
Abstract
The Extreme Learning Machine (ELM) is a highly efficient model for real-time network retraining due to its fast learning speed, unlike traditional machine learning methods. However, the performance of ELM can be negatively impacted by the random initialization of weights and biases. Moreover, poor input feature quality can further degrade performance, particularly with complex visual data. To overcome these issues, this paper proposes optimizing the input features as well as the initial weights and biases. We combine both Convolutional Neural Network (CNN) and Convolutional AutoEncoder (CAE) extracted features to optimize the quality of the input features. And we use our hybrid Grey Wolf Optimizer-Multi-Verse Optimizer (GWO-MVO) metaheuristic for initializing weights and biases by applying four fitness functions based on: the norm of the output weights, the error rate on the training set, and the error rate on the validation set. Our method is evaluated on image classification tasks using two benchmark datasets: CIFAR-10 and CIFAR-100. Since image quality may vary in real-world applications, we trained and tested our models on the dataset’s original and noisy versions. The results demonstrate that our method provides a robust and efficient alternative for image classification tasks, offering improved accuracy and reduced overfitting.
Keywords
Introduction
Traditional learning techniques face challenging issues, such as slow learning speed, intensive human intervention, and poor learning scalability. Extreme Learning Machine (ELM) [1] is a simple machine learning method that offers advantages over traditional learning algorithms. This method is known for its breakneck learning speed compared to conventional methods, as it requires no iterative gradient-based training. Moreover, no parameters need to be tuned except the architecture size. Therefore, ELM can be used to address problems that require real-time network retraining. ELM has also demonstrated exemplary performance in various fields such as medicine [2, 3], chemistry [4], transportation [5], economics [6], and robotics [7].
However, the random initialization of input weights and biases, as well as the learning procedure that aims to minimize the error on the training set, can reduce the prediction accuracy and produce the overfitting problem. On the other hand, it has been shown that ELM encounters challenges when dealing with complex visual data, particularly when the spectral information of each pixel in the image is given directly as input [8].
Since the quality of images can vary in real-world applications, some works have investigated the effect of noise on the image classification task. Models trained with a noisy version of the training set and tested on data with the same noise configuration have performed worse than models trained and tested on the original data [9, 10]. However, most image classification systems ignore preprocessing and suppose that the image quality does not vary.
Multiple contributions have been made to improve the performance of ELMs. Many of these contributions aim to optimize the initialization of weights and biases to increase the prediction accuracy while ignoring the overfitting problem. Another part of the contributions focuses on improving the quality of ELM input features. Feeding the ELM classifier with high-level feature representations extracted by a deep neural network has become a promising direction [8, 11, 12, 13, 14]. However, little attention has been paid to image quality during the feature extraction phase.
In this work, we are interested in improving the basic ELM model in two aspects: the optimization of the initialization of weights and biases and the preprocessing of images with or without noise.
Metaheuristics have proven their efficiency in optimizing the input parameters of ELM. Most contributions in this field aim to minimize the error rate on the training or validation set. This paper investigates the effectiveness of the hybrid Grey Wolf Optimizer-Multi-Verse Optimizer (GWO-MVO) metaheuristic, which has proven its performance in estimating the optimal dropout value in [15].
On the other hand, Convolutional Neural Networks (CNNs) have been widely used for feature extraction in image classification tasks. While current CNN-based methods have shown improved robustness over previous approaches, overfitting and noise present additional challenges [10]. Convolutional Autoencoders (CAE) [16], based on the Autoencoder (AE) architecture, have shown promising performance in handling highly variable conditions. However, they still provide poor precision compared with traditional deep networks such as VGG16 [17]. Therefore, in this article, we propose to combine the features extracted by the basic CNN with those extracted by CAE.
To the best of our knowledge, this is the first study to optimize the ELM model’s input features and initial parameters simultaneously for noisy image classification tasks. The main contributions of our work can be summarized as follows:
Feeding ELM with relevant features extracted by both models, CNN and CAE. Proposing a GWO-MVO-based approach to select initial values of weights and biases for the ELM model. Improving the ELM performance and generalization capacity by single and multi-objective optimization using these three properties:
the norm of the output weights of the ELM network, the error rate on the training set, and the error rate on the validation set. Applying our method to image classification problems, whether noisy or not.
The remainder of this article is organized as follows: Section 2 presents related work. Section 3 gives the theoretical background of the techniques used in this work. Section 4 presents the concepts of the hybrid GWO-MVO algorithm. Sections 5 and 6 explain our method. Section 7 reports and discusses the obtained results. Finally, Section 8 concludes the paper, highlights its limitations, and discusses potential future research directions.
In this section, we first present some research studies of the ELM model using metaheuristics. Then, we describe the most important studies that used deep learning models to extract relevant features from images. Finally, we discuss the effect of image quality on the classification task.
Metaheuristic-based ELM
Random initialization of weights and biases further improves the speed of ELM’s learning algorithm. However, it reduces the performance of ELM in complex classification tasks and causes the overfitting problem as it affects the classification boundaries. Therefore, more nodes should be used for better generalization than classical training approaches, which significantly increases the testing time.
Metaheuristics represent a family of methods that have proven to be effective in solving what are known as complex optimization problems. As a result, metaheuristic-based approaches have been widely used with success in weight and bias initialization.
A hybrid evolutionary extreme learning machine (E-ELM) algorithm was proposed in [18]. The approach used the Differential Evolution (DE) algorithm to optimize initial weight and bias values. The root mean squared error (RMSE) was used as the fitness function, and the sigmoid as the activation function. A new selection strategy was presented such that when the difference in fitness between individuals is slight, the one with the smallest value of the norm of the output weights is selected. The proposed approach was evaluated on both regression and classification tasks. Although E-ELM outperformed traditional machine learning algorithms in terms of performance and speed, the results cannot be generalized, as the tested problems are simple and do not require a large number of hidden nodes. DE algorithm was replaced by the Particle Swarm Optimization (PSO) algorithm in [19] so that the input weights and hidden biases were bounded in the interval of [
Mohapatra et al. used an improved cuckoo search-based extreme learning machine (ICSELM) to classify medical datasets [20]. The performance was analyzed and compared with traditional ELM, online sequential extreme learning algorithm (OSELM), and other conventional artificial neural networks. The results obtained showed that ICSELM could outperform the other models. The authors in [21] presented an efficient computer-aided diagnosis (CAD) model to classify mammography images as benign or malignant. The model uses conventional feature extraction techniques to extract relevant features from mammography images. Then, a modified variant of PSO, named MODPSO, is employed to optimize the parameters of the ELM hidden layer by considering the RMSE on the validation set as the fitness function. The effectiveness of the proposed model was assessed across three mammography datasets, surpassing other state-of-the-art models. In [22], a hierarchical approach based on the ELM classifier was introduced to detect and classify cyber-attacks effectively. The novel metaheuristic, Harris Hawks Optimizer (HHO), was employed to determine the optimal input feature subset and fine-tune the ELM weights. Two objective functions were used; the first seeks to reduce the number of features and increase classification accuracy, while the second aims to minimize the crossover error rate (CER). As a result, this approach led to substantial enhancements in detection rates, particularly on the UNSWNB-15 dataset. Dogan et al. proposed a hybrid methodology that combines the ELM model with GoogLeNet transfer learning to detect dry beans [23]. The research investigated the application of the Salp Swarming Algorithm (SSA) to optimize ELM parameters and enhance the performance of the ELM classifier. The RMSE on the validation set was employed as the fitness function. The SSA-ELM model successfully classified 14 different types of dry beans. The comparative results highlighted the superior performance of this hybrid approach over traditional machine learning algorithms.
Numerous studies have explored this optimization domain, investigating other metaheuristic approaches, such as Firefly Algorithm (FA) [24], Dolphin Swarm Algorithm (DSA) [25], Whale Optimization Algorithm (WOA) [26], Ant Lion Algorithm (ALA) [27], GWO [28], and Harmony Search (HS) [29].
