
Abstract
Stance detection for user reviews on social platforms aims to classify the stance of users’ reviews toward a specific topic. Existing studies focused on the internal semantic features of reviews’ texts, but ignored the external knowledge associated with the review. This paper retrieves external knowledge related to the key information of each review by mapping it to a knowledge graph. Thereafter, this paper infuses the external knowledge into deep learning model for stance detection. Considering that infusing external knowledge may bring noise to the model, this paper adopts the personalized PageRank method to filter the introduced irrelevant external knowledge. Infusing external knowledge can improve the classification performance by providing background knowledge. In addition to considering the textual features of reviews when constructing the stance detection model, this paper employs a gated graph neural network (GGNN) approach to fuse the structural information between reviews to capture the interactions of reviews. The experiments show that the model improves 1.5% –6.9% in macro-average scores compared to six benchmark models in this paper. By combining the textual features and structural information of reviews and introducing external knowledge, the model effectively improves the stance detection performance.
Introduction
With the development of social media, people tend to post reviews on hot topics and express their opinions through online social platforms, such as Weibo, Twitter, and Facebook. Users rely on these platforms to follow the development of hot topics and explore public opinions through communication and interaction with other users. Stance detection is based on methods, such as machine learning, to detect whether the text of a user’s review on a given topic is support, deny, or neutral [1]. It has been shown that stance detection tasks play a crucial role in opinion control and rumor identification [2], which has led to wide academic interest in automatic extraction of feature information for stance detection [3].
Stance holding is a subjective and inter-subjective phenomenon that is influenced by subjective personal views and objective factors (e.g., cultural, social) [4]. The development of stance detection research lingers in its infancy because the division of the role of subjective and objective factors on stance detection remains unclear. Several competitions have successively proposed stance detection tasks, among which the well-known ones are NLPCC and Semeval. These competitions publish stance detection tasks by providing datasets, evaluating metrics, and attracting many scholars to participate in them. Prior research proposed stance detection models on the basis of CNN [5], Bi-LSTMs [6, 7], and other deep learning approaches [8], to effectively capture stance information.
Stance detection is closely related to sentiment analysis, as a person’s stance is often reflected in their sentiment. Recognizing this relationship, many studies have leveraged sentiment information to improve stance detection performance [9–13]. In addition, the textual content of reviews can most intuitively reflect a user’s stance. Many studies have demonstrated that extracting textual features from reviews, such as word/phrase occurrence, pretrained word embedding, can also effectively capture stance information [14–17]. For example, Mohtarami et al. [15] utilized an end-to-end approach to automate stance detection, they used graphical CNN [16] and long short-term memory networks (LSTM) to extract features from the input tweet text and introduced similarity matrices to calculate the relevance to the target topic or statement of the tweet, accordingly. In addition, prior studies have shown that considering text features and social information, such as relationships between users or reviews, significantly outperforms stance detection approaches that rely on either text features or social information alone [18–22].
However, most existing studies on stance detection have not fully leveraged external knowledge and structural information, which have been shown useful for improving performance on other text classification tasks. Specifically, (1) most existing studies on stance detection have not utilized external knowledge from knowledge graphs. Knowledge graphs contain broad contextual information that can enhance the understanding of reviews. Incorporating such external knowledge into stance detection models may strengthen their robustness and improve accuracy. (2) most studies have not fully leveraged structural information, such as relationships between reviews, for stance detection. Structural information reflects the patterns of community opinions and stances.
This paper proposes a novel method that combines knowledge graph and gated graph neural network model (KRGGNN), to address research gaps in stance detection by utilizing external knowledge and structural information. While incorporating supplemental contextual information from knowledge graphs for review texts, the KRGGNN model captures the network structure between reviews. Specifically, this paper leverages a widely used open source knowledge graph (WordNet) to infuse external knowledge to reviews by constructing contextual association subgraphs. we use personalized PageRank (PPR) filtering methods to reduce the noise brought by external knowledge. In addition, this paper employs a GGNN to combine the textual features and structural information among reviews for stance detection, which considers the mutual influence of related reviews in stance detection tasks.
The model provides several key contributions as follows: Thy paper introduces external knowledge to the review text by using knowledge graphs and employing PPR to filter the subgraphs. This approach enhances the model’s understanding by incorporating essential background knowledge and mitigating the potential noise introduced by external knowledge infusion. By utilizing graph neural networks, the model combines textual features and network structure information between reviews. This integration allows for the incorporation of both textual features and network relationships in stance detection. The model incorporates structural information and introduces external knowledge to the review text, and the macro average score is improved by 1.5% –6.9% compared with other benchmark models.
The paper is structured as follows: Section 2 presents related works on stance detection. Section 3 details the framework of the KRGGNN model in this paper. Section 4 presents the experimental setups and results, and performs the analysis of experimental results. Section 5 concludes the paper.
Related works
This paper introduces external knowledge to review text and uses graph neural networks to obtain structural information between reviews. Related research approaches are divided into two categories: (1) text classification research of introducing external knowledge; (2) stance detection research of incorporating structural information.
Text classification research of introducing external knowledge
Infusing external knowledge can improve the performance of many natural language processing tasks (NLP), including text classification. Chen et al. [21] proposed a natural language model on the basis of neural networks and combined it with external inference knowledge. The model uses a co-attention mechanism to achieve soft-alignment of premises and hypotheses and then merges synonym, antonym, hyponym, and hypernym shared between the words included by premises and hypotheses as relational features of the two words into the co-attentive mechanism. Experimental results demonstrate that utilizing external knowledge can effectively improve the model’s performance and external knowledge by providing additional valid information when the training data is limited. However, excessive external knowledge may increase the amount of noise to the model, eventually decreasing the prediction performance of the model. To reduce the noise, the KES model [22] uses PPR to filter irrelevant external knowledge while introducing external knowledge to obtain external knowledge that is more relevant to the given text object. The model introduces external knowledge using WordNet, an open source knowledge graph, for key information in the premise and hypothetical text, and constructs subgraphs with key information and external knowledge as nodes. However, for most of the classification models that introduce external knowledge, the prediction performance of the model is seriously affected by the excessive noise caused by the external knowledge to the model. The model adopts the PPR filtering method to filter the irrelevant external knowledge in the graph to reduce the noise impact of the external knowledge on the model. Meanwhile, to capture the structural and semantic information of the knowledge graph, the model uses relational graph convolutional neural network (RGCN) to encode subgraphs. The experimental results show that appropriately introducing external knowledge and using PPR to filter irrelevant external knowledge can capture the effective information from the large-scale and noisy knowledge graphs and further improve the detection performance of the model.
Hence, this paper extends the method of introducing external knowledge to stance detection. By using WordNet to introduce external knowledge to the review and applying PPR filtering method to reduce noise to enhance the performance of our model. In addition, this paper uses RGCN to encode the subgraph to obtain the vector representation for the review.
Stance detection research of incorporating structural information
Stance detection incorporating structural information aims to build the stance detection model that takes into account the network structural relationships between reviews. Several studies have found that in addition to the textual features of reviews, structural information also can improve model performance of stance detection. BranchLSTM [23] is a time-series model based on stance detection model that uses conversation threads to introduce the structural relationships of the reviews. Each conversation thread comprises an original review and some embedded replies, where the embedded replies may be a response to the original review or a re-reply review to another embedded replies. The model divides each conversation thread into multiple linear chain branches. A branch is a linear branch of a leaf node review in a conversation thread and that node going up the parent node to the root node, which contains the original review and multiple embedded replies. The model uses word2vec to combine the word vectors of the review text with additional extracted features to obtain the initial vector representation of the reviews during data preprocessing. It then feeds the reviews contained in each branch into the LSTM model in order of depth in the branch to achieve information propagation of the relevant reviews. The model is further improved by constructing a time series model to combine structural information between reviews and text features. In addition to the use of time series models, incorporating structural information can be achieved using graph neural network methods. Li et al. [17] used news articles as the research object and first used deep learning based on text features, such as Hierarchical LSTM [24], Skip-Thought Embedding [25], Bias Features [26], and several other methods. Then, GCN is used to obtain network information between tweets for graph models constructed with political figures, users, and news articles as objects. The experiments show that the effect of joint text and network features for stance detection is significantly better than that of stance detection using either of the features.
To incorporate structural information and textual features, this paper constructs a graph model which based on deep learning networks, to obtain the network structure information between different reviews.
