
Abstract
Objective:In order to save teachers’ correcting time, improve the accuracy and efficiency of English composition grading.Methods: This paper briefly introduces the algorithm of deep sentence smoothness and text semantic matching based on graph neural network, and then designs an automatic scoring algorithm for English text. Result: The experimental data was collected from 12,000 essays written by international students in the United States in the Pratt & Whitney Foundation’s Automated Student Value Assessment Project (ASAP), and these data were graded through a comparative experiment,Through comparative tests, the automatic scoring algorithm designed in this paper can achieve better scoring results and better handle automatic essay scoring problems. Among all the experimental mean values of evaluation methods, the experimental mean value of the algorithm designed in this paper is 0.790, the smoothness algorithm is 0.768, and the text matching vector is 0.759. The experimental mean values of the other two traditional automatic scoring algorithms are 0.710 and 0.712 respectively, and the results are lower than the algorithm designed in this paper. Conclusion: According to the experimental results, it can be concluded that good feature selection can give good scoring performance to the algorithm and cope with the problem of automatic scoring. At the same time, it also confirms the feasibility of the algorithm designed in this paper, which can be effectively applied in practical English composition scoring.
Introduction
English education has received great attention, and writing is an important part of exams such as the middle school entrance examination, CET-4 and CET-6, TOEFL, and IIELTS [1, 2]. Writing can comprehensively reflect students’ understanding and application abilities of language, such as the use of vocabulary and grammar and the mastery of discourse structure. However, due to the complex subjective expressions involved in English writing, it cannot be simply evaluated through mechanical means, which brings many problems to the grading work. From the perspective of grading, compared to objective questions and subjective questions with smaller length, the difficulty of grading an essay is greater and requires a lot of manpower and material resources.In simulated exams, examiners need to perform high-load homework in a closed environment, which is inevitably influenced by personal subjectivity and external factors, resulting in incomplete agreement on the evaluation standards, making the structure not objective enough, resulting in errors, and damaging the fairness of grades [3, 4]. In order to save teachers’ correction time and improve the accuracy and efficiency of English essay grading, this article applies automatic grading technology to English texts. During this period, smoothness is a key attribute of the text, reflecting its readability and comprehensibility. Therefore, it is often used as an important indicator for scoring. The article precisely captures this key factor and will design an English text automatic scoring algorithm based on sentence smoothness features and text matching features, and compare its performance with other algorithms to explore its feasibility. Due to the different domestic and foreign environments, this type of research is still in the preliminary stage. Through this preliminary exploration, the article aims to better fill this research gap and lay the foundation for further development in this field.
Word2vec word vector model
Principle of Word2vec word vector model
Bengio proposed a neural language model, introducing neural networks into the training of speech models, and using language models to generate word vectors, which are essentially the use of context words to predict the central word or the use of the first n words to predict the next word. Word vectors are a by-product of this. Later, Mikolov proposed the Word2vec model, which aims at better obtaining word vectors [5]. Word2vec model adopts two more efficient neural network models and Skip-Gram, and simultaneously utilizes hierarchical Softmax and negative sampling technology [6, 7]. Continuous Bag-of-Words (CBOW) belongs to the continuous bag-of-words model, which removes the time-consuming non-linear hidden layer [8, 9, 10].
Function derivation
The CBOW model predicts
The weight matrix from the hidden layer to the output layer is
The maximum likelihood function and gradient descent method are used to solve the parameters. For Skip-Gram model, the calculation process is the opposite of CBOW, predicting
Softmax is used in the classification process to implement multiple classifications. Softmax is used to map some output neurons to real numbers between 0 and 1, and normalize the sum to 1, so that the probability of multiple classes adds up to 1. The function is defined as follows:
Where
Doc2vec sentence vector model principle
Representing a sentence or a document as a vector is an important problem that can have many applications, such as similarity calculation, classification, clustering, etc. For short texts, the bag of words model is usually used, but the bag of words model has the disadvantages of ignoring word order and syntactic and semantic information. Doc2vec overcomes the shortcomings of the traditional bag of words model and can learn the vector representation of sentences unsupervised through machine learning in large-scale corpora [11, 12, 13].