Image feature extraction based on deep learning models
Feature extraction is an essential phase in the construction of computer vision systems. The main goal of this phase is to preserve only the critical aspects of the input data in robust and discriminative representations. Recently, machine learning algorithms have been widely used in this context as they can efficiently compress the data into a lower dimensional representation without significant loss of information.
Niu and Suen proposed a hybrid method for handwritten digit recognition [30]. This method consists of two classifiers: CNN and Support Vector Machine (SVM). First, CNN is trained on the training set to build the new feature vector that represents the input of the SVM. Then, the SVM classifier will be trained to perform the recognition task. The proposed approach was evaluated on the MNIST dataset. The results showed that this method outperformed previous works.
Feature extraction from complex industry data was studied in [31]. The objective was to estimate the etch rate from OES data of a plasma etching process. Since the input data structure is two-dimensional, the CAE model adapted for visual data was used for feature extraction. Initially, CAE is trained on the OES data. After that, the outputs of the encoder pooling layers will be concatenated and passed to the Support Vector Regression (SVR) model. The SVR is trained in a supervised manner to make the final predictions. The results clearly demonstrated the importance of the feature extraction step.
CNN was also used to extract features from Synthetic Aperture Radar (SAR) images in [13]. The output of the CNN model fed an ELM classifier to perform recognition. The tests were conducted on the MSTAR database. The proposed CNN-ELM model outperforms other traditional methods for SAR image recognition in terms of accuracy and time.
To solve the problem of CNN overfitting during feature extraction while taking advantage of the learning speed of the ELM model, CNN was replaced by wide ResNet (WRN) in [8]. Like the previous contributions, the feature extractor, WRN, in this case, is trained in a supervised manner to construct the feature vector that feeds the ELM model. The proposed DW-ELM approach was evaluated on five benchmark datasets (CIFAR-100, CIFAR-10, STL-10, Flower-102, and Fashion-MNIST). The results showed a significant improvement in the accuracy as well as the training stability of the proposed DW-ELM compared to SVM-based classification approaches.
Pintelas et al. propose a hybrid method between CAE and CNN to classify high-dimensional visual data [32]. This data type usually contains noise and redundant information, so CAE extracts relevant features to feed the CNN model with a high-level feature representation. The proposed model is evaluated on datasets from three application domains: plant diseases, skin cancer, and DeepFake detection. The results proved that this approach represents a helpful attempt to improve the performance of deep learning models.
In [33], a methodology employing exemplary pyramid-based deep feature extraction was introduced to detect cervical cancer. The main objective was classifying cervical cells in pap-smear images to identify cancerous cases. Initially, this approach utilizes transfer learning-based feature extraction with DarkNet19 or DarkNet53 networks in an exemplary pyramid structure to generate 21,000 features. Subsequently, the Neighborhood Component Analysis (NCA) technique selects the 1,000 most informative and weighted features. These selected features are then used for classification via the SVM algorithm. The effectiveness of this model was validated successfully using the SIPaKMeD and Mendeley LBC datasets.
Jiang et al. proposed a new image classification architecture named CofaNet [34]. This architecture combines CNN and transformer-based fused attention to overcome the limitations of transformers in capturing local context. Experimental results on three benchmark datasets demonstrated CofaNet’s excellent performance compared with some transformer-based networks.
Image quality effect on classification task
Due to the importance of the image classification problem in computer vision, it has been widely studied in machine learning. However, most works focus on high-quality datasets, neglecting that image quality varies significantly depending on the captures used and the lighting conditions in the real world. Few works have investigated the presence of noise in training and/or test data.
Dodge and Karam showed that deep learning networks are sensitive to blur and noise [35]. Four state-of-the-art CNN architectures were studied, where each model was trained on the original images and tested on the same images in their original state, with noise and blur. The results showed that the image classification performance under noise or blur is degraded. Authors proposed to train the models on low-quality images, but there was no study about the effect of noise and blur on the training set.
Paranhos da Costa et al. considered the case where the training set contains low-quality images [9]. The principle was to extract features from the input images by two hand-crafted feature extraction methods (LBP and HOG) and then pass them to the SVM classifier. Several versions of the training and testing set were created (the original version without noise and versions with only one type of noise). Each model is trained on one of the training set versions and tested on each test set version. The paper also analyses the effects of denoising techniques by restoring noisy images. The results show that noise makes the classification problem more difficult since none of the classifiers was able to exceed the performance of the classifier trained and tested on the original dataset, even when applying denoising techniques. However, this study only considered conventional hand-crafted feature extraction methods.
Following the same methodology in [9], Nazaré et al. evaluated the performance of CNN models [10]. Both Gaussian and salt & pepper noise were used with different degrees of noise. Denoising methods were applied for each dataset version. As a result, 21 classifiers were created. The results indicate that although injecting noise into the training data makes classification more complicated, it can be beneficial for applications where image quality is subject to variation after deployment. On the other hand, applying denoising methods cannot guarantee a good improvement, but quite the opposite.
Hossain et al. address the vulnerability of CNNs to image distortion [36]. They note that even minor levels of noise or blur can significantly impact CNN performance. To overcome these limitations, the authors propose a distortion-robust module called DCT-Net. This module integrates the Discrete Cosine Transform (DCT) into a deep network built on top of the VGG16 architecture. This approach effectively handles diverse types of distortion, generalizes well to unseen distortions, and performs competently on benchmark datasets.
Researchers in [37] also addressed the problem of the sensitivity of deep neural networks to image quality variations during testing. They introduced an approach that uses discrete vector quantization (VQ) to create a robust, quality-independent representation. This model demonstrated substantial progress by applying self-attention, achieving a new state-of-the-art result on ImageNet-C and a notable improvement in accuracy on other benchmark datasets.
Background
This section provides a brief theoretical overview of the techniques used to better understand this work.
Extreme Learning Machine
The Extreme Learning Machine (ELM) was first proposed in 2004 by Huang et al. [1]. ELM belongs to the family of single hidden-layer feedforward networks (SLFN). Unlike conventional neural networks based on the backpropagation (BP) algorithm, ELM uses the Moore Penrose (MP) generalized inverse to estimate the target outputs. This significantly reduces the training time.
For a training set
where
We can reduce the equation and write it in the form:
where
The steps of the training procedure of an ELM are outlined in Algorithm 1.
The convolutional neural network (CNN) is a feedforward neural network adapted to grid-like topologies like images. Inspired by Hubel and Wiesel’s 1962 work on simple and complex cells, Fukushima [38] developed the first model under the name “neocognitron”. Other architectures were later proposed, such as LeNet-5 [39], AlexNet [40], VGGNet [17], GoogLeNet [41], and ResNet [42].
Rather than having only the classification part like a multi-layer perceptron (MLP) model, a CNN model has two parts: feature extraction and classification, as shown in Fig. 1. The feature extraction part compresses the images by retrieving significant features. And the classification part combines the obtained features to classify the images.