Models
In this paper, the review text is mapped to the WordNet knowledge graph to extract review-related subgraphs, which are introduced into the stance detection model as external knowledge to provide the model with additional contextual knowledge that may be critical.
Specifically, keywords are extracted from the reviews to match the knowledge graph. Then, a review-level contextual association subgraph is extracted in the knowledge graph, i.e., a knowledge graph subgraph comprising matched words and the first-order neighbor nodes of these words in the knowledge graph is extracted. To reduce noise information in external knowledge, PPR [20] is employed to filter the contextual association subgraphs. Then, RGCN is used to perform graph representation learning on the filtered contextual association subgraph to obtain the knowledge representation of the reviews. Finally, this paper utilizes GGNN to combine textual features and structural relationships of reviews for stance detection. The specific architecture KRGGNN is shown in Fig. 1.
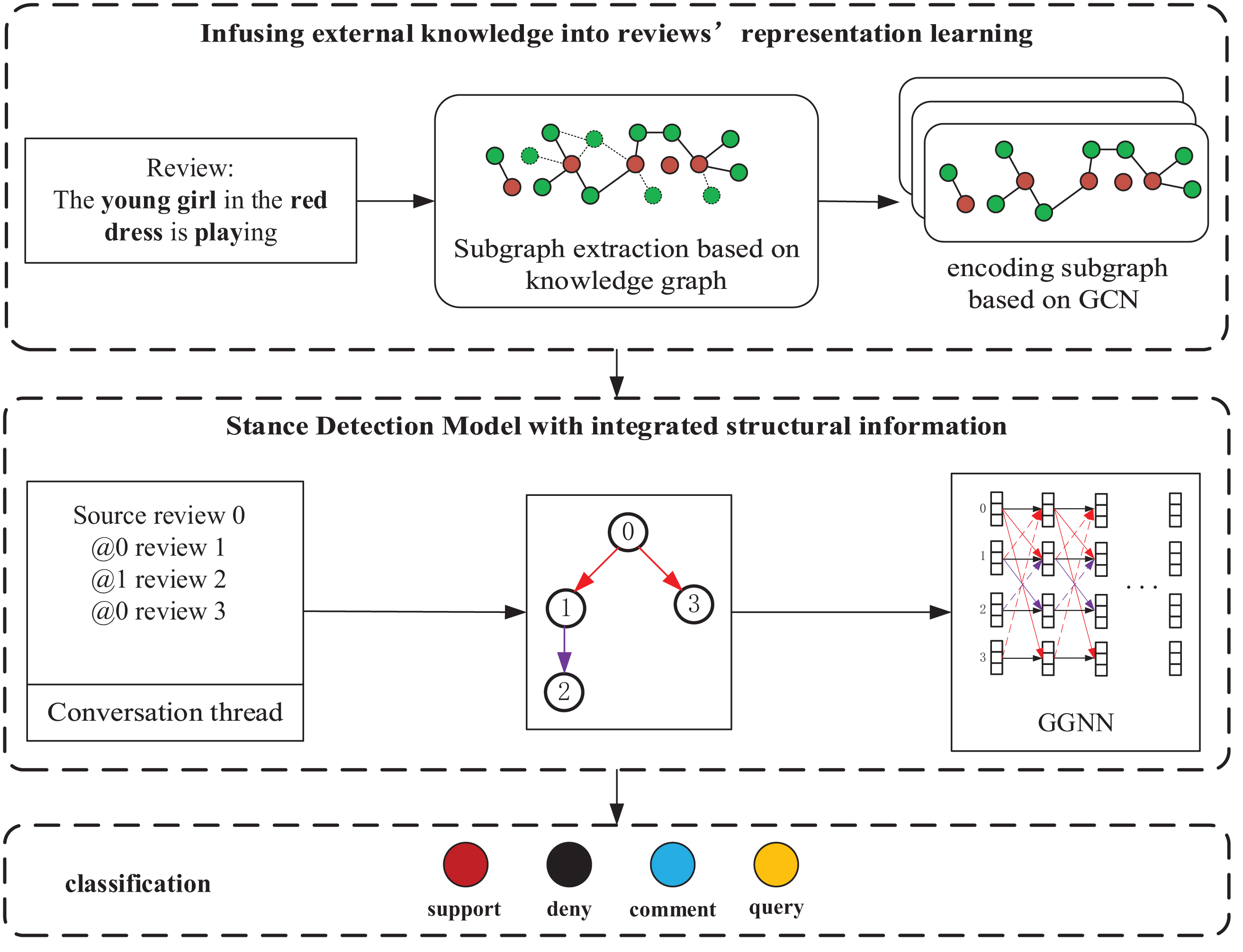
Stance detection model KRGGNN based on GGNN and introducing external knowledge.
This part introduces external knowledge by using the subgraphs mapped from the reviews in the knowledge graph as contexts. First, the knowledge graph retrieves external knowledge related to the reviews, and a contextual association subgraph of the reviews is extracted in the knowledge graph. Given that the introduced external knowledge is often overly large and contains significant noise, PPR method filters the contextual association subgraphs for external knowledge. Finally, a relational graph convolutional network is used to encode the contextual association subgraph and obtain a vector representation of the reviews. The representation learning model of reviews is shown in Fig. 2.
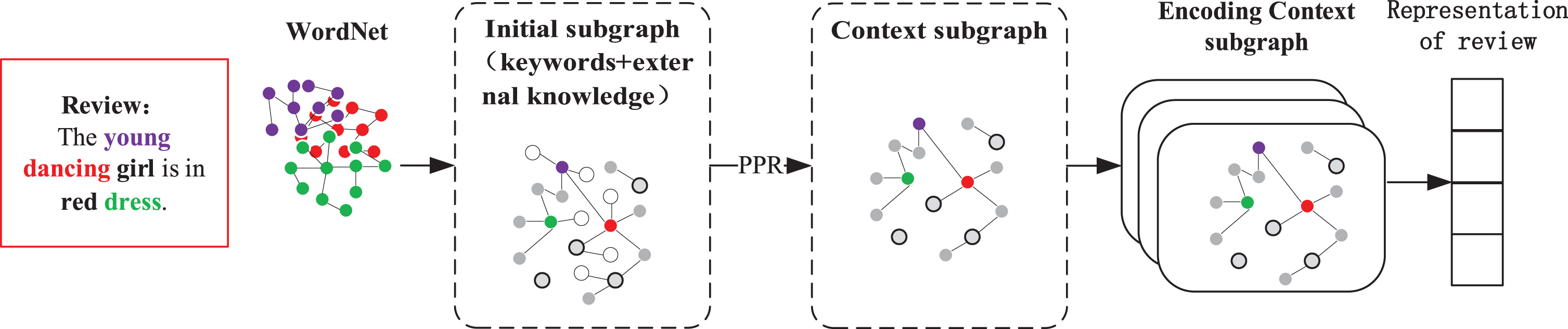
Review representation learning model by introducing external knowledge.
To extract a contextual subgraph of the review text from the knowledge graph, key information in the review must be mapped to the knowledge graph to retrieve external knowledge related to the review. Then, the contextual subgraphs associated with the reviews are extracted from the knowledge graph to achieve the introduction of external knowledge. For the target review, stopwords are filtered to obtain keywords based on the review. The set of words constructed by the keywords extracted from the reviews is denoted as:
To introduce external knowledge related to the reviews, W must be mapped to the WordNet knowledge graph. For the word w p in the review TC, the words that are semantically related to the word and the semantic relations between them are extracted in the WordNet dictionary to construct a contextual association subgraph on the basis of the target review. The semantic relations considered include:
For example, the text of review TC is “The young dancing girl is in red dress” and the review must be filtered for stopwords to obtain the keywords on the basis of the review. The set of keywords extracted from the review is young, girl, red, dress, dance.
The extracted keywords are then mapped to the Wordnet knowledge graph to extract the contextual association subgraph G. First, keywords extracted from the review are used as the initial nodes, and then the knowledge graph is used to retrieve the first-order neighbors of each initial node. Figure 3 shows that the word “girl” in TC is mapped to the knowledge graph for contextual subgraph matching to achieve external knowledge introducing. Context matching for a single word yields a contextual subgraph of a single word comprising an initial node, its first-order neighbors in the knowledge graph, and the edges connecting these nodes.