Doc2vec architecture
Doc2vec trains sentence vectors in a very similar way to Word2vec. The core idea of training word vectors is that each word, the word in context, can have an impact. Similarly, Doc2vec is trained in the same way, for a sentence, if you want to predict the words in the sentence, then you can combine the way to generate features based on other words and the relationship between other words and sentences. The Doc2vec framework is shown in Fig. 1.
Doc2vec model framework.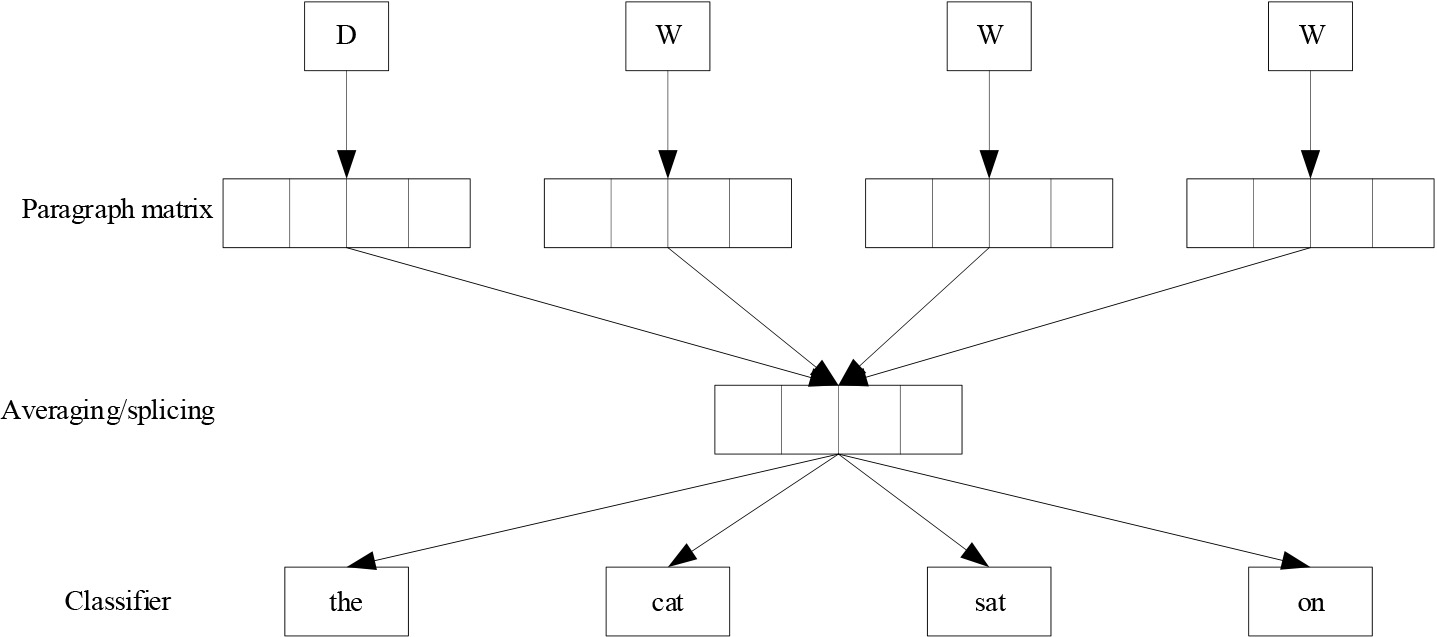
Paragraphs are mapped to a vector space, represented by columns of matrix D, and words are similarly mapped to a vector space of the same level, represented by columns of matrix W. Then the paragraph vector and word vector are concatenated or averaged to get the feature, and the next word is predicted according to this feature. The process of predicting the current word based on the paragraph matrix and the context word, the paragraph vector is shared across all sentences of a paragraph, and the paragraph vector is also trained during the construction of the model. The process of predicting a random word in a paragraph according to the paragraph vector. This training method ignores the context of the word and uses Softmax classification to predict other words in the sentence.
