
Abstract
Machine learning black boxes, exemplified by deep neural networks, often exhibit challenges in interpretability due to their reliance on complicated relationships involving numerous internal parameters and input features. This lack of transparency from a human perspective renders their predictions untrustworthy, particularly in critical applications. In this paper, we address this issue by introducing the design and implementation of CReEPy, an algorithm for symbolic knowledge extraction based on explainable clustering. Specifically, CReEPy leverages the underlying clustering performed by the ExACT or CREAM algorithms to generate human-interpretable Prolog rules that mimic the behaviour of opaque models. Additionally, we introduce CRASH, an algorithm for the automated tuning of hyper-parameters required by CReEPy. We present experiments evaluating both the human readability and predictive performance of the proposed knowledge-extraction algorithm, employing existing state-of-the-art techniques as benchmarks for comparison in real-world applications.
Introduction
There has been a growing demand for transparency in recent years, particularly in critical domains [14, 15]. This demand has led to a lack of trust amongst humans in predictions obtained from machine learning (ML) models that lack interpretability. Such models are often referred to as opaque or black boxes (BBs) due to their opacity. While complex ML models tend to offer superior predictive performance, they pose challenges when it comes to human inspection. Consequently, the use of opaque models for high-stakes decisions necessitates the derivation of human-intelligible knowledge to ensure accountability and understanding.
To retain the predictive capabilities of ML models, many strategies for achieving explainable behaviours have been proposed in the literature [2, 19]. These include the adoption of interpretable ML predictors [27] and mechanisms designed to reverse-engineer the predictors’ behaviour [23]. Symbolic knowledge-extraction (SKE) techniques play a major role in this context, operating in a post-processing phase to distill interpretable knowledge from a BB predictor. Building upon recent advancements in the SKE field [8], we present CReEPy, a novel, general-purpose knowledge-extraction algorithm based on interpretable clustering. CReEPy applies to any type of BB predictor.
CReEPy is built upon the ExACT and CREAM clustering algorithms. It pedagogically [1] explains BBs performing classification or regression tasks and operating on continuous input features. CReEPy proves the effectiveness of exploiting explainable clustering to achieve the interpretability of BBs. Indeed, it enables the extraction of more concise and accurate explanations compared to analogous state-of-the-art techniques.
Since to execute CReEPy a set of parameters is required (e.g., the chosen explainable clustering algorithm and, in turn, the corresponding hyper-parameters), we also designed an automated tuning algorithm, named CRASH.
Accordingly, the paper is organised as follows: Section 2 introduces background information on the topics discussed here and related works present in the literature. Section 3 and 4 describe the CReEPy and CRASH algorithms, respectively. Experiments and benchmark comparisons are discussed in Section 5. Finally, conclusions are drawn in Section 6.
Related works
Symbolic knowledge extraction
SKE consists of obtaining human-interpretable rules out of BB predictors using a surrogate, explainable model that is capable of mimicking the BB, named in this context underlying model. The underlying model may be a classifier, a regressor, a clustering technique, or any other opaque predictor. The mimicking capabilities of the surrogate model are assessed via the comparison of the outputs provided by the underlying and surrogate models with respect to the same inputs. SKE techniques are currently applied in a wide range of contexts [3, 45].
The construction of the surrogate predictor may be performed in a decompositional or pedagogical way [1]. In the former case, the BB kind and internal structure are considered, so these algorithms are not general and can be applied only to a subset of BBs, e.g., RefAnn [44] accepts as underlying predictors only neural networks having a single hidden layer. On the other hand, pedagogical techniques only consider the underlying BB input/output relationship and thus they are more general and present no constraints on the BB type and complexity.
In the following, we provide a brief description of the SKE algorithms chosen as benchmarks for the experiments presented in this work.
Iter
I
To extract rules, the I
At the end of the process, each partition is converted into a human-interpretable rule associated with a constant output value.
GridEx and GridREx
The GridEx algorithm [40] is a pedagogical technique performing symbolic knowledge extraction from BBs designed for regression tasks. Thanks to the generalisation proposed in [37, 39] it can be also applied to explain classifiers. In both cases, data sets have to be described by continuous features. It draws inspiration from I
The partitioning strategy adopted by GridEx consists of the recursive input feature space splitting into smaller subregions according to a similarity threshold. At the end of the partitioning, each region is translated into a human-readable rule, having preconditions describing the region and a postcondition representing the associated output value, which is a constant obtained by averaging the underlying model predictions for the samples included in the region.
