
Abstract
Creative influence is responsible for a considerable part of the creative process of an artist and can largely be associated with their social circle. It has been observed that the type and amount of relationships with other fellow artists correlates with the success of an artist. Most of the recent literature has focused on using artefact similarity as a proxy for creative influence between two artists. However, this approach neglects the significance of an artist’s social network. In this work, we rely on an ontology that comprehensively model the relationship between individuals as a Knowledge Graph and we design an explainable method based on graph theory to predict the influences of an artist given their social network. We evaluate our method on a dataset of relationships between Jazz musicians and achieve accurate results when compared to baselines that rely on the distribution of the data. Our results are aligned with relevant works from the socio-cognitive and psychology fields. We show that our method generalises to resources where information on influence is not directly available and can be used to enrich existing Knowledge Graphs. The code and the ontology developed is shared at https://github.com/n28div/influence_prediction under CC-BY license.
Introduction
Identifying, capturing and hypothesising the influences of an artist is a fundamental aspect that is considered when analysing an artefact or, in general, an artist [11]. A unique and precise definition of creative influence is yet to be defined. The main difficulty lies in the subjective nature of the problem. Identifying the influence of an artist on another artist requires a profound knowledge of both entities, their geographical location, the socio-cultural context in which they lived, the technicalities of their artefacts, the artistic field and so on. Indeed, an unambiguous definition of creative influence has been identified as a problematic aspect to explore [10].
Nonetheless, understanding who are the artists who influenced other artists is an important aspect that plays a pivotal role in the creative process. One of the major aspects that correlates with artistic influence is the amount of success of an artist. Mitali and Ingram [19] analyses the work of 90 pioneers in the abstract art movement. The results provide very strong evidence that the success and fame of an artist are mostly related to their social relationships. While it is true that creativity fosters those relationships, the more artists get deeper into a clique formed by other meaningful artists, the more their work is acclaimed by critics. For instance, the success of the band The Velvet Underground is often associated with their relationship with the artist Andy Warhol [16].
To understand the influence on an artist, it is hence important to take into account the social relationships of the artist well. Most recent approaches, however, neglect this aspect and only rely on perceptual features of an artefact - i.e. relying on similarity as a proxy - for creative influence Abe et al. [1], Elgammal and Saleh [7], O’Toole and Horvát [21], Park et al. [22], Saleh et al. [28]. Even though perceptual features yield promising results, they neglect the incidence of the social circle. This hinders the possibility of hypothesising influence between artists whose stylistic genres are completely different. For instance, the personal relationship between Ravi Shankar, a popular Indian artist and George Harrison, the Beatles’ main guitarist, largely influenced the music from the Beatles [2], although the two artists performed two radically different music genres. Similarly, by persuading a solely similarity-based approach it is unfeasible to detect artistic influences between two artists that perform on different domains, such as in the example of The Velvet Underground and Andy Warhol.
In this work, we propose a method to predict the influence of musical artists by taking into account their social networks. We design an ontology, aligned to the Polifonia Ontology Network [6], that models social relationships between artists as complex situations involving different agents and concepts. We refactor the data from the Linked Jazz project [23] 1 , a Knowledge Graph encoding curated relationship between Jazz musicians (among which creative influence), to comply with the ontology and rely on it as a ground truth to perform influence prediction. We frame the influence prediction task as a classification problem where one has to identify and rank artists according to their likelihood to be influential for a given artist. Our approach is based on techniques from graph theory, namely the f-communicability of a graph [27]. Informally, the f-communicability of a graph provides information on how close two artists are as a function of their connections. The shorter the connections between two artists, the higher their communicability. We consider the f-communicability between nodes i and j as the degree of influence that j has on i or, in other words, how influenced is i with respect to j. Our method assigns a weight to each relation in the Knowledge Graph based on the type of relationship. We approximate the weighting function by maximising the f-communicability between influential relationships asserted in the original Knowledge Graph in an optimisation procedure. We evaluate our results through the use of standard information retrieval measures (MRR, MAP, DCG) and compare our method with baselines that rely on the distribution of the data. We show that learning weights for a relationship type results in the best performance. The relative importance assigned to each relationship aligns with other relevant studies from the socio-cognitive and psychology fields, thus further validating our method.
Our contributions can be summarised as follows: an ontology to model the relationships between human agents, with a particular focus on artists; an explainable method to predict creative influence between artists.
The paper is structured as follows: in Section 2 we provide a review of related works addressing the prediction and identification of influence between artists. In Section 3 we present and analyse the data used in the experiments and we describe the developed ontology. In Section 4 we describe the method used to predict creative influence between artists. In Section 5 we describe the experimental setup while in Section 6 we present the obtained results. Section 7 summarises the results of previous sections and highlights potential extensions and future work.
Related works
Evaluating the influences of an artist, and in particular of a composer or a musician, is mostly considered a subjective task. Usually, experts analyse the compositions of an artist in a critical way to relate them to other important artists. One approach to detecting creative influence is to directly analyse explicit influence connections, curated by human annotators. Smith and Georges [30], for example, analyses the influences identified in the Classical Music Navigator (CMS) to better understand the influence of the composers in the dataset. A similar approach is taken by Georges and Seckin [9], where the data on creative influence is used to investigate the similarity of musical compositions.
Relying on similarity as a proxy for creative influence is a popular approach that has been explored using different techniques. Abe et al. [1] define a framework where influence can be modelled using a graph structure. Edges are added to the graph by taking into account the similarity between the two artworks. Several works have explored this approach in the visual art domain with promising results [7, 28] and in the musical domain. O’Toole and Horvát [21] models the influence of musical composition as the probability of success of a composition given its similarity to other popular compositions. In Park et al. [22], the influence of a composer on another composer is measured as the degree of similarity between their compositions. A composer is classified as influential when musical features of its compositions are re-used by other composers.
Relying on artefact similarity, however, can be a problematic approach in art. Influence can affect an artist in a negative way, in the sense that the influenced artist deliberately abstains from his influence [10]. These kinds of artists are sometimes defined as deviant artists [31, 34]. Mauskapf et al. [17] investigates similarity with respect to socio-cultural indicators, such as geographical and temporal location or organisational system in which the artist lives. Findings suggest that highly embedded individuals, i.e. individuals with a dense social network, are more likely to produce novel artefacts that can be influential to other artists. Borowiecki [5] analyses influence of the teacher-student relationship through a combination of artifact features. Albeit with different intensities, findings highlight the importance of such a relationship, as also observed in Simonton [29]. Analysing the social network of artists using complex network tools has been explored in literature [7, 26]. The relationships taken into account are often the result of heuristic methods or are limited to a few relationship types, such as teacher-student or bandmates. Relying on a rich social network where different relationship types are taken into account has been proven to be an effective way of uncovering meaningful insights [24] from data. Moreover, considering many different relationship types is an important requirement, as it has been largely discussed how different relationship ties can contribute differently to creative influence [15, 29].
Differently from the described approaches, we investigate the importance of social relationships without taking into account any information on the creative artefact. Our approach can be easily integrated with other methods that use similarity, to yield a more general method for uncovering hidden relations when perceptual similarity is the only measure taken into account.
Data
This section provides a detailed description and analysis of the data used in our method. In Section 3.1 we propose our ontology to model complex personal relationships. In Section 3.2 we describe how the Linked Jazz [23] Knowledge Graph is refactored to comply with the developed ontology.
Relationship ontology
Our proposed ontology is built upon the concept of social relation from the DOLCE ontology [4]. A social relation is a situation involving a source of information 2 , some participants and a role that qualifies the type of the relation.
The ontology takes into account only pairwise relationships. This is intended as the two agents (source and target) that partake in the relationship. In this way, it is possible to define a relation between sets of entities while retaining the directedness of the relationship. An example is the Mentorship relation, where a single mentor might have multiple students. The source of information tracks the provenance of the relationship assertion. The relationship types are described in Table 1.
