
Abstract
Open access to datasets is increasingly driving modern science. Consequently, discovering such datasets is becoming an important functionality for scientists in many different fields. We investigate methods for dataset recommendation: the task of recommending relevant datasets given a dataset that is already known to be relevant. Previous work has used meta-data descriptions of datasets and interest profiles of authors to support dataset recommendation. In this work, we are the first to investigate the use of co-author networks to drive the recommendation of relevant datasets. We also investigate the combination of such co-author networks with existing methods, resulting in three different algorithms for dataset recommendation. We obtain experimental results on a realistic corpus which show that only the ensemble combination of all three algorithms achieves sufficiently high precision for the dataset recommendation task.
Introduction
The availability of open data is increasingly driving modern science in different fields, ranging from astrophysics [42] to earth sciences [3,6], and from medicine [13,24] to AI [17]. Scientists are encouraged by funding agencies to publish datasets using the FAIR principles [41]. It is widely acknowledged that open and FAIR datasets contribute to both the transparency of science, to its quality, its reproducibility and indeed to the speed of scientific developments [12]. For example, publishing open datasets has been widely acknowledged as a key factor in the rapid scientific response to the COVID-19 pandemic [10].
Given these developments, the task of finding relevant datasets is becoming increasingly important for scientists. At the same time, the increasing volume of scientific datasets that is available online brings with it a need for intelligent tooling to support this task. Commercial providers have started offer dataset search services to scientists, such as Dataset Search from Google [5], Mendeley Data search from Elsevier (
Besides keyword search, a well-known alternative search paradigm is recommendation search [20], where a known item of interest (e.g. a product) is used to recommend similar items that are also of interest. This paradigm has also been applied to scientific publications (see [2] for a recent survey). In this paper, we will develop algorithms for recommendation search for scientific datasets instead of publications. Recommendation search has been explored for scientific dataset in earlier work (see our discussion in Section 2), but we are the first to propose the use of co-author networks as a major information source for the recommendation algorithm. Our working hypothesis is that we provide a new hypothesis for dataset recommendation: “If the authors of two datasets have a strong relationship in the co-author network, then these two datasets can be connected with a recommendation link”. Furthermore, we will combine the co-author-network-based algorithm with existing methods for dataset recommendation. Different from keyword-based dataset search (such as provided by the Google Dataset Search engine), our methods recommend datasets based on a given dataset, instead of recommending datasets for a given set of keywords. We use both a graph embedding method and a ranking method from information retrieval to construct an ensemble method for dataset recommendation. The graph embedding approach transfers the authors from the co-author network into a vector space that allows us to calculate the similarity between authors. The ranking method from information retrieval improves the ranking of datasets that are similar to the given dataset. We perform experiments with these methods on a realistic corpus of datasets and co-author relations. Among these different methods, only the ensemble method that combines all three of them results in a reasonable precision (0.75), although at the cost of low recall.
The main contributions of this paper are: (1) We construct a co-author network based on the Microsoft Academic Knowledge Graph (MAKG,
Related work and motivation
Co-author networks play a very import role in the study of academic collaborations, and in attempts to provide maps of academic fields of study. In [16], a co-author network was used to searching promising researchers via network centrality metrics. Even more ambitiously, [9] used a co-author network to predict possible future strong researchers. Sun et al. [33] provided an approach to predict future co-author relationships with the help of heterogeneous bibliographic networks.
Because of the increasing importance of open datasets for modern science, a number of dataset search engines can be found online nowadays, including Google Dataset Search,1
An alternative search process is to recommend datasets based on the datasets which were found by other search engines. In our previous papers [39,40], we also adopted such a recommendation paradigm “if you like this dataset/query, you’ll also like these datasets…”. There are several other interesting works on dataset recommendation. Michael et al. [15] propose a system that recommends suitable datasets based on a given research problem description, which achieved an F1 score of 0.75 and a user satisfaction score of 0.88 on real world data. Chen et al. [8] study the problem of recommending the appropriate datasets for authors, by using a multi-layer network learning model on the information from a three-layered network composed by authors, papers, and datasets, and achieved an F1 score at 3 of 0.54, dropping to 0.28 for F1 at 10. Ellefi et al. [11] provide a dataset recommendation approach by considering the overlap between the schema of two datasets, which achieved perfect recall and a precision of 0.53. Altaf et al. [1] provide a dataset recommendation method based on a set of research papers given by the user, achieving 0.92 recall score and 0.18 precision score. Giseli et al. [28] present two approaches for dataset recommendation, based on Bayesian classifiers and on Social Network connections, which achieved a mean average precision score of around 0.6. Both of their approaches use vocabularies, classes and properties of datasets to rank the datasets for recommendation. In contract, Gogal et al. [27] represented the researchers in vector space based on their publications, and then use cosine similarity between the vectors of the publications of researchers and the vectors of the datasets to do recommendation, achieving a normalized discounted cumulative gain score (NDCG) at 10 of 0.89 and precision at 10 of 0.61.