Unfortunately, in some real-world applications, the undesired discretisation introduced by the constant outputs of GridEx may hinder the predictive performance of the extractor. GridREx [28] overcomes this issue by training a linear model inside each identified hypercubic region. Linear models are fitted on the instances contained in the corresponding hypercubes and each cube is associated with a rule having a set of conditions on the input variables as antecedent part, equally to I
A disadvantage shared by GridEx and GridREx is that they perform a symmetric partitioning – i.e., during a given iteration, they split each input dimension in a given number of congruent partitions. Therefore, this strategy may lead to suboptimal solutions when applied to real-world data sets.
REAL
Rule-extraction-as-learning (REAL; [11]) is a pedagogical SKE procedure to explain BB classifiers operating upon binary input features. However, by performing an upstream feature binarisation, it is possible to adopt it also for other kinds of input attributes, e.g., discrete or even continuous. REAL aims at extracting human-interpretable lists of conjunctive rules via a learning process based on sampling and queries. Output rules are mainly if-then rules where the post-condition is a class label and the pre-conditions are Boolean predicates over individual input features. Pre-conditions usually concern a subset of the input features, previously generalised by dropping redundant and/or non-discriminant antecedents.
Cart
C
Explainable clustering via ExACT and CREAM
ExACT [31] is an algorithm performing explainable clustering. It merges the aggregation strategies found in traditional clustering techniques with the cluster assignment approach using decision trees, similar to other explainable or interpretable clustering procedures [4, 17]. For this reason, with ExACT it is possible to obtain explainable clusters by inducing a top-down decision tree over the training data according to a strictly hierarchical strategy. Indeed, identified clusters have the peculiarity of being concentric. The strategy adopted for the tree’s internal nodes is to use hypercubic splits to separate whole clusters of data while avoiding the presence of instances from multiple clusters inside the same hypercubic region.
To partition the input space, ExACT adopts Gaussian mixture models (GMMs; [26]) to find clusters and DBSCAN [13, 24] to remove the outliers from these clusters, before approximating them with hypercubes. Explainability is achieved thanks to this approximation of each identified cluster. The concentric nature of the ExACT’s hierarchical approximations enables the creation of a global interpretable clustering in the form of a rule list, where each cluster is simply expressed through a rule having a single hypercube inclusion constraint, starting from the innermost cluster through the outermost. The same structure may be used to provide local explanations for single clustering assignments.
CREAM [32] extends ExACT by providing a more complex splitting strategy based on the iterative greedy minimisation of the predictive error measured for each possible split.
Users may leverage the automated O
SKE via explainable clustering with CReEPy
In this section, we introduce the design and implementation of a novel knowledge-extraction technique, named CReEPy (Clustering-based REcursive Extraction as a PYramid; [35]), capable of deriving human-interpretable rules in Prolog syntax from BB models of any type and suitable for both classification and regression tasks. Aligned with the concept presented in [30, 34], CReEPy performs knowledge extraction by employing a preliminary interpretable clustering technique (i.e., ExACT or CREAM) on the training data. To extract knowledge from a predictive model, the data set output feature (i.e., the ground truth) is replaced with the opaque predictions provided by the BB. CReEPy is also suitable for performing rule induction when directly applied to a data set. In the first case, CReEPy explains the predictions through human-interpretable knowledge. Otherwise, it provides interpretable relationships between the data set’s input and output attributes.
The CReEPy Algorithm
CReEPy has been designed to be independent of the underlying clustering method. Consequently, it can be employed in conjunction with various clustering techniques, as long as they offer hypercubic approximations of the input space. Moreover, there is potential for future extensions of CReEPy to support other tree-based clustering approaches, as such methods essentially segment the input feature space with cuts perpendicular to the axes, and each path from the tree root to a leaf can be translated into a hypercube.
Being explicitly designed to work seamlessly with ExACT and CREAM, CReEPy generates logic knowledge in the form of a Prolog theory (examples of which are detailed in the experiment section). The Prolog theory effectively mimics the decision-making process of the underlying BB model, with each clause corresponding to an approximated cluster identified by ExACT or CREAM. The interpretability of the BB is enhanced through the transition from completely opaque outcomes to the generation of classification or regression rules that are both human- and machine-interpretable, describing the rationale behind the predictions.
