
Abstract
FL is a futuristic research topic that enables cross-sectoral training in ML systems in various organizations with some privacy restrictions. This review article establishes the extensive review of FL with different privacy-preserving techniques and the obstacles involved in the existing privacy-preserving model. This review is initiated by providing the background of FL and provides an overview of the technical details of the component involved in FL. Then it provides a brief review of the around 75 articles related to privacy-preserving in the FL-enabled techniques. Compared to the other survey articles this presented review article provides a brief analysis of the different privacy terms utilized in FL. The categorization of the privacy preservation models in FL highlights the significance of the model and the obstacles that limit the application of the particular privacy preservation model in real-time application. Further, this review articles ensure the details about the year of publishing, performance metrics analyzed in different articles along with their achievements. The limitation experienced in each category of the privacy-preserving technique is elaborated briefly, which assists future researchers to explore more privacy-preserving models in FL.
Introduction
Federated Learning (FL) theory was initially proposed in 2016 [1, 2, 3], where the main objective of FL is to secure the owners’ data based on data training using Machine Learning (M.L) techniques. Due to the capability to support group training of regional learning models without impacting data privacy, FL has drawn considerable attention [1]. The fundamental tenet of FL is to safeguard information users’ confidentiality by using ML models depending on data dispersed throughout many devices. Setting up a coordinating server in FL is required because it is responsible for collecting participant-reported gradients and providing the participants with recent data [4]. Edge devices can learn a shared global model through FL, a unique decentralized model used for privacy protection by preventing edge devices from releasing confidential details to the cloud server. When using FL, a shared global model is downloaded from a cloud server hy user that trains it using local data provided by various people, and then forwards the modified gradient data to the cloud server [1]. The application of FL is broad in several fields like medical fields, financial fields, etc. Hence, the user data generated by mobile devices, including smartphones and automobiles, is enormous that comes in many different forms [2].
Creating secure data pathways, protecting privacy, maximizing bandwidth and network communication, and lowering latency are all advantages of FL [5]. FL includes many advantages but it still includes some drawbacks like high transmission cost and bandwidth. Various privacy issues still exist in FL, in a network of shared parameters, a remote hacker can carry out a variety of attacks to gain access to users’ private images from surveillance cameras, and the critical reactions of automated cars can also be violated by numerous enemies, and wearable gadgets can even be used to alter health information for patients [1, 6]. FL will safeguard data of users’ privacy by developing ML models depending on datasets dispersed across various devices [4]. The importance of security and data privacy has become a significant global concern due to the growing awareness of huge organizations failing to user privacy and data security [7]. Google suggested that FL be used to address the aforementioned issues. The term “metadata” refers to a neural network’s weight, gradient, and structure [4], hence, the security of data can be enhanced while the communication burden is reduced. Since there is no capability to defend against external attacks, FL holds a vital role in the maintenance of privacy; its initial goal is to stop neighbors from data theft [8].
The numerous iterations of DL algorithms, intends majority of DP-based approaches [2, 9, 10] to utilize more information security budgets, increasing the potential for privacy violations. To maintain utility and privacy, certain solutions typically lose some accuracy of the model. When using cryptographic techniques like FHE, SMC-based systems typically demand enormous processing, making them ineffective in practical applications. Furthermore, FL frequently results in significant transmission power, which is largely controlled by the interaction between cloud servers and clients [2]. The fog-cloud network’s IoT applications are encouraged to run at various nodes due to the decentralized blockchain technology [11, 12], with various implementation techniques including fault-tolerant systems, consensus, miners, and smart contracts for server and client the blockchain technology is used [12]. The traffic flow can be predicted in TFP and centralized ML techniques by training with sufficient data in sensor. In TFP, centralized ML methods are typically utilized to predict traffic flow by training with sufficient sensor data [13]. HE and SMC-based approaches securely aggregate them. The user’s privacy is protected, and the server receives correct aggregate information as a result. Approaches based on HE and SMC are susceptible to security threats because of their high computational cost and restriction on the server’s ability to monitor and control single updates [14, 15, 16, 17].
