
Abstract
Extracting more information from feature interactions is essential to improve click-through rate (CTR) prediction accuracy. Although deep learning technology can help capture high-order feature interactions, the combination of features lacks interpretability. In this paper, we propose a multi-semantic feature interaction learning network (MeFiNet), which utilizes convolution operations to map feature interactions to multi-semantic spaces to improve their expressive ability and uses an improved Squeeze & Excitation method based on SENet to learn the importance of these interactions in different semantic spaces. The Squeeze operation helps to obtain the global importance distribution of semantic spaces, and the Excitation operation helps to dynamically re-assign the weights of semantic features so that both semantic diversity and feature diversity are considered in the model. The generated multi-semantic feature interactions are concatenated with the original feature embeddings and input into a deep learning network. Experiments on three public datasets demonstrate the effectiveness of the proposed model. Compared with state-of-the-art methods, the model achieves excellent performance (
Keywords
Introduction
The click-through rate (CTR) prediction problem is currently receiving significant attention from academia and industry in the fields of computational advertising and recommender systems [1, 2, 3, 4, 5, 6]. The CTR prediction estimates whether a user will click on a given advertisement. It is a typical application of binary classification problems. In actual scenarios, a slight increase in the accuracy of CTR prediction can bring considerable benefits to related businesses such as advertising ranking [1], advertising bidding [7], and search engine [8].
The accuracy of CTR prediction depends not only on the model structure and algorithm but also on the input data [2, 3, 8, 9]. Recent research shows that it is crucial to consider the interactions between features [6, 10, 11, 12, 13]. Therefore, designing novel and efficient feature interaction methods has become essential for model improvement [6, 12, 13, 14, 15, 16, 17, 18]. Traditional CTR prediction methods such as Logistic Regression (LR) [19] and Factorization Machine (FM) [10] are good at processing original features or low-order interactive features [4, 10, 19, 20], and deep learning methods such as DeepCrossing [11] and DeepFM [21] are better at processing high-order interaction features [5, 11, 21, 22, 23]. At present, the widely used attention mechanism helps models learn the importance of different features, thereby further improving the performance of models [24, 25, 26, 27, 28, 29].
These existing models usually map all features to a shared space, which leads to only a shallow representation of the features. In actual scenarios, a feature can express multiple meanings, and the interaction between different features often contains high-level semantic concepts such as sentiment and intention. The above phenomena can be regarded as a feature-level semantic gap [30, 31], which will be weakened in this paper by learning the multi-semantic relations during feature interactions. Figure 1 shows an example of multi-semantic feature interaction, where the user is an athlete (occupation: athletes), the item is a pair of shoes (type: shoes), and the banner is on the home page (banner-position: home page). Interaction A (occupation, type) and Interaction B (banner-position, type) are two types of interaction. The left part of Fig. 1 shows the traditional methods, i.e., Interaction A and Interaction B are embedded in the same semantic space (Space: x0y). The right side of Fig. 1 shows the method used in this paper, i.e., Interaction A and Interaction B are embedded in two semantic spaces (Space: X0Y) and (Space: X0Z). (Space: X0Y) reflects the preferences of different professional users for items, i.e., the influence of user preferences on advertising clicks, so Interaction A is more important than B. Different banner positions represent the investment of the advertiser, so (Space: X0Z) learns the impact of advertisers on advertising clicks, which is more important for Interaction B.
An example of multi-semantic feature interaction.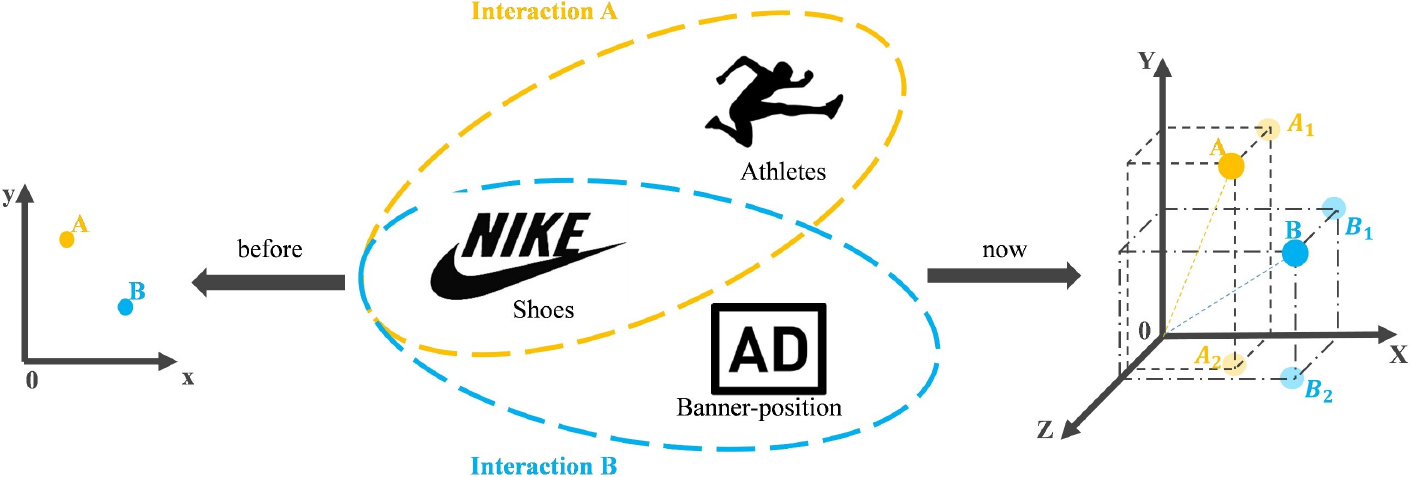
If features are embedded in a unique space, all interaction relationships will only be restricted to the same semantic space. Furthermore, if we embed features into different spaces before feature interaction, the number of embedding parameters will be doubled or more. Under normal circumstances, the embedding parameters have accounted for most of the total model parameters. Therefore, in this paper, we choose to achieve semantic diversity after feature embedding. The way we adopt differs from explicitly combining feature embedding vectors, i.e., automatically and emphatically selecting meaningful interaction relationships.
