
Abstract
Virtual borders are employed to allow humans the interactive and flexible restriction of their mobile robots’ workspaces in human-centered environments, e.g. to exclude privacy zones from the workspace or to indicate certain areas for working. They have been successfully specified in interaction processes using methods from human-robot interaction. However, these methods often lack an expressive feedback system, are restricted to robot’s on-board interaction capabilities and require a direct line of sight between human and robot. This negatively affects the user experience and interaction time. Therefore, we investigate the effect of a smart environment on the teaching of virtual borders with the objective to enhance the perceptual and interaction capabilities of a robot. For this purpose, we propose a novel interaction method based on a laser pointer, that leverages a smart home environment in the interaction process. This interaction method comprises an architecture for a smart home environment designed to support the interaction process, the cooperation of human, robot and smart environment in the interaction process, a cooperative perception including stationary and mobile cameras to perceive laser spots and an algorithm to extract virtual borders from multiple camera observations. The results of an experimental evaluation support our hypotheses that our novel interaction method features a significantly shorter interaction time and a better user experience compared to an approach without support of a smart environment. Moreover, the interaction method does not negatively affect other user requirements concerning completeness and accuracy.
Introduction
Nowadays, physical environments become more and more smart comprising different kinds of sensors and actuators for the perception and manipulation of the environment. These devices are connected via a network with each other, and in combination with intelligent software, such a smart environment is able to provide context-aware services to humans resulting in an intelligent environment [4]. A certain form of a smart environment, which we deal with in this work, is a smart home equipped with computing and information technology providing services to residents [2]. When additionally integrating a robot into a smart environment, this combination is referred to a network robot system (NRS), which extends the perceptual and interaction capabilities of the robot and environment [38]. This allows especially mobile robots, which are able to move in the environment using their locomotion system [10], to provide complex services to the residents, e.g. providing sophisticated healthcare services [25], tidying up rooms [33] or supporting humans in a kitchen [35]. The locations, that can be reached using the locomotion systems, are defined as the mobile robot’s workspace.
Although residents appreciate the services of mobile robots in their home environments, there are scenarios in which humans want to restrict the workspaces of their mobile robots, i.e. they want to define restriction areas. For example, restriction areas are needed (1) to exclude intimate rooms, such as bed- or bathrooms, due to privacy concerns [48], (2) to exclude carpet areas from the mobile robot’s workspace to avoid navigation errors [18] or (3) to indicate certain areas for working, such as spot vacuum cleaning [16]. These scenarios can be summarized to the problem, that we deal with in this work: the restriction of a 3-DoF mobile robot’s workspace and change of its navigational behavior according to the humans’ needs. A 3-DoF mobile robot operates on the ground plane and has three degrees of freedom, i.e. 2D position and orientation. The described problem is highly relevant for users living in human-robot shared spaces, such as home environments. Since a restriction area cannot be directly perceived by the mobile robot due to computational or perceptual limitations and/or explicit knowledge of a human is required, an interaction process between human and robot is necessary. This interaction process has to (1) allow a transfer of spatial information concerning the restriction areas and (2) has to provide a feedback channel to inform the human about the progress of the interaction process and its results.
Current state-of-the-art solutions focus on methods from the field of human-robot interaction (HRI) to specify restriction areas. For this purpose, the concept of a virtual border is employed, which is a non-physical border not directly visible to the user but that effectively and flexibly restricts a mobile robot’s workspace [43]. Thus, a mobile robot changes its navigational behavior and respects the user-defined restriction areas. In order to specify a virtual border in an interaction process, a user employs an interaction method, that is built around a user interface for interaction. Current interaction methods are either based on visual displays or mediator-based pointing gestures, e.g. using a laser pointer as pointing device [45]. Especially, the latter one is a natural and intuitive method of non-verbal communication making it applicable by non-expert users [46]. These non-expert users are residents of home environments and do not have much experience with robots but can interact with common consumer devices, such as tablets or smartphones.
However, despite of the natural and intuitive interaction using pointing gestures, this category of interaction methods requires a direct line of sight between human and robot’s on-board camera. Due to the limited field of view of mobile robots’ cameras, this yields a limited interaction space affecting the quality of interaction negatively, e.g. in terms of interaction time. Moreover, the feedback capabilities are limited to the mobile robot’s on-board components, e.g. non-speech audio [22] or colored lights giving feedback [5]. This also affects the quality of interaction negatively, e.g. in terms of user experience. Therefore, in this work our objective is the investigation of the role of a smart home environment in the interaction process to overcome these limitations. We hypothesize that the additional components of a smart home environment can improve the interaction time and user experience compared to a solution without support of a smart environment because additional sensors and actuators increase the perception and interaction capabilities. Moreover, we hypothesize that other user requirements, such as accuracy and completeness of the interaction method [45], will not be negatively affected.
Based on this objective, we contribute the following aspects to the state of the art. We investigate the effect of a smart environment on the interaction process of restricting a mobile robot’s workspace. Therefore, we propose a novel interaction method incorporating a smart home environment and laser pointer as interaction device. This interaction method encompasses (1) an architecture for a smart environment designed to support the interaction process, (2) the cooperation of human, robot and smart environment in the interaction process, (3) a cooperative perception including stationary and mobile cameras to perceive laser spots and (4) an algorithm to extract virtual borders from multiple camera observations.
The remainder of this paper is structured as follows: in the next section, we give an overview of related works concerning the restriction of mobile robots’ workspaces, the integration of robots into smart environments and interaction opportunities of network robot systems. Based on our objective and contributions of related works, we point out a research gap and formulate three open research questions as basis for the remainder of this work. Afterwards, we first formally define a virtual border as a concept to flexibly define restriction areas. This is the basis for our novel interaction method addressing the problem of restricting a mobile robot’s workspace. Details on the interaction method and how it addresses the research questions are given in Section 4. Subsequently, we evaluate the interaction method in comparison to a baseline method with the focus on the test of our hypotheses. Finally, we conclude our work, point out current limitations and suggest future work.
Related work
Mobile robot workspace restriction
As already stated in the introduction, current solutions to restrict the workspace of a mobile robot are based on sole HRI without support of a smart environment. Commercial solutions comprise magnetic stripes placed on the ground [29] and virtual wall systems based on beacon devices [8], that emit infrared light beams. Despite their effectiveness, they are intrusive, i.e. additional physical components on the ground are necessary to restrict the workspace, and inflexible, i.e. restriction areas are limited to certain sizes and shapes. Thus, they are not applicable for our problem because the considered scenarios require restriction areas of arbitrary sizes and shapes. An alternative is sketching restriction areas on a map of the environment containing occupancy probabilities [1]. These maps are created by today’s home robots and are used for navigation purposes. However, this interaction method is inaccurate, i.e. there are strong inaccuracies between the user-defined restriction areas as a result of an interaction process and the restriction areas to be intended for restriction by a human. This is caused by a correspondence problem between points on the map and in the environment [45]. In order to address this shortcoming, Sprute et al. introduced a framework for interactive teaching of virtual borders based on robot guidance [43]. This allows a user to guide a mobile robot, e.g. using a laser pointer as interaction device, and specify a virtual border as the robot’s trajectory [46]. Although this interaction is accurate due to the accurate localization of the mobile robot, the framework suffers from a linear interaction time regarding the border length and lacks an expressive feedback system. This is caused by the requirement concerning a direct line of sight between human and robot and limited on-board feedback capabilities. A comprehensive user study dealing with different HRI methods for teaching virtual borders revealed augmented reality as the most powerful interface for the given task [45]. However, this approach requires specialized hardware, i.e. a RGB-D tablet, which limits the potential number of users. Nonetheless, the user study showed that 36% of the participants, i.e. the second largest group, also preferred a laser pointer as interaction device due to its simplicity, comfort and intuitiveness during interaction. These advantages of a laser pointer are also revealed in other robot tasks, such as guiding a mobile robot to a 3D location [21], controlling a robot using stroke gestures [19] and teaching visual objects [34].