The prime intention of the research is to analyze different privacy-preserving FL techniques. The collected articles are categorized into perturbation-based privacy-preserving FL, Blockchain-based privacy-preserving FL, encryption-based techniques, and anonymization-based techniques. This article provides the achievements and the research gaps. The analysis is done based on performance metrics, and categories help the researchers to obtain insights about the widely used metrics and techniques and it supports research to develop a new technique by fulfilling the research gap.
The review article is organized as follows: Section 2 consists of the research details the background of the FL techniques along with the privacy concern. Section 3 of the review article provides a taxonomy of the privacy preservation model in FL. Section 4 of the article provides a review of the existing privacy preservation techniques employed in FL. Section 5 provides the analysis of the existing methods in terms of performance metrics, achievement, year, and journal of publication. Section 6 provides the research gaps in the existing privacy preservation model. The article is concluded in Section 7.
Background
To resolve the problems of legalization, data privacy, and transmission costs Google researchers introduced the idea of FL (FL) in 2016 [18, 19, 20, 21, 22, 23, 24]. The phrase “FL” was initially used by [20] in 2016 to solve privacy issues. Its central concept is to train ML models on distinct datasets dispersed through several applications or organizations, which can somewhat protect the privacy of local data. Since FL has grown quickly and turned into a popular subject of study in the field of AI [25, 26, 27]. The key drivers of the development are the numerous and effective applications of ML technologies, big data growth, and international legal requirements for protecting data privacy [27].
Due to the increasing significance of the privacy of data, FL was created. DL will be severely hampered as a result of people’s growing reluctance to provide their sensitive data as security awareness rises. However, in reality, the majority of businesses, except for a few large corporations, only have insufficient evidence of low quality, which is inadequate for the adoption of data-hungry AI services. The data from commercial businesses often have a large amount of potential worth from an enterprise’s point of view. Data is typically not shared between businesses, or even between sections inside the same business. Because of this, data within a single organization is frequently represented by isolated islands. The majority of a user’s data, including their travel history, insurance status, and other private details, also includes the user’s identity. Uploading unencrypted original data to the Deep Lerning (DL) server, in this case, is dangerous. By aggregating the approach among several clients while preserving the privacy of their data, it can increase the model’s efficacy [28].
A distributed ML strategy known as an FL method involves training models on endpoints, businesses, or persons under centralized management without utilizing local datasets. This guarantees the confidentiality of the data used for training. The parameters trained are periodically collected by an edge server or cloud server to build and update a better and more precise model, which is then distributed back for local training to the edge devices. In general, the FL training process consists of five parts. The FL server initially chooses an ML model that are trained using the clients local databases. In the second step, the current clients subset is selected using a client selection algorithm like Federated Client Selection (FedCS) [29]. The initial model is thirdly broadcast to the chosen clients by the server. The clients train the model locally using the most recent global model parameters. The fourth phase is when each client in the subset updates the server. Finally, without gaining access to any client data, the FL server gets the updates and aggregates them using aggregation methods like FedAvg [30] that results in a new global model. The FL server coordinates the training procedure and sends each round’s modifications to the chosen clients global model. Until the necessary degree of accuracy is attained, the processes will be performed iteratively [24].
Compared to conventional, centralized ML training, FL offers several clear advantages. The utilization of local data rather than sending data often to a remote server considerably reduces both time and bandwidth needed for training and inference. Due to the data remaining on the device of user, FL assures user security and privacy when using the updated model for prediction on the user’s device. Moreover, since the models are trained on edge devices, collaborative learning with FL is simple and uses less energy. The phrase implies that FL can be used in edge computing environments. It is a method that makes it possible to train ML models on mobile edge networks. Hence, utilizing FL in the EC paradigm could reduce the costs associated with communication as well as challenges related to security, privacy, and legalization [24].
Taxonomy
The existing privacy-preserving model used in the research articles is detailed and categorized in this section. The privacy-preserving schemes mentioned in the existing works are categorized into a)Encryption-based privacy-preserving, b)Perturbation-based privacy-preserving, c)anonymization-based privacy-preserving, d) blockchain-based privacy-preserving, and e) trusted execution-based privacy-preserving. Figure 1 Illustrates the categorization of techniques.