As ExACT and CREAM clusters are structured as hierarchical cubes and difference cubes – defined through interval inclusions and exclusions – Prolog theories are particularly suitable, benefitting from the inherent ordering of clauses. Consequently, each clause can be associated only with preconditions referring to the inclusion in a hypercube, assuming the exclusion from all the cubes described by the preceding clauses as true. The expressiveness of this semantics is thus exploited at its limit by ordering the Prolog rules starting from the one associated with the innermost hypercubic region and then following the hierarchy up to the outermost region—equivalent to the surrounding cube of the data set at hand. The last rule may be extended to a default rule to achieve 100% completeness [29].
User-defined parameters
The human-readability extent of the output theory provided by CReEPy critically depends on the number of clauses composing the theory and, in turn, on the number of preconditions appearing in each clause. The number of clauses can be controlled by users via a hyper-parameter tuning phase, considering that these are produced based on the clusters identified with the underlying clustering techniques. As a consequence, pivotal hyper-parameters that must be set by users to obtain high-quality knowledge with CReEPy, possibly with the aid of CRASH, are those required by ExACT and CREAM, namely: θ is a predictive error threshold calibrating the trade-off between predictive performance and human-readability extent (number of clauses) of the explainable clustering. Only nodes associated with predictive errors larger than the user-defined threshold are further partitioned in the successive iterations of the algorithm. This parameter should be set according to the task at hand, e.g., it may represent an upper-bound for the rate of incorrect predictions in classification tasks as well as for the mean squared error in regression tasks; δ is the maximum allowed depth. Given the recursive nature of ExACT and CREAM, users can tune this parameter to stop the algorithm’s input space partitioning after the desired quantity of iterations. The maximum depth is not reached if the tree expansion pre-emptively terminates due to the absence of further nodes having predictive error greater than θ; ξ is an upper-bound for the number of clusters identifiable via GMMs during the execution of ExACT and CREAM.
It is worthwhile to point out that the clustering algorithm adopted in CReEPy is itself a hyper-parameter that may be tuned with CRASH.
The set of CReEPy’s hyper-parameters is completed by an optional input feature relevance set and a corresponding threshold, aimed at limiting the rule preconditions to the only features with relevance greater than the threshold. Indeed, CReEPy assigns a precondition to each input dimension, i.e., an interval inclusion constraint for each input feature. Therefore, in the default version of the algorithm, each Prolog clause has n preconditions for n-dimensional data sets. This may be limiting in terms of human readability when dealing with high-dimensional data sets.
We highlight here that the input feature relevance is calculated outside CReEPy, so users are not bound to a specific method, as far as they provide the feature relevance set normalised in the [0, 1] interval. A relevance score for each input feature is mandatorily required. A suitable and fast solution to obtain these scores can be found within the Python Scikit-library.
1
It is worthwhile to point out that the feature relevance threshold does not affect the underlying clustering, but only the translation into Prolog rules performed by CReEPy starting from the tree provided by ExACT or CREAM (cf. R
1:
2: D′← C
3: regions← C
4:
5:
6:
7: instance← I
8: instance← T
9:
10:
11:
12:
13:
14:
15:
16:
17:
18:
19:
20:
21:
22:
23:
24:
25:
26: region← D
27:
28:
29:
30:
31:
32:
33:
34:
35: drop dimension from the inputs of region
36:
37:
38:
39:
40:
41:
42: head← head ∪ {output label of region}
43:
44: head← head ∪ {output value of region}
45:
46: head← head ∪ {output variable of region}
47: body← body ∪ {equation describing region}
48:
49:
50:
The translation into Prolog rules is executed according to the following criteria: for each leaf of the tree identified via the underlying clustering technique a rule is created; individual rules are if-then logic rules where the conditional part is a conjunction of interval inclusion constraints on the input features and the corresponding action is a constant value (e.g., a class label or a number) or a linear combination of the input variables; constraints are defined in the internal nodes of the tree; actions are described in the leaves of the tree; all variables having relevance smaller than the user-defined threshold are removed from the conditional part of the logic rules; the resulting rules are converted into a theory having Prolog format, both human- and agent-interpretable.