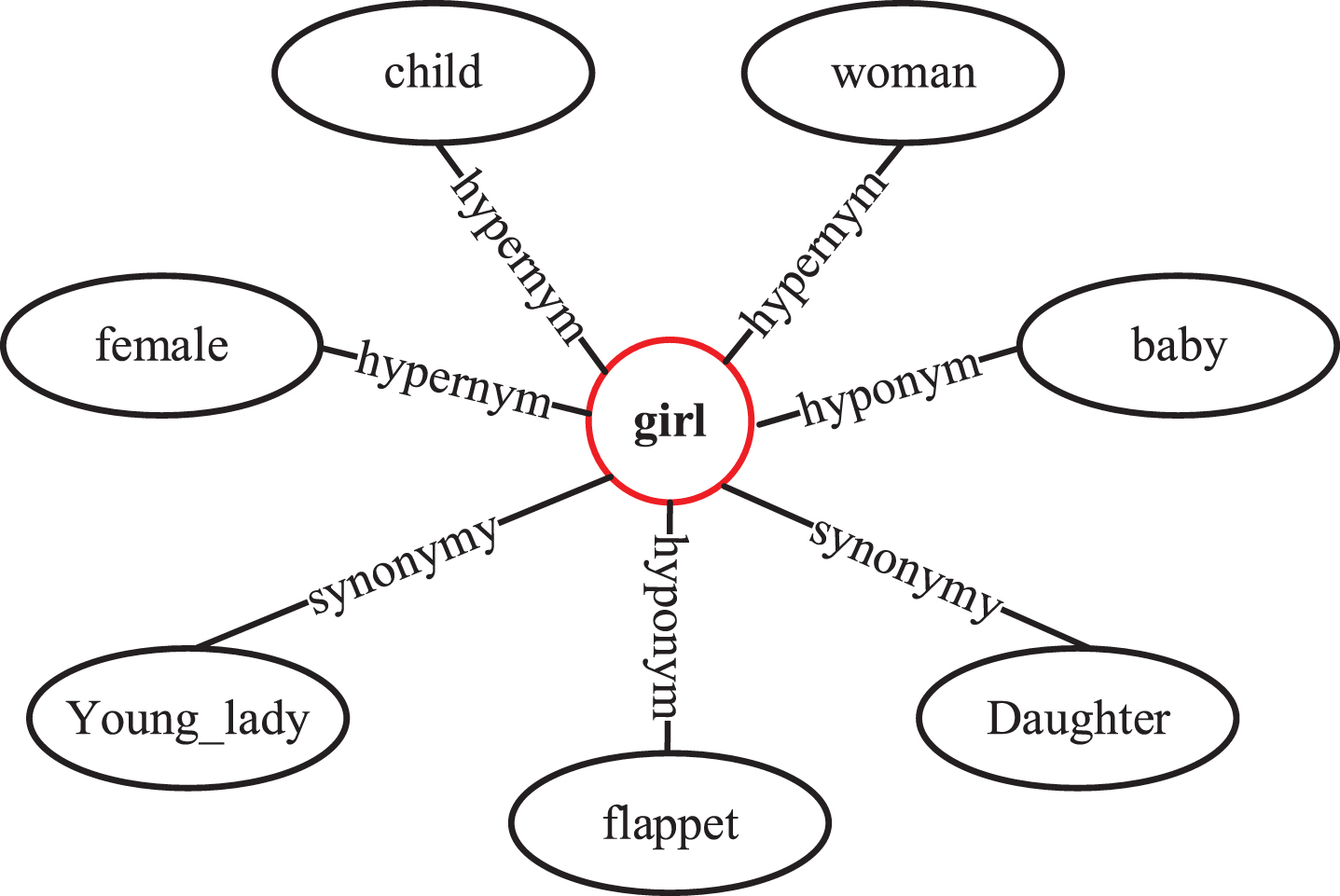
Matching process of external knowledge contextual association subgraph of keywords.
To introduce the external knowledge of the reviews, the contextual words of all keywords in the reviews and the semantic relationships between these words must be extracted from the knowledge graph. Figure 4 shows the contextual information extracted for all keywords in the reviews to construct a contextual association subgraph, denoted as graph G. The red nodes denote the initial nodes, i.e., the keywords W. The black nodes comprise the first-order neighbor nodes that are retrieved from the knowledge graph.
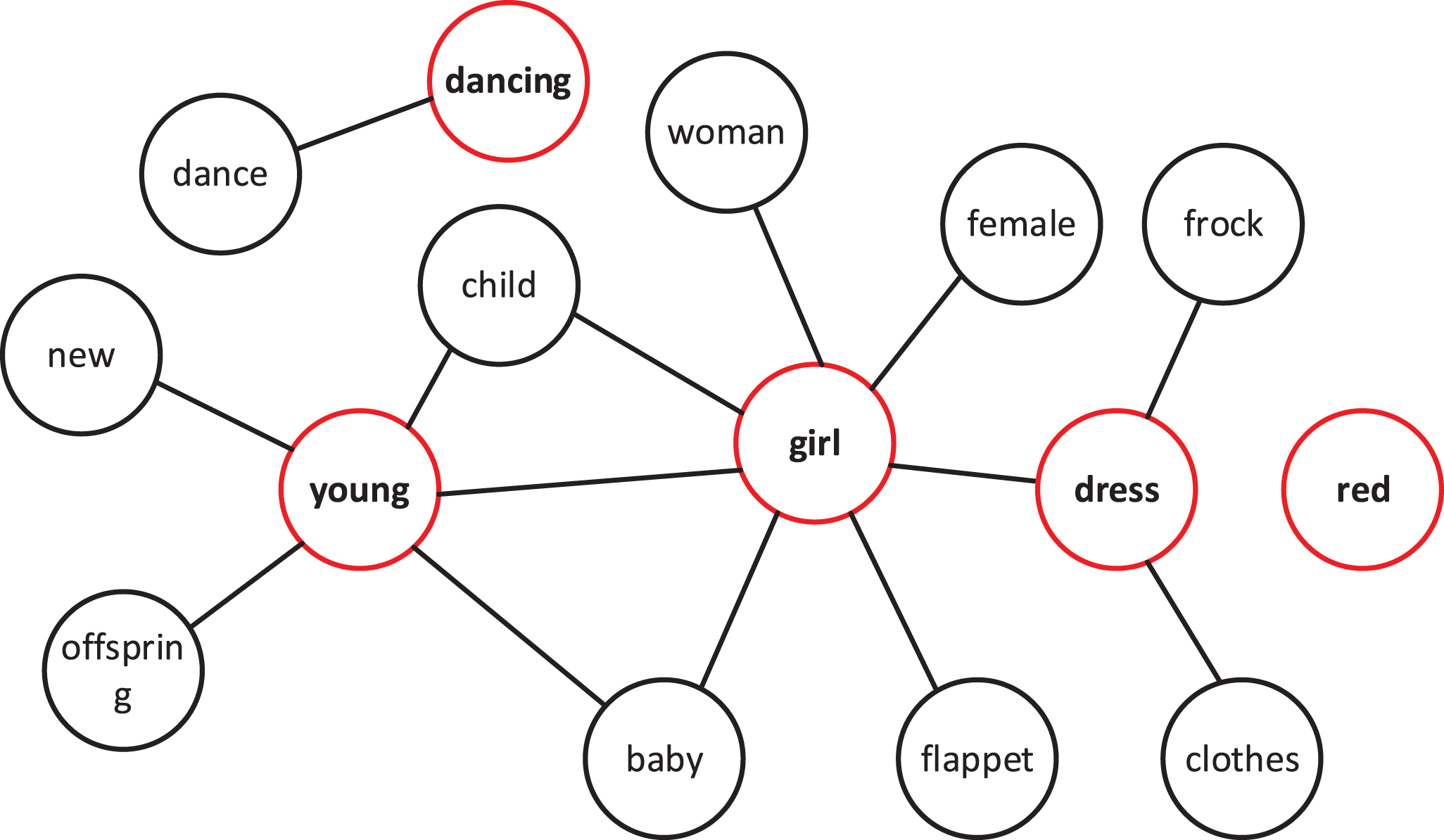
Subgraph constructed by key information of review.
