this point, the connection weight value is 1, and the transfer function is:
When performing weighted summation, the formula becomes:
And at this point, the transfer function is:
For an information system represented by a binary group <U, A>, where
So for the neighborhood of
Among them,
Assuming
Among them,
The lower approximation of decision is also called the positive domain of decision, and the symbol is POSB (D). For
Among them, the vertical bar of
So for decision attributes, conditional attributes with high dependency are naturally more important and have better classification performance. For decision attributes with low dependency, they are redundant attributes that can be filtered out [12].
The fruit fly species themselves have superior perceptual and sensory abilities compared to other species. The fruit fly can obtain the direction of the food source through smell, and after approaching the food, use its keen vision to discover the location of food and companion gatherings, thus flying towards that direction. The steps of the fruit fly optimization algorithm are as follows:
Randomly start the fruit fly task and divide it into two parts. Compute the random direction and distance of each fruit fly and produce an olfactory search error. Since the direction of the food position cannot be predicted, it is necessary to first calculate the distance to the origin, and then calculate the decision price according to the taste. The calculated number is the distance difference; Put the price decision into the decision function, calculate the taste of the fruit flying area, find the most delicious one, save the value, match ( Repeat the previous steps in the iterative optimization phase. If the taste is greater than the previous value, control the fruit fly community to fly in that direction if available, otherwise stop the algorithm [13].
Since the optimization model of EMIS adaptability is a multi-objective nonlinear optimization model, and the ideal values of each target are inconsistent, some indicators are as large as possible, some indicators are as small as possible, and some indicators are neither as large as possible nor as small as possible. It is difficult to use conventional nonlinear programming methods to solve the problem, and new optimization algorithms need to be studied. At present, multi-objective problems can be solved by changing the objective function, utilizing constraint processing techniques, utilizing comparison criteria and dominance relationships, etc. There are also various algorithms for solving them, such as coevolutionary adaptive genetic algorithm, evolutionary difference algorithm, etc. [14].
In order to avoid premature convergence of the optimization algorithm, multi population is a good solution to solve the problem of single population. The introduction of co evolution idea (evolutionary and collaborative processes are carried out in each iteration) into the multi population Evolutionary algorithm has achieved good results in improving the convergence and premature convergence of the algorithm, but it also affects the Rate of convergence. The author proposes a server hybrid clustering algorithm based on Fuzzy clustering and improved GRNN. Taking advantage of GRNN’s advantages in nonlinear mapping and learning speed, the classical GRNN algorithm is formed by adding coordinated Evolutionary algorithm.
Step 1: Initializes the operation parameters, with a maximum number of iterations g_ Num, population size, etc., and read the model parameters, set the initial iteration number g_ Ctr Step 2: Randomly initializes the Step 3: For subpopulations
Calculate the fitness of the current chromosome and submit the chromosome with the best fitness of the first popj to the local population to establish the initial local population; For individuals in the population, the fitness variance is calculated as oi, and the threshold for the size of individual differences is given as
Among them, Obtain the mutation probability according to the adaptive mutation probability Eq. (12) and perform the mutation operation.
Judging evolutionary algebra: Using the roulette wheel method for individual screening and replication. Sort according to the fitness values of each subpopulation in the global population, and increase Step 4: Perform domain based local adaptive evolution operations on local populations, including the following steps:
Calculate the fitness of the current chromosome and perform mutation operations on the local population based on the adaptive mutation probability Eq. (13).
Among them, NG represents the algebra where there has been no optimal solution since the last occurrence of the optimal solution to the present day; Cof is the coefficient of increase in the probability of variation [16]. Sort the individuals in the local population according to their individual fitness, and delete a certain number of individuals with lower fitness. Step 5: Collaborative operations between
For a given threshold If population Step 6: After completing the calculation of various groups in sequence, if the current number of iterations is greater than or equal to g_ Num, then the calculation ends and the chromosome with the best fitness is output. Otherwise, go to Step 3.
Based on adaptive indicators and quantitative methods, combined with the structure of the EMIS, the optimized EMIS is determined through indicators related to the system structure, such as the degree of interaction between modules, convergence coefficient, and modular layering. The specific application strategy is as follows:
Determine the maximum number of layers According to the optimized EMIS indicator value, the maximum number of layers in the information system can be obtained through Eq. (14) as follows:
Determine the improved results The MLD value calculated by Eq. (15) should be as close as possible to its corresponding optimization results, and combined with the current situation of Efficient Management Information Systems, improved results can be obtained. The quantification formula of modular layering degree can be used to obtain.
Among them,
Algorithm improvement ideas
The author uses the above four algorithms. In order to take advantage of their automaticity in Data cleansing and solve nonlinear problems, the original classical algorithm must be changed from a prediction algorithm to a clustering hybrid algorithm. There are still two problems in the initial transition from GRNN to clustering algorithm:
Although GRNN algorithm has made some improvements in Rate of convergence and has fallen into the minimum compared with BP and RBF neural networks, it is still slower than other algorithms, and when the amount of data is large, falling into the minimum will cause a great waste of time and resources; In addition, due to the large amount of data collected from the cloud platform, which has 23 dimensional characteristics, if not filtered, whether input into the coordinated Evolutionary algorithm or GRNN algorithm will cause a serious decline in Algorithmic efficiency; In response to the above two issues, in the GRNN algorithm, the author uses the improved Drosophila optimization algorithm to replace the original gradient descent method. The Drosophila population is divided into two parts to automatically find the optimal solution without manual selection, eliminating artificial interference and accelerating the Rate of convergence speed. The author added the neighborhood rough set algorithm to the algorithm scheme, which first filters all features before inputting them into subsequent steps [17]. However, features with a contribution of 0–50% are not completely removed. The program performs offline neighborhood rough set algorithm calculations based on the clustering centers adjusted each time. If a feature with a contribution of more than 50% is found, the data is added, if the original feature contribution decreases to less than 50%, replace the physical dimension data to ensure that the classification contribution of each input into GRNN algorithm is the largest, which improves the overall Algorithmic efficiency efficiency and enhances the real-time performance of the data.