Based on the above core ideas, we aim to learn the impact of various semantic spaces to attenuate the semantic gap in feature interaction. We will utilize convolution operations to achieve feature interaction in various semantic spaces. Although this method adds some convolution kernel parameters to the network, it avoids a large scale of feature embedding parameters. Semantic diversity expands the interaction space from one dimension to multiple dimensions, so it is necessary to use the attention mechanism to identify important semantics and features. We use and make adjustments on Squeeze-and-Excitation Networks (SENet) to obtain global semantic information and dynamically implement weight distribution, achieving semantic diversity and feature diversity. Finally, in order not to miss any useful information, the original features and multi-semantic interactive features are input into a deep neural network (DNN) to capture high-order feature interactions effectively. To summarize, the major contributions of this paper are listed as follows:
Inspired by the new perspective of semantic diversity in CTR prediction, we propose a multi-semantic convolution-based feature interaction learning network (MeFiNet), which learns the interaction of the same pair of features under different semantics to weaken the feature-level semantic gap, thus helping to mine richer and more diverse value information in feature interactions. For further performance gains, we propose an improved Squeeze & Excitation method based on SENet to learn the importance of different feature interactions in different semantic spaces. The method enhances the representation of the model in terms of semantics and features. The proposed model is evaluated on three benchmark datasets. It consistently outperforms state-of-the-art deep models on MovieLens-1M, Criteo, and Avazu datasets. Further experiments also show that the improved Squeeze & Excitation attention method, multi-semantic interaction module, and high-order interaction module all help improve the performance of the model.
The rest of this paper is organized as follows. We begin by reviewing some work relevant to our proposed model in Section 2. Then in Section 3, we introduce our model presented in this paper. Experiment results and analysis are shown in Section 4. Finally, we conclude the paper in Section 5.
CTR prediction models
The LR model is the earliest and most classic CTR prediction model [19]. It has a simple structure and is easy to implement but unsuitable for processing nonlinear characteristics. The FM [10] model uses the idea of latent vectors proposed in the matrix factorization model to expand each feature into a k-dimensional latent vector for feature interaction, which makes it perform better than the generalized linear model and other advanced models at the time. Therefore, many FM-based variant models, such as FFM [4] and iFFM [20], are proposed. With the successful application of deep learning in computer vision and natural language processing, many CTR models based on deep learning have been proposed in recent years to model high-order feature interactions. FNN [22] uses the FM model to pre-train the embedding vectors and input them into a multi-layer perceptron (MLP) system. DeepCrossing [11] uses the residual network structure instead of the commonly used MLP to combine features automatically. Wide&Deep (WDL) [23] is the first deep model that uses a parallel structure to train the wide and deep parts jointly to increase memory and generalization capabilities. However, the wide part’s original features and feature combinations still need to be manually designed. DeepFM [21] is different from WDL. It uses FM as a wide part to learn low-order interactions and applies end-to-end model training. However, relying on DNNs to build complex models and learn high-order interaction features is insufficient. It is recommended to implement an explicit design of learning interactive features in a deep architecture [9]. Experts also believe that the data determines the upper limit of machine learning, and the algorithm will only approach this upper limit as much as possible.
Feature engineering and representation learning
There are usually two ways to process data: feature engineering and representation learning. The former refers to the manual data processing by experienced experts to obtain satisfactory or interactive features. Commonly used methods include feature scaling, decomposition, and aggregation [32]. The latter refers to the automatic learning of useful features through models to obtain better feature representation [1, 8], such as the embedding technology and the feature combination, usually used in CTR models based on deep learning. For instance, PNN [14] models the interaction relationship of features through vectors’ inner product (IPNN) or outer product (OPNN). NFM [12] introduces the Bi-Interaction pooling operation to learn 2-order interactions, significantly facilitating the modeling of higher-order and non-linear feature interactions in the deep fully connected layers. Deep Cross Network (DCN) [6] uses the cross network to learn bounded-degree feature combinations explicitly. It generates high-degree interaction at each layer while retaining the interaction information of the previous layer. DCN V2 [13] expands the weight parameters from the original vector to the matrix and leverages low-rank techniques to improve the ability to model cross features. In addition to these interactive methods, there are also some mature models that implement feature representation learning, such as convolutional neural networks [15, 16, 17], graph neural networks [18], and knowledge graphs [33].
Features imply different semantics in different scenarios. The concept of semantics appeared in natural language processing in the early days and is currently being used more and more in other research fields such as image annotation and recommender systems. IA-MSL [34] uses images annotated in two or more related semantic spaces to train the model, which overcomes the independence of mandatory conditions caused by a single space and the problem of ignoring spatial correlation. CCPM [15] introduces the convolutional neural network (CNN) to model important semantic features. CCPM, FGCNN [16], and MeFiNet are all based on CNN for feature interactions. The difference is that CCPM simply repeats the CNN operations, FGCNN uses a fully connected layer to reorganize the vectors to gain new features based on the CNN output, while MeFiNet extends the CNN channels to multi-semantic spaces and focuses on the importance of semantic spaces and features. TFNet [35] introduces multiple tensors to implement multi-semantic spaces, which brings more additional parameters than CNN in MeFiNet.
