
Abstract
Network data is ubiquitous, such as telecommunication, transport systems, online social networks, protein-protein interactions, etc. Since the huge scale and the complexity of network data, former machine learning system tried to understand network data arduously. On the other hand, thought of multi-granular cognitive computation simulates the problem-solving process of human brains. It simplifies the complex problems and solves problems from the easier to harder. Therefore, the application of multi-granularity problem-solving ideas or methods to deal with network data mining is increasingly adopted by researchers either intentionally or unintentionally. This paper looks into the domain of network representation learning (NRL). It systematically combs the research work in this field in recent years. In this paper, it is discovered that in dealing with the complexity of the network and pursuing the efficiency of computing resources, the multi-granularity solution becomes an excellent path that is hard to go around. Although there are several papers about survey of NRL, to our best knowledge, we are the first to survey the NRL from the perspective of multi-granular computing. This paper proposes the challenges that NRL meets. Furthermore, the feasibility of solving the challenges of NRL with multi-granular computing methodologies is analyzed and discussed. Some potential key scientific problems are sorted out and prospected in applying multi-granular computing for NRL research.
Introduction
A network is a set of items, which we will call vertices or sometimes nodes, with connections or edges between them [1]. Network is ubiquitous in our life and objects that connected by relationships can be abstracted as networks. The network data is the abstraction for the complex interactions among the large-scale distributed information system and it exists widely in the physical world. The social activities among people, the interactions between human-beings, the units in social organizations, the transportation of the industrial products or vehicles, etc. can be abstracted as information networks. In the field of industrial robot fault detection, the network analysis can mine the hidden knowledge from the expert knowledge graph, so as to build the intelligent recognition algorithm for fault diagnosis in industrial robot operation [2]. Network analysis has been a non-trivial domain in the big-data intelligent mining and have attracted an enormous amount of research [1, 3].
Early network analysis mainly focuses on the centrality (some individuals have strong influence) and connectivity (how individuals are connected through the network) of nodes. In the following decades, with the expansion of data scale and the improvement of computing capacity, a large number of studies have shifted from analyzing the characteristics of nodes and edges in individual small-scale networks to analyzing the statistical characteristics of large-scale networks [4]. For example, the statistical method of quantitative large-scale network formed around 2002. The statistical method finds out the statistical characteristics that can describe the structure and behavior of network system, builds a mathematical network model, and predicts the behavior and local rules of the network system based on these statistical characteristics. The academic community has made great progress in the first two goals (characterizing and modeling network structures), but it has only just begun to study the impact of network structures. In recent years, people have also studied heterogeneous information networks, edge weights, super-edges and other problems [4].
Intuitively, the network or graph can be represented by tables. Considering a simple example from Singh [5], a social network describing actors and their participation in events. It is also called affiliation network [6]. This simple structure can be represented as several distinct graphs. We may construct a network in which the actors are nodes and edges correspond to actors who have participated in an event together. Nevertheless, for the large-scale networks with millions of nodes and edges, the table presentation makes the application of machine learning infeasible. A good representation for large-scale network data is key for subsequent analysis.
Representation is not a new word though. It is used in many fields to extract the features of cognitive objects such as images [7]. To extract features of graphs, traditional approaches often rely on summary graph statistics (e.g., degrees or clustering coefficients) [8], kernel functions [9], or carefully engineered features [10, 11]. Since these hand engineered features are inflexible i.e., they cannot adapt during the learning process, the traditional method of manual designing of graph features is inefficient and not feasible for large-scale network analysis. Moreover, the matrix network representation is usually high dimensional and sparse matrix. It consumes too much computational resource. More recently, people seek to learn representations that encode the features of graphs via self-irritation of model, like the process of image feature learning.
In recent years, machine learning methods and the feature extraction technologies represented by deep learning have achieved great success[12, 13, 14, 15]. For network feature extraction, one of the key preconditions for analyzing network data via machine learning technologies is how to present the data, that is, how to extract the data features.
This article discusses the use of multi-granularity cognitive computing in the field of network representation learning, and the idea of multi-granularity cognitive computing is widely present in the fields of data mining and artificial intelligence. Granular computing simulates the way the human brain thinks, i.e. hierarchically simplifies complex things, extracts and mines the multi-granularity features of objects. This is of great significance for improving the performance and effectiveness of data mining algorithms. The network data is naturally complex, and the network structure features have multi-granularity characteristics. Therefore, it is necessary to study and summarize the existing work in the field of network representation learning from the perspective of multi-granularity computing. This article is based on this idea and provides a unique perspective to summarize the relevant papers in the NRL field. Researchers engaged in granular computing research or NRL research can better understand how multi-granularity computing ideas are embodied and implemented in the NRL field through this article. This can help granular computing researchers understand the application of granular computing ideas in the NRL field, and can also help NRL researchers to inspire them to use multi-granularity computing ideas to achieve better NRL research results.
Network data representation and network representation learning
Graph is a ubiquitous way to organize a diverse set of real-world information. Intuitively, the network or graph can be represented by tables, that shows which two nodes are connected. Considering a simple example from Singh [5], a social network describing actors and their participation in events. Such social networks are commonly called affiliation networks [6] and are easily represented by three tables representing the actors, the events, and the participation relationships. Even this simple structure can be represented as several distinct graphs. We may construct a network in which the actors are nodes and edges correspond to actors who have participated in an event together.
For large scale networks that is consisted by millions or billions of nodes, the traditional network representation brings billions of dimensions. This makes the application of machine learning infeasible. Unfortunately, there is no straightforward way to encode this high-dimensional, non-Euclidean information about graph structure into a feature vector. For the task of big-data analysis using machine learning methods, the significant issues are how to represent and select the feature of the data. A good representation for meta data is key for subsequent analysis. Representation is not a new word though. It is used in many fields to extract the features of cognitive objects such as images. Since 1989, image features have been designed manually by people [7]. To extract features of graphs, traditional approaches often rely on summary graph statistics (e.g., degrees or clustering coefficients) [8], kernel functions [9] or carefully engineered features to measure local neighborhood structures [10, 11]. Since these hand engineered features are inflexible i.e., they cannot adapt during the learning process, the traditional method of manual designing of graph features is inefficient and not feasible for large-scale network analysis. More recently, people seek to learn representations that encode the features of graphs via self-irritation of model, like the process of image feature learning. This is the motivation of network representation learning.
Network representation learning (NRL) tries to learn low-dimensional vectors to represent each vertex of networks. Such that, NRL encodes the attributes of each vertex such as the structural properties into a vector space. Through this way, the high-dimensional vectors in adjacency matrix for each of the vertices is represented into a coarser granular level so that the off-the-shelf machine learning methods can be applicable. From the perspective of granularity computing, this is essentially a transformation of data from finer granularity level to coarser level. Thus, NRL transforms the extremely high-dimensional representation of large network into representation in low-dimension and dense vector space, which will be easy to be processed by machine learning technologies. NRL is essentially discovering the latent discriminatory factors behind data.
Due to the interconnections and interactions of information on different scales in networks, NRL models that can investigate the latent law and discover the influential factors behind the data on multi-granularities may introduce improvement for NRL. With respect to the common characteristics of components in networks and the challenges in NRL, we discuss how to design the NRL models by taking advantage of human cognitive laws and network features.
The development of NRL
The traditional representation learning method of network data is mainly based on spectral method, optimization method and probability generation model. Spectral method refers to the general designation of a class of algorithms that take advantage of the spectral characteristics of matrix such as eigenvalue, eigenvector, singular value and singular vector [16]. General way is commonly used to obtain the low-dimensional representation of matrix [17]. For example, the classic PCA (principal components analysis) algorithm is to reduce the dimension of the feature vectors selected by the sample covariance matrix. The network can be represented as an adjacency matrix as input to the PCA or singular value decomposition (SVD) to obtain a low dimensional representation of the node. This representation is usually of poor quality due to the lack of information within the nodes [18].
The NRL algorithms based on the optimization method solve a well-designed objective function and take the vector representation of vertices in the low-dimensional space as the parameter. Y Jacob et al. propose LSHM (latent space heterogeneous model) algorithm [19] to learn node vectors and the label of linear classification function. The objective function includes two parts: First, the adjacent nodes of the label should be as similar as possible; The ability of classification function to predict known tags. In the prediction of network information transmission, the traditional method is to first discover the hidden structure of communication from the user’s behavior [20], that is, to establish a new network. Reference [21] studies the low-dimensional representation of user nodes in the continuous hidden space. The network representation learning algorithms based on optimization methods are closely related to specific network analysis tasks. All of them use the random gradient descent method which has low convergence efficiency and may lead to over-fitting problems.
Other research uses a probability-based sampling process to model the generation process of network data. The solutions of these models are usually Gibbs sampling, variational inference and expectation maximization algorithm. Such algorithms are more representative of PLSA [22] and LDA [23] algorithms, which are essentially probabilistic graph models. Ramesh Nallapati et al. propose the LINK-PLSA-LDA model for academic paper citation network [24], Jonathan Chang et al. propose the RTM model [25]. The RTM model assumes that if there is edge between two text nodes, their distribution in the topic space should be similar. Tuan MV Le et al. extend the RTM model and propose the PLANE model [18] which learns the low-dimensional representation for the topic and the text nodes from a visual perspective.
With the development of representation learning technology in the field of natural language processing(NLP) [26, 27, 28], NRL researchers have employed their methods to develop algorithms and have achieved remarkable improvements, such as DeepWalk [29],LINE [30],PTE [31], node2vec [32], etc. Moreover, there have been a lot of NRL research works based stochastic language models. They combine network properties with the spirit of multi-granular computing methodologies.