Recommendations for a variety of other scholarly tasks is a very popular domain for recommendation systems. There are several existing works using co-authorship between authors for such scholarly recommendation. Guo et al. [18] provided a three-layered recommendation model to recommend papers based on co-authorship as well as paper-author, paper-citation and paper-keyword links, and achieved a recall score of 0.42 and an NDCG score of 0.39. Sugiyama and Kan [32] used collaborative filtering to recommend potential papers for authors, which achieved an NDCG score of 0.5 and an MRR score of 0.76. A related task is tackled in Rajanala and Singh [29], who are using limited co-authorship in author information as well as titles and descriptions of papers to recommend venues, achieving a 30% higher accuracy with comparing to existing approaches. Finally, Huynh et al. [19] used probability theory and graph theory on a co-author network to recommend future potential co-authors.
Many of these approaches use both the content and the meta-data of the datasets. For example, Kato et al. test datasets from 74 dataset search engines with a dataset retrieval task by using the content of these datasets [21]. However, the contents of scientific datasets is in general extremely heterogeneous, ranging from numerical time sequences, to genetic codes, to astrophysical observations, to geodata, to spreadsheets with economic indicators and many others. Furthermore, the specific type of a dataset is often not even explicitly indicated. In our previous work we have therefore limited ourselves to the use of only the meta-data descriptions of datasets as the signal to do dataset recommendation. In [40], we used ontology-based concept similarity, a machine learning approach for text similarity and an information retrieval approach, all applied only to the title and other meta-data fields of the dataset. Our experimental results showed that the information retrieval approach could outperform others, but the performance of this approach was still relatively low.
This provides us with the motivation to search for other signals that can be used to improve the results of dataset recommendation, besides title and meta-data, while abstaining from the contents of the dataset. A very little explored signal for dataset recommendation is the academic co-author network. Even though from existing work, we know that co-author networks can be used to make meaningful predictions and analyses, it is not a priori clear whether such links between co-authors can also be exploited to find relevant links between datasets, in order to drive dataset recommendation.
The motivating question for this paper is therefore whether a co-author network can contribute to dataset recommendation. And more elaborately, whether we can use such co-author analysis in an ensemble combination with other approaches to obtain maximally good result. Our research questions are therefore as follows:
How to do dataset recommendation by using a co-author network? And how to combine existing dataset recommendation methods with such a co-author network based approach? How to evaluate the recommendation approach between datasets and to evaluate the quality of recommendation links built by our recommendation approach? How to obtain and use real data for our experiments on the recommendation and evaluation approach?
In this section, we will introduce three dataset recommendation algorithms that we will test in our experiments: the first is based on computing paths in a co-author network, the second is based on vector embeddings of author computed from the academic network, and the third is a ranking method often used in information retrieval.
The term “dataset” has various definitions in the literature (e.g. [7]) and unfortunately there is no universal agreement on what counts as single dataset or a collection of datasets. For the purposes of this paper we sidestep these principled discussions, and we take a purely operational approach: an object counts as a dataset if either of our experimental corpora ScholExplorer or Mendeley (see Section 5) classify it as a dataset.
As we mentioned before, the goal of dataset recommendation is to map one or more given datasets to a collection of recommended datasets. This makes dataset recommendation different from dataset search which amounts to mapping a query to a collection of datasets. Before introducing specific dataset recommendation algorithms, we give the general definition of dataset recommendation.
(Dataset Recommendation).
Let
Based on this definitions, the goal of this paper is to compute recommendation relationships between datasets. We will propose different dataset recommendation algorithms that implement the function
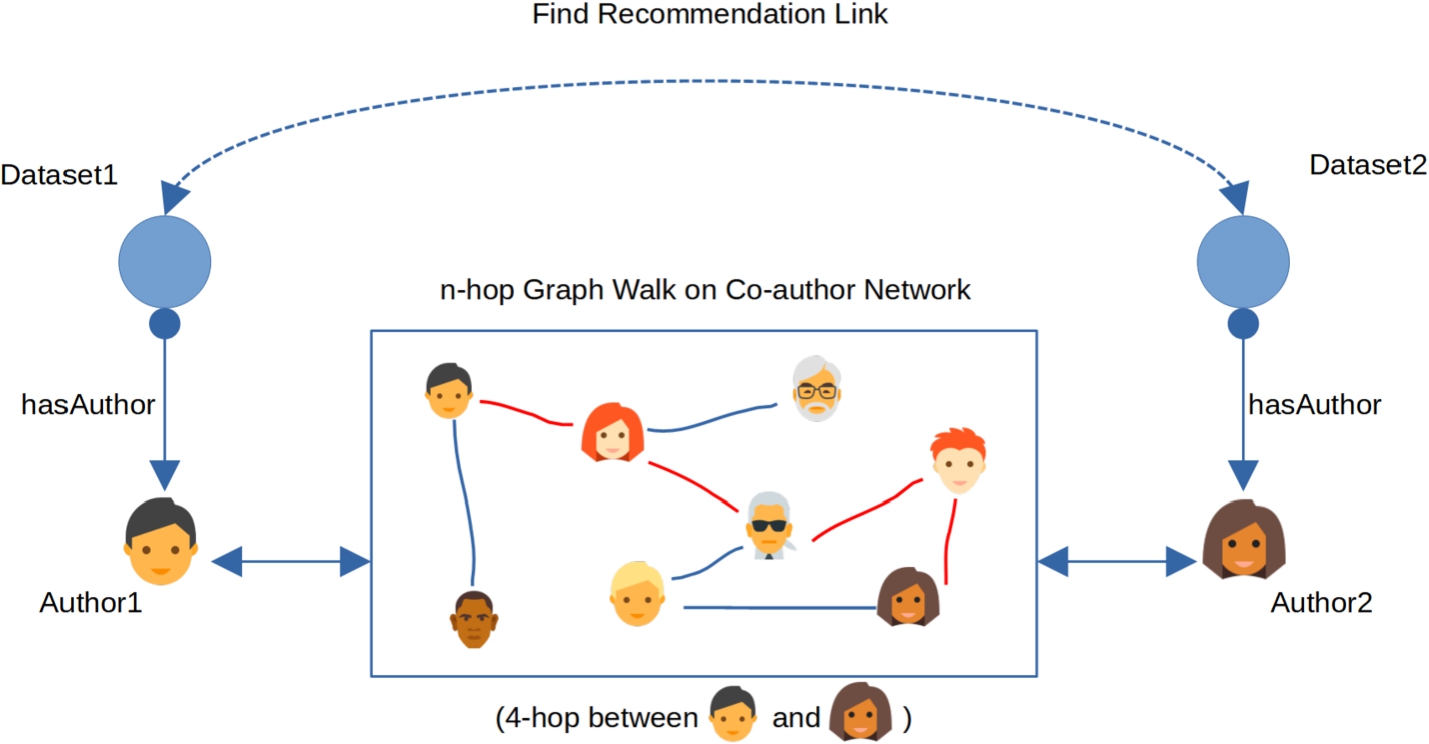
Recommendation pathway between Dataset1 and Dataset2 based on co-author network.