Attention mechanism
The attention mechanism can help models distinguish the importance of features and is widely used in machine translation [36, 37], speech recognition [38, 39], and other fields. AFM [24] is the first CTR prediction model to try the attention mechanism. It calculates the attention score of interaction features. The different attention mechanisms have also been used in several state-of-the-art CTR prediction models. DIN [25] uses an attention network to capture user interests from historical behaviors. DHAN [26] exploits a hierarchical attention network to gain different importance in different dimensions. AutoInt [27] leverages a multi-head self-attention network to learn feature interactions explicitly. SENet [28] has achieved remarkable results in computer vision and is gradually paid attention to by researchers in CTR [29]. It obtains the global spatial information through the Squeeze operation and then uses the Excitation operation to capture the interdependencies between channels. Both FiBiNet [29] and MeFiNet learn the importance through SENet. However, FiBiNet only leverages SENet to learn the importance of features, while our proposed MeFiNet improves SENet to focus on the importance of each semantic and feature.
Proposed model
The architecture of our proposed CTR prediction model MeFiNet.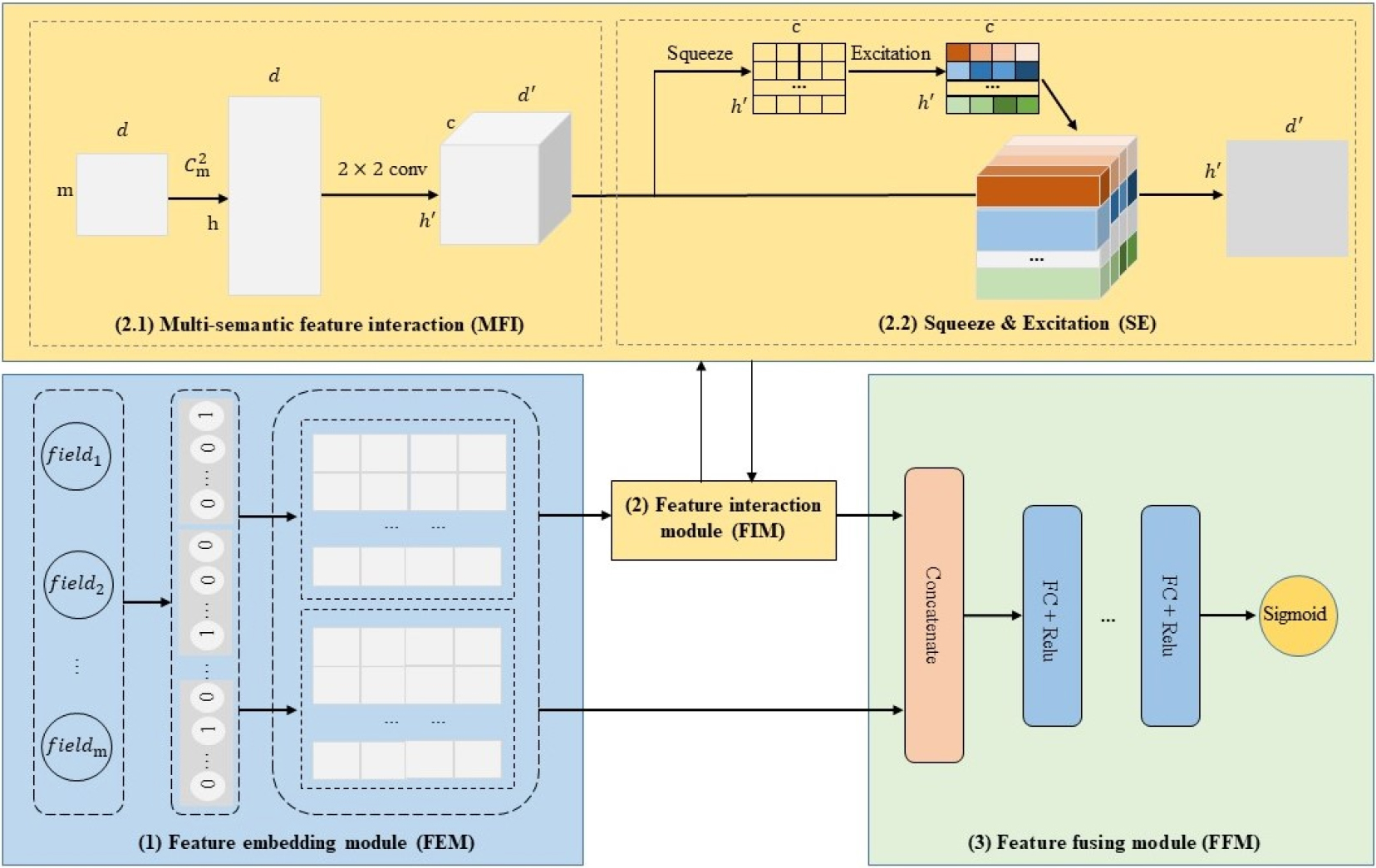
As illustrated in Fig. 2, the proposed model MeFiNet consists of three parts: 1) Feature embedding module (FEM), 2) Feature interaction module (FIM), and 3) Feature fusion module (FFM).