Relationships modelled in the ontology
Relationships modelled in the ontology
Figure 1 visually represents the ontology. The class
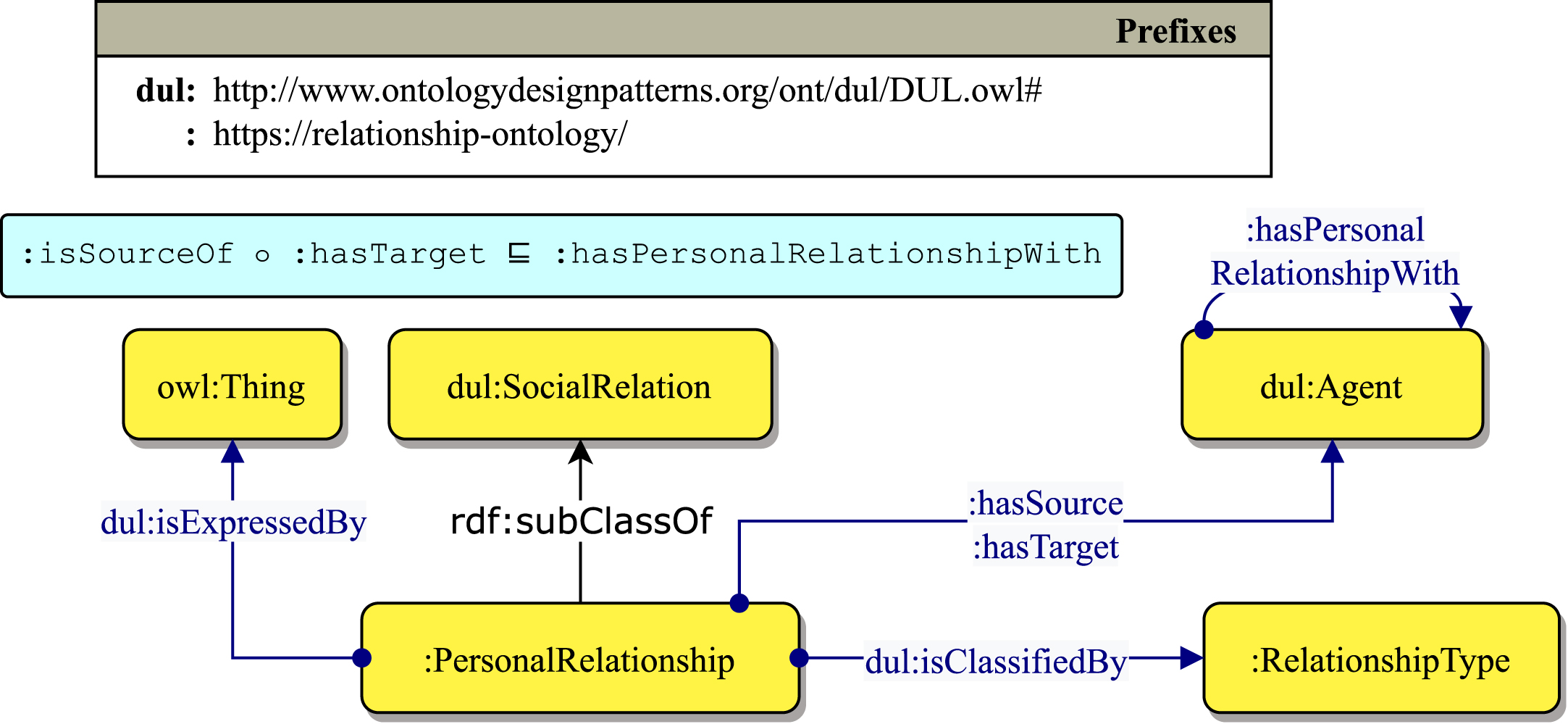
Ontology in Graffoo syntax. A pairwise relationship involving two agents is reified as a
In Fig. 2 an example of how the ontology can be used to define the friendship relationship of Table 1 is described. In order to define a friendship relationship between the musicians Trent Reznor and David Bowie it is sufficient to add the triple
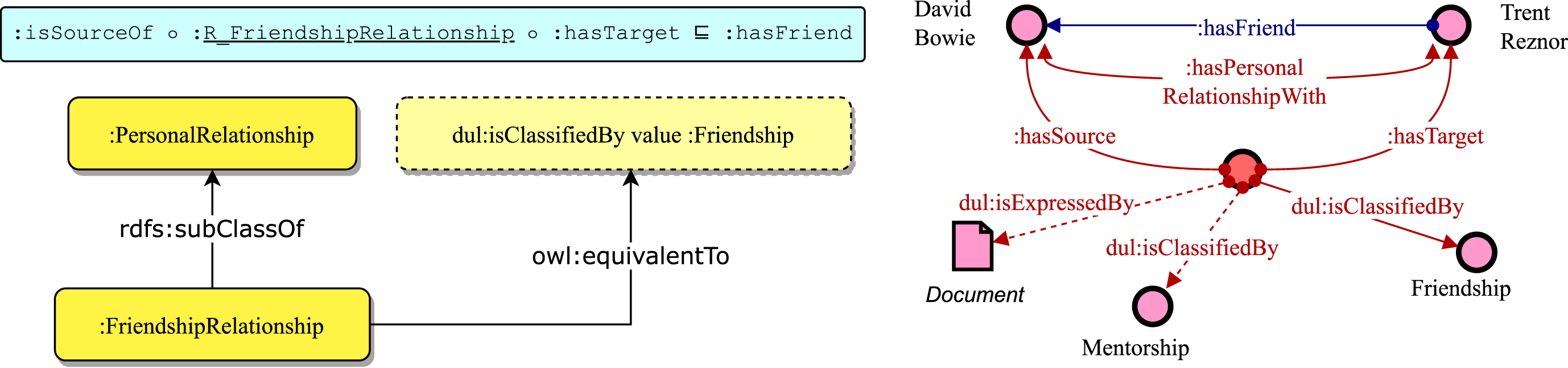
Example of the friendship relationship using the ontology. The
The implemented reification allows us to represent the relationship as a whole rather than flattening it into a binary relation, resulting in a richer characterisation of the relationship and a high degree of control in further refining it. For example, in Fig. 2 the dashed properties represent refinement operations over the initial definition. It is possible to classify the relationship as both a friendship and mentorship relationship while adding documents that act as references to back up the assertion.
We rely on the data from the Linked Jazz project [23]. Linked Jazz is a Knowledge Graph containing information about famous jazz musicians and their social connections to other musicians. Data is semi-automatically annotated from the transcription of artists’ interviews using crowd-sourced annotations. While some relationship types are objective (e.g. bandmate relationship) some have a subjective definition (e.g. influence relationship) and need to be interpreted in the context of the interview. Annotators are provided with a definition for each relationship type, which partly addresses this issue. Modelling social relations as linked open data has shown how it is possible to uncover meaningful relationships between entities that are otherwise difficult to uncover [24].
We align the Linked Jazz KG to our ontology (described in Section 3.1) through the use of a SPARQL construct query.
The refactored KG contains 1 431 artists with 63 relations on average between each artist. Figure 3 shows the distribution of the relationship between the entities in the KG. The most frequent relationship is the acquaintance one. This is not surprising, as the extraction of Linked Jazz has been performed from interviews. Whenever an artist mentions another artist, if the context and the information available are insufficient to hypothesise a more specific relationship, the annotators have been instructed to rely on the most generic relationship [23]. Given the distribution of Fig. 3 and the total of artists (1 431), it follows that many artists have more than one relationship type with the same artist. This happens, for instance, with Toshiko Akiyoshi 3 and Count Basie 4 , where Toshiko Akiyoshi has 5 different types of relationships with Count Basie.