In this section we will briefly introduce the idea of a dataset recommendation algorithm based on a co-author network. The intuition is to construct a pathway from one dataset to another with the help of a co-author network, as shown in Fig. 1.
To find such relationships, we take into account the authors of the datasets. The authors of the datasets are then matched to the authors of in the publication co-author network. At this point we can use the co-author network to find (potential) links between the authors of the datasets. Eventually we build recommendation links between datasets through links between authors. Then, as shown in Fig. 1, the recommendation pathway from Dataset1 to Dataset2 is “Dataset1 → Author1 → (Co-)Author network → Author2 → Dataset2”.
We will now formalise the co-author network based approach. First off, we define a co-author network.
(Co-Author Network).
Let
A co-author network is a set of co-author relations,
In the co-author network definition, we have the definition of co-author relationship between two author, denoted by
Then we will introduce the connection between authors in co-author network. We define this connection as a co-author path between authors.
(Co-author Path).
Let
A co-author path between authors is a function
In this definition, the co-author path between two authors can also be considered as an n-hop walk from one author to another. So we also call this approach as graph walk based approach. For instance, when we have 3-hop walk from author
Then, we have the definition of dataset recommendation based on a co-author network.
(Recommendation based on Co-author Network).
Let
We can specialise this into a definition of dataset recommendation based on an n-hop graph walk in a co-author network. Let (Dataset recommendation based on n-hop walk on co-author network).
Knowledge graph embedding based approach
A knowledge graph embedding is the transformation of the entities and relationship of a knowledge graph into a vector space [36]. There are many existing and popular knowledge graph embedding models, such as ComplEx [34], TransE [4], TransR [26], RESCAL [22] and many others. See [25,37] for a survey. An embedding of a co-author graph in a vector spaces allows us to generate new (predicted) links between the authors. We can then use such predicted links between authors as a way to recommend datasets, just as we used the existing co-author links between authors above. In this paper, we will use the pre-trained author entity embedding, which is trained by ComplEx on the Microsoft Academic knowledge graph.

Recommendation pathway between Dataset1 and Dataset2 based on graph embedding.
Figure 2 shows the overview of using a graph embedding for dataset recommendation. We would use the graph embedding of co-author network to construct the vector space which contains all the vectors of authors. Then we use the cosine similarity metric between author vectors to do link prediction: to predict a link between authors with a high similarity. We then use the predicted links to build the recommendation links between datasets, based on the similarity between the authors of datasets.
Based on this intuition, we have the following definition of link prediction based on authors with graph embedding.
Let
Where
Finally, we have the definition of dataset recommendation with graph embedding on an academic graph.
(Dataset Recommendation with graph embedding on an academic graph).
Let
BM25 based approach
BM25 (also known as Okapi BM25) [30] is a ranking function used by search engines to estimate the relevance of documents to a given search query in information retrieval. BM25 uses IDF(inverse document frequency) to add weight to each keyword in the query. The documents will then be sorted by the keywords contained in each document to be ranked.
