
Abstract
Feature selection is a complicated multi-objective optimization problem with aims at reaching to the best subset of features while remaining a high accuracy in the field of machine learning, which is considered to be a difficult task. In this paper, we design a fitness function to jointly optimize the classification accuracy and the selected features in the linear weighting manner. Then, we propose two hybrid meta-heuristic methods which are the
Keywords
Introduction
Thousands of applications have boosted the developments of machine learning, however, extracting the useful knowledge from the collected data is more and more complicated than before [1, 2]. Data mining is the process of finding meaningful information and models from large-scale data, but the collected data may contain uninformative or even misleading features in practice [3]. Feature selection is one of the major pre-processing means of eliminating the redundant and irrelevant data from the whole data set, which can reduce the dimensionality of the data sets, accelerate the learning process and improve the classification accuracy [4].
Feature selection aims at choosing the optimal subsets from the whole data sets but without losing any classification accuracy or even improving it compared to the originals [5]. Therefore, feature selection techniques are widely used in reducing the number of selected features in high-dimensional data sets [6].
Feature selection methods can be broadly categorized into three classes correspond to the way that they are integrated with classification model: wrappers, filters, and embedded methods [7]. The wrapper methods utilize learning algorithm as the classifier into the classification process to determine whether a certain feature should be chosen or not, by which to gradually generate a robust subset. Some well-known classifiers are widely used in the state-of-the-art works, such as machine learning classifier, Las Vegas wrapper and natural network-based method [8]. On the other hand, filter methods categorize the features into certain criteria and only the features with high scores will be chosen. There are some popular filter methods proposed in the literature, for instance, Information Gain (IG), Trace Ratio Criterion (TRC) and ReliefF [9]. In addition, the embedded methods are proposed to solve the existed problems in filter-based methods cause they exploit the interaction with the classifier and the correlation between the feature and label is further considered [10].
As for the process that how to select the optimal subset from the initial data set is considered to be the essential aspect of the feature selection, namely, “subset generation” [11]. Generally speaking, there are three main search methods that commonly used in subset generation, which are complete search, random search and heuristic search, respectively. The complete search generates all possible feature subsets from the original data set, evaluates each of those feature subsets, and selects the best one. Thus, if the number of the features is
An alternative method that may overcome the drawbacks of the two previous strategies is to utilize the heuristic search. As described in [12], a heuristic search can be clarified as a depth-first search and provides heuristic information to orient the search into the direction of the search goal, which tends to be significantly more cost-effective than the complete and random searches in the field of feature selection optimization. Meta-heuristic search is a special type of heuristic search, which can be defined as "a upper general template that can be applied as guiding strategies when projecting underlying heuristics to deal with specific optimization problems" in [13].
Based on the success of previous meta-heuristic algorithms in solving various optimization problems, more and more innovative nature-inspired algorithms are being proposed in the recent years. For example, BES was firstly proposed by Alsattar et al. [14] in 2020 to mainly simulate the hunting strategy and intelligent social behavior of bald eagles when they were looking for preys. Additionally, BES has the advantage of solving various complex numerical optimization problems effectively and may be applied in extensive prospects optimistically in the future because of its strong global search ability [15]. However, BES was originated proposed for continuous optimization, which indicates that BES cannot be directly utilized in feature selection optimization since the solution to the problem is discrete. Moreover, the convergence accuracy of BES is not so satisfactory in solving some certain problems [16]. As a new type of efficient nature-inspired meta-heuristic method, BES has not been applied for the domain of feature selection yet. Therefore, modifying BES into the feature selection field and improving the performance of BES is a considerable research in this work.
On the other hand, PSO is deemed as one of the most well-known meta-heuristic algorithms in the state-of-the-art works [17]. PSO was firstly proposed by Kennedy and Eberhart in 1995 [18], which simulated the regularity of birds’ foraging behaviors in nature. Generally speaking, PSO is effective in solving various optimization problems due to its unique characteristics like simplicity, applicability and low complexity [19]. PSO has been successfully applied to manage optimization problems in various fields, such as edge detection, path planning, clustering analysis, power system operations, image segmentation and so on. Nevertheless, PSO may have certain drawbacks of premature convergence and tight relation between the values and the variants [20].
In the recent years, a huge number of hybrid meta-heuristic algorithms are proposed to solve combinative optimization problems. A clever combination of the meta-heuristic algorithms can unite the advantages of the each optimizer and eliminate the disadvantages of those hybrid strategies [21]. More specifically, the hybridization of local search process and the evolutionary computation can directly refine the achieved solutions during searching. The evolutionary computation is capable to recognize the promising solution space that may exist more solutions with high quality, thus the performance of the hybrid algorithms will be improved to some extent [22]. In summary, the hybrid strategy that combines the each strength of the excellent meta-heuristic algorithms is a candidate effective direction to solve the designed feature selection problem in this paper.
To the best of our knowledge, this work is the first attempt to hybridize BES and PSO to solve the proposed feature selection problems. Totally, the key contributions of this paper are listed as follows:
The most important purpose of this paper is to improve the classification accuracy while reducing the selected features. Based on that, we design a linear weighting fitness function to jointly tackle the above contradictory objectives. We aim at solving the designed fitness function by utilizing the advantages of BES and alleviate its shortcomings by hybridizing it with PSO. Firstly, the main procedures of the original algorithms are displayed briefly. Next, we plan to embed PSO into the searching phase and swooping phase to enhance the exploitation capability of BES. Further, a new chaotic map is adopted to broaden the solution space and maintain the diversity of the population obtained by the hybrid method. Finally, the binarization strategy is designed and optimized in the hybrid method since the solution to the feature selection problem is binary. In order to confirm the effectiveness of the proposed hybrid methods, the experiments are conducted on 17 classical UC Irvine (UCI) Machine Learning Repository data sets as well as the comparison are carried out with five well-established algorithms from the literature in terms of the various indicators, such as fitness value, classification accuracy, CPU running time and the selected feature numbers.
The rest of this paper is listed as follows. Section 2 introduces the research overview in the field of feature selection optimization. Section 3 specifies the preliminaries of this paper, including giving a formulated fitness function and explaining the original methods. The details of the hybrid meta-heuristic algorithm are exposed in Section 4. Section 5 presents the experimental results and provide the relevant analysis of the obtained results. Finally, Section 6 concludes this paper and suggests the future work. The Tables A-1 and A-2 of Appendix A describes all the symbols and abbreviations used in this paper.
As early as 1998, Kohavi et al. [23] have proved that the wrapper-based feature selection method is good at improving the performance of the learning process and eliminating unnecessary information in the whole data set. From the perspectives of actual applications, the wrapper-based selection method usually achieves better classification accuracy than the filter-based method [24], therefore many wrapper-based selection methods can be found in the literature. However, wrapper methods are usually much slower than filter methods, so filter methods are more scalable to data sets with a very large number of features.
As a powerful swarm intelligence-based method, PSO has become a research highlight in optimizing the selection of the final feature subset. Sharkawy et al. [25] used PSO technique in determining the particle type and dimensions in transformer oil. Sakri et al. [26] embedded PSO algorithm into various renowned classifiers to increase the accuracy level of predicting women breast cancer recurrence. Another research paper in the optimization field of medicine was presented by Inbarani et al. in [27]. The authors proposed new supervised feature selection methods based on hybridization of PSO and other PSO-based methods for the diseases diagnosis. In [28], Chuang et al. introduced Logistic map and Tent map into binary PSO model to determine the inertia weight of PSO and implement the feature selection. More details of PSO applied in feature selection can be found in [29].
Besides PSO, many classical meta-heuristic algorithms have been modified to be applicable for feature selection optimizations since they showed competitive results in selecting the informative features compared to other search methods. The examples of the abovementioned meta-heuristic algorithms are binary gray wolf optimization (BGWO) [30], binary dragonfly algorithm (BDA) [31], unsupervised ant colony optimization (UACO) [32], binary bat algorithm (BBA) [33], binary firefly algorithm (BFA) [34], and so on.
Designing new optimizers to improve the performance of the meta-heuristic algorithms are new research trend in feature selection optimization. Mafarja et al. [35] introduced two binary variants of the whale optimization algorithm (WOA) algorithm, which are tournament and roulette wheel selection mechanisms instead of using a random operator in the searching process, as well as enhancing the exploitation of the WOA by using crossover and mutation operators in the algorithm. Peng et al. [36] introduced ant colony optimization (ACO) algorithm into feature selection to effectively eliminate redundant features and prevent feature selection from falling into a local optimum. In [37], the authors presented several feature selection algorithm models based on the granular information, which are improved binary genetic algorithm with feature granulation (IBGAFG), the improved neighborhood rough set with sample granulation (INRSG) and granularity
In addition, BES was proposed to mainly solve the complex numerical optimization problems. For examples, Bharanidharan et al. [41] proposed an improved BES to increase the accuracy of the machine learning techniques in diagnosing dementia and the results demonstrated the accuracy of Support Vector Machine could be increased from 64% to 88% when BES was used for transforming the features. Sayed et al. [42] used BES to find the optimal values of the hyperparameters of a SqueezeNet architecture in their proposed melanoma skin cancer prediction model. In addition, the utilization of BES in the proposed model could effectively increase the robustness and efficiency of the proposed model compared to those state-of-the-art methods. Zhang et al. [43] proposed polar-coordinate BES (PBES) for curve approximation problem and they strengthened the exploration and exploitation capabilities of BES by distributing the initialized individuals more uniform and introducing some parameters inside the algorithm. The experimental results also confirmed the superior of PBES to some well-known meta-heuristic algorithms. However, BES has not been utilized in the area of feature selection since it was proposed for solving the problems with continuous solution space.
