
Abstract
In multiple criteria decision making (MCDM) with interval-valued belief distributions (IVBDs), individual IVBDs on multiple criteria are combined explicitly or implicitly to generate the expected utilities of alternatives, which can be used to make decisions with the aid of decision rules. To analyze an MCDM problem with a large number of criteria and grades used to profile IVBDs, effective algorithms are required to find the solutions to the optimization models within a large feasible region. An important issue is to identify an algorithm suitable for finding accurate solutions within a limited or acceptable time. To address this issue, four representative evolutionary algorithms, including genetic algorithm, differential evolution algorithm, particle swarm optimization algorithm, and gravitational search algorithm, are selected to combine individual IVBDs of alternatives and generate the minimum and maximum expected utilities of alternatives. By performing experiments with different numbers of criteria and grades, a comparative analysis of the four algorithms is provided with the aid of two indicators: accuracy and efficiency. Experimental results indicate that particle swarm optimization algorithm is the best among the four algorithms for combining individual IVBDs and generating the minimum and maximum expected utilities of alternatives.
Keywords
Introduction
In the Internet and Big Data era, human lifestyles have undergone an unprecedented revolution. An individual’s life is filled with a lot of data, which makes people more informed than ever before. At the same time, people must choose between deriving useful information and knowledge from data for use in practice and abandoning their attempt to employ data in real problems. Because of the availability of information, people usually choose to find effective information and knowledge from various types of data and use them in practical cases. Such a choice improves their capability to handle complex problems. The choice also results in more uncertain environments associated with real problems than before due to the randomness, unavailability, noise, sparsity, and variety of data. In this environment, people may have difficulty directly finding overall solutions to real problems. A feasible way to overcome the difficulty is to analyze real problems from multiple different perspectives, and then combine the relevant analyses to generate overall problem solutions. This method is called multiple criteria decision making (MCDM) in an uncertain environment.
To effectively model and analyze uncertain MCDM problems, many attempts have been made with the help of different uncertain expressions. Representative expressions include intuitionistic fuzzy sets [1], hesitant fuzzy linguistic sets [2], hesitant fuzzy sets [3], probabilistic linguistic sets [4], belief distributions [5], interval-valued fuzzy sets [6], interval-valued hesitant fuzzy linguistic sets [7], interval-valued intuitionistic fuzzy sets [8], interval-valued hesitant fuzzy sets [9], interval type-2 fuzzy sets [10], and interval-valued belief distributions [11]. In theory, MCDM methods with these expressions are sufficient for analyzing all real problems. From real cases or numerical examples in these studies, few methods are found which aim to solve large-scale problems with many alternatives and criteria. In addition to this, when interval-valued assessments are adopted, such as interval-valued hesitant fuzzy elements or interval-valued belief distributions, the search space for finding solutions increases exponentially with the increase in the number of interval-valued hesitant fuzzy element values or the number of interval-valued belief distribution grades.
Evolutionary computation provides a feasible and effective way to find acceptable or satisfactory solutions within a limited time. When MCDM problems are regarded as multi-objective optimization (MOO) problems constructed on a common set of variables, many evolutionary MOO approaches have been developed to find the optimum trade-off among criteria which is the most consistent with the preference of a decision maker [12, 13, 14, 15, 16, 17]. Three methods (priori, interactive, and posteriori) are usually applied to combine the preferences of a decision maker with the MOO process [15, 16]. If the preferences of a decision maker are not considered in the MOO process, the results of the MOO may not be satisfactory.
In practice, individual assessments on different criteria may not be always constructed on a common set of variables. For example, a radiologist determines whether a nodule of a patient is malignant from the perspectives of contour, echogenicity, calcification, and vascularity. It cannot be said that the judgments on the nodule with the consideration of contour and those with the consideration of any other perspective are made by the radiologist through the same set of variables (or features). As another example, when the same discipline at different universities is compared, many criteria are considered, such as research projects, publications, awards, patents, social services, and excellent alumni. Individual assessments on different criteria are generated from different data rather than common data. When encountering these situations, a decision maker takes into account the individual assessments on all criteria synthetically rather than improving the values of most objectives and balancing them to generate solutions. MCDM problems with large search spaces in these situations can also be solved by using evolutionary algorithms. For example, Javanbarg et al. [18] used particle swarm optimization (PSO) algorithm [19] to solve MCDM problems modeled by a fuzzy analytic hierarchy process, and Chen and Huang [20] used PSO algorithm to solve MCDM problems modeled by interval-valued intuitionistic fuzzy numbers.