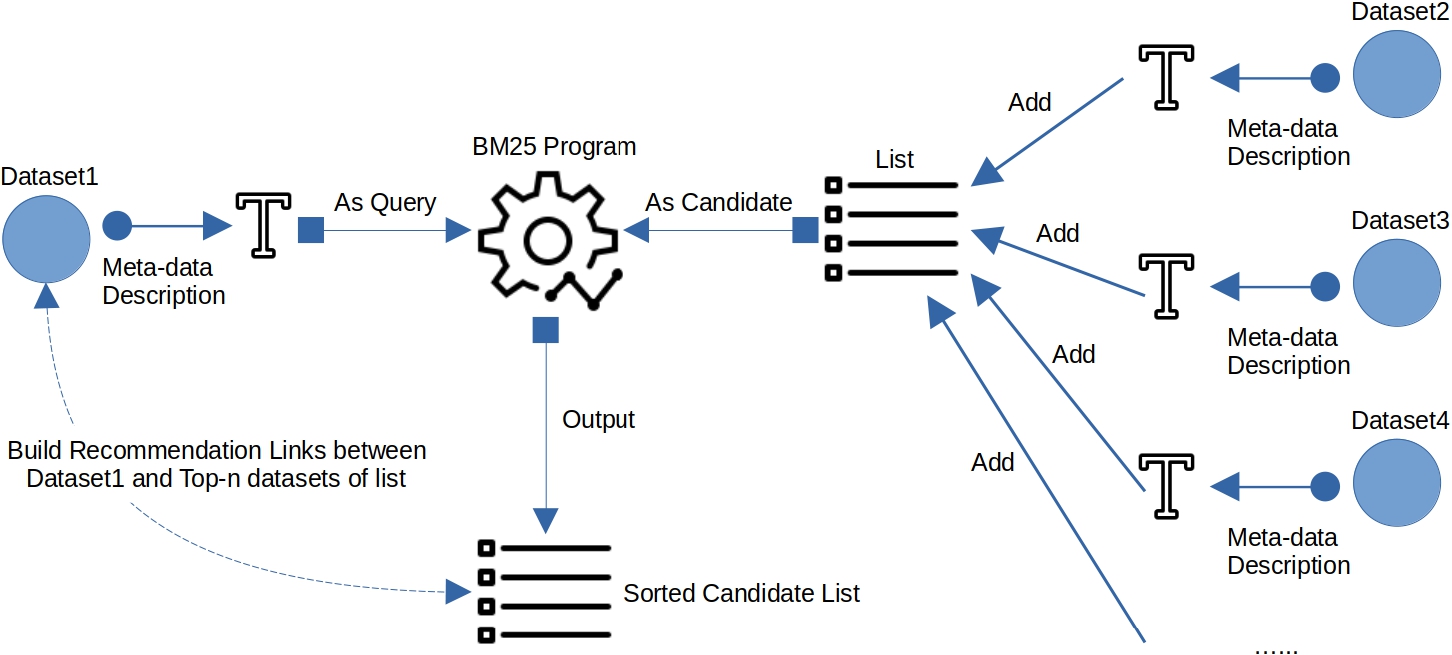
Dataset recommendation based on BM25.
As already motivated in the introduction, in this paper we will only consider and treat the meta-data description (title and description) of one dataset as one document, without looking into dataset itself. This is because there is too much variety in the format of datasets. Our work is in contrast to for example [7], which said that the challenge of data reuse could also be applied to dataset search, including data in formats that are difficult or expensive to use. In practice, too much variety in the format of datasets would bring difficulty to recommendation in our work and would make it expensive to use the dataset itself. However, compared to the dataset itself, the metadata of the dataset is much easier to use in our work. Figure 3 shows the overview of using the BM25 ranking approach for dataset recommendation. We treat the meta-data description of given dataset as given document (query), and the meta-data descriptions of candidate datasets as candidate documents to rank. With the given document, BM25 can rank the candidate documents based on the meta-data description of the given dataset. The definition of the meta-data description is as follows.
Let
We also have the definition of BM25 based on the meta-data description of datasets.
(BM25 on Meta-data Description of Datasets).
Let
We can now give the definition of dataset recommendation with BM25 on meta-data descriptions of datasets.
(Dataset Recommendation with BM25 on Meta-data Description).
Let
Note that this threshold is less than or equal to the size of the dataset set returned by BM25 based on the query dataset, which means that
Dataset recommendation algorithms
In this section, we will provide the algorithms based on the recommendation approaches introduced in previous section.
Recommendation algorithm with co-author network
The first recommendation algorithm uses dataset recommendation approach based on co-author network.

Graph walk in co-author network:
We first explain how to perform a graph walk in a co-author network with Algorithm 1. For this algorithm, We need as input the max. hop number in addition to the starting authors (seed authors) and the network itself. The max-hop number nn is used to limit the maximum distance of our graph walk from the seed author. The maximum distance mentioned here refers to the shortest distance between the seed author and the target author in the co-author graph. Note that, all authors within distance n are treated equally as candidate recommendations, and are not ranked based on distance. In later experiments, we iterate over different versions of n to measure the effect of distance in the co-author network. Lines 3–6 of the Algorithm 1 are about how to use the hop number to limit the result of the graph walk.

Dataset recommendation with graph walk:
Algorithm 2 shows our first algorithm for dataset recommendation. In this algorithm, we first perform a graph walk in the co-author network separately for all authors contained in a given dataset. The graph walks for authors here all respect the given max-hop number. We then find the datasets corresponding to these authors found by the graph walk, and these are the datasets to be recommended.
We will now introduce the dataset recommendation algorithm based on the co-author network approach combined with the author embedding approach. The author embedding is based on the knowledge graph embedding approach which was introduced in Definition 7. In contrast to the previous algorithm, this algorithm not only uses the graph walk but also the vector similarity in the vector space. As vector space we use the pre-trained entity embedding provided by MAKG,4

Graph walk + author embedding in co-author network:
Algorithm 3 shows how to combine the co-author network approach with the approached based author similarity in the entity embedding. For all authors obtained from the graph walk, we additionally compute the similarity between these authors and the seed author in the pretrained vector space. Then we select authors whose vector similarity is higher than the threshold we give. This is as mentioned in lines 5–9 of the Algorithm 3.
