
Abstract
This is an extended, revised version of Philipson (2017). Findability and interoperability of some PIDs, Persistent Identifers, and their compliance with the FAIR data principles are explored, where ARKs, Archival Reource Keys, were added in this version. It is suggested that the wide distribution and findability (e.g. by simple ‘googling’) on the internet may be as important for the usefulness of PIDs as the resolvability of PID URIs – Uniform Resource Identifiers. This version also includes new reasoning about why sometimes PIDs such as DOIs, Digital Object Identifiers, are not used in citations. The prevalence of phenomena such as link rot implies that URIs cannot always be trusted to be persistently resolvable. By contrast, the well distributed, but seldom directly resolvable ISBN, International Standard Book Number, has proved remarkably resilient, with far-reaching persistence, inherent structural meaning and good validatability, through fixed string-length, pattern-recognition, restricted character set and check digit. Examples of regular expressions used for validation of PIDs are supplied or referenced. The suggestion to add context and meaning to PIDs, making them “identify themselves”, through namespace prefixes and object types is more elaborate in this version. Meaning can also be inherent through structural elements, such as well defined, restricted string patterns, that at the same time make PIDs more “validatable”. Concluding this version is a generic, refined model for a PID with these properties, in which namespaces are instrumental as custodians, meaning-givers and validation schema providers. A draft example of a Schematron schema for validation of “new” PIDs in accordance with the proposed model is provided.
Keywords
Introduction: Identifiers in science
Identifiers in science may refer to digital or physical objects, or concepts. PIDs such as ORCIDs (Open Researcher and Contributor IDs) [24] may refer to persons, or, like the recently launched ROR (Research Organization Registry) [39] identifiers, to research organizations. This paper will focus on PIDs for research outputs, ‘things’ such as articles, datasets, samples, concepts etc. But, as suggested in Section 7, ORCIDs or RORs may be an optional part of a modular, integrated identifier for research outputs. PIDs may be general or domain-specific. Among the more prevalent general PID-types are ARK, DOI, Handle and UUID (Universally Unique Identifier). There are also old, bibliographic identifiers like ISBN. Created in the 1960’s and 1970’s of the print era, how come they survived into this digital age? Some reasons might be: they are well distributed across the internet and widely used by stakeholders (libraries, publishers, readers). They have a semantic structure, identifying well-defined objects, and a fairly precise validation mechanism through fixed string-lengths, limited character-set and check digits. Some of these properties are shared by ARKs, DOIs, Handles and UUIDs, or other more domain specific identifiers used for scholarly data, but seldom all of them simultaneously. The focus here is on findability and ‘validatability’ of PIDs of different types.
Identifiers – why do we need them?
The general purpose of identifiers is to serve as references to the objects that they are supposed to identify. Preferably they should indicate, in and by themselves, what types of objects they are meant to identify. Far from all PIDs do that. It is often left to the names of things to provide context and meaning. Context may be added by means of location within an hierarchical system, e.g. as in Linnéan taxonomy, where scientific names situate a species within a genus, sometimes also containing the provenance of that name, serving to disambiguate between names of species belonging to widely different genera, e.g. Asterina gibbosa Gaillard 1897 – a fungus, and Asterina gibbosa (Pennant, 1777) – an echinoderm, a starfish. It also happens that ‘things’, objects are renamed later, as with the preceding fungus species now having the accepted scientific name Asterolibertia gibbosa (Gaillard) Hansf. 1949, or are assigned an identifier: urn:lsid:catalogueoflife.org:taxon:02af8238-ac8f-11e3-805d-020044200006:col20150401 [2]. However, even if a PID may well serve the need for disambiguation by uniquely identifying an object, it may still be no better – sometimes perhaps even worse – at giving access to said object, or at least to a page with metadata about it. The identifier assigned above is neither directly resolvable nor ‘googlable’, while the scientific name is at least easily findable via a search engine. The PID type here, a LSID (Life Science Identifier), represented as a uniform resource name (URN), has also been criticized for not being resolvable as a HTTP URI and violating the web architecture [46]. The initial objectives of LSIDs may be well worth pursuing, notably to specify a “method for discovering multiple locations for data-retrieval ... and ... to discover multiple independent sources of metadata for any identified thing” [46], but judging from individual instances these objectives seem not to be fully achieved yet.