Existing studies show that less attention has been paid to the application of evolutionary algorithms to MCDM with different sets of variables used on different criteria. This makes it questionable whether MCDM methods with different ways to characterize different types of uncertain nature (e.g., [3, 7, 8, 9, 10, 11]) can be applied to solve MCDM problems with large search spaces. There is a gap between the solution requirements of large-scale MCDM problems and relevant studies on effective solution approaches. Although there are few studies on the combination of evolutionary algorithms and MCDM with different sets of variables (e.g., [18, 20]), some important issues deserve investigation. The issues include: (1) why PSO algorithm has been selected for application in MCDM; (2) whether PSO algorithm can be applied to MCDM with different types of uncertain expressions other than interval-valued intuitionistic fuzzy numbers and fuzzy triangular numbers; and (3) which evolutionary algorithm has better performance when applied to MCDM with a specific type of uncertain expression. In fact, different evolutionary algorithms can be applied to solve the same real problem. For example, when determining the near-optimal scheme for recharging batteries at a battery swapping station, Wu et al. [21] used three representative evolutionary algorithms including genetic algorithm (GA) [22, 23], differential evolution (DE) algorithm [24], and PSO algorithm to find the minimum running cost. Their experimental results show that GA and DE algorithms achieve higher accuracies and lower efficiencies than PSO algorithm; specifically, PSO algorithm fails to obtain the objective. Inspired by this, much attention should be paid to a key issue, which is comparing the accuracies [21, 25] and efficiencies [14, 26] of different representative evolutionary algorithms for solving large-scale MCDM problems with specific types of uncertain expressions and different sets of variables.
In this paper, to address this key issue, we aim to compare the accuracies and efficiencies of four representative evolutionary algorithms, which are GA, DE algorithm, PSO algorithm, and gravitational search algorithm (GSA) [27], for analyzing MCDM problems modeled by interval-valued belief distributions (see Section 2). Because combining individual interval-valued belief distributions is an important and necessary MCDM sub-process of MCDM, the combination processes using the four algorithms are presented. To fairly compare the four algorithms, their original versions (instead of their extensions) are used in the processes. With the aid of the processes, experiments with different numbers of criteria and grades used to profile interval-valued belief distributions are performed to compare the accuracies and efficiencies of the four algorithms for combining interval-valued belief distributions and generating the expected utilities. The comparative analysis of experimental results helps select the appropriate evolutionary algorithm to find satisfactory solutions to MCDM problems with interval-valued belief distributions within a limited or acceptable time. A sensitivity analysis of the accuracies and efficiencies of the four algorithms is provided to highlight the conclusion drawn from the comparative analysis.
The rest of this paper is organized as follows. Section 2 recalls the modeling of MCDM problems by using belief distributions and interval-valued belief distributions. Section 3 presents the processes of four evolutionary algorithms for combining interval-valued belief distributions. Section 4 compares the accuracies and efficiencies of the four algorithms for combining interval-valued belief distributions. The results of the four algorithms for generating the expected utilities are compared in Section 5. A sensitivity analysis of the performance of the four algorithms is provided in Section 6. Finally, this paper is concluded in Section 7.
Preliminaries
Modeling of MCDM problems using belief distributions
In the evidential reasoning (ER) approach [28, 29, 30], which is a type of multiple criteria utility function method, belief distribution is used to characterize the uncertain preferences of a decision maker. Because belief distribution is a special case of interval-valued belief distribution, the method for modeling MCDM problems using belief distribution is reviewed first.
Suppose that alternative
Assume that criteria weights are represented by
Combination of belief distributions
The contents in the above section show that the ER rule [32] is the key to find solutions to MCDM problems modeled by belief distributions, which is simply presented as follows.
.
[32] Given individual assessments
where
and
In Definition 1,
Due to the lack of sufficient data and knowledge or the nature of the decision problems under consideration, in some situations, a decision maker can only provide interval-valued belief distributions (IVBDs) as the evaluations of alternatives. For example, when a radiologist provides the diagnostic category in thyroid imaging reporting and data system published by Horvath et al. [34] for the thyroid nodule of a patient, he or she only reports the interval-valued cancer risk rather than the precise cancer risk of the patient.