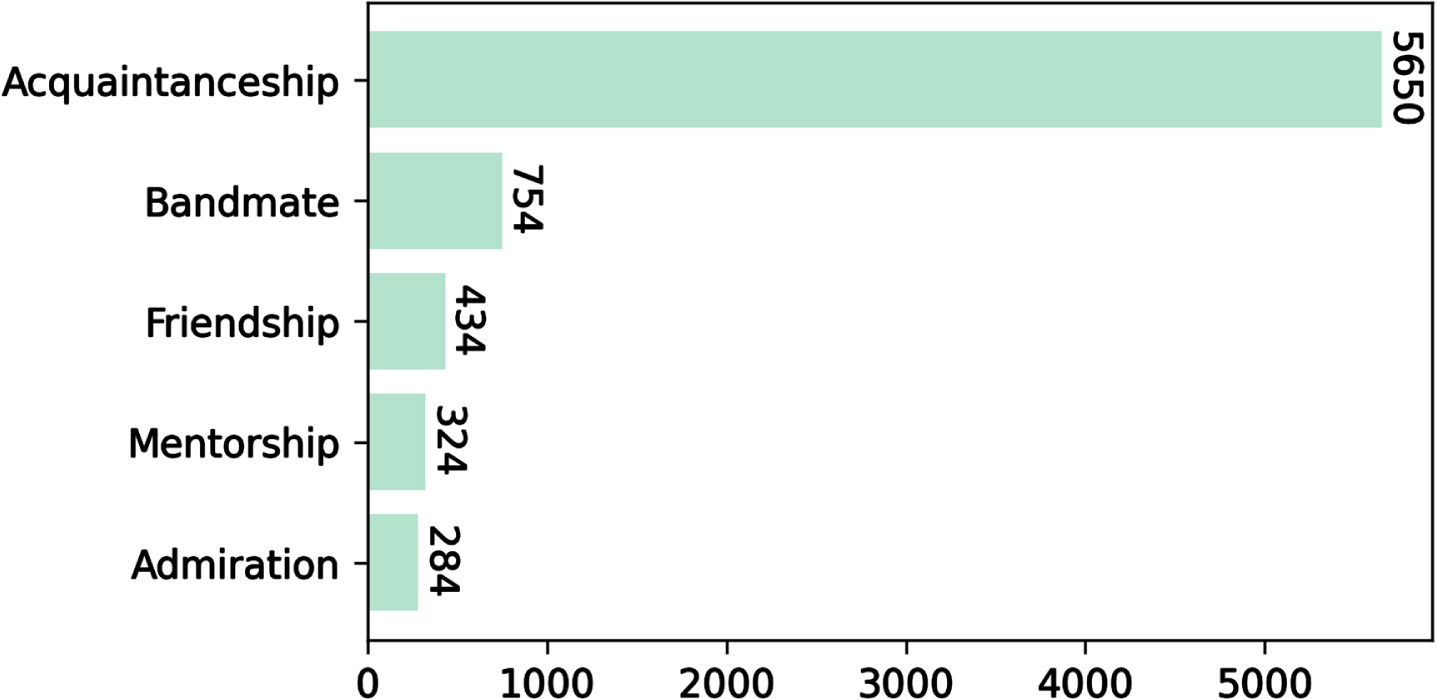
Relation distribution in the Linked Jazz KG.
Figure 4 shows the co-occurrence of different relationship types between the same two artists. As could be easily hypothesised from Fig. 3, the acquaintance relationship is the one that co-occurs the most with the other ones. Indeed, it can be interpreted as a generalisation of any possible relationship. Interestingly, the friendship relationship is the one that most co-occurs with the bandmate one. This confirms the arguments of Mitali and Ingram [19]: the social circle of artists impacts their careers. Indeed, when two artists are friends it is highly likely that they collaborate as well in some creative endeavour. The same happens when an artist is a mentor of another one, as hypothesised by Simonton [29].
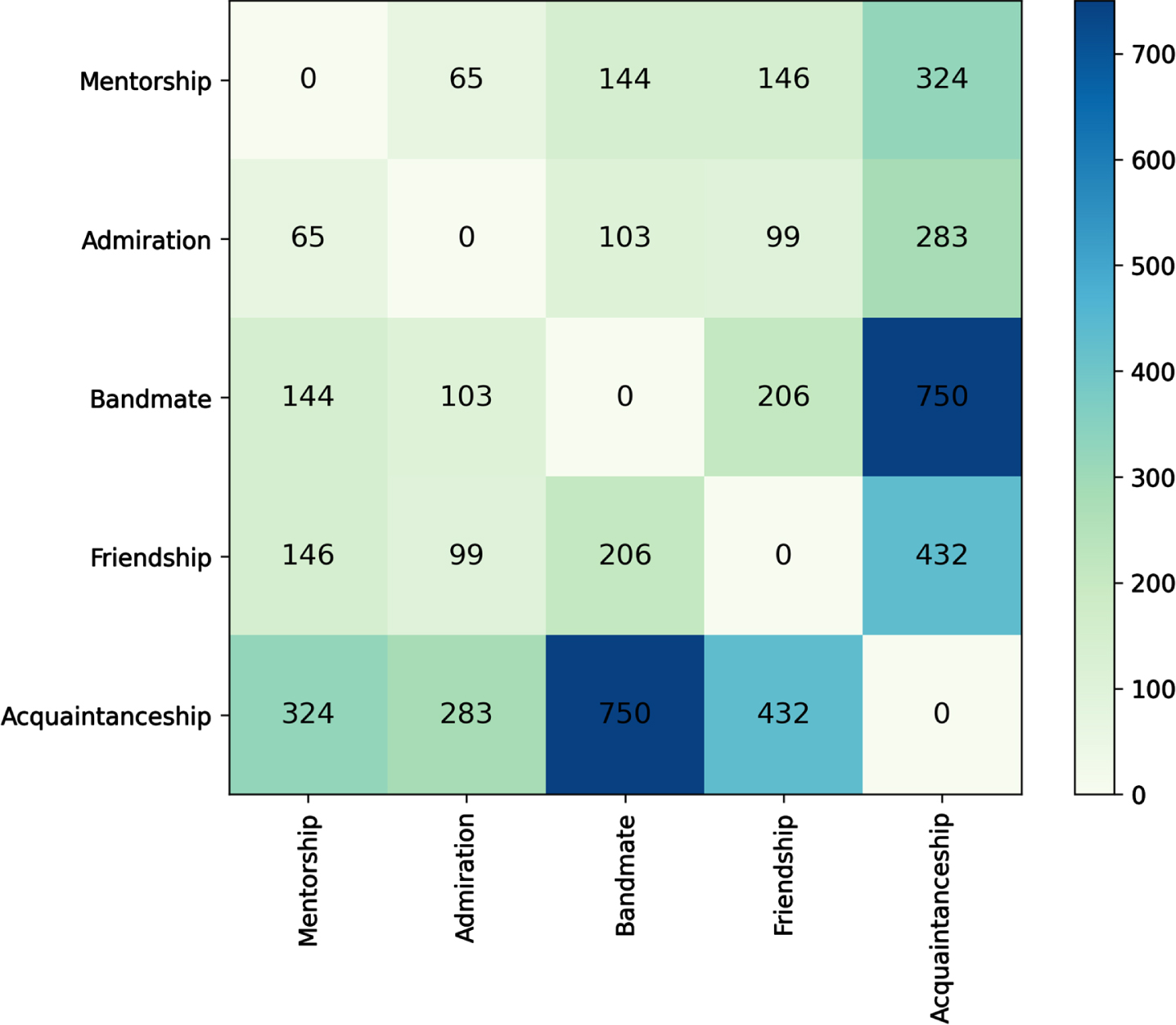
Co-occurence of pairwise relationships in the Linked Jazz KG.
The Linked Jazz Knowledge Graph contains explicit information on the influence between two artists. This allows its use as a dataset for influence prediction since the ground truth is manually extracted. However, the distribution of the dataset is limited to jazz artists. This results in a narrow evaluation of our proposed method, which is not guaranteed to accurately predict influence relations between artists in other musical domains, such as pop, classical or rock music. To check the generality of our proposed method, we rely on the MEETUPS Knowledge Graph [32]. The MEETUPS KG is built by applying a complex knowledge extraction pipeline on Wikipedia pages to extract entities participating in a historical meetup. A historical meetup is identified from an artist’s Wikipedia biography when it mentions at least one or more participants and places. Moreover, the time when the meetup took place and the purpose of the encounter is extracted. The possible encounter purposes are business career; personal life; coincidence; education; public celebration; and music making.