After introducing the graph walk and vector similarity combination algorithms, we will introduce our second dataset recommendation method, as shown in Algorithm 4.

Dataset recommendation with graph walk and author embedding:
Different from Algorithm 2, Algorithm 4 requires the additional input of the MAKG pre-trained vector space
We will now discuss the dataset recommendation algorithm by using the combination of graph walk, author embedding and BM25 approach. This algorithm is based on Definition 10, which uses the descriptions of datasets for dataset ranking.

Dataset ranking with BM25:
In Algorithm 5,
After introducing the algorithm that uses BM25 for dataset ranking, we will introduce our third dataset recommendation algorithm, which is a combination of co-author network, author embedding and dataset ranking, as shown in Algorithm 6.
In Algorithm 6, line 2–7 is same as the steps in Algorithm 4, for using a graph walk and author embedding to find a list of datasets with the help of co-author network. After that, we use BM25 to rank and filter the list of obtained datasets, as shown in line 8 of Algorithm 6. Finally our algorithm returns a filtered list of datasets as the recommended datasets for the given dataset

Dataset recommendation with graph walk, author embedding and dataset ranking:
We will now introduce the experimental data we used in the recommendation experiments we performed to evaluate the algorithms above.
The metadata types contained in mendeley dataset, ScholeXplorer dataset and MAKG dataest
The metadata types contained in mendeley dataset, ScholeXplorer dataset and MAKG dataest
Elsevier provided a very large and popular dataset search engine, Mendeley Data ,5
Each Mendeley dataset contains several types of metadata: descriptive metadata (e.g. title, description, authors and ID), administrative metadata (e.g. creation date) and legal metadata (e.g. dataset creators and public licence), shown in Table 1. What will be covered in this paper is the descriptive metadata, where the title and description are used for the BM25 method, and title is used to match with datasets from other sources.
ScholeXplorer8
Different from Mendeley Data, ScholeXplorer stores data in the format of dataset-pairs. For each pair, it contains one link and two datasets. For each dataset, it also has descriptive metadata, administrative metadata and legal metadata, shown in Table 1.
The datasets from ScholeXplorer are used as candidate recommendation datasets in this paper. The links of each pair contained in ScholeXplorer are used as a gold standard evaluation criterion for our recommendation algorithms. We also use the title and description for BM25-based dataset ranking approach.
Microsoft Academic Graph (MAG) is a huge graph containing information on research outcomes (publications and datasets) and researchers, and the relationships between these [31]. Microsoft academic knowledge graph (MAKG) is a large RDF knowledge graph based on Microsoft Academic Graph [14]. MAKG contains information on publications, authors, indexes, journals, institutions, etc., as well as their scholarly relationships with each other. MAKG also provides an NTriple RDF dump,9
In this paper we will use the triples with the ‘creator’ predicate from MAKG as co-author network, since these triples show the creator relationship between authors and research outcomes. We also use title of MAKG datasets for matching with datasets from different sources. For author embeddings, we will use the pre-trained entity embedding10
We build our author network with the help ofthe MAKG academic graph, using the MAKG data-set [14]. The schema11
For instance, if we take two RDF triples from MAKG:
where each triple means the create-relationship between paper (subject) and author (object). Then we use the “Construct” function of SPARQL12

This gives us the co-author triples:
With the help of this SPARQL query, we create the co-author network from the SPARQL endpoint of all the MAKG author-paper triples. We have made this co-author graph available online [38].
In this section we will introduce our experimental design and the validation of our gold standard.

The overviwe of dataset recommendation and evaluation in our experiments.
First off, we will give a brief introduction of how dataset recommendation based on ensemble methods with co-author network works in our experiments, which is shown in Fig. 4. Our dataset recommendation experiment is to recommend datasets from ScholeXplorer source for given Mendeley datasets. We use a matching approach to match Mendeley datasets and ScholeXplorers datasets with MAKG datasets. Then we recommend target MAKG datasets for seed MAKG datasets, based on dataset authors by using the co-author-based recommendation approach. We then combine the author recommendation approach with the dataset ranking approach to do the final dataset recommendation.
Here we will introduce the gold standard for evaluation and how to evaluate our different recommendation algorithms in the experiments.
Gold standard
The gold standard we use is from ScholeXplorer. ScholeXplorer provides links between datasets, as well as links between dataset and paper. These links are from providers of datasets, data centers or organizations that provide data storage and management, such as CrossRef, DataCite, and OpenAIRE. So these links between datasets are convincing to be used as the gold standard for our evaluation.
Evaluation for dataset recommendation
For a given dataset, our evaluation takes into account two lists: the list of datasets returned by the recommendation algorithm, and the list of datasets that are linked to the given dataset in the gold standard. Then we use the F1-measure to evaluate it. The intersection of the two lists we mentioned is the true positive in the F1-measure. The list of datasets returned by the recommendation algorithm is the predicted condition positive in the F1-measure, and the list of datasets that are linked to the given dataset in the gold standard is the Actual condition positive in the F1-measure. We then can calculate the recall, precision and F1-score with these, and obtain the evaluation results of dataset recommendation approach. using the standard mathematical formulae for F1-score:
Matching between datasets from different sources
In this part, we will introduce the approach to match datasets from different sources or in different format.