Network robot systems
In order to benefit from the advantages of laser pointers and reduce their limitations caused by the requirement concerning a direct line of sight for interaction and limited on-board feedback capabilities, we investigate the incorporation of a smart home environment with additional sensors and actuators into the interaction process. This integration of robots into smart environments is known as network robot systems (NRS) [38]. Such a system is characterized by five elements: physical embodiment, autonomous capabilities, network-based cooperation, environment sensors and actuators and human-robot interaction. Other related terms are ubiquitous robots [23], physically embedded intelligent systems (PEIS) [36], Kukanchi [30] and informationally structured environment [31]. This ubiquitous robotics paradigm is leveraged to provide more complex and more efficient robot services to humans. For example, Sandygulova et al. developed a portable ubiquitous robotics testbed consisting of a kitchen equipped with a wireless sensor network, a camera and mobile robot [37] and Djaid et al. integrate a robot wheelchair with a manipulatable arm into an intelligent environment [11]. Other applications comprise the improvement of a mobile robot’s object search [41], the development of a human-aware task planner based on observations of the smart environment [9] and a gesture-based object localization approach for robot applications in intelligent environments [42]. All these approaches show that the cooperation between robots and a smart environment can improve the quality of robot applications, e.g. through enhanced perception and interaction abilities [40].
Interaction in smart environments
However, only a single attempt was made to employ a smart environment to restrict the workspace of a mobile robot, i.e. Liu et al. use several bird’s eye view cameras mounted in the environment to visualize a top view of the environment on a tablet’s screen on which the user can draw arbitrary restriction areas [26]. But this approach relies on a full camera view coverage of the environment and does not deal with partial occlusions, e.g. by furniture. Therefore, it is not applicable to our problem because a home environment is typically not fully covered by cameras due to privacy concerns [3]. Nonetheless, there are already works dealing with the recognition of laser pointer gestures using cameras of a smart environment, e.g. Shibata et al. propose a laser pointer approach to allow humans to control a mobile robot [39]. Similarly, Ishii et al. use cameras integrated into the environment for laser spot tracking allowing a human to define stroke gestures with a laser pointer to control a network-connected mobile robot [19]. These approaches are no more limited to the mobile robot’s field of view and thus increase the interaction space. However, the gestures are exclusively recognized by cameras integrated in the smart environment. Hence, the interaction strongly depends on the number of cameras in the environment and their fields of view. There is no work considering a cooperative behavior employing cameras from the smart environment and the mobile robot for this task. This would be an opportunity to overcome issues concerning camera view coverage and occlusions. Moreover, smart environments provide additional visualization capabilities that could be used to provide feedback to the human, e.g. visual displays integrated into the environment [6,20].
Research gap
These findings lead us to the general question, we want to answer in this work: how can a smart home environment improve the interaction process of restricting a mobile robot’s workspace using a laser pointer with respect to the interaction time and user experience? This question involves research questions of (1) which sensors and actuators of a smart environment can be used to benefit the interaction process, (2) how to realize a cooperation of human, robot and smart environment in the interaction process and (3) how to cooperatively perceive and combine multiple camera observations of laser points to restrict the mobile robot’s workspace. These questions are the basis for the remainder of this work, which will be answered by prototypically implementing a solution and an empirical evaluation.
Virtual borders
Before we present our solution to the given problem, we first introduce the concept of a virtual border in more detail. As already mentioned, this is a non-physical border not directly visible to a human but respected by a mobile robot during navigation. It comprises spatial information necessary to define a restriction area in an interaction process. Thus, a virtual border can be used to interactively specify restriction areas, such as carpets or privacy zones. This concept was already formally defined as a triple In this work, we only consider 100% to indicate occupied areas, but in the future this component could be used to model levels of restriction. For example, an occupancy of 75% could mean that a mobile robot should avoid this area unless it is necessary.
Due to the advantages of mobile robot applications integrated into smart environments and the drawbacks of current solutions for our problem, i.e. the restriction of a mobile robot’s workspace and change of its navigational behavior, we take up the opportunity of an enhanced perception and interaction capability provided by a smart home environment in this work. To this end, we first present a smart home design and explain how smart home components can be leveraged to address limitations of current solutions. Subsequently, we describe how these smart home components are incorporated into the interaction process between human and robot. Thus, this cooperative behavior results in a novel interaction method based on human-robot-environment interaction. Finally, we present details on the cooperative perception based on smart home’s and mobile robot’s cameras, which is a fundamental part of the proposed interaction method. It is the goal to combine multiple camera observations of laser points and extract a single virtual border from these observations. For this purpose, we developed a novel multi-stage algorithm addressing several challenges.
Smart environment design
As stated in Section 2, laser pointers are quite popular for human-robot interactions involving the transfer of spatial information due to their natural interaction mimicking human pointing gestures. For example, our baseline method for the restriction of a mobile robot’s workspace employs a laser pointer as interaction device [46]. Nonetheless, this kind of interaction features some drawbacks. The major drawback of the existing interaction method is the requirement concerning a direct line of sight between human and robot when specifying virtual borders. Thus, the mobile robot has to follow the laser spot, but it is restricted by velocity constraints, which lead to a relatively long interaction time. Moreover, only limited feedback about the current state of the interaction process can be conveyed using simple on-board LEDs and non-speech audio sound, e.g. the robot provides a beep sound whenever a laser spot is detected. However, no complex feedback concerning the spatial information of the specified virtual borders can be provided to the human using these communication channels. Another drawback of the baseline approach is the interaction to change between different states of the interaction process, e.g. specifying virtual border points or the seed point. For this purpose, visual codes generated by the laser pointer or push buttons on the mobile robot are provided. But visual codes can be error-prone due to changing light conditions and interaction using buttons requires the user to be in the vicinity of the robot.