Deep sentence smoothness algorithm based on multi-feature fusion
Smoothness is a key attribute of text, and constructing the structure of smooth text is an important problem in natural language processing. In automatic essay scoring, a good essay always has a special high-level logical and thematic structure, in which the actual word and sentence selection and the arrangement between them serve this high-level structure. Therefore, a deep sentence smoothness algorithm integrating multiple features is proposed. The specific architecture is shown in Fig. 2.
Statement smoothness algorithm architecture.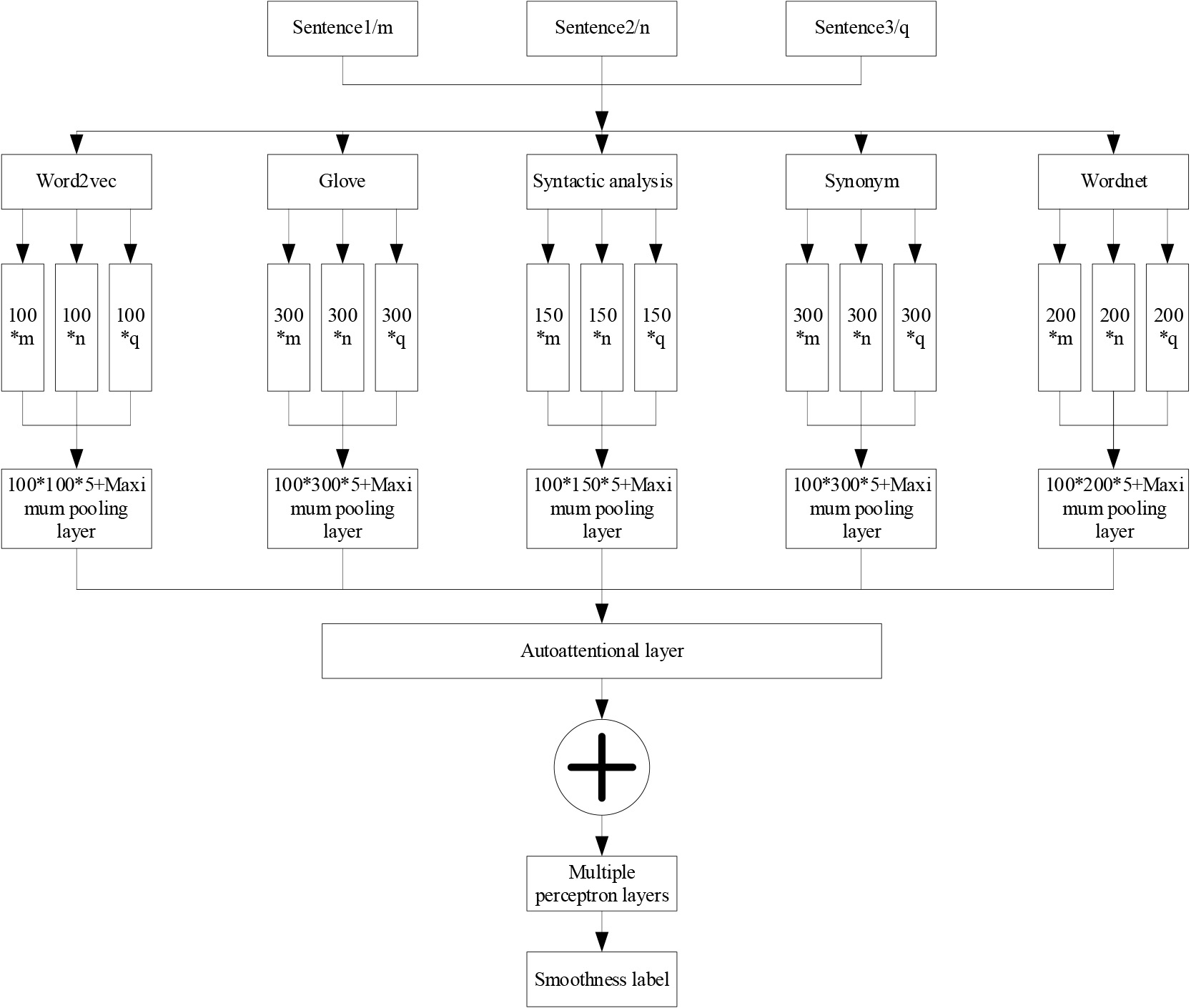
It can be seen that the algorithm architecture mainly covers two parts: the first part uses many features to represent words vectorically, and then forms a variety of different sentence representation matrices to form the input layer; The second part is the network structure of the smoothness algorithm, which carries out feature extraction and relationship modeling between sentences, including convolution layer, pooling layer, self-attention layer, multi-layer perceptron layer and output layer.The advantage of this algorithm is that feature fusion improves the accuracy, robustness and stability of the algorithm, while reducing the data dimension, processing missing data, and improving the interpretability of the model. In practical applications, feature fusion has been widely used and has become one of the core techniques of many algorithms.Overall, deep sentence smoothness algorithms that integrate multiple features have prominent advantages in text recognition.