While scientific names are often useful for describing objects, they have other drawbacks compared to PIDs, some of which were identified by [36]. For example, homonymy and disambiguation should be no problem for ‘globally unique identifiers’ [23]. And while concatenations or abbreviations may be problematic in the use of names for identification, string-length and pattern restrictions are useful for validation of identifiers. Missing or added characters, and some types of misspellings are easier to detect and validate in standardized identifiers of fixed string-length or well-defined character patterns. Inconsistent encoding should also not be a problem in PIDs with restricted character sets. However, these desired properties of some identifiers may conflict with the interest in having also transparent, meaningful PIDs that at least in part “speak for themselves”.
FAIR principles
The FAIR guiding principles aim “to make (meta)data

The FAIR data principles [15].
The FAIR principles clearly need interpretation to become fully operational, and such work is also well in progress [9,11,48]. Further explications of some of the principles are also available in [16]. Figuring prominently in the explications of all these principles, particularly interoperability, is the requirement that metadata should be machine readable “a conditio sine qua non for FAIRness” [17]. Providing machine-readable metadata is also used by fairmetrics.org as a measure of Findability [13].
However, the FAIR principles do not say anything explicitly about validation. Here we argue by contrast, that particularly for Interoperability and Re-usability it is crucial that metadata can be properly validated as compliant with an accepted metadata standard. It has been remarked that this is already implied by the FAIR principle R1.3 above, but even so, only indirectly and in an ambiguous way. There are several cases where general data repositories, professing to be FAIR and to comply with accepted metadata standards both for their default output and export formats, nevertheless fail to validate against schemas of these same standards [37]. Fairmetrics.org [48] explicates R1.3, as measuring a “Certification from a recognized body, of the resource meeting community standards”, by means of a valid electronic signature, such as a verisign signature [12]. One might ask, then, whether general data repositories such as Harvard’s Dataverse,1
The current FAIR principles of Accessibility, particularly A1 above, imply that identifiers should be resolvable, seemingly disregarding the general awareness of phenomena like ‘link rot’ and ‘reference rot’ [18,26,27,44]. A 2013 study in BMC Bioinformatics analyzed nearly 15,000 links in abstracts from Thomson Reuters’ Web of Science citation index and found that the median lifespan of web pages was 9.3 years, and just 62% were archived [25]. This happens although there is an understanding that “[u]nique identifiers, and metadata describing the data, and its disposition, should persist – even beyond the lifespan of the data they describe” [7]. A recent study of some 40 research data repositories found that only one of these (3%) was compliant with the FAIR principle of Accessibility requiring “a clear policy statement (or various examples of data this has actually happened to) indicating that metadata is still available even if the data is removed” [11]. The argument here is not that resolvable, persistent URIs should be avoided as identifiers, but they may not be sufficient to guarantee persistence. As has been eloquently remarked, “persistent URIs must be used to be persistent” [41] (my emphasis). Resolvable URIs as PIDs work by decoupling the location and the identification functions of URIs. The custodian of a web resource maintains the correspondence between the identifying URI and the locating URI in the resolver’s look-up table as the resource’s location changes over time. ... The solution comes at a price because it requires operating a resolver infrastructure and maintaining the look-up table that powers it [41].
This is true of ARKs, DOIs, as well as Handles, PURLs (Persistent Uniform Resource Locators) and URNs. There are in fact numerous cases when the lookup-table is not maintained and updated as required. A case in point are two PURLs from the FAIR metrics found in [48],
Again, going back to the question of resolvability, the relationship between identifiers such as DOIs and URIs is not always straightforward, and sometimes involves a chain of redirects (‘303s’), before reaching a destination holding also the appropriate metadata [42,43]. Faced with a non-resolving PID-URI an alternative might be to try the identifiers.org SPARQL endpoint [49]. But it only works if the potential corresponding URIs have been assigned the property owl:sameAs just as the submitted subject URI.