Categorization of privacy-preserving techniques in FL.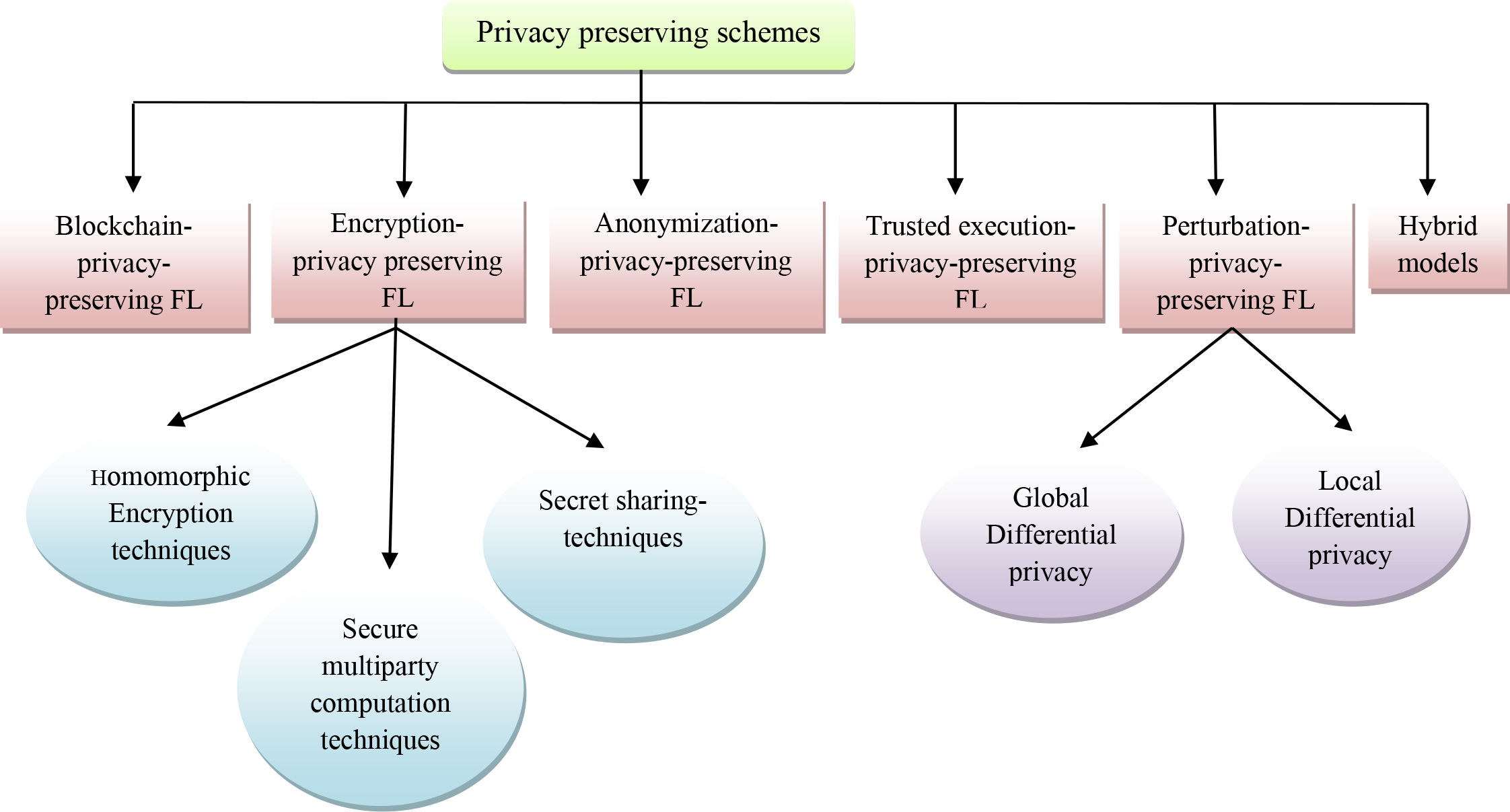
The encryption-based techniques generally utilize the cryptographic approach that sefeguards the data privacy in FL. The encryption techniques employed in the obtained research articles are further categorized into Harmonic encryption-based techniques and Secure multiparty-based techniques.