The goal of text matching is to evaluate the semantic similarity between the original text and the target text, which is very important in many natural language processing tasks. For example, information retrieval, automatic question answering, machine translation, dialogue system and repetition problems can be abstracted into text semantic matching problems to some extent. Based on this, the text semantic matching algorithm architecture of graph neural network is given, as shown in Fig. 3.
Text matching algorithm architecture.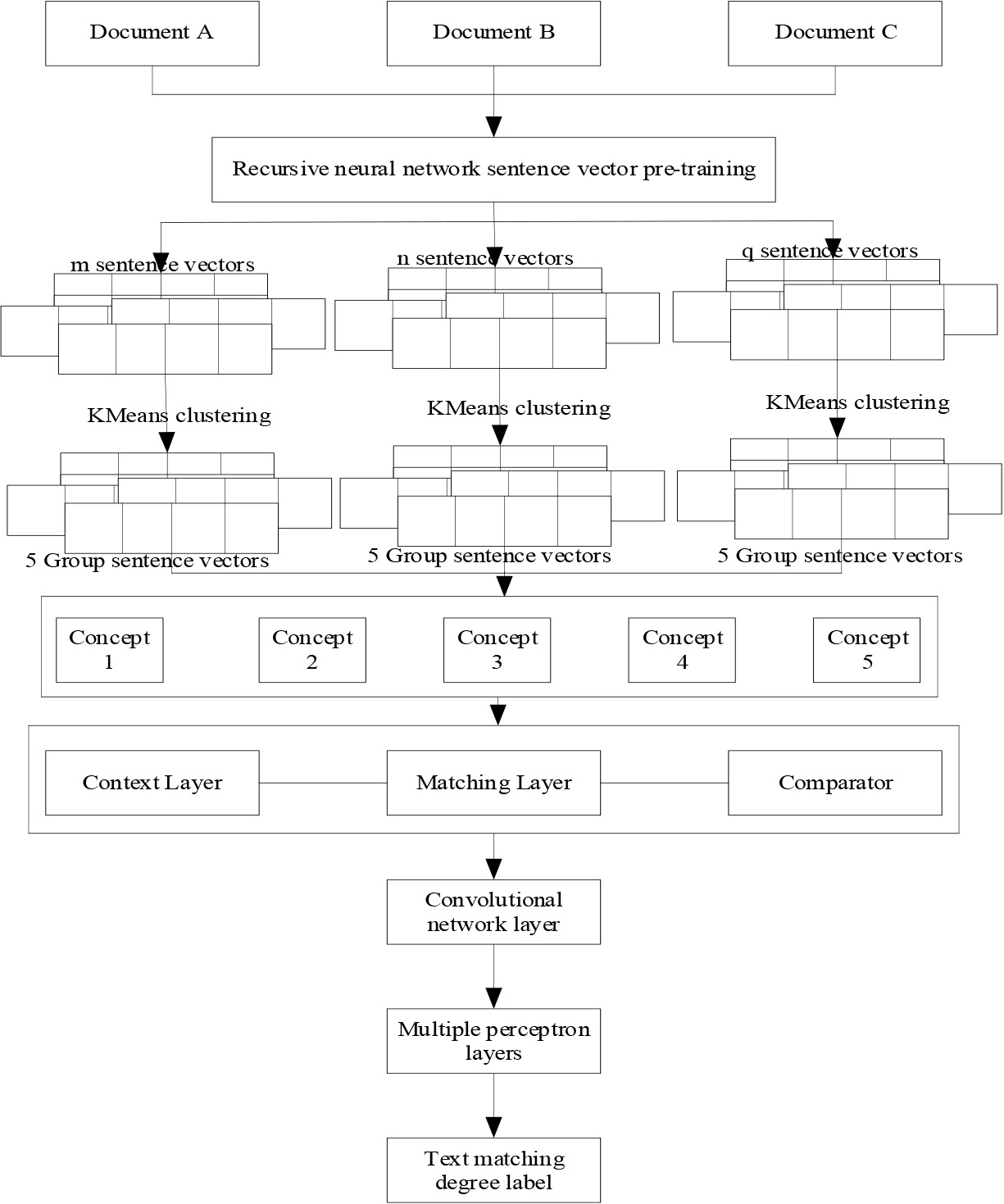
It can be seen that the text semantic matching degree algorithm based on graph neural network mainly covers four parts: the first part can preprocess the sentence and pre-train the sentence vector, and extract the structural features of the article by using recurrent neural network; In the second part, we cluster the sentences and combine the sentence vectors from the three documents to form the concept. The third part is used to construct the vertices and edges of the graph in the graph convolution Network, use the Triplet Network to form the eigenimage vector of the fixed points in the graph, and use the sentence Tf-idf similarity to form the edge weights. The fourth part includes the graph convolutional network layer, and then the multi-layer perceptron layer and the output layer, which are used to train the vertex feature vector, and then get the similarity feature of the document.The algorithm has the following advantages: First, it can learn end-to-end. End-to-end means efficient, can effectively reduce the information asymmetry of the intermediate link, once the problem is found in the terminal, each link of the entire system can be adjusted. Second, good at reasoning. Large-scale graph data can express human common sense and expert rules that are rich and contain logical relations. Graph nodes define understandable symbolic knowledge, and irregular graph topologies express reasoning relations such as dependence, dependency and logical rules among graph nodes, so they have strong reasoning ability. Third, it is analyzable. Graphs have a strong semantic visualization ability, which is enjoyed by all GNN models, and thus gives them strong parsing ability.Therefore, the text matching degree algorithm based on graph neural network can effectively deal with text matching problems.