The inputs of the CTR prediction model usually contain user information, product information, and context information. They are mostly sparse features and encoded as one-hot vectors. However, these vectors tend to be of huge dimension and highly sparse. Through embedding technologies, they are transformed from a high-dimensional sparse classification space to a low-dimensional dense continuous space. The output of the embedding layer can be expressed as:
where
To enrich embedding vectors and avoid inconsistency in the gradient direction when updating parameters [16, 40, 41], we introduce another embedding matrix
Notation information
The feature interaction module (FIM) consists of two sub-modules, multi-semantic feature interaction (MFI) and Squeeze & Excitation based on SENet (SE).
Multi-semantic feature interaction
For most models, no matter which interaction method (e.g., inner product, outer product, or Hadamard product) is used, they only consider those interactions in the same semantic space and ignore the diversity of different semantic spaces. In this section, we gradually implement the construction process of multi-semantic spaces.
The concept of ‘channel’ in CNN is used to realize the diversity of semantic space. It introduces specific hidden layers to enhance feature extraction capabilities and reduce network parameters. We extract local features through small convolution kernels. One convolution kernel is used to extract one feature pattern, and multiple convolution kernels can extract multiple different feature patterns. However, multi-order interactions based on convolution operations bring more complexity to the model. Besides, convolution operations extract only neighbor patterns, which lose most interaction information. After careful consideration, we only use 2-order feature interactions and take some special measures, i.e., before inputting the data into the convolutional layer, we re-plan them by sorting and copying the embedding vector
The process of multi-semantic feature interaction.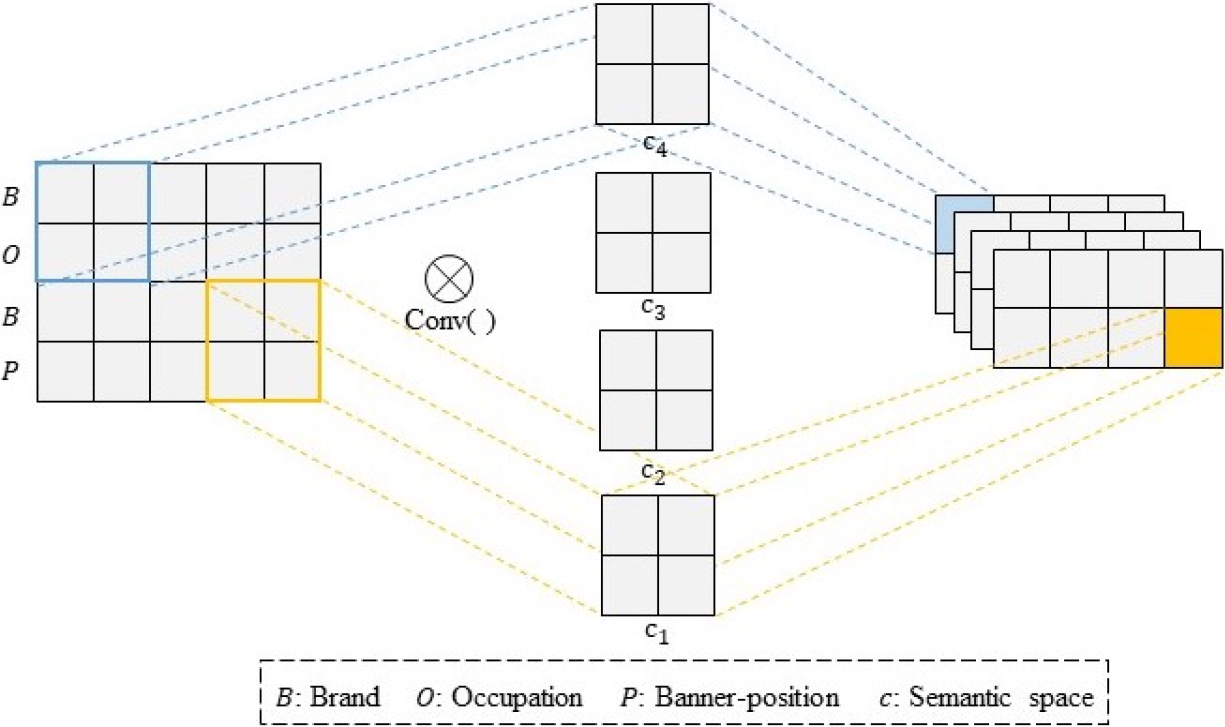
First, we expand the dimension of
where
Research on the attention mechanism proves that different characteristics have different importance to the target variable. Similarly, different features in different semantic spaces are essential to the target variable in a multi-semantic scenario. Specifically, due to the diversity of semantic spaces, different semantic spaces have different influences on features. In addition, it is not sufficient to assign the same weight to different interactive features even in the same space. As shown in Fig. 1, interactions A and B emphasize user and advertiser semantic space. Therefore, this paper considers that different interactive features in semantic spaces affect targets, involving semantic diversity and feature diversity.
In the field of computer vision, SENet [28] learns the importance of different channels and uses global information to recalibrate features. Inspired by SENet, we transfer channel attention to semantic spatial attention. However, SENet focuses on semantic diversity and ignores different features in the same space. To overcome its limitation, we propose an improved Squeeze & Excitation method based on SENet, which extends the original channel attention to multiple semantic attentions with different features.