From a predictive perspective, the quality of rules provided by CReEPy can be assessed via standard scores generally adopted for ML classification and regression tasks, e.g., accuracy and F1 score for the former and mean absolute/squared error and R2 score for the latter. Dedicated scoring metrics for symbolic knowledge evaluation, as Q s and FiRe, may be used as well [33, 36], to account simultaneously for fidelity and readability.
Automated hyper-parameter tuning for CReEPy: The CRASH optimiser
In this section we provide the details about the optimiser algorithm designed to automatise the hyper-parameter tuning of CReEPy, named CRASH (Clustering-based Rule extraction Automated Selection of Hyper-parameters) and whose workflow is resumed in Algorithm 2.
1:
2: Π← ∅ (set of all configurations
3: O ← (Δ, Ψ, p
max
, r
min
, pat0) (O
4:
5: Π← Π ∪ S
6: algorithm, D, Γ, Ψ, O
7: [2])
8:
9:
10:
11: Π← ∅ (set of all configurations
12: π*←
13: components ← 2 (current number of components
14:
15: data← S
16: Π′← S
17: D, algorithm, components, O
18: [2]) (current configurations
19: S
20:
21:
22: π*←π′*
23: Π ← Π ∪ Π′
24:
25:
26:
27:
28: n ← components · 100
29:
30:
31:
32:
33:
34: orchid←
35:
36:
37:
38:
39: to optimise the depth and threshold parameters of
40: algorithm adopting c Gaussian components
41:
42:
43:
44:
45:
46:
47:
The CRASH Algorithm
CRASH is based on the iterative exploration of the hyper-parameter space to highlight the values corresponding to the best CReEPy instances in terms of both predictive performance and human readability. The notion of best instance is defined according to the following equation:
In CRASH, each parameter is searched individually, e.g., by fixing all the others and studying how the predictive error and readability of CReEPy change by altering the values of that parameter. Some parameters are searched exhaustively, others with a grid search or iteratively according to ad-hoc criteria. In more detail, the optimisation is exhaustive for the underlying clustering algorithm (i.e., currently both ExACT and CREAM are tested). Numeric parameters are considered between their minimum values and corresponding user-defined upper-bounds, iteratively increased by fixed or variable quantities, possibly until a patience expiration.
CRASH may be summarised as follows: pick a clustering algorithm suitable for CReEPy; identify the clustering hyper-parameters tunable via automated procedures and those that cannot be automatically estimated; fix all parameters of the second group to their minimum accepted values; run the proper optimisation algorithm to find the best values for the remaining parameters; store the best parameter configuration amongst those obtained during step 4; increase the value of a parameter amongst those fixed in step 3 and repeat from step 4 until it is possible to find better configurations, until the maximum parameter values are reached, or until the patience expires; repeat from step 1 with a different algorithm; return the best configuration according to (1).
Currently, automatically tunable clustering parameters are the maximum depth δ and the error threshold θ (step 2), which can be estimated via O
Since the execution time of CReEPy critically depends on the number of training instances (cf. Section 5.2), slicing of the training data set is performed during step 4. In particular, we fixed an upper-bound to the number of training instances equal to the number of Gaussian components × 100. This is a reasonable choice, given that n Gaussian components imply the identification of n clusters. By assuming balanced clusters, 100 training instances per cluster allow CReEPy to learn the clusters’ peculiarities while remaining fast.
As mentioned above, to run CRASH users should define a set of parameters. We point out that the default values of these parameters are usually suitable to obtain satisfying results, comparable with or better than a manual tuning of CReEPy. The set of parameters required by CRASH depends on the clustering techniques to be tested. Currently, only the aforementioned ExACT and CREAM algorithms are supported by CReEPy. Therefore, both are examined within CRASH, and its parameters are those needed to parametrise ExACT and CREAM, tuned via the automated O Δ is the upper-bound for the estimation of the optimum clustering depth. The search may be pre-emptively stopped if growing depths result in no better parameter configurations. This parameter is used within O Γ is the upper-bound for the estimation of the optimum number of Gaussian components to be used within the explainable clustering. The search may be pre-emptively stopped if growing numbers of components result in no better parameter configurations; Ψ is the fidelity/readability trade-off, defining the importance of the CReEPy’s readability extent against that of its predictive performance. Small Ψ values tend to neglect the readability impact. For instance, if Ψ = 0.1 it is not relevant if a CReEPy instance produces 2 or 8 rules. Conversely, if Ψ = 1 the instance producing 8 rules is penalised; pat0 is the patience to adopt in the absence of better parameter configurations when iteratively estimating the optimum predictive error threshold of ExACT and CREAM. This parameter is used within O p
max
, r
min
are the maximum predictive error increase and the minimum readability enhancement, respectively, that are accepted/required during the estimation of the clustering error threshold. These parameters are used within O
Experiments
Experiments to assess the capabilities of CReEPy applied to classification and regression tasks in comparison with state-of-the-art analogous techniques are described in the following. All the adopted implementations are included within the PSyKE framework 2 [9, 41].
