
Abstract
Gas masks are essential respiratory protective equipment commonly used by laborers who work in harsh environments. However, respiratory diseases and accidents can occur due to the absence of gas masks. To prevent these accidents, this paper developed an object detector that uses convolutional neural networks (CNNs) to detect whether workers are wearing gas masks. To achieve this goal, a gas mask detection dataset was constructed derived from real industrial scenarios and Faster R-CNN was improved for gas mask wearing detection. Firstly, to address the multi-scale problem in real scenes, the Feature Pyramid Network was introduced into Faster R-CNN to effectively fuse features between different levels and improve the detection ability of small objects. Secondly, the Online Hard Sample Mining algorithm was used to alleviate the class imbalance problems in the dataset. Finally, Mixup and Mosaic were used in the training process to augment the data and make the model better adapt to different scenes and complex backgrounds. After multiple experiments, the combination of the three optimization strategies improved the
Keywords
Introduction
The health and safety of workers in industrial production has been a longstanding concern for both companies and governments. Researchers and technicians have made significant efforts to increase awareness of occupational safety, prevent accidents, establish effective occupational safety systems, and cultivate a safety culture. It is well-known that industrial production unavoidably generates harmful gases, dust, and particles that can cause damage to the respiratory system of workers who are exposed to these environments for extended periods. Therefore, protective measures must be implemented to safeguard the health of workers. In practice, gas masks are the most commonly used respiratory protection device, which can effectively filter out harmful substances from the air and protect the respiratory system of workers. However, accidents such as respiratory injuries and poisoning occasionally occur because gas masks are not worn as required. To address this issue, it is necessary to establish an effective gas mask wearing detection system that reminds workers to wear gas masks and promotes awareness of occupational safety.
In recent years, convolutional neural networks (CNNs)-based object detection algorithms have been widely used in security monitoring and surveillance. Current object detection algorithms can be divided into two types: one-stage and two-stage models. One-stage models, such as YOLO series [1,9,23–25], SSD [19], and RetinaNet [15], use a single network to directly predict bounding boxes and classifications, treating detection as a regression problem. While these models are known for their high real-time speed and simple structures, they often compromise on detection accuracy. In contrast, two-stage models divide the detection process into two stages. In the first stage, the algorithm generates several proposal regions for the objects. In the second stage, it detects the proposal regions to obtain precise coordinates and category information. Two-stage models generally offer higher detection accuracy, but require more computation than one-stage models. The classical two-stage models include Fast R-CNN [6], Faster R-CNN [26], Cascade R-CNN [2], Dynamic R-CNN [34]. Researchers have proposed various CNNs-based object detection models for occupational safety and public health, including methods for safety helmet detection [13,27], safety harness detection [3], and face mask detection [20,28,32]. These models aim to improve the accuracy and real-time performance of object detection systems by using transfer learning approaches, novel feature fusion methods and some special strategies. In other industrial scenes, high-precision detection methods have been proposed for coated fuel particles [8] and tiny defects on PCB surfaces [33]. Furthermore, a novel architecture has been developed for detecting leaks in gas pipelines [21].
Object detection models based on convolutional neural networks have shown great potential in enhancing occupational safety and public health. However, the success of these models relies heavily on the availability of large datasets, which is a key characteristic of deep learning approaches. To address this problem, a gas mask detection dataset was built and analyzed to identify the challenges in developing an effective gas mask wearing detection system. On the one hand, the size of the targets in the dataset varies greatly and there are a large number of small targets. In the detection process, small targets have less feature information and are easily confused with the background, resulting in a large number of false detections. On the other hand, the dataset suffers from class imbalance problems, where the number of samples in different foreground classes (e.g., different object categories) is significantly unbalanced. Additionally, the foreground of interest may occupy a relatively small portion of the image. These issues can lead to difficulties in training object detection models and inaccurate identification of negative examples.