The steps of the hybrid clustering algorithm proposed by the author are as follows:
Step 1: Input the dataset into the coordinated Evolutionary algorithm for preliminary Fuzzy clustering, select 2.0 as the weighting index m according to experience, and initialize the cluster center; Step 2: In order to reduce the dimensionality of the data and accelerate the speed and efficiency of the GRNN algorithm, each feature in the dataset is used as a conditional attribute, and the clustering category results are used as decision attributes; Step 3: Use the coordinated Evolutionary algorithm again to process the reduced data, adjust the value of the weighting coefficient m, set the number of clusters and stop threshold; Step 4: Calculate the membership degree of the sample and calculate the clustering center based on the membership degree; Step 5: Calculate the distance from each sample to the cluster center, and select the sample point closest to the cluster center as the training sample; Step 6: Train the GRNN model using the selected training samples, and improve it by using the improved Drosophila optimization algorithm when searching for the global optimal solution; Step 7: Initialize the fruit fly population and divide it into two parts. Search around the optimal solution and a larger range, estimate the distance from the origin, calculate the taste concentration judgment value, and pass the taste concentration judgment value Spread into the training function of the GRNN algorithm for network training; Step 8: Find out the individual with the largest flavor concentration, enter the iterative optimization stage, repeat step 7, judge whether the flavor concentration is better than the previous concentration, if so, retain its coordinates and control the drosophila population to fly to the place, avoid the gradient descent falling into the problem of local minima, and speed up the Rate of convergence; Step 9: Use the trained GRNN model to predict and classify the reduced dataset again, and obtain a new classification identifier; Step 10: Update the clustering center based on the new classification identifier, and if the results are consistent with the previous results, the entire algorithm ends; Otherwise, go to step 11; Step 11: Adjust the decision attribute values of the neighborhood rough set algorithm, recalculate the contribution of candidate features and active features offline, adjust the candidate features and active feature sets based on the set threshold, and then proceed to step 5 for further calculation [18].
Definition of cloud computing technology
Cloud computing technology refers to the technology of providing virtualized, dynamically scalable resources through the Internet, that is, through the delivery, use, and increase mode of Internet related services. Cloud is a metaphorical term that compares the internet and the internet. In the past, the abstraction of underlying infrastructure in the graph, as well as the Internet and telecommunications networks, were often represented by clouds. Narrowly defined cloud computing technology is a technology that obtains required resources in an easily scalable and on-demand manner through the network, and is the delivery and usage mode of IT infrastructure. Guangyi Cloud Computing Technology refers to the technology of obtaining required services through the network in an easily scalable and on-demand manner, which is the delivery and usage mode of services. This service technology means that computing power can be circulated as a commodity through the internet, which can be technology for other services, IT, software, and internet related technologies.
Advantages of cloud computing technology
One is the powerful virtualization capability. In cloud computing infrastructure, various computing resources are dynamically allocated and deployed to meet the needs of applications and services at different times, forming a unified resource pool connected together. Cloud computing technology does not need to worry about the specific location where applications run. In fact, users do not need to know. It only runs somewhere in the “cloud” and supports users to use various terminals to obtain application services from any location. The second is to carry out rapid services and quickly deploy business. The powerful management system of cloud computing technology can quickly access and integrate existing databases and capability components of other business on the cloud computing platform to meet business needs and quickly deploy business. Cloud computing technology platforms usually develop capability components, development environments, and development interfaces to facilitate free developers to develop new businesses through a certain business model and achieve a win-win situation with cloud computing technology service providers. SaaS services based on cloud computing technology platforms support users’ self built and customized services. Users can build and customize cloud services according to their needs through the Internet interface on the cloud computing technology platform. The third is the scale of the economy. ‘Cloud’ refers to having a considerable scale. Cloud providers utilize cloud computing technology to centrally deploy computing and storage resources, and provide services to enterprises and individuals by constructing and operating large-scale, low-cost commercial computer data centers. It not only endows users with almost unlimited and affordable computing power, but also avoids the low efficiency of users repeatedly building “chimney style” information systems.
Experimental plan design and result analysis
Experimental plan design
All the experiments conducted by the author were conducted on a cloud platform, and the training and testing data were obtained from the running cloud platform. All virtual resources were from the Centos University Management System. In the platform, there are a total of 5000 virtual resources, of which 3027 can be put into actual use. The platform’s management server collects 23 performance information from all virtual resources every half an hour, hereinafter referred to as static information, and also collects this data during task execution, hereinafter referred to as dynamic data, the data of the author’s experiment is based on these data.
Redundant feature experiment
In this experiment, 23 dimensional static information data is first input into the coordinated Evolutionary algorithm algorithm, and the number of clustering categories is set to 5 according to experience and task clustering results, so the decision attribute of neighborhood rough set algorithm is these five categories, and the feature contribution of 23 features to each category is calculated. The average value of the results of three experiments of neighborhood rough set algorithm is shown in Table 1. From the table, it can be seen that due to the same initial configuration of virtual resources, bandwidth, CPU frequency, system type, etc., their contribution to clustering is 0, and these characteristics can be completely disregarded; In addition, I/O read/write errors and the number of floating point digits are not different from each other, and the system digits have little impact on the overall performance of the machine. The difference between the CPU utilization of the system layer and the user layer can be reflected from the overall CPU utilization. The contribution to clustering is small, and can also be ignored; However, the size and utilization of memory, CPU, and disk space have a significant impact on host performance. Although their contribution to each category varies, they are all key features [19].