Over the past decades, hybridizing various meta-heuristic optimizers to utilize the advantage of each one has attracted more and more attention in feature selection optimization. Reportedly, the hybrid algorithms are capable to achieve better performance in dealing with specific problems, especially if they are related to real-life [44]. The first hybrid meta-heuristic algorithm proposed for feature selection problems can be trace back to 2004 in [45], which combined genetic algorithm (GA) and the local search operators to fine-tune the search process. In [46], Nemati et al. proposed a novel feature selection algorithm that made use of advantages of both ACO and GA for maximizing predictive accuracy, and finding the smallest subset of features. Zheng et al. [47] proposed a hybrid filter-wrapper feature subset selection algorithm called the maximum spearman minimum covariance cuckoo search (MSMCCS), which aimed at combining the efficiency of filters with the greater accuracy of wrappers. Mafarja et al. [48] developed a wrapper-based feature selection method that combined GWO and WOA to alleviate the drawbacks of both algorithms and may experimentally outperform other state-of-the-art approaches in their research. Moreover, Qasim et al. [49] presented a hybrid algorithm between BDA and the statistical dependence, which guided BDA and used
Due to the nature of simplicity and high performance, PSO are regularly adopted to be hybridized with other meta-heuristic algorithms in feature selection optimization. For instance, Xue et al. [50] developed PSO and GA to decrease data size and increase the precision and effectiveness of specific data sets. In [51], Ke et al. proposed a hybrid PSO with a spiral-shaped mechanism (HPSO-SSM) for selecting the optimal feature subset for classification via a wrapper-based approach. Adamu et al. [52] presented a novel hybrid binary version of enhanced chaotic CSA and PSO algorithm (ECCSPSOA) to solve feature selection problems, in which PSO was used to converge into the best global solution in the search field. Tawhid et al. [53] combined the bat algorithm with its capacity for echolocation helping explore the feature space and enhanced version of PSO with its ability to converge to the best global solution in the search space. Besides, Tashi et al. [54] proposed a binary version of the hybrid GWO and PSO (i.e., BGWOPSO) to find the best feature subset and used it as a wrapper feature selection method in their research.
According to no free lunch (NFL) theorem [55], there is no one common algorithm can solve all optimization problems optimally. Despite the abovemetioned works may solve the feature selection problem well in the literature, they are perhaps restricted in the specific data sets or certain scenarios. In other words, the performance of the proposed algorithms may somehow degrade in solving other types of data sets or optimized problems [56]. Therefore, making the efforts to improve the effectiveness of the exiting meta-heuristic algorithm is worthwhile. Due to the high exploration capability of BES, we plan to apply it into feature selection and intend to hybridize it with other optimizers to further discover its potential and solve feature selection problems more efficiently in this work.
Preliminaries
Fitness function
Feature selection is known as a multi-objective optimization by nature. A common prior method to solve the multi-objective optimization is to aggregate the multiple objectives into a single objective, thus simplifying the calculations and reaching a proper solution [57]. The main purpose for feature selection is to minimize the number of selected features while maximize the accuracy of the chosen features in most cases [58]. Based on the above background, we design a linear weighting formulation for jointly optimizing the two objectives, which is expressed as follows:
where Fitness(S) denotes the obtained fitness value of a given subset
From Eq. (1), we can conclude that the two optimization objectives are trade-off, since a subset with a higher classification accuracy corresponds to a larger selected feature number and vice versa. Thus, achieving a higher classification accuracy while maintaining a smaller selected features becomes a challenging task.
Moreover, Feature selection is described as an NP-hard problem in the previous work [59], which indicates that the designed fitness function is difficult to be solved by conventional algorithms. In recent researches, population-based evolutionary algorithms which belong to meta-heuristic algorithms may solve the considered NP-hard problem to some extent [60], thus we plan to tackle the such problem by utilizing effective evolutionary algorithms such as BES and PSO.
As a nature-based meta-heuristic algorithm, BES was proposed to simulate the hunting strategy or intelligent social behavior of bald eagles when they look for fish. The process of bald eagle’s hunting is divided into three stages. In the first stage (i.e., selecting space), the eagles tend to select the space with the largest number of preys. In the second stage (i.e., searching in space), the eagles move around the selected space to find prey. In the third stage (i.e., swooping to the preys), the eagles swing from the best position identified in the second stage and determine the best hunting point. Moreover, the movements of the eagles depend on a central point in these stages. In the selecting stage, the eagles move from the center point to the selected search space. In the searching stage, the eagles search around the central point in the search space. In the swooping stage, the eagles move from the center of the search space to the preys.
Accordingly, the main procedure of the algorithm can be divided into three parts: selecting phase, searching phase and swooping phase. These behaviors can be defined as follows.
Selecting phase. Eagles identify the food and select the best area in the selected search space (according to the amount of food) in this phase. Therefore, this behavior can be modeled as:
where Searching phase. In this phase, eagles search for prey in the selected search space and move in different directions within the spiral space to speed up the search process. The best position is mathematically expressed as:
where
where
where
where
where Swooping phase. Eagles swing from the best position in the search space to their target prey in this phase. Consequently, all points also tend to move towards the best point. This behavior can be mathematically modeled as:
where
where
where
where
The main procedures of BES are shown in Algorithm 3.2.
[] BES Algorithm Initialize the population size
PSO was inspired by the swarming or collaborative behaviors of birds foraging to their foods in biological populations. The basic core idea of PSO algorithm is to share the information of individuals in the group. Then the movement of the whole group produces an evolutionary process from disorder to order in the problem-solving space, so as to obtain the optimal solution of the problem.
PSO can take birds foraging randomly in a space as an example. All birds do not know where the food is, but they know how far it is. The simplest and effective way is to search the surrounding area of the bird nearest to the food. A possible solution obtained by PSO algorithm is represented by a particle and the population is consist of all the candidate particles. In each iteration, a particle will accelerate towards its own optimal solution or towards to the global optimal position found by any particle in the population so far. This means that if a particle finds a better solution, the remaining particles will move towards it and the population finally reach to the optimal solution to a certain problem. In order to realize the above objectives, each particle has two properties that are position (
where
The main procedures of PSO are shown in Algorithm 3.3. [] PSO Algorithm Initialize the population size
Motivation of hybridization
It is known that the solution to the feature selection problem is discrete and the dimension of the solution is equal to the feature number in the selected subset, which means the solution space is huge if the subset characterizes lots of features. On the other hands, PSO as a novel computational intelligence technique, has succeeded in many continuous problems. In addition, there are some well-known binary versions of PSO are proposed to solve mono- and multi-objective optimization problems in the literature. For example, Nguyen et al. [61] proposed a dynamic sticky binary PSO by developing a dynamic parameter control strategy based on an investigation of exploration and exploitation in the binary search spaces. Luh et al. [62] proposed a modified binary PSO algorithm that adopts the concept of genotype-phenotype representation to apply for continuum structural topology optimization. Moreover, Chauhan et al. [63] extended the application of Gompertz PSO for solving binary optimization problems. However, as an emerging intelligent optimization method, there is few research concentrated on developing the binary BES. Since PSO are embedded into BES in this research, the existed binary versions are not suitable for the proposed hybrid method, which motivates us to improve BES and PSO to be applicable for the designed fitness function.
According to the previous studies [42], BES shows great advantages in dealing with some specific optimization problems. More specifically, BES is capable of covering the search space better, allowing for rapid convergence in the initial iterations. However, BES has been found to lack adequate searching efficiency and has a tendency to become stuck in local optima, which can negatively impact the final outcome [64]. Moreover, combing BES with powerful operators with other meta-heuristic algorithms to improve its performance is also recommended by the proposers in [14]. On the other side, PSO shows the characteristics of few parameters need to be adjusted, the simple principle and easily to be implemented in most optimization problems. Unfortunately, PSO exhibits certain limitations, including poor local search capabilities, imprecise search accuracy, and premature convergence [65]. Since both BES and PSO are effective meta-heuristic algorithms, and PSO is often combined with other algorithms to propose a new hybrid meta-heuristic algorithm, which motivates us to consider combining the two algorithms. By overcoming the shortcomings of the originals and maximizing their advantages, it is possible to quickly find the high-quality candidate solutions to the proposed feature selection problems.
In this work, we firstly propose a combinative strategy to effectively regard the two algorithms as one, and further we introduce a new chaotic map to adjust the parameter of the hybrid method, which will balance the exploitation and exploration capabilities of the proposed algorithm.
HBBP
In this work, we propose a combination of BES and PSO following the taxonomy of low-level teamwork hybrid (LTH) group [13]. More specifically, we embed PSO into BES to improve the convergence accuracy of BES, so as to develop a wrapper-based feature selection method.
Principle of hybridization
Since BES is divided into three phases, the selecting phase is orientated to the search place, while the searching phase and the swooping phase are utilized to locate the direction of the optimal solution and finally to reach to the optimal. Thus, we deploy PSO into BES in the searching phase and the swooping phase.
Strategy of hybridization
In the searching phase and the swooping phase of BES, the new generated solutions are the best solutions at each iteration, i.e., the outputs of these phase can be regarded as the personal optimal solutions in PSO. By the nature of BES, it also maintains a variable, namely,
Solution update method
Through the above principle and combination strategy, we reformulate the Eq. (3) into the follows:
In addition, the Eq. (11) is reformulated into the follows:
The structure of HBBP is displayed in Fig. 1.