Detecting objects of varying sizes is a major challenge in computer vision due to the use of multi-layer convolution that extracts information in a “shallow to deep” manner. Shallow features have high resolution and rich geometric information but lack semantic information, while deep features have rich semantic information but low resolution. With the increase of model layers, semantic information is gradually diluted for small targets until it disappears. For large targets, sufficient semantic information may be extracted in deeper layers, but at this time, the semantic information of small targets has been lost. As such, retaining semantic information for both small and large targets is difficult in object detection. To overcome this shortcoming, SSD [19] uses multiscale feature maps to detect targets. It uses large feature maps to detect relatively small targets, while small feature maps are responsible for detecting large targets. However, because the semantic information of low-level features is not sufficient, it is difficult to detect small targets accurately. Feature Pyramid Network (FPN) [14] has been developed to fuse low-level feature maps with high-level feature maps to obtain a new feature map for more accurate predictions. This integration of semantic and geometric information makes FPN highly effective in improving the detection accuracy of small targets. Furthermore, recent studies have demonstrated the advantages of bidirectional feature fusion, as seen in the simple yet effective Path Aggregation Network (PANet) [18]. Although PANet’s bidirectional fusion is relatively straightforward, other researchers have explored more complex bidirectional fusion techniques, such as ASFF [17], NAS-FPN [5], and BiFPN [30]. Compared with PAFPN, ASFF, and BiFPN, FPN is simple and versatile. Its structure is relatively simple, easy to implement, and can be applied to various target detection algorithms. At the same time, the performance of FPN is excellent, and it can achieve good results in various object detection tasks.
In the field of object detection, the imbalance problems include class imbalance, scale imbalance, spatial imbalance and objective imbalance [22]. This paper will focus on class imbalance, which often manifest as foreground-foreground and foreground-background class imbalance. The former can be mitigated by balancing the number of categories in the data through data augmentation methods, repeated sampling, etc. The latter can be mitigated by controlling the proportion of positive and negative samples during training, which can be accomplished through sampling methods. The simplest method is to manually set the ratio of positive to negative samples, which will be time-consuming. In the two-stage models, Girshick et al. [29] proposed Online Hard Example Mining (OHEM) to solve the class imbalance problem by selecting difficult samples to train the network. OHEM avoids hyperparameters tuning and focuses on difficult foreground and background objects. However, the multi-task loss function (including classification loss and localization loss) defined in OHEM ignores the influence of different loss types in the training process, which can lead to a lack of attention to localization accuracy in later stages of training. To solve this problem, Li et al. [12] proposed S-OHEM to sample training samples according to the distribution of loss. Compared to OHEM, S-OHEM selects difficult samples based on the distribution of different loss functions, avoiding only using high-loss samples to update model parameters. However, S-OHEM introduces additional hyperparameters and does not provide a universal way to select hyperparameters. In one-stage algorithms, improving the loss function is a common method to solve the class imbalance problem, such as Balanced Cross Entropy and Focal Loss [15]. Focal Loss focuses on difficult samples and solves the problem of low classification accuracy for classes with few samples, but it pays too much attention to outliers. GHM [10] uses the gradient modulus length to distinguish between outlier and normal samples. GHM reduces the attention of the model to the samples that are difficult to classify and improves the performance of the model. However, GHM requires additional calculation of the gradient, which increases the computational burden and training time. In addition, GHM still needs to manually adjust some hyperparameters, such as the number of groups and the boundary value of the gradient modulus length, which requires a certain amount of time and effort.
This work aims to enhance gas mask wearing detection by incorporating FPN into the Faster R-CNN algorithm, which facilitates multi-scale prediction, and thus improves the model’s ability to detect small targets and its overall stability. To mitigate the imbalance problem, we utilize OHEM during training, while also employing Mixup and Mosaic data augmentation techniques to improve the model’s discriminative ability and prevent overfitting. By integrating these three improvements, the final model achieves more stable performance in gas mask wearing detection, demonstrating the effectiveness of our approach. In brief, the contribution of this article is summarized as follows.
We propose a gas mask wearing detection method by integrating the Feature Pyramid Network into the Faster R-CNN, which effectively improves the model’s ability to detect small targets and increases its stability.
To effectively alleviate the imbalance problem and accelerate model convergence, we introduce the Online Hard Sample Mining algorithm during the training process.