In this situation, individual IVBDs are represented by
Normalized IVBDs are valid but valid IVBDs may be unnormalized [35].
From normalized individual IVBDs, a pair of optimization problems is constructed by using the ER rule to generate the aggregated IVBD
In the pair of optimization problems,
Solving this model, in which
The combination of individual belief distributions by using the ER rule to generate the aggregated belief distribution
When the number of criteria
In the following, the original processes of the four evolutionary algorithms for solving the pair of optimization problems shown in Eqs (14)–(17) are presented to facilitate comparing the accuracies and efficiencies of the four algorithms. When the objective in Eq. (14) is changed to that in Eq. (22), the similar processes of the four algorithms can be used to determine the minimum and maximum expected utilities, which are omitted to avoid repetition. To guarantee a fair comparison, extensions of the four algorithms are not adopted.
GA process for combining individual IVBDs
The GA process for combining individual IVBDs is presented as follows.
Step 1: Initialization
For the pair of optimization problems in Eqs (14)–(17), the
Randomly generating
Step 2: Performance evaluation
When the lower bound of
Step 3: Selection
The selection probability of the chromosome
where
Step 4: Crossover
After selection, two chromosomes
Step 5: Mutation
After the selection and crossover operations, a chromosome
where
As presented in Section 2.1,
and When
where
and
By following a similar rule, the normalized belief distribution is obtained as
and Note that as After the selection, crossover, and mutation operations are performed, the fitness values of all chromosomes are recalculated to update the best objective with the corresponding solution. If The DE algorithm process for combining individual IVBDs is presented as follows. For the pair of optimization problems in Eqs (14)–(17), the Step 6: Update
Step 7: Termination
Step 1: Initialization
The
Step 2: Performance evaluation
Through the same process as Section 3.1, the fitness value of the individual
Step 3: Mutation
For the individual
and
To guarantee that the mutated belief distribution is feasible,
Step 4: Crossover
Given a random indicator of crossover
and
Then, the crossed individual
Step 5: Selection
If the fitness value of the crossed individual
Step 6: Update
After the mutation, crossover, and selection operations are performed, the fitness values of all individuals are recalculated to update the best objective with the corresponding solution.
Step 7: Termination
If
The PSO algorithm process for combining individual IVBDs is presented as follows.
Step 1: Initialization
For the pair of optimization problems in Eqs (14)–(17), the position and the velocity of the
and
The
Step 2: Performance evaluation
Through the same process as Section 3.1, the fitness value of each particle is obtained. From the fitness values of all particles, the initial value of the best position of each particle and that of the best position of all particles are also obtained as
and
Step 3: Position update
Two random real numbers
and
To avoid extreme velocity,
From the updated velocity of the particle
To guarantee the feasibility of the updated position of the
The feasible updated position of the
Step 4: Best position update
After the positions of all particles are updated, the fitness values of all particles are recalculated to update the historical best position of each particle and the historical best position of all particles to be
Step 5: Termination
If
The GSA process for combining individual IVBDs is presented as follows.
Step 1: Initialization
For the pair of optimization problems in Eqs (14)–(17), the position and velocity of the
The
Step 2: Performance evaluation
Through the same process as Section 3.1, the fitness value of each agent is obtained.
Step 3: Update of gravitational coefficient and inertial mass
In the
and
respectively. By using
where
The passive and active gravitational masses
Step 4: Calculation of the total force acting on the
th agent
In the
and
where
Assume that
where
Step 5: Calculation of acceleration and velocity
The acceleration of the
Step 6: Update of the agent’s position
From the acceleration of the
where
The resulting velocity is then used to calculate the updated position of the
Through the same process as Step 3 of Section 3.3, the normalized position of the
Step 7: Termination
If
For a MCDM problem modeled by IVBDs, the aggregated IVBD of each alternative is usually used to analyze the problem. Although the final solution cannot be directly generated from the aggregated IVBDs of alternatives in most cases, beneficial analyses can be generally obtained. More importantly, the aggregated IVBDs of alternatives can be combined with the utilities of grades
The optimal
and the solution time using the four algorithms to combine specified IVBDs with 12 sets of
The optimal
Suppose that all individual IVBDs are normalized in a MCDM problem, which makes Eqs (2.3)–(2.3) hold. There are two types of situations in which IVBDs are normalized. One is that
and
or
and
while the other is that
The IVBDs in the first type of situation are regarded as specified and those in the second type of situation as general. In the following, specified IVBDs are first used as foundations to compare the accuracies [21] and efficiencies [14] of the four evolutionary algorithms presented in Section 3 for combining individual IVBDs.