Encryption-based techniques
The encryption-based techniques generally utilize the cryptographic approach to safeguard the data privacy in FL. The encryption techniques employed in the obtained research articles are further categorized into Harmonic encryption-based techniques and Secure multiparty-based techniques. Asad M. et al. [1] presented a Federated Optimization approach utilized to improve the protection of privacy and efficiency of communication in FL. The benefit of this method is it compresses both downstream and upstream communication and deduced the communication overhead. This method does not suit the high dimensional datasets. A lightweight encryption protocol was designed by Fang C. et al. [2] that provided the preservation of privacy and the efficiency of training was enhanced using the optimization. This provided a high efficiency in training and a significant reduction in computational cost. The Double-key ElGamal protocol used in this method slows down the working. Moreover, Liu Y. et al. [13] presented an approach based on the prediction of traffic flow using FL.
Homomorphic encryption methods
Homomorphic encryption converts the data to the cipher text and enables the mathematical operation of the encrypted outcome without affecting the quality of the data. This homomorphic method is found to be productive in preserving confidential data during the parameter exchange in FL training. The homomorphic method is widely utilized in various FL methods in [3, 31, 32, 33].
The multi-key homomorphic encryption is presented by Ma J. et al. [33] to protect the private information from leakage during the public sharing of data. The homomorphic encryption is thus found to be effective in concerning energy consumption, cost, and accuracy. However, this model never resists the attacks generated by malevolent users and thus the model is not preferable for the actual IoT framework. Moreover, Fang C. et al. [3] developed a scheme called communication efficient and privacy-preserving method for the FL model with three key components gradient spatial sparsification, bidirectional compression, privacy-preserving protocol. The cryptographic protocol used is not safe. An FL technique that was decentralized in the blockchain was developed byYazdinejad A. et al. [32] that addressed the security issues. The parameter tuning was a hard task to achieve.
Secure multi-party (SMC) methods
The secure multi-party computation is characterized by the cryptographic scheme that empowers the distributed members to collectively estimate the cost function without exposing their private data. Hence, the multi-party-based technique is utilized in the privacy preservation model such as [4, 34, 35, 36, 37].
A framework was designed by Lu Y. et al. [34] for privacy-preserving at the edge that rained the model of numerous end users without any change of local data. The leakage level of privacy is measured along with the local data. Furthermore, Liu G. et al. [35] used the protocol for preserving the data and privacy in FL that depends on the co-utility. This method does not follow updated values that were not affected by the updated values. The protection against the bad updates was attained by reputation that consumed more time delay. The SMC is utilized by Zhou Z. et al. [36] to attain modal training and to solve the issues related to entity alignment. Further, the SMC model supports user withdrawal in FL scenarios to reduce the computational cost and achieve the highest accuracy. However, the model fails to detect malicious users to establish the dynamic FL framework that mitigates the data spill by the attackers. Similarly, Li Y. et al. [4] presented a multi-party secure chained computing framework using FL.
However, the aforementioned models are only suitable for synchronous FL platforms. Hence, the asynchronous federated SMC was presented by Gu B. et al. [37] to ensure the confidentiality and integrity of the vertically portioned data. The computational complexities and costs are further reduced to a great extent through the asynchronous federated SMC models.
Secret sharing-based techniques
Secret sharing is characterized as the cryptographic technique that ensures the original data’s reconstruction after the combination of the total number of shares. To prevent data spill during data transfer secret sharing is utilized by Zhu H. et al. [38], in which the individual confidential data were divided into random distributions.
Blockchain-based techniques
Blockchain is a decentralized ledger that accumulates the owner’s data, which is not accessed or altered by any illegitimate users making it more secure. Blockchain technology is utilized in various existing techniques like [5, 12, 39, 40, 41, 42, 43, 44, 45, 46, 47] to prevent confidential data from external attackers. The blockchain concatenates various components like attackers, servers, and clients. The privacy preservation model employed by Awan S. et al. [44] utilizes the distributed ledger for data exchange between the participating components. This model assists in modal training without compromising the verifiability and transparency of the decentralized network. Furthermore, Kong Q. et al. [31] and Liu H. et al. [43] presented FL-based detection of collaborative intrusion in vehicular edge computing as well as vehicular-fog-based navigation. Then, Ur Rehman et al. [5] mentioned a Reputation-Aware FL based on blockchain technology. In addition, Li J. et al. [39] presented blockchain Assisted Decentralized FL (BLADE-FL) approach for enhancing FL security and Kang J. et al. [40] studied the theory of contract and reputation by combining these two using an approach of joint optimization for making secure management of reputation. Afaq A. et al. [41] reviewed the blockchain-based model for improving reliability, privacy, and security. Kang J. et al. [42] studied the scheme for the selection of reliable workers based on FL.