CNN architecture, adapted from [43].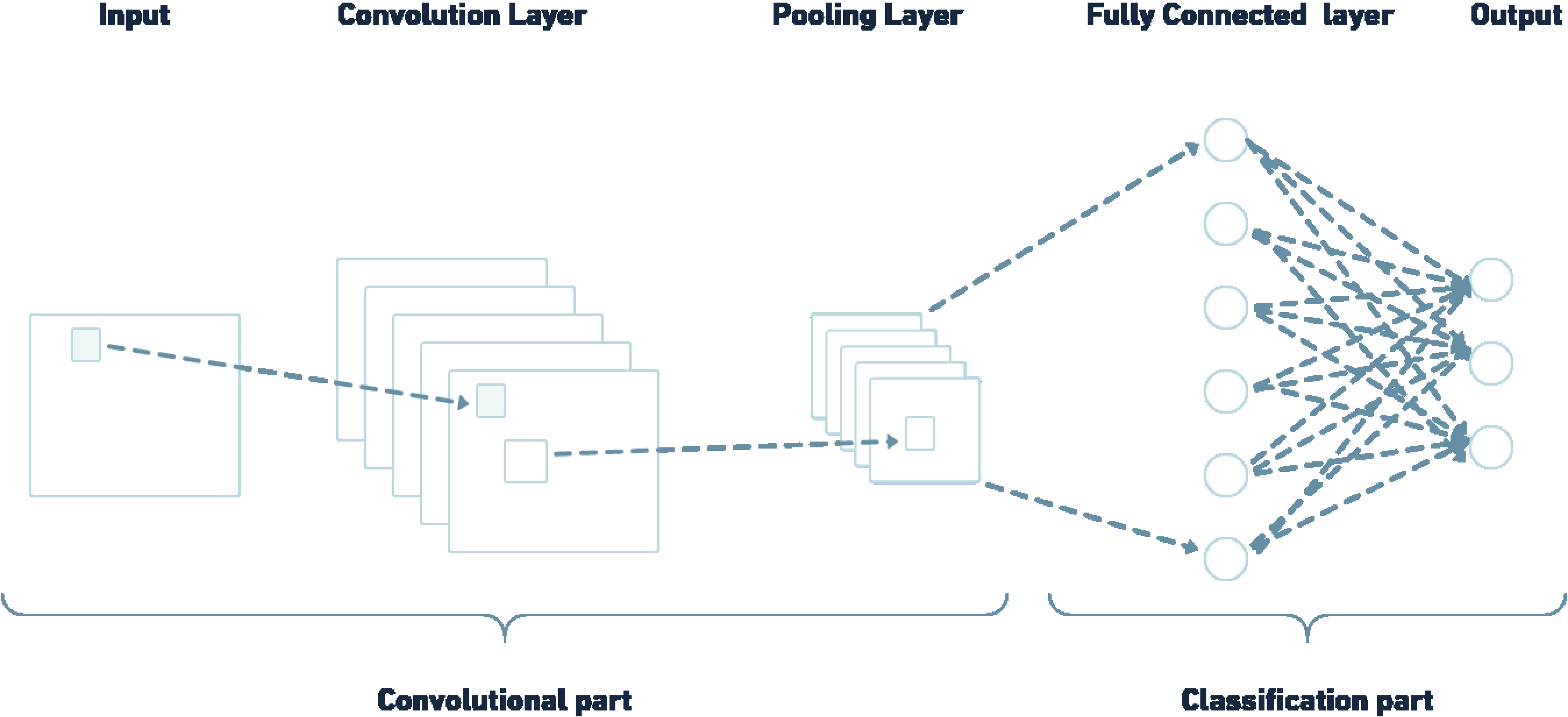
The feature extraction part is mainly composed of two components, the convolution layer and the pooling layer. The convolution layer consists of a set of filters (kernels). The output of a convolution layer is calculated by a dot product between the input matrix and the kernel, this is known as the convolution operation. This operation can be represented mathematically as follows:
where for a layer
Usually, a convolutional layer is followed by a pooling layer that applies a statistical measure such as maximum, mean, and median. This reduces the output resolution of the convolutional layer.
The classification part consists of one or more fully connected layers (FC) and a softmax output layer used for classification. The main idea is to take the output of the previous part and group them to define the output label.
Convolutional Autoencoder (CAE) [16] is a variant of the AE network adapted for 2D image structure as it is composed of convolutional layers. CAEs are mainly used to reconstruct input images by compressing them and removing noise while keeping the most significant features. They can also be seen as unsupervised dimensionality reduction models.
ACEs are composed of two parts based on convolutional layers, the encoder and the decoder. The encoder extracts the features of the input image into a lower-dimensional representation. In contrast, the decoder reconstructs this compressed representation by generating an output image similar to the input image. Figure 2 illustrates the basic architecture of the CAE model.
Basic architecture of CAE model, adapted from [32].
Besides the convolutional and pooling layers explained before, CAEs contain two other types: deconvolutional and unpooling layers. The deconvolutional and unpooling layers do the opposite operations of the convolutional and pooling layers, respectively, to allow the reconstruction of the original size of each sub-region. These two types of layers are only found at the decoder level. Note that the deconvolution operation is, in fact, the transposition operation.
Single-objective optimization
A single objective optimization problem (SOOP) has a single objective function
where
The concept of Pareto optimal is introduced when two or more objective functions need to be optimized. The goal in a multi-objective optimization problem (MOOP) is to find the global minimum/maximum
Metaheuristics have proven to be very effective in solving continuous optimization problems. Grey Wolf Optimizer (GWO) [45] is one of the swarm intelligence algorithms designed for continuous optimization problems. The social behavior of wolves in the wild inspired GWO. Due to its simplicity to implement, as it requires few parameter settings, it has been applied with success to several complex optimization problems. However, it is sensitive to stagnation in local optima. We have previously proposed in [15], a hybrid search method based on GWO and Multi-Verse Optimizer (MVO) [46] to ensure a good balance between exploration and exploitation. MVO is a Metaheuristic inspired by the multiverse theory in astrophysics. The multiverse theory explains how big bangs create multiple universes and how these universes interact with each other. Motivated by the results obtained in estimating the dropout probability in a deep neural network, we investigate the performance of GWO-MVO for image classification. In the following, we provide the inspiration and mathematical modeling of the proposed GWO-MVO.
Inspiration
Like GWO, the GWO-MVO algorithm is mainly inspired by grey wolves’ leadership hierarchy and hunting behavior. Grey wolves often prefer to live in packs with a strict social hierarchy. Four hierarchical levels are established to keep discipline within the group. The pack is led by the leader wolves called alpha (
Mathematical modeling
Social hierarchy
Wolves are ranked in the population according to their fitness value. The first, second, and third best are alpha, beta, and delta, respectively. While the remaining wolves are considered
Encircling prey
The encircling strategy around the prey can be modeled mathematically by the following equations:
where
where
Assuming that the alpha, beta, and delta leaders have good knowledge of the prey, these three wolves guide the search mechanism. Thus, each wolf updates its position according to the following equations:
To further enhance the exploitation/local search process around the best individual
where
In image classification, generating relevant features that enable the classifier to identify different classes is crucial. In this work, we propose a method that leverages the strengths of two models: CNN and CAE. Our approach uses the extracted features from both models to feed the ELM classifier.
First, the CNN and CAE models are trained on the training set for a few epochs. The CNN model performs feature extraction through its designated feature extraction part, while the CAE model employs its encoder to generate feature vectors. These two sets of feature vectors, derived from the CNN and CAE models, are combined to form the input vector for the ELM classifier.
Once the ELM input vector is defined, the GWO-MVO
Flowchart of the proposed approach.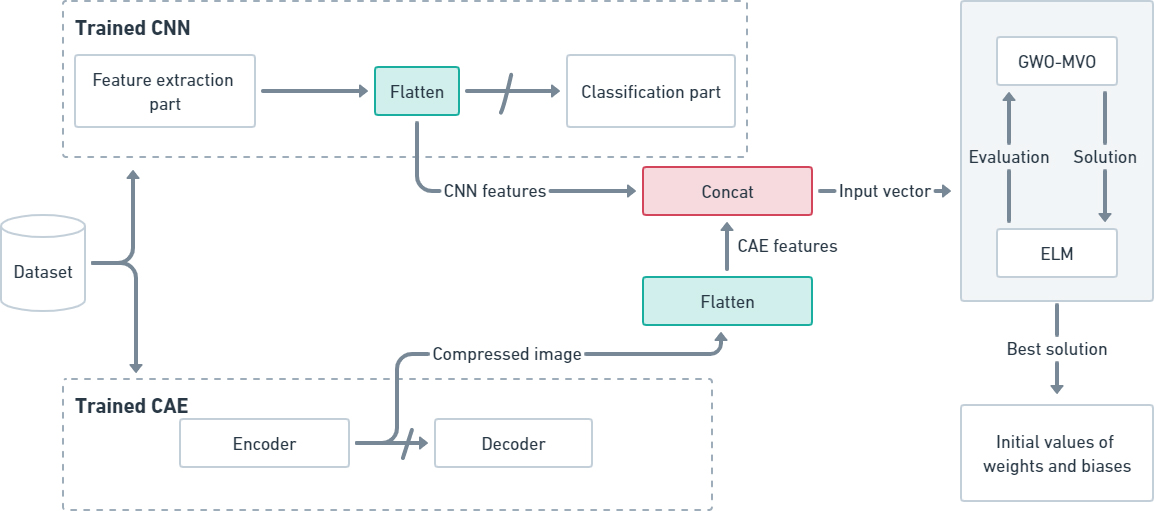
In this section, we present and explain in depth the GWO-MVO method used in initializing the weights and biases of the ELM classifier.