Addressing these shortcomings of the baseline approach, we propose the incorporation of additional smart home components in the interaction process as the answer to our first research question. This deals with the question of which sensors and actuators of the smart environment can be used to benefit the interaction process. Our proposed smart home environment is shown in Fig. 1 and mainly consists of three components: (1) a camera network comprising stationary RGB cameras, (2) a smart display and (3) a smart speaker allowing the processing of voice commands. The first component, i.e. the camera network, is intended to increase the perceptual capabilities in combination with the mobile robot’s on-board camera. Stationary cameras are integrated (yellow and red fields of view) to cover certain areas of the environment, while a mobile camera mounted on a robot (blue field of view) can observe areas that are not covered by the stationary cameras due to their installation or occlusions, e.g. under the table. Hence, this combination allows perception even if the stationary cameras do not cover all areas of the environment, which is typically the case in smart home environments. The second component, i.e. the smart display, is intended to provide expressive feedback to the user by visualizing the progress and result of the interaction process. Finally, it is the idea to employ a smart speaker to facilitate the change of different states of the interaction process using voice commands.

A person defines a virtual border in the environment using a laser pointer. The spot is observed by stationary cameras in the environment (yellow and red) and a mobile camera on a robot (blue). A smart display (top right) provides visual feedback of the complex spatial information, and a smart speaker facilitates interaction.
In order to achieve our objective of a reduced interaction time and increased user experience compared to the baseline approach, we propose a new interaction method leveraging the combination of a mobile robot and the described smart home environment in the interaction process. We denote this combination as network robot system (NRS) in the following. This interaction method is intended to answer our second research question of how to realize a cooperation of human, robot and smart environment in the interaction process. As pointed out in the introduction, the interaction process between human and robot (1) has to allow a transfer of spatial information from human to robot and (2) has to provide feedback about the interaction process from robot to human. The first property is addressed by allowing a user to specify virtual borders by “drawing” directly in the environment using a common laser pointer. A laser spot is cooperatively perceived by the stationary camera network and the mobile robot’s on-board camera.
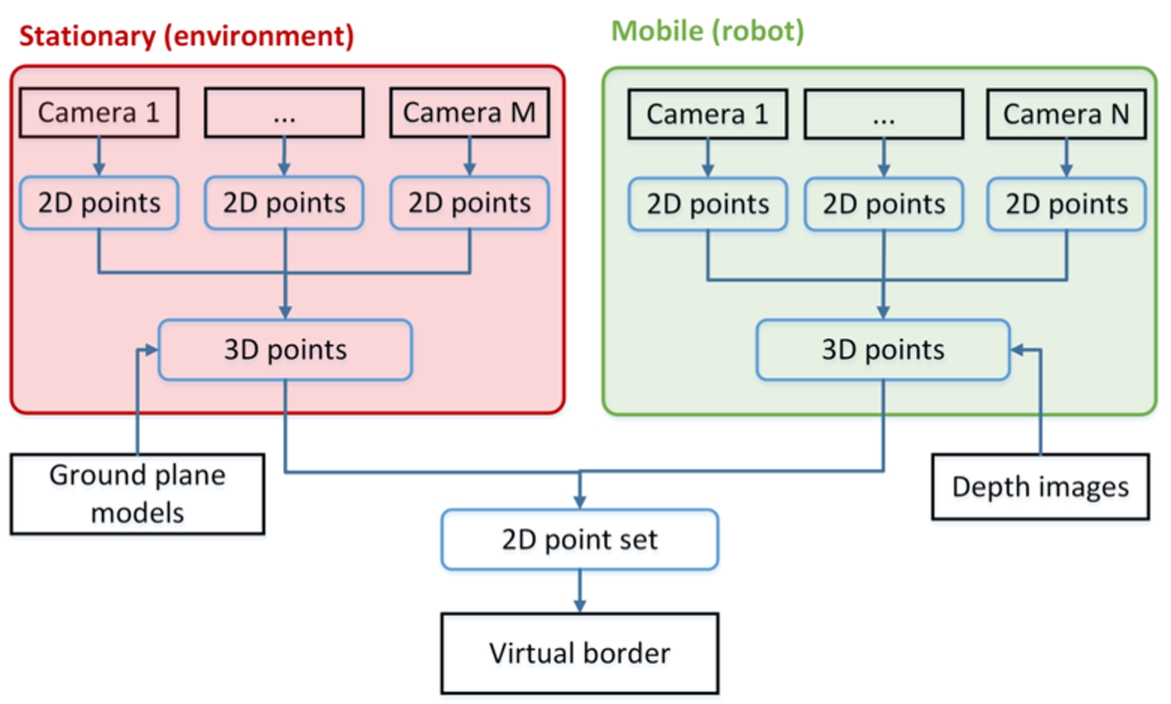
Architecture of the cooperative perception for specifying virtual borders based on multiple camera views.
The interaction method comprises several internal states, that reflect the three components of a virtual border as described in Section 3. The states are described as follows:
In order to switch between the different states, a user can employ the following speech commands, that are perceived and processed using the smart speaker integrated into the smart home:
Finally, we realize the second property of an interaction process, i.e. a feedback channel from robot to human, by extending the baseline’s feedback system. In addition to mobile robot’s non-speech audio sound and colored light feedback indicating state changes and the detection of a laser spot, we use the smart display integrated into the environment to provide more complex feedback. This includes the visualization of the 2D OGM of the environment, the mobile robot’s current position on the map and the progress of the spatial information transfer. After successfully accomplishing an interaction process, the mobile robot’s workspace containing the user-defined virtual borders is also shown on the display.
While the incorporation of the smart display and smart speaker in the interaction method is straightforward, the incorporation of the camera network, which is used to increase the interaction space, is more challenging. There are mainly two reasons: (1) multiple cameras, stationary and mobile, have to be integrated into an architecture that supports the interaction process and (2) a single virtual border has to be extracted from multiple camera observations including noisy data.
Architecture
Addressing the first aspect, we propose the architecture, that is illustrated in Fig. 2, as a first part of our answer to the third research question of how to cooperatively perceive and combine multiple camera observations to restrict the mobile robot’s workspace. The architecture consists of M stationary cameras integrated in the environment and N mobile cameras on mobile robots.2
Although we consider a single mobile robot in this work, we designed the architecture with multiple mobile cameras due to scalability options in the future.