The automatic essay scoring algorithm designed in this paper integrates the sentence smoothness features and text matching features. The overall architecture of the algorithm is composed of the basic algorithm layer, the engine layer and the interface layer, as shown in Fig. 4.
The basic algorithm layer contains some basic algorithms and models used in the system, which are called by the engine layer. Among them, the word vector module includes pre-trained Word2vec word vector model and Glove model, and the neural network model module includes convolutional neural network, self-attention network and graph convolutional network and other common deep learning models. In the engine layer, there are algorithm engines and storage engines. Among them, the storage engine consists of the MySQL database and disk file format, which is mainly used to store data sets for the algorithm engine to call. The algorithm engine includes sentence smoothness calculation engine, text matching calculation engine and total score calculation algorithm engine. In the interface layer, it involves four kinds of apis, such as smoothness score API, text match score API, total score API, and user interaction API. Among them, the first three apis interact with the corresponding engine, and the last API is used to input the score type required by the user. After the user API gets these data, the first three apis are called to obtain the score and transmit it to the user.This automatic essay scoring algorithm, which integrates sentence smoothness features and text matching features, has the advantages of smoothness feature matching algorithms, such as accuracy, robustness, stability, and reduction of data processing dimensions. It also integrates the advantages of text matching algorithms, such as being able to learn end-to-end, good at reasoning, and strong parsing.It can be seen that this algorithm combines the advantages of integrating sentence smoothness features and text matching features, and is even more suitable for the development of essay grading.