The structure of HBBP.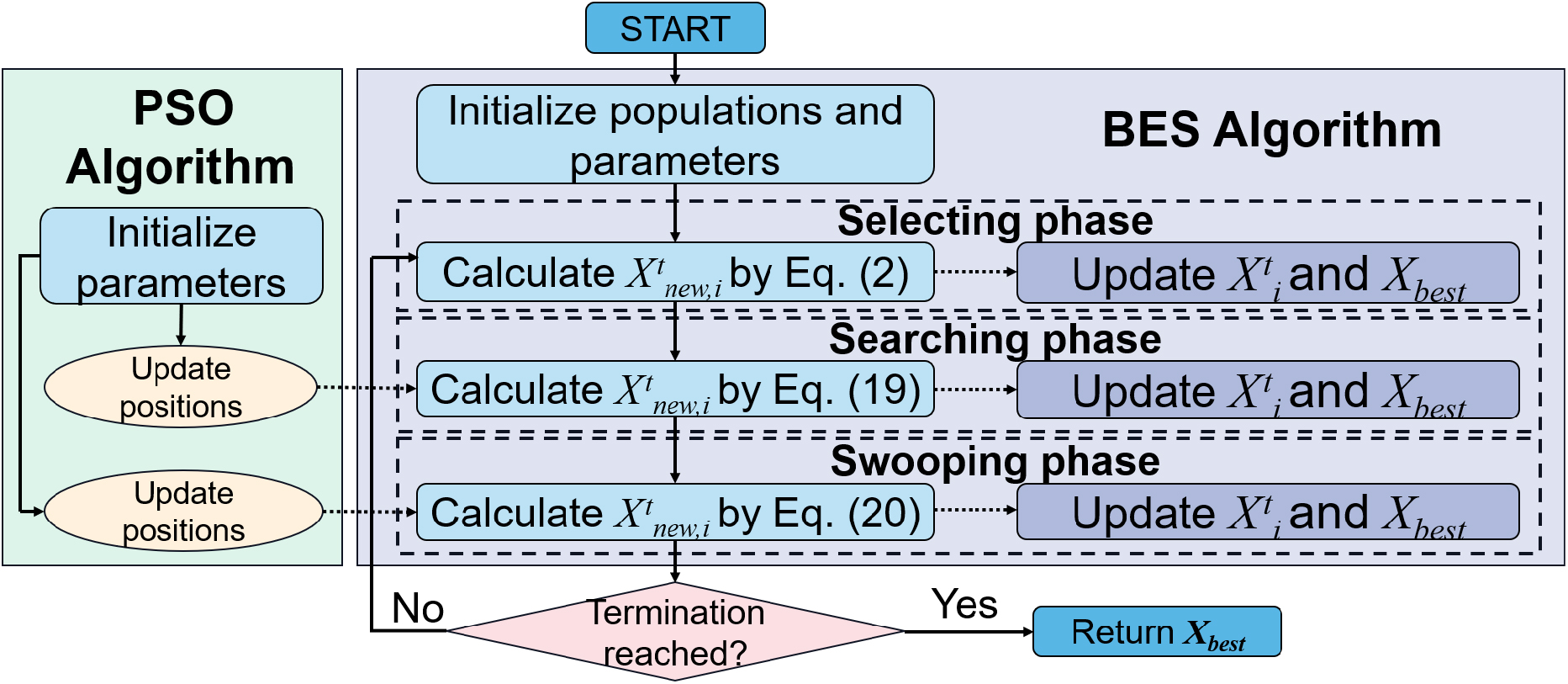
In this part, a chaotic map is adopted into HBBP. It is widely known that the inertia coefficient
Chaotic map
Chaos can be mathematically defined as a semi-random number generated by a simple deterministic system. Chaotic map is used to generate chaos between 0 and 1 to replace the pseudo-random number generator in the optimization field. In general, chaos has the characteristics of nonlinearity, ergodicity, local instability, overall stability and long term unpredictability [66]. Mathematically, chaos performs the search faster than ergodic search and thereby we adopt chaos in meta-heuristic algorithms to potentially generate a diverse population of candidate solutions in the initialization stage.
In this paper, a chaotic map called Logist-sine (LS) [67] is used to adjust the value of
where
The curve of 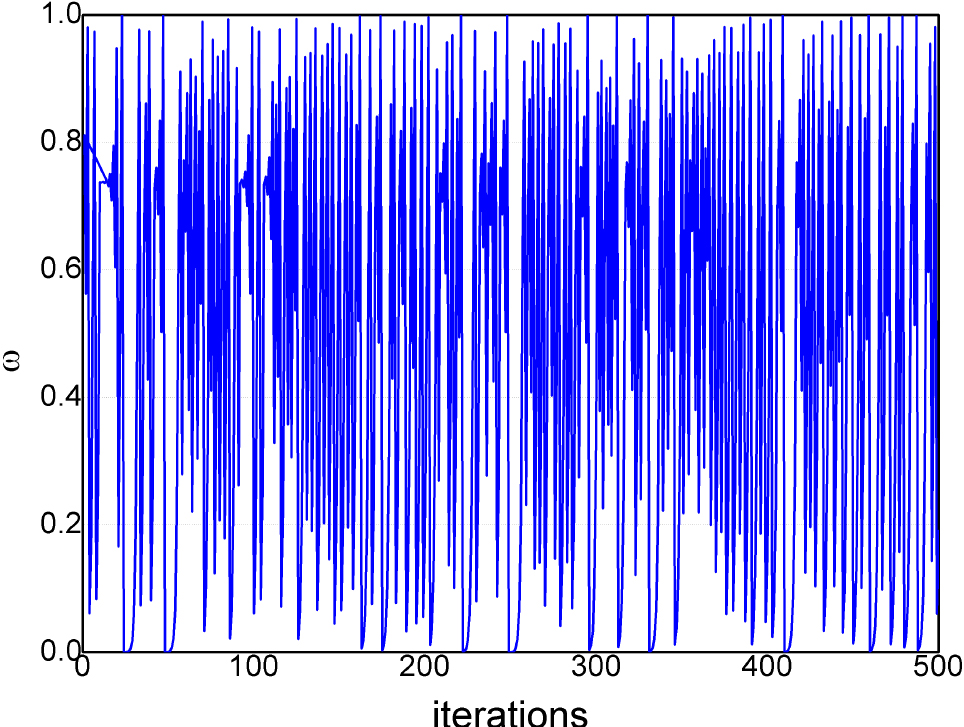
Accordingly, with the utilization of the proposed chaotic map, Eqs (19) and (20) are reformulated into the Eqs (22) and (23), respectively:
BES and PSO are originally developed to solve the continuous optimization problems, however the proposed feature selection formulation is discrete. Specifically, the solution is binary. The solution to the proposed problem can be represented as 1 (the feature is selected) or 0 (the feature is discarded) for each feature, and the dimension of the solution is as same the number of the features in the tested data set. Thus, the proposed hybrid algorithm should be altered from continuous-solving to the binary-solving for the feature selection optimization. In this section, the binary strategy is introduced in the proposed methods.
A common method to convert the continuous problem-solving algorithm to the binary one is to adopt the transfer function [68]. For most binary optimization problems, two types of transfer function that are named according to the shape of the function curve, called
The transfer rate can be described as follows [70].
where
The curve of 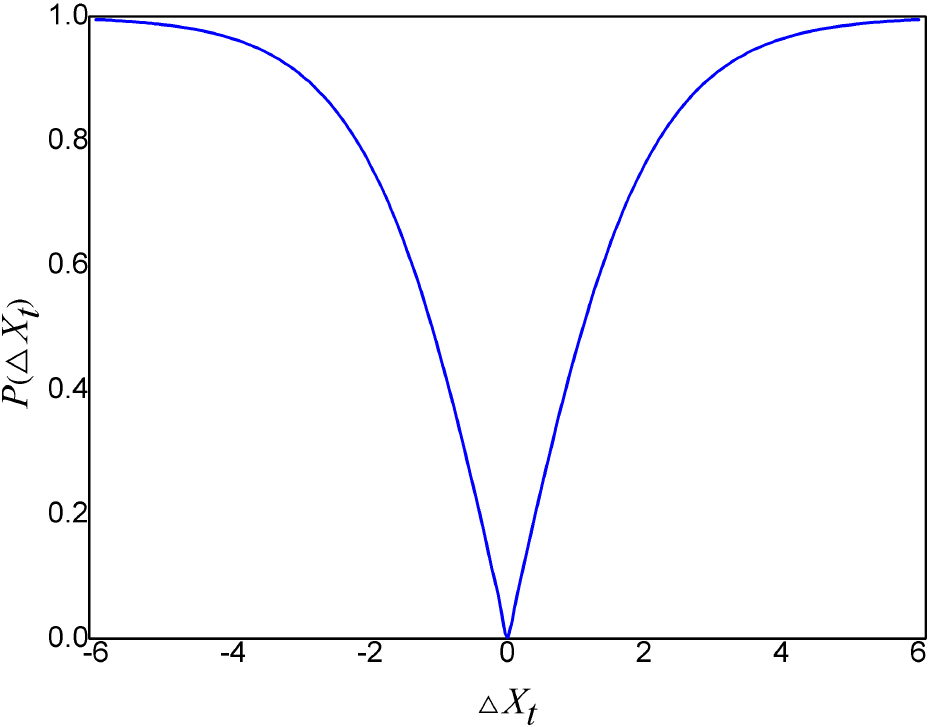
The transfer factor of HBBP is described as follows.
The transfer factor of HCBP is defined as follows.
HBBP and HCBP share a common function that is iteratively defined as follows.
where
The main procedures of the proposed binary optimization are shown in Algorithm 4.4.3. [] Binary Optimization Initialize the parameters and achieve the population from different hybrid algorithms in previous iterations
Return
At this point, all the details of the proposed hybrid algorithms have been introduced, and the general framework of HBBP and HCBP are presented in Algorithm 4.4.3.
[] The proposed hybrid algorithm Initialize the population size
As shown in Algorithm 4.4.3, there are three loops executed in the algorithm, namely, the maximum iteration
Solution expression
The solution expression is also an important issue in a problem-solving algorithm when dealing with feature selection problems. Referred to the previous work in [71], we use a
where
In this section, the results of the proposed hybrid algorithms are presented. The benchmark data sets are firstly introduced before the experiments. Then we report the parameter values used in the experiments. Next, some algorithms in the literature are adopted as comparisons to the proposed hybrid algorithm in various perspectives. Finally, the results are analyzed and the performance of the algorithms are evaluated.