Assuming we have finally found a single seemingly reliable custodian for our PIDs and URIs, promising 24/7 resolution and top quality metadata, should we rest content with that? In law and journalism it is desirable not to judge by the testimony of only one witness or source. The evidence of at least two, mutually independent sources is generally preferred. Multiple resolution of any PID by several different proxy servers, as we already know, still means single custodianship of that lookup-table that has to be managed and updated in order for the PID to resolve as expected. Clark describes it as representing a stage in the evolution of PIDs, that will eventually be surpassed by a more mature age when we supply also data types to come with the PIDs, in order to make them more machine actionable [4]. But we want more than that. We want backup for custodians. We need trustworthy, independent witnesses from different loci in space-time to provide multiple access to, or identification (findability) of resources through PIDs. Thus, we accept “that an object may have multiple PIDs”. Ideally these multiple PIDs should get to “know about” each other as a way towards interoperability [4]. This can be achieved already, e.g. by means of Linked Open Data (LOD), sameAs-relationships and tools provided by n2t.net , unpaywall.org and the identifiers.org SPARQL endpoint referred to above. Multiple identifiers from different namespaces for the same object may even be desirable in order to ensure interoperability in different environments [35]. It is also in line with the principle of the semantic web known as the NUNA, Non-Unique Naming Assumption, implying that “things described in RDF data can have more than one name” and any object may be identified by more than one URI, serving in RDF as ‘names’ of things [5].
However, this does not imply that any identifier, any PID is as good as the other. In fact, there are significant differences in quality between identifiers, particularly in terms of ‘validatability’ and ‘meaningfulness’. We are getting there a bit later.
But first, having referred to linked data and sameAs-relationships as a possible solution to achieving interoperability, what about long-term sustainability? Are LOD, relying heavily on opaque URIs, fit for survival? Archival information packages for long-term preservation need to be independently understandable [3], carrying meaning within themselves, while external links may no longer be resolvable. Thus, opaque URI strings lacking an inherently meaningful structure will give little or no clue about content or provenance, unless they can import some meaning from outside, through resolution or sameAs links.
Just how “persistent” are PIDs really? Even if not always resolvable, are they in general still ‘findable’, well distributed over the internet in time and space? Are they ‘validatable’ (e.g. through fixed string-length, pattern-recognition, restricted character set, built-in checkdigit, built-in type)? Are they FAIR?
We try ‘googling’ an older, presumably less well-known example: ISBN:2130381030. L’Identité : séminaire interdisciplinaire dirigé par Claude Lévi-Strauss, 1974–1975 (Paris: PUF, 1983). Without prefix (2130381030) the precision is between 14/39 and 22/50; with prefix (ISBN2130381030) it reaches as high as 17/18 (date: 2017-01-30).
ark:/12148/bpt6k97497t8
ark:/13960/t6c25cm5g9
ark:/67531/metapth346793/??10
What about the “validatability” of ARKs, then? As exemplified above, ARKs match the regular expression
Thus, ARKs have the potential to offer stricter constraints for validation locally, than those represented by the regular expression above. But for this, it would be desirable to have a kind of lookup service for the NAANS, a directory, which for each NAAN – a little like MIRIAM – informed about the permitted character sets of its substrings, string-length limits, possible structure and regular expressions for validation. This could balance out the lack of semantic content in ARKs, that might otherwise limit their use and, possibly, persistence.
The Findability by simple ‘googling’ and current Accessibility of the example ARKs above presently (July 2019) still seems quite good. At least the first of these examples seems to be well distributed, producing an impressive precision score of 27/27 by simple googling of “12148/bpt6k97497t” (each hit actually containing a reference to the same document by Buffon in the Gallica collection). The second example apparently has a narrower distribution, but the few items found still display good precision, 4/4. The third example, without inflection, has been used extensively as a paradigmatic case, so should perhaps be considered outside competition here, but anyway also shows good precision. The long-term sustainability and persistence of ARKs, that is, the future preservation of their connection with the objects they are supposed to identify may be difficult to predict, but given their present apparent “findability” and at least potential “validatability”, they might be able to compete with ISBNs in the future.