The challenges in NRL
The ubiquitous multi-granularity, multi-scale, multi-level, evolving and complex characteristics of network data bring great challenges to the study of network representation learning. Bengio et al. [33] argue that the original data is generated by multi-source of factors, and a good feature extraction can only be achieved if representation learning models can learn to identify and disentangle the underlying explanatory factors hidden in the observed milieu of low-level sensory data. In the data of networks, the discriminative information is distributed on multiple granular layers due to the hierarchical characteristics of network data.
Handling the network data of millions or billions of nodes is one of the challenges in NRL. The large-scale network data introduces the problem of computability. Vertices in networks are interactive each other and simply breaking any linkage will introduce new interferences and noise. It’s difficult to define where the analysis or representation should start with. This is the reason that traditional network analysis algorithms always focus on the stochastic analysis but cannot obtain high performance in the sequent network inference tasks.
Most prior works on NRL have treated this with a ’one-size fits all’ approach. Nonetheless, network information has the multi-scale properties, and a single granularity of representation for nodes cannot fully explain the connections between nodes in network. It is desired to learn the embedding in a multi-granular granulation model to gradually shift the focus to the unexplained node connectivity behaviors [34]. These ‘one-size fits all’ approaches fail to explicitly capture the multiple scales of relationships in network.
Due to the hierarchical components in networks, features that on multiple granular layers may be difficult to capture. When representing the features that across multiple granular layers, NRL models should handle the contradiction between sparsity and interconnection. For instance, the community structure, which is widely existing in almost all the network data, is an important mesoscopic description of network structure. The sparsity and interconnection of network data introduces challenges in community structure constraint NRL. On the other hand, two nodes in different communities can have strong connections in microscope because of the interconnections in networks. The recent works such as LINE [30] and GraRep [35] extend NRL to higher order proximity approximation but the mesoscopic description of network is largely ignored. Furthermore, the nodes or components in networks may be created by multiple type of sources, such as text, image, video, sound, etc. If we use different types of models to handle the heterogeneous data, the non-coupling problems between interconnection and semantic similarities may emerge. In addition, the data of networks accumulates and evolve quickly with time. People need to analyze the status of components and predict the developing tendency in networks depends on the historic and new coming data.
Hierarchical information in networks and multi-granular computing
The hierarchical taxonomy in NRL results is discussed by Liu et al. [36] and Ma et al. presents a NRL algorithm for preserving the hierarchical taxonomy in networks [37]. Both of the two works reveal that the existence of hierarchical information in networks. Therefore, some research work on network representation which embodies the thought of multi-granularity cognitive computing is categorized. The possibility of using multi-granular computing methodologies to create NRL model for extracting the hierarchical and multi-granular features of network data is discussed in the following chapters. This paper discusses the representation learning algorithms for network data, and sorts out the possible multi-level features in network in the perspective of multi-granular cognitive computing.
Representation learning is the algorithm designed by people to automatically include the hidden features in the original data in the training results. The output of representation learning (also treated as the features of the original data) will be directly used for sequent inference tasks such as node classification, prediction, target recognition, etc. In addition, multi-granular cognitive computing is a set of methodology that inspired by human cognitive laws. It can be used to gradually process information on multi-granularities such as recognizing complex things in multiple scales, multi-layers, and providing approximate solutions for complex problems.
Granular computing has emerged as one of the fastest growing intelligent computing paradigms in the domain of cognitive intelligence and artificial intelligence [38]. It is often loosely regarded as an umbrella term to cover theories, methodologies, techniques, and tools that make use of granules in complex problem solving [39]. Granulation, an operation to construct or decompose granules, is one of the key issues of granular computing [40]. Inspired by human ways of granulating and manipulating information, Zadeh proposes a theory of fuzzy information granulation (TFIG) [41, 42]. The proposed fuzzy theories could provide a granular representation of uncertain information about a variable of interest. Liu et al. develop a multiple granularity concept generation model as hierarchical concept trees as shown in Fig. 1. Xu et al. develop an adaptive hierarchical clustering approach to generate a hierarchical tree [43] for mining the data that has hierarchical properties. Emad et al. propose a multi-connect architecture (MCA) associative memory to improve the Hopfield neural network by modifying the net architecture, learning and convergence processes [44]. It can learn and recognize unlimited patterns in varying size with acceptable percentage noise rate in comparison to the traditional Hopfield neural network.
Hierarchical concept tree [45].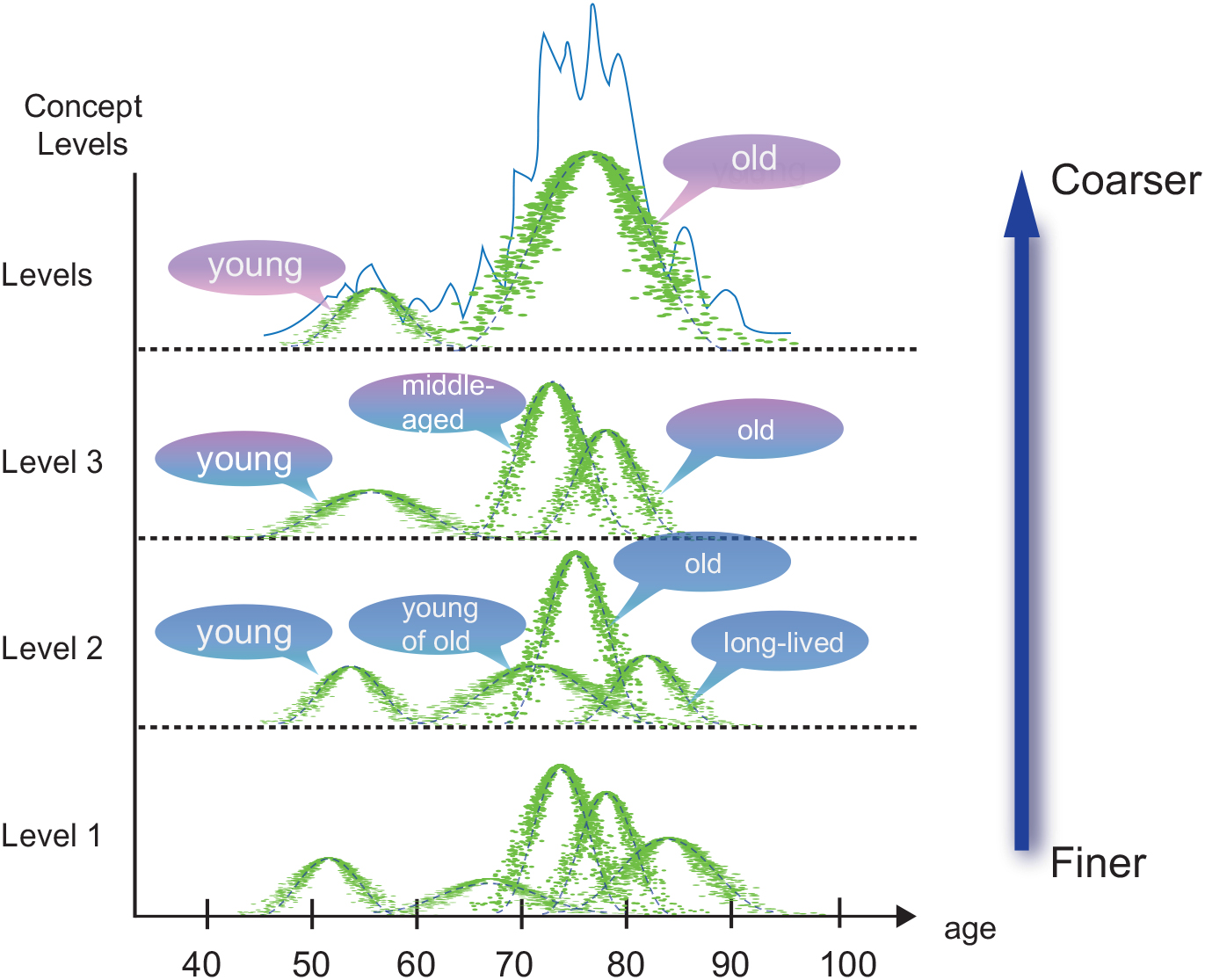
Multi-granular computation treats the complex problems as a set of child problems which have different scale of complexity. As the human recognition principle, a man may handle a complex problem from coarse to fine. In multi-granular perspective, the NRL models may process the complex network analysis problems progressively, and solve the problems on different granular layers step by step. Multi-granular computing methodologies may offer new ideas and approaches for solving such contradictions. In multi-granular perspective, models processing representation learning problem on a unique granular layer will ignore the multi-scale structural properties and the nodes do not share attributes between different granular layers. The multi-granular methodologies may inspire the NRL model to handle the nodes that were not previously seen and process the evolving situations without launching additional rounds of optimizations. Exploring the reflection of multi-granularity methodologies in existing NRL algorithms and analyzing the issues of application of multi-granular computing in NRL are believed to be significant. We hope to provide some reference and inspirations for applying the idea of multi-granularity computation to the research community of NRL.
In the NRL research, we should also pay attention to the cognitive rules of humans and the latent multi-granular features of the network itself. The success of deep learning is a concrete demonstration of the multi-granular cognitive mechanism. Soujanya et al. [46] apply deep convolutional neural networks for natural language feature extracting and combine the feature vectors of multi-model heterogenous data such as text, image and audio. In the feature extraction for network, there are also some studies that embody the multi-granular cognitive mechanism, such as GraRep [35], NEU [47], HARP [48], AROPE [49] and MOANA [50].
As NRL has the contradictions and challenges resulted by the multi-granular characteristics of networks discussed above, most of those representation methods suffer from the ineffectiveness of extracting the multi-granular features by hinging on a ‘one size fits all’ approach to network representation learning [51]. Therefore, some former studies about NRL have taken into account the hierarchical properties of network data such as GraRep [35], WALKLETS [52], HARP [48] and AROPE [49]. Phenomena and approaches that of using multi-layer representation and heterogeneous information are used for network knowledge extractions.