Squeeze
In multi-semantic interaction, each of the learned filters operates with a local receptive field, and consequently, every semantic space
where
The improved Squeeze & Excitation method.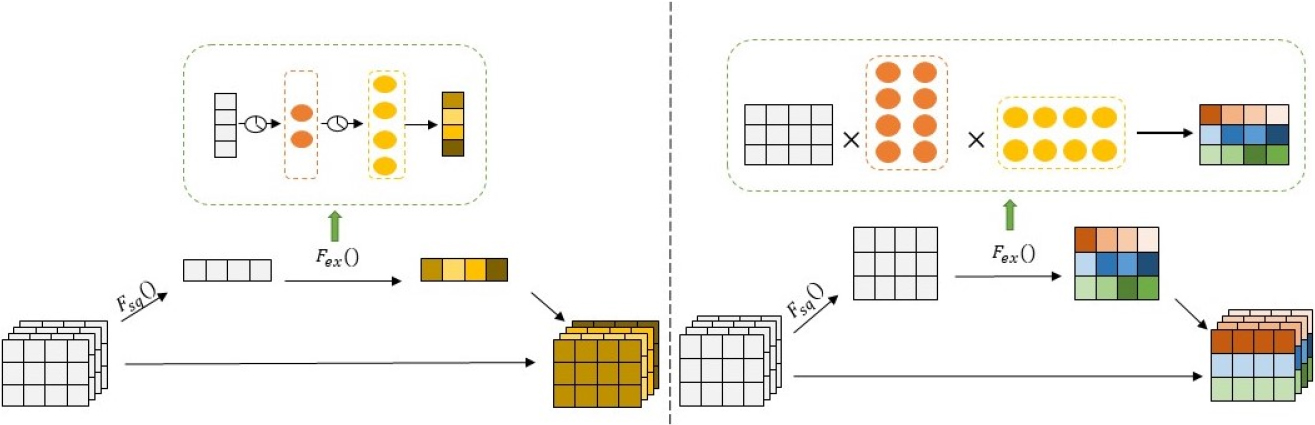
Excitation
This step is used to learn the weight of each semantic based on the semantic descriptor. We generally use two fully connected (FC) layers as a simple self-gating mechanism to achieve Excitation for the one-dimensional global descriptor. In this paper, the multi-semantic global descriptor with different features obtained by Squeeze aggregation information is two-dimensional, as shown in Fig. 4. To reduce the computational complexity and achieve the same effect, we leverage two matrices to learn the weights. The first learned weight matrix
where
Re-Weighting and Aggregation
First, we perform semantic-wise multiplication between the convolution interaction features F and the attention scores B. The output of the Re-Weight is expressed as:
where
Secondly, different semantic spatial information of
where
Since the low-order feature interaction still misses some helpful information. To improve the expressive ability of the model, we add multiple FC layers to generate high-order feature interactions. The processing procedure is described as follows.
First, we combine the multi-semantic interactive feature
Then, we get
where
Finally, since CTR prediction is a binary classification problem, we select the Sigmoid function as the activation function.
We choose cross entropy loss as the objective function.
where
Feature interaction module (FIM), the key module in our proposed MeFiNet, has the highest complexity among all modules and differs from other models. In the following, we will analyze the complexity of this module from space and time perspectives.
Space complexity
FIM includes two sub-modules. There are
Time complexity
The size of the output feature map of each convolution kernel is
Experiments
In this section, we perform extensive experiments on three benchmark datasets to evaluate our proposed MeFiNet. We aim to answer the following research questions:
RQ1: Can our proposed model perform better than other competitive models? RQ2: Are the key components in MeFiNet (i.e., SE, FIM, FFM) helpful in improving CTR prediction results? RQ3: How do hyper parameters such as the number of semantic spaces, the dimension of feature embedding, and the width of convolution kernel affect the performance of MeFiNet?
Experimental settings
Datasets
We conduct experiments on three real-world datasets, namely MovieLens-1M,1
Both Criteo and Avazu datasets are enormous. Limited by the experimental conditions, we selected about a quarter as the experimental data. In the experiment, each dataset is divided into a training set (64%), a verification set (16%), and a test set (20%). Table 2 summarizes the statistics of the three datasets.
Statistics of datasets
Evaluation Metrics
We evaluate model performance using two classic CTR criteria: the area under the ROC curve (AUC) and Logloss. AUC is used as an evaluation standard to avoid the influence of thresholds by converting predicted probabilities into categories. It is suitable for the imbalance of positive and negative samples. The value of AUC usually spans from 0.5 to 1, and a higher AUC indicates better model performance. Logloss (Cross Entropy) reflects the average deviation of the prediction results. It pays more attention to the sorting ability of the algorithm. Generally, lower Logloss indicates better performance. In the CTR prediction task, it is considered very meaningful to increase the AUC by 1 or decrease the Logloss by 1.
Baselines
We compare our model with the following methods.
Implementation Details
The experimental hardware platform is Intelö Core i5-4200H CPU @ 2.80 GHz 2.79 GHz, 8 GB memory, 1 TB hard disk, 64-bit operating system, and x64-based processor. The experiment runs on the Tensorflow1.15, and the programming language is python3.7.
The overall performance of different models on three datasets
We try different CTR models for comparative experiments on MovieLens-1M, Criteo and Avazu, using AUC and Logloss as evaluation indicators. The performance is shown in Table 3, where the underlined numbers represent the best performance among all benchmark models, and the bold numbers represent the best in all models. From the table, we can get the following observations.