While such purposes do not exactly match the interpersonal relationship we are interested in (Table 1), it is possible to extend MEETUPS and align it to the ontology of Section 3.1. In principle, all the historical meetups in the KG imply that the artists that take part in it are acquaintances. A more fine-grained alignment can be obtained by posing additional assumptions, described in Table 2.
MEETUPS alignment to our proposed ontology
MEETUPS alignment to our proposed ontology
Based on these alignments we refactored the MEEETUPS KG to comply with the ontology presented in Section 3.1. The refactoring was performed by a script automatising the retrieval of all the meetups from the KG. For each meetup, the script retains the participants and the purpose of the meetup. Then, for each pair of participants in a meetup,
Moreover, if
where
This results in a Knowledge Graph containing more than 2 million triples, with a total of 93 394 unique artists and 537 303 asserted relationships. Figure 5 shows the distribution of the relationship between the entities in the KG. Since we fall back to the acquaintanceship relation when the meetup purpose is not alignable to the ontology of Section 3.1, it is also the most frequent relationship in the KG. Compared to Linked Jazz, the distribution of the relationship is more balanced. For instance, the fellowship and friendship relationships are much more prominent than the ones of Fig. 3. Moreover, the bandmate relationship is less prominent. This is a direct result of the information contained in Wikipedia biographies, which is often incomplete when compared to more authoritative resources [12].
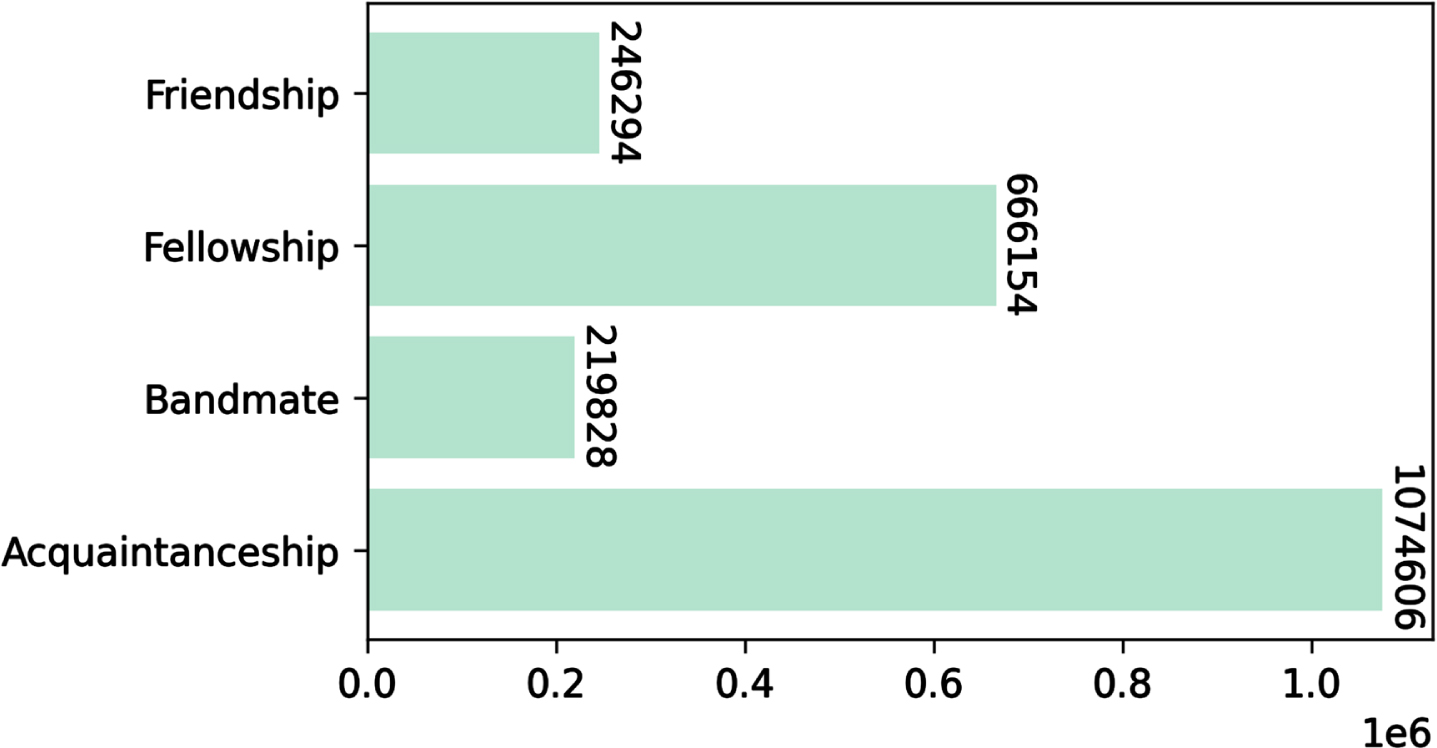
Relation distribution in the aligned MEETUPS Knowledge Graph.
Figure 6 shows the co-occurrence of different relationship types between the same two artists is shown. Similarly to Linked Jazz (Fig. 4) the friendship relationship highly co-occurs with the bandmate one. Further providing evidences to the work of Mitali and Ingram [19].
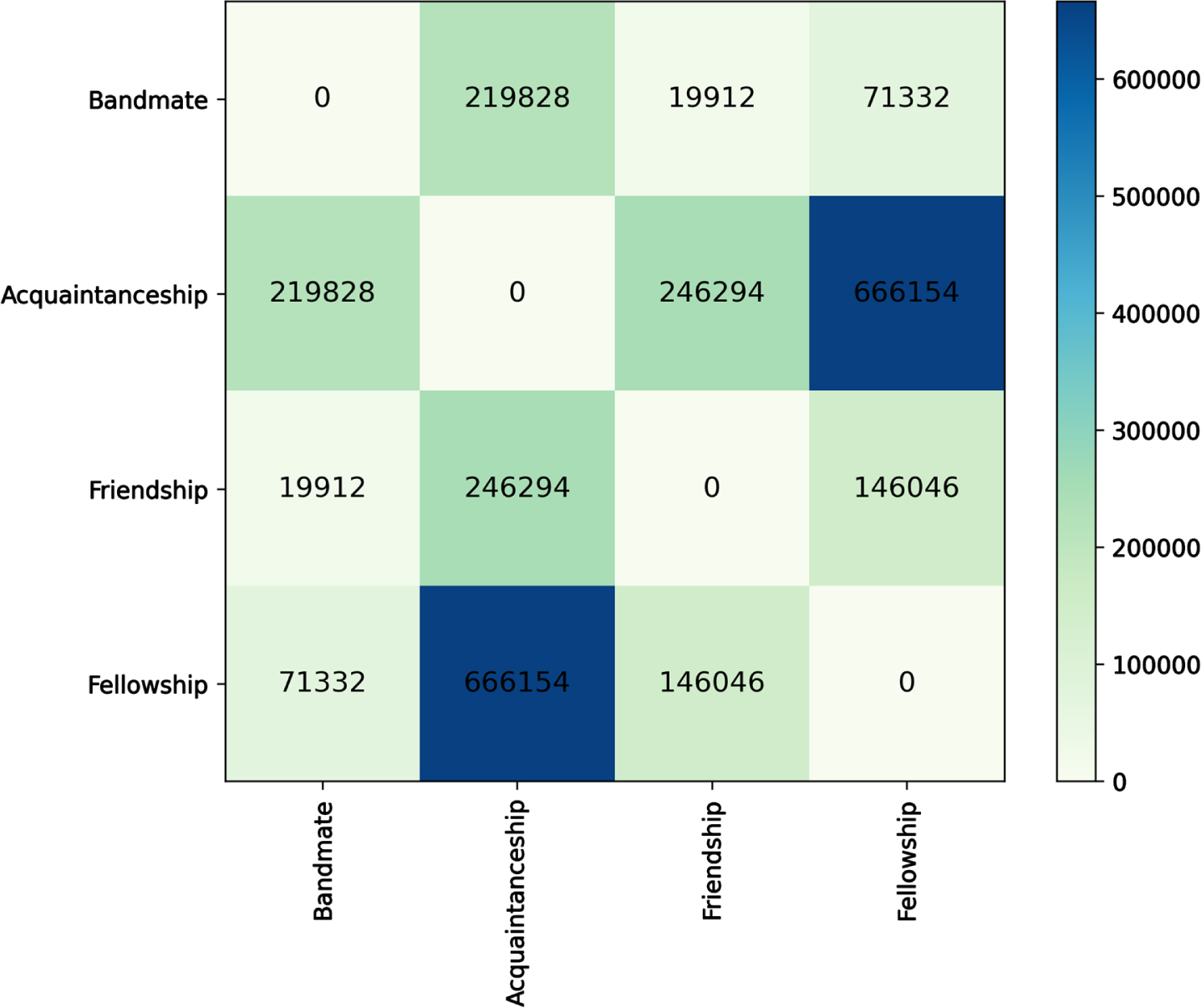
Co-occurence of pairwise relationships in the aligned MEETUPS KG.