The FL with committee consensus was presented by Li Y. et al. [45] to mitigate the security issues experienced in the modal training process. This model productively minimizes consensus computing, mitigate malicious attacks, and exhibits preferable achievement under malicious condition. Yet, the low training accuracy remains the main drawback due to the lack of network optimization. The blockchain-enabled hierarchical crowd-sourcing FL was presented by Zhao Y. et al. [46] that enhanced the utility and optimized the functional appliance. The FL with membership proof, which was presented by Jiang C. et al. [47], emancipated the threshold without affecting the security requirements. This model provided communication and computation overload.
Anonymization-based technique
Though the perturbation methods guarantee strong privacy they experience degradation in the utilization of data. The delicate attributes that reveal the identity of the individuals are modified or removed to ensure data privacy. Hence, Domingo-Ferrer J. et al. [48] and Choudhury O. et al. [49] utilized the anonymization technique to prevent the private information leakage via the attackers. The anonymity-based technique that was analytically defensible with few protocols was utilized in [48] that enhances the utility rate and the privacy of the system. Further, the utility and modal performance anonymization was enhanced and established in [49], which provided a maximum privacy level.
Perturbation privacy-preserving technique
In the perturbation methods, the sensitive data was added with pre-determined the random noise before the data transmission to the miners. The perturbation techniques were classified into x local differential privacy and local differential privacy. Many researchers utilize differential privacy in FL [29, 30, 50, 51, 52, 53, 54, 55, 56, 57] to secure the user’s data. Zhao B., et al. [50] presented the FL approach to prevent privacy leakage in industrial big data. Similarly, Pan Q. et al. [30] presented a mechanism of joint protection on the technologies of differential privacy (DP) and FL (FL) for energy harvesting (EH), and forecasting the speed of traffic on FASTGNN was studied by Zhang C. et al. [51]. Lee H. et al. [29] described a strategy on the digestive neural network (DNN) utilized for the training of FL in an effective and secure condition. Wang X. et al. [52] reviewed the strategies of privacy with decryption and encryption techniques based on non-Gaussian local features. The system based on differential privacy was presented by Wei K. et al. [53], the noise was added before the model aggregation. This model concentrated on satisfying the client’s requirements while increasing the privacy levels and the convergence rate. Zhao Y. et al. [54] demonstrated that differential learning based on differential privacy was utilized in the Internet of Vehicles (IoV) that enhanced the security of the delicate information of the clients. By using differential privacy, the adversaries found it difficult to track the vehicle’s location. Yang J. et al. [55] utilized differential privacy that tuned the modal parameters at facial identification modal training on the client side. Differential privacy was adopted to enhance security by minimizing the malware propagation threats on social media. Yet, the low convergence speed was the main drawback of the system. Huang X. et al. [56] utilized differential privacy that mitigated the issues related to the unbalanced data by updating the user’s training parameters. The FL techniques along with the Differential privacy were utilized by Olowononi F.O. et al. [57] that maximized the resiliency in the vehicular networks. However, there experience a drop-in accuracy in the differential privacy model due to the influence of privacy cost variation.
Trusted execution-technique
The trusted execution environment (TEE) was considered to be a pre-eminent technique that prevents threats against the gradient and the model parameters. The training of integrity protocol based on TEE was designed by Chen Y. et al. [58] to recognize the generative attacks in the networks. Hence, by using TEE the participants were prohibited from the collaborative training considering the availability and the confidentiality prospects.