Solution representation and initialization
A solution is defined by a wolf’s position, representing a vector containing possible values of weight
where
The position of an agent
All individuals’ initial weights and biases are randomly generated between
The choice of the fitness function is crucial for any Metaheuristic, as it defines the search space. For this reason, we have defined four fitness functions that will be used separately in the solution evaluation of the two approaches described in the previous section. The evaluation of each solution must first go through the ELM learning procedure.
According to Bartlett’s theory [47], the smaller the norm of the weights, the better the generalization performance of the network. For this reason, we aim to minimize the norm of the weight matrix. Our first fitness function is defined as follows:
Most previous works have assumed that it is not vital to evaluate the training set since the ELM training procedure will indeed reduce the training error. However, the choice of initial weights and biases can easily affect the training error. Therefore, our second evaluation function is defined by the classification error rate on the training set.
where, tp is the true positive, tn is the true negative, fp is the false positive and fn is the false negative.
For better generalization, our third function is defined by the classification error rate on the validation set. We used 5-fold cross-validation to save time. Five-fold cross-validation has proven to be useful in many models [48]. The training set is randomly and equally divided into five parts. At each step, one of the partitions is chosen for validation, and the four remaining are used for training. The procedure is repeated five times so that each partition is used exactly once as a validation set. The fitness function is calculated by the average error rate over the five validation sets, as shown in the following formula:
In order to prevent the overfitting problem, the fourth fitness function aims at optimizing the error rate on both the training and validation sets at once. This is what we call a multi-objective optimization problem. The weighted sum method combines the two objective functions into a single function. We also used the 5-fold cross-validation method. The final fitness function is calculated using the formula (27).
where
The GWO-MVO algorithm starts by initializing a population of potential solutions and then tries to find a good solution iteratively. Through the search process, the algorithm mimics the search mechanism of gray wolves to evolve the population across generations. ELM classifier is built for each solution to evaluate its fitness. The overall method is repeated over a specified number of iterations, fixed empirically. The global GWO-MVO
Experiments
In this section, we first introduce our test environment. Then, we present the datasets used for the evaluation and the experimental setup. Finally, we discuss the different results obtained.
Software and hardware setup
We ran all our tests on a desktop computer with the following characteristics: an AMD RYZEN 7 3700X CPU with 16 GB of RAM, a single GPU (RTX 2060 super), and an Ubuntu 18.04 operating system.
All our programs were developed in Python using the Keras API and the basic data science libraries (scikit-learn, NumPy, SciPy, and pandas).
Experimental data
Dataset description
Dataset description
Parameter settings
Examples of original and noisy images for each training set. The first line shows the original image and the second represents images with Gaussian noise (
CAE architecture.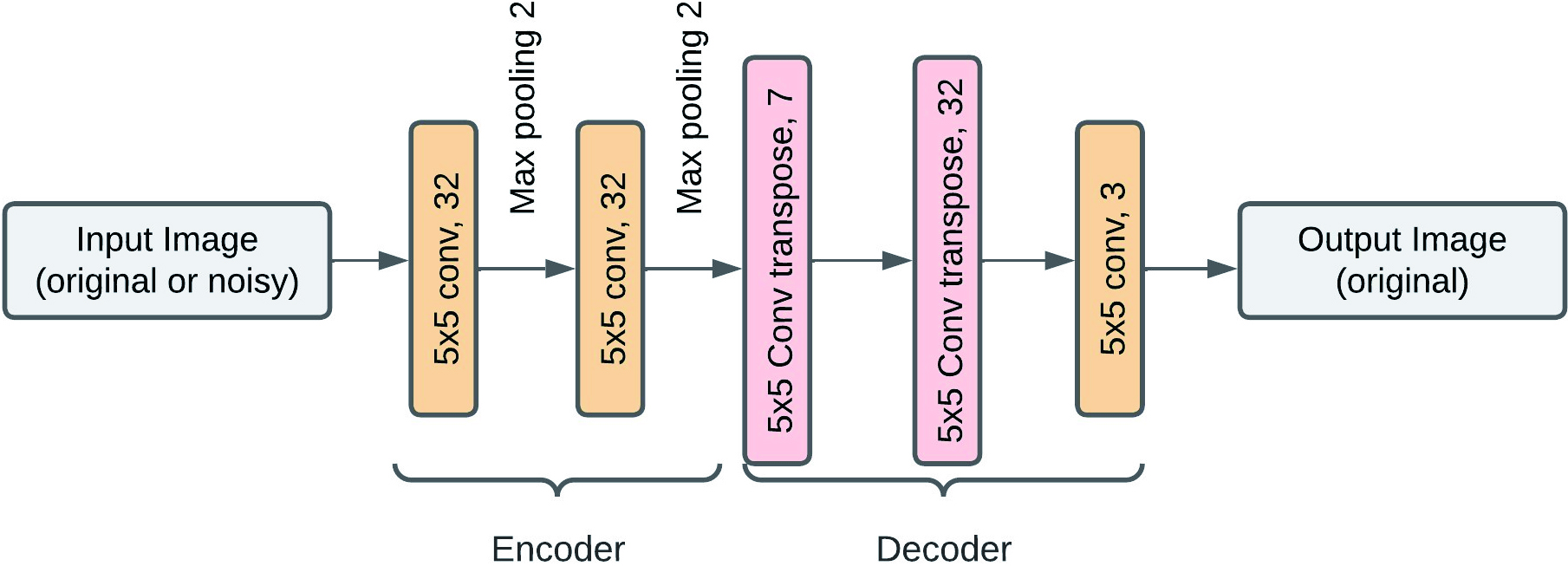
Comparative performance of the ELM model initialized by GWO-MVO using 100 hidden nodes based on different input types on the CIFAR-10 dataset (both test versions).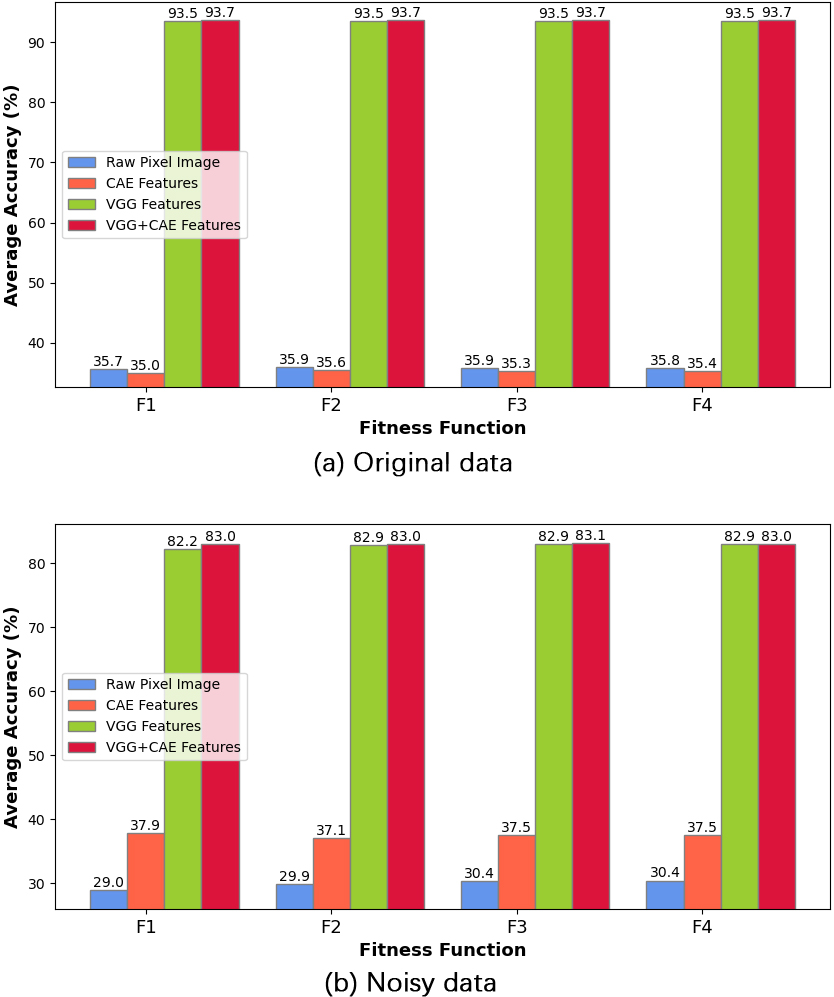
All the proposed approaches have been evaluated on the image classification task. Therefore, we used two benchmark datasets: CIFAR-10 and CIFAR-100. They are popular benchmark datasets for image classification because they are well-known, standardized, and provide a good range of complexity to test. Besides, the datasets are large enough to provide a meaningful challenge but not so large that they require extensive computational resources. Table 1 gives a summary of the datasets used.