The subgraph G obtained after contextual matching of reviews may contain substantial noise from the first-order neighbor nodes. For example, the concept of “girl” is directly mapped to WordNet with over 500 first-order neighbor nodes, and a large number of these nodes are only related to the semantic relationship of the word, not to the current review. In this paper, we employ PPR algorithm to unrelated nodes and reduce noise from excessive external knowledge. The PPR algorithm adds a bias to each node on the basis of the PPR:
After the iteration is completed, the PPRϵR
n
is normalized to obtain
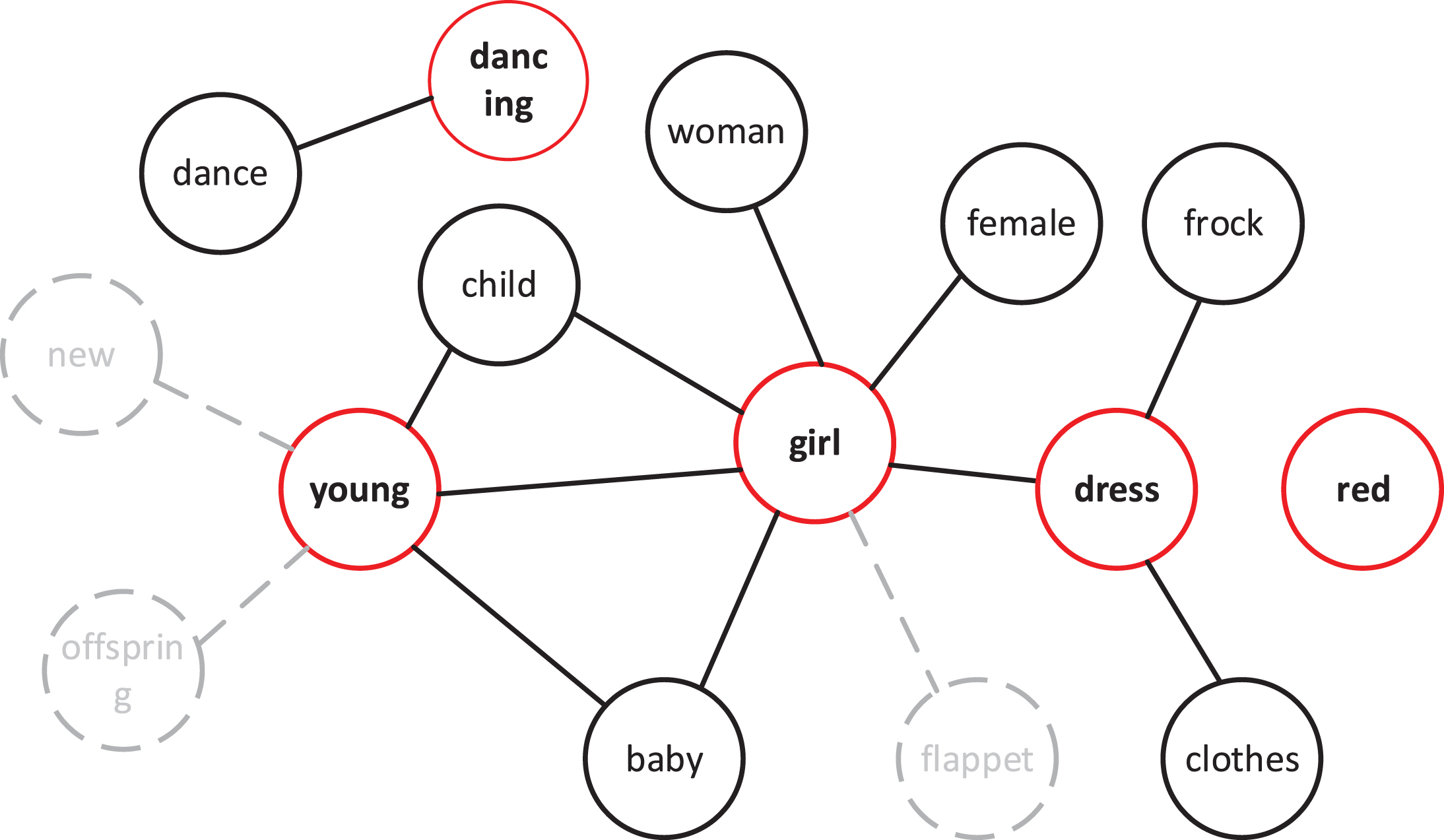
Association subgraph of review context after filtering nodes.
The KRGGNN model uses a relational graph convolutional network (RGCN) [27] approach to learn graph representations of contextually related subgraphs of reviews. This method is an extension of the graph convolutional network (GCN) approach to handle heterogeneous graph models.
To obtain the graph representation of the review TC, the representation h
v
of each node in the graph G′ must be aggregated.
This section considers the external structural relationships between reviews by using the GGNN model to capture the structural features between reviews. Given that reviews are structured as conversation threads on a topic, conversation threads are used to construct the graph model.
This section considers the external structural relationships between reviews by using the GGNN model to capture the structural features between reviews. Given that reviews are structured as conversation threads on a topic, conversation threads are used to construct the graph model.
First, the definition of a conversation thread is given. For a particular topic T, S is an original review posted on that topic. Moreover, the review S comprises a series of replies R i .
In Fig. 6, the original review S is replied by users with ids 6l5b2no, dl5xleh, and dl5hnsx. Meanwhile, user dl5xleh is replied by user dl6bm8l. Based on the above interactions between users, the original reviews and all replies between users are constructed as a conversation thread. In this conversation thread, each review holds a stance on topic T. The conversation thread contains the original review and multiple replies, i.e. C< –Source: [Reply1, Reply2:[Reply3], Reply4], and a mutual relationship exists between the reviews and the reviews.

Conversation threads for reviews.
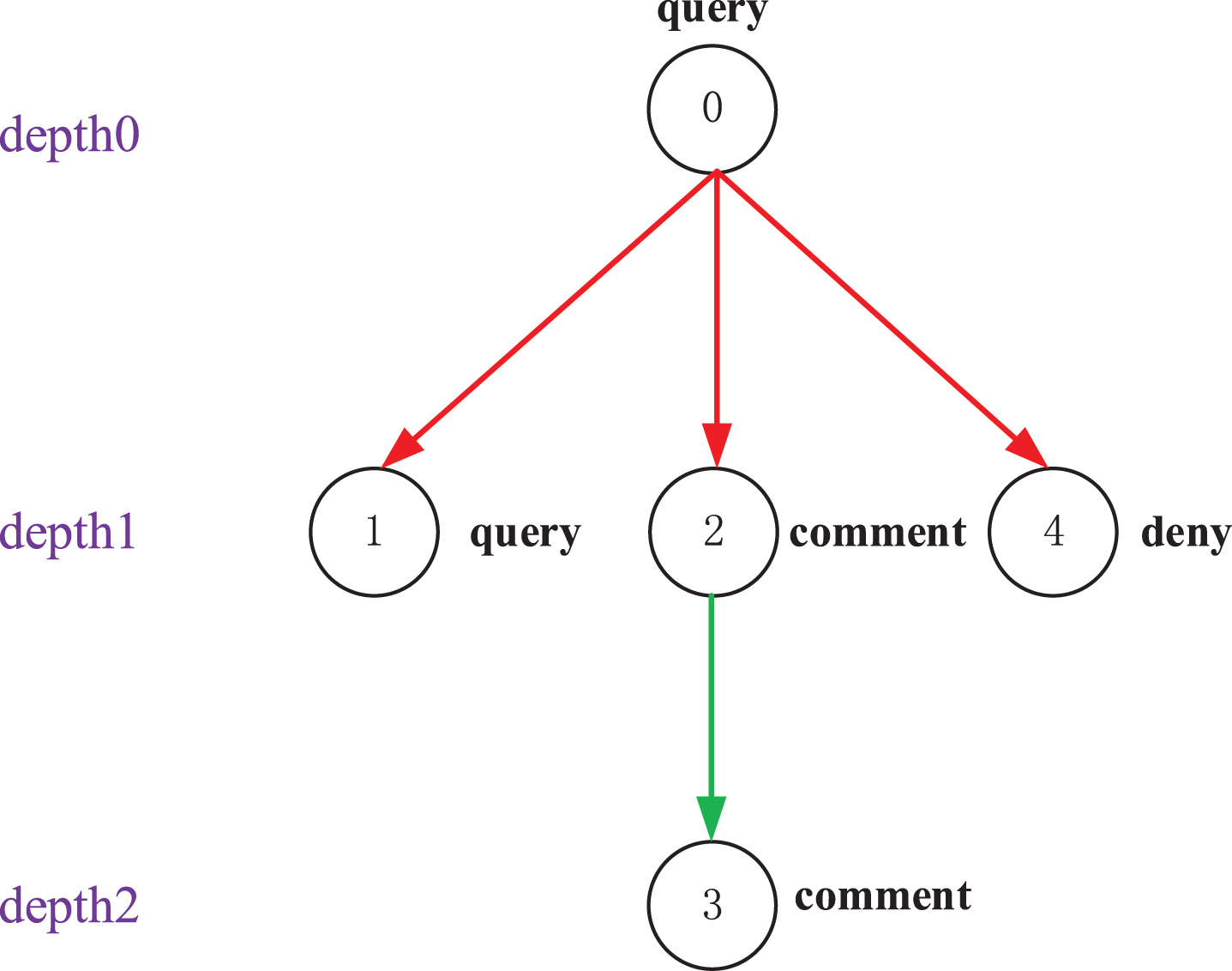
The conversation thread shown in Fig. 6 can be constructed as the graph model, as shown in Fig. 7. Each node represents a review with its corresponding stance label, and the edges of different colors represent various depths of the conversation thread. To investigate the effect of review depth on stance detection in the conversation threads, the depth is constructed for all reviews in this study. This depth is represented as the depth size of different reviews located in the conversation thread.