For instance, GraRep proves that the DeepWalk as well as the skip-gram model with negative sampling [28] can be essentially optimized as a matrix factorization problem. By extending the length of the sampling path, the global structural information for the graph can be captured. Through this way, in the perspective of granular computing, the GraRep is actually an extension of DeepWalk as it added global knowledge into the representation. In the work of NEU [47], the author analyzes the network representation method that can be viewed as matrix factorization. They find that the performance of representation will be better if the high-order information of graph vertices can be contained in the factorization of a matrix. But the complexity will increase as the order of information goes higher. The higher-order information can be equally viewed as the finer knowledge in granular computing. Adding the finer information into systems surely brings in complexity. The instances above are all about representing the structural property from coarser to finer. They encode more information about networks and so that the richness of the knowledge extracted from networks is increased. On the contrast, works such as [51], HARP [48] represent the information from finer to coarser. WALKLETS captures the coarser information by sub-sampling. Thereby, more global structure properties in the graph are captured. HARP explicitly introduces the hierarchical representation learning problem for graphs. They simplify the original graph by collapsing nodes and edges and approximating the structures using a smaller scale of graphs which contains fewer nodes and edges. Their approximation of the original graph into hierarchical small scale graphs can be seen as encoding the complex whole information into multi granular layers. In order to shift the embedding vectors between proximities of arbitrary orders, AROPE [49] reveals the intrinsic relationship between proximities of different orders. This work can be viewed as the concrete study of network representation model on multi-granularities.
Those works can be seen as embodiments of multi-granular computing methodologies. They represent the latent knowledge in networks on multi-granular layers. In the following chapters, we specifically discuss, in the domain of network analysis and representation, how the former works are combined with the idea of multi-granular knowledge extractions. And considering the shortages in current NRL studies, we propose the advantages in multi-granular cognitive computing that will be helpful in network representation learning. By the integration of the methodology of multi-granular recognizing computing, we hope to propose some inspiration for improving the performance of NRL algorithm and exploring the essential principle of NRL, especially in the time-limited, structure-constraint and data-streaming scenarios.
In this paper, we focus on the recently proposed NRL methods that were developed under the consider of using multi-granular computation thoughts and aiming to address the goal of network inference. The taxonomy structure of the related works is shown in Fig. 2.
The taxonomy of multi-granular network representation learning methods.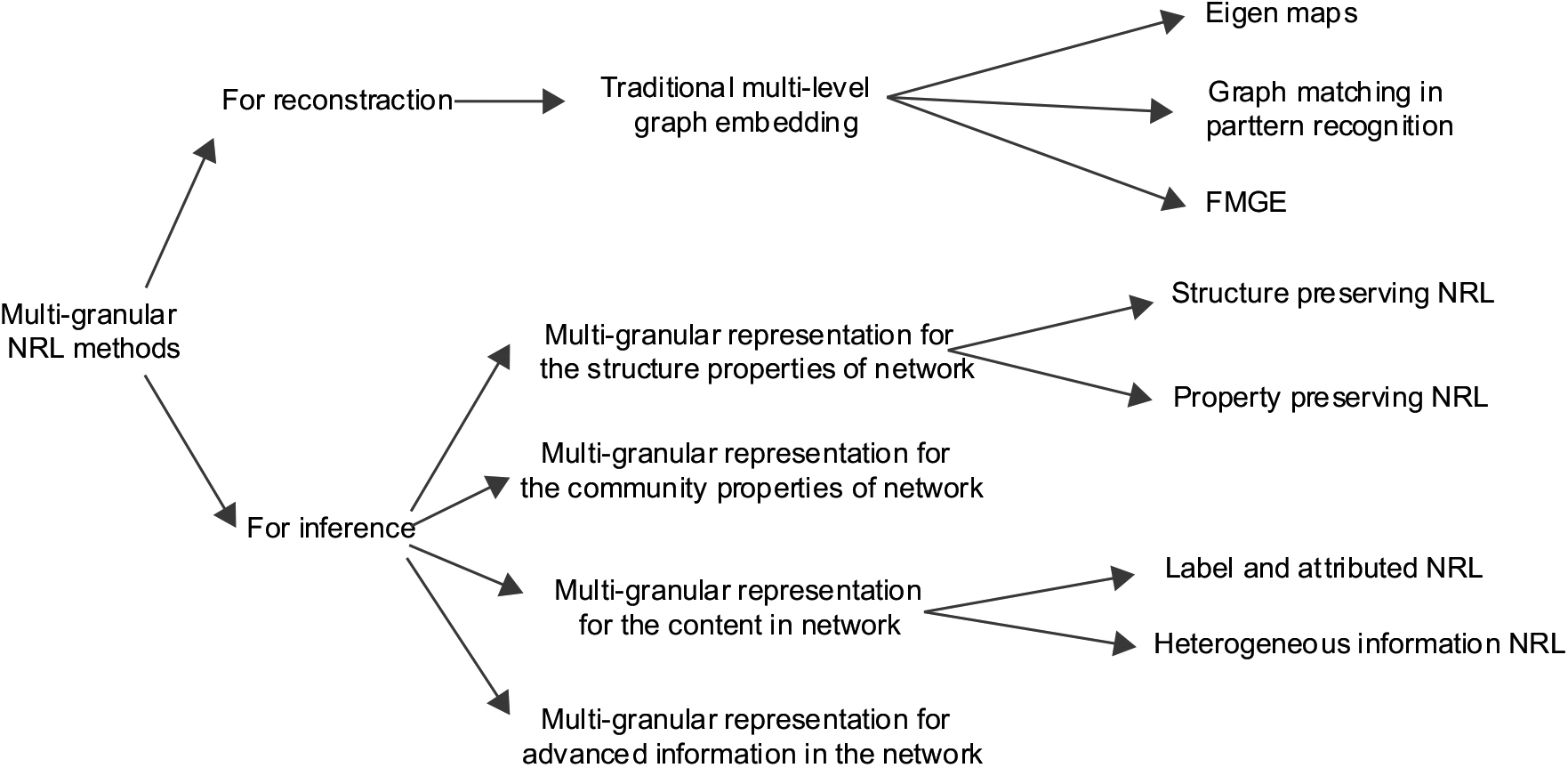
Research [37, 53] show that networks often exhibit hierarchical organization and granular computing provides true and natural representations of such hierarchical systems. To our best knowledge, we are the first to survey the NRL technologies with the perspective of multi-granular computing, which is consistent with human thinking [38], although there are several papers about survey of NRL [54, 55]. Moreover, this survey provides a review of the state-of-the-art network representation learning techniques with the perspective of multi-granular computation methodologies. It covers traditional methods on network analysis but mainly focuses on the multi-granular characteristics of the network data and the resulting contradictions and challenges in NRL field. Furthermore, it discusses the emerging of a brunch of works that borrow the multi-granular computing methodologies for the hierarchical network feature extraction to face those challenges. By doing so, we hope to provide a new and significant perspective for NRL community and focus on the most essential and ubiquitous multi-layer characteristics of network data. In particular, this survey has three major contributions:
We analyze the contradictions in NRL research and depends on which, a new taxonomy for categorizing the NRL research works that can be seen as the embodiments of multi-granularity computing methodologies is proposed.
We show the connections between human-being’s recognition law and multi-granular computing in feature extractions and analyze the potential advantages of applying multi-granular computing into NRL research.
We discuss issues and deficiencies of multi-granularity methods in current NRL research and propose research prospects and potentiality of applying multi-granular methodologies in further research of NRL.
The rest of this article is organized as follows. In Section 2, we introduce preliminaries and definitions required to understand the models discussed next. In Section 3, we present a multi-granularity perspective on categorizing the existing representative NRL techniques. A list of successful applications of network representation learning are discussed in Section 4. We discuss potential research directions in Section 5, and conclude this article in Section 6.
Preliminaries and definitions
In this section, as preliminaries, we first define notations that are used to discuss the NRL research next, followed by a formal definition of the NRL problem. For ease of presentation, we first define a list of common notations that will be used throughout the survey, as shown in Table 1.
A summary of common notations
A summary of common notations
This section first discusses the traditional graph embedding method, and then discusses the multi-granularity representation learning method for structural information preserving, community information preserving, content information preserving, and for advanced network referring tasks. It can be seen that in different types of presentation learning methods, the multi-granularity computing methodology is embodied in different ways and has different connotations.
Multi-level embedding for graphs
Graph embedding offers a straightforward solution, by employing the representational power of symbolic data structures and the computational superiority of feature vectors [58]. It acts as a bridge between structural and statistical approaches [59, 60] and allows a pattern recognition task to benefit from the computational efficiency of state-of-the-art statistical models and tools [61] along with the convenience and representational power of classical symbolic representations. This permits the last three decades of research on graph-based structural representations in various domains [62], to benefit from the state-of-the-art machine learning models and tools. For further reading on the application of graph embedding, interested readers can refer to[63].
As most of the existing methods on graph embedding can only handle the graphs that are comprised of edges with a single attribute and vertices with either no or only symbolic attributes, people design graph embedding methods for attributed graphs with many symbolic as well as numeric attributes on both nodes and edges [64, 65, 66]. The method is named fuzzy multilevel graph embedding and is abbreviated as FMGE. It preserves multi-facet information (see Fig. 3) from global, topological, and local point of views and is based on multilevel analysis of a graph for embedding it into a feature vector. FMGE employs fuzzy overlapping trapezoidal intervals for minimizing the information loss while mapping from continuous graph space to discrete feature vector space. FMGE has built-in unsupervised learning abilities and thus is inexpensively deployable to a wide range of application domains [66].