Benchmark data sets
In this paper, 17 well-known data sets drawn from the UCI data repository [72] are selected as the benchmark to conduct the relative experiments. In addition, Table 1 describes the details of these data sets in terms of data set names, number of features and number of instances.
Benchmark data sets
Benchmark data sets
An example of binary representation of solution.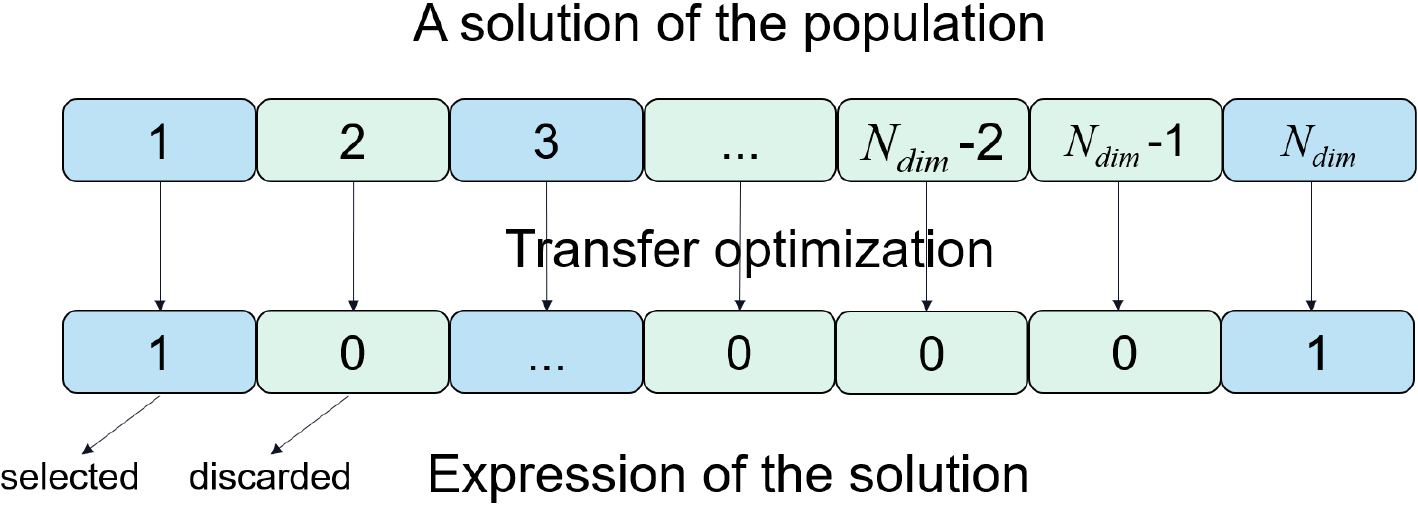
All the experiments are implemented on a PC with a 8th generation Intel Core i5 processor (i5-8500U) and the base frequency of the processor is 3.00 GHz. The random access memory (RAM) is 16 GB and a external GPU named 1050TI is equipped with the PC. Moreover, all algorithms are programmed by Python 3.10 and the actual Python code of the proposed hybrid algorithms can be freely downloaded at “
Parameter tuning
In the process of solving the meta-heuristic based feature selection problem, choosing a proper set of values for the involved parameter in the algorithm plays an important role as these parameters are tightly related to the convergence rate and control the whole learning process, which may determines whether the proposed model is successful or not. It is worthy noting that there are some parameters used in the proposed hybrid algorithm, such as
First of all, the cognition factor
Another pair of parameters that should be carefully considered are the multiplier of chaos (i.e.,
In order to reduce the randomness, the experiment on each combination is conducted in 30 times and the average results are listed in Tables 2 and 3. Accordingly, HCBP achieves the best among the indicators when
Parameter tuning results of
and
in the proposed hybrid algorithm
Parameter tuning results of
Parameter tuning results of
For the remaining parameters used in the proposed hybrid algorithm, we use the recommended values in the literature and the details are listed in Table 4.
Parameter settings of the proposed hybrid algorithm
In this part, we verify the effectiveness of two common transfer function (i.e.,
In addition to notice that except the transfer rate, other details of
Average results of 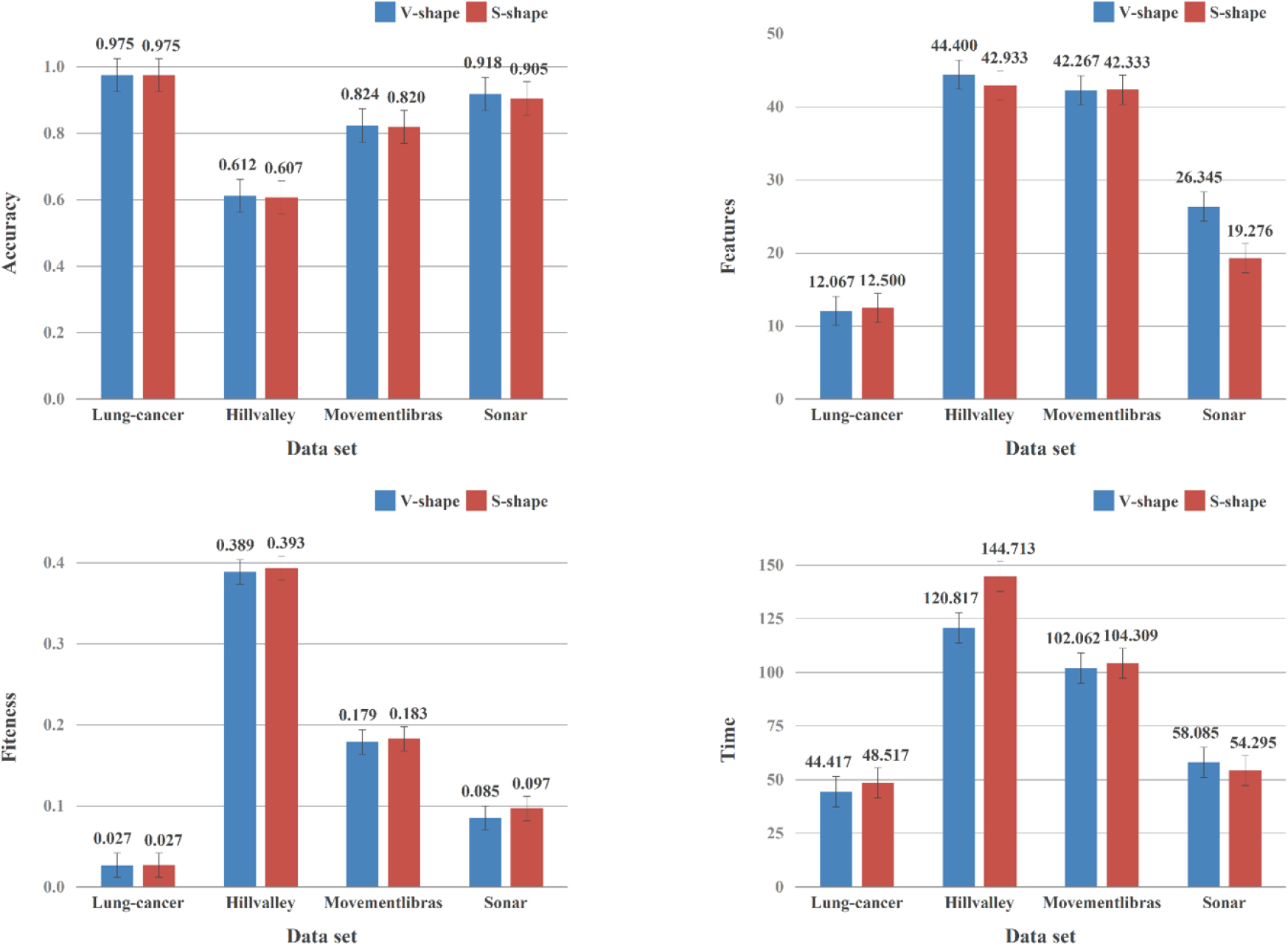
In this work, we utilize
The core idea of
Particularly, the Euclidean distance from the validation samples to the learning samples is adopted to calculate the relevance in the following experiments. In this research, the training set is further divided into a learning set with 80% of the instances and the rest is assigned to the validation set, which is also in accordance to [77]. Totally, during each iteration, the classifier is trained using the feature subset from the learning set and its performance is evaluated on the validation set.
From the point of view of fairness, we also originally planned to adopt Lung-cancer to tune the number of neighbors of
Average results of various number of neighbors (
) of
NN classifier in the proposed hybrid algorithm
Average results of various number of neighbors (
In this paper, six optimization algorithms are adopted as comparison with HBBP and HCBP, which are BES[14], BPSO[78], BGWOPSO[54], BBA[33], BDA[79] and BGWO[30], respectively. The comparative six algorithms are all wrapper-based meta-heuristic algorithms, wherein the
Key parameter settings of the comparative algorithms
Key parameter settings of the comparative algorithms
In this followings, the performance of each algorithm is evaluated in the four indicators, which are fitness value, classification accuracy, the number of selected features and CPU running time, respectively. For each indicator, there are two statistical measures used to represent the results obtained by different experiments, which are the average value (AVG) and the standard deviation (STD). In addition, two non-parametric statistical tests, namely Wilcoxon rank-sum and Friedman are performed at 5% significance level for the fitness value and the classification accuracy to display the significance of the two indicators in this paper. The reason that we adopt the two non-parametric statistical tests is because they are not necessary to assume the obtained results distributed normally, which may provide a more scientific comparative conclusion in practice [80].