Hybrid privacy preserving technique
Hybrid privacy-preserving methods were devised and utilized in recent years for effective balance in the tradeoff amoung data privacy and utility. The hybrid techniques were utilized in [7, 59, 60] to ensure the delicate data and increased the data utility privacy. The differential privacy was combined with the homomorphic encryption presented by Zhou C. et al. [7]that prevented data from attack and realized the accumulation of model parameters. It ensured the model and data security and restricted the collision attack generated by various entities. However, the computational cost remained a hectic issue that restricts the feasibility of the hybrid model.
A protection aggregation framework with Homomorphic and differential privacy was presented by Jia B. et al. [59] to mitigate various security vulnerability attacks, as follows model reverse attacks and model extraction attacks. The encryption algorithm combined with differential privacy and space differential gradient (SDG) was utilized by Yin L. et al. [60] to avoid data disclosure at the content and the data level. The storage and transmission efficiency was increased by employing the SDG in the privacy preservation frameworks. Yet, the hybrid model suffers from a drop in accuracy if there was an increase in user numbers in the cloud.
Other privacy preservation FL techniques
Si W. and Liu C. [61] presented the analysis of multimedia data using the method of deep cooperation and preservation of privacy. The lightweight protocol enabled the participants to transmit private data and combined the encrypted fragments. The semi-honest servers were prevented from enabling malicious attacking activities that affected data privacy. The verifiable FL was presented by Fu A. et al. [62] to protect privacy in the big data mining process. The privacy gradients were protected by the blinding technology employed in this research. The privacy-enhanced FL (PEFL) given by Zhang J. et al. [63] utilized the homomorphic cryptosystem that encrypts the local gradient of the users. The non-iterative federative learning scheme was presented by Wang F. et al. [64], which helped to aggregate and utilize the data of multiple owners without disclosing private information. Furthermore, Lu X. et al. [8] analyzed the edge computing mechanism using Asynchronous learning for effective tasks among the nodes without affecting their data. Furthermore, Khan L.U. et al. [65] presented a framework of DFL for 6G-enabled autonomous driving cars. Similarly, Tan J. et al. [66] described the network based on FL for the enhancement of security to minimize the cost of training.
Analysis of the existing works
Various existing privacy-preserving techniques in FL on the basis of various criteria are analysed and provided in this section.
Analysis based on the year of publication
The research papers from 2015 to 2022, are considered in which most of the research papers were published during the year 2021 for the FL based on privacy preservation. The analysis of the reviewed papers regarding the year of publication is revealed in Fig. 2.
Year of publication.
Year of publication.
Various privacy preservation methods
Analysis based on the year of publication.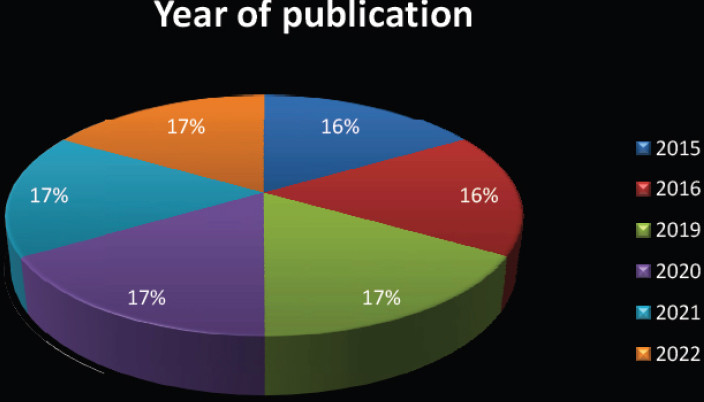
The analysis of the various FL methods are presented in Table 2, and the reviewed outcomes represents that most of the recent papers utilized is Encryption-based techniques. Consequently, Blockchain and the Perturburation-techniques are also significant methods frequently utilized for privacy preservation. The chart analysis of the reviewed papers along with the various reviewed methods is shown in Fig. 3.
Analysis on metrics
The metrics used by various researchers for the analysis of privacy preservation based on FL is represented in Table 3. The metrics such as accuracy, efficiency, execution time, precision, prediction error, and so on are measured which are analyzed and interpreted in Fig. 4.