ASAP data set
ASAP data set
Architecture of automatic essay scoring algorithm that incorporates sentence smoothness features and text matching features.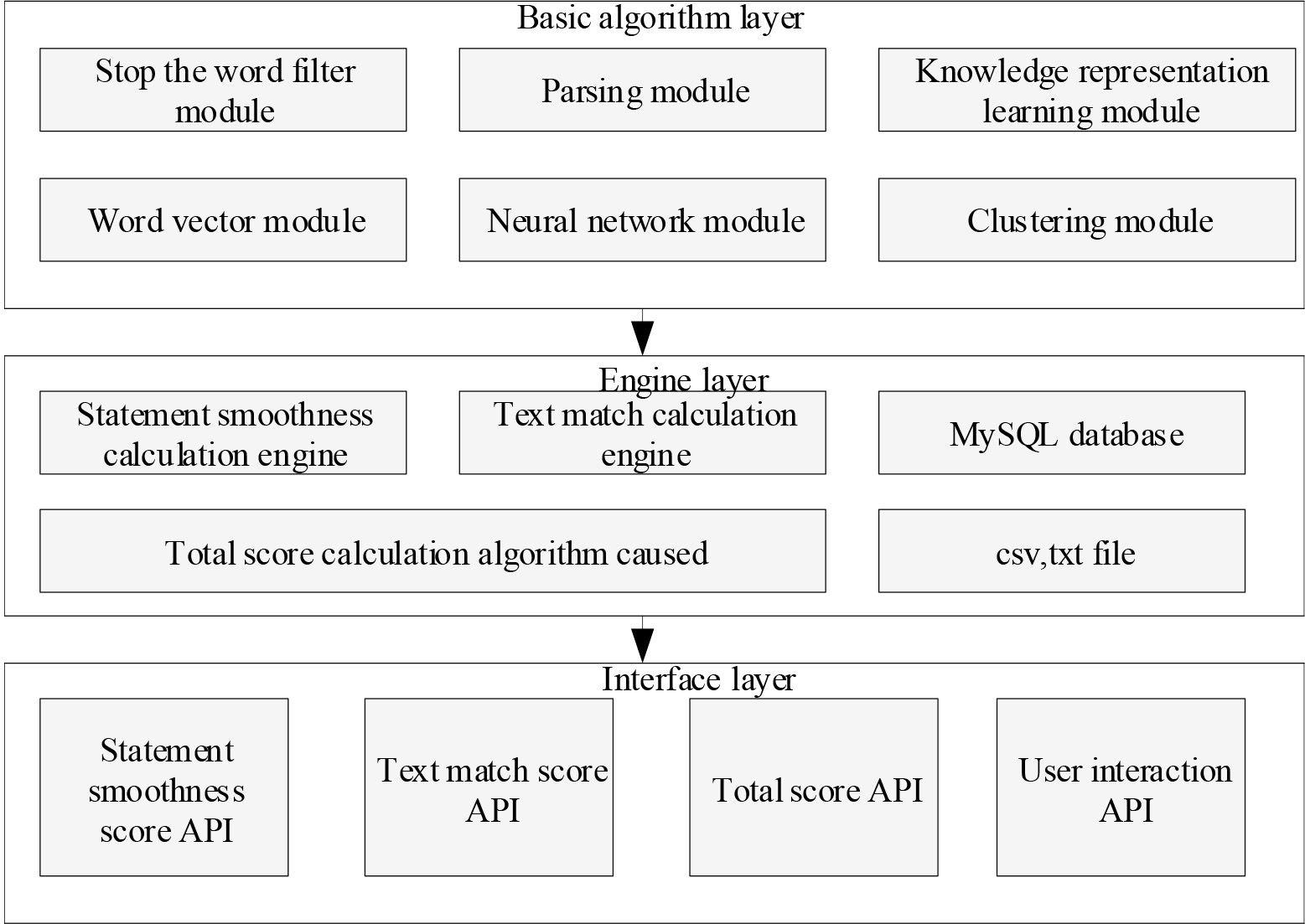
Experimental data
The essay experimental data came from the Pratt & Whitney Foundation’s Automated Student Value Assessment Project (ASAP), which aims to develop an automatic essay scoring algorithm for student writing. The essay data of 12,000 international students in the United States is divided into eight sets, and each essay set has a corresponding profile. The selected articles are generally between 150 and 500 words long. These 8 data sets have their own characteristics, which can better test the feasibility of the scoring algorithm. The corresponding data sets are shown in Table 1.