Predictive performance and readability assessments
To assess the capabilities of CReEPy in explaining opaque ML predictors we carried out several experiments involving real-world data sets. We selected the Iris data set 3 [16] as a case study for classification and 6 data sets from real use cases taken from the StairwAI EU Project 4 to test CReEPy in regression tasks.
Classification: The iris data set case study
The Iris data set represents a simple classification task with 4 continuous input features expressing as many characteristics of iris flowers. The target is the species of the flowers, which in this specific context may assume 3 possible distinct values. The data set is reported in 1a. In all panels of Fig. 1 only the 2 most relevant input features are shown, i.e., petal length and width expressed in cm.
Symbolic knowledge extraction performed on the Iris data set.
Our experiments on this data set are based on a k-nearest neighbours (k-NN) opaque classifier, having k = 7. The corresponding decision boundaries are depicted in 1b.
Decision boundaries identified by CReEPy and other SKE techniques are reported in the other panels of Fig. 1. The hyper-parameters used for each SKE technique are listed in the following. GridEx We adopted 2 different instances of GridEx. The one corresponding to 1c produces 3 output rules (one per possible output class) and performs 14 slices only along input features having importance greater than 0.99—i.e., only along the most important feature, the petal length. Conversely, the GridEx instance shown in 1d performs 5 slices along each input dimension having importance greater than 0.80—i.e., petal length and width. This results in the 5 output rules depicted in the figure. C I REAL The input space partitioning obtained with REAL is depicted in 1i. No parameter tuning is required for this algorithm. CReEPy Figures 1g and 1h correspond to CReEPy instances with feature relevance thresholds equal to 0.99 and 0.80, respectively, and exploiting ExACT as underlying clustering technique. The former implies considering only the most relevant feature when performing the knowledge extraction. By relaxing the threshold to 0.80 the second most important input feature is considered, as for GridEx. Analogously, Figs. 1j and 1k show CReEPy instances adopting the CREAM underlying clustering with different parametrisations of the input feature importance threshold. The input space partitioning reported in 1g is equivalent to the Prolog theory shown in Listing 1. The Prolog theory corresponding to the decision boundaries of 1h is shown in Listing 2. The values of the other parameters required by CReEPy have been estimated with CRASH. As a result, all CReEPy instances rely on underlying clusterings using 2 Gaussian components, an error threshold equal to 0.02 and a maximum depth of 2.
Table 1 summarises the predictive performance measured for each SKE technique. The number of extracted rules is also listed as an index of the human-interpretability extent. Furthermore, we adopted the Jaccard index [25] to compare the decision boundaries of the black-box to those of the knowledge-extraction techniques. Essentially, the Jaccard index is a measure of intersection over union, calculated as follows for each of the Iris classes (S = Setosa, Ve = Versicolor, Vi = Virginica):
Assessments for the SKE techniques applied to a 7-NN performing classification on the Iris data set
Regression data sets used to test CReEPy and compare it to analogous techniques. For each data set are reported: a unique identifier, the name of the data set, the number of considered input features, the name of the considered output feature, and the mean absolute error measured for the BB trained on the data set
From the results shown in Table 1, it is evident that CReEPy, compared to other state-of-the-art analogous techniques, can achieve comparable or even better predictive performance. As for the number of extracted rules, CReEPy provides 3 rules, the optimum result given that it is applied to a classification task having 3 possible outcomes. The similarity exhibited by the decision boundaries obtained with CReEPy with respect to the BB aligns with that observed for the other state-of-the-art competitors (>90%).