10.1007/978-3-319-07443-6_3912
10.1002/asi.2325613
10.1177/03063127770070011214
10.1002/(SICI)1097-4571(199510)46:9<646::AID-ASI2>3.0.CO;2-115
10.1007/s11192-007-1682-316
10.1023/B:SCIE.0000018543.82441.f117
Now, following are two DOIs from Wiley Online Library 1996 and Springer 2001 that still do not seem to resolve properly (tested 2017-01-31, 2018-11-11, 2019-07-30):
10.1002/(SICI)1520-6297(199601/02)12:1<67::AID-AGR6>3.3.CO;2-# 18
10.1007/s00145-001-0001-x19
However, these DOIs, again from Wiley Online (1996, 1998) that were earlier unresolvable (at 2017-01-31), are proof that some PIDs might (re)gain resolvability later:
10.1002/(SICI)1520-6297(199601/02)12:1<67::AID-AGR6>3.3.CO;2-K20
10.1002/(SICI)1520-6297(199811/12)14:6<475::AID-AGR5>3.3.CO;2-621
Obviously, all these DOIs, whether resolvable or not, vary substantially in string-length, from just 17 to over 60 characters, some involving abbreviations of journals or organisations, one an ISBN, and some containing characters in need of special XML-encoding, different from URI. Note that although the two last items in the first group are from the same journal, Scientometrics, they are quite different in structure. Anyway, all the above DOI examples are valid in accordance with the best we can offer as a regular expression restriction, with only partial pattern recognition:
But then, according to the same partial restriction, defined by the regex above, this entirely fake DOI is equally valid:
To be sure, there are other regular expression restrictions suggested for DOIs, those that are even more permissive (as DataCite 4.1, with the pattern value for doiType set to “
By contrast, UUIDs v5 are eminently “validatable”, with a character set restricted to digits and lower case [a-f], and a fixed string length, 36 characters including hyphens, in a recognizable, precise pattern: “8-4-4-4-12”, allowing for validation by a regular expression such as
Generally speaking, although it is preferable that identifiers be findable and identifiable also in their unprefixed, pure form, typed identifiers give context by means of namespace prefixes of a metadata standard, a vocabulary or ontology. A typed identifier “introduces itself”, telling us what kind of identifier it is, and what type of objects it is used for. Most importantly the namespace tells us what schema(s) or which rules should be used for its validation.
Page [34] claimed that e.g. “dc:title” is adding “unnecessary complexity (why do we need to know that it’s a “dc” title?)” in the JSON expression:

A simple answer is that namespaces are important to retain meaning from context, serving as a key to interpretation for the future. Long-term preservation of archival information packages (AIP), in order to ensure that these will be “independently understandable” [3] for the future should mean in a case like this, that the dc specification and schemas valid at the time be archived together with the records [32], or at least that there is provenance metadata including timestamps and namespace of terms used. Metadatafiles in XML usually have a xsi:schemaLocation indicating which schema to validate against. This information, together with timestamped metadata elements such as ‘dateIssued’ should be sufficient to provide context. For JSON metadata there are name/value pairs such as
A “new” contextual, integrated, validatable PID?
As seen in the case of Handle above, validatability sometimes comes at a cost: transparency lost. Are we forced to make a choice between the two? Can we create identifiers that are both fully validatable and at the same time more meaningful, providing context? So, here we suggest a model for a “new” PID, with a limited character set, at least for the object id part, defined by namespace specifications and schemas.


It is a model of a contextual, validatable identifier, structured into modules (sub-strings) separated by a dot (.). To make it easier to implement, and more generalizable, there are no character set or string-length restrictions for the first two modules, except that they should not contain the dot (.), which is the module separator. Nevertheless, this means already existing namespaces and object types could already be used to create a PID in accordance with this model.