Unlike Linked Jazz, MEETUPS is not limited to jazz music but spans different music genres, since there is not any constraint on the biographies used to extract information. For this very reason, MEETUPS does not assert any influence relationship, as they can not be extracted from historical meetups events. To overcome this issue, we extract influence relationships by relying on the AllMusic 5 website, which states a list of known influences for each artist. The information obtained on AllMusic are humanly curated through crowd-sourcing. Hence they are representative of the most important influences of an artist. We collect 12 580 influence relationships involving 3 723 artists in MEETUPS KG. Note that, compared to the 242 199 artists contained in the MEETUPS KG, influence coverage is still relatively low. Moreover, the provenance and accuracy of the information in AllMusic is explicitly clear. We will use the extracted influences as a benchmark to assess the accuracy of our proposed method as an unsupervised influence detection method.
This section provides a detailed description of our method. In Section 4.1 we describe in detail the algorithm used to compute the influences between entities in the KG while in Section 4.2 we describe the procedure designed to learn the weight of each relationship type.
f-communicability as influence indicator
Once relations are represented using the ontology described in Section 3.1, the resulting Knowledge Graph is a formally defined social network of artists. By only relying on the binary projections of the reified relationships we can extract a directed graph G where entities are directly connected through a set of edges E, such as in the example of Fig. 7. To quantify the influence of one artist on another, we exploit tools that pertain to the analysis of complex networks.
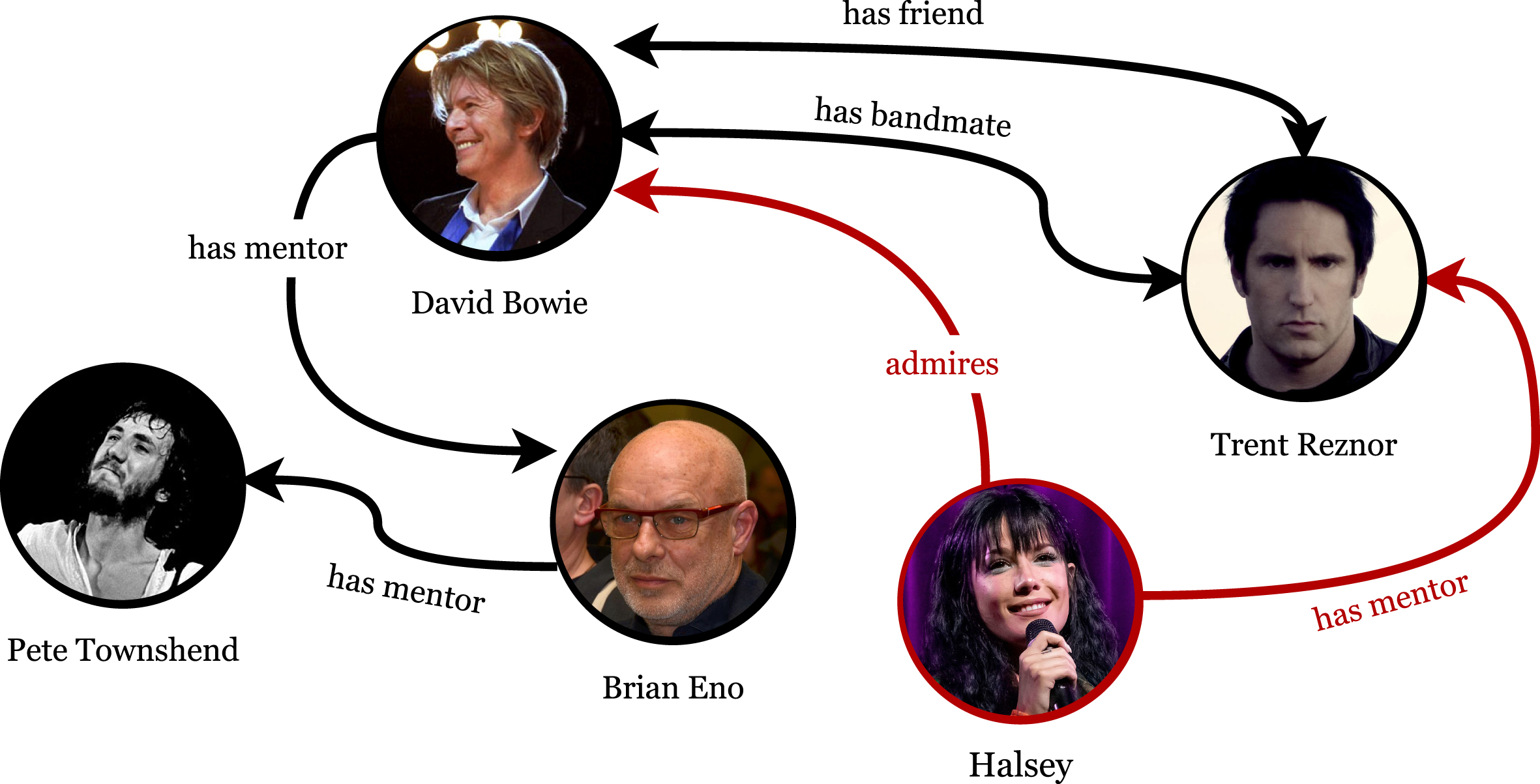
Example of social graph. Intuitively, the communicability between Halsey and David Bowie should be high given the direct and non-direct connections. Nonetheless, the communicability with Pete Townshend should be considered as well, since there is a chain of relations that connects the two artists.
Our approach is based on the f-communicability measure between the nodes in a graph, which is defined as a function of the paths that connect two distinct nodes. Generally, we say that a node is highly communicative with another node if many paths connect the nodes. The length of the connecting path is an important factor that needs to be considered. If a piece of information (e.g. creative influence) has to travel along the graph, a short path is more convenient than a longer one. As a consequence, artists should be more influenced by close connections. Nonetheless, long connections should not be completely ignored. The f-communicability score measure between two connected nodes changes as the length of the path changes: the shorter the path, the higher the communicability of the nodes.
Figure 7 shows an example of a social network among artists. Even though close connections should be considered more important, connections that are not too far still conceive a lot of interesting information when the creative process is being considered.
In our setting, the f-communicability is an indicator of how influential an artist is with respect to the other artists in the Knowledge Graph. We define a Knowledge Graph KG as a directed edge-labelled graph G = (V, E, L) where V represents the set of nodes in the graph, E the set of edges and L the set of labels that can be assigned to an edge e ∈ E. L is the set of binary projections obtained from the relationship types of Table 1.