Given that the reviews of each conversation thread affect one another, extracting the structural features of the reviews can contribute to detecting the stance of reviews. In this paper, a GGNN [28] is used to capture the structural features between reviews. The method uses GRU units [29] to efficiently propagate information to neighboring nodes of the target node to capture relevant features of other nodes. The GGNN method is an extension of GNN [30] that does not need to reach node feature convergence to obtain the representation vectors of nodes and is able to handle heterogeneous graphs. Before passing the nodes’ feature representations FϵR d into the GGNN model, the adjacency matrix A for the graph model must be constructed. To make the stance detection model capable of handling directed heterogeneous graphs, the outgoing edges, the incoming edged, and types of edges are taken into account when constructing the adjacency matrix.
The set of nodes of the graph model is assumed to be NϵR n (denotes the number of nodes), and r denotes the total depth of the conversation thread of graph model, with each depth denoted as a type of edge. The adjacency matrix is denoted as A = [A in ;A out ]ϵRn,(n ×r ×2) where A out ϵR(n,n ×r) and A in ϵR(n,n ×r) represent the adjacency matrix of the outgoing edge and the adjacency matrix of the incoming edge, respectively. In Fig. 7, two types of edges are defined. This includes the edge of a node with Depth 0 pointing to a node with Depth 1, which is denoted as a “type 1” edge, and the edge of a node with depth 1 pointing to a node with Depth 2, which is denoted as a “type 2” edge. Then, the outgoing edge adjacency matrix and the incoming edge adjacency matrix are constructed on the basis of the edge types. The graph model shown in Fig. 7, which constitutes the adjacency matrix of incoming and outgoing edges as shown in Fig. 8.
Graph model based on conversation threads.
The information propagation process of GGNN is described in the following.
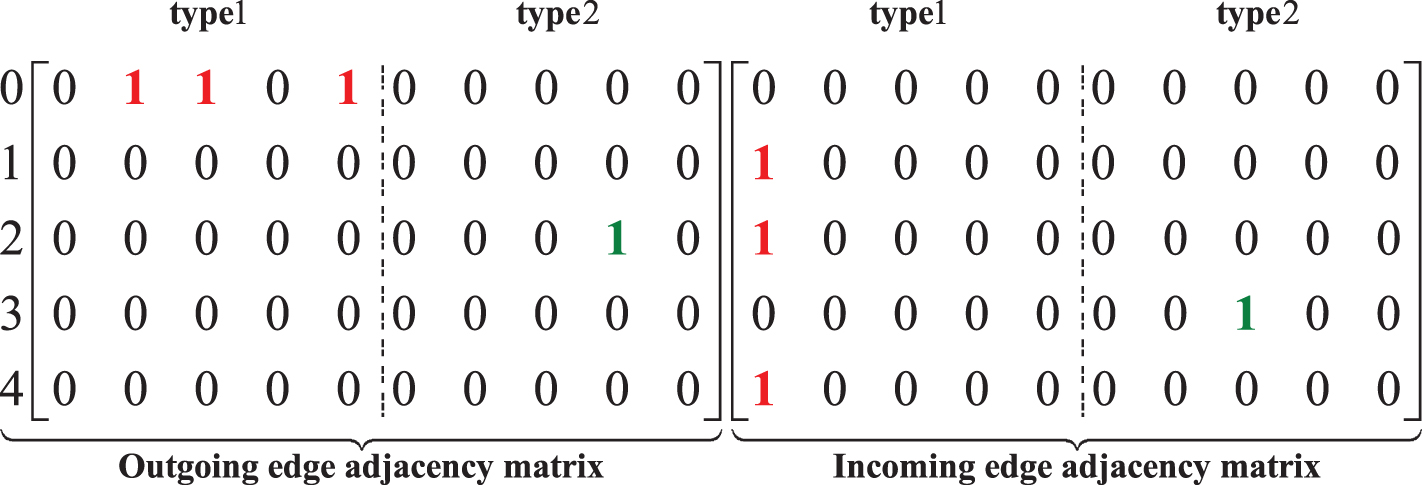
Adjacency matrix.
Where W1, W2 and b1, b2 denote learnable parameters. Given that we consider incoming and outgoing edges separately, the node hidden states H(t–1) also consider the hidden representations
For
The next equation is the update process of the model similar to GRU, where I(t) is used as the input value and H(t–1) as the hidden state at the previous moment.
After obtaining the data of the reset gate and update gate, the hidden state H(t–1) outputted at the previous moment must be reset and then updated using the data output from the update gate.
The reset the gate dot the hidden state to reset the hidden state output at the previous moment, and then the data are concatenated with the input value I(t) and multiplied by the corresponding learnable parameter matrix to obtain H(t). Next, the update gate Z(t) is used to update H(t–1) and
Through the above node information propagation, the final hidden representation H(T) ∈ Rn×d′ of all nodes is obtained after iterating over a certain time step T, where d′ is the dimension of the node output.
By splicing the initial feature matrix XϵR
d
of the conversation thread and the final hidden representation H(t), the nodes’ own features are preserved, and then inputting yϵR
n
×c to the activation function.
The problem addressed in this paper is a multi-classification problem (support, negative, comment and query). Therefore, the cross-entropy loss function is used to train the model in this paper,
In this section, we conducted extensive experiment to evaluate the effectiveness of KRGGNN with the following objectives.
Dataset
The dataset used in this paper is the data of rumor stance detection published for Task 7 of Semeval 2019 competition. It includes 8,574 comments, of which 1,184 are labeled as supportive, 606 as negative, 608 as querying, and 6,176 as commenting. The reviews in the dataset focus on nine different topics, such as climate change and natural disasters. The stances expressed in the reviews of each conversation thread are specific to that topic. The training set contains 272 conversation threads, the validation set contains 25 conversation threads, and the test set contains 28 conversation threads. The distribution of the dataset is shown in Table 1.
Description of the stance dataset
Description of the stance dataset
Then, we cleaned the review texts in the datasets. Reviews with blank or contained useless characters were deleted, to prevent noise from affecting model training. The statistics of the data after preprocessing are shown in Table 2
Description of the preprocessed dataset
The next step is to remove stopwords from the reviews, and NLTK stopwords corpus is used. To introduce external information, WordNet is used in this paper to match hypernym, hyponyms, synonyms, and entailment words of the review keywords.
This paper employs three evaluation metrics: precision rate P, recall rate R, and F1 score, which is the arithmetic mean of precision rate and recall rate.
TP, FP, FN, and TN represent the number of predicted positive samples that are correct, the number of predicted positive samples that are incorrect, the number of predicted negative samples that are incorrect, and the number of predicted negative samples that are correct, respectively.
As shown in Table 2, there were many “comment” categories in the dataset, and very little data in the “deny” and “query” categories. Limited data exists for the “deny” and “query” categories. Due to the serious imbalance in data distribution, the macro-average scores are used to evaluate the performance of the constructed stance detection model for this multi-class problem.
In the word vector acquisition of the review text, the Glove word vector with dimension 200 is utilized for initialization. For the review context extracted using external knowledge from WordNet, the RGCN method is utilized to encode the reviews. The size of the hidden layer is set to 200, the dimension of output review encoding to 300, and set two base vectors. When building the GGNN stance detection model for information propagation, three information propagation steps are set. Meanwhile, through several experimental comparisons, the best performance of the model is achieved when the learning rate is set to 0.001, and the batch size is set to 32.