Multi-facet view of discriminatory information in graph.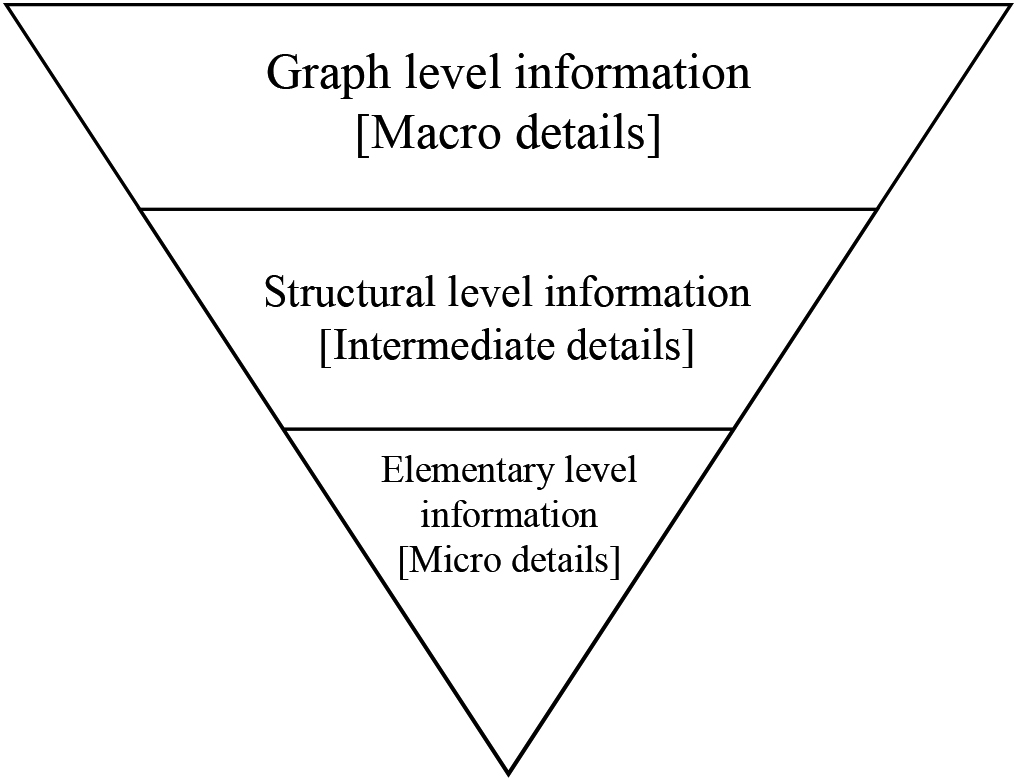
The Fuzzy Multilevel Graph Embedding method (FMGE) performs multilevel analysis of graph to extract discriminatory information of three different levels. These include the graph level information, structural level information and the elementary level information. The three levels of information represent three different views of graph for extracting global details, details on the topology of graph and details on elementary building units of graph. The feature vector of FMGE is named Fuzzy Structural Multilevel Feature Vector – FSMFV (see Fig. 4) [67].
The feature vector of FMGE [67].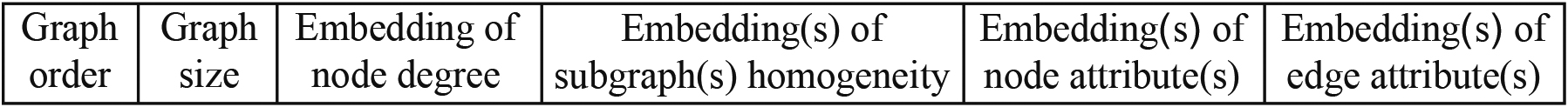
The vector of FMGE, i.e. The Fuzzy Structural Multilevel Feature Vector (FSMFV) consists of six part of feature vectors. Graph order is the number of vertices contained in the graph. A graph vertex is an abstract representation of the primitive components of underlying content. The order of a graph provides very important discriminatory topological information on the graph. Graph order (
There are correlations and differences between graph embedding and network representation learning. The goal of graph embedding is similar to network representation learning, that is, to embed a graph into a low-dimensional vector space [68]. The theoretical connection between skip-gram based network embedding algorithms and the theory of graph Laplacian is provided in the work [69]. However, graph embedding can be regarded as a special case of network representation learning as graph embedding mainly works on graphs constructed from feature represented data sets, where the proximity among nodes encoded by the edge weights is well defined in the original feature space. On the other side, network representation learning works on the naturally formed networks and targets the inference of networks such as node classification, link prediction, visualization [70].
Although there are differences between graph embedding and NRL, the multi-granular attribute exist in data of networks and it is explicitly proposed and studied in graph embedding domain [66]. This shows that the multi-granular methodology may help us to analyze the graphs and networks, both of which are consisted of vertices and edges.
The original network structure is usually represented by adjacency matrix, which explicitly contains the information of connections between all the vertices in the graph. This can be regarded as the finest granular information representation. In DGCC [40], data is considered as knowledge in the lowest(finest) granularity level, and knowledge is considered to be the abstraction of data in different higher granularity layers. As the opinion of DGCC, the adjacency representation of original networks can be regarded as the knowledge in the finest granular layer. The process of NRL is essentially an extraction of knowledge from the information on the finest granular layer but the knowledge is required to contain the whole or partial of properties of the original network.
Typically, the purpose of network embedding is extracting the feature of graph which can be viewed as automatic feature engineering. The unsupervised feature learning for the graph is traditionally based on the spectral properties of various matrix representations of graph, such as adjacency matrix and Laplacian matrix [56]. Some of the representative works for this are dimensional-deduction techniques such as PCA [71] and IsoMap [72]. PCA is linear and IsoMap is a non-linear way of dimensionality reduction techniques [73, 61]. These kinds of feature extraction are essentially obtaining the higher-order knowledge of networks while the original representations such as the adjacency matrix can be viewed as the knowledge on the lowest granular level.
Since the invention of word2vec [26, 28], the skip-gram model, which is borrowed from natural language processing domain, has significantly advanced the research of network embedding, such as the recent emergence of the DeepWalk [29], LINE [30], PTE [31], and node2vec [32] approaches.
The most representative work inspired by word2vec that represent the network as a document should be DeepWalk. It generates the corpus by randomly walking along the edges between vertices. Optimize the objective by maximizing the likelihood of the neighborhood existence. After DeepWalk, Tang et al. propose the LINE model(Large-scale information network embedding). Based on DeepWalk, LINE represents the relationships between nodes as 1st-order and 2nd-order proximities. Taking the KL divergence between the empirical distribution and the model as the optimization objective, the low-dimensional vector representation of nodes was learned by the random gradient descent method. However, LINE only models the first-order and second-order information of linkage but the higher-order information is ignored. The DeepWalk and LINE have no clear winning sampling strategy that works across all networks and all prediction tasks. In 2016, node2vec is proposed for overcoming this limitation by designing a flexible objective that is not tied to a particular sampling strategy and provides parameters to tune the explored search space.
GraRep [35] extends the length of the path of random walk in DeepWalk. It inspects the global probability transition matrix and improves the amount of information that contained in the random walk. Then use matrix factorization for optimization. In this way, the finer information is encoded and the model represents more detailed structure properties of networks. It’s reasonable that GraRep has higher complexity of computing because encoding finer knowledge introduces higher complexity in the perspective of multi-granular computing [74].
Yang et al. [47] analysis the NRL algorithms which can be viewed as matrix factorization and shows that this kind of NRL algorithms can be improved when higher order proximities are encoded into the proximity matrix. However, an accurate computation of high-order proximities is time-consuming and thus not scalable for large-scale networks. They propose network embedding update(NEU) algorithm based on the lower order proximities to avoid computation consumption but the algorithm can only process the unweighted and undirected graphs. Zhang et al. [49] propose the AROPE model which supports shifts across arbitrary orders with a low marginal cost. This can be seen as a concrete work for shifting NRL model between different granularities. AROPE suffers from searching the optimal hyper parameters for different task of network inference.
We can see some manifestation of multi-granular methodologies in the factorizing of the adjacency matrix. For instance, LINE encodes only the first and second order information than DeepWalk. In the process of generating the corpus, GraRep encodes nodes in the longer path to enrich the information contained in the granule and reaches higher perceptions as well as the higher computation consumptions. This is also shown by the NEU algorithm.
Heatmap of cosine distance from vertex 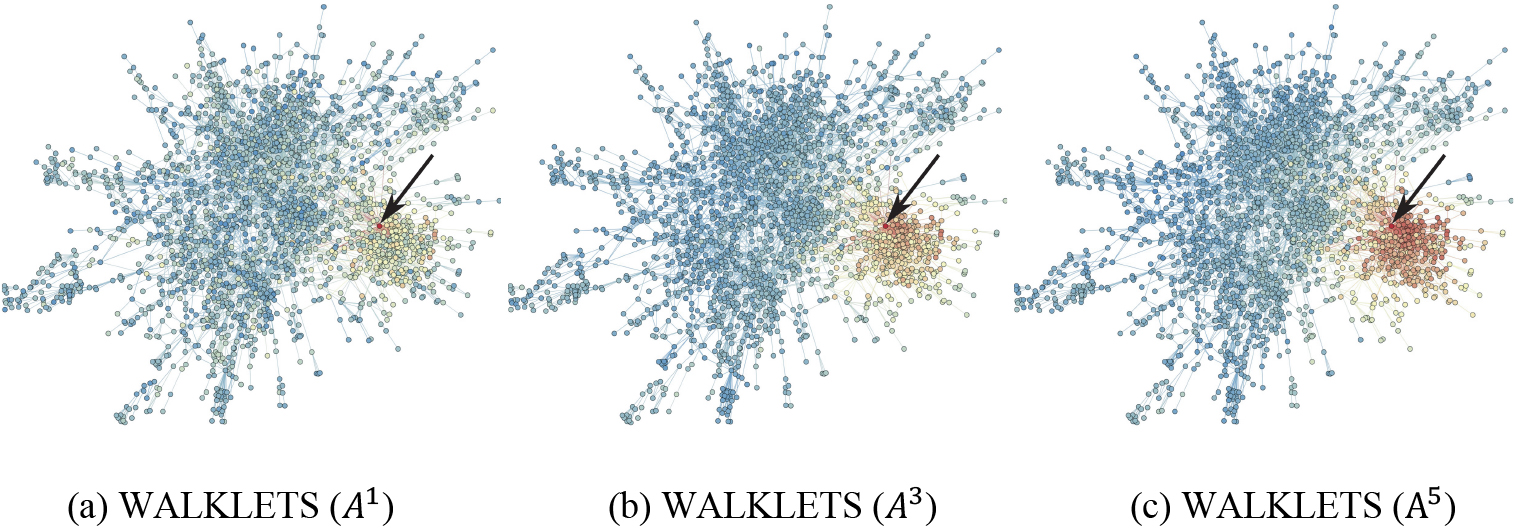
Illustration of graph coarsening algorithms [48].