Analysis on metrics
Analysis on metrics
The analysis of the reviewed papers regarding the published journals, the reviewed papers are published in the journals of IEEE, Springer, Elsevier, MDPI, Hindawi, arXiv, and Wiley are tabulated in Table 4. Based on the analysis, which is revealed that Springer, IEEE, and the MDPI are the most published journals from the reviewed papers on privacy preservation based on FL. The chart analysis regarding the published journals along with the reviewed papers are shown in Fig. 4.
Analysis on published journals
Analysis on published journals
Chart analysis based on the various methods.
The analysis of the reviewed papers regarding the achievement is Tabulated in Table 5 and Fig. 6 reveals the chart analysis regarding the achievements.
Analysis on published journals
Analysis on published journals
Analysis based on metrics.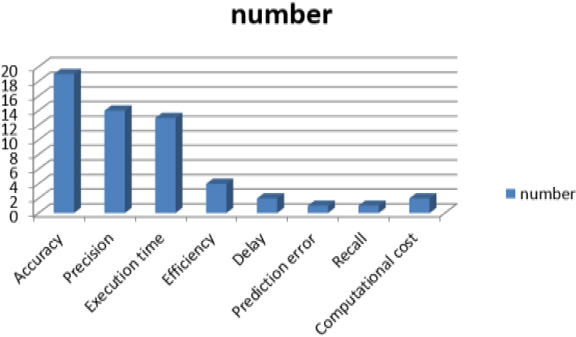
Analysis on published journals.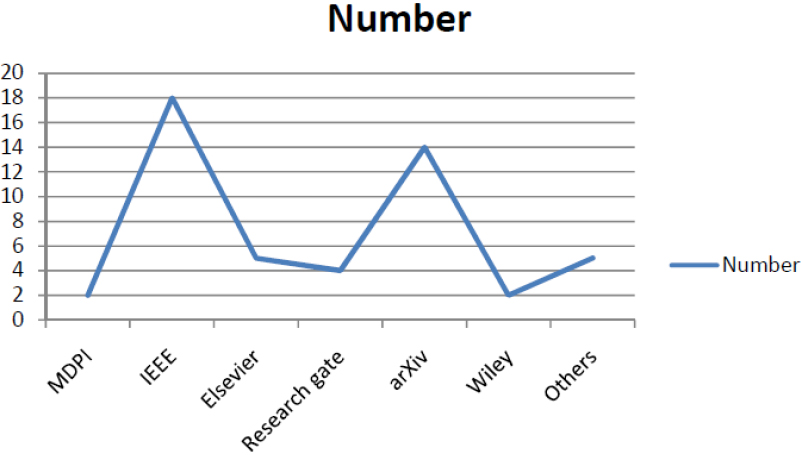
Chart analysis on achievements.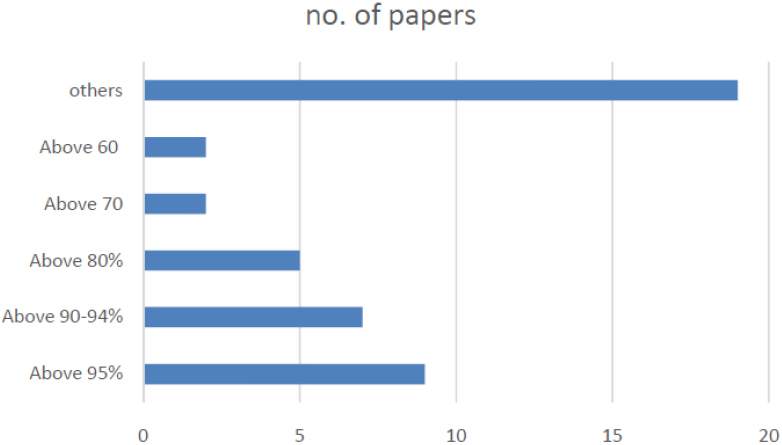
The limitations experienced in the existing methods are briefly illustrated in this section, which enables the researchers to obtain deep insight to the techniques.