We propose a new gas mask detection dataset to meet the needs of practical applications, it contains 6143 pictures and 9724 labeled information.
The rest of this article is organized as follows. Section 2 details the dataset and methods used in this work. Section 3 gives the analysis of experimental information and experimental results. Section 4 is the conclusion of this paper.
Method
Gas mask detection dataset
The dataset used in this work consists of data from real industrial scenarios and some scenarios similar to industrial scenarios. The following is a detailed description of the gas mask detection dataset.
A brief introduction to gas masks
Gas masks are generally divided into two types: filtered and isolated gas masks. Filtered gas masks primarily filter harmful gases and dust particles via a filter box or filter cotton. Isolated gas masks create a barrier between the wearer’s respiratory system, eyes, and face from the contaminated air by supplying oxygen from a gas storage system. These are usually used in narrow, low-oxygen scenarios where long work hours are required. Compared to isolated gas masks, filtered gas masks have a wider range of industrial applications. The gas mask detection dataset focuses specifically on the 3M filtered gas masks shown in Fig. 1, which are commonly used in industrial production.

3M gas mask.
The label names and descriptions of the dataset
In this work, head orientations are divided into three categories based on the direction in which the subject is facing the camera: front-facing, side-facing and back-facing. These three categories are further subdivided into seven labels by taking into account whether or not the subject is wearing a gas mask. Table 1 gives a detailed description of the name and meaning of each label. Figure 2 shows examples of annotations. In real industrial scenarios, workers may enter production workshops wearing masks that do not provide adequate respiratory protection. This situation is just as worrying as not wearing a gas mask, so labels 5 and 6 have been included in the dataset.

Visualization of labels.
To increase the diversity of the dataset, this work has collected samples from environments similar to the primary data collection site. We used web crawler technology to obtain negative samples as supplementary data from image websites such as Bing Image Library and Baidu Image Library. Figure 3 shows the supplementary data. There are 6134 images from 15 different scenes in the dataset. Among them, 5180 samples from 11 scenes are used as the training data set, and 954 samples from the rest of the scenes are used as the test dataset.

The supplementary data from other scenarios and websites.