LR performs the worst. It only learns the original features and does not consider the correlation between the features. The performance of FM is not as good as the models based on deep learning. It just adds the learning of 2-order feature interactions but does not consider high-order feature interactions. Among all deep learning-based models, CCPM only calculates local feature interactions and ignores global information, so the performance is the worst. IPNN uses inner products to interact with embedding features, which performs best on the Avazu dataset. Both WDL and DeepFM use a parallel Structure. DeepFM uses the FM model for low-level interactions and outperforms WDL. It performs best on the Criteo dataset. FGCNN uses CNN and a fully connected recombination layer to build new features, and it performs well on the MovieLens-1M and Avazu datasets. FiBiNet distinguishes the importance of features based on SENet in the embedding layer and uses the bilinear structure for feature combination, which performs best on MovieLens-1M. The proposed MeFiNet model performs best. On the MovieLens-1M dataset, the AUC increased by 0.15%, and Logloss decreased by 0.4%; On the Criteo dataset, AUC increased by 0.1%, and Logloss decreased by 0.12%; On the Avazu dataset, AUC increased by 0.14%, Logloss decreased by 0.13%. In actual scenarios, a slight increase in the AUC of offline models may bring additional millions of dollars to online applications yearly. Therefore, the performance advantage of MeFiNet is of great significance. By comparing the AUC and Logloss indicators of MeFiNet on the three datasets, we have found that the performances on the MovieLens-1M and Avazu datasets are better than that of the Criteo dataset. After analysis, we conclude that MeFiNet can highlight its advantages when the amount of data or the number of features is small.
The following is an experiment to study the impact of critical components in MeFiNet on performance. Each variant is realized by removing relevant components.
w/o SE. We remove the SE sub-module (attention mechanism) in this variant and retain the MFI sub-module. w/o FIM. We remove the FIM module and only the original feature embedding vectors are directly input into the DNN of the FFM module. w/o FFM. We remove the FFM module and replace it with the binary classification function, i.e., removing the high-order feature interactions and keeping only the shallow structure of the model.
The experimental results are shown in Table 4, from which we can get the following observations.
The performance comparison of different components in MeFiNet
The FFM component has the most significant impact on the results because the high-order interaction of features brings much information to the model. (a) Compared with MeFiNet, w/o FFM gets a lower AUC and higher Logloss (specifically, The FIM component is also very crucial for the model. After removing FIM, the entire model is equivalent to a single DNN where the original features are directly input into the MLP after embedding. The result of w/o FIM is inferior to MeFiNet on the three datasets ( When the features are greatly increased, adding an attention module can effectively improve the model’s performance. Compared with MeFiNet, w/o SE decreases the performance by 0.15% AUC and 0.44% LogLoss on MovieLens-1M, by 0.1% AUC and 0.12% LogLoss on Criteo. The SE module significantly impacts the dataset Avazu, in which AUC decreased by 0.26% and Logloss increased by 0.33%. In conclusion, increasing the attention mechanism SE helps selectively emphasize important features, suppress less important ones, and improve the model’s performance.