Most of the essays in the dataset are manually entered into the computer and stored in the tab-separateb Value(TSV) file and Microft Excel file format. The ASAP project also uses data desensitization techniques to anonymize the data and ensure the privacy of the authors. Using algorithms including Named Entity Recognition(NER) technology, identify information such as “organization”, “person”, ‘place” in the article and replace it with the words “@PERSONI” [14, 15]. In the selection of evaluation index, Quadratic Weight Kappa value used by the official data source is selected to quadratic Weight Kappa to indicate consistency, with a value range of [0,1], where 0 indicates inconsistency. 1 indicates consistency. If the articles in dataset M have a total of N possible scores, then
The calculation of Quadratic Weight Kappa in the whole dataset M is as follows:
Where,
Fisher Transformation is an approximately variously stable transformation with different scoring ranges of different data sets. The influence of its final Mean Quadratic Weight Kappa needs to be normalized, as shown in the following formula:
In this way, the Mean Quadratic Weight of Kappa after conversion can be obtained, which is the value of Kappa as the final evaluation index.
Pytorch deep learning technology is used to build the model, and the training server is selected by 8-core inteli7-6850k CPU, 32G memory, and equipped with an NVIDIA GeForce GTX 1070 graphics card. The network Settings of the text matching degree algorithm based on neural network are as follows: the convolution kernel size is 100*300*5; The GloVe vector has 200 dimensions; The output dimension of LSTM is 100, the number of layers of multi-layer perceptron is 3, and the dimensional distribution is [100,50,20]. While using the Adam optimizer, set the batch size to 128 and the epochs to 10. In order to better reflect the performance of the automatic essay scoring algorithm, A comparative test was carried out with the deep sentence smoothness algorithm integrating multi-features, the text matching algorithm based on neural network, the EASE algorithm and the CNN-LSTM algorithm. The specific setting details are as follows: First, the input of LSTM layer removes the sentence smoothness vector
Experimental results
Based on the selection of the above data set and the setting of the experiment, the experiment of automatic essay scoring algorithm is carried out here and compared with other scoring algorithms. The results obtained are shown in Table 2.
Comparison of experimental results
Comparison of experimental results
It can be seen that all algorithms, including EASE algorithm, have achieved good experimental results, indicating that through a good feature selection, traditional machine learning algorithms can also perform automatic scoring of English as a good feature. Meanwhile, it has been proved that automatic scoring tasks can conduct more accurate modeling by artificially selecting multiple article features and some deep features. It also explains the reasons why the two deep features of the text choice sentence smoothness and text matching can bring better results. Therefore, the results of
In summary, this paper first explains Word2vec word vector model and Doc2vec sentence vector model, which lays a solid theoretical foundation for the empirical analysis of automatic essay scoring. Secondly, the paper analyzes the algorithms related to English essay scoring, including the deep sentence smoothness algorithm based on multi-features and the text matching algorithm based on graph neural network. Then, based on these two algorithms, an automatic essay scoring algorithm is designed and the corresponding architecture is given. Finally, in order to test the feasibility of the algorithm designed in this paper, a comparative test was carried out, compared with EASE algorithm, Model(sb), Model(SA) and CNN-LSTM. The results showed that, the mean value of model (All) is 0.790, higher than that of other algorithms, which confirms the feasibility of the algorithm designed in this paper and can make due contributions to the automatic scoring of English compositions.In the future, in the field of education, it can not only save teachers’ correcting time, but also improve the accuracy and efficiency of English composition scoring, avoid the influence of subjective factors or fatigue errors in teachers’ scoring, and give the most authentic scoring results to a great extent, which has a high application prospect.