The third module, the objectId (local ID) has a limited character set, selected to escape ambiguous interpretations (excluding the letters ‘l’ and ‘o’, as possible to confuse with numbers) and, to avoid making local uniqueness case-dependent [33], restricted to lower case letter characters and digits. The full stop or dot (.) was chosen as module separator, since it works well in both xml- and http-environments, without encoding, and is not subject to confusion as sometimes hyphens and dashes (en-dash and em-dash) can be. It also works for tokenization of strings. The object type identified in the second module should belong to the initial namespace prefix. Every namespace can have as many object types as needed. Namespace schemas could also define valid data types for their different object types, thus supplying PIDs with data types, in order to make them even more machine actionable [4].
The scalability of this model will mainly depend on the 10-character objectId and the size of the permitted character set. An objectId limited to the proposed character set [a-kmnp-z0-9] will have 3410 permutations within each namespace (and possibly objectType), still better than e.g. a 7 character Handle with NOID.
The objectId module, thus, could be validated separately by a regular expression restricted to
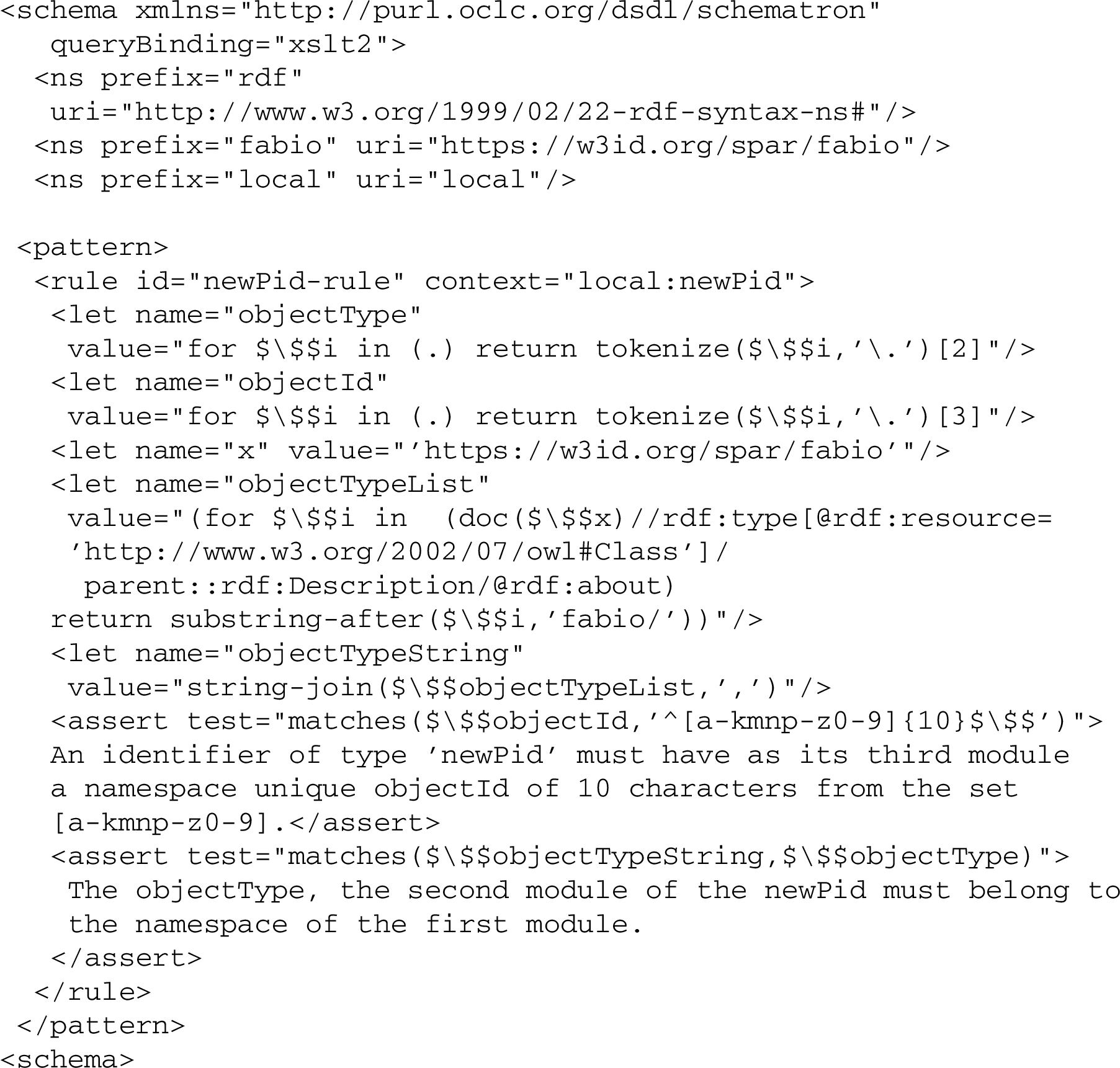
One might consider generalizing such a validation schema to the extent possible, so that the namespace URI in $objectTypeList, from which the $ objectType should be drawn, was automatically construed based on the namespacePrefix (module 1) of the newPid instance to be validated. This could be achieved by having the namespacePrefix expressed as a link with a namespace URI, e.g. such as fabio33
It is also conceivable, in order to allow for integration of already existing identifier schemes, that a namespace sets its own character set and string-length restrictions, to be declared by the validation rules of that namespace. For “narrow” namespaces, lacking defined diverse object types, possibly since they comprise basically only one type of object (as for ISBNs and ISSNs) we suggest as a default second module value ‘NOT’ = No Object Type. So we could have an IGSN, International Geo Sample Number [40], with string-length of objectID set to 9, expressed in this model:
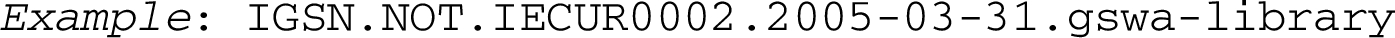
The identifier should be fully validatable, as a whole or in part (modules), in the corresponding namespace(s). The last two modules are optional, but they are meant to offer built in data provenance. For organisation identifiers, we hope that the recently launched ROR-IDs will become a global standard, like ORCIDs for persons. Then we could replace the last module in the IGSN-PID above with “05h2dda38”.