CIFAR-10 dataset [49]: is a popular classification dataset in machine learning. It has a total of 60,000 colored images of size CIFAR-100 dataset [50] is a database similar to CIFAR-10, except it has 100 classes containing 600 colored images each. It includes 500 training images and 100 test images per class.
Comparative performance of the ELM model initialized by GWO-MVO using 100 hidden nodes based on different input types on the CIFAR-100 dataset (both test versions).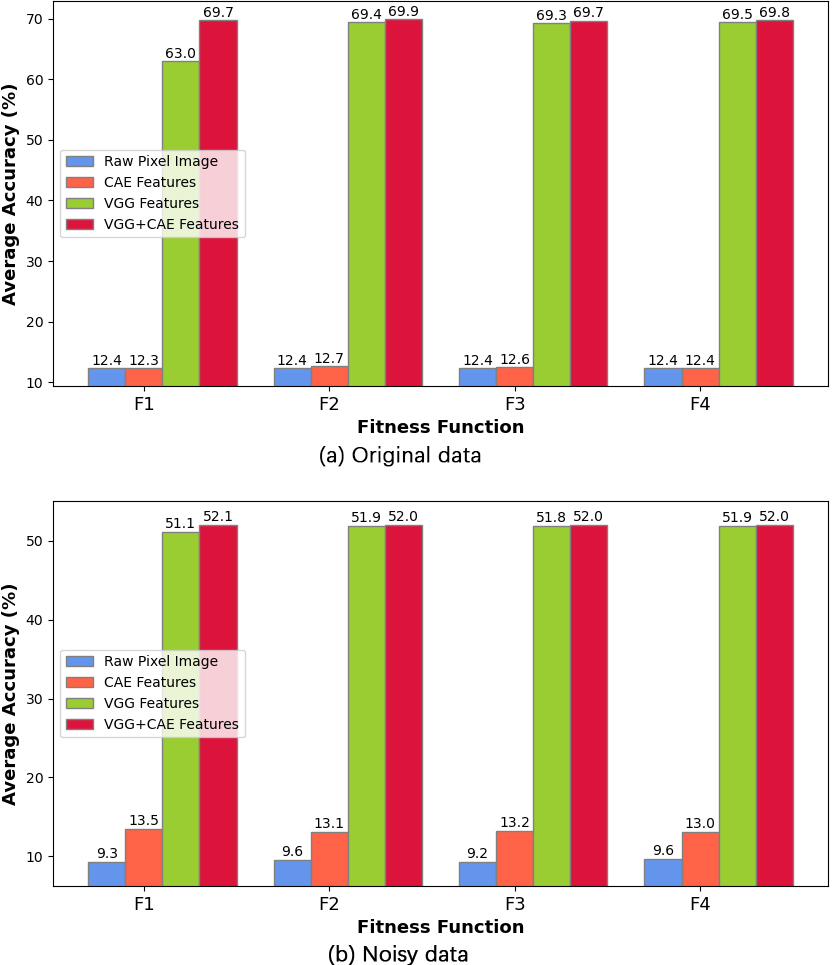
Generalization gaps on CIFAR-10 and CIFAR-100 based on the feature input type.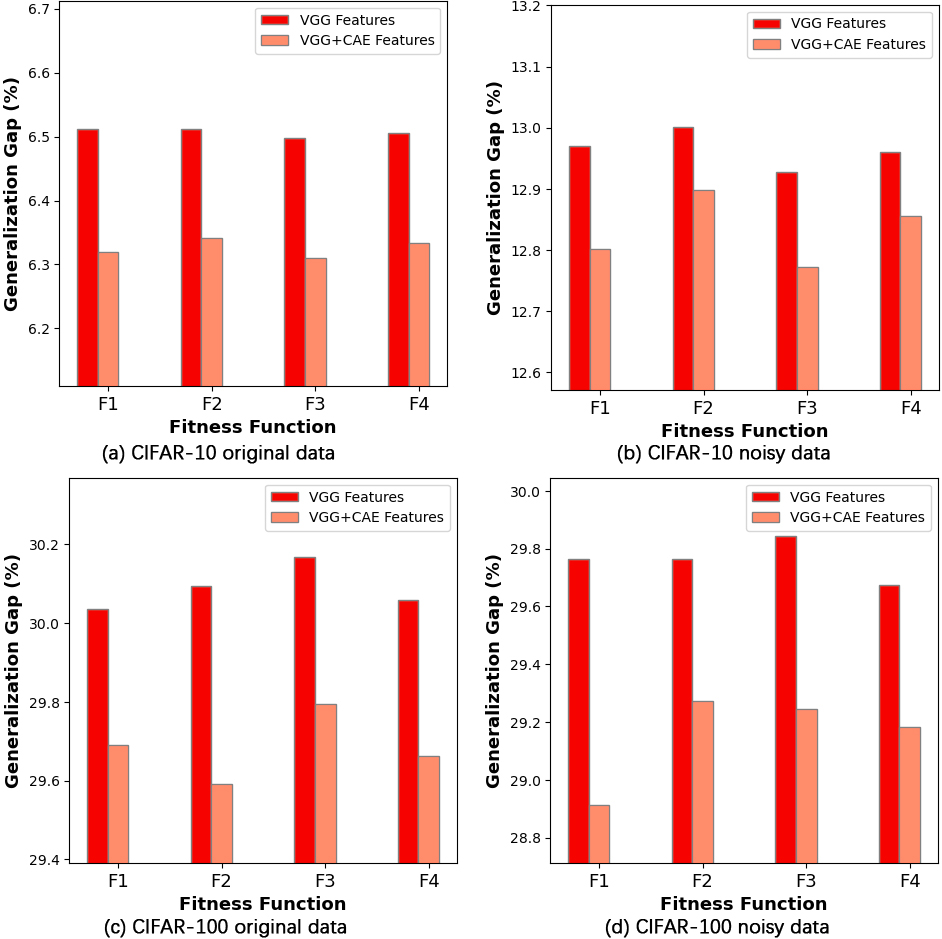
Test accuracy values across ten executions for studied ELM initialization techniques with VGG 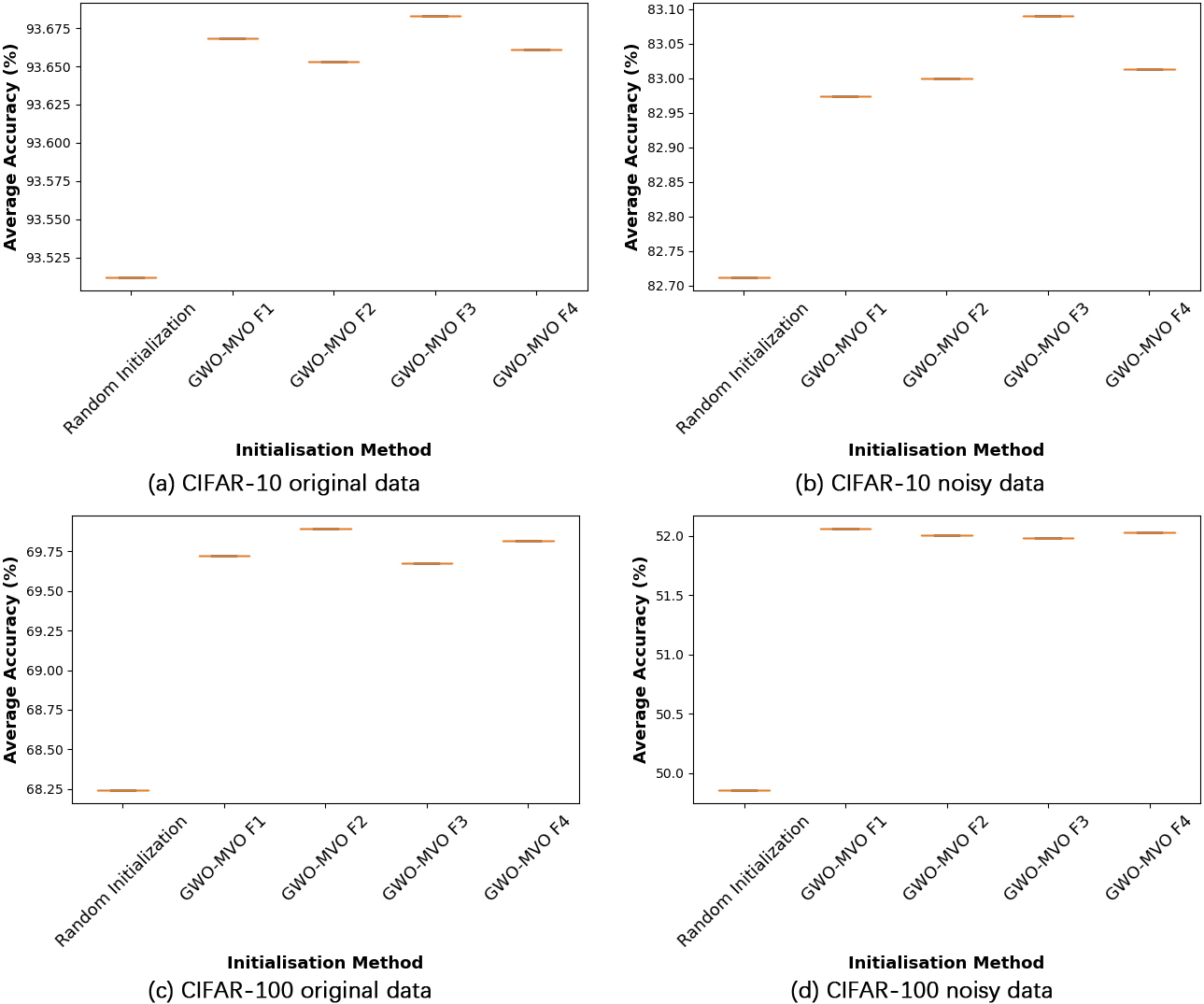