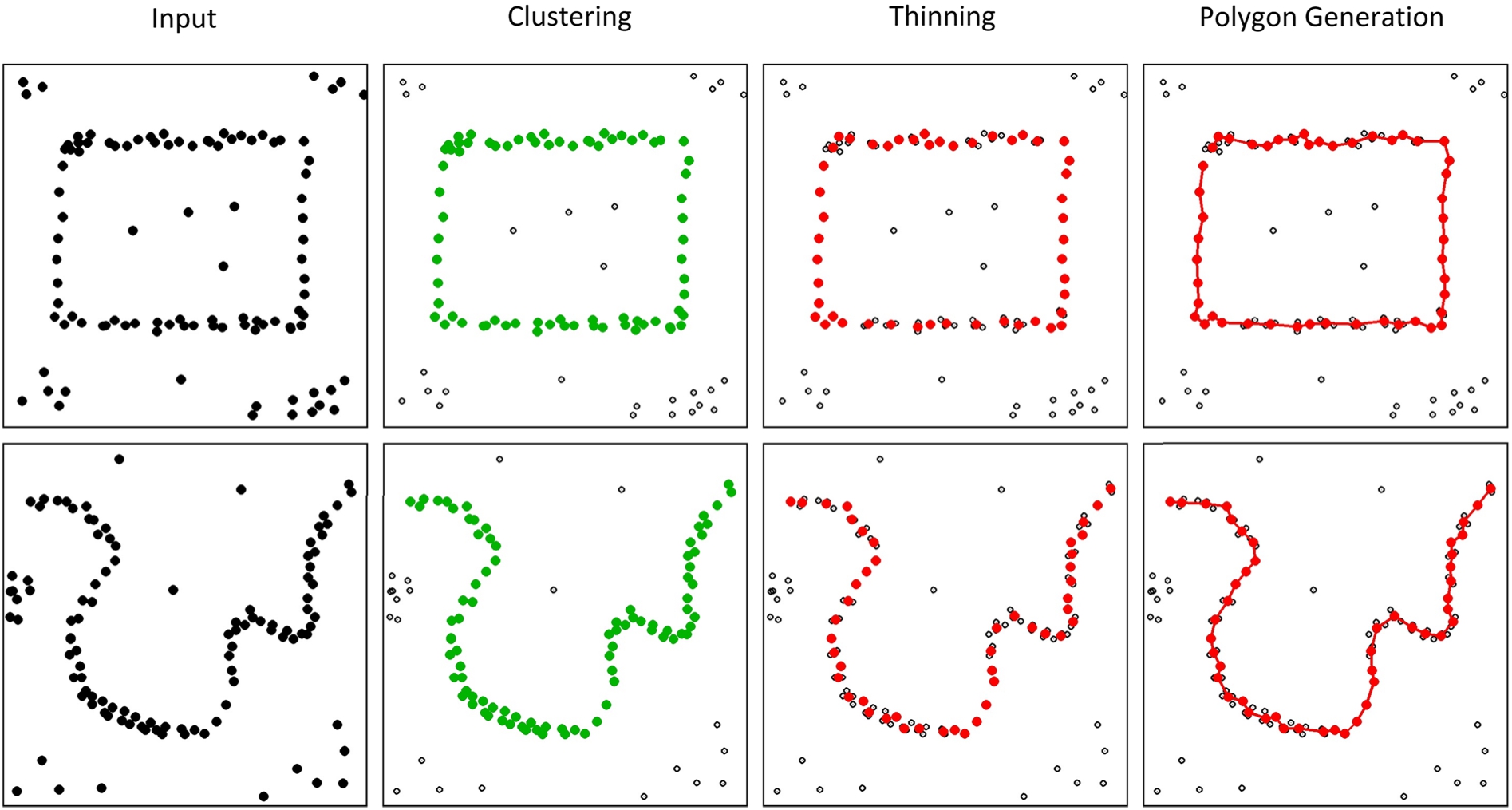
Processing stages extracting a polygonal chain from a point set including noise. Each row corresponds to a user-defined point set, a polygon in the first and a separating curve in the second row. The first column visualizes the input point set containing virtual border points but also noise and other clusters. The points assigned to the virtual border cluster are colored green in the second column. Thinning the virtual border cluster yields the red point set in column three. This is used to generate a polygonal chain as shown in the last column.
While the extraction of the seed point

Clustering step
Clustering The first stage of the extraction algorithm is the clustering stage as denoted in Algorithm 1. The input is a 2D point set
Thinning The second stage of the algorithm is the thinning stage (Algorithm 2), that reduces the number of points in the largest cluster from the previous stage. It is designed to remove spatially redundant data points and to smooth data points due to localization errors and calibration inaccuracies. Thus, it addresses the third and fourth challenge of the virtual border extraction step. For this purpose, the thinning algorithm identifies spatially nearby data points and replaces them by their mean value. To this end, the point p with most neighbors within a distance

Thinning step

Polygon generation step
Polygon generation Finally, the thinned point set is the input
We use the parameter values shown in Table 1 for the algorithms. These were determined experimentally.
Parameter values for the algorithms
In order to evaluate our proposed interaction method and our hypotheses concerning user requirements, such as interaction time, user experience, completeness and accuracy, we conducted an experimental evaluation involving multiple participants and three scenarios for restriction areas in a smart home environment. The evaluation was inspired by the USUS framework, that provides a methodological framework to evaluate certain aspects of a system involving the interaction of human and robot [47].
Independent variables
In our experiment, we manipulated a single independent variable, i.e. the interaction method. This variable can have one of the two values:
Hypotheses
The objective of the experimental evaluation was the test of the following hypotheses:
Setup
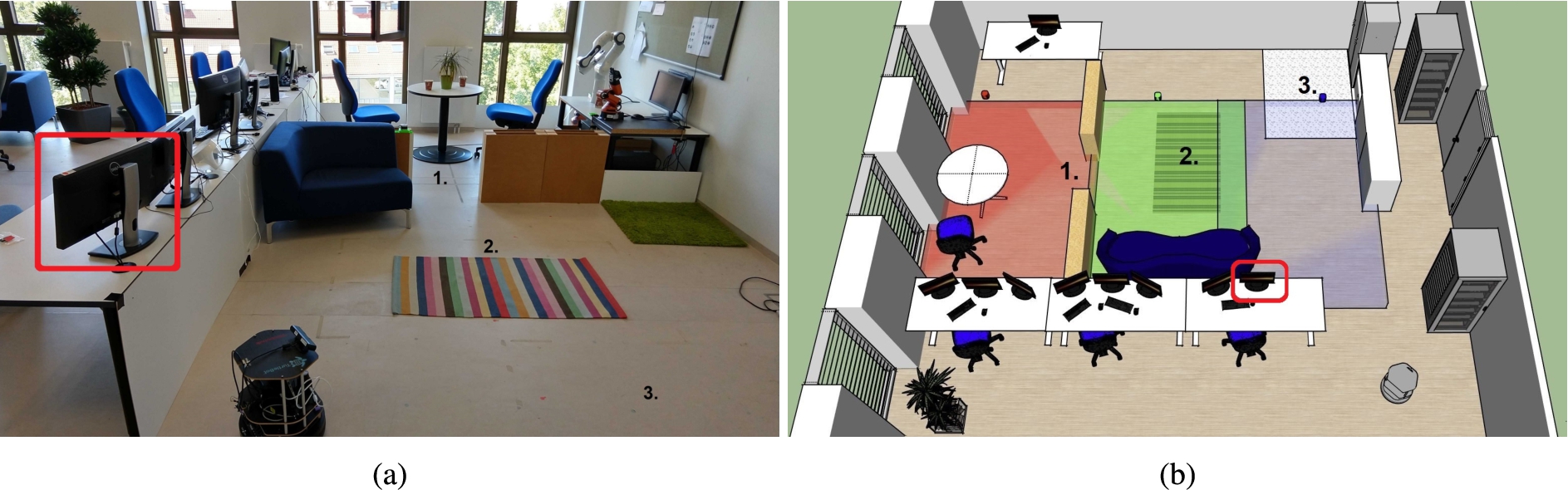
Image and 3D sketch of the lab environment. The three evaluation scenarios are numbered, and the three cameras’ fields of view are visualized in red, green and blue. The position of the smart display for feedback is encircled in red, and the mobile robot’s initial pose is depicted in the bottom right of the sketch.