In addition, w/o SE performs better than w/o FIM. Firstly, the FIM component consists of MFI and SE. Secondly, By only deleting the SE component and retaining the MFI component, i.e., adding multi-semantic feature interaction on w/o FIM, the model can obtain better results than w/o FIM on the MovieLens-1M and Criteo datasets. It also proves that combining the deep learning-based model with feature interaction is very effective in enhancing the ability of feature representation learning.
Several critical parameters in MeFiNet impact the model’s performance, such as the semantic space, the embedding dimension, and the convolution kernel width. To study the impact of these hyper-parameters, we investigate how the MeFiNet model works by changing one hyper-parameter while fixing the others on three datasets in this subsection.
Impact of semantic spaces
Different feature interactions exist in semantic spaces, such as user and advertiser spaces. These spaces are implemented based on convolutional layers in this paper. The multi-semantic spaces help obtain richer semantic interaction features but also increase the parameters that need to be optimized. We conducted experiments on three datasets to study the impact of semantic spaces. The experimental results are shown in Fig. 5, where Fig. 5a–c is about AUC, and Fig. 5d–f is about Logloss.
Impact of semantic spaces.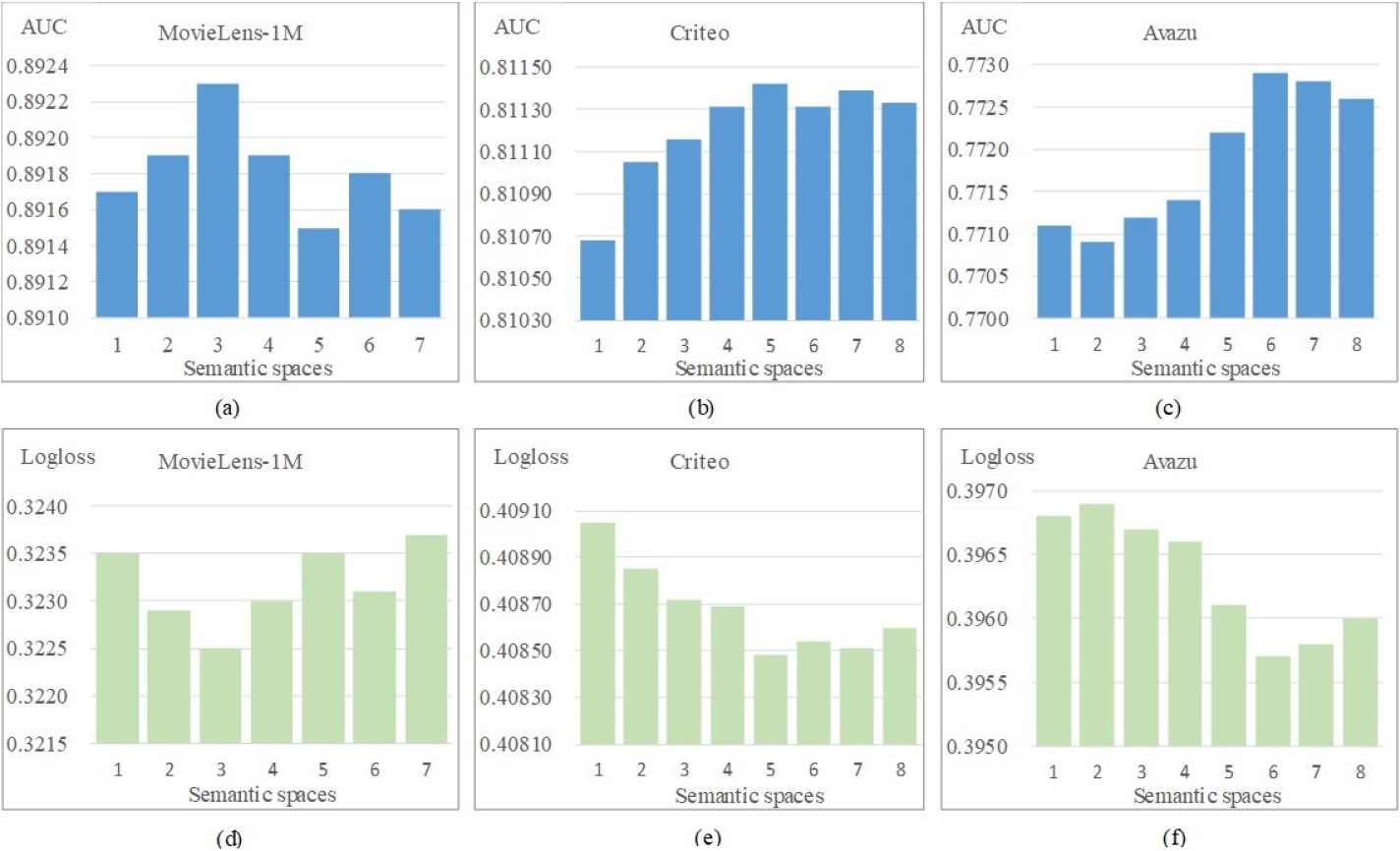
For the MovieLens-1M dataset, the model performs best when the number of semantic spaces is 3, i.e., it obtains the largest AUC and the smallest Logloss. For the Criteo dataset, as the number of semantic spaces increases, the model performance has a growing trend, and then the growth slows down. When the number of semantic spaces is 5, the model obtains the best AUC and Logloss. For the Avazu dataset, when the number of semantic spaces is 6, the values of AUC and Logloss are significantly improved, and the model performance is the best.
From the overall change of the two indicators on the three datasets, the model’s performance is first improved and then decreased when the number of semantic spaces increases. Because increasing the number of semantic spaces too much will create more parameters and lead to a more complex network structure, the model will likely perform poorly due to overfitting.
Generally, a larger feature embedding dimension will contain more information. However, if we blindly increase the embedding dimension, it may be less conducive to the presentation of information. We conduct relevant experiments on three datasets to explore the impact of different embedding dimensions of feature vectors on the model’s performance. For the MovieLens-1M dataset, the dimensions are from 4 to 64. For the Criteo and Avazu datasets, the dimensions are from 2 to 32. The experimental results are shown in Fig. 6, from which we can observe:
With the increase of embedding dimension, AUC increases, and Logloss decreases. When a specific dimension is reached, the performance decreases due to too large parameters and complex convergence. For the MovieLens-1M dataset, when the dimension is 8, AUC reaches the maximum, and Logloss decreases the smallest. For the Criteo dataset, the model performs best when the dimension is 8. For the Avazu dataset, the model performs best when the dimension is set to 4. We can achieve good performance by appropriately defining the dimension of embedded features. For the three datasets, it is more appropriate to set embedding dimensions as 4–8.