We focus on the aggregation of specified IVBDs satisfying
and
For simplicity, assume that
with
and
With this assumption, without loss of generality, four evolutionary algorithms are used to determine
To fairly compare the four algorithms, it is specified that
The optimal
and the solution time using the four algorithms to combine specified IVBDs with 12 sets of
The optimal
Suppose that the optimal values of
As for the optimal
The optimal
The optimal
For a MCDM problem with general IVBDs, suppose that
and
with
and
On this assumption, normalized IVBDs are combined using the pair of optimization problems shown in Eqs (14)–(17). With 12 sets of
The optimal
and the solution time using the four algorithms to generate the expected utilities from specified IVBDs with 12 sets of
The optimal
The optimal
Suppose that the optimal values of
From the observations shown in Table 4,
When the aggregated IVBDs of alternatives are not needed, the optimal expected utilities of alternatives are required to generate a solution to an MCDM problem with the aid of a decision rule. In this situation, we compare the accuracies and efficiencies of the four evolutionary algorithms for generating the optimal expected utilities using specified and general IVBDs.
Utility comparison of the four evolutionary algorithms using specified IVBDs
In the same situation as specified in Section 4.1, GA, DE, PSO, and GSA are used to solve the optimization model shown in Eqs (22)–(25) to find the optimal
The optimal
and the solution time using the four algorithms to generate the expected utilities from general IVBDs with 12 sets of
The optimal
The optimal
Suppose that the optimal
Table 6 shows that
In the same situation as specified in Section 4.2, experiments similar to those in Section 5.1 are performed to generate the optimal
The optimal
and the solution time using the four algorithms to combine specified IVBDs with
The optimal
The optimal
Table 7 shows that
The conclusion of
In Sections 4 and 5, experiments to compare the accuracies and efficiencies of the four evolutionary algorithms are conducted on the condition that
To investigate this, when
To facilitate observing the movement of the optimal
Movement of the optimal 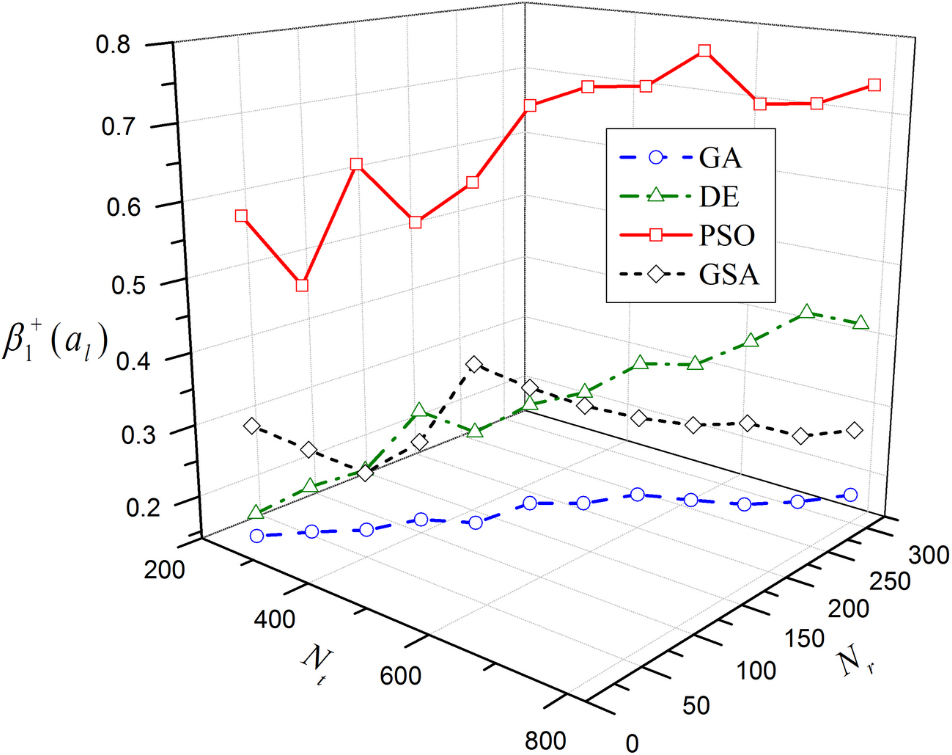