Contribution of various dimensional features to different classes
Contribution of various dimensional features to different classes
This experiment selects reduced 11 as feature data based on a 50% threshold to improve the operation of the GRNN algorithm, three sets of control experiments are set up to record four indicators. Firstly, in the cloud platform, the training can be completed offline, so the training time has little impact on the platform, so the running time of this experiment refers to the time from the input of a new data to the input of clustering results after the model training is completed, which is also the testing time [20]. The other two indicators of CPU and memory usage represent the resource usage of the computer when running algorithms. Running algorithms that render the local computer inoperable is unacceptable to the platform. The specific recording results are shown in Fig. 2. In order to ensure that all results are between 0 and 120, divide the convergence step result by 10 and draw it in the bar graph. In terms of running time, the improved GRNN algorithm has increased the speed of other control groups by 1.43, 3.22, and 3.72 times, respectively; In terms of convergence steps, they have also been reduced by 1.61, 5, and 6 times, respectively, among them, the neighborhood rough set algorithm uniquely added by the author ranks second in these two indicators, which is superior to existing literature algorithms, proving the necessity of the author’s improvement. In terms of resource utilization, compared to the last two control groups, the CPU utilization rate was controlled below 40% and the memory utilization rate was controlled below 60%, ensuring that the local machine can complete other tasks normally without being affected [21].
Comparison of this algorithm with previous research.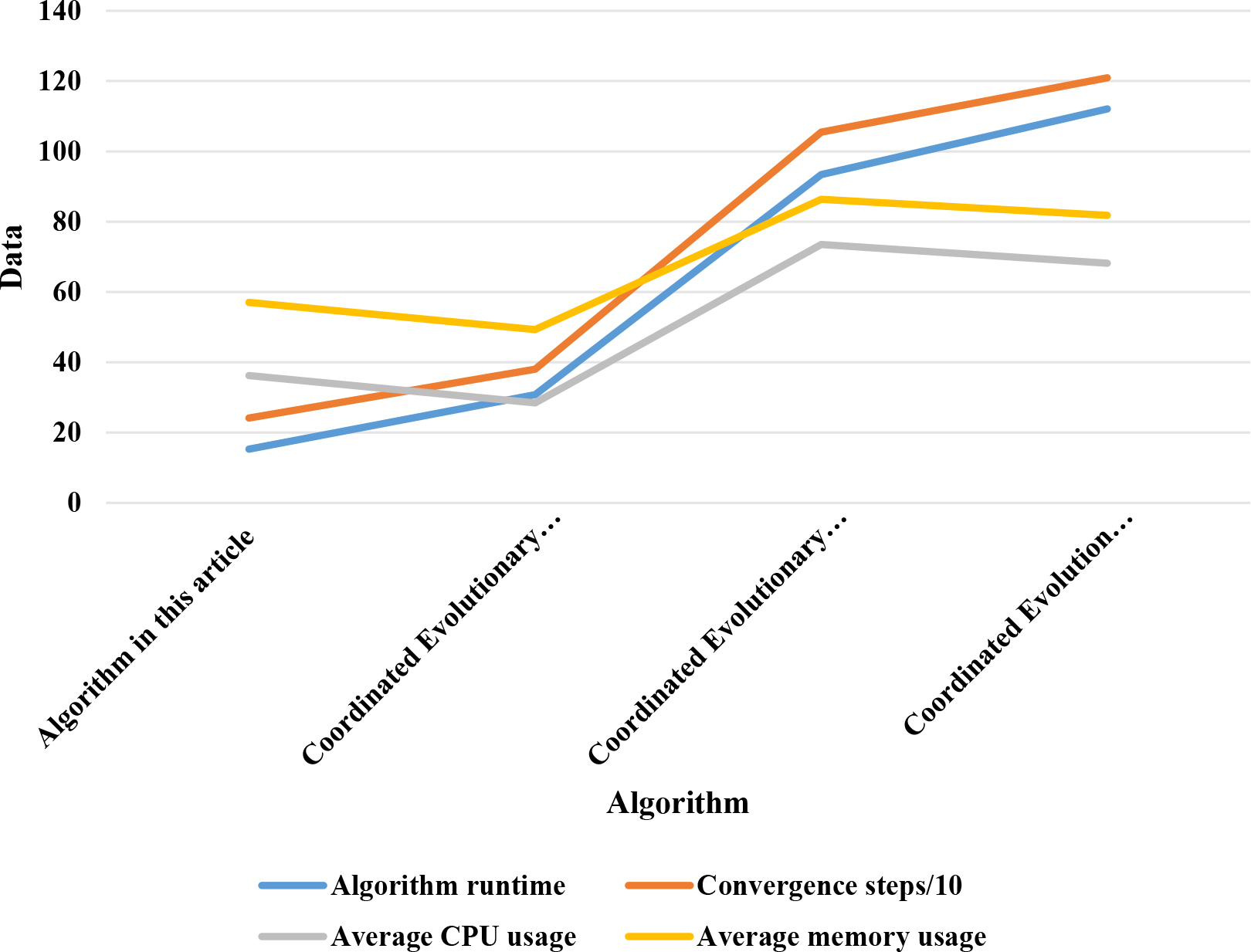
In this group of experiments, the clustering results were verified to be true and effective, and the scheduling efficiency of the cloud platform was improved. The CPU and memory usage data for each virtual resource’s dynamic information are averaged, using CPU utilization as the horizontal axis and memory usage as the vertical axis, as shown in Figs 3–6, draw scatter plots for the experimental and control groups.