To test our hypotheses, we motivated our experimental setup by three scenarios for restriction areas as presented in the introduction, i.e. (1) privacy zones, (2) carpets and (3) dirty areas. For this purpose, we set up a home environment in our 8 m × 5 m lab environment comprising free space, walls, plants and furniture, such as tables and chairs. Additionally, we integrated adjustable walls with a height of 0.5 m to model two different rooms in the environment. Besides, we placed a carpet on the ground and some dirt in one area of the environment as basis for the evaluation scenarios. An image and 3D sketch of the environment is shown in Fig. 4.
As a mobile robotic platform, we employed a TurtleBot v2 equipped with a laser scanner for localization and a front-mounted RGB-D camera. This is a typical evaluation platform whose mobile basis is similar to a vacuum cleaning robot with differential-drive wheels. The camera’s color images were captured with a resolution of 640 × 480 pixels, and the depth sensor had a resolution of 160 × 120 pixels. Additionally, the robot had a colored on-board LED, three push buttons and a speaker. A prior OGM of the environment (2.5 cm per cell) was created beforehand using a Simultaneous Localization and Mapping (SLAM) algorithm running on the mobile robot [15], and the mobile robot was localized inside the environment using the adaptive Monte Carlo localization approach [13]. This allows the robot to determine its 3-DoF pose, i.e. position and orientation, with respect to the map coordinate frame.
In order to take advantage of a smart home environment as described in Section 4.1, we mounted three RGB cameras with an image resolution of
After setting up the experimental environment, each participant was introduced to the following three evaluation scenarios. These scenarios covered both types of virtual borders and are good representatives for restriction areas:
In addition to the camera view coverage of the restriction areas as described, it was possible that participants temporarily occluded restriction areas with their bodies depending on their positions during interaction.
In this experiment, we applied a within-subjects design, i.e. each participant evaluated both interaction methods in all three evaluation scenarios. The order of the selected interaction method was randomized to avoid order effects. After selecting an interaction method, an experimenter explained a participant how to employ the selected interaction method, i.e. a short introduction into the different states of the system, how to switch between states and how to use the laser pointer. Afterwards, a participant had some time to get familiar with the interaction device, i.e. the participant could use the laser pointer and guide the mobile robot. This took approximately five minutes. Subsequently, the participant started to specify virtual borders for the three scenarios. The order of the different scenarios was randomized. At the beginning of each scenario, the mobile robot’s initial pose was set to a predefined pose to allow the comparison between the results. This initial pose, that was not covered by a stationary camera, is shown in the bottom right of Fig. 4b.
The shortest paths to the restriction areas in the three scenarios were between 2.50 m and 5.40 m (Scenario 1: 5.40 m, Scenario 2: 2.50 m and Scenario 3: 3.00 m). Since we applied a within-subjects design, this procedure resulted in six runs per participant (three scenarios and two interaction methods) and a participant could compare both interaction methods. After performing the practical part of the experiment, each participant was asked to answer a post-study questionnaire concerning his or her user experience with the interaction methods. An experiment with a single participant took approximately 20 minutes in total.
Measurement instruments
During the experiment, the time needed to specify a virtual border for each participant, interaction method and scenario was measured. Thus, we obtained six measurements for each participant. The time measurement started with the change from the Default state to one of the active states and ended with the integration of the virtual border into the prior map. Moreover, the time measurement was decomposed according to the three active states of the system, i.e. guiding the mobile robot (
In addition to the time, an experimenter documented if a participant successfully specified a virtual border for an evaluation scenario, i.e. a participant could specify the virtual border points
To measure the user experience, participants were asked to answer a post-study questionnaire. In addition to general information, such as age, gender and experience with robots, the questionnaire contained five statements concerning the user experience, that could be rated on 5-point Likert items with numerical response format. This questionnaire was inspired by the questionnaire of Rouanet et al., who used a similar questionnaire to assess the usability and user experience of human-robot interfaces [34]. The questionnaire included the following statements about the experiment (translated from German):
I had problems to define the virtual borders (1 = big problems, 5 = no problems) It was intuitive to define the virtual borders (1 = not intuitive, 5 = intuitive) It was physically or mentally demanding to define the virtual borders (1 = hard, 5 = easy) It was easy to learn the handling of the interaction method (1 = hard, 5 = easy) I liked the feedback of the system (1 = bad/no feedback, 5 = good feedback)
Furthermore, the participants were asked if the smart environment supported the interaction process. They could answer the question with yes or no.
The fourth evaluation criterion is the accuracy, that we assessed by calculating the Jaccard similarity index (JSI) between a user-defined UD and its associated ground truth GT virtual border:
Participants
The experiment was conducted with a total of 15 participants (11 male, 4 female) with a mean age of
Tools
We implemented all components of the system as ROS nodes [32]. ROS is a modular middleware architecture that allows communication between several components of a system, that are called nodes. ROS is the de facto standard for robot applications and provides a large set of tools to accelerate prototyping and error diagnosis. We organized all our nodes in packages to allow the easy distribution of our implementation. In order to save resulting maps of an interaction process for evaluation purposes, we implemented a node that directly stores the map on the hard disk whenever a new map is defined by a participant. Furthermore, we used integrated time functionality of ROS to perform time measurements for the evaluation. The visualization on the smart display was based on RVIZ, which is a 3D visualization tool for ROS.
Analysis & results
To test our hypotheses, we report the analysis and results of the experimental evaluation in this subsection. In case of statistical tests to identify differences between the interaction methods, we chose a significance level of
Interaction time
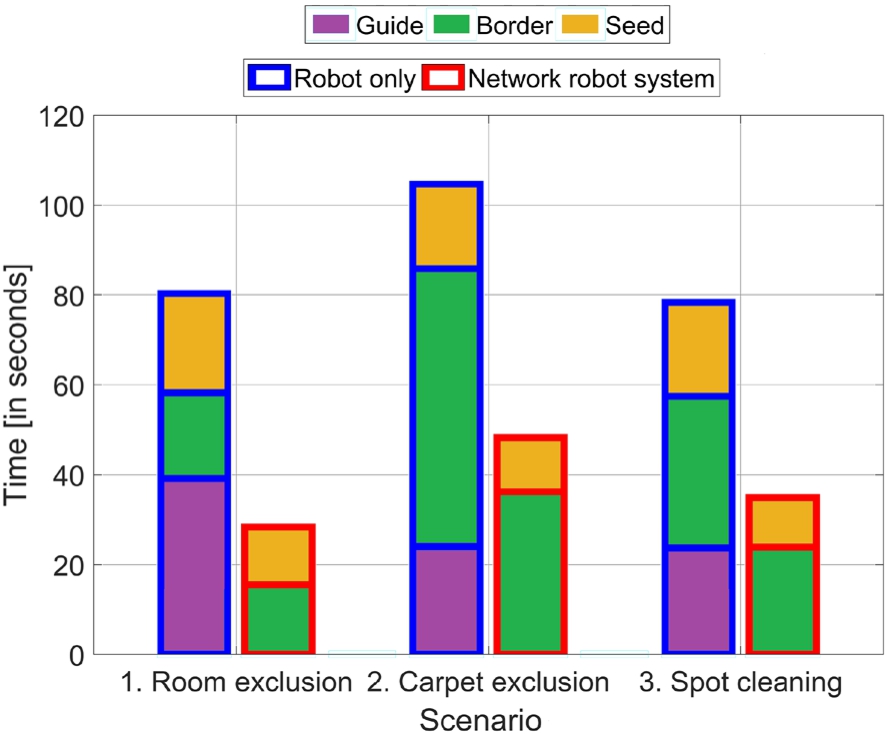
Interaction time for both interaction methods (blue and red contours around bars) based on the scenarios. Each bar is subdivided into the three active states of the system.