Encryption-based techniques
The main limitation observed from the differential privacy-related methods is that they consume more privacy budgets as a consequence of multiple interactions of computational algorithms employed in the method, which leads to privacy leakage. The main drawback is that majority of the DP-based methods is the multiple iterations of DL algorithms cause intake large privacy budget, that leads to leakage in privacy [2]. The conventional SMC-based privacy preservation methods demand huge computational costs while utilizing the cryptographic models that resist them in using the real-time scenario [1]. The traditional methods generally exhibit huge communication overhead that affects the interaction of the data users and providers, which in turn degrades the data utility [1]. The conventional encryption strategies fail to address the client drop-out issue, which leads to the key reconstruction of all the data users that increase the computational complexity of fog computing. Further, the scheme fails to consider the new joiners, who tend to leak sensitive information [7]. The homomorphic encryption authorizes the computations on the encrypted model update. All the users share a similar public key for both the encryption and decryption process. Hence, the conventional homomorphic encryption schemes are vulnerable to internal curious attacks and Collison attacks, which threaten the security between the server and the device [3]. Homomorphic encryption needs the polynomial approximation in the case of non-linear functions, which results in a tradeoff between privacy and accuracy [3].
Blockchain-based static directives are vulnerable to scams and irresistible frauds, which makes the conventional blockchain not suitable for real-time environments [12]. The involvements and perplexities of a large number of participants in blockchain-based privacy-preserving FL systems generate heterogeneity in multiple data at multiple stages that affect the reliability of the techniques [5]. The consensus mechanism, so-called Proof of Quality (PoQ) is utilized to determine rewards allotment in the blockchain and restricts the single-point-failure. However, they are forced to involve third-party intrusion, so-called miners in blockchain, to save the collection system in a decentralized manner. This generates the model leakage because the model parameters are open to the miners in the blockchain [5].
Security attacks on FL, such as Byzantine attacks and model poisoning attacks aim at disrupting model convergence and due to the learning process [48]. Privacy protection technologies are differential privacy [3]. K-anonymity, l-diversity, and t-closeness cannot resist background knowledge attacks [56].
Most of the existing research employed differential privacy (DP) [50] to prevent the FL model against security threats. Even though DP is found to be a better model to satisfy the privacy requirement, generally it provides low data utility due to the influence of excessive noise [49]. The perturbation technique generally involves tampering with and deleting the sensitive information in the table, which may result in the loss of relevant information in the data. The computational complexity in recovering the data and the delay in the execution time is considered the major drawback of the perturbation-based technique [57].
The implementation process and the complexities in the network slow down the entire authentication model, which affects the quality of the data utility service [58].
Model security will be threatened through some attacks, which obtain the information of training data set from model parameters [60]. The trade-off between the computational cost and the accuracy is the main drawback experienced in the Hybrid privacy-preserving technique [60]. The consumption of time is the main drawback of the hybrid preserving technique due to the complexities experienced in modal training [7]. The privacy model based on hybrid techniques is vulnerable to prevailing security attacks, such as the model reverse attack and the model extraction attack [59]. The larger noise due to the integration of differential privacy results in the degraded model performance on a specific dataset. Further, the differential privacy of the participant parameter tends to be invalid if there is an alteration in the privacy budgets of the user by the malicious nodes [59].
The communication efficiency of the three-tier architecture FL is the major difficult task thus, there is the requirement of optimizing the communication strategy and also to make sure the applications of FL [5]. The unexpected behavior as well as the intended performances negatively influence the time of convergence and the precision of the FL. Thus, there is a need for various optimization algorithms for modeling the possible worker selection method [40]. The computational complexity of the FL is high due to the enormous hyperparameter modeling in the privacy preservation techniques thus, the development of an effective preservation technique is required [31].
FL is a new emerging topic, which is applicable in all aspects of life such as hardware and software platforms and real-time applications. FL is also categorized under collaborative training, in which the algorithm gets strained across various servers or devices. This review article highlights one of the main obstacles in FL known as data privacy. This article reviews around 75 articles related to the FL concepts and provides deep insights into the privacy-preserving mechanism involved in the article. This article elaborates on brief insights into the different privacy-preserving methods and the challenges employed in FL. Further, this research elucidates achievements and the challenges observed in the existing techniques. However, the research article leaves the future scope of reviewing the different applications of privacy-preserving FL in various domains.