From the perspective of the change of structure information in granule, some work is to increase the information capacity by increasing the depth of random walk or the number of transition matrices which leads to the increase of computation quantity. Like GraRep, NEU, etc., the refinement of granularity results in improved accuracy, but at the same time increases the computational overhead and the model becomes infeasible for large-scale networks (over 1 million nodes). Thus, how to find a suitable granularity of information and find a compromise between precision and performance is a problem. In the framework of matrix decomposition, we must measure the increase of granularity caused by the number of transition matrices and answer questions like which leads to the increase of computation, how much computation is increased, is it linear? Can we predict the computation time in advance according to the number of nodes to be examined? DeepWalk is essentially a matrix decomposition problem. In the DeepWalk framework, how to use approximated solutions to achieve the purpose of making precision within a reasonable range as well as the reducing the system consumption. Such problems are worth studying.
In addition to the methods that increase the information in the granule to obtain the finer representation of network knowledge, on the contrast, the works that decrease information in granule and transform the knowledge from finer to coarser are also proposed in recent years. B. Perozzi et al.proposes the WALKLETS algorithm [51] which extract the network structure property knowledge from finer to coarser by subsamples the sequences in random walk. It can be seen as the reversed process of GraRep which encodes the finer structural knowledge by creating the k-length path of sequence of vertices via transition matrix multiplication. Afterward, WALKLETS extract the network representation vectors on a specific level of granularity through matrix factorization. This work shows that the selection of granularity is significant and not the finer representation the better. They also define the multi-scale representation learning: Given a graph
Different from most NRL methods, [57] explicitly model an edge as a function of node embeddings. They are able to reduce the final node representation dimension significantly and they find that explicitly modeling edges can drastically reduce the representation dimensionality. This method obtains highly improvements of the link-prediction tasks. They use only 8 or 16 dimensions per node and that reaches the same or higher AOC value that baseline methods need 128 or higher dimensions to get. It can be seen that applying multi-granularity computation methodologies can decrease the computation consumptions while reaching or exceeding the precision of the baseline methods.
For the research of ’from finer to coarser’, such as WALKLETS, HARP, etc. WALKLETS achieves the goal of multi-granular NRL on the scale. It obtains the different granularity through sub-sampling on the raw data. The multi-granularity method is not integrated in the calculation model, because the later processing model is fixed for the same sample result. This is different from the typical multi-granularity calculation model like deep learning, which is to form multi-granularity solution layer by layer for the original data. Each granular layer is related and different, and it is a unified whole. The validity of WALKLETS stems from the fact that network topology does have multi-scale characteristics, and network nodes have characteristics of multi-scales. However, the WALKLETS model only use simple sub-sampling way and a fixed post-processing model. It separate the original connection between each granular layer. This is the limitation of WALKLETS. It fails to exert the effect of deep learning in image, speech and NLP.
Another work proposed by H Chen, B Perozzi et al. is HARP [48], a novel method for learning low dimensional embeddings of a graph nodes that preserves higher-order structural features. They show that DeepWalk, LINE, and node2vec have at least two main disadvantages: (1) higher-order graph structural information is not modeled, and (2) their stochastic optimization can fall victim to poor initialization. HARP finds smaller graph approximations as initial representations. They propose a general meta-strategy to improve all of the state-of-the-art neural algorithms for embedding graphs, including DeepWalk, LINE, and Node2vec. Nevertheless, HARP model lacks a criterion to evaluate the granular level of the granule. That criterion is necessary to show and improve the granulation quality of models. Figure 6 illustrates the edge collapsing strategies when coarsening the original graph. In detail, Fig. 6(a): Edge collapsing on a graph snippet. Fig. 6(b): How edge collapsing fails to coalesce star-like structures. Figure 6(c): How star collapsing scheme coalesces the same graph snippet efficiently.
In HARP, edge collapsing is used for coarsening and then the refinement is made through layer by layer merging. However, it is a problem that HARP adopts a uniform reduction method for the whole network. The reduction of the global nature of network will erase the relationship between the local node and the overall behavior of the larger community. For example, the activity of a small group may affect the speech of the larger population. HARP still has some deficiencies in the expression and correlation of structural information across multiple granular layers.
Those cases above show that the concrete embodiment of the multi-granularity idea in the study of NRL for structural properties preserving. It can be seen that, due to the multi-granularity characteristics, the multi-granularity methods have been successfully applied in NRL to preserve structural properties, such as GraRep, NEU, WALKLETS, HARP, etc. They provide good inspirations for improving the efficiency of large-scale network data processing and algorithm model performance in further data mining tasks.
In the research field of complex network analysis, the properties of community structures in the network have been studied by many researchers. It’s natural to see that the community structure, as a mesoscopic level of organization, is a common feature of networks [75, 76, 77, 78]. Peter J. Mucha et al. developed a methodology to remove these limits, generalizing the determination of community structure via quality functions to multi-slice networks that are defined by coupling multiple adjacency matrices (CMAM) [79].
A lot of works propose methods for detecting the community structure in complex networks. They show the hierarchical organization of communities [80, 81, 82]. Hence the hierarchical organizations in link communities widely exist in complex networks which shows big significance of studying the representation learning methods that can preserve the hierarchical community structures in networks. Some works on NRL consider preserving the structural properties of community. However, method that explicitly represent the community properties in a hierarchical way is not seen by now. The hierarchical organizations that widely exist in link communities of networks may be ignored.
Wang et al. [83] assume that if the representation of a node is similar to that of a community, the node may have a high propensity to be in this community, they introduce an auxiliary community representation matrix to bridge the representations of nodes with the community structure. They propose a model of nonnegative matrix factorization(M-NMF) for network embedding which preserves both the microscopic structure and the mesoscopic community structure [75]. They adopt the non-negative matrix factorization NMF model [84] to factorize the pairwise node similarity matrix and learn the representations of nodes. So that the microscopic structure, i.e., the first-order and second-order proximities of nodes, is preserved. Meanwhile, the community structure is detected by modularity maximization [85].
WALKLETS captures multiple scales of social relationships [51].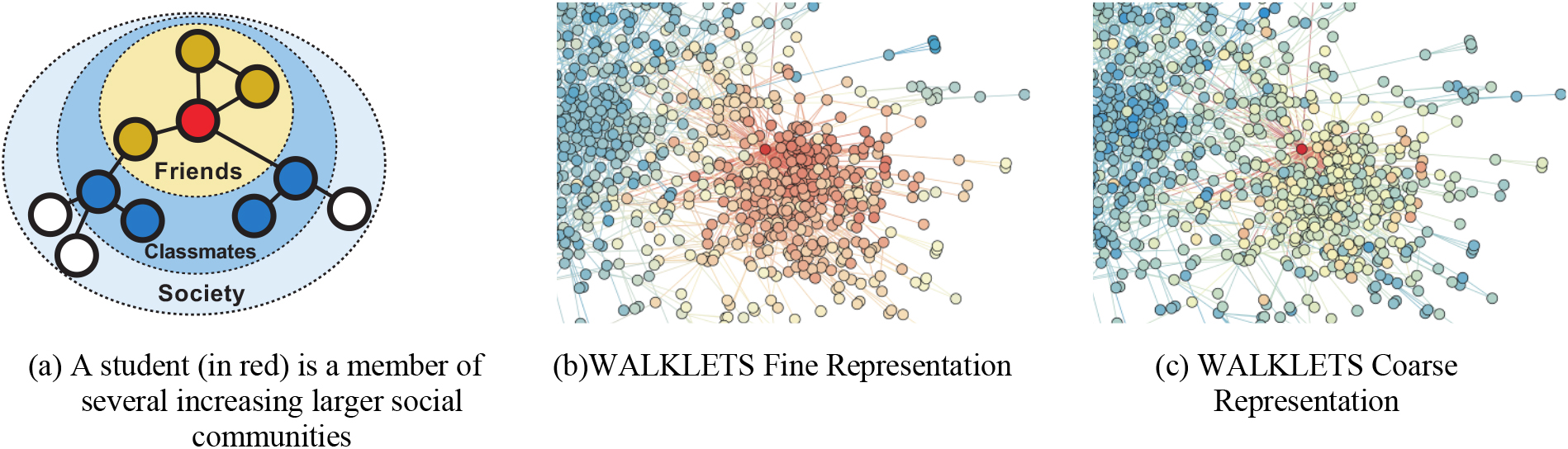
It is desirable to have a family of representations which captures the full range of an individual’s community membership. The WALKLETS show some results about this topic (see Fig. 7). WALKLETS captures multiple scales of social relationships like those shown in Fig. 7(a). The scale of community is illustrated as a heatmap on the original graph in Fig. 7(b) and Fig. 7(c). Color depicts cosine distance to a single vertex, with red indicating close vertices (low distance), and blue far vertices (high distance). Figure 7(b): Only immediate are near the input vertex in a fine-grained representation. Figure 7(c): In a coarse representation, all vertices in the local cluster of the graph are close to the input vertex. Subgraph from the Cora citation network [51].