Thanks to the versatility of the underlying clustering constituting the core of CReEPy, it is possible to apply this latter to regression tasks as well. All the data sets used here as case studies are composed of continuous features; 2 of them have 5 input features, and the remaining have 1 input feature. A different BB has been applied to each data set to draw predictions. A comparison between the knowledge extraction performed on the aforementioned data sets by CReEPy and other state-of-the-art analogous methods (namely, GridEx, GridREx and C
Results of CReEPy applied to the 6 data sets described in Table 2. For each data set the number of extracted rules (R) and the MAE with respect to the data (D) and the underlying BB model are provided. Results are compared with those of GridREx, GridEx, and Cart applied to the same data sets. Best results are highlighted in bold
Results of CReEPy applied to the 6 data sets described in Table 2. For each data set the number of extracted rules (R) and the MAE with respect to the data (D) and the underlying BB model are provided. Results are compared with those of GridREx, GridEx, and C
It is important to note that only the MAE is reported in Table 3 as a measure of predictive performance, since other metrics such as the mean squared error or the R2 score were entirely aligned with the MAE and expressed the same quality ranking. The number of extracted rules is taken as a readability measure since readability for humans decreases if the quantity of rules increases. Another index used to assess and compare the quality of extractors is the completeness of the extracted knowledge [36], but in this particular case study is not relevant, since all the procedures achieve a level of completeness above 99%.
CReEPy proved to be superior to C
The most interesting comparison is with GridREx, able as well to provide local approximations in the form of linear input variable combinations. By exploiting CReEPy it is possible to achieve approximately the same predictive performance shown by GridREx with far better readability (for instance, 2 output rules instead of 5 or 4, by considering experiments on data sets #2, #5 and #6). In conclusion, our proposed knowledge extractor performing an upstream interpretable clustering via ExACT is absolutely competitive with state-of-the-art SKE algorithms.
Our experiments are completed by a quantitative assessment of the computational time required by CReEPy to perform the knowledge extraction. Tests consider regression data set #1, by performing both row and column slicing on it. In particular, a comparison of the computational time required to handle the data set with different numbers of input features and instances has been performed. Results are reported in Fig. 2. Measurements have been averaged upon 100 executions.
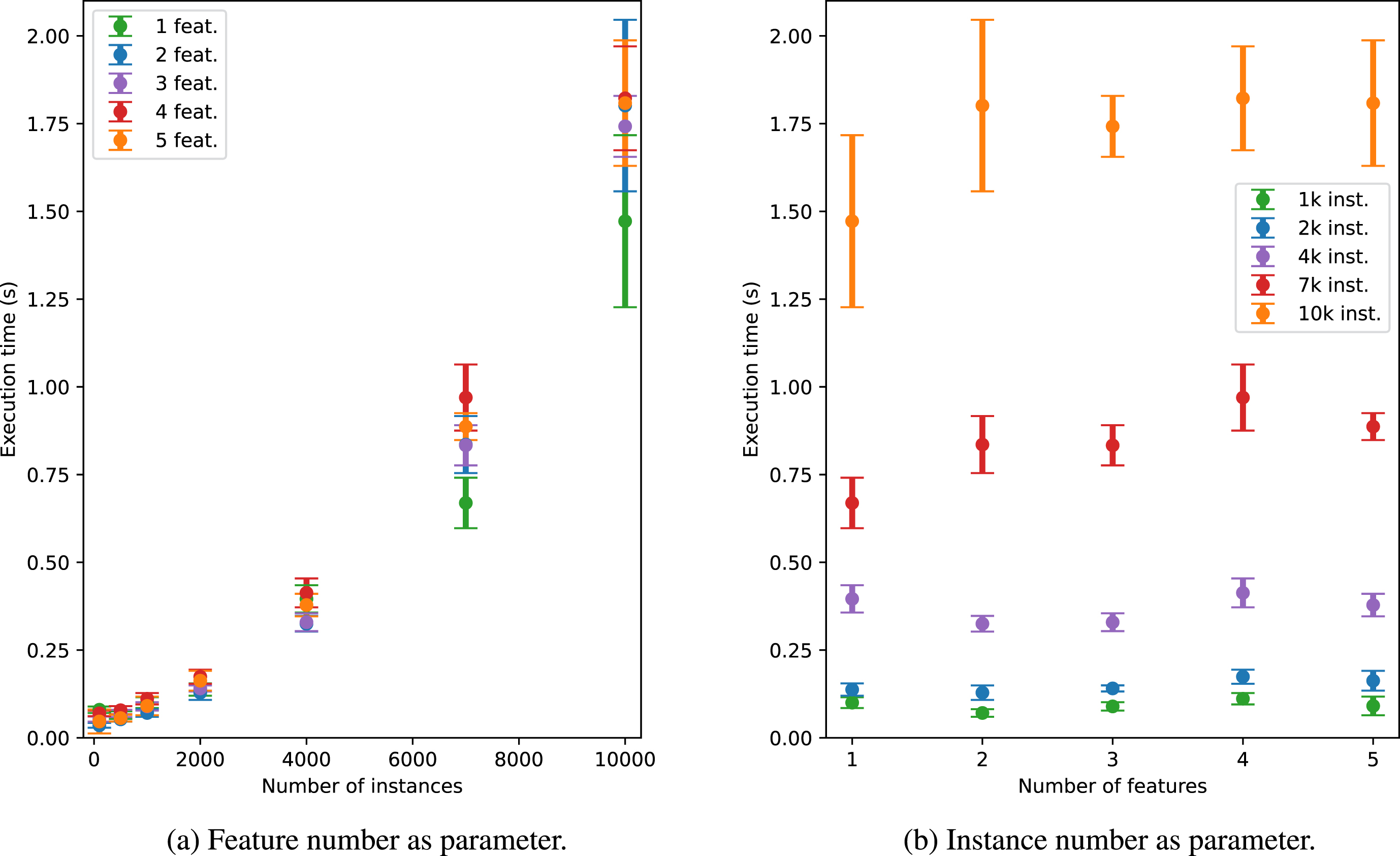
Execution time of CReEPy with respect to the number of input features of the domain and the number of instances adopted for the training.