Moreover, the overall wins of the four indicators are also utilized to represent the fairer counts of wins for each method. The term of “win” is used to count the number of the methods that achieve the best results, and the “win” is normalized to be “1” in each data set for all comparative methods. Therefore, a win of 1 is assigned to a method when it is the only winner, but dividing the ‘1 win’ among all methods tied in achieving the best result, with a fractional number of win assigned to each method, which is inversely proportional to the number of tied methods. For example, if four methods (also equals to the whole number of the comparative methods) all achieve the best result in a specific data set, the win of each winner (all the methods are the “winners”) is 0.25, etc. Totally, the overall wins are the sum of the wins in the whole data set of this method. An example of win is visualized as Fig. 6, wherein “Method1”, “Method2” and “Method4” all achieve the best result (i.e., “result1”, “result2” and “result4”, respectively), hence the number of win of these three methods are all set to be “0.33 (1/3)”.
An example of “win” of the comparative methods in one data set.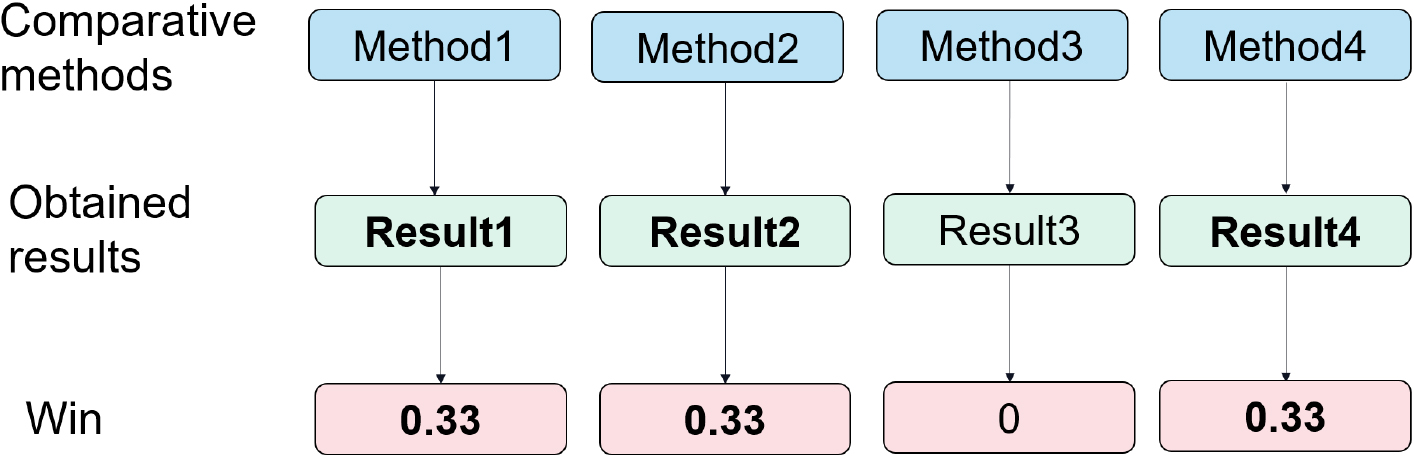
Fitness function values obtained by HCBP, HBBP, BES and PSO
In this section, the obtained results are presented by categories, then the results are analyzed and discussed subsequently. In order to evaluate the effectiveness of the proposed hybrid algorithm, we firstly perform the experiments between the two hybrid strategies and the originals (i.e., BES and BPSO). Next we choose hybrid strategy with the better performance to compare with the state-of-the-art algorithms (i.e., BGWOPSO, BBA, BDA and BGWO). It is noted that the best results of each experiment are highlighted in bold font.
The results of HCBP, HBBP, BES and PSO
Table 7 displays the fitness values of HCBP, HBBP, BES and BPSO. From the results, HCBP achieves the best on 13 data sets (76.47%), thereby the overall wins is ranked first (44.06% wins), which shows great advantages than the others. HBBP achieves 4.99 overall wins (29.35%), followed by BES with 2.99 overall wins. In addition, BPSO is ranked forth with 1.5 wins (8.82%). The STD results show that the above algorithms are quite stable and the difference between each data sets is slight. The overall wins and F-test statistic results of average fitness values of HCBP are both ranked first, which supports the superiority of HCBP on the other side. The reason that HCBP outperforms HBBP is due to the chaos utilization for the position updating in this kind of hybrid strategy indeed works, which will further broaden the solution space and maintain the diversity of the population at each iteration when the algorithm is running, thus HCBP is more likely to find the optimal solutions than HBBP. In addition, we can conclude that HCBP and HBBP both have certain advantages over the original algorithms, which illustrates that the framework of the hybrid model is effective. In other words, the hybrid methods overcome the main limitation of trapping in local optima better than the original algorithms, thus boosting the capabilities of BES and BPSO in balancing between exploration and exploitation.
In order to compare the significance of the fitness values obtained by the various algorithms, we conduct the Wilcoxon sum-rank test for each of the proposed hybrid methods against the original optimizers and the results are displayed in Table 8. As can be seen from the results, HCBP and HBBP both outperform BPSO significantly on 9 data sets, respectively. It is noticed that the meaningless results (the “meaningless” indicates the significance of the proposed hybrid method against the originals is same, in other words, the Wilcoxon sum-rank test results are “1” on these data sets. In order to make the results shown in Table 8 and in the relative significance tables more clear for reading, we replace the results “1” with “NaN” in the rest of this paper) are ignored, thus HCBP and HBBP both outperform BPSO on more than half of the meaningful data sets. The phenomenon demonstrates that the two hybrid methods are both effective in dealing with the proposed feature selection problems and the chaos utilization in hybridization can further improve the performance in optimizing fitness values since HCBP performs better than BES on 3 data sets named Lung, Sonar and Wine compared to HBBP. Surprisingly, the results also indicate from the other side that BES is a candidate effective method that can tackle the feature selection problems better than BPSO because it can reach to an equivalent significance compared to the hybrid methods on majority of the data sets.
values of the Wilcoxon sum-rank test for the fitness values of obtained by HCBP, HBBP versus the basic optimizers (
are significant and shown in bold, NaN: Not Applicable)
Figures 7 and 8 illustrate the results of convergence curves obtained by the two proposed hybrid methods and the originals. It is noticed that the curves are derived from the 15th test of each experiment. Intuitively, the hybrid methods always reach to the faster convergence rate in most cases than the originals. In particular, from these figures, it can be seen that HCBP is faster than HBBP on the data sets named Hillvalley, Lung, Lymphography and Movementlibras. The results affirm the conclusion that the improved factor (i.e., the chaos) introduced in HCBP may speed up the convergence rate compared to HBBP. Therefore, HCBP can always accelerate to find the optimal solution among the comparative algorithms.
Convergence curves obtained by HCBP, HBBP, BES and PSO in first 9 data sets.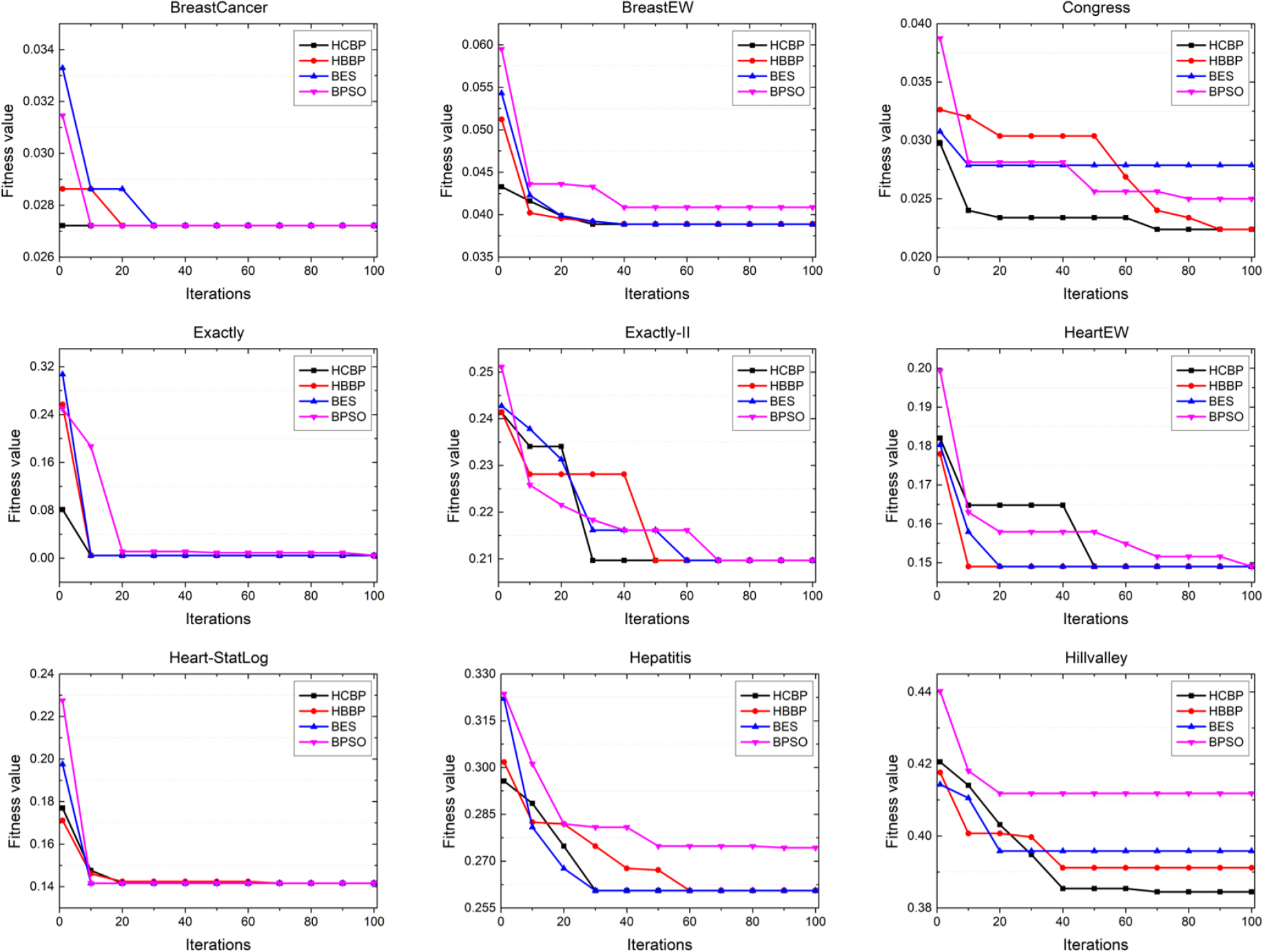
Convergence curves obtained by HCBP, HBBP, BES and PSO in last 8 data sets.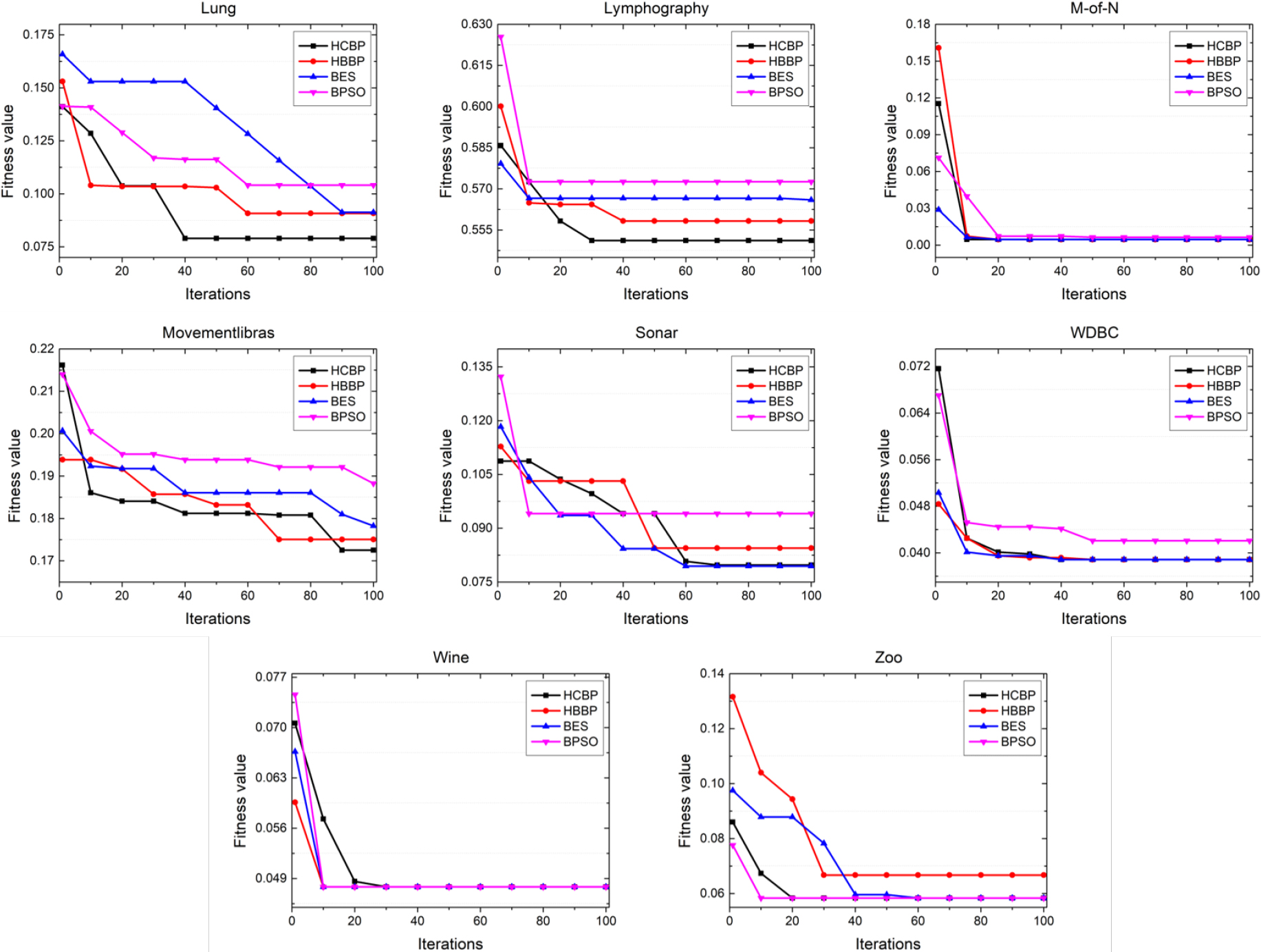