We created a noisy version for each dataset to consider the effect of noise on the training and testing set. We applied Gaussian noise with a mean of 0 and a standard deviation of 50. This particular standard deviation value was selected based on its ability to create a challenging test environment for Gaussian noise, as highlighted in [10]. Figure 4 gives an example of both original and noisy images from the training set for each dataset.
Generalization gaps on CIFAR-10 and CIFAR-100 based on the initialization type.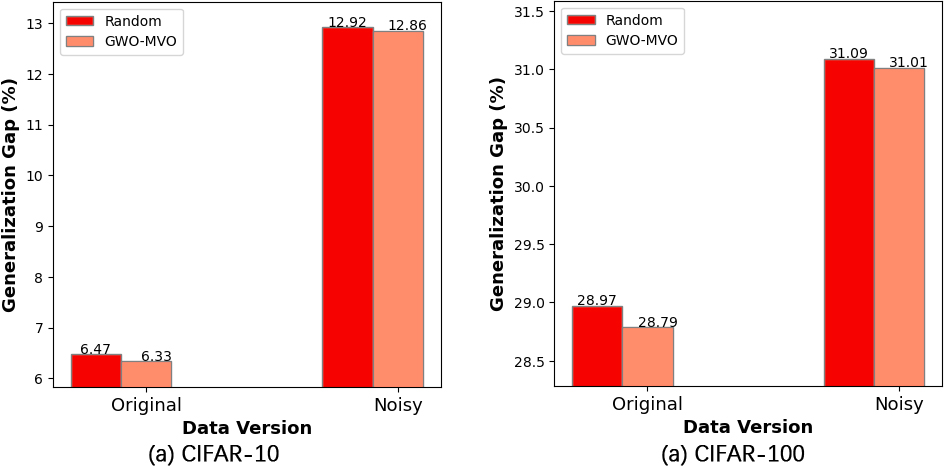
ELM model performance using GWO-MVO initialization and 100 hidden nodes on the four fitness functions for the CIFAR-10 dataset (both test versions).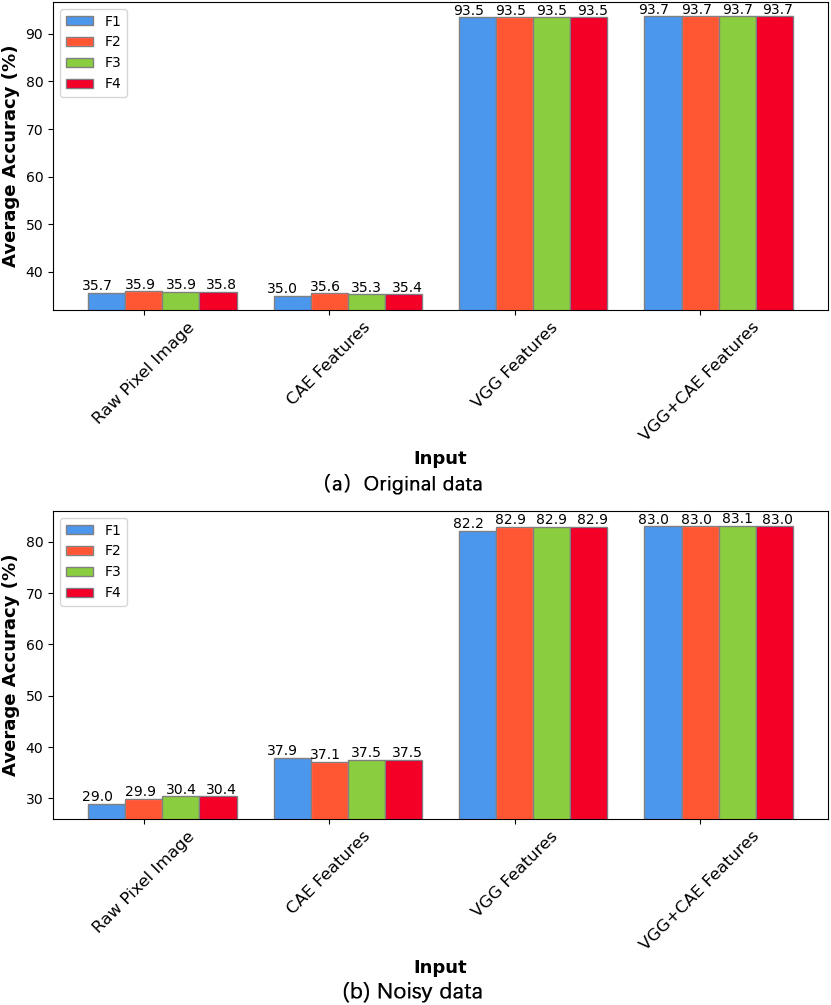
In this part, we give the implemented CNN and CAE architectures and the configuration of the different parameters.