As we discussed before, we will use the co-author network of MAKG to construct a recommendation pathway from a Mendeley dataset to a ScholeXplorer dataset (shown in Fig. 4). Also for our gold standard, we will match Mendeley datasets with ScholeXplorer datasets to obtain the gold standard recommendation links. These two task all require the matching between datasets from different sources. We must therefore use an approach for matching such datasets from different sources, and we will use a simple approach for this, based on matching titles of the datasets:
(Matching between Datasets from Different Sources).
Given two datasets
The matching approach is used to decide whether MAKG, ScholeXplorer and Mendeley refer to the same dataset. To check if this matching approach performs well, we set up an experiment to evaluate the quality and performance of this matching approach, which will give us an indication of the quality of our gold standard recommendation links. We select 26,928 pairs of datasets, where
for each pair of datasets, one from ScholeXplorer source and the other from MAKG source, both of them have same title;
for each dataset in these pairs, it must contain (at least one) DOI or URL in its metadata.
We also set four baselines for evaluating the matching approach:
(Strong baseline) Two datasets are the same if they have the same title and (at least one) same DOI or URL.
(moderately strong baseline) Two datasets are the same if they have the same title and their authors are the same.
(Likely weak baseline) Two datasets are the same if they have the same title and their publishers are the same.
(Weak baseline) Two datasets are the same if they have the same title and the count numbers of their authors are the same.
The strong baseline, requiring the same DOI or URL, will give a very strong matching link between two datasets. This is because DOIs and URLs are used as identifiers of datasets. Note however that DOIs/URLs are not a perfect key to match two datasets or papers. This is because,although two different datasets or papers will rarely if ever have the same URI or DOI, a single dataset or paper will often have multiple DOIs. For example, the DOIs
Results of evaluating heterogeneous datasets matching approach
Results of evaluating heterogeneous datasets matching approach
We have therefore tested the different matching criteria on a set of 26,928 pairs from ScholeXplorer and MAKG that have at least one DOI or URL each, and that share the same title, with the results shown in Table 2. We find that 60% of pairs meet the strong baseline which means that the datasets share at least one DOI or URL when they have same title. And if we consider all the plausible baselines (i.e. all baselines except the weak baseline), twe have about 83% pairs which is counted in correct matching. This result means that our approach for matching datasets from different sources is convincing in most cases.
Here we will introduce the real-world data we used in our experiments.
Co-author network. The co-author network we used is built with 130,638,555 papers from MAKG, where each of these papers contains at least two authors. (There are a further 107,993,471 single-authored MAKG papers, which cannot help us provide the co-author relationship between authors). As said above, the links between authors here are based on the co-authorship relationship between the authors, which means that if two authors have a co-authorship, then there will be a link between those two authors.
List of given datasets. We use 2370 datasets from Mendeley Data. These were obtained by first randomly selecting 1 million datasets from Mendeley, and then selecting all those that can be matched against MAKG datasets with our matching approach discussed above.
Gold standard. We match each of the 2370 given dataset with ScholeXplorer datasets, and count all the datasets linked to matched ScholeXplorer datasets as Gold Standard datasets. we found a total of 38,655 datasets in ScholeXplorer that have a gold standard link to any of the 2370 given datasets.
ScholeXplorer provides “related-to” links between dataset and literature/dataset objects. These links come from data providers or high quality data sources. This means that these links from ScholeXplorer are trusted and can be used as a high-quality Gold Standard in our evaluation. These ScholeXplorer links are bi-direction and one object can be linked to multiple objects.
List of candidate datasets. We use 28,981 of these ScholeXplorer datasets as candidate datasets. All these ScholeXplorer datasets are the ones which are not only matched to MAKG datasets but are also contiained in the Gold Standard. We have used here only these datasets from the gold standard as alternative datasets, as they already meet our requirements for doing experiments:
They guarantee the possibility that we recommend the correct linked dataset: for each given dataset the linked dataset from the gold standard is in the candidate dataset. We also have “noisy” datasets: for each given dataset, the datasets linked in the gold standard for the other given datasets can be considered as “noisy” datasets, Each candidate dataset can be found by the co-author network recommendation method: all candidate datasets can be matched to the MAKG, which ensures that the MAKG-based co-author network can potentially find the datasets by walking the author graph through them to find the authors of the datasets.
Experimental set-up
Here we will introduce our experiments. Our experiments are based on the previously proposed recommendation algorithms for the dataset. Our experiments are step-by-step incremental, meaning that we start with just using the co-author network, we then add other methods step by step, finally the full ensemble method. For experiments using only graph walk, we use 1-hop to 3-hop walking settings for the graph walk in the co-author network, respectively. For experiments using graph walk and author embedding for recommendations, we set minimal thresholds for the cosine-similarity between the author embeddings from 0.3 to 0.7, increasing these in steps of 0.1 each time, while keeping the same graph walk settings. We did not investigate similarity thresholds of 0.1 and 0.2: requiring only such a low similarity demand means that there is almost no benefit from having the embedding. The reason for dropping minimal similarity thresholds of 0.8 and up is that these lead to very small answer sets. Finally, for the recommendation experiments considering the dataset ranking with BM25, we gave BM25 thresholds of two and three times the number of gold standard results, respectively. This means that if for a given dataset we can find n gold standard linked datasets, then the threshold of BM25 is
This gives us three different types of experiments: GraphWalk based experiments, GraphWalk+Embedding based experiments, and GraphWalk+Embedding+BM25 based experiments.