The interaction times of the experiment are summarized in Fig. 5. Each bar comprises the measurements of all 15 participants for an interaction method and scenario. Hypothesis 1 stated that the interaction time would be reduced when using the NRS compared to the Robot only interaction method. To test this hypothesis, we first ran Shapiro–Wilk tests to test for normality of the data (differences in the interaction times between the two interaction methods), which is an assumption of parametric statistical hypothesis tests, e.g. a paired t-test. These tests only became significant for the third scenario ( 1. Room exclusion: 2. Carpet exclusion: 3. Spot cleaning:
Our proposed NRS approach is significantly faster compared to the baseline approach. This results in speedups of 2.8, 2.2 and 2.2 for Scenarios 1, 2 and 3.
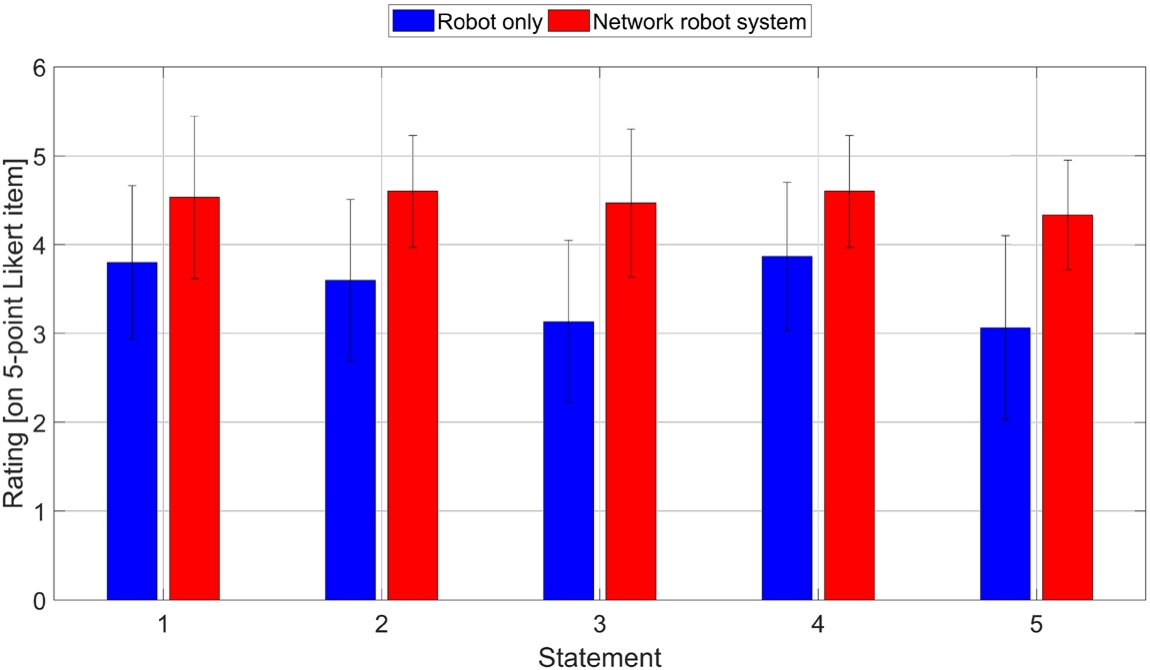
User experience for both interaction methods showing mean and standard deviation depending on the statements.
The reason for this significant difference is revealed by the decomposition of the time measurements. While the time for the Robot only approach is composed of all active states of the system, our NRS approach does not include the Guide state. This is a consequence of the human-robot-environment interaction where the NRS automatically sends the mobile robot to the intended restriction area when a laser spot is detected by a stationary camera. Therefore, the user is not restricted to the mobile robot’s line of sight and does not have to manually guide the mobile robot to the intended restriction area. Thus, the NRS approach can avoid the time in the Guide state. This time primarily depends on the distance between the robot’s start pose and the restriction area. As described in Section 5.4, the distances in our scenarios ranged from 2.5 m to 5.4 m. If the distances would be smaller, the time in the Guide state would also decrease. However, we think that we chose the distances quite liberally since much larger distances would be even realistic, e.g. in typical home environments with a single charging station for the mobile robot.
Another reason for the time difference between the interaction methods is the time in the state Border, which is linear with respect to the border length [46]. Thus, if the user-defined virtual border is short, e.g. 0.70 m for Scenario 1, our NRS approach is only slightly faster in this state, i.e. 4 seconds difference. But if we consider a larger virtual border, e.g. the 6.50 m long border around the carpet (Scenario 2), our approach is even 26 seconds faster on average. The reason for this is the mobile robot’s velocity limitation (0.2 m/s) to ensure a safe and smooth movement of the robot. By using our NRS approach, this speed limitation can be reduced if the laser spot is in the field of view of one of the stationary cameras. Our interaction method is then only limited by the detection rate of the cameras (25 frames/s). Hence, it also features a linear interaction time, but with a smaller gradient.
Another speedup is achieved when specifying the seed point (Seed state) because a user can directly indicate the seed point with laser points, which are detected by a stationary camera. In case of the Robot only approach, a user additionally has to rotate the mobile robot around its vertical axis to adjust the camera’s field of view. This rotation takes additional interaction time. In summary, the results support Hypothesis 1.
In order to assess the user experience and test Hypothesis 2, i.e. the user experience is better when employing the NRS compared to the Robot only interaction method, we considered the participants’ answers of the questionnaire introduced in Section 5.5. The participants’ answers to the questionnaire are visualized in Fig. 6 with their mean (M) and standard deviation (SD) per statement and interaction method.
Since Likert-item data violate the assumption of normality, we ran a Wilcoxon signed-rank test on the 15 answers per statement to determine whether there are statistically significant differences between both interaction methods. We found statistically significant differences for all statements in the questionnaire:
Statement 1: Statement 2: Statement 3: Statement 4: Statement 5:
Our proposed interaction method based on a NRS is better rated by the participants for all statements compared to the baseline approach. Participants had significantly less problems defining the virtual borders with a NRS (
Although the median should be used to describe the central tendency in non-parametric tests, we report the mean value in this paragraph to better reveal the differences between the interaction methods. This is valid since we consider an interval-level of measurement [17]. Moreover, since other studies often report mean values for Likert-items, we also want to make our results better comparable.