Baselines
KGRGCN
A variant of the model proposed KRGGNN model. It removes the network structure part, i.e., instead of using the GGNN model to realize the information propagation between reviews only the text features, which consider introducing external knowledge. KGRGCN uses WordNet knowledge graph to introduce external knowledge to dataset, then uses RGCN to propagate information to the constructed sub-model, and finally directly uses Softmax for stance classification.
CLEARumor [29]
The ELMo method is used in word embedding process, to obtain the contextual information of the review text and uses a convolutional neural network model to perform stance detection. The model only extracts the textual features of reviews, but does not take into account the structural relationships between the reviews.
BranchLSTM [23]
The model is constructed on the basis of the LSTM model for conversation threads, and the information acquisition of review representation vectors is performed on them. This model takes into account the network structure relationship between reviews while utilizing text representations.
BranchGRU [31]
A variant of BranchLSTM model, which replaces the LSTM with GRU model for capturing stance information.
BERT [32]
BERT model has achieved state-of-the-art results on various natural language understanding tasks. Proposed by Google in 2018, BERT leverages a transformer architecture and self-supervised learning to produce contextualized word embeddings that capture rich semantic relationships. We utilize BERT model as a baseline in this work to predict users stance detection.
TreeGGNN [33]
This model adopts the GGNN model to leverage structural information for stance detection task, but no external knowledge is introduced to the reviews in the process of data preprocessing.
Analysis of experimental results
The experiments in this paper are stance detection for the information of review on social platforms, namely, Twitter and Reddit. Table 3 verifies the effectiveness of the model proposed in this paper by comparing the KRGGNN stance detection model with other benchmark models. Table 3 presents that the KRGGNN and TreeGGNN models have outstanding performance compared with other models, and the KRGGNN model has the highest accuracy score among all models, and the recall rate is only second to TreeGGNN. The BranchGRU model performs best in terms of recall, considering not only the structural relationship between reviews, but also exploiting the temporal relationship between reviews published sequentially. The KRGGNN model extracts only the structural features between comments. However, KRGGNN even outperforms the new Transformer model BERT, which ignore external knowledge and structural information of reviews.
Comparison of F1 scores of each model for different categories
Comparison of F1 scores of each model for different categories
As shown in Table 4, KRGGNN achieves 1.5% higher macro-average scores compared with TreeGGNN, which does not introduce external knowledge for the context of the reviews. This suggests that external knowledge improves stance detection performance. CLEARumor model has the worst performance compared with other models. It does not use structure or external knowledge, only text features. This shows that text features alone cannot effectively extract stance. Table 4 also provides the F1 scores of the model on the basis of the four stance categories. Then, the evaluation score of “deny” is significantly lower than the other categories in all models. Considering two possible reasons: (1) the uneven distribution of the original dataset, with the ratio of “deny” data to other data being 1 : 11, this also leads to a certain bias of the model toward other categories of data and undertraining of that category; (2) for a given “deny” review text, which generally behaves as an implicit expression of negative thoughts. Given that tone of the text and the way of expression play crucial roles in whether the model can accurately extract valid information, identifying the “deny” reviews is also difficult for the model. Meanwhile, compared with other baselines, the model’s performance is more stable in each category compared with other models. Therefore, the overall of KRGGNN is better than the baseline models.
Comparison of precision and recall of models
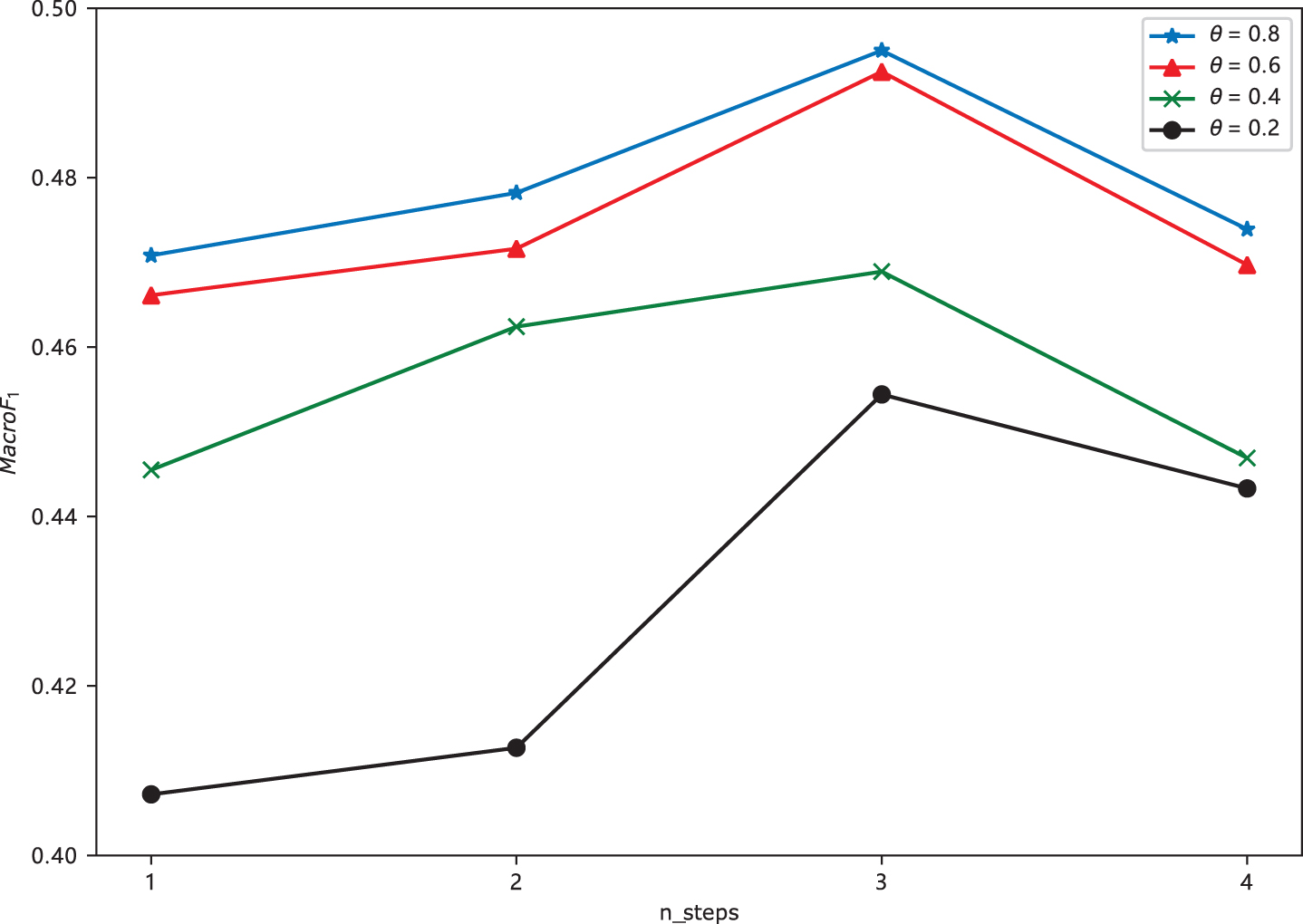
To investigate the effect of the number of GGNN propagation steps on the model performance in the stance detection model, the trend of MacroF1 score is observed by setting different filtering thresholds θ for external knowledge in the step from [1, 4]. In which, the threshold θ of PPR was also adjusted as a hyperparameter. The values for θ in {0.2, 0.4, 0.6, 0.8} are taken accordingly, and the macro-average scores trend of the graph based on different datasets are shown in Figs. 9–11.
Trend of macro-average scores of the model with different propagation steps.