Scatter diagram of dynamic information of resources using this algorithm.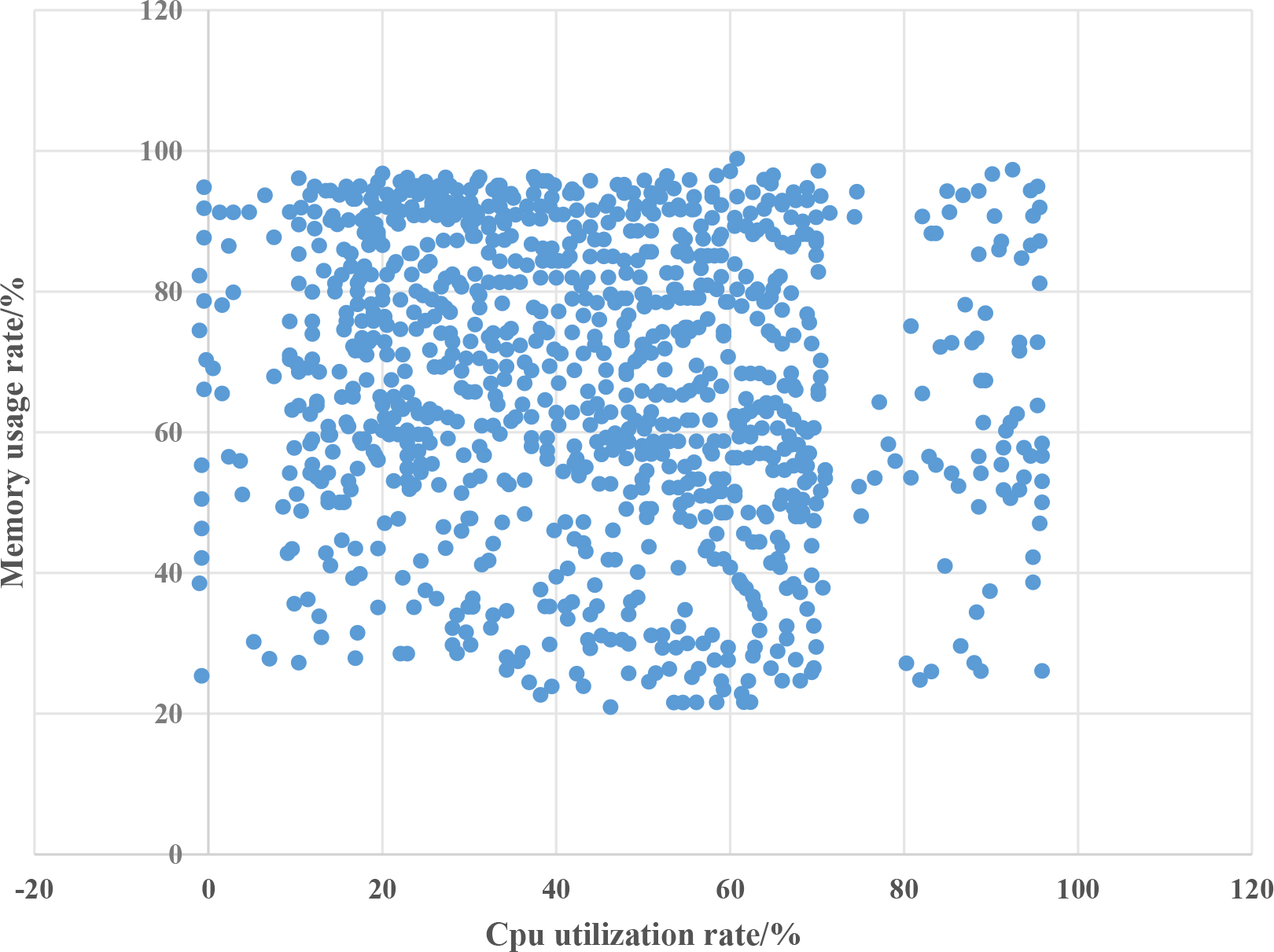
The difference in memory utilization in Figs 3–6 is not significant, and the values are relatively high. Because virtual resources in cloud platforms are all virtual machines running on physical machines, the performance is average, and the memory allocated to them is not very large. In addition, running cloud clients on them will cause a certain amount of memory usage, and then running certain tasks with large memory, so the experimental effect is not very obvious [22]. However, the CPU utilization can show the effectiveness of the algorithm proposed in this paper. In Fig. 4, the pure coordination Evolutionary algorithm+GRNN algorithm can see that the CPU utilization rate of most virtual resources is between 80–100%, which indicates that the clustering effect is very poor, resulting in continuous resources under heavy load still have tasks to be issued, resources can not provide normal services, and the platform is paralyzed; But after adding neighborhood rough sets, redundant features and data are reduced, and clustering algorithms are showing initial results. The CPU utilization rate of virtual resources is gradually evenly distributed between 20% and 100%, but there are still a large number of machines that are under high load for a long time, this is unacceptable; After removing the neighborhood rough set algorithm and adding the improved fruit fly optimization algorithm, the problem of GRNN network being prone to getting stuck in the minimum value is solved. It can be seen that there are no virtual resources that are constantly occupied by the CPU, which is a dead state, and the utilization rate is also controlled below 90%, however, at the same time, the number of machines with 0–5% occupancy rate has increased significantly, which means that more machines are scheduled to be in an executable state without tasks after clustering [23]. In clustering algorithms, the corresponding bad points have increased and the accuracy has decreased, which is a waste of resources for cloud platforms; It can be seen that the CPU utilization of the vast majority of resources is controlled between 10% and 60%, allowing resources to not only complete tasks but also provide other services to the outside world. Although some resources still have utilization rates of 80% to 100%, in the elastic deployment of cloud platforms, these resources will return to normal after a period of time.
The sales processing process of a certain enterprise is shown in Fig. 7. With the increase of enterprise scale and business volume, existing sales processing systems cannot adapt to the current changes.