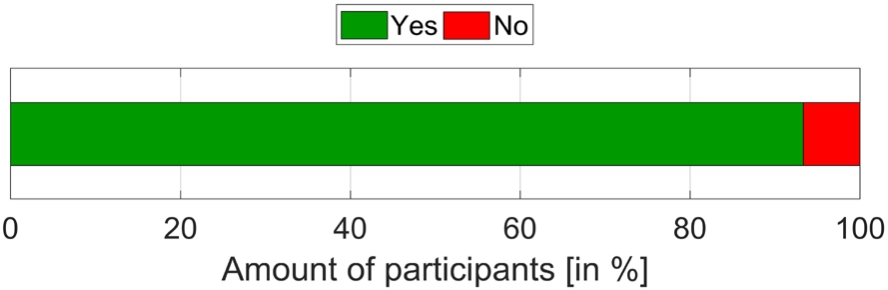
Answers of the participants to the question if the smart environment supported the interaction process.
Hypothesis 3 stated that the completeness does not significantly get worse when employing the NRS compared to the Robot only interaction method. The success rates are summarized in Fig. 8 as bars. Both interaction methods feature the same high success rate, i.e. 91.1% on average. Furthermore, the success rates for the three scenarios are the same (93.3% for Scenarios 1 and 2; 86.7% for Scenario 3). There were nine participants who performed all their runs successfully, four participants who failed for one of their six runs, and two participants incorrectly defined a virtual border in two of their six runs. The reason for these incorrect runs was the definition of the seed point
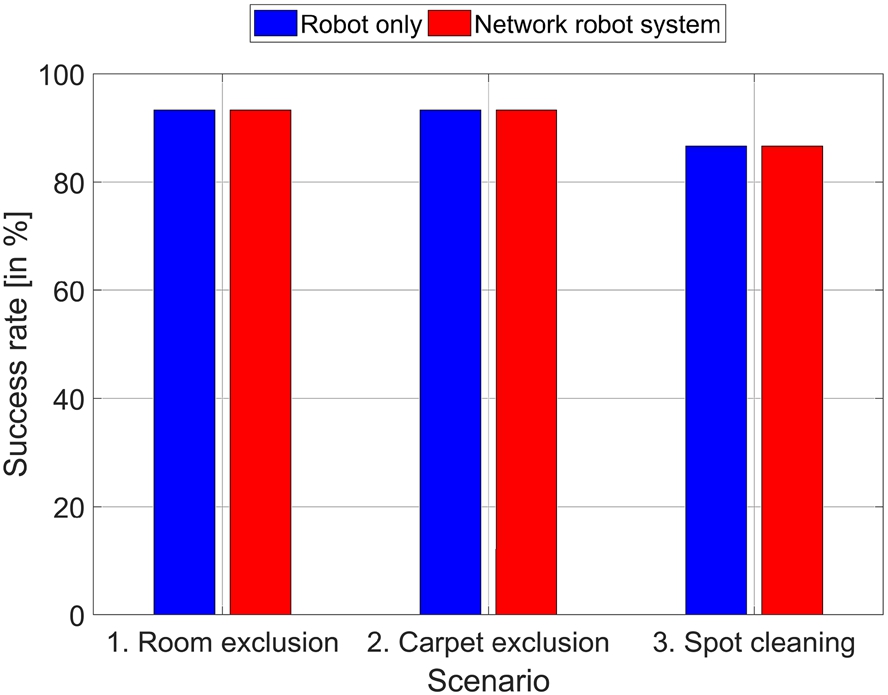
Completeness for both interaction methods depending on the scenarios.
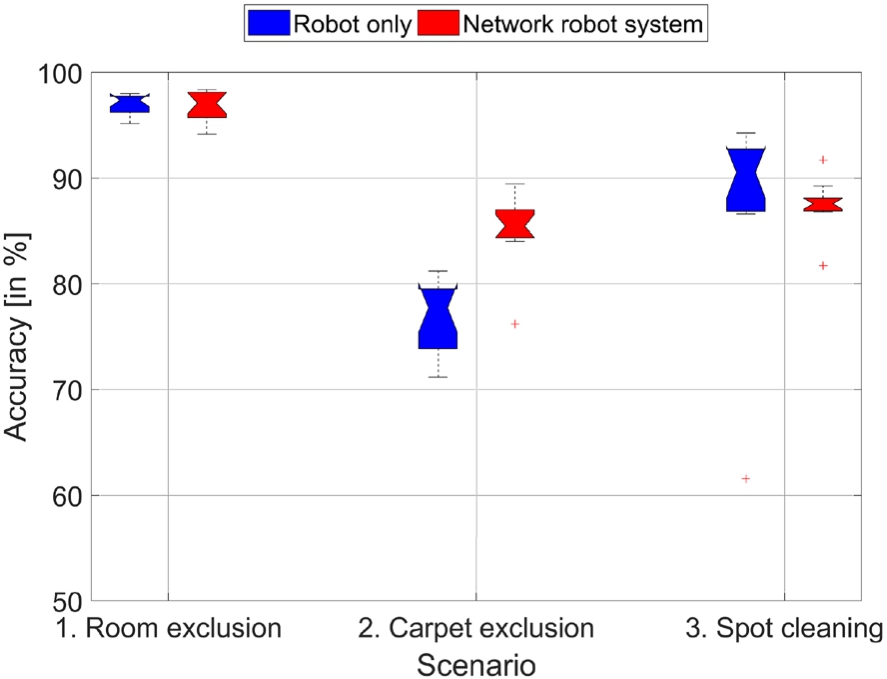
Quantitative accuracy results for both interaction methods depending on the scenarios.