The data provided in Fig. 4a shows that the categories “front_head_wear_wrong” and “side_head_wear_wrong” have significantly fewer samples compared to the other categories. While this distribution may reflect the real-world scenario, it may lead to an imbalance between foreground and foreground and consequently, a reduction in the classification accuracy of the model. At this stage, due to unforeseen circumstances, we are unable to collect an even number of samples for each category. We plan to address this issue by collecting additional data in the subsequent phases of this project to refine the dataset. Figure 4b shows a scatter plot describing the length-width distribution of the labelled bounding boxes in the dataset. The majority of the bounding boxes are smaller than
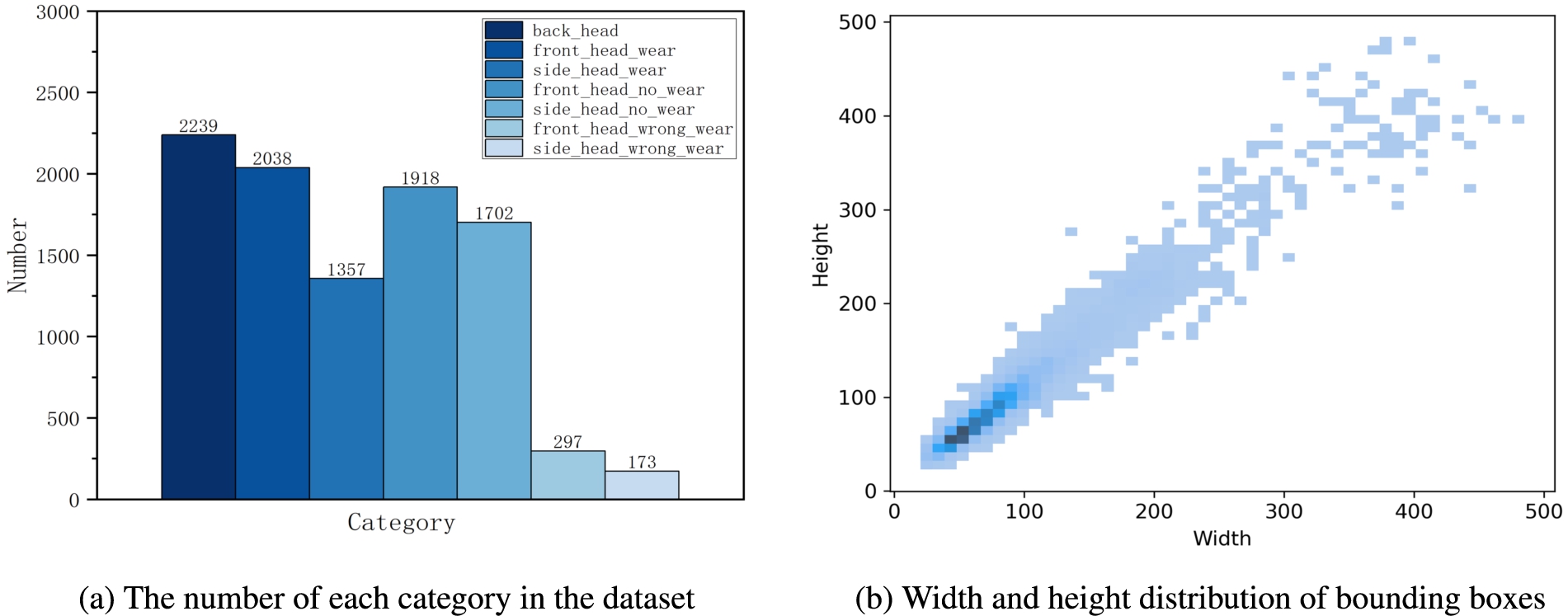
The statistics of the gas mask detection dataset.

The visualization effect of mixup and mosaic.
Data augmentation is an effective method for addressing imbalance issues and improving the generalization ability of models by utilizing a larger amount of data. Therefore, it is necessary to apply data augmentation techniques to expand the gas mask detection dataset. Given the labour-intensive nature of data collection and annotation, we employed two strategies to augment our existing data. Prior to training, we used data augmentation techniques such as random rotation, shearing and flipping to expand our dataset. During training, we further enhanced our data by using the MixUp [35] and Moscia [1] techniques to generate additional samples. The effect of these augmentations is shown in Fig. 5.
Mixup is a technique that mixes input and output data from different samples to generate new training samples. It can limit model overfitting to a single sample, further improving the model’s ability to discriminate target features from background features. The samples are interpolated using Eq. (1) and Eq. (2).
Faster R-CNN network
Faster R-CNN consists of three main components: Backbone, Region Proposal Network (RPN) and Region of Interest (ROI) head [26]. Both the RPN and the ROI head share the feature map extracted from the backbone. The RPN generates proposal regions based on the input feature map, and then these regions are processed by the ROI Head, which performs coordinate regression and classification. Prior to RPN, Fast R-CNN used a selective search algorithm [6] to generate candidate boxes, which is computationally expensive. To address this problem, RPN was developed by using convolutional neural networks for feature extraction to generate candidate box locations. This approach reduces the computational overhead associated with selective search algorithms.