The f-communicability between nodes i, j in G is defined as a function of the adjacency matrix A of the graph G. Since G is a labelled graph, by taking only the edges labelled l ∈ L we can obtain a set of |L| adjacency matrices, one for each label. We write A
l
as the adjacency matrix obtained from the subgraph of G having only edges labelled as l. The adjacency matrix A can hence be obtained as
To maintain the semantics of each predicate as formalised in KG, we need to take into account the fact that edges labelled differently should be weighted differently in A. For instance, it is reasonable to assume that two artists who are acquaintance will be less important than them being in a mentorship relationship. We define the weighting function
The f-communicability indicates the robustness of the communication between pairs of nodes measured in terms of the number of paths connecting two nodes. Therefore, before giving the f-communicability formula, we introduce the notion of a path in a graph. A path P between u, v ∈ V is a sequence of edges e
i
∈ E connecting the two nodes. The weight w (P) of the path is defined as follows
The weight α
k
defines how the importance of a path should decay as its length increases. The weights α
k
need to be carefully chosen in order to make sure that the sum of Equation 5 converges to the finite value. This is done by using a succession that converges to 0 [27], ensuring that paths of length ∞ will have a null weight. Choosing how α
k
changes as a function of the path length k results in different graph measures, such as the Kantz centrality [8, 13]. We follow the definition of Estrada and Hatano [8] and set α
k
such that it results in the exponential matrix function. This means that longer paths will be exponentially less prominent. It is easy to see that as the path length goes to infinity, its weight tends to 0. Given the computational cost of computing the exact exponential function (particularly for large matrices), we define α
k
as an approximation of the exponential matrix function. This is done by truncating the power series that represents such a function. Equation 5 is hence updated to be

Examples of equation 6 computed on the example from Fig. 7. The labels TD, DB, BE, TR and H are used to represent the nodes of, respectively, Pete Townshend, Brian Eno, David Bowe, Trent Reznor and Halsey. For simplicity of understanding the weights of equation 1 are considered to be w (l) =1 ∀ l ∈ L. Relations that represent direct influence (e.g. H → DB) are not added to the graph. In Figure a the adjacency matrix obtained from Equation 1 is shown. Note that the nodes that have redundant connections (e.g. DB → TR) have a value of 2. In Figure b the f-communicability function is computed for walks of length 1. Nodes that were previously disconnected (e.g. TR → PT) are now connected. The same happens in Figure c, except that new connections have a lower weight (e.g. H → PT).
In Equation 2 we defined the adjacency matrix by relying on the weighting function w, which assigns a weight to each predicate of the KG. In this setting, each predicate is a social relationship. Defining the weight of a social relationship is an elaborate task, particularly when it needs to be contextualised in the creative domain. Perry-Smith [25] argues on the existence of strong and weak social ties and their influence on creativity. Strong ties, defined as highly redundant connections between two individuals (e.g. Trent Reznor and David Bowie in Fig. 7) are found to positively correlate with creativity but does not discuss the weight that should be assigned to a specific relationship type. Simonton [29] argues that some particular relationships, such as the mentor-pupil one, have a higher influence on the creative process of an artist when compared to others. A straightforward approach, which serves as a baseline, is to assign to each relation type the same weight (w (l) =1 ∀ l ∈ L) and ignore the arguments above. Similarly, it is possible to follow a distributional approach and assume that the importance of a relationship is (inversely) proportional to the distribution of that relationship among the reference population. This can be done by defining the weight of the label to be (inversely) proportional to their distribution in the graph, which results in
A more flexible approach is to learn the weights assigned to w by fitting the data in the Knowledge Graph. This can be obtained by framing the problem of predicting creative influence as a multi-class classification problem. Given an edge e = (i, j), we can interpret f
D
(i, j) as a score indicating whether e ∈ E with l ∈ label (e) where l is the label assigned to the edges that semantically states that i is creatively influenced by j. Essentially, the f-communicability of a pair of nodes (i, j) (f
D
(i, j) measures the degree to which i is creatively influenced by j). To do that, we learn the weighting function α
k
by minimising the cross entropy loss between f
D
(A′) and
While aggregating relations using a sum, as done in Equation 1 is a reasonable approach, it is also reasonable to suppose that the joint presence of two relationships, e.g. friendship and mentorship together, might be more (or less) important than the sum of the two components - i.e. the combination of two weighted relationships is a non-linear combination. To take this additional consideration into account we perform a non-linear combination using a Multi-Layer Perceptron (MLP) model with one hidden layer using a ReLU activation. In that case, equation 1 is updated to
The computational complexity of the method described so far is non-trivial. The time complexity of the method is dependant on the matrix multiplication algorithm at hand, and is proportional to the degree D of Equation 6. If we take into account the traditional school-book algorithm for matrix multiplication, which has polynomial complexity O (n3), then the time complexity of the described method is still polynomial, since D is a constant and generally we have that D < 5. However, when handling large graphs, the space complexity induced by A
ij
(Equation 6) hinders the scalability of the method. Given a graph G = (V, E, L), the space complexity of A
ij
is O (V2). If we assume the use of standard 32 bit floating point operations, then the space requirement for Linked Jazz is little over 8 Megabytes (14312 · 32bit) while the space needed for MEETUPS is nearly 35 Gigabyte (943942 · 32 bit). As a result, a barebone implementation of the method hardly scales to moderately big Knowledge Graphs. The matrix A
ij
, however, is generally an highly sparse matrix, since direct relationship between artists are uncommon. For instance, the sparsitiy degree of the MEETUPS KG, computed as the ration between the asserted edges and all the possible edges (i.e.
Experiments
In this section, we describe the experiment that we perform on the method proposed in Section 4. In Section 5.1 we describe the experimental setup and the results obtained using the Linked Jazz KG.
Linked jazz
We experiment with the methods of Section 4 on the Linked Jazz KG, described in Section 3.2. Given the relationships of Fig. 3, we need to learn the specific weight of each relationship type.
In order to learn the weights of the function w of Equation 1 we split the data into the usual training and testing partitions, where the testing partition is 20% of the total data. The resulting training and testing data are hence composed of, respectively, 56 and 14 artists. Since the amount of explicitly stated influences available in the KG is much lower than the total amount of edges, the split is only based on nodes that have some influence edges asserted. This allows us to effectively evaluate the accuracy of the model with respect to creative influence prediction. Given the small size of both splits, we evaluate the models on aggregate values from a set of 5 distinct experiments on different subsets of the data. This helps us mitigate the noise due to the low amount of data available.
We evaluate each model using Mean Reciprocal Rank (MRR), Mean Average Precision (MAP) and Discounted Cumulative Gain (DCG). All the listed metrics measure how high are ranked appropriate values, e.g. how high are ranked actual influential artists with respect to a reference artist. MRR can be interpreted as how far is the first influential artist in the ordered list. MAP is the average of the number of relevant entries within the first k results, where k is the number of influences of each artist. DCG evaluates the results by penalising when relevant entries are not positioned at the top of the list. Each model is trained using COCOB [20], a parameter-free optimisation method, and cross-evaluated in 5 different runs, where elements in the training and testing set are changed. The results are averaged between different runs. All the experiments are performed on an Intel i9 with 128GB of RAM and an Nvidia RTX3090 with 24GB of VRAM.
We compare each model with a straightforward baseline inspired by the arguments of Simonton [29]. The author concludes that the relationships that mostly influence the creativity of an artist are those with friends, mentors, pupils and fellows. We hence predict a relation of creative influence whenever one of these relationship is asserted between two nodes in the Knowledge Graph. This baseline serve as a quantitative evaluation of the importance of indirect realations, since the baseline only takes into account direct relationships.
Results
This section described the results of the experiments of Section 5. In particular, in Section 6.1 we describe the results on the Linked Jazz dataset, while on Section 6.2 we show how the method trained on the Linked Jazz dataset can be used in an unsupervised fashion to discover influence relationships on MEETUPS.
Linked Jazz result
Figure 9 shows the importance of the degree D of Equation 5 (the maximum length of the path connecting two artists). Taking into account indirect relationship, through the use of the f-communicability approach, outperforms the other heuristics in almost every measure. Moreover, the results highlight how using paths whose length extends at most up to 2 nodes obtains the best results. Influences from artists that are difficult to reach, i.e. that are separated by many other nodes, add noise to the f-communicability matrix. In fact, Perry-Smith [25] argues that creative influence can be classified into two main categories: strong and weak influence, where strong influence, as opposed to weak influence, is the result of many redundant connections between two nodes and plays a pivotal role in the creative process of an artist. Taking into account long paths results in many connections that eventually turn a weak influence into a strong one. This can also be seen in the example of Fig. 2. The influence of Pete Townshend on Halsey can be safely ignored. Taking into account walks longer than degree 2 would turn this relationship into a strong one. In Equation 5 longer paths are considered less important. However, this proves not to be enough, as the number of distinct longer walks from two entities mitigates this discount and results in less accurate predictions. Further investigation on other converging series used for decaying weights can result in more accurate performances.