We have opted for straightforward architectures that ensure the reduction of input features, thereby enhancing the learning speed of ELM.
CNN architectures
In our work, we adopted the CIFAR-VGG architecture, a modified version of VGG16 that addresses the overfitting problem by using dropout and weight decay techniques [17, 51]. This architecture is considered the gold standard as it offers a simplified effective network, unlike more complex and manually optimized modern architectures. To ensure performance, we used the same architecture provided in (
CAE architectures
We employed a straightforward and standard CAE architecture to enable dimensionality reduction and feature extraction. Figure 5 describes the CAE structures used.
We further used the Adam optimizer, a learning rate equal to
Parameter settings
The control parameters were tuned empirically through an experimental study considering the learning time and the memory space. The values of the parameters used in our experimental study are given in Table 2.
Results and discussion
In the rest of this section, we report the results of our tests. We performed ten separate runs for each method.
Input feature impact
The ELM model is initialized using the GWO-MVO technique and evaluated with four input types: the raw pixel image, the CAE feature vector, the VGG feature vector, and the combined VGG-CAE feature vector. Figures 6 and 7 compare the different approaches on the two datasets, CIFAR-10 and CIFAR-100, with a fixed set of 100 hidden nodes. Each figure includes both evaluation scenarios: original data and data with noise.
In both evaluation scenarios and across the four fitness functions, we observe that the VGG feature vector and the combined VGG
Conversely, we notice that the CAE feature vector yields the lowest results on the original version of the datasets. However, the model fed directly with image pixels, without the feature extraction process, performs the worst on the noisy version.
One of the critical factors in machine learning is the ability of the model to fit new data correctly. Figure 8 illustrates the generalization gap of the two feature vectors, VGG and VGG
ELM initialization impact
We draw box plots to analyze the impact of different initialization methods for ELM input parameters, which clearly represent the data dispersion and outliers. We compare the five initialization methods: random, GWO-MVO, with the four fitness functions:
The comparison presented in Fig. 9 reveals the superiority of GWO-MVO, regardless of the fitness function employed. In addition to the significance of the chosen input features, these results strongly highlight the necessity of initializing the ELM with appropriate input parameters.
Figure 10 depicts the generalization gap observed in the two versions of the two datasets. The figure focuses on two initialization methods, random initialization and our GWO-MVO method, using the
In addition to the influence of VGG
Fitness function impact
Figures 11 and 12 give an overview of how the ELM model initialized by GWO-MVO performs on the four fitness functions for the two datasets, CIFAR-10 and CIFAR-100, respectively. The evaluation includes the four input types presented in Section 7.4.1, using 100 hidden nodes. Both figures show the two evaluation scenarios, including the original dataset and the dataset with added noise.
ELM model performance using GWO-MVO initialization and 100 hidden nodes on the four fitness functions for the CIFAR-100 dataset (both test versions).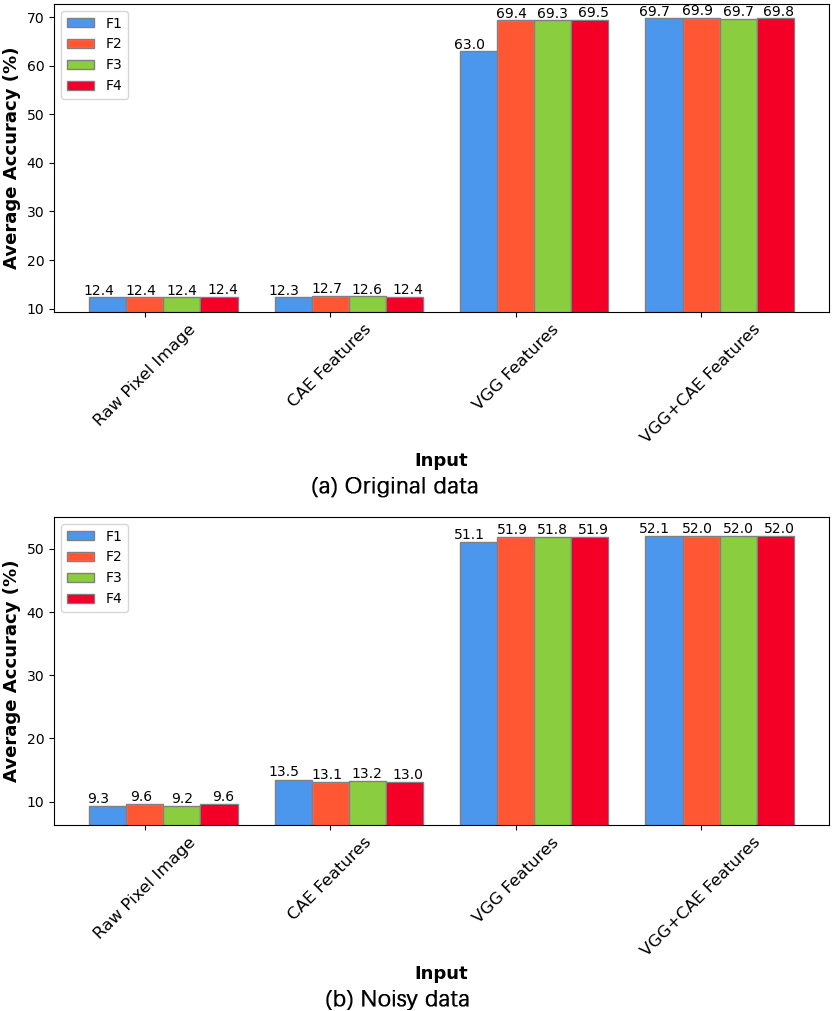
The results demonstrate a close similarity in the performance of the four evaluation functions, making it challenging to specify the clear best function. However, the
Best average accuracy and standard deviation for the original data version
Average accuracy over the two test sets based on the number of ELM hidden nodes.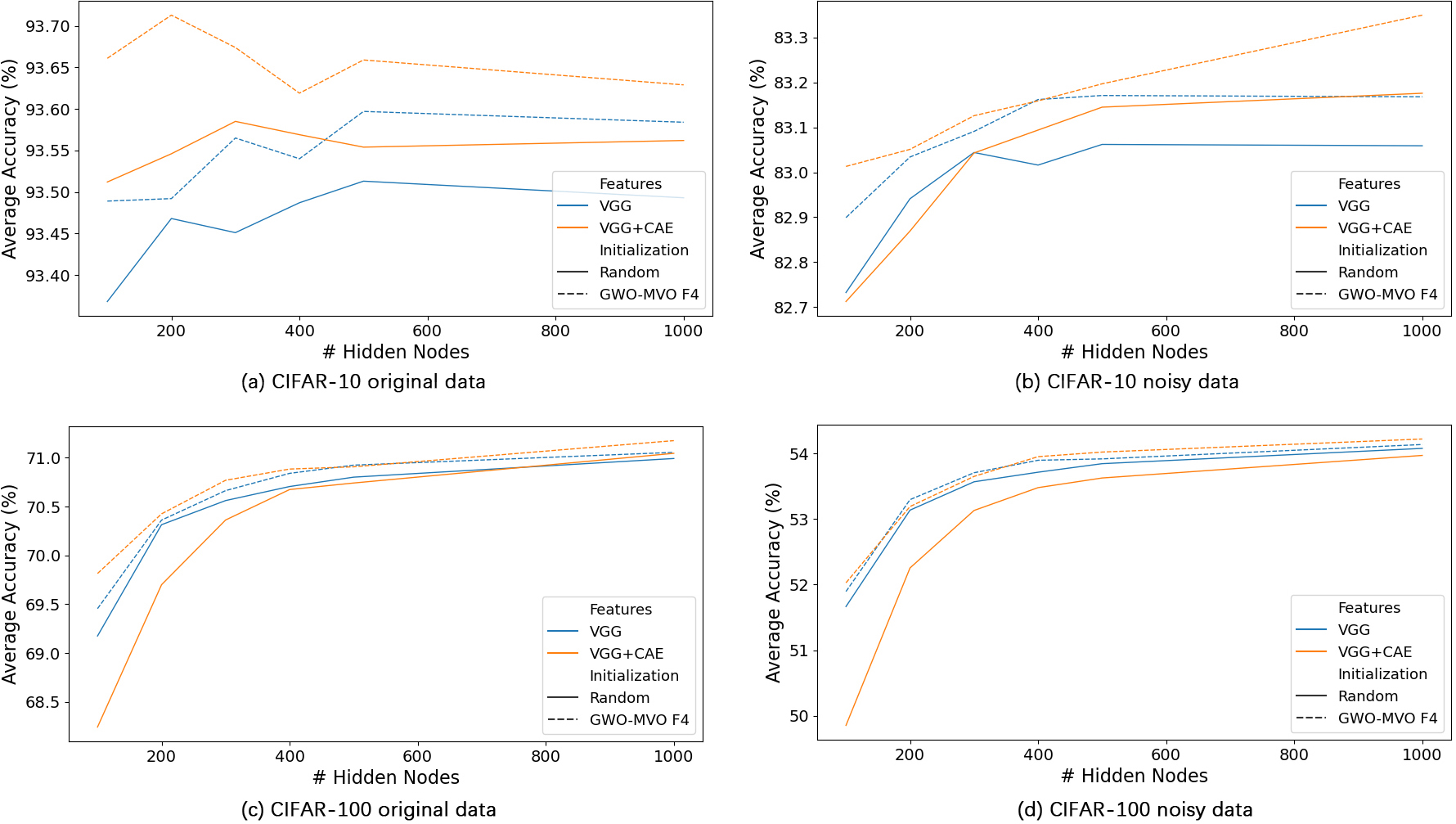
Best average accuracy and standard deviation for the noisy data version
Best average accuracy and standard deviation for the noisy data version
Ablation study of key components in our method using 100 hidden nodes on CIFAR-10.