The range of each indicator obtained through the survey questionnaire is shown in Table 2. Based on Table 2 and sample data, the constraint conditions obtained through Minitab are
Range and ideal values of each indicator
Scatter diagram of dynamic information of coordinated Evolutionary algorithm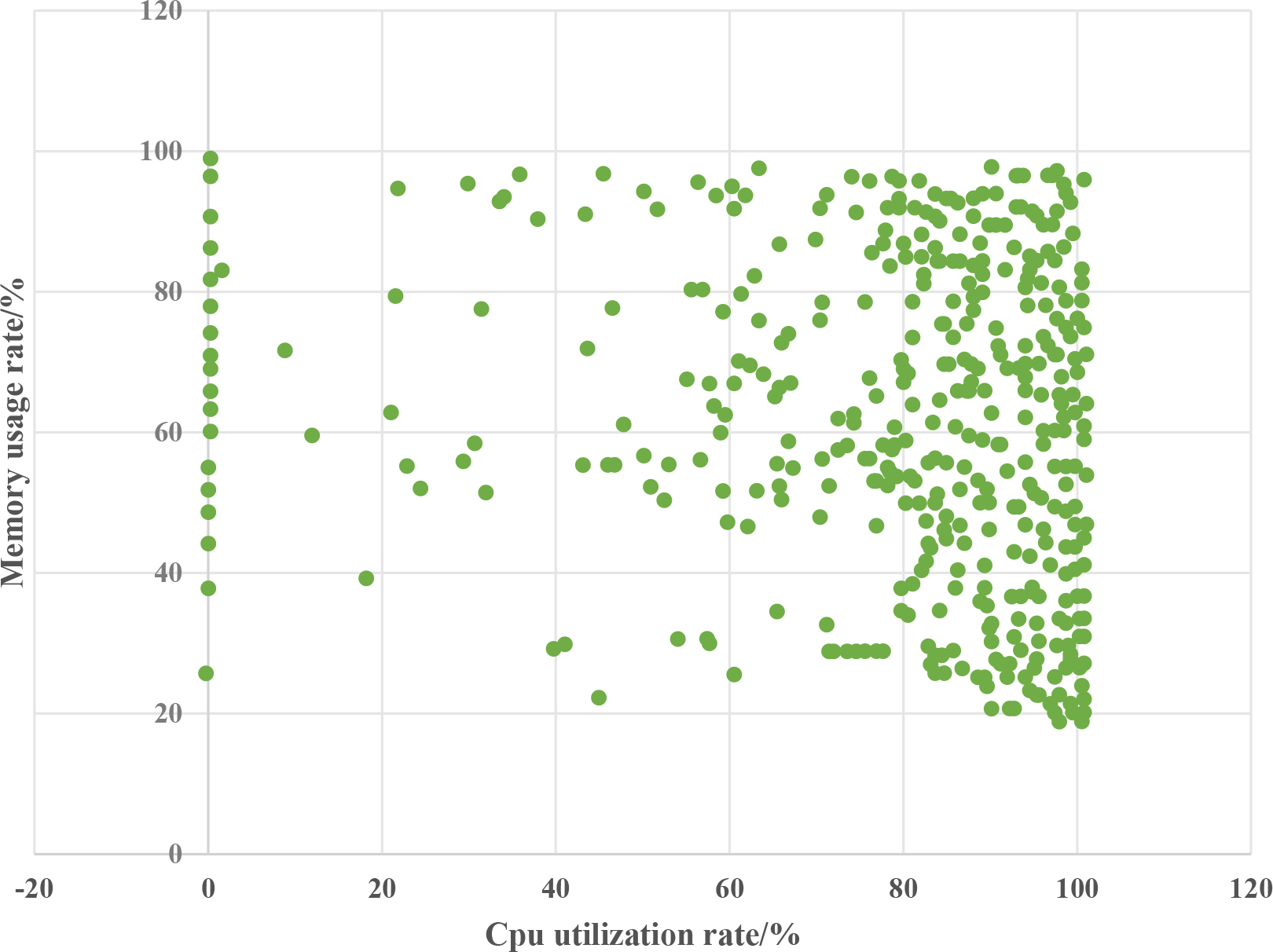
Combining the quantification method of indicators, based on the adaptive optimization model and the obtained model data, algorithm 1 is applied to solve the model, and the optimization results of each indicator are shown in Table 3. According to the optimized indicator values in Table 3, it can be seen that improving the original sales processing process with a cost of approximately 280000 yuan over a period of 5 months can achieve 99% satisfaction.
Original and improved process indicator values
Dynamic information scatter diagram of coordinated Evolutionary algorithm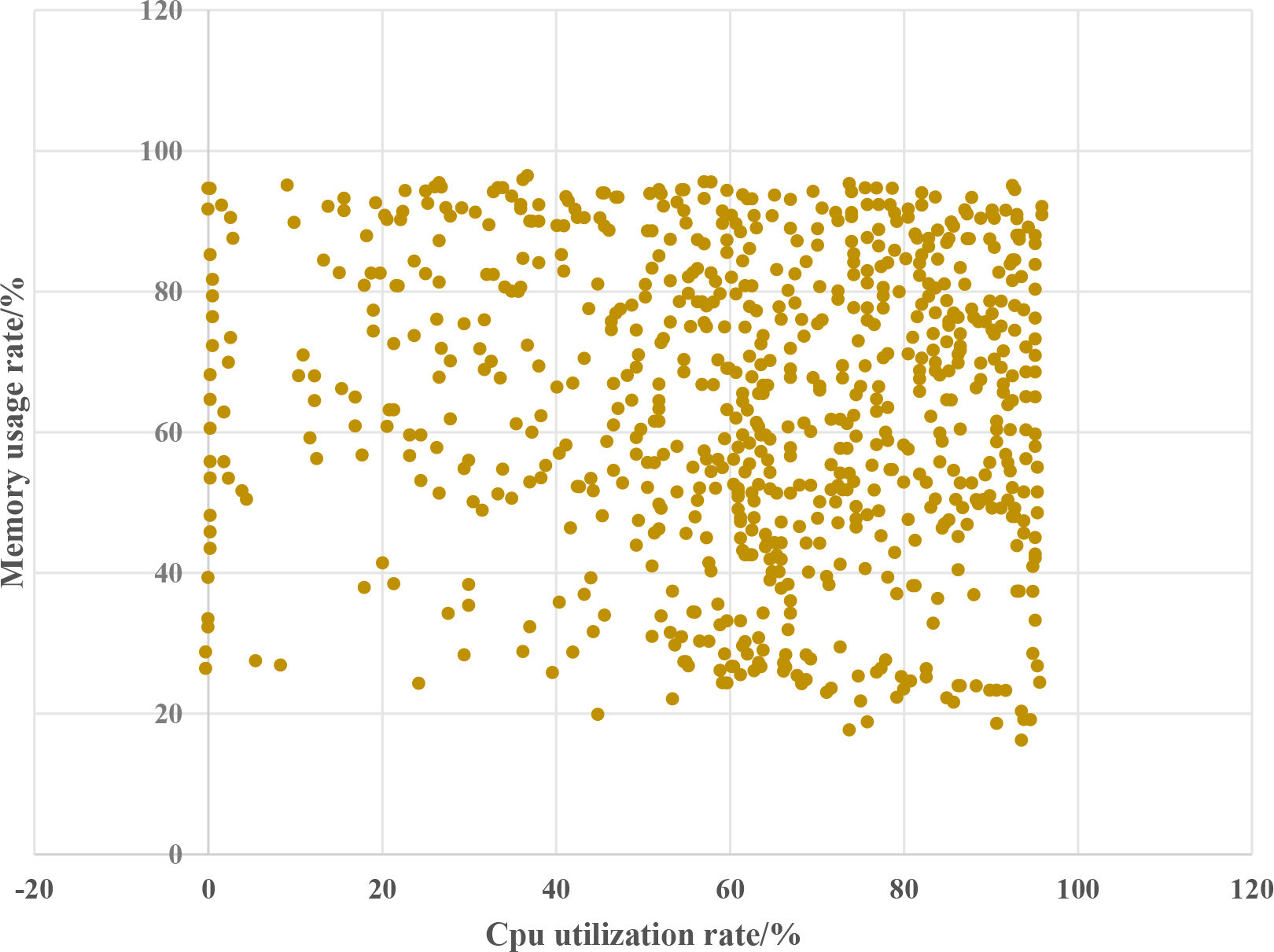
Dynamic information scatter diagram of coordinated Evolutionary algorithm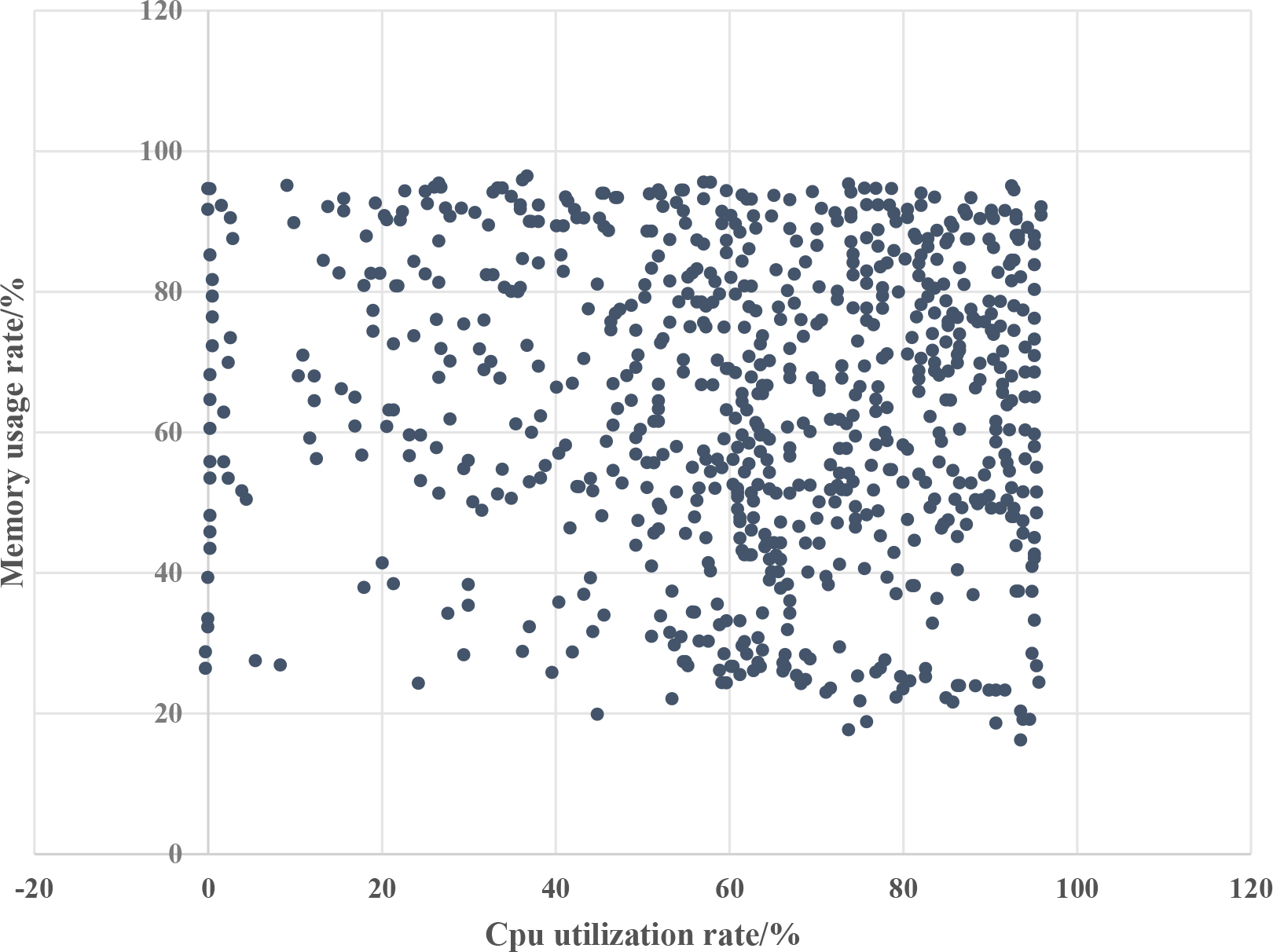
According to the application strategy of EMIS adaptive optimization, the optimized EMIS process is determined based on the interaction degree between modules, convergence coefficient, and modularization layering degree of the model.
Determine the maximum number of layers By combining the quantification formula of interaction degree and convergence coefficient between modules, Determine the improved processing flow Based on the methods of process improvement in reality and the optimization results of existing indicators, an improved processing flow is proposed as shown in Fig. 7, providing reference for enterprises to improve this process. The modular layering degree of the improved process is about 0.3, which is close to the ideal indicator value of 0.31 after optimization. Meanwhile, compared to the original sales processing flow and the improved processing flow, the improved sales processing flow can better adapt to the current situation of the enterprise, that is, the improved processing system has better adaptability.