Many NRL methods aim to preserve the local structure of a node, including neighborhood structure, high-order proximity as well as community structure. Conversely, any works that explicitly represent the community properties in hierarchical way are not proposed, although the multi-scale community has been studied by former researchers and the hierarchical organization of communities and multi-scale community detection methods have been discussed by former works. This may ignore the hierarchical organization properties which widely exist in link communities in networks.
Granular computing is a broad concept. In addition to consider the structure and community information in granule obtained by NRL algorithms, the content in the network can also be regarded as information which should be contained in information granule. In reality, network vertices contain rich information (such as text), which cannot be well applied with algorithmic frameworks of typical representation learning methods. In this character, we discuss about the methods of information network representation which considers the content in nodes and edges in the network. Different from the NRL methods discussed above, the connotation of multi-granularity is neither the variety of amount of nodes nor the scale of communities. Moreover, the content or side information on nodes and edges are regarded as another kind of information granule.
With the proliferation of rich graph contents, such as user profiles in social networks, and gene annotations in protein interaction networks, it is necessary to consider both the structure and content information of graph for high-quality graph clustering. In the field of graph clustering, for the task of content-enriched graph embedding, AGC [87] proposes an approach by considering the side info: They quantify vertex-wise attribute proximity into edge weights and employ truncated, attribute-aware random walks to learn the latent representations for vertices so that the localized structural and attributive information of vertices are encoded.
Le et al. [18] join the various representations of a document (words, links, topics, and coordinates) within a generative model and learn the representation of nodes in the topic space based on the Relational Topic Model (RTM) [25]. They estimate the hidden representations of the vertex associated with a text document through maximum a posteriori (MAP) estimation using EM algorithm [88]. PTE [31], inspects the representation problem of large-scale heterogeneous text networks and use the represented vectors for prediction tasks. PTE add different types of information as new kinds of information granule. They encoded three types of text networks which can be seen as three kinds of information granules. Qiu, Yu et al. [69] show that all of the aforementioned models with negative sampling can be unified into the matrix factorization framework with closed forms. Their analysis and proofs show that as an extension of LINE, PTE can be seen as the joint factorization of multiple networks’ Laplacians which can be viewed, in the perspective of multi-granularity computing, as mixing types of information into granule when granulating the text information in the network.
(a) Deepwalk as matrix factorization. (b) Text associated matrix factorization in TADW [86].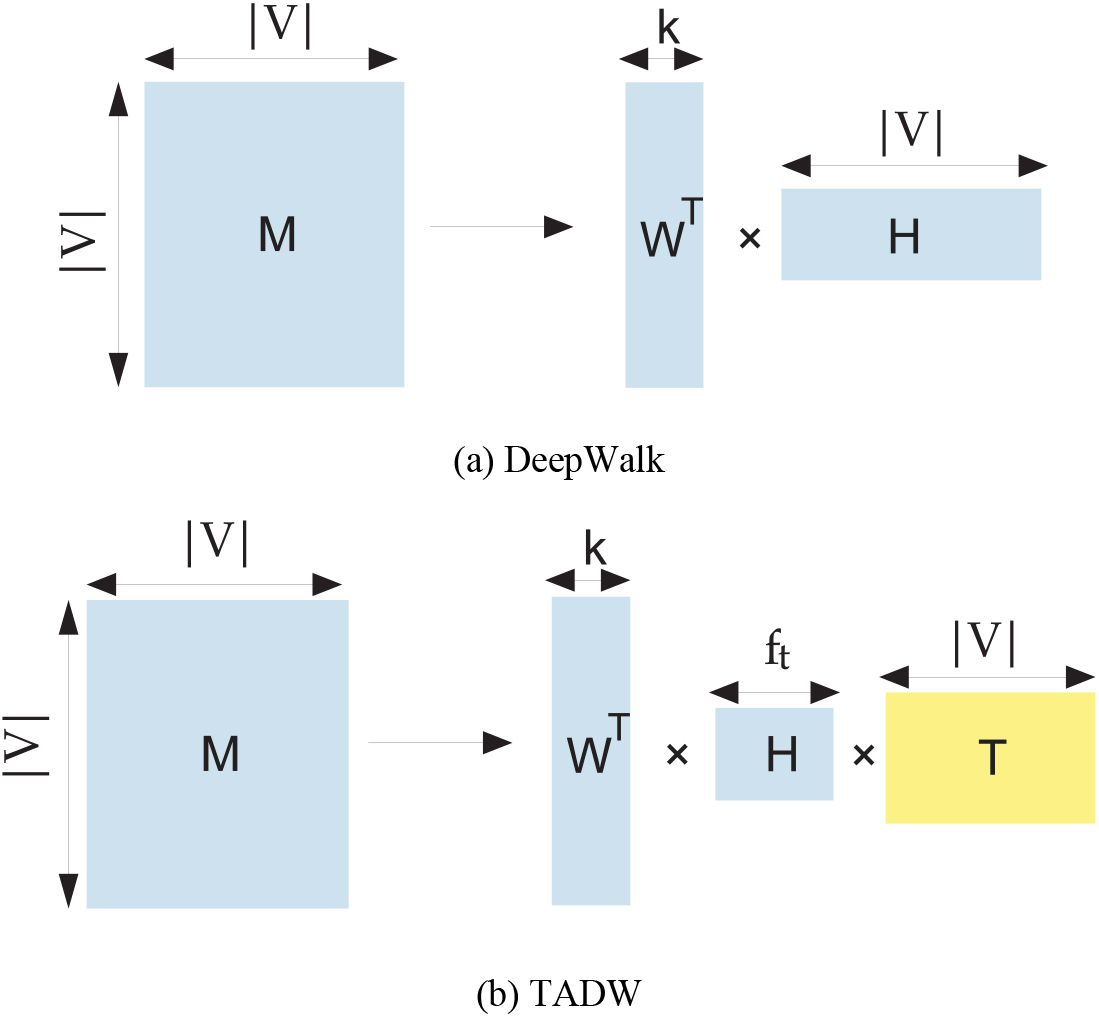
Yang et al. propose TADW [86]. TADW (Text-associated DeepWalk) incorporates text features of vertices into network representation learning under the framework of matrix factorization. Depends on the matrix factorization view of DeepWalk(see Fig. 8(a)).They introduce text information into MF for NRL. Figure 8(b) shows the main idea of this method: factorize matrix M into the product of three matrices:
In order to increase the discrimination in the task of node classification, the MMDW (Mar-margin DeepWalk) utilize the semi-supervised learning for NRL [89] based on the matrix factorization NRL model and mar-margin classifier. In perspective of multi-granular computing, the label information can be viewed as the addition of granules in the NRL process. Similarly, the DDRW (Discriminative Deep Random Walk) [89] jointly train the DeepWalk model and max-margin classifier to improve the performance of node classification.
Another work that focuses on the difference of relationships using associated text information in the NRL is CANE [90]. CANE utilize the text information to describe the difference of style of relationships in social networks such as co-authors of papers. They assume that the representative vector of each node consists of text representation and structural representation. Such that the node representation encodes the context information due to the text representations are correlated with the neighbors in the network. The convolutional neural networks are used to encode the text information on two nodes connected by one edge. Lu et al. [91] consider the embedding of relational structure in heterogeneous information networks. This is a concrete work of applying multi-granularity computing methodologies in merging the structural granule with the content granule in the NRL models.
Pan et al. propose TriDNR [92], a tri-party deep network representation model, using information from three parties: node structure, node content, and node labels (if available) to jointly learn optimal node representation. As a result, the learned representations is enhanced by the three sides of network information. LANE [93] incorporate the label information into the representation of networks based on spectral techniques.