Table 9 specifies the results of classification accuracy obtained by HCBP, HBBP and the originals. The distribution of the optimal results are similar to Table 7. Totally, the overall wins of HCBP is 7.32, which is the highest among the comparative algorithms. HBBP is ranked second with 3.82 overall wins. Followed by BES with 3.32 overall wins and the lowest number of wins is achieved by BPSO. The average results of overall wins of classification accuracy support our judgments mentioned above and the hybrid algorithm further embodies the advantages than the originals. Specifically, BES outperforms BPSO on 5 data sets, i.e., BreastEW, Heart-StatLog, Hillvalley, M-of-N and WDBC, which indicates that BES is more effective in dealing with the designed feature selection problem to some degree. From the STD results, it can be observed that all the comparative algorithms are stable and equivalent since HBBP and BPSO both achieve best on 8 data sets, HCBP and BES are ranked first with 9 data sets. Additionally, F-test statistic results support the superiority of HCBP over the others. Therefore, from the results of the fitness value and classification accuracy, we can conclude that the two hybrid strategies are both competitive compared to the originals, as well as the chaos utilization in HCBP significantly improves the performance of the proposed method, which contributes to finding more optimal solutions.
Table 10 displays the significance of the classification accuracy obtained by the hybrid methods versus the basic optimizers. The results expose the supremacy of the hybrid methods in achieving the higher classification accuracy compared to the originals. Other conclusions are similar to the discussion held on Table 8.
Classification accuracy obtained by HCBP, HBBP, BES and PSO
The results of average CPU running time obtained by each of the 30 runs of each comparative algorithm are reported in Table 11. HBBP shows dominant advantages over HCBP and BPSO, which is beyond our expectations before the experiments. As a natural side effect, the hybrid algorithms often consume more computational time than the originals because they may introduce various variants to improve the performance of the algorithms. For HCBP, the biggest change to HBBP is that it embeds the chaos initializations into the searching phase and the swooping phase, which will certainly increase the computational time in practice. Meanwhile, the chaos of HCBP will enhance the capabilities of exploring more solutions space during the searching, as a result, the computational time has to increase. On the other hand, the reason that HBBP consumes less running time than BES is due to the direction of the optimal solutions in the searching phase and the swooping phase are oriented, which may lead to the decrement of the computational time when the algorithm is executed. Surprisingly, the overall wins of BES is much greater than BPSO, which indicates that BES may solve the formulated feature selection problem faster than some meta-heuristic methods proposed in early time. Moreover, F-test statistic shows that HBBP performs better than HCBP on the other hand. It is worth noting that the difference of the CPU running time between HCBP and HBBP is not obvious, even less than 1 second on the majority of the data sets. Therefore, although HCBP always consumes more time than HBBP, it is always acceptable in the scenario that the proposed problem asks for a higher classification accuracy.
CPU running time (in seconds) obtained by HCBP, HBBP, BES and PSO
Moreover, the number of selected features are displayed in Table 12. As can be seen, HBBP shows a competitive results among the comparative algorithms and it achieves the minimum value on 13 data sets (76.47%). As expected, the overall wins of HBBP is ranked first and is much greater than the others (49.94% overall wins). Totally, HBBP combines the advantages of BES and BPSO, which may help it to escape from the local optima more likely compared to the originals. Therefore, HBBP is capable to acquire a lower number of selected features. Intuitively, as we discussed in 3.1, a higher classification accuracy usually corresponds to a larger selected features, thus HCBP is difficult to reach a satisfactory results in terms of the selected features since it has won the best performance in classification accuracy observed from the former experiments. Amazingly, compared to the basic algorithms BES and BPSO, HCBP also shows a slight advantage on the data set named Heart-StatLog, Movementlibras, Sonar and Zoo and ranked second in F-test statistic. In addition to notice, STD results show that HCBP is ranked first and provides best results on 11 data sets (64.71%), while HBBP hits the minimum values on 9 data sets (52.94%), which are far better than BES and BPSO actually. Thus, HCBP performs quite stable among the comparative algorithms.
Number of selected features obtained by HCBP, HBBP, BES and PSO
Table 13 exhibits the overall performance of the proposed two hybrid models against the basic optimizers. Note that the results of CPU running time are disregarded since the scale of the values for computational time and other evaluation metrics are quite different. In other words, the discrepancy of CPU running time is much larger than others, thus taking CPU running time into account may lead to some inaccurate conclusions. Besides, the computational time can be ignored because many practical optimized problems tend to pursue a higher classification accuracy in most cases. Conclusively, it can be seen from the comparative results listed in Table 13, HCBP achieves the best performance in terms of the F-test statistic results. Therefore, we choose HCBP to conduct the following experiments.
Overall rank by F-test for HCBP, HBBP, BES and BPSO based on fitness, accuracy and selected features
In this section, the results are compared among HCBP and several algorithms in the literature on the same data sets to further verify the performance of the proposed method. The results are listed in the followings.
The fitness function values obtained by HCBP, BGWOPSO, BBA, BDA and BGWO are described in Table 14. Focused on the overall wins, HCBP shows an overwhelming advantage over the comparative algorithms on most of the data sets, thereby the overall wins of HCBP is much greater than the others. BBA is ranked second with 3.5 overall wins. Other algorithms can solely reach to optimal on one data set or even zero, which leads to the lowest overall wins among the comparative methods. As for the standard deviation values, HCBP hits the minimum values on 13 data sets (76.47%), followed by BBA on 6 data sets (35.29%), as well as BGWOPSO outperforms others on Sonar and BGWO does not achieve any optimal at all. In addition, the F-test statistic results further confirm the superiority of HCBP over other competitors.