The resulting PIDs should be minted within the corresponding namespaces, which would also be the ‘custodians’ and resolving authorities of their respective PIDs, responsible for uniqueness within the namespace. Another task would be to monitor and assign sameAs-properties to PIDs that refer to the same ‘thing’ in other namespaces.
It has been suggested that in order “to build more connected, cross-linked and digitally accessible Internet content” it is necessary “to assign recognizable, persistent, globally unique, stable identifiers to ... data objects” [23]. The model proposed here aims to promote “new” PID strings that are universally unique and stable, recognizable through validation and enough inherent meaning to make them useful and understandable also in the future, thus, with a good potential for backup and persistence.
The purpose of this paper was to analyse some of the more prevalent general PIDs used in scholarly communication, identify some of their shortcomings and find out how PIDs could be made more FAIR. Real examples of PIDs were analysed to find out what additional requirements there might be to make them fully Findable, Accessible, Interoperable and Re-usable – FAIR. The “novelty” of the paper, if any, is the “widening” of the FAIR principles to have Findability include also rate of distribution or dissemination (e.g. as measured by means of ‘googling’) and Interoperability or Re-usability to include also ‘validatability’. Further, as against earlier insistence on the opaqueness of PIDs as a warrant for persistence, we argued for the importance of adding enough meaning to PIDs, through namespace prefixes and object types, so as to enhance their future use, distribution, findability and interpretability, and to safeguard against failed resolvability. The custodianship and minting of PIDs, we suggested to be the responsibility of the custodians of namespaces, as these are already assuming the administration of specifications, validation schemas, vocabularies or ontologies, and should be well qualified for the task. The minting algorithm, the patterns for PID-recognition, restriction in character set, string-length (with possible checkdigit) of objectId module should all be part of the validation schemas. These namespaces should then be able to register their schemes with n2t.net or identifiers.org , as already happens. And there might be several services such as the SPARQL endpoint of identifiers.org for registering sameAs-links. To create, maintain and make our PIDs truly persistent, widely used and FAIR should be a cooperative effort of the whole scholarly community.