Results and analysis
After the above introduction of our experimental design and validation, we will analyse and discuss the results of our experiments in this section.
Results of experiments
Results of
experiments
Results of
Results of
Results of
Results of
Tables 3, 4, 5 and 6 show all the results for the three types of experiments. Through these three experiments we find that the recommendation algorithm that combines graph walk, author embedding and dataset ranking methods performs best and reached the maximum F1 score at hop-2 graph walk with an author embedding threshold of 0.7. We will now analyze the results of each experiment in detail.
First we discuss the results of the
We then discuss the results of the
However, we still find one problem in Table 4: when performing the hop-3 graph walk, the original precision (experimental results in Table 4) was too low, resulting in the author’s vector similarity threshold of 0.3 to 0.6 failing to raise the precision to an acceptable range, thus making the F1 score still very low. So we need to reduce the list of recommended datasets found by the recommendation algorithm even further to improve the precision.
We therefore turn to the results of the
The size of returned datasets by recommendation approaches (the baseline = 38,655 is the size of gold standard for all the seed datasets)
We also show the size of returned datasets per recommendation approach in Table 7 and Fig. 5. As can be seen from the size of the returned datasets, our best precision approach (hop-3,

Comparison between baseline = 38,655 (the size of gold standard) and the size of returned datasets by recommendation approaches: 1hop (left), 2hop (middle) and 3hop (right).
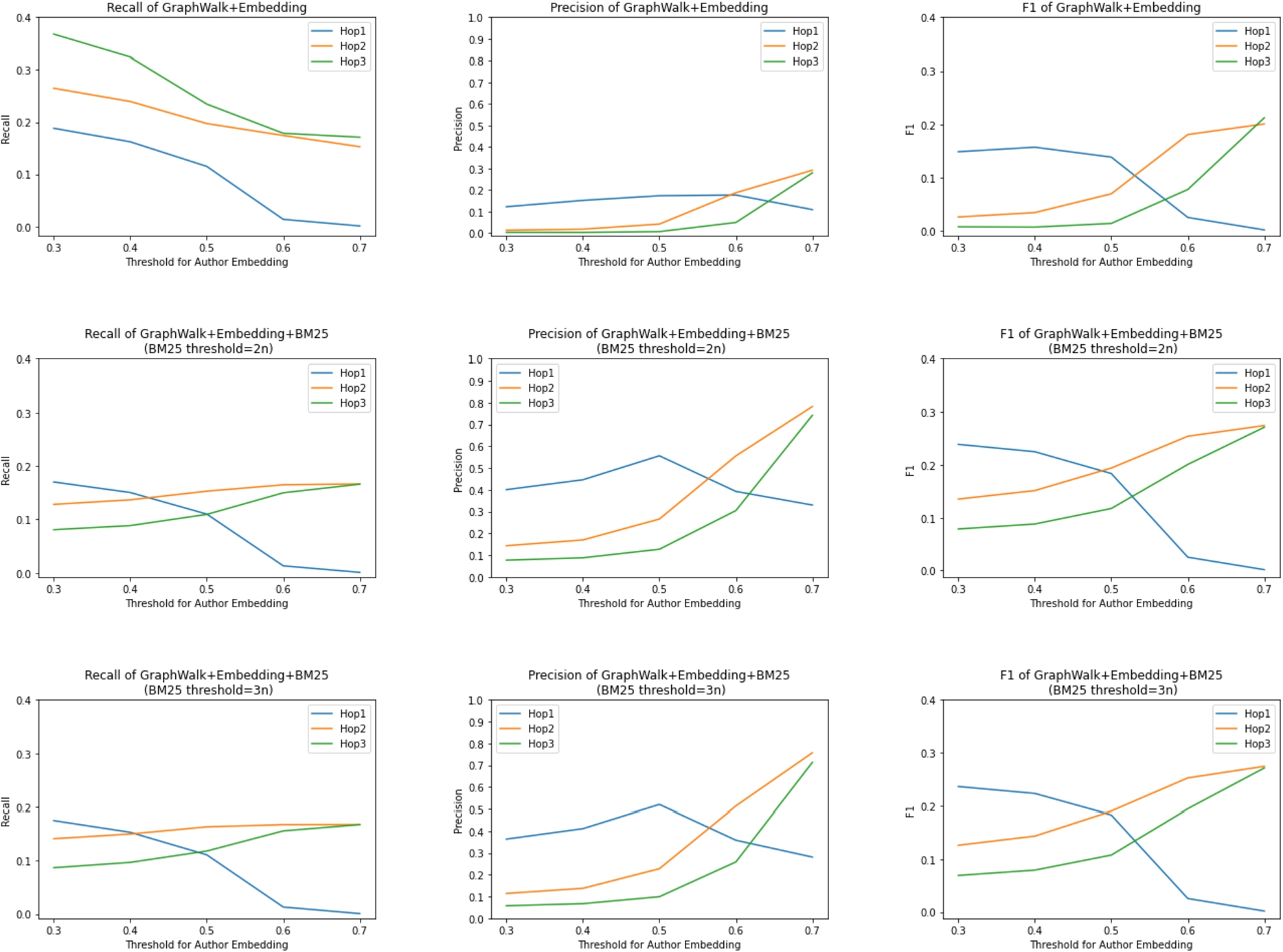
Recall (column 1), precision (column 2) and F1 score (column 3) for
To be able to compare more intuitively the changes in recall, precision and F1 score of the results in Table 4, Table 5 and Table 6, we introduce Fig. 6. The first row of Fig. 6 shows the results of Table 4, the second row shows the results of Table 5, and the third row shows the results of Table 6.