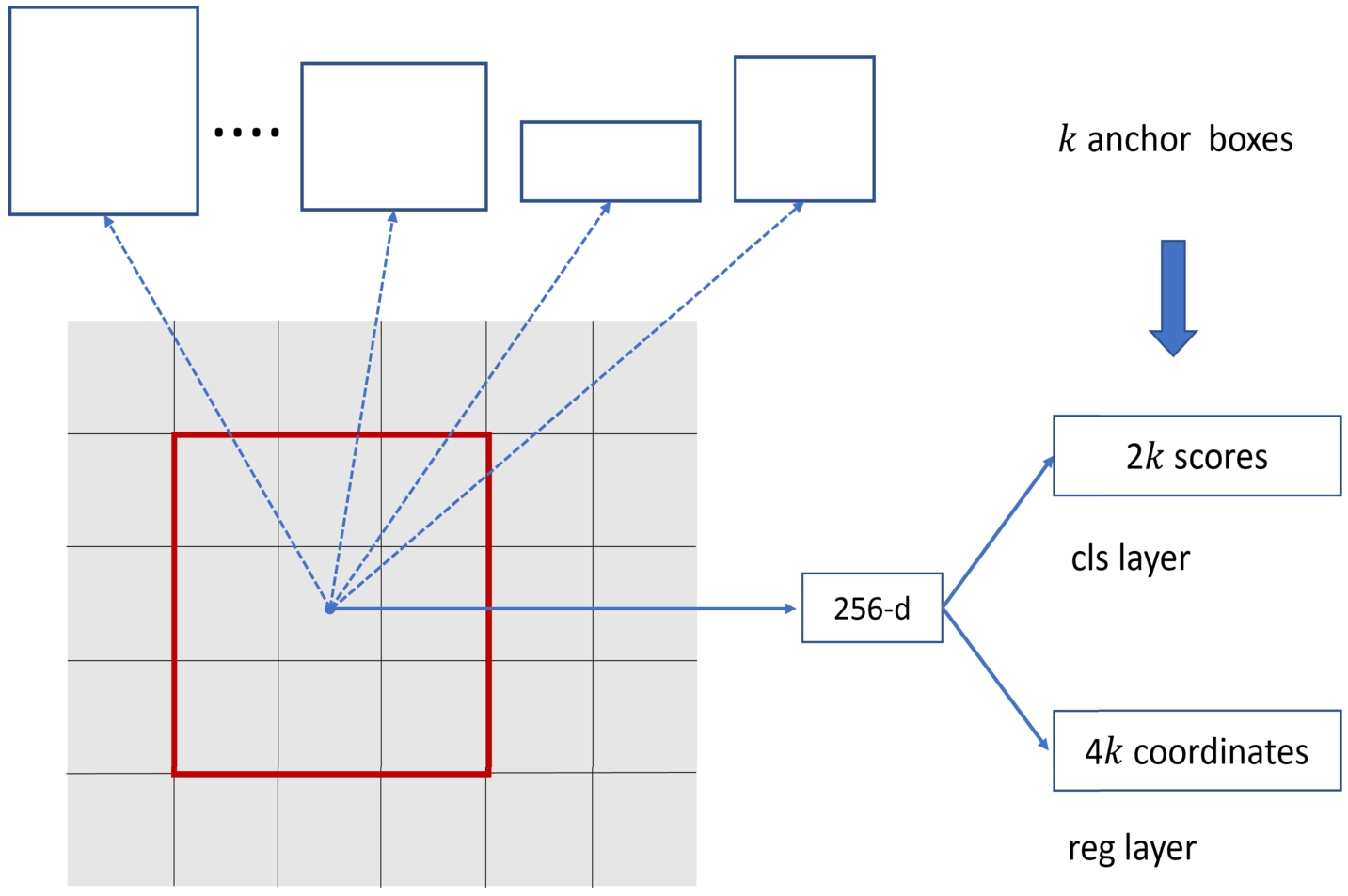
Region proposal network.
The main idea of RPN shown in Fig. 6 is to generate numerous candidate boxes of possible targets. The input of RPN is derived from the feature maps generated by the backbone. It then uses a sliding window to process these feature maps and simultaneously predict k candidate boxes. Each sliding window generates a 256-dimensional intermediate vector and feeds this vector into two fully connected layers for category and coordinate prediction. The class score is the probability that a candidate box belongs to foreground and background. In the algorithm, the k candidate boxes are parameterised as anchors. To make the network more applicable to targets of different shapes and sizes, RPN presets k anchor boxes with different aspect ratios at each position of the feature map to predict candidate regions for images of different scales. Therefore, all sliding windows simultaneously predict k anchor boxes, and the output of each sliding window is
The Feature Pyramid Network (FPN) mainly solves the multi-scale problem in object detection, and significantly improves the performance of small object detection by simply changing the network connectivity, with no increase in the computational complexity of the original model. During the forward computation of a convolutional neural network, the lower layers contain less semantic information but provide a more accurate target location. Conversely, the higher layers contain more semantic information but offer a coarser target location. To address this issue, FPN combines semantic features and location information from both higher and lower layers of the network using bottom-up paths, top-down paths, and horizontal connections. This approach greatly improves the model’s ability to detect multi-scale objects, especially small objects. The structure of FPN is shown in Fig. 7.