Sales processing flow of a certain enterprise.
From Fig. 8, it can be seen that the improved sales processing process eliminates redundant audit and inspection processes, improving the processing efficiency of the sales process. The optimization results for MLD, IDM, and CC of the improved process in Table 3 are consistent. As shown in Fig. 8, after integrating sales related activities, the improved sales processing process has added a “inventory query” module to improve customer satisfaction. The SD optimization results of the improved process in Table 3 are consistent. The process adjustments are all carried out in the same department, and it is acceptable to have a smaller impact range, adjustment difficulty, and confusion, which is consistent with the optimization results of CIR, DDI, and CDI in Table 3.
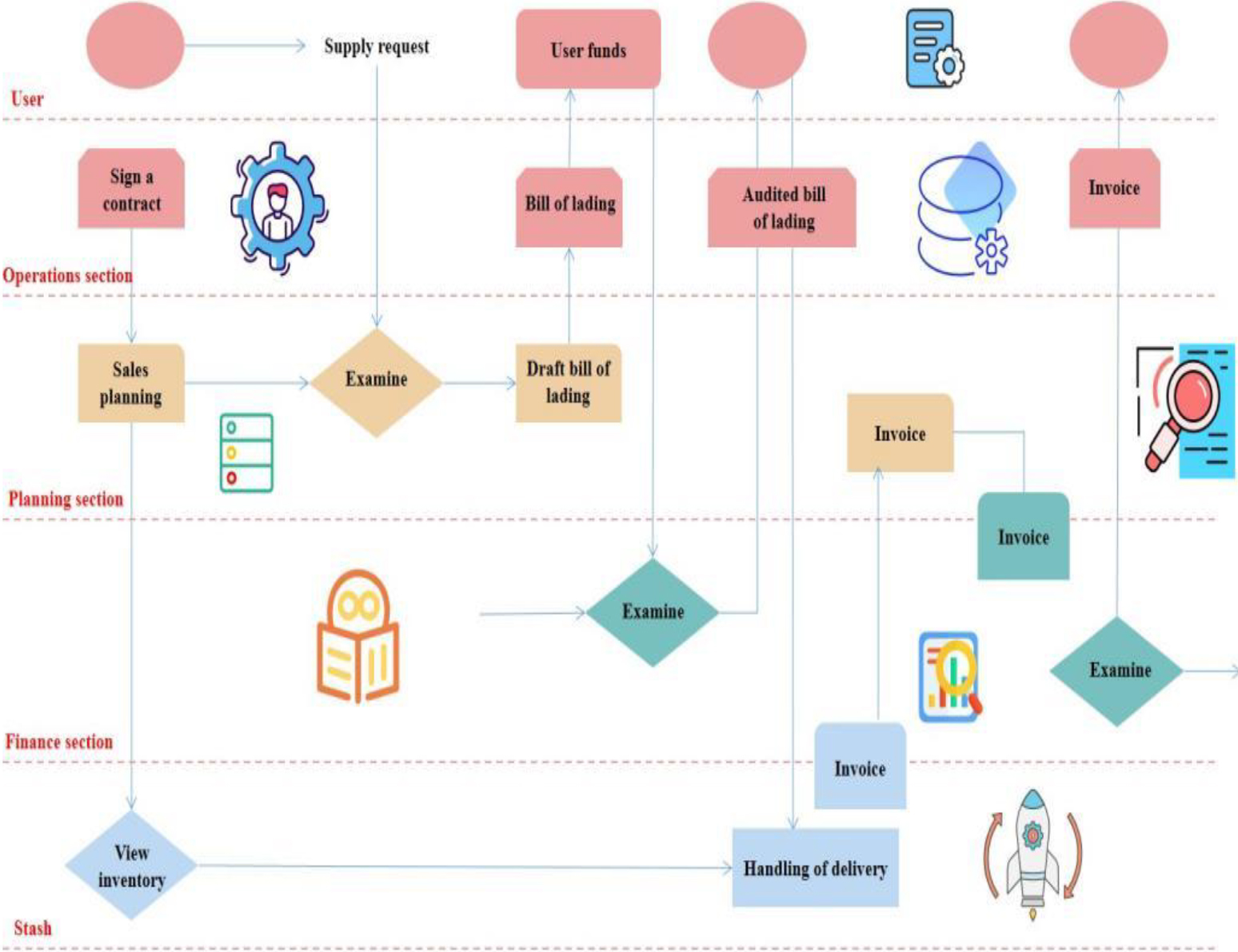
Improved sales processing flow.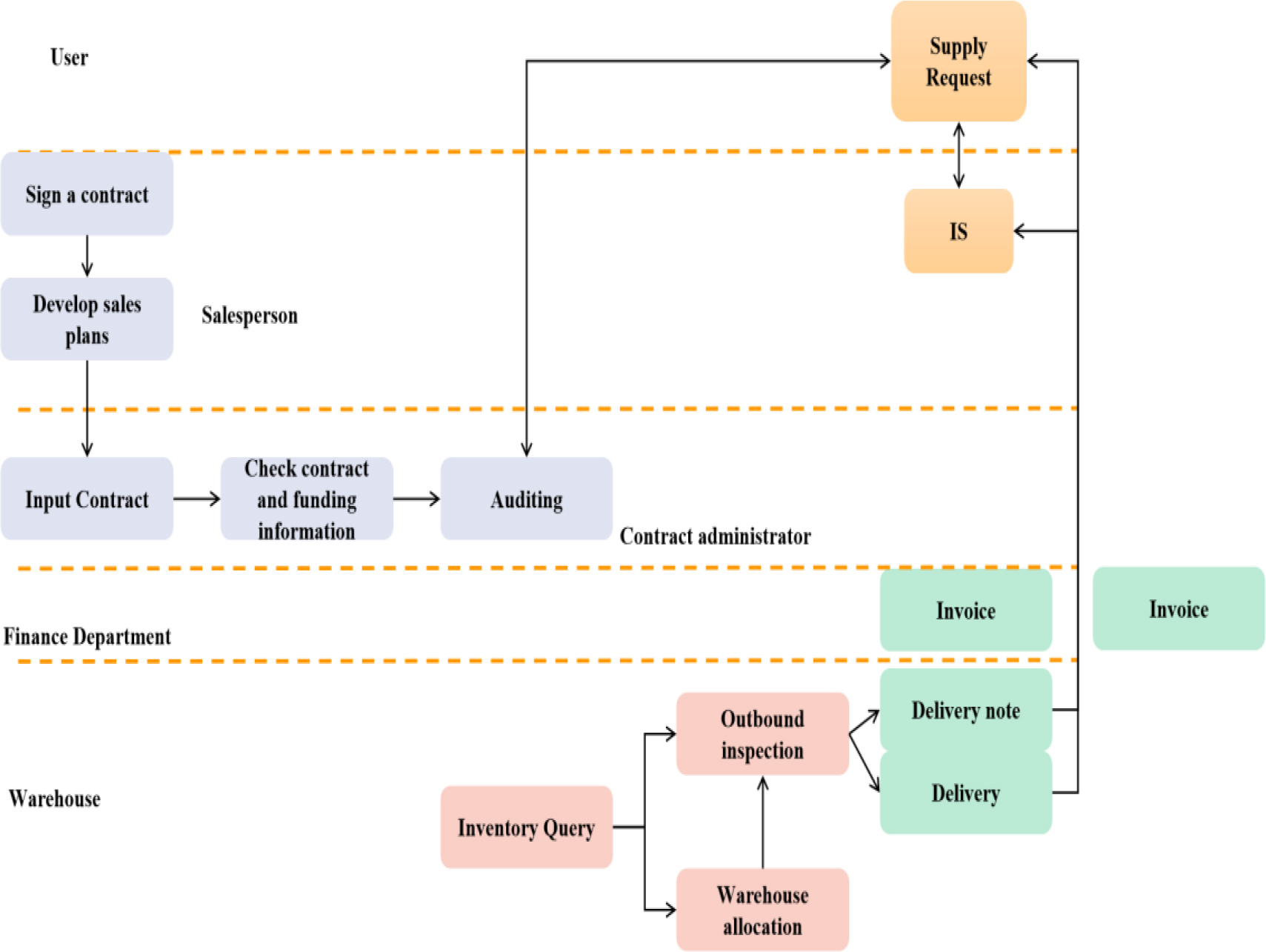
Cloud computing technology provides an opportunity for innovation in information management in vocational colleges. Firstly, cloud computing technology can greatly reduce the cost of information management in vocational colleges and greatly improve the efficiency of information management in vocational colleges. In order to implement cloud computing technology services in vocational colleges, virtual resource pools can be established to eliminate idle computers, as well as computer hard drives, memory, etc. within the scope of the school, and then connect to the network for application. You can enjoy the high-end information management services brought by cloud computing technology, thereby saving education costs and reducing the purchase and maintenance expenses of hardware equipment such as computers and network exchanges, Enhance the comprehensive efficiency of capital input and output. The second is that cloud computing technology can optimize the management of educational resources in vocational colleges, integrate high-quality resources from vocational colleges to achieve joint construction and sharing, not only promoting educational fairness but also improving educational efficiency. Cloud computing technology can run through Collaborative learning, ubiquitous learning and mobile learning in the teaching management of higher vocational colleges, so as to build an interactive and collaborative platform for learners. This not only allows the majority of teachers and students in vocational colleges to share resource information, complement research materials, collaborate on research projects, and publish research results, but also communicates learning tasks to students through the internet, allowing them to submit learning results, thereby improving the school’s teaching management level. Thirdly, cloud computing technology can improve the security management level of data storage in vocational colleges. For vocational colleges, the most core content of information-based