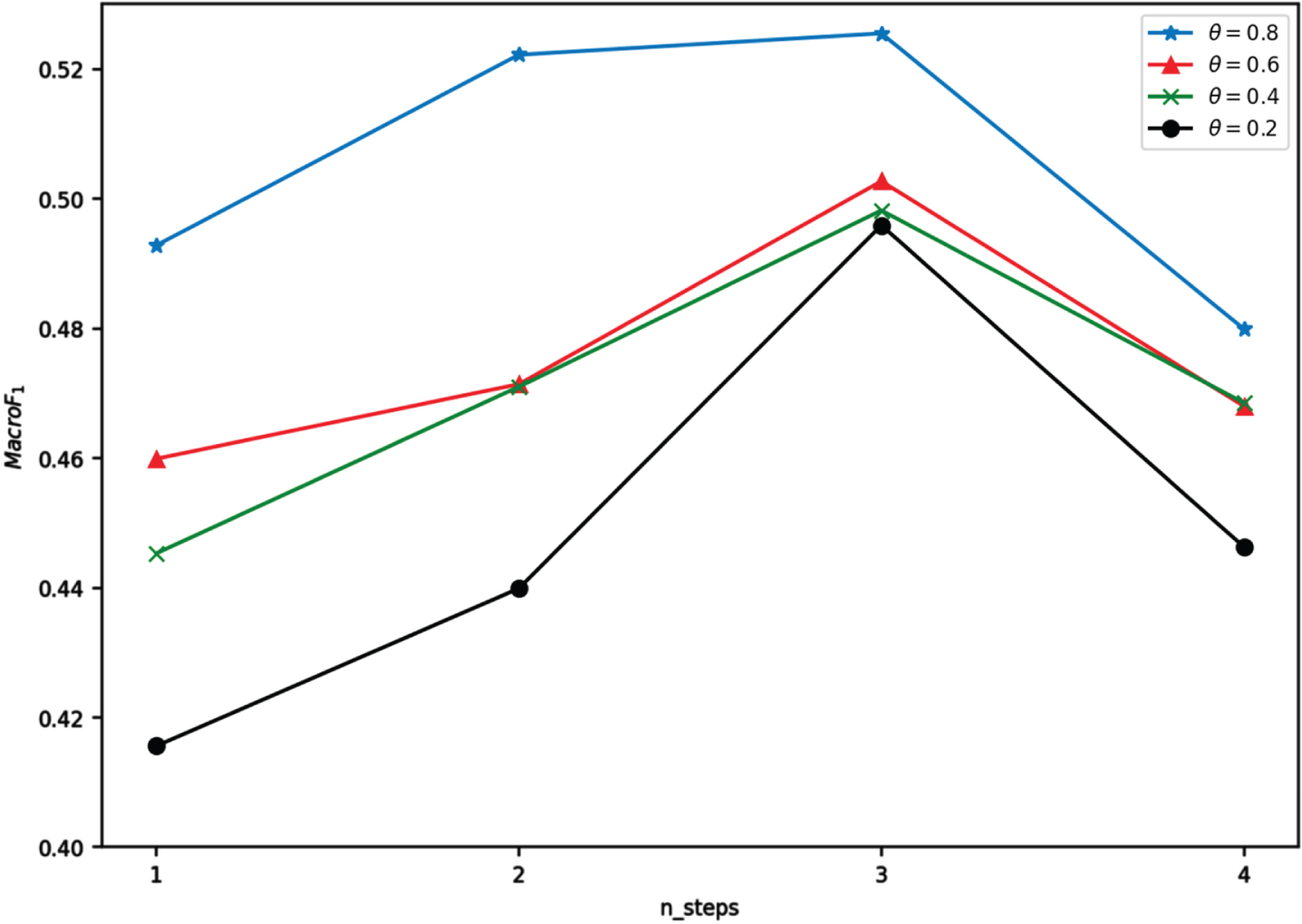
Trend of macro-average scores of the model with different propagation steps for Reddit platform data.
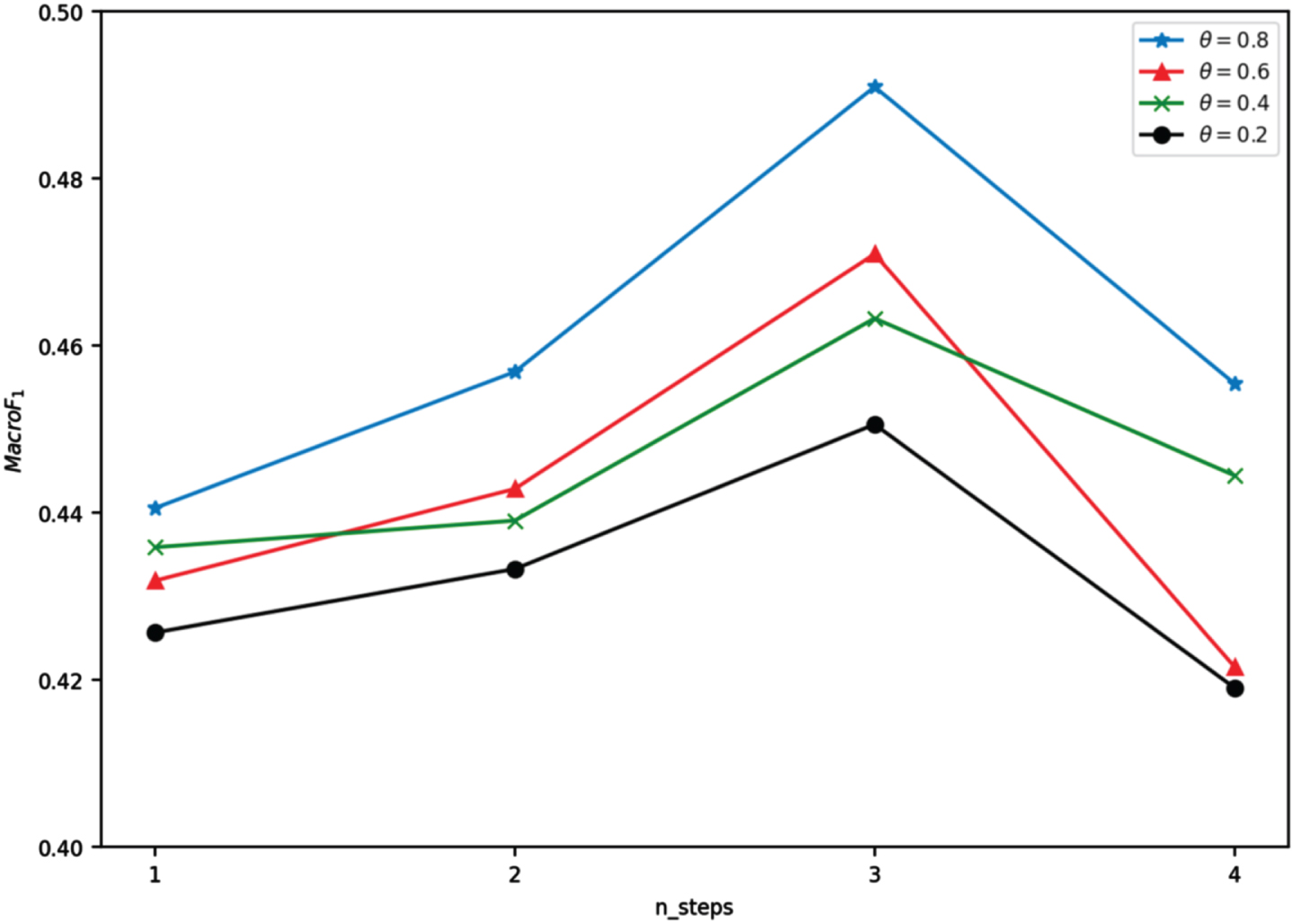
Trend of macro-average scores of the model for Twitter platform data with different propagation steps.
Figure 9 exhibits that the overall performance of our model is optimal when the threshold value θ is set to 0.8, while the worst performance is achieved when θ= 0.2. Considering that the larger the threshold value is, the more external information is filtered. The extracted external knowledge brings more favorable additional background knowledge to the text content. However, an overly low threshold introduces excessive, useless external knowledge, creating noise that negatively impacts prediction effectiveness. Figures 9–11 demonstrate the trend of MacroF1 derived from data located on Reddit and Twitter data. The experimental results also show that GGNN propagation steps also affect model prediction performance. When the number of propagation steps increases from 1 to 3, the average macro scores also increase, indicating that the model’s performance can be effectively improved by information propagation between nodes, i.e., by using the network structure relationship between nodes. The prediction effectiveness decreases when the number of propagation steps rises to 4, which may be due to overfitting.
From a macroscopic point of view, all the models perform poorly for the given stance detection data. To investigate the reasons for their existence, this paper analyzes them in terms of the depth of the reviews (Table 5). Given the reviews with depth 0 have the highest percentage of “Support” data, the best performance is predicted for this category. Currently, reviews with depth 0 are the original reviews on a topic, and the number of “Deny” category with this depth is 0. Therefore, the evaluation score of the “deny” category with this depth is abnormal and does not have any reference. The number of “query” reviews is mainly distributed in the data of depth 0, and the model has a considerable bias toward other categories in the cases of Depths 1 and 2, thus the prediction is not good. The number of “comment” category is the highest in the whole data, and it is concentrated in the data of Depths 1 and 2, and the experiments show that the model can detect the stance more accurately on the basis of this category.