Multi-layer Graph Convolutional Network (GCN) with first-order filters [95].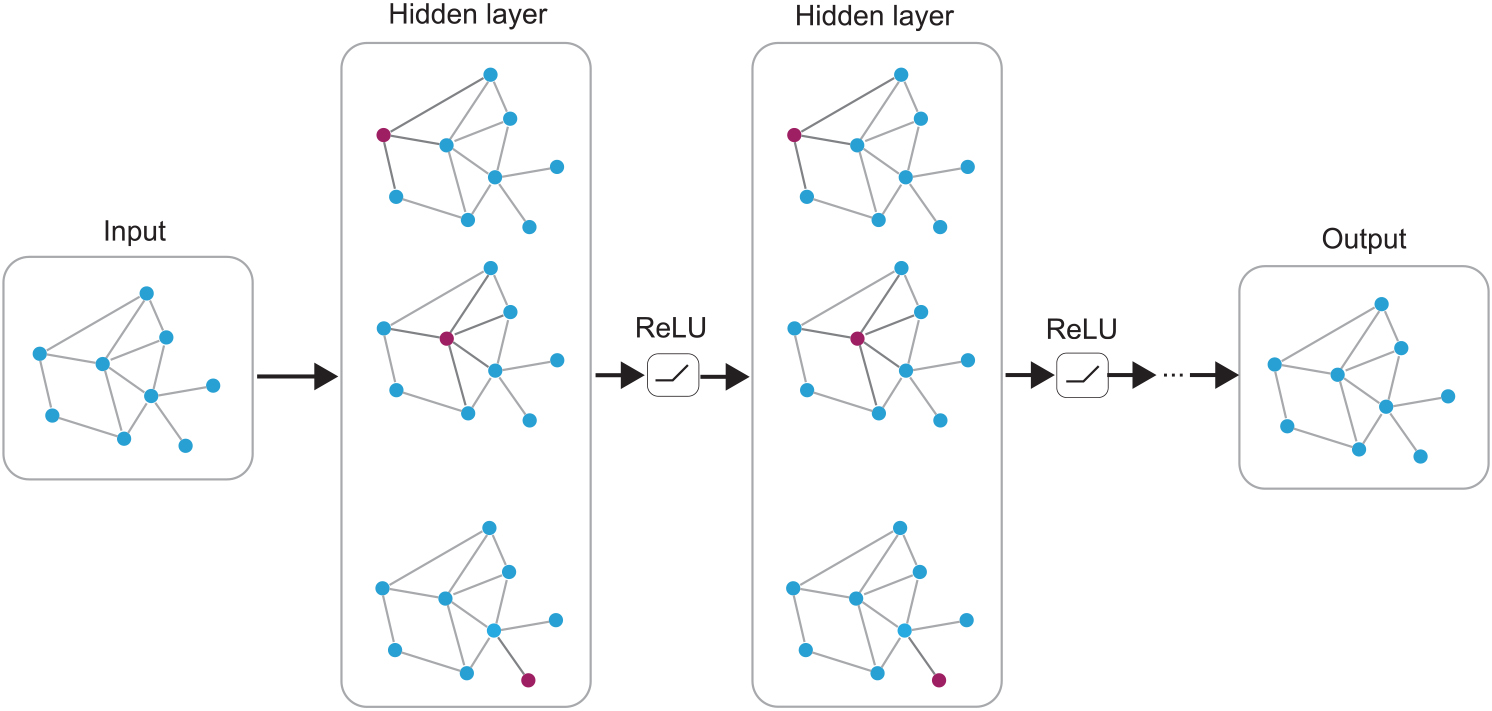
The graph convolutional networks (GCN) models (see Fig. 9) that appear in recent years generalize well-established neural models like RNNs or CNNs to work on arbitrarily structured networks. And these models achieve remarkable success. From RNNs and CNNs, the GCNs [94, 95, 96, 97, 98] borrow the idea of facilitating the multi-layer connecting models to extract multi-granular features of objects and these works are the typical embodiments of multi-granular computing methodologies. These models mainly adopt that information aggregating among neighborhood of nodes and nodes’ features such as text-data or protein-protein interactions to generate representations. They extract the local structural features between node and its neighborhoods by operations that similar with the convolutional kernels of CNNs. In addition, the mechanism of sharing parameters among nodes increases the efficiency of model training.
The content of nodes and edges are all considered as the addition of network representation through the approaches adopt various strategies. The side information can be viewed as additional information granule to obtain the finer knowledge of networks and the accuracy of model should be higher at a finer level of granularity.
The characteristics of multi-granularity information should also be considered and captured progressively. Although these models consider the problem of multi-data sources, they may have latent multi-level features in the data characteristics as well. Existing models do not consider these problems. If the multi-level features are considered while finer granule is grained by side information, the property of multi-granularity in side information and structural information would be obtained simultaneously by NRL model.
The network analysis and mining task is far from just node classification, link prediction, community detection, etc. There are also many specific and more advanced analysis tasks, such as information diffusion mechanism [99], information cascade [100] and anomaly detection [101]. Advanced information preserving network representation learning tend to jointly consider representation and its specific network inference tasks. Methods for representing the structural properties of networks are designed while the domain knowledge of specific tasks is also needed to be considered. This requires researchers to have domain knowledge, and at the same time, model designing needs to consider the application scenarios. This section will discuss the embodiment of multi-granularity ideas in the NRL methods that contain advanced information.
In DGCC [40], data is considered to be knowledge in the lowest granularity level while knowledge is considered to be the abstraction of data in different granularity layers. People combine the advanced network analysis tasks and their domain knowledge for these special tasks in order to obtain the network representations which contains the properties for the advanced tasks. Wang et al. discussed the relationship between the prior knowledge of domain experts and the knowledge mined from data [102]. They address these basic issues of data mining from the viewpoint of informatics [103].
Domain-oriented knowledge is the information on higher granularity. Here the multi-granularity network representation has the connotation that the domain knowledge, as the information on the higher granularity, was combined with the structural properties of networks as the information on the lower granularity.
Information diffusion [99] is a ubiquitous phenomenon on the web, especially in social networks. Bourigault et al. [21] propose asocial network embedding algorithm for predicting information diffusion. The basic idea is to map the observed information diffusion process into a heat diffusion process modeled by a diffusion kernel in the continuous space. On the other hand, for the task of popular topic detecting, Leskovec et al. [104] show that the temporal dynamics of the most popular topics in social media are indeed made up of successive bursts of popularity based on the work of Kleinberg [105] which yield a nested representation of the set of bursts that imposes a hierarchical structure on the overall stream. If the hierarchical structure is considered in the representing learning, there may be some improvement for the information diffusion tasks.
Information cascades are identified to be a major factor in almost every plausible or disastrous social network phenomenon, such as viral marketing and diffusion of innovation. Predicting the increment of cascade size after a given time interval becomes significant in the social analysis [100]. Different from the previous work that all depends on bag of hand-crafting features to represent the cascade and network structures. Li et al. [106] use the idea of network representation learning to achieve an end-to-end learning model to predict the information cascade. Once the representation of this cascade is obtained, a multi-layer perceptron [107] can be adopted to output the final predicted size of this cascade. However, any work for explicitly extracting the multi-granular knowledge for information cascade will be significant due to the multi-scale properties in the information cascade [108].
Summary of the key works of each Section of the survey
Summary of the key works of each Section of the survey
To the best of our knowledge, other network representation approaches for advanced information representation such as anomaly detection do not show multi-granular properties or there is no work about the multi-granular property preserving network representation learning for anomaly detection in graphs. There exists a representative work for detecting the anomaly based on the network representation learning which is proposed by Hu et al. in 2016 [101]. The summery of key research works mentioned in above sections for multi-granular NRL analysis is listed in Table 2.
We look into this topic to find if there is any multi-granular method for applying network representations for specific network inference tasks. The representation of networks has multiple ways of applications. The important tasks in network analysis involve predictions and classifications over nodes and edges such as node classification, link prediction, community detection, and visualization. There are surely some other applications which are not so widely concerned and we will discuss them if needed.
Node classification
Node classification is predicting the most probable labels of nodes in a network [109]. For instance, in a social network, we need to predict the interest of a node depends on its structural properties [110, 111] or in a protein-protein interaction network we need to predict the functional labels of proteins [112]. This is the most common application of NRL. Given some nodes with known labels in a network, the node classification problem is to classify the rest nodes into different classes. The classification accuracy will increase if we consider the community properties of nodes such as the work of M-NMF [83]. They got higher performance than DeepWalk, LINE [30], GraRep [35] and node2vec [32] in the task of node classification. Through this, they verified the necessity of introducing mesoscopic community structure to network representation learning. As the community has the multi-scale properties, we may obtain different classification result if we consider the community structure at different granular levels when we represent the networks into low dimensional vector space.
Link prediction
Link prediction has attracted a large amount of research as a fundamental problem on network data mining [10, 113]. Most often, some links are observed, and one is attempting to predict unobserved links, or there is a temporal aspect: a snapshot of the set of links at time
Network representation captures the implicit structural properties of networks which are highly related to link prediction and inference. Hence the application of network representation brings in improvements for link prediction tasks. Various studies on network representation learning demonstrate their performance on link prediction task [70]. Nevertheless, multi-granular network representation may allow us to implement link prediction on multi granularities due to the multi-granular structural properties of networks. For instance, when the stream data of networks obtained, some scenarios require process tasks like link predicting in limited time. The coarser representation of network data which consumes fewer computation resources may meet that requirement.
Performances of typical NRL algorithms that are listed in this paper
Performances of typical NRL algorithms that are listed in this paper
The performances of some typical network representation learning algorithms are listed in Table 3. To make a fair comparison, we selected the Cora [95] and CiteSeer [118] datasets to compare the performance of these algorithms on the node classification task. The original papers of these algorithms include experimental results on these two datasets. In addition, we also listed the performance of these algorithms on the link prediction task, which is generally given in terms of the area under the ROC curve (AUC). Note the BlogCatalog [117] dataset is used for this link prediction performance comparison.
Community detection, which is also called as group detection in link mining area [116], the goal of which is to cluster the nodes in the graph into groups(clusters) that share some common characteristics. The nodes within the same cluster are more similar to each other than the nodes in different clusters. In traditional way, a lot of works have been proposed in various communities to address node clustering problem in graph. For the single type of nodes and edges without attributes, agglomerative or divisive clustering methods are used. The deterministic methods such as blockmodeling [6], Spectral graph partitioning [104, 119], edge betweenness [120, 121, 83] separate the graph into clusters while based on the stochastic blockmodeling from social network analysis. The observed social network is assumed to be a realization from a pair-dependent stochastic blockmodel [1]. Several works such as generalization and extension of stochastic blockmodeling are committed [122, 123, 124]. To exploit multi-relational data to detect indicators of collaboration, Adibi et al. [125] propose a hybrid approach that initially posits potential groups using knowledge-based reasoning techniques. A generative model for multi-type link generation proposed by Kubica et al. [126, 127]. Wang et al. [128] propose a generalization of the general stochastic blockmodeling approach that allows joint inference of groups and topics based on observed relationships and their textual attributes. Such a model provides a mechanism to connect an observed relationship with its underlying context.
Recently, network representation learning research provides new approaches for the task of group detection and community detection which can also be achieved via directly doing clustering on the learned representation of nodes. Many typical clustering methods, such as K-means [129], can be directly adopted to cluster nodes based on their learned representations. Many researchers have tested their network representation learning work on the task of community detection [130, 131].For instance, Wang et al. [83] did the community preserving network embedding on node clustering. The network datasets such as YAGO [132] and Freebase [133] are used for experiments.