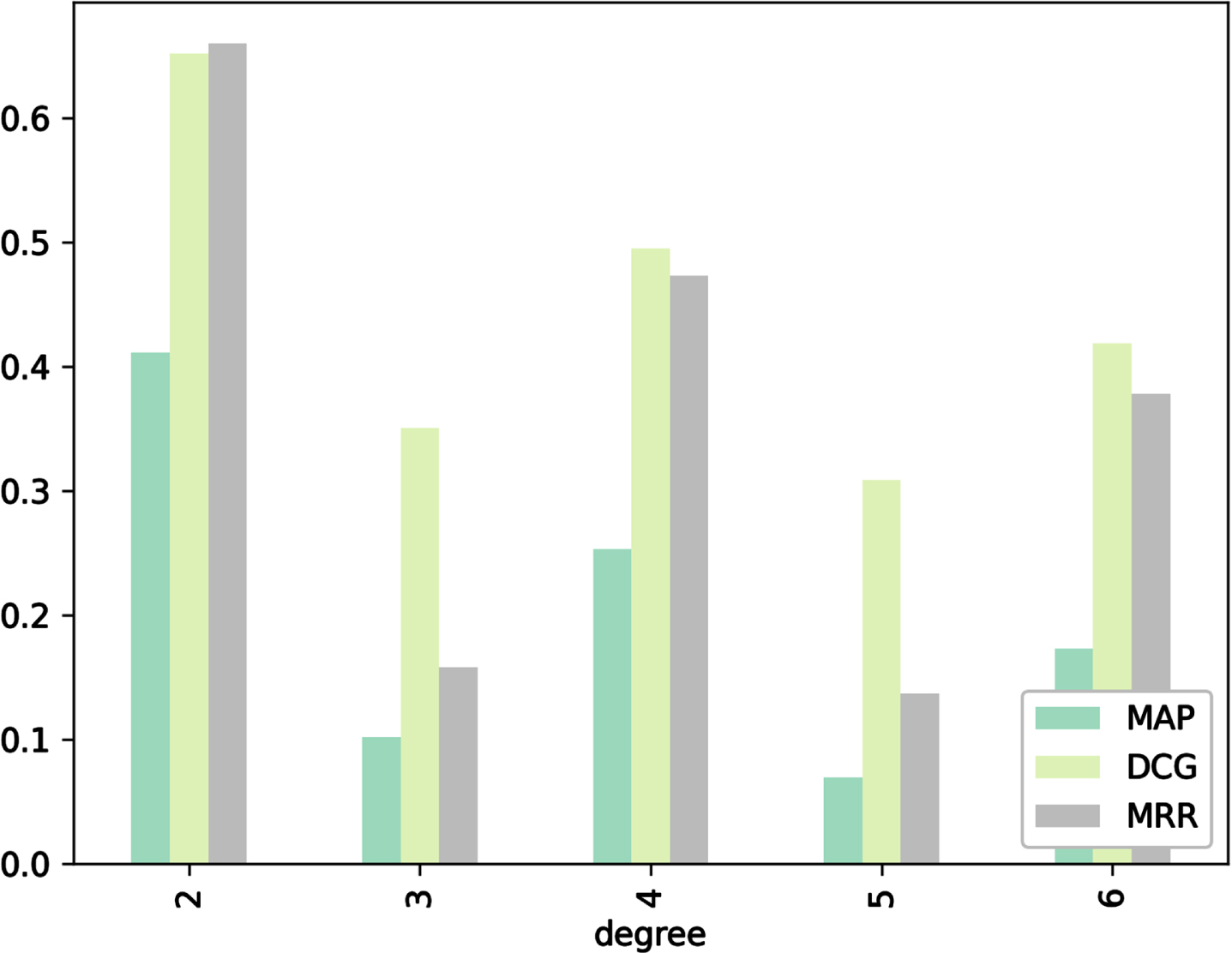
Aggregate value combining all methods as a function of the variable D in Equation 5.
This result is consistent among each different method, as can also be seen in Fig. 10, where the importance of the degree D is compared between each different method. Using a smaller path length generally results in better performances. Notably, learning the weight of each relationship allows higher path lengths to achieve decent performances on average. The reason is explained by the distribution of the relationships of Figs. 3 and 4. The acquaintanceship relationship is much more frequent than all the other relationship. As such, taking longer paths results in taking into account long chains of acquaintances. The small world problem arises [18]: the social network of the artist is over-extended and relationships that should not be taken into account are on the other hand created, as a result of the acquaintanceship chain. Learning the weight of a relationship entails learning to discard the importance of relationships that degenerate into a small-world scenario.
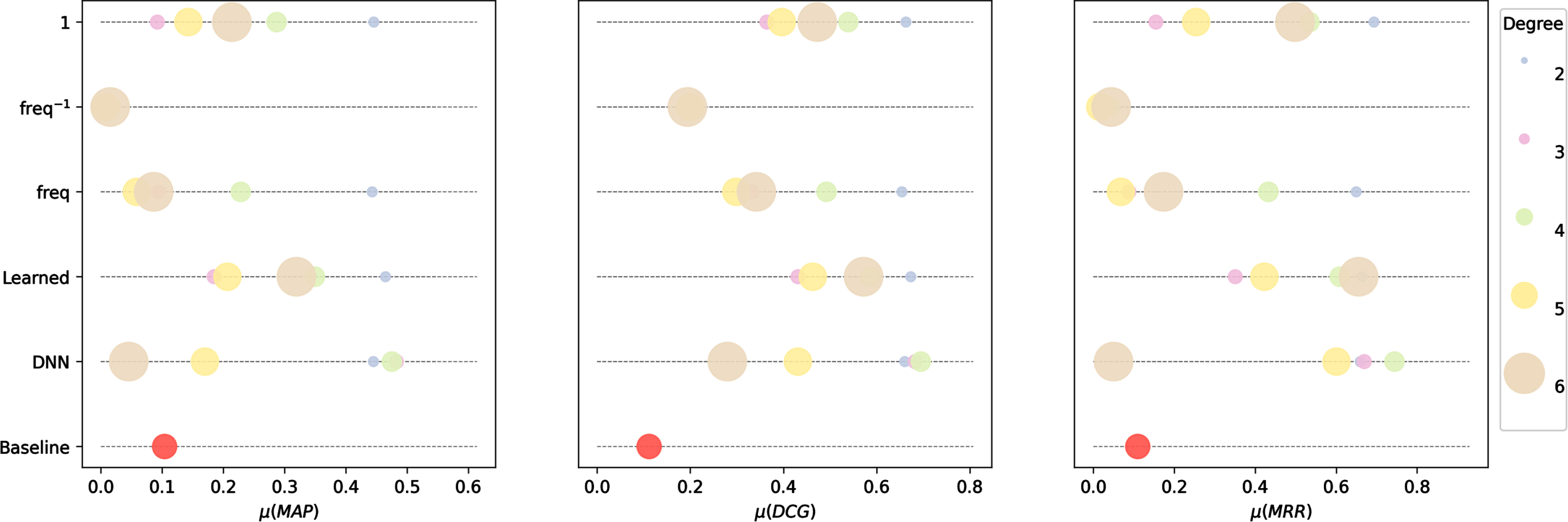
Mean of MAP, DCG and MRR metrics compared among different methods with different degree D.
Table 3 reports the results obtained from the experiments of Section 5 with D = 2. In general, all the proposed heuristics largely outperform the baseline, showing that indirect relationships are a fundamental aspect of influence prediction, as also confirmed by social studied [25, 26]. Learning the function w used in Equation 6 leads to the best results on aggregate with respect to all the metrics taken into account except for MRR, where a uniform score works surprisingly well. Using a neural network as illustrated in Equation 7, despite being a promising approach, does not result in a definite gain with respect to the simpler model of Equation 1. The main reason might be the small amount of training data. In Linked Jazz, influence relationship are rather limited and the network is not able to generalise.