By looking at the first column (recall), we can clearly see that the recall decreases after adding the BM25 method, especially when the author similarity threshold is 0.3 to 0.5. We can also see that the recall of hop-1 is higher than hop-2 and hop-3 for lower embedding threshold T after adding BM25. This is because the BM25 approach reduces relatively less the size of the returned datasets on hop-1 than on hop-2 and hop-3, which is shown in Table 7. Removing relatively more datasets means more returned gold standard datasets may be removed. And because recall is based on the size of the gold standard datasets in the returned datasets, this leads to the reason why recall is lower in hop-2 and hop-3.
Then, by looking at the second column, we can see that the precision has improved significantly after adding the BM25 method, and that the maximum value of precision can be increased from about 0.3 to about 0.8 for hop-2 and hop-3. For hop-1, we can see that the precision decreases when the embedding threshold increases. This is because the size of the returned dataset is very small at this point, with about one thousand returned at
Thanks to the significant improvement in the precision, we can conclude from the third column that the F1 score will improve with the addition of the BM25 method.
We then proceed to analyze Fig. 6 to see if the BM25 threshold affects the experimental results. By comparing the second and third rows, we can see that there is no significant change in recall, precision and F1 score for different BM25 thresholds. This shows that the BM25 threshold (i.e., the maximum number of returned data sets) does not affect our experimental results.
Competing results from the literature
In Section 2, we described several other works on dataset recommendation and the broader task of scholarly recommendation, together with their experimental results, which we repeat in Table 8. At first sight, our precision score of 0.74 is competitive with the results from the literature, while our low recall of 0.16 leads to a fairly low F1 score. However, we should refrain from a strict comparison. The interest in dataset recommendation is fairly recent, and the community has not yet converged on a standardised task definition, nor on shared benchmark datasets. The papers mentioned in Section 2 use different input data, in other words they perform different tasks: recommending datasets based on a research problem description, based on the dataset schemas, based on a set of research papers given by the user, etc. All this makes a comparison to our methods (using a co-author network and meta-data from the datasets) not very meaningful.
We will now summarise the effect of the different algorithms, hops and thresholds by analysing all the aforementioned results. The first effect concerns different algorithms:
When using only the graph walk algorithm, the precision is too low, which means that the recommended datasets are too often not the ones in the gold standard. By adding author embedding similarity, the precision increases but is still not high, with some cost of recall. By adding BM25 ranking, the precision is good enough but recall is still low.
High precision means that most of datasets recommended by our algorithm are correct (as judged against the gold standard). This also means that our algorithm often returns useful datasets for users, but does succeed in return all useful datasets. This trade-off of a high precision against a low trade-off is similar to the behaviour of typical search engine.
Then we will discuss the effect of the similarity threshold for author embeddings. A higher threshold causes recall to go down, precision to go up, and F1 score to go up as well. This means that a high similarity threshold for author embeddings benefits our algorithm, again causing a trade-off of high precision against lower recall.
Finally, concerning the effect of multi-hops, Table 4, shows that a high hop count will cause an increase in recall, which means that our algorithm would cover more correct datasets from the gold standard.
Conclusion and discussion
In this paper we have investigated the use of a co-author network in ensemble methods for scientific dataset recommendation. Our recommendation algorithm involves three methods: a graph walk in a co-author network, author similarity in a graph embedding, and the ranking of datasets based on textual descriptions. We used real-world open source data to experiment with and evaluate the recommendation algorithm. The final results confirm that when we combine all three methods and use the farthest possible graph walking distance and the most stringent threshold for the graph embedding similarity threshold, we can obtain high precision recommendation results, albeit at a low recall. This means that our ensemble method is able to recommend relatively good datasets but will not recommend all good datasets. This behaviour is similar to that of most widely used search engines.
Our recommendation methods are restricted to datasets for which authors and metadata are known. Our methods do handle poor metadata (in fact, the poor quality of the metadata is one of the reasons that we need an ensemble method), but our methods do rely on some of the meta-data and author-information being present.
Also, the co-authorship patterns are different in different research domain (for example, high energy physics has papers with more than 300 authors). As a result, the information content of a single hop in such networks would be different. This different “weight” of a single hop in different co-author communities is an interesting aspect for future work.
After obtaining a reasonably high precision performance with our ensemble method, the next challenge will be to improve the recall performance. In this work, the upper bound of recall is based on the number of returned datasets following the co-author relationship between authors. In future work, we will use other information sources such the affiliation of the author, or the research domain of the author, or a citation-graph among authors to expand the set of potentially related authors without sacrificing precision.
Usig a citation network (in contrast to or in combination with a co-author network) is another future point for dataset recommendation. Citation information between papers and between authors is already widely used for paper recommendation [23,35]. We could consider adding a citation network into our ensemble methods.
Footnotes
Acknowledgements
This work was funded by Elsevier’s Discovery Lab. This work was also funded by the Netherlands Science Foundation NWO grant nr. 652.001.002 which is also partially funded by Elsevier. The first author is funded by the China Scholarship Council (CSC) under grant nr. 201807730060.