Impact of embedding dimensions.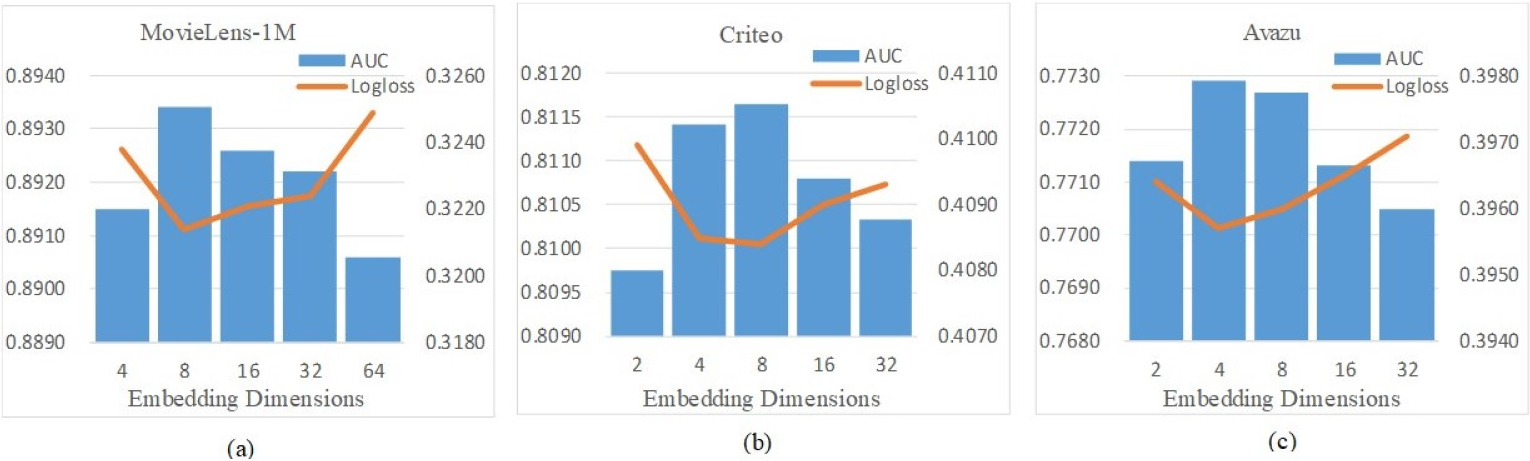
Impact of convolution kernel widths.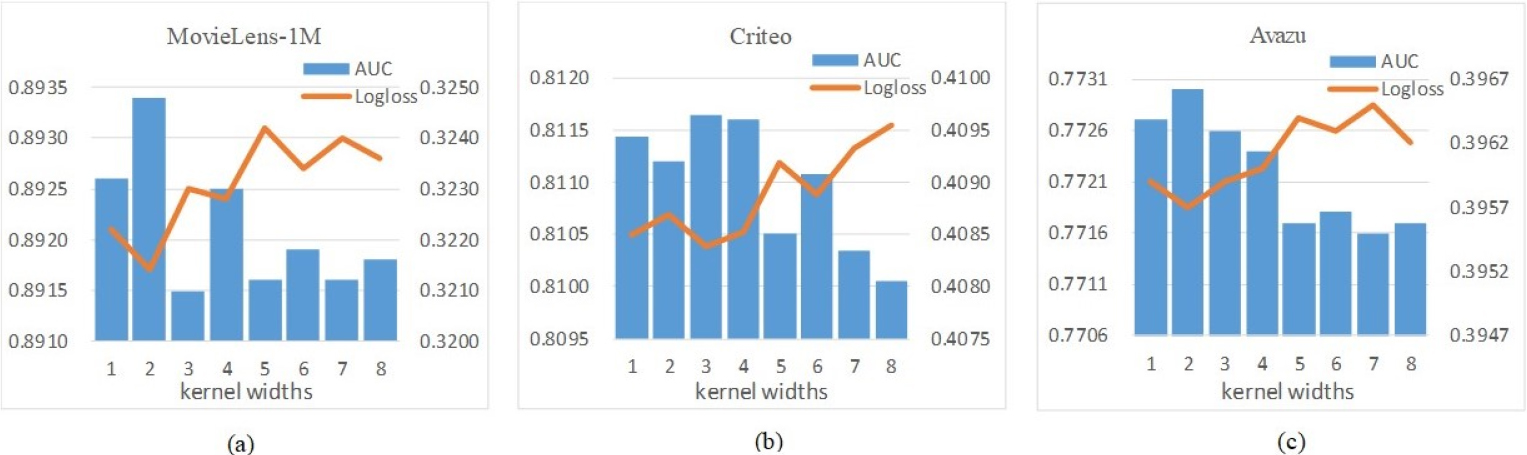
The width of the convolution kernel determines the perception range of the 2-order interaction. When the width increases, the feature interaction will span a larger embedding dimension, containing more information. The dimension of the feature obtained after the interaction will decrease in return. However, at this time, the parameter amount of the convolution kernel will become larger, and the update will become more complicated. To better observe the impact of changes in the width of the convolution kernel, we uniformly set the embedding dimension of the interactive feature to 8. The width varies from 1 to 8. The result is shown in Fig. 7.
In the MovieLens-1M dataset, the performance is the best when the width is 2. With the kernel width increasing, the model’s performance becomes poorer. For the Criteo dataset, when the width changes between 3 and 4, the model performs better than others. For the dataset Avazu, the model performance is much better than other values when the width is kept at 1–4, especially 2. It can be seen that properly increasing the width of convolution interaction helps improve the model’s performance. The performance of small window interaction is better than that of a large window on the whole. When the width is small, the convolution kernel has fewer interaction parameters, and the convolution computational complexity is not high. At the same time, the interactive features maintain an appropriate dimension, which will not cause too many parameters to converge or too little information to be obtained because the width is too large.
To take advantage of the rich and diverse semantic relationships in feature interactions, we propose to use multiple semantic spaces to learn feature interactions and establish a new model MeFiNet for CTR prediction. We use convolution operations to construct multiple semantic spaces, which helps to learn the latent semantic expression of features and avoids the unity and randomness of a single embedding space. To identify the importance of semantic features, we propose an improved Squeeze & Excitation method based on SENet. It uses global information to dynamically re-adjust the weight distribution. Experimental results on three public datasets show the superior performance of MeFiNet. Further experiments have verified that the deep learning framework is even more potent with effective feature combinations as input. Learning multiple semantic feature interactions improves CTR prediction accuracy, making the model more complex. In the future, we will study lightweight methods to obtain more semantic information from feature interactions while making the model less complicated.
Footnotes
Acknowledgments
This work is partly supported by the Shanghai Science and Technology Innovation Action Plan Project (No. 22511100700).
Conflict of interest
No conflict of interest exists in the submission of this manuscript, and manuscript is approved by all authors for publication. I would like to declare on behalf of my coauthors that the work described is original research that has not been published previously, and not under consideration for publication elsewhere, in whole or in part. All the authors listed have approved the manuscript that is enclosed. And this article does not contain any studies with human participants performed by any of the authors.