Score for each category of data at different depths
We also investigated the impact of using different word vectors on the model. During the preprocessing of the data, word2vec and glove were used to construct the initial vector representation of the vocabulary. The vectors obtained based on these two methods were input into the model for training. A comparison of each evaluation metric is shown in Fig. 12.
Figure 12 exhibits that the initialization of the word vectors using glove yields better scores in all aspects than word2vec. Compared with word2vec, the word vectors obtained by the statistically based model glove are more effective for stance detection. Given that the dataset comprises datasets from Reddit and Twitter platforms, this paper explores the effect of the data from the platforms on the model, as shown in Fig. 12(b).
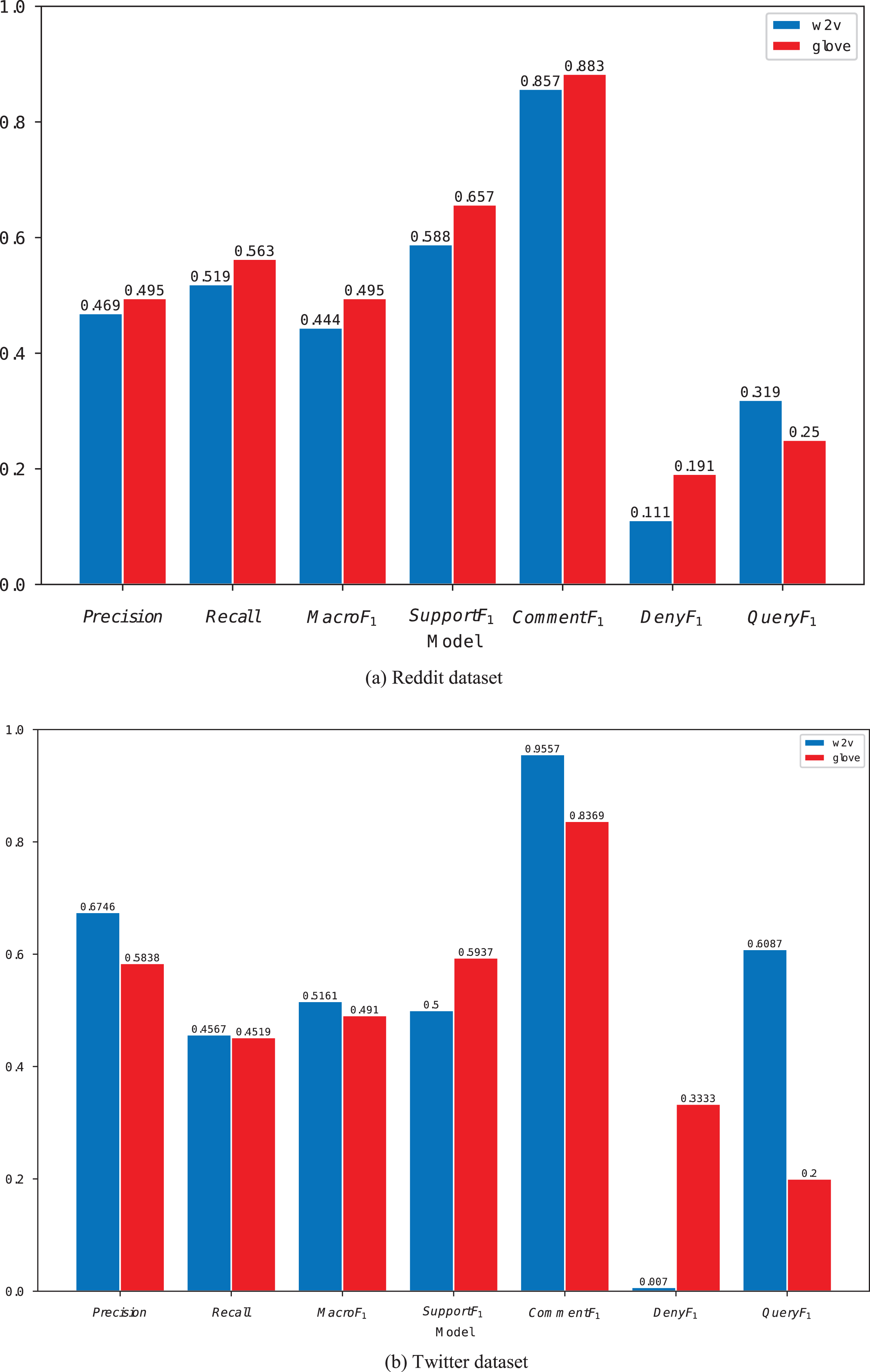
Comparison of prediction performance of initialized word vectors for w2v and glove-based methods in different platforms.
The results show that the model significantly outperforms Twitter for the Reddit dataset, possibly because Reddit users express more formal reviews, whereas Twitter reviews are more colloquial, which makes it easier for the model to extract feature information from Reddit reviews compared with Twitter. However, the F_1 of the model on the Reddit platform is 0 for the stance category “Deny.” Given that the number of “Deny” in the given Reddit data is extremely small, the model cannot learn the basic features of the “deny” category reviews during training. Therefore, it is poor at predicting this category.
The KRGGNN model incorporates external knowledge into a stance detection framework. Existing stance detection models only consider the internal semantic features of reviews, ignoring external knowledge. Inspired by the text entailment of introducing external knowledge, this work infuses external knowledge into stance detection model in this paper. To verify the effectiveness of external knowledge, we compare the performance of five benchmark models with the KRGGNN stance detection model in this paper. Tables 2 and 3 show that KRGGNN is significantly outperforms the baselines models in macro-average and precision metrics, indicating the importance of external knowledge.
In addition, the KRGGNN also incorporates structural information between reviews, i.e., captures the interactions between reviews. As shown in Table 3, the TreeGGNN and KRGGNN models that incorporate structural information outperform the other benchmark models in terms of macro-average scores, which indicates that incorporating structural information can effectively capture stance information. However, the KRGGNN improves the macro-average score by 1.5% compared to the TreeGGNN model without external knowledge, which also demonstrates that the introduction of external knowledge on top of the incorporation of structural information can be effective for stance detection.
Furthermore, we investigate the effect of different propagation steps on the model performance. Figures 9–11 show performance improves as propagation increases from 1 to 3 steps, indicating the model adequately captures stance. However, the performance of the model decreases when the propagation step is 4. This also indicates that the model is able to capture the stance information adequately when the propagation step is 3 and overfitting occurs when the propagation step is 4. Finally, we investigate the performance of the model at different depths of reviews. In general, the model shows a decreasing trend of effectiveness as the depth continues to increase. Given the different expressions of the reviews at different depths, the textual replies to the reviews when the depth is larger may simply be a reply to the previous reviews. We can only capture the current review’s stance on a specific topic by studying the feature information of the previous reply-review, and in a sense the greater the depth the more implicit the review-expression is, which also makes it more difficult to detect the stance.
Conclusion
This paper proposes KRGGNN, a novel stance detection model that introduces external knowledge. KRGGNN uses knowledge graphs to extract contextually relevant subgraphs based on reviews, and then employs RGCN to encode the subgraphs, providing additional useful background knowledge to the model. In building the stance detection model, we employ the GGNN technique to extract the structural relationships between reviews. Experimental results reveal that both external knowledge and structure information significantly improve effectiveness, Infusing knowledge to gain enhanced review representations and incorporating relationships between reviews can boost model performance.
However, the publication of comments also has a temporal order, but this method does not utilize the relationship between comments, which may enhance comment representations and provide additional context information for stance detection. We will consider using time series methods such as TimeGAN and Transformer to model the relationship between comments in future work. In addition, the stance distribution in the dataset may be imbalanced, which could lead to problems of prediction instability and significant biases in the trained stance detection model. In our future work, we will explore using loss functions aimed at reducing biases, down-sampling techniques, and other methods to improve the stability of the model’s predictions.
Footnotes
Acknowledgments
This work was supported by Shanghai Philosophy and Social Science Planning Project (No.2021BTQ003), National Social Science Foundation of China (No. 22CGL050).
Authors’ contributions
Liu Chen: Conceptualization; Methodology. Zhou Kexin: Visualization; Writing - Original Draft; Zhou Lixin: Writing- Reviewing and Editing; Supervision.