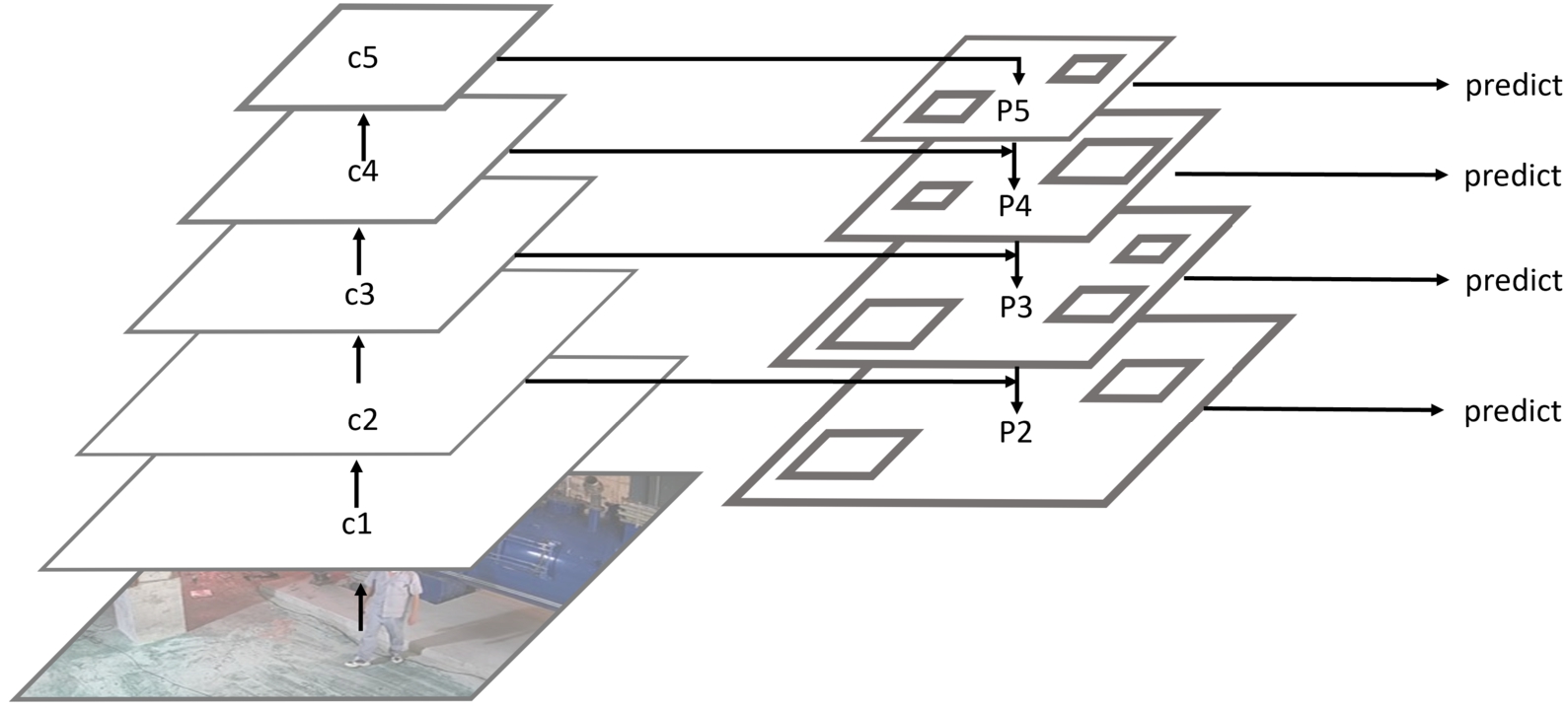
Feature Pyramid Network.