SD: Standard deviation, Acc: Accuracy, GG: Generalization gap.
Ablation study of key components in our method using 100 hidden nodes on CIFAR-100
SD: Standard deviation, Acc: Accuracy, GG: Generalization gap.
Figure 13 displays the average accuracy achieved on the test set, according to the number of hidden nodes, for both the original and noisy versions of the CIFAR-10 and CIFAR-100 datasets. Regarding input features, the comparison focuses on VGG and VGG
We observe that increasing the number of hidden nodes enhances accuracy. However, this observation is inconsistent with the CIFAR-10 dataset, particularly with the original data. On the other hand, despite the superior performance of approaches using VGG
Comparing average accuracy between different metaheuristic-based ELM approaches using 100 Hidden Nodes
Comparison between different classifiers performance
1000 hidden nodes were used for the ELM classifier. Acc: Accuracy, TT: Training time.
Comparison with similar methods on CIFAR-10 and CIFAR-100
Acc: Best accuracy, Err: Best error rate.
To facilitate the numerical comparison of the results, we provide in Tables 3 and 4 the best outcomes achieved on the test set for each tested method. The best results are highlighted in bold, while the worst results are underlined.
Upon initial observation, it is evident that our approach achieved superior performance in both versions of the two datasets. For the CIFAR-10 dataset, the best results on the test set, when models were trained and tested on the original and noisy data, were 93.71%
We further find that models fed directly by the input images, without going through the feature extraction process, perform the worst. Especially when using the GWO-MVO optimization algorithm with the
To investigate the effectiveness of the critical components of our approach, we conduct ablation studies. Tables 5 and 6 provide details on standard deviation, mean accuracy, best accuracy, worst accuracy, and the rate of generalization gap for both CIFAR10 and CIFAR100 datasets. The outcomes of the two datasets in both versions show remarkable similarity. Initially, we observe a significant enhancement in test accuracies and standard deviation when VGG features are used. However, this gain is accompanied by a deterioration in the generalization gap due to the overfitting problem of VGGs. Subsequently, integrating CAE features may decrease the accuracy in some cases, but it improves the generalization gap. Furthermore, by optimizing ELM weights and biases using GWO-MVO, our method achieves greater competitiveness in prediction stability, evident from the further improvements in all metrics.
To validate our approach, GWO-MVO-ELM is compared with two other metaheuristic-based ELM models: PSO-ELM and GWO-ELM. Table 7 presents the average accuracy results. We note that VGG
Additional experiments are conducted with other classifiers to further verify the superiority of the proposed method. The classifiers evaluated were KNN, RBF-kernel SVM, standard ELM, and our optimized ELM. Each classifier was fed with the VGG
Our proposed method with the three fitness functions
On the other hand, our approach shows the worst training time, particularly with the two functions that use cross-validation,
Comparison with previous works
To conduct a comprehensive evaluation of our method, we compare it with similar works of equivalent complexity on the CIFAR-10 and CIFAR-100 datasets. The proposed method is compared with several other approaches, including VGG16 [17], DCNN [10], VGG-16-pruned-A[52], VGG16-AFP-E [53], DCT-Net [36], SNN-VGG-15 [54], and CIFAR-VGG [51]. The results are shown in Table 9, and the best ones are in bold.
As can be seen, our method outperformed all the compared approaches, achieving the highest accuracies on both versions of the two datasets. This improvement is particularly notable in the case of the noisy version of the data, where our technique significantly outperforms the others. We reached an accuracy of 93.8% on the standard CIFAR-10 dataset and 83.47% on the noisy version. For CIFAR-100, our method achieved accuracies of 71.4% and 54.57% on the original and noisy data, respectively. These outcomes further highlight the strong performance of our approach across both datasets and the superior stability obtained on noisy data.
Conclusion
In this study, we proposed a new method for improving the basic ELM model for the image classification task. Our proposal focuses on the input features as well as the initial weights and biases of the model. Features extracted from CNN and CAE were used as input to the ELM model. While the hybrid GWO-MVO metaheuristic was used for weight and bias optimization. Four fitness functions were applied by considering three properties: the norm of the output weights, the training set’s error rate, and the validation set’s error rate. We validated our method on two benchmark datasets: CIFAR-10 and CIFAR-100. We even considered the variation in real-life image quality by training and testing our models on the original and noisy datasets. The obtained results revealed the effectiveness of our method.
The proposed method capitalizes on the strengths of the ELM classifier and the VGG and CAE models in a synergistic manner that effectively mitigates the limitations of each model. While using VGG features enhances the performance of the ELM model, combining these features with those extracted by CAE not only boosts accuracy but also reduces overfitting. Furthermore, using the GWO-MVO algorithm for ELM hyperparameter initialization provides an additional advantage. An essential benefit of our approach is its ability to achieve good performance with a few hidden nodes, significantly reducing hyperparameter tuning time. Experimental results demonstrate the robustness of our method, even when applied to datasets with high noise levels. The technique maintains its efficacy in such challenging conditions, showcasing its suitability for real-world scenarios. Furthermore, our method outperforms other classifiers, KNN, SVM, conventional ELM, PSO-ELM, and GWO-ELM.
In summary, the superior performance of our proposed approach can be attributed to several crucial factors, including the consistent prediction stability, the ability to fully exploit the classification power of the ELM classifier, and the capacity to reduce overfitting. On the other hand, even though reducing input features using deep learning extraction can improve training time, optimizing ELM weights and bias is still time-consuming. Hence, enhancing training time remains an area that requires attention and improvement. In our future work, we plan to further improve our model by optimizing both the CNN and CAE architectures. Future efforts will also focus on optimizing the architecture of our approach by adapting parallelism in the ELM parameter tuning phase to enhance training time.