The comparison of the significance of the fitness values between HCBP and other optimizers are represented in Table 15. It can be observed from the results that HCBP performs far better than the algorithms from the literature. More specifically, BGWOPSO, BBA, BDA and BGWO are respectively dominated by HCBP on 100%, 47.06%, 82.35% and 88.24% of meaningful data sets. In addition, HCBP does not outperform HBBP on any data set, which indicates that the two hybrid methods are equivalent to each other measured by the metric of Wilcoxon sum-rank test.
Fitness function values obtained by HCBP, BGWOPSO, BBA, BDA and BGWO
Fitness function values obtained by HCBP, BGWOPSO, BBA, BDA and BGWO
Figures 9 and 10 describe the convergence curves obtained by HCBP and the comparative algorithms when they are running. The source data of each curves are also derived from the 15th test as addressed before. From the curves, we can see that HCBP can nearly achieve the optimal convergence rate on the whole data sets except Lymphography. Specifically, HCBP achieves the minimum convergence value on 9 data sets, which are BreastEW, Congress, Hepatitis, Hillvalley, Movementibras, Sonar, WDBC, Wine and Zoo, respectively. Therefore, the hybrid strategy of BES and PSO effectively works and the chaos utilization of the hybrid method can broaden the solution space and direct the population to a promising area, which contributes to leading the population out of the local optima and accelerates HCBP to converge to the optimal solutions rapidly.
Convergence curves obtained by HCBP, BGWOPSO, BBA, BDA and BGWO in first 9 data sets.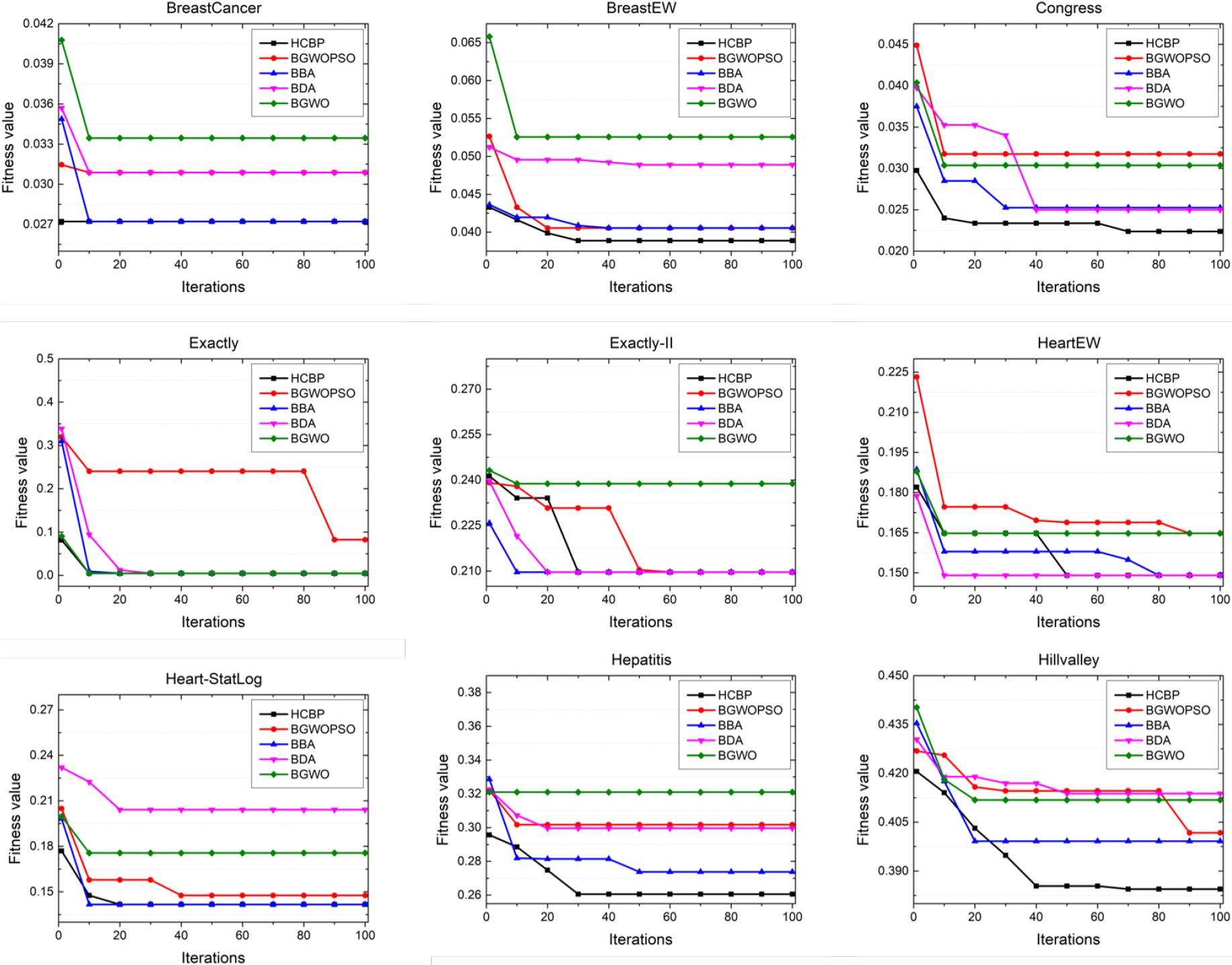
Convergence curves obtained by HCBP, BGWOPSO, BBA, BDA and BGWO in last 8 data sets.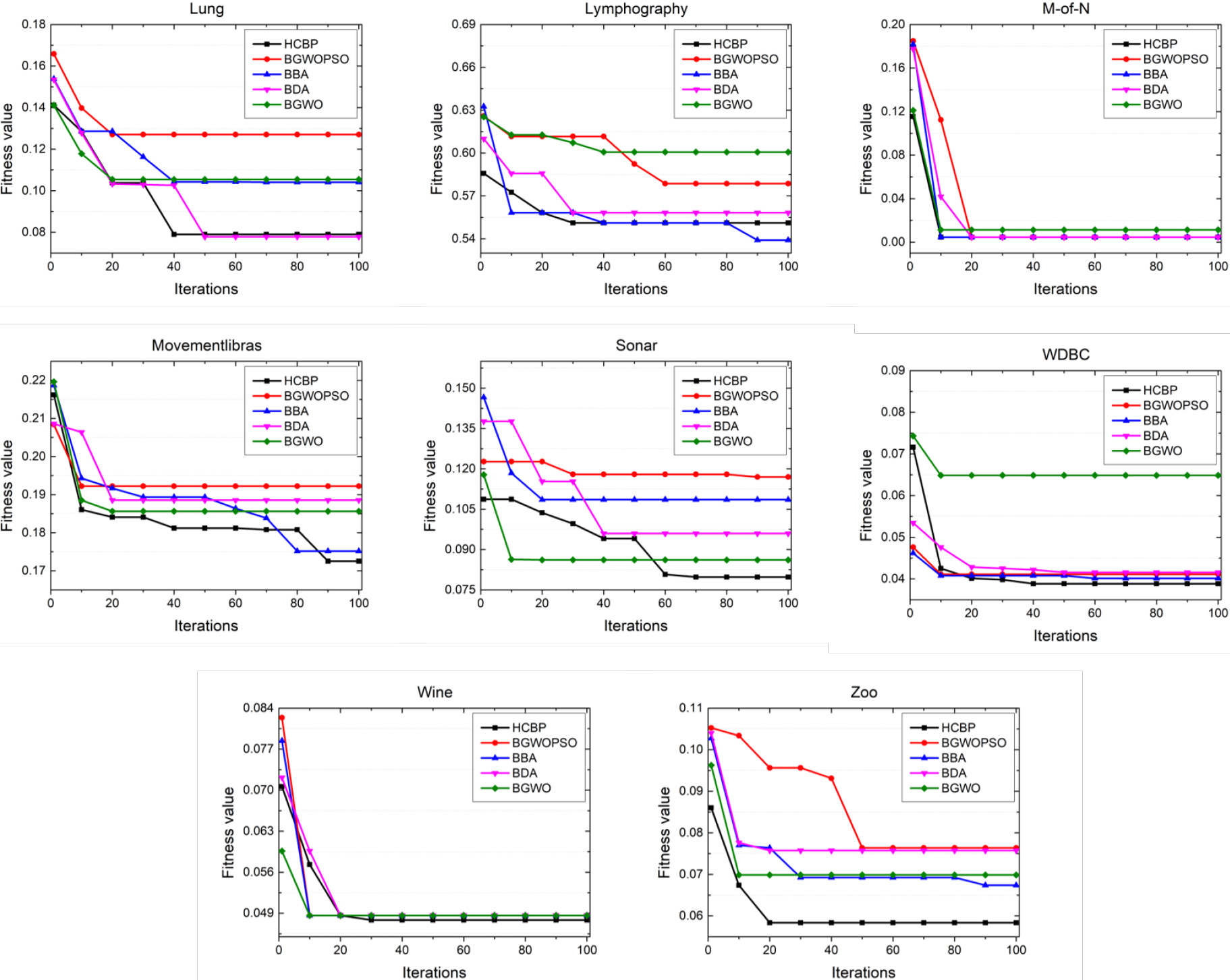
The average classification accuracy with F-test statistic obtained by HCBP and the comparative algorithms are presented in Table 16. Intuitively, the distribution of the results are similar to Table 14. Specifically, HCBP shows dominant position over others and the overall wins of the average accuracy can account for over 64% among the comparative algorithms (11 wins, 64.71%). It also can be observed that the overall wins of BBA is ranked second with 5 wins, however, BDA only gain the optimal value in dealing with one data set and BGWO does not reach to any optimal at all. Moreover, HCBP varies relatively smaller than others according to the STDs, as well as F-test results illustrate that HCBP performs far better than BGWOPSO, BDA and BGWO.