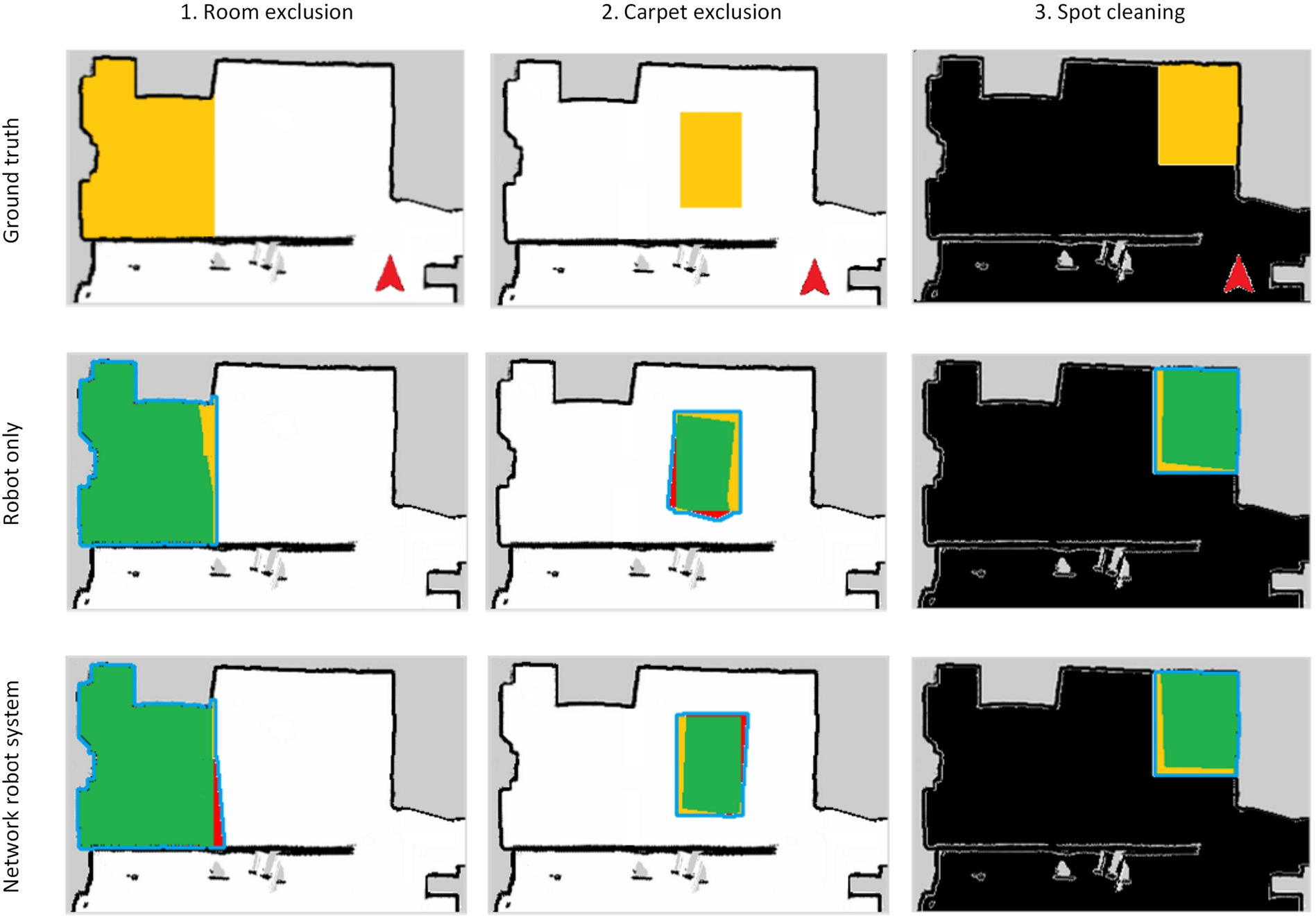
Visualization of representative accuracy results. The first row shows ground truth maps for all three scenarios containing occupied (black), free (white) and unknown (gray) areas. The yellow cells indicate the area to be specified by a participant during an interaction process (GT). The robot’s start pose is visualized as a red arrow. The following rows visualize the qualitative accuracy results for both interaction methods. A user-defined area as result of an interaction process is colored in green and red. Green pixels indicate the overlap of ground truth and user-defined areas (GT ∩ UD), while red pixels show areas defined by the user but not contained in the ground truth map (UD ∖ GT). A blue contour surrounds the union set of both areas (GT ∪ UD). Colors are only used for visualization.
Finally, Hypothesis 4 stated that the accuracy does not significantly get worse when employing the NRS compared to the Robot only interaction method. The JSI values resulting from the experimental evaluation are presented in Fig. 9. To test the hypothesis, we again explored the data for normality and outliers using Shapiro–Wilk test and boxplot interpretation. The Shapiro–Wilk tests did not become significant for any scenario indicating a normal distribution of the data. However, since the data for Scenarios 2 and 3 contain some outliers, we preferred a Wilcoxon signed-rank test to a paired t-test. The statistical results were different for the three scenarios:
1. Room exclusion: 2. Carpet exclusion: 3. Spot cleaning:
There is no significant difference for Scenario 1 (NRS:
We designed our experimental evaluation according to the idea that the environment is partially observed by stationary cameras and that there are typical restriction areas, such as carpets or privacy zones. This is a typical setting for a smart home environment. In this case, our results suggest that a smart environment can significantly improve the interaction time (Hypothesis 1) and user experience (Hypothesis 2) while not negatively affecting the completeness (Hypothesis 3) and accuracy (Hypothesis 4).
However, there are two important aspects, that influence the speedup in the interaction time: (1) the stationary cameras’ coverage of the environment and (2) the distance between the mobile robot’s start pose and the restriction area. If we would decrease the number of cameras in the environment and thus the camera coverage, this would result in a smaller reduction of the interaction time. This would finally degenerate to the baseline approach if there is no camera coverage. Moreover, the speedup strongly depends on the distance between the mobile robot’s start pose and the restriction area, which influences the performance of the baseline approach. This is due to the fact that the baseline approach requires a direct line of sight between human and robot, and thus a human first has to guide the mobile robot to the restriction area. For these reasons, it is not possible to report a specific speedup value. Nonetheless, in the evaluation scenarios we chose a typical camera coverage and reasonable distances, which are typical for home environments with a single charging station for a mobile robot. Hence, we conclude that the interaction time improves with the support of a smart environment, but we cannot report a specific speedup value. Therefore, the reported speedups in Section 5.8.1 are intended to give an estimate and are only valid for this specific experimental evaluation.
In case of the user experience, participants appreciated aspects, such as a reduced mental or physical demand during interaction and an improved feedback of the system. These are effects of the incorporation of the smart environment’s components. However, a participant also wished an even stronger feedback system. The participant did not like the change of attention between the sketching of the virtual border on the ground and the view on the smart display, which was positioned aside on a table. Therefore, we conclude that our choice of smart home components improved the user experience significantly but the incorporation of more expressive feedback channels could improve the user experience even more.
Conclusions & future work
In this work, we investigated the effect of a smart home environment on the interaction process of restricting a mobile robot’s workspace. For this purpose, we developed a novel interaction method leveraging a smart home environment and laser pointer in the interaction process. This NRS was designed to support the interaction process in terms of perception and interaction abilities. To this end, we first selected smart home components that we employed to realize a cooperative behavior between human, robot and smart environment in the interaction process. Especially, the cooperative perception involving stationary and mobile cameras to perceive laser spots and an algorithm to extract virtual borders from multiple camera observations is a major contribution of this work. This cooperation between mobile robot and smart environment neutralized the mobile robot’s perceptual and interaction limitations. This was supported by an experimental evaluation that revealed an improvement of interaction time and user experience compared to a baseline method while preserving the high completeness and accuracy of the baseline. Hence, we conclude that a smart environment can improve the interaction process of restricting a mobile robot’s workspace.
Nonetheless, the experimental evaluation also revealed current limitations of this work. For example, a participant wished a stronger feedback system without change of attention between the restriction area on the ground and the map shown on the smart display. For this purpose, an augmented reality solution would be promising, e.g. projectors integrated into the smart environment could visualize the user-defined virtual borders directly on the ground without change of attention. Although there are already solutions in the industrial context [14,24], projectors are not yet widely distributed in current smart homes. Moreover, we currently evaluated our interaction method with a single mobile robot, which is valid for most households. However, it would be interesting to incorporate multiple robots into the interaction process to increase the number of mobile cameras. Our proposed architecture already considers this aspect (Fig. 2), but more work on the cooperation between multiple mobile robots in such a scenario is needed.
Footnotes
Acknowledgement
This work is financially supported by the German Federal Ministry of Education and Research (BMBF, Funding number: 13FH006PX5). We would also like to thank all participants who took part in the experimental evaluation for their time and valuable feedback.