Result from the experiment described in Section 5. Each value is reported alongside its standard deviation
In Table 4 the weights learned by the best method of Table 3 are described. Judging from the mean and median values, the most important relationships are the friendship and mentorship relationship. The former aligns with the findings of [19]: the influences of famous artists can be largely associated with the connections they have with other meaningful artists from the same clique. An interesting phenomenon happens with the mentorship relationship. Artists are more influenced by their mentos (has mentor relationship) rather than their pupils. This aligns with the findings of [29], where mentors are seen as a bridge between two artists. Finally, it is possible to confirm the hypotheses made from Table 10: being the most present one, the acquaintance relationship should not be considered particularly important. Indeed, we can see that a negative weight is placed on that relationship, resuling in higher performances as also seen in Table 6.
Statistics on the learned weights from the best model of Table 3
In Table 5, the Pearson correlation between the metric results and the weight placed on each relationship is described. While the negative importance of the acquaintance relationship is confirmed again. Interestingly, the friendship relationship is the one that most positively correlates with correct influence detection. This aligns with several different studies that highlights how friendship has a big influence on the creative process of an artist [19, 29].
Correlation between the weight of a relationship and the results in the best method of Table 3
In Fig. 11 the precision-recall curve obtained by using the learned weights that yields the best performances on Linked Jazz is reported. We consider as ground-truth the influences reported on the AllMusic website. Note that the ground truth should not be seen as an oracle, but rather as an highly incomplete set of influences. In this setting, it is clear that a higher recall is preferable to a higher precision.
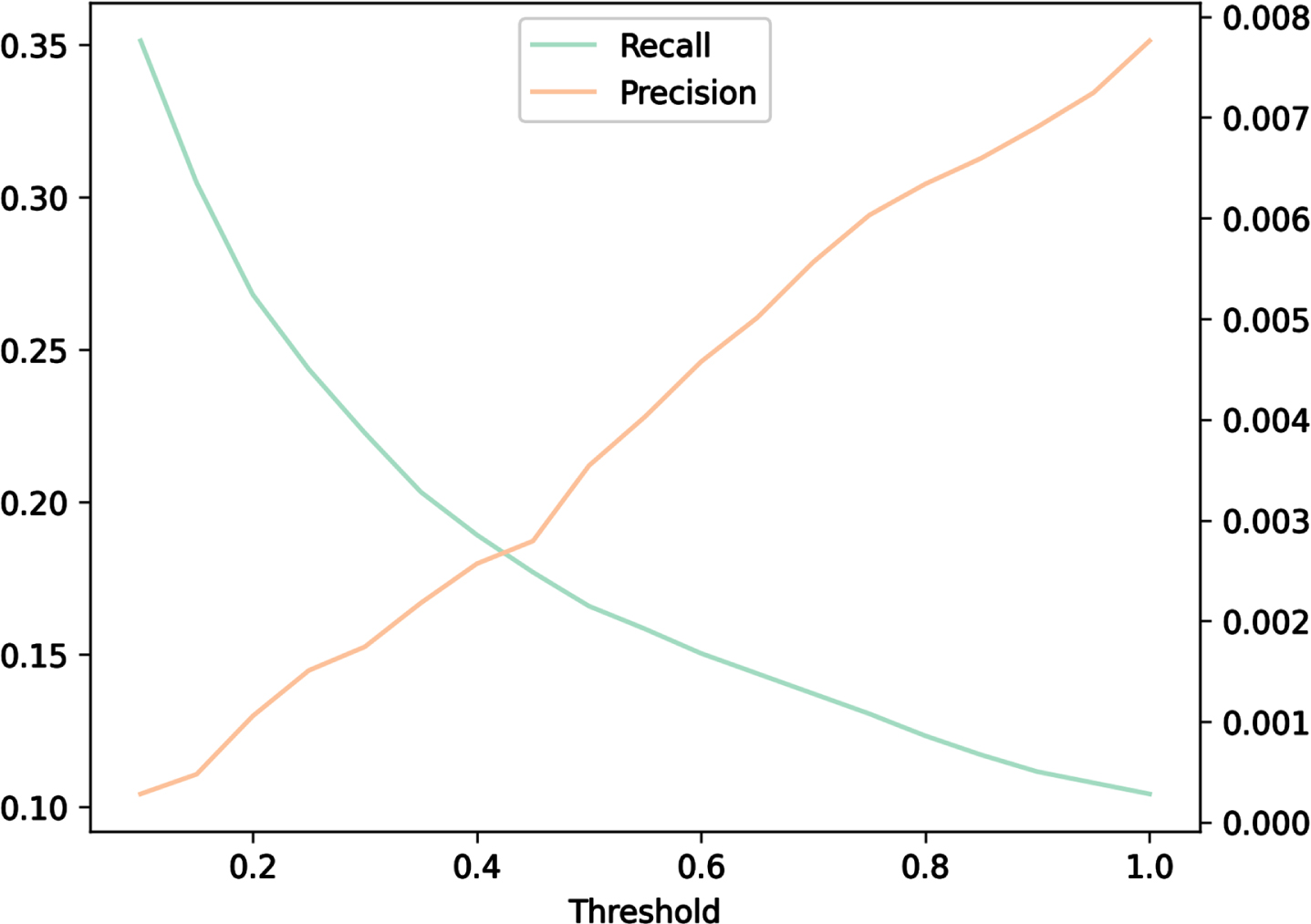
Precision-recall curve on the influences detected in MEETUPS as a function of the threshold.
The graph of Table 11 shows how reducing the threshold (i.e. making more conservative predictions) results in a much higher threshold with a negligible precision drop. Indeed, the break-even point (i.e. the point in which the precision and recall curves intersect, ≈0.4) suggests a conservative use of the prediction method.
In this work, we present a novel method, described in Section 4, to detect creative influence between artists using techniques based on graph theory and complex network science. Our method takes into account the individuality of a relationship type through the use of an ontology illustrated in Section 3.1. By framing the influence prediction task as a classification task we are able to obtain an interpretable model that performs better than robust baselines. The results described in Section 6 highlight how a straightforward combination of the different graph planes identified by the different relationship types results in accurate results. Moreover, the weights assigned to each relationship type are in line with relevant socio-cognitive and psychological findings, thus additionally validating the results. Our attempt to increase the accuracy of our results through the use of a machine learning approach led to less accurate predictions. Nonetheless, it is difficult to objectively rule out the possibility of combining machine learning techniques with our methods given the limited amount of training data publicly available.
We show that our method can be used to support the enhancement and integration of additional information on existing Knowledge Graphs that encode interpersonal relationship. By relying on MEETUPS, which is automatically extracted using a complex NLP pipeline, and on our method it is possible to automatically detect relationships from textual content and formulate hypotheses on creative influence.
Future works include extending the training dataset available since the main problem with the experiments relying on the neural network can be re-conducted to the limited amount of training data for the model. Possible approaches includes employing data augmentation techniques, in order to exploit the data as much as possible and reduce the chances of overfitting the model. Additionally, more complex neural network architectures can be used to approximate and integrate the f-communicability function, such as graph neural network models [33].
Finally, clustering methods are an interesting approach to explore, in order to detect communities of artists within the f-communicability matrix obtained from the method of Section 4.1. This would enable the identification of cliques of artists that are socially related and hence provide a tool to better understand the creative process of an artist. Combining the relationship types with additional relevant information, such as the socio-cultural context [17], is also an interesting improvement worth investigating. Similarly, combining our approach with the one identified by Saleh et al. [28], where influence between artists is modelled on the basis of the similarity between their artefacts, is an interesting approach as it could help increase the accuracy while also providing examples of artefacts where such similarities can be identified.
Footnotes
Acknowledgments
The authors would like to thank Daniele Marini for his exploratory work on the subject and Alba Morales Tirado for the integration of MEETUPS. This project has received funding from the FAIR – Future Artificial Intelligence Research foundation as part of the grant agreement MUR n. 341 and from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 101004746.
An information object in DOLCE.