The central challenge for community detecting network representation learning is to develop scalable methods that can exploit increasingly complex graphs to aid the knowledge discovery process [116]. In the process of NRL, integrating the multi-scale properties in representation vectors may bring some probabilities for overcoming that challenge. For instance, Xu et al. [43] propose the hierarchical clustering which is the embodiment of multi-granular methodologies dealing with the clustering problem. It views the data as the nodes in a tree and analysis data on different granularities by clustering on multi-granularities. This idea can be integrated into the tasks like node clustering or community detection for network data mining.
Visualization
Visualization of nodes of networks makes it easy to see a big picture of a sophisticated network and the structure of networks becomes intuitive. It’s also a typical application of low-dimensional vectors obtained by NRL. Some properties of networks can be easily discriminated by visualization. Hence, LINE, GraRep, EOE [111] and SDNE [101] are applied to a citation network DBLP and generate a meaningful layout of the network using a visualization tool such as t-SNE [134]. Pan et al. [92] show the visualization of another citation network Citeseer-M10 [135] consisting of scientific publications.
The low-dimensional representation of multi-granular NRL may show network attributes on different granular layers. On the other hand, the multi-granular methodology can be used to simplify the result of the visualized data. For instance, coarser visualization shows us the global characteristics of networks while the finer visualization shows us the specific local properties of nodes or communities. This allows us to transfer the visualization appearance among different levels of granularities and obtain the multi-granular result as we want.
Advanced applications of NRL
In addition to the original network inference tasks such as node classification, link prediction, community detection and visualization, people also implement NRL models for advanced network analysis such as anomaly detection [101], recommendation [136, 137], information cascade [138], knowledge graph [139], identity detection across networks [50, 140, 141] and outlier detection [142]. For such more specific tasks, the models need to consider the specific factors that can discriminate the network data for the target applications. The most important issue is how to incorporate the domain-oriented knowledge in to the NRL models and generate the knowledge contained granule for the advanced, domain-oriented, specific network inference tasks. In the multi-granular computing perspective, this problem can be viewed as how to let the coarser knowledge in higher level merge into in the model when granulation.
Issues and open research problems
We discuss about the issues exist in the study of multi-granular network representation. Nevertheless, some of the issues exist not only in the multi-granular NRL but also in general NRL studies, such as the meaning of each dimension of representation vector
There are many theoretical issues to be studied for implementing multi-granular NRL model. For instance, large scale streaming data requires NRL algorithms to process the time-limited scenarios and provide solutions on different granularity levels in a timely way. Meanwhile, seeking an optimal granularity level and reasonable approach of granulation for a specific network inference task becomes an important problem. We sort out the issues and scientific problems in six aspects below, and discuss the future research prospects for such problems.
Progressive multi-granular NRL model
Usually, coarser answers could be generated in a higher granularity layer with less time cost, while finer solutions in a lower granularity layer with more time cost [40]. Progressive variable granularity NRL algorithms and models should be developed for the scenarios of multiple range of time-limits. The matrix factorization based NRL algorithms such as GraRep [35] and TADW [86] suffer from high computational cost but how to approximate the network information and simplify the computation of matrix factorization becomes significant. It’s desired that the coarser answers can be generated at first, and more exact answers will be available in lower granularity layers later. We need to select the optimal granular layer depends on the attributes of a network and the specific analysis tasks. Any conclusive laws that can guide the granularity process will be of great value.
Granulation of network made at several different layers.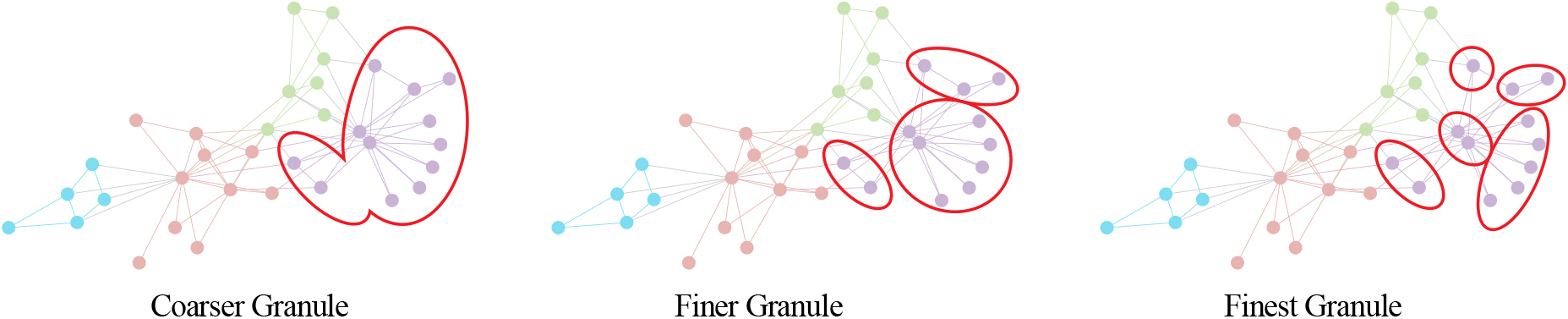
Data, information and knowledge should be represented in a multiple granularity space together by a multiple granularity joint NRL model. The multi-granular representation of such NRL models could be used in problem solving simultaneously in a parallel way. As shown in Fig. 10, granulation of network data can be made at several different layers simultaneously. Representations in different layers might be either dependent or independent. Such that, the mechanisms for joint computing and NRL in a multiple granularity space is required. Moreover, the merging and decomposing mechanisms for granules across multi-granular layers are also needed. WALKLETS shows some results that can offer multi-granularity representations for structural properties preserving. However, any models that can transform the granule across multi-granular layers via approximating graph structures such as edge collapse is needed for the task of multi-granular joint solving problems. In addition, the well-designed models that can process the granules consisted of multi-granular information sources such as side information, community information, etc. in parallel way should be of great significance.
Multi-granular representation for network evolutions
For the scenario of online learning of dynamic networks, edges and nodes are disappeared or added to networks over time. Most of the existing NRL methods can only repeat to compute the result when changes appear. DeepWalk and its similar models show some capabilities to handle the new-coming node online. But for multi-granular NRL, how to deal with the data streaming situation and how to determine the optimal granularity for data streaming need more research to answer. The high-efficient approximation mechanisms for large-scale streaming network data processing is of great value in the situation of time-limited dynamic network inference. We noticed that Dongsheng Duan et al. focus on the problems of dynamic networks [143] and Sun et al. [144] embeds network transfer behaviors in vector space. But how to merge together the methodologies of incremental computing and the methodologies of multi-granular computing, in the NRL model, to exploit the advantages of incremental computing when processing large-scale networks by NRL model is still of great interests.
The criterion for describing the size of granule obtained by NRL
We see the way of granulation in NRL has different types. Some of them achieve this by increasing the order of proximities or transforming matrices such as GraRep, LINE and NEU. On the other hand, the models like TADW, TriDNR add side information to increase the knowledge that the representation contains. This can be viewed as representation on the finer granular level. In the respective of multi-granular computing, information granulation for obtaining finer or coarser granule should have a criterion to describe the size of granule. However, lacking of the criterions for assessing the size of granule may be the reason that it’s impossible for NRL researchers to seek the optimal granularity when doing multi-granular NRL tasks. If there is a reliable criterion to evaluate the amount of information that represented by the granule generated by multi-granular NRL model, seeking the optimal granularity and granulation methods would become possible. Thus, how to represent the level of granularity is still a significant problem.
Evaluate and avoid the influence of unbalance in networks
The power law distribution property indicates that few nodes occupied more edges but most nodes are associated with a small number of edges. How this unbalance influent NRL and how to prevent this introducing negative influence in the multi-granular NRL process are still largely untouched.
Representation for the higher-order structural properties in networks
Multi-granular computing for NRL transforms the knowledge from finer representation to coarser one. It’s worth mentioning that most of the complex local structure of a node can be considered to provide higher level constraints. Recent NRL methods assume that the nodes share common edge should have higher proximity and they work well for some tasks such as link prediction. However, the node’s centrality information which is usually related to a more complex structure would be ignored. Similar problems of higher-order structural representation like motifs [40] structure preserving representation are still an open problem for multi-granular network representation learning research.
Conclusion
Networks have its complexity and highly abstract information and characteristics. This has attracted various data mining research. Comparing with the traditional network analysis methods, network representation learning maps the original data into lower dimensional space for applying the off-the-shelf machine learning algorithms. But the NRL algorithm meets some bottlenecks such as low-efficiency and low-accuracy. Considering the multi-level characteristics and the resulting contradictions in NRL, the application of multi-granular methodology is applicable. Multi-granular methodology is inspired by human recognition methods. It approximates the complex information into coarser knowledge and simplifies the original problems by decomposing the original problem into multiple granularities. In the perspective of multi-granular computing, the finer granularity of NRL can be obtained by encoding more detailed information into models and the improvement that achieved by the algorithms can be viewed as that getting more accuracy at the finer granular level. We propose a multi-granularity perspective on recent NRL research and sort out several prospect scientific problems about how to apply multi-granular computing methodologies in future NRL research. Although quite a number of former works show the inspirations of multi-granular methodology in recent research works of NRL, there should be more better-designed and explicit applications of multi-granular computation methodology in NRL models.
Footnotes
Acknowledgments
This work is supported in part by the Science and Technology Research Program of Chongqing Municipal Education Commission (Grant No. KJZD-M202203201, KJQN202303203), Doctoral Fund of Chongqing Industry Polytechnic College (No. 2023GZYBSZK3-03), the National Science Foundation of China (No.6206049), the Excellent Young Scientific and Technological Talents Foundation of Guizhou Province (QKH-platform talent [2021] No.5627), and the Science and Technology Top Talent Project of Guizhou Education Department (QJJ2022[088]).
Conflict of interest
The authors declare that they have no conflicts of interest to report regarding the present study.
Funding statement
The author(s) received no specific funding for this study.