In order to compare the significance of the classification accuracy obtained by different algorithms, we also conduct Wilcoxon sum-rank test for HCBP against the other competitors. Table 17 support the arguments that HCBP can gain a higher accuracy compared to the original algorithms on the majority of the meaningful data sets. Moreover, there is no obvious difference in the comparison of significance between the two hybrid methods for reaching to the subset with optimal classification accuracy. Therefore, it can be concluded that HBBP can also outperform other comparative algorithms in achieving a higher accuracy.
From the results appeared in Table 14, 16 and 17, we can see that HCBP outperforms the comparative algorithms on the majority of the data sets and quite stable when it is running. These advantages can be reasoned that the hybrid strategy effectively works during the process of finding the optimal solution in discrete space. In addition to notice that all the algorithms are originated to solve the continuous optimization problems and they all utilize the transfer function to convert the continuous solutions to binary ones, which may also indicate that the proposed binary strategy is beneficial for the hybrid algorithm and can promote the effectiveness of the algorithm. On the other side, BES performs better in tackling some optimization problems compared to some existed meta-heuristic algorithms in the literature, such as GWO [81] and PSO [82]. Thus some rational improvements of BES may facilitate the designed formulated problem be solved more efficiently. To be specific, HCBP broadens the solution space, which may maintain the diversity of the population of candidate solutions, thus balancing the capabilities of exploration and exploitation. The main limitation of other algorithms is the so-called "stagnation", namely, these methods may be easily falling in to the local optima and difficult to escape from it, however, HCBP is capable to mitigate such dilemma more validly. Additionally, the chaos utilization of HCBP provides the possibility to overcome the above restriction and the transfer strategy is suitable for the proposed hybrid method, therefore the indicators such as fitness value and classification accuracy of HCBP are much better than the other comparative algorithms.
Classification accuracy obtained by HCBP, BGWOPSO, BBA, BDA and BGWO
The results of average computational time in seconds for each algorithm over 30 runs are exhibited in Table 18. According to the results, BGWOPSO consumes the least average CPU running time on 12 data sets (the number of wins is 12) and followed by HCBP with 3 overall wins. On STDs, HCBP shows a leading result on 7 data sets and BGWOPSO can reach to the minimum value on 8 data sets. Although HCBP is not the fastest algorithm in dealing with the such designed feature selection problem, we can see that the results are quite close to BGWOPSO on most data sets and shows a superiority over BBA, BDA and BGWO a lot. Consequently, HCBP is ranked second in F-test statistic and the overhead of HCBP is satisfactory since the introduced improved factors consume less extra computational time than we expected.
Additionally, the average number of selected features obtained by HCBP and other comparative algorithms are listed in Table 19. Surprisingly, HCBP tends to select fewer features compared to others as it achieves best results on 10 data sets and shares first rank with BDA. Moreover, HCBP hits the minimum values on 13 data sets in terms of the STD results, which is far better than BGWOPSO, BBA, BDA and BWGO. The F-test statistic results of average selected features covers that HCBP is ranked behind BDA but better than BGWOPSO, BBA and BGWO. By comprehensive considerations, HCBP can achieve the best average classification accuracy while remaining a relatively fewer number of selected features among the comparative algorithms, thus it is able to apply to most applications to tackle the designed formulated problem well.
CPU running time (in seconds) obtained by HCBP, BGWOPSO, BBA, BDA and BGWO
Number of selected features obtained by HCBP, BGWOPSO, BBA, BDA and BGWO
Moreover, the overall comparisons between HCBP and the other optimizers are exposed in Table 20. As can been seen, the final rank of HCBP is better than the comparative algorithms, which indicates that the quality of the best solution returned by HCBP is beyond the other peer. The main reason for the superiority of HCBP is because the improved factors in our proposed method such as hybridization of the originals, chaos utilization and customized binarization optimization can alleviate the stagnation problems effectively. In each iteration, the fitness function of every individual of the population is calculated by BES and the position of the candidate solution is updated by PSO. Since BES and PSO have been proved to be an outstanding meta-heuristic algorithm in the literature, the efficient hybridization of them may further improve the performance of the solving process of the designed feature selection problem theoretically. The chaos initialization in HCBP may maintain the diversity of the population, which enables the population in each generation to seek the optimal solution in a more promising space. The binary strategy helps HCBP to transfer the solution to binary form more impactfully compared to other optimizers. To sum up, the proposed hybrid method helps to discover better solution, meanwhile it helps the algorithm to avoid trapping in local optima. Therefore, HCBP is capable to achieve a higher classification accuracy, a better fitness function value, a rational computational time and a proper number of selected features.
Overall rank by F-test for HCBP, BGWOPSO, BBA, BDA and BGWO based on fitness, accuracy and selected features
Average classification accuracy obtained by HCBP, HBBP and other filter-based algorithms
In this section, the classification accuracy of the proposed hybrid wrapper-based algorithm (HCBP) is compared with several well-established filter-based algorithms that are Correlation feature selection (CFS), fast correlation-based filter (FCBF), F-score, IG and Spectrum, respectively. The results of classification accuracy obtained by the above filter-based algorithms are reported in [83]. In addition to notice that the
From the results on the same 10 data sets reported from the literature, we can see that HCBP achieves best accuracy on 7 data sets (70.00%) and HBBP hits the maximum on 5 data sets (50.00%), which both take substantial advantages over the competitors. In addition, FCBF and Spectrum respectively reach to the unique optimal on the data set named Breastcancer and Lymphography, However, CFS, F-Score and IG do not achieve the optimal accuracy on any data set.
The main reason for the good performance of HCBP and HBBP on the majority of the data sets is the hybridization of the advantage of BES and PSO. On the other side, HCBP shows dominant position over HBBP as shown in the previous experiments is because that the chaos initialization may improve the quality of the population and contribute to finding more solutions with high classification accuracy. Furthermore, HCBP and HBBP are capable to map the solution from the continuous to binary values by utilizing the proposed optimized transfer function. It is noted that although the hybrid algorithm shows great superiority than the comparative filter-based algorithms on the tested data sets in tackling the designed formulated problem, this does not mean that the proposed algorithm is the best choice than the filter-based methods to deal with all feature selection optimization problems, particularly considering that the filter approach is much faster and more scalable than the wrapper approach.
Conclusion and future work
In this paper, we develop a hybrid population-based evolutionary algorithm that embed PSO into BES to alleviate its drawbacks and jointly tackle the designed formulated single-objective feature selection problem. Firstly, we introduce the main procedures of the original algorithms, i.e., BES and PSO, followed by the analysis of their advantages and disadvantages. Secondly, we propose two hybrid algorithms that are HBBP and HCBP to efficiently overcome the shortcomings of conventional BES. In addition, based on HBBP, HCBP adopts a new chaotic map called
In the future, we plan to investigate the efficiency of HCBP and HBBP in other research fields such as engineering applications [84], networks applications [85], parameters control applications [86] and so on. Moreover, introducing more powerful operators such as opposite-based learning [87], Lévy flight [88] to improve the performance of BES to solve the feature selection problem can also be addressed in future work.
Footnotes
Acknowledgments
This study is supported in part by the National Natural Science Foundation of China (62172186, 62002133, 61872158, 62272194), in part by the Science and Technology Development Plan Project of Jilin Province (20210101183JC, 20210201072GX), and in part by the Young Science and Technology Talent Lift Project of Jilin Province (QT202013).
List of symbols and abbreviations
The meaning of symbols in this paper
Parameter(s)
The Corresponding Meaning
The weights of classification accuracy in Eq. (1)
The weights of feature reduction in Eq. (1)
The classification accuracy of the subset
for a certain classifier in Eq. (1)
Cn, Tn
The number of selected features in the subset and the number of total features in the data set in Eq. (1)
The position of search agent
The number of iteration
The control weight related to the position in Eq. (2)
Generating a random number varies in [0, 1]
The current optimal position from the past
The mean position considering all useful information from the previous points
The
th eagle’s position at
th iteration
The step factor in the searching phase
The inertia coefficients that control the position of eagle in polar coordinates
The polar angle and polar diameter of the spiral equation
Estimating the corner position during the point search around the center point in Eqs. (7), (8), (10)
The number of search cycle in Eq. (10)
The step factor in the swooping phase in Eqs. (11), (12)
The control weights that increase the movement intensity of the eagle to the best point and center point in Eq. (12)
The position of eagle in polar coordinates
The population size in Algorithms 3.2, 3.3, 4.4.3
The population in Algorithms 3.2, 3.3, 4.4.3
The maximum iteration in Algorithms 3.2, 3.3, 4.4.3
The personal optimal solution at the current iteration in Eq. (18)
The global optimal solution during the searching process in Eq. (18)
The inertia coefficient that controls the local search or global search and varies from (0, 1) in Eq. (18)
The cognition factor and social factor in Eq. (18)
The index of the chaotic sequence in Eq. (21)
The
th element in the chaotic map in Eq. (21)
A multiplier of chaos that varies in [0,4] in Eq. (21)
mod
The modulo operation in Eq. (21)
The transfer factor in the proposed hybrid algorithm in Eq. (24)
The
th dimension in the solution obtained in selecting phase at
th iteration in Eq. (27)
The population from different hybrid algorithms in previous iterations in Algorithm 4.4.3
The dimension size of the solution in Algorithm 4.4.3
The expansions of abbreviations in this paper
Abbreviations
Expansions
HBBP
HCBP
BES
PSO
IG
TRC
UCI
BGWO
BDA
UACO
BBA
BFA
WOA
ACO
IBGAFG
INRSG
ROGA
BSF
IBDA
EPD
CSA
PBES
GA
BGWOPSO
NFL
BPSO
AVG
STD
F-test
CFS
FCBF