In this paper, ResNet [7] is used as the backbone. It has five convolutional processes, and the first convolutional process is not included in the feature pyramid because it is computationally intensive. The outputs of the last four convolutional processes are denoted as C2, C3, C4, C5 and the outputs of FPN are denoted as p2, p3, p4, p5. C5 enters the top-down path by a
In the training process, RPN will produce a large number of random candidate boxes. Due to the small proportion of the gas mask target in the image, the number of background candidate boxes will be too large, and the ratio between the number of background candidate boxes and foreground candidate boxes will be seriously unbalanced, which may result in a model that is highly biased towards background prediction. To address the problem of unbalanced positive and negative samples, this article uses the Online Hard Example Mining in the training process of Faster R-CNN. As shown in Fig. 8, ROI head is expanded into two networks that share parameters. One of the ROI head’s parameters is fixed, which is used to calculate and sort the loss of all candidate regions and select some regions with significant losses as complex samples. The other ROI Head is trainable, its input is the hard samples selected by the previous ROI Head, and its output is the predicted bounding box coordinates and classification results. In a word, OHEM adds another ROI head to select hard examples and then uses them to train the standard ROI head. OHEM can improve model accuracy, reduce overfitting, and improve training computational efficiency. In addition, the algorithm does not need to set the ratio of positive and negative samples, greatly reducing the difficulty of training.
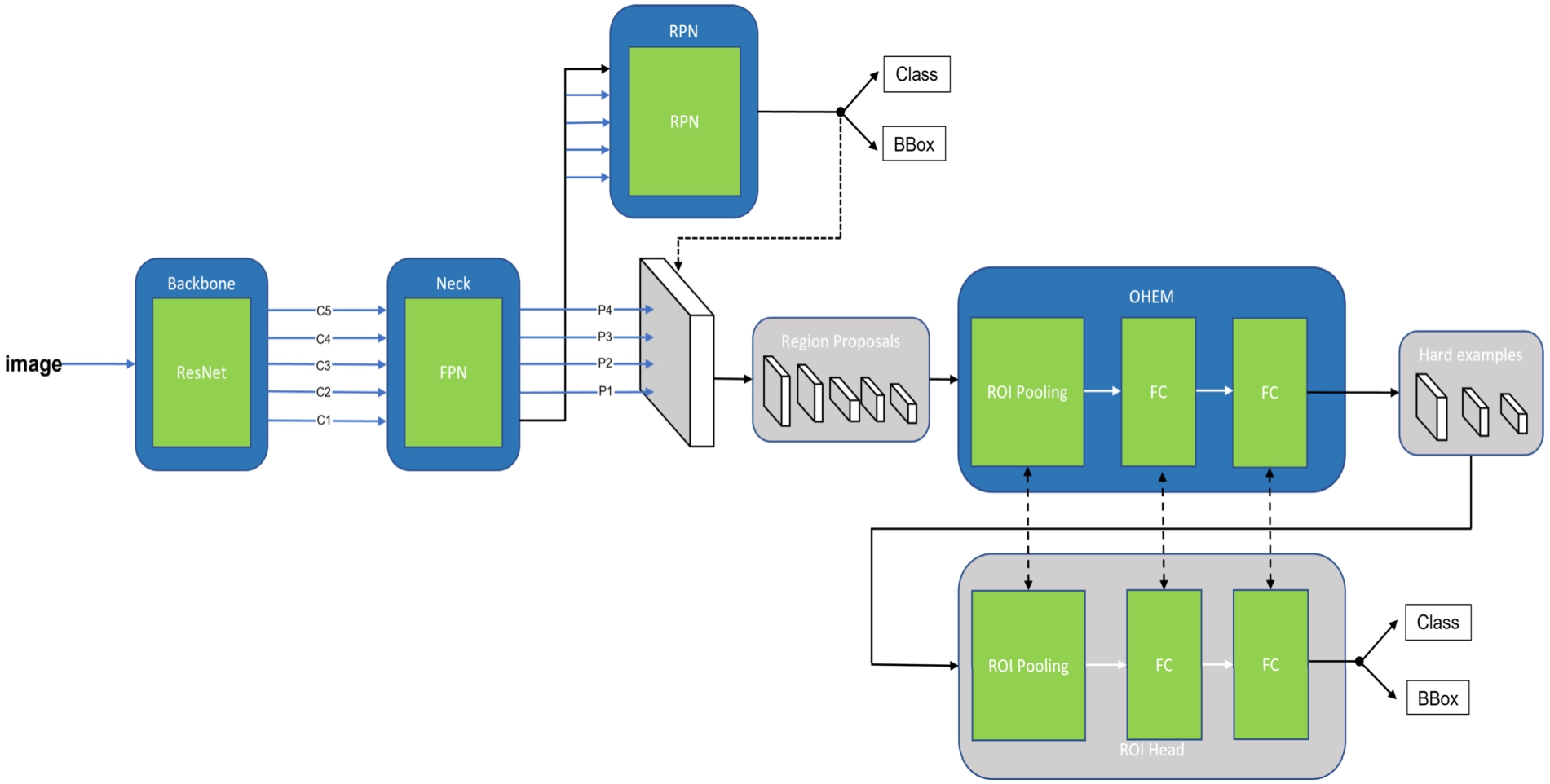
The structure of Faster R-CNN with FPN and OHEM.
Experimental platform and parameters
Our models were trained and tested on the Nvidia GTX 3090, using randomly sized images of
Evaluation metrics
In this article, the trained Faster R-CNN is used to perform experiments on a test dataset to verify its recognition accuracy and generalization ability. Unlike the classification task, the output in the object detection task is the confidence level and the coordinates of the detected object. When evaluating the performance of the model, the confidence threshold and the intersection union ratio (
The
Experimental results and analysis
This section compares different methods in Faster R-CNN using a test input size of
Effects comparison of different methods
Effects comparison of different methods
The
Comparison with other models
The
Detection effect under different confidence thresholds