education management is the construction of resource libraries. As an important carrier for popularizing education management, the safe storage of resource libraries is the lifeline of information-based education management. Under normal circumstances, even if the anti-virus security mechanism is well done, it is difficult to resist the invasion of Computer virus. Due to improper operations by managers, data loss or damage can often occur, resulting in catastrophic impacts on information-based education management. Cloud computing technology provides a security guarantee mechanism for this. Fourthly, cloud computing technology has brought greater development space for information management in vocational colleges. Cloud computing technology provides available conditions for vocational colleges to widely carry out ubiquitous learning and mobile learning. As the fastest developing cloud computing technology in current information technology, it has built a good platform for the reform and innovation of information management in vocational colleges. With its convenient and fast resource utilization, powerful storage and computing capabilities, and flexible business expansion, it will undoubtedly bring new horizons to the innovative development of information management in vocational colleges.
The optimization research of EMIS adaptability can deeply understand the adaptability characteristics of EMIS, understand the laws of information systems, and provide theoretical basis and feasible methods for improving the adaptability of EMIS. A clear and accurate understanding of the cloud server situation in a cloud platform is something that every maintenance and development personnel hope to achieve. The hierarchical clustering of cloud servers is crucial for the scheduling and management of the entire cloud platform, providing normal services, and improving platform utilization efficiency. The author proposes a server hybrid clustering algorithm based on Fuzzy clustering and improved GRNN. Taking advantage of GRNN’s advantages in nonlinear mapping and learning speed, the classical GRNN algorithm is formed by adding coordinated evolutionary algorithm, and the improved drosophila optimization algorithm and neighborhood rough set algorithm are added to the algorithm, the original algorithm has been improved to a certain extent in terms of speed, efficiency, and effectiveness. Systematic research on the optimization of information systems is also the foundation and key to building high-performance information systems, achieving orderly information flow, and promoting the process of social informatization.
Data availability statement
The data of this paper can be obtained through the email to the authors.
Funding
There is no funding information for the work in this paper.
Footnotes
Conflict of interest
The authors declare that there is no conflict of interest regarding the publication of this work.