From 2a it is clear that the execution time grows by augmenting the number of training instances. Clues on the independence of required time with respect to the number of input features may be found in the same figure. Such independence is clearly noticeable in 2b, showing that the computational time is always smaller than 2, 1 and 0.5 seconds for 10 000, 7 000 and 4 000 instances, respectively, regardless of the input feature quantity. In conclusion, we suggest fastening CReEPy, when necessary, by reducing the number of training data points instead of the number of input features.
In this paper, we introduce CReEPy for SKE, applicable to any kind of opaque ML classifier or regressor operating on data sets characterised by continuous input features. CReEPy demonstrates superior performance compared to existing techniques in terms of predictive accuracy and human interpretability. The algorithm operates in two phases: it applies an explainable clustering technique to the training data, followed by the knowledge extraction phase. The human readability of the extracted knowledge is ensured by presenting it to users in the form of a logic theory adhering to the Prolog syntax.
We employ two upstream clustering techniques, namely ExACT and CREAM, specifically designed for CReEPy. These algorithms exploit GMMs and DBSCAN to identify clusters and approximate them with human-interpretable hypercubic regions described by interval inclusion constraints on the input features.
Furthermore, we introduce CRASH, a dedicated procedure aimed at automatically tuning the hyper-parameters required by CReEPy, along with the underlying clustering technique. This ensures that CReEPy produces high-quality knowledge.
Our future research endeavours will concentrate on developing more sophisticated and effective clustering techniques compatible with CReEPy. Specifically, we aim to enhance the rationale behind region approximation in ExACT and CREAM, as well as address the limitations associated with the application of GMMs and DBSCAN in the current versions of the algorithms. We also plan to exploit fuzzy rules to modify the format of the human-interpretable rules presented to end-users and to separate the outputs provided by CReEPy from the ordered rule lists currently used, especially to support local explanations. Our final aim is to conceive an efficient method to translate the ordered rule lists provided by CReEPy into unordered sets, without noticeable conciseness losses. These efforts will enhance the knowledge interpretability extent for all users, regardless of their technical background.
Footnotes
Acknowledgments
This work has been supported by the EU ICT-48 2020 project TAILOR (No. 952215) and the European Union?s Horizon Europe AEQUITAS research and innovation programme under grant number 101070363.
Conflict of interest
The authors have no conflict of interest to declare.
https://cordis.europa.eu/project/id/101017142; data sets are publicly available at ![]()