Movement of the optimal 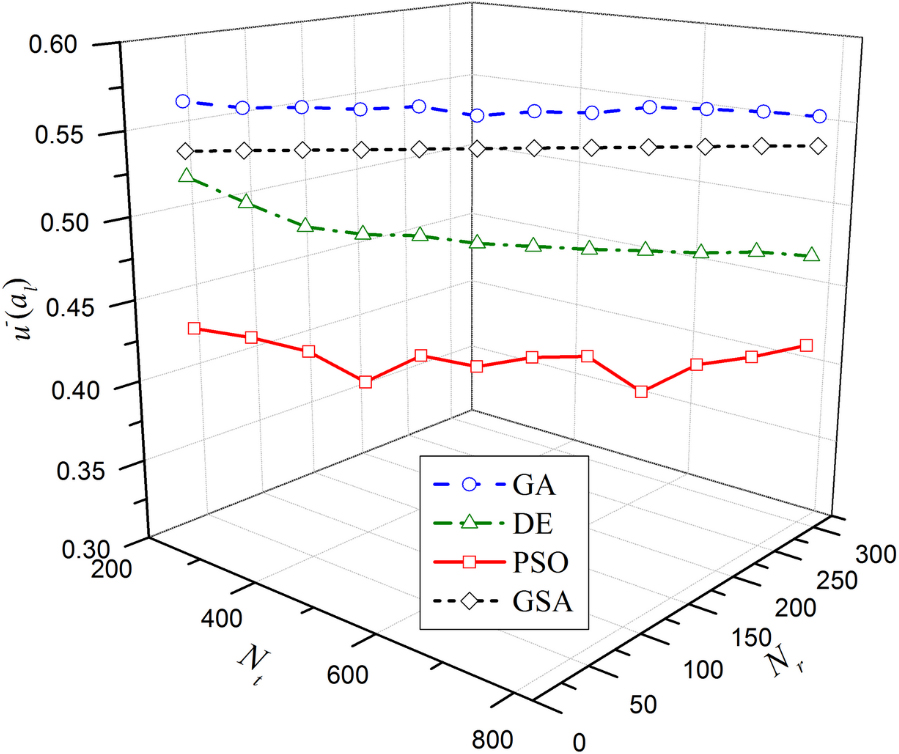
Figure 1 shows that with the increase in
As for the efficiencies of the four algorithms, Tables 9 and 10 show that
In the process of solving MCDM problems with IVBDs, individual IVBDs are explicitly combined to generate an aggregated IVBD or implicitly combined in the optimization model of generating the minimum and maximum expected utilities. For an MCDM problem with a large number of criteria and grades, implementing the accurate combination of IVBDs within an acceptable time is difficult. Evolutionary algorithms provide effective methods for overcoming this difficulty. When these algorithms are selected to combine IVBDs or generate the expected utilities by implicitly combining IVBDs, a new issue occurs: which algorithm is suitable for accurately combining IVBDs within an acceptable time? To address this issue, four representative evolutionary algorithms with many extensions and applications, including GA, DE algorithm, PSO algorithm, and GSA, are selected to explicitly and implicitly combine IVBDs. By performing experiments on combining IVBDs and generating the expected utilities, a comparative analysis of the four algorithms is provided with the help of two indicators: accuracy and efficiency. The analysis indicates that PSO algorithm is more suitable than the other three algorithms to combine IVBDs and generate the expected utilities. This conclusion is highlighted by a sensitivity analysis of the four algorithms’ accuracies and efficiencies.
In this paper, we only compare the original versions of the four evolutionary algorithms for analyzing MCDM problems with IVBDs. Whether the extensions of the four algorithms can improve their accuracies and efficiencies for combining IVBDs deserves consideration, and will be investigated in the future. In addition, for MCDM problems with other types of uncertain preferences, such as linguistic term set, intuitionistic fuzzy set, hesitant fuzzy set, and interval type-2 fuzzy set, it would also be interesting to compare the accuracies and efficiencies of the four algorithms for analyzing the problems.
Footnotes
Acknowledgments
This research is supported by the National Natural Science Foundation of China (Grant Nos. 71622003, 71571060).