This work compared Faster R-CNN with classic models such as SSD, YOLOv3, RetinaNet, YOLOv5, and Cascade R-CNN [2], as well as recent models such as YOLOX [4], YOLOv6 [11], YOLOv7 [31], and Dynamic R-CNN [34]. To demonstrate the model’s detection ability at different input scales, we conducted tests using input sizes of
In practical applications, a high confidence threshold is typically employed to filter out a large number of false detections. However, as the confidence threshold increases, the false negative rate of the model also increases, leading to decreased stability. To demonstrate the robustness of our model, we evaluate its detection accuracy at different confidence thresholds (0.1, 0.2, 0.3 and 0.4) on the original

Visualization results from the test dataset.
In order to effectively demonstrate the outcomes of our research, we selected some images from our test dataset to illustrate the results of our experiments. As can be seen in Fig. 9, our model demonstrates a high degree of accuracy in detecting the objects of interest, with a decent recognition impact overall. The target location of the model is largely accurate, with fewer false positives. However, there are some instances where the model mis-detected the backgrounds, resulting in false positives in the output. It is worth noting that our approach is not without its limitations, and there is still room for improvement. Future research could explore other techniques to improve the detection accuracy of gas masks in some challenging scenarios, such as false detection of complex backgrounds.
In this article, we present our work on producing a gas mask dataset and training an effective gas mask detector using the classical Faster R-CNN to meet the practical needs in industrial production. To address the multi-scale problem, we incorporated the Feature Pyramid Network into the Faster R-CNN, resulting in a substantial improvement in the detection performance of the model. To address the issue of class imbalance, we utilized OHEM during the training process. Furthermore, to enhance the dataset during the model’s training, we applied Mixup and Mosaic techniques. Based on the experimental results, we analyzed the problems encountered during the dataset and model training. However, there is still ample room for improvement in our research. In future work, we plan to extend the number of scenarios, enrich the dataset, and conduct in-depth analyses of the features of each scenario. Moreover, we will explore better models and investigate effective deployment systems to meet real engineering needs.
Footnotes
Acknowledgements
This project was supported by the Provincial Natural Science Foundation of Anhui (No. 2108085QF264, 2108085QF